
Predicting Dynamic User–Item Interaction with Meta-Path Guided Recursive RNN †



Abstract
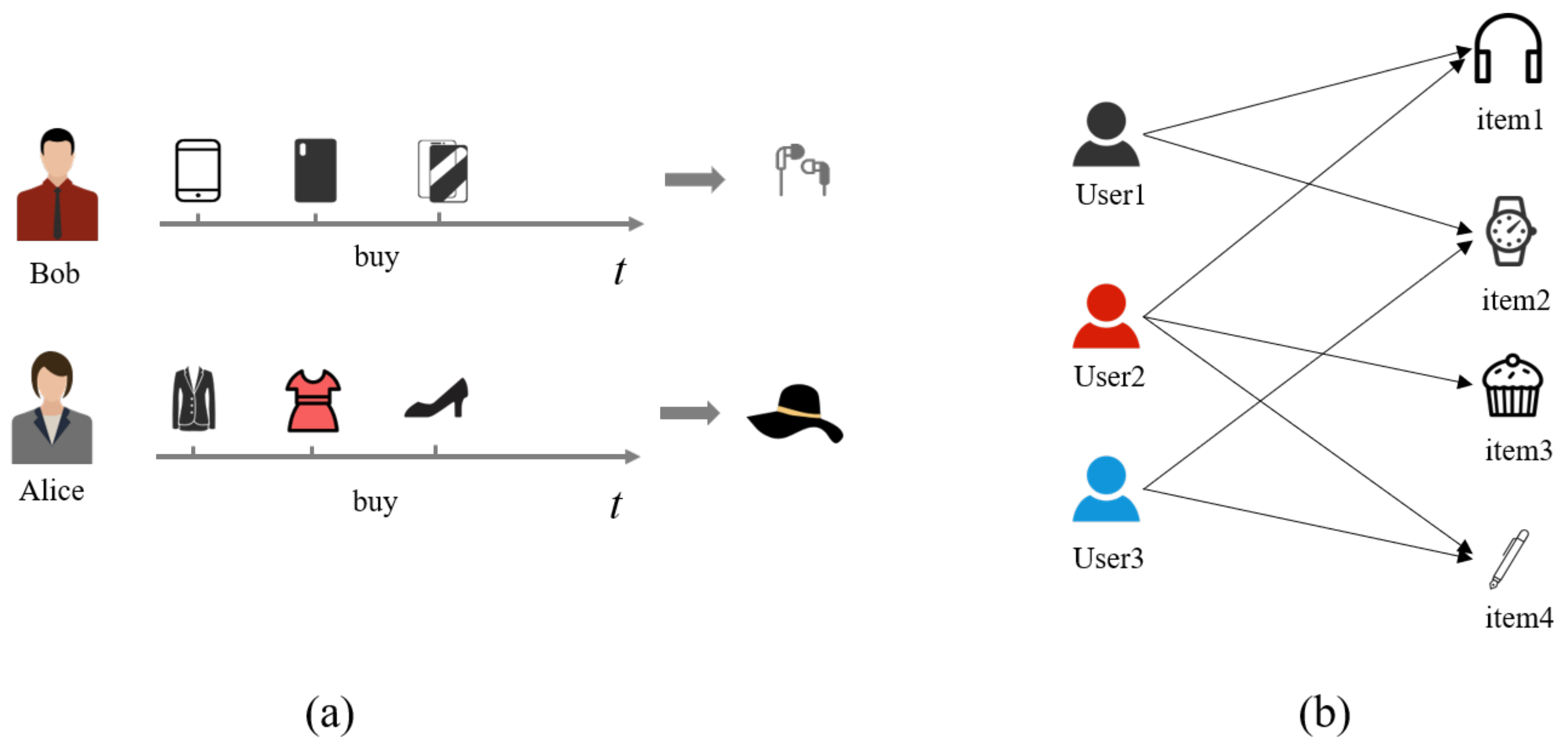
:1. Introduction
- To acquire the rich auxiliary information from the user–item interaction data, we model the original user–item interaction data as sequences and graphs, respectively. A word2vec module is proposed on the interaction sequence of each user, which aims to learn the initial embedding that preserves the sequential pattern and semantic information from sequences. Then a skip-gram-based meta-path module is proposed to the user–item interaction graph for capturing the heterogeneous information and the higher-order user–item relationships.
- We propose to apply the GCN module to learn the node features of the user–item interaction graph, so that the similar users or items are closer in the feature space.
- Comprehensive experiments are conducted over three user–item interaction graph datasets. The result demonstrates the effectiveness of our method against several competitive baselines.
2. Related Work
2.1. Collaborative Filtering Recommendation
2.2. Deep Learning-Based Recommendation
2.3. Graph-Based Recommendation
2.4. Temporal Network Embedding
3. Preliminary and Problem Definition
3.1. Preliminary
3.2. Problem Definition
4. Methodology
4.1. Auxiliary Information Extraction
4.2. Dynamical Embedding Generation
4.3. Overall Objective Function
5. Experiment
5.1. Dataset
- Wikipedia editing dataset: This dataset contains one month of edits made on Wikipedia pages. We select the 1000 pages that get the most edits as items and editors who made at least 5 edits as users. In total, we have 8227 users. There are 157,474 interactions between the selected users and pages in total, and the edited text is considered as features.
- Reddit post dataset: This dataset includes one month of posts made by users on subreddits. We select the 1000 most active subreddits as items and the 10,000 most active users. There are 672,447 interactions and the text of each post is converted to a feature vector.
- JingDong dataset: This dataset is extracted from JD.com, which contains the records of users’ online behaviors on the JingDong website. It contains 1,198,735 interactions between 10,692 users and 303,150 items from March 2020 to April 2020.
5.2. Baselines and Evaluation Metrics
- LSTM [45] is an important ingredient of RNN architectures. Here we simply record the sequence of items, dropping of the time information.
- Time-LSTM [45] is a new LSTM variant, which equips LSTM with time gates to model the time intervals.
- Jodie [36] is a coupled recurrent neural network model to learn the dynamic embeddings of users and items. Here we ignore the one-hot embedding for item in Jodie, because it cannot be utilized in a large number of items.
- NGCF [28] is a recommendation framework based on a graph neural network, which explicitly encodes the collaborative signal in user–item bipartite graph by performing embedding propagation.
- LightGCN [31] is a state-of-the-art collaborative filtering based method. It simplifies the design of GCN to make it more concise and appropriate for recommendation.
- RRNN-S [1] is a recent state-of-the-art recursive RNN based shift embedding model for predicting dynamic user–item interaction.
5.3. Results
5.3.1. Comparison with Baselines
5.3.2. Ablation Study
- MRRNN-1 drops the meta-path module which is able to acquire the heterogeneity and semantic information from user–item interaction graph. Only the embedding learned by the word2vec module is fed to the prediction model.
- MRRNN-2 drops the word2vec module which can capture the sequential information from the interaction sequence. Only the feature vectors extracted by the meta-path module are fed to the remaining part of MRRNN-S.
- MRRNN-3 drops the GCN module which is designed to catch the structural information from the user–item interaction graph. Only the feature vectors processed by the meta-path module and word2vec module are input into the model.
- MRRNN-4 drops the meta-path, word2vec, and GCN modules at the same time, and randomly initializes the embedding by a normal distribution as the model input.
5.3.3. Parameters Sensitivity Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yin, C.; Wang, S.; Du, J.; Zhang, M. Recursive RNN Based Shift Representation Learning for Dynamic User-Item Interaction Prediction. In Proceedings of the International Conference on Advanced Data Mining and Applications, Foshan, China, 12–14 November 2020; pp. 379–394. [Google Scholar]
- Hosseini, M.; Maida, A.S.; Hosseini, M.; Raju, G. Inception lstm for next-frame video prediction (student abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13809–13810. [Google Scholar]
- Barman, P.P.; Boruah, A. A RNN based Approach for next word prediction in Assamese Phonetic Transcription. Procedia Comput. Sci. 2018, 143, 117–123. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Zhang, M.; Leskovec, J.; Zhao, M.; Li, W.; Wang, Z. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 968–977. [Google Scholar]
- Huang, C.; Wu, X.; Zhang, X.; Zhang, C.; Zhao, J.; Yin, D.; Chawla, N.V. Online purchase prediction via multi-scale modeling of behavior dynamics. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2613–2622. [Google Scholar]
- Cai, X.; Han, J.; Yang, L. Generative adversarial network based heterogeneous bibliographic network representation for personalized citation recommendation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5747–5754. [Google Scholar]
- Lei, C.; Liu, D.; Li, W.; Zha, Z.-J.; Li, H. Comparative deep learning of hybrid representations for image recommendations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2545–2553. [Google Scholar]
- Soh, H.; Sanner, S.; White, M.; Jamieson, G. Deep sequential recommendation for personalized adaptive user interfaces. In Proceedings of the 22nd International Conference on Intelligent User Interfaces, Limassol, Cyprus, 13–16 March 2017; pp. 589–593. [Google Scholar]
- Zhang, Q.; Wang, J.; Huang, H.; Huang, X.; Gong, Y. Hashtag Recommendation for Multimodal Microblog Using Co-Attention Network. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3420–3426. [Google Scholar]
- Lv, F.; Jin, T.; Yu, C.; Sun, F.; Lin, Q.; Yang, K.; Ng, W. SDM: Sequential deep matching model for online large-scale recommender system. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2635–2643. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. arXiv, 2015; arXiv:1511.06939. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar]
- Dong, X.; Yu, L.; Wu, Z.; Sun, Y.; Yuan, L.; Zhang, F. A hybrid collaborative filtering model with deep structure for recommender systems. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1309–1315. [Google Scholar]
- Yin, C.; Wang, S.; Miao, H. Recursive LSTM with shift embedding for online user-item interaction prediction. In Proceedings of the 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), Beijing, China, 19–23 October 2020; pp. 10–12. [Google Scholar]
- Wang, S.; Hu, L.; Wang, Y.; Cao, L.; Sheng, Q.Z.; Orgun, M. Sequential recommender systems: Challenges, progress and prospects. arXiv, 2019; arXiv:2001.04830. [Google Scholar]
- Bellogín, A.; Parapar, J. Using graph partitioning techniques for neighbour selection in user-based collaborative filtering. In Proceedings of the Sixth ACM Conference on Recommender Systems, Dublin, Ireland, 9–13 September 2012; pp. 213–216. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Loepp, B.; Ziegler, J. Towards interactive recommending in model-based collaborative filtering systems. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 546–547. [Google Scholar]
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. CSUR 2019, 52, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.-T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Ebesu, T.; Fang, Y. Neural citation network for context-aware citation recommendation. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, 7–11 August 2017; pp. 1093–1096. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.-Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Xiang, L.; Yuan, Q.; Zhao, S.; Chen, L.; Zhang, X.; Yang, Q.; Sun, J. Temporal recommendation on graphs via long-and short-term preference fusion. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 723–732. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.-S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Zhou, H.; Tan, Q.; Huang, X.; Zhou, K.; Wang, X. Temporal Augmented Graph Neural Networks for Session-Based Recommendations. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, 11–15 July 2021; pp. 1798–1802. [Google Scholar]
- Sun, J.; Guo, W.; Zhang, D.; Zhang, Y.; Regol, F.; Hu, Y.; Guo, H.; Tang, R.; Yuan, H.; He, X. A framework for recommending accurate and diverse items using bayesian graph convolutional neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 2030–2039. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Fan, Z.; Liu, Z.; Zhang, J.; Xiong, Y.; Zheng, L.; Yu, P.S. Continuous-time sequential recommendation with temporal graph collaborative transformer. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, Australia, 1–5 November 2021; pp. 433–442. [Google Scholar]
- Jiang, X.; Lu, Y.; Fang, Y.; Shi, C. Contrastive Pre-Training of GNNs on Heterogeneous Graphs. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, Australia, 1–5 November 2021; pp. 803–812. [Google Scholar]
- Zheng, J.; Ma, Q.; Gu, H.; Zheng, Z. Multi-view Denoising Graph Auto-Encoders on Heterogeneous Information Networks for Cold-start Recommendation. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, 14–18 August 2021; pp. 2338–2348. [Google Scholar]
- Zhou, L.; Yang, Y.; Ren, X.; Wu, F.; Zhuang, Y. Dynamic network embedding by modeling triadic closure process. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 571–578. [Google Scholar]
- Kumar, S.; Zhang, X.; Leskovec, J. Predicting dynamic embedding trajectory in temporal interaction networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1269–1278. [Google Scholar]
- Li, J.; Dani, H.; Hu, X.; Tang, J.; Chang, Y.; Liu, H. Attributed network embedding for learning in a dynamic environment. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 387–396. [Google Scholar]
- Zhu, D.; Cui, P.; Zhang, Z.; Pei, J.; Zhu, W. High-order proximity preserved embedding for dynamic networks. IEEE Trans. Knowl. Data Eng. 2018, 30, 2134–2144. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv, 2018; arXiv:1810.04805. [Google Scholar]
- Nguyen, G.H.; Lee, J.B.; Rossi, R.A.; Ahmed, N.K.; Koh, E.; Kim, S. Continuous-time dynamic network embeddings. In Proceedings of the Companion Proceedings of the The Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 969–976. [Google Scholar]
- Xu, D.; Ruan, C.; Korpeoglu, E.; Kumar, S.; Achan, K. Inductive representation learning on temporal graphs. arXiv, 2020; arXiv:2002.07962. [Google Scholar]
- Ye, W.; Wang, S.; Chen, X.; Wang, X.; Qin, Z.; Yin, D. Time matters: Sequential recommendation with complex temporal information. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 1459–1468. [Google Scholar]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Zhu, Y.; Li, H.; Liao, Y.; Wang, B.; Guan, Z.; Liu, H.; Cai, D. What to Do Next: Modeling User Behaviors by Time-LSTM. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3602–3608. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Description |
|---|---|
| the set of user–item interaction | |
| and | the set of users and items |
| u and i | the dynamic embedding of user and item at timestamp t |
| and | the static embedding of user u and item i |
| E and E | the static embedding matrices of users and items |
| the predicted embedding of user u at time t + Δ | |
| the predicted embedding of item i at time t + Δ |
| Data | #Users | #Items | #Interactions |
|---|---|---|---|
| Wikipedia | 8227 | 1000 | 157,474 |
| 10,000 | 1000 | 672,447 | |
| JingDong | 10,692 | 303,150 | 1,198,735 |
| Datasets | Metric | LSTM | Time-LSTM | Jodie | NGCF | LightGCN | RRNN-S | MRRNN-S |
|---|---|---|---|---|---|---|---|---|
| Wikipedia | MRR | 0.332 * | 0.351 * | 0.741 * | - | - | 0.756 * | 0.779 * |
| Recall@10 | 0.401 * | 0.452 * | 0.803 * | 0.198 * | 0.248 * | 0.837 * | 0.801 * | |
| MRR | 0.343 * | 0.355 * | 0.718 * | - | - | 0.733 * | 0.766 * | |
| Recall@10 | 0.530 * | 0.575 * | 0.832 * | 0.254 * | 0.287 * | 0.842 * | 0.856 * | |
| JingDong | MRR | 0.039 * | 0.047 * | 0.080 | - | - | 0.089 * | 0.264 * |
| Recall@10 | 0.057 * | 0.064 * | 0.131 * | 0.010 * | 0.013 * | 0.142 * | 0.343 * |
| Datasets | Metric | MRRNN-1 | MRRNN-2 | MRRNN-3 | MRRNN-4 | MRRNN-S |
|---|---|---|---|---|---|---|
| Wikipedia | MRR | 0.753 | 0.483 | 0.581 | 0.449 | 0.779 |
| Recall@10 | 0.782 | 0.610 | 0.692 | 0.583 | 0.801 | |
| JingDong | MRR | 0.19 | 0.009 | 0.121 | 0.003 | 0.264 |
| Recall@10 | 0.261 | 0.012 | 0.220 | 0.005 | 0.343 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Yin, C.; Li, J.; Wang, F.; Wang, S. Predicting Dynamic User–Item Interaction with Meta-Path Guided Recursive RNN. Algorithms 2022, 15, 80. https://doi.org/10.3390/a15030080
Liu Y, Yin C, Li J, Wang F, Wang S. Predicting Dynamic User–Item Interaction with Meta-Path Guided Recursive RNN. Algorithms. 2022; 15(3):80. https://doi.org/10.3390/a15030080
Chicago/Turabian StyleLiu, Yi, Chengyu Yin, Jingwei Li, Fang Wang, and Senzhang Wang. 2022. "Predicting Dynamic User–Item Interaction with Meta-Path Guided Recursive RNN" Algorithms 15, no. 3: 80. https://doi.org/10.3390/a15030080
APA StyleLiu, Y., Yin, C., Li, J., Wang, F., & Wang, S. (2022). Predicting Dynamic User–Item Interaction with Meta-Path Guided Recursive RNN. Algorithms, 15(3), 80. https://doi.org/10.3390/a15030080