
Data Mining Algorithms for Smart Cities: A Bibliometric Analysis



Abstract
:1. Introduction
- Which are the main DM techniques used in the context of smart cities?
- How can the knowledge base for the interdisciplinary field of smart cities and their intellectual structure be identified?
- How does the field of DM for smart cities quantitatively evolve over time, specifically with regards to publication and citation counts?
- What is the conceptual structure of data technologies for smart cities?
- What is the social network structure of data technologies for the smart cities scientific community?
2. Conceptual Framework
2.1. The Internet of Things (IoT)
2.2. Social Media (SM)
2.3. Smart Cities
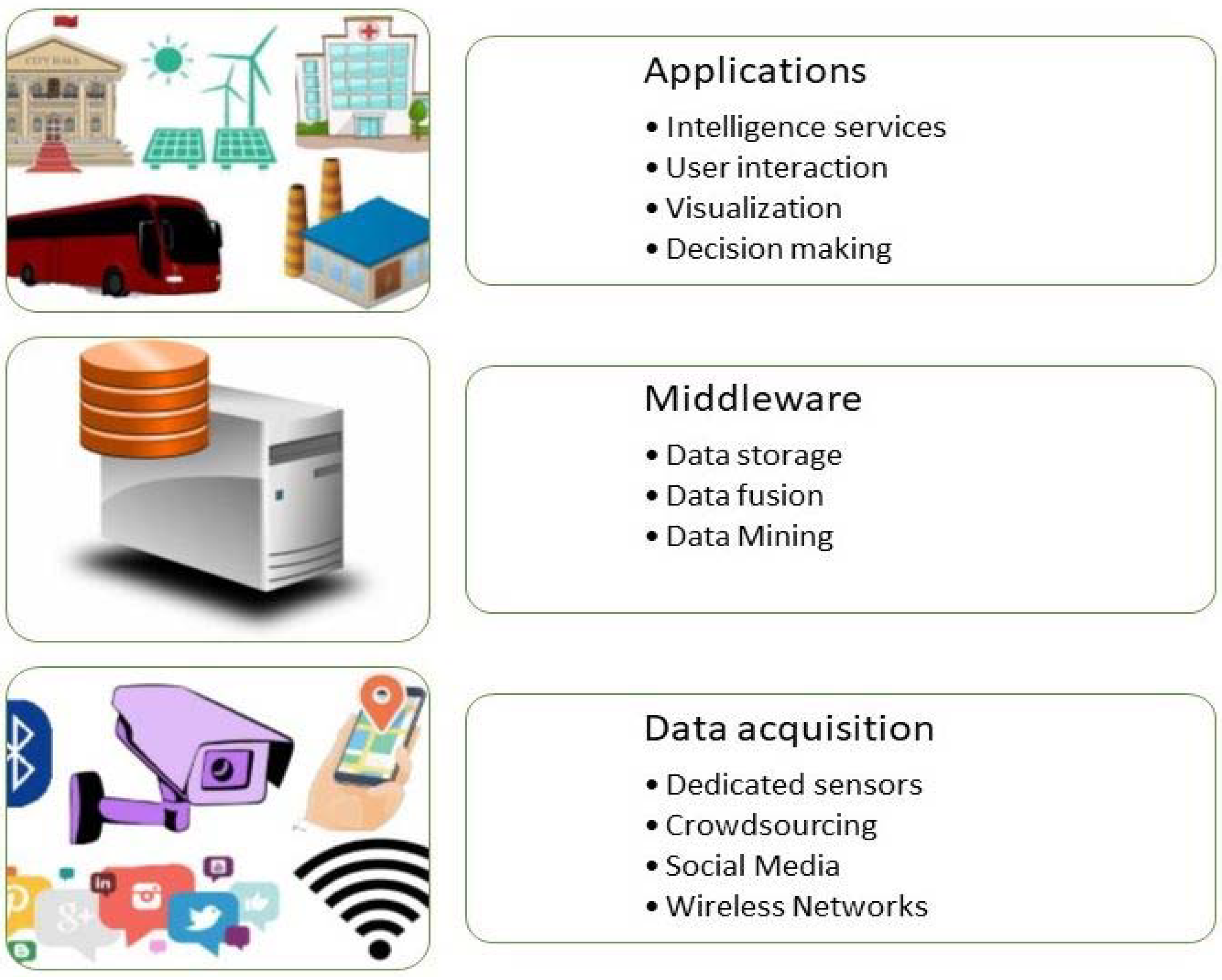
- The “instrumentation” layer. The distributed sensor grid is embedded in infrastructure for acquiring and transferring real-time environmental and social data. Data acquisition elements are responsible for collecting and locally storing external data. It can capture any kind of information, including images, video, sound, temperature, humidity, pressure, etc. The network elements are used for data transferring and information routing between the distributed sensor layer and the service-oriented middleware layer. In other studies [29,30,33,45], we find this layer as two separate layers, sensors and network layer.
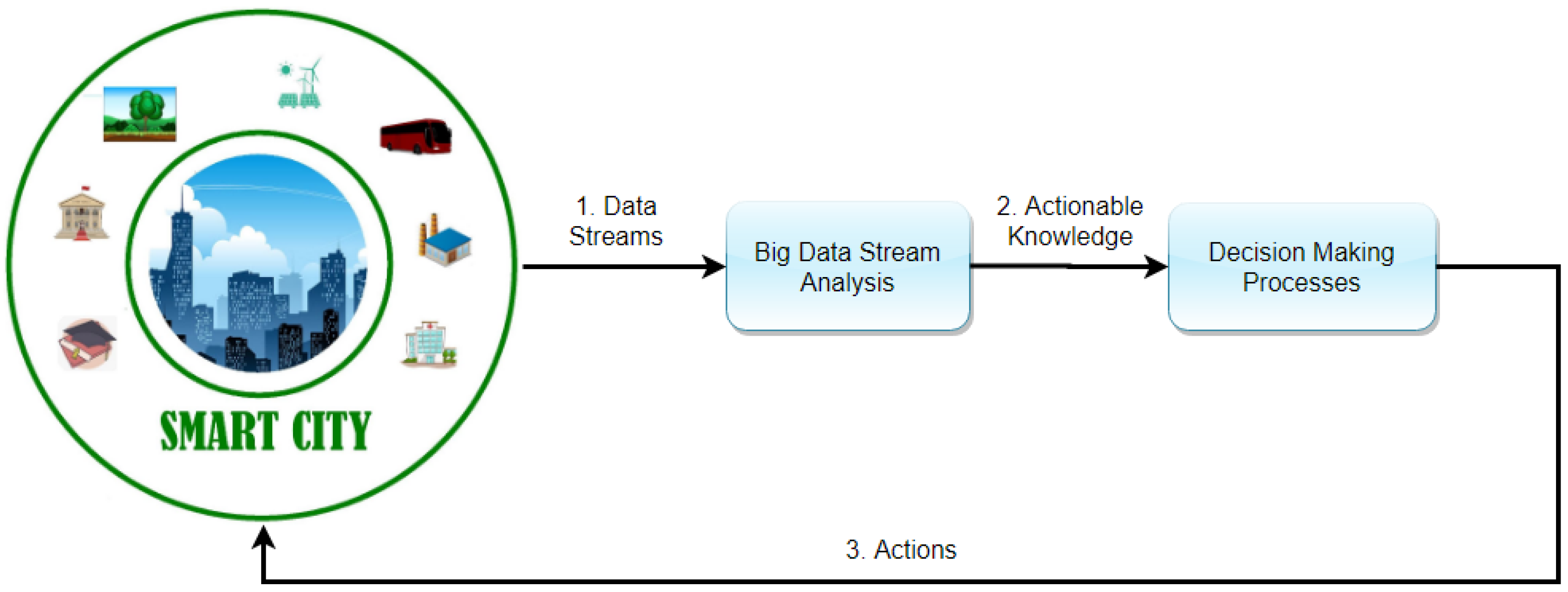
- The service-oriented middleware layer takes charge of massive data storage, real-time analysis, and processing. It is based on cloud computing, DM, and highly efficient index services. The results can be used to support the decision making and effective operation of smart city applications.
- The application layer for end users applies tailored intelligence services to different domains, and it is responsible for interacting directly with the user. It provides the user with information in a comprehensible manner, such as graphical forms, tables, or other presentation types, and facilitates interaction with the system.
2.4. Data Mining Technologies for Smart Cities
2.4.1. Data Preprocessing
2.4.2. Machine Learning (ML) Algorithms
Classification
Forecasting
Unsupervised Learning
Association Rules
Spatial Mining
Natural Language Processing
Sentiment Analysis
User Interface and Visualization
3. Methodology
- Quantitative method: a bibliometric analysis, and
- Qualitative method: a critical review of the 100 most cited articles.
3.1. Bibliometrics
3.2. Bibliometric Analysis Software
3.3. Information Retrieval
4. Results
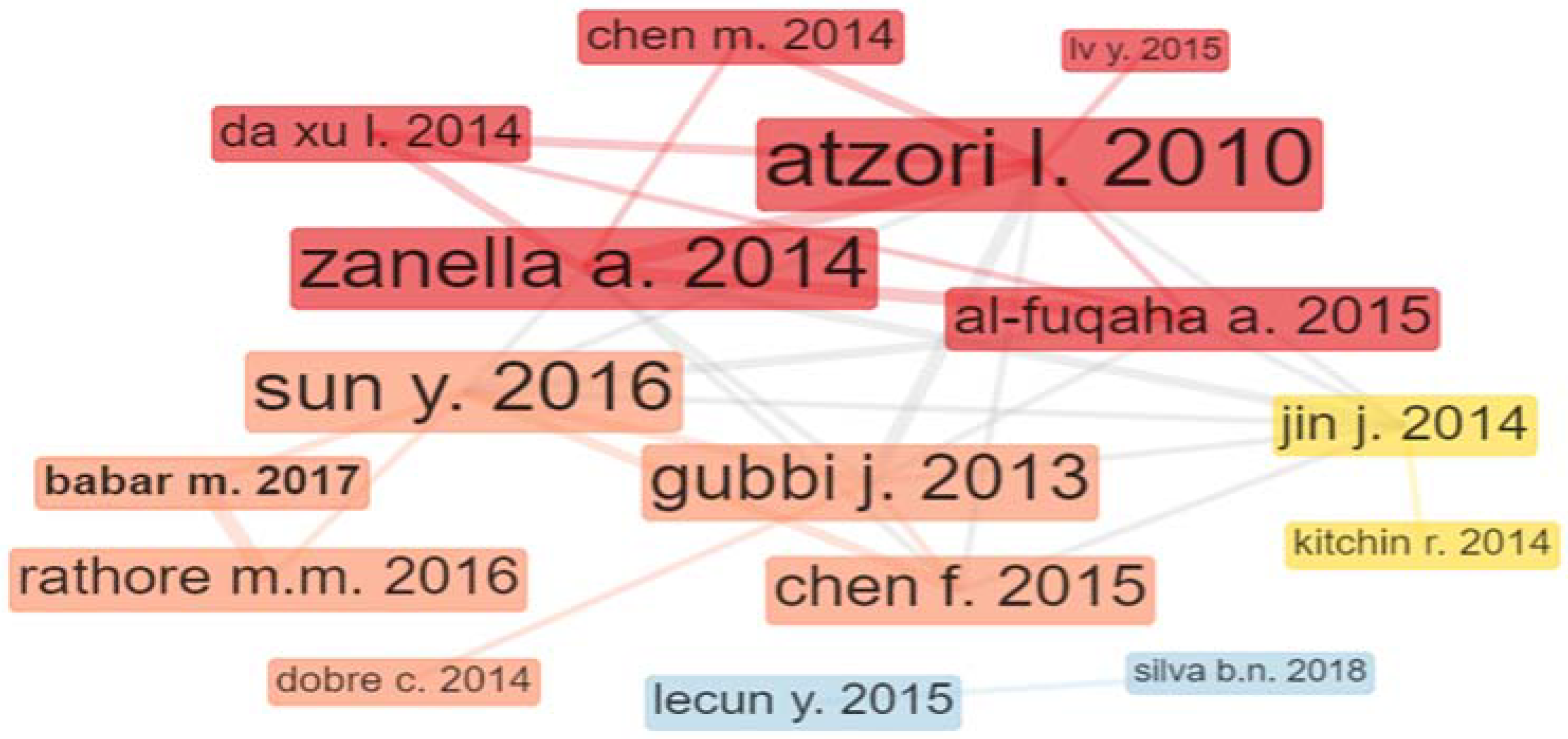
4.1. Most Cited Articles
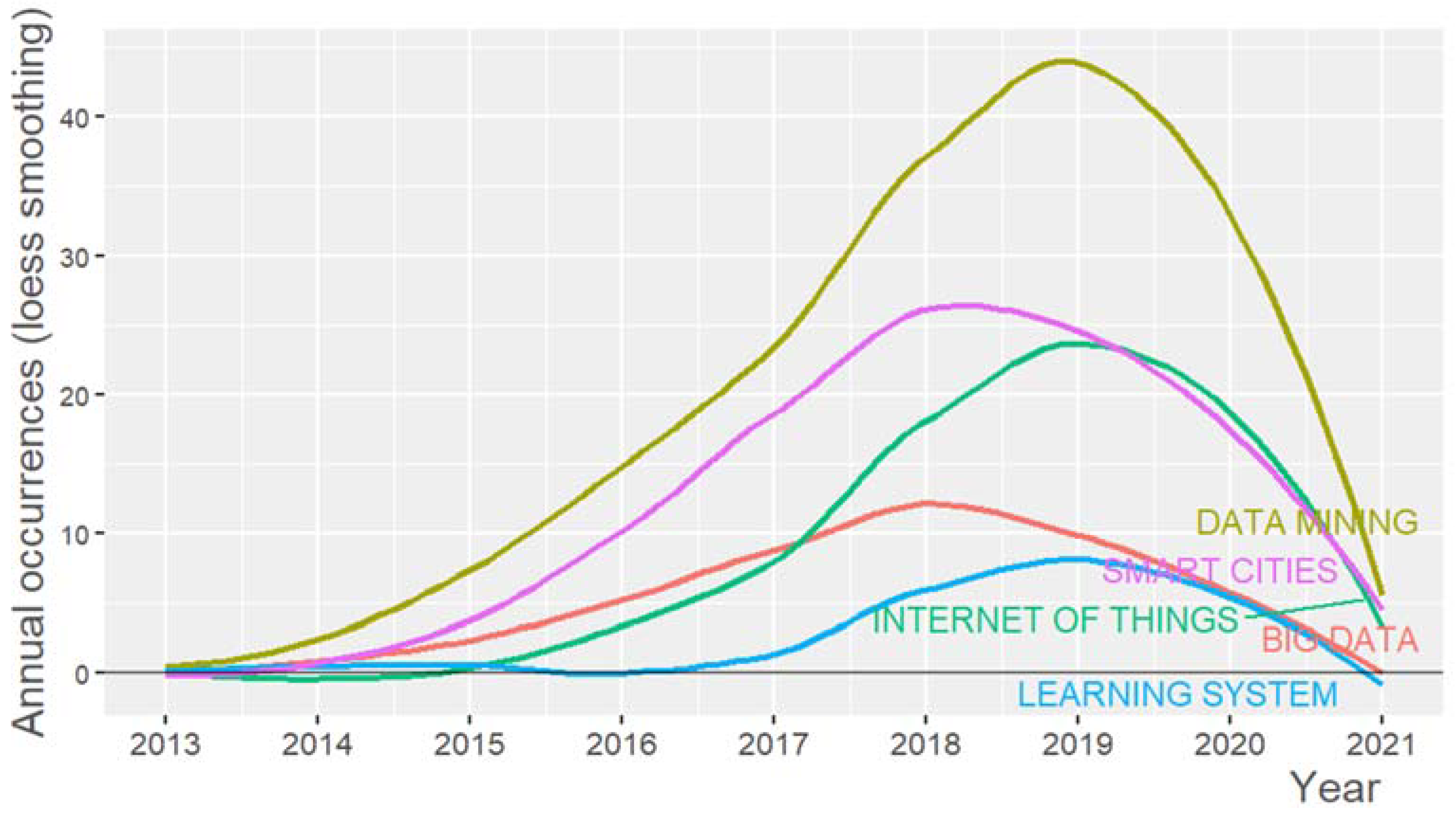
4.2. Annual Scientific Production
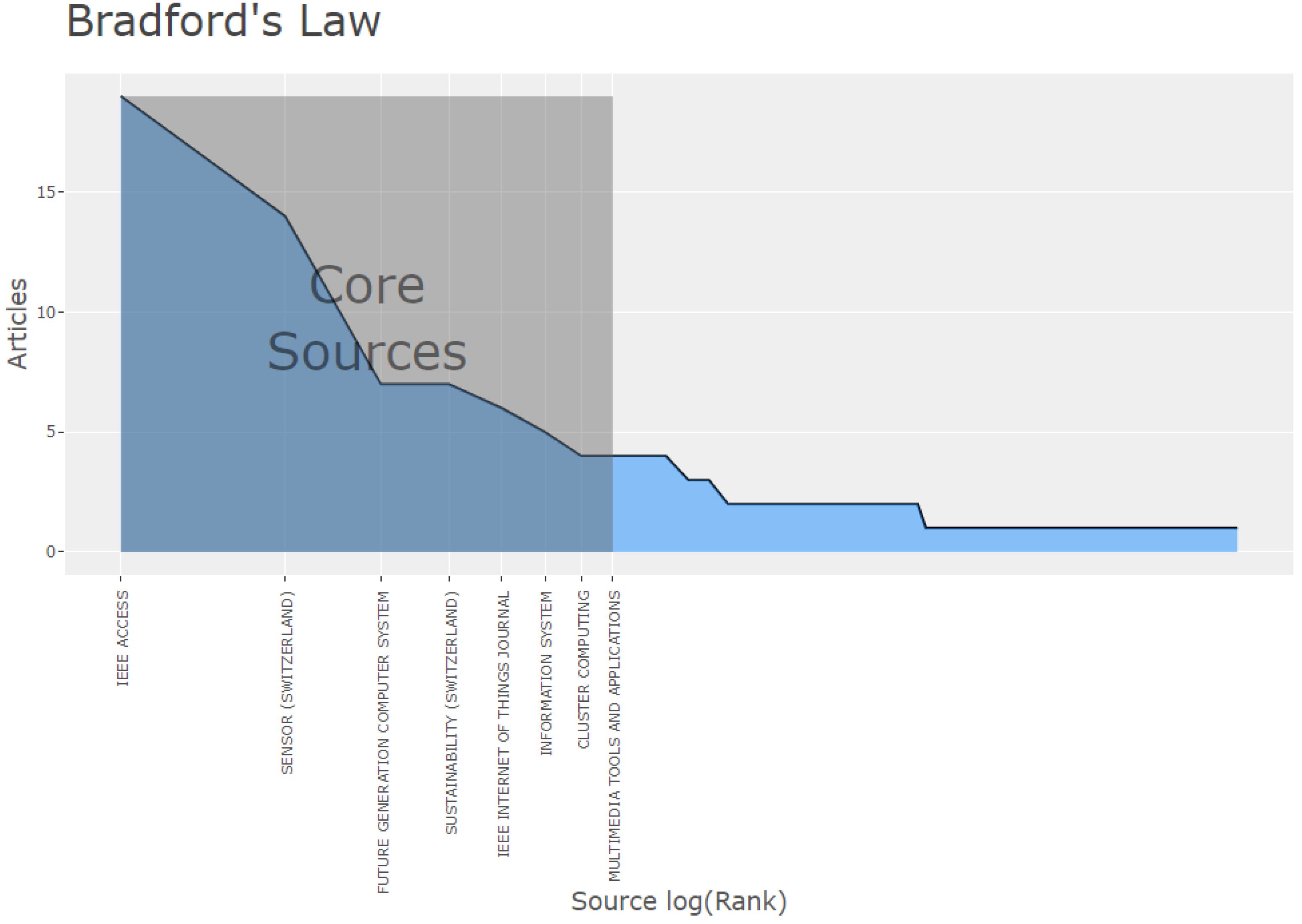
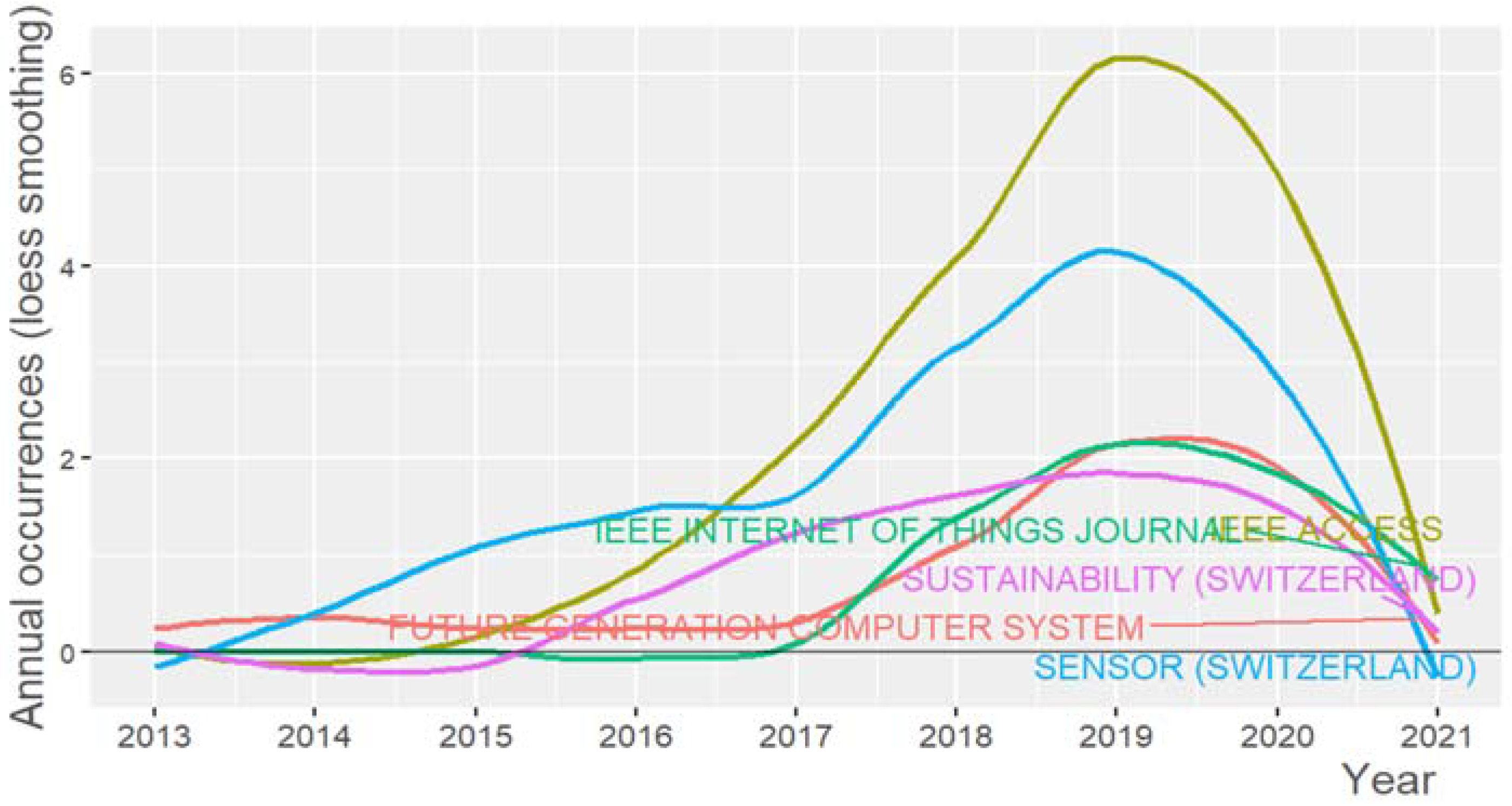
4.3. Sources
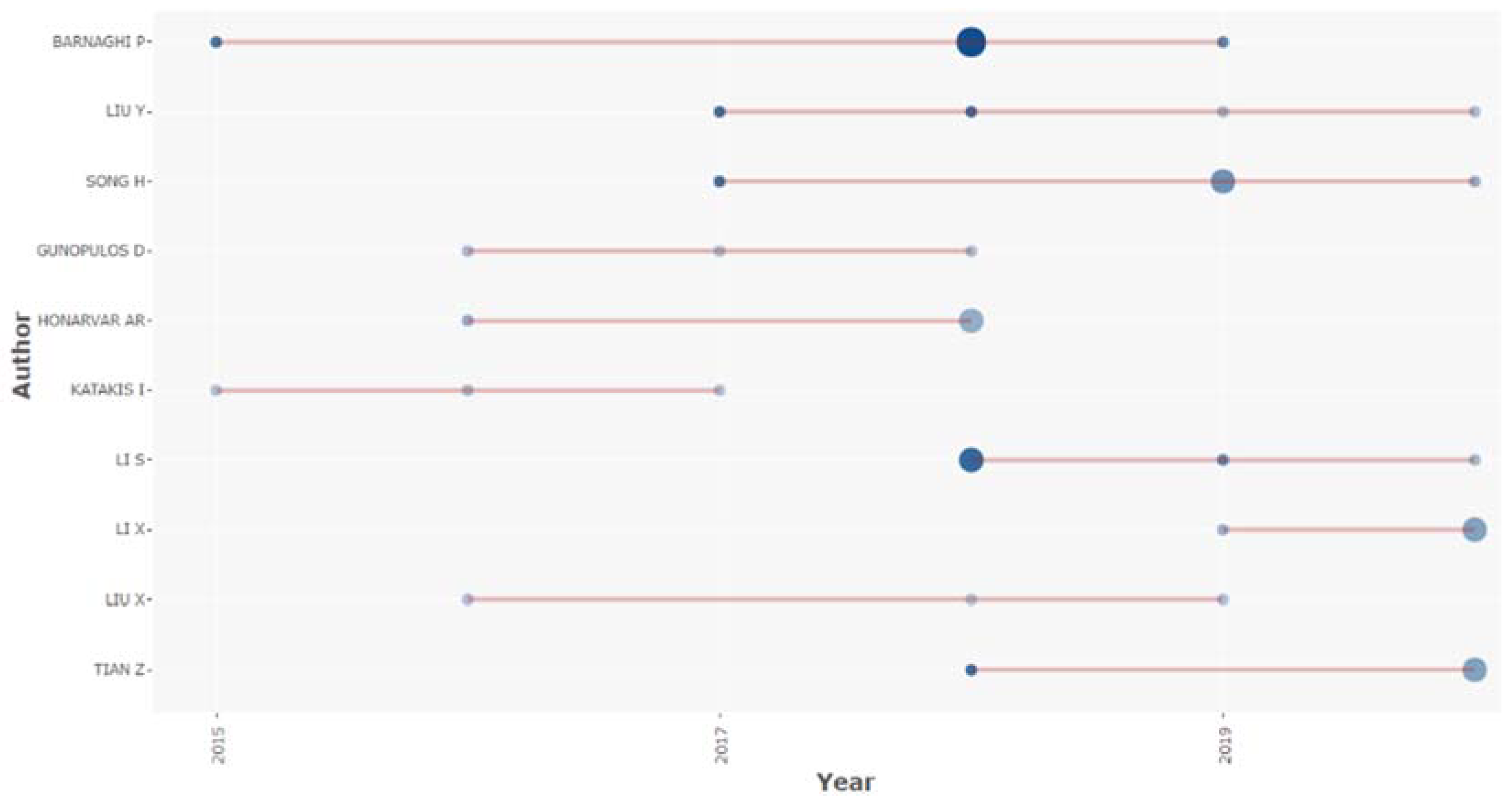
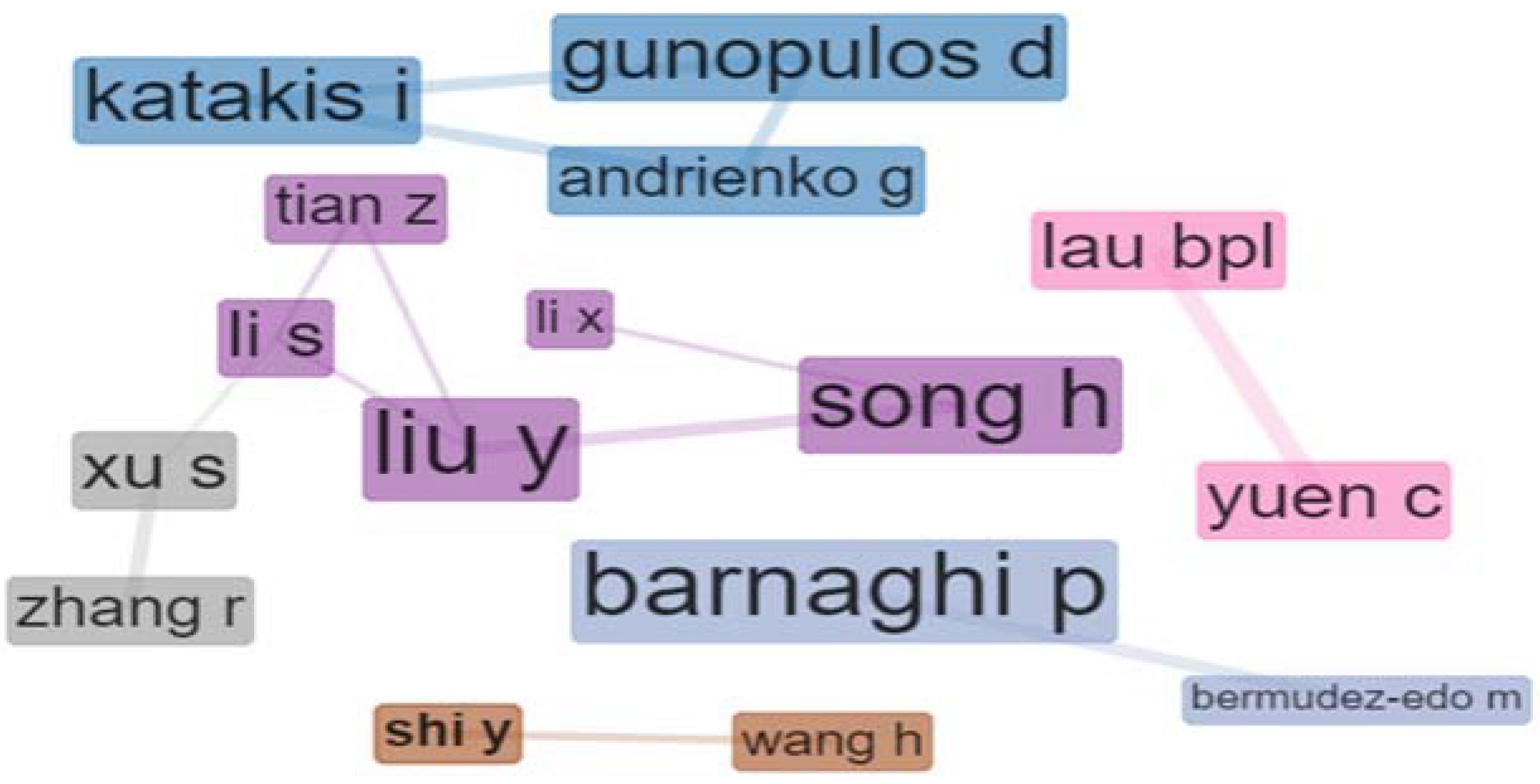
4.4. Authors
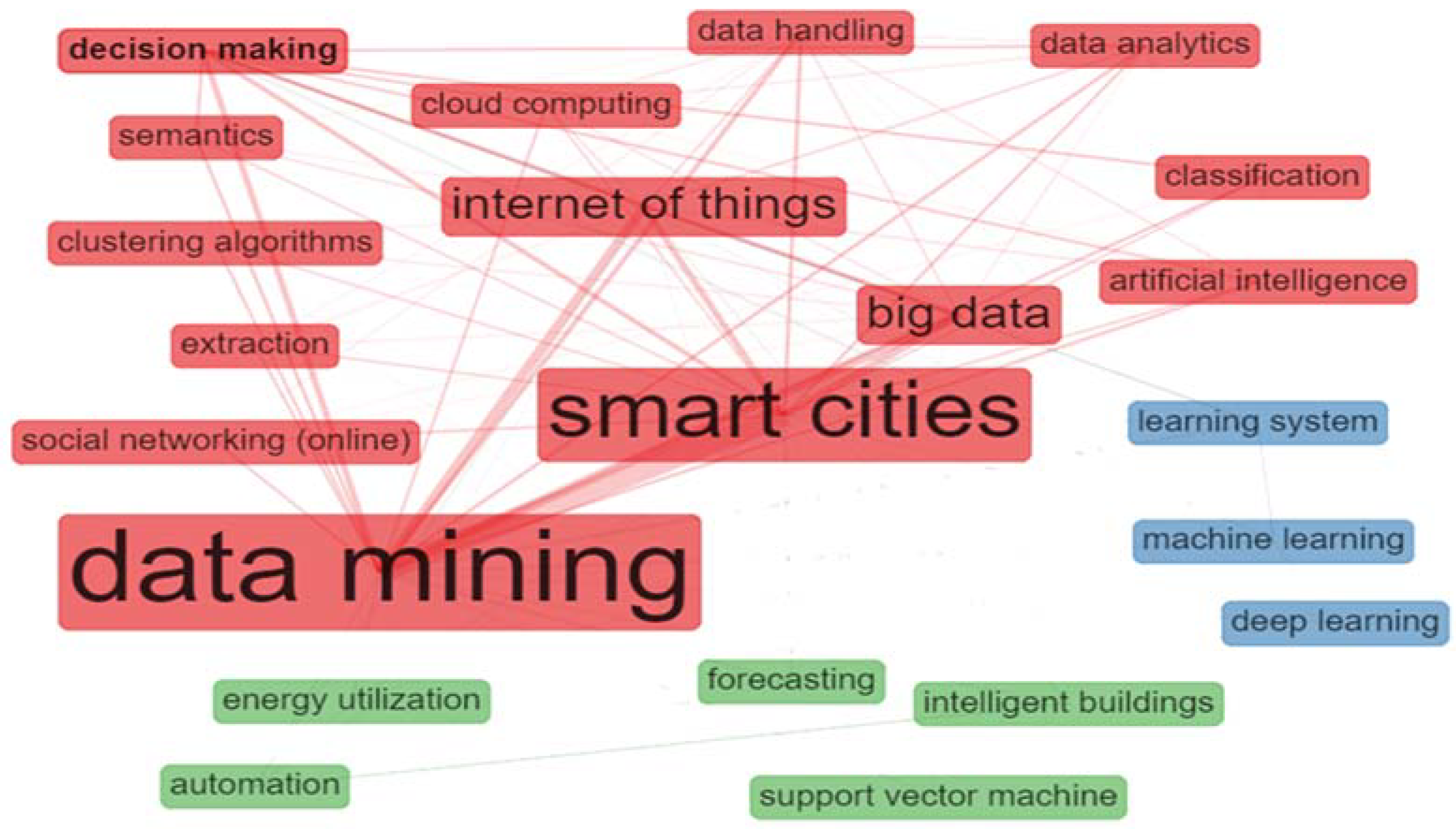
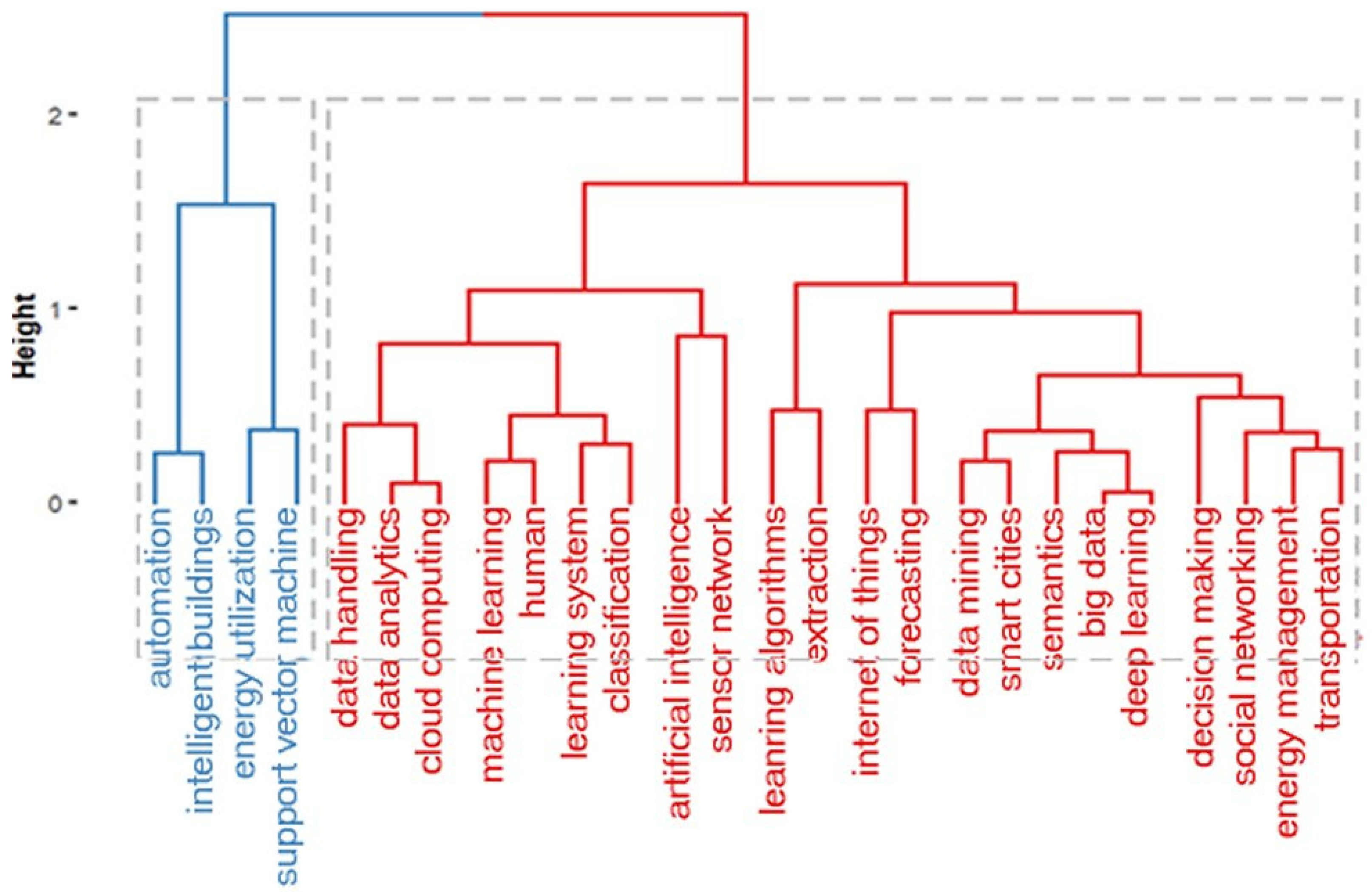
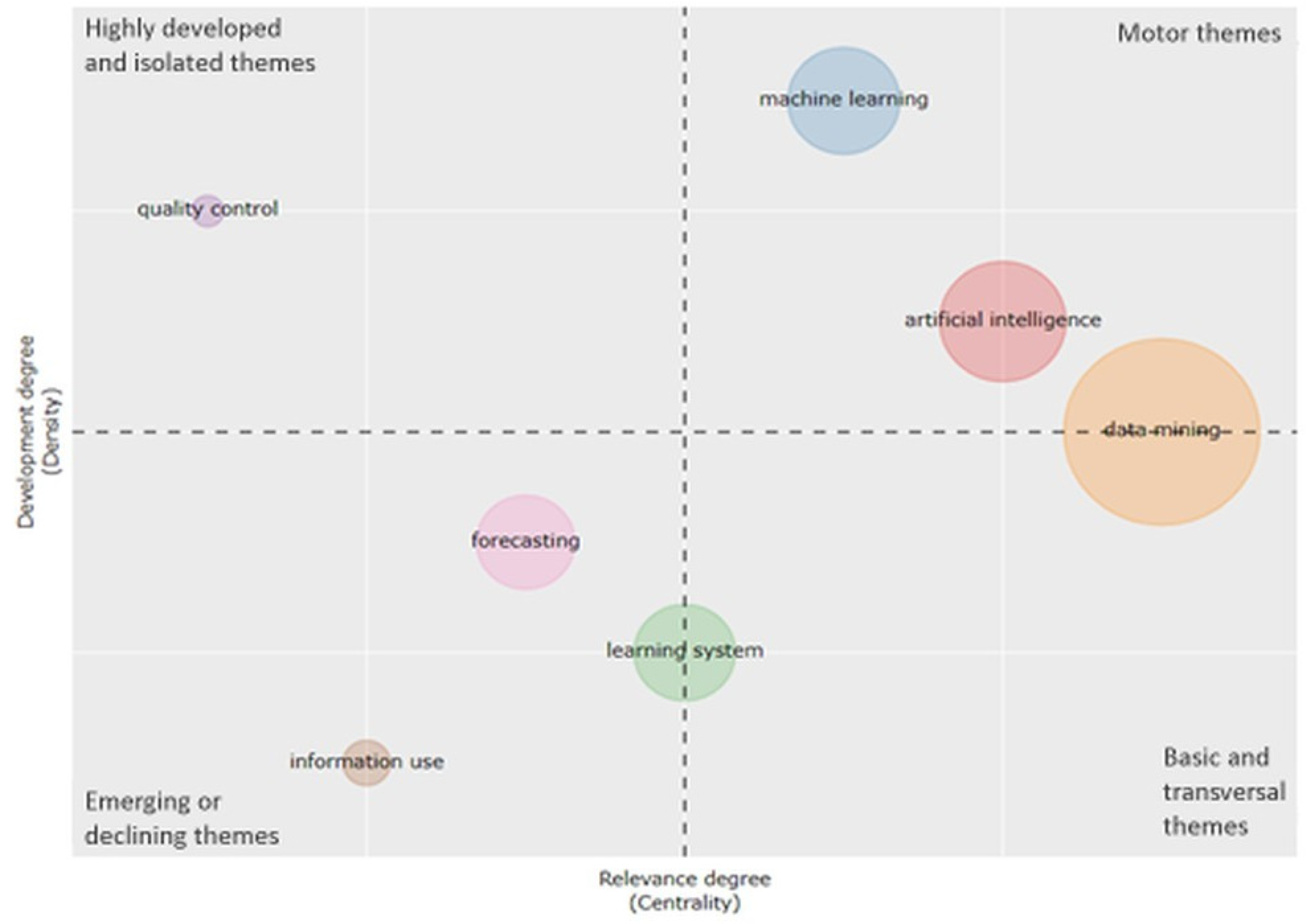
4.5. Content
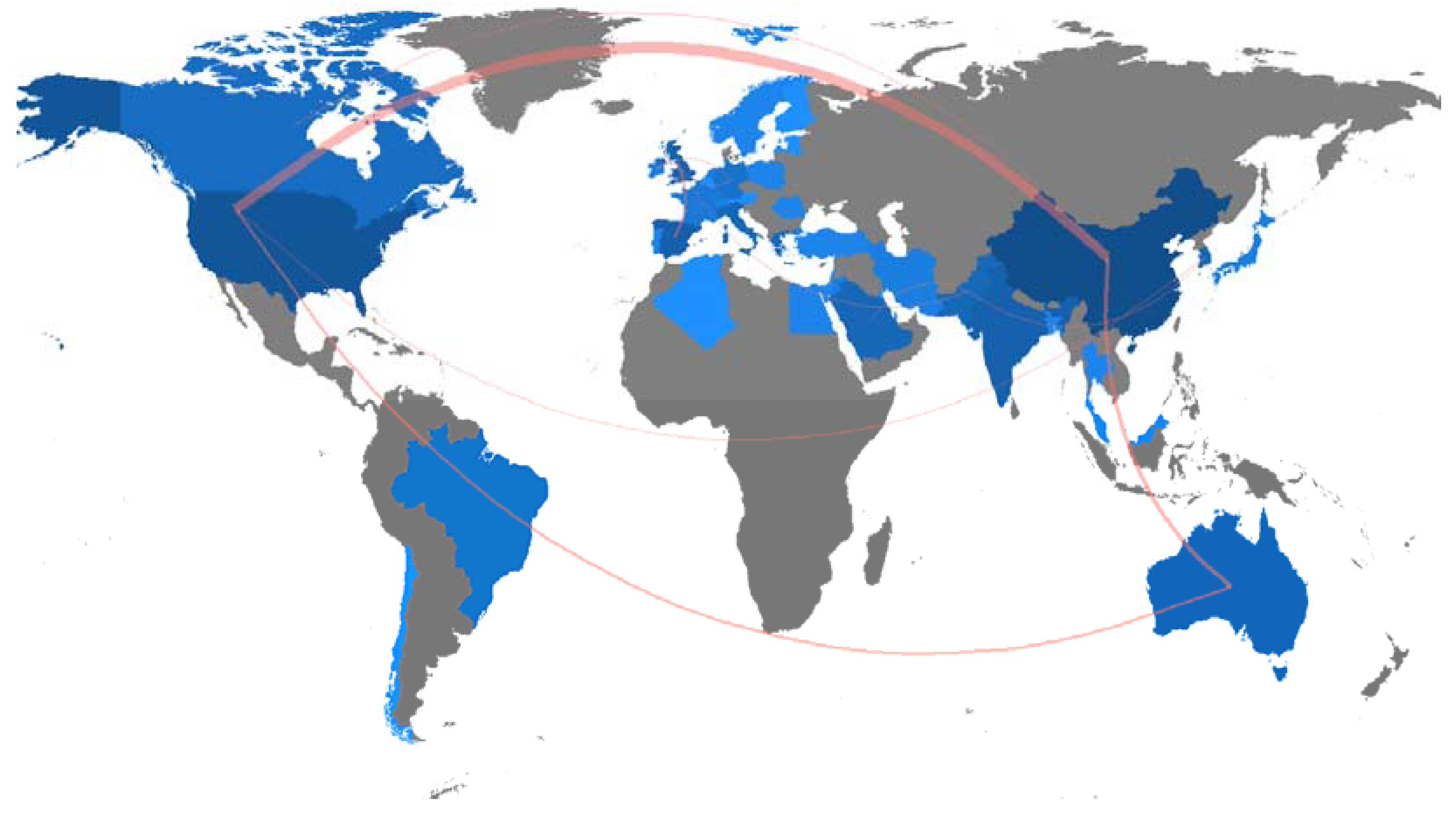
4.6. Social Structure
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANFIS | Adaptive Neuro-Fuzzy Inference System |
| ANN | Artificial Neural Networks |
| AR | Association Rules |
| ARIMA | Auto-Regressive Integrated Moving Average |
| BN | Bayesian Network |
| BoW | Bag of Words |
| BP | Back Propagation |
| BRANN | Bayesian Regularized Artificial Neural Network |
| CBoW | Continuous Bag of Words |
| CNN | Convolutional Neural Network |
| CP-ANN | Counter-Propagation Artificial Neural Network |
| DBN | Deep Belief Network |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
| DL | Deep Learning |
| DLM | Dictionary Learning Model |
| DM | Data Mining |
| DRF | Deep Reinforcement Learning |
| DSL | Digital Subscriber Line |
| DT | Decision Trees |
| DTW | Dynamic Time Warping |
| EA | Evolutionary Algorithms |
| EM | Expectation—Maximization algorithm |
| ETS | Exponential Smoothing State-Space Model |
| FER | Facial Expression Recognition |
| FL | Fuzzy Logic |
| GCT | Granger Causality Test |
| GIS | Graphic Information System |
| GSM | Global System for Mobile communications |
| GPL | General Public License |
| HC | Hierarchical Clustering |
| ICT | Information and Communication Technologies |
| I-EPOS | Iterative Economic Planning and Optimized Selections |
| IF | Impact Factor |
| IoT | Internet of Things |
| KNN | K Nearest Neighbors |
| LDA | Latent Dirichlet Allocation |
| LinR | Linear Regression |
| LogR | Logistic Regression |
| LRT | Likelihood Ratio Test |
| LS | Least Squares |
| LSTM | Long Short-Term Memory |
| LTE | 3GPP Long-Term Evolution |
| ML | Machine Learning |
| MP | Multilayer Perceptron |
| NB | Naïve Bayes |
| NLP | Natural Language Processing |
| NMF | Non-Negative Matrix Factorization |
| OC-SVM | One-Class Support Vector Machines |
| OD | Open Data |
| OD matrix | Origin Destination matrix |
| PAM | Partitioning Around Medoids |
| PCA | Principal Component Analysis |
| POI | Places Of Interest |
| PY | Publication Year |
| RBF | Radial Basis Function |
| RF | Random Forest |
| RFID | Radio Frequency Identification |
| RL | Reinforcement Learning |
| RNN | Recurrent Neural Networks |
| SA | Sentiment Analysis |
| SMA | Social Media Analysis |
| SOM | Self-Organizing Map |
| SSNO | Semantic Sensor Network Ontology |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| TC | Total Citations |
| TESLA | Taylor Expanded Analog Forecasting Algorithm |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Citations | Author(s) | Publication Year | Title | |
|---|---|---|---|---|
| 1 | 276 | Marjani et al. | 2017 | Big IoT Data Analytics: Architecture, Opportunities, and Open Research Challenges |
| 2 | 149 | Lin et al. | 2017 | A Survey of Smart Parking Solutions |
| 3 | 129 | Khan et al. | 2015 | Towards Cloud Based Big Data Analytics for Smart Future Cities |
| 4 | 98 | Yassine et al. | 2017 | Mining Human Activity Patterns from Smart Home Big Data for Health Care Applications |
| 5 | 97 | Manic et al. | 2016 | Building Energy Management Systems: The Age of Intelligent and Adaptive Buildings |
| 6 | 93 | Yang et al. | 2017 | Utilizing Cloud Computing to Address Big Geospatial Data Challenges |
| 7 | 78 | Liang et al. | 2018 | A Survey on Big Data Market: Pricing, Trading and Protection |
| 8 | 69 | Chen et al. | 2018 | Tripimputor: Real-Time Imputing Taxi Trip Purpose Leveraging Multi-Sourced Urban Data |
| 9 | 68 | Moreno et al. | 2017 | Applicability of Big Data Techniques To Smart Cities Deployments |
| 10 | 60 | Osman | 2019 | A Novel Big Data Analytics Framework for Smart Cities |
| 11 | 60 | Din et al. | 2019 | The Internet of Things: A Review of Enabled Technologies and Future Challenges |
| 12 | 60 | Sun and Axhausen | 2016 | Understanding Urban Mobility Patterns with a Probabilistic Tensor Factorization Framework |
| 13 | 55 | Moustafa et al. | 2019 | An Ensemble Intrusion Detection Technique Based on Proposed Statistical Flow Features for Protecting Network Traffic of Internet of Things |
| 14 | 54 | Garcia-Font et al. | 2016 | A Comparative Study of Anomaly Detection Techniques for Smart City Wireless Sensor Networks |
| 15 | 52 | Li et al. | 2015 | Big Data in Smart Cities |
| 16 | 51 | Pena et al. | 2016 | Rule-Based System to Detect Energy Efficiency Anomalies in Smart Buildings, a Data Mining Approach |
| 17 | 47 | Khan et al. | 2017 | Smart City and Smart Tourism: A Case of Dubai |
| 18 | 47 | Anatharam et al. | 2015 | Extracting City Traffic Events From Social Streams |
| 19 | 47 | Li et al. | 2013 | Geomatics for Smart Cities-Concept, Key Techniques, and Applications |
| 20 | 45 | Coelho et al. | 2017 | A GPU Deep Learning Metaheuristic Based Model for Time Series Forecasting |
| 21 | 45 | Nef et al. | 2015 | Evaluation of Three State-of-the-Art Classifiers for Recognition of Activities of Daily Living from Smart Home Ambient Data |
| 22 | 37 | Liu et al. | 2017 | Exploring Data Validity in Transportation Systems for Smart Cities |
| 23 | 36 | Perez-Chacon et al. | 2018 | Big Data Analytics for Discovering Electricity Consumption Patterns in Smart Cities |
| 24 | 35 | Lau et al. | 2019 | A Survey of Data Fusion in Smart City Applications |
| 25 | 34 | Sun et al. | 2018 | Learning Sparse Representation with Variational Auto-Encoder for Anomaly Detection |
| 26 | 34 | Massana et al. | 2017 | Identifying Services for Short-Term Load Forecasting Using Data Driven Models in a Smart City Platform |
| 27 | 34 | De Gennaro et al. | 2016 | Big Data for Supporting Low-Carbon Road Transport Policies in Europe: Applications, Challenges, and Opportunities |
| 28 | 31 | Li et al. | 2019 | IoT Data Feature Extraction and Intrusion Detection System for Smart Cities Based on Deep Migration Learning |
| 29 | 31 | Chui et al. | 2017 | Disease Diagnosis in Smart Healthcare: Innovation, Technologies and Applications |
| 30 | 30 | Qiu et al. | 2018 | Automatic Non-Taxonomic Relation Extraction from Big Data in Smart City |
| 31 | 29 | Yao et al. | 2017 | A Co-Location Pattern-Mining Algorithm with A Density-Weighted Distance Thresholding Consideration |
| 32 | 29 | Xu et al. | 2017 | A Latency and Coverage Optimized Data Collection Scheme for Smart Cities Based on Vehicular Ad-Hoc Networks |
| 33 | 29 | Kim and Chung | 2017 | Depression Index Service Using Knowledge Based Crowdsourcing in Smart Health |
| 34 | 28 | Fernadez-Ares et al. | 2017 | Studying Real Traffic and Mobility Scenarios for a Smart City Using a New Monitoring and Tracking System |
| 35 | 28 | Cerrruela Garcia et al. | 2016 | State of the Art, Trends and Future of Bluetooth Low Energy, Near Field Communication and Visible Light Communication in the Development of Smart Cities |
| 36 | 26 | Musto et al. | 2015 | Crowdpulse: A Framework for Real-Time Semantic Analysis of Social Streams |
| 37 | 24 | Fotopoulou et al. | 2016 | Linked Data Analytics in Interdisciplinary Studies: The Health Impact of Air Pollution in Urban Areas |
| 38 | 23 | Moustaka et al. | 2018 | A Systematic Review for Smart City Data Analytics |
| 39 | 23 | Waheed et al. | 2018 | A Bibliometric Perspective of Learning Analytics Research Landscape |
| 40 | 23 | Ju et al. | 2018 | Citizen-Centered Big Data Analysis-Driven Governance Intelligence Framework for Smart Cities |
| 41 | 23 | Liu et al. | 2016 | A Cloud-Based Taxi Trace Mining Framework for Smart City |
| 42 | 22 | Yang et al. | 2019 | A Model of Customizing Electricity Retail Prices Based on Load Profile Clustering Analysis |
| 43 | 21 | Soomro et al. | 2019 | Smart City Big Data Analytics: An Advanced Review |
| 44 | 21 | Bermudez-Edo et al. | 2018 | Analyzing Real World Data Streams with Spatio-Temporal Correlations: Entropy vs. Pearson Correlation |
| 45 | 21 | Gomede et al. | 2018 | Application of Computational Intelligence to Improve Education in Smart Cities |
| 46 | 21 | Giatsoglou et al. | 2016 | Citypulse: A Platform Prototype for Smart City Social Data Mining |
| 47 | 20 | de Souza et al. | 2019 | Data Mining and Machine Learning to Promote Smart Cities: A Systematic Review from 2000 to 2018 |
| 48 | 20 | Semanski et al. | 2017 | Spatial Context Mining Approach For Transport Mode Recognition From Mobile Sensed Big Data |
| 49 | 19 | Huang et al. | 2016 | An Energy-Efficient Train Control Framework for Smart Railway Transportation |
| 50 | 19 | Liang et al. | 2020 | A Research on Remote Fracturing Monitoring and Decision-Making Method Supporting Smart City |
| 51 | 18 | Xhafa and Barolli | 2014 | Semantics, Intelligent Processing and Services for Big Data |
| 52 | 16 | Kolozali et al. | 2019 | Observing the Pulse of a City: A Smart City Framework for Real-Time Discovery, Federation, and Aggregation of Data Streams |
| 53 | 16 | Shirowzhan, and Sepasgozar | 2019 | Spatial Analysis Using Temporal Point Clouds in Advanced GIS: Methods for Ground Elevation Extraction in Slant Areas and Building Classifications |
| 54 | 16 | Lin et al. | 2017 | Analyzing the Relationship Between Human Behavior and Indoor Air Quality |
| 55 | 15 | Jia et al. | 2018 | Data Driven Congestion Trends Prediction of Urban Transportation |
| 56 | 15 | Lei et al. | 2016 | Robust K-Means Algorithm with Automatically Splitting and Merging Clusters and its Applications for Surveillance Data |
| 57 | 14 | Alkhatib et al. | 2019 | An Arabic Social Media Based Framework for Incidents and Events Monitoring in Smart Cities |
| 58 | 14 | Gaber et al. | 2019 | Internet of Things and Data Mining: From Applications to Techniques and Systems |
| 59 | 14 | Eirinaki et al. | 2018 | A Building Permit System for Smart Cities: A Cloud-Based Framework |
| 60 | 14 | Costa et al. | 2018 | Twittersensing: An Event-Based Approach for Wireless Sensor Networks Optimization Exploiting Social Media in Smart City Applications |
| 61 | 14 | Nesi et al. | 2016 | Geographical Localization of Web Domains and Organization Addresses Recognition by Employing Natural Language Processing, Pattern Matching and Clustering |
| 62 | 13 | Chammas et al. | 2019 | An Efficient Data Model for Energy Prediction Using Wireless Sensors |
| 63 | 13 | Leung et al. | 2019 | AI-Based Sensor Information Fusion for Supporting Deep Supervised Learning |
| 64 | 13 | D’Aniello et al. | 2018 | An Approach Based on Semantic Stream Reasoning to Support Decision Processes in Smart Cities |
| 65 | 13 | Honavar and Sami | 2016 | Extracting Usage Patterns from Power Usage Data of Homes’ Appliances in Smart Home Using Big Data Platform |
| 66 | 12 | Chen et al. | 2019 | Visualization Model of Big Data Based on Self-Organizing Feature Map Neural Network and Graphic Theory for Smart Cities |
| 67 | 12 | Khadam et al. | 2019 | Digital Watermarking Technique for Text Document Protection Using Data Mining Analysis |
| 68 | 12 | Gonzalez-Vidal et al. | 2018 | BEATS: Blocks of Eigenvalues Algorithm for Time Series Segmentation |
| 69 | 12 | Tse et al. | 2018 | Social Network Based Crowd Sensing for Intelligent Transportation and Climate Applications |
| 70 | 12 | Olszewski et al. | 2018 | Solving “Smart City” Transport Problems by Designing Carpooling Gamification Schemes with Multi-Agent Systems: The Case of the So-Called “Mordor of Warsaw” |
| 71 | 12 | Zear et al. | 2016 | Intelligent Transport System: A Progressive Review |
| 72 | 11 | Rawashdeh et al. | 2020 | A Knowledge-Driven Approach for Activity Recognition in Smart Homes Based on Activity Profiling |
| 73 | 11 | Kong et al. | 2019 | CoPFun: an Urban Co-occurrence Pattern Mining Scheme Based on Regional Function Discovery |
| 74 | 11 | Bellini et al. | 2017 | Wi-Fi Based City Users’ Behaviour Analysis for Smart City |
| 75 | 11 | Oralhan et al. | 2017 | Smart City Application: Internet of Things (IoT) Technologies Based Smart Waste Collection Using Data Mining Approach and Ant Colony Optimization |
| 76 | 11 | Wang and Li | 2016 | Traffic and Transportation Smart with Cloud Computing on Big Data |
| 77 | 10 | Ammer et al. | 2019 | Comparative Analysis of Machine Learning Techniques for Predicting Air Quality in Smart Cities |
| 78 | 10 | Zou et al. | 2018 | A Novel Network Security Algorithm Based on Improved Support Vector Machine from Smart City Perspective |
| 79 | 10 | Tausif et al. | 2017 | Towards Designing Efficient Lightweight Ciphers for Internet of Things |
| 80 | 10 | Souza et al. | 2016 | Using Big Data and Real-Time Analytics to Support Smart City Initiatives |
| 81 | 9 | Pasupa et al. | 2019 | Thai Sentiment Analysis with Deep Learning Techniques: A Comparative Study Based on Word Embedding, POS-Tag, and Sentic Features |
| 82 | 9 | Noura et al. | 2019 | Automatic Knowledge Extraction to Build Semantic Web of Things Applications |
| 83 | 9 | Qiu et al. | 2017 | A Data-Driven Robustness Algorithm for the Internet of Things in Smart Cities |
| 84 | 8 | Kumar et al. | 2020 | A Strong and Efficient Baseline for Vehicle Re-Identification Using Deep Triplet Embedding |
| 85 | 8 | Serrano and Bajo | 2019 | Deep Neural Network Architectures for Social Services Diagnosis in Smart Cities |
| 86 | 8 | Pan, Hariri, and Pacheco | 2019 | Context Aware Intrusion Detection for Building Automation Systems |
| 87 | 8 | Liang et al. | 2019 | Search Engine for the Internet of Things: Lessons from Web Search, Vision, and Opportunities |
| 88 | 8 | Puschmann et al. | 2019 | Using LDA to Uncover the Underlying Structures and Relations in Smart City Data Streams |
| 89 | 8 | Zuhairy and Al Zamil | 2018 | Energy-Efficient Load Balancing in Wireless Sensor Network: An Application of Multinomial Regression Analysis |
| 90 | 7 | Duan et al. | 2020 | Operating Efficiency-Based Data Mining on Intensive Land Use in Smart City |
| 91 | 7 | Bosse and Engel | 2019 | Real-Time Human-In-The-Loop Simulation with Mobile Agents, Chat Bots, and Crowd Sensing for Smart Cities |
| 92 | 7 | Wang et al. | 2019 | Next Location Prediction Based On An Adaboost-Markov Model of Mobile Users |
| 93 | 7 | Bracco et al. | 2018 | Advancing Climate Science with Knowledge-Discovery Through Data Mining |
| 94 | 7 | Zaree and Honarvar | 2018 | Improvement of Air Pollution Prediction in a Smart City and its Correlation with Weather Conditions Using Metrological Big Data |
| 95 | 6 | Hassib et al. | 2019 | An Imbalanced Big Data Mining Framework for Improving Optimization Algorithms Performance |
| 96 | 6 | Tsai et al. | 2018 | Data Analytics for Internet of Things: A Review |
| 97 | 6 | Chen and De Luca | 2018 | Technologies for Developing a Smart City in Computational Thinking |
| 98 | 6 | Zhang and Yuan | 2017 | The GPS Trajectory Data Research Based on the Intelligent Traffic Big Data Analysis Platform |
| 99 | 5 | Visvizi and Lytras | 2020 | Sustainable Smart Cities And Smart Villages Research: Rethinking Security, Safety, Well-Being, And Happiness |
| 100 | 5 | Anchal and Mittal | 2019 | Data Mining Techniques for IoT Enabled Smart Parking Environment: Survey |
References
- Townsend, A.M. Smart Cities: Big Data, Civic Hackers, and the Quest for a New Utopia; W.W. Norton & Company: New York, NY, USA, 2013. [Google Scholar]
- Le-Dang, Q.; Le-Ngog, T. Internet of Things (IoT) Infrastructures for Smart Cities. In Handbook of Smart Cities: Software Services and Cyber Infrastructure; Springer: Cham, Switzerland, 2018; pp. 1–30. [Google Scholar]
- Bermudez-Edo, M.; Barnaghi, P.; Moessner, K. Analysing Real World Data Streams with Spatio-temporal Correlations: Entropy vs. Pearson Correlation. Autom. Constr. 2018, 88, 87–100. [Google Scholar] [CrossRef]
- Anatharam, P.; Barnaghi, P.; Thirunarayan, K.; Sheth, A. Extracting City Traffic Events from Social Streams. ACM Trans. Intell. Syst. Technol. 2015, 6, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Lisdorf, A. Demystifying Smart Cities: Practical Perspectives on How Cities Can Leverage the Potential of New Technologies; Apress: Copenhagen, Denmark, 2020. [Google Scholar]
- Lombardi, P.; Giordano, S. Evaluating the Smart and Sustainable Built Environment in Urban Planning. In Handbook of Research on Social, Economic, and Environmental Sustainability in the Development of Smart Cities; IGI Global: Hershey, PA, USA, 2015; pp. 44–59. [Google Scholar]
- He, X.; Wang, K.; Huang, H.; Liu, B. QoE-Driven Big Data Architecture for Smart City. IEEE Commun. Mag. 2018, 56, 88–93. [Google Scholar] [CrossRef]
- Bellini, P.; Cenni, D.; Nesi, P.; Paoli, I. Wi-Fi Based City Users’ Behaviour Analysis for Smart City. J. Vis. Lang. Comput. 2017, 42, 31–45. [Google Scholar] [CrossRef]
- Giatsoglou, M.; Chatzakou, D.; Gkatziaki, V.; Vakali, A.; Anthopoulos, L. CityPulse: A Platform Prototype for Smart City Social Data Mining. J. Knowl. Econ. 2016, 7, 344–372. [Google Scholar] [CrossRef]
- Siryani, J.; Tanju, B.; Eveleigh, T.J. A Machine Learning Decision-Support System Improves the Internet of Things’ Smart Meter Operations. IEEE Internet Things J. 2017, 4, 1056–1066. [Google Scholar] [CrossRef]
- Khan, Z.; Anjum, A.; Soomro, K.; Tahir, M.A. Towards cloud based big data analytics for smart future cities. J. Cloud Comput. 2015, 4, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Mystakidis, A.; Stasinos, N.; Kousis, A.; Sarlis, V.; Koukaras, P.; Rousidis, D.; Kotsiopoulos, I.; Tjortjis, C. Predicting COVID-19 ICU Needs Using Deep Learning, XGBoost and Random Forest Regression with the Sliding Window Technique. Available online: https://smartcities.ieee.org/newsletter/july-2021/predicting-covid-19-icu-needs-using-deep-learning-xgboost-and-random-forest-regression-with-the-sliding-window-technique (accessed on 5 August 2021).
- Chatzinikolaou, T.; Vogiatzi, E.; Kousis, A.; Tjortjis, C. Smart Healthcare Support Using Data Mining and Machine Learning. IoT and WSN based Smart Cities: A Machine Learning Perspective. EAI/Springer Innov. Commun. Comput. 2021, in press. [Google Scholar]
- Nousi, C.; Belogianni, P.; Koukaras, P.; Tjortjis, C. Mining Data to Deal with Epidemics: Case Studies to Demonstrate Real World AI Applications. In Handbook of Artificial Intelligence in Healthcare; Lim, C.-P., Vaidya, A., Jain, K., Mahorkar, V.U., Jain, L.C., Eds.; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Koukaras, P.; Rousidis, D.; Tjortjis, C. Forecasting and Prevention mechanisms using Social Media in Healthcare. Stud. Comput. Intell. 2020, 891, 121–137. [Google Scholar]
- Sun, L.; Axhausen, K.W. Understanding urban mobility patterns with a probabilistic tensor factorization framework. Transp. Res. Part B Methodol. 2016, 91, 511–524. [Google Scholar] [CrossRef]
- Cook, D.J.; Duncan, G.; Sprint, G.; Fritz, R. Using Smart City Technology to Make Healthcare Smarter. Proc. IEEE 2018, 106, 708–722. [Google Scholar] [CrossRef] [PubMed]
- Habibzadeh, H.; Boggio-Dandry, A.; Qin, Z.; Soyata, T.; Kantarci, B.; Mouftah, H. Soft Sensing in Smart Cities: Handling 3Vs Using Recommender Systems, Machine Intelligence, and Data Analytics. IEEE Commun. Mag. 2018, 56, 78–86. [Google Scholar] [CrossRef]
- Mohanty, S.; Choppali, U.; Kougianos, E. Everything You Wanted to Know About Smart Cities: The Internet of Things is the backbone. IEEE Consum. Electron. Mag. 2016, 5, 60–70. [Google Scholar] [CrossRef]
- Alfa, A.S.; Maharaj, B.T.; Ghazalech, H.A.; Awoyemi, B. The Role of 5G and IoT in Smart Cities. In Handbook of Smart Cities: Software Services and Cyber Infrastructure; Springer: Cham, Switzerland, 2018; pp. 31–54. [Google Scholar]
- Ejaz, W.; Anpalagan, A. Internet of Things for Smart Cities: Technologies, Big Data and Security; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Demirer, V.; Aydin, B.; Celic, S.B. Exploring the Educational Potential of Internet of Things (IoT) in Seamless Learning. In The Internet of Things: Breakthroughs in Research and Practice; IGI Global: Hershey, PA, USA, 2017; pp. 1–15. [Google Scholar]
- Honavar, A.R.; Sami, A. Extracting Usage Patterns from Power Usage Data of Homes’ Appliances in Smart Home using Big Data Platform. Int. J. Inf. Technol. Web Eng. 2016, 11, 39–51. [Google Scholar] [CrossRef]
- Anjomshoa, F.; Aloqaily, M.; Kantarci, B.; Erol-Kantarci, M.; Schuckers, S. Social Behaviometrics for Personalized Devices in the Internet of Things Era. IEEE Access 2017, 5, 12199–12213. [Google Scholar] [CrossRef]
- Panda, S. (Ed.) Security Issues and Challenges in Internet of Things. In The Internet of Things: Breakthroughs in Research and Practice; IGI Global: Hersey, PA, USA, 2017; pp. 189–204. [Google Scholar]
- Cisco. Cisco Annual Internet Report (2018–2023); Cisco: San Jose, CA, USA, 2020. [Google Scholar]
- Shariatmadari, H.; Iraji, S.; Jantti, R. From Machine-to-Machine Communications to Internet of Things: Enabling Communication Technologies. In From Internet of Things to Smart Cities: Enabling Technologies; Sun, H., Wang, C., Ahmad, B.I., Eds.; CRC Press: Boca Raton, FL, USA, 2018; pp. 3–34. [Google Scholar]
- Marjani, M.; Nasaruddin, F.; Gani, A.; Karim, A.; Hashem, I.; Siddiqa, A.; Yaqoob, I. Big IoT Data Analytics: Architecture, Opportunities, and Open Research Challenges. IEEE Access 2017, 5, 5247–5261. [Google Scholar]
- Li, D.; Shan, J.; Shao, Z.; Zhou, X.; Yao, Y. Geomatics for Smart Cities—Concept, Key Techniques, and Applications. Geo-Spat. Inf. Sci. 2013, 16, 13–24. [Google Scholar] [CrossRef] [Green Version]
- Massana, J.; Pous, C.; Burgas, L.; Melendez, J.; Colomer, J. Identifying services for short-term load forecasting using data driven models in a Smart City platform. Sustain. Cities Soc. 2017, 28, 108–117. [Google Scholar] [CrossRef] [Green Version]
- Aydin, G.; Hallac, I.R.; Karakus, B. Architecture and Implementation of a Scalable Sensor Data Storage and Analysis System Using Cloud Computing and Big Data Technologies. J. Sens. 2015, 2015, 834217. [Google Scholar] [CrossRef]
- Lee, H. The Internet of Things and Assistive Technologies for People with Disabilities: Applications, Trends, and Issues. In The Internet of Things: Breakthroughs in Research and Practice; Panda, S., Ed.; IGI Global: Hershey, PA, USA, 2017; pp. 161–187. [Google Scholar]
- Moreno, M.; Terroso-Saenz, F.; Gonzalez-Vidal, A.; Valdez-Vela, M.; Skarmeta, M.; Zamora, M.A.; Chang, V. Applicability of Big Data Techniques to Smart Cities Deployments. IEEE Trans. Ind. Inform. 2017, 13, 800–809. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Font, V.; Garrigues, C.; Rifa-Pous, H. A Comparative Study of Anomaly Detection Techniques for Smart City Wireless Sensor Networks. Sensors 2016, 16, 868. [Google Scholar] [CrossRef] [Green Version]
- Fernadez-Ares, A.; Mora, A.; Arenas, M.; Garcia-Sanchez, P.; Romero, G.; Rivas, V.; Castillo, P.A.; Merelo, J. Studying real traffic and mobility scenarios for a Smart City using a new monitoring and tracking system. Future Gener. Comput. Syst. 2017, 76, 163–179. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, X.; Liu, A.; Hu, C. A Latency and Coverage Optimized Data Collection Scheme for Smart Cities Based on Vehicular Ad-Hoc Networks. Sensors 2017, 17, 888. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Yang, C.; Jiang, L.; Xie, S.; Zhang, Y. Intelligent Edge Computing for IoT-Based Energy Management in Smart Cities. IEEE Netw. 2019, 33, 111–117. [Google Scholar] [CrossRef]
- Wang, X.; Li, Z. Traffic and Transportation Smart with Cloud Computing on Big Data. Int. J. Adv. Comput. Sci. Appl. 2016, 13, 1–16. [Google Scholar]
- Arribas-Bel, D.; Kourtit, K.; Nijkamp, P.; Steenbruggen, J. Cyber Cities: Social Media as a Tool for Understanding Cities. Appl. Spat. Anal. Policy 2015, 8, 231–247. [Google Scholar] [CrossRef]
- Koukaras, P.; Tjortjis, C.; Roussidis, D. Social Media Types: Introducing a Data Driven Taxonomy. Computing 2020, 102, 295–340. [Google Scholar] [CrossRef]
- Roussidis, D.; Koukaras, P.; Tjortjis, C. Social Media Prediction: A Literature Review. Multimed. Tools Appl. 2020, 79, 6279–6311. [Google Scholar] [CrossRef]
- Tse, R.; Zhang, L.F.; Lei, P.; Pau, G. Social Network Based Crowd Sensing for Intelligent Transportation and Climate Applications. Mob. Netw. Appl. 2018, 23, 177–183. [Google Scholar] [CrossRef]
- Souza, A.; Figueredo, M.; Cacho, N.; Araujo, D.; Prolo, C.A. Using Big Data and Real-Time Analytics to Support Smart City Initiatives. IFAC Pap. 2016, 49, 257–262. [Google Scholar] [CrossRef]
- Ju, J.; Liu, L.; Feng, Y. Citizen-Centered Big Data Analysis-Driven Governance Intelligence Framework for Smart Cities. Telecommun. Policy 2018, 42, 881–896. [Google Scholar] [CrossRef]
- Li, D.; JianJun, C.; Yuan, Y. Big data in smart cities. Sci. China Inf. Sci. 2015, 58, 108101. [Google Scholar] [CrossRef]
- Stimmel, C.L. Building Smart Cities: Analytics, ICT, and Design Thinking; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Christantonis, K.; Tjortjis, C. Data Mining for Smart Cities: Predicting Electricity Consumption by Classification. In Proceedings of the IEEE 10th International Conference on Information, Intelligence, Systems and Applications (IISA 2019), Patras, Greece, 15–17 July 2019. [Google Scholar]
- Liu, Y.; Weng, X.; Wan, J.; Yue, X.; Song, H.; Vasilakos, A.V. Exploring Data Validity in Transportation Systems for Smart Cities. IEEE Commun. Mag. 2017, 55, 26–33. [Google Scholar] [CrossRef]
- Perez-Chacon, R.; Luna-Romera, J.M.; Troncoso, A.; Martinez-Alvarez, F.; Riquelme, J.C. Big Data Analytics for Discovering Electricity Consumption Patterns in Smart Cities. Energies 2018, 11, 683. [Google Scholar] [CrossRef] [Green Version]
- Pieroni, A.; Scarpato, N.; Di Nunzio, L.; Fallucchi, F.; Raso, M. Smarter City: Smart Energy Grid based on Blockchain Technology. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8, 298–306. [Google Scholar] [CrossRef]
- Del Casino, V.J., Jr. Social Geographies II: Robots. Prog. Hum. Geogr. 2016, 40, 846–855. [Google Scholar] [CrossRef]
- Brisismi, T.S.; Cassandras, C.G.; Osgood, C.; Paschalidis, I.C.; Zhang, A.Y. Sensing and Classifying Roadway Obstacles in Smart Cities: The Street Bump System. IEEE Access 2016, 4, 1301–1312. [Google Scholar] [CrossRef]
- D’Aniello, G.; Gaeta, M.; Orciuoli, F. An Approach Based on Semantic Stream Reasoning to Support Decision Processes in Smart Cities. Telemat. Inform. 2018, 35, 68–81. [Google Scholar] [CrossRef]
- Khan, S.M.; Woo, M.; Nam, K.; Chathoth, P.K. Smart City and Smart Tourism: A Case of Dubai. Sustainability 2017, 9, 2279. [Google Scholar] [CrossRef] [Green Version]
- Kar, A.; Mustafa, S.; Gupta, M.; Ilavarasan, P.; Dwivedi, Y. Understanding Smart Cities: Inputs for Research and Practice. In Advances in Smart Cities: Smarter People, Governance, and Solutions; Kar, A.K., Gupta, M.P., Ilavarasan, P.V., Dwivedi, Y.K., Eds.; CRC Press: Boca Raton, FL, USA, 2017; pp. 1–8. [Google Scholar]
- Williamson, B. Computing brains: Learning algorithms and neurocomputation in the smart city. Inf. Commun. Soc. 2017, 20, 81–99. [Google Scholar] [CrossRef] [Green Version]
- Osman, A. A Novel Big Data Analytics Framework for Smart Cities. Future Gener. Comput. Syst. 2019, 91, 620–633. [Google Scholar] [CrossRef]
- Fotopoulou, E.; Zafeiropoulos, A.; Papaspyros, D.; Hasapis, P.; Tsiolis, G.; Bouras, T.; Mouzakitis, S.; Zanetti, N. Linked Data Analytics in Interdisciplinary Studies: The Health Impact of Air Pollution in Urban Areas. IEEE Access 2016, 4, 149–164. [Google Scholar] [CrossRef]
- Yao, X.; Chen, L.; Peng, L.; Chi, T. A co-location pattern-mining algorithm with a density-weighted distance thresholding consideration. Inf. Sci. 2017, 396, 144–161. [Google Scholar] [CrossRef]
- Yassine, A.; Singh, S.; Alamri, A. Mining Human Activity Patterns from Smart Home Big Data for Health Care Applications. IEEE Access 2017, 5, 13131–13141. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques, 2nd ed.; Morgan Kaufmann Publishers: San Francisco, CA, USA, 2005. [Google Scholar]
- Martinez-Espana, R.; Bueno-Crespo, A.; Timon, I.; Soto, J.; Munoz, A.; Cecilia, J.M. Air-Pollution Prediction in Smart Cities through Machine Learning Methods: A Case Study in Murcia, Spain. J. Univers. Comput. Sci. 2018, 24, 261–276. [Google Scholar]
- Zhang, D.; Tsai, J.J. Advances in Machine Learning Applications in Software Engineering; Idea Group Publishing: Hersey, PA, USA, 2007. [Google Scholar]
- Djenouri, D.; Laidi, R.; Djenouri, Y.; Balasingham, I. Machine Learning for Smart Building Applications: Review and Taxonomy. ACM Comput. Surv. 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Ploennigs, J.; Ba, A.; Barry, M. Materializing the Promises of Cognitive IoT: How Cognitive Buildings are Shaping the Way. IEEE Internet Things J. 2018, 5, 2367–2374. [Google Scholar] [CrossRef]
- Din, I.U.; Guizani, M.; Rodrigues, J.; Hassan, S.; Korotaev, V. Machine Learning in the Internet of Things: Designed Techniques for Smart Cities. Future Gener. Comput. Syst. 2019, 100, 826–843. [Google Scholar] [CrossRef]
- Nef, T.; Urwuler, P.; Buchler, M.; Tarnanas, I.; Stucki, R.; Cazzoli, D.; Muri, R.; Mosimann, U. Evaluation of Three State-of-the-Art Classifiers for Recognition of Activities of Daily Living from Smart Home Ambient Data. Sensors 2015, 15, 11725–11740. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Venkatesh, J.; Aksani, B.; Chan, C.; Akyurek, A.; Simunic, T. Modular and Personalized Smart Health Application Design in a Smart City Environment. IEEE Internet Things J. 2018, 5, 614–623. [Google Scholar] [CrossRef]
- Zhang, N.; Chen, H.; Chen, X.; Chen, J. Forecasting Public Transit Use by Crowdsensing and Semantic Trajectory Mining: Case Studies. Int. J. Geo-Inf. 2016, 5, 180. [Google Scholar] [CrossRef] [Green Version]
- De Gennaro, M.; Paffumi, E.; Martini, G. Big Data for Supporting Low-Carbon Road Transport Policies in Europe: Applications, Challenges, and Opportunities. Big Data Res. 2016, 6, 11–25. [Google Scholar] [CrossRef]
- Lau, B.P.; Marakkalage, S.; Zhou, Y.; Hasan, N.; Yuen, C.; Zhang, M.; Tan, U. A Survey of Data Fusion in Smart City Applications. Inf. Fusion 2019, 52, 357–374. [Google Scholar] [CrossRef]
- Zear, A.; Singh, P.K.; Singh, Y. Intelligent Transport System: A Progressive Review. Indian J. Sci. Technol. 2016, 9, 1–8. [Google Scholar] [CrossRef]
- Wang, J. Encyclopedia of Data Warehousing and Mining; Information Science Reference: Hersey, PA, USA, 2009. [Google Scholar]
- Sajjad, M.; Nasir, M.; Muhammad, K.; Khan, S.; Jan, Z.; Kumar Sangaiah, A.; Elhoseny, M.; Wook Baik, S. Raspberry Pi Assisted Face Recognition Framework for Enhanced Law-Enforcement Services in Smart Cities. Future Gener. Comput. Syst. 2020, 108, 995–1007. [Google Scholar] [CrossRef]
- Gomede, E.; Gaffo, F.H.; Brigano, G.; de Barros, R.; Mendes, L. Application of Computational Intelligence to Improve Education in Smart Cities. Sensors 2018, 18, 267. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hashemi, M. Reusability of the Output of Map-Matching Algorithms Across Space and Time Through Machine Learning. IEEE Trans. Intell. Transp. 2017, 18, 3017–3026. [Google Scholar] [CrossRef]
- Huang, J.; Deng, Y.; Yang, Q.; Sun, J. An Energy-Efficient Train Control Framework for Smart Railway Transportation. IEEE Trans. Comput. 2016, 65, 1407–1417. [Google Scholar] [CrossRef]
- Manic, M.; Wijayasekara, D.; Amarisnghe, K.; Rodriguez-Andina, J. Building Energy Management Systems: The Age of Intelligent and Adaptive Buildings. IEEE Ind. Electron. Mag. 2016, 10, 25–39. [Google Scholar] [CrossRef]
- Lin, T.; Rivano, H.; Le Mouel, F. A Survey of Smart Parking Solutions. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3229–3253. [Google Scholar] [CrossRef] [Green Version]
- Dunham, M.H.; Sridhar, S. Data Mining: Introductory and Advanced Topics; Pearson Education: New Delhi, India, 2006. [Google Scholar]
- Shen, M.; Tang, X.; Zhu, L.; Du, X.; Guizani, M. Privacy-Preserving Support Vector Machine Training Over Blockchain-Based Encrypted IoT Data in Smart Cities. IEEE Internet Things J. 2019, 6, 7702–7712. [Google Scholar] [CrossRef]
- Lin, B.; Huangfu, Y.; Lima, N.; Lobson, B.; Kirk, M.; O’Keeffe, P.; Pressley, S.; Walden, V.; Lamb, B.; Cook, D. Analyzing the Relationship between Human Behavior and Indoor Air Quality. J. Sens. Actuator Netw. 2017, 6, 13. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C. Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Olszewski, R.; Palka, P.; Turek, A. Solving “Smart City” Transport Problems by Designing Carpooling Gamification Schemes with Multi-Agent Systems: The Case of the So-Called “Mordor of Warsaw”. Sensors 2018, 18, 141. [Google Scholar] [CrossRef] [Green Version]
- Rawashdeh, M.; Al Zamil, M.G.; Samarah, S.; Hossain, M.S.; Muhammad, G. A Knowledge-Driven Approach for Activity Recognition in Smart Homes Based on Activity Profiling. Future Gener. Comput. Syst. 2020, 107, 924–941. [Google Scholar] [CrossRef]
- Tzirakis, P.; Tjortjis, C. T3C: Improving a Decision Tree Classification Algorithm’s Interval Splits on Continuous Attributes. Adv. Data Anal. Classif. 2017, 11, 353–370. [Google Scholar] [CrossRef]
- Tjortjis, C.; Keane, J. T3: An Improved Classification Algorithm for Data Mining. Lect. Notes Comp. Sc. 2002, 2412, 50–55. [Google Scholar]
- Christantonis, K.; Tjortjis, C.; Manos, A.; Filippidou, D.; Mougiakou, E.; Christelis, E. Using Classification for Traffic Prediction in Smart Cities. In Proceedings of the 16th International Conference on Artificial Intelligence Applications and Innovations (AIAI 20), Halkidiki, Greece, 5–7 June 2020. [Google Scholar]
- Liapis, S.; Christantonis, K.; Chazan-Pantzalis, V.; Manos, A.; Filippidou, D.; Tjortjis, C. A Methodology Using Classification for Traffic Prediction: Featuring the Impact of COVID-19. Integr. Comput. Aided Eng. (ICAE) 2021, in press. [Google Scholar] [CrossRef]
- Musto, C.; Semeraro, G.; Lops, P.; de Gemmis, M. CrowdPulse: A framework for real-time semantic analysis of social streams. Inf. Syst. 2015, 54, 127–146. [Google Scholar] [CrossRef]
- Christantonis, K.; Tjortjis, C.; Manos, A.; Filippidou, D.; Christelis, E. Smart Cities Data Classification for Electricity Consumption & Traffic Prediction. Autom. Softw. Enginery 2020, 31, 49–69. [Google Scholar]
- Badii, C.; Nesi, P.; Paoli, I. Predicting Available Parking Slots in Critical and Regular Services by Exploiting a Range of Open Data. IEEE Access 2018, 6, 44059–44071. [Google Scholar] [CrossRef]
- Brisimi, T.S.; Xu, T.; Wang, T.; Dai, W.; Adams, W.G.; Paschalidis, I.C. Predicting Chronic Disease Hospitalizations from Electronic Health Records: An Interpretable Classification Approach. Proc. IEEE 2018, 106, 690–707. [Google Scholar] [CrossRef]
- El-Wakeel, A.S.; Li, J.; Noureldin, A.; Hassanein, H.S.; Zorba, N. Towards a Practical Crowdsensing System for Road Surface Conditions Monitoring. IEEE Internet Things J. 2018, 5, 4672–4685. [Google Scholar] [CrossRef]
- Sajjad, M.; Nasir, M.; Ullah, F.; Muhammad, K.; Sangaiah, A.; Baik, S.W. Raspberry Pi Assisted Facial Expression Recognition Framework for Smart Security in Law-Enforcement Services. Inf. Sci. 2019, 479, 416–431. [Google Scholar] [CrossRef]
- Li, F.; Lehtomaki, M.; Elbernik, S.O.; Vosselman, G.; Kukko, A.; Puttonen, E.; Chen, Y.; Hyyppa, J. Semantic Segmentation of Road Furniture in Mobile Laser Scanning Data. ISPRS J. Photogramm. Remote Sens. 2019, 154, 98–113. [Google Scholar] [CrossRef]
- Kwoczek, S.; Di Martino, S.; Nejdl, W. Predicting and visualizing traffic congestion in the presence of planned special events. J. Vis. Lang. Comput. 2014, 25, 973–980. [Google Scholar] [CrossRef]
- Jiang, J.; Claudel, C. A High Performance, Low Power Computational Platform for Complex Sensing Operations in Smart Cities. HardwareX 2017, 1, 22–37. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Li, D.; Deng, L.; Gupta, B.B.; Wang, H.; Choi, C. A Novel CNN Based Security Guaranteed Image Watermarking Generation Scenario for Smart City Applications. Inf. Sci. 2019, 479, 432–447. [Google Scholar] [CrossRef]
- Ghosh, J.; Nag, A. An Overview of Radial Basis Function Networks. In Radial Basis Function Networks 2: New Advances in Design; Howlett, R.J., Jain, L.C., Eds.; Springer: Berlin, Germany, 2001; pp. 1–36. [Google Scholar]
- Huang, C.J.; Kuo, P.H. A Deep CNN-LSTM Model for Particulate Matter Forecasting in Smart Cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [Green Version]
- Cao, J.; Cao, M.; Wang, J.; Yin, C.; Wang, D.; Vidal, P. Urban Noise Recognition with Convolutional Neural Network. Multimed. Tools Appl. 2019, 78, 29031–29041. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhou, D.; Zeng, A.X. HeartID: A Multiresolution Convolutional Neural Network for ECG-Based Biometric Human Identification in Smart Health Applications. IEEE Access 2017, 5, 11805–11816. [Google Scholar] [CrossRef]
- Fenza, G.; Gallo, M.; Loia, V. Drift-Aware Methodology for Anomaly Detection in Smart Grid. IEEE Access 2019, 7, 9645–9657. [Google Scholar] [CrossRef]
- Usman, M.; Jan, A.; He, X.; Chen, J. P2DCA: A Privacy-Preserving-Based Data Collection and Analysis Framework for IoMT Applications. IEEE J. Sel. Areas Commun. 2019, 37, 1222–1230. [Google Scholar] [CrossRef]
- Hariri, R.; Fredericks, E.M.; Bowers, K.M. Uncertainty in Big Data Analytics: Survey, Opportunities, and Challenges. J. Big Data 2016, 6, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Shamshirband, S.; Hadipoor, M.; Baghban, A.; Mosavi, A.; Bukor, J.; Varkonyi-Koczy, A.R. Developing an ANFIS-PSO Model to Predict Mercury Emissions in Combustion Flue Gases. Mathematics 2019, 7, 965. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, R.; Doctor, F.; More, B.; Mahmud, S.; Yousuf, U. Big Data Analytics: Computational Intelligence Techniques and Application Areas. Technol. Forecast. Soc. Chang. 2020, 153, 119253. [Google Scholar] [CrossRef] [Green Version]
- Obinikpo, A.A.; Kantarci, B. Big Sensed Data Meets Deep Learning for Smarter Health Care in Smart Cities. J. Sens. Actuator Netw. 2017, 6, 26. [Google Scholar] [CrossRef] [Green Version]
- Coelho, I.M.; Coelho, V.N.; Luz, E.J.D.S.; Ochi, L.; Guimaraes, F.; Rios, E. A GPU deep learning metaheuristic based model for time series forecasting. Appl. Energy 2017, 201, 412–418. [Google Scholar] [CrossRef]
- Vazquez-Canteli, J.R.; Ulyanin, S.; Kampf, J.; Nagy, Z. Fusing TensorFlow with building energy simulation for intelligent energy management in smart cities. Sustain. Cities Soc. 2019, 45, 243–257. [Google Scholar] [CrossRef]
- Moustafa, N.; Turnbull, B.; Choo, K. An Ensemble Intrusion Detection Technique Based on Proposed Statistical Flow Features for Protecting Network Traffic of Internet of Things. IEEE Internet Things J. 2019, 6, 4815–4830. [Google Scholar] [CrossRef]
- Singh, G.; Bansal, D.; Sofat, S. A Smartphone Based Technique to Monitor Driving Behavior Using DTW and Crowdsensing. Pervasive Mob. Comput. 2017, 40, 56–70. [Google Scholar] [CrossRef]
- Zou, X.; Cao, J.; Guo, Q.; Wen, T. A Novel Network Security Algorithm Based on Improved Support Vector Machine from Smart City Perspective. Comput. Electron. Eng. 2018, 65, 67–78. [Google Scholar] [CrossRef]
- Ta-Shma, P.; Akbar, A.; Gerson-Golan, G.; Hadash, G.; Carrez, F.; Moessner, K. An Ingestion and Analytics Architecture for IoT Applied to Smart City Use Cases. IEEE Internet Things J. 2018, 5, 765–774. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Wang, X.; Xiong, N.; Shao, J. Learning Sparse Representation with Variational Auto-Encoder for Anomaly Detection. IEEE Access 2018, 6, 33353–33361. [Google Scholar] [CrossRef]
- Pena, M.; Biscarri, F.; Guerrero, J.I.; Monedero, I.; Leon, C. Rule-based system to detect energy efficiency anomalies in smart buildings, a data mining approach. Expert Syst. Appl. 2016, 56, 242–255. [Google Scholar] [CrossRef]
- Kanellopoulos, Y.; Antonellis, P.; Tjortjis, C.; Makris, C.; Tsirakis, N. K-Attractors: A Partitional Clustering Algorithm for Numeric Data Analysis. Appl. Artif. Intell. 2011, 25, 97–115. [Google Scholar] [CrossRef]
- Gan, G.; Ma, C.; Wu, J. Data Clustering: Theory, Algorithms and Applications; American Statistical Association: Alexandria, VA, USA, 2007. [Google Scholar]
- Lei, J.; Jiang, T.; Wu, K.; Du, H.; Zhu, G.; Wang, Z. Robust K-means Algorithm with Automatically Splitting and Merging Clusters and its Applications for Surveillance Data. Multimed. Tools Appl. 2016, 75, 12043–12059. [Google Scholar] [CrossRef]
- Nesi, P.; Pantaleo, G.; Tenti, M. Geographical Localization of Web Domains and Organization Addresses Recognition by Employing Natural Language Processing, Pattern Matching and Clustering. Eng. Appl. Artif. Intell. 2016, 51, 202–211. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, J.; Wen, F.; Dong, Z. A Model of Customizing Electricity Retail Prices Based on Load Profile Clustering Analysis. IEEE Trans. Smart Grid 2019, 10, 3374–3386. [Google Scholar] [CrossRef]
- Pournaras, E.; Pilgerstorfer, P.; Asikis, T. Decentralized Collective Learning for Self-managed Sharing Economies. ACM Trans. Auton. Adap. Syst. 2018, 13, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Ghafari, S.M.; Tjortjis, C. A Survey on Association Rules Mining Using Heuristics. WIREs Data Min. Knowl. Discov. 2019, 9, e1307. [Google Scholar] [CrossRef]
- Dong, D.; Tjortjis, C. Experiences of Using a Quantitative Approach for Mining Association Rules. In Proceedings of the 4th International Conference Intelligent Data Engineering and Automated Learning, Hong Kong, China, 21–23 March 2003. [Google Scholar]
- Kong, X.; Li, M.; Li, J.; Tian, K.; Hu, X.; Xia, F. CoPFun: An Urban Co-Occurrence Pattern Mining Scheme Based on Regional Function Discovery. World Wide Web 2019, 22, 1029–1054. [Google Scholar] [CrossRef]
- Yakhchi, S.; Ghafari, S.; Tjortjis, C.; Fazeli, M. ARMICA-Improved: A New Approach for Association Rule Mining. Lect. Notes Artif. Int. 2017, 10412, 296–306. [Google Scholar]
- Agrawal, R.; Strikant, R. Fast Algorithms for Mining Association Rules. In Proceedings of the 20th VLDB Conference, Santiago, Chile, 12–15 September 1994. [Google Scholar]
- Shirowzhan, S.; Sepasgozar, S. Spatial Analysis Using Temporal Point Clouds in Advanced GIS: Methods for Ground Elevation Extraction in Slant Areas and Building Classification. Int. J. Geo-Inf. 2019, 8, 120. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, C.; Pozdnoukhov, A. Enabling real-time city sensing with kernel stream oracles and MapReduce. Pervasive Mob. Comput. 2013, 9, 708–721. [Google Scholar] [CrossRef]
- Mystakidis, A.; Tjortjis, C. Big Data Mining for Smart Cities: Predicting Traffic Congestion using Classification. In Proceedings of the 11th International Conference on Information, Intelligence, Systems and Applications, Piraeus, Greece, 15–17 July 2020. [Google Scholar]
- Costa, G.D.; Duran-Faundez, C.; Andrade, D.C.; Rocha-Junior, J.B.; Peixoto, J.P.J. TwitterSensing: An Event-Based Approach for Wireless Sensor Networks Optimization Exploiting Social Media in Smart City Applications. Sensors 2018, 18, 1080. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lane, H.; Howard, C.; Hapke, H.M. Natural Language Processing in Action: Understanding, Analyzing and Generating Text with Python; Manning Publications: Shelter Island, NY, USA, 2019. [Google Scholar]
- Qiu, J.; Chai, Y.; Liu, Y.; Gu, Z.; Li, S.; Tian, Z. Automatic Non-Taxonomic Relation Extraction from Big Data in Smart City. IEEE Access 2018, 6, 74854–74864. [Google Scholar] [CrossRef]
- Beleveslis, D.; Tjortjis, C.; Psaradelis, D.; Nikoglou, D. A Hybrid Method for Sentiment Analysis of Election Related Tweets. In Proceedings of the 4th IEEE SE Europe Design Automation, Computer Engineering, Computer Networks, and Social Media Conference (SEEDA-CECNSM), Piraeus, Greece, 20–22 September 2019. [Google Scholar]
- Oikonomou, L.; Tjortjis, C. A Method for Predicting the Winner of the USA Presidential Elections Using Data Extracted from Twitter. In Proceedings of the 3rd SE European Design Automation, Computer Engineering, Computer Networks and Society Media Conference (SEEDA_CECNSM18), Kastoria, Greece, 22–24 September 2018. [Google Scholar]
- Eirinaki, M.; Dhar, S.; Mathur, S.; Kaley, A.; Patel, A.; Joshi, A.; Shah, D. A Building Permit System for Smart Cities: A Cloud-Based Framework. Comput. Environ. Urban 2018, 70, 175–188. [Google Scholar] [CrossRef]
- Tsiara, E.; Tjortjis, C. Using Twitter to predict Chart Position for Songs. In Proceedings of the 16th International Conference on Artificial Intelligence and Innovations (AIAI 20), Halkidiki, Greece, 5–7 June 2020. [Google Scholar]
- Lee, K.M.; Yoo, J.; Kim, S.; Lee, J.; Hong, J. Autonomic Machine Learning Platform. Int. J. Inf. Manag. 2019, 49, 491–501. [Google Scholar] [CrossRef]
- Badii, C.; Bellini, P.; Difino, A.; Nesi, P. Sii-Mobility: An IoT/IoE Architecture to Enhance Smart City Mobility and Transportation Services. Sensors 2019, 19, 1. [Google Scholar] [CrossRef] [Green Version]
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-tool for comprehensive science mapping analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Andres, A. Measuring Academic Research; Chandos Publishing: Oxford, UK, 2009. [Google Scholar]
- Waheed, H.; Hassan, S.; Aljohani, N.R.; Wasif, M. A Bibliometric Perspective of Learning Analytics Research Landscape. Behav. Inf. Technol. 2018, 37, 941–957. [Google Scholar] [CrossRef]
- Roemer, R.C.; Borchardt, R. Meaningful Metrics; Association of College and Research Libraries: Chicago, IL, USA, 2015. [Google Scholar]
- Aria, M.; Cuccurullo, C. Bibliometrix R Package. Available online: http://www.bibliometrix.org (accessed on 23 November 2019).
- Gilani, E.; Salimi, D.; Jouyandeh, M.; Tavasoli, K.; Wong, W. A trend study on the impact of social media in decision making. Int. J. Data Netw. 2019, 3, 201–222. [Google Scholar] [CrossRef]
- De Bellis, N. Bibliometrics and Citation Analysis: From the Science Citation Index to Cybermetrics; The Scarecrow Press Inc.: Lanham, ML, USA, 2009. [Google Scholar]
- Costas, R.; Bordons, M. Is G-index Better than H-index? An Exploratory Study at the Individual Level. Scientometrics 2008, 77, 267–288. [Google Scholar] [CrossRef] [Green Version]
- Yaminfirooz, M.; Gholinia, H. Multiple h-index: A new scientometric indicator. Electron. Libr. 2015, 33, 547–556. [Google Scholar] [CrossRef]
- Clarivate. Key Words Plus Generation, Creation, and Changes. Available online: https://support.clarivate.com/ScientificandAcademicResearch/s/article/KeyWords-Plus-generation-creation-and-changes?language=en_US (accessed on 20 February 2021).
- Esfahani, H.J.; Tavasoli, K.; Jabbarzadeh, A. Big data and social media: A scientometrics analysis. Int. J. Data Netw. 2019, 3, 145–164. [Google Scholar] [CrossRef]
- Avramidou, A.; Tjortjis, C. Predicting CO2 Emissions for Buildings Using Regression and Classification. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Halkidiki, Greece, 25–27 June 2021; pp. 543–554. [Google Scholar]

















| Description | Results |
|---|---|
| Timespan | 2013–2021 (February) |
| Sources (Journals) | 112 |
| Documents | 197 |
| Average years from publication | 2.61 |
| Average citations per document | 15.88 |
| Average citations per year per doc | 3.648 |
| References | 9761 |
| DOCUMENT TYPES | |
| Article | 177 |
| Conference paper | 1 |
| Editorial | 6 |
| Review | 13 |
| DOCUMENT CONTENTS | |
| Keywords Plus (ID) | 1537 |
| Author’s Keywords (DE) | 664 |
| AUTHORS | |
| Authors | 682 |
| Author Appearances | 778 |
| Authors of single-authored documents | 10 |
| Authors of multi-authored documents | 672 |
| AUTHORS COLLABORATION | |
| Single-authored documents | 10 |
| Documents per Author | 0.289 |
| Authors per Document | 3.46 |
| Co-Authors per Document | 3.95 |
| Collaboration Index | 3.59 |
| Year | Number of Articles | Mean TC Per Article | Mean TC Per Year | Citable Years |
|---|---|---|---|---|
| 2013 | 1 | 47 | 5.87 | 8 |
| 2014 | 1 | 18 | 2.57 | 7 |
| 2015 | 7 | 43.14 | 7.19 | 6 |
| 2016 | 19 | 25.05 | 5.01 | 5 |
| 2017 | 25 | 44.32 | 11.08 | 4 |
| 2018 | 36 | 13.81 | 4.60 | 3 |
| 2019 | 54 | 10.91 | 5.45 | 2 |
| 2020 | 47 | 1.89 | 1.89 | 1 |
| 2021 | 7 | 0.29 | - | 0 |
| Sources | Articles |
|---|---|
| IEEE Access | 19 |
| Sensors | 14 |
| Future Generation Computer Systems | 7 |
| Sustainability | 7 |
| IEEE Internet of Things Journal | 6 |
| Information Systems | 5 |
| Cluster Computing | 4 |
| Multimedia Tools and Applications | 4 |
| Sustainable Cities and Society | 4 |
| Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery | 4 |
| Source | h-Index | g-Index | m-Index | Total Citations | Articles | PY Start |
|---|---|---|---|---|---|---|
| IEEE Access | 9 | 19 | 1.5 | 652 | 19 | 2016 |
| Sensors | 8 | 14 | 1.14 | 239 | 14 | 2015 |
| Future Generation Computer System | 5 | 7 | 0.62 | 134 | 7 | 2014 |
| Sustainability | 4 | 7 | 0.8 | 107 | 7 | 2017 |
| IEEE Internet of Things Journal | 4 | 6 | 1 | 95 | 6 | 2018 |
| Information Systems | 3 | 5 | 0.43 | 39 | 5 | 2015 |
| Cluster Computing | 2 | 4 | 0.67 | 16 | 4 | 2019 |
| Multimedia Tools and Applications | 2 | 4 | 0.33 | 21 | 4 | 2016 |
| Sustainable Cities and Society | 4 | 4 | 0.8 | 65 | 4 | 2017 |
| Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery | 3 | 4 | 0.75 | 43 | 4 | 2018 |
| Authors | Articles | Articles Fractionalized |
|---|---|---|
| Barnaghi P. | 5 | 1.34 |
| Liu Y. | 4 | 0.75 |
| Song H. | 4 | 0.64 |
| Gunopulos D. | 3 | 0.45 |
| Honarvar Ar. | 3 | 1.50 |
| Katakis I. | 3 | 1.29 |
| Li S. | 3 | 0.70 |
| Li X. | 3 | 0.83 |
| Liu X. | 3 | 1.00 |
| Tian Z. | 3 | 0.57 |
| Documents Written | No. of Authors | Proportion of Authors |
|---|---|---|
| 1 | 607 | 0.890 |
| 2 | 58 | 0.085 |
| 3 | 14 | 0.021 |
| 4 | 2 | 0.003 |
| 5 | 1 | 0.001 |
| Author | h_Index | g_Index | m_Index | TC | NP | PY_Start |
|---|---|---|---|---|---|---|
| Barnaghi P. | 5 | 5 | 0.714 | 104 | 5 | 2015 |
| Liu Y. | 3 | 4 | 0.600 | 71 | 4 | 2017 |
| Song H. | 3 | 4 | 0.600 | 54 | 4 | 2017 |
| Gunopulos D. | 2 | 3 | 0.333 | 10 | 3 | 2016 |
| Honarvar Ar. | 2 | 3 | 0.333 | 21 | 3 | 2016 |
| Katakis I. | 2 | 3 | 0.286 | 10 | 3 | 2015 |
| Li S. | 2 | 3 | 0.500 | 34 | 3 | 2018 |
| Li X. | 2 | 3 | 0.667 | 11 | 3 | 2019 |
| Liu X. | 1 | 2 | 0.167 | 4 | 3 | 2016 |
| Tian Z. | 2 | 3 | 0.500 | 36 | 3 | 2018 |
| Country | Frequency |
|---|---|
| China | 129 |
| USA | 55 |
| India | 27 |
| Spain | 23 |
| U.K. | 22 |
| Greece | 19 |
| Brazil | 17 |
| Italy | 17 |
| Pakistan | 17 |
| Saudi Arabia | 17 |
| Country | Total Citations | Average Article Citations |
|---|---|---|
| China | 473 | 11.26 |
| USA | 357 | 25.50 |
| Spain | 341 | 26.23 |
| Malaysia | 276 | 276.00 |
| Korea | 184 | 20.44 |
| Canada | 113 | 37.67 |
| Brazil | 62 | 12.40 |
| United Kingdom | 59 | 11.80 |
| Greece | 55 | 9.17 |
| Singapore | 40 | 13.33 |
| Words | Occurrences |
|---|---|
| data mining | 168 |
| smart cities | 106 |
| internet of things | 76 |
| big data | 45 |
| learning system | 21 |
| data handling | 20 |
| decision making | 19 |
| machine learning | 18 |
| forecasting | 17 |
| data analytics | 16 |
| artificial intelligence | 15 |
| semantics | 15 |
| automation | 13 |
| classification | 13 |
| clustering algorithms | 13 |
| energy use | 13 |
| intelligent buildings | 12 |
| extraction | 11 |
| social networking (online) | 11 |
| support vector machine | 11 |
| cloud computing | 10 |
| deep learning | 10 |
| information management | 10 |
| urban transportation | 10 |
| human | 9 |
| From | To | Frequency |
|---|---|---|
| China | USA | 15 |
| China | Australia | 5 |
| Spain | United Kingdom | 4 |
| USA | Australia | 4 |
| China | Canada | 3 |
| Germany | Ireland | 3 |
| Pakistan | Korea | 3 |
| Pakistan | Saudi Arabia | 3 |
| United Kingdom | Germany | 3 |
| United Kingdom | Ireland | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kousis, A.; Tjortjis, C. Data Mining Algorithms for Smart Cities: A Bibliometric Analysis. Algorithms 2021, 14, 242. https://doi.org/10.3390/a14080242
Kousis A, Tjortjis C. Data Mining Algorithms for Smart Cities: A Bibliometric Analysis. Algorithms. 2021; 14(8):242. https://doi.org/10.3390/a14080242
Chicago/Turabian StyleKousis, Anestis, and Christos Tjortjis. 2021. "Data Mining Algorithms for Smart Cities: A Bibliometric Analysis" Algorithms 14, no. 8: 242. https://doi.org/10.3390/a14080242
APA StyleKousis, A., & Tjortjis, C. (2021). Data Mining Algorithms for Smart Cities: A Bibliometric Analysis. Algorithms, 14(8), 242. https://doi.org/10.3390/a14080242