
Multi-Color Channels Based Group Sparse Model for Image Restoration



Abstract
:1. Introduction
2. GSP Model
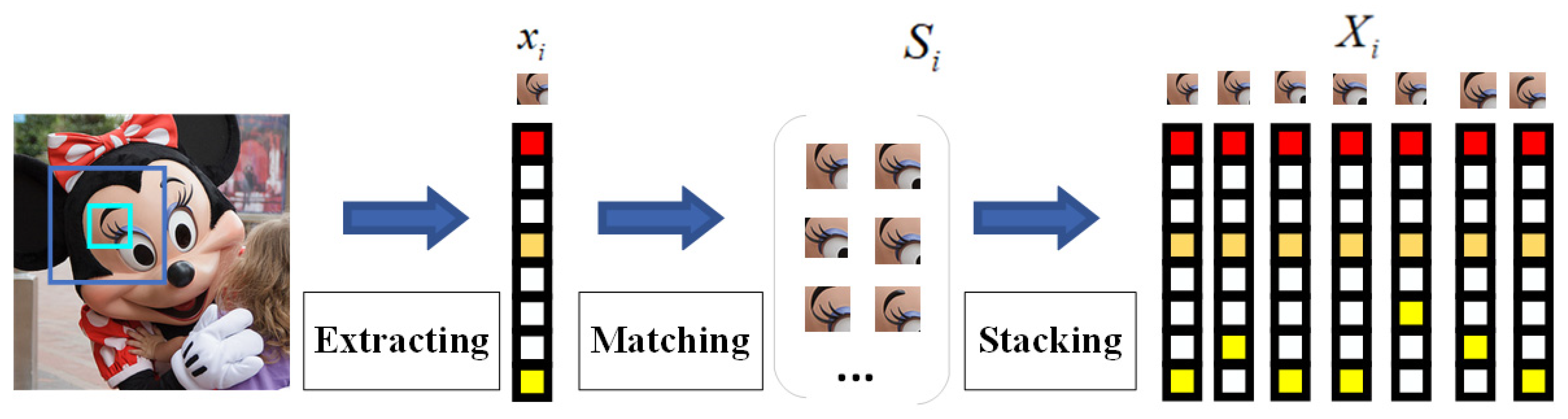
2.1. Image Group Construction
2.2. Sparse Representation Model
2.3. Learning a Dictionary
3. Proposed Multi-Color Channels Based GSR Model
3.1. Construction of the Proposed Model
3.1.1. Construction of Image Groups
3.1.2. Proposed Sparse Representation Model
3.1.3. Adaptive Dictionaries
3.2. Implementation of the Proposed Method
3.2.1. Solution of the Coefficients
3.2.2. Adaptive Parameters
| Algorithm 1 The proposed multi-color-channels-based GSR model |
| Procedures of multi-color-channels-based GSR model |
| Initialization: set , ; For k = 1, …, Iter do Construct image group . For Each group do Construct via SVD Update via (17) Update via (16) Update end for end for Output: the final restored image |
4. Experimental Results
4.1. Objective Assessment
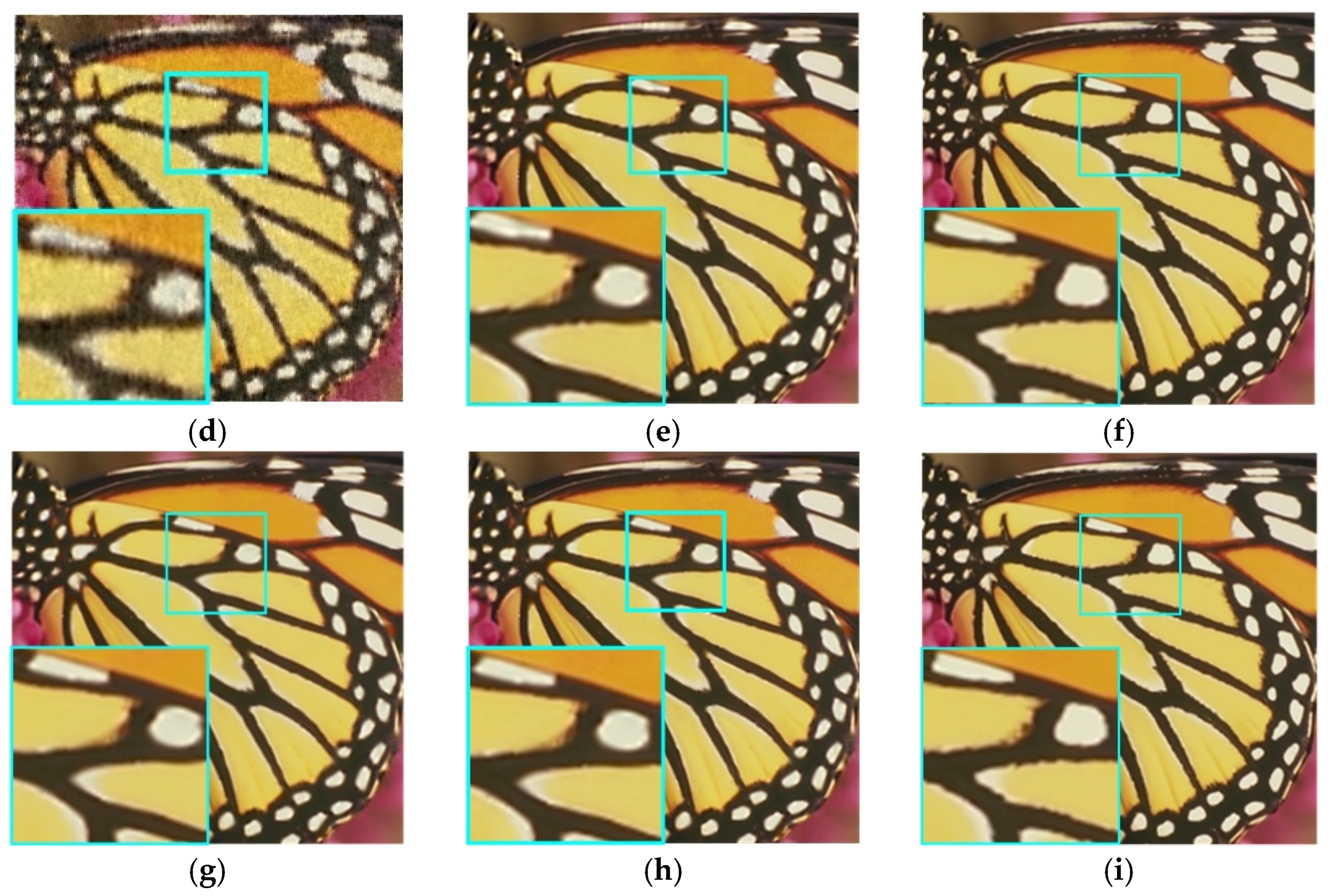
4.2. Subjective Assessment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Buades, A.; Coll, B.; Morel, J.M. A Non-Local Algorithm for Image Denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 60–65. [Google Scholar]
- Dabov, K.; Foi, A.; Egiazarian, K. Video Denoising by Sparse 3D Transform-Domain Collaborative Filtering. In Proceedings of the 2007 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 145–149. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Blind Image Deblurring Using Dark Channel Prior. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Zhou, M.; Chen, H.; Paisley, J.; Ren, L.; Li, L.; Xing, Z.; Dunson, D.; Sapiro, G.; Carin, L. Nonparametric Bayesian dictionary learning for analysis of noisy and incomplete images. IEEE Trans. Image Process. 2012, 21, 130–144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, K.H.; Ye, J.C. Annihilating filter-based low-rank hankel matrix approach for image inpainting. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2015, 24, 3498–3511. [Google Scholar]
- Zhang, J.; Zhao, D.; Zhao, C.; Xiong, R.; Ma, S.; Gao, W. Compressed Sensing Recovery via Collaborative Sparsity. In Proceedings of the 2012 Data Compression Conference, Snowbird, UT, USA, 10–12 April 2012; pp. 287–296. [Google Scholar]
- Yuan, X.; Huang, G.; Jiang, H.; Wilford, P.A. Block-Wise Lensless Compressive Camera. In Proceedings of the 2017 IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 31–35. [Google Scholar]
- Osher, S.; Burger, M.; Goldfarb, D.; Xu, J.; Yin, W. An iterative regularization method for total variation-based image restoration. Siam J. Multiscale Model. Simul. 2005, 4, 460–489. [Google Scholar] [CrossRef]
- Yuan, X. Generalized Alternating Projection Based Total Variation Minimization for Compressive Sensing. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 2539–2543. [Google Scholar]
- Rudin, L. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Li, H.; Liu, F. Image Denoising via Sparse and Redundant Representations over Learned Dictionaries in Wavelet Domain. In Proceedings of the 2009 Fifth International Conference on Image and Graphics, Xi’an, China, 20–23 September 2009; pp. 754–758. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-Local Sparse Models for Image Restoration. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2272–2279. [Google Scholar]
- Zhang, J.; Zhao, D.; Gao, W. Group-based sparse representation for image restoration. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2014, 23, 3336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zha, Z.; Yuan, X.; Wen, B.; Zhang, J.; Zhou, J.; Zhu, C. Image Restoration Using Joint Patch-Group Based Sparse Representation. IEEE Trans. Image Process. 2020, 29, 7735–7750. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, X.; Suo, J.; Brady, D.J.; Dai, Q. Rank Minimization for Snapshot Compressive Imaging. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2990–3006. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable Optimization-Inspired Deep Network for Image Compressive Sensing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1828–1837. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2808–2817. [Google Scholar]
- Dong, W.; Wang, P.; Yin, W.; Shi, G.; Wu, F.; Lu, X. Denoising prior driven deep neural network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2305–2318. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Lun, D.P.K. Robust fringe projection profilometry via sparse representation. IEEE Trans. Image Process. 2016, 25, 1726–1739. [Google Scholar]
- Dong, W.; Zhang, L.; Shi, G.; Wu, X. Image deblurring and super-resolution by adaptive sparse domain selection and adaptive regularization. IEEE Trans. Image Process. 2011, 20, 1838–1857. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Zhang, X.; Wu, Y.; Tang, L.; Zha, Z. Nonconvex weighted lp minimization based group sparse representation framework for image denoising. IEEE Signal Process. Lett. 2017, 24, 1686–1690. [Google Scholar] [CrossRef]
- Dong, W.; Shi, G.; Li, X. Nonlocal image restoration with bilateral variance estimation: A low-rank approach. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2013, 22, 700–711. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Shi, G.; Ma, Y.; Li, X. Image restoration via simultaneous sparse coding: Where structured sparsity meets gaussian scale mixture. Int. J. Comput. Vis. 2015, 114, 217–232. [Google Scholar] [CrossRef]
- Zha, Z.; Yuan, X.; Wen, B.; Zhou, J.; Zhang, J.; Zhu, C. A Benchmark for Sparse Coding: When Group Sparsity Meets Rank Minimization. IEEE Trans. Image Process. 2020, 29, 5094–5109. [Google Scholar] [CrossRef] [Green Version]
- Zha, Z.; Yuan, X.; Wen, B.; Zhou, J.; Zhu, C. Group sparsity residual constraint with non-local priors for image restoration. IEEE Trans. Image Process. 2020, 29, 8960–8975. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, L.; Zuo, W.; Zhang, D.; Feng, X. Patch Group Based Nonlocal Self-Similarity Prior Learning for Image Denoising. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 244–252. [Google Scholar]
- Zha, Z.; Liu, X.; Huang, X.; Shi, H.; Xu, Y.; Wang, Q.; Tang, L.; Zhang, X. Analyzing the Group Sparsity Based on the Rank Minimization Methods. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo, Hong Kong, China, 10–14 July 2017; pp. 883–888. [Google Scholar]
- Hu, W.; Li, X.; Cheung, G.; Au, O. Depth Map Denoising Using Graph-Based Transform and Group Sparsity. In Proceedings of the 2013 IEEE 15th International Workshop on Multimedia Signal Processing, Pula, Italy, 30 September–2 October 2013; pp. 1–6. [Google Scholar]
- Routray, S.; Ray, A.K.; Mishra, C. An efficient image denoising method based on principal component analysis with learned patch groups. Signal Image Video Process. 2019, 13, 1405–1412. [Google Scholar] [CrossRef]
- Mo, J.; Zhou, Y. The research of image inpainting algorithm using self-adaptive group structure and sparse representation. Clust. Comput. 2018, 22, 7593–7601. [Google Scholar] [CrossRef]
- Wen, B.; Ravishankar, S.; Bresler, Y. Structured overcomplete sparsifying transform learning with convergence guarantees and applications. Int. J. Comput. Vis. 2015, 114, 137–167. [Google Scholar] [CrossRef]
- Elad, M.; Yavneh, I. A plurality of sparse representations is better than the sparsest one alone. IEEE Trans. Inf. Theory 2009, 55, 4701–4714. [Google Scholar] [CrossRef]
- Daubechies, I.; Defrise, M.; Mol, C.D. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 2010, 57, 1413–1457. [Google Scholar] [CrossRef] [Green Version]
- Chang, S.G.; Yu, B. Adaptive wavelet thresholding for image denoising and compression. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2000, 9, 1532. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Afonso, M.V.; Bioucas-Dias, J.M.; Figueiredo, M.A. An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 2011, 20, 681–695. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, H.; Xiong, R.; Zhang, X.; Zhang, Y.; Ma, S.; Gao, W. Nonlocal gradient sparsity regularization for image restoration. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1909–1921. [Google Scholar] [CrossRef]
- Guo, Q.; Gao, S.; Zhang, X.; Yin, Y.; Zhang, C. Patch-based image inpainting via two-stage low rank approximation. IEEE Trans. Vis. Comput. Graph. 2017, 24, 2023–2036. [Google Scholar] [CrossRef]
- Li, M.; Liu, J.; Xiong, Z.; Sun, X.; Guo, Z. MARLow: A Joint Multiplanar Autoregressive and Low-Rank Approach for Image Completion. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 819–834. [Google Scholar]
- Zha, Z.; Wen, B.; Yuan, X.; Zhou, J.; Zhu, C.; Kot, A.C. A hybrid structural sparsification error model for image restoration. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef]
- Tirer, T.; Giryes, R. Image restoration by iterative denoising and backward projections. IEEE Trans. Image Process. 2019, 28, 1220–1234. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pixel Missing Rate | Methods | Bahoon | Butterfly | Girl | Lena | Mural | Nanna | Average |
|---|---|---|---|---|---|---|---|---|
| 80% | SALSA | 24.41 | 21.91 | 23.03 | 27.32 | 22.45 | 23.20 | 23.72 |
| BPFA | 23.25 | 21.06 | 22.47 | 27.56 | 21.10 | 22.38 | 22.97 | |
| GSR | 24.57 | 26.03 | 25.50 | 31.41 | 26.01 | 25.24 | 26.46 | |
| NGS | 24.89 | 23.85 | 24.27 | 28.87 | 23.78 | 24.58 | 25.04 | |
| TSLRA | 25.49 | 25.32 | 25.15 | 30.58 | 25.21 | 25.55 | 26.22 | |
| JPG-SR | 25.40 | 26.58 | 25.55 | 31.25 | 26.29 | 25.92 | 26.83 | |
| GSRC-NLP | 25.55 | 26.78 | 26.02 | 30.51 | 26.56 | 26.17 | 26.93 | |
| MAR-LOW | 26.40 | 30.86 | 29.21 | 33.83 | 29.66 | 29.68 | 29.94 | |
| HSSE | 25.57 | 26.61 | 26.12 | 31.83 | 26.23 | 26.27 | 27.11 | |
| Proposed | 26.43 | 30.90 | 29.28 | 33.85 | 29.67 | 29.70 | 29.97 | |
| 70% | SALSA | 25.71 | 24.85 | 24.99 | 29.62 | 24.69 | 25.34 | 25.87 |
| BPFA | 24.57 | 23.95 | 24.71 | 30.37 | 23.34 | 24.47 | 25.24 | |
| GSR | 26.17 | 28.92 | 27.86 | 33.54 | 28.46 | 27.89 | 28.81 | |
| NGS | 26.08 | 26.36 | 26.18 | 30.77 | 26.29 | 26.35 | 27.01 | |
| TSLRA | 26.72 | 27.76 | 27.09 | 32.64 | 27.22 | 27.32 | 28.13 | |
| JPG-SR | 26.80 | 29.24 | 27.96 | 33.40 | 28.50 | 28.24 | 29.02 | |
| GSRC-NLP | 26.98 | 29.47 | 28.20 | 33.85 | 28.71 | 28.51 | 29.29 | |
| MAR-LOW | 28.70 | 33.82 | 32.14 | 36.21 | 32.26 | 32.75 | 32.65 | |
| HSSE | 26.87 | 29.29 | 28.25 | 33.86 | 28.57 | 28.49 | 29.22 | |
| Proposed | 28.72 | 33.90 | 32.26 | 36.23 | 32.30 | 32.77 | 32.70 |
| Pixel Missing Rate | Methods | Bahoon | Butterfly | Girl | Lena | Mural | Nanna | Average |
|---|---|---|---|---|---|---|---|---|
| 60% | SALSA | 26.78 | 27.02 | 26.79 | 31.42 | 26.50 | 26.97 | 27.58 |
| BPFA | 25.82 | 26.06 | 26.68 | 32.38 | 25.17 | 26.14 | 27.04 | |
| GSR | 27.74 | 31.09 | 29.54 | 35.80 | 29.98 | 30.13 | 30.71 | |
| NGS | 27.29 | 28.37 | 27.83 | 32.81 | 27.99 | 28.06 | 28.73 | |
| TSLRA | 27.92 | 29.42 | 28.91 | 34.26 | 29.07 | 29.17 | 29.79 | |
| JPG-SR | 28.14 | 31.15 | 29.87 | 35.44 | 30.15 | 30.37 | 30.85 | |
| GSRC-NLP | 28.31 | 31.46 | 30.17 | 35.95 | 30.33 | 30.59 | 31.14 | |
| MAR-LOW | 30.78 | 36.33 | 34.58 | 38.30 | 34.64 | 35.44 | 35.01 | |
| HSSE | 28.25 | 31.54 | 30.20 | 35.93 | 30.31 | 30.53 | 31.13 | |
| Proposed | 30.80 | 36.41 | 34.70 | 38.34 | 34.70 | 35.55 | 35.08 | |
| 50% | SALSA | 27.98 | 29.03 | 28.32 | 33.26 | 28.17 | 28.57 | 29.22 |
| BPFA | 27.13 | 28.16 | 28.46 | 34.15 | 27.20 | 28.17 | 28.88 | |
| GSR | 29.42 | 32.78 | 31.93 | 37.64 | 31.73 | 32.16 | 32.61 | |
| NGS | 28.49 | 30.28 | 29.60 | 34.56 | 29.88 | 29.71 | 30.42 | |
| TSLRA | 29.15 | 31.01 | 30.48 | 35.52 | 30.62 | 30.87 | 31.28 | |
| JPG-SR | 29.61 | 32.83 | 31.77 | 37.18 | 31.72 | 32.21 | 32.55 | |
| GSRC-NLP | 29.75 | 33.02 | 31.95 | 37.64 | 31.88 | 32.36 | 32.77 | |
| MAR-LOW | 32.88 | 38.70 | 37.01 | 40.24 | 36.98 | 38.22 | 37.34 | |
| HSSE | 29.79 | 33.29 | 32.19 | 37.84 | 31.95 | 32.50 | 32.93 | |
| Proposed | 32.91 | 38.80 | 37.15 | 40.30 | 37.10 | 38.37 | 37.44 |
| Images | Pixel Missing Rate 80% | Pixel Missing Rate 70% | Pixel Missing Rate 60% | Pixel Missing Rate 50% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IR-CNN | IDBP | Proposed | IR-CNN | IDBP | Proposed | IR-CNN | IDBP | Proposed | IR-CNN | IDBP | Proposed | |
| Cowboy | 25.47 | 24.43 | 29.38 | 27.54 | 27.15 | 32.31 | 29.95 | 28.97 | 35.36 | 31.96 | 31.40 | 38.12 |
| 0.8622 | 0.8400 | 0.9343 | 0.9163 | 0.8955 | 0.9621 | 0.9479 | 0.9273 | 0.9770 | 0.9660 | 0.9522 | 0.9854 | |
| Girl | 25.36 | 25.03 | 29.28 | 27.78 | 27.45 | 32.26 | 30.10 | 29.32 | 34.70 | 32.10 | 31.09 | 37.15 |
| 0.8135 | 0.7999 | 0.9212 | 0.8910 | 0.8698 | 0.9549 | 0.9327 | 0.9102 | 0.9720 | 0.9564 | 0.9371 | 0.9823 | |
| Flower | 28.41 | 28.12 | 32.14 | 30.77 | 30.49 | 35.11 | 32.97 | 32.16 | 37.59 | 35.28 | 34.15 | 40.00 |
| 0.8586 | 0.8413 | 0.9381 | 0.9140 | 0.8943 | 0.9652 | 0.9460 | 0.9264 | 0.9786 | 0.9661 | 0.9508 | 0.9864 | |
| Lake | 25.24 | 25.39 | 28.86 | 27.59 | 27.87 | 31.33 | 29.75 | 29.53 | 33.76 | 31.80 | 31.47 | 35.84 |
| 0.8278 | 0.8203 | 0.9115 | 0.8914 | 0.8805 | 0.9433 | 0.9302 | 0.9155 | 0.9623 | 0.9535 | 0.9421 | 0.9743 | |
| Mickey | 26.45 | 25.40 | 29.57 | 29.66 | 28.69 | 32.24 | 31.82 | 31.18 | 34.51 | 34.25 | 33.14 | 36.62 |
| 0.8671 | 0.8436 | 0.9260 | 0.9220 | 0.9023 | 0.9532 | 0.9474 | 0.9319 | 0.9687 | 0.9637 | 0.9517 | 0.9787 | |
| Mural | 25.75 | 25.26 | 29.67 | 28.73 | 27.68 | 32.30 | 30.58 | 29.79 | 34.70 | 32.20 | 31.35 | 37.10 |
| 0.7923 | 0.7694 | 0.8960 | 0.8721 | 0.8388 | 0.9393 | 0.9091 | 0.8824 | 0.9633 | 0.9361 | 0.9148 | 0.9780 | |
| Average | 26.11 | 25.61 | 29.82 | 28.68 | 28.22 | 32.59 | 30.86 | 30.16 | 35.10 | 32.93 | 32.10 | 37.47 |
| 0.8369 | 0.8191 | 0.9211 | 0.9011 | 0.8802 | 0.9530 | 0.9356 | 0.9156 | 0.9703 | 0.9570 | 0.9415 | 0.9808 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, Y.; Zhou, C.; Zhang, C.; Sun, L.; Zhou, C. Multi-Color Channels Based Group Sparse Model for Image Restoration. Algorithms 2022, 15, 176. https://doi.org/10.3390/a15060176
Kong Y, Zhou C, Zhang C, Sun L, Zhou C. Multi-Color Channels Based Group Sparse Model for Image Restoration. Algorithms. 2022; 15(6):176. https://doi.org/10.3390/a15060176
Chicago/Turabian StyleKong, Yanfen, Caiyue Zhou, Chuanyong Zhang, Lin Sun, and Chongbo Zhou. 2022. "Multi-Color Channels Based Group Sparse Model for Image Restoration" Algorithms 15, no. 6: 176. https://doi.org/10.3390/a15060176
APA StyleKong, Y., Zhou, C., Zhang, C., Sun, L., & Zhou, C. (2022). Multi-Color Channels Based Group Sparse Model for Image Restoration. Algorithms, 15(6), 176. https://doi.org/10.3390/a15060176