
Point Cloud Upsampling Algorithm: A Systematic Review


Abstract
:1. Introduction
- (1)
- We provide a comprehensive review of point cloud upsampling, including benchmark datasets, evaluation metrics, optimization-based point cloud upsampling, and deep learning-based point cloud upsampling. To the best of our knowledge, this is the first survey paper that comprehensively introduces point cloud upsampling.
- (2)
- We provide a systematic overview of recent advances in deep learning-based point cloud upsampling in a component-wise manner, and analyze the strengths and limitations of each component.
- (3)
- We compare the representative point cloud upsampling methods on commonly used datasets.
- (4)
- We provide a brief summary, and discuss the challenges and future research directions.
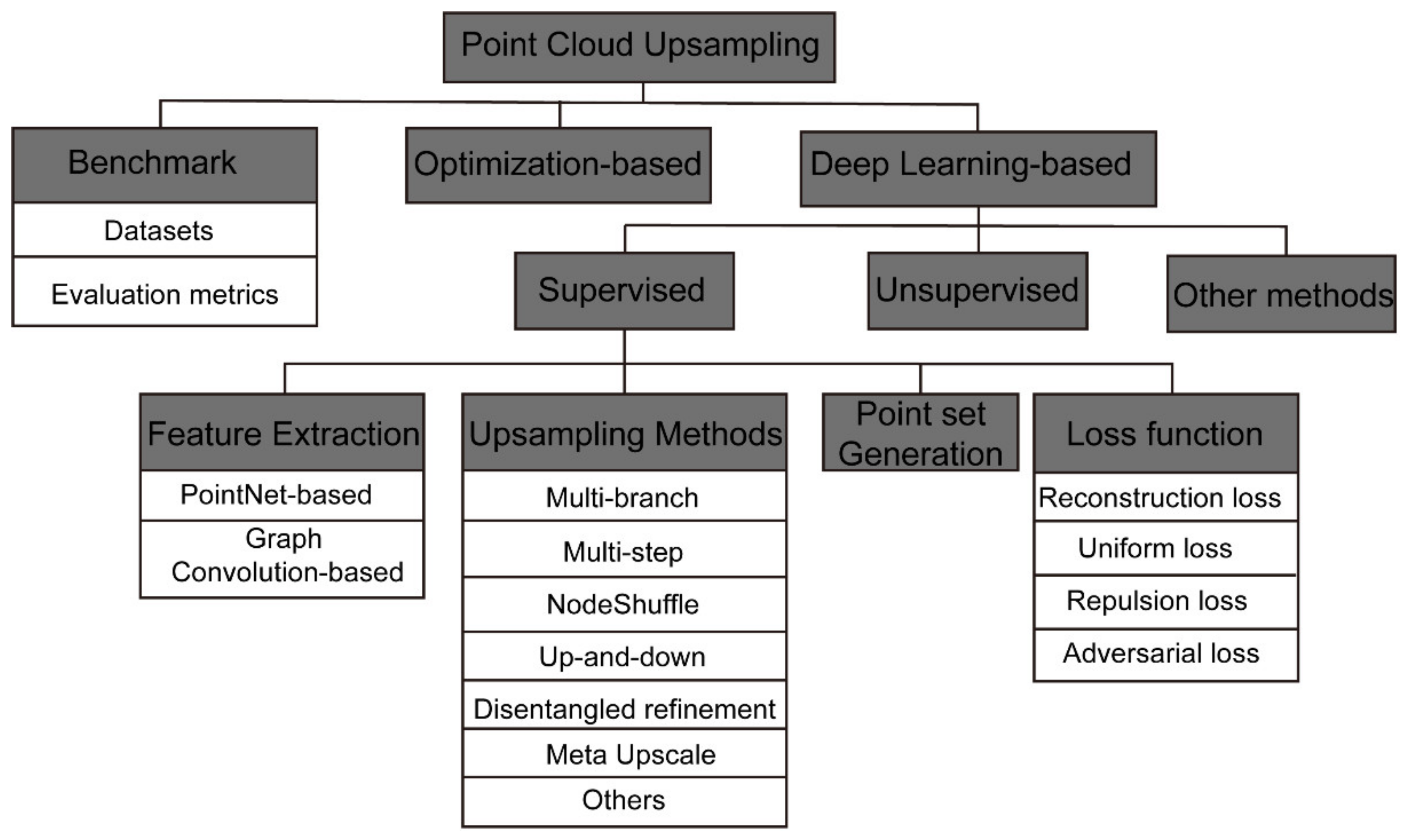
2. Benchmark
2.1. Datasets
2.2. Evaluation Metrics
3. Optimization-Based Point Cloud Upsampling
4. Deep Learning-Based Point Cloud Upsampling
4.1. Supervised Upsampling
4.1.1. Feature Extraction Components
PointNet-Based Feature Extraction
Graph Convolution-Based Feature Extraction
4.1.2. Upsampling Component
4.1.3. Point Set Generation
4.1.4. Loss Function
4.2. Unsupervised Upsampling
4.3. Other Methods of Point Cloud Upsampling Models
5. Algorithm Comparison and Analysis
6. Conclusions and Future Work
- (1)
- Network structure. (a) Feature extraction: This is a meaningful research direction to provide different scales of information for the upsampling component by improving the feature extraction component. (b) Upsampling component: At present, there are different forms of upsampling methods, and determining how to perform effective and efficient upsampling remains to be studied. (c) Coordinate reconstruction: The existing coordinate reconstruction method is relatively simple, and a significant amount of research should focus on exploration to improve the coordinate reconstruction method. (d) Optimizing the model structure: People are currently pursuing the model’s performance more than paying attention to the size and calculation time of the model. Reducing the model size and speeding up the prediction while maintaining performance remains a problem.
- (2)
- Loss function. In addition to designing a good network structure, improving the loss function can also improve the performance of the algorithm. The loss function establishes constraints between the low-resolution point cloud and the high-resolution point cloud, and optimizes the upsampling process according to these constraints. Commonly used loss functions include CD, EMD, and Uniform, which are often weighted and combined into a joint loss function in practical applications. For point cloud upsampling, exploring the potential relationship between low-resolution and high-resolution point clouds and seeking a more accurate and effective loss function is a promising research direction. For example, current point cloud upsampling algorithms have difficulties in filling large holes. Exploring suitable inpainting loss functions to constrain the generated point clouds to fill holes is a promising research direction.
- (3)
- Dataset. At present, there is no universally recognized benchmark dataset. The datasets used by researchers for training and testing are very different, which is not conducive to the comparison between various models and subsequent improvement. Although very difficult, it is important to propose a high-quality benchmark dataset.
- (4)
- Evaluation metrics. Evaluation metrics are one of the most basic components of machine learning. If performance cannot be accurately measured, it will be difficult for researchers to verify improvements. Point cloud upsampling is currently facing such a problem and requires more accurate metrics. At present, there is no unified and applied evaluation metrics for point cloud upsampling. Thus, more accurate metrics for evaluating upsampling quality are urgently needed.
- (5)
- Unsupervised upsampling. As mentioned in Section 4.2, it is difficult to collect point clouds of the same object at different resolutions, and the low-resolution point clouds in the training set are often obtained by downsampling the real point clouds. Supervised learning may learn the inverse process of downsampling. Therefore, unsupervised upsampling of point clouds is a promising research direction.
- (6)
- Applications. Point cloud upsampling can assist other point cloud deep learning tasks. For example, SAUM [51] uses a point cloud upsampling module to achieve point cloud completion, and HPCR [52] uses point cloud upsampling to improve the point cloud reconstruction effect. GeoNet [53] learns geodesic-aware representations and achieves better results by integration with PU-Net. PointPWC-Net [54] uses an upsampling method to effectively process 3D point cloud data and estimate the scene flow from the 3D point cloud DUP-Net [55] uses an upsampling network to add points to reconstruct the surface smoothness to defend against adversarial attacks from other point cloud datasets. Varriale et al. [56] applied point cloud upsampling to cultural heritage analysis, which reduced hardware equipment costs and improved data accuracy. Applying point cloud upsampling to more specific scenes, such as target tracking, scene rendering, video surveillance, and 3D reconstruction, will attract increasing research attention.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alexa, M.; Behr, J.; Cohen-Or, D.; Fleishman, S.; Levin, D.; Silva, C.T. Computing and rendering point set surfaces. IEEE Trans. Vis. Comput. Graph. 2003, 9, 3–15. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d Scene Understanding Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-Annotated 3d Reconstructions of Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Yu, L.; Li, X.; Fu, C.-W.; Cohen-Or, D.; Heng, P.-A. Pu-Net: Point Cloud Upsampling Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2790–2799. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep Learning on Point Sets for 3d Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D Shapenets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H. Shapenet: An information-rich 3d model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar] [CrossRef]
- Lian, Z.; Godil, A.; Fabry, T.; Furuya, T.; Hermans, J.; Ohbuchi, R.; Shu, C.; Smeets, D.; Suetens, P.; Vandermeulen, D. SHREC’10 Track: Non-rigid 3D Shape Retrieval. 3DOR 2010, 10, 101–108. [Google Scholar] [CrossRef] [Green Version]
- Bogo, F.; Romero, J.; Loper, M.; Black, M.J. FAUST: Dataset and Evaluation for 3D Mesh Registration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3794–3801. [Google Scholar]
- Uy, M.A.; Pham, Q.-H.; Hua, B.-S.; Nguyen, T.; Yeung, S.-K. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1588–1597. [Google Scholar]
- Yu, L.; Li, X.; Fu, C.-W.; Cohen-Or, D.; Heng, P.-A. Ec-Net: An Edge-Aware Point Set Consolidation Network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 386–402. [Google Scholar]
- Li, R.; Li, X.; Fu, C.-W.; Cohen-Or, D.; Heng, P.-A. Pu-Gan: A Point Cloud Upsampling Adversarial Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7203–7212. [Google Scholar]
- Qian, G.; Abualshour, A.; Li, G.; Thabet, A.; Ghanem, B. PU-GCN: Point Cloud Upsampling using Graph Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Qian, Y.; Hou, J.; Kwong, S.; He, Y. PUGeo-Net: A Geometry-Centric Network for 3D Point Cloud Upsampling. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 752–769. [Google Scholar]
- Yifan, W.; Wu, S.; Huang, H.; Cohen-Or, D.; Sorkine-Hornung, O. Patch-Based Progressive 3D Point Set Upsampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5958–5967. [Google Scholar]
- Berger, M.; Levine, J.A.; Nonato, L.G.; Taubin, G.; Silva, C.T. A benchmark for surface reconstruction. ACM Tran. Graph. 2013, 32, 1–17. [Google Scholar] [CrossRef]
- Fan, H.; Su, H.; Guibas, L.J. A Point Set Generation Network for 3D Object Reconstruction From A Single Image. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Hobart, Australia, 4–8 December 2006; pp. 1015–1021. [Google Scholar]
- Wu, H.; Zhang, J.; Huang, K. Point cloud super resolution with adversarial residual graph networks. arXiv 2019, arXiv:1908.02111. [Google Scholar] [CrossRef]
- Lipman, Y.; Cohen-Or, D.; Levin, D.; Tal-Ezer, H. Parameterization-free projection for geometry reconstruction. ACM Trans. Graph. 2007, 26, 22-es. [Google Scholar] [CrossRef]
- Huang, H.; Li, D.; Zhang, H.; Ascher, U.; Cohen-Or, D. Consolidation of Unorganized Point Clouds for Surface Reconstruction. ACM Trans. Graph. 2009, 28, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Preiner, R.; Mattausch, O.; Arikan, M.; Pajarola, R.; Wimmer, M. Continuous projection for fast L1 reconstruction. ACM Trans. Graph. 2014, 33, 47:1–47:13. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Wu, S.; Gong, M.; Cohen-Or, D.; Ascher, U.; Zhang, H. Edge-aware point set resampling. ACM Trans. Graph. 2013, 32, 1–12. [Google Scholar] [CrossRef]
- Wu, S.; Huang, H.; Gong, M.; Zwicker, M.; Cohen-Or, D. Deep points consolidation. ACM Trans. Graph. 2015, 34, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Dinesh, C.; Cheung, G.; Bajić, I.V. 3D Point Cloud Super-Resolution via Graph Total Variation on Surface Normals. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4390–4394. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. Acm Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Mandikal, P.; Radhakrishnan, V.B. Dense 3D Point Cloud Reconstruction Using a Deep Pyramid Network. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Hilton Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1052–1060. [Google Scholar]
- Zeng, G.; Li, H.; Wang, X.; Li, N. Point cloud up-sampling network with multi-level spatial local feature aggregation. Comput. Electr. Eng. 2021, 94, 107337. [Google Scholar] [CrossRef]
- Luo, L.; Tang, L.; Zhou, W.; Wang, S.; Yang, Z.-X. PU-EVA: An Edge-Vector Based Approximation Solution for Flexible-Scale Point Cloud Upsampling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16208–16217. [Google Scholar]
- Ding, D.; Qiu, C.; Liu, F.; Pan, Z. Point Cloud Upsampling via Perturbation Learning. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4661–4672. [Google Scholar] [CrossRef]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. Deepgcns: Can Gcns Go as Deep as Cnns? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9267–9276. [Google Scholar]
- Ballester, P.; Araujo, R.M. On the performance of GoogLeNet and AlexNet applied to sketches. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Zhao, Y.; Xie, J.; Qian, J.; Yang, J. PUI-Net: A Point Cloud Upsampling and Inpainting Network. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Nanjing, China, 16–18 October 2020; pp. 328–340. [Google Scholar]
- Han, B.; Zhang, X.; Ren, S. PU-GACNet: Graph attention convolution network for point cloud upsampling. Image Vision Comput. 2022, 118, 104371. [Google Scholar] [CrossRef]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 206–215. [Google Scholar]
- Zhang, P.; Wang, X.; Ma, L.; Wang, S.; Kwong, S.; Jiang, J. Progressive Point Cloud Upsampling via Differentiable Rendering. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4673–4685. [Google Scholar] [CrossRef]
- Li, R.; Li, X.; Heng, P.-A.; Fu, C.-W. Point cloud upsampling via disentangled refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 344–353. [Google Scholar]
- Ye, S.; Chen, D.; Han, S.; Wan, Z.; Liao, J. Meta-PU: An Arbitrary-Scale Upsampling Network for Point Cloud. IEEE Trans. Vis. Comput. Graph. 2021, 1077–2626. [Google Scholar] [CrossRef]
- Wang, G.; Xu, G.; Wu, Q.; Wu, X. Two-Stage Point Cloud Super Resolution with Local Interpolation and Readjustment via Outer-Product Neural Network. J. Syst. Sci. Complex. 2020, 34, 68–82. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural. Inf. Process. Syst. 2014, 63, 139–144. [Google Scholar] [CrossRef]
- Lv, W.; Wen, H.; Chen, H. Point Cloud Upsampling by Generative Adversarial Network with Skip-attention. In Proceedings of the 2021 2nd International Symposium on Computer Engineering and Intelligent Communications (ISCEIC), Nanjing, China, 6–8 August 2021; pp. 186–190. [Google Scholar]
- Li, X.; Own, C.-M.; Wu, K.; Sun, Q. CM-Net: A point cloud upsampling network based on adversarial neural network. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–2 July 2021; pp. 1–8. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Liu, X.; Han, Z.; Wen, X.; Liu, Y.-S.; Zwicker, M. L2g auto-encoder: Understanding point clouds by local-to-global reconstruction with hierarchical self-attention. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 989–997. [Google Scholar]
- Liu, X.; Liu, X.; Han, Z.; Liu, Y.-S. SPU-Net: Self-Supervised Point Cloud Upsampling by Coarse-to-Fine Reconstruction with Self-Projection Optimization. arXiv 2020, arXiv:2012.04439. [Google Scholar] [CrossRef]
- Zhang, W.; Jiang, H.; Yang, Z.; Yamakawa, S.; Shimada, K.; Kara, L.B. Data-driven Upsampling of Point Clouds. Compu.-Aid. Design 2019, 112, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Naik, S.; Mudenagudi, U.; Tabib, R.; Jamadandi, A. FeatureNet: Upsampling of Point Cloud and It’s Associated Features. In Proceedings of the SIGGRAPH Asia 2020 Posters, Virtual, 4–13 December 2020; pp. 1–2. [Google Scholar]
- Wang, K.; Sheng, L.; Gu, S.; Xu, D. Sequential point cloud upsampling by exploiting multi-scale temporal dependency. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4686–4696. [Google Scholar] [CrossRef]
- Son, H.; Kim, Y.M. SAUM: Symmetry-Aware Upsampling Module for Consistent Point Cloud Completion. In Proceedings of the Asian Conference on Computer Vision, Singapore, 20–23 May 2021. [Google Scholar]
- Wang, T.; Liu, L.; Zhang, H.; Sun, J. High-Resolution Point Cloud Reconstruction from a Single Image by Redescription. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- He, T.; Huang, H.; Yi, L.; Zhou, Y.; Wu, C.; Wang, J.; Soatto, S. Geonet: Deep geodesic networks for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6888–6897. [Google Scholar]
- Wu, W.; Wang, Z.Y.; Li, Z.; Liu, W.; Fuxin, L. PointPWC-Net: Cost Volume on Point Clouds for (Self-) Supervised Scene Flow Estimation. In Proceedings of the European Conference on Computer Vision, Online, 23-28 August 2020; pp. 88–107. [Google Scholar]
- Zhou, H.; Chen, K.; Zhang, W.; Fang, H.; Zhou, W.; Yu, N. Dup-net: Denoiser and upsampler network for 3d adversarial point clouds defense. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1961–1970. [Google Scholar]
- Varriale, R.; Parise, M.; Genovese, L.; Leo, M.; Valese, S. Underground Built Heritage in Naples: From Knowledge to Monitoring and Enhancement. In Handbook of Cultural Heritage Analysis; D’Amico, S., Venuti, V., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 2001–2035. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Name | Samples | Training | Test | Type | Representation |
|---|---|---|---|---|---|
| ModelNet10 [7] | 4899 | 3991 | 605 | Synthetic | Mesh |
| ModelNet40 [7] | 12,311 | 9843 | 2468 | Synthetic | Mesh |
| ShapeNet [8] | 51,190 | - | - | Synthetic | Mesh |
| SHREC15 [9] | 1200 | - | - | Synthetic | Mesh |
| FAUST [10] | 300 | 100 | 200 | Real-world | Mesh |
| ScanObjectNN [11] | 2902 | 2321 | 581 | Real-world | Point Clouds |
| Name | Samples | Training | Test | Type | Representation |
|---|---|---|---|---|---|
| PU-Net [5] | 60 | 40 | 20 | Synthetic | Mesh |
| EC-Net [12] | 36 | 36 | - | Synthetic | CAD |
| PU-GAN [13] | 147 | 120 | 27 | Synthetic | Mesh |
| PU1K [14] | 1147 | 1020 | 127 | Synthetic | Mesh |
| PUGeo-Net [15] | 103 | 90 | 13 | Synthetic | Mesh |
| Methods | Uniformity for Different | P2F | CD | HD | Param. | ||||
|---|---|---|---|---|---|---|---|---|---|
| 0.4% | 0.6% | 0.8% | 1.0% | 1.2% | Kb | ||||
| EAR [1] | 16.84 | 20.27 | 23.98 | 26.15 | 29.18 | 5.82 | 0.52 | 7.37 | - |
| PU-Net [5] | 29.74 | 31.33 | 33.86 | 36.94 | 40.43 | 6.84 | 0.72 | 8.94 | 814.3 |
| MPU [16] | 7.51 | 7.41 | 8.35 | 9.62 | 11.13 | 3.96 | 0.49 | 6.11 | 76.2 |
| PU-GAN [13] | 3.38 | 3.49 | 3.44 | 3.91 | 4.64 | 2.33 | 0.28 | 4.64 | 684.2 |
| PU-GCN [14] | - | - | - | - | - | 2.94 | 0.25 | 1.82 | 76.0 |
| Dis-PU [39] | - | - | - | - | - | 4.14 | 0.31 | 4.21 | - |
| PU-EVA [31] | 2.26 | 2.10 | 2.51 | 3.16 | 3.94 | - | 0.27 | 3.07 | - |
| L2G-AE [46] | 24.61 | 34.61 | 44.86 | 55.31 | 64.94 | 39.37 | 6.31 | 63.23 | - |
| SPU-Net [47] | 4.82 | 5.14 | 5.86 | 6.88 | 8.13 | 6.85 | 0.41 | 2.18 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhao, W.; Sun, B.; Zhang, Y.; Wen, W. Point Cloud Upsampling Algorithm: A Systematic Review. Algorithms 2022, 15, 124. https://doi.org/10.3390/a15040124
Zhang Y, Zhao W, Sun B, Zhang Y, Wen W. Point Cloud Upsampling Algorithm: A Systematic Review. Algorithms. 2022; 15(4):124. https://doi.org/10.3390/a15040124
Chicago/Turabian StyleZhang, Yan, Wenhan Zhao, Bo Sun, Ying Zhang, and Wen Wen. 2022. "Point Cloud Upsampling Algorithm: A Systematic Review" Algorithms 15, no. 4: 124. https://doi.org/10.3390/a15040124