
A New Hyper-Parameter Optimization Method for Power Load Forecast Based on Recurrent Neural Networks

Abstract
:1. Introduction
2. Preliminaries
2.1. Bayesian Optimization
2.2. Particle Swarm Optimization
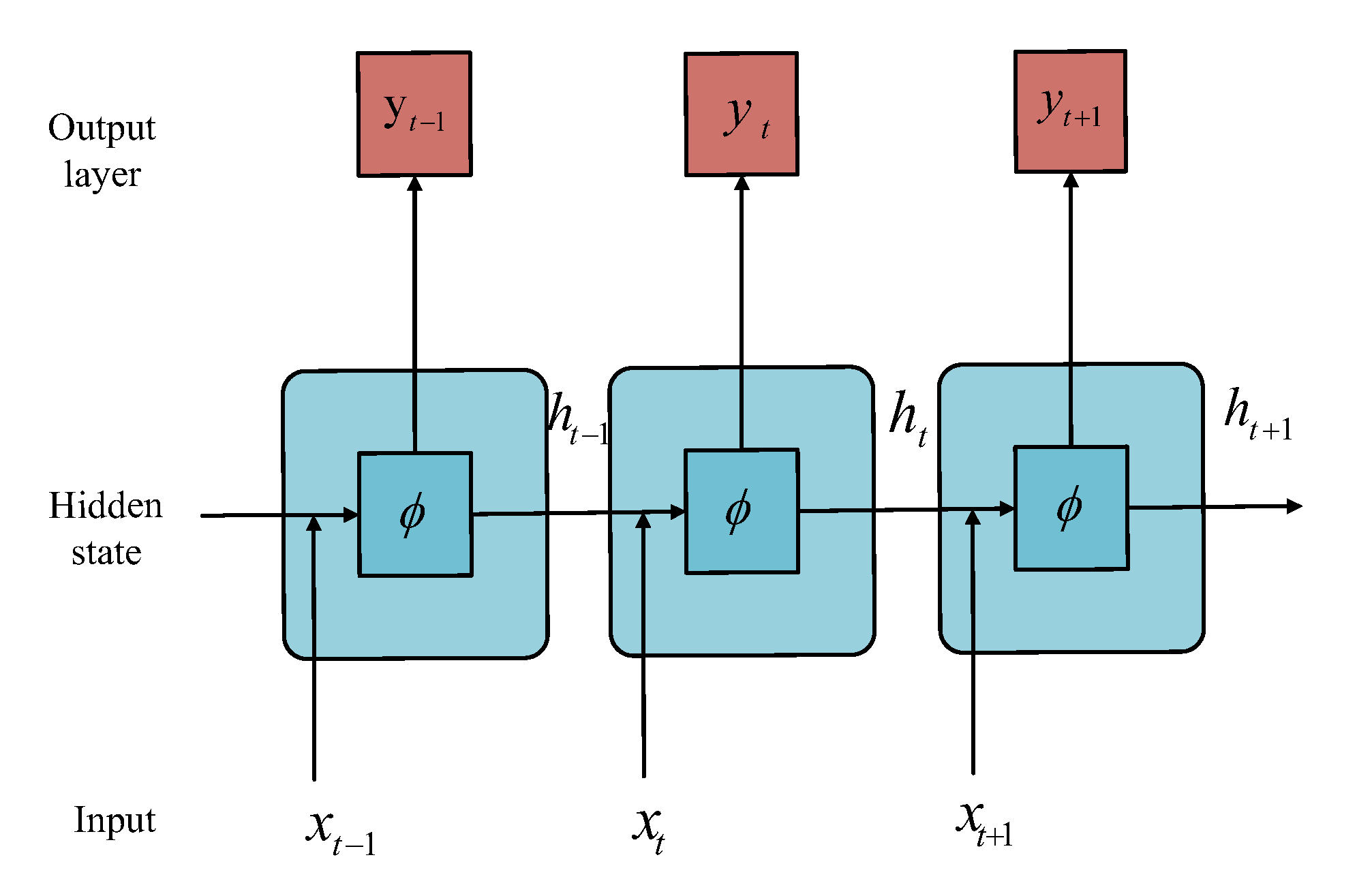
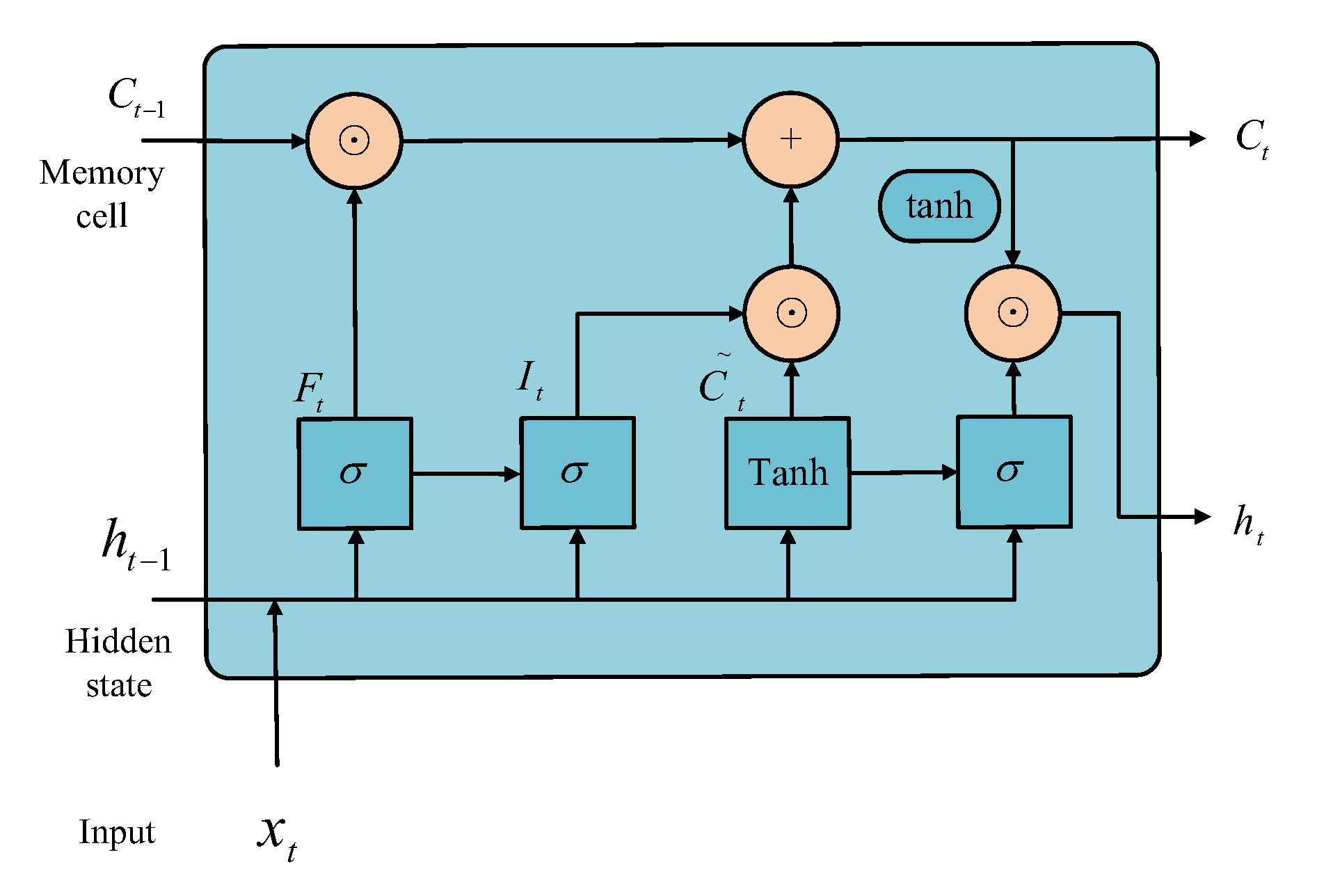
2.3. Recurrent Neural Network
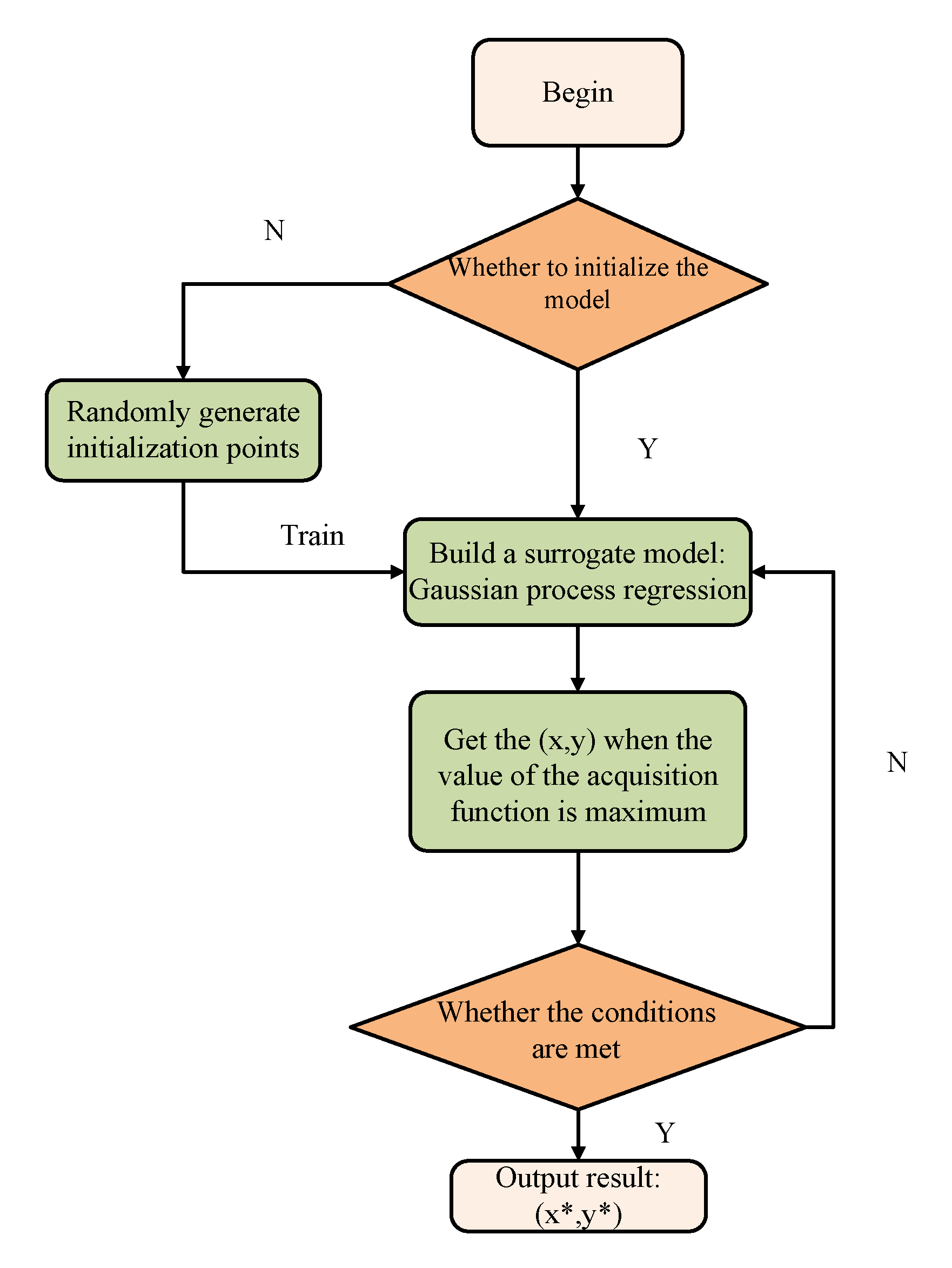
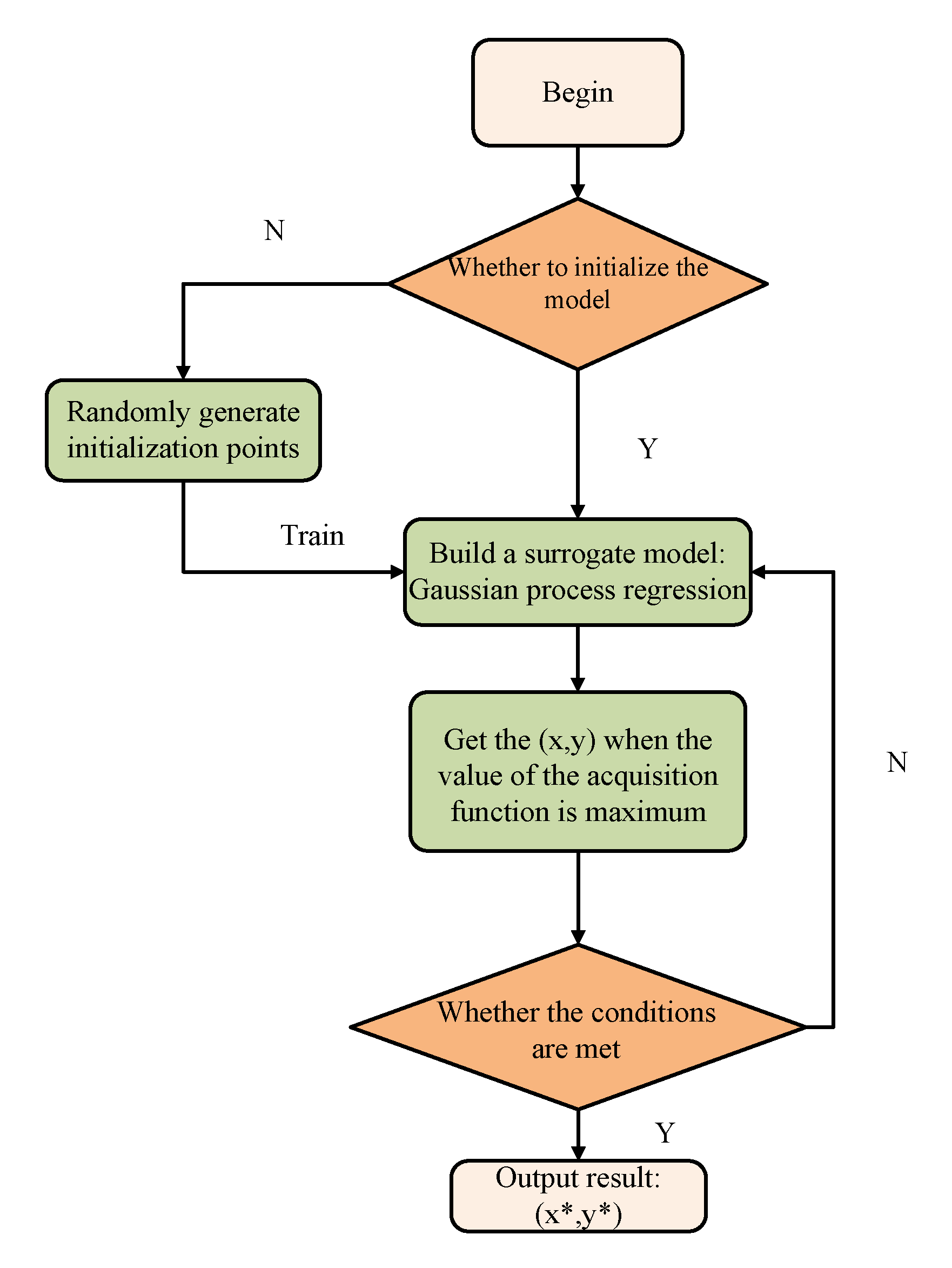
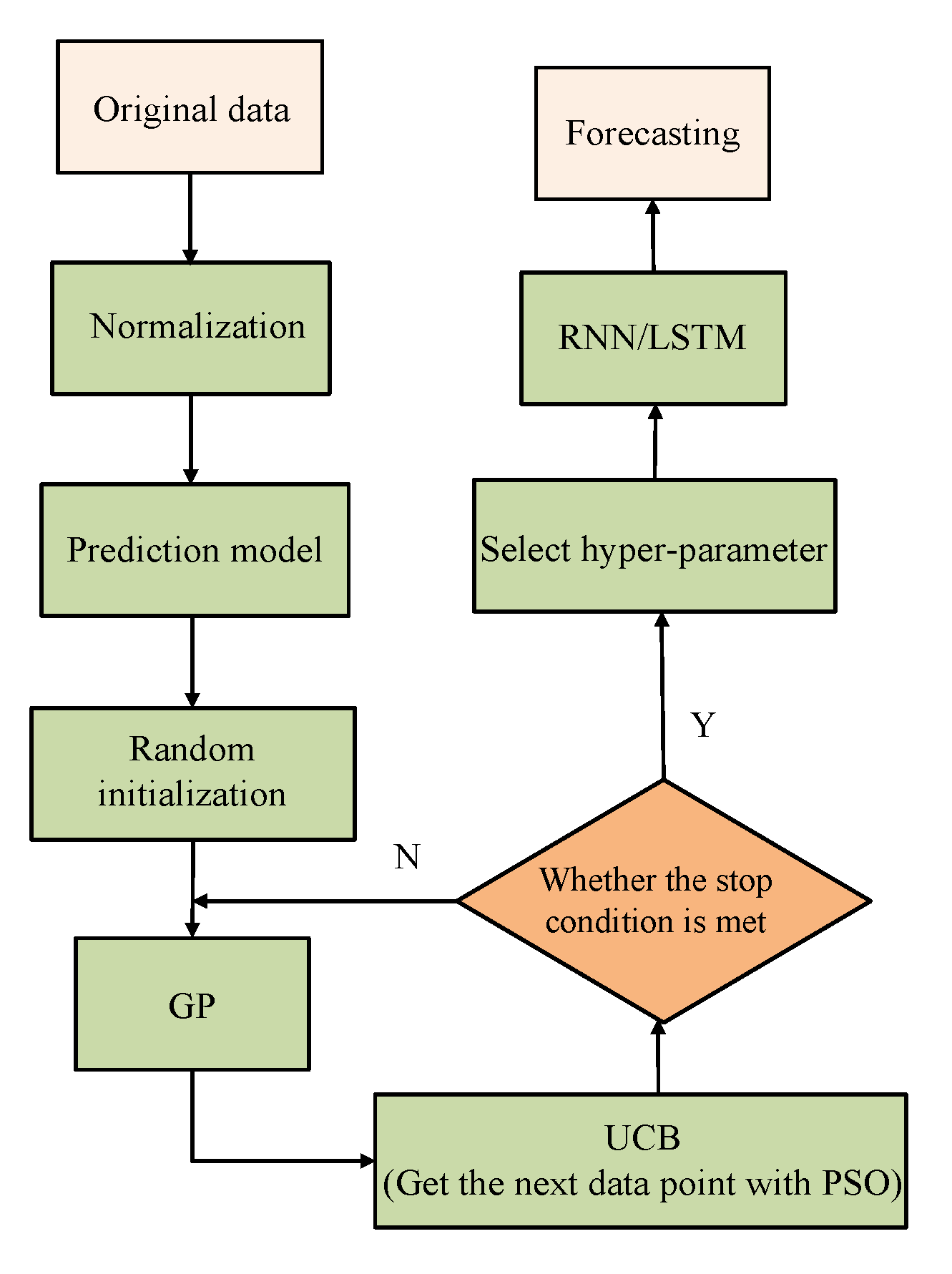
3. BO-PSO
3.1. Algorithm Framework
3.2. Algorithm Framework
| Algorithm 1 BO-PSO. |
| Input: surrogate model for f, acquisition function |
| Output: hyper-parameters vector optimal |
| Step 1. Initialize hyper-parameters vector ; |
| Step 2. For do: |
| Step 3. Using algorithm 1 to maximize the acquisition function to get the next evaluation point: ; |
| Step 4. Evaluation objective function value ; |
| Step 5. Update data: , and update the surrogate model; |
| Step 6. End for. |
4. Results
4.1. Data Sets and Setups
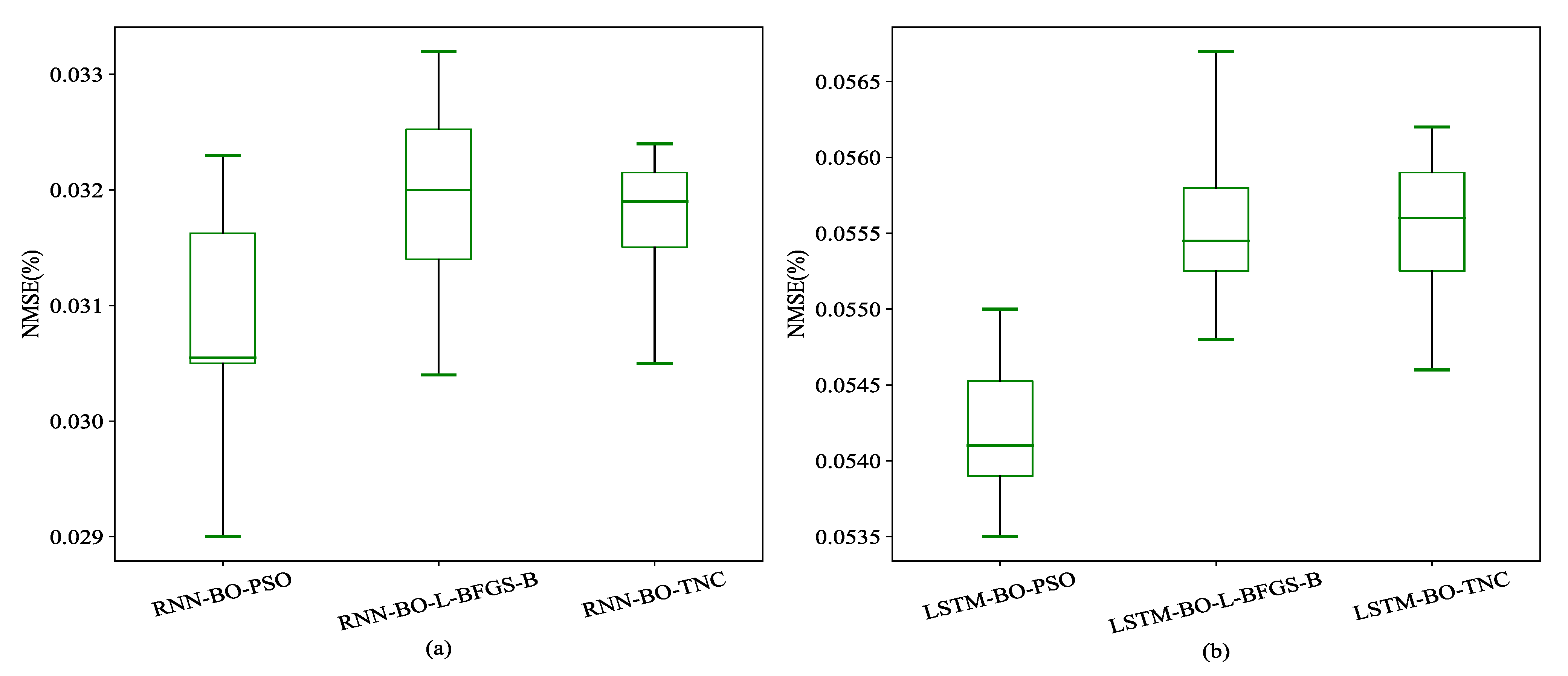
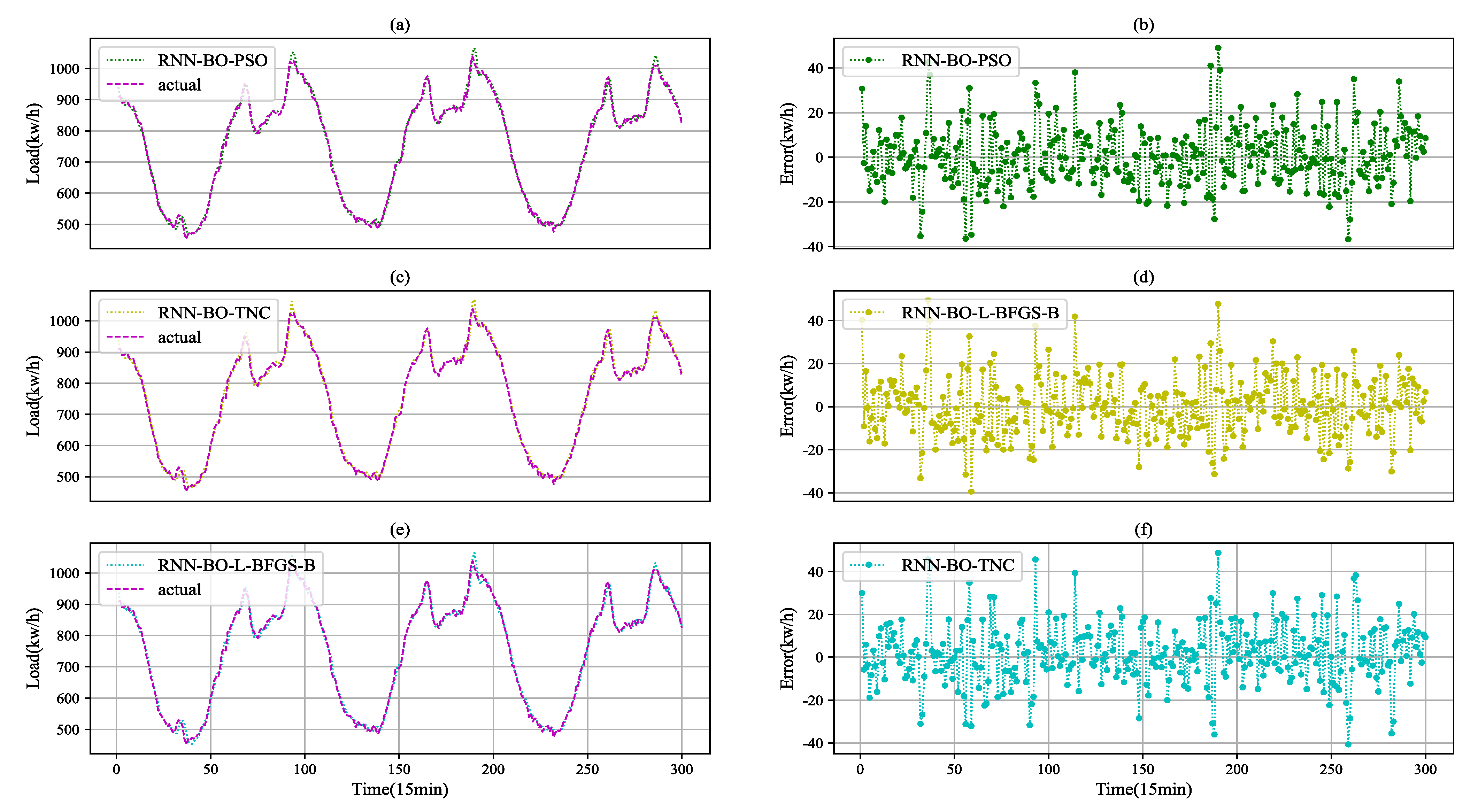
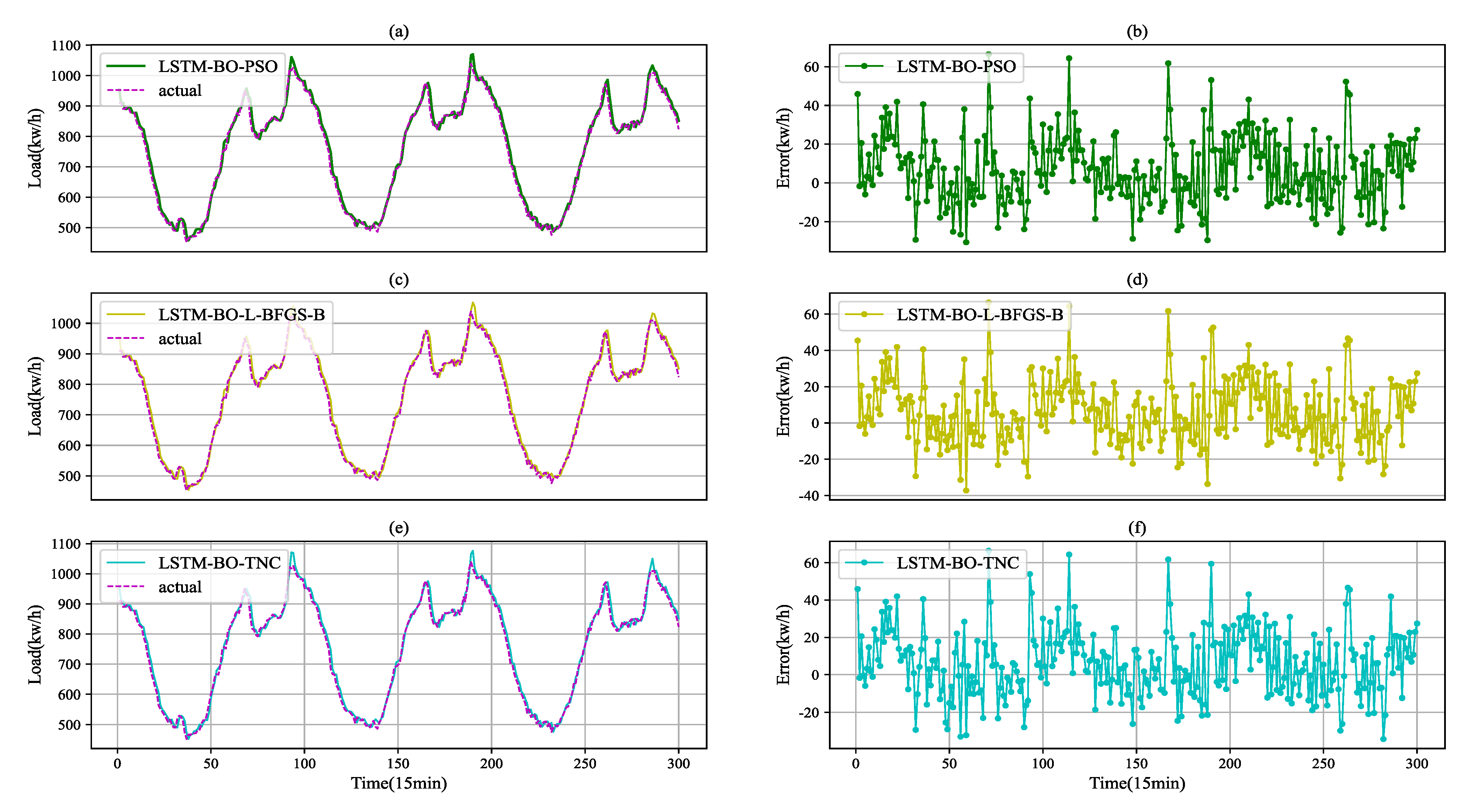
4.2. Comparative Prediction Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gülcü, A.; KUş, Z. Hyper-parameter selection in convolutional neural networks using microcanonical optimization algorithm. IEEE Access 2020, 8, 52528–52540. [Google Scholar] [CrossRef]
- Fan, S.K.S.; Hsu, C.Y.; Tsai, D.M.; He, F.; Cheng, C.C. Data-driven approach for fault detection and diagnostic in semiconductor manufacturing. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1925–1936. [Google Scholar] [CrossRef]
- Fan, S.K.S.; Hsu, C.Y.; Jen, C.H.; Chen, K.L.; Juan, L.T. Defective wafer detection using a denoising autoencoder for semiconductor manufacturing processes. Adv. Eng. Inform. 2020, 46, 101166. [Google Scholar] [CrossRef]
- Park, Y.J.; Fan, S.K.S.; Hsu, C.Y. A Review on Fault Detection and Process Diagnostics in Industrial Processes. Processes 2020, 8, 1123. [Google Scholar] [CrossRef]
- Pu, L.; Zhang, X.L.; Wei, S.J.; Fan, X.T.; Xiong, Z.R. Target recognition of 3-d synthetic aperture radar images via deep belief network. In Proceedings of the CIE International Conference, Guangzhou, China, 10–13 October 2016. [Google Scholar]
- Wang, S.H.; Sun, J.D.; Phillips, P.; Zhao, G.H.; Zhang, Y.D. Polarimetric synthetic aperture radar image segmentation by convolutional neural network using graphical processing units. J. Real-Time Image Process. 2016, 15, 631–642. [Google Scholar] [CrossRef]
- Stoica, P.; Gershman, A.B. Maximum-likelihood DOA estimation by data-supported grid search. IEEE Signal Process. Lett. 1999, 6, 273–275. [Google Scholar] [CrossRef]
- Bellman, R.E. Adaptive Control Processes: A Guided Tour; Princeton University Press: Princeton, NJ, USA, 2015; pp. 1–5. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Frazier, P.I. A tutorial on Bayesian optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.Y.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Cho, H.; Kim, Y.; Lee, E.; Choi, D.; Lee, Y.; Rhee, W. Basic enhancement strategies when using Bayesian optimization for hyperparameter tuning of deep neural networks. IEEE Access 2020, 8, 52588–52608. [Google Scholar] [CrossRef]
- Jones, D.R.; Schonlau, M.; Welch, W.J. Efficient global optimization of expensive black-box functions. J. Glob. Optim. 1998, 13, 455–492. [Google Scholar] [CrossRef]
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef] [Green Version]
- Nash, S.G. A survey of truncated-Newton methods. J. Comput. Appl. Math. 2000, 124, 45–59. [Google Scholar] [CrossRef] [Green Version]
- Bai, Q.H. Analysis of particle swarm optimization algorithm. Comput. Inf. Sci. 2010, 3, 180. [Google Scholar] [CrossRef] [Green Version]
- Regulski, P.; Vilchis-Rodriguez, D.S.; Djurović, S.; Terzija, V. Estimation of composite load model parameters using an improved particle swarm optimization method. IEEE Trans. Power Deliv. 2014, 30, 553–560. [Google Scholar] [CrossRef]
- Schwaab, M.; Biscaia, E.C., Jr.; Monteiro, J.L.; Pinto, J.C. Nonlinear parameter estimation through particle swarm optimization. Chem. Eng. Sci. 2008, 63, 1542–1552. [Google Scholar] [CrossRef]
- Wenjing, Z. Parameter identification of LuGre friction model in servo system based on improved particle swarm optimization algorithm. In Proceedings of the Chinese Control Conference, Zhangjiajie, China, 26–31 July 2007. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Proceedings of the Neural Information Processing Systems Foundation, Granada, Spain, 20 November 2011. [Google Scholar]
- Krajsek, K.; Mester, R. Marginalized Maximum a Posteriori Hyper-parameter Estimation for Global Optical Flow Techniques. In Proceedings of the American Institute of Physics Conference, Paris, France, 8–13 July 2006. [Google Scholar]
- Fumo, N.; Biswas, M.R. Regression analysis for prediction of residential energy consumption. Renew. Sustain. Energy Rev. 2015, 47, 332–343. [Google Scholar] [CrossRef]
- Liao, Z.; Gai, N.; Stansby, P.; Li, G. Linear non-causal optimal control of an attenuator type wave energy converter m4. IEEE Trans. Sustain. Energy 2019, 11, 1278–1286. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, S.J. Cross-scale recurrent neural network based on Zoneout and its application in short-term power load forecasting. Comput. Sci. 2020, 47, 105–109. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. arXiv 2012, arXiv:1206.2944. [Google Scholar]
- Brochu, E.; Cora, V.M.; De Freitas, N. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv 2010, arXiv:1012.2599. [Google Scholar]
- Rasmussen, C.E. Gaussian processes in machine learning. In Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, February 2003. [Google Scholar]
- Mahendran, N.; Wang, Z.; Hamze, F.; De Freitas, N. Adaptive MCMC with Bayesian optimization. In Proceedings of the Artificial Intelligence and Statistics, La Palma, Canary Islands, Spain, 21–23 April 2012. [Google Scholar]
- Hennig, P.; Schuler, C.J. Entropy Search for Information-Efficient Global Optimization. J. Mach. Learn. Res. 2012, 13, 1809–1837. [Google Scholar]
- Toscano-Palmerin, S.; Frazier, P.I. Bayesian optimization with expensive integrands. arXiv 2018, arXiv:1803.08661. [Google Scholar]
- Garrido-Merchán, E.C.; Hernández-Lobato, D. Dealing with categorical and integer-valued variables in bayesian optimization with gaussian processes. Neurocomputing 2020, 380, 20–35. [Google Scholar] [CrossRef] [Green Version]
- Oh, C.; Tomczak, J.M.; Gavves, E.M. Combinatorial bayesian optimization using the graph cartesian product. arXiv 2019, arXiv:1902.00448. [Google Scholar]
- Dai, Z.; Yu, H.; Low, B.K.H.; Jaillet, P. Bayesian optimization meets Bayesian optimal stopping. In Proceedings of the PMLR, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Gong, C.; Peng, J.; Liu, Q. Quantile stein variational gradient descent for batch bayesian optimization. In Proceedings of the PMLR, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Paria, B.; Kandasamy, K.; Póczos, B. A flexible framework for multi-objective Bayesian optimization using random scalarizations. In Proceedings of the PMLR, Toronto, AB, Canada, 3–6 August 2020. [Google Scholar]
- Fan, S.K.S.; Jen, C.H. An enhanced partial search to particle swarm optimization for unconstrained optimization. Mathematics 2019, 7, 357. [Google Scholar] [CrossRef] [Green Version]
- Fan, S.K.S.; Zahara, E. A hybrid simplex search and particle swarm optimization for unconstrained optimization. Eur. J. Oper. Res. 2007, 181, 527–548. [Google Scholar] [CrossRef]
- Hung, C.; Wan, L. Hybridization of particle swarm optimization with the k-means algorithm for image classification. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Image Processing, Nashville, TN, USA, 30 March–2 April 2009. [Google Scholar]
- Srinivas, N.; Krause, A.; Kakade, S.M.; Seeger, M. Gaussian process optimization in the bandit setting: No regret and experimental design. arXiv 2009, arXiv:0912.3995. [Google Scholar]
- Jiang, M.; Luo, Y.P.; Yang, S.Y. Stochastic convergence analysis and parameter selection of the standard particle swarm optimization algorithm. Inf. Process. Lett. 2007, 102, 8–16. [Google Scholar] [CrossRef]
- Zheng, Y.; Ma, L.; Zhang, L.; Qian, J. On the convergence analysis and parameter selection in particle swarm optimization. In Proceedings of the 2003 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 03EX693), Xi’an, China, 5 November 2003. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameters | Type | Range |
|---|---|---|
| Feature length | Integer | (5, 50) |
| Number of network units | Integer | (5, 50) |
| Batch size of training data | Integer | (32, 4096) |
| Model | |
|---|---|
| RNN-BO-PSO | 0.9909 |
| RNN-BO-L-BFGS-B | 0.9908 |
| RNN-BO-TNC | 0.9907 |
| LSTM-BO-PSO | 0.9951 |
| LSTM-BO-L-BFGS-B | 0.9945 |
| LSTM-BO-TNC | 0.9948 |
| Model | Feature Length | Number of Network Units | Batch Size of Training Data |
|---|---|---|---|
| RNN-BO-L-BFGS-B | 44 | 34 | 64 |
| RNN-BO-TNC | 49 | 34 | 64 |
| RNN-BO-PSO | 47 | 38 | 64 |
| LSTM-BO-L-BFGS-B | 23 | 33 | 64 |
| LSTM-BO-TNC | 23 | 32 | 64 |
| LSTM-BO-PSO | 45 | 38 | 32 |
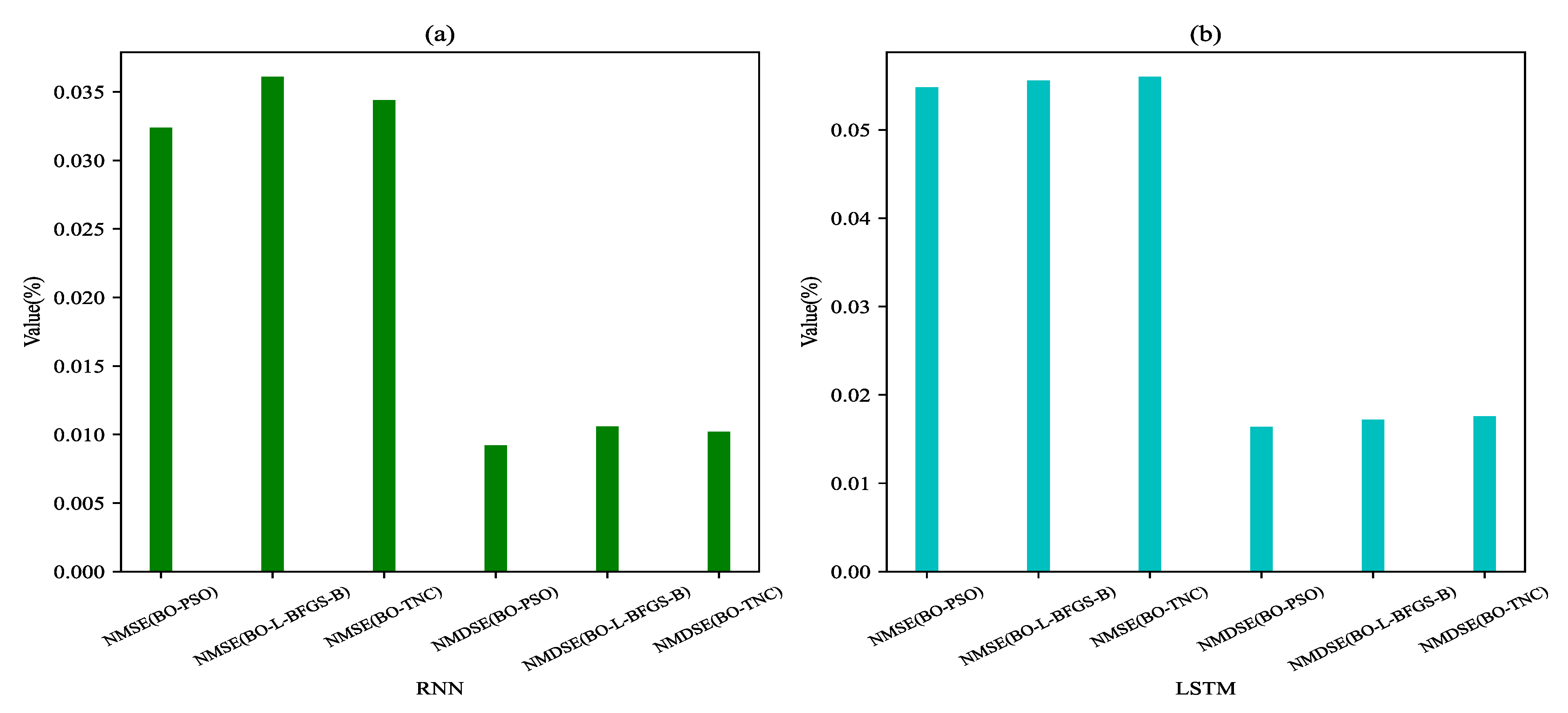
| Model | NMSE (%) | NMDSE (%) |
|---|---|---|
| RNN-BO-L-BFGS-B | 0.0361 | 0.0106 |
| RNN-BO-TNC | 0.0344 | 0.0102 |
| RNN-BO-PSO | 0.0324 | 0.0092 |
| LSTM-BO-L-BFGS-B | 0.0549 | 0.0172 |
| LSTM-BO-TNC | 0.0560 | 0.0177 |
| LSTM-BO-PSO | 0.0556 | 0.0164 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhang, Y.; Cai, Y. A New Hyper-Parameter Optimization Method for Power Load Forecast Based on Recurrent Neural Networks. Algorithms 2021, 14, 163. https://doi.org/10.3390/a14060163
Li Y, Zhang Y, Cai Y. A New Hyper-Parameter Optimization Method for Power Load Forecast Based on Recurrent Neural Networks. Algorithms. 2021; 14(6):163. https://doi.org/10.3390/a14060163
Chicago/Turabian StyleLi, Yaru, Yulai Zhang, and Yongping Cai. 2021. "A New Hyper-Parameter Optimization Method for Power Load Forecast Based on Recurrent Neural Networks" Algorithms 14, no. 6: 163. https://doi.org/10.3390/a14060163
APA StyleLi, Y., Zhang, Y., & Cai, Y. (2021). A New Hyper-Parameter Optimization Method for Power Load Forecast Based on Recurrent Neural Networks. Algorithms, 14(6), 163. https://doi.org/10.3390/a14060163