2.1. Related Work
Without loss of generality, we can state the classic unconstrained single-objective continuous DOP as follows.
where
,
d is the search space dimensionality,
S is the search space,
t denotes the time,
is the set of parameters of the current environment,
, is the objective function that returns a value
using the feasible solution from the search space at time
t,
—is a set of feasible solutions at time
.
There are a lot of approaches that have been proposed to handle DOPs, some of them are described below:
Detection-based approaches. This group of methods can be divided into two subcategories: a solution reevaluation [
8,
17] and detection changes in an algorithm’s behavior [
18,
19]. The solution reevaluation is based on the reevaluation of some solution at a given frequency. If the fitness value of this solution is changed, then the environment is changed too. The second way is based on monitoring the drop in the average performance of an algorithm over several generations. Additionally, some algorithms evaluate the diversity of fitness values.
Introducing diversity when changes are detected. When solving the stationary optimization problem, the population has to converge to an optimum. When solving DOP, if the whole population is converged to some optimum and the environment is changed, the algorithm cannot react to the change quickly and effectively. The following approach has been proposed to diversify the population. In [
18], a partial hypermutation step has been proposed. It replaces a predefined percentage of individuals, generated randomly from the feasible search space. The proposed genetic programming approach [
19] increases the mutation factor, reduces elitism, and increases the probability of crossover when the environment is changed.
Maintaining diversity during the search. Methods from this group do not detect directly when the environment is changed. They are based on keeping the diversity of the population on the same level. In the random immigrants method [
20], a predefined number of randomly generated individuals are added to the population in every generation. The sentinel placement method [
21] initializes the predefined number of points that cover the search space. Authors use the proposed method to cover the search space more uniformly.
Memory approaches. If the changes in the environment are periodical, i.e., the landscape of the problem can return, it is useful to contain previous solutions to save computational resources. The previous good solutions are stored in a direct memory [
22,
23].
Prediction approaches. In this case, a heuristic tries to find some patterns that are predictable and use this information to increase the search performance when the environment is changed. A prediction of the optima movement is described in [
24]. The prediction model is based on a sequence of optimum positions found in the previous environments.
Multi-population approaches. The idea of the approach is to share responsibilities between populations. For example, the first population may focus on searching for the optimum while the second population focuses on tracking any environmental changes. The approach [
25] uses the predefined number of small populations to find better solutions and one big population to track changes. Another method [
26] uses the main big population to optimize the current environment and dedicates some small populations to track the changes in the environment.
Most of the modern approaches utilize the multi-population concept, for example, in [
27], a general adaptive multi-swarm framework is proposed, in which the number of swarms is dynamically adapted and some of the swarms are set to an inactive state to save computational resource. In the AMP framework proposed in [
28], several heuristics are applied, including population exclusion, avoidance of explored peaks, population hibernation and wakening, as well as the Brownian movement.
Other studies, such as [
29] or [
30], propose the use of clustering methods for dividing the population into sub-swarms, and depending on a threshold condition, close swarms could be merged into one. In some papers, such as [
31,
32] it was shown that the idea of having multiple dynamic swarms could be efficiently applied also to static test suites such as the well-known Congress on Evolutionary Computation competition problems [
33], real-world problems, such as energy consumption optimization [
34] or constrained optimization problems [
35].
Although there is a certain amount of studies on dynamic optimization, which use DE-based algorithms, such as DynPopDE [
15], most of them are focused on PSO due to its simplicity and ability to converge fast. However, in stationary environments, hybrid approaches are well-known, for example, in [
36], a hybrid algorithm is applied to the optimal design of water distribution systems, in [
37], the algorithm with repulsive strategy is proposed, and in [
38], the soft island model with different types of populations is proposed. Considering these studies, the development of hybrid approaches combining PSO and DE could be a promising research direction.
2.2. Generalized Moving Peaks Benchmark
As mentioned before, real-world dynamic optimization problems have complex landscapes and, therefore, algorithms applied to them have to be able to find desirable solutions while also reacting to the environmental changes. The latter is important due to the fact that these changes cause the shift of the optimal solution, namely, the previously found solution becomes suboptimal and the new one should be found for a current environment. Thus, in order to evaluate the performance of the proposed algorithms, it is crucial to use benchmark problems that can be described by the following features:
Easy implementation;
High configurability with respect to the number of components, the shape of components, dimension, environmental change frequency, and severity;
Variety of characteristics (modularity, components with different condition numbers, different intensity of local and global modality, heterogeneity, different levels of irregularities, symmetric and asymmetric components, and so on).
One of the most popular and well-known generators for DOP benchmarks is the Moving Peaks Benchmark (MPB) [
8], which is based on changing the components and their locations over time. However, this benchmark generator cannot be considered useful or practical due to its irrelevance to real-world problems. Therefore, the Generalized Moving Peaks Benchmark (GMPB) generator was later proposed [
10]. GMPB is a benchmark generator with fully controllable features: it is capable of generating problems with fully non-separable to fully separable structure, with homogeneous or highly heterogeneous, balanced or highly imbalanced sub-functions, with unimodal or multimodal, symmetric or asymmetric and smooth or highly irregular components.
The GMPB benchmark generator, introduced in [
10], has the following baseline function:
In these formulas the following notations are used: x is a solution vector, d is the number of dimensions, m is the number of components, is the vector of center positions of the -th component at time , is the rotational matrix of component k in the environment t, is a width matrix (it is a diagonal matrix where each diagonal element is the width of the component k), and, finally, , , and are the irregularity parameters of the component k. Here, for each component, the height, width, irregularity, and all other parameters change as soon as the environmental change happens.
The mentioned function (1) can be used with basic parameters, thus, in the simplest form: in the case where the generated DOP would be symmetric, unimodal, and smooth, the result would be easily optimized. To make the generated problems more complex, the irregularity parameters and should be changed. By setting different values to those parameters the end-user can get irregular and/or multimodal optimization tasks.
The higher values of the irregularity parameters ( and ) increase the number of local optima in a given peak. It should be noted that identical values of the irregularity parameters lead to the symmetric DOPs, while the components with different values are asymmetric. Additionally, each component’s intensity of irregularities, number of local optima, and asymmetry degree change over time due to the fact that parameters and change over time.
The rotation matrix is obtained for each component k by rotating the projection of solution x onto all existing unique planes of the search space by a given angle. For that purpose, a Givens rotation matrix is constructed, which is firstly initialized as an identity matrix and then altered. Besides, it should be noted that the initial rotation matrix is obtained by using the Gram-Schmidt orthogonalization method on a matrix with normally distributed entries.
For DOPs obtained by the MPB generator, the width of each component or peak is, in other words, the same in all dimensions, therefore, the shape of components is cone-like with circular contour lines. It was changed for the GMPB benchmark generator, namely, each peak’s width was changed from a scalar variable to a vector with d dimensions. Thus, a component generated by GMPB has a width value in each dimension.
The condition number of a component is the ratio of its largest width value to its smallest value, and if a component’s width value is stretched in one axis’s direction more than the other axes, then, the component is ill-conditioned. As result, the ill-conditioning degree of each component can be determined by calculating the condition number of the diagonal matrix . So, the GMPB generator, unlike the MPB generator, is capable of creating components with various condition numbers, i.e., it can additionally generate ill-conditioned peaks.
The modularity can be obtained by composing several sub-functions generated by the GMPB (in that case each sub-function is obtained from the baseline function by varying its parameters listed above). Each sub-function in composition can have a different number of peaks and dimensions, thus, the landscapes of sub-functions can have different features, and, as result, the generated compositional function can be heterogeneous. Additionally, compositional DOPs generated by the GMPB have a lot of local optima in their landscape, which can change to the global optimum after environmental changes.
2.3. mQSO Algorithm
The multi-swarm Quantum Swarm Optimization algorithm is a well-known approach for dynamic optimization proposed in [
13]. The main features of the mQSO are the usage of several swarms at the same time, application of exclusion, anti-convergence, and charged and quantum swarms. The swarm is divided into several sub-swarms with the aim to let every small swarm seek and track different local optima. However, a simple division into several small swarms is not enough: if there will be no interaction between sub-swarms, then some of them may converge to the same local optimum.
In mQSO, two forms of swarm interaction are applied: exclusion and anti-convergence. The exclusion mechanism makes sure that two or more swarms are not clustering around the same peak. To prevent this, a competition between swarms is used, in particular, when their swarm attractors, i.e., best solutions, are within the exclusion radius , the swarm, which is further from the optimum, is excluded.
The anti-convergence mechanism works as follows: when all of the swarms have converged to their corresponding local optima, the worst swarm is reinitialized, thus, some part of the total population is always searching for new local optima. The anti-convergence implements global information sharing between all swarms. The convergence to the local optimum is detected when the neutral swarm size is smaller than the predefined convergence radius .
The mQSO starts by randomly initializing
swarms of
particles each within the
-dimensional search space with positions
,
,
,
. In the implementation in this study, the mQSO uses two types of particles: neutral and quantum, but not charged, as used in [
10]. The update rule for the neutral particles is as follows:
where
is the particle index in the population,
is the velocity of i-th particle in
-th swarm,
,
is current particle position,
is the personal best position,
and
are random vectors in
,
and
are social and cognitive parameters,
is the inertia factor,
—is the global best solution,
denotes the element-wise product. The quantum particles in mQSO are sampled within the
-dimensional ball of radius
around the best particle as follows:
The quantum local search is performed for steps for all the best solutions in each swarm .
2.4. Proposed Algorithm
In this study, the modification of the mQSO algorithm is proposed, in which the search operators from the differential evolution are applied. One of the most common DE search operators is the rand/1, in which the position of the individual is updated based on the position of three randomly chosen individuals with indexes r
1, r
2, and r
3, and the scaling factor
F. In this study this operator is applied as follows:
where
F is the scaling factor parameter, usually within the
interval, and
is the mutant solution for individual
in swarm
.
As some of the previous studies have shown, the DE is not very efficient compared to PSO in optimizing dynamically changing environments. This is mainly due to the much faster convergence of PSO-like algorithms. However, they often suffer from premature convergence, which is usually not the case for DE-based algorithms. Thus, in this study, the rand/1 operator is applied to the particles’ positions with a small probability of
. There are two possible options for applying the rand/1 strategy within PSO, namely applying it to the current positions of particles, as in Equation (6), or to the personal best positions. In other words, the following equation can be applied instead:
Setting the proper value for the scaling factor
F is one of the key problems in parameter adaptation methods for DE, as the method is highly sensitive to this value. In this study, the scaling factor parameter
F was sampled using the Cauchy distribution with location parameter
mF and scale parameter 0.1 (denoted as
). The
F value was generated until it fell within the
interval. The usage of Cauchy distribution was originally proposed in the JADE [
39] algorithm, where F values were tuned based on their successful application. Although the success-based adaptation of scaling factors is not considered in this study, sampling
F values should allow for improving the search by increasing the diversity of generated trial solutions. The mF parameter, used as a location for Cauchy distribution, could be set to any value within
to get different search properties.
In differential evolution the mutation step is followed by crossover, in particular, the binomial crossover is usually applied with probability
Cr. The binomial crossover is described as follows:
where
is a randomly chosen index from
.
After crossover, in classical DE the selection operation is performed, where new solutions are remembered only if their fitness is better than the fitness of the corresponding parent. Unlike DE, in the proposed mQSODE algorithm the newly generated positions are always remembered independent of the fitness values.
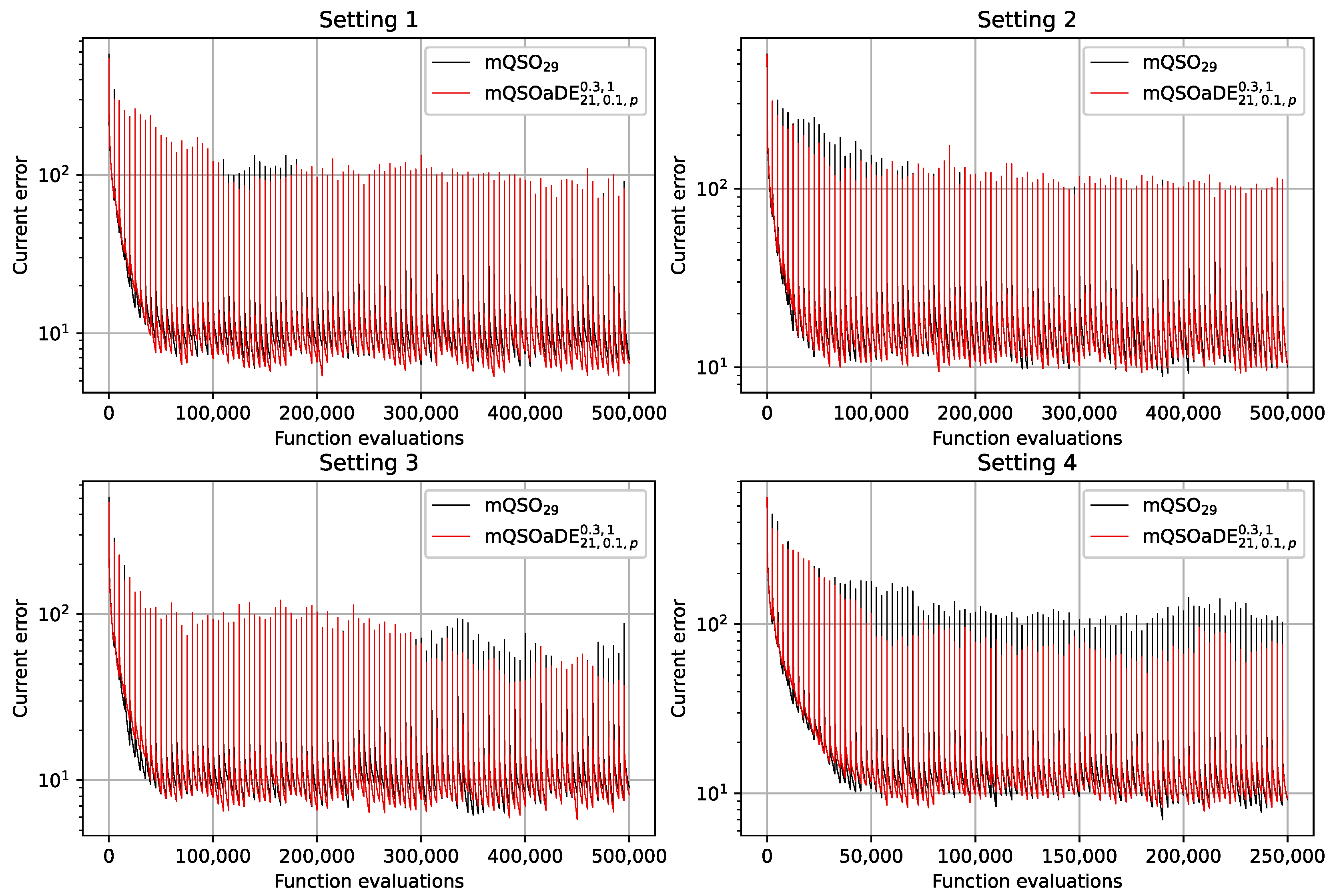
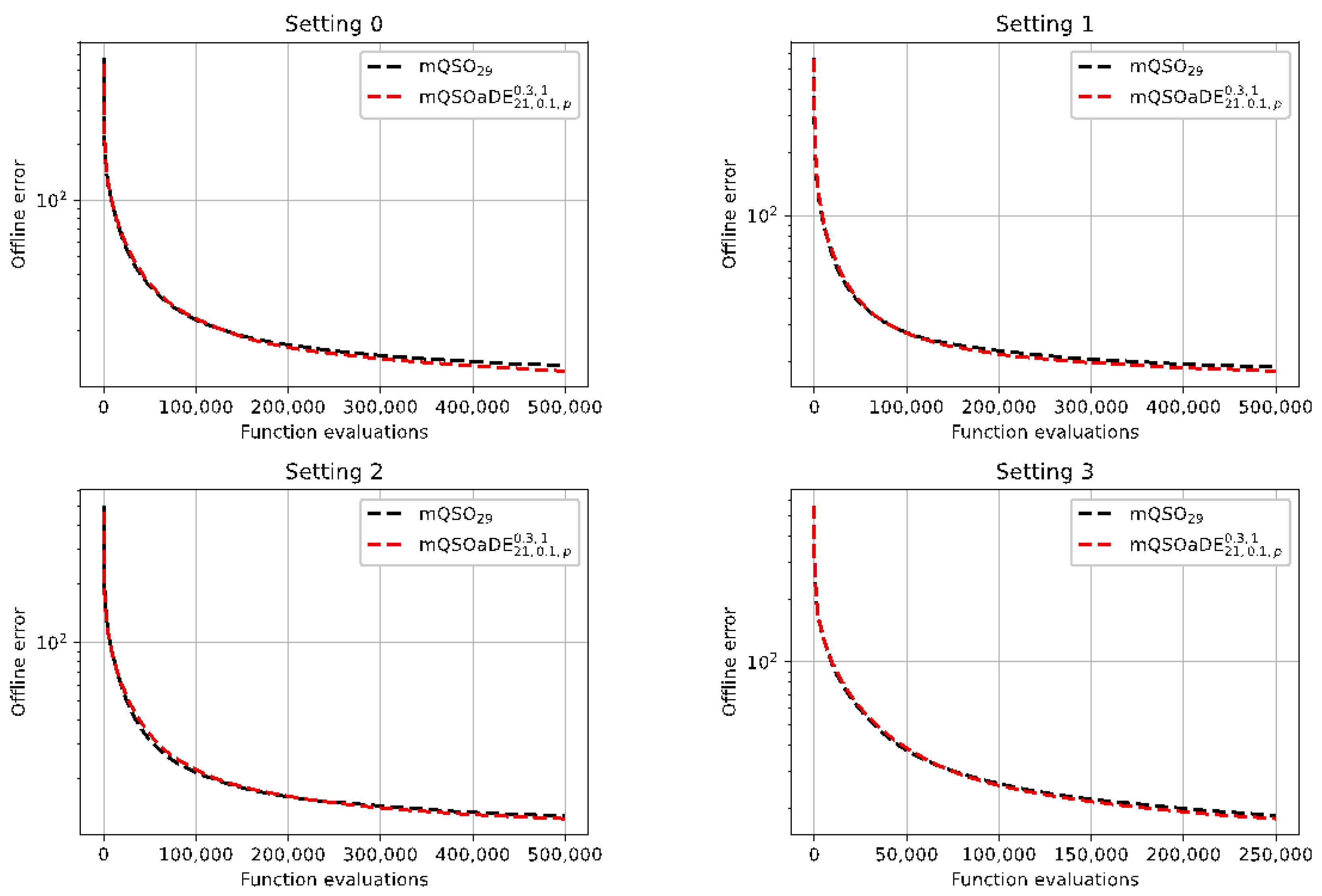
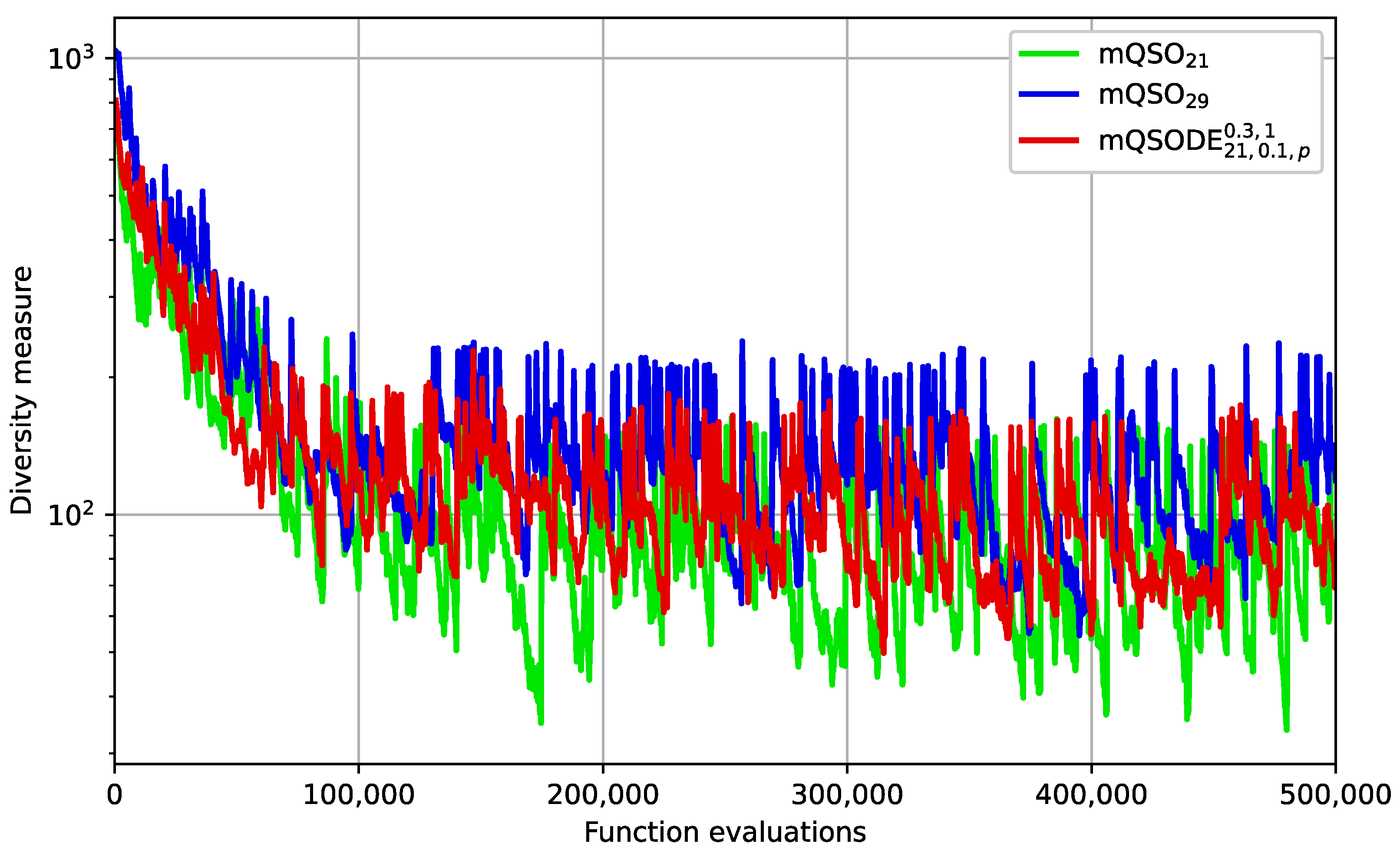
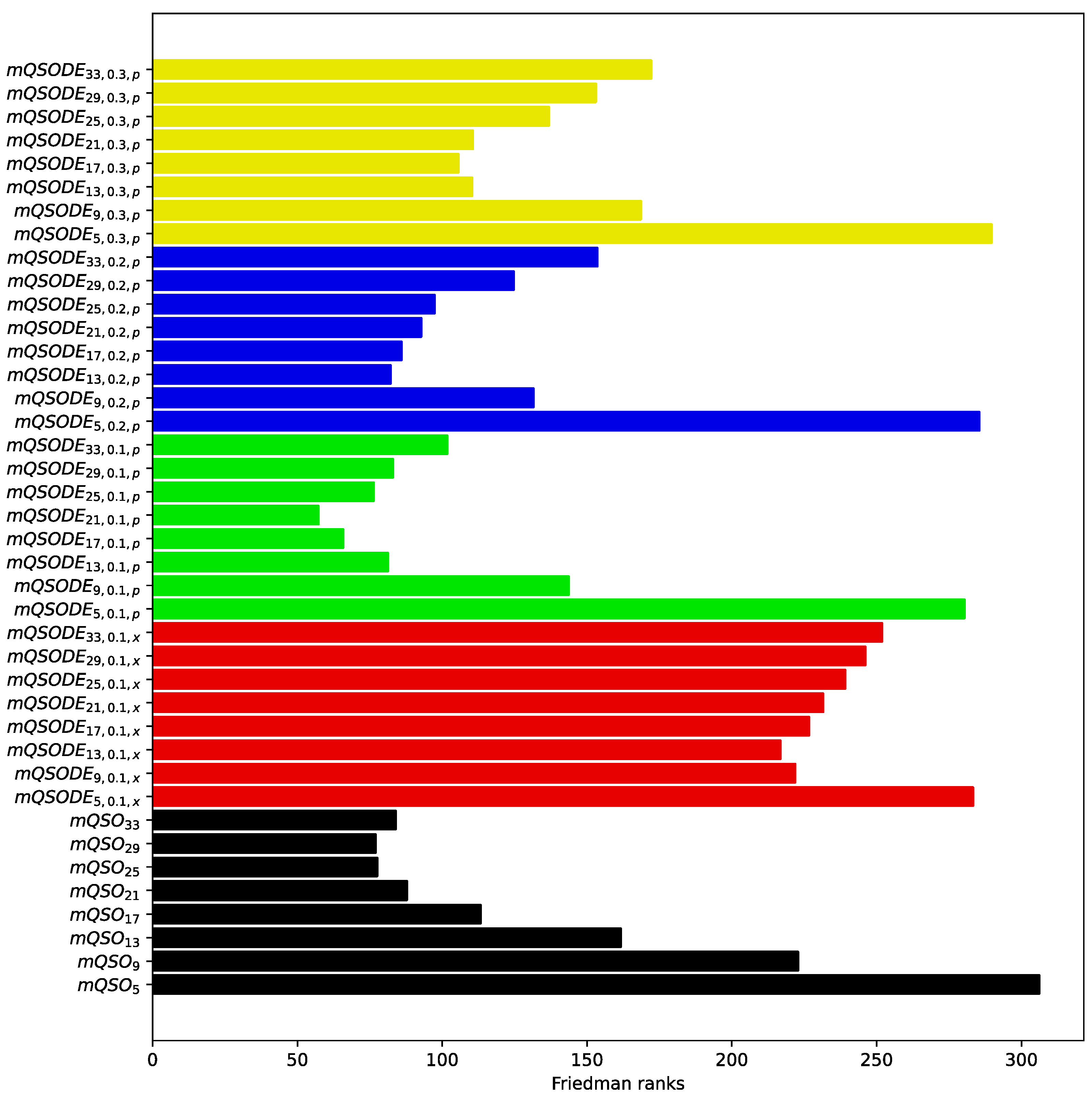
The pseudocode of the proposed mQSODE algorithm is shown in
Figure 1.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}