Abstract
This article considers the problem of image segmentation based on its representation as an undirected weighted graph. Image segmentation is equivalent to partitioning a graph into communities. The image segment corresponds to each community. The growing area algorithm search communities on the graph. The average edge weight in the community is a measure of the separation quality. The correlation radius determines the number of next nearest neighbors connected by edges. Edge weight is a function of the difference between color and geometric coordinates of pixels. The exponential law calculates the weights of an edge in a graph. The computer experiment determines the parameters of the algorithm.
1. Introduction
Segmentation is the division of an image into areas with close pixel color characteristics [1]. Image segmentation is one of the most relevant in computer vision and pattern recognition systems [2,3,4]. Segmentation uses color intensity to split monochrome images. Segmentation works in the color feature space for color images. Segmentation algorithms depend on the choice of color model. Segmentation results are not strictly defined. The correctness of segmentation algorithms is assessed on the basis of expert assessments. Image collections with test segmentation are used to test segmentation algorithms. Experts perform ground truth for images of these collections [5]. There are no universal segmentation algorithms that work successfully on arbitrary images.
Most segmentation algorithms present the image as values of some function in the nodes of the square grid. Differential based on finite differences are calculated for these functions. Special image points are used for segmentation. This approach has several drawbacks when applied to noisy or illuminated images. Pre-filtering the image reduces the impact of these factors. However, filters blur the image and degrade the quality of segmentation.
Image processing methods based on graph theory have been actively developed recently. A weighted graph is uniquely mapped to an image. Image segmentation is equivalent to partitioning a graph into subgraphs [6,7,8,9,10]. Community allocation on the graph is used in this approach. Finding communities is clustering the graph. Community searches are typically applied to network data. Communities represent a subset of graph nodes that are more strongly connected to each other than to other nodes. The number of edges is a connectivity measure for an unweighted graph. The weight of the edges is considered for the weighted graph. Edge weights between community nodes are greater than with other nodes.
The graph nodes correspond to the image pixels. The graph edges define a measure of pixel similarity. The graph is mapped to the image so that pixels with close color characteristics are strongly related. Defining communities on a graph groups image points by similar color features. The image segment corresponds to the community on the graph.
One of the applied values for segmentation algorithms is understanding road scenes and highlighting the road in the image. This problem is relevant for the inventory of roads and smart vehicles [11]. The task of highlighting a roads segment is difficult due to differences in road types, objects on the roads, and lighting conditions. The main requirements for such an algorithm are the speed of operation and the accuracy of determining road edges. Excess objects on the sides of the road should not fall into the segment.
Algorithms for highlighting communities on graphs provide a high level of image segmentation quality. However, these algorithms have high computational complexity and long running times. These disadvantages do not allow these algorithms to be used directly. Community highlighting algorithms work in the image preprocessing or image postprocessing stages. The purpose of the paper is to develop an image segmentation algorithm based on highlighting communities on a graph with acceptable running time. The developed algorithm is used to highlight the road segment. The algorithm calculates the real road width based on the image segment and optical system parameters.
2. Related Works
Communities can stand out using a variety of algorithms. Direct application of fast and greedy method [12] and label propagation algorithms [13] is computationally intensive. Therefore, additional transformations are applied. Image partitions into superpixels [14] are one of these transformations. The superpixel is a small image segment [15]. There are several approaches to breaking an image into superpixels [16,17,18,19]. The accuracy of this approach is limited by the superpixels size. Another way to reduce the complexity of community-based segmentation on a graph is based on reducing the amount of information. The threshold principle for determining the graph edge weight reduces the image graph connectivity [20]. This approach segments monochrome images based on highlighting communities on a graph. However, this algorithm is very sensitive to threshold selection. The threshold value is selected manually for each image.
The search for communities in the graph can be used in the post-processing step of the segmented image [21]. The graph is mapped to a segmented image. Some segments are further combined to optimize graph partitioning [21,22]. This approach is effective for images with a large number of small segments [23]. The algorithm for segmentation of the original image based on communities on graphs was proposed in reference [24]. However, this algorithm includes some simplifications. The algorithm considers only the edges for the nearest neighbors. The algorithm has a low speed.
Segmentation based on the graph-theoretic approach and the search for communities can only be applied to a part of the image. The number of pixels decreases significantly after the background is removed. This transformation allows the construction of a fully connected graph based on superpixels [25]. After that, the authors of this work performed clustering of the graph based on geometric features. The third step was to refine the boundaries.
Feature vectors can be used to cluster graphs corresponding to the image [26]. Feature vectors are constructed from the internal structure of graphs and reflect the internal nodes’ connectivity. Feature vectors can be used in various graph clustering algorithms.
Algorithms that exist to analyze social networks can be used to detect communities on graphs derived from the image [27,28]. In this case, it is necessary to reduce the number of nodes that are performed using superpixels.
Subgraph splitting methods based on community allocation produce the best results for artificial objects such as cultural heritage artifacts [29]. The eigenvector of the modularity matrix corresponding to the largest positive eigenvalue, the authors recursively identify multilevel subgroups in the graph. The cluster tree strategy creates a cluster map with a variable level of detail. This approach finds the optimal number of clusters.
The main problem with using community search algorithms on graphs for image segmentation is the large amount of computation. One possible solution is to distribute labels [30]. This approach selects a node label to optimize the objective function by considering the available labels in the neighborhood of the node.
There are several algorithms for detecting the road in an image using a vanishing point: the dominant segment method [31], the parallel line method [32] and the pixel texture orientation method [33]. The most likely area of the road is assessed by the soft voting scheme [33,34] or by comparison with the pattern [35] in these methods. These methods provide a good result for flat asphalt roads with a flat edge. For roads with uneven lighting, the result is poor. Noises and obstacles strongly influence segmentation outcomes. These algorithms have high computational complexity and are not applicable in real-time systems. These algorithms are also not applicable in real road conditions in the presence of cars and pedestrians.
Road selection algorithms based on image segmentation typically involve two steps. In the first step, the algorithm analyzes the color [36,37], texture [38] or road boundaries [39]. The road highlight method can use a combination of these features [40,41]. Machine learning methods highlight the road in the second step [42]. Pre-filtering eliminates most noise. However, large objects cause segmentation errors. Obstacles lead to an incomplete allocation of the road or detect extra areas as part of the road.
Algorithms for marking the road segment based on deep learning of neural networks have been actively used recently [43]. The first convolutional neural networks for road segmentation were end-to-end trainees [44]. Various variants of neural networks solved the same problem [45,46]. Conditional random fields improved segmentation results [47]. Extended convolutions solved the problem of decreasing expansion [48]. The use of artificial neural networks requires human control at the stage of training set formation [49,50,51]. This approach is the most effective. However, it is expensive and non-scalable. Non-human methods use information about the color and texture of the road [33,52] or a geometric model of the road scene [53].
3. Method
We mapped an undirected graph to the image. The graph node corresponds to each pixel of the image. is the set of the graph nodes. We entered the correlation radius between the pixels. The correlation radius indicates the maximum distance between pixels whose nodes are connected by an edge in the graph. If then edges exist only between the nearest neighbors. In this case, the degree of the graph node is 8 if the pixel is not located on the image boundary. If then each node is connected to the nearest neighbors and the next nearest neighbors. The degree of each node is 24 if the pixel is not located at the image boundary.
The edge weight depends on the color coordinates of the pixels corresponding to the graph nodes. We use the RGB color model to encode the image. The three intensities of the base colors were mapped to the pixel with coordinates . is the intensity of red. is the intensity of green. is the intensity of blue. The edge weight was calculated based on the distance between the pixels corresponding to the nodes of the graph.
The five-dimensional space was used to initially represent the image. The point of this space represents a pixel with coordinates . The choice of a formula for calculating the distance between points and was determined by setting the segmentation problem. The image segment includes pixels close to each other in color and different in color from the remaining pixels. The function should depend on the color difference of the pixels. The distance between pixels must increase as the color coordinate difference increases. Pixels of the same segment must be localized in the image. The function should increase as the geometric distance between pixels increases.
We used the function of the distance between pixels and decreasing in exponential law.
The distance between pixels is zero if their colors match. The distance between pixels grows rapidly as the color coordinate difference increases.
There are other metrics for measuring the distance between points. The Euclidean metric in five-dimensional space requires additional scaling over heterogeneous coordinates.
This metric does not increase quickly enough when the color changes. A metric growing exponentially across all coordinates leads to the dominance of spatial coordinates over color coordinates.
Image segmentation is equivalent to cutting a graph into subgraphs in this model. Pixels of one segment must be close to each other in color characteristics and differ from another segment pixels. The formula for edge weight depends on the distance between pixels.
The edge weight is 1 if the pixel colors match. The edge weight decreases as the distance between the color coordinates increases. If the color coordinates are different, then the edge weight decreases as the difference between the geometric coordinates of the pixels increases. Nodes of one segment are strongly connected to each other and weakly connected to nodes outside the segment. Communities on graphs meet these requirements [19]. The segmentation problem boils down to the problem of finding a community on graphs.
We entered the matrix of edge weights for the graph . The element of the matrix is equal to the edge weight between nodes and . The matrix is symmetric with respect to the main diagonal. If the image is , then the matrix size is . The matrix is very large for conventional images. A large number of elements in matrix is zero. The number of non-zero elements depends on the correlation radius . If then each row has no more than 8 non-zero elements. If then the number of non-zero elements are not more than 24.
The area growing algorithm was used to search for communities on a graph in this work. The task was to find a community that includes a node . This process corresponds to finding a segment that includes this point. The average edge weight of subgraph is calculated at each step. Nodes from the set associated with at least one node from were considered at each iteration. The association of such a node with the community nodes was calculated as the sum of the edge weights.
If a node’s association with a community exceeds a threshold, the node joins the community . The threshold value was calculated based on the average community edge weights . The condition of joining node to the community is written as an inequality.
The parameter varies the image segmentation accuracy. This parameter determines the color difference that the algorithm perceives as close colors. The correlation radius also has an effect on segmentation accuracy. This parameter determines the number of edges coming from each node and increases the weight of the connection between the vertex and the community.
The algorithm is recursive. All points of the already formed community were considered at each step. All out-of-community points were checked for each community point. Asymptotic complexity for this algorithm is quadratic in number of pixels .
The average edge weight changes as the community grows. The usual behavior of average community edge weight is presented in Figure 1.
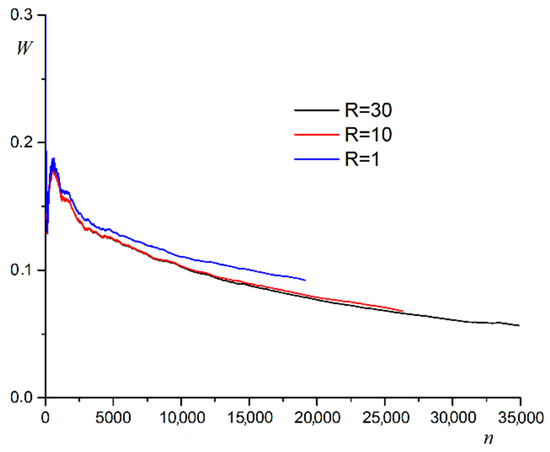
Figure 1.
Dependence of average edge weight in the community on the number of nodes included at different .
The average edge weight in the community decreases rapidly at first. Subsequently, the average edge weight comes to an asymptotic value. Increasing the correlation radius increases the size of the community. This fact is explained by the increase in the number of neighbors at each node. An increase in the correlation radius results in a slight decrease in the average edge weight in the community.
The image segment is easily computed from the set of community subgraph nodes. If the image is segmented completely, then segments formed around different points are calculated.
4. Computer Experiment
A computer experiment tests an algorithm on color images with a color depth of 1 byte per pixel. We used a computer with a quad-core processor and a frequency of 2600 MHz to carry out the experiment. The software package was implemented in C++. The algorithm highlights a segment in the center of the image. The result was compared to a manually selected segment. The dependence of the results for the algorithm on its parameters was investigated in a computer experiment. The experiment was carried out on a collection of 100 images. The most accurate segmentation was performed at parameter values . An example of algorithm operation at different values of parameter and is shown in Figure 2.

Figure 2.
Example of algorithm operation at R = 1 and different values of parameter h: (a) initial image, (b) ground truth, (c) h = 0.005, (d) h = 0.01.
Increasing the parameter reduces the size of the segment. Two parameters were used to compare segmentation results numerically. The segmentation efficiency is equal to the relative number of pixels correctly assigned by the algorithm to the segment.
is the number of pixels that the algorithm correctly classified. is the number of pixels in ground truth. The algorithm error is calculated as the ratio of the misclassified pixels number to the total number of pixels in the segment defined by the algorithm .
The calculation of these coefficients was performed on the image collection. An average value was calculated for these coefficients. At and the coefficients are , . At and the coefficients are , . Lowering the threshold parameter improves the segmentation accuracy with a slight reduction in errors.
The segmentation accuracy is improved by increasing the correlation radius . Examples of segmentation at and different values are given in Figure 3.

Figure 3.
Examples of segmentation at and different values : (a) , (b) , (c) , (d) .
Increasing the correlation radius significantly improves segmentation efficiency (, , , ). Further, increasing the correlation radius does not change the segmentation efficiency. Relative segmentation error decreases as correlation radius increases (, , , ). The number of misclassified nodes is growing slowly. The number of nodes in the community increases rapidly. The ratio of these values decreases.
Examples of segment highlighting in different images are shown in Figure 4.


Figure 4.
Examples of segment highlighting in different images: (a) source image, (b) the result of the algorithm.
5. Applying to a Road Image
We used our segmentation algorithm to determine the width of the road from its photo. This problem is relevant for automatic road inventory systems. The camera was mounted on a mobile laboratory. The camera photographed the road through the windshield. The problem is determining the width of the road from this photo of it. The camera parameters and its placement were known.
Calculating the width of a road involves five steps. The road segment is highlighted in the first phase. The boundary of the road segment is defined in the second step. The left and right edge pixels of the road are determined in the third step. The road boundaries are approximated by straight lines in the fourth step. The width of the road is calculated from the line equations in the fifth step.
Our algorithm was used to highlight a segment of the road. The correct calculation of the segment depends on the selection of the start point. We used an approximate model to image the road in the photo. The image includes four areas: (1) road, (2) sky, (3) objects to the left of the road, and (4) objects to the right of the road. The general model of the road image is shown in Figure 5a. We considered the case of a direct road section outside intersections. This assumption was justified. The camera operator independently selected the shooting moment. The road can go up or down the slope. The position of the chamber can be shifted from the center to the edge of the road. These factors resulted in the displacement of points A, B, C and D in the road image (Figure 5b).
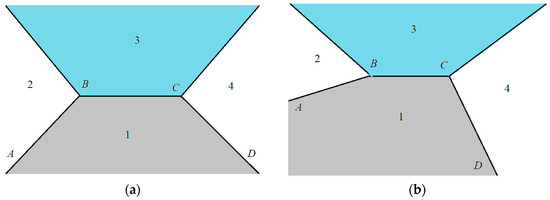
Figure 5.
Schematic model of the road image: (a) direct image of the road, (b) image of the road with displacement.
Our algorithm highlights segment 1. The image dimensions are . The point with coordinates belongs to the road segment. The coordinates of the point were calculated from the upper left corner. However, this is a bad candidate for the starting point of the segment based on the computer experiment results. Road markings are present on real roads. This point is often located on the road marking line. We used the starting point with coordinates . Upward displacement is necessary to ignore the image of the windshield bottom. Solid dividing lines are an insurmountable obstacle to the algorithm. Only one lane was highlighted by the algorithm in this case. The algorithm calculated two segments in this case. The starting point of the second segment has coordinates . The road segment is equal to the combination of the two segments. The two segments match when there is no solid dividing line. The option to manually select an additional segment start point was provided for complex road images with a large number of layout lines.
The segment boundary is defined in the second step. The border has a thickness of one pixel. Boundary pixels are located in the segment. The pixel neighboring the top is located outside the segment. This condition uniquely defines boundary pixels. Examples of highlighting a road segment and its boundaries are shown in Figure 6.

Figure 6.
Examples of highlighting a road segment (b) and its boundaries (c), (a) is original image.
The road edge pixels were highlighted in the third step. The segment boundary was not a straight line for several reasons. Interference includes objects at the edge of the road, the presence of cars and other objects on the road, such as lighting features. The algorithm highlights a section of the minimally distorted edge of the road. Points A and D were calculated as the leftmost and rightmost points of the road outline. Contour areas in a width were treated as images of the edge of the road. Examples of road outline and road edge images are shown in Figure 7.

Figure 7.
Examples of highlighting road boundaries: (a) original image, (b) road contours, (c) road boundaries.
The edges of the road are approximated by straight lines.
The least squares method is used to calculate coefficients a and b. The quadratic error function R is calculated for road edge points.
is the number of dots in the one edge road image. are coordinates of points at the road edge. Coefficients a and b are calculated based on the condition that the quadratic error function is minimal.
The solution of this equations system is expressed through the coordinates of the road edge points.
The coefficients were calculated independently for the left and right road edges. The result is two pairs of coefficients and . The first coefficients correspond to the straight left edge of the road. The second coefficients determine the right edge of the road. These two lines intersect at point .
Examples of road edge approximation for the road segment and the original image are shown in Figure 8. The road edge lines are drawn to the intersection point.

Figure 8.
Examples of road edge approximation for the road segment (a) and the original image (b). Red lines show the border of the road.
6. Calculating the Width of a Road
We considered rays in the optical system to determine the real width of the road. Parameter is the real width of the road. Parameter is the width of the road in the image. The width of the road in the image depends on the measurement point due to the perspective effect. Parameter is the height from the top edge of the image at which the road width is measured. This point in the image corresponds to a point at a distance from the camera. Parameter is the height of the camera above the road. Parameter is the distance from the lens to the matrix in the camera. The optical system parameters are shown in Figure 9.
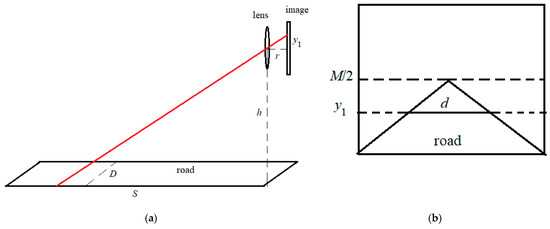
Figure 9.
The optical system parameters. (a) Imaging the road in the lens, (b) parameters in the image.
The height of the point in the image and the distance to the point on the road are related by the formula (Figure 9a).
We write down the formula for a thin lens.
Parameter is the focal length of the lens.
This expression is substituted in formula (13).
The selection of fixed values and results in measuring the width of the road at the same distance from the camera. If the shooting is performed on a fixed hardware platform, then remains the same. Value is a parameter of the algorithm. This parameter is fixed in the program.
We write down the formula for the width of the road (Figure 9b).
The expression (15) is substituted into this formula.
The formula (16) is used for .
is measured in meters in this formula. The algorithm measures in pixels in the image. The coefficient converts the distance in pixels into meters. depends on the resolution of the camera.
The new factor is introduced for ease of calculation.
This factor defines the specifications for image acquisition. It depends on the camera used and its position.
Parameter can be obtained by calibration the system. Several photos of roads with a known width are necessary for calibration. The algorithm determines the width for these shots. Coefficient k is calculated from known values , and . The average value is used in further system operation.
The width of the road in the photo is calculated based on the straight equations for the road boundaries. The value is substituted in Equation (9).
The coordinate values and are calculated from these equations. The width of the road is defined as the difference between the two values.
The width of the road in the image is expressed through the equation’s coefficients for lines.
The width of the real road is calculated by substituting formula (27) into formula (25).
We used a value of . is the height of the image in pixels.
These formulas apply only to the horizontal road. If the road is on the rise, then the formula gives an increased value for the width of the road. If the road slopes, then the formula gives an underestimated value. The presence of a road slope or rise is determined by the position of the horizon line in the image. For a horizontal road, the horizon line is located in the middle of the image. The horizon line is above the middle of the image for rising. The horizon line is below the middle of the slope. The algorithm cannot highlight the horizon line in the image due to the presence of objects obscuring it. One point on the horizon line is calculated as the intersection of the straight road boundaries . This point is sufficient to define the entire horizon line. If the road is horizontal, then . is greater than for the rising (). The coordinate is less than for the slope M/2 ().
The geometric transformation of the road image is performed to obtain the true value of the road width at . This transformation is demonstrated in Figure 10.
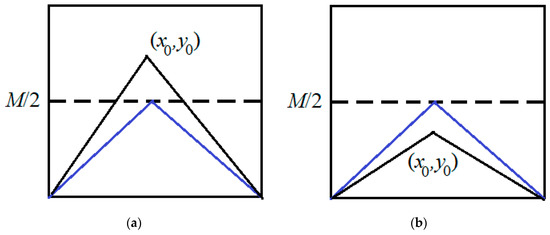
Figure 10.
The road image is converted at . The black line is the original image of the road. A blue line is an image of a road after conversion ((a) rising, (b) slope).
The image is compressed along the OY axis at . The image stretches along the OY axis at . The equations for straight approximating road edges change after conversion.
The true value of the road width is calculated using the modified formula.
We tested the proposed algorithm on a collection of 100 images. Images were obtained by the same camera mounted on a car. The training set included five road images of known width. The road width of the training set was measured manually. The road segment was highlighted for all images in the collection. Road widths were measured manually to check the accuracy of the algorithm. The difference between the results of the algorithm and the results of manual measurement do not exceed 5%.
7. Conclusions
Our segmentation algorithm is based on representing the image as a weighted graph. Image segmentation is performed as a selection of subgraphs whose nodes are more strongly connected to each other than to other nodes. Our algorithm differs in two ways from other algorithms. Edges are connected, not only nodes of the nearest neighboring pixels, but also nodes at some distance from each other in graph construction. Considering long-range correlations increases the efficiency of image segmentation. Increasing the radius of node correlation increases the running time of the algorithm. There is an optimal correlation radius . The efficiency of the algorithm remains unchanged when this threshold is exceeded. The second feature of the algorithm is to consider not the weight of the edge with the nearest community node, but the total weight of all edges within the correlation radius. This approach allows the algorithm to bypass point features in the image. The communication threshold for including a node in a community is constantly changed and calculated based on the edges of the formed community. This allows the algorithm to segment images with gradient fill. However, this approach leads to an increase in the number of nodes mistakenly included in the community in the absence of clear boundaries in the image.
We compared the results of our algorithm with similar works. Images of 200 different roads were used for testing. The images were obtained using a video recorder and from various sources on the Internet. Figure 11 shows examples of the original images, ground truth, the results of articles [54,55], the results of our algorithm.

Figure 11.
Segmentation examples: (a) original images, (b) ground truth, (c) [54], (d) [55], (e) our algorithm.
As can be seen from Figure 11, our algorithm provides segmentation results close to ground truth. The algorithm from article [54] produces similar results in terms of segmentation quality. However, our algorithm works faster. All images were 492 × 318 in size. Average operating time of the algorithm in [54] was 6.9 s. The average running time of the algorithm in [55] was 7.1 s. A similar algorithm from article [56] works in 957.2 s. Our algorithm performs segmentation on the same set of images over an average time of 2.3 s.
Author Contributions
Conceptualization, S.V.B.; methodology, S.Y.B.; software, S.V.B.; formal analysis, S.Y.B.; writing—review and editing, S.V.B. and S.Y.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Matta, S. Review: Various Image Segmentation Techniques. IJCSIT 2014, 5, 7536–7539. [Google Scholar]
- Wang, Y.; Wang, C. Computer vision-based color image segmentation with improved kernel clustering. Int. J. Smart Sens. Intell. Syst. 2015, 8, 1706–1729. [Google Scholar] [CrossRef]
- Khan, W. Image segmentation techniques: A survey. J. Image Graph. 2013, 1, 166–170. [Google Scholar] [CrossRef]
- Wu, H.; Liu, Q.; Liu, X. A review on deep learning approaches to image classification and object segmentation. Comput. Mater. Contin. 2019, 60, 575–597. [Google Scholar] [CrossRef]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE TPAMI 2011, 33, 898–916. [Google Scholar] [CrossRef]
- Belim, S.V.; Kutlunin, P.E. Boundary extraction in images using a clustering algorithm. Comput. Opt. 2015, 39, 119–124. [Google Scholar] [CrossRef]
- Boykov, Y.; Funka-Lea, G. Graph Cuts and Efficient N-D Image Segmentation. Int. J. Comput. Vision 2006, 70, 109–131. [Google Scholar] [CrossRef]
- Xu, B.; Bu, J.; Chen, C.; Wang, C.; Cai, D.; He, X. EMR: A Scalable Graph-Based Ranking Model for Content-Based Image Retrieval. IEEE Trans. Knowl. Data Eng. 2015, 27, 102–114. [Google Scholar] [CrossRef]
- Vicente, S.; Kolmogorov, V.; Rother, C. Graph cut based image segmentation with connectivity priors. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zheng, Q.; Li, W.; Hu, W.; Wu, G. An Interactive Image Segmentation Algorithm Based on Graph Cut. Procedia Eng. 2012, 29, 1420–1424. [Google Scholar] [CrossRef][Green Version]
- Hillel, A.B.; Lerner, R.; Levi, D.; Raz, G. Recent progress in road and lane detection: A survey. Mach. Vis. Appl. 2014, 25, 727–745. [Google Scholar] [CrossRef]
- Clauset, A.; Newman, M.E.J.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef] [PubMed]
- Raghavan, U.S.; Albert, R.; Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef]
- Linares, O.A.; Botelho, G.M.; Rodrigues, F.A.; Neto, J.B. Segmentation of large images based on super-pixels and community detection in graphs. IET Image Process. 2017, 11, 1219–1228. [Google Scholar] [CrossRef]
- Ren, X.; Malik, J. Learning a classification model for segmentation. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 10–17. [Google Scholar]
- Liu, Y.; Lai, S.; Du, T.; Yu, Y. Hybrid superpixel segmentation. In Proceedings of the 2015 International Conference on Image and Vision Computing New Zealand (IVCNZ), Auckland, New Zealand, 23–24 November 2015; pp. 1–6. [Google Scholar]
- Zhao, J.; Bo, R.; Hou, Q.; Cheng, M.M.; Rosin, P. FLIC: Fast linear iterative clustering with active search. Comp. Visual Media 2018, 4, 333–348. [Google Scholar] [CrossRef]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. TurboPixels: Fast superpixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef]
- Cigla, C.; Alatan, A.A. Efficient graph-based image segmentation via speeded-up turbo pixels. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3013–3016. [Google Scholar]
- Mourchid, Y.; Hassouni, M.E.; Cherif, H.A. New image segmentation approach using community detection algorithms. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 2016, 8, 195–204. [Google Scholar]
- Nair, R.S.; Vineetha, K.V. Modularity Based Color Image Segmentation. IJIREEICE 2016, 3, 109–113. [Google Scholar]
- Pourian, N.; Karthikeyan, S.; Manjunath, B.S. Weakly supervised graph based semantic segmentation by learning communities of image-parts. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1359–1367. [Google Scholar]
- Shijie, L.; Wu, D.O. Modularity-based image segmentation. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 570–581. [Google Scholar] [CrossRef]
- Belim, S.V.; Larionov, S.B. An algorithm of image segmentation based on community detection in graphs. Comput. Opt. 2016, 40, 904–910. [Google Scholar] [CrossRef]
- Yu, J.; Tu, X.; Yang, Q.; Liu, L. Supervoxel-based graph clustering for accurate object segmentation of indoor point clouds. In Proceedings of the 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 7137–7142. [Google Scholar]
- Sarcheshmeh Pour, Y.; Tian, Y.; Zhang, L.; Jung, A. Flow-based clustering and spectral clustering: A comparison. In Proceedings of the 55th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–3 November 2021; pp. 1292–1296. [Google Scholar]
- Gammoudi, I.; Mahjoub, M.A. Brain tumor segmentation using community detection algorithm. In Proceedings of the International Conference on Cyberworlds (CW), Caen, France, 28–30 September 2021; pp. 57–63. [Google Scholar]
- Srivastava, V.; Biswas, B. Mining on the basis of similarity in graph and image data. In Advanced Informatics for Computing Research; Springer: Singapore, 2019; Volume 956, pp. 193–203. [Google Scholar]
- Cao, B.G.; Messinger, D.W. Automatic clustering of inks in cultural heritage artifacts via optimal selection of graph modularity. In Proceedings of the SPIE 11727, Algorithms, Technologies, and Applications for Multispectral and Hyperspectral Imaging XXVII, Online, 12–16 April 2021; Volume 11727. [Google Scholar]
- Yazdanparast, S.; Jamalabdollahi, M.; Havens, T.C. Linear time community detection by a Novel modularity gain acceleration in label propagation. IEEE Trans. Big Data 2021, 7, 961–966. [Google Scholar] [CrossRef]
- Ding, W.; Li, Y. Efficient Vanishing Point Detection Method in Complex Urban Road Environments. IET Comput. Vis. 2015, 9, 549–558. [Google Scholar] [CrossRef]
- Ding, W.; Li, Y.; Wang, W.; Zouet, Y. Vanishing point detection algorithm for urban road image based on the envelope of perpendicular and parallel lines. Acta Opt. Sin. 2014, 34, 1015002. [Google Scholar] [CrossRef]
- Kong, H.; Audibert, J.-Y.; Ponce, J. General road detection from a single image. IEEE Trans. Image Process. 2010, 19, 2211–2220. [Google Scholar] [CrossRef] [PubMed]
- Zheng, T.; Cheng, X.; Chao, M.; Renfa, L.; Xiaodong, W. Road Segmentation Based on Vanishing Point and Principal Orientation Estimation. J. Comput. Res. Dev. 2014, 51, 762–772. [Google Scholar]
- Wang, K.; Huang, Z.; Zhong, Z. Algorithm for Urban Road Detection Based on Uncertain Bezier Deformable Template. J. Mech. Eng. 2013, 49, 143–150. [Google Scholar] [CrossRef]
- He, Y.; Wang, H.; Zhang, B. Color-Based Road Detection in Urban Traffic Scenes. IEEE Trans. Intell. Transp. Syst. 2004, 5, 309–319. [Google Scholar]
- Gao, D.; Li, W.; Duan, J.; Zheng, B. A practical method of road detection for intelligent vehicle. In Proceedings of the 2009 IEEE International Conference on Automation and Logistics, Shenyang, China, 5–7 August 2009; pp. 980–985. [Google Scholar]
- Hao, F.; Rui, J.; Jiapeng, L. Segmentation of Full Vision Image Based on Color and Texture Features. Trans. Beijing Inst. Technol. 2010, 30, 934–939. [Google Scholar]
- Zhang, G.; Zheng, N.; Cui, C.; Yan, Y.; Yuan, Z. An Efficient Road Detection Method In Noisy Urban Environment. In Proceedings of the IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 556–561. [Google Scholar]
- Wang, K.; Huang, Z.; Zhong, Z. Multi-featrue Fusion Based Lane Understanding Algorithm. China J. Highw. Transpor. 2013, 26, 176–183. [Google Scholar]
- Yu, Z.; Zhang, W.; Vijaya Kumar, B.V.K. Robust rear-view ground surface detection with hidden state conditional random field and confidence propagation. In Proceedings of the International Conference on Image Processing, Paris, France, 27–30 October 2014; pp. 991–995. [Google Scholar]
- Chen, C.-L.; Tai, C.-L. Adaptive fuzzy color segmentation with neural network for road detections. Eng. Appl. Artif. Intell. 2010, 23, 400–410. [Google Scholar] [CrossRef]
- Ma, W.C.; Wang, S.; Brubaker, M.A.; Fidler, S.; Urtasun, R. Find your way by observing the sun and other semantic cues. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 6292–6299. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Gao, H.; Yuan, H.; Wang, Z.; Ji, S. Pixel Transposed Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1218–1227. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Jiqing, C.; Depeng, W.; Teng, L.; Huabin, W. All-weather road drivable area segmentation method based on CycleGAN. Vis. Comput. 2022. [Google Scholar] [CrossRef]
- Levi, D.; Garnett, N.; Fetaya, E.; Herzlyia, I. Stixelnet: A deep convolutional network for obstacle detection and road segmentation. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 109.1–109.12. [Google Scholar]
- Han, X.; Lu, J.; Zhao, C.; Li, H. Fully Convolutional Neural Networks for Road Detection with Multiple Cues Integration. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–26 May 2018; pp. 4608–4613. [Google Scholar]
- Yao, J.; Ramalingam, S.; Taguchi, Y.; Miki, Y.; Urtasun, R. Estimating Drivable Collision-Free Space from Monocular Video. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 420–427. [Google Scholar]
- Zhang, D.; Liu, Y.; Si, L.; Zhang, J.; Lawrence, R.D. Multiple instance learning on structured data. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; pp. 145–153. [Google Scholar]
- Alvarez, J.M.A.; Lopez, A.M. Road Detection Based on Illuminant Invariance. IEEE Trans. Intell. Transp. Syst. 2011, 12, 184–193. [Google Scholar] [CrossRef]
- Wang, W.; Ding, W.; Li, Y.; Yang, S. An Efficient Road Detection Algorithm Based on Parallel Edges. Acta Opt. Sin. 2015, 35, 0715001. [Google Scholar] [CrossRef]
- Li, Y.; Ding, W.; Zhang, X.; Ju, Z. Road Detection Algorithm for Autonomous Navigation Systems based on Dark Channel Prior and Vanishing Point in Complex Road Scenes. Robot. Auton. Syst. 2017, 88, 202–228. [Google Scholar] [CrossRef]
- Kong, H.; Sarma, S.E.; Tang, F. Generalizing Laplacian of Gaussian Filters for Vanishing-Point Detection. IEEE Trans. Intell. Transp. Syst. 2013, 14, 408–418. [Google Scholar] [CrossRef]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).