
Techniques and Paradigms in Modern Game AI Systems

Abstract
1. Introduction
2. Background
2.1. Game AI Benchmarks
2.2. Game Features
2.2.1. Real Time
2.2.2. Imperfect Information
2.2.3. Stochasticity
2.2.4. Cooperation
2.2.5. Heterogeneous
2.3. Game AI Modeling
3. Game AI Techniques
3.1. Real-Time Planning
3.2. Learning
3.2.1. Evolutionary Methods
3.2.2. Supervised Learning
3.2.3. Reinforcement Learning
3.2.4. Multi-Agent Learning
4. Milestones of Game AI Systems
4.1. Board Games
4.2. Card Games
4.2.1. HUNL
4.2.2. Mahjong
4.2.3. Doudizhu
4.3. Video Games
5. Paradigms and Trends
5.1. Common Paradigms
5.1.1. AlphaGo Series
5.1.2. CFR Series
5.1.3. DRL Series
5.2. Techniques for Game Features
5.2.1. Self-Play Scheme
5.2.2. Imperfect Information
5.2.3. Heterogeneous Agents
5.3. Future Trends
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Turing, A.M. Computing machinery and intelligence. In Parsing the Turing Test; Springer: Berlin/Heidelberg, Germany, 2009; pp. 23–65. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef]
- Moravčík, M.; Schmid, M.; Burch, N.; Lisỳ, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; Bowling, M. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker. Science 2017, 356, 508–513. [Google Scholar] [CrossRef] [PubMed]
- Brown, N.; Sandholm, T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science 2018, 359, 418–424. [Google Scholar] [CrossRef]
- Brown, N.; Sandholm, T. Superhuman AI for multiplayer poker. Science 2019, 365, 885–890. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Chung, J.; Mathieu, M.; Jaderberg, M.; Czarnecki, W.M.; Dudzik, A.; Huang, A.; Georgiev, P.; Powell, R.; et al. Alphastar: Mastering the real-time strategy game starcraft ii. DeepMind Blog 2019, 2. Available online: https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii (accessed on 8 August 2022).
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Debiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Ye, D.; Chen, G.; Zhang, W.; Chen, S.; Yuan, B.; Liu, B.; Chen, J.; Liu, Z.; Qiu, F.; Yu, H.; et al. Towards playing full moba games with deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 621–632. [Google Scholar]
- Risi, S.; Preuss, M. From chess and atari to starcraft and beyond: How game ai is driving the world of ai. KI-Künstliche Intell. 2020, 34, 7–17. [Google Scholar] [CrossRef]
- Yin, Q.; Yang, J.; Ni, W.; Liang, B.; Huang, K. AI in Games: Techniques, Challenges and Opportunities. arXiv 2021, arXiv:2111.07631. [Google Scholar]
- Copeland, B.J. The Modern History of Computing. Available online: https://plato.stanford.edu/entries/computing-history/ (accessed on 10 July 2022).
- Tesauro, G. Temporal difference learning and TD-Gammon. Commun. ACM 1995, 38, 58–68. [Google Scholar] [CrossRef]
- Schaeffer, J.; Lake, R.; Lu, P.; Bryant, M. Chinook the world man-machine checkers champion. AI Mag. 1996, 17, 21. [Google Scholar]
- Campbell, M.; Hoane, A.J., Jr.; Hsu, F.h. Deep blue. Artif. Intell. 2002, 134, 57–83. [Google Scholar] [CrossRef]
- Bowling, M.; Burch, N.; Johanson, M.; Tammelin, O. Heads-up limit hold’em poker is solved. Science 2015, 347, 145–149. [Google Scholar] [CrossRef]
- Li, J.; Koyamada, S.; Ye, Q.; Liu, G.; Wang, C.; Yang, R.; Zhao, L.; Qin, T.; Liu, T.Y.; Hon, H.W. Suphx: Mastering mahjong with deep reinforcement learning. arXiv 2020, arXiv:2003.13590. [Google Scholar]
- Fu, H.; Liu, W.; Wu, S.; Wang, Y.; Yang, T.; Li, K.; Xing, J.; Li, B.; Ma, B.; Fu, Q.; et al. Actor-Critic Policy Optimization in a Large-Scale Imperfect-Information Game. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Zha, D.; Xie, J.; Ma, W.; Zhang, S.; Lian, X.; Hu, X.; Liu, J. Douzero: Mastering doudizhu with self-play deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 12333–12344. [Google Scholar]
- Guan, Y.; Liu, M.; Hong, W.; Zhang, W.; Fang, F.; Zeng, G.; Lin, Y. PerfectDou: Dominating DouDizhu with Perfect Information Distillation. arXiv 2022, arXiv:2203.16406. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Schwalbe, U.; Walker, P. Zermelo and the early history of game theory. Games Econ. Behav. 2001, 34, 123–137. [Google Scholar] [CrossRef]
- Osborne, M.J.; Rubinstein, A. A Course in Game Theory; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Watson, J. Strategy: An Introduction to Game Theory; WW Norton: New York, NY, USA, 2002; Volume 139. [Google Scholar]
- Sunehag, P.; Lever, G.; Gruslys, A.; Czarnecki, W.M.; Zambaldi, V.; Jaderberg, M.; Lanctot, M.; Sonnerat, N.; Leibo, J.Z.; Tuyls, K.; et al. Value-decomposition networks for cooperative multi-agent learning. arXiv 2017, arXiv:1706.05296. [Google Scholar]
- Rashid, T.; Samvelyan, M.; Schroeder, C.; Farquhar, G.; Foerster, J.; Whiteson, S. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4295–4304. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30, 6382–6393. [Google Scholar]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Hart, P.; Nilsson, N.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Stockman, G. A minimax algorithm better than alpha-beta? Artif. Intell. 1979, 12, 179–196. [Google Scholar] [CrossRef]
- Kocsis, L.; Szepesvári, C. Bandit based monte-carlo planning. In Proceedings of the European Conference on Machine Learning, Berlin, Germany, 18–22 September 2006; pp. 282–293. [Google Scholar]
- Gelly, S.; Silver, D. Combining online and offline knowledge in UCT. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 273–280. [Google Scholar]
- Gelly, S.; Silver, D. Monte-Carlo tree search and rapid action value estimation in computer Go. Artif. Intell. 2011, 175, 1856–1875. [Google Scholar] [CrossRef]
- Chaslot, G.M.B.; Winands, M.H.; Herik, H. Parallel monte-carlo tree search. In Proceedings of the International Conference on Computers and Games, Beijing, China, 29 September–1 October 2008; pp. 60–71. [Google Scholar]
- Ginsberg, M.L. GIB: Imperfect information in a computationally challenging game. J. Artif. Intell. Res. 2001, 14, 303–358. [Google Scholar] [CrossRef][Green Version]
- Bjarnason, R.; Fern, A.; Tadepalli, P. Lower bounding Klondike solitaire with Monte-Carlo planning. In Proceedings of the Nineteenth International Conference on Automated Planning and Scheduling, Thessaloniki, Greece, 19–23 September 2009. [Google Scholar]
- Frank, I.; Basin, D. Search in games with incomplete information: A case study using bridge card play. Artif. Intell. 1998, 100, 87–123. [Google Scholar] [CrossRef]
- Cowling, P.I.; Powley, E.J.; Whitehouse, D. Information set monte carlo tree search. IEEE Trans. Comput. Intell. Games 2012, 4, 120–143. [Google Scholar] [CrossRef]
- Whitehouse, D.; Powley, E.J.; Cowling, P.I. Determinization and information set Monte Carlo tree search for the card game Dou Di Zhu. In Proceedings of the 2011 IEEE Conference on Computational Intelligence and Games (CIG’11), Seoul, Korea, 31 August 2011–3 September 2011; pp. 87–94. [Google Scholar]
- Burch, N. Time and Space: Why Imperfect Information Games Are Hard. Available online: https://era.library.ualberta.ca/items/db44409f-b373-427d-be83-cace67d33c41 (accessed on 10 July 2022).
- Eiben, A.E.; Smith, J.E. Introduction to Evolutionary Computing; Springer: Berlin/Heidelberg, Germany, 2003; Volume 53. [Google Scholar]
- Rechenberg, I. Evolutionsstrategien. In Simulationsmethoden in der Medizin und Biologie; Springer: Berlin/Heidelberg, Germany, 1978; pp. 83–114. [Google Scholar]
- Dawkins, R.; Krebs, J.R. Arms races between and within species. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1979, 205, 489–511. [Google Scholar]
- Angeline, P.; Pollack, J. Competitive Environments Evolve Better Solutions for Complex Tasks. In Proceedings of the 5th International Conference on Genetic Algorithms, San Francisco, CA, USA, 1 June 1993; pp. 264–270. [Google Scholar]
- Reynolds, C.W. Competition, coevolution and the game of tag. In Proceedings of the Fourth International Workshop on the Synthesis and Simulation of Living Systems, Boston, MA, USA, 6–8 July 1994; pp. 59–69. [Google Scholar]
- Sims, K. Evolving 3D morphology and behavior by competition. Artif. Life 1994, 1, 353–372. [Google Scholar] [CrossRef]
- Smith, G.; Avery, P.; Houmanfar, R.; Louis, S. Using co-evolved rts opponents to teach spatial tactics. In Proceedings of the 2010 IEEE Conference on Computational Intelligence and Games, Copenhagen, Denmark, 18–21 August 2010; pp. 146–153. [Google Scholar]
- Fernández-Ares, A.; García-Sánchez, P.; Mora, A.M.; Castillo, P.A.; Merelo, J. There can be only one: Evolving RTS bots via joust selection. In Proceedings of the European Conference on the Applications of Evolutionary Computation, Porto, Portugal, 30 March–1 April 2016; pp. 541–557. [Google Scholar]
- García-Sánchez, P.; Tonda, A.; Fernández-Leiva, A.J.; Cotta, C. Optimizing hearthstone agents using an evolutionary algorithm. Knowl.-Based Syst. 2020, 188, 105032. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Konda, V.; Tsitsiklis, J. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems 12 (NIPS 1999), Denver, CO, USA, 29 November–4 December 1999; Volume 12. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Espeholt, L.; Soyer, H.; Munos, R.; Simonyan, K.; Mnih, V.; Ward, T.; Doron, Y.; Firoiu, V.; Harley, T.; Dunning, I.; et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. In Proceedings of the International Conference on Machine Learning. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1407–1416. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hart, S.; Mas-Colell, A. A simple adaptive procedure leading to correlated equilibrium. Econometrica 2000, 68, 1127–1150. [Google Scholar] [CrossRef]
- Zinkevich, M.; Johanson, M.; Bowling, M.; Piccione, C. Regret minimization in games with incomplete information. Adv. Neural Inf. Process. Syst. 2007, 20, 1729–1736. [Google Scholar]
- Tammelin, O. Solving large imperfect information games using CFR+. arXiv 2014, arXiv:1407.5042. [Google Scholar]
- Brown, N.; Sandholm, T. Solving imperfect-information games via discounted regret minimization. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1829–1836. [Google Scholar]
- Lanctot, M.; Waugh, K.; Zinkevich, M.; Bowling, M.H. Monte Carlo Sampling for Regret Minimization in Extensive Games. In Proceedings of the NIPS, Vancouver, BC, Canada, 6–11 December 2009; pp. 1078–1086. [Google Scholar]
- Schmid, M.; Burch, N.; Lanctot, M.; Moravcik, M.; Kadlec, R.; Bowling, M. Variance reduction in monte carlo counterfactual regret minimization (VR-MCCFR) for extensive form games using baselines. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 2157–2164. [Google Scholar]
- Waugh, K.; Schnizlein, D.; Bowling, M.H.; Szafron, D. Abstraction pathologies in extensive games. In Proceedings of the AAMAS, Budapest, Hungary, 10–15 May 2009; pp. 781–788. [Google Scholar]
- Waugh, K.; Morrill, D.; Bagnell, J.A.; Bowling, M. Solving games with functional regret estimation. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Brown, N.; Lerer, A.; Gross, S.; Sandholm, T. Deep counterfactual regret minimization. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 793–802. [Google Scholar]
- Li, H.; Hu, K.; Ge, Z.; Jiang, T.; Qi, Y.; Song, L. Double neural counterfactual regret minimization. arXiv 2018, arXiv:1812.10607. [Google Scholar]
- Steinberger, E. Single deep counterfactual regret minimization. arXiv 2019, arXiv:1901.07621. [Google Scholar]
- Steinberger, E.; Lerer, A.; Brown, N. DREAM: Deep regret minimization with advantage baselines and model-free learning. arXiv 2020, arXiv:2006.10410. [Google Scholar]
- Brown, G.W. Iterative solution of games by fictitious play. Act. Anal. Prod. Alloc. 1951, 13, 374–376. [Google Scholar]
- Heinrich, J.; Lanctot, M.; Silver, D. Fictitious self-play in extensive-form games. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 805–813. [Google Scholar]
- Heinrich, J.; Silver, D. Deep reinforcement learning from self-play in imperfect-information games. arXiv 2016, arXiv:1603.01121. [Google Scholar]
- McMahan, H.B.; Gordon, G.J.; Blum, A. Planning in the presence of cost functions controlled by an adversary. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 536–543. [Google Scholar]
- Lanctot, M.; Zambaldi, V.; Gruslys, A.; Lazaridou, A.; Tuyls, K.; Pérolat, J.; Silver, D.; Graepel, T. A unified game-theoretic approach to multiagent reinforcement learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4193–4206. [Google Scholar]
- Bansal, T.; Pachocki, J.; Sidor, S.; Sutskever, I.; Mordatch, I. Emergent complexity via multi-agent competition. arXiv 2017, arXiv:1710.03748. [Google Scholar]
- Jaderberg, M.; Dalibard, V.; Osindero, S.; Czarnecki, W.M.; Donahue, J.; Razavi, A.; Vinyals, O.; Green, T.; Dunning, I.; Simonyan, K.; et al. Population based training of neural networks. arXiv 2017, arXiv:1711.09846. [Google Scholar]
- Zhao, E.; Yan, R.; Li, J.; Li, K.; Xing, J. AlphaHoldem: High-Performance Artificial Intelligence for Heads-Up No-Limit Texas Hold’em from End-to-End Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 22 February–1 March 2022; Volume 36, pp. 4689–4697. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Johanson, M. Measuring the size of large no-limit poker games. arXiv 2013, arXiv:1302.7008. [Google Scholar]
- Zha, D.; Lai, K.H.; Cao, Y.; Huang, S.; Wei, R.; Guo, J.; Hu, X. Rlcard: A toolkit for reinforcement learning in card games. arXiv 2019, arXiv:1910.04376. [Google Scholar]
- Zhou, H.; Zhang, H.; Zhou, Y.; Wang, X.; Li, W. Botzone: An online multi-agent competitive platform for ai education. In Proceedings of the 23rd Annual ACM Conference on Innovation and Technology in Computer Science Education, Larnaca, Cyprus, 2–4 July 2018; pp. 33–38. [Google Scholar]
- Sutton, R.S. Learning to predict by the methods of temporal differences. Mach. Learn. 1988, 3, 9–44. [Google Scholar] [CrossRef]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef]
- Czarnecki, W.M.; Gidel, G.; Tracey, B.; Tuyls, K.; Omidshafiei, S.; Balduzzi, D.; Jaderberg, M. Real world games look like spinning tops. Adv. Neural Inf. Process. Syst. 2020, 33, 17443–17454. [Google Scholar]
- Lyu, X.; Baisero, A.; Xiao, Y.; Amato, C. A Deeper Understanding of State-Based Critics in Multi-Agent Reinforcement Learning. arXiv 2022, arXiv:2201.01221. [Google Scholar] [CrossRef]
- Sutton, R. The bitter lesson. Incomplete Ideas 2019, 13, 12. [Google Scholar]
- Schaller, R.R. Moore’s law: Past, present and future. IEEE Spectr. 1997, 34, 52–59. [Google Scholar] [CrossRef]
- Wurman, P.R.; Barrett, S.; Kawamoto, K.; MacGlashan, J.; Subramanian, K.; Walsh, T.J.; Capobianco, R.; Devlic, A.; Eckert, F.; Fuchs, F.; et al. Outracing champion Gran Turismo drivers with deep reinforcement learning. Nature 2022, 602, 223–228. [Google Scholar] [CrossRef]
- Kurach, K.; Raichuk, A.; Stańczyk, P.; Zając, M.; Bachem, O.; Espeholt, L.; Riquelme, C.; Vincent, D.; Michalski, M.; Bousquet, O.; et al. Google research football: A novel reinforcement learning environment. arXiv 2019, arXiv:1907.11180. [Google Scholar] [CrossRef]
- Baker, B.; Kanitscheider, I.; Markov, T.; Wu, Y.; Powell, G.; McGrew, B.; Mordatch, I. Emergent tool use from multi-agent autocurricula. arXiv 2019, arXiv:1909.07528. [Google Scholar]


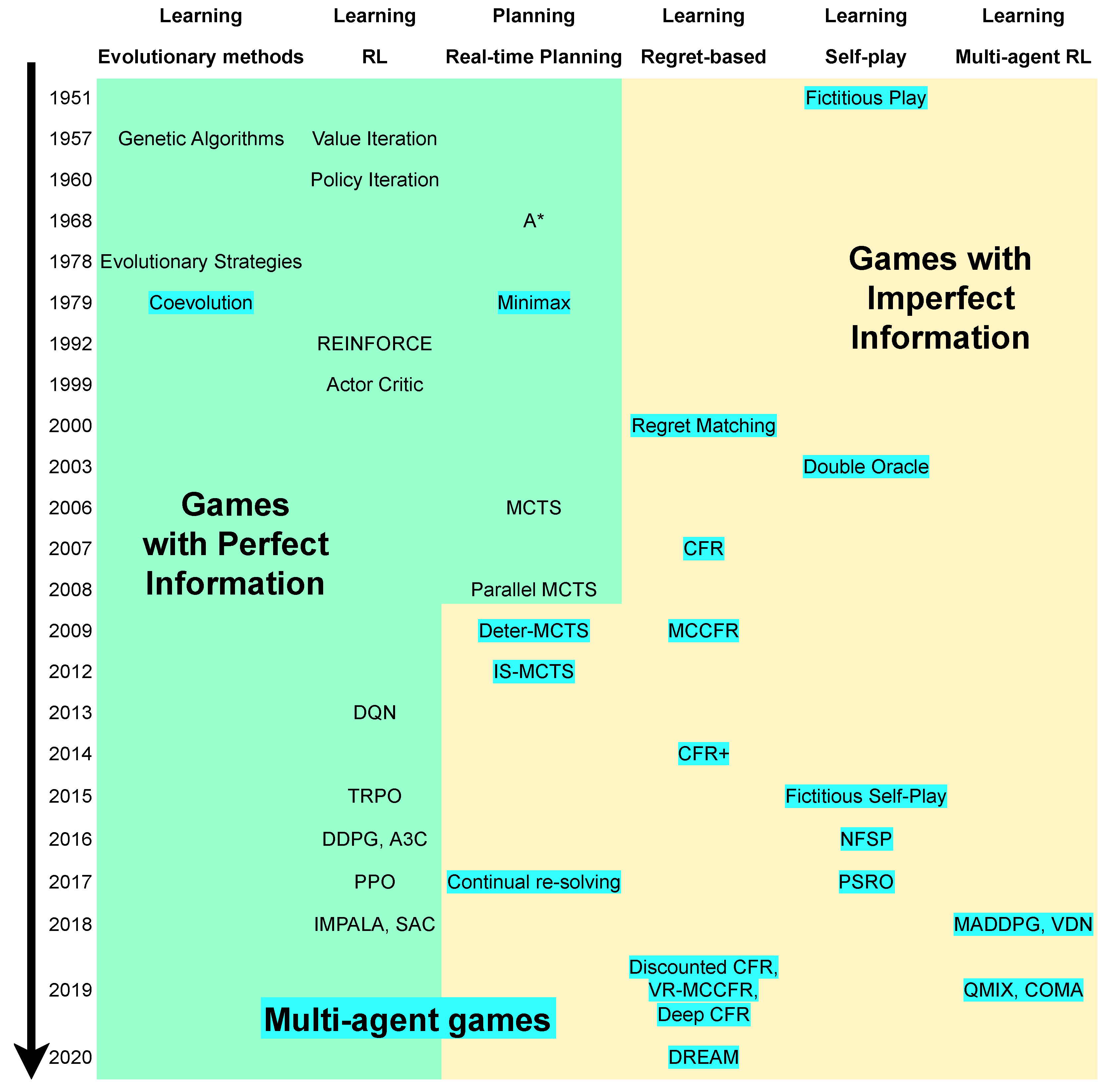{kind=link}
| Game Types | Name | Players | Real-Time | Imperfect Information | Stochasticity | Cooperation | Heterogeneous |
|---|---|---|---|---|---|---|---|
| Board games | Go | 2 | ✗ | ✗ | ✗ | ✗ | ✗ |
| Card games | HUNL | 2 or 6 | ✗ | ✓ | ✓ | ✗ | ✗ |
| Riichi Mahjong | 4 | ✗ | ✓ | ✓ | ✗ | ✗ | |
| 1-on-1 Mahjong | 2 | ✗ | ✓ | ✓ | ✗ | ✗ | |
| Doudizhu | 3 | ✗ | ✓ | ✗ | ✓ | ✗ | |
| Video games | Starcraft | 2 | ✓ | ✓ | ✓ | ✗ | ✓ |
| Dota 2 | 10 | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Honour of Kings | 10 | ✓ | ✓ | ✓ | ✓ | ✓ |
| AI System | Prior Knowledge | Training Pipeline | Inference | RL Algorithm |
|---|---|---|---|---|
| AlphaGo | policy network rollout policy value network | SL + RL SL SL | MCTS + NN | PG |
| AlphaGo Zero | policy-value network | RL | MCTS-RL | |
| AlphaZero | ||||
| DeepStack | DCFV network | SL | Continual re-solving + NN | N/A |
| Libratus | blueprint strategy | Abstraction + MCCFR | Nested-safe subgame solving | |
| Pluribus | ||||
| AlphaHoldem | policy-value network | RL | NN | Trinal-clip PPO |
| Suphx | policy networks global reward predictor | SL + RL SL | pMCPA finetune + NN | PG with entropy |
| JueJong | policy-value network | RL | NN | ACH |
| DouZero | value network | RL | One-step greedy + NN | DMC |
| PerfectDou | policy-value network | RL | NN | PPO |
| AlphaStar | policy-value network | SL+RL | NN | UPGO |
| OpenAI Five | policy-value network | RL | Minimax drafting NN | PPO |
| JueWu | policy-value network drafting value network | RL+SL+RL SL | MCTS drafting NN | Dual-clip PPO |
| AI System | Self-Play Scheme | Imperfect Information | Heterogeneous Agents |
|---|---|---|---|
| AlphaGo | Uniform Random | N/A | N/A |
| AlphaGo Zero | Best | ||
| AlphaZero | Latest | ||
| DeepStack | N/A | CFR | |
| Libratus | |||
| Pluribus | |||
| AlphaHoldem | K-Best | No use | |
| Suphx | Latest | Oracle Guiding | |
| JueJong | Latest | ACH | |
| DouZero | Latest | No use | |
| PerfectDou | Latest | PID | |
| AlphaStar | Population | PID | Population |
| OpenAI Five | Heuristic | No use | Random |
| JueWu | Heuristic | PID | Knowledge Distillation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Li, W. Techniques and Paradigms in Modern Game AI Systems. Algorithms 2022, 15, 282. https://doi.org/10.3390/a15080282
Lu Y, Li W. Techniques and Paradigms in Modern Game AI Systems. Algorithms. 2022; 15(8):282. https://doi.org/10.3390/a15080282
Chicago/Turabian StyleLu, Yunlong, and Wenxin Li. 2022. "Techniques and Paradigms in Modern Game AI Systems" Algorithms 15, no. 8: 282. https://doi.org/10.3390/a15080282
APA StyleLu, Y., & Li, W. (2022). Techniques and Paradigms in Modern Game AI Systems. Algorithms, 15(8), 282. https://doi.org/10.3390/a15080282