Let
A be a multivariate time series with
n independent variables, each of
m distinct points (from one to
m), and no missing values;
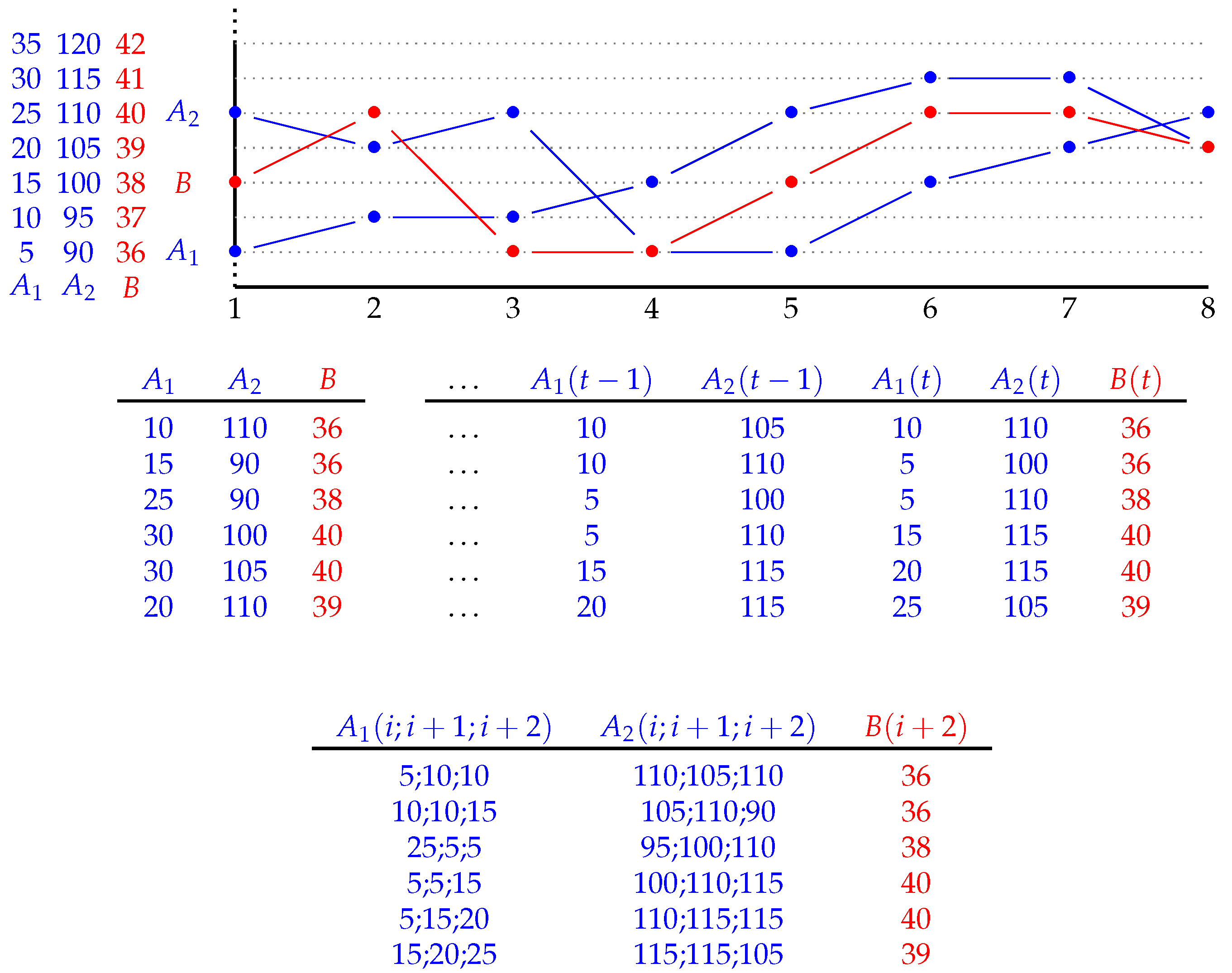
Figure 1 (top) is an example with
and
. Any such time series can be interpreted as a temporal data set on its own, in the form of (3). In our example, this corresponds to interpreting the data as in
Figure 1 (middle, left). As explained in the previous section, the regression problem for
B can be solved in a static way. Moreover, by suitably pre-processing
A as in (6), the problem can be seen as a temporal regression problem; in our example, this corresponds to interpreting the data as in
Figure 1 (middle, right). The algorithm Temporal C4.5 and its implementation Temporal J48 [
16,
17] are symbolic (classification and) regression trees that can be considered as an alternative to classic solutions, whose models are interpretable, as they are based on decision trees, use lags (but not lagged variables), and are natively temporal. Briefly, Temporal C4.5 is the natural theoretical extension of C4.5 developed by Quinlan in the 1990s for the temporal case when dealing with more than propositional instances such as multivariate time series, and Temporal J48 is WEKA’s extension of J48 to the temporal case; observe that such a distinction must be made since the implementation details may differ between public libraries, but the theory, in general, is the same.
Our approach using Temporal J48 for regression is based on two steps:(i) a filter applied to the original data
and (ii) a regression tree extraction from the filtered data, similar to the classic decision tree extraction problem. The first step consists of extracting from
a new data set, in which each instance is, in itself, a multivariate time series. Having fixed a maximum lag
l, the
i-th new instance (
) is the chunk of the multivariate time series
A that contains, for each variable
, the values at times from
i to
, for
(i.e., an
l-points multivariate time series). Such a short time series, so to say, is labelled with the
-th value of the dependent variable
B. In this way, we have created a new data set with
instances, each of which is a time series. In our example, this is represented as in
Figure 1 (bottom), where
. The second step consists of building a regression tree whose syntax is based on a set of decisions that generalizes the propositional decision of the standard regression tree. Observe that time series describe continuous processes, and when discretized, it makes less sense to model the behaviour of such complex objects at each point. Thus, the natural way to represent time series is an interval based ontology, and the novelty of the proposed methodology is to make the decision over intervals of time. The relationships between intervals in a linear understanding of time are well known; they are called Allen’s relations [
19], and despite a somewhat cumbersome notation, they represent the natural language in a very intuitive way. In particular, Halpern and Shoham’s modal logic of Allen’s relations (known as HS [
18]) is the time interval generalization of propositional logic and encompasses Allen’s relations in its language (see
Table 1). Being a modal logic, formulas can be propositional or modal, the latter being, in turn, existential or universal. Let
be a set of propositional letters (or atomic propositions). Formulas of HS can be obtained by the following grammar:
where
,
is any of the modality corresponding to Allen’s relation, and
denotes its universal version (e.g.,
). On top of Allen’s relations, the operator
is added to model decisions that are taken on the same interval. For each
, the modality
, corresponding to the inverse relation
of
, is said to be the transpose of the modality
, and vice versa. Intuitively, the formulas of HS can express the properties of a time series such as if there exists an interval in which
is high, during which
is low, then …, as an example of using existential operators, or as if during a certain interval,
is always low, then …, as an example of using universal ones. Formally, HS formulas are interpreted on time series. We define:
where
is the domain of the time series,
is the set of all strict intervals over
having cardinality
, and:
is a valuation function, which assigns to each proposition
the set of intervals
on which
p holds. Following the presentation, note that we deliberately use
l for the domain of
T, which is also the maximum fixed lag. The truth of formula
on a given interval
in a time series
T is defined by structural induction on formulas as follows:
where
. It is important to point out, however, the we use logic as a tool; through it, we describe the time series that predict a certain value, so that the expert is able to understand the underlying phenomenon. The semantics of the relations
allows us to ease such an interpretation:
From the syntax, we can easily generalize the concept of decision and define a set of temporal and atemporal decisions
, where:
where
,
, and
is an interval operator of the language of HS. The value
allows us a certain degree of uncertainty: we interpret the decision
on an interval
with a certain value
as true if and only if the ratio of points between
x and
y satisfying
is at least
. A temporal regression tree is obtained by the following grammar:
where
S is a (temporal or atemporal) decision and
, in full analogy with non-temporal trees. The idea that drives the extraction of a regression tree is the same in the propositional and the temporal case, and it is based on the concept of splitting by variance. The result is a staircase function, with the additional characteristic that each leaf of the tree, which represents such a function, can be read as a formula of HS. Therefore, if a propositional tree for regression gives rise to tree rules of the type if
two units before now and
one unit before now, then, on average,
when used on lagged data, Temporal J48 gives rise to rules of the type if mostly
during an interval before now and mostly
in an interval during it, then, on average,
. It should be clear, then, that Temporal J48 presents a superior expressive power that allows one to capture complex behaviours. It is natural to compare the statistical behaviour of regression trees over lagged data and that of Temporal J48 using the same temporal window.
A temporal regression tree such as Temporal J48 is extracted from a temporal data set following the greedy approach of splitting by variance as in the propositional case. Being sub-optimal, a worse local choice may, in general, produce better global ones. This is the idea behind feature selection: different subsets of attributes lead to different local choices, in search for global optima. In the case of temporal regression trees, however, the actual set of interval relations that are used for splitting behaves in a similar way: given a subset of all possible relations, a greedy algorithm for temporal regression trees’ extraction may make worse local choices that may lead to better global results. Therefore, we can define a generalization of (11):
in which
represents a selection of features and
represents a selection of interval relations to be used during the extraction. This is a multi-objective optimization problem that generalizes the feature selection problem, and we can call it the feature and language selection problem. Observe that there is, in general, an interaction between the two choices: different subsets of features may require different subsets of relations for a regression tree to perform well. The number of interval relations that are actually chosen, however, does not affect the interpretability of the result, and therefore, it is not optimized (in the other objective function).







{kind=link}
{kind=link}
