
Research and Challenges of Reinforcement Learning in Cyber Defense Decision-Making for Intranet Security


Abstract
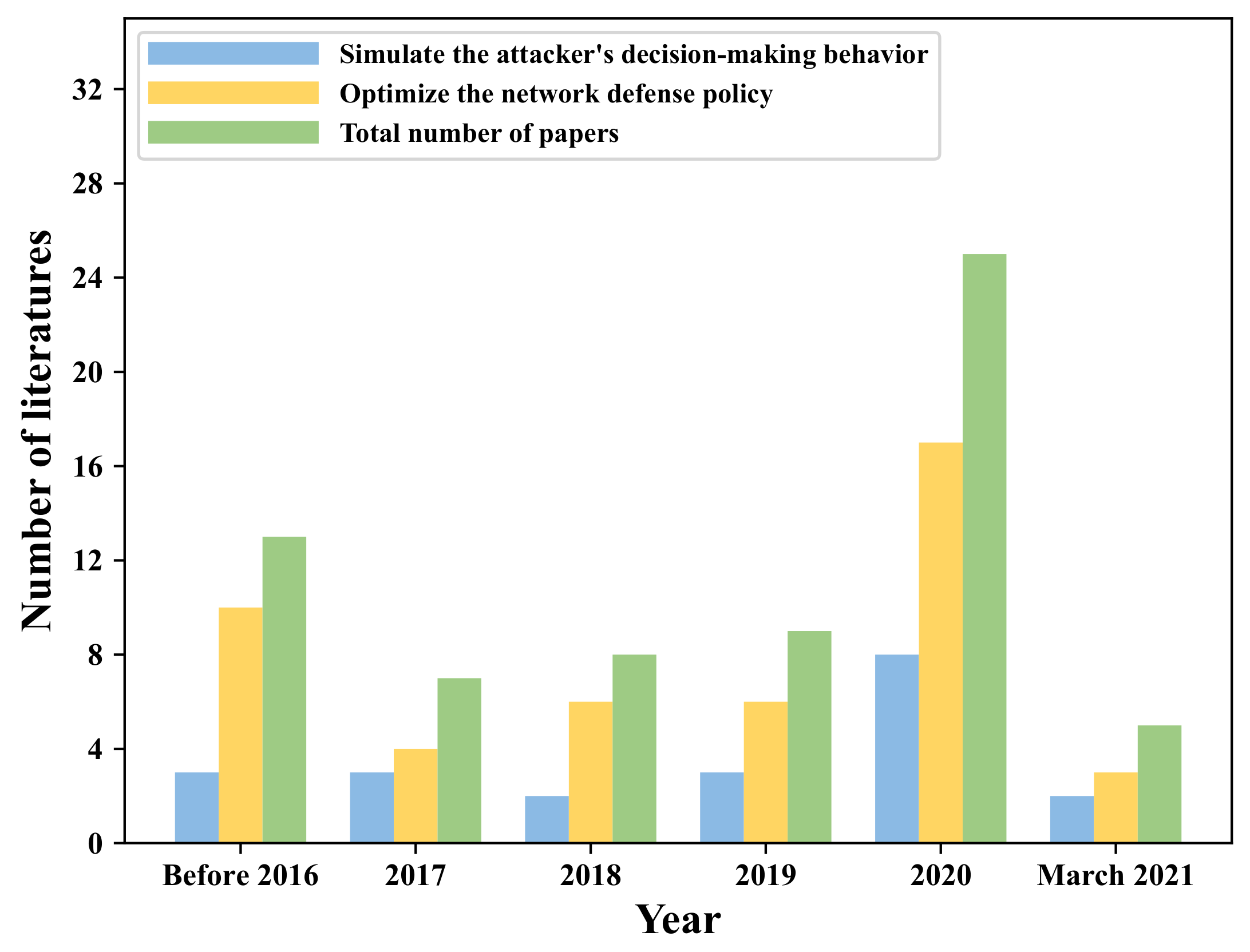
:1. Introduction
- (1)
- Targeted: On one hand, the development of attack techniques has enriched the existing attack surface. Experienced attackers who are able to integrate collected information and knowledge to choose appropriate actions in a task-oriented manner. Therefore, isolated defense technology no longer works in these cases, security experts need to make decisions under different threat situations, which requires more precise objectives.
- (2)
- Organized: In order to obtain the continuous attack effect, the attacker will constantly look for vulnerabilities, and carry out more intelligent attacks by coordinating the attack resources. To fight against the attacker, it is also necessary for the defender to allocate defense resources to deal with both known and unknown threats.
- (1)
- A new framework PDRR (Pentest Design Response Recovery) was proposed to distinguish different cyber defense decision-making tasks. The framework aimed to demarcate the boundaries of the problems, which can help researchers better understand the cyber defense decision-making problem;
- (2)
- Based on the proposed framework, the existing research literature was summarized from the perspectives of the attack and defender respectively. We first discussed the problem characteristics from different perspectives, and then categorized literature according to the type of problem and the adopted decision-making model, and finally compared the problem characteristics, strategies, tasks, advantages and disadvantages used in different literature.
- (3)
- After summarizing the existing literature, we analyzed the future direction and challenges from the perspectives of reinforcement learning algorithms and cyber defense decision-making tasks respectively. The purpose of this discussion is to help researchers understand the cyber defense decision-making task more clearly, and to promote the applications of reinforcement learning algorithms to this task.

2. Research Background
2.1. Decision-Making Models
2.2. RL Algorithms
3. PDRR—A Framework for Recognizing Cyber Defense Decision-Making
- Pentest: Pentest, also known as penetration test, attack planning, risk assessment, or vulnerability assessment, is a method to identify potential risks by simulating the decision-making process of attackers. The purpose of the test is not only to find a single vulnerability in the target network, but to form a series of attack chains (multi-step attacks) to reach the target node. The path from the starting node to the target node is called the attack path.
- Design: Design is the decision-making task made by defenders to optimize the deployment of defense resources and design defense mechanisms before cyber attacks occur. The defense resources could be the experts, the number of security devices or the deployment location.
- Response: Response in the process requires defenders to be able to identify, analyze, and deal with threats. In the real world, defenders often need to analyze a great number of real-time traffic data to prevent or detect threats.
- Recovery: Recovery after the event refers to the decision-making mechanism that takes effect after the attack has occurred, to restore business function or minimize loss as soon as possible.

4. Survey from the Attacker’s Perspective
4.1. Problem Characteristics
4.2. Related Work
5. Survey from the Defender’s Perspective
5.1. Problem Characteristics
5.2. Design
5.3. Response
5.4. Recovery
6. Open Directions and Challenges
6.1. Challenges in Reinforcement Learning Algorithms
6.2. Challenges in Cyber Defense Decision-Making

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Implementation | Model | Literature | Convenience | Fidelity | Expansibility |
|---|---|---|---|---|---|
| Network Simulation | MulVAL [111] | [112,113,114,115] | Middle | Low | Low |
| Petri net [116] | [58] | Low | High | High | |
| NS3 [117] | [118] | Middle | High | Middle | |
| Mininet [119] | [65] | Middle | Middle | Middle | |
| Testing platform | NASim [59] | [48] | High | Middle | High |
| CyberBattleSim [120] | - | High | Middle | High |
- (1)
- Convenience: How easy the platform is to use, which is evaluated on the basis of the size of the package, the platform on which it is running, the language in which it is compiled, and how it is installed.
- (2)
- Fidelity: Closeness to the real world, which is mainly evaluated from action design, network environment, evaluation indexes, etc.
- (3)
- Expansibility: The difficulty of secondary development, which is evaluated based on the open source degree of the platform and the difficulty of the experiment of researchers.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- CNCERT. The Overview of Chinese’s Internet Security Situation in 2020. 2021. Available online: https://www.cert.org.cn/publish/main/46/index.html (accessed on 13 March 2022).
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Masduki, B.W.; Ramli, K.; Saputra, F.A.; Sugiarto, D. Study on implementation of machine learning methods combination for improving attacks detection accuracy on Intrusion Detection System (IDS). In Proceedings of the 2015 International Conference on Quality in Research (QiR), Lombok, Indonesia, 10–13 August 2015; pp. 56–64. [Google Scholar]
- Li, J.H. Cyber security meets artificial intelligence: A survey. Front. Inf. Technol. Electron. Eng. 2018, 19, 1462–1474. [Google Scholar] [CrossRef]
- Xin, Y.; Kong, L.; Liu, Z.; Chen, Y.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine learning and deep learning methods for cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Dasgupta, D.; Akhtar, Z.; Sen, S. Machine learning in cybersecurity: A comprehensive survey. J. Def. Model. Simul. 2020. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Zha, D.; Xie, J.; Ma, W.; Zhang, S.; Lian, X.; Hu, X.; Liu, J. DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning. arXiv 2021, arXiv:2106.06135. [Google Scholar]
- Nguyen, T.T.; Reddi, V.J. Deep reinforcement learning for cyber security. IEEE Trans. Neural Netw. Learn. Syst. 2019. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994; Elsevier: Burlington, MA, USA, 1994; pp. 157–163. [Google Scholar]
- Murphy, K.P. A Survey of POMDP Solution Techniques. Environment 2000, 2, X3. [Google Scholar]
- Ross, S.; Pineau, J.; Paquet, S.; Chaib-Draa, B. Online planning algorithms for POMDPs. J. Artif. Intell. Res. 2008, 32, 663–704. [Google Scholar] [CrossRef]
- Warrington, A.; Lavington, J.W.; Scibior, A.; Schmidt, M.; Wood, F. Robust asymmetric learning in pomdps. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11013–11023. [Google Scholar]
- Huang, Y.; Guo, X.; Song, X. Performance analysis for controlled semi-Markov systems with application to maintenance. J. Optim. Theory Appl. 2011, 150, 395–415. [Google Scholar] [CrossRef]
- Huang, Y.; Guo, X.; Li, Z. Minimum risk probability for finite horizon semi-Markov decision processes. J. Math. Anal. Appl. 2013, 402, 378–391. [Google Scholar] [CrossRef]
- Piunovskiy, A.; Zhang, Y. Continuous-Time Markov Decision Processes; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Guo, X.; Liao, Z.W. Risk-sensitive discounted continuous-time Markov decision processes with unbounded rates. SIAM J. Control Optim. 2019, 57, 3857–3883. [Google Scholar] [CrossRef]
- Zhang, Y. Continuous-time Markov decision processes with exponential utility. SIAM J. Control Optim. 2017, 55, 2636–2660. [Google Scholar] [CrossRef] [Green Version]
- Bertsekas, D.; Tsitsiklis, J.N. Neuro-Dynamic Programming; Athena Scientific: Belmont, MA, USA, 1996. [Google Scholar]
- Hasselt, H.V. Double Q-learning. In Proceedings of the 23rd International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2010; Volume 2, pp. 2613–2621. [Google Scholar]
- Hasselt, H.V.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Anschel, O.; Baram, N.; Shimkin, N. Averaged-dqn: Variance reduction and stabilization for deep reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 176–185. [Google Scholar]
- Kim, S.; Asadi, K.; Littman, M.; Konidaris, G. Removing the target network from deep Q-networks with the Mellowmax operator. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 2060–2062. [Google Scholar]
- Asadi, K.; Littman, M.L. An alternative softmax operator for reinforcement learning. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 243–252. [Google Scholar]
- Song, Z.; Parr, R.; Carin, L. Revisiting the softmax bellman operator: New benefits and new perspective. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 18–23 January 2019; pp. 5916–5925. [Google Scholar]
- Kong, W.; Krichene, W.; Mayoraz, N.; Rendle, S.; Zhang, L. Rankmax: An Adaptive Projection Alternative to the Softmax Function. Adv. Neural Inf. Process. Syst. 2020, 33, 633–643. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Greensmith, E.; Bartlett, P.L.; Baxter, J. Variance reduction techniques for gradient estimates in reinforcement learning. J. Mach. Learn. Res. 2004, 5, 1471–1530. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Chou, P.W.; Maturana, D.; Scherer, S. Improving stochastic policy gradients in continuous control with deep reinforcement learning using the beta distribution. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 834–843. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hoffmann, J. Simulated Penetration Testing: From “Dijkstr” to “Turing Test++”. In Proceedings of the Twenty-Fifth International Conference on Automated Planning and Scheduling, Jerusalem, Israel, 7–11 June 2015; pp. 364–372. [Google Scholar]
- Sarraute, C.; Buffet, O.; Hoffmann, J. Penetration Testing==POMDP Solving? arXiv 2013, arXiv:1306.4714. [Google Scholar]
- Brock, O.; Trinkle, J.; Ramos, F. SARSOP: Efficient Point-Based POMDP Planning by Approximating Optimally Reachable Belief Spaces. In Robotics: Science and Systems IV; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar] [CrossRef]
- Sarraute, C.; Buffet, O.; Hoffmann, J. POMDPs make better hackers: Accounting for uncertainty in penetration testing. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 1816–1824. [Google Scholar]
- Zhou, T.Y.; Zang, Y.C.; Zhu, J.H.; Wang, Q.X. NIG-AP: A new method for automated penetration testing. Front. Inf. Technol. Electron. Eng. 2019, 20, 1277–1288. [Google Scholar] [CrossRef]
- Schwartz, J.; Kurniawati, H.; El-Mahassni, E. POMDP+ Information-Decay: Incorporating Defender’s Behaviour in Autonomous Penetration Testing. In Proceedings of the International Conference on Automated Planning and Scheduling, Nancy, France, 14–19 June 2020; Volume 30, pp. 235–243. [Google Scholar]
- Ghanem, M.C.; Chen, T.M. Reinforcement learning for efficient network penetration testing. Information 2020, 11, 6. [Google Scholar] [CrossRef] [Green Version]
- Walraven, E.; Spaan, M.T. Point-based value iteration for finite-horizon POMDPs. J. Artif. Intell. Res. 2019, 65, 307–341. [Google Scholar] [CrossRef]
- Schwartz, J.; Kurniawati, H. Autonomous penetration testing using reinforcement learning. arXiv 2019, arXiv:1905.05965. [Google Scholar]
- Nguyen, H.V.; Nguyen, H.N.; Uehara, T. Multiple Level Action Embedding for Penetration Testing. In Proceedings of the 4th International Conference on Future Networks and Distributed Systems (ICFNDS), St. Petersburg, Russia, 26–27 November 2020; pp. 1–9. [Google Scholar]
- Dulac-Arnold, G.; Evans, R.; van Hasselt, H.; Sunehag, P.; Lillicrap, T.; Hunt, J.; Mann, T.; Weber, T.; Degris, T.; Coppin, B. Deep reinforcement learning in large discrete action spaces. arXiv 2015, arXiv:1512.07679. [Google Scholar]
- Pozdniakov, K.; Alonso, E.; Stankovic, V.; Tam, K.; Jones, K. Smart security audit: Reinforcement learning with a deep neural network approximator. In Proceedings of the 2020 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), Dublin, Ireland, 15–19 June 2020; pp. 1–8. [Google Scholar]
- Maeda, R.; Mimura, M. Automating post-exploitation with deep reinforcement learning. Comput. Secur. 2021, 100, 102108. [Google Scholar] [CrossRef]
- Sultana, M.; Taylor, A.; Li, L. Autonomous network cyber offence strategy through deep reinforcement learning. In Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications III; International Society for Optics and Photonics: Bellingham, WA, USA, 2021; Volume 11746, p. 1174622. [Google Scholar]
- Applebaum, A.; Miller, D.; Strom, B.; Foster, H.; Thomas, C. Analysis of automated adversary emulation techniques. In Proceedings of the Summer Simulation Multi-Conference, Bellevue, WA, USA, 9–12 July 2017; pp. 1–12. [Google Scholar]
- Elderman, R.; Pater, L.J.; Thie, A.S.; Drugan, M.M.; Wiering, M.A. Adversarial Reinforcement Learning in a Cyber Security Simulation. In Proceedings of the International Conference on Agents and Artificial Intelligence (ICAART), Porto, Portugal, 24–26 February 2017; pp. 559–566. [Google Scholar]
- Niculae, S. Reinforcement Learning vs. Genetic Algorithms in Game-Theoretic Cyber-Security. Ph.D Thesis, University of Bucharest, Bucharest, Romania, 2018. [Google Scholar]
- Butz, M.V.; Wilson, S.W. An algorithmic description of XCS. In Proceedings of the International Workshop on Learning Classifier Systems, Cagliari, Italy, 21–23 June 2000; pp. 253–272. [Google Scholar]
- Bland, J.A.; Petty, M.D.; Whitaker, T.S.; Maxwell, K.P.; Cantrell, W.A. Machine learning cyberattack and defense strategies. Comput. Secur. 2020, 92, 101738. [Google Scholar] [CrossRef]
- Schwartz, J.; Kurniawatti, H. NASim: Network Attack Simulator. 2019. Available online: https://networkattacksimulator.readthedocs.io/ (accessed on 13 March 2022).
- Ng, A.Y.; Jordan, M. PEGASUS: A policy search method for large MDPs and POMDPs. In Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence, San Francisco, CA, USA, 30 June–3 July 2000; pp. 406–415. [Google Scholar]
- Ganesan, R.; Jajodia, S.; Shah, A.; Cam, H. Dynamic scheduling of cybersecurity analysts for minimizing risk using reinforcement learning. ACM Trans. Intell. Syst. Technol. (TIST) 2016, 8, 1–21. [Google Scholar] [CrossRef]
- Winterrose, M.L.; Carter, K.M.; Wagner, N.; Streilein, W.W. Balancing security and performance for agility in dynamic threat environments. In Proceedings of the 2016 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Toulouse, France, 28 June–1 July 2016; pp. 607–617. [Google Scholar]
- Wang, S.; Pei, Q.; Wang, J.; Tang, G.; Zhang, Y.; Liu, X. An intelligent deployment policy for deception resources based on reinforcement learning. IEEE Access 2020, 8, 35792–35804. [Google Scholar] [CrossRef]
- Panfili, M.; Giuseppi, A.; Fiaschetti, A.; Al-Jibreen, H.B.; Pietrabissa, A.; Priscoli, F.D. A game-theoretical approach to cyber-security of critical infrastructures based on multi-agent reinforcement learning. In Proceedings of the 2018 26th Mediterranean Conference on Control and Automation (MED), Zadar, Croatia, 19–22 June 2018; pp. 460–465. [Google Scholar]
- Han, Y.; Rubinstein, B.I.; Abraham, T.; Alpcan, T.; De Vel, O.; Erfani, S.; Hubczenko, D.; Leckie, C.; Montague, P. Reinforcement learning for autonomous defence in software-defined networking. In Proceedings of the International Conference on Decision and Game Theory for Security, Seattle, WA, USA, 29–31 October 2018; pp. 145–165. [Google Scholar]
- Liu, Z. Reinforcement-Learning Based Network Intrusion Detection with Human Interaction in the Loop. In Proceedings of the International Conference on Security, Privacy and Anonymity in Computation, Communication and Storage, Nanjing, China, 18–20 December 2020; pp. 131–144. [Google Scholar]
- Piplai, A.; Ranade, P.; Kotal, A.; Mittal, S.; Narayanan, S.N.; Joshi, A. Using Knowledge Graphs and Reinforcement Learning for Malware Analysis. In Proceedings of the 4th International Workshop on Big Data Analytics for Cyber Intelligence and Defense, IEEE International Conference on Big Data, Atlanta, GA, USA, 10–13 December 2020. [Google Scholar]
- Venkatesan, S.; Albanese, M.; Shah, A.; Ganesan, R.; Jajodia, S. Detecting stealthy botnets in a resource-constrained environment using reinforcement learning. In Proceedings of the 2017 Workshop on Moving Target Defense, Dallas, TX, USA, 30 October 2017; pp. 75–85. [Google Scholar]
- Miller, P.; Inoue, A. Collaborative intrusion detection system. In Proceedings of the 22nd International Conference of the North American Fuzzy Information Processing Society, NAFIPS 2003, Chicago, IL, USA, 24–26 July 2003; pp. 519–524. [Google Scholar]
- Malialis, K. Distributed Reinforcement Learning for Network Intrusion Response. Ph.D. Thesis, University of York, York, UK, 2014. [Google Scholar]
- Sun, Y.; Xiong, W.; Yao, Z.; Moniz, K.; Zahir, A. Network defense strategy selection with reinforcement learning and pareto optimization. Appl. Sci. 2017, 7, 1138. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Li, Y.; Xiong, W.; Yao, Z.; Moniz, K.; Zahir, A. Pareto optimal solutions for network defense strategy selection simulator in multi-objective reinforcement learning. Appl. Sci. 2018, 8, 136. [Google Scholar] [CrossRef] [Green Version]
- Chung, K.; Kamhoua, C.A.; Kwiat, K.A.; Kalbarczyk, Z.T.; Iyer, R.K. Game theory with learning for cyber security monitoring. In Proceedings of the 2016 IEEE 17th International Symposium on High Assurance Systems Engineering (HASE), Orlando, FL, USA, 7–9 January 2016; pp. 1–8. [Google Scholar]
- Sahabandu, D.; Moothedath, S.; Allen, J.; Bushnell, L.; Lee, W.; Poovendran, R. A Multi-Agent Reinforcement Learning Approach for Dynamic Information Flow Tracking Games for Advanced Persistent Threats. arXiv 2020, arXiv:2007.00076. [Google Scholar]
- Hu, Z.; Zhu, M.; Liu, P. Online algorithms for adaptive cyber defense on bayesian attack graphs. In Proceedings of the 2017 Workshop on Moving Target Defense, Dallas, TX, USA, 30 October 2017; pp. 99–109. [Google Scholar]
- Hu, Z.; Zhu, M.; Liu, P. Adaptive Cyber Defense Against Multi-Stage Attacks Using Learning-Based POMDP. ACM Trans. Priv. Secur. (TOPS) 2020, 24, 1–25. [Google Scholar] [CrossRef]
- Alauthman, M.; Aslam, N.; Al-Kasassbeh, M.; Khan, S.; Al-Qerem, A.; Choo, K.K.R. An efficient reinforcement learning-based Botnet detection approach. J. Netw. Comput. Appl. 2020, 150, 102479. [Google Scholar] [CrossRef]
- Servin, A.; Kudenko, D. Multi-agent reinforcement learning for intrusion detection. In Adaptive Agents and Multi-Agent Systems III. Adaptation and Multi-Agent Learning; Springer: Berlin/Heidelberg, Germany, 2005; pp. 211–223. [Google Scholar]
- Liu, M.; Ma, L.; Li, C.; Li, R. Fortified Network Security Perception: A Decentralized Multiagent Coordination Perspective. In Proceedings of the 2020 IEEE 3rd International Conference on Electronics Technology (ICET), Chengdu, China, 8–12 May 2020; pp. 746–750. [Google Scholar]
- Huang, L.; Zhu, Q. Adaptive honeypot engagement through reinforcement learning of semi-markov decision processes. In Proceedings of the International Conference on Decision and Game Theory for Security, Stockholm, Sweden, 30 October–1 November 2019; pp. 196–216. [Google Scholar]
- Huang, L.; Zhu, Q. Strategic Learning for Active, Adaptive, and Autonomous Cyber Defense. In Adaptive Autonomous Secure Cyber Systems; Springer: Cham, Switzerland, 2020; pp. 205–230. [Google Scholar]
- Wei, F.; Wan, Z.; He, H. Cyber-attack recovery strategy for smart grid based on deep reinforcement learning. IEEE Trans. Smart Grid 2019, 11, 2476–2486. [Google Scholar] [CrossRef]
- Wu, J.; Fang, B.; Fang, J.; Chen, X.; Chi, K.T. Sequential topology recovery of complex power systems based on reinforcement learning. Phys. A Stat. Mech. Its Appl. 2019, 535, 122487. [Google Scholar] [CrossRef]
- Debus, P.; Müller, N.; Böttinger, K. Deep Reinforcement Learning for Backup Strategies against Adversaries. arXiv 2021, arXiv:2102.06632. [Google Scholar]
- Jajodia, S.; Ghosh, A.K.; Swarup, V.; Wang, C.; Wang, X.S. Moving Target Defense: Creating Asymmetric Uncertainty for Cyber Threats; Springer Science & Business Media: New York, NY, USA, 2011. [Google Scholar]
- Jiang, W.; Fang, B.X.; Tian, Z.H.; Zhang, H.L. Evaluating network security and optimal active defense based on attack-defense game model. Chin. J. Comput. 2009, 32, 817–827. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Montresor, A.; Jelasity, M. PeerSim: A scalable P2P simulator. In Proceedings of the 2009 IEEE Ninth International Conference on Peer-to-Peer Computing, Seattle, WA, USA, 9–11 September 2009; pp. 99–100. [Google Scholar]
- Leyi, S.; Yang, L.; Mengfei, M. Latest research progress of honeypot technology. J. Electron. Inf. Technol. 2019, 41, 498–508. [Google Scholar]
- Xuan, P.; Lesser, V.; Zilberstein, S. Communication decisions in multi-agent cooperation: Model and experiments. In Proceedings of the Fifth International Conference on Autonomous Agents, Montreal, QC, Canada, 28 May–1 June 2001; pp. 616–623. [Google Scholar]
- Miller, P.; Mill, J.L.; Inoue, A. Synergistic Perceptual Intrusion Detection with Reinforcement Learning (SPIDER). In Proceedings of the Fourteenth Midwest Artificial Intelligence and Cognitive Sciences Conference (MAICS 2003), Cincinnati, OH, USA, 12–13 April 2003; pp. 102–108. [Google Scholar]
- Archive, U.K. KDD Cup 1999 Data. 1999. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 13 March 2022).
- Singh, N.K.; Mahajan, V. Smart grid: Cyber attack identification and recovery approach. In Proceedings of the 2019 2nd International Conference on Innovations in Electronics, Signal Processing and Communication (IESC), Shillong, Indian, 1–2 March 2019; pp. 1–5. [Google Scholar]
- Ng, A.Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the 16th International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; pp. 278–287. [Google Scholar]
- Zhifei, S.; Er, M.J. A survey of inverse reinforcement learning techniques. Int. J. Intell. Comput. Cybern. 2012, 5, 293–311. [Google Scholar] [CrossRef]
- Arora, S.; Doshi, P. A survey of inverse reinforcement learning: Challenges, methods and progress. Artif. Intell. 2021, 297, 103500. [Google Scholar] [CrossRef]
- Ditzler, G.; Roveri, M.; Alippi, C.; Polikar, R. Learning in nonstationary environments: A survey. IEEE Comput. Intell. Mag. 2015, 10, 12–25. [Google Scholar] [CrossRef]
- Padakandla, S.; Prabuchandran, K.; Bhatnagar, S. Reinforcement learning algorithm for non-stationary environments. Appl. Intell. 2020, 50, 3590–3606. [Google Scholar] [CrossRef]
- Marinescu, A.; Dusparic, I.; Clarke, S. Prediction-based multi-agent reinforcement learning in inherently non-stationary environments. ACM Trans. Auton. Adapt. Syst. (TAAS) 2017, 12, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Al-Shedivat, M.; Bansal, T.; Burda, Y.; Sutskever, I.; Mordatch, I.; Abbeel, P. Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lecarpentier, E.; Rachelson, E. Non-Stationary Markov Decision Processes a Worst-Case Approach using Model-Based Reinforcement Learning. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 1–18. [Google Scholar]
- Peters, O. The ergodicity problem in economics. Nat. Phys. 2019, 15, 1216–1221. [Google Scholar] [CrossRef] [Green Version]
- Moreira, C.; Tiwari, P.; Pandey, H.M.; Bruza, P.; Wichert, A. Quantum-like influence diagrams for decision-making. Neural Netw. 2020, 132, 190–210. [Google Scholar] [CrossRef]
- Doctor, J.N.; Wakker, P.P.; Wang, T.V. Economists’s views on the ergodicity problem. Nat. Phys. 2020, 16, 1168. [Google Scholar] [CrossRef]
- Bowers, K.D.; Van Dijk, M.; Griffin, R.; Juels, A.; Oprea, A.; Rivest, R.L.; Triandopoulos, N. Defending against the unknown enemy: Applying FlipIt to system security. In Proceedings of the International Conference on Decision and Game Theory for Security, Budapest, Hungary, 5–6 November 2012; pp. 248–263. [Google Scholar]
- Laszka, A.; Horvath, G.; Felegyhazi, M.; Buttyán, L. FlipThem: Modeling targeted attacks with FlipIt for multiple resources. In Proceedings of the International Conference on Decision and Game Theory for Security, Los Angeles, CA, USA, 6–7 November 2014; pp. 175–194. [Google Scholar]
- Chapman, M.; Tyson, G.; McBurney, P.; Luck, M.; Parsons, S. Playing hide-and-seek: An abstract game for cyber security. In Proceedings of the 1st International Workshop on Agents and CyberSecurity, Paris, France, 6 May 2014; pp. 1–8. [Google Scholar]
- Tandon, A.; Karlapalem, K. Medusa: Towards Simulating a Multi-Agent Hide-and-Seek Game. In Proceedings of the 27th International Joint Conference on Artificial Intelligence and the 23rd European Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 5871–5873. [Google Scholar]
- Pandey, S.; Kühn, R. A random walk perspective on hide-and-seek games. J. Phys. A Math. Theor. 2019, 52, 085001. [Google Scholar] [CrossRef] [Green Version]
- Tandon, A.; Karlapalem, K. Agent Strategies for the Hide-and-Seek Game. Ph.D. Thesis, International Institute of Information Technology Hyderabad, Hyderabad, India, 2020. [Google Scholar]
- Ou, X.; Govindavajhala, S.; Appel, A.W. MulVAL: A Logic-based Network Security Analyzer. In USENIX Security Symposium; USENIX: Baltimore, MD, USA, 2005; Volume 8, pp. 113–128. [Google Scholar]
- Durkota, K.; Lisỳ, V.; Kiekintveld, C.; Bošanskỳ, B.; Pěchouček, M. Case studies of network defense with attack graph games. IEEE Intell. Syst. 2016, 31, 24–30. [Google Scholar] [CrossRef]
- Yichao, Z.; Tianyang, Z.; Xiaoyue, G.; Qingxian, W. An improved attack path discovery algorithm through compact graph planning. IEEE Access 2019, 7, 59346–59356. [Google Scholar] [CrossRef]
- Chowdhary, A.; Huang, D.; Mahendran, J.S.; Romo, D.; Deng, Y.; Sabur, A. Autonomous security analysis and penetration testing. In Proceedings of the 2020 16th International Conference on Mobility, Sensing and Networking (MSN), Tokyo, Japan, 17–19 December 2020; pp. 508–515. [Google Scholar]
- Hu, Z.; Beuran, R.; Tan, Y. Automated Penetration Testing Using Deep Reinforcement Learning. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Genoa, Italy, 7–11 September 2020; pp. 2–10. [Google Scholar]
- Petri, C. Kommunikation Mit Automaten. Ph.D. Thesis, University of Hamburg, Hamburg, Germany, 1962. [Google Scholar]
- Riley, G.F.; Henderson, T.R. The ns-3 network simulator. In Modeling and Tools for Network Simulation; Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–34. [Google Scholar]
- Otoum, S.; Kantarci, B.; Mouftah, H. A comparative study of ai-based intrusion detection techniques in critical infrastructures. ACM Trans. Internet Technol. (TOIT) 2021, 21, 1–22. [Google Scholar] [CrossRef]
- Team, M. Mininet An Instant Virtual Network on Your Laptop (or other PC). 2012. Available online: http://mininet.org/ (accessed on 13 March 2022).
- Team, M.D.R. CyberBattleSim. Created by Christian Seifert, Michael Betser, William Blum, James Bono, Kate Farris, Emily Goren, Justin Grana, Kristian Holsheimer, Brandon Marken, Joshua Neil, Nicole Nichols, Jugal Parikh, Haoran Wei. 2021. Available online: https://github.com/microsoft/cyberbattlesim (accessed on 13 March 2022).
- Lanctot, M.; Zambaldi, V.; Gruslys, A.; Lazaridou, A.; Tuyls, K.; Pérolat, J.; Silver, D.; Graepel, T. A unified game-theoretic approach to multiagent reinforcement learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4193–4206. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]

| Type | Ref | U | P | C | N | Policy | Description |
|---|---|---|---|---|---|---|---|
| POMDP | [41] | 🗸 | 🗸 | × | × | SARSOP [42] | (1) Introduce beliefs to reflect uncertainty; (2) Excessive computational complexity. |
| [43] | 🗸 | 🗸 | × | × | Improved SARSOP | (1) Introduce network structure to reduce complexity; (2) Not applicable when structure changes. | |
| [44] | 🗸 | × | × | × | Improved RL | Introduce the network information gain to evaluate actions. | |
| [45] | 🗸 | 🗸 | 🗸 | × | Improved Bayesian RL | Introduce the information decay factor to reflect the influence of the adversary. | |
| [46] | 🗸 | 🗸 | × | × | Improved GIP [47] | (1) Path coverage exceeds that of human in small networks; (2) Computational cost exceeds that of human on medium LANs. | |
| MDP | [40] | 🗸 | × | × | × | - | Modeling as deterministic planning. |
| [48] | 🗸 | × | × | × | Q-learning, Deep Q-learning | (1) Build a system to simulate attack; (2) Ignore the defender and normal user. | |
| [49] | 🗸 | × | × | × | DQN with WA [50] | (1) Introduce “WA” to reduce action space; (2) Use graph embedding method to abstract state; (3) Low-dimensional vectors lacks interpretability. | |
| [51] | 🗸 | × | × | × | RNN | The RNN algorithm can also work well when the environment changes. | |
| [52] | 🗸 | × | × | × | A2C, Q-Learning, SARSA | (1) The A2C algorithm performs better than other algorithms. (2) State representation lacks interpretability. | |
| [53] | 🗸 | × | × | × | DQN, PPO | (1) The stability and generalization are disscussed for the first time. (2) Current algorithms have poor generalization performance. | |
| Markov Game | [54] | 🗸 | × | 🗸 | 🗸 | Planning-based | Design dynamic network configurations to compare attack and defense interactions. |
| [55] | 🗸 | × | 🗸 | × | Strategy sets | (1) The adaptability of algorithms to the adversary is verified. (2) The task is far from real world. | |
| [56] | 🗸 | × | 🗸 | 🗸 | Q-learning, DQN, XCS [57] | (1) Designed a attack-defense multi-agent system. (2) Different action usages are not discussed. | |
| [58] | 🗸 | × | 🗸 | × | DQN | (1) Verify the algorithm’s applicability. (2) The defined model is difficult to scale. |
| Type | Model | Ref | F | L | C | Policy | Description |
|---|---|---|---|---|---|---|---|
| Design | MDP | [61] | × | × | 🗸 | Value Iteration | Dynamic optimization algorithm and manual intervention are combined. |
| [62] | 🗸 | × | 🗸 | Q-learning | Proposed a new adaptive control framework. | ||
| [63] | × | 🗸 | 🗸 | Q-learning | Proposed a spoofing resource deploy algorithm without strict constraints on attacker. | ||
| Markov Game | [64] | − | × | 🗸 | Q-learning | An algorithm that can obtain the optimal security configuration in multiple scenarios; | |
| Response | MDP | [65] | 🗸 | × | 🗸 | DDQN, A3C | (1) Design an autonomous defense scenarios and interfere with training process; (2) observation is less limited. |
| [66] | 🗸 | 🗸 | × | DQN | (1) The convergence is accelerated by expert artificial reward (2) Limited reward setting. | ||
| [67] | × | × | × | Q-learning | (1) Knowledge graph is used to guide the algorithm design (2) High trust in open source data. | ||
| [68] | − | × | 🗸 | Value Iteration | (1) Introduces a botnet detector based on RL; (2) Action cost not taken into account. | ||
| [69] | − | × | 🗸 | Reward structure | Multi-agent network with collaborative framework and group decision-making. | ||
| [70] | × | × | × | Sarsa | (1) Hierarchical collaborative team learning can extend to large scenarios; (2) Difficult to guarantee convergence. | ||
| Markov Game | [71] | × | 🗸 | 🗸 | Q-learning | (1) Pareto optimization is used to improve Q-learning’s efficiency; (2) The attacker takes random actions. | |
| [72] | × | 🗸 | 🗸 | Q-learning | (1) A defense policy selection simulator is constructed; (2) Random attack actions. | ||
| [73] | 🗸 | 🗸 | × | Q-learning | (1) Respond to attacks with limited information; (2) Rely on expertise to evaluate rewards. | ||
| [74] | 🗸 | 🗸 | 🗸 | MA-ARNE | Solving resource utilization and effective detection of APT with MARL. | ||
| POMDP | [75] | × | 🗸 | 🗸 | Q-learning | POMDP is modeled based on Bayes attack graph. | |
| [76] | × | 🗸 | 🗸 | Q-learning | (1) The transfer probability is estimated using Thompson sampling; (2) Fixed attack transfer probability. | ||
| [77] | 🗸 | 🗸 | × | Value Iteration | (1) Adaptively adjust the recognition configuration according to the false alarm rate; (2) Cannot face adaptive attackers well. | ||
| [78] | 🗸 | 🗸 | 🗸 | Q-learning | (1) Multi-agent collaboration model based on signal and hierarchy; (2) Cannot guarantee the convergence. | ||
| [79] | 🗸 | 🗸 | 🗸 | Q-learning | (1) A decentralized threat perception model is proposed; (2) Value functions needs expert knowledge. | ||
| SMDP | [80,81] | − | × | 🗸 | Q-learning; | The interaction in the honeypot is modeled as a semi-Markov process. | |
| Recovery | MDP | [82] | − | × | × | DDPG | (1) The continuous numerical method is used to obtain a better real-time recovery policy; (2) Low convergence rate. |
| [83] | − | × | × | Q-learning | (1) Proposed an effective strategy based on a realistic power flow model with RL; (2) Low convergence rate. | ||
| [84] | − | × | × | DDPG | Applied reinforcement learning to backup policy. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Sun, D.; Jiang, F.; Chen, X.; Zhu, C. Research and Challenges of Reinforcement Learning in Cyber Defense Decision-Making for Intranet Security. Algorithms 2022, 15, 134. https://doi.org/10.3390/a15040134
Wang W, Sun D, Jiang F, Chen X, Zhu C. Research and Challenges of Reinforcement Learning in Cyber Defense Decision-Making for Intranet Security. Algorithms. 2022; 15(4):134. https://doi.org/10.3390/a15040134
Chicago/Turabian StyleWang, Wenhao, Dingyuanhao Sun, Feng Jiang, Xingguo Chen, and Cheng Zhu. 2022. "Research and Challenges of Reinforcement Learning in Cyber Defense Decision-Making for Intranet Security" Algorithms 15, no. 4: 134. https://doi.org/10.3390/a15040134
APA StyleWang, W., Sun, D., Jiang, F., Chen, X., & Zhu, C. (2022). Research and Challenges of Reinforcement Learning in Cyber Defense Decision-Making for Intranet Security. Algorithms, 15(4), 134. https://doi.org/10.3390/a15040134