
An Efficient Parallel Algorithm for Detecting Packet Filter Conflicts


Abstract
:1. Introduction
- Select the first matching filter in the filter database.
- Assign each filter a priority and select the matching filter with the highest priority.
- Assign each field a priority and select the matching filter with the most specific matching field with the highest priority.
2. Related Work
2.1. Existing Conflict-Detection Algorithms
- f[1] is a prefix of g[1], and g[2] is a prefix of f[2].
- g[1] is a prefix of f[1], and f[2] is a prefix of g[2].
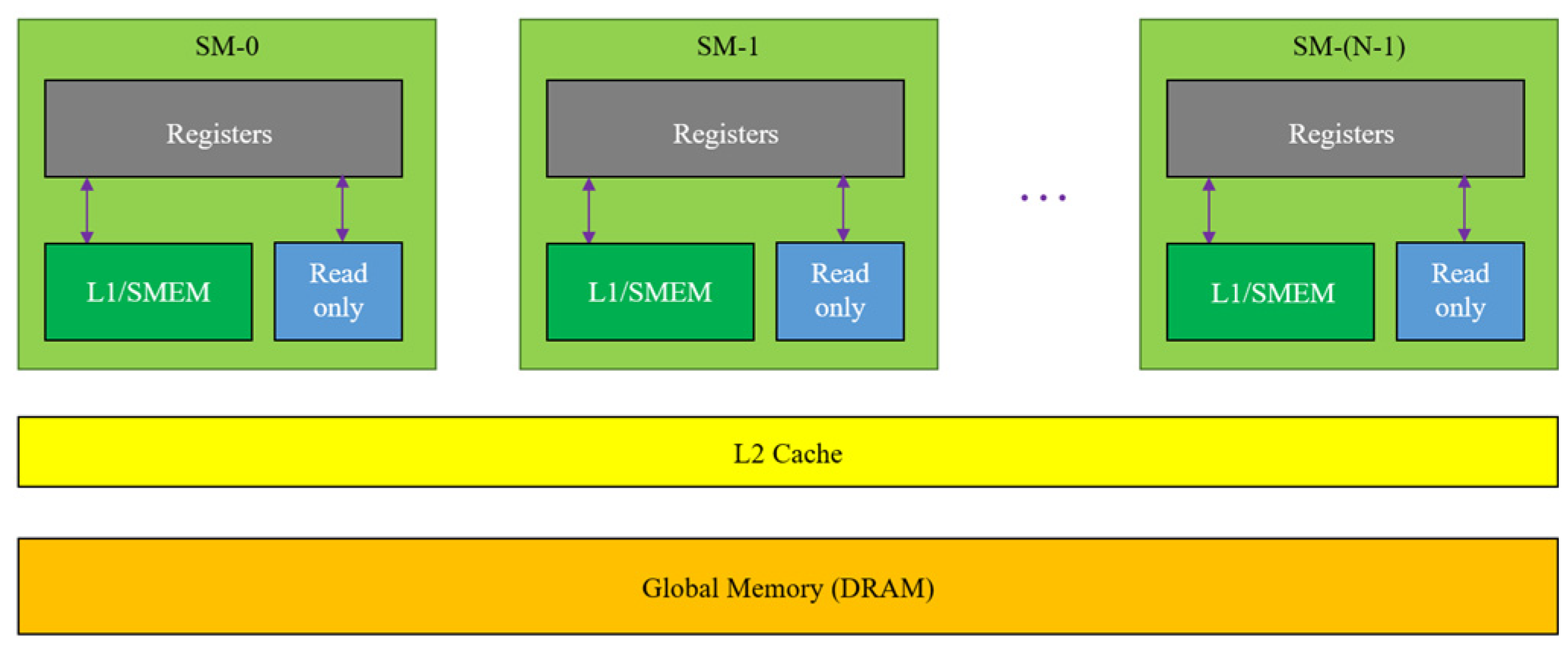
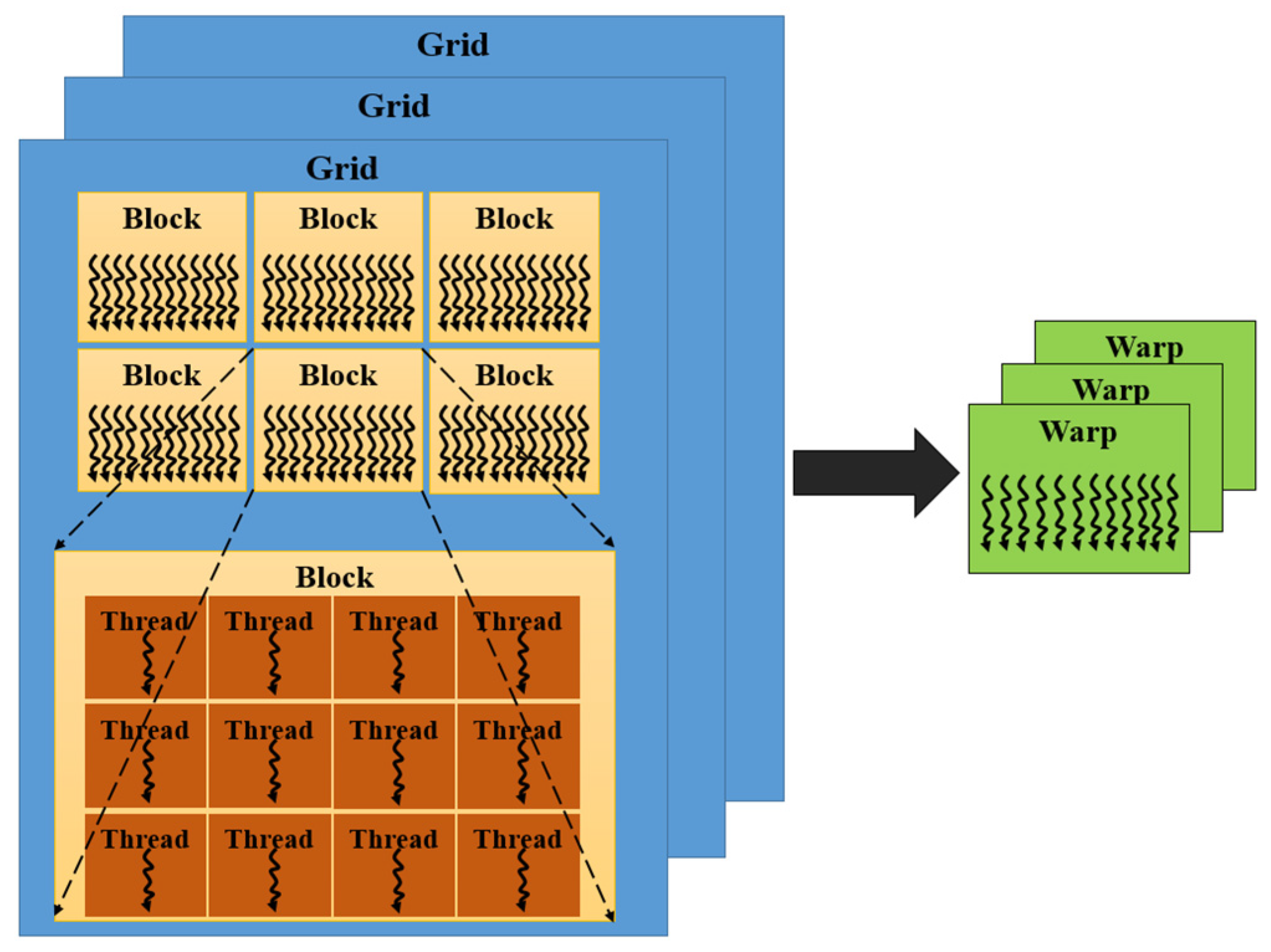
2.2. CUDA Architecture and Programming Model
- Registers: These are private to each thread, suggesting that registers assigned to one thread are invisible to other threads.
- L1/Shared memory (SMEM): Every SM has a fast, on-chip scratchpad memory that can be used as an L1 cache and SMEM. All threads in a CUDA block can share shared memory, and all CUDA blocks running on a given SM can share the physical memory resources provided by the SM.
- Read-only memory: Each SM has an instruction cache, constant memory, texture memory, and a read-only cache.
- L2 cache: The L2 cache is shared across all SMs; therefore, every thread in every CUDA block can access this memory.
- Global memory: As with the L2 cache, all threads can read and write this memory, but it is slower to access than other memories. This memory can be used to exchange data between the GPU and the CPU.
3. Definition and Method of 5D Conflict Detection
3.1. Definition of 5D Filter Conflict
- .
- .
3.2. Conflict Detection for 5D Filters
- : This case indicates that the prefix fields of filters f and g conflict, as defined by [3]. Therefore, when the matched results of the non-prefix fields of f and g are all nonempty sets, f conflicts with g. The filter pair (F0, F1) belongs to this case because the non-prefix field matched results of F0 and F1 are all nonempty sets (Table 2).
- : This case indicates that the prefix fields of f have at least one field content contained in g. Thus, if the matched result of non-prefix fields of f and g are all nonempty sets, and there is a field s such that , f conflicts with g. Both filter pairs, (F0, F3) and (F1, F2), belong to this case (Table 2); therefore, conflicts occurred in both cases. However, in the matching of non-prefix fields in (F0, F3), it did not find any field s such that . Thus, (F0, F3) did not have conflict.
- : This case suggests that the contents in the prefix fields of f and g are equal. Therefore, when the matched results in the non-prefix fields of f and g are all nonempty, and we find any two fields s and t such that , then f and g have conflict. The filter pair, (F2, F3), is categorized into this case because it can find the DP and protocol fields that satisfy condition 2, as defined in Section 3.1.
- It determines whether the matching result of the prefix fields of the filters satisfies any of the cases mentioned above. If it does, execute step 2; otherwise, terminate the process.
- It matches the non-prefix field content based on the cases satisfied and then determines whether the matched result is the case for conflict to occur.
4. Conflict-Detection Algorithms Using GPU
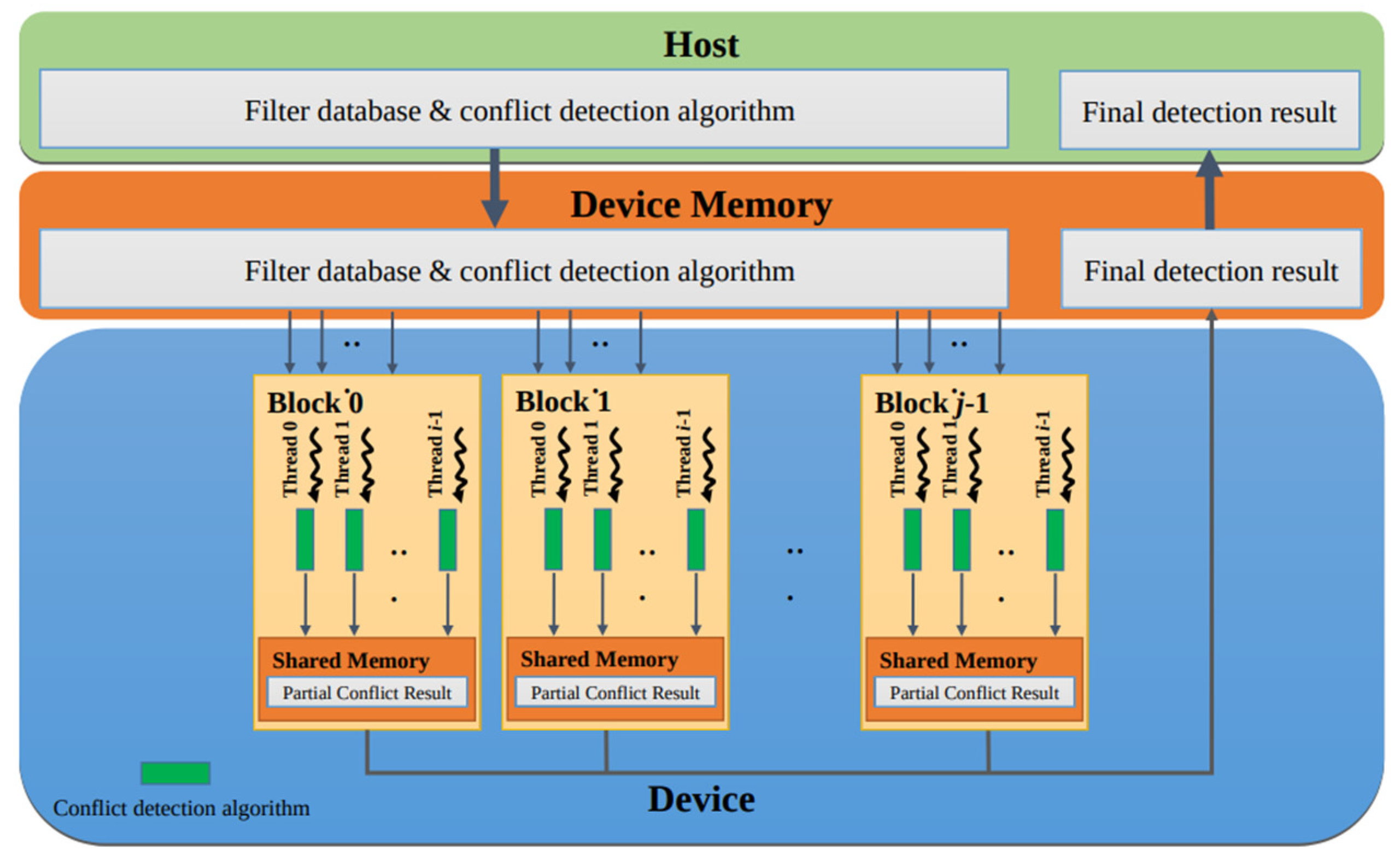
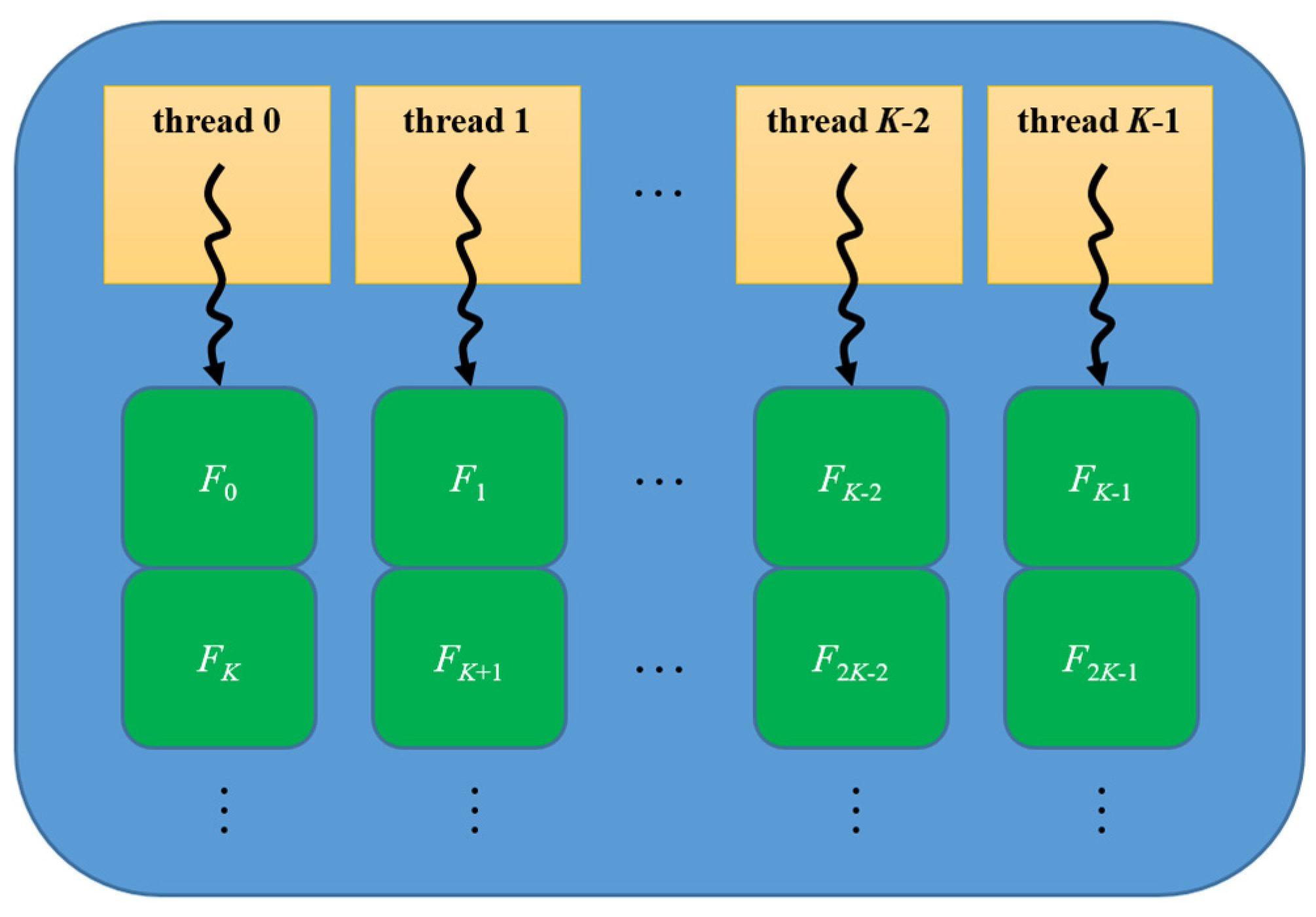
4.1. General Parallel Conflict-Detection Algorithm
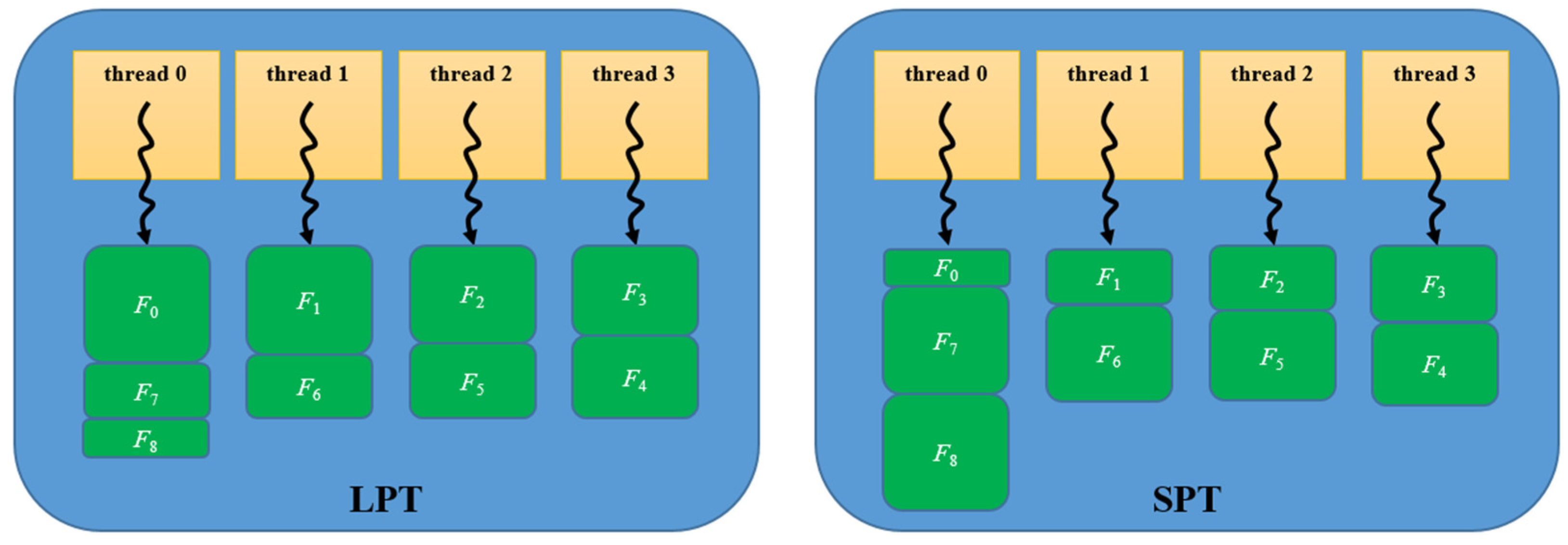
4.2. Workload Scheduling Problem
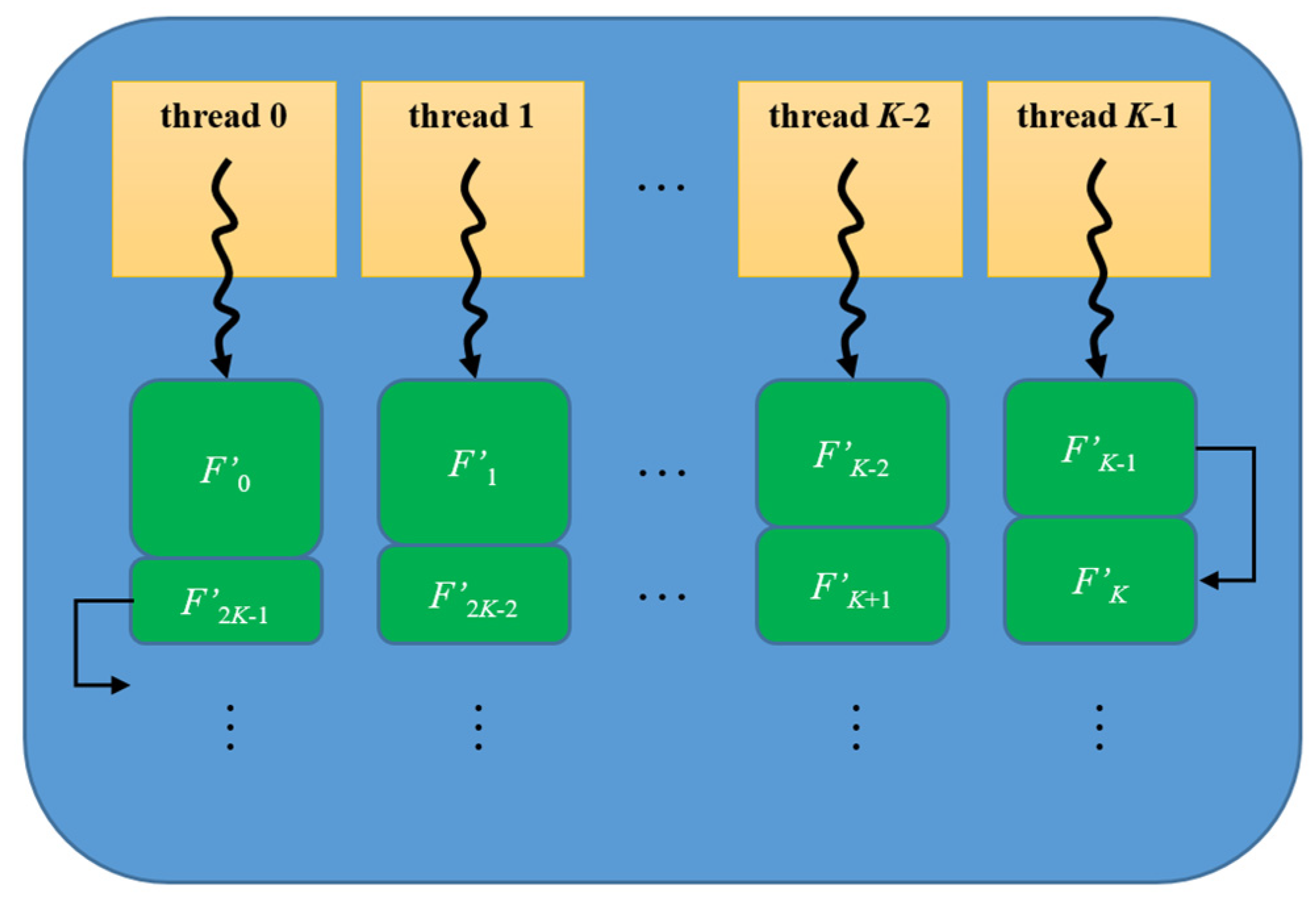
4.3. Enhanced Parallel Conflict-Detection Algorithm
| Algorithm 1: Parallel function of EPCDA |
| Input: filter database filter[] Output: conflict results 1 threadID = blockIdx.x ∗ blockDim.x + threadIdx.x; 2 threadSize = blockDim.x ∗ gridDim.x; 3 base = threadSize ∗ 2; 4 start = (base − 1) − threadID; 5 i = threadID; // dispatch direction . 6 do 7 for j i + 1 to filter.size() – 1 do 8 detection(filter[j], filter[i]); 9 end 10 i += base; 11 while i filter.size(); 12 i = start; // dispatch direction . 13 do 14 for j i + 1 to filter.size() – 1 do 15 detection(filter[j], filter[i]); 16 end 17 i += base; 18 while start filter.size(); |
5. Results and Discussion
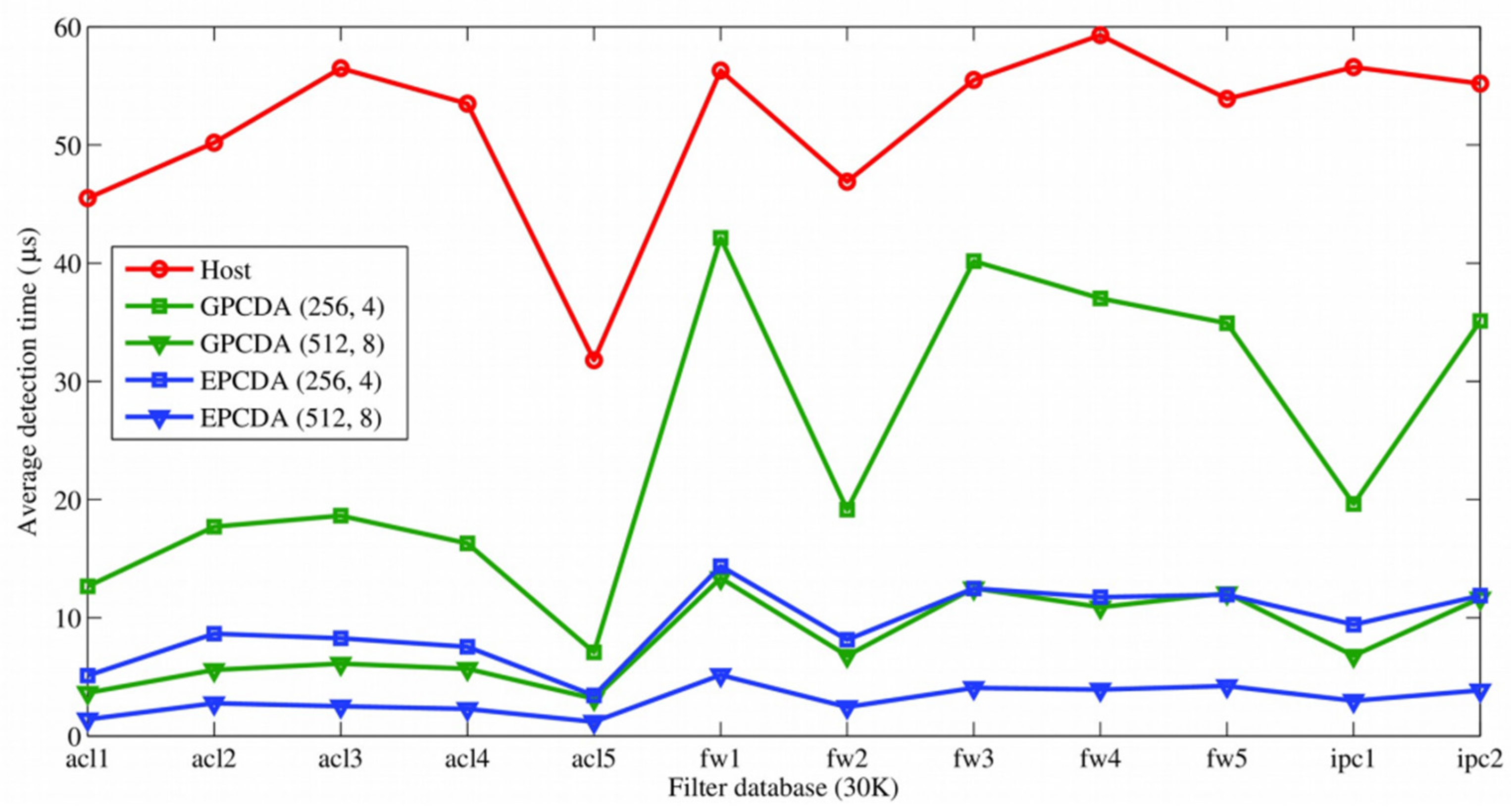
5.1. Comparing Speed Performance
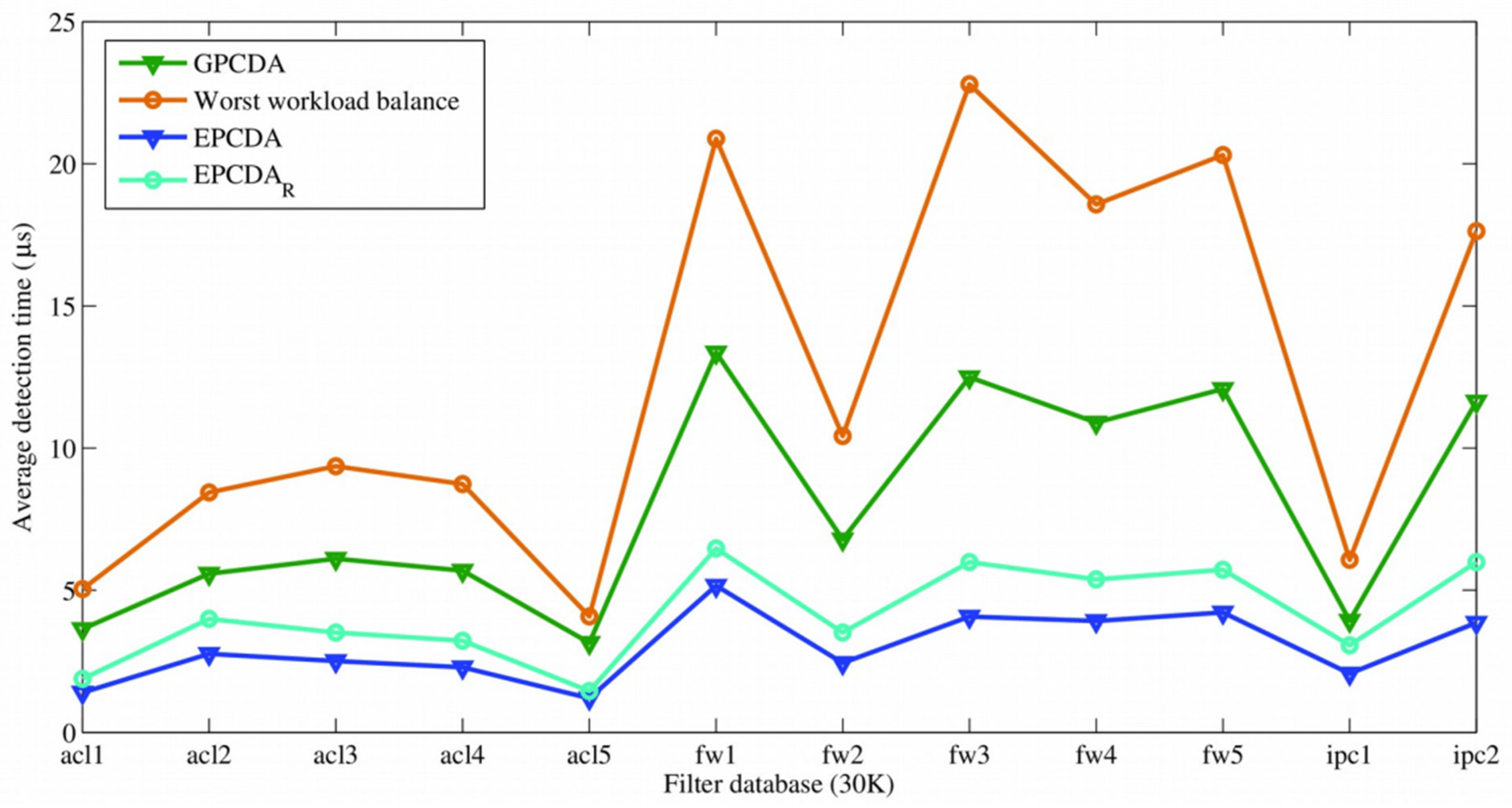
5.2. Comparison of Performance for Different Workload Dispatch Methods
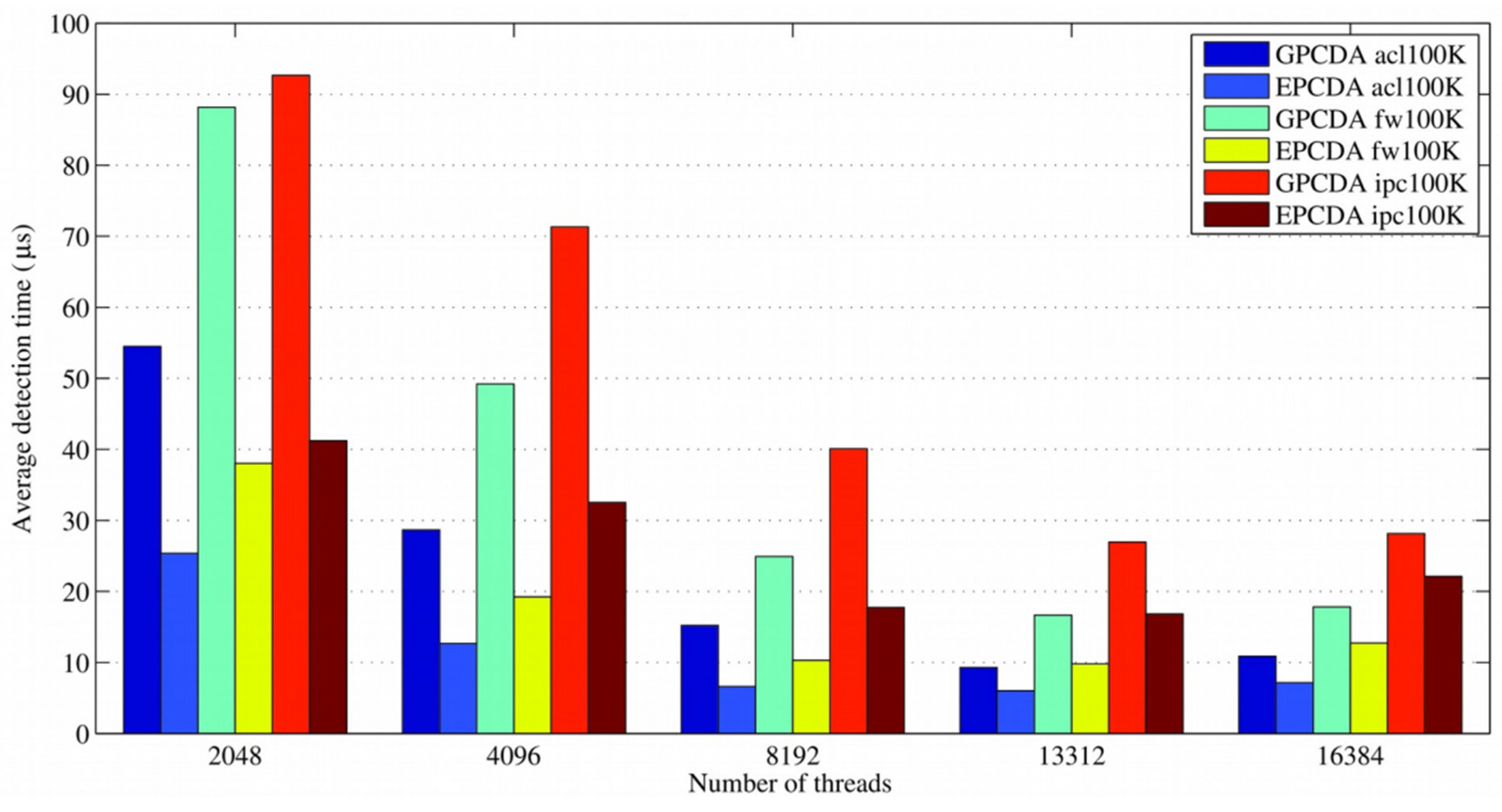
5.3. Analysis of Parallelism Efficiency
5.4. Limitations of Parallel Computation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- David, E.T. Survey and Taxonomy of Packet Classification Techniques. ACM Comput. Surv. 2005, 37, 238–275. [Google Scholar] [CrossRef] [Green Version]
- Hongxin, H.; Gail, J.A.; Ketan, K. Detecting and Resolving Firewall Policy Anomalies. IEEE Trans. Dependable Secur. Comput. 2012, 9, 318–331. [Google Scholar] [CrossRef]
- Hari, A.; Suri, S.; Parulkar, G. Detecting and Resolving Packet Filter Conflicts. In Proceedings of the IEEE INFOCOM, Tel Aviv, Israel, 26–30 March 2000; pp. 318–331. [Google Scholar]
- Baboescu, F.; Varghese, G. Fast and Scalable Conflict Detection for Packet Classifier. Comput. Netw. 2003, 42, 717–735. [Google Scholar] [CrossRef]
- Vamanan, B.; Vijaykumar, T.N. TreeCAM: Decoupling Updates and Lookups in Packet Classification. In Proceedings of the Seventh Conference on Emerging Networking EXperiments and Technologies, Tokyo, Japan, 6–9 December 2011; pp. 1–12. [Google Scholar]
- Lu, H.; Sahni, S. Conflict Detection and Resolution in Two-Dimensional Prefix Router Tables. IEEE ACM Trans. Netw. 2005, 13, 1353–1363. [Google Scholar] [CrossRef] [Green Version]
- OpenFlow Specification v1.5.1. Available online: https://opennetworking.org/wp-content/uploads/2014/10/openflow-switch-v1.5.1.pdf (accessed on 1 May 2022).
- Qu, Y.R.; Zhou, S.; Prasanna, V.K. Performance Modeling and Optimizations for Decomposition-Based Large-Scale Packet Classification on Multi-Core Processors. In Proceedings of the 2014 IEEE 15th International Conference on High Performance Switching and Routing, Vancouver, BC, Canada, 1–4 July 2014; pp. 154–161. [Google Scholar]
- Qu, Y.R.; Prasanna, V.K. Compact Hash Tables for High-Performance Traffic Classification on Multi-Core Processors. In Proceedings of the IEEE 26th International Symposium on Computer Architecture and High Performance Computing, Paris, France, 22–24 October 2014; pp. 17–24. [Google Scholar]
- Qu, Y.R.; Zhou, S.; Prasanna, V.K. Scalable Many-Field Packet Classification on Multi-Core Processors. In Proceedings of the 25th International Symposium on Computer Architecture and High Performance Computing, Porto de Galinhas, Brazil, 23–26 October 2013; pp. 33–40. [Google Scholar]
- Abbasi, M.; Shokrollahi, A. Enhancing the Performance of Decision Tree-Based Packet Classification Algorithms Using CPU Cluster. Clust. Comput. 2020, 23, 3203–3219. [Google Scholar] [CrossRef]
- Shen, T.; Zhang, D.-F.; Xie, G.-G.; Zhang, X.-Y. Optimizing Multi-Dimensional Packet Classification for Multi-Core Systems. J. Comput. Sci. Technol. 2018, 33, 1056–1071. [Google Scholar] [CrossRef]
- Han, S.; Jang, K.; Park, K.; Moon, S. PacketShader: A GPU-Accelerated Software Router. Comput. Commun. Rev. 2010, 40, 195–206. [Google Scholar] [CrossRef]
- Hung, C.L.; Wang, H.H.; Guo, S.W.; Lin, Y.L.; Li, K.C. Efficient GPGPU-Based Parallel Packet Classification. In Proceedings of the IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications, Changsha, China, 16–18 November 2011; pp. 1367–1374. [Google Scholar]
- Kang, K.; Deng, Y. Scalable Packet Classification via GPU Metaprograming. In Proceedings of the 2011 Design, Automation & Test in Europe, Grenoble, France, 14–18 March 2011; pp. 1–4. [Google Scholar]
- Hsieh, C.L.; Weng, N. High Performance Multi-Field Packet Classification Using Bucket Filtering and GPU Processing. In Proceedings of the 2014 ACM/IEEE Symposium on Architectures for Networking and Communications Systems, Los Angeles, CA, USA, 20–21 October 2014; pp. 233–234. [Google Scholar]
- Qu, Y.R.; Zhang, H.H.; Zhou, S.; Prasanna, V.K. Optimizing Many-Field Packet Classification on FPGA, Multi-Core General Purpose Processor, and GPU. In Proceedings of the 2015 ACM/IEEE Symposium on Architectures for Networking and Communications Systems, Oakland, CA, USA, 7–8 May 2015; pp. 87–98. [Google Scholar]
- Lee, C.L.; Lin, Y.S.; Chen, Y.C. A Hybrid CPU/GPU Pattern-Matching Algorithm for Deep Packet Inspection. PLoS ONE 2015, 10, e0139301. [Google Scholar] [CrossRef]
- Chu, H.M.; Li, T.H.; Wang, P.C. IP Address Lookup by Using GPU. IEEE Trans. Emerg. Top. Comput. 2015, 4, 187–198. [Google Scholar] [CrossRef]
- Greenberg, S.; Sheps, T.; Leon, D.A.; Ben-Shhimol, Y. Packet Classification Using GPU and One-Level Entropy-Based Hashing. IEEE Access 2020, 8, 80610–80623. [Google Scholar] [CrossRef]
- Varvello, M.; Laufer, R.; Zhang, F.; Lakshman, T.V. Multi-Layer Packet Classification with Graphics Processing Units. IEEE ACM Trans. Netw. 2016, 24, 2728–2741. [Google Scholar] [CrossRef]
- Baláž, M.; Helebrandt, P. Accelerating SDN Control Plane with GPGPU-Based Packet Classification. In Proceedings of the 17th International Conference on Emerging eLearning Technologies and Applications, Starý Smokovec, Slovakia, 21–22 November 2019; pp. 36–41. [Google Scholar]
- Mahdi, A.; Rafiee, M. A Calibrated Asymptotic Framework for Analyzing Packet Classification Algorithms on GPUs. J. Supercomput. 2019, 75, 6574–6611. [Google Scholar] [CrossRef]
- Abbasi, M.; Tahouri, R.; Rafiee, M. Enhancing the Performance of the Aggregated Bit Vector Algorithm in Network Packet Classification Using GPU. PeerJ Comput. Sci. 2019, 5, e185. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, Y.-H.; Shih, W.-C.; Chang, Y.-K. Efficient Hierarchical Hash Tree for OpenFlow Packet Classification with Fast Updates on GPUs. J. Parallel Distrib. Comput. 2022, 167, 136–147. [Google Scholar] [CrossRef]
- Srinivasan, V.; Varghese, G.; Suri, S.; Waldvogel, M. Fast and Scalable Layer Four Switching. Comput. Commun. Rev. 1998, 28, 191–202. [Google Scholar] [CrossRef] [Green Version]
- Lakshman, T.V.; Stiliadis, D. High-Speed Policy-Based Packet Forwarding Using Efficient Multi-Dimensional Range Matching. In Proceedings of the ACM SIGCOMM, Vancouver, BC, Canada, 31 August–4 September 1998; pp. 203–214. [Google Scholar]
- Baboescu, F.; Varghese, G. Scalable Packet Classification. IEEE ACM Trans. Netw. 2005, 13, 2–14. [Google Scholar] [CrossRef]
- Lai, C.Y.; Wang, P.C. Fast and Complete Conflict Detection for Packet Classifiers. IEEE Syst. J. 2017, 11, 1137–1148. [Google Scholar] [CrossRef]
- Lee, C.-L.; Hsu, Y.-C.; Chen, Y.-C.; Hsieh, H.-C. A Fast Bit-Vector-Based Conflict Detection Algorithm for Packet Classifiers. In Proceedings of the 8th IIAE International Conference on Industrial Application Engineering, Matsue, Japan, 26–30 March 2020; pp. 12–16. [Google Scholar]
- Kuo, Y.-H.; Tsai, J.-S.; Leung, T. A Multilevel Bit Vector Minimization Method for Fast Online Detection of Conflicting Flow Entries in OpenFlow Table. Comput. Commun. 2021, 167, 31–47. [Google Scholar] [CrossRef]
- Bentley, L.B.; Ottmann, T.A. Algorithms for Reporting and Counting Geometric Intersections. IEEE Trans. Comput. 1979, 28, 643–647. [Google Scholar] [CrossRef]
- Lee, C.L.; Lin, G.Y.; Chen, Y.C. An Efficient Conflict Detection Algorithm for Packet Filters. IEICE Trans. Inf. Syst. 2012, 95, 472–479. [Google Scholar] [CrossRef] [Green Version]
- Srinivasan, V.; Suri, S.; Varghese, G. Packet Classification Using Tuple Space Search. Comput. Commun. Rev. 1999, 29, 135–146. [Google Scholar] [CrossRef]
- Zhang, X.; Yin, Y.; Liu, W.; Peng, Z.; Zhang, G.; Wang, Y.; Tateiwa, Y.; Takahashi, N. A Conflict Detection Method for IPv6 Time-Based Firewall Policy. In Proceedings of the 2019 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking, Xiamen, China, 16–18 December 2019; pp. 435–442. [Google Scholar]
- CUDA C++ Programming Guide 2022. Available online: http://docs.nvidia.com/CUDA/CUDA-c-programming-guide/ (accessed on 1 May 2022).
- Bruno, J.; Coffman, E.G.; Sethi, R. Scheduling Independent Tasks to Reduce Mean Finishing-Time. Commun. ACM 1974, 17, 382–387. [Google Scholar] [CrossRef]
- Horowitz, E.; Sahni, S. Exact and Approximate Algorithms for Scheduling Non-Identical Processors. J. ACM 1976, 23, 317–327. [Google Scholar] [CrossRef]
- Graham, R.L. Bounds on Multiprocessing Timing Anomalies. SIAM J. Appl. Math. 1969, 17, 416–429. [Google Scholar] [CrossRef] [Green Version]
- Taylor, D.E.; Turner, J.S. Classbench: A Packet Classification Benchmark. IEEE ACM Trans. Netw. 2007, 15, 499–511. [Google Scholar] [CrossRef] [Green Version]
- NVIDIA GeForce GTX 970. Available online: https://www.nvidia.com/en-us/geforce/900-series/ (accessed on 1 May 2022).
- NVIDIA Visual Profiler 2022. Available online: https://developer.nvidia.com/nvidia-visual-profiler (accessed on 1 May 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
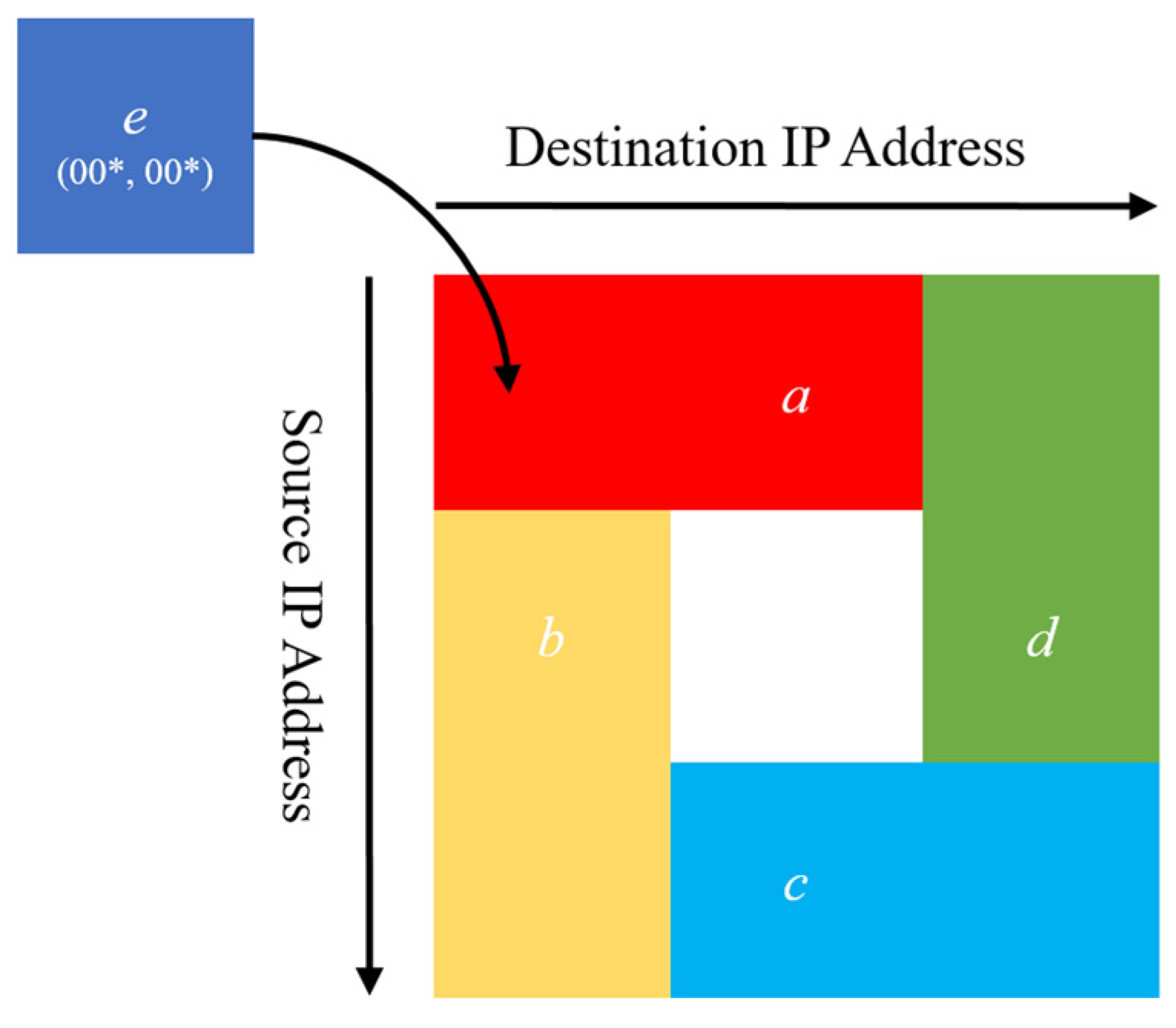
| Filter | Source IP Address | Destination IP Address | Action |
|---|---|---|---|
| a | 00* | * | Accept |
| b | * | 00* | Reject |
| c | 11* | * | Accept |
| d | * | 11* | Reject |
| Filter | SA | DA | SP | DP | Protocol |
|---|---|---|---|---|---|
| F0 | 101* | 01* | * | 0–1023 | TCP |
| F1 | 10* | 010* | * | 80 | * |
| F2 | 10* | 0* | * | * | UDP |
| F3 | 10* | 0* | * | 0–1023 | * |
| Parameter | Notation |
|---|---|
| blockIdx.x | index of block |
| theradIdx.x | index of thread |
| blockDim.x | number of threads in each block |
| gridDim.x | number of blocks in each grid |
| threadID | current thread ID |
| Databases | Statistics | Average Detection Time (µs) | |||
|---|---|---|---|---|---|
| Number of Filters | Number of Conflicts | Host | GPCDA | EPCDA | |
| ACL1 | 99,341 | 1,144,326 | 247.69 | 17.78 | 7.35 |
| ACL2 | 74,194 | 10,851,664 | 128.47 | 21.45 | 8.78 |
| ACL3 | 99,542 | 25,600,127 | 266.86 | 33.85 | 13.92 |
| ACL4 | 99,121 | 14,013,339 | 262.43 | 29.82 | 12.40 |
| ACL5 | 98,098 | 15 | 236.45 | 17.47 | 7.35 |
| FW1 | 87,986 | 207,072,436 | 227.10 | 70.82 | 21.79 |
| FW2 | 96,092 | 417,272,543 | 242.96 | 33.67 | 13.27 |
| FW3 | 84,472 | 227,534,381 | 207.72 | 74.92 | 20.04 |
| FW4 | 83,811 | 144,579,158 | 209.64 | 53.26 | 19.61 |
| FW5 | 83,677 | 333,717,457 | 183.99 | 65.89 | 19.65 |
| IPC1 | 99,284 | 49,864,378 | 263.68 | 35.90 | 15.42 |
| IPC2 | 100,000 | 308,440,932 | 279.19 | 52.15 | 18.91 |
| Database | Algorithm | Filter Size | ||||
|---|---|---|---|---|---|---|
| 5K | 10K | 15K | 20K | 30K | ||
| ACL5 | Host | 2.94 | 10.91 | 13.69 | 21.08 | 31.91 |
| GPCDA (256, 8) | 0.72 | 1.61 | 2.06 | 2.86 | 3.97 | |
| GPCDA (512, 4) | 0.90 | 1.92 | 2.52 | 3.40 | 4.73 | |
| EPCDA (256, 8) | 0.34 | 0.72 | 0.88 | 1.37 | 1.72 | |
| EPCDA (512, 4) | 0.35 | 0.82 | 1.00 | 1.56 | 1.97 | |
| FW4 | Host | 10.45 | 20.85 | 30.73 | 40.11 | 59.46 |
| GPCDA (256, 8) | 4.10 | 7.55 | 9.20 | 11.85 | 16.63 | |
| GPCDA (512, 4) | 4.74 | 8.23 | 10.69 | 13.11 | 20.00 | |
| EPCDA (256, 8) | 2.29 | 2.51 | 3.64 | 4.35 | 6.00 | |
| EPCDA (512, 4) | 2.71 | 2.93 | 4.26 | 5.14 | 7.08 | |
| IPC1 | Host | 8.82 | 19.06 | 28.18 | 37.57 | 56.53 |
| GPCDA (256, 8) | 1.82 | 3.77 | 5.35 | 6.42 | 10.03 | |
| GPCDA (512, 4) | 2.23 | 4.48 | 6.38 | 7.64 | 12.17 | |
| EPCDA (256, 8) | 0.96 | 2.12 | 2.58 | 3.21 | 4.72 | |
| EPCDA (512, 4) | 1.12 | 2.46 | 3.01 | 3.70 | 5.45 | |
| Database | Algorithm | Filter Size | ||||
|---|---|---|---|---|---|---|
| 5K | 10K | 15K | 20K | 30K | ||
| ACL2 | Host | 8.69 | 18.19 | 26.16 | 34.83 | 50.10 |
| GPCDA (256, 8) | 1.88 | 3.34 | 4.51 | 6.60 | 9.20 | |
| GPCDA (512, 4) | 2.42 | 4.22 | 5.65 | 8.16 | 11.26 | |
| EPCDA (256, 8) | 0.87 | 1.87 | 2.54 | 3.29 | 4.36 | |
| EPCDA (512, 4) | 1.00 | 2.18 | 3.02 | 3.86 | 5.16 | |
| FW2 | Host | 7.70 | 16.80 | 25.08 | 33.41 | 49.57 |
| GPCDA (256, 8) | 1.80 | 3.69 | 5.35 | 6.46 | 9.92 | |
| GPCDA (512, 4) | 2.38 | 4.79 | 6.68 | 7.98 | 12.62 | |
| EPCDA (256, 8) | 0.90 | 1.78 | 2.25 | 2.81 | 4.32 | |
| EPCDA (512, 4) | 1.04 | 2.04 | 2.55 | 3.21 | 4.89 | |
| IPC2 | Host | 8.64 | 18.57 | 27.73 | 36.94 | 55.20 |
| GPCDA (256, 8) | 3.28 | 5.12 | 8.87 | 10.31 | 17.48 | |
| GPCDA (512, 4) | 3.40 | 5.54 | 9.37 | 11.25 | 18.51 | |
| EPCDA (256, 8) | 1.72 | 2.97 | 3.57 | 4.43 | 6.41 | |
| EPCDA (512, 4) | 1.95 | 3.35 | 3.97 | 4.98 | 7.42 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.-L.; Lin, G.-Y.; Chen, Y.-C. An Efficient Parallel Algorithm for Detecting Packet Filter Conflicts. Algorithms 2022, 15, 237. https://doi.org/10.3390/a15070237
Lee C-L, Lin G-Y, Chen Y-C. An Efficient Parallel Algorithm for Detecting Packet Filter Conflicts. Algorithms. 2022; 15(7):237. https://doi.org/10.3390/a15070237
Chicago/Turabian StyleLee, Chun-Liang, Guan-Yu Lin, and Yaw-Chung Chen. 2022. "An Efficient Parallel Algorithm for Detecting Packet Filter Conflicts" Algorithms 15, no. 7: 237. https://doi.org/10.3390/a15070237
APA StyleLee, C.-L., Lin, G.-Y., & Chen, Y.-C. (2022). An Efficient Parallel Algorithm for Detecting Packet Filter Conflicts. Algorithms, 15(7), 237. https://doi.org/10.3390/a15070237