

Comparison of Different Radial Basis Function Networks for the Electrical Impedance Tomography (EIT) Inverse Problem

 , ,
, ,
Abstract
:1. Introduction
1.1. Significance of the Work
1.2. Organization of the Paper
2. The Continuum Model for EIT
2.1. The Complete Electrode Model
2.2. FEM Formulation
3. The Radial Basis Function Network
4. Numerical Simulations
4.1. Generating Training Data
4.2. Choosing Number of RBF in Hidden Layer
4.3. Reconstructed Images
4.4. Comparison of the Different Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheney, M.; Isaacson, D.; Newell, J.C. Electrical impedance tomography. SIAM Rev. 1999, 41, 85–101. [Google Scholar] [CrossRef]
- Harris, N.; Suggett, A.; Barber, D.; Brown, B. Applications of applied potential tomography (APT) in respiratory medicine. Clin. Phys. Physiol. Meas. 1987, 8, 155. [Google Scholar] [CrossRef]
- Akbarzadeh, M.; Tompkins, W.; Webster, J. Multichannel impedance pneumography for apnea monitoring. In Proceedings of the Twelfth Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Philadelphia, PA, USA, 1–4 November 1990; IEEE: Philadelphia, PA, USA, 1990; pp. 1048–1049. [Google Scholar]
- Colton, D.L.; Ewing, R.E.; Rundell, W. Inverse Problems in Partial Differential Equations; Siam: Philadelphia, PA, USA, 1990; Volume 42. [Google Scholar]
- Borcea, L. Electrical impedance tomography. Inverse Probl. 2002, 18, R99. [Google Scholar] [CrossRef]
- Ramirez, A.; Daily, W.; LaBrecque, D.; Owen, E.; Chesnut, D. Monitoring an underground steam injection process using electrical resistance tomography. Water Resour. Res. 1993, 29, 73–87. [Google Scholar] [CrossRef]
- Kaup, P.G.; Santosa, F.; Vogelius, M. Method for imaging corrosion damage in thin plates from electrostatic data. Inverse Probl. 1996, 12, 279. [Google Scholar] [CrossRef]
- Alessandrini, G.; Beretta, E.; Santosa, F.; Vessella, S. Stability in crack determination from electrostatic measurements at the boundary-a numerical investigation. Inverse Probl. 1995, 11, L17. [Google Scholar] [CrossRef]
- Alessandrini, G.; Rondi, L. Stable determination of a crack in a planar inhomogeneous conductor. SIAM J. Math. Anal. 1999, 30, 326–340. [Google Scholar] [CrossRef]
- Hyvonen, N.; Seppanen, A.; Staboulis, S. Optimizing electrode positions in electrical impedance tomography. SIAM J. Appl. Math. 2014, 74, 1831–1851. [Google Scholar] [CrossRef]
- Boyle, A.; Adler, A. The impact of electrode area, contact impedance and boundary shape on EIT images. Physiol. Meas. 2011, 32, 745. [Google Scholar] [CrossRef]
- Khalighi, M.; Vahdat, B.V.; Mortazavi, M.; Hy, W.; Soleimani, M. Practical design of low-cost instrumentation for industrial electrical impedance tomography (EIT). In Proceedings of the 2012 IEEE International Instrumentation and Measurement Technology Conference Proceedings, Graz, Austria, 13–16 May 2012; IEEE: Graz, Austria, 2012; pp. 1259–1263. [Google Scholar]
- Pidcock, M.; Kuzuoglu, M.; Leblebicioglu, K. Analytic and semi-analytic solutions in electrical impedance tomography: I. Two-dimensional problems. Physiol. Meas. 1995, 16, 77–90. [Google Scholar] [CrossRef]
- Pidcock, M.; Kuzuoglu, M.; Leblebicioglu, K. Analytic and semi-analytic solutions in electrical impedance tomography. II. Three-dimensional problems. Physiol. Meas. 1995, 16, 91. [Google Scholar] [CrossRef] [PubMed]
- Calderón, A. On an inverse boundary value problem, Seminar on Numerical Analysis and its Applications to Continuum Physics (Rio de Janerio). 1980. Available online: https://www.scielo.br/j/cam/a/fr8pXpGLSmDt8JyZyxvfwbv/?lang=en (accessed on 19 August 2023).
- Victor, I. Inverse Problems for Partial Differential Equations; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Astala, K.L. Paivarinta Calderon’s inverse conductivity problem in the plane. Ann. Math. 2003, 163, 265. [Google Scholar] [CrossRef]
- Barceló, T.; Faraco, D.; Ruiz, A. Stability of Calderón inverse conductivity problem in the plane. J. Math. Pures Appl. 2006, 88, 522–556. [Google Scholar] [CrossRef]
- Zhang, G. Uniqueness in the Calderón problem with partial data for less smooth conductivities. Inverse Probl. 2012, 28, 105008. [Google Scholar] [CrossRef]
- Imanuvilov, O.; Uhlmann, G.; Yamamoto, M. The Calderón problem with partial data in two dimensions. J. Am. Math. Soc. 2010, 23, 655–691. [Google Scholar] [CrossRef]
- Wang, C.; Lang, J.; Wang, H.X. RBF neural network image reconstruction for electrical impedance tomography. In Proceedings of the 2004 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 04EX826), Shanghai, China, 26–29 August 2004; IEEE: Shanghai, China, 2004; Volume 4, pp. 2549–2552. [Google Scholar]
- Wang, P.; Li, H.l.; Xie, L.l.; Sun, Y.c. The implementation of FEM and RBF neural network in EIT. In Proceedings of the 2009 Second International Conference on Intelligent Networks and Intelligent Systems, Tianjin, China, 1–3 November 2009; IEEE: Tianjin, China, 2009; pp. 66–69. [Google Scholar]
- Hrabuska, R.; Prauzek, M.; Venclikova, M.; Konecny, J. Image reconstruction for electrical impedance tomography: Experimental comparison of radial basis neural network and Gauss–Newton method. IFAC-PapersOnLine 2018, 51, 438–443. [Google Scholar] [CrossRef]
- Wang, H.; Liu, K.; Wu, Y.; Wang, S.; Zhang, Z.; Li, F.; Yao, J. Image reconstruction for electrical impedance tomography using radial basis function neural network based on hybrid particle swarm optimization algorithm. IEEE Sens. J. 2020, 21, 1926–1934. [Google Scholar] [CrossRef]
- Michalikova, M.; Abed, R.; Prauzek, M.; Koziorek, J. Image reconstruction in electrical impedance tomography using neural network. In Proceedings of the 2014 Cairo International Biomedical Engineering Conference (CIBEC), Giza, Egypt, 11–13 December 2014; IEEE: Giza, Egypt, 2014; pp. 39–42. [Google Scholar]
- Michalikova, M.; Prauzek, M.; Koziorek, J. Impact of the radial basis function spread factor onto image reconstruction in electrical impedance tomography. IFAC-PapersOnLine 2015, 48, 230–233. [Google Scholar] [CrossRef]
- Griffiths, D.J. Introduction to Electrodynamics; AIP Publishing: New York, NY, USA, 2005. [Google Scholar]
- Jackson, J.D. Classical Electrodynamics; AIP Publishing: New York, NY, USA, 1999. [Google Scholar]
- Folland, G. Introduction to Partial Differential Equations; Mathematical Notes; Princeton University Press: Princeton, NJ, USA, 1995; Volume 17. [Google Scholar]
- Somersalo, E.; Cheney, M.; Isaacson, D. Existence and uniqueness for electrode models for electric current computed tomography. SIAM J. Appl. Math. 1992, 52, 1023–1040. [Google Scholar] [CrossRef]
- Kupis, S. Methods for the Electrical Impedance Tomography Inverse Problem: Deep Learning and Regularization with Wavelets. Ph.D. Thesis, Clemson University, Clemson, SC, USA, 2021. [Google Scholar]
- Vauhkonen, P. Image Reconstruction in Three-Dimensional Electrical Impedance Tomography (Kolmedimensionaalinen Kuvantaminen Impedanssitomografiassa); University of Kuopio: Kuopio, Finland, 2004. [Google Scholar]
- Park, J.; Sandberg, I.W. Universal approximation using radial-basis-function networks. Neural Comput. 1991, 3, 246–257. [Google Scholar] [CrossRef]
- Adler, A.; Lionheart, W.R. Uses and abuses of EIDORS: An extensible software base for EIT. Physiol. Meas. 2006, 27, S25. [Google Scholar] [CrossRef] [PubMed]
- Dimas, C.; Uzunoglu, N.; Sotiriadis, P. An efficient Point-Matching Method-of-Moments for 2D and 3D Electrical Impedance Tomography Using Radial Basis functions. IEEE Trans. Biomed. Eng. 2021, 69, 783–794. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
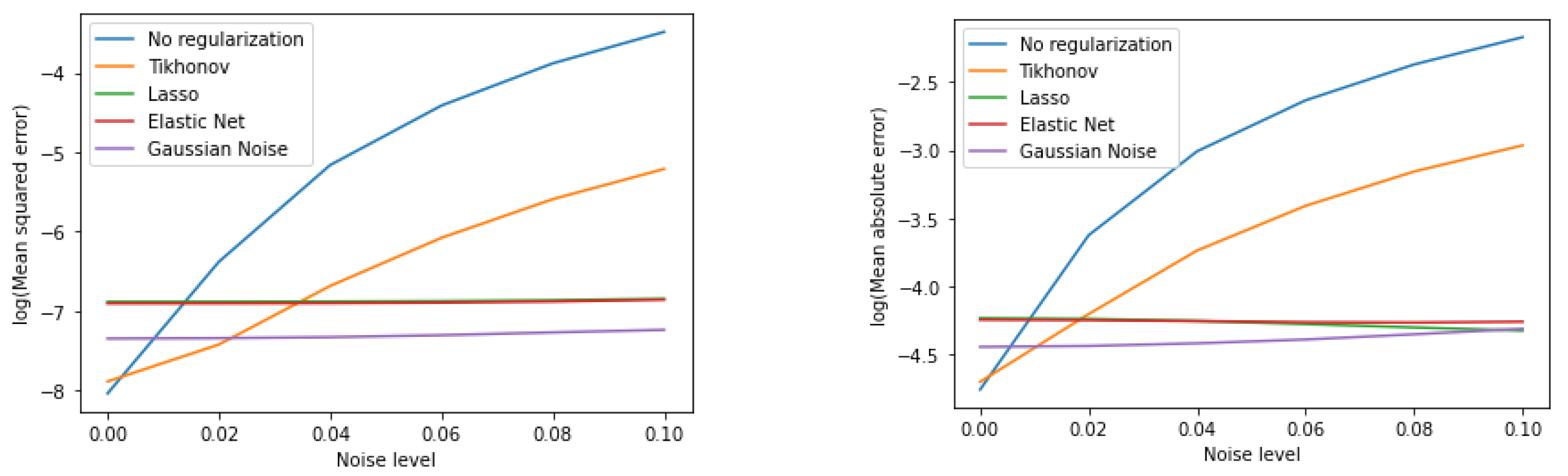
| Noise | No Regularization | Tikhonov | Lasso | Elastic Net | Gaussian Noise |
|---|---|---|---|---|---|
| 0% | 0.0003 ± 0.0019 | 0.0004 ± 0.0023 | 0.001 ± 0.0053 | 0.001 ± 0.0051 | 0.0006 ± 0.0036 |
| 2% | 0.0017 ± 0.0046 | 0.0006 ± 0.0025 | 0.001 ± 0.0053 | 0.001 ± 0.0052 | 0.0006 ± 0.0036 |
| 4% | 0.0057 ± 0.0152 | 0.0012 ± 0.0035 | 0.001 ± 0.0053 | 0.001 ± 0.0052 | 0.0007 ± 0.0036 |
| 6% | 0.0121 ± 0.0323 | 0.0023 ± 0.0054 | 0.001 ± 0.0054 | 0.001 ± 0.0053 | 0.0007 ± 0.0037 |
| 8% | 0.0207 ± 0.0553 | 0.0037 ± 0.0084 | 0.001 ± 0.0055 | 0.001 ± 0.0054 | 0.0007 ± 0.0038 |
| 10% | 0.0307 ± 0.082 | 0.0054 ± 0.0122 | 0.0011 ± 0.0056 | 0.001 ± 0.0055 | 0.0007 ± 0.0038 |
| Noise | No Regularization | Tikhonov | Lasso | Elastic Net | Gaussian Noise |
|---|---|---|---|---|---|
| 0% | 0.0085 ± 0.0158 | 0.009 ± 0.0171 | 0.0144 ± 0.0285 | 0.0143 ± 0.0282 | 0.0117 ± 0.0225 |
| 2% | 0.0266 ± 0.0314 | 0.0149 ± 0.0193 | 0.0144 ± 0.0285 | 0.0142 ± 0.0282 | 0.0118 ± 0.0225 |
| 4% | 0.0494 ± 0.0574 | 0.0238 ± 0.0261 | 0.0142 ± 0.0287 | 0.0141 ± 0.0283 | 0.012 ± 0.0226 |
| 6% | 0.0718 ± 0.0835 | 0.033 ± 0.0346 | 0.0138 ± 0.0289 | 0.014 ± 0.0285 | 0.0123 ± 0.0227 |
| 8% | 0.0935 ± 0.1091 | 0.0425 ± 0.0438 | 0.0135 ± 0.0293 | 0.014 ± 0.0288 | 0.0128 ± 0.023 |
| 10% | 0.1143 ± 0.1328 | 0.0516 ± 0.0528 | 0.0132 ± 0.0298 | 0.0141 ± 0.0291 | 0.0134 ± 0.0232 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faiyaz, C.A.; Shahrear, P.; Shamim, R.A.; Strauss, T.; Khan, T. Comparison of Different Radial Basis Function Networks for the Electrical Impedance Tomography (EIT) Inverse Problem. Algorithms 2023, 16, 461. https://doi.org/10.3390/a16100461
Faiyaz CA, Shahrear P, Shamim RA, Strauss T, Khan T. Comparison of Different Radial Basis Function Networks for the Electrical Impedance Tomography (EIT) Inverse Problem. Algorithms. 2023; 16(10):461. https://doi.org/10.3390/a16100461
Chicago/Turabian StyleFaiyaz, Chowdhury Abrar, Pabel Shahrear, Rakibul Alam Shamim, Thilo Strauss, and Taufiquar Khan. 2023. "Comparison of Different Radial Basis Function Networks for the Electrical Impedance Tomography (EIT) Inverse Problem" Algorithms 16, no. 10: 461. https://doi.org/10.3390/a16100461
APA StyleFaiyaz, C. A., Shahrear, P., Shamim, R. A., Strauss, T., & Khan, T. (2023). Comparison of Different Radial Basis Function Networks for the Electrical Impedance Tomography (EIT) Inverse Problem. Algorithms, 16(10), 461. https://doi.org/10.3390/a16100461