

RMFRASL: Robust Matrix Factorization with Robust Adaptive Structure Learning for Feature Selection


Abstract
:1. Introduction
2. Related Work
2.1. Notations
2.2. Introduction of Indicator Matrix
3. Robust Matrix Factorization with Robust Adaptive Structure Learning
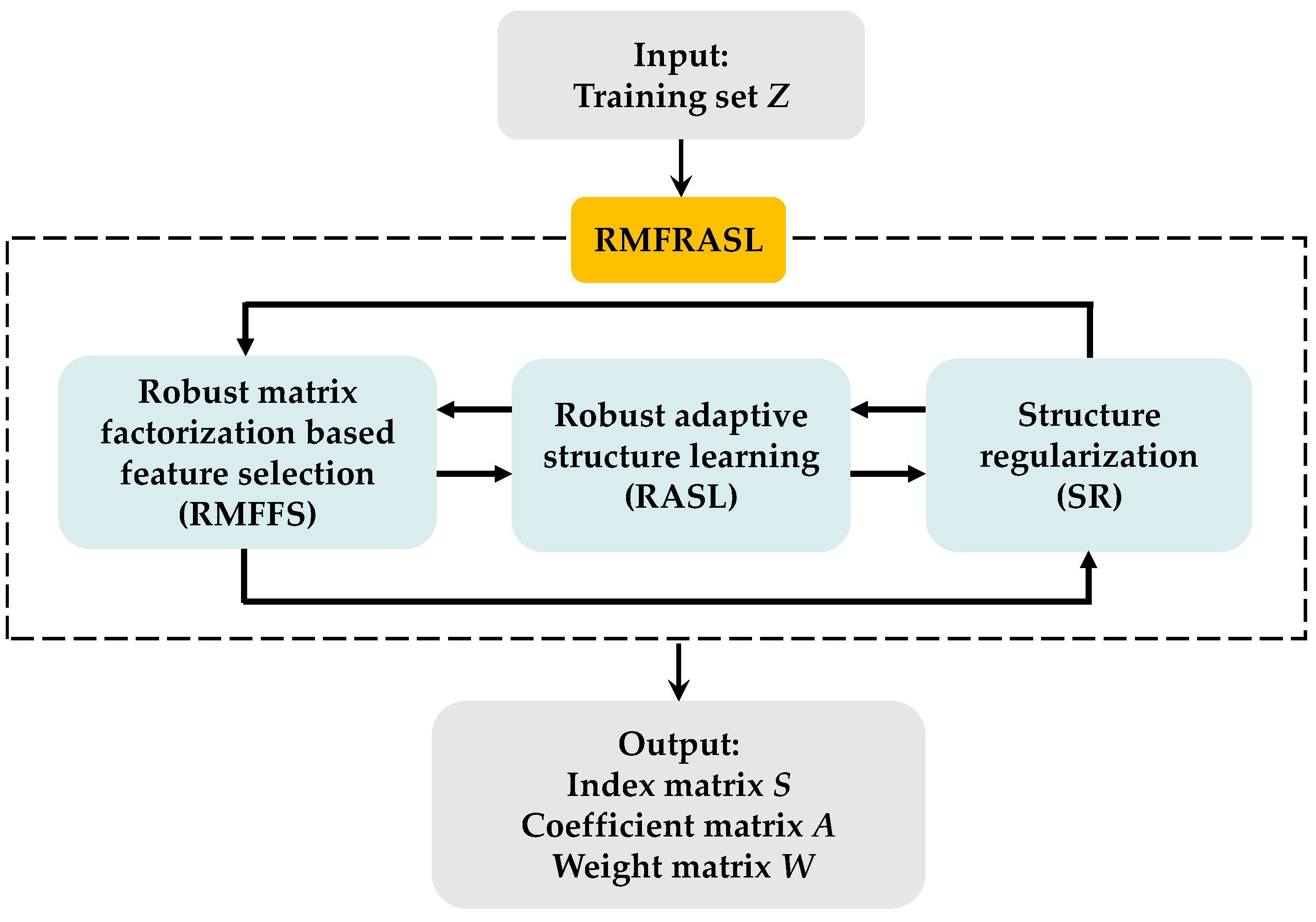
3.1. The Proposed RMFRASL Model
3.1.1. RMFFS Model
3.1.2. RASL Model
3.1.3. SR Model
3.1.4. The Framework of RMFRASL
3.2. Model Optimization
3.2.1. Fix A and W; Update S
3.2.2. Fix S and W; Update A
3.2.3. Fix S and A; Update W
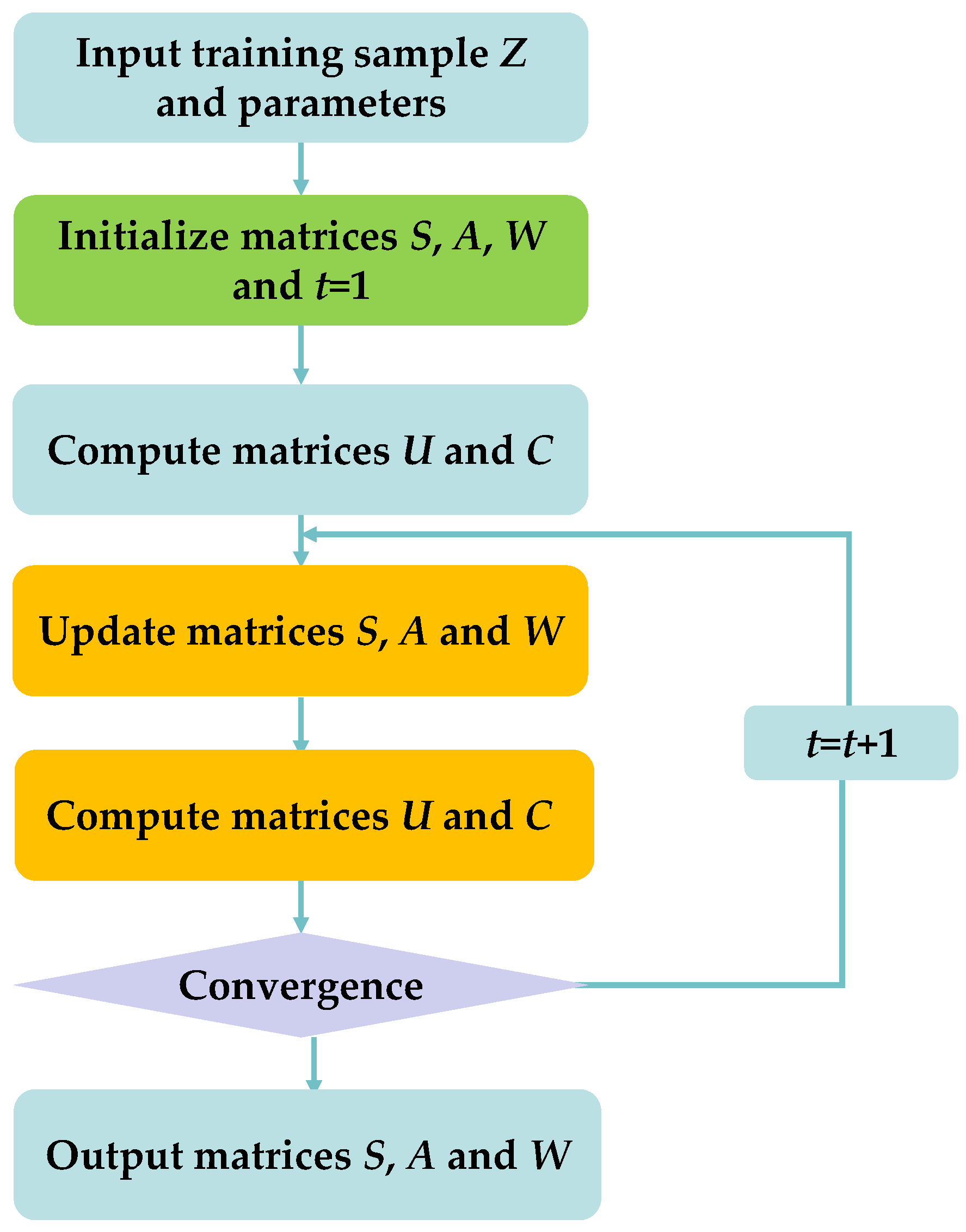
3.3. Algorithm Description
| Algorithm 1 RMFRASL algorithm |
| Input: The matrix of sample dataset , parameters α > 0, β > 0, λ > 0 1: Initialization: matrices S0, A0, and W0 are initial nonnegative matrices, t = 0 2: Calculate matrices Ut, and Ct according to Equations (16) and (29), 3: Repeat 4: Update St according to Equation (20) 5: Update At according to Equation (26) 6: Update Wt according to Equation (33) 7: Update Ut and Ct according to Equations (16) and (29) 8: Update t = t + 1 9: Until the objective function is convergent. |
| Output: Index matrix S, coefficient matrix A, and weight matrix W |
3.4. Computational Complexity Analysis
4. Convergence Analysis
5. Experiments and Analysis
5.1. Description of Compared Methods
5.2. Description of Experimental Data
5.3. Experimental Evaluation
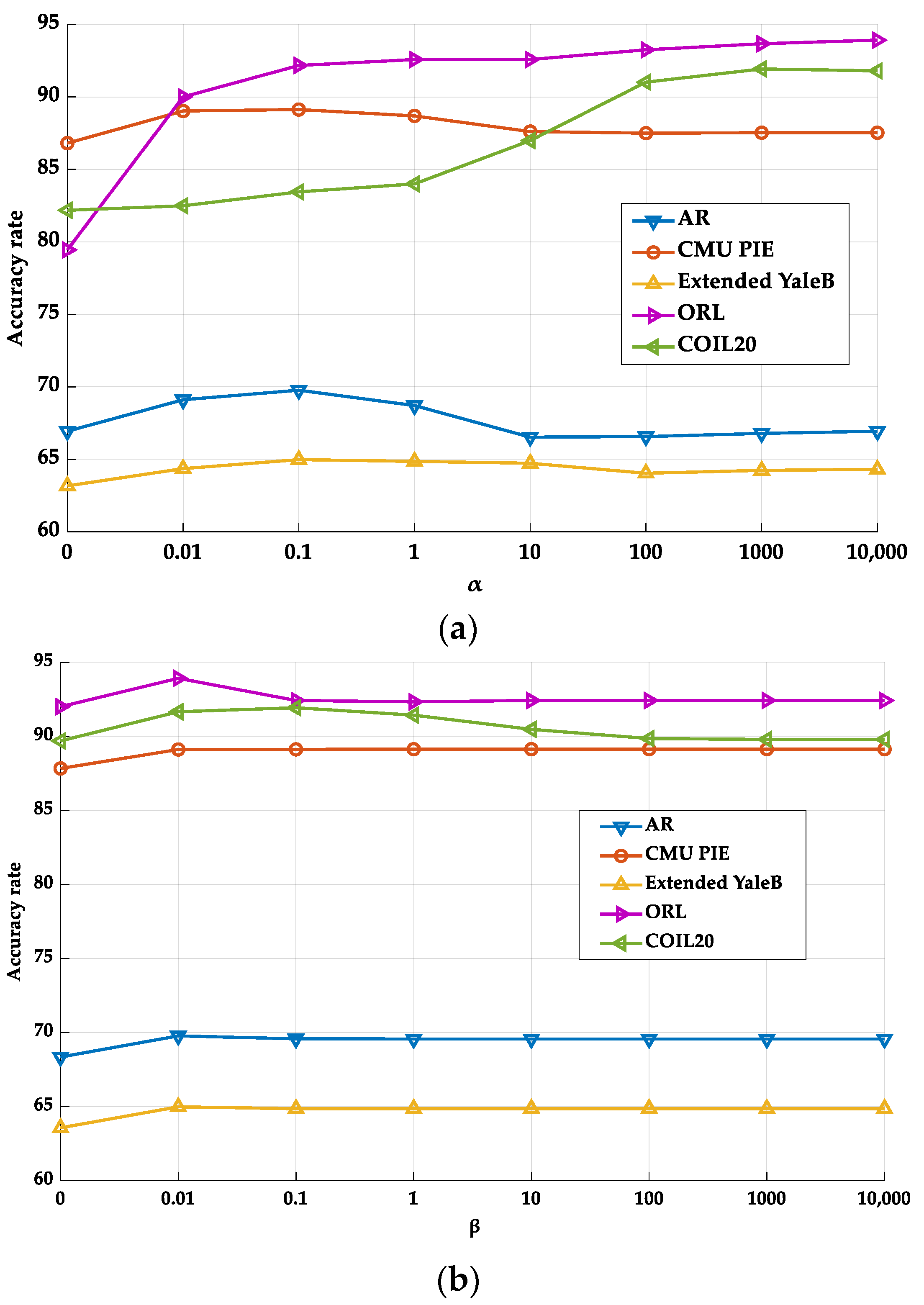
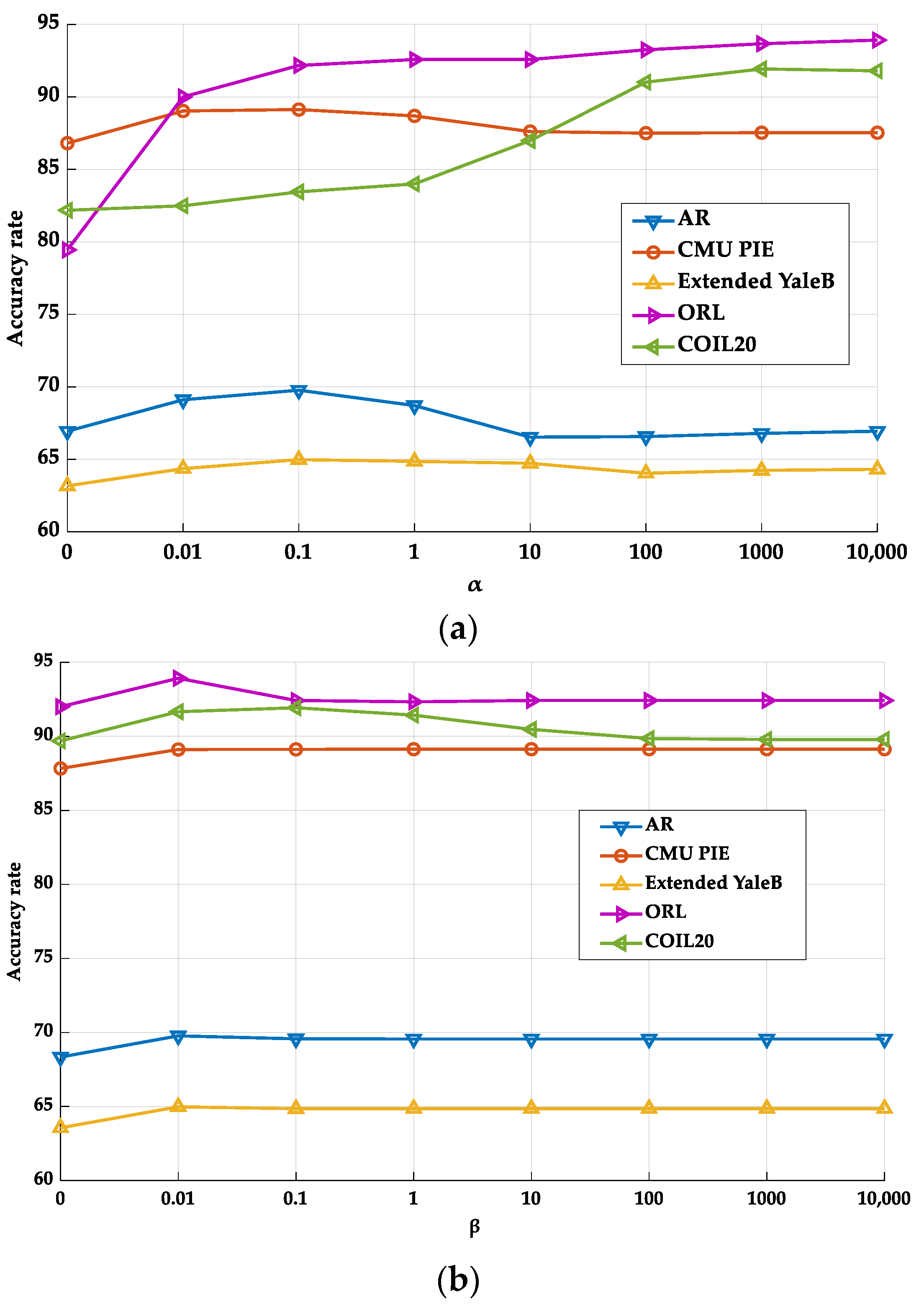
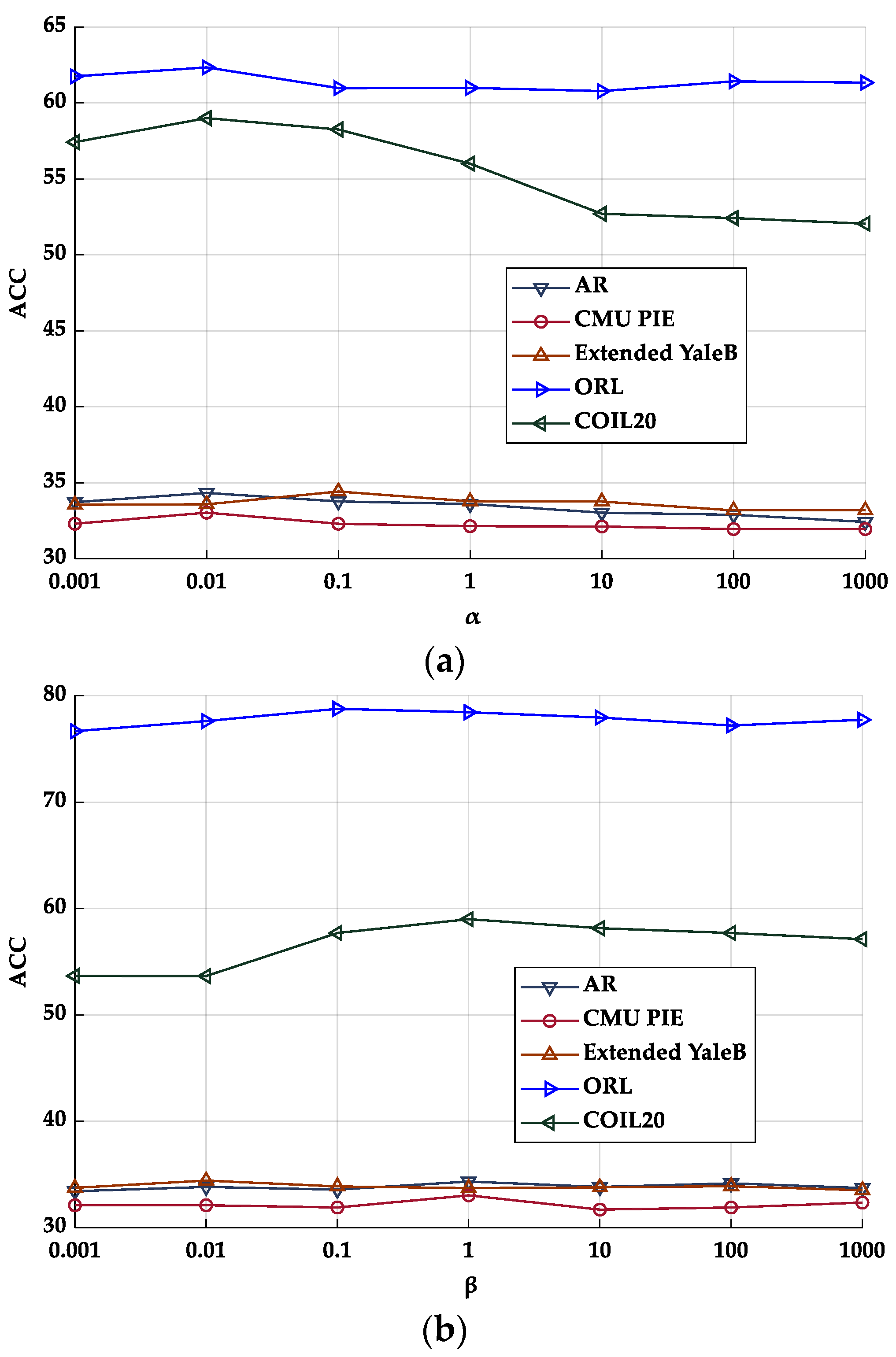
5.4. Experimental Setting
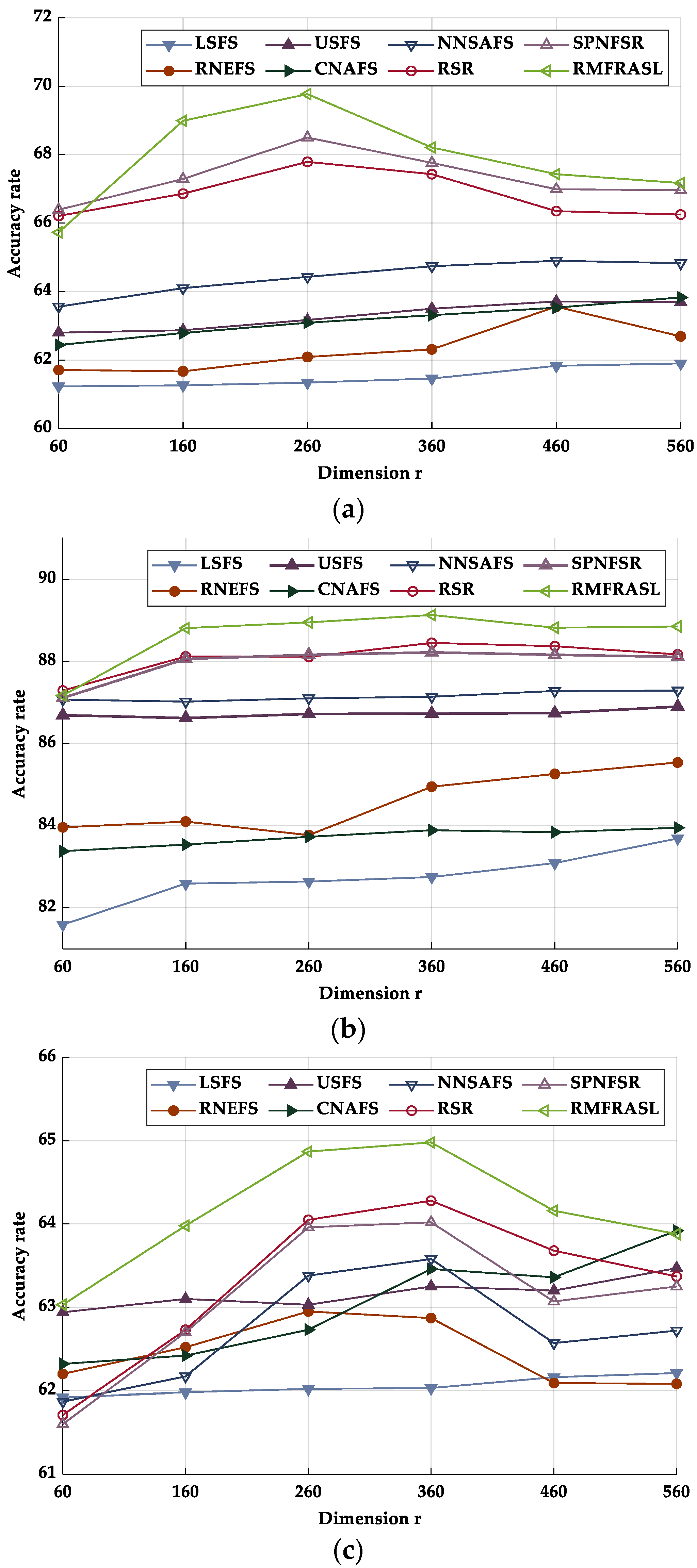
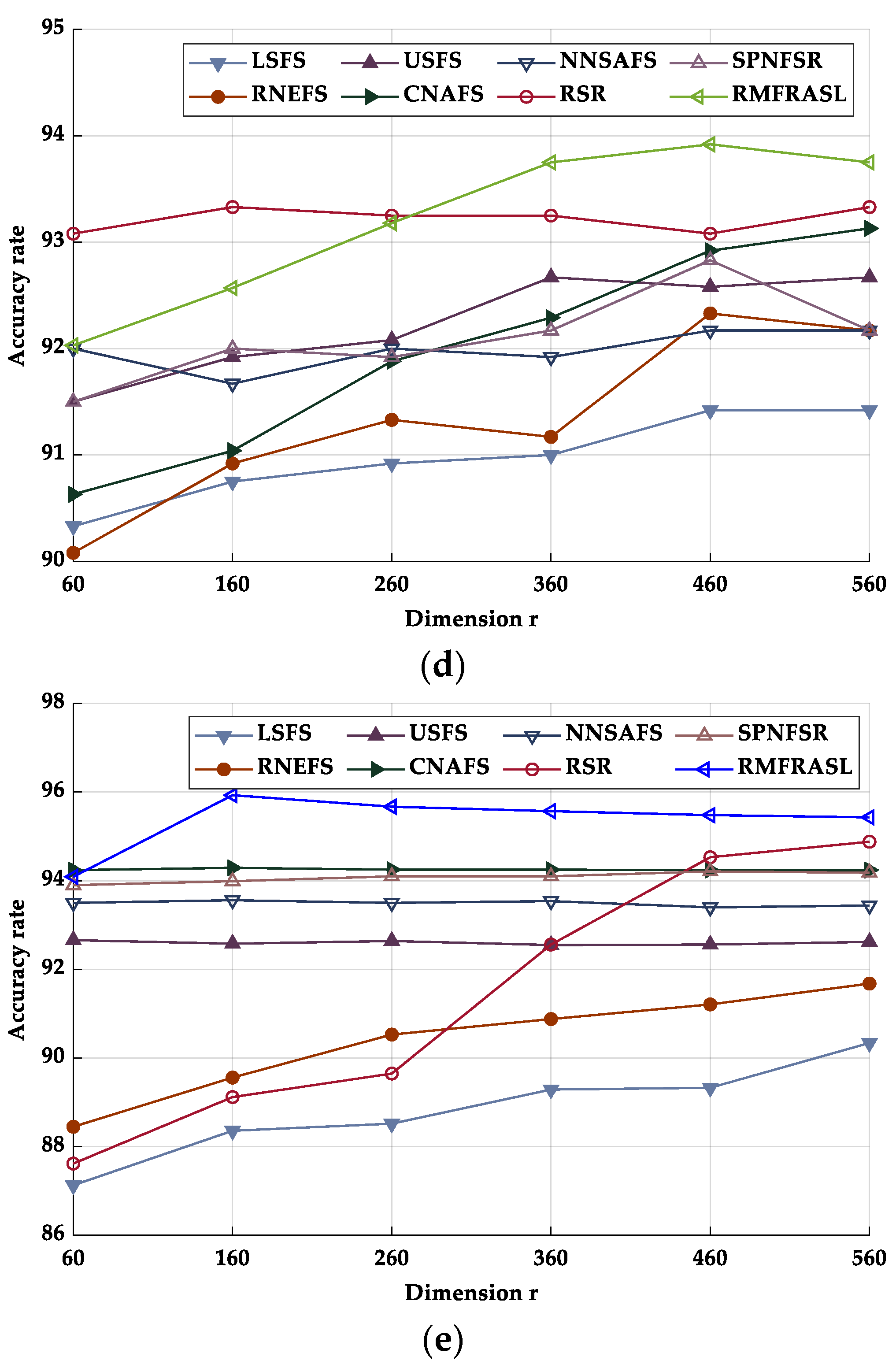
5.5. Analysis of Experimental Results
5.5.1. Classification Performance Analysis
5.5.2. Clustering Performance Analysis
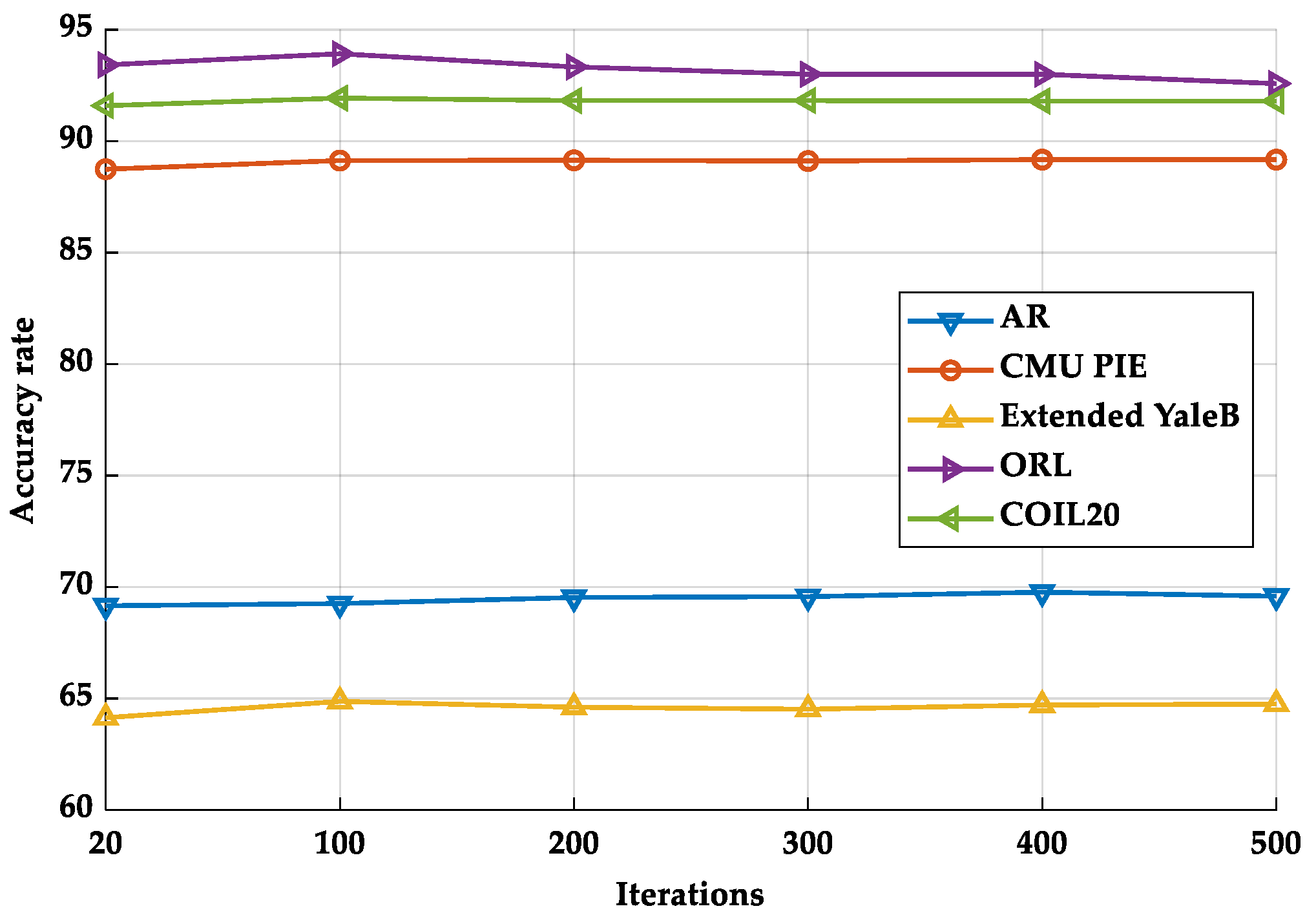
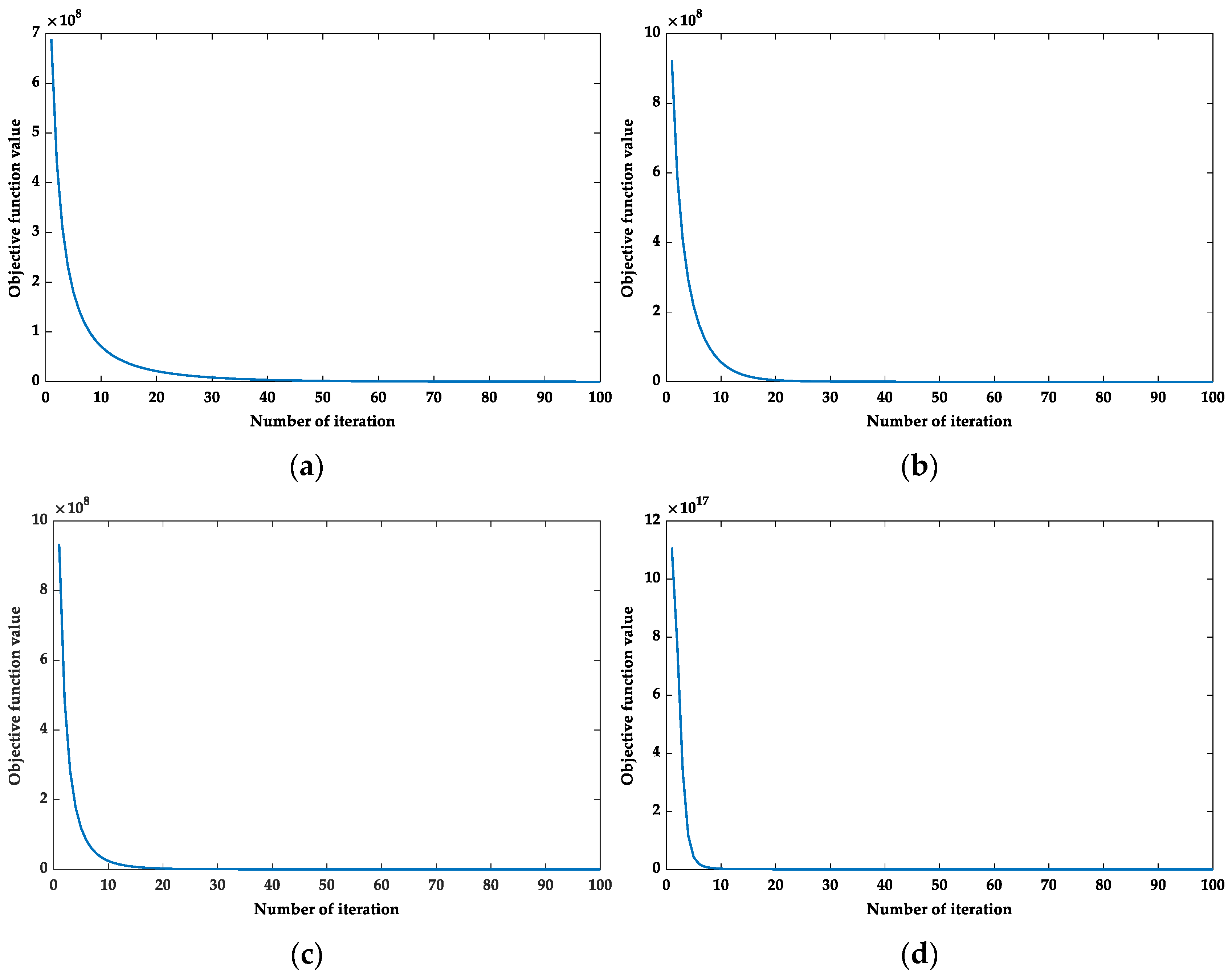
5.5.3. Convergence Analysis
6. Discussion and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, X.; Fang, L.; Hong, X.; Yang, L. Exploiting mobile big data: Sources, features, and applications. IEEE Netw. 2017, 31, 72–79. [Google Scholar] [CrossRef]
- Cheng, X.; Fang, L.; Yang, L.; Cui, S. Mobile big data: The fuel for data-driven wireless. IEEE Internet Things J. 2017, 4, 1489–1516. [Google Scholar] [CrossRef]
- Lv, Z.; Lou, R.; Li, J.; Singh, A.K.; Song, H. Big data analytics for 6G-enabled massive internet of things. IEEE Internet Things J. 2021, 8, 5350–5359. [Google Scholar] [CrossRef]
- Tang, C.; Zheng, X.; Liu, X.; Zhang, W.; Zhang, J.; Xiong, J.; Wang, L. Cross-view locality preserved diversity and consensus learning for multi-view unsupervised feature selection. IEEE Trans. Knowl. Data Eng. 2021, 34, 4705–4716. [Google Scholar] [CrossRef]
- Jin, J.; Xiao, R.; Daly, I.; Miao, Y.; Wang, X.; Cichocki, A. Internal feature selection method of CSP based on L1-norm and Dempster-Shafer theory. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4814–4825. [Google Scholar] [CrossRef] [PubMed]
- Zhu, F.; Ning, Y.; Chen, X.; Zhao, Y.; Gang, Y. On removing potential redundant constraints for SVOR learning. Appl. Soft Comput. 2021, 102, 106941. [Google Scholar] [CrossRef]
- Li, Z.; Nie, F.; Bian, J.; Wu, D.; Li, X. Sparse pca via L2,p-norm regularization for unsupervised feature selection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Luo, F.; Zou, Z.; Liu, J.; Lin, Z. Dimensionality reduction and classification of hyperspectral image via multistructure unified discriminative embedding. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Awotunde, J.B.; Chakraborty, C.; Adeniyi, A.E. Intrusion detection in industrial internet of things network-based on deep learning model with rule-based feature selection. Wirel. Commun. Mob. Comput. 2021, 2021, 7154587. [Google Scholar] [CrossRef]
- Aminanto, M.E.; Choi, R.; Tanuwidjaja, H.C.; Yoo, P.D.; Kim, K. Deep abstraction and weighted feature selection for Wi-Fi impersonation detection. IEEE Trans. Inf. Secur. 2017, 13, 621–636. [Google Scholar] [CrossRef]
- Zhang, F.; Li, W.; Feng, Z. Data driven feature selection for machine learning algorithms in computer vision. IEEE Internet Things J. 2018, 5, 4262–4272. [Google Scholar] [CrossRef]
- Qi, M.; Wang, T.; Liu, F.; Zhang, B.; Wang, J.; Yi, Y. Unsupervised feature selection by regularized matrix factorization. Neurocomputing 2018, 273, 593–610. [Google Scholar] [CrossRef]
- Zhai, Y.; Ong, Y.S.; Tsang, I.W. The emerging “big dimensionality”. IEEE Comput. Intell. Mag. 2014, 9, 14–26. [Google Scholar] [CrossRef]
- Bermejo, P.; Gámez, J.A.; Puerta, J.M. Speeding up incremental wrapper feature subset selection with Naive Bayes classifier. Knowl. -Based Syst. 2014, 55, 140–147. [Google Scholar] [CrossRef]
- Cheng, L.; Wang, Y.; Liu, X.; Li, B. Outlier detection ensemble with embedded feature selection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3503–3512. [Google Scholar]
- Lu, Q.; Li, X.; Dong, Y. Structure preserving unsupervised feature selection. Neurocomputing 2018, 301, 36–45. [Google Scholar] [CrossRef]
- Li, X.; Zhang, H.; Zhang, R.; Liu, Y.; Nie, F. Generalized uncorrelated regression with adaptive graph for unsupervised feature selection. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1587–1595. [Google Scholar] [CrossRef]
- He, X.; Cai, D.; Niyogi, P. Laplacian score for feature selection. Adv. Neural Inf. Process. Syst. 2005, 18, 1–8. [Google Scholar]
- Liu, Y.; Ye, D.; Li, W.; Wang, H.; Gao, Y. Robust neighborhood embedding for unsupervised feature selection. Knowl.-Based Syst. 2020, 193, 105462. [Google Scholar] [CrossRef]
- Wang, F.; Zhu, L.; Li, J.; Chen, H.; Zhang, H. Unsupervised soft-label feature selection. Knowl.-Based Syst. 2021, 219, 106847. [Google Scholar] [CrossRef]
- Yuan, A.; You, M.; He, D.; Li, X. Convex non-negative matrix factorization with adaptive graph for unsupervised feature selection. IEEE Trans. Cybern. 2020, 52, 5522–5534. [Google Scholar] [CrossRef] [PubMed]
- Shang, R.; Zhang, W.; Lu, M.; Jiao, L.; Li, Y. Feature selection based on non-negative spectral feature learning and adaptive rank constraint. Knowl.-Based Syst. 2022, 236, 107749. [Google Scholar] [CrossRef]
- Zhao, H.; Li, Q.; Wang, Z.; Nie, F. Joint Adaptive Graph Learning and Discriminative Analysis for Unsupervised Feature Selection. Cogn. Comput. 2022, 14, 1211–1221. [Google Scholar] [CrossRef]
- Zhu, P.; Zuo, W.; Zhang, L.; Hu, Q.; Shiu, S.C. Unsupervised feature selection by regularized self-representation. Pattern Recognit. 2015, 48, 438–446. [Google Scholar] [CrossRef]
- Shi, L.; Du, L.; Shen, Y.D. Robust spectral learning for unsupervised feature selection. In Proceedings of the 2014 IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; pp. 977–982. [Google Scholar]
- Du, S.; Ma, Y.; Li, S.; Ma, Y. Robust unsupervised feature selection via matrix factorization. Neurocomputing 2017, 241, 115–127. [Google Scholar] [CrossRef]
- Miao, J.; Yang, T.; Sun, L.; Fei, X.; Niu, L.; Shi, Y. Graph regularized locally linear embedding for unsupervised feature selection. Pattern Recognit. 2022, 122, 108299. [Google Scholar] [CrossRef]
- Hou, C.; Nie, F.; Li, X.; Yi, D.; Wu, Y. Joint embedding learning and sparse regression: A framework for unsupervised feature selection. IEEE Trans. Cybern. 2013, 44, 793–804. [Google Scholar]
- Wang, S.; Pedrycz, W.; Zhu, Q.; Zhu, W. Subspace learning for unsupervised feature selection via matrix factorization. Pattern Recognit. 2015, 48, 10–19. [Google Scholar] [CrossRef]
- Zhu, F.; Gao, J.; Yang, J.; Ye, N. Neighborhood linear discriminant analysis. Pattern Recognit. 2022, 123, 108422. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1548–1560. [Google Scholar]
- Dreves, A.; Facchinei, F.; Kanzow, C.; Sagratella, S. On the solution of the KKT conditions of generalized Nash equilibrium problems. SIAM J. Optim. 2011, 21, 1082–1108. [Google Scholar] [CrossRef]
- Zhou, W.; Wu, C.; Yi, Y.; Luo, G. Structure preserving non-negative feature self-representation for unsupervised feature selection. IEEE Access 2017, 5, 8792–8803. [Google Scholar] [CrossRef]
- Yi, Y.; Zhou, W.; Liu, Q.; Luo, G.; Wang, J.; Fang, Y.; Zheng, C. Ordinal preserving matrix factorization for unsupervised feature selection. Signal Process. Image Commun. 2018, 67, 118–131. [Google Scholar] [CrossRef]
- Yang, Y.; Shen, H.T.; Ma, Z.; Huang, Z.; Zhou, F. ℓ 2, 1-norm regularized discriminative feature selection for unsupervised learning. Int. Jt. Conf. Artif. Intell. 2011, 22, 1589–1594. [Google Scholar]
- Yi, Y.; Wang, J.; Zhou, W.; Fang, Y.; Kong, J.; Lu, Y. Joint graph optimization and projection learning for dimensionality reduction. Pattern Recognit. 2019, 92, 258–273. [Google Scholar] [CrossRef]
- Martinez, A.; Benavente, R. The AR Face Database: Cvc Technical Report; Universitat Autònoma de Barcelona: Bellaterra, Spain, 1998; Volume 24. [Google Scholar]
- Sim, T.; Baker, S.; Bsat, M. The CMU pose, illumination, and expression (PIE) database. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Washington, DC, USA, 21–21 May 2002; pp. 53–58. [Google Scholar]
- Georghiades, A.S.; Belhumeur, P.N.; Kriegman, D.J. From few to many: Illumination cone models for face recognition under variable lighting and pose. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 643–660. [Google Scholar] [CrossRef] [Green Version]
- Samaria, F.; Harter, A. Parameterisation of a Stochastic Model for Human Face Identification. In Proceedings of the 1994 IEEE Workshop on Applications of Computer Vision, Sarasota, FL, USA, 5–7 December 1994; pp. 138–142. [Google Scholar]
- Nene, S.; Nayar, S.; Murase, H. Columbia object image library (COIL-20). In Technical Report, CUCS-005-96; Columbia University: New York, NY, USA, 1996. [Google Scholar]
- Dai, J.; Chen, Y.; Yi, Y.; Bao, J.; Wang, L.; Zhou, W.; Lei, G. Unsupervised feature selection with ordinal preserving self-representation. IEEE Access 2018, 6, 67446–67458. [Google Scholar] [CrossRef]
- Tang, C.; Li, Z.; Wang, J.; Liu, X.; Zhang, W.; Zhu, E. Unified One-step Multi-view Spectral Clustering. IEEE Trans. Knowl. Data Eng. 2022, 1–11. [Google Scholar] [CrossRef]
- Tang, C.; Zhu, X.; Liu, X.; Li, M.; Wang, P.; Zhang, C.; Wang, L. Learning a joint affinity graph for multiview subspace clustering. IEEE Trans. Multimed. 2018, 21, 1724–1736. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Zheng, X.; Zhang, W.; Zhu, E. Consensus graph learning for multi-view clustering. IEEE Trans. Multimed. 2021, 24, 2461–2472. [Google Scholar] [CrossRef]
- Zhu, F.; Gao, J.; Xu, C.; Yang, J.; Tao, D. On selecting effective patterns for fast support vector regression training. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3610–3622. [Google Scholar] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| Sample matrix | d | Dimension of sample | |
| Indicator matrix | n | Number of samples | |
| Low-dimensional feature matrix | k | Number of selected features | |
| Weight matrix | L1-norm | ||
| Identity matrix | L2-norm | ||
| Diagonal matrix | L21-norm | ||
| Diagonal matrix | Matrix trace operation |
| Matrix | Complexity | Matrix | Complexity |
|---|---|---|---|
| S | O(max (dn2, nd2)) | U | O(dn2) |
| A | O(max (kn2, kdn)) | C | O(kn2) |
| W | O(max (nd2, dn2)) |
| Method | AR | CMU PIE | Extended YaleB | ORL | COIL20 |
| RNEFS [20] | 11.57 | 15.43 | 13.89 | 1.698 | 4.187 |
| USFS [21] | 36.12 | 30.09 | 18.27 | 18.29 | 8.524 |
| CNAFS [22] | 11.81 | 14.19 | 11.48 | 4.292 | 5.382 |
| NNSAFS [23] | 34.83 | 52.95 | 43.70 | 4.261 | 8.775 |
| RSR [25] | 3.607 | 4.920 | 4.377 | 1.553 | 1.805 |
| SPNFSR [34] | 15.21 | 18.24 | 16.24 | 7.291 | 8.924 |
| RMFRASL | 2.250 | 2.687 | 2.493 | 1.190 | 1.504 |
| Method | Objective Function | L21-Norm |
|---|---|---|
| LSFS [19] (2005) | No | |
| RNEFS [20] (2020) | No | |
| USFS [21] (2021) | No | |
| CNAFS [22] (2020) | No | |
| NNSAFS [23] (2022) | No | |
| RSR [24] (2015) | Yes | |
| SPNFSR [34] (2017) | Yes | |
| RMFRASL (2022) | Yes |
| Database | Image Size | Number of Classes | Each Class Size | Tr | Te |
|---|---|---|---|---|---|
| AR | 32 × 32 | 100 | 14 | 7 | 7 |
| CMU PIE | 32 × 32 | 68 | 24 | 12 | 12 |
| Extended YaleB | 32 × 32 | 38 | 64 | 20 | 44 |
| ORL | 32 × 32 | 40 | 10 | 7 | 3 |
| COIL20 | 32 × 32 | 20 | 72 | 20 | 52 |
| Databases | Accuracy Rate | Parameter {α, β} | Dimension r |
|---|---|---|---|
| AR | 69.77 ± 0.79 | {0.1, 0.01} | 260 |
| CMU PIE | 89.17 ± 0.80 | {0.1, 1} | 360 |
| Extended YaleB | 64.98 ± 0.75 | {0.1, 0.01} | 360 |
| ORL | 93.92 ± 1.56 | {10000, 0.01} | 460 |
| COIL20 | 95.93 ± 1.17 | {1000, 0.1} | 160 |
| Method | AR | CMU PIE | Extended YaleB | ORL | COIL20 |
|---|---|---|---|---|---|
| LSFS | 61.90 ± 2.35 (560) | 83.69 ± 1.36 (560) | 61.21 ± 1.56 (560) | 91.42 ± 3.07 (560) | 90.34 ± 1.48 (560) |
| RNEFS | 63.56 ± 1.48 (460) | 85.54 ± 1.29 (560) | 62.95 ± 0.75 (260) | 92.33 ± 2.00 (460) | 91.68 ± 0.93 (560) |
| USFS | 63.71 ± 2.71 (460) | 86.90 ± 1.17 (560) | 63.57 ± 1.38 (560) | 92.67 ± 1.93 (560) | 92.66 ± 1.39 (60) |
| CNAFS | 63.83 ± 1.66 (560) | 83.95 ± 1.56 (560) | 63.92 ± 1.12 (560) | 93.13 ± 1.85 (560) | 94.29 ± 1.22 (160) |
| NNSAFS | 64.90 ± 2.12 (460) | 87.29 ± 0.64 (560) | 63.58 ± 1.39 (360) | 92.17 ± 1.81 (560) | 93.56 ± 1.32 (160) |
| RSR | 67.79 ± 2.03 (260) | 88.45 ± 0.90 (360) | 64.28 ± 1.10 (360) | 93.33 ± 1.47 (560) | 94.88 ± 1.15 (560) |
| SPNFSR | 68.50 ± 0.91 (260) | 88.22 ± 1.02 (360) | 64.02 ± 1.95 (360) | 92.83 ± 1.81 (560) | 94.21 ± 1.42 (460) |
| RMFRASL | 69.77 ± 0.97 (260) | 89.17 ± 0.80 (360) | 64.98 ± 0.75 (360) | 93.92 ± 1.56 (460) | 95.93 ± 1.17 (160) |
| Databases | ACC% | NMI% | Parameter {α, β} | Dimension r |
|---|---|---|---|---|
| AR | 34.33 ± 1.33 | 65.56 ± 1.04 | {0.01, 1} | 380 |
| CMU PIE | 33.03 ± 0.90 | 56.66 ± 0.97 | {0.01, 1} | 480 |
| Extended YaleB | 34.42 ± 1.16 | 57.26 ± 1.87 | {0.1, 0.01} | 350 |
| ORL | 61.75 ± 2.42 | 78.78 ± 1.24 | {0.01, 0.1} | 270 |
| COIL20 | 59.90 ± 1.56 | 72.56 ± 1.07 | {0.01, 1} | 240 |
| Method | AR | CMU PIE | Extended YaleB | ORL | COIL20 |
|---|---|---|---|---|---|
| LSFS | 29.89 ± 1.37 | 26.88 ± 0.94 | 32.82 ± 0.93 | 55.57 ± 2.65 | 53.42 ± 2.77 |
| RNEFS | 30.37 ± 1.34 | 28.13 ± 0.59 | 33.99 ± 0.60 | 59.79 ± 2.22 | 55.67 ± 1.99 |
| USFS | 31.00 ± 1.17 | 28.50 ± 1.59 | 33.39 ± 0.90 | 57.79 ± 2.15 | 58.73 ± 3.66 |
| CNAFS | 31.10 ± 1.67 | 30.38 ± 1.38 | 34.33 ± 0.77 | 57.53 ± 0.00 | 58.27 ± 3.67 |
| NNSAFS | 31.10 ± 1.70 | 31.32 ± 1.43 | 33.76 ± 0.62 | 57.79 ± 5.01 | 58.55 ± 3.25 |
| RSR | 32.91 ± 1.22 | 32.17 ± 1.42 | 33.52 ± 0.80 | 58.79 ± 3.52 | 55.77 ± 1.65 |
| SPNFSR | 33.13 ± 0.80 | 32.07 ± 1.01 | 33.57 ± 0.91 | 59.57 ± 2.85 | 57.10 ± 3.46 |
| RMFRASL | 34.33 ± 1.33 | 33.03 ± 0.90 | 34.42 ± 1.16 | 61.75 ± 2.42 | 59.90 ± 1.56 |
| Method | AR | CMU PIE | Extended YaleB | ORL | COIL20 |
|---|---|---|---|---|---|
| LSFS | 63.00 ± 0.75 | 52.81 ± 0.51 | 55.13 ± 1.40 | 75.96 ± 1.18 | 64.92 ± 1.71 |
| RNEFS | 62.87 ± 0.77 | 53.64 ± 0.55 | 55.51 ± 0.82 | 78.13 ± 0.82 | 65.55 ± 1.42 |
| USFS | 63.04 ± 1.14 | 54.01 ± 1.10 | 56.10 ± 0.91 | 76.71 ± 1.61 | 67.92 ± 1.69 |
| CNAFS | 63.03 ± 1.01 | 54.63 ± 0.82 | 56.34 ± 1.37 | 75.90 ± 0.00 | 68.66 ± 2.15 |
| NNSAFS | 63.99 ± 1.17 | 53.78 ± 1.25 | 56.26 ± 1.38 | 72.26 ± 2.43 | 69.19 ± 2.38 |
| RSR | 63.53 ± 0.91 | 54.98 ± 1.06 | 56.66 ± 1.69 | 76.09 ± 1.47 | 66.60 ± 1.91 |
| SPNFSR | 64.68 ± 0.66 | 55.18 ± 0.86 | 57.18 ± 1.05 | 78.68 ± 1.41 | 70.89 ± 1.53 |
| RMFRASL | 65.56 ± 1.04 | 56.66 ± 0.97 | 57.26 ± 1.87 | 78.78 ± 1.24 | 72.56 ± 1.07 |
| Method | AR | CMU PIE | Extended YaleB | ORL | COIL20 |
|---|---|---|---|---|---|
| RNEFS | 15 | 23 | 14 | 12 | 15 |
| USFS | 13 | 30 | 17 | 15 | 20 |
| CNAFS | 409 | 510 | 398 | 24 | 30 |
| NNSAFS | 15 | 45 | 5 | 5 | 24 |
| SPNFSR | 396 | 410 | 412 | 462 | 490 |
| RMFRASL | 37 | 21 | 20 | 8 | 11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, S.; Huang, L.; Li, P.; Luo, Z.; Wang, J.; Yi, Y. RMFRASL: Robust Matrix Factorization with Robust Adaptive Structure Learning for Feature Selection. Algorithms 2023, 16, 14. https://doi.org/10.3390/a16010014
Lai S, Huang L, Li P, Luo Z, Wang J, Yi Y. RMFRASL: Robust Matrix Factorization with Robust Adaptive Structure Learning for Feature Selection. Algorithms. 2023; 16(1):14. https://doi.org/10.3390/a16010014
Chicago/Turabian StyleLai, Shumin, Longjun Huang, Ping Li, Zhenzhen Luo, Jianzhong Wang, and Yugen Yi. 2023. "RMFRASL: Robust Matrix Factorization with Robust Adaptive Structure Learning for Feature Selection" Algorithms 16, no. 1: 14. https://doi.org/10.3390/a16010014
APA StyleLai, S., Huang, L., Li, P., Luo, Z., Wang, J., & Yi, Y. (2023). RMFRASL: Robust Matrix Factorization with Robust Adaptive Structure Learning for Feature Selection. Algorithms, 16(1), 14. https://doi.org/10.3390/a16010014