
Comparison of Profit-Based Multi-Objective Approaches for Feature Selection in Credit Scoring

Abstract
:1. Introduction
2. Related Work
2.1. Profit Scoring
2.2. Feature Selection
2.3. Multi-Objective Optimization
3. Methods
3.1. Multi-Objective Optimization
3.2. Non-Dominated Genetic Algorithm (NSGA-II)
| Algorithm 1 Pseudo code for NSGA-II. Algorithm for NSGA-II |
| Initialize population, Pt, of size N Q0 = Ø F0 = Fitness evaluation of P0 (F1, F2, …) = Non dominated sorting of P0 to establish rank Determine crowding distance of (F1, F2, …) while stop criterion not satisfied do Qt = selection, crossover, mutation, recombination of Pt Rt = Qt ∪ Pt Ft = Fitness_Evaluation(Rt) (F1, F2, …) = Non dominated sorting of Rt to establish rank Determine crowding distance Pt+1 = select new population of size N based on rank and highest crowding distance end while |
3.3. Non-Dominated Genetic Algorithm (NSGA-III)
| Algorithm 2 Pseudo code for NSGA-III. Algorithm for NSGA-III |
| Initialize reference points Initialize population, P0, of size N while stop criterion not satisfied do St = Ø, i =1 Qt = selection, crossover, mutation, recombination of Pt Rt = Qt ∪ Pt (F1, F2, …) = Non dominated sorting (Rt) while |St| < N do St = St ∪ Fi i = i + 1 end while Fl = Fi (Fl last front included) if |St| = N then Pt+1 = St else |
| Individuals to be chosen K = N − | Pt+1 |: Normalize objectives Associate each member s of St with a reference point Compute niche count of reference point Choose K members chosen one at a time from Fl to obtain Pt+1 end if end while |
3.4. Non-Dominated Binary Grasshopper Optimization Algorithm (NSBGOA)
| Algorithm 3 Pseudo code for NSBGOA. Algorithm for NSBGOA |
| Input: • Population size, N • maxIter Steps T = 0 Gt = Initialize grasshopper positions Pt = Gt Ft = Fitness wvaluation of population, Pt bestFrontt, fitnessOfBestFrontt = non-dominated sorting of Pt and Ft while t < maxIter do: Update c for grasshopper in Gt normalize the distances between grasshoppers in References [1,4] Gt = compute and update new grasshopper positions Pt = Gt Ft = evaluate fitness of population, Pt bestFrontt, fitnessOfBestFrontt = non-dominated sorting of Pt and Ft Zt = Sort Pt by position on fronts Gt+1 = Ø i =1 while i <= N do: Gt+1 = Gt+1 ∪ ith member of Pt i = i + 1 end while bestFrontt+1, fitnessOfBestFrontt+1 = non-dominated sorting of Gt+1 and Ft t = t +1 end while S = bestFront Output • set of non-dominated solutions, S |
3.5. Expected Maximum Profit (EMP)
- b = 0 with probability p0 that the loan is repaid in full,
- b = 1 with probability p1 that no portion of the loan is repaid,
- b is uniformly distributed within (0,1) with g(b) = 1 − p0 − p1.
3.6. Performance Metrics
4. Empirical Evaluation
4.1. Problem Formulation
- Available features X, (Equation (10)) a set of j variables that could be used to predict loan repayment.
- Cardinality (number of features), N, (Equation (11)) is the number of selected features per solution.
- Expected Maximum Profit, EMP, (Equation (8)) a profit-based measure for credit scoring.
- Ease of explanation, C, (Equation (12)) a vector representing the ease of explaining each variable to stakeholders.
- Default status, D, (Equation (13)) is a vector with loan repayment information for each borrower.
- Borrower information, B, (Equation (14)) a matrix with feature values for each borrower.
4.2. Contribution
4.3. Data and Objectives
4.4. Analysis
5. Results

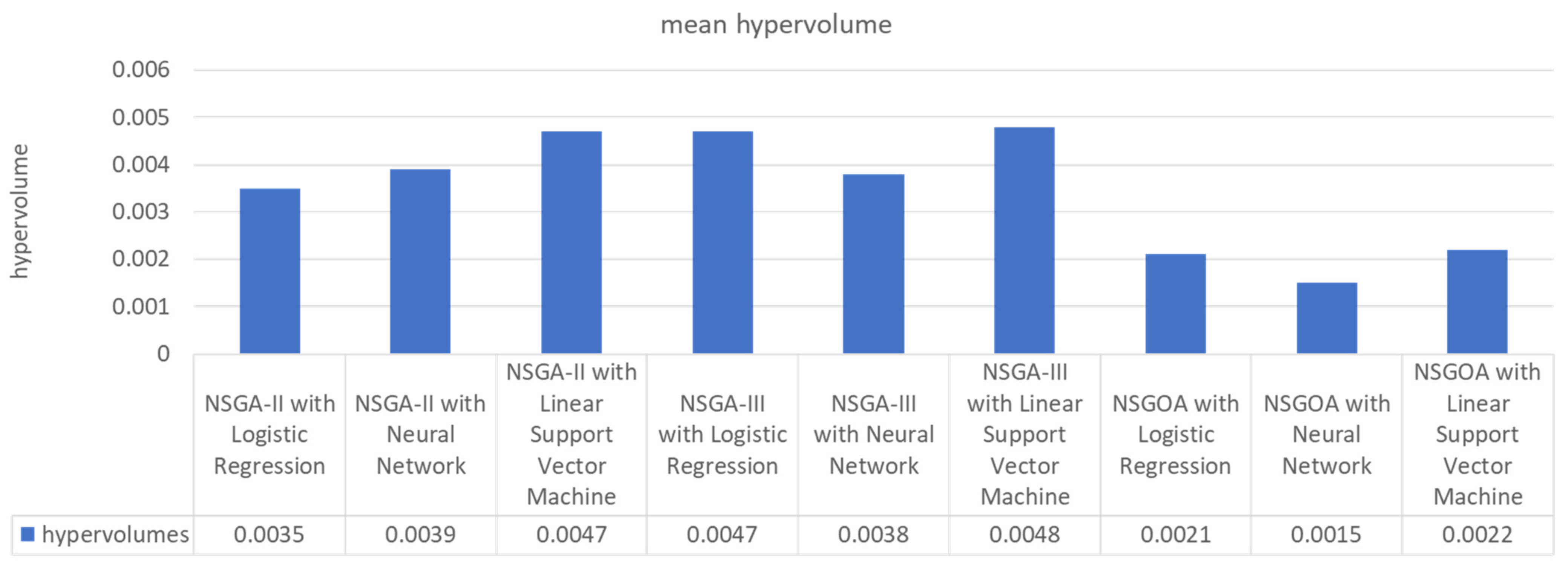{kind=link}
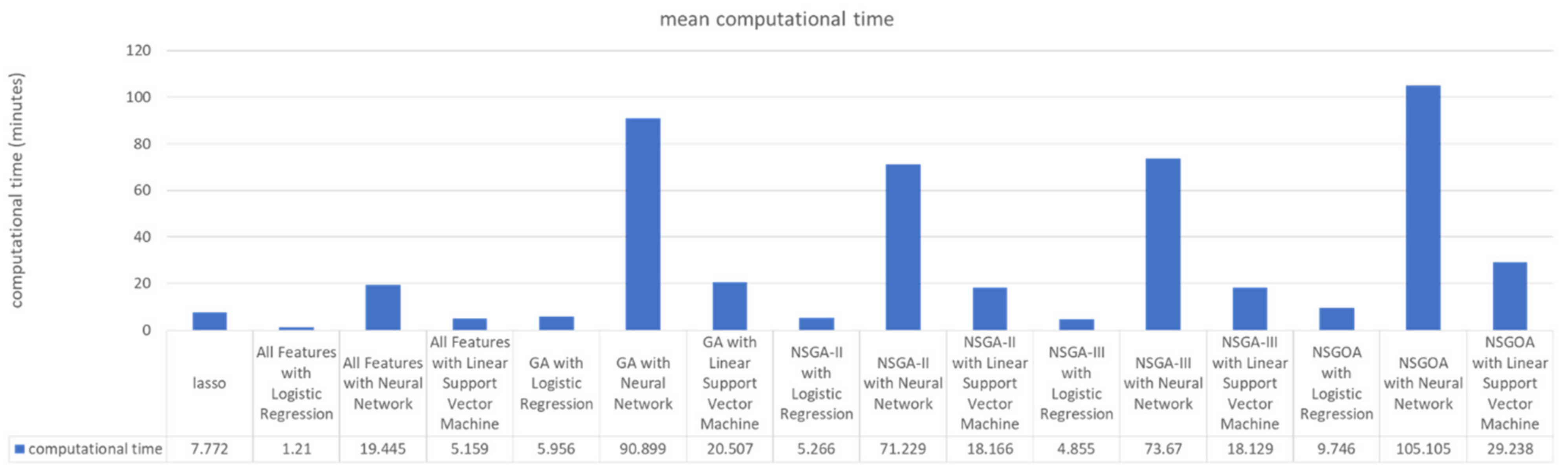{kind=link}
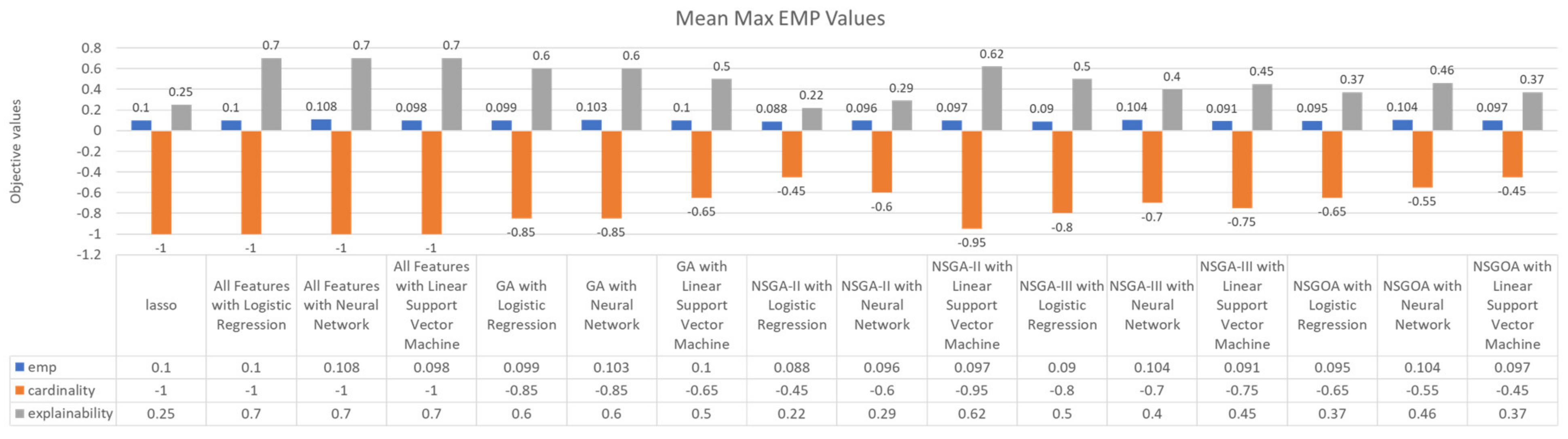{kind=link}
{kind=link}
| Algorithm | Number of Features | Objective | Value |
|---|---|---|---|
| Lasso | 20 | emp | 0.1 |
| cardinality | −1 | ||
| affordability | 0.25 | ||
| All features with Logistic Regression | 20 | emp | 0.1 |
| cardinality | −1 | ||
| affordability | 0.7 | ||
| All features with Neural Network | 20 | emp | 0.103 |
| cardinality | −1 | ||
| affordability | 0.7 | ||
| All features with Linear Support Vector Machine | 20 | emp | 0.098 |
| cardinality | −1 | ||
| affordability | 0.7 | ||
| GA with Logistic Regression | 17 | emp | 0.099 |
| cardinality | −0.85 | ||
| affordability | 0.6 | ||
| GA with Neural Network | 17 | emp | 0.103 |
| cardinality | −0.85 | ||
| affordability | 0.6 | ||
| GA with Linear Support Vector Machine | 13 | emp | 0.1 |
| cardinality | −0.65 | ||
| affordability | 0.5 |
6. Discussion
6.1. Base Classifier
6.2. Feature Selection Algorithm
6.3. Application
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thomas, L.C.; Edelman, B.D.; Crook, N.J. Credit Scoring and Its Applications; Society for Applied and Industrial Mathematics: Philadelphia, PA, USA, 2002. [Google Scholar]
- Guyon, I.; Gunn, S.; Nikravesh, M.; Zadeh, L.A. Feature Extraction, Foundations and Applications; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Djeundje, V.B.; Crook, J.; Calabrese, R.; Hamid, M. Enhancing credit scoring with alternative data. Expert Syst. Appl. 2021, 163, 113766. [Google Scholar] [CrossRef]
- Maldonado, S.; Flores, Á.; Verbraken, T.; Baesens, B.; Weber, R. Profit-based feature selection using support vector machines—General framework and an application for customer retention. Appl. Soft Comput. J. 2015, 35, 740–748. [Google Scholar] [CrossRef] [Green Version]
- Maldonado, S.; Bravo, C.; López, J.; Pérez, J. Integrated framework for profit-based feature selection and SVM classification in credit scoring. Decis. Support Syst. 2017, 104, 113–121. [Google Scholar] [CrossRef] [Green Version]
- Odu, G.O.; Charles-Owaba, O.E. Review of Multi-criteria Optimization Methods—Theory and Applications. IOSR J. Eng. 2013, 3, 1–14. [Google Scholar] [CrossRef]
- Kozodoi, N.; Lessmann, S.; Papakonstantinou, K.; Gatsoulis, Y.; Baesens, B. A multi-objective approach for profit-driven feature selection in credit scoring. Decis. Support Syst. 2019, 120, 106–117. [Google Scholar] [CrossRef]
- Emmerich, M.T.; Deutz, A.H. A tutorial on multiobjective optimization: Fundamentals and evolutionary methods. Nat. Comput. 2018, 17, 585–609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Obayashi, S.; Deb, K.; Poloni, C.; Hiroyasu, T.; Murata, T. Evolutionary Multi-Criterion Optimization. In Proceedings of the 4th International Conference, EMO 2007, Proceedings 13, Matsushima, Japan, 5–8 March 2007; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Mafarja, M.; Aljarah, I.; Faris, H.; Hammouri, A.I.; Al-zoubi, A.M.; Mirjalili, S. Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Syst. Appl. 2019, 117, 267–286. [Google Scholar] [CrossRef]
- Hichem, H.; Elkamel, M.; Rafik, M.; Mesaaoud, M.T.; Ouahiba, C. A new binary grasshopper optimization algorithm for feature selection problem. J. King Saud Univ. Comput. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Usman, A.M.; Yusof, U.K.; Naim, S. Filter-Based Multi-Objective Feature Selection Using NSGA III and Cuckoo Optimization Algorithm. IEEE Access 2020, 8, 76333–76356. [Google Scholar] [CrossRef]
- Simumba, N.; Okami, S.; Kodaka, A.; Kohtake, N. Hybrid Many Objective Metaheuristics for Feature Selection Based on Stakeholder Requirements in Credit Scoring with Alternative Data No Title. 2021; Unpublished manuscript, under review. [Google Scholar]
- Ishibuchi, H.; Imada, R.; Setoguchi, Y.; Nojima, Y. Performance Comparison of NSGA-II and NSGA-III on Various Many-Objective Test Problems. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2016. [Google Scholar]
- Maldonado, S.; Pérez, J.; Bravo, C. Cost-based feature selection for Support Vector Machines: An application in credit scoring. Eur. J. Oper. Res. 2017, 261, 656–665. [Google Scholar] [CrossRef] [Green Version]
- Serrano-Cinca, C.; Gutiérrez-Nieto, B. The use of profit scoring as an alternative to credit scoring systems in peer-to-peer (P2P) lending. Decis. Support Syst. 2016, 89, 113–122. [Google Scholar] [CrossRef]
- Verbraken, T.; Member, S.; Verbeke, W.; Baesens, B. A Novel Profit Maximizing Metric for Measuring Classification Performance of Customer Churn Prediction Models. IEEE Trans. Knowl. Data Eng. 2013, 25. [Google Scholar] [CrossRef]
- Verbraken, T.; Bravo, C.; Weber, R.; Baesens, B. Development and application of consumer credit scoring models using profit-based classification measures. Eur. J. Oper. Res. 2014, 238, 505–513. [Google Scholar] [CrossRef] [Green Version]
- Bonev, B.; Escolano, F.; Cazorla, M. Feature selection, mutual information, and the classification of high-dimensional patterns. Pattern Anal. Appl. 2008, 11. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso: A retrospective. J. R. Stat. Soc. 2011, 73, 273–282. [Google Scholar] [CrossRef]
- Han, L.; Han, L.; Zhao, H. Engineering Applications of Artificial Intelligence. Eng. Appl. Artif. Intell. 2013, 26, 848–862. [Google Scholar] [CrossRef]
- Zhang, Z.; He, J.; Gao, G.; Tian, Y. Sparse multi-criteria optimization classifier for credit risk evaluation. Soft Comput. 2019, 23, 3053–3066. [Google Scholar] [CrossRef]
- Xue, B.; Cervante, L.; Shang, L.; Zhang, M. A Particle Swarm Optimisation Based Multi-Objective Filter Approach to Feature Selection for Classification. In Proceedings of the PRICAI 2012: Trends in Artificial Intelligence. PRICAI 2012. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Papouskova, M.; Hajek, P. Two-stage consumer credit risk modelling using heterogeneous ensemble learning. Decis. Support Syst. 2019, 118, 33–45. [Google Scholar] [CrossRef]
- Emmanouilidis, C.; Hunter, A.; Macintyre, J.; Cox, C. Selecting Features in Neurofuzzy Modelling by Multiobjective Genetic Algorithms. In Proceedings of the ICANN’99. 9th International Conference on Artificial Neural Networks, Edinburgh, UK, 7–10 September 1999; pp. 749–754. [Google Scholar]
- Xue, B.; Cervante, L.; Shang, L.; Browne, W.N.; Zhang, M. A Multi-Objective Particle Swarm Optimisation for Filter Based Feature Selection in Classification Problems. Conn. Sci. 2012, 24, 91–116. [Google Scholar] [CrossRef]
- Doerner, K.; Gutjahr, W.J.; Hartl, R.F.; Strauss, C.; Stummer, C. Pareto Ant Colony Optimization: A Metaheuristic Approach to Multiobjective Portfolio Selection. Ann. Oper. Res. 2004, 131, 79–99. [Google Scholar] [CrossRef]
- Wagner, T.; Beume, N.; Naujoks, B. Pareto-, Aggregation-, and Indicator-Based Methods in Many-Objective Optimization. In Proceedings of the 4th International Conference, EMO 2007, Matsushima, Japan, 5–8 March 2007; pp. 742–756. [Google Scholar]
- Deb, K.; Jain, H. Handling many-objective problems using an improved NSGA-II procedure. In Proceedings of the 2012 IEEE Congress on Evolutionary Computation (CEC’12), Kraków, Poland, 28 June–1 July 2012; pp. 1–8. [Google Scholar]
- Censor, Y. Pareto Optimality in Multiobjective Problems. Appl. Math. Optim. 1977, 4, 41–59. [Google Scholar] [CrossRef]
- Li, B.; Li, J.; Tang, K.; Yao, X. Many-objective evolutionary algorithms: A survey. ACM Comput. Surv. 2015, 48. [Google Scholar] [CrossRef] [Green Version]
- Saremi, S.; Mirjalili, S.; Lewis, A. Advances in Engineering Software Grasshopper Optimisation Algorithm: Theory and application. Adv. Eng. Softw. 2017, 105, 30–47. [Google Scholar] [CrossRef] [Green Version]
- Mays, E.; Nuetzel, P. Credit Scoring for Risk Managers: The Handbook for Lenders; Ch. Scorecard Monitoring Reports; South-Western Publishing: Mason, OH, USA, 2004. [Google Scholar]
- Audet, C.; Bigeon, J.; Cartier, D.; Le Digabel, S.; Salomon, L. Performance indicators in multiobjective optimization. Eur. J. Oper. Res. 2021, 292, 397–422. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. German Credit Dataset; University of California, School of Information and Computer Science: Irvine, CA, USA, 2019. [Google Scholar]
- Khan, S.; Asjad, M.; Ahmad, A. Review of Modern Optimization Techniques. Int. J. Eng. Tech. Res. 2015. [Google Scholar] [CrossRef]




| Predicted Class | |||
|---|---|---|---|
| Non-Default | Default | ||
| Actual | Non-default | Benefit: ROI Probability: π1 (1 − F1) | Cost: -ROI Probability: π1 F1 |
| Default | Cost: -LGD × EAD/A Probability: π0 (1 − F0) | Benefit: LGD × EAD/A Probability: π0 F0 | |
| Objective | Optimization | Function |
|---|---|---|
| Expected maximum profit (EMP) | maximize | |
| Number of features (cardinality) | maximize | |
| Ease of explanation per feature set | maximize |
| Algorithm | Mean # of Features/Solution | Objective | Min | Max | SD | Mean | Nadir Point |
|---|---|---|---|---|---|---|---|
| NSGA-II with Logistic Regression | 11.8 | emp | 0.083 | 0.093 | 0.087 | 0.087 | 0.093 |
| cardinality | −0.8 | −0.4 | −0.59 | −0.59 | −0.4 | ||
| ease of explanation | 0.15 | 0.5 | 0.31 | 0.31 | 0.5 | ||
| NSGA-II with Neural Network | 9.1 | emp | 0.084 | 0.096 | 0.09 | 0.09 | 0.096 |
| cardinality | −0.65 | −0.2 | −0.455 | −0.455 | −0.2 | ||
| ease of explanation | 0.15 | 0.4 | 0.245 | 0.245 | 0.4 | ||
| NSGA-II with Linear Support Vector Machine | 12 | emp | 0.082 | 0.095 | 0.088 | 0.088 | 0.095 |
| cardinality | −0.8 | −0.3 | −0.6 | −0.6 | −0.3 | ||
| ease of explanation | 0.15 | 0.5 | 0.34 | 0.34 | 0.5 | ||
| NSGA-III with Logistic Regression | 12.4 | emp | 0.084 | 0.09 | 0.087 | 0.087 | 0.09 |
| cardinality | −0.8 | −0.5 | −0.62 | −0.62 | −0.5 | ||
| ease of explanation | 0.2 | 0.5 | 0.335 | 0.335 | 0.5 | ||
| NSGA-III with Neural Network | 11.5 | emp | 0.09 | 0.104 | 0.093 | 0.093 | 0.104 |
| cardinality | −0.8 | −0.35 | −0.575 | −0.575 | −0.35 | ||
| ease of explanation | 0.1 | 0.5 | 0.28 | 0.28 | 0.5 | ||
| NSGA-III with Linear Support Vector Machine | 11.9 | emp | 0.084 | 0.091 | 0.087 | 0.087 | 0.091 |
| cardinality | −0.75 | −0.45 | −0.595 | −0.595 | −0.45 | ||
| ease of explanation | 0.15 | 0.45 | 0.31 | 0.31 | 0.45 | ||
| NSGBOA with Logistic Regression | 10 | emp | 0.091 | 0.096 | 0.093 | 0.093 | 0.096 |
| cardinality | −0.65 | −0.25 | −0.5 | −0.5 | −0.25 | ||
| ease of explanation | 0.25 | 0.45 | 0.35 | 0.35 | 0.45 | ||
| NSGBOA with Neural Network | 9.5 | emp | 0.088 | 0.104 | 0.097 | 0.097 | 0.104 |
| cardinality | −0.7 | −0.25 | −0.475 | −0.475 | −0.25 | ||
| ease of explanation | 0.2 | 0.6 | 0.356 | 0.356 | 0.6 | ||
| NSGBOA with Linear Support Vector Machine | 11.7 | emp | 0.087 | 0.097 | 0.094 | 0.094 | 0.097 |
| cardinality | −0.75 | −0.45 | −0.586 | −0.586 | −0.45 | ||
| ease of explanation | 0.3 | 0.45 | 0.393 | 0.393 | 0.45 |
| Algorithm | Number of Features | Objective | Value |
|---|---|---|---|
| Lasso | 20 | emp | 0.1 |
| cardinality | −1 | ||
| affordability | 0.25 | ||
| All features with Logistic Regression | 20 | emp | 0.1 |
| cardinality | −1 | ||
| affordability | 0.7 | ||
| All features with Neural Network | 20 | emp | 0.103 |
| cardinality | −1 | ||
| affordability | 0.7 | ||
| All features with Linear Support Vector Machine | 20 | emp | 0.098 |
| cardinality | −1 | ||
| affordability | 0.7 | ||
| GA with Logistic Regression | 17 | emp | 0.099 |
| cardinality | −0.85 | ||
| affordability | 0.6 | ||
| GA with Neural Network | 17 | emp | 0.103 |
| cardinality | −0.85 | ||
| affordability | 0.6 | ||
| GA with Linear Support Vector Machine | 13 | emp | 0.1 |
| cardinality | −0.65 | ||
| affordability | 0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Simumba, N.; Okami, S.; Kodaka, A.; Kohtake, N. Comparison of Profit-Based Multi-Objective Approaches for Feature Selection in Credit Scoring. Algorithms 2021, 14, 260. https://doi.org/10.3390/a14090260
Simumba N, Okami S, Kodaka A, Kohtake N. Comparison of Profit-Based Multi-Objective Approaches for Feature Selection in Credit Scoring. Algorithms. 2021; 14(9):260. https://doi.org/10.3390/a14090260
Chicago/Turabian StyleSimumba, Naomi, Suguru Okami, Akira Kodaka, and Naohiko Kohtake. 2021. "Comparison of Profit-Based Multi-Objective Approaches for Feature Selection in Credit Scoring" Algorithms 14, no. 9: 260. https://doi.org/10.3390/a14090260
APA StyleSimumba, N., Okami, S., Kodaka, A., & Kohtake, N. (2021). Comparison of Profit-Based Multi-Objective Approaches for Feature Selection in Credit Scoring. Algorithms, 14(9), 260. https://doi.org/10.3390/a14090260