1. Introduction
Unmanned Aerial Vehicle (UAV) swarm formation has applications in many areas of research, such as infrastructure inspection [
1], surveillance [
2,
3], target tracking [
4], and precision agriculture [
5]. There are existing methods in the literature to control UAV swarms using centralized methods [
6,
7,
8,
9,
10,
11], where there is a command center (centralized system) computing optimal motion commands for the UAVs. Centralized methods are relatively easy to develop and implement, but computational complexity grows exponentially with the size of the swarm. To address this challenge, we present a decentralized UAV swarm formation control approach using decentralized Markov decision process framework. The main goal this study is to drive the swarm fly and hover in a certain geographical region while forming a certain geometrical shape. The motivation for studying such problems comes from data fusion applications with UAV swarms where the fusion performance depends on the strategic relative separation of the UAVs from each other [
12,
13]. We previously studied decentralized decision making frameworks for UAV swarm formation in two-dimensional (2D) scenarios [
14], while in this study, we decentralized control strategies in three-dimensional (3D) scenarios.
The formation control of vehicle swarms has many applications in areas including infrastructure inspection, precision agriculture, intelligent transportation, and surveillance. In many applications in these domains, strategic placement of the vehicles (forming a certain geometrical shape, e.g., points on the surface of a sphere) can lead to significant gains in data fusion performance due to the different vantage points of the sensors on-board the vehicles observing a target of interest [
10]. Suppose the vehicles carry optical cameras generating 2D images of a 3D object, and if the goal is to reconstruct the 3D shape of the object via the 2D images (i.e., tomography-based methods), the strategic placements of the vehicles around the object can have significant impact on the performance of the 3D shape reconstruction.
Different formation control settings have been studied in the past: ground vehicles [
15,
16,
17], unmanned aerial vehicles (UAVs) [
18,
19], surface and underwater autonomous vehicles (AUVs) [
20,
21]. Regardless of settings, there are many different methodologies developed by the researchers to tackle formation control problem, e.g., behavior-based, virtual structure, and leader following. The authors of [
22,
23] developed a behavior-based approach in which they described the desired behavior for each robot, e.g., collision avoidance, formation keeping, and target seeking. The control commands for the robot is determined by weighing the relative importance of each behavior. The virtual structure approach [
24,
25] takes a physical object shape as a reference and mimics the formation of that shape. The robots are required to communicate with each other in order to achieve a formation in this approach which requires significant communication costs (e.g., bandwidth). The leader following approach [
15] requires a robot, assigned as a leader, which moves according to a predetermined trajectory. The other robots, the followers, are designed to follow the leader, maintaining a desired distance and orientation with respect to the leader. The main drawback of this approach is that the followers are dependent on the leader to achieve the goal (formation). The system may collapse if the leader fails when the leader possibly runs short on power or when the communications link fails. Considering the aforementioned limitations of formation control, which specifically stem from centralized approaches, we develop a decentralized Markov decision process (Dec-MDP)-based formation control approach for a UAV swarm. Our decentralized control strategies are robust to failures of individual UAVs in the swarm and also robust to communications link failures.
Centralized control strategies for UAV swarm control are well studied [
7,
8,
9,
11,
26]. For instance, the authors of [
6,
7] developed UAV control strategies for target tracking in a centralized setting. In centralized systems like these, typically, there exists a notional fusion center (a computing node) that collects and fuses the sensor measurements (e.g., using Bayes’ theorem) from all the UAVs and runs a tracking algorithm (e.g., Kalman filter) to maintain and update the estimate of the state of the system. More importantly, the fusion center computes the combined optimal control commands for all the UAVs to maximize the system performance. For instance, the authors of [
10] used the notion of fusion center to control fixed-wing UAVs for multitarget tracking while accounting for collision avoidance and wind disturbance on UAVs. Although, these centralized control and fusion strategies are easy to implement, they are computationally expensive especially if the swarm is large. Specifically, the computational complexity increases exponentially with the number of UAVs in the swarm.
To tackle these challenges, a few studies in the literature developed decentralized control strategies [
14,
26,
27,
28,
29]. The authors of [
26] used the decentralized partially observable Markov decision process (Dec-POMDP) to formulate and solve a target tracking problem with a swarm of decentralized UAVs. As solving decentralized POMDP is very difficult (as is the case with solving any decision-theoretic methods), the authors introduced an approximate dynamic programming method called
nominal belief-state optimization (NBO) to solve the control problem. The authors in [
30] developed a UAV formation control approach using decentralized Model Predictive Control (MPC). In their work, the UAVs were able to avoid collisions with multiple obstacles in a decentralized manner. They used a figure of eight as a reference trajectory; their results show that the UAVs were able to avoid collision with obstacles and among themselves. Several recent papers describe the formation control of different geometric shapes, e.g., multi-agent circular shape with a leader [
9]. The authors of [
9] propose centralized formation control, which is not suitable for swarm control when the number of UAVs in the swarm is large. Although decentralized control methods exist in the literature, our method is novel in the sense that each UAV in the swarm optimizes its own control commands and its nearest neighbor’s controls over time. Then, each UAV implements its own optimized controls, and discards the neighbor’s controls. We anticipate, from this decentralized control optimization approach, a global cooperative behavior among the UAVs emerges mimicking a centralized control approach. The authors of [
31] demonstrated a successful use of a distributed UAV control framework for wildfire monitoring while avoiding in-flight collisions. The authors of [
32] introduced path tracking and desired formation for networked mobile vehicles using non-linear control theory to maintain the formation in the network. They have showed that path tracking error of each vehicle is reduced to zero and formation is achieved asymptotically. As centralized control strategies suffer from exponential computational complexity and high memory usage, the decentralized control methods are being actively pursued in the context of swarm control, especially when the size of the swarm is large. A survey of these decentralized control strategies can be found in [
29].
In this paper, we develop a novel decentralized UAV swarm formation control approach using Dec-MDP formation. In this problem, the goal is to optimize the UAV control decisions (e.g., waypoints) in a decentralized manner, such that the swarm forms a certain geometrical shape while avoiding collisions. We use dynamic programming principles to solve the decentralized swarm motion control problem. As most dynamic programming problems suffer from the curse of dimensionality, we adapt a fast heuristic approach called
nominal belief-state optimization (NBO) [
10,
33] to approximately solve the formation control problem. We perform simulation studies to validate our control algorithms and compare their performance with centralized approaches for bench marking the performance.
Key Contributions
We formulate the UAV swarm formation control problem as a decentralized Markov decision process (Dec-MDP).
We extend an approximate dynamic programming method called nominal belief-state optimization (NBO) to solve the formation control problem.
We perform numerical studies in MATLAB to validate the swarm formation control algorithms developed here.
One of the key contributions of this paper is to induce cooperative behavior among the UAVs in the swarm via the following novel decentralized control optimization strategy:
- –
Each UAV i optimizes the control vector at time k, where is the control vector for UAV i, and is the control vector for its nearest neighbor.
- –
Next, UAV i discards the optimized controls for its neighbor and implements just its own controls .
- –
Each UAV in the system implements the above approach.
The rest of the paper is organized as follows.
Section 2 provides the problem specification and objectives. We also formulate the problem using decentralized Markov decision process in
Section 2 followed by the discussion on the NBO approach in
Section 3. UAV motion model and dynamics are provided in
Section 4. In
Section 5, we discuss simulation results to evaluate the performance of our method.
2. Problem Formulation
Unmanned aerial vehicles: We consider quadrotor motion dynamics in 3D, as modeled in [
34,
35]. In this study, our goal is to optimize the
waypoints (position coordinates in 3D space) for the quadrotors to guide the UAVs to their destination formation shape while avoiding collisions.
Communications and Sensing: We assume that UAVs are equipped with sensing systems and wireless transceivers with which each UAV learns the exact location and the velocity of the nearest neighboring UAV. Our decentralized control method requires only the kinematic state (location and velocity) of the nearest neighbor to optimize the control commands of the local UAV.
Objective: The goal is to control the swarm (optimizing waypoints) in a decentralized manner, such that the swarm arrives at a certain pre-determined 3D geometrical surface in the shortest time possible while avoiding collisions.
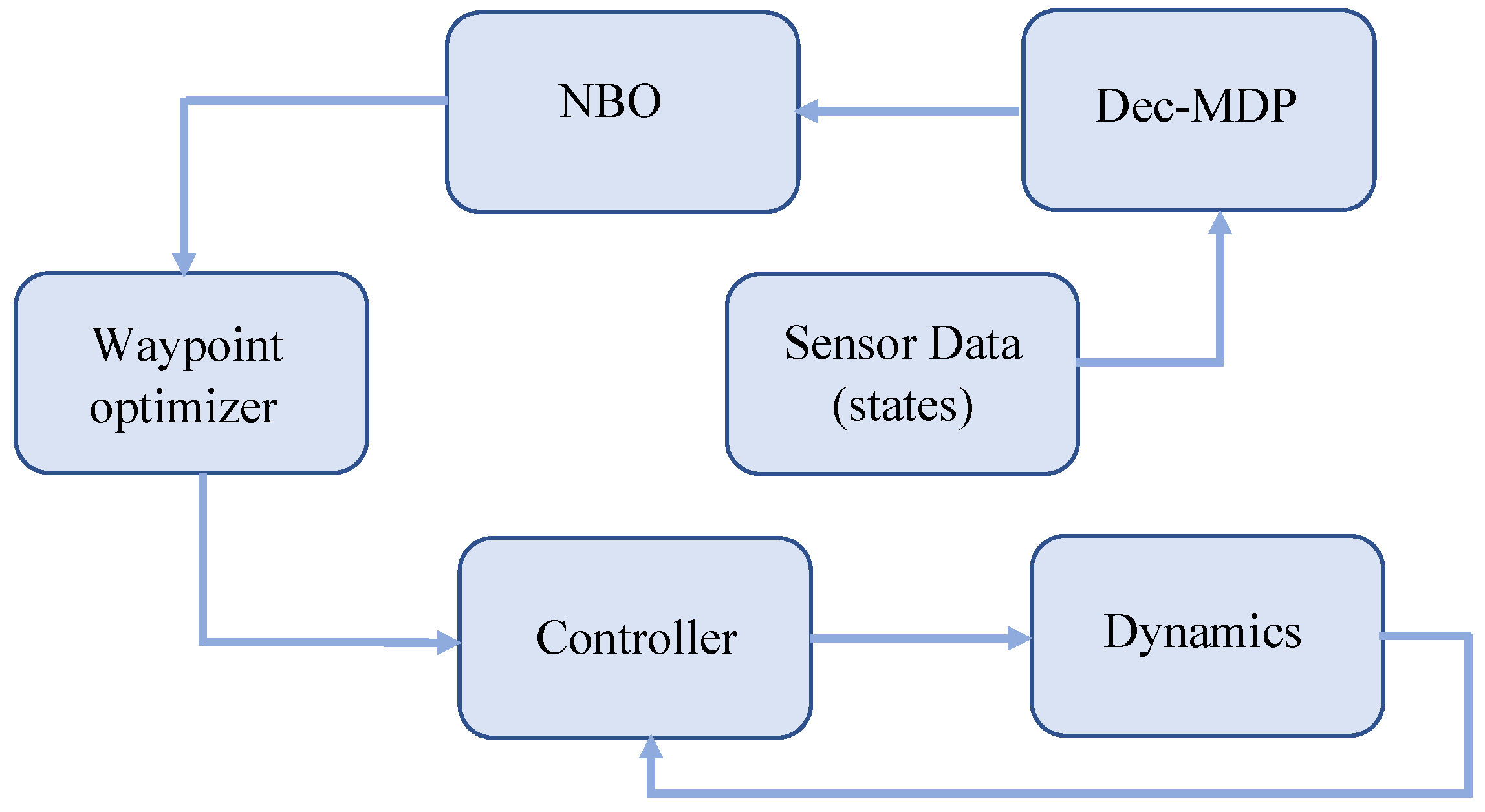
We formulate the swarm formation control problem as a decentralized Markov decision process (Dec-MDP). Dec-MDP is a mathematical formulation useful for modeling control problems for decentralized decision making. This formulation has the following advantages: (1) allows us to efficiently utilize the computing resources on-board all the UAVs, (2) requires less computational time compared to centralized approaches, (3) as UAVs are decentralized, point of failure of the entire mission is minimal, (4) decentralized approach provides robustness to addition or deletion of UAVs to the swarm, (5) UAVs do not need to rely on a central command center for evaluating optimal control commands. We define the key components of Dec-MDP as follows. Here, k represents the discrete-time index.
Dec-MDP Ingredients
Agents/UAVs: We assume there are N UAVs in our system. The set of UAVs is given by an index vector . This index vectors may be referred to as a set of agents or set of independent decision makers. Here, a UAV can be considered an agent or a decision maker.
States: We model the system dynamics in discrete time, where k represents the time index. The state of the system includes the locations and velocities of all the UAVs in the system.
Actions: The actions are the controllable aspects of the system. We define action vector , where represents the action vector at UAV i, which includes the position coordinates in 3D for the UAV.
State Transition Law: State transition law describes how the state evolves over time. Specifically, the transition law is a conditional probability distribution of the next state given the current state and the current control actions (assuming the Markovian property holds). The transition law is given by
, where
is the conditional probability distribution. Since the state of the system only includes the states of the UAVs, the state transition law is completely determined by the dynamics of the UAVs (discussed in the next section). In other words, the transition law is given by
, where
represents the state of the
ith UAV and
indicates the local dynamic controls (position coordinates) of
ith UAV,
represents the motion model as discussed in
Section 4, and
represents noise, which is modeled as a zero-mean Gaussian random variable.
Cost Function: The cost function deals with cost of being in a given state and performing actions . Here, represents the global state, i.e., the state of all the UAVs in the system. Since the problem is decentralized, each UAV only has access to its local state and the state of the nearest neighboring UAV. Let represent that local system state at UAV i, where is the state of the nearest neighboring UAV, and .
Let
be the destination location UAV
i must reach, and
is the distance between the UAVs below which the UAVs are considered to be at the risk of collision. We now define the local cost function for UAV
i, as follows:
where
represents the location of the
ith UAV,
and
are weighting parameters,
represents the distance between locations
a and
b, and
is the indicator function, i.e.,
if the argument
a is true and 0 otherwise.
By minimizing the above cost function, each UAV optimizes its own control commands and that of its neighbor, but only implement its own local control commands and discards the commands optimized for its neighbor. The first part of the cost function lets the UAV reach its destination, while the second part minimizes the risk of collisions between UAVs.
The Dec-MDP starts at an initial random state
and the state of the system evolves according to the state-transition law and the control commands applied at each UAV. The overall objective is to optimize the control commands at each UAV
i such that the expected cumulative local cost over a horizon
H (shown below) is minimized. where
is the initial local state at UAV
i, and the expectation
is over the stochastic evolution of the local state over time (due to the random variables present in the UAV dynamic equations).
5. Simulation Results
We assume that each UAV has its own on-board computer to compute the local optimal control decisions. We implement the above-discussed NBO approach to solve the swarm control problem in MATLAB. We test our methods in two scenarios—a spherical shape with and without an obstacle. The UAVs are aware of the shape dimensions and the exact location of shape. Each UAV randomly picks a location on the formation shape, and uses the NBO approach to arrive at this location. We use MATLAB’s fmincon to solve the NBO optimization problem. Here, we set the horizon length to time steps.
We define the following metrics to measure the performance of our formation control approach: (1) -average computation time to evaluate the optimal control commands and (2) : time taken for the swarm to arrive on the formation shape. As a benchmark method, we use a centralized approach to solve the above-discussed swarm formation control problem. In other words, we use a single NBO algorithm, which optimizes the motion control commands for all the UAVs together based on the global state of the system. We implement this centralized algorithm in MATLAB.
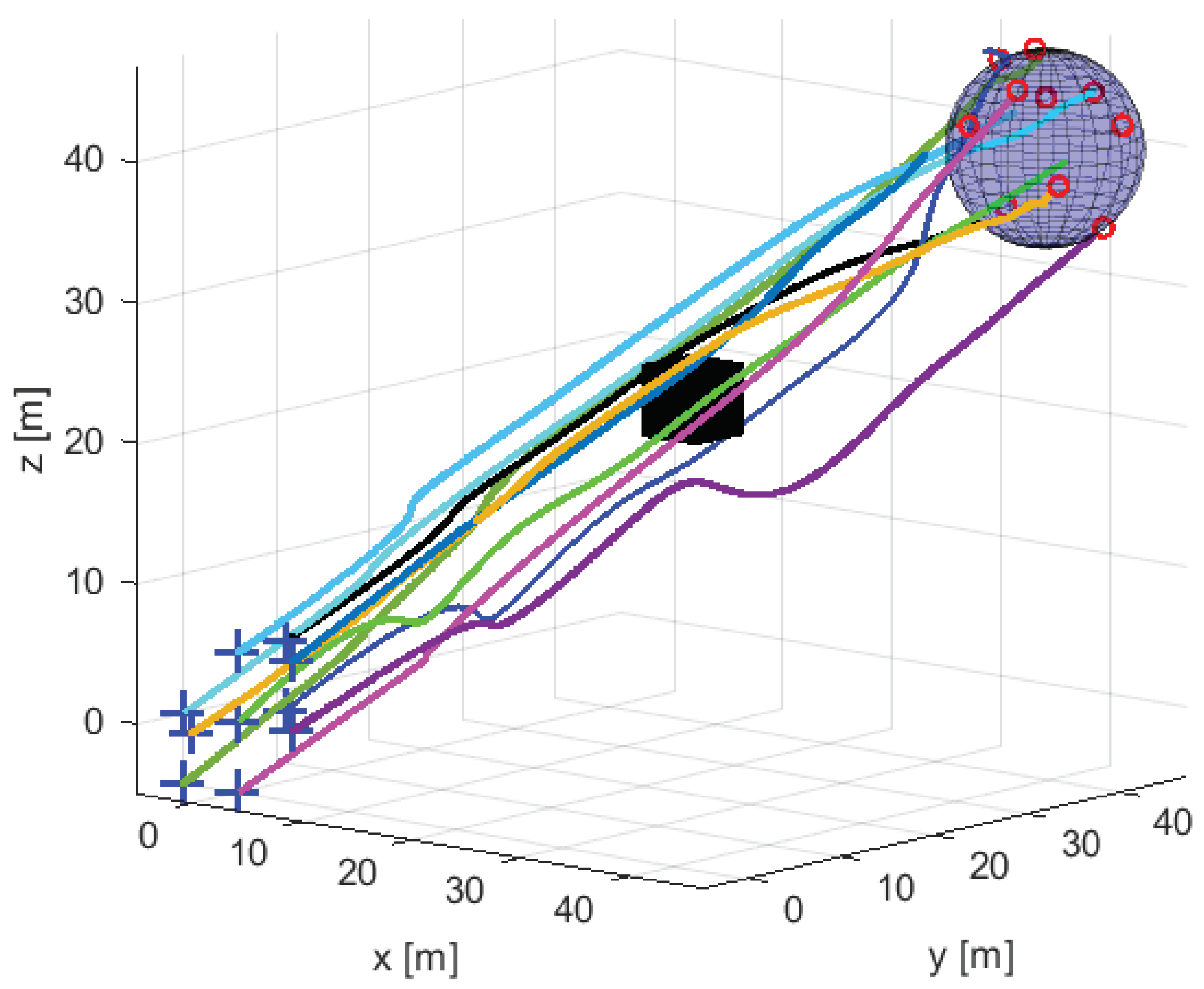
We implement the Dec-MDP approach with a spherical formation shape with and without an obstacle. The resulting swarm motion is shown in
Figure 2 for the spherical formation shape in the absence of any obstacle using the cost function described in Equation (
1). The scenario with an obstacle considers the following cost function.
where
is the location of an obstacle,
is a collision threshold with the obstacle, and
is a weighting parameter. The indicator function
, if the argument
b is true and 0 otherwise. The resulting motion of the scenario with the obstacle is shown in
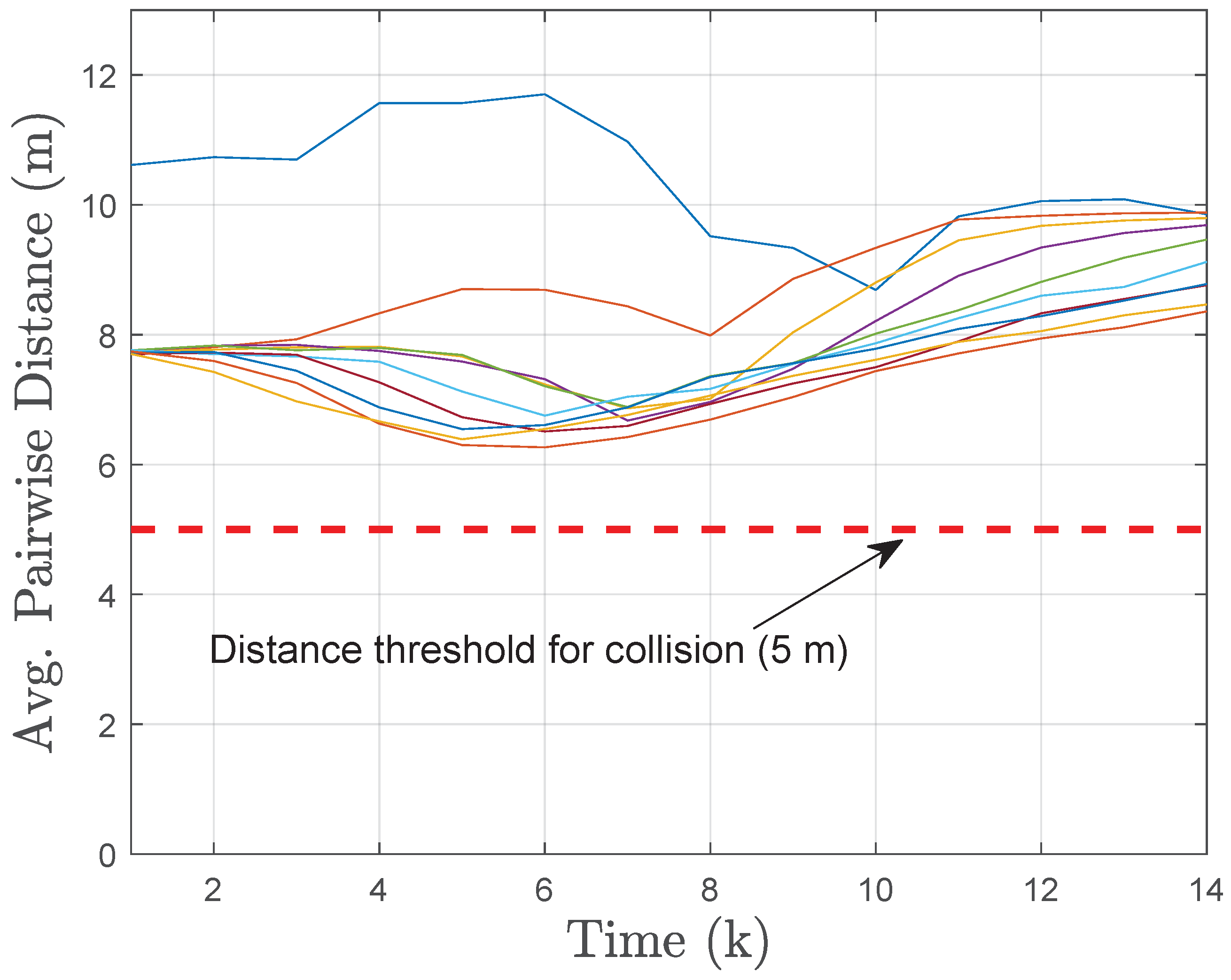
Figure 3. For this scenario, we also plot the distance between every pair of UAVs in the swarm, as shown in
Figure 4. Here, we assume that there is a collision risk between a pair of UAVs when the distance between them is less than 5 m. Clearly, the
Figure 3 and
Figure 4 demonstrate that our decentralized algorithm drives the swarm to the destination while successfully avoiding collisions between the UAVs.
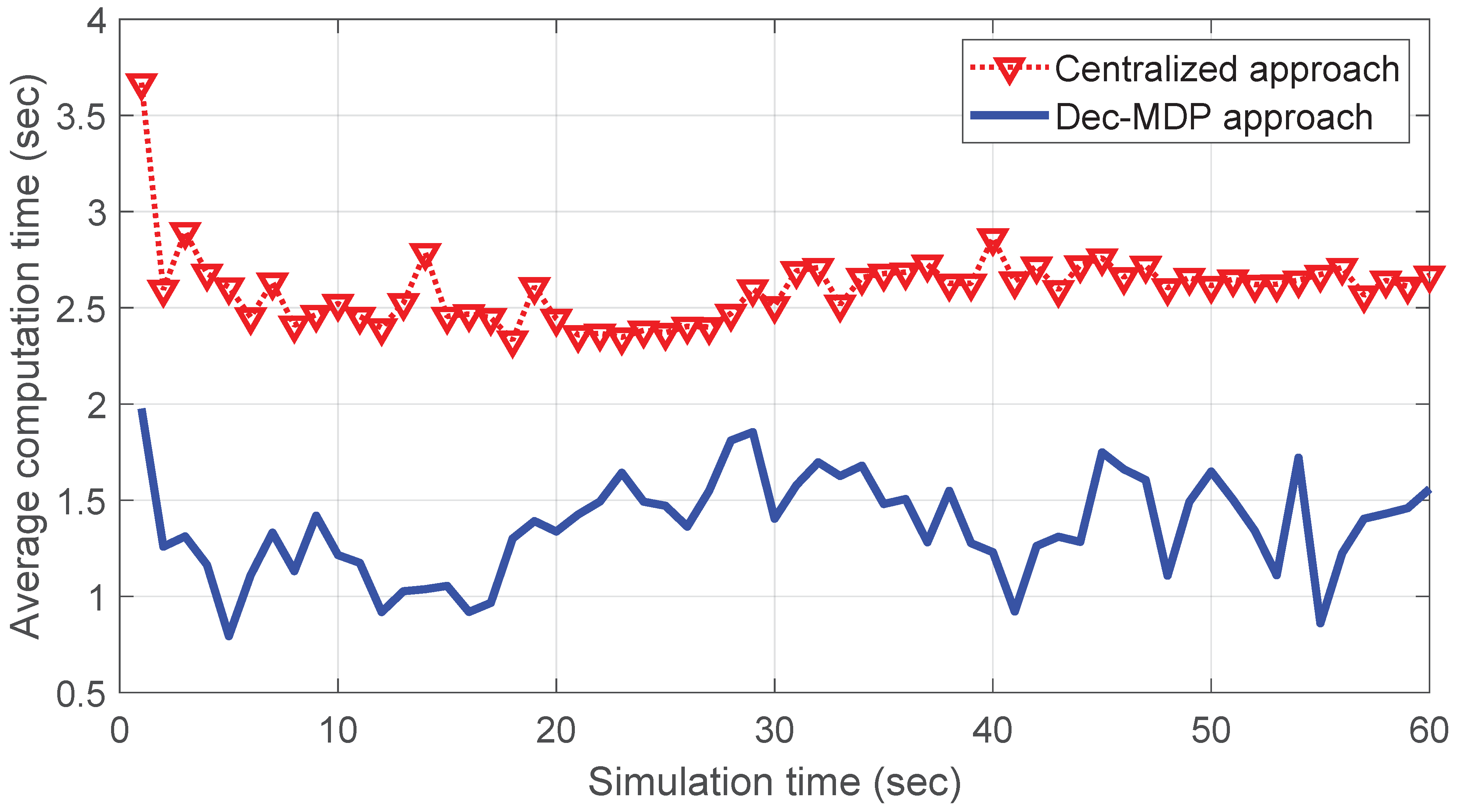
We calculate the
and
values for both the centralized and the decentralized algorithms for 10 UAVs.
Figure 5 and
Table 1 clearly demonstrate that our decentralized method significantly outperforms the centralized method with respect to both the metrics
and
.
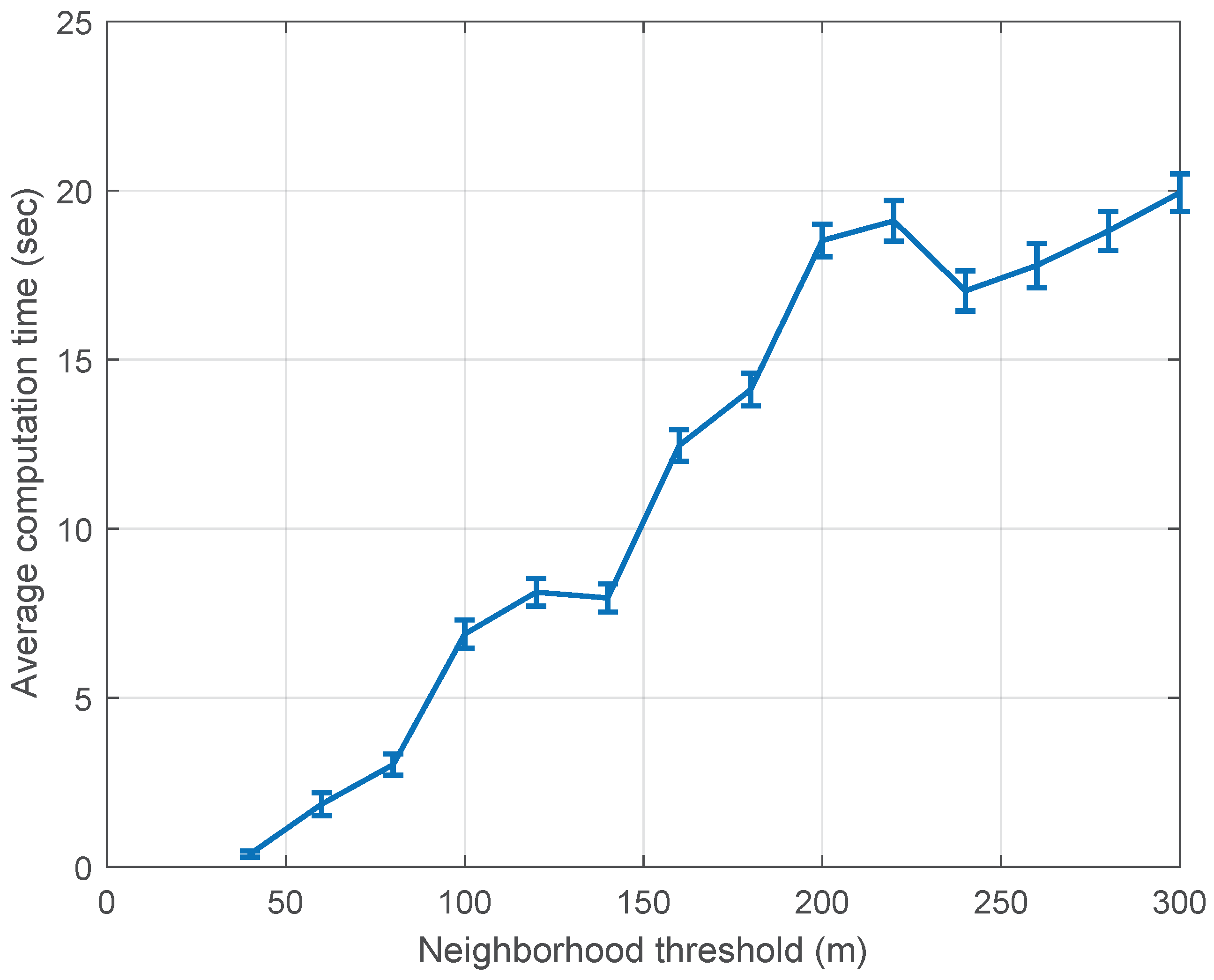
We now compute average computation time and average pairwise distance with respect to neighborhood threshold where each UAV communicates with other UAVs within the radius of neighborhood threshold. If neighborhood threshold is infinity, a UAV can communicate with all other UAVs in the swarm. UAVs optimize their decisions together with neighbors, which depend on neighborhood threshold and implement its own control. We expect that, with the increase in neighborhood threshold, average computation time rises and, after certain neighborhood threshold, average computation time saturates.
Figure 6 shows average computation time rise until neighborhood threshold reach 240 m and then waves between 20 to 25 s.
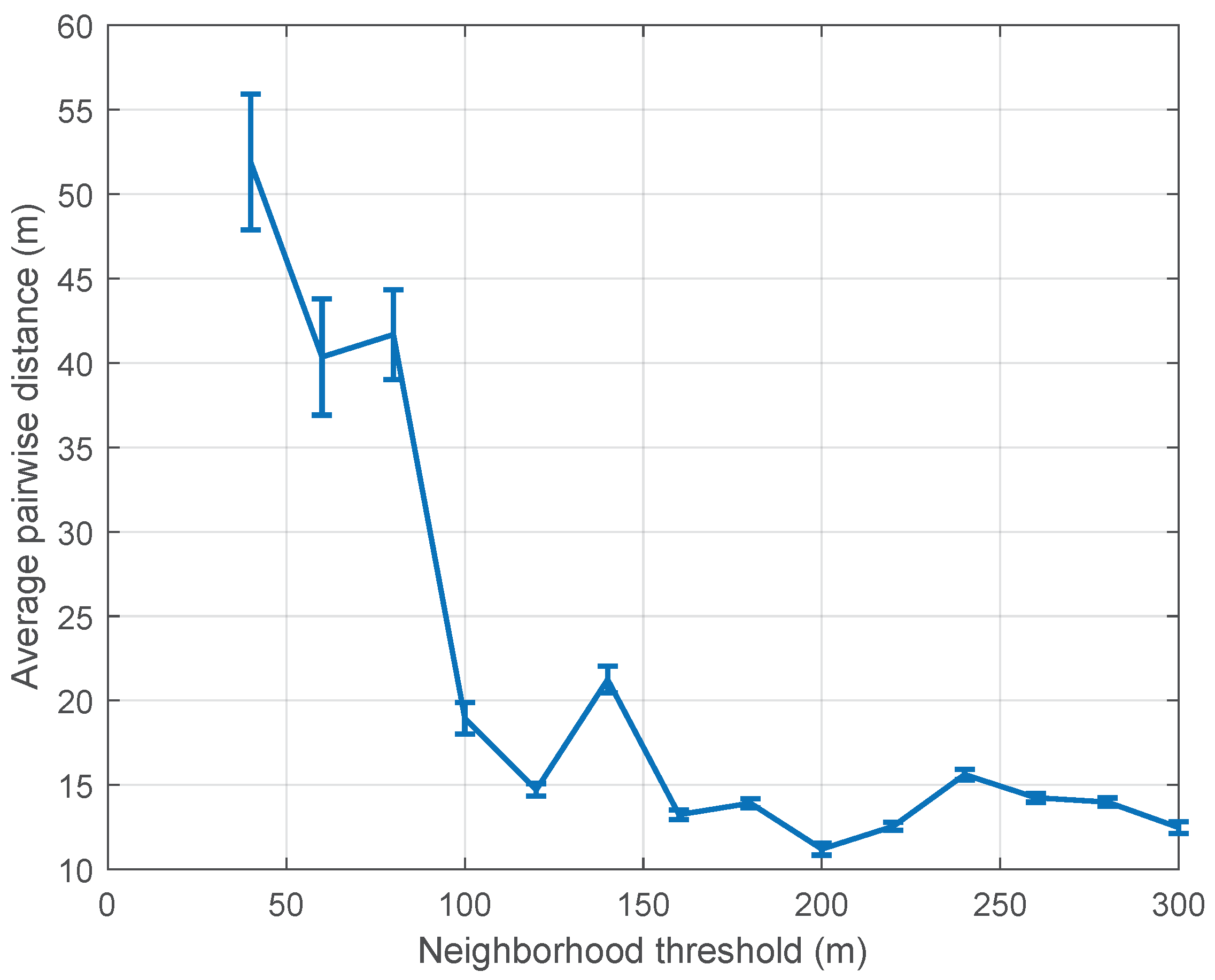
We also expect that with the increase of neighborhood threshold, average pairwise distance drops. The reason we are interested in analyzing average pairwise distance is, we expect the swarm to be as close as possible while avoiding collision between UAVs. Small average pairwise distance allows the swarm to be more cooperative while saving battery life as communication distance depends on distance between UAVs.
Figure 6 and
Figure 7 suggest that a neighborhood threshold of more than 130 m allows UAVs to stay close in the swarm with reasonable computation cost.
6. Conclusions
In this paper, we developed decentralized control method for UAVs in the context of formation control. Specifically, we extended a decision-theoretic formulation called decentralized Markov decision process (Dec-MDP) to develop near real-time decentralized control methods to drive a UAV swarm from an initial formation to a desired formation in the shortest time possible. As decision-theoretic approaches suffer from the curse of dimensionality, for computational tractability, we extended an approximate dynamic programming method called nominal belief-state optimization (NBO) to approximately solve the Dec-MDP. For benchmarking, we also implemented a centralized approach (Markov decision process-based) and compared the performance of our decentralized control methods against the centralized methods. In the context of the formation control problem, our results show that the average computation time for obtaining the optimal controls and the time taken for the swarm to arrive at the formation shape are significantly less with our Dec-MDP approach compared with that of the centralized methods. We also studied the impact of neighborhood threshold on multiple performance metrics in a UAV swarm.
The formation control approach discussed in this thesis can be extended to 3D formation, and these formations can be used to sense the environments for 3D reconstruction of a scene. The vantage points of the UAVs in the swarm in 3D formation can be exploited for the efficient reconstruction of the scene in 3D, while extending tomography-type approaches. The decentralized control strategies presented in this thesis can be extended to control the motion of the UAVs in the swarm to maximize the efficiency of the above 3D scene reconstruction process. These methods have several applications, including the use of drones to map unexplored and unsafe regions (e.g., caves, underground mines, toxic environments).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}