
KDAS-ReID: Architecture Search for Person Re-Identification via Distilled Knowledge with Dynamic Temperature

Abstract
:1. Introduction
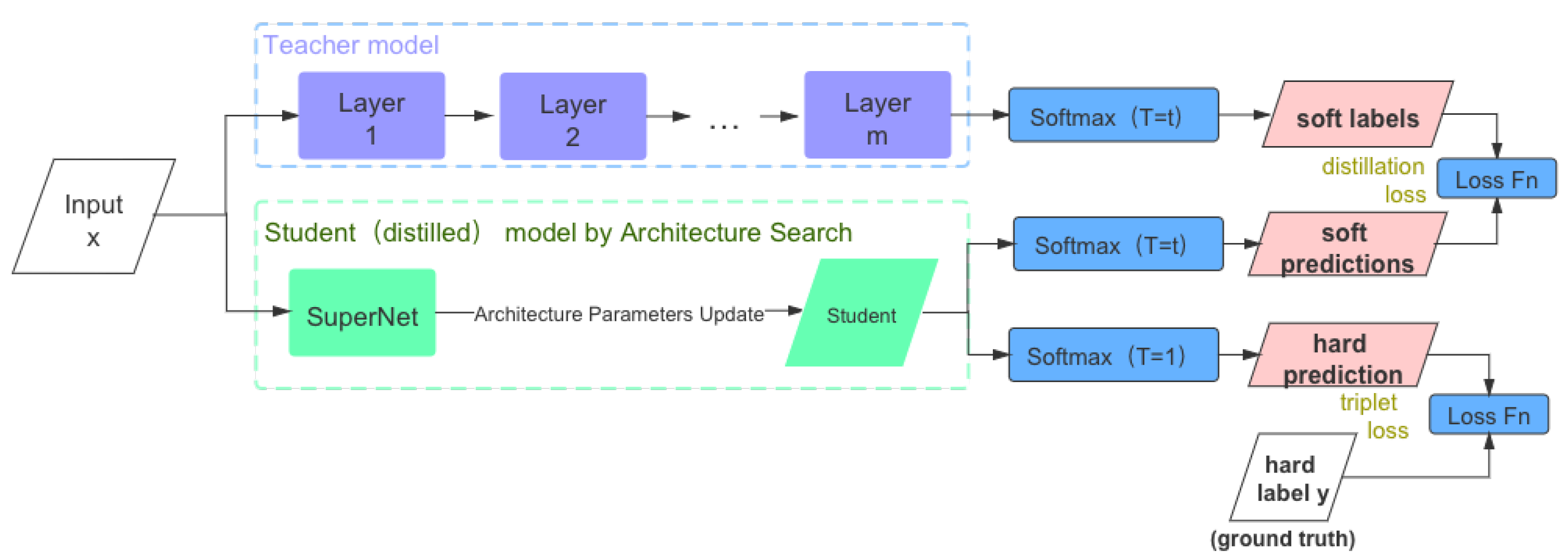
- Person re-identification is essentially a retrieval problem that aims at retrieving images of persons-of-interest. Previous Re-ID convolutional neural networks are usually built upon backbones for image classification, such as ResNet [1], Inception [6], and VGG [7]. In this paper, the NAS algorithm is recommended based on knowledge distillation that aims at designing a convolutional neural network backbone that performed well in the Re-ID task. More concretely, we first trained a teacher model on Market-1501 which built upon ResNet backbones and pre-trained on the ImageNet. Cross-entropy loss is replaced by distillation loss, which is computed by the soft targets and the outputs of the candidates model after softmax;
- With the success of deep learning, the demand for architecture engineering is also growing, and an increasing number of researchers focus on CNN architecture because the performance of CNNs depend on their architecture. Because of the features of NAS, we considered a distillation loss with dynamic temperature in hopes of breaking the limit of the teacher model. We started searching and training with a high temperature and gradually reduced to 1 to control the importance of the knowledge of teacher model;
- Extensive experiments showed that our work achieves a competitive accuracy compared with the teacher model, while the searched model has less than 50% parameters of the teacher model. In addition, rank-1 with 94.6% accuracy is achieved on market-1501 by using the search space of Auto-ReID.
2. Related Works
2.1. Person Re-ID
2.2. Neural Architecture Search
2.3. Knowledge Distillation
3. Methods
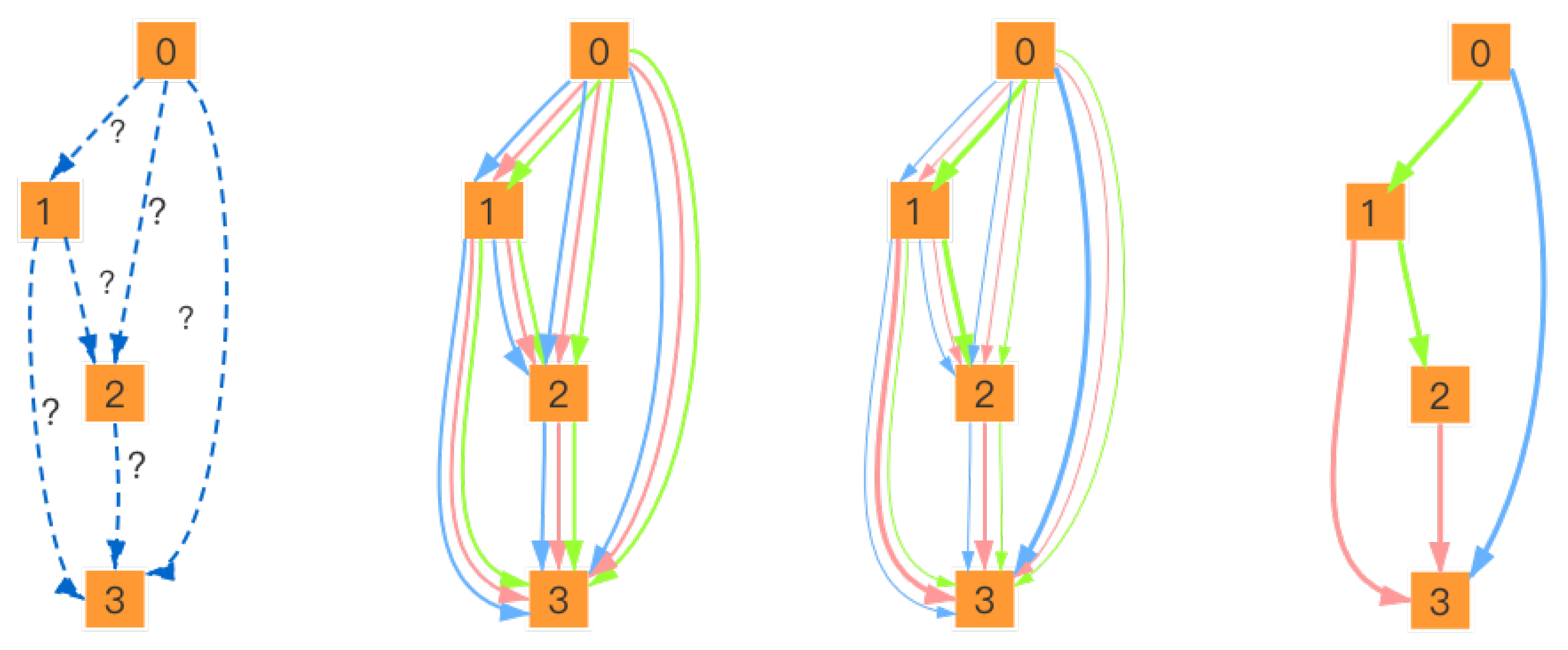
3.1. Preliminaries of DARTS
3.2. ReID Search Algorithm with Knowledge Distillation
3.2.1. Search Space
- part-aware module
- max pooling
- average pooling
- depth-wise separable convolution
- dilated convolution
- zero operation
- identity mapping.
3.2.2. Network Structure
3.2.3. Search Algorithm
| Algorithm 1: The KDAS-ReID Algorithm |
 |
3.3. Evaluation Based on Knowledge Distillation
3.3.1. Knowledge Distillation
3.3.2. Architecture Search with Distilled Knowledge
3.3.3. Knowledge Distillation with Dynamic Temperature
4. Experiments
4.1. Datasets and Evaluation Metrics
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.2. Implementation Details
4.2.1. Search Configurations
4.2.2. Training Configurations
4.3. Ablation Study
- Baseline. Directly searching on the Re-ID dataset with differentiable architecture search strategy and adopted the search space of Auto-ReID [4]. The loss is computed by the cross-entropy function and the triplet function.
- Baseline + Distillation. Based on Baseline, we use the objective loss (Equation (9)) which is composed of triplet loss and distillation loss instead of the original loss function. Considering the effect of the distillation loss heavily relying on a well-performance teacher model, we use the official ResNet-50 network which pre-trains on the ImageNet as the backbone of the teacher model. In addition, the temperature is retained during the whole search stage.
- Distillation + Dynamic Temperature. To break the limit of the teacher model, we introduce the distillation loss with dynamic temperature T. We start searching with a high value of temperature and decrease evenly; finally, the temperature T will decrease to 0 at the 190th epoch.
4.4. Architecture Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. arXiv 2020, arXiv:2001.04193. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Quan, R.; Dong, X.; Wu, Y.; Zhu, L.; Yang, Y. Auto-reid: Searching for a part-aware convnet for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3750–3759. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning deep feature representations with domain guided dropout for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1249–1258. [Google Scholar]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond triplet loss: A deep quadruplet network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 403–412. [Google Scholar]
- Sarfraz, M.S.; Schumann, A.; Eberle, A.; Stiefelhagen, R. A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 420–429. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-driven deep convolutional model for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3960–3969. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Mu Lee, K. Part-aligned bilinear representations for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 402–419. [Google Scholar]
- Suganuma, M.; Shirakawa, S.; Nagao, T. A genetic programming approach to designing convolutional neural network architectures. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017; pp. 497–504. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Smash: One-shot model architecture search through hypernetworks. arXiv 2017, arXiv:1708.05344. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the 2019 AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4780–4789. [Google Scholar]
- Bender, G.; Kindermans, P.J.; Zoph, B.; Vasudevan, V.; Le, Q. Understanding and simplifying one-shot architecture search. In Proceedings of the International Conference on Machine Learning PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 550–559. [Google Scholar]
- Lorenzo, P.R.; Nalepa, J. Memetic evolution of deep neural networks. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018; pp. 505–512. [Google Scholar]
- Xiao, X.; Yan, M.; Basodi, S.; Ji, C.; Pan, Y. Efficient hyperparameter optimization in deep learning using a variable length genetic algorithm. arXiv 2020, arXiv:2006.12703. [Google Scholar]
- Lorenzo, P.R.; Nalepa, J.; Kawulok, M.; Ramos, L.S.; Pastor, J.R. Particle swarm optimization for hyper-parameter selection in deep neural networks. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017; pp. 481–488. [Google Scholar]
- Ba, L.J.; Caruana, R. Do deep nets really need to be deep? arXiv 2013, arXiv:1312.6184. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar]
- Sau, B.B.; Balasubramanian, V.N. Deep model compression: Distilling knowledge from noisy teachers. arXiv 2016, arXiv:1610.09650. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1318–1327. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Dong, X.; Yang, Y. Searching for a robust neural architecture in four gpu hours. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1761–1770. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Pedestrian alignment network for large-scale person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3037–3045. [Google Scholar] [CrossRef] [Green Version]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Huang, H.; Li, D.; Zhang, Z.; Chen, X.; Huang, K. Adversarially occluded samples for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5098–5107. [Google Scholar]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-level factorisation net for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2109–2118. [Google Scholar]
- Si, J.; Zhang, H.; Li, C.G.; Kuen, J.; Kong, X.; Kot, A.C.; Wang, G. Dual attention matching network for context-aware feature sequence based person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5363–5372. [Google Scholar]
- Wang, C.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Mancs: A multi-task attentional network with curriculum sampling for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Berlin, Germany, 27 March 2018; pp. 365–381. [Google Scholar]
- Fu, Y.; Wei, Y.; Zhou, Y.; Shi, H.; Huang, G.; Wang, X.; Yao, Z.; Huang, T. Horizontal pyramid matching for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Dublin, Ireland, 17–19 October 2019; Volume 33, pp. 8295–8302. [Google Scholar]
- Xu, J.; Zhao, R.; Zhu, F.; Wang, H.; Ouyang, W. Attention-aware compositional network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2119–2128. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. Svdnet for pedestrian retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3800–3808. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2285–2294. [Google Scholar]
- Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; Kautz, J. Joint discriminative and generative learning for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2138–2147. [Google Scholar]
- Wei, L.; Zhang, S.; Yao, H.; Gao, W.; Tian, Q. Glad: Global-local-alignment descriptor for pedestrian retrieval. In Proceedings of the 25th ACM international conference on Multimedia, Aires, Argentina, 22–23 May 2017; pp. 420–428. [Google Scholar]



{kind=link}
{kind=link}
| Architectures | mAP | Rank-1 | Rank-5 | Rank-10 | Params(M) |
|---|---|---|---|---|---|
| ResNet-18 [1] | 66.0 | 85.2 | 94.6 | 96.5 | 11.6 |
| ResNet-34 [1] | 68.0 | 86.7 | 94.8 | 96.6 | 21.7 |
| ResNet-50 [1] | 68.5 | 87.2 | 95.5 | 97.1 | 25.1 |
| DARTS [15] | 65.2 | 85.6 | 94.3 | 96.4 | 9.1 |
| GDAS [32] | 66.8 | 86.5 | 94.7 | 96.9 | 13.5 |
| Baseline 1 | 71.7 | 87.9 | 95.9 | 97.4 | 11.2 |
| Baseline 2 | 71.5 | 87.0 | 95.7 | 97.3 | 9.8 |
| Baseline 3 | 72.3 | 89.0 | 96.5 | 97.9 | 12.0 |
| Baseline 4 | 72.1 | 88.6 | 96.4 | 97.9 | 11.4 |
| Baseline + Distillation 1 | 74.7 | 89.7 | 96.2 | 97.6 | 16.5 |
| Baseline + Distillation 2 | 75.8 | 91.0 | 96.6 | 98.0 | 15.0 |
| Baseline + Distillation 3 | 75.3 | 89.9 | 96.5 | 98.1 | 14.3 |
| Baseline + Distillation 4 | 74.9 | 89.3 | 96.5 | 97.7 | 12.1 |
| Distillation + Dynamic Temperature 1 | 77.0 | 91.1 | 97.0 | 97.9 | 14.3 |
| Distillation + Dynamic Temperature 2 | 76.9 | 91.1 | 96.7 | 97.9 | 15.7 |
| Distillation + Dynamic Temperature 3 | 76.0 | 90.0 | 96.6 | 98.0 | 16.4 |
| Distillation + Dynamic Temperature 4 | 75.7 | 90.1 | 96.5 | 98.0 | 15.4 |
| Methods | Backbone | Params (M) | Market-1501 | |
|---|---|---|---|---|
| R-1 | mAP | |||
| PAN [33] | ResNet50 | >25.1 | 82.8 | 63.3 |
| TriNet [34] | ResNet50 | 25.1 | 84.9 | 69.1 |
| AOS [35] | ResNet50 | >25.1 | 86.4 | 70.4 |
| MLFN [36] | ResNeXt-50 | >25.0 | 90.0 | 74.3 |
| DuATM [37] | DenseNet-121 | >8.0 | 91.4 | 76.6 |
| PCB [11] | ResNet50 | 27.2 | 93.8 | 81.6 |
| Mancs [38] | ResNet50 | >25.1 | 93.1 | 82.3 |
| HPM [39] | ResNet50 | 25.1 | 94.2 | 82.7 |
| Auto-ReID [4] | - | 13.1 | 94.5 | 85.1 |
| Teacher Model | ResNet50 | >25.1 | 93.7 | 83.2 |
| KDAS-ReID | - | 14.3 | 94.7 | 85.3 |
| Using the re-ranking technique [30] | ||||
| TriNet [34] | ResNet50 | 25.1 | 86.7 | 81.1 |
| AOS [35] | ResNet50 | >25.1 | 88.7 | 83.3 |
| AACN [40] | GoogleNet | >8.0 | 88.7 | 83.0 |
| PSE+ECN [10] | ResNet50 | >25.1 | 90.3 | 84.0 |
| PCB [11] | ResNet50 | 27.2 | 95.1 | 91.9 |
| Auto-ReID [4] | - | 13.1 | 95.4 | 94.2 |
| Teacher Model | ResNet50 | >25.1 | 94.7 | 93.1 |
| KDAS-ReID | - | 14.3 | 95.6 | 94.7 |
| Methods | Labeled | Detected | ||
|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | |
| PAN [30] | 36.9 | 35.0 | 36.3 | 34.0 |
| SVDNet [41] | 40.9 | 37.8 | 41.5 | 37.3 |
| HA-CNN [42] | 44.4 | 41.0 | 41.7 | 38.6 |
| AOS [35] | - | - | 47.7 | 43.3 |
| MLFN [36] | 54.7 | 49.2 | 52.8 | 47.8 |
| PCB [11] | - | - | 63.7 | 57.5 |
| Mancs [38] | 69.0 | 63.9 | 65.5 | 60.5 |
| DG-Net [43] | - | - | 65.6 | 61.1 |
| Auto-ReID [4] | 77.9 | 73.0 | 73.3 | 69.3 |
| Teacher Model | 76.3 | 71.5 | 71.9 | 68.0 |
| KDAS-ReID | 78.0 | 73.2 | 73.4 | 70.0 |
| Methods | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| GoogleNet [6] | 47.6 | 65.0 | 71.8 | 23.0 |
| PDC [12] | 58.0 | 73.6 | 79.4 | 29.7 |
| GLAD [44] | 61.4 | 76.8 | 81.6 | 34.0 |
| PCB [11] | 68.2 | 81.2 | 85.5 | 40.4 |
| Auto-ReID [4] | 78.2 | 88.2 | 91.1 | 52.5 |
| Teacher Model | 77.1 | 86.6 | 90.1 | 51.2 |
| KDAS-ReID | 78.4 | 88.3 | 91.1 | 53.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, Z.; Yang, K.; Jiang, K.; Chen, S. KDAS-ReID: Architecture Search for Person Re-Identification via Distilled Knowledge with Dynamic Temperature. Algorithms 2021, 14, 137. https://doi.org/10.3390/a14050137
Lei Z, Yang K, Jiang K, Chen S. KDAS-ReID: Architecture Search for Person Re-Identification via Distilled Knowledge with Dynamic Temperature. Algorithms. 2021; 14(5):137. https://doi.org/10.3390/a14050137
Chicago/Turabian StyleLei, Zhou, Kangkang Yang, Kai Jiang, and Shengbo Chen. 2021. "KDAS-ReID: Architecture Search for Person Re-Identification via Distilled Knowledge with Dynamic Temperature" Algorithms 14, no. 5: 137. https://doi.org/10.3390/a14050137
APA StyleLei, Z., Yang, K., Jiang, K., & Chen, S. (2021). KDAS-ReID: Architecture Search for Person Re-Identification via Distilled Knowledge with Dynamic Temperature. Algorithms, 14(5), 137. https://doi.org/10.3390/a14050137