1. Introduction
Electrical Impedance Tomography (EIT) is the only imaging modality that allows for visualization of the conductivity distribution inside the human body. When it is compared to other modalities such as magnetic resonance imaging (MRI) and computed tomography scan (CT), it has several benefits. First, the cost of hardware is comparatively cheap, as the system is less complex than MRI and CT scan systems. Second, it is long-term applicable on the bedside, as there is no need for X-ray radiation or strong magnetic fields [
1]. Third, it is not harmful, as the currents injected into the body are very small.
An EIT measurement is performed as follows. Electrodes are placed on the boundary of the domain. Small alternating currents are injected into the electrodes, while the resulting potential difference at the other electrode pairs is measured one after the other. From these measurements, the conductivity distribution can be calculated through various approaches.
EIT has a wide range of medical applications as a non-invasive imaging technique. One of its most important applications is lung monitoring. It can be used to observe regional lung ventilation and perfusion [
2], which can provide valuable information to healthcare professionals. Moreover, it can also help doctors assess the health of a patient’s lungs by monitoring lung recruitment and collapse [
3]. In addition, EIT can be used to estimate the size and volume of the bladder [
4]. EIT can even be used to track 3D brain activity [
5] and has potential applications in breast cancer imaging [
6]. Outside the medical context, EIT can be used, e.g., monitoring the production of semiconductors [
7] and for detecting cracks in concrete damage in concrete [
8].
As EIT belongs to the class of ill-posed non-linear inverse problems, it has tremendous limitations in its spatial resolution. This is due to several facts, the main reason is that EIT belongs to the class of soft-field tomography. This means that the path of the current changes with the conductivity distribution itself. Also, the fact that the voltages on the boundary do not depend continuously on the conductivity inside the human body. Thus, a big change in conductivity does not necessarily correspond to a big change in the voltage measurements. Inversion of this leads to problems during reconstruction. Also, numerical implementations of various algorithms pose problems in terms of stability and accuracy. This wide range of problems makes reconstruction challenging.
In general, there are two modes of reconstruction, time-dependent and time-independent. Time-dependent reconstruction provides a difference image from one time step to another. This process makes the reconstruction quality better, as systematical errors cancel out. Time-independent reconstruction, in contrast, processes one voltage measurement to a conductivity distribution. This is more complex as factors like uncertainty in the exact knowledge of the geometry and other errors are not suppressed. Thus, time-independent reconstructions are typically of lower quality. The choice of reconstruction mode can have a significant impact on the accuracy and effectiveness of EIT in various applications. Some applications like breast cancer force the choice of time-independent reconstruction, as for one measurement the system behaves quasi-static. During one examination, the breast cancer will not change in such a way that a time-dependent reconstruction would be helpful.
Breast cancer has the highest mortality associated with cancer among women worldwide. In 2022, 2.3 million women around the world suffered from breast cancer, while 0.68 million died from it [
9]. However, early detection of breast cancer can rapidly decrease these rates. If the cancer has not spread, the relative 5-year cancer survival rate is 99% [
10]. When the cancer has spread regionally in the breast, the rate drops to 86% [
10]. Only when the cancer has metastasized to far body regions, the rate drops to 27% [
10]. Thus, early detection of breast cancer is vital. The gold standard for non-invasive examination of the breast region for breast cancer is X-ray mammography. However, due to pain from the compression of the breast, many eligible women avoid this opportunity for examination. In Germany, only around 50% of all eligible women participate in the screening [
11]. Thus, other techniques for the detection of breast cancer would be helpful.
Electrical Impedance Tomography (EIT) has emerged as a promising alternative. This technique visualizes the conductivity distribution within the human body, exploiting the fact that cancerous tissue exhibits higher electrical conductivity than surrounding fatty tissue [
12]. This contrast aids in image reconstruction and potential tumor detection.
Despite its potential, the interpretation of EIT images remains challenging due to their low spatial resolution. This issue is further compounded by the fact that EIT is a highly non-linear inverse problem, which often results in reconstruction artifacts that can be misinterpreted as tumors.
Numerous studies have addressed these challenges. For instance, Cherepenin et al. developed a 3D EIT-based breast cancer detection system [
13]. Murillo-Oritzs et al. tested the “MEIK electroimpedance v.5.6” screening system [
14], while Hong et al. designed an EIT screening system integrated into a bra [
6]. For a more comprehensive overview of available systems and methodologies, we recommend survey papers by Zou et al. [
15] and Zuluaga-Gomez et al. [
16].
In this simulation study, we assess the performance of three machine learning models—Random Forest (RF), Support Vector Machine (SVM), and an Artificial Neural Network (ANN)—in interpreting EIT images. Our focus is on the auxiliary classification that these models provide, which could be instrumental in aiding any potential reconstruction process. This approach is designed to enhance the interpretability of EIT images and increase the accuracy of breast cancer detection in a simulated setting. Through this work, we aim to contribute to the ongoing efforts to advance EIT as a reliable tool for breast cancer detection.
2. Materials and Methods
Our study is structured as follows. First, we generate training data through simulation, which is explained in detail in the first subchapter. Then we elaborate on the choice of machine learning models in the following subchapter. At last, we give a motivation for our chosen evaluation score.
2.1. Generation of Training Data
Creating an extensive empirical dataset for EIT is hindered by the invasive nature of biopsy collection and ethical complexities. Obtaining real-case data is challenging due to privacy constraints and patient consent requirements. Simulations serve as a non-invasive and cost-effective alternative, allowing for the generation of diverse training data and the exploration of imaging parameters, crucial for refining EIT systems in breast cancer detection. For the training data we have used the general approach explained by Rixen et al., where they were able to produce EIT images from real-world measurements, but trained the ANN using only simulated data [
17]. We used finite element method (FEM) simulation for the open source Electrical Impedance Tomography and Diffuse Optical Tomography Reconstruction Software (EIDORS) library [
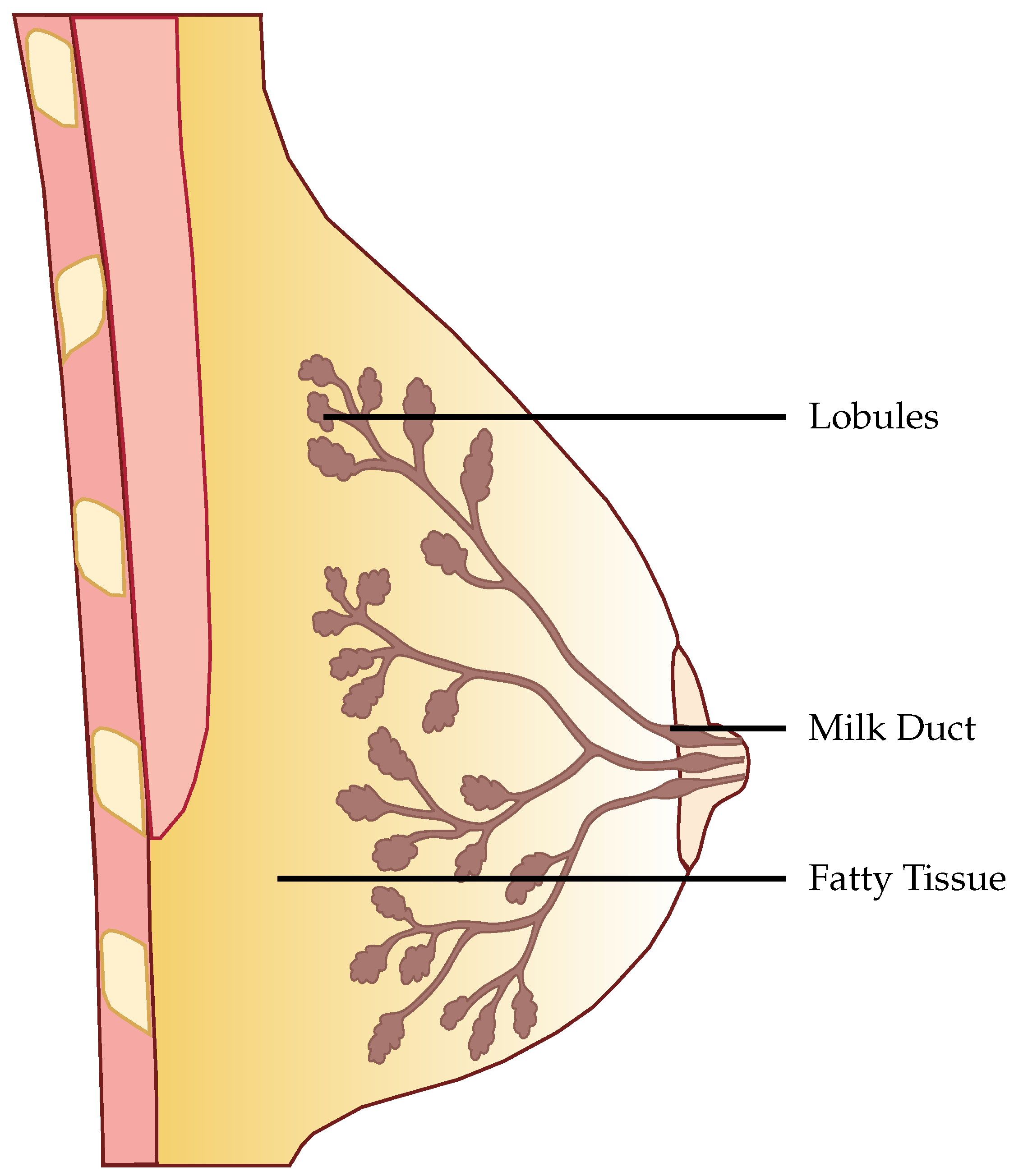
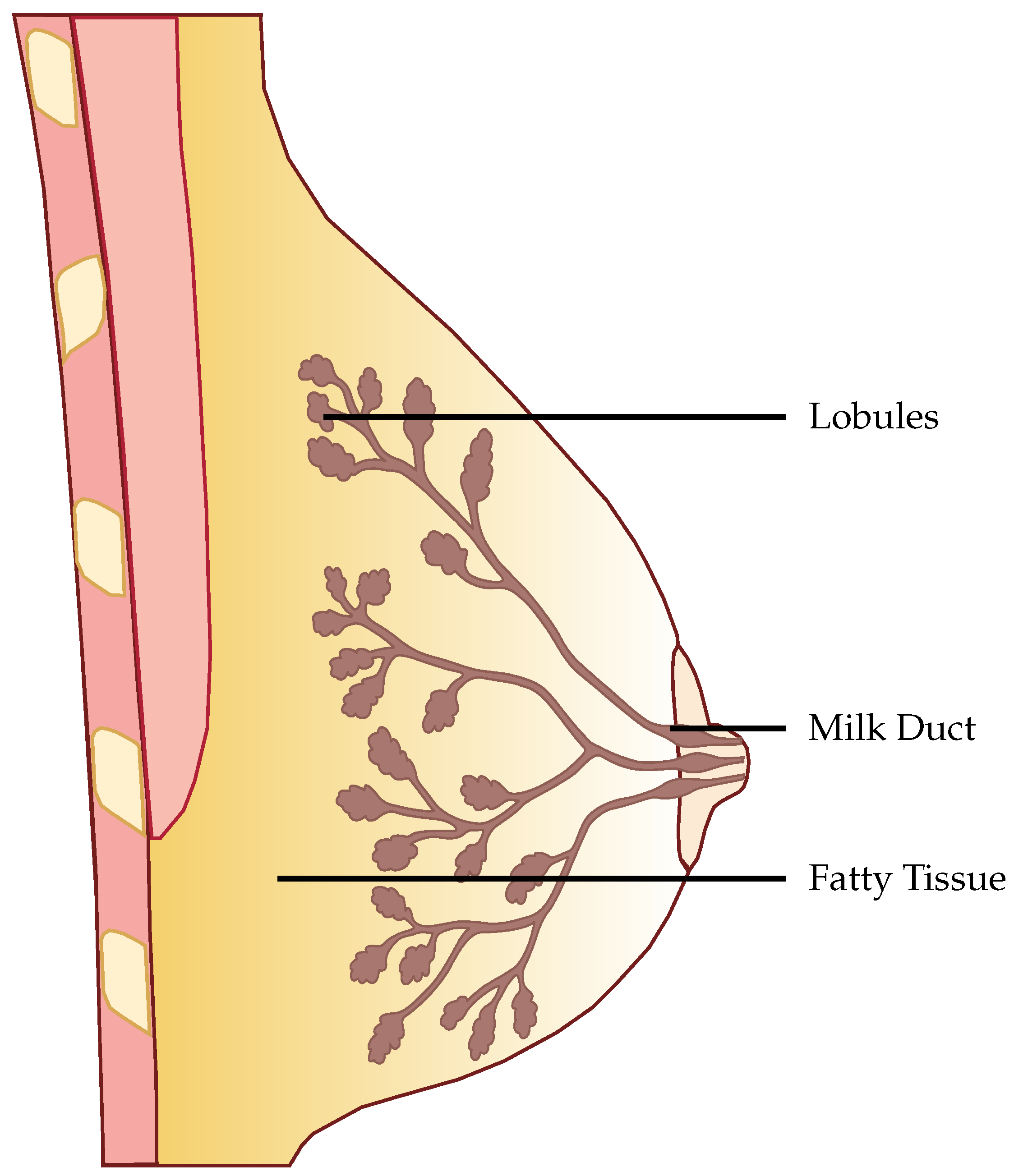
18]. EIDORS is a community-driven software package written in Matlab for FEM simulation in an EIT setting. The structure of the anatomical female breast is illustrated in
Figure 1. In
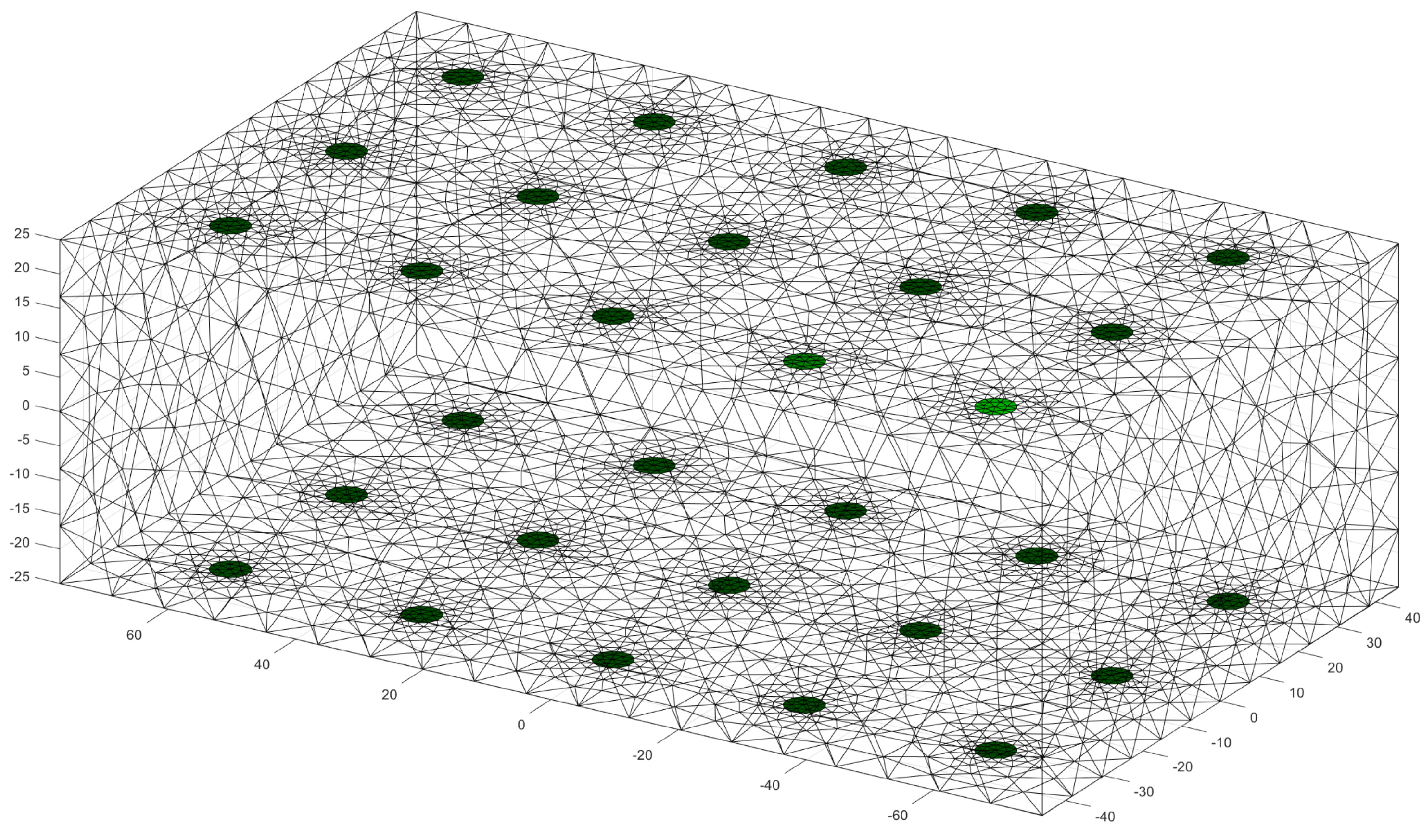
Figure 2 the used FEM model can be seen. The dimensions of the model are
. The electrodes have a radius of
. Fifteen electrodes are placed on each side of the model, thus, a total of 30 electrodes are involved in the model. The mesh size of the model was set to
, as this allows for a trade-off between the spatial resolution of the model and computation time. To avoid overfitting, 7500 different models were created. Each realization of the model was constructed according to the following rules.
To simulate the contact between electrode and breast, the contact impedance
where
is the contact impedance,
is a weighting factor which, weights the contribution of the random sampling and
n is sampled from a normal distribution
.
was set to 1. This allows for modeling the variety in contact impedance.
We incorporated four different tissues into the model. On 5 sides of the model, a thick layer of skin was introduced.
The glandular tissue was positioned within the domain, forming a truncated cone. The wider end of the cone was placed on the side without skin tissue and tapered towards the opposite end. This provided boundaries for the placement of the gland lobes. Within the cone, the lobes were placed randomly. Due to the inability to measure individual lobes, they were approximated as larger lobes [
19]. These larger lobes had radii in all three spatial axes
r sampled from a normal distribution
with
, as reported in [
19]. The orientation of these larger lobes was determined randomly by sampling all three Euler angles from 0 to
. A total of 20 larger lobes were positioned within the domain. From these larger lobes, a chain of ellipsoids or spheres with a radius of
extended towards the center of the truncated cone, as shown in
Figure 3.
Just like big lobes in the glandular structure, the tumors are not perfect spheres and are distorted in all three spatial directions. The radii followed a normal distribution with the mean depending on the dataset created and a fixed standard deviation of
. We analyzed different mean values of radii from
up to
. The tumor was placed randomly, however, it was guaranteed that they always had contact with the glandular structure. An example of a tumor placement can be found in
Figure 3, where the tumor is marked in yellow. Space that is not filled with any other tissue is assigned to fatty tissue.
The values for the conductivities of skin, fat, tumor, and glandular tissue are sampled as follows. In the literature, the values of all these tissue types are not fixed and have variations. For skin, the biggest conductivity value found is
, the minimum value is
, while the mean is
[
20]. Fatty tissue ranges from
to
with a mean of
[
12]. Glandular tissue ranges from
to
with a mean of
[
21]. The conductivities were sampled such that they follow a normal distribution with a mean value given by the literature and a standard deviation
, such that the
-interval lies within the minimum and maximum range. After a value is sampled, each mesh element is varied
around the value, to model inhomogeneities inside the tissue [
20].
The injection-measurement pattern was set to adjacent-adjacent for each electrode plane. In our set-up, we have 3 planes of 10 electrodes each.
When the voltages were simulated, white Gaussian noise was added to the voltages with the help of the EIDORS function add_noise(). The magnitude of the noise was set regarding the characteristics of the dataset.
From this general structure of the data set, we can vary the following attributes:
In
Section 3, we give the parameters for all performed analyses. Note that every data set had a 50/50 split of healthy and carcinogenic breast tissue. Furthermore, we note that this was done on purpose, to provide a balanced dataset for proper training. If we had a data set containing a realistic proportion of tumors, the models would get good results by simply guessing non-tumor every time.
2.2. Choice of Models
We have chosen RF, SVM and ANN as the basic models for our comparison, each with different underlying principles. SVMs, as linear models, define a boundary through linear algebra, while RFs, as ensemble learning models, generate multiple decision trees during training and combine these decisions to make predictions, providing valuable insight into the origins of their output. On the other hand, ANNs, due to their non-linear nature, are able to capture intricate relationships between data points, potentially offering superior performance in dealing with the inherently ill-posed and non-linear problem of identifying conductive enclosures, particularly tumours in our context. Detailed explanations of these models are given in the following sections.
2.3. Random Forests
The RF model is based on an ensemble of single decision trees first developed by Breiman [
22]. A decision tree is a type of model used for classification and regression. It operates by using the values of the input features to recursively partition the data into subsets. For every division, select the feature that divides the data most effectively. The tree continues to grow until all the data in a subset belong to the same class, or until a stopping criterion has been met. The final tree can be used to classify new data by following the splits from the root to a leaf node. The class label is assigned to the leaf node. The subdivisions in a decision tree are chosen to maximize the reduction in impurity. Either Gini impurity or entropy is commonly used to measure this reduction in impurity based on the training data. The impurity gives insight into the separability of the data. For more information about the Gini impurity and entropy in RFs, we recommend the PhD thesis from Gilles [
23]. If only one decision tree is used, the process is prone to overfitting, as it will be specifically fit to the dataset. To tackle this issue, an ensemble of decision trees called random forest is used.
For the implementation of the model, we used the scikitlearn-library [
24].
For a given dataset, the hyperparameters of RFs were optimized through grid search. The inputs to the RF classifier wee:
- 1.
n_estimators: number of trees in the forest varied from 15 to 350.
- 2.
max_features: number of features looked at for the best split (we tested “sqrt” and “log2”).
- 3.
max_depth: maximum depth of a single tree, varied from 15 to 150.
- 4.
bootstrap: the whole dataset used for a single tree, either “True” or “False”.
2.4. Support Vector Machines
SVMs take a different approach to classification, employing linear algebra to find a separation between the classes. This is done by fitting a hyperplane that best separates the clusters, such that the margin between the closest data point from each class and the hyperplane is maximized. These closest points are called support vectors. If a direct separation in the dimensionality of the data is not possible, the data is transformed to a higher dimension, where the fitting is carried out. This is done through the kernel-trick. A commonly used kernel is the radial basis function (RBF) kernel [
25].
We also used the scikitlearn-library for the implementation of the model [
24].
Just like in the case of RFs, for SVMs we also performed a grid search for the optimal parameters for a given data set. As a kernel, we used the RBF kernel. We performed a grid search on the following inputs to determine the best-performing SVM:
- 1.
C: regularization parameter for the -regularization.
- 2.
gamma: controls the shape of the decision boundary.
2.5. Artificial Neural Networks
ANNs model the structure of our brain, in order to approximate (non-linear) functions. They consist of synapses that have multiple inputs and multiple outputs, the inputs are connected through a linear function and is made non-linear through a non-linear activation function. The synapses are modeled as matrix multiplications with the input, while the result is fed through an activation. The training is done in a supervised manner, which means that the input data and the appropriate output data is provided during training. The parameters of the ANN are then altered such that they maximize the user-specified loss function.
For the implementation of our ANN, we used Keras Tensorflow [
26].
In our case, the implemented ANN had nine fully connected layers, which decreased from 680 neurons in the first layer down to 15 in the last hidden layer. For all but the last layer, Rectified Linear Units (ReLUs) were used as activation functions. The last layer used sigmoid as an activation function to bind the classification between 0 and 1.
2.6. Evaluation Score
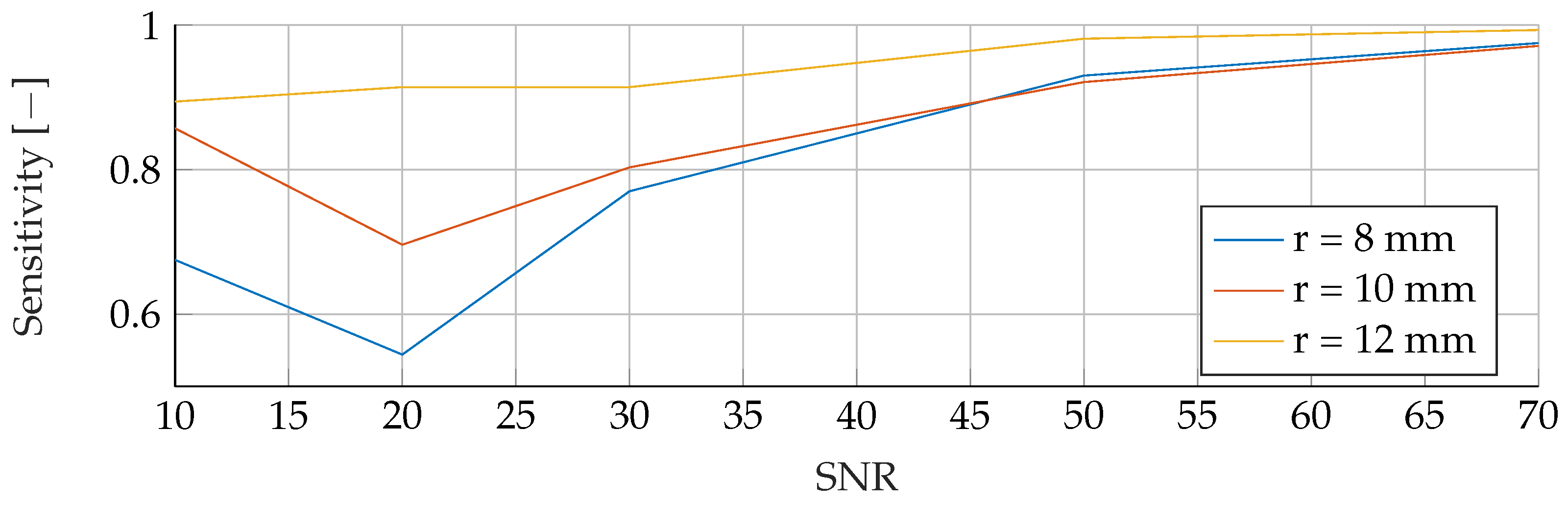
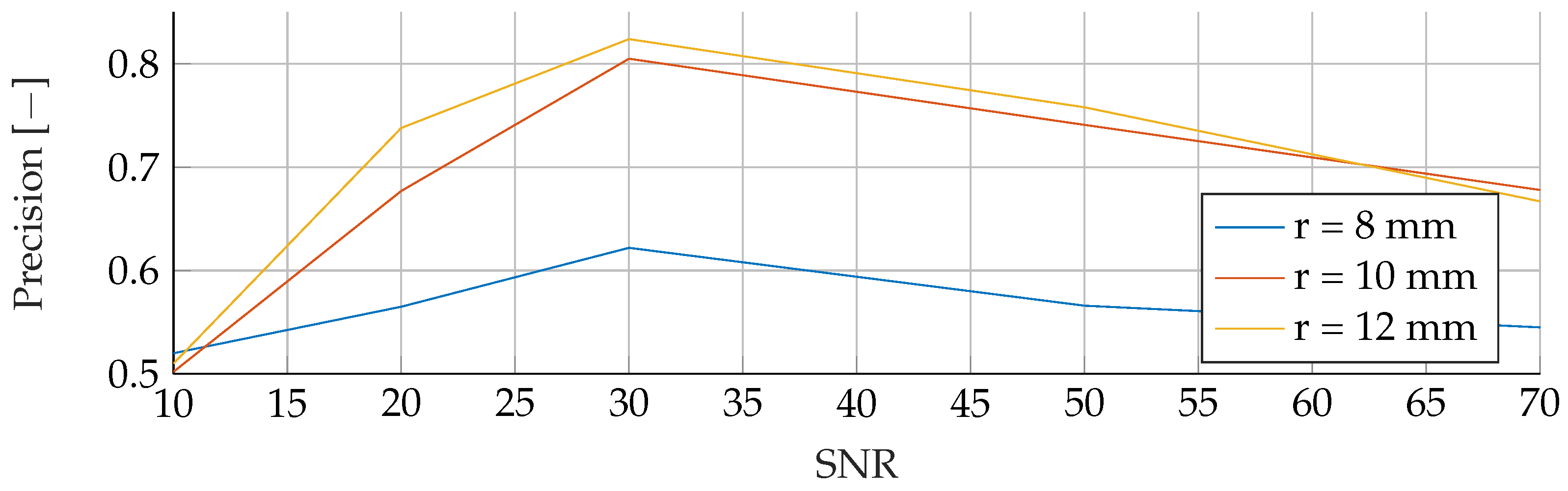
For the evaluation of the different models and data combinations, the F1-Score was chosen. In a real-world setting, it is utterly important to not miss any cases of breast cancer. Further, avoidance of false positives is also really important, as the patient might undergo unnecessary stress.
The F1-Score is calculated from 2 metrics [
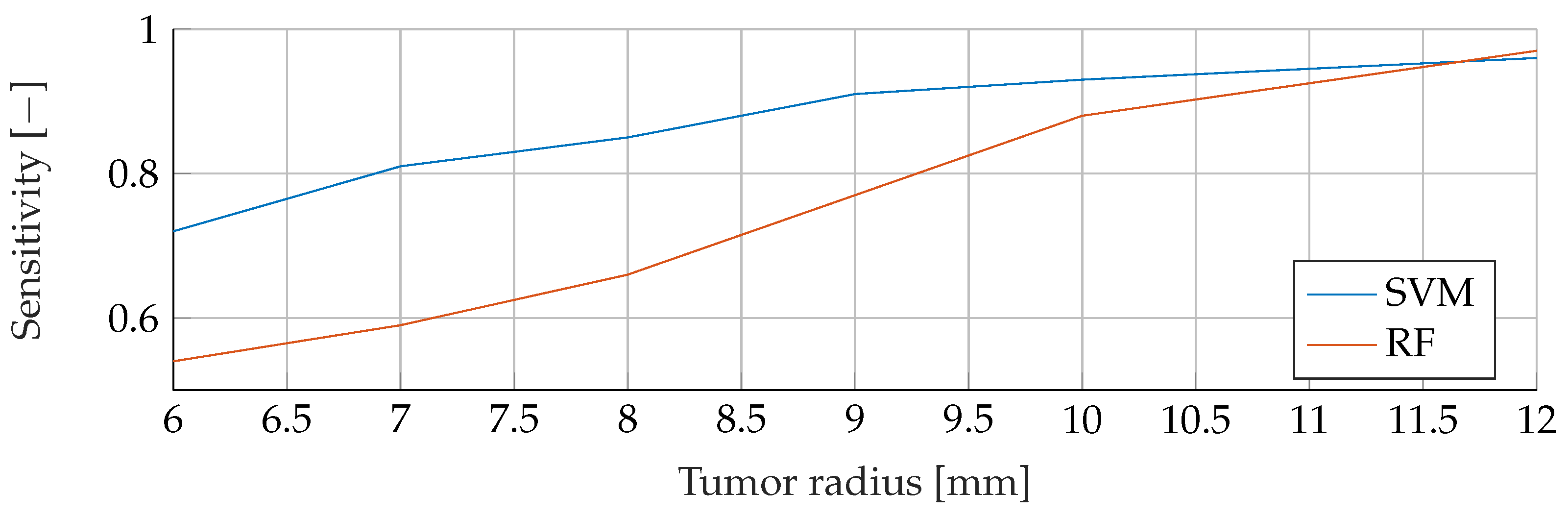
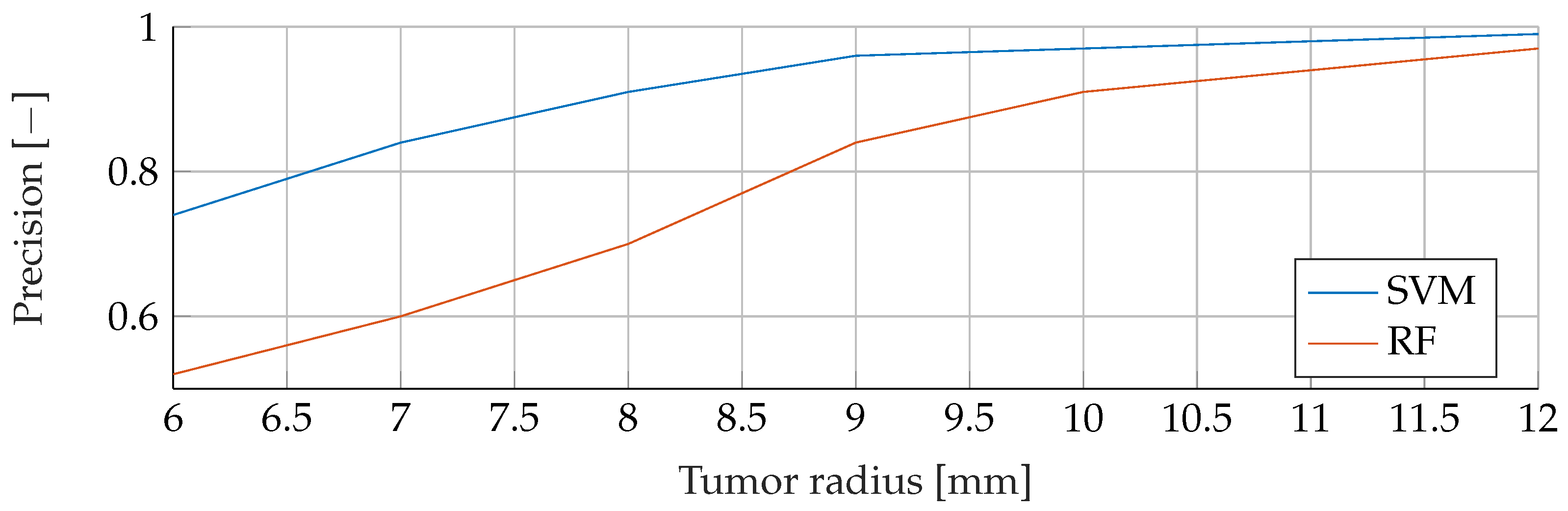
27]. First, the Precision, measures how many positive predictions by the model were correct. Second, the Sensitivity, which measures how many of the positive samples out of the dataset were correctly predicted. Thus, it takes into account wrongly identified as positive. Positive, in this case, means a tumor is present. The F1-Score takes not only into account how many tumors the model classified rightfully as a tumor, but also how many predictions were falsely identified as a tumor.
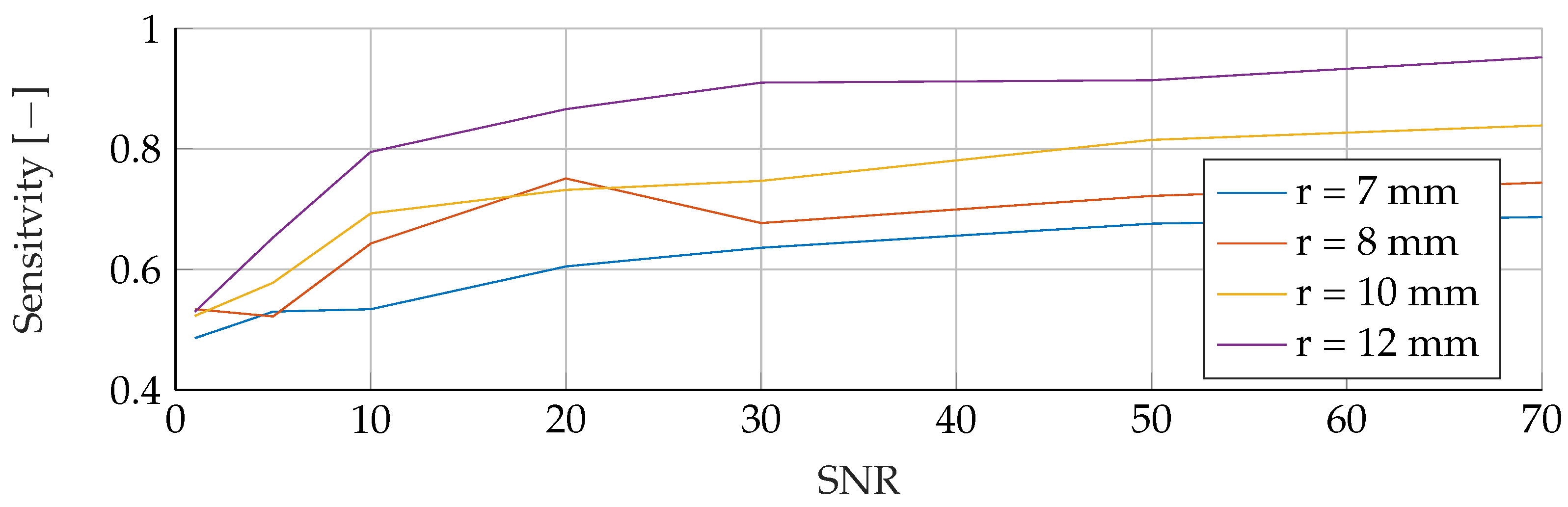
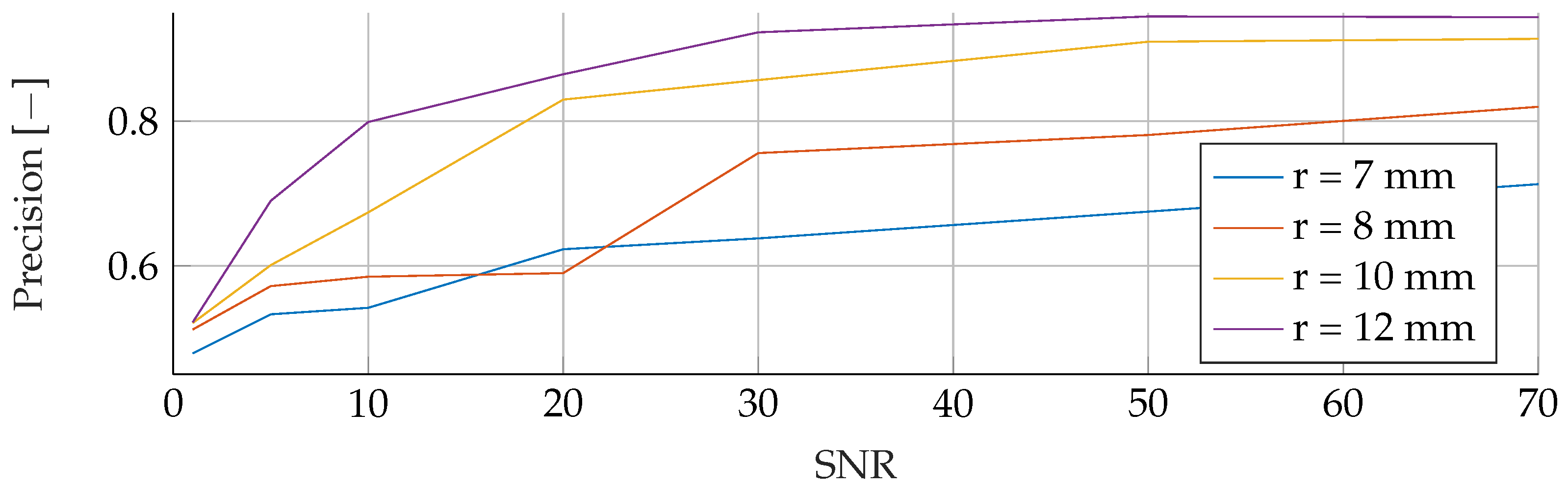
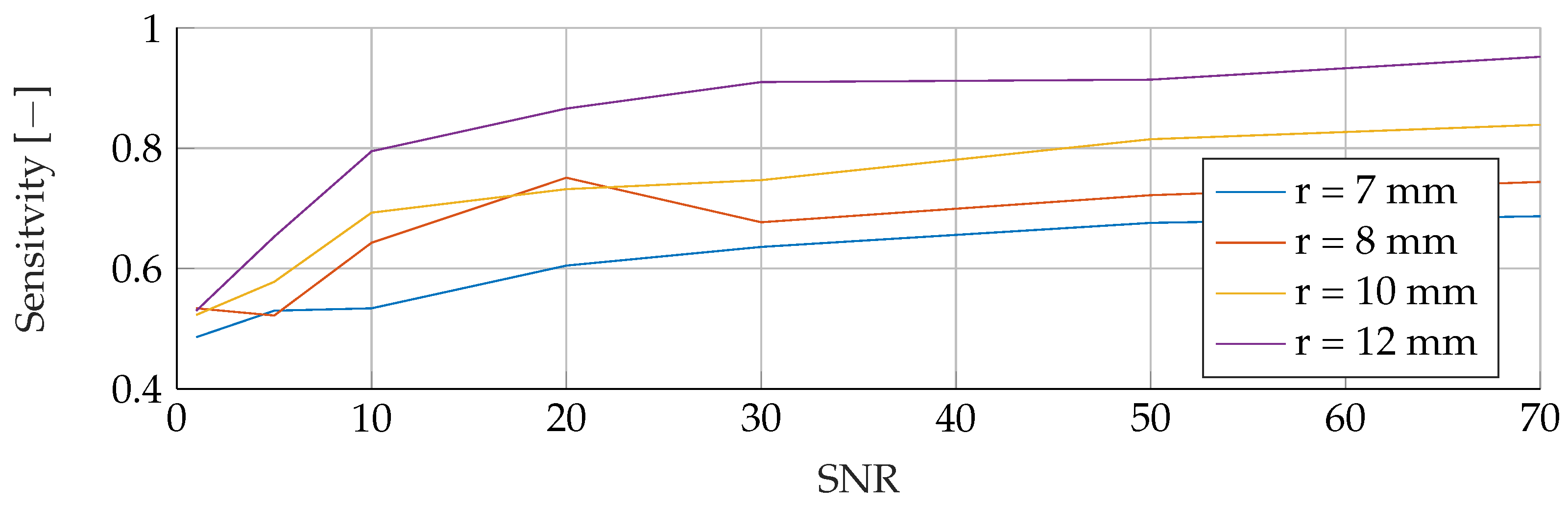
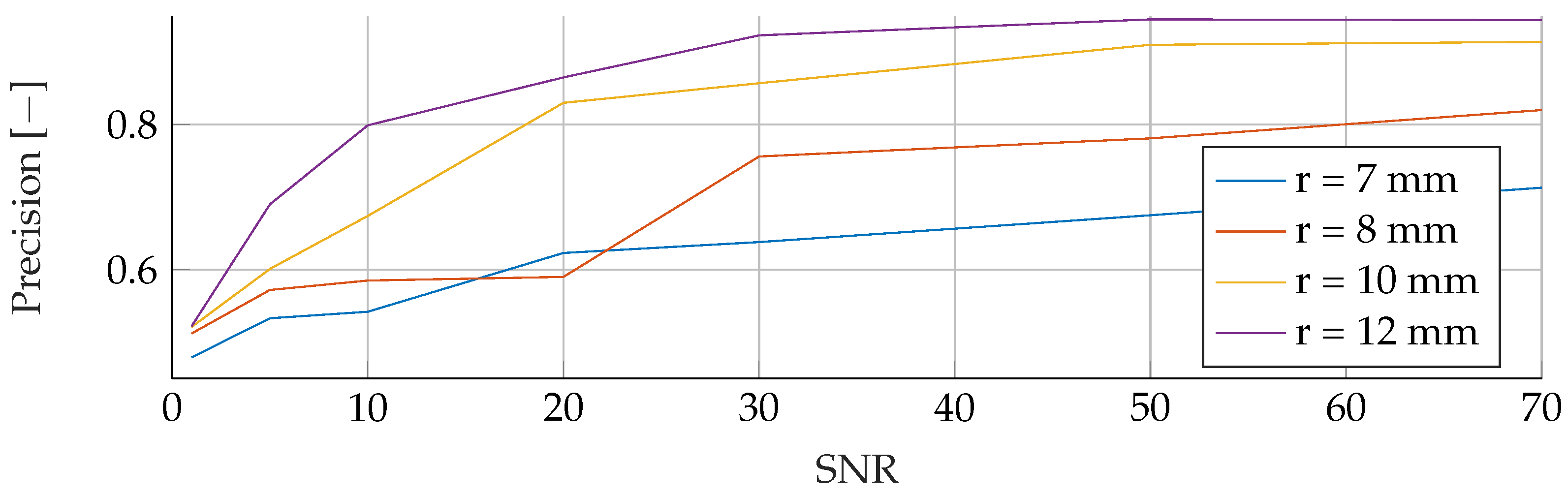
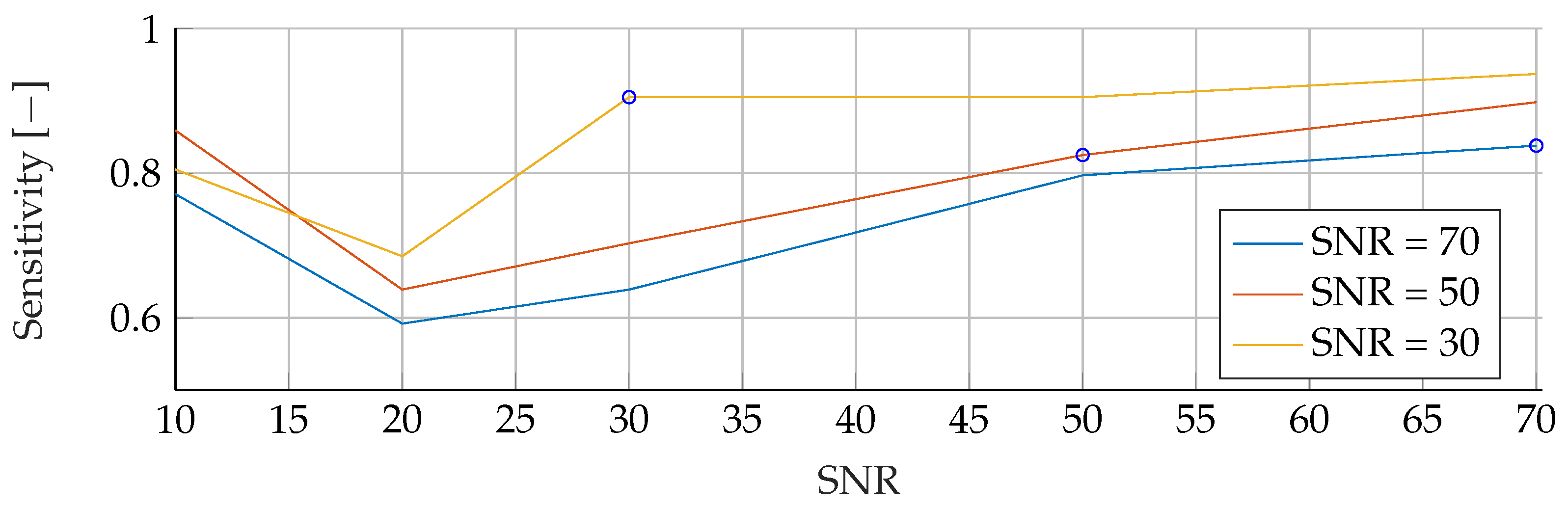
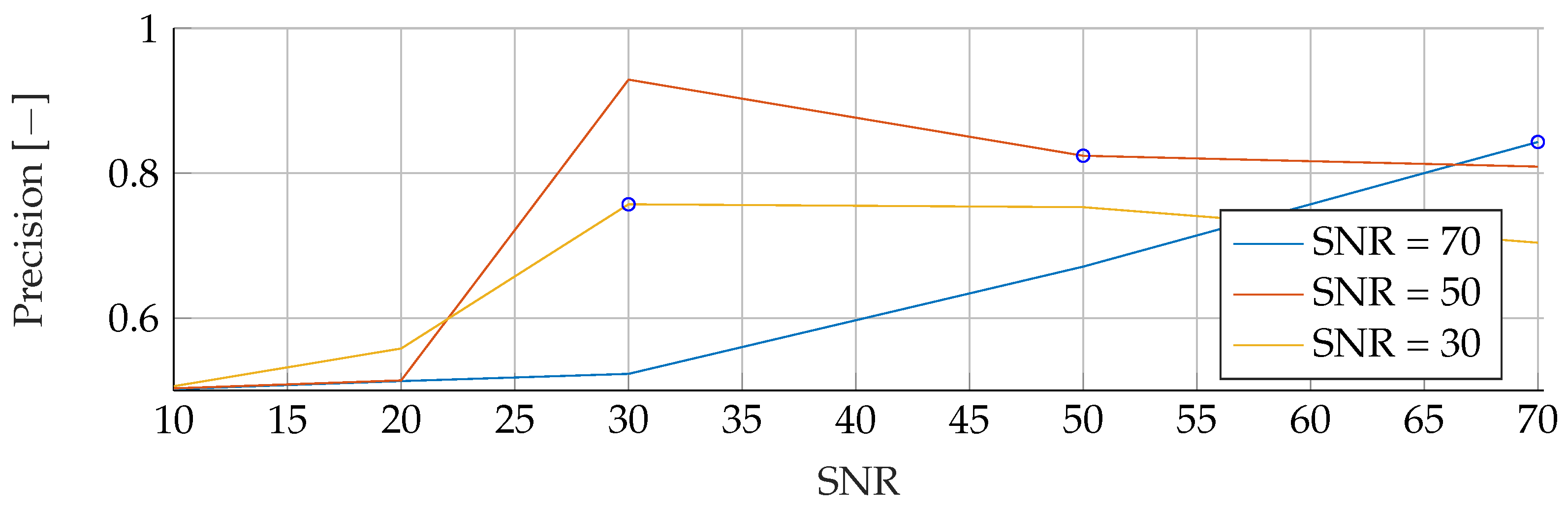
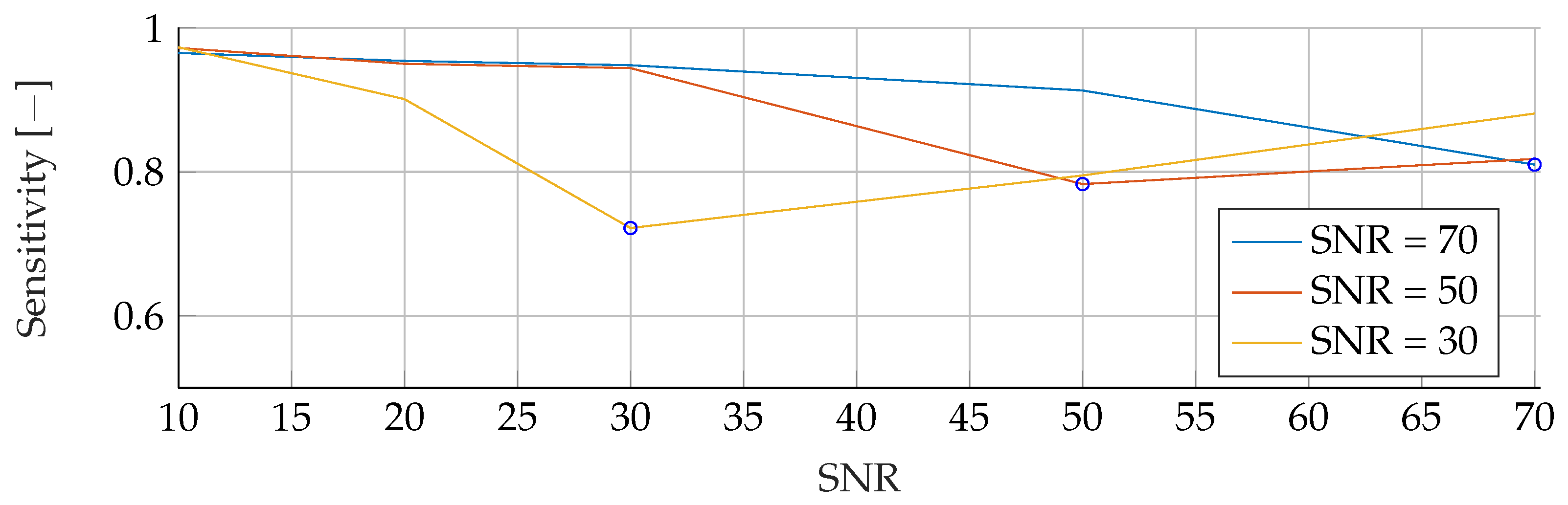
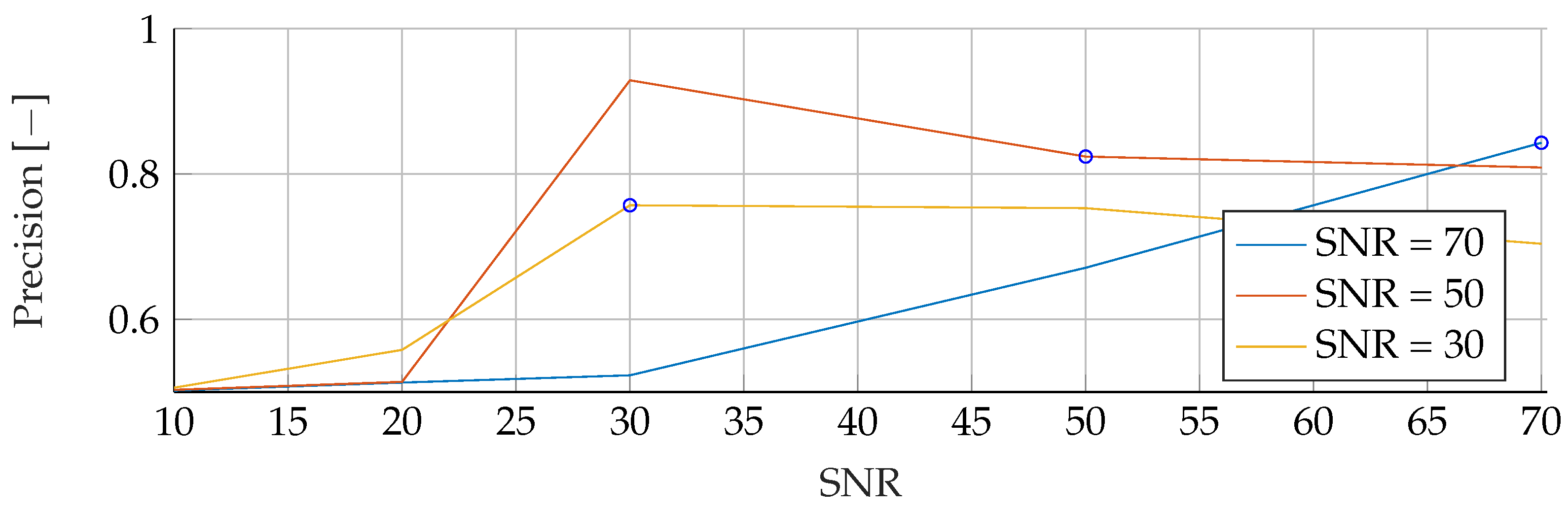
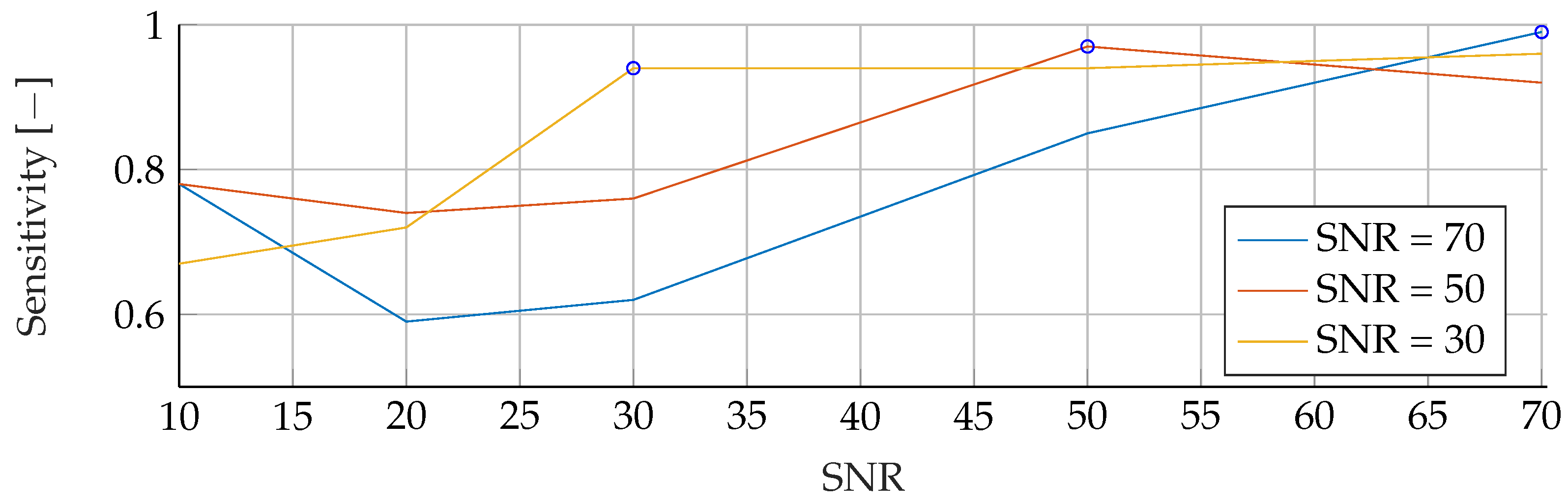
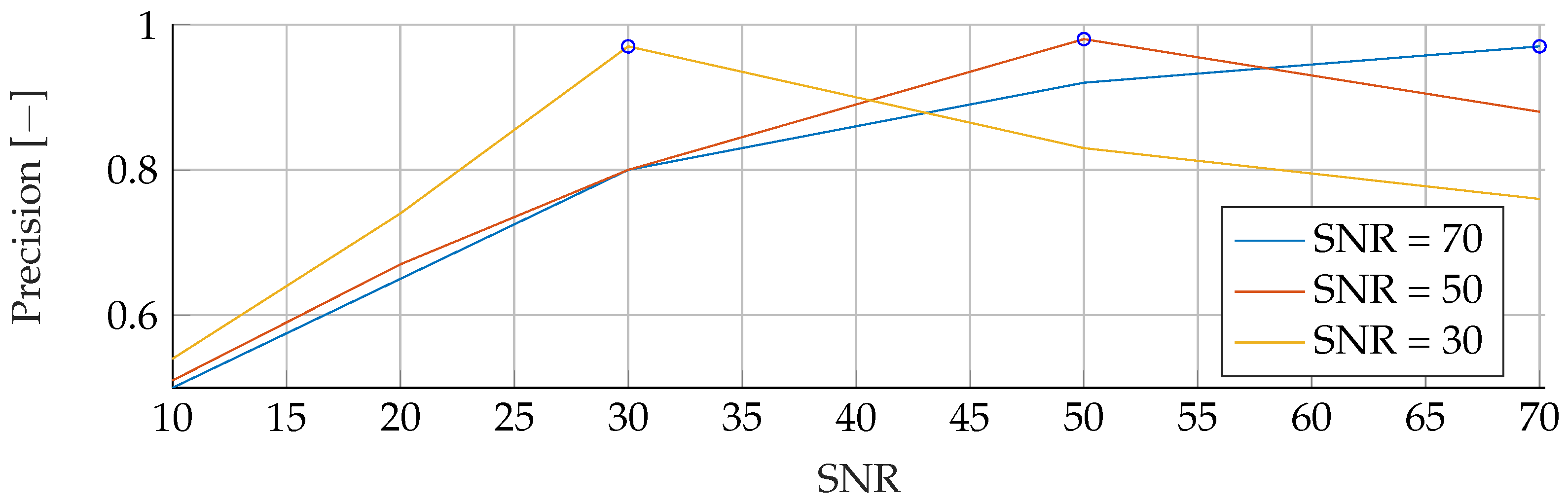
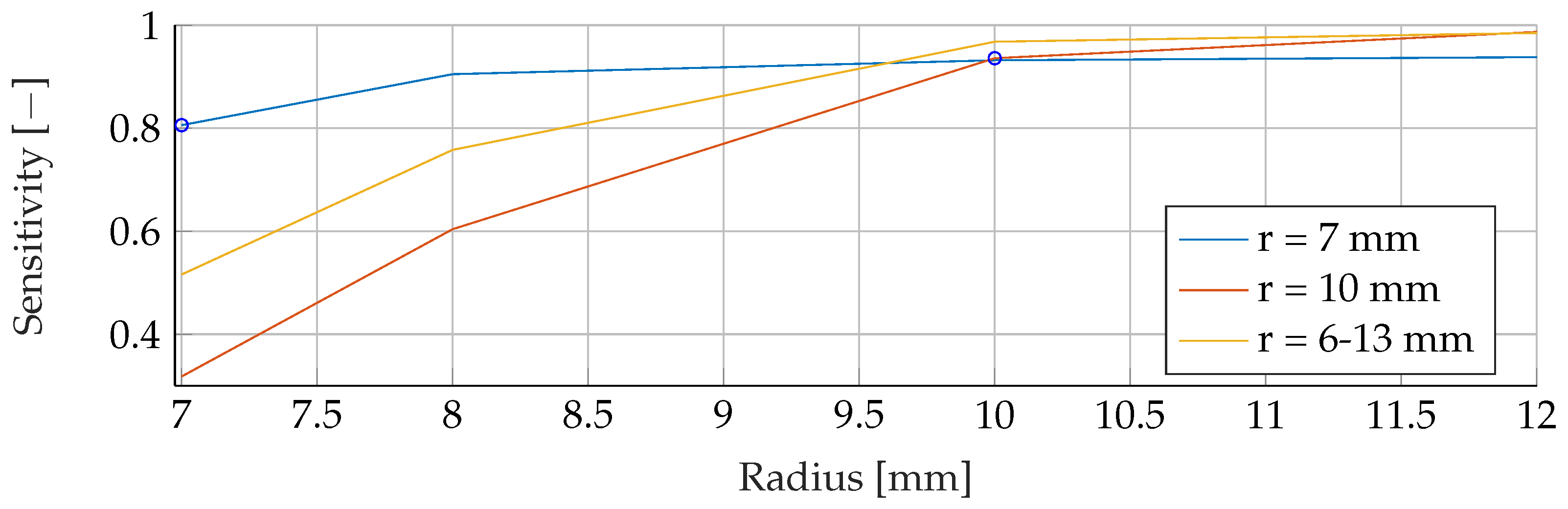
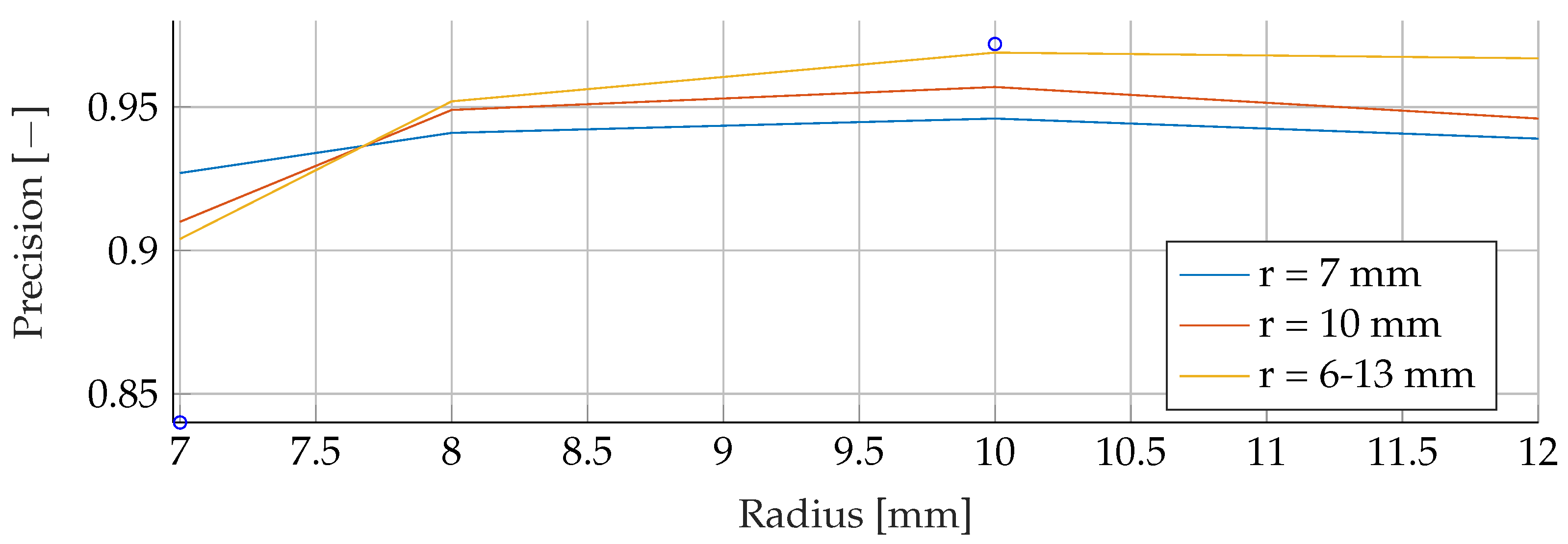
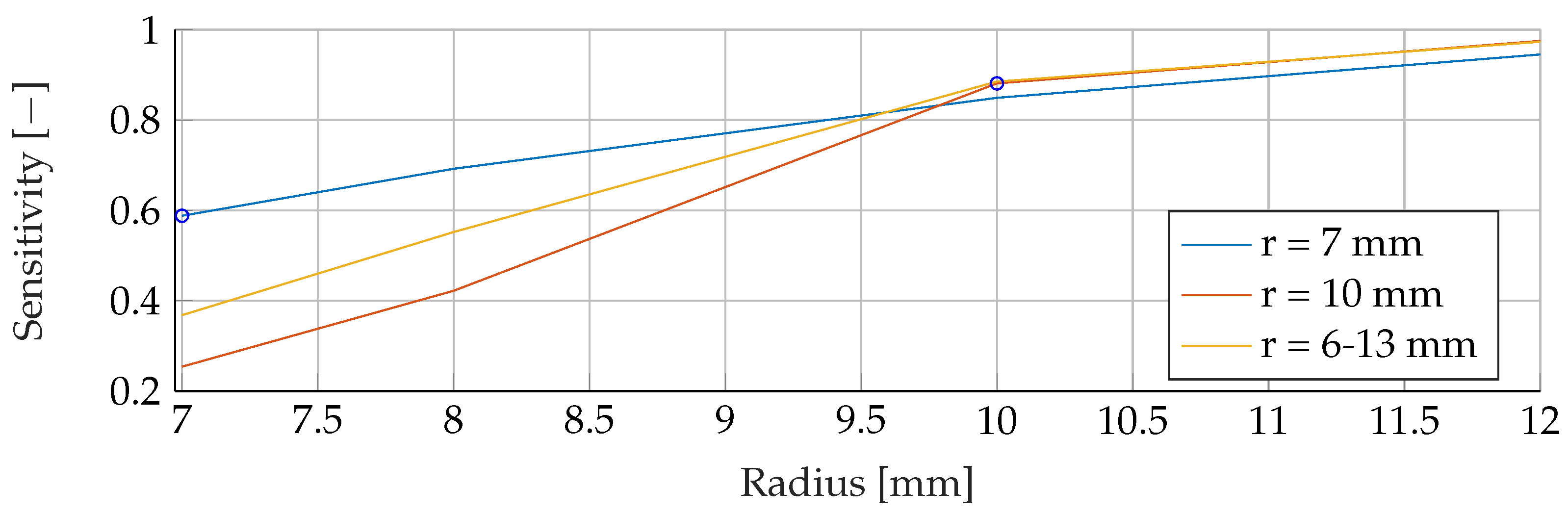
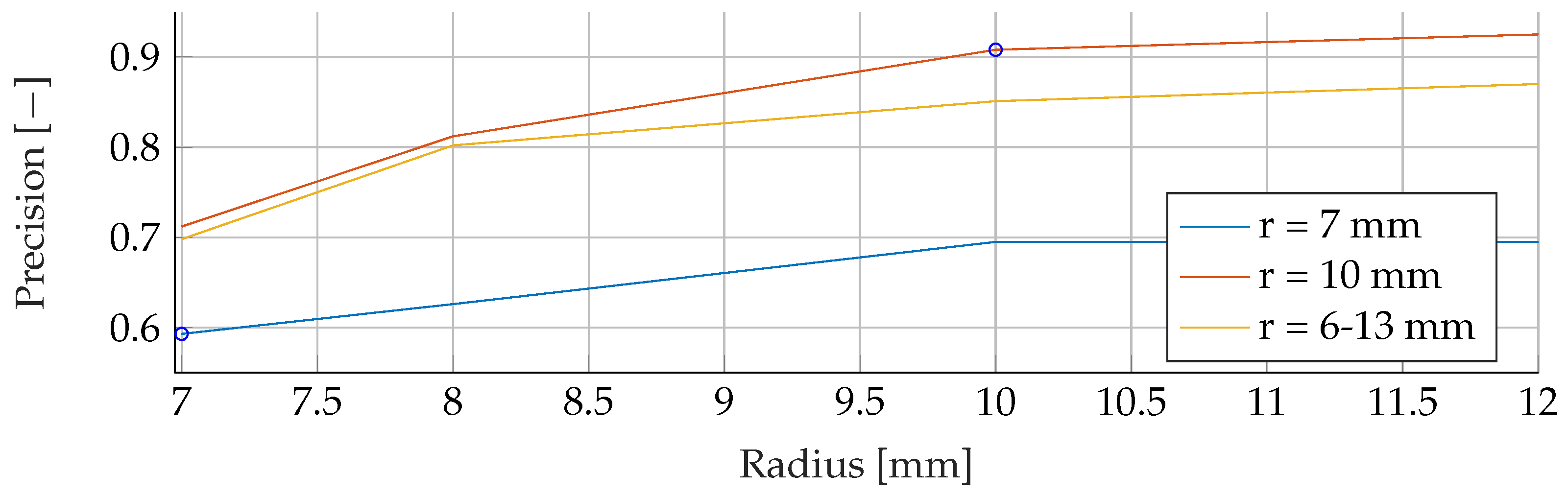
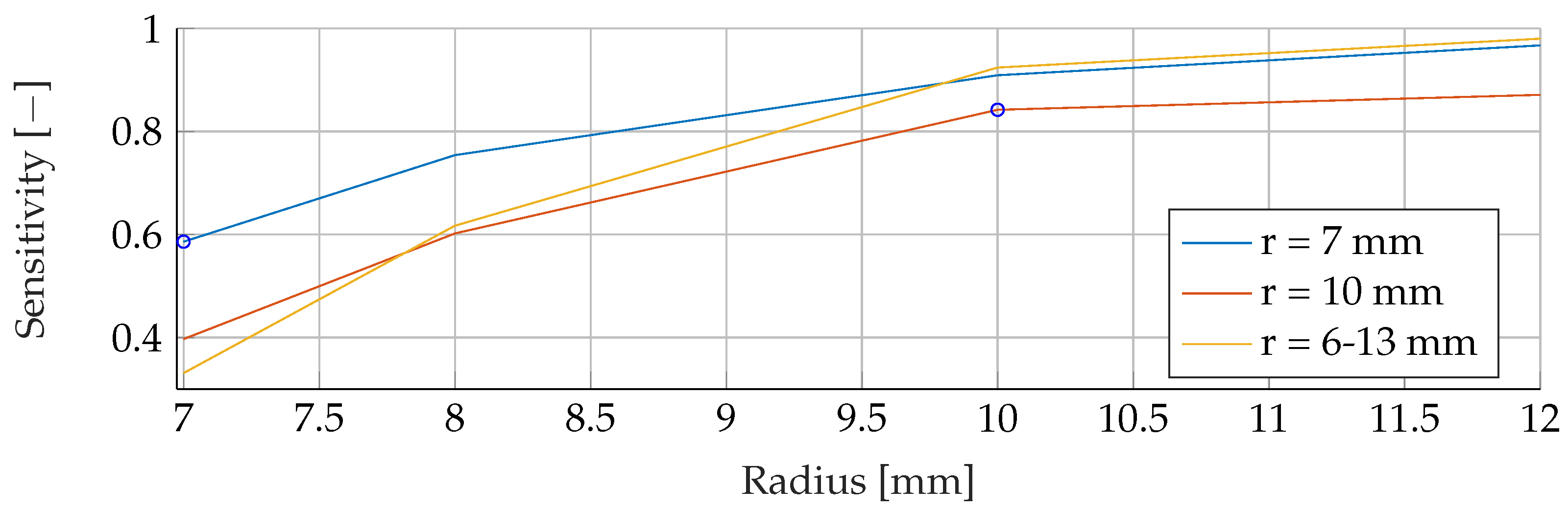
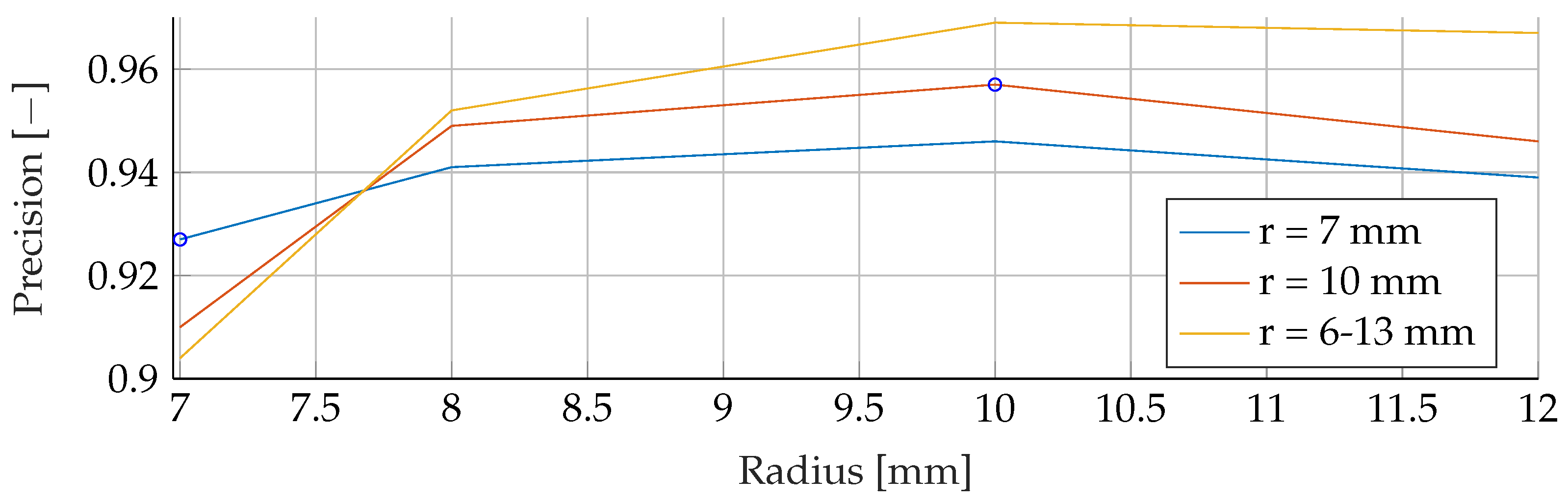
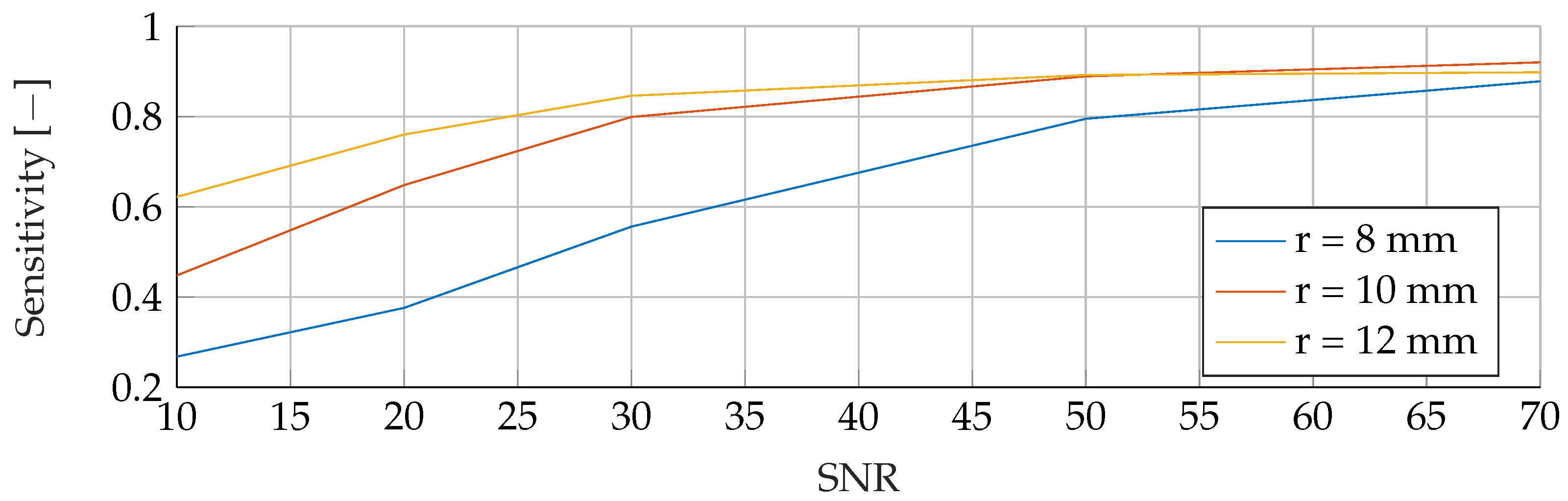
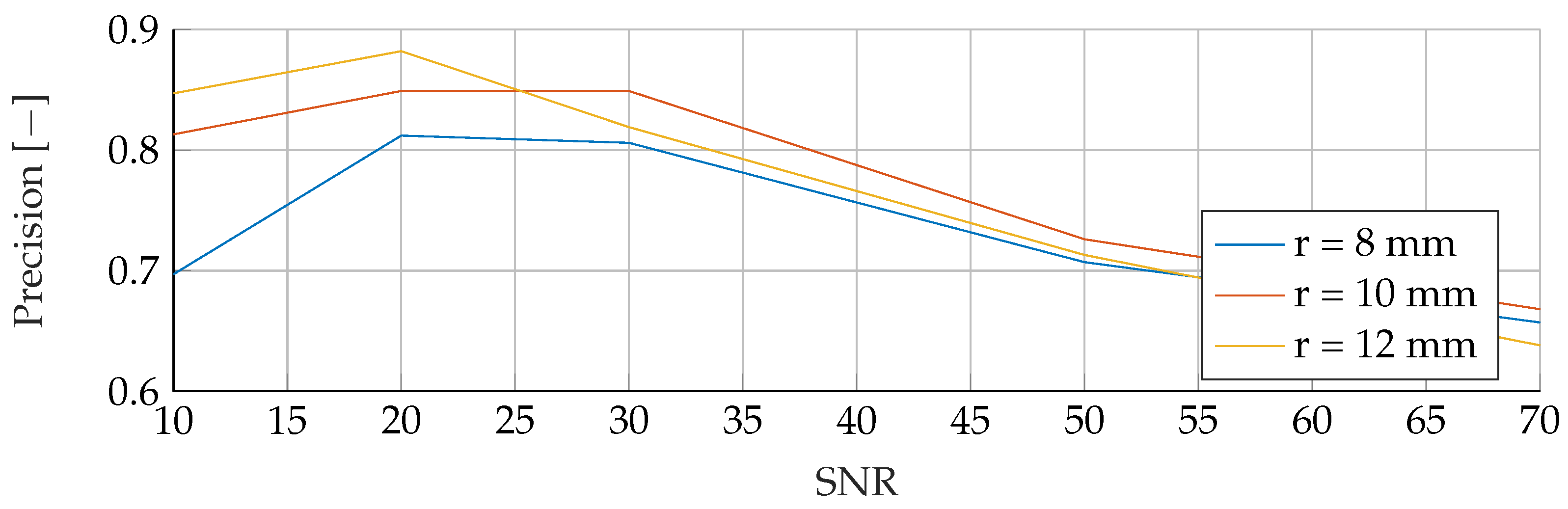
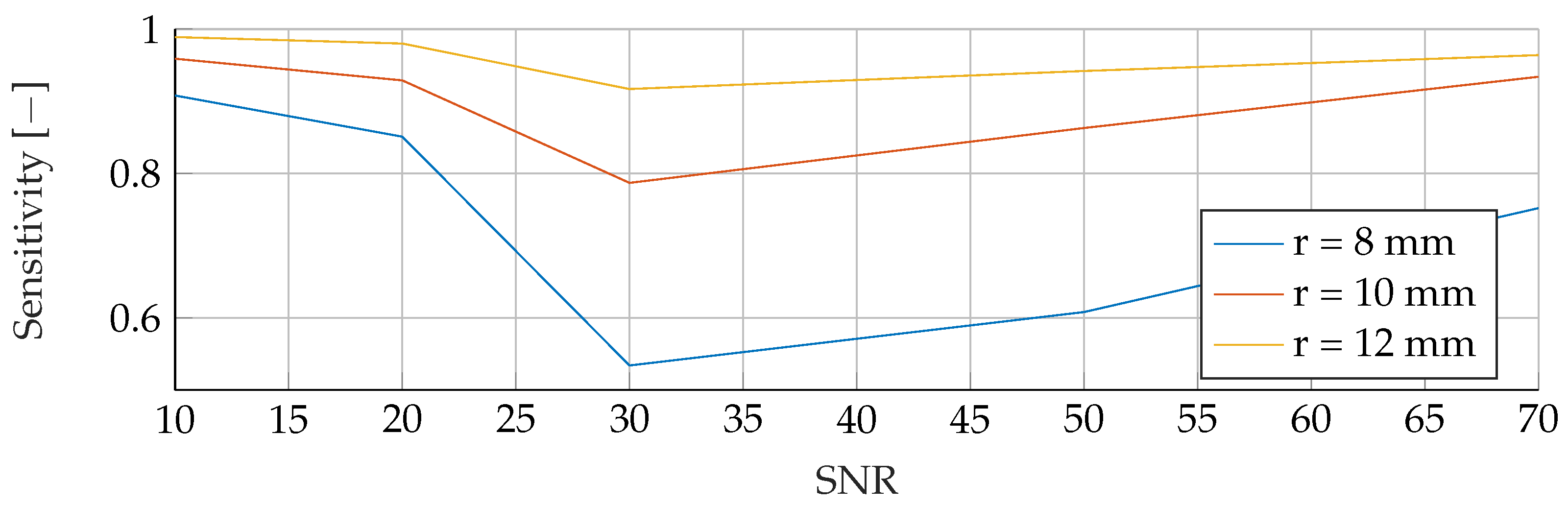
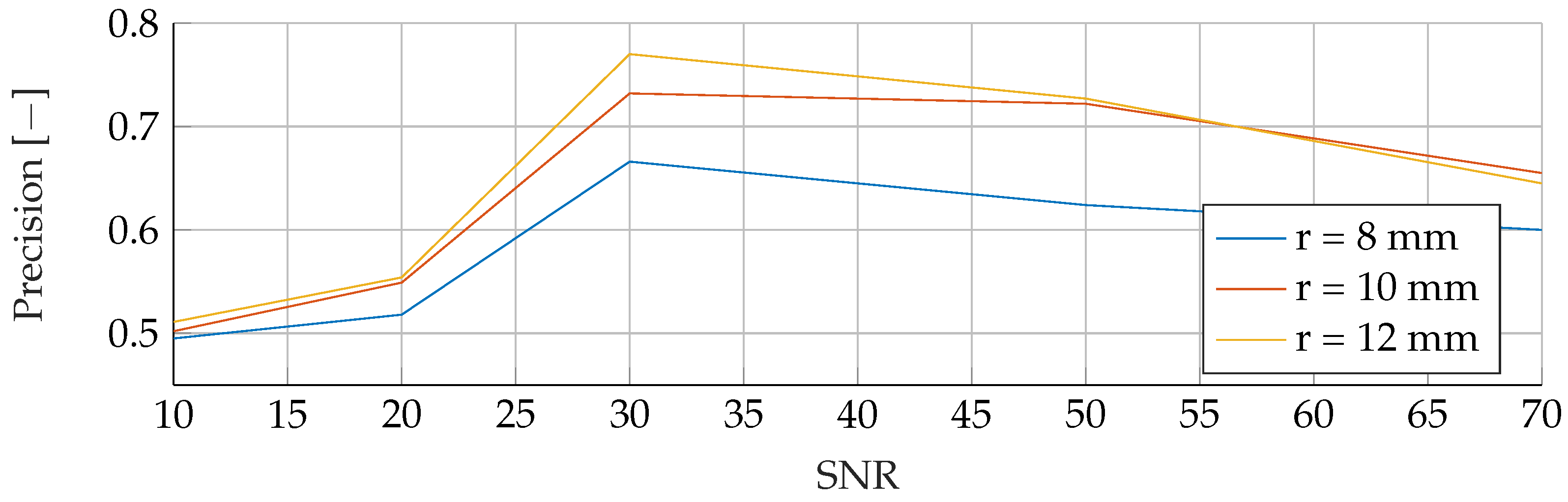
In the
Appendix A, we have provided the Precision and Sensitivity for each figure in the results section of the paper. Readers who are interested in further understanding are kindly asked to see the
Appendix A for further details. We have limited our analysis to the F1-Score, as it is useful for avoiding false positives in the real world. the second reason is that adding additional metrics would increase the length of the paper even further, as we provide combinatorial analysis for different noise setups and tumor radii.
2.7. Evaluation Methodology
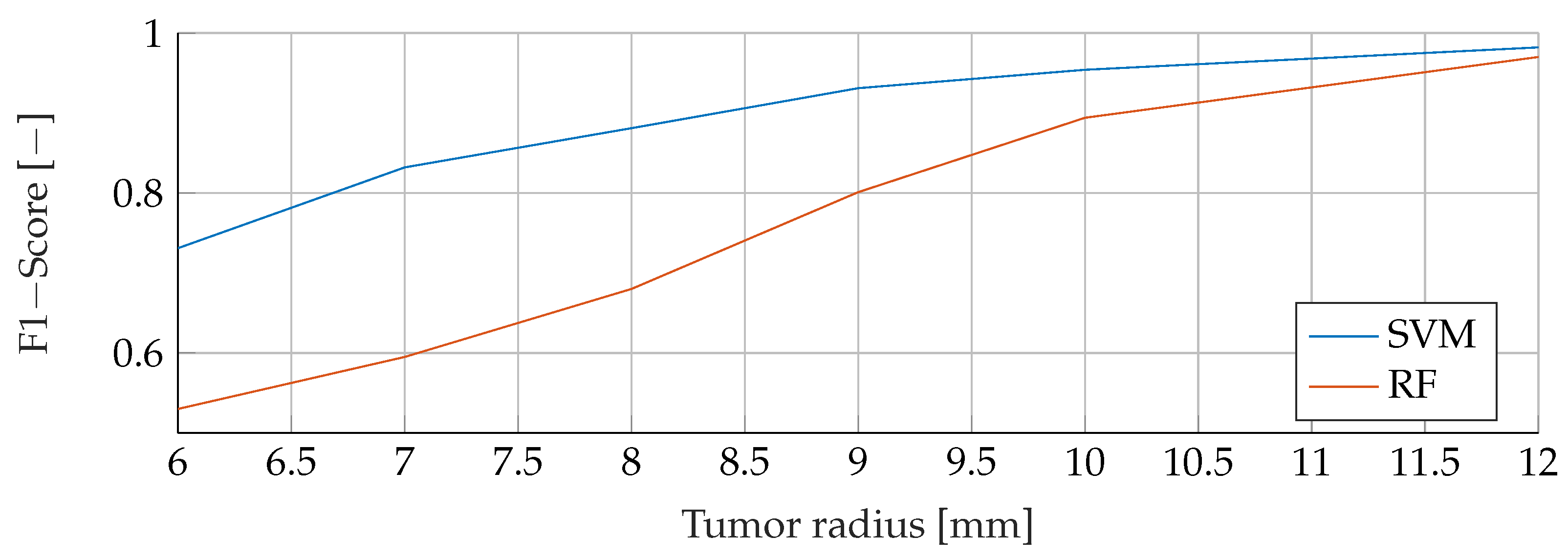
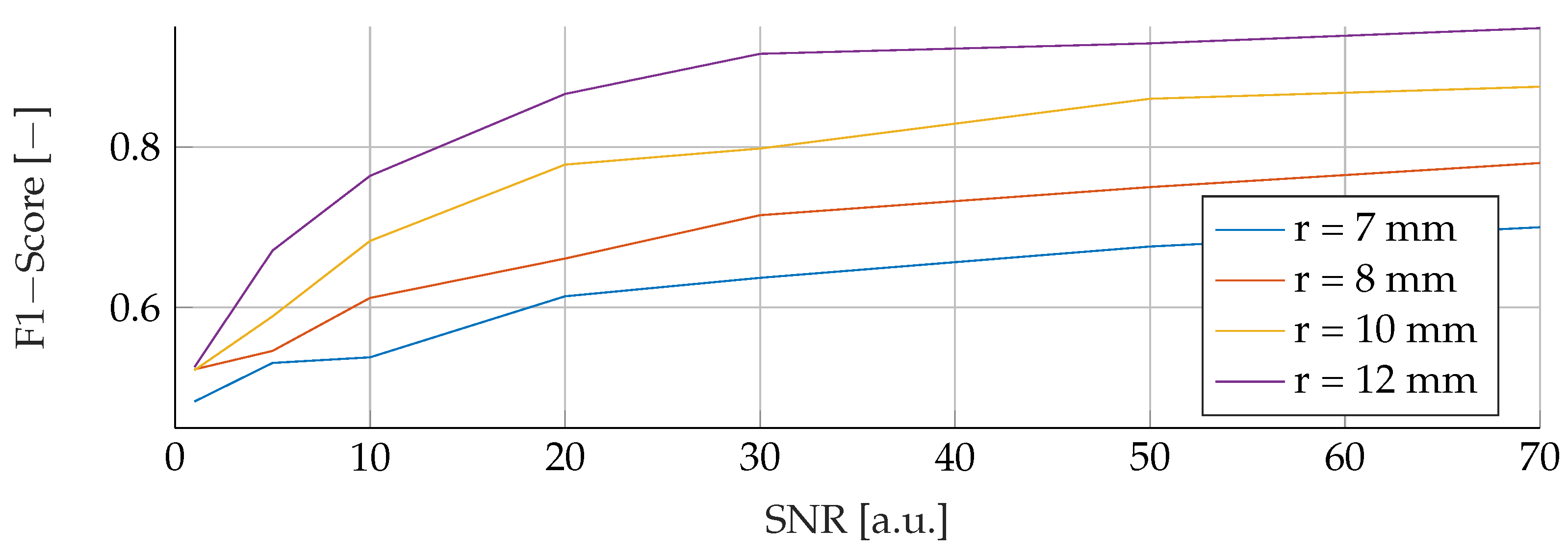
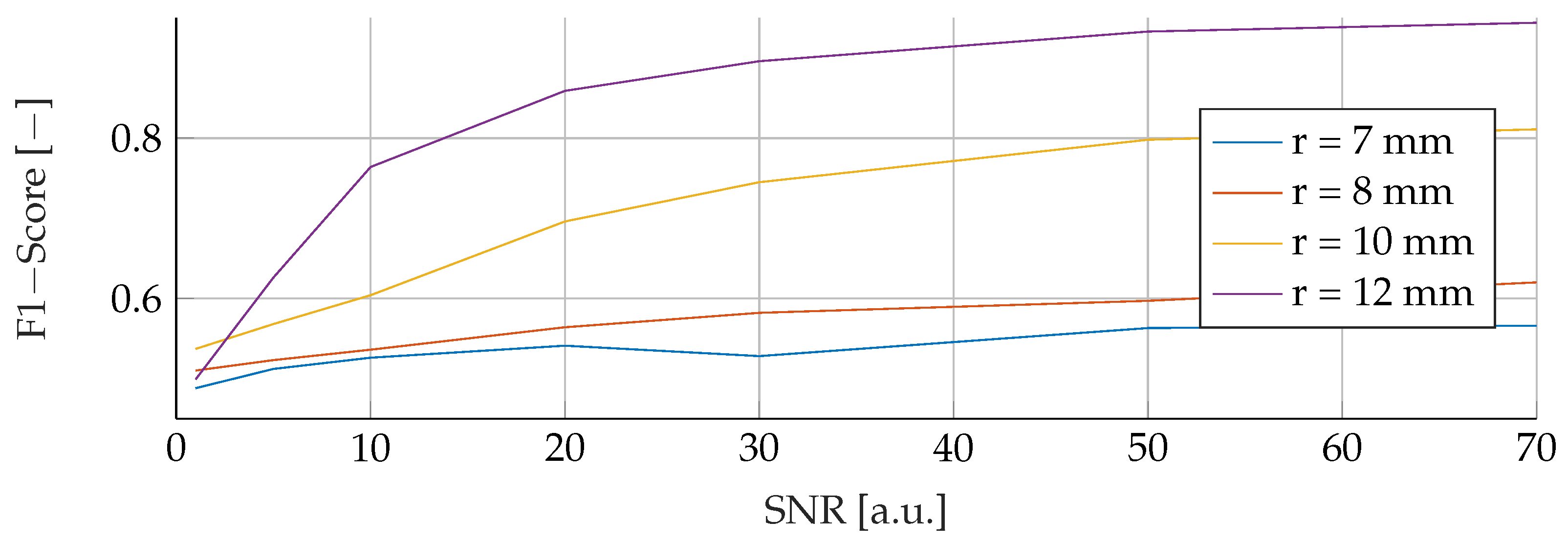
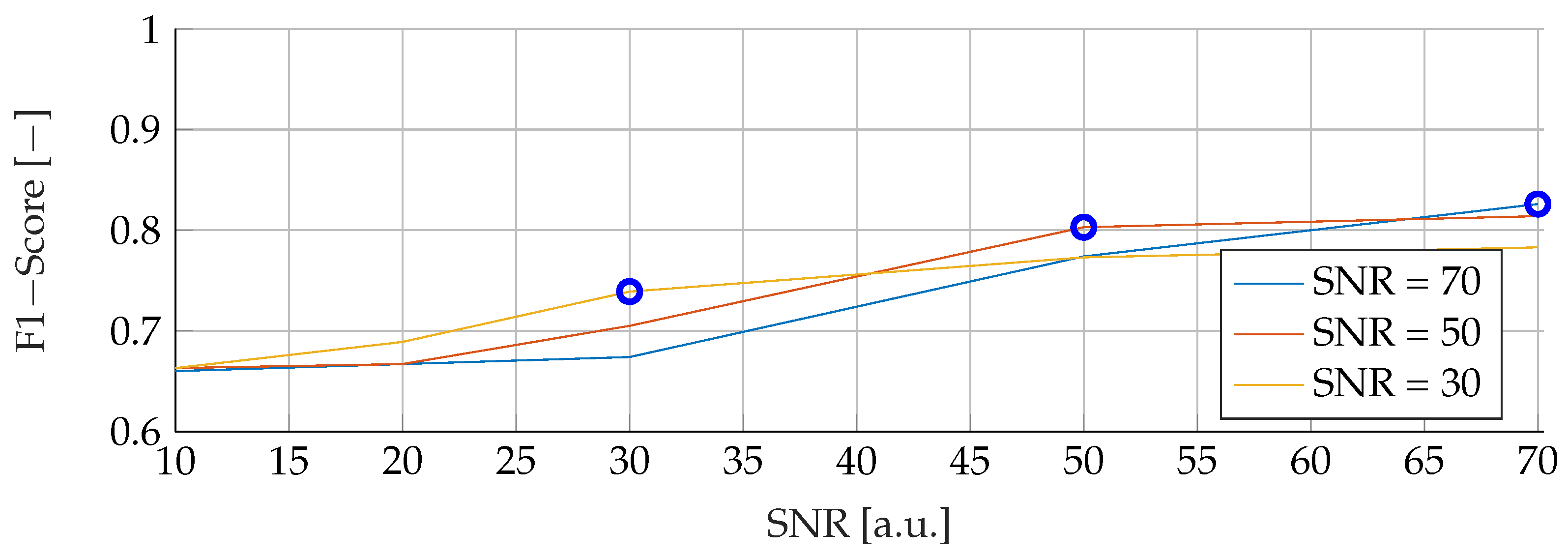
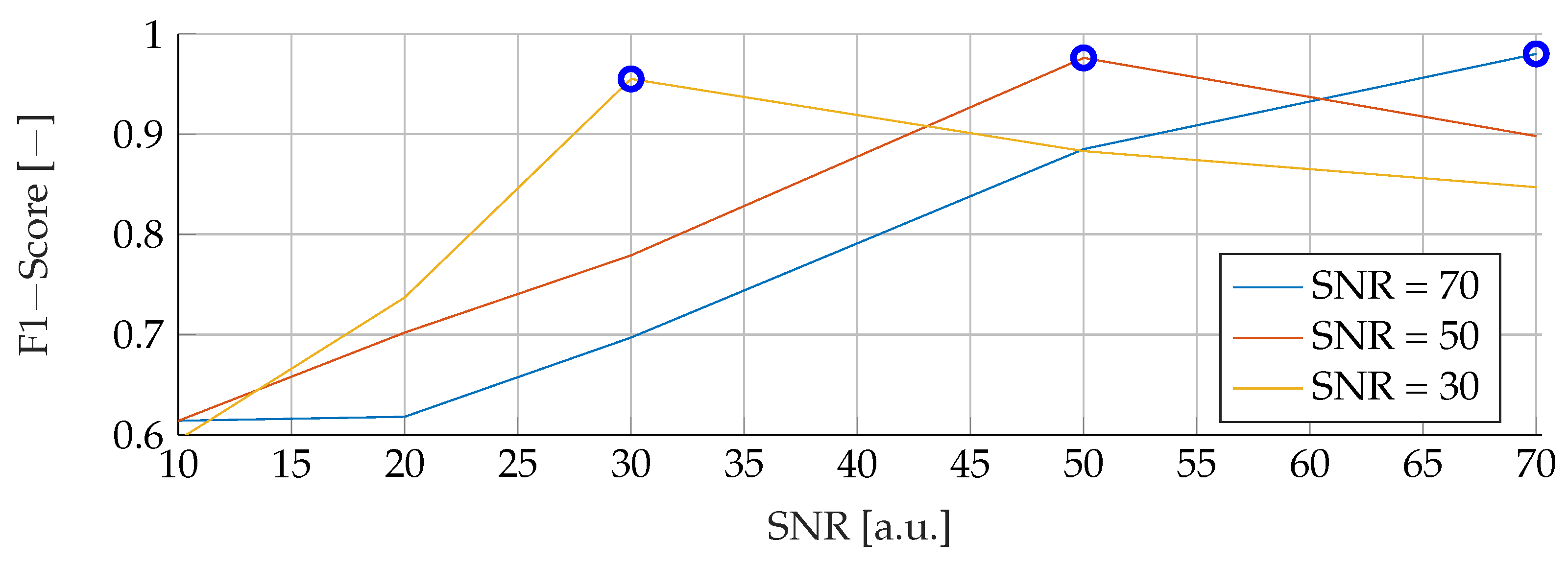
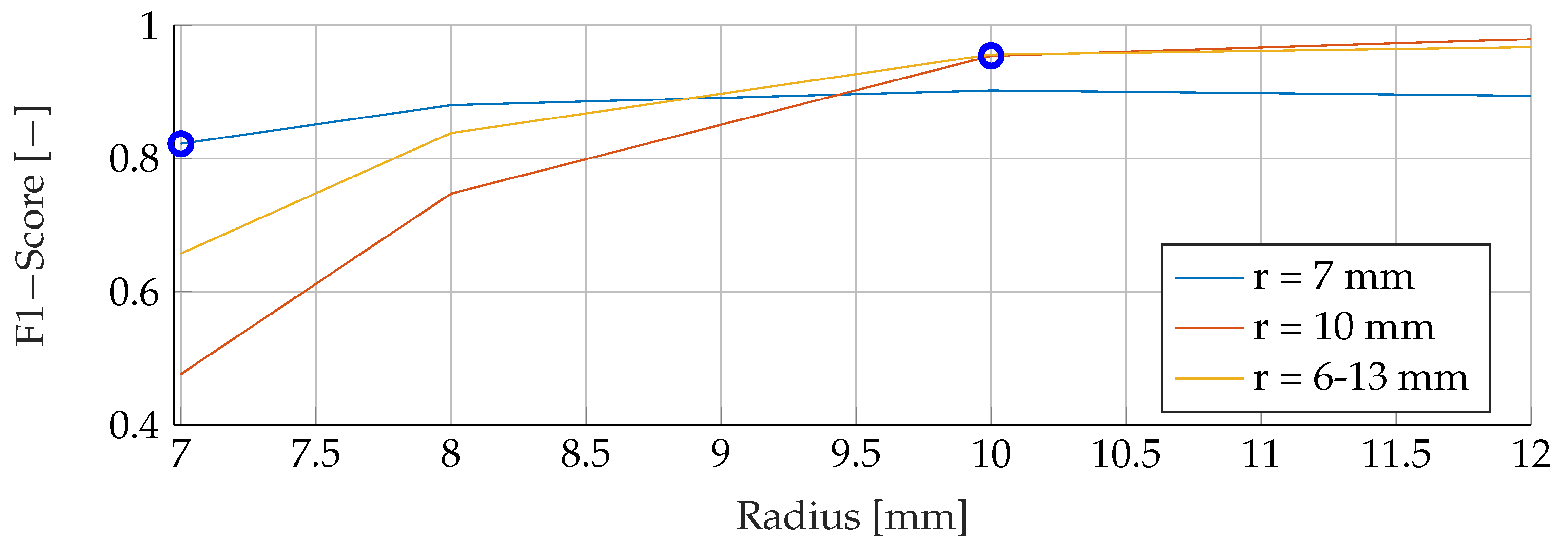
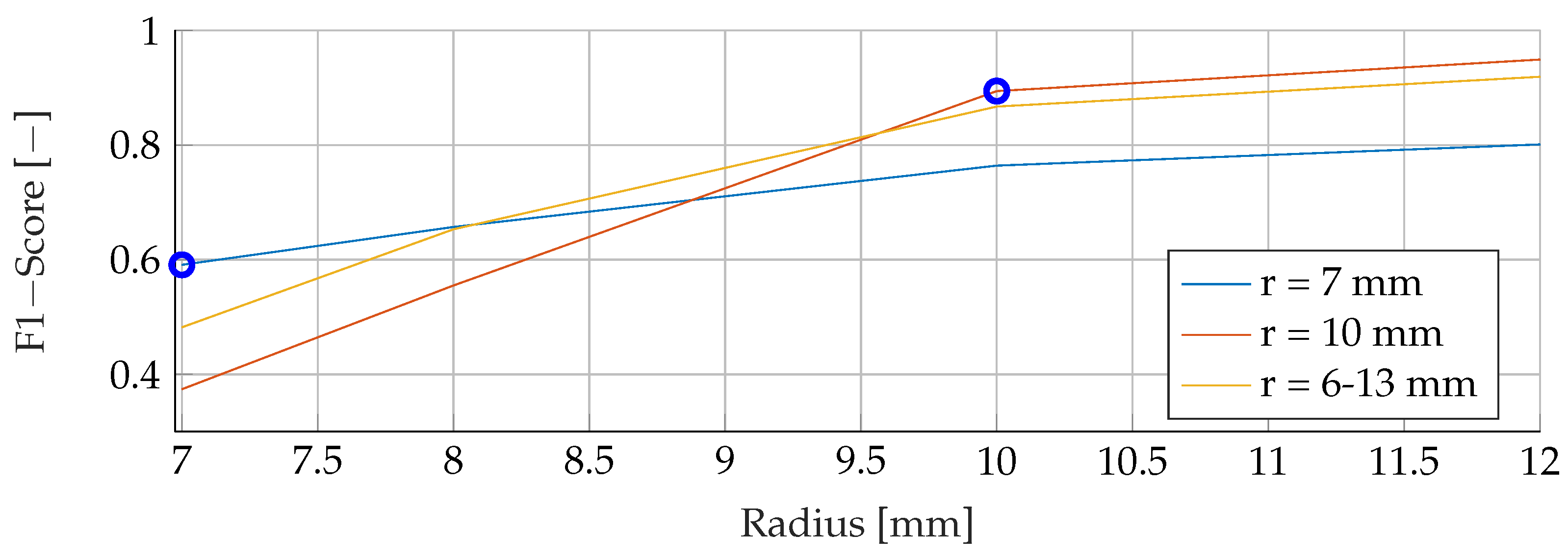
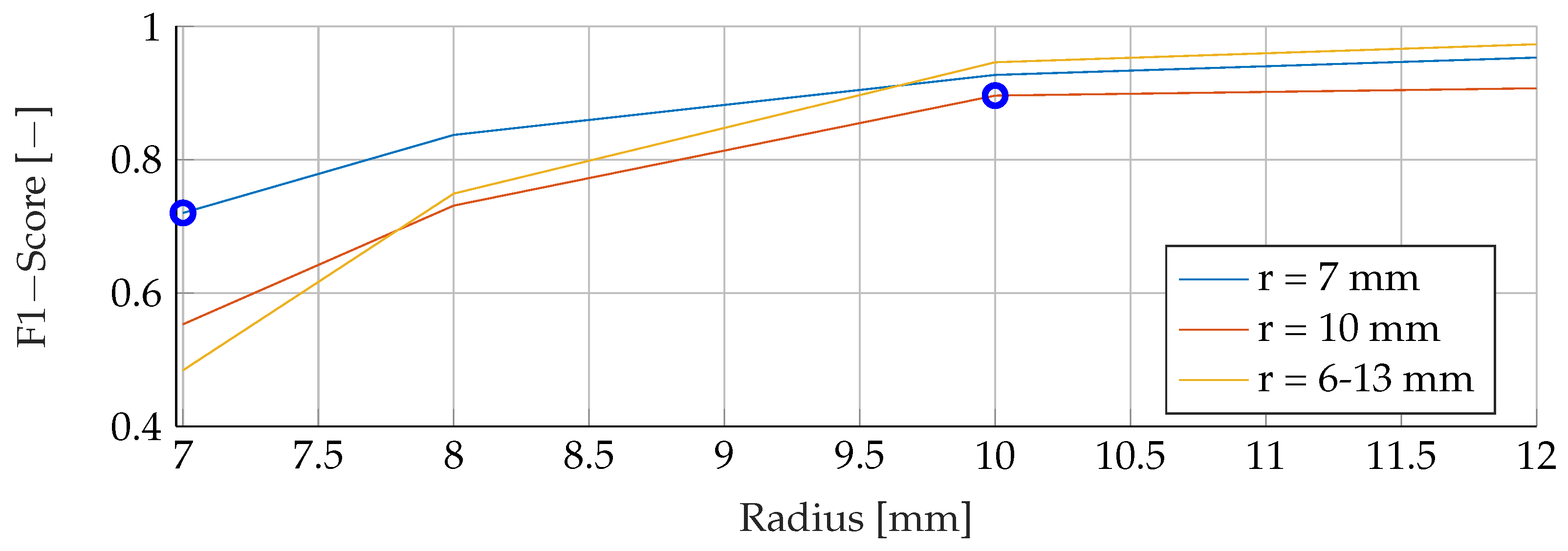
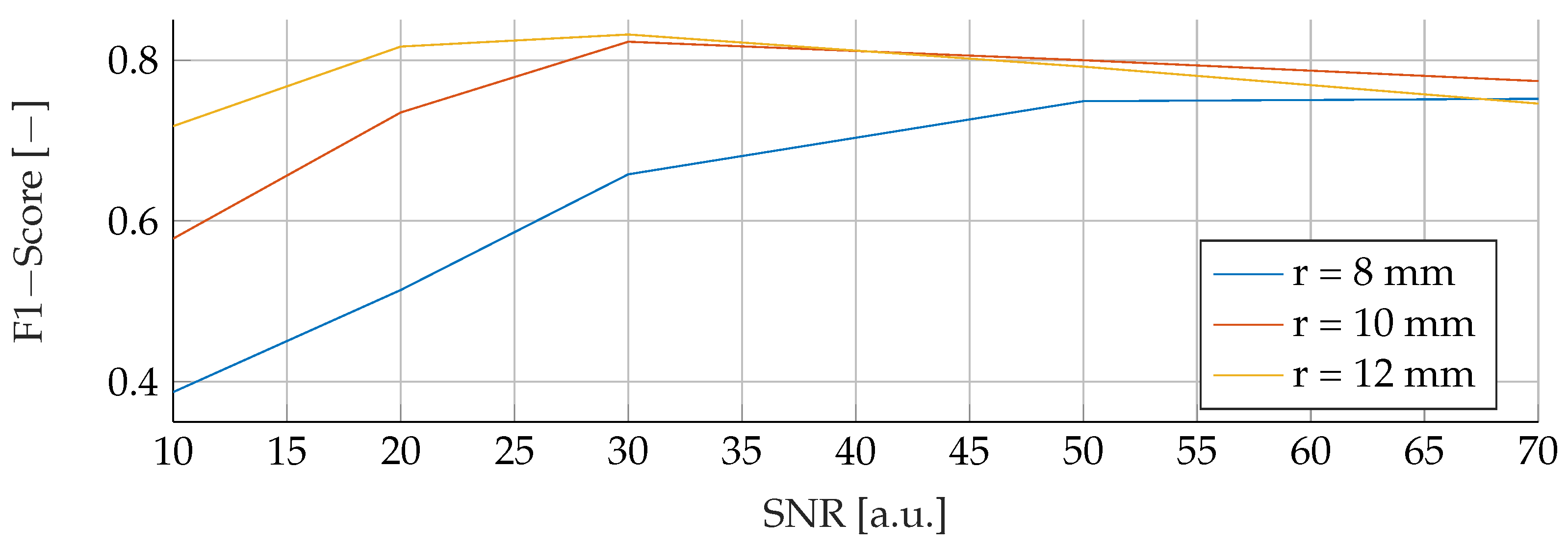
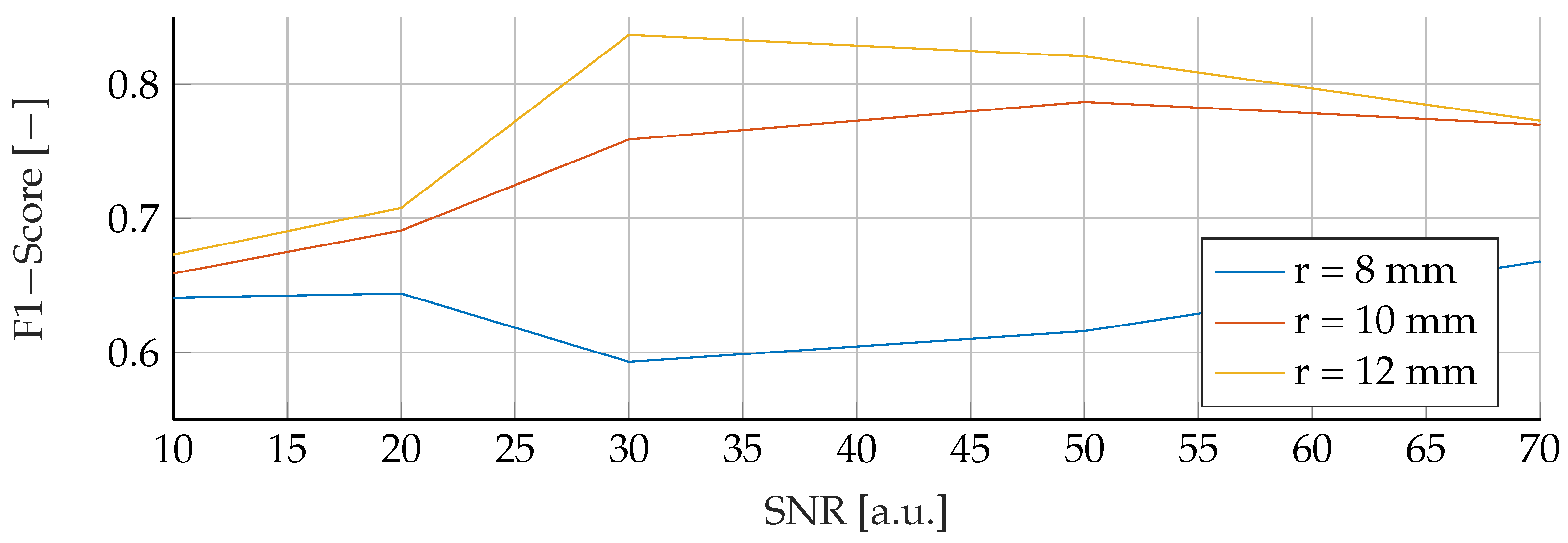
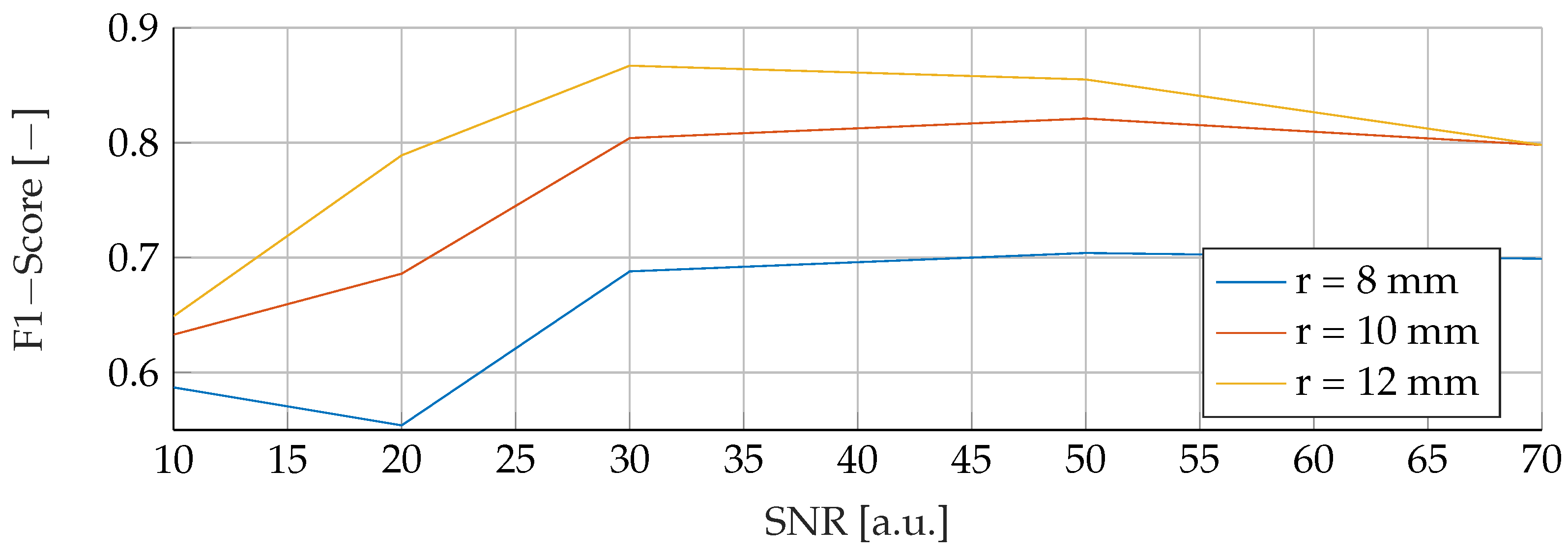
Our proposed models were subjected to a thorough evaluation process across a variety of carefully crafted simulated scenarios. We began by examining the models’ performance in noise-free conditions, focusing on the relationship between tumor radii variations and the resultant F1-Score. To mimic real-world conditions, we introduced noise at various signal-to-noise ratios (SNRs) and assessed the models’ robustness against these perturbations. We also evaluated the stability of the models by training them at specific SNRs and testing them under different noise levels, revealing valuable insights into their adaptability. Furthermore, we conducted an in-depth investigation into the models’ performance when trained with a wide range of mean tumor radii. Finally, we put the models to the test under stringent conditions involving a broad range of tumor radii and an SNR of 30. This rigorous evaluation process aimed to provide a detailed understanding of the models’ capabilities and constraints, thereby presenting a holistic view of their performance across diverse simulated scenarios.
4. Discussion and Outlook
In this study, we evaluated three different classification models for breast cancer detection using EIT images. We found that all three models were able to produce meaningful results for data outside the trained distributions.
RFs were a robust choice under varying noise conditions, as they showed exceptional resistance to variations in SNR. On the other hand, SVMs showed resilience to changes in tumor size, indicating their potential for the detection of tumors of different sizes.
However, it is important to note that when the SNR drops too low, all models become unreliable in their predictions. This underlines the fact that for accurate and reliable predictions, a certain level of SNR must be maintained.
Solely based on score, SVMs would be the choice for the prediction of breast cancer. They consistently achieved the best F1 scores in all tests, indicating their superior performance in terms of precision and recall. Furthermore, SVMs performed well even in scenarios involving small tumors, which is critical for detecting breast cancer at an early stage.
Furthermore, when considering real-world applications, the adoption of RFs may be favored due to their enhanced interpretability, allowing clinicians to better understand the model’s decisions and incorporate their own expertise. RFs provide feature importance analysis and transparency by examining decision boundaries, which are critical for promoting trust and informed decision-making in the medical domain. However, further research is needed to comprehensively evaluate the interpretability of RFs compared to SVMs and ANNs in different clinical contexts.
Despite these promising results, our study has some limitations. One such limitation is the fixed breast size used in our simulations. In reality, the size of the breast varies considerably from person to person, and this variation could potentially affect the potentials at the electrodes. Future research should consider including differently shaped breasts in the simulations to account for this variability.
Another area for improvement is the pre-processing of the voltages. Our study suggests that reducing dimensionality can improve the performance of prediction models by making them more robust and requiring fewer parameters for training. This may be an important consideration for future studies aimed at optimizing the performance of models used to interpret EIT images.
As of now, an EIT-based setup is behind in minimal size compared to classical screening techniques like mammography [
28].
In conclusion, our study provides valuable insights into the use of classification models for the interpretation of EIT images in the detection of breast cancer. Although further research is needed to address the identified limitations, our findings represent a step forward in improving early detection and ultimately survival rates for breast cancer patients.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}