1. Introduction
In many optimization or variational inequality (VI) problems, some data can depend on parameters, and it is important to analyze the regularity of the solution with respect to those parameters. For a detailed account of some classical results on the topic of parametric optimization, the reader can refer to [
1]. The investigation of the Lipschitz behavior of solutions to convex minimization problems, from the point of view of set valued analysis, has also been carried out in the influential paper [
2], and recently extended to abstract quasi-equilibrium problems in [
3]. On a more applied context, in the case of linear programming, sharp Lipschitz constants for feasible and optimal solutions of some perturbed linear programs were derived in [
4,
5]. Another influential paper focusing on the estimate of Lipschitz constants for the solutions of a perturbed system of equalities and inequalities is [
6], while in [
7], the estimate of the Lipschitz constant is connected with of the role played by the norm of the inverse of a non-singular matrix in bounding the perturbation of the solution of a system of equations in terms of a right-hand side perturbation. The topic of parametric sensitivity analysis for variational inequalities has been developed by many authors in recent decades, and the excellent monograph [
8] contains many related results. Let us notice, however, that while the number of papers dealing with local parametric differentiability for variational inequalities is very large, the investigation of parametric variational inequalities under the mere Lipschitz assumptions on data have received less attention, in particular with respect to the problem of estimating the global Lipschitz constant of the solution.
The local Lipschitz continuity of the solution of a variational inequality with parametric constraint set was investigated in [
9], while more recently, the authors [
10] derived an estimate of the global Lipschitz constant of the unique solution of a parametrized variational inequality, by making an extensive use of Lagrange multipliers techniques. Specifically, the Lagrange multiplier computations were used to derive the contribution of the parametric variation in the constraint set to the corresponding variation in the solution of the variational inequality. Interestingly enough, similar results were obtained in [
11] with purely geometric methods. In [
12], the authors improved the above-mentioned estimate but realized that, due to the complexity of the problem, their estimates were also far from being optimal.
In this paper, we derive new estimates for the Lipschitz constant of the solution of a parametric variational inequality, which considerably improve the previous ones. We then combine our results with a variant of the algorithm proposed in [
13,
14] to provide an approximation, on a given interval, of a univariate Lipschitz function whose analytic expression is unknown, but can be computed in arbitrarily chosen sample points (such a function is often called a black box-function). It turns out that the same algorithm also provides an approximation of the integral of the black-box function on the interval under consideration. Thus, we can use our estimate of the Lipschitz constant of the solution, to approximate its mean value on a given interval. Our results are then applied to investigate a class of Nash and generalized Nash equilibrium problems on networks.
The specific class of Nash equilibrium problems known as Network Games (or games played on networks) was investigated for the first time in the paper by Ballester et al. [
15]. Players are modeled as nodes of a graph, and the social or economic relationship between any two players is represented by a link connecting the two corresponding nodes. Two players connected with a link are called neighbors. Considering linear-quadratic utility functions, the authors were able to express the unique Nash equilibrium as a series expansion involving the powers of the adjacency matrix of the graph, thus showing that, although players only interact with their neighbors, the equilibrium also depends on indirect contacts (i.e., neighbors of neighbors, neighbors of neighbors of neighbors, and so on). A wealth of social and economic processes may be modeled using the theory of Network Games; see, for instance, the papers [
16,
17,
18,
19], the survey [
20] and the monograph [
21]. The solution methods used in all the above-mentioned references combine the best response approach with some results of Graph Theory (see, e.g., [
22]). It is worth noticing that although the connection between variational inequalities and Nash equilibrium problems was proven about forty years ago [
23], very few papers have dealt with the variational inequality approach to Network Games and, in this regard, the interested reader can find a detailed investigation in [
24]. Furthermore, the case of
generalized network Nash equilibrium problems with shared constraints has not yet been investigated within the above-mentioned framework, with the only exception of the paper [
25].
The paper is organized as follows. In
Section 2, we provide estimates of the Lipschitz constant of the solution of our parametric VI in a general case, as well as in four different cases where the dependence on the parameter is more specific. In
Section 3, we describe the algorithm used to approximate the solution components and their mean values.
Section 4 is devoted to the application of our results to a class of Network Games, and is structured in three subsections. Specifically, in
Section 4.1 we provide the basic concepts on Network Games, in
Section 4.2 we describe the quadratic reference model of a network Nash equilibrium problem, while in
Section 4.3 we first recall the definition of generalized Nash equilibrium problem with shared constraints, and the concept of variational solution, and then consider the quadratic reference model in this new setting. In
Section 5, we apply our estimates and algorithm to some parametric network games. We then summarize our work and outline some future research perspectives in a small conclusion section. The paper ends with
Appendix A, where we derive some exact results that can be obtained in the special case where the Lipschitz constant of the operator of the variational inequality equals its strong monotonicity constant.
2. Problem Formulation and Lipschitz Constant Estimates
Let
and, for each
,
be a nonempty, closed and convex subset of
. We denote with
the scalar product in
. The variational inequality on
, with parameter
, is the following problem: for each
, find
such that:
In the case where, for each
the solution of (
1) is unique, we will prove, assuming the Lipschitz continuity of
F and of the parametric functions describing
, the Lipschitz continuity of the solution map
and derive an a priori estimate of its Lipschitz constant
. Specifically, we estimate
in the general case where the variables
t and
x cannot be separated, as well as in the separable case where
. Moreover, in the special circumstance where
, for any
, two simplified formulas are derived. We then focus on computing approximations for the mean value of the components
,
:
We recall here some useful monotonicity properties.
Definition 1. A map is monotone on a set if and only if If the equality holds only when , F is said to be strictly monotone.
A stronger type of monotonicity is given by the following definition.
Definition 2. is α-strongly monotone on A if and only if : The concepts of strict and strong monotonicity coincide for linear operators and they are equivalent to the positive definiteness of the corresponding matrix. When F also depends on a parameter, the following property is useful.
Definition 3. is uniformly α-strongly monotone on A if and only if : Sufficient conditions for the existence and uniqueness of the solution of a variational inequality problem can be found in [
8]. We mention here the following classical theorem which, in the parametric case, has to be applied for each
.
Theorem 1. Let be a closed and convex set and continuous on K. If K is bounded, then the variational inequality problem admits at least one solution. If K is unbounded, then the existence of a solution is guaranteed by the following coercivity condition:for and some . Furthermore, if F is α-strongly monotone on K, then the solution exists and is unique. Let us now prove two theorems, along with three corresponding corollaries, which constitute the main contribution of the paper. Such results, at different levels of generality, ensure that the unique solution of (
1) is Lipschitz continuous, and also provide an estimate of the Lipschitz constant of the solution.
Theorem 2 (General case).
Assume that is uniformly α-strongly monotone on and F is Lipschitz continuous on with constant L, i.e., Moreover, we assume that is a closed and convex set for any , and there exists such thatwhere denotes the projection of x on the closed convex set . Then, for any , there exists a unique solution of the and is Lipschitz continuous on , with an estimated constant equal towhere and . Proof. The existence and uniqueness of the solution
follows from Theorem 1. Given
, we denote
and
. We know that
hold for any
, due to the characterization of the projection onto a closed convex set and the Brower fixed point theorem (see, e.g., [
8]). Hence, we obtain the following estimate:
where the second inequality follows from assumption (
3) and the non-expansiveness of the projection map. Moreover, we have
It is well-known that
, since the assumptions guarantee that the following inequalities
hold for any
and
. Thus, we obtain
hence
is well defined. Notice that if
, then
for any
, while if
then
for any
. Moreover, we have
thus, if
, we have
It follows from (
5) and (
6) that
hence
It follows from (
4) and (
7) that
Notice that
if and only if
. Therefore, in the case
, we obtain
while in the case
, we obtain
If we set
and
, then we can write
and the estimate (
8), which, in case
, reads as
In case
, we have
, and the estimate (
9) reads as
where
An analytical study of the function
f (see
Appendix A.1) provides
and
Moreover, it is easy to check that the following inequality
holds for any
. Therefore, we obtain
thus the thesis follows. □
Corollary 1 (General operator and constant feasible region).
Assume that F satisfies the same assumptions of Theorem 2 and the feasible region K does not depend on t. Then, the solution of the VI() is Lipschitz continuous on with estimated constant equal to .
Proof. Since
K does not depend on
t, inequality (
3) holds with
. Hence, Theorem 2 guarantees that
is Lipschitz continuous on
with a constant equal to
where
and
. It is sufficient to prove that if
, then
Since
, we have
thus
On the other hand, we have
hence
Since
and
hold for any
, we obtain
The latter inequality is equivalent to
Since
and
hold for any
, we obtain
On the other hand, we have
Therefore, the proof is complete. □
Theorem 3 (Separable operator).
Assume that is separable, i.e,where is α-strongly monotone on and Lipschitz continuous on with constant , and is Lipschitz continuous on with constant . Moreover, we assume that is a closed and convex set for any , and there exists , such that (3) holds. Then, for any , there exists a unique solution of the , and is Lipschitz continuous on with an estimated constant equal towhere , and . Proof. The existence and uniqueness of the solution
follows from Theorem 1. Given
, we denote
and
. For any
, we have the following estimate:
Since
, we have
hence
is well defined. Notice that if
, then
for any
, while if
, then
for any
. Moreover, we have
thus, if
, we have
It follows from (
11) and (
12) that
hence
It follows from (
10) and (
13) that
Notice that
if and only if
. Therefore, in the case
, we obtain
while in the case
, we obtain
If we set
,
and
, then we can write
, and the estimate (
14), in the case
, reads as
In the case
, we have
and the estimate (
15) reads as
where
An analytical study of the function
f (see
Appendix A.2) provides
and
Moreover, it is easy to check that the following inequality
holds for any
and
. Therefore, we obtain
thus the thesis follows. □
Corollary 2 (Separable operator and constant feasible region).
Assume that F satisfies the assumptions of Theorem 3 and the feasible region K does not depend on t. Then, the solution of the VI() is Lipschitz continuous on with estimated constant equal to .
Proof. Theorem 3 guarantees that
is Lipschitz continuous on
with a constant equal to
where
,
and
. Moreover, similarly to the proof of Corollary 1, where
is replaced by
, it can be proved that if
, then
□
In the special case where
F does not depend on
t, we obtain the same estimate proved in [
12].
Corollary 3 (Constant operator).
Assume that F and K satisfy the assumptions of Theorem 3 and F does not depend on t, i.e., . Then, the solution of the VI() is Lipschitz continuous on with estimated constant equal to Proof. If
, then
, and Theorem 3 guarantees that
is Lipschitz continuous on
with a constant equal to
where
and
.
Moreover, it is easy to check that
thus the thesis follows. □
Table 1 summarizes the estimate of the Lipschitz constant of
depending on the features of the map
F and the feasible set
K.
Theorems 2 and 3, along with Corollaries 1, 2 and 3, do not provide the solution of the parametric VI in closed form, but guarantee that it is a Lipschitz continuous function of the parameter t and provide an estimate of the corresponding constant. The knowledge of the Lipschitz constant is a key tool to provide lower and upper approximations of both the solution and its mean value on , as the algorithm described in the next section shows.
3. Approximation Algorithm
Let
be any component of the solution vector
x of (
1); assume that
is a Lipschitz continuous function and
is an estimate of its Lipschitz constant, i.e.,
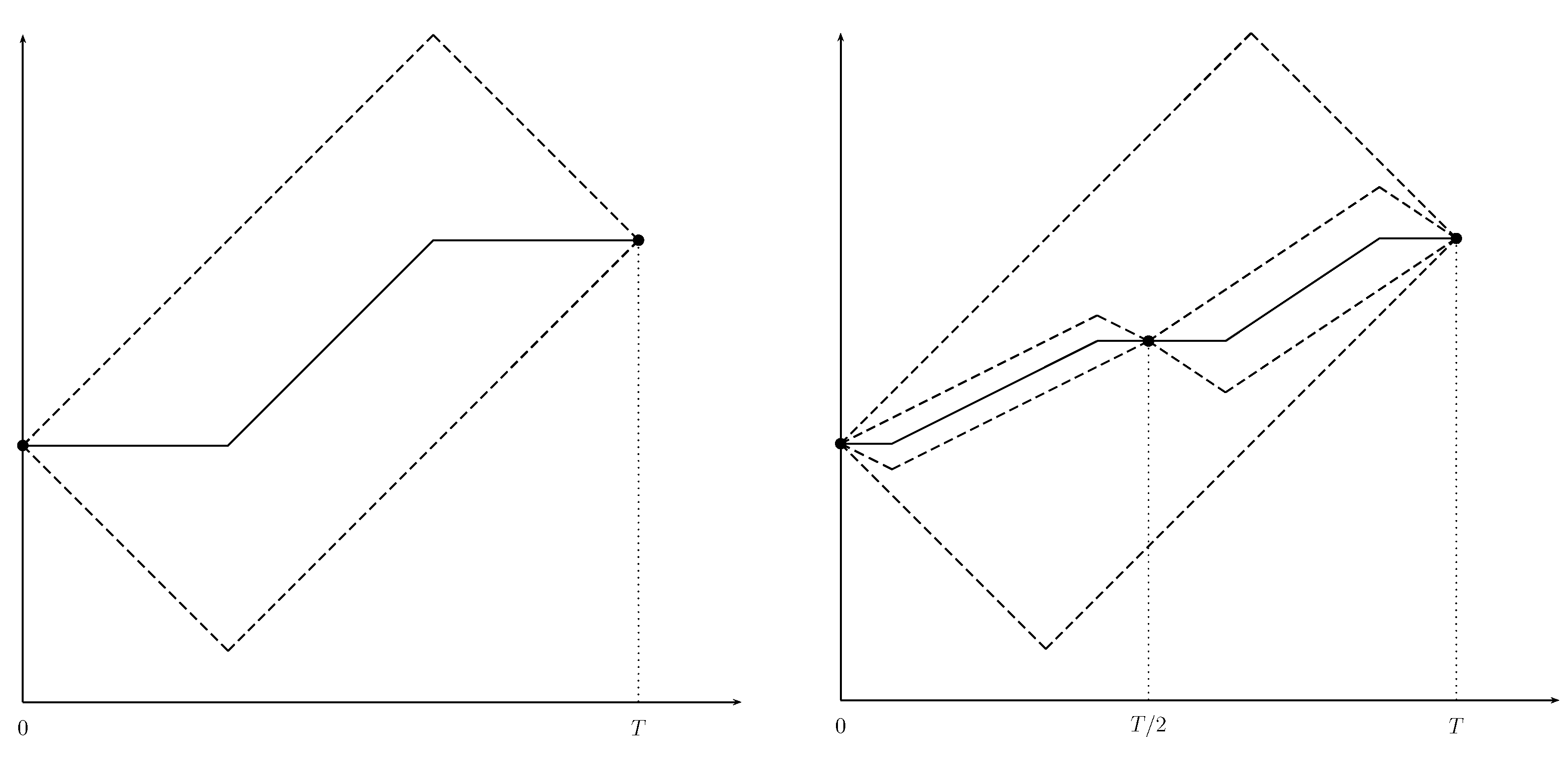
Furthermore, let I be the integral of over and, to begin with, assume that we only know the value of at the two endpoints . We wish to construct an approximation of in the interval and also obtain an estimate of the value of I, together with an estimate of the error .
The Lipschitz continuity of
allow us to localize its graph by drawing four lines passing trough the points
and
, with slopes
and
. We thus construct a parallelogram
containing the unknown graph of the function (see
Figure 1, left). Specifically, the two upper and the two lower sides of the parallelogram (dashed lines) correspond, respectively, to an
upper bound and a
lower bound for
. The functions
and
can be written as follows:
Denote now with
an approximation of the value of
at some
, with
the error on the estimate, and with
the largest possible absolute error on the estimate, whence:
where the equality sign holds when
coincides with its upper or lower bound. The case where
can be called the
worst case, and the value of
that minimizes
is the mean value
which yields
The graph of
, in the worst case, is represented by the solid line in
Figure 1, on the left. In order to obtain a global measure of the error in the interval
, in the worst case, it is then natural to define:
which is equal to the half of the area of
, denoted by
, and thus
.
We thus have an approximation of the function , together with the estimates and of the worst case local and total error, respectively. The average worst case error is defined as .
We want now to approximate the integral
I of
over
. Notice that lower and upper bounds for
I are given, respectively, by
The estimate of
I that differs the less from the two extreme
and
is the average value
For this choice of , the error can reach the value of in the worst case.
It follows from (
17) that
is equal to the integral of the approximating function
. We remark from (
19) that the total worst case error
coincides with the estimate of the error
on the integral
. Hence, both for the estimate of the function and of its integral, the quantity that measures the corresponding errors is the same, and it is exactly half the area of the parallelogram
. It is easy to check (see [
13,
14]) that, for any pair of points
(with
), the area of parallelogram
is
Now, we want to analyze how the evaluation of
in a further point improves the approximation procedure. For this, let
,
, let
be an arbitrary point in
and repeat the previous procedure in the intervals
and
, respectively. The graph of
is now contained in the union of parallelograms
and
. Therefore, a new sample point allows to better locate the graph of
. In this case, the bounding functions are computed as follows:
where
and
denote the update estimates of the Lipschitz constant of
in the intervals
and
, respectively.
For the two sub-intervals, we can provide approximations of and of its integral, and estimates of the corresponding errors and .
We observe that the smaller the sum of the areas of the new parallelograms is, the better the new estimate of the function is. Hence, with the evaluation of at new points and repeating the above procedure, we can further improve the approximation and its integral, as specified by the following algorithm.
Step 0. (Initialization)
Fix a positive constant
, which represents the desired maximum error on the integral of
(or total worst case error in the estimate of
itself). Create a list of evaluation points, which initially contains the two endpoints 0 and
T, and the corresponding list of function values
. Calculate the area
of parallelogram
by means of (
20) and initialize a list of parallelograms’ areas.
Step 1. (New evaluation)
Locate the parallelogram having the largest area, and the corresponding interval, say (at the first step, coincides with the whole interval ). Add the new evaluation point , and update the lists of points and function values accordingly. Compute the two Lipschitz constants in the intervals and . Update the parallelograms’ areas list by removing the area of parallelogram and inserting the areas of the two new parallelograms and .
Step 2. (Stopping rule)
At the
k-th iteration of the algorithm, we thus have divided the interval
with
points, which we reorder as
, and we denote with
the estimate of the Lipschitz constant of
in
. The bounding functions in
are then given by:
In the next result, we provide a complexity analysis of the algorithm.
Theorem 4. After k iterations of the algorithm, the worst case error is, at most, equal towhereis the worst case error before the algorithm starts. Therefore, the algorithm stops after at most iterations. Proof. At each iteration, we need to compute the two new estimates of the Lipschitz constant in the intervals
and
. Such estimates are less than or equal to the Lipschitz estimate
in the interval
. Since the area of each parallelogram given by Formula (
20) (and thus the error on the integral) is an increasing function of
, the worst case occurs when the two estimates coincide with
. Hence, the worst case complexity analysis of the algorithm reduces to that of the algorithm where the Lipschitz estimate is not updated at any iteration. Therefore, following the same argument as in [
13], we can prove the inequality
where
denotes the sum of the areas of all parallelograms generated by the algorithm after
k iterations,
is the area of the parallelogram before the algorithm starts, and
i is the integer such that
. Since the worst case error
after
k iterations is
,
, and
, we obtain the following inequality from (
22):
thus (
21) holds.
If we denote
, then
thus, we obtain
hence (
21) guarantees that the worst case error after
iterations is less than
; that is, the algorithm stops after at most
iterations. □
4. Application to Parametric Network Games
The theoretical results proved in
Section 2 and the approximation algorithm described in
Section 3 can be applied to any parametric VI in the form (
1). It is well known that parametric VIs in the form (
1) can be viewed as the dynamic equilibrium models, in the case where the problem data depend on a time parameter
t. Several applications of these models have been studied in recent years (see, e.g., [
26,
27] and references therein). On the other hand, network games are an interesting class of non-cooperative games with an underlying network structure, which can be modeled through VIs [
24]. A number of applications of network games have been analyzed in the literature, from social networks to juvenile delinquency (see, e.g., [
20,
21] and references therein).
In this section, we apply the results of
Section 2 and
Section 3 to a class of parametric network games, which can be modeled as parametric VIs in the form (
1), where both the players’ utility functions and their strategy sets depend on a time parameter. Specifically, in
Section 4.1, a brief recall of Graph Theory and Game Theory concepts is given together with the definition of parametric network games. Then, we focus on the linear-quadratic model, both in the framework of the network Nash equilibrium problem (
Section 4.2) and the network generalized Nash equilibrium problem (
Section 4.3).
4.1. Basics of Network Games
We begin with a recapitulation of foundational Graph Theory concepts. We define a graph g as a pair of sets , where V represents the set of nodes, while E represents the set of arcs composed of pairs of nodes . Arcs sharing identical terminal nodes are categorized as parallel arcs, while arcs in the form of are designated as loops. For the context at hand, we exclusively consider simple graphs, which are characterized by the absence of both parallel arcs and loops. Within our framework, the players are represented by the n nodes of the graph. Furthermore, we operate within the framework of undirected graphs, wherein arcs and are considered equivalent. Two nodes v and w are adjacent if they are connected by the arc . The information regarding the adjacency of nodes can be stored in the form of the adjacency matrix G, where the elements assume a value of 1 when is an arc and 0 otherwise. Notice that matrix G is symmetric and with diagonal elements equal to 0. For a specific node v, the nodes that share a direct link with it through arcs are referred to as the neighbors of v. These neighbors are collated within the set . The cardinality of is the degree of v.
A walk is defined as a sequence comprising both graph nodes and graph edges , for any , where the arc has endpoints and . Notice that within a walk, the possibility of revisiting a node or traversing an arc multiple times is permitted. The length of a walk is equal to the number of its arcs. The indirect connections between any two nodes within the graph are described through the utilization of the powers of the adjacency matrix G. Indeed, it can be proved that the element of provides the number of walks of length k between the nodes and .
We now recall some concepts of Game Theory, which will then be adapted to our specific framework. A strategic game (in normal form) is a model of interaction among decision makers, which are usually called players. Each player has to make a choice among various possible actions, but the outcome of her choice also depends on the choice made by the other players. The elements of the game are:
A set of n players;
A set , for each player , called the strategy (or action) set of player i; each element is called a strategy profile;
For each player , a set of preferences, according to which they can order the various profiles;
For each player , a utility (or payoff) function, , which represents their preferences such that to higher values there correspond better outcomes. Let us notice that the utility function of player i does not merely depend on , but on the whole strategy profile ; that is, the interaction with the other players cannot be neglected in their decision processes.
In the case of more than two players, it is important to distinguish the action of player i from the action of all the other players. To this end, we will use the notation to denote the subvector , and write . Since each player i wishes to maximize their utility, and only controls her action variable , a useful solution concept is that of Nash equilibrium of the game.
Definition 4. A Nash equilibrium is a vector such that: The interested reader can find a comprehensive theoretical treatment of Game Theory in the book [
28], along with various applications.
We now adapt the above concepts to our parametric network problem and, for simplicity, still denote the set of players by
instead of
. Thus, consider an interval
, and for each
, denote with
the parametric strategy space of player
i, while
is called the parametric space of action profiles. Each player
i is endowed with a payoff function
that he/she wishes to maximize. The notation
is often utilized when one wants to emphasize the dependence on the graph structure. We wish to find a Nash equilibrium of the parametric game; that is, for each
, we seek an element
such that for each
:
A characteristic of network games is that the vector is only made up of components such that ; that is, j is a neighbor of i. For modeling purposes, and also for simplifying the analysis, it is common to make further assumptions on how variations in the actions of a player’s neighbors affect her marginal utility. We assume that the type of interaction does not change in and, in the case where , we obtain the following definitions.
Definition 5. We say that the network game has the property of strategic substitutes if for each player i the following condition holds: Definition 6. We say that the network game has the property of strategic complements if for each player i the following condition holds: We will use the variational inequality approach, pioneered by [
23] (in the non-parametric case), to solve Nash equilibrium problems. If, for each
, the
are continuously differentiable functions on
, and
are concave, the Nash equilibrium problem is equivalent to the variational inequality
:
For each
, find
such that
where
is also called the
pseudo-gradient of the game, according to the terminology introduced by Rosen [
29].
In the following subsection, we introduce the parametric linear-quadratic utility functions, which will be used both for the Nash equilibrium problem and the generalized Nash equilibrium problem. This simple functional form as been extensively used in the literature (see, e.g, [
20]) because, in the case on non-negative strategy space, it allows solutions in closed form. We consider instead the case where the strategy space of each player has a (parameter-dependent) upper bound.
4.2. The Linear-Quadratic Network Nash Equilibrium Problem
Let
for any
,
, where, for each
i,
is a positive and Lipschitz continuous function on
. The payoff of player
i is given by:
In this model
is a positive Lipschitz function, and
describes the interaction between a player and their neighbors, which corresponds to the case of strategic complements. Moreover, since
is the same for all players, they only differ because of their position in the network. The pseudo-gradient’s components are given by:
which can be written in compact form as:
where
. We will seek Nash equilibrium points by solving the variational inequality: for each
, find
such that
Lemma 1. F is uniformly strongly monotone if , where is the spectral radius of G.
Proof. The symmetric matrix is positive definite if and only if its minimum eigenvalue is positive. On the other hand, . Since G is a symmetric non-negative matrix, the Perron–Frobenius Theorem guarantees that , hence is positive definite if and only if . This condition does not depend on . □
Notice that, when
, the map
F in (
28) satisfies the assumptions of Theorems 2 and 3 with constants
,
,
, where
is the Lipschitz constant of
, and
. Moreover, the feasible region
satisfies assumption (
3) with constant
, where
is the Lipschitz constant of
for any
(see [
11]). Therefore, it follows from Theorems 2 and 3 that the Nash equilibrium
is a Lipschitz continuous function with estimated constant equal to
.
Remark 1. The game under consideration also falls, for each , in the class of potential games according to the definition introduced by Monderer and Shapley [30]. Indeed, a potential function is given by: Monderer and Shapley have proven that, in general, the solutions of the problemform a subset of the solution set of the Nash game. Because both problems have a unique solution under the condition , it follows that the two problems share the same solution. 4.3. The Linear-Quadratic Network Generalized Nash Equilibrium Problem
We start this subsection with a recall of generalized Nash equilibrium problems (GNEPs) with shared constraints and their variational solutions. More details can be found in the already-mentioned paper by Rosen, and in the more recent papers [
31,
32,
33,
34,
35,
36,
37,
38]. We directly introduce the parametric case, and all the following definitions and properties hold for any fixed
.
In GNEPs, the strategy set of each player is dependent on the strategies of their rivals. In this context, we examine a simplified scenario where the variable
x is constrained to be non-negative (
). Moreover, we consider a function
, which characterizes the collective constraints shared among the players. For each
t, and for each move
of the other players, the strategy set of player
i is then given by:
Definition 7. The GNEP is the problem of finding, for each , such that, for any , and We assume that that, for each fixed
, the functions
are concave and continuously differentiable, and the components of
are convex and continuously differentiable. As a consequence, a necessary and sufficient condition for
to satisfy (
31) is
Thus, if we define
as in (
26), and
it follows that
is a GNE if and only if,
,
and
The above problem, where the feasible set also depends on the solution, is called a quasi-variational inequality (with parameter t), and its solution is as difficult as the original GNEP. Let us now remark that even if the strict monotonicity assumption on F is satisfied for each t, the above problem (equivalent to the original GNEP) has infinite solutions. We can select a specific solution by studying its Lagrange multipliers.
Thus, assume that, for each
,
is a solution of GNEP. Hence, for each
i,
solves the maximization problem
Under some standard constraint qualification, we can then write the KKT conditions for each maximization problem. We then introduce the Lagrange multiplier
associated with the constraint
and the multiplier
associated with the nonnegativity constraint
. The Lagrangian function for each player
i reads as:
and the KKT conditions for all players are given by:
Conversely, under the assumptions made, if, for any fixed t, , where and , satisfy the KKT system (34)–(36), then is a GNE. We are now in position to classify equilibria.
Definition 8. Let be a GNE which, together with the Lagrange multipliers and , satisfies the KKT system of all players. We call a normalized equilibrium if there exists a vector and a vector such thatwhich means that, for a normalized equilibrium, the multipliers of the constraints shared by all players are proportional to a common multiplier. In the special case where, for some t, for any i, i.e., the multipliers coincide for each player, is calledvariational equilibrium (VE). Rosen [29] proved that if the feasible set, which in our case is:is compact and convex, then there exists a normalized equilibrium for each . Now, let us define, for each
, the vector function
as follows:
The variational inequality approach for finding the normalized equilibria of the GNEP is expressed by the following theorem, which can be viewed as a special case of Proposition
in [
34] in a parametric setting.
Theorem 5. - 1.
Suppose that is a solution of , where , a constraint qualification holds at and are the multipliers associated with . Then, is a normalized equilibrium such that the multipliers of each player i satisfy the following conditions: - 2.
If is a normalized equilibrium such that the multipliers of each player i satisfy the following conditions:for some vector and , then is a solution of and are the corresponding multipliers.
The
variational equilibria can then be computed by solving, for any
, the following variational inequality: find
such that
As an example of network GNEP, we consider the same payoff functions defined as in (
27), while the strategy set of player
i is given by the usual individual constraint
and an additional constraint, shared by all the players, on the total quantity of activities of all players, that is
where
is a given positive and Lipschitz continuous function. Depending on the specific application, the additional constraint can have the meaning of a collective budget upper bound or of a limited availability of a certain commodity. If
, then the variational equilibrium can thus be found by solving
, where
F is the same as in (
28) and
Notice that
satisfies Assumption (
3), with constant
M equal to the Lipschitz constant of the function
C (see [
11]). Therefore, Theorems 2 and 3 guarantee that the variational equilibrium
is a Lipschitz continuous function with estimated constant equal to
.







{kind=link}
{kind=link}