1.2. Literature Review
A number of studies (see, for example, Zhandire [
2], Mpfumali et al. [
3], Govender et al. [
4] and Mutavhatsindi et al. [
5]) have been carried out for forecasting global horizontal irradiance in South Africa. A unified approach to solar power forecasting remains a challenge in South Africa. Roman et al. [
6], considered a modelling framework that was based on multiple quantile regression whereas Bacher et al. [
7] suggested the application of quantile regression as well as statistical smoothing techniques.
Solar power forecasting depends on the use of indicators such as moistness, sun’s path, temperature, solar power yard attributes that utilise energy from the sun to deliver solar power and dissipating process. Photovoltaic (PV) cells are used to come up with electric power from the sun’s energy. The energy delivered relies upon radiation extracted and on the attributes of the solar panel. This study will benefit the general public by providing forecasting information that is vital for competent use, solar power trading, managing the electricity grid and, improving energy quality supplied to the grid and will assist with decreasing the costs that are identified with climate reliance.
Solar power forecasting which is based on several time horizons performs a vital role in health facilities, building conveyance frameworks, research institutions, schools, PV storage structures management and many other systems that depend on energy. It helps power grid operators in accommodating the load to be able to enhance transportation of energy, assign the necessary balance of energy from other sources during the period when solar power is inaccessible, activities to do with maintenance at the solar power plants. When considering time horizon from various minutes to a few hours, i.e., for a very short term time scale, trend models using on-site measurements are adequate. Hourly predictions containing high geographical and physical settlements that are found from ground-based images are also important.
Various authors have ventured into solar power forecasting using numerical weather prediction models, time series regression, artificial intelligence and many more. In Raza et al. [
8], the authors forecasted PV yield over the range of forecasting horizon utilising diverse ordered scales. They did a study and reviewed PV forecast models where they looked at different variables used for forecasting it, that is its yield control profile and execution matrices to assess the predicted model. Their research was based on time series regression techniques and artificial intelligence. In Hong et al. [
9], the authors did a study on introducing global energy forecasting in a competition that was done in 2014, a probabilistic estimation of energy using four tracks for the following variables: price, wind, load and sunlight energy-based predictions. The paper aimed at producing decade ahead probabilistic forecasts.
A day-ahead prediction of sunlight-based power yield from plants extracting solar energy in America in the Southwest was done in Larson et al. [
10]. The study made use of forecasting methods for the day-ahead hourly averaged energy output from solar power plants dependent on optimisation with the use of least squares prediction on weather factors using numerical methods. Three different prediction strategies were assessed against data that were from some two tracking 1MWp plants that were in California for the years 2011–2014.
In Trapero et al. [
11], the authors did an analysis applying kernel density forecasting methods, instability prediction models and a mixture of the two models with the main thrust on enhancing the predicting interim performance. An analysis was done using the two methods based on non-parametric kernel density estimation on a minute to minute solar irradiance. To incorporate volatility forecasts, Generalized Autoregressive Conditional Heteroskedasticity (GARCH) and Single Exponential Smoothing (SES) estimation were used. Ranganai and Sigauke [
12] applied additive quantile regression to model global horizontal irradiance. They used long-range dependence models on three sites based in South Africa and found that all the models were anti-persistent. Furthermore, in Govender et al. [
4], the authors looked at the clustering of solar irradiance patterns related to cloud cover forecasting from climate predictions using numerical data for the forecasting of solar power or irradiance for the following day.
Amarasinghe et al. [
13] used a generalised ensemble model incorporating deep learning methods to come up with solar power predictions. A comparison of the performance of this method was done against support vector regression, deep belief network and random forest regression models and their results showed that their proposed method was the best. Marizt et al. [
14] applied GPR for energy predictions using the Bayesian framework. In Dahl and Bonilla [
15], the authors worked on a study applying Gaussian process models to forecast solar power for 37 residential sites in a town called Adelaide in Australia. They used an integrated multi-site model without using prior data de-trending, this was achieved by capturing diurnal cycles, and discovered that the multi-site modelling was better than the single-site methods with varying weather conditions. In Hanany et al. [
16], the authors did a forecasting study on GHI by applying GPR basing their study on kernel study. They applied several kernels and found that the quasi-periodic kernels outperformed most of them. Research on forecasting of solar power using grouped Gaussian processes was done by Dahl and Bonilla [
17]. They applied to multitask GP models with observations being linear with several latent node functions and also based on weight functions on priors. They used grouped coupled priors to solve spatial dependence between functions. Their method improved forecasting accuracy as compared to benchmark models used.
Tipping [
18] did research making use of a Bayesian framework to obtain sparse solutions to regression and classification of tasks applying linear parameter models. The research adopted a method called relevant vector machine (RVM) and a function family of the support vector machine (SVM). They found that the Bayesian method provides accurate values which make use of fewer basic functions than the SVM.
Quinonero [
19] applied Gaussian processes and relevance vector machines from a Bayesian perspective not applying sampling methods of their interest in computational effection models. They worked on an improved RVM which showed that it had better predictive power. They also looked at another type of GP called reduced rank Gaussian processes (RRGPs) which are equivalent to the infinite extended linear models. Their results proved that the GPs will encounter a problem of the appropriateness of predictiveness of predictive variances, which was solved by modifying the classic RRGP. GPs and RVMs were used to derive equations for predicting uncertainty in time series that is multi-step allowing predictive uncertainties.
Martino and Read [
20] studied probabilistic Bayesian analysis by applying a joint relationship between Gaussian processes and relevance vector machines. They used these to come up with a framework to view these approaches by applying kernel ridge regression and drawing connections among them by including aspects such as filtering, smoothing and interpolation. A relationship between these methods and the other methods such as linear kernel smoothers, Kalman filtering, smoothing and interpolation was studied. The results showed that the GP had a good behaviour of the predictive variance but it is restricted by the choice of a kernel function and its results of Kalman smoothing produced the same results.
1.3. Contributions and Research Highlights
The main contribution of this paper is in the use of a GPR model coupled with the core vector methodology which is used in forecasting GHI using South African data. To the best of our knowledge, this is the first application of GPR coupled with core vector regression in which the minimum enclosing ball is applied on GHI data. The other contribution is the application of MEB to select an appropriate kernel to be used coupled with GPR, it finds the ball that contains a given set of points with a minimum radius. The selection of kernels using MEB gives a description of the data domain that is accurate for a given data set. The CVM algorithm is much faster than the benchmark models, it can manage a bigger dataset than the SVM and GBM. The minimum enclosed ball is the computation of the smallest circle that accommodates the list of sets of points in the Euclidean plane. GPR takes into consideration real-time system forecasting and this improves the accuracy of the forecasts. This enables one to easily identify changes in the immediate, especially when dealing with weather conditions that are constantly evolving. This is an aspect that is ignored by most researchers when forecasting energy. The last contribution is that of combining forecasts, this was done by combining GPR and CVR. Bates and Granger [
21] analyzed the effects of combining forecasts and demonstrated that a combination of two coupled models improves forecasts since it reduces errors and this makes the forecasts more accurate.
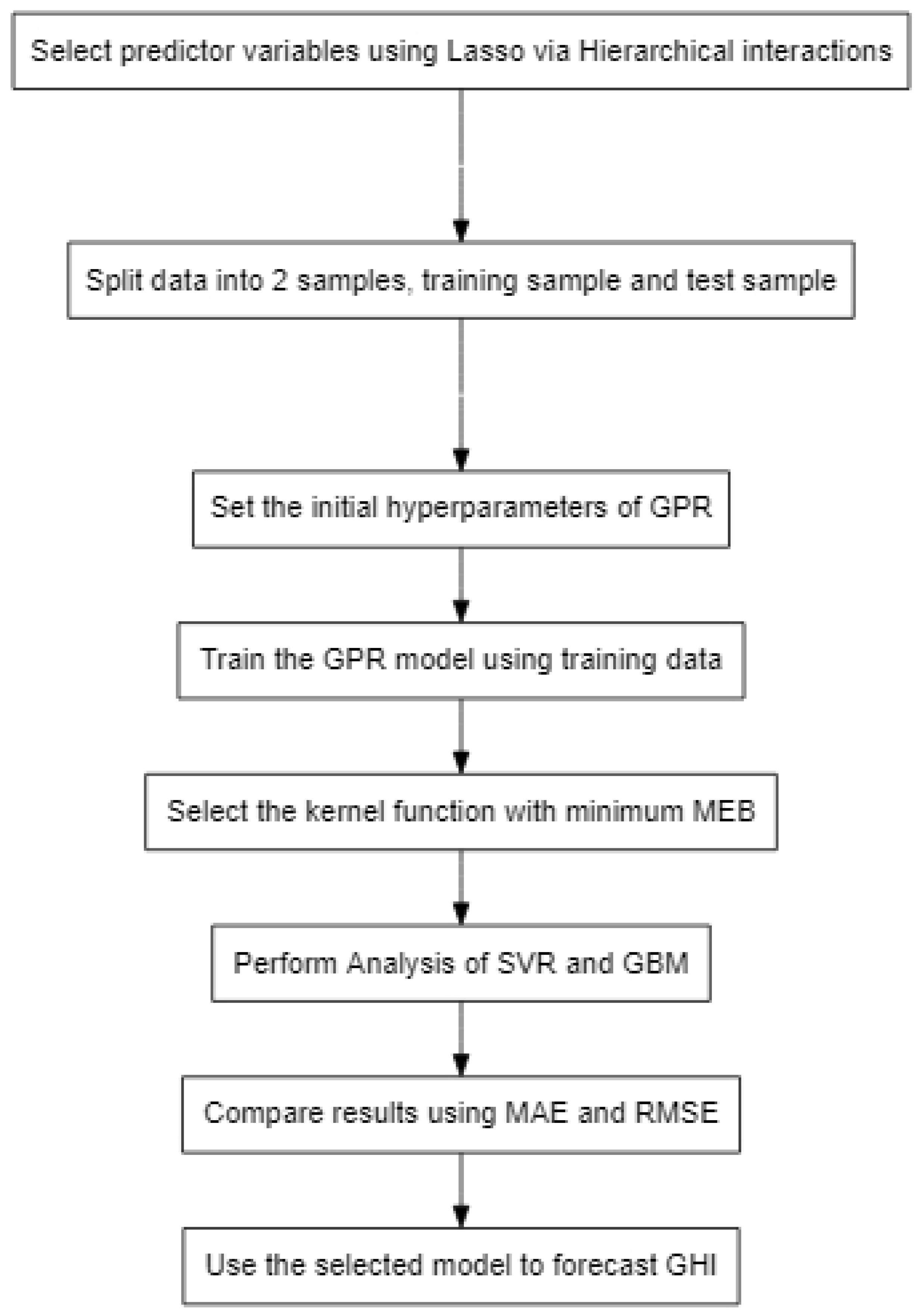
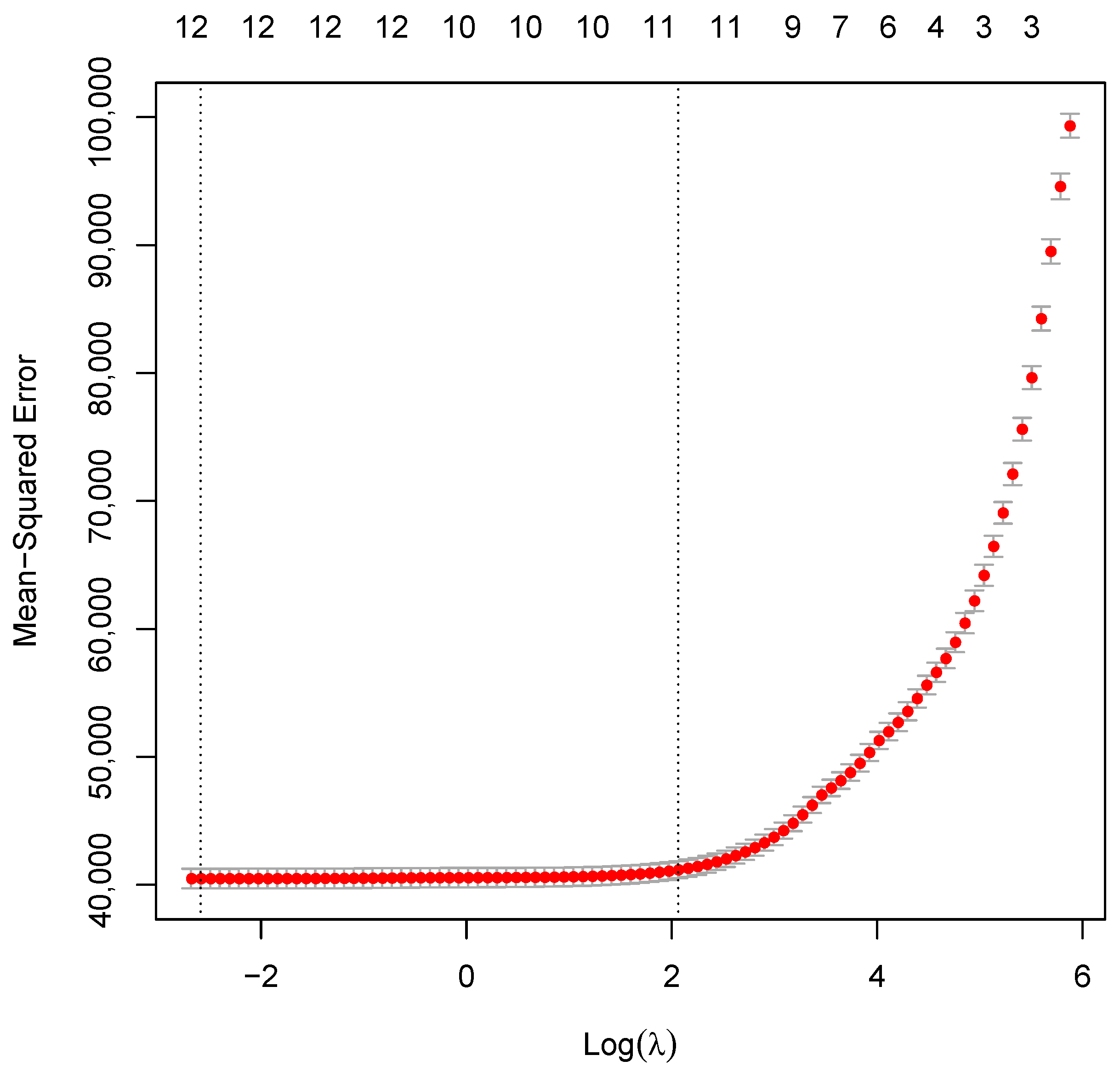
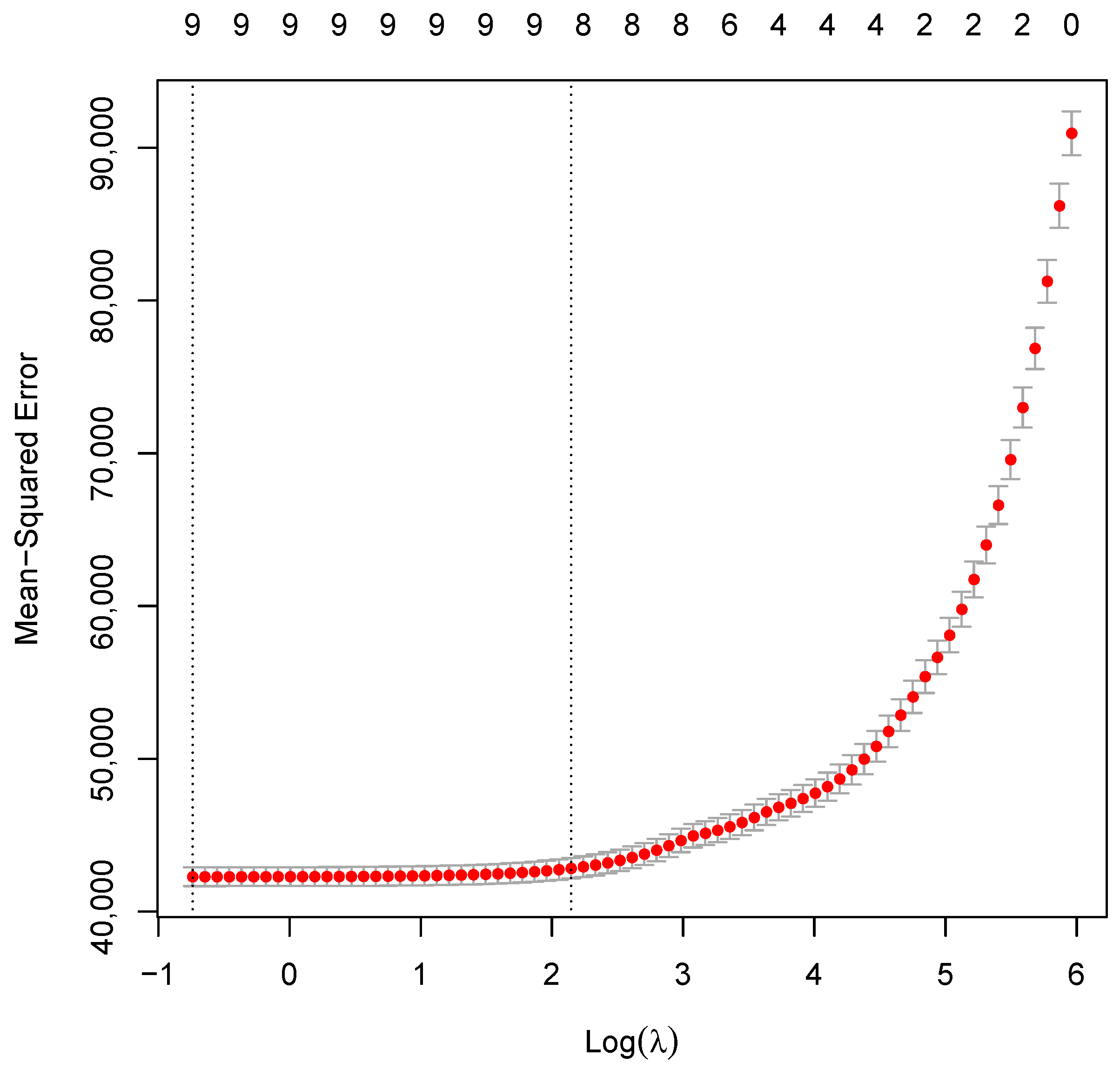
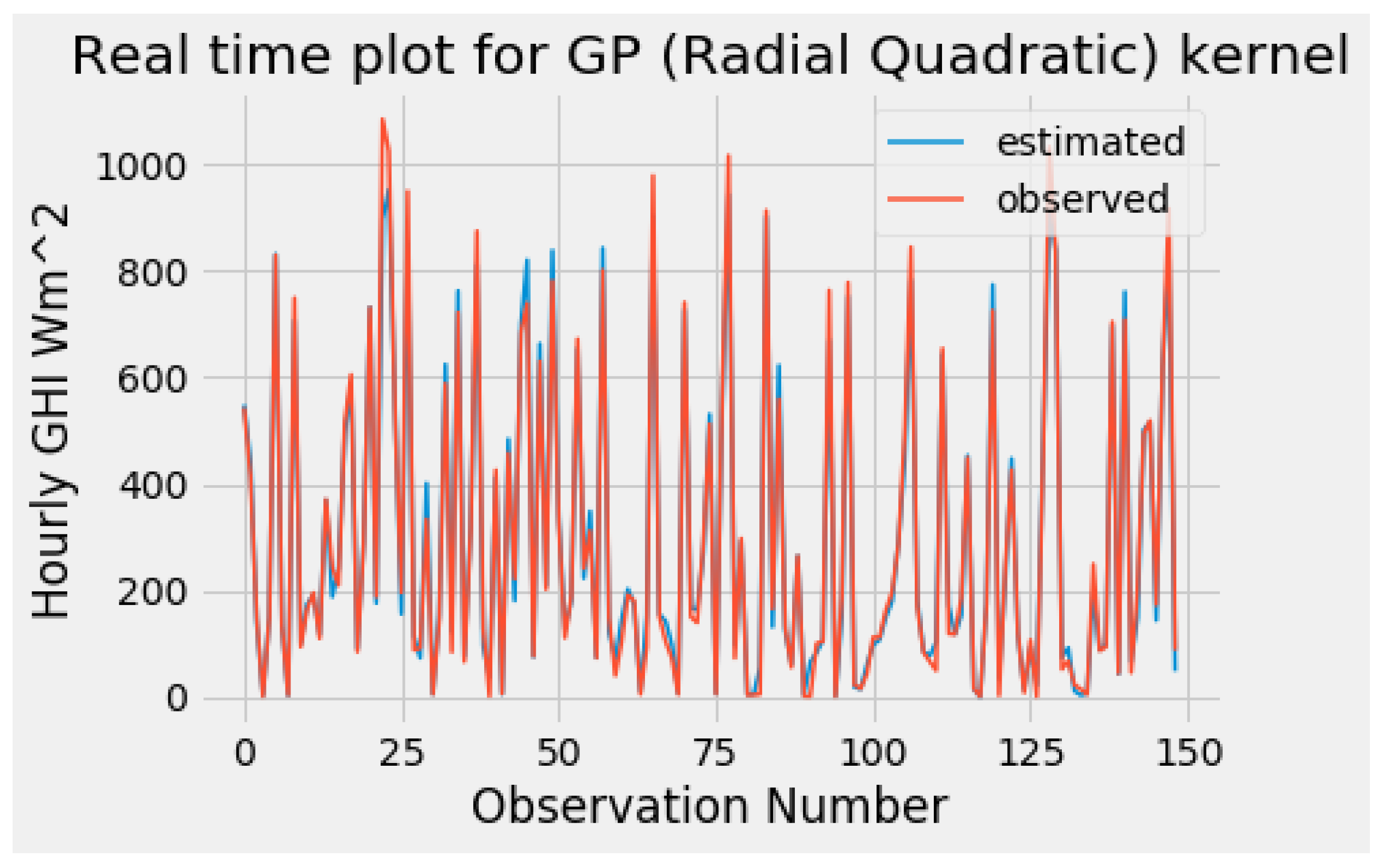
Lasso via hierarchical interactions was applied to select appropriate variables. Application of the GPR technique was used to determine the parameters of the models, which was done using the Bayesian approach to estimation. CVR is used for kernel selection by applying the concept of minimum enclosing ball to choose the appropriate kernel to use. The ratio between margin and radius of the minimum enclosed ball (MEB) is used to calculate a measure of goodness of a kernel to produce a new minimization formulation of kernel learning. After coming up with the Gaussian process regression model we then compared the results with two benchmark models, which are the gradient boosting method (GBM) and support vector modelling (SVM). The model evaluation was done using the following metrics: root mean square error (RMSE), mean absolute error (MAE), mean average percentage error (MAPE) and percentage bias (Pbias) RSME and the MAE for predictive models in each of the two different areas.
The sections that follow are arranged as follows: in
Section 2, models are presented starting with GPR modelling followed by the benchmark models, which are the GBM and SVR, respectively. In
Section 3, empirical results are presented.
Section 4 presents the discussions while
Section 5 concludes the paper.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}