3.1. Ant Colony Optimization Metaheuristic
ACO has been designed for graph problems and, thus, it can be applied directly to the TSP, which is modeled as a weighted graph [
24,
25,
26]. All arcs are associated with a pheromone trail value
and some heuristic information value
. Initially, the pheromone trails are assigned with equal values, i.e.,
, where
is the initial pheromone value. The heuristic information at environment
T is defined as
. A colony of
artificial ants is initially positioned in different randomly selected cities. Each ant
k will select the next city to visit based on the existing pheromone trails
and the defined heuristic information
of arc
. Each ant will visit all cities once, in order to represent a feasible DTSP solution. Then, the pheromone trails associated with the
solutions constructed by the ants will be reinforced according to their quality value.
3.1.1. Constructing Solutions
With a probability
, where
is a parameter of the decision rule, the
k-th chooses the next city
j from city
i, from a probability distribution that is defined as follows:
where
and
are the existing pheromone trail and heuristic information values, respectively,
is the set of cities that ant
k has not visited yet, and
and
are the two parameters that determine the relative influence of the pheromone trail and heuristic information, respectively. With probability
, ant
k chooses the next city, i.e.,
j, with the maximum probability as follows [
27]:
This selection process will continue until each ant has visited all cities once and only once, as shown in Algorithm 1. The constructed solutions will be evaluated based on Equation (
3).
3.1.2. Updating Pheromone Trails
The pheromone update procedure consists of two parts: (1) pheromone evaporation, in which all pheromone trails are reduced by a constant rate; and (2) pheromone deposit, in which ants increase the pheromone trails associated with their constructed solutions.
In this work, the pheromone policy of the
Ant System (
AS) algorithm is used, which is one of the best-performing ACO variants [
28,
29]. Firstly, in the pheromone update procedure of
AS, an evaporation is performed on all pheromone trails as follows:
| Algorithm 1 Construct Solutions (t) |
- 1:
for each ant k do - 2:
- 3:
random - 4:
- 5:
while length not equal with n do - 6:
select next city - 7:
- 8:
end while - 9:
- 10:
end for
|
where
is the rate of evaporation.
Thereafter, the best ant is allowed to deposit pheromone as follows:
where
is the solution generated by the best ant and
, where
is the quality value of DTSP solution
. The best ant to deposit pheromone may be either the best-so-far ant, in which case
, where
is the solution quality of the best-so-far ant, or the iteration-best ant, in which case
, where
is the solution quality of the best ant of the iteration. By default, the iteration-best ant is used to update the pheromone trails and, occasionally, the best-so-far ant. The pheromone trail values in
AS are kept to the interval
, where
and
are the minimum and maximum pheromone trails limits, respectively. The overall
AS pheromone update is presented in Algorithm 2, lines 1–20.
3.2. Adapting in Dynamic Environments
ACO algorithms have proven effective in addressing dynamic optimization problems because they are very robust algorithms, according to Bonabeau et al. [
30]. However, when a dynamic change occurs, the ACO’s pheromone trails of the previous environment will become outdated because they will be associated with the previous optimum. A straightforward way to tackle the dynamic changes in the DTSP using a conventional ACO, such as the
AS, is to restart the optimization process whenever changes occur. In particular, the pheromone trail limit values
and
are reset back to their initial values, and all the pheromone trails are re-initialized to the initial
value, as in Equation (
5), whenever a dynamic change is detected.
There are two concerns when restarting an ACO: (1) the dynamic changes are not always detectable [
31], and (2) a portion of the previous pheromone trails that can help discover the new optimum faster is erased [
32]. For the first concern, the changes in the DTSP can be detected by re-evaluating a constant solution (or detector) on every iteration (note that more than one detector can be used). If a change occurs in the quality of the detector, then a dynamic change is recorded. In this way, a change is always detected for the DTSP with node changes but not for the DTSP with weight changes. This is because the weights affected by the dynamic change may not belong to that particular detector, and hence, its quality will not be affected [
10]. For the second concern, the pheromone trails of the previous environment will be most probably useful when the changing environments are correlated, e.g., when the dynamic changes are small to medium, the new environment is more likely to be similar to the previous environment. As a consequence, some of the previous pheromone trails will still be useful to the new environment.
| Algorithm 2 Pheromone Update () |
- 1:
ifAS is selected then - 2:
- 3:
- 4:
for do - 5:
- 6:
end for - 7:
- 8:
- 9:
for each arc do - 10:
- 11:
end for - 12:
for do - 13:
if then - 14:
- 15:
end if - 16:
if then - 17:
- 18:
end if - 19:
end for - 20:
end if - 21:
if P-ACO is selected then - 22:
- 23:
if then - 24:
- 25:
for each arc do - 26:
- 27:
end for - 28:
end if - 29:
- 30:
for each arc do - 31:
- 32:
end for - 33:
end if
|
Therefore, a more efficient way is to allow the pheromone evaporation defined in Equation (
5) to remove the useless pheromone trails and utilize the useful pheromone trails of the previous environment. Specifically, the useless pheromone trails will reach the
value due to the constant deduction of pheromone evaporation, whereas the useful pheromone trails will be reinforced up to the
due to the pheromone deposit in Equation (
6). In other words, ACO will be able to adapt to the newly generated environment.
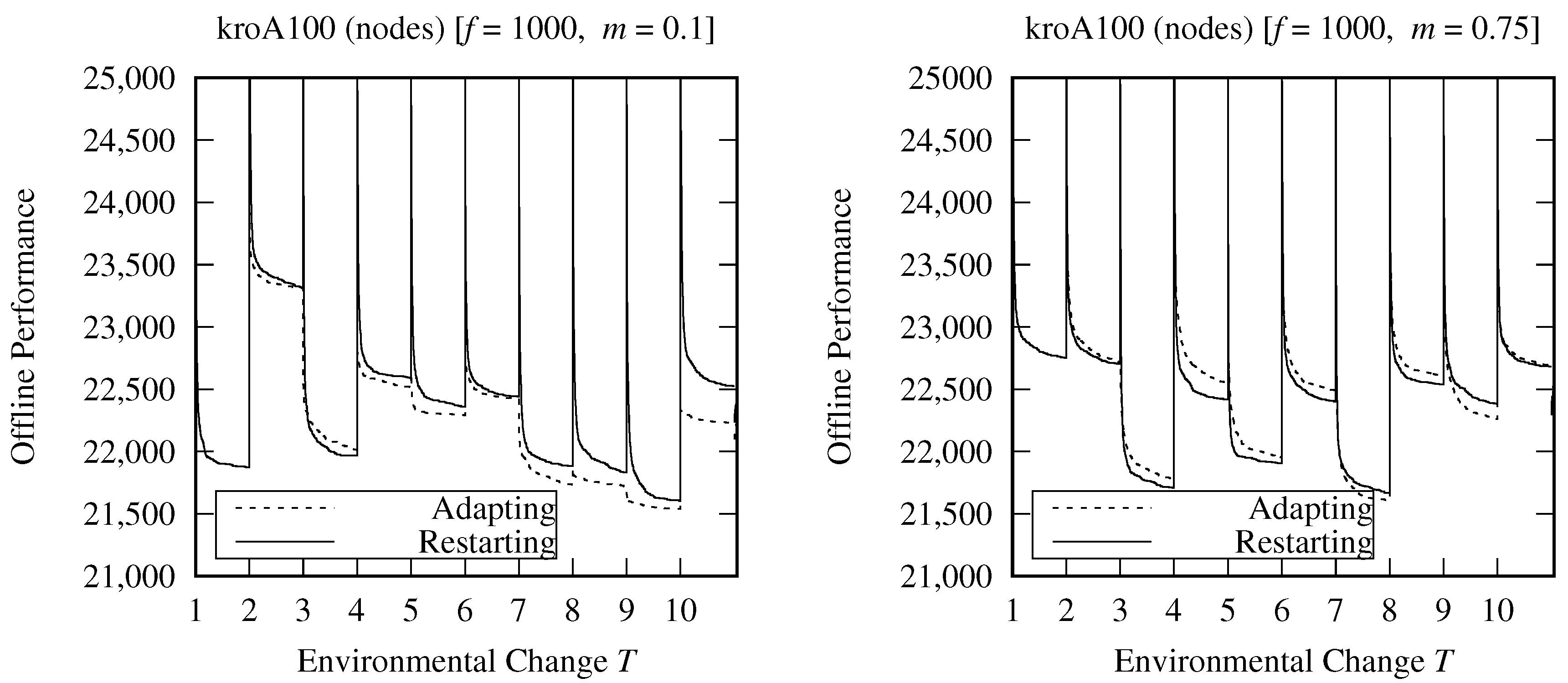
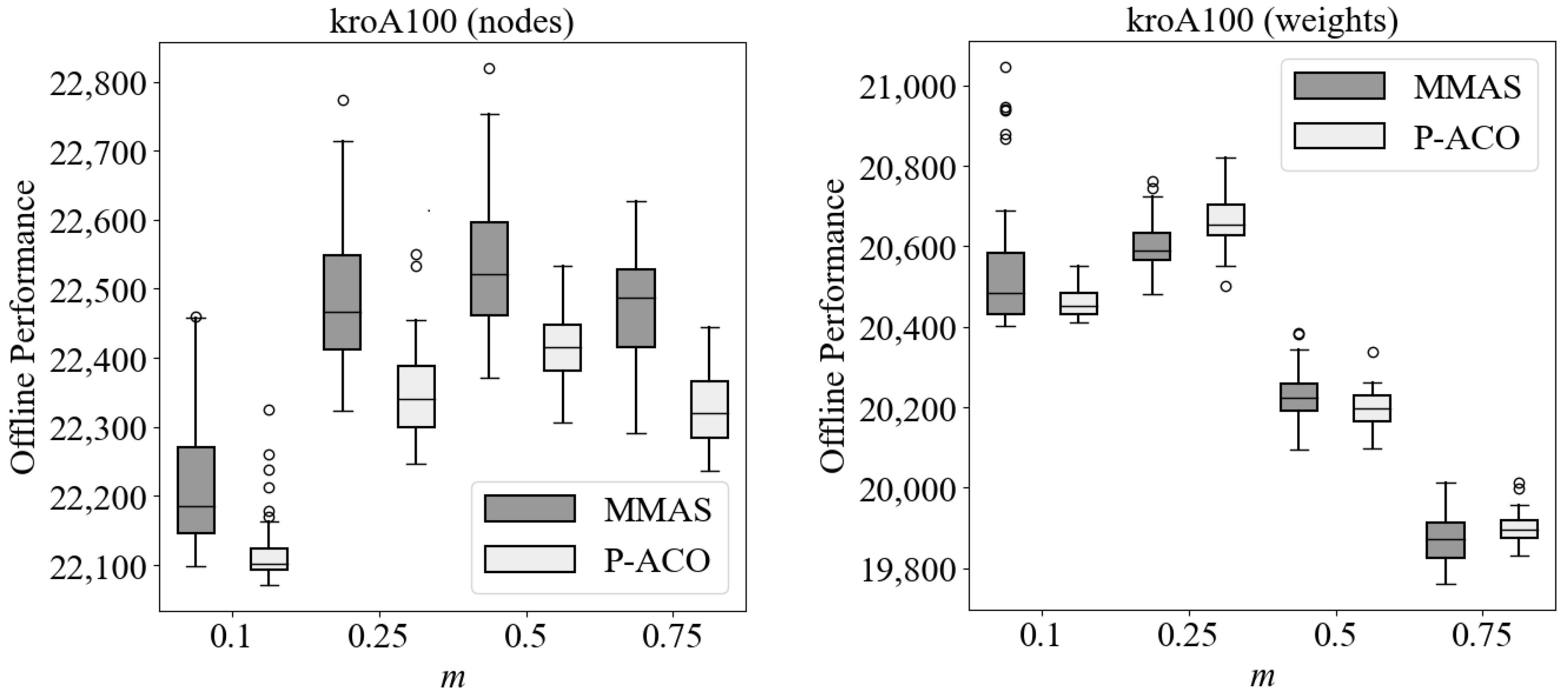
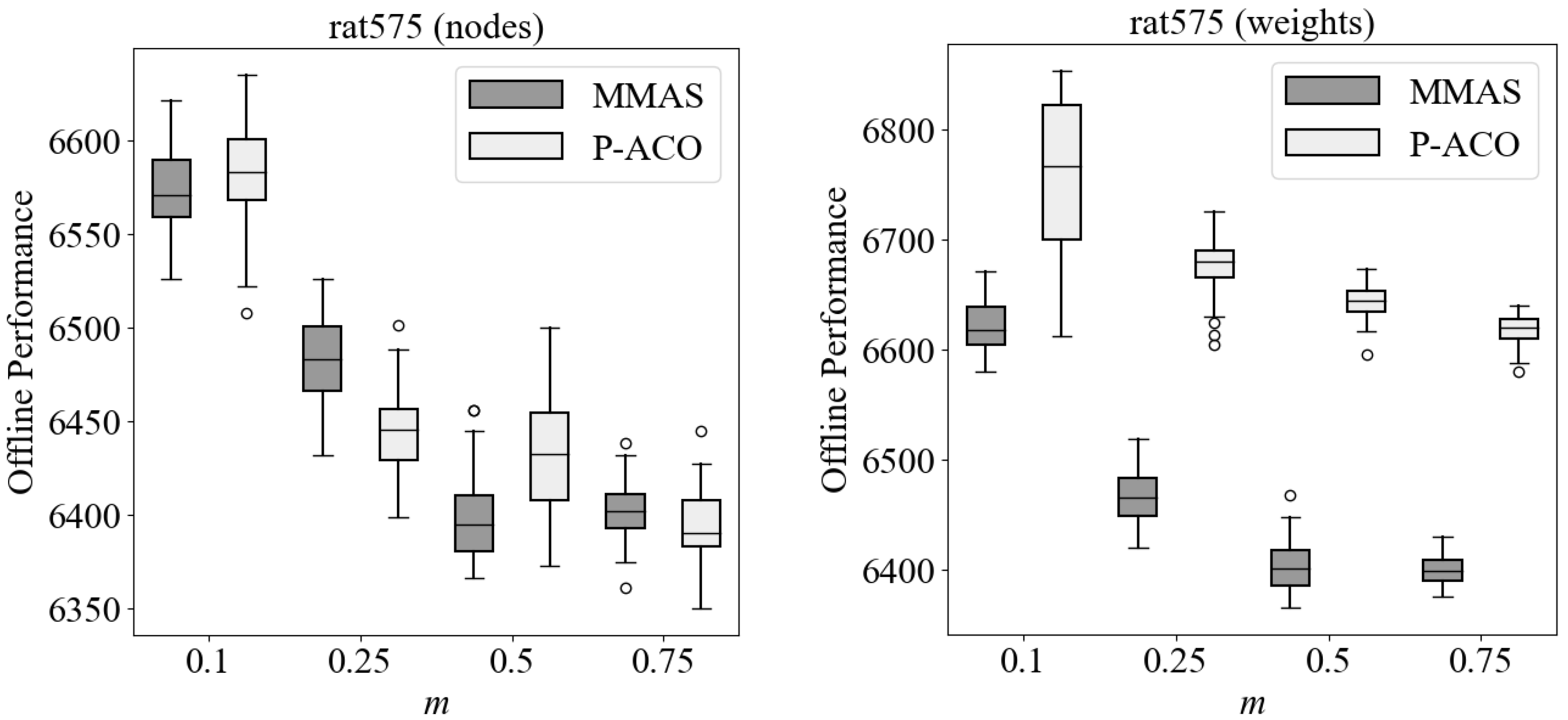
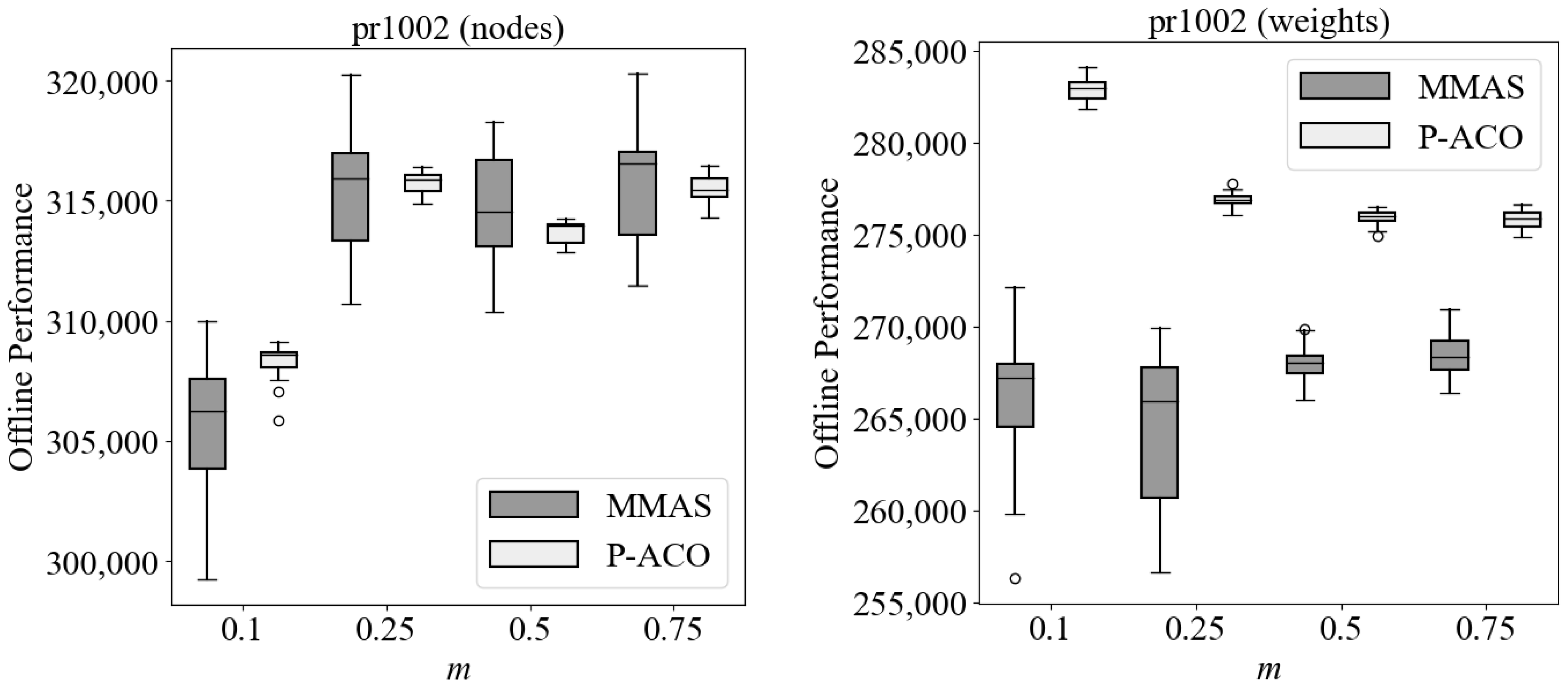
Figure 1 demonstrates the performance of
AS with and without pheromone re-initialization and proves our claims above. Specifically, it can be easily observed that when the dynamic changes are small (i.e.,
), adapting to the changes maintains better offline performance (see Equation (
9)) in most environmental changes (except when
), whereas when the dynamic changes are severe (i.e.,
), re-initializing the pheromone trails maintains better offline performance in most environmental changes (except when
and
). More details regarding the experimental setup of
Figure 1 are given later in
Section 4.
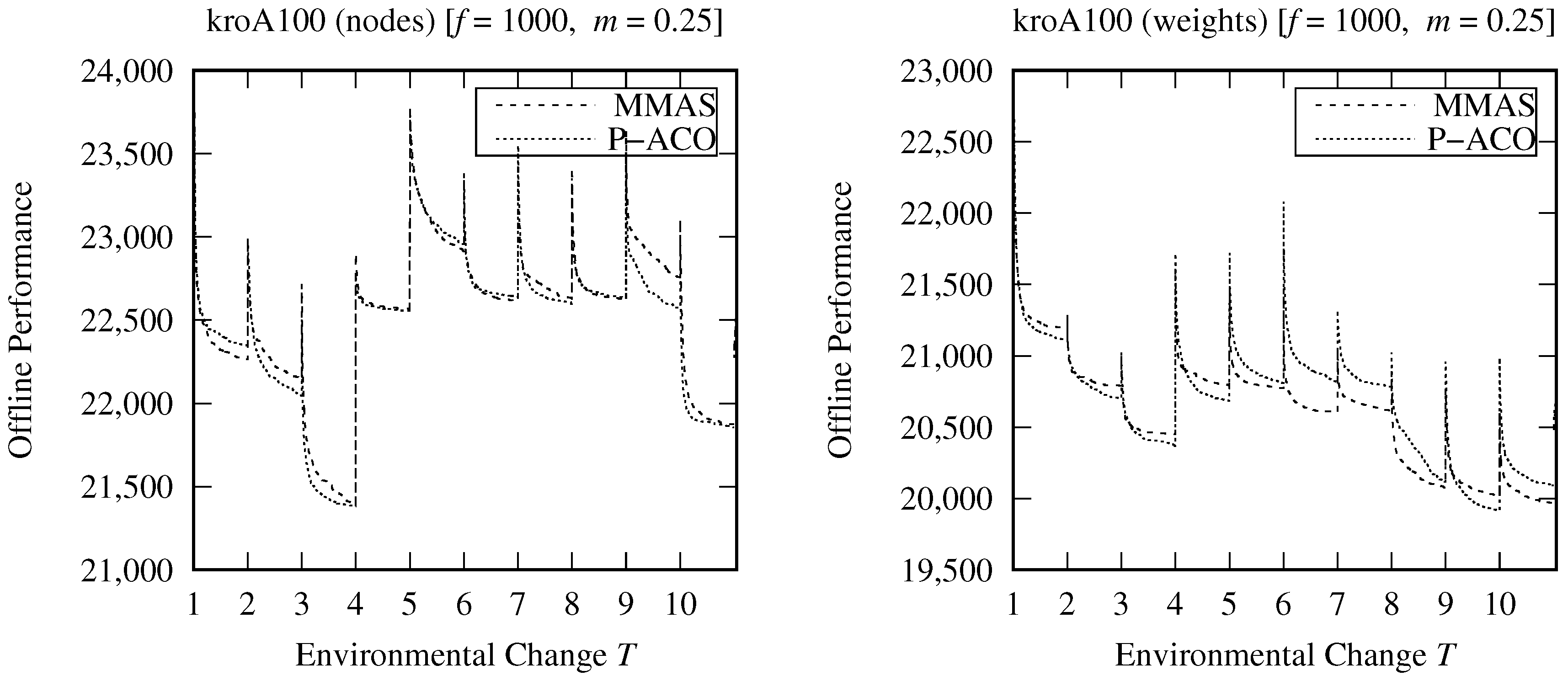
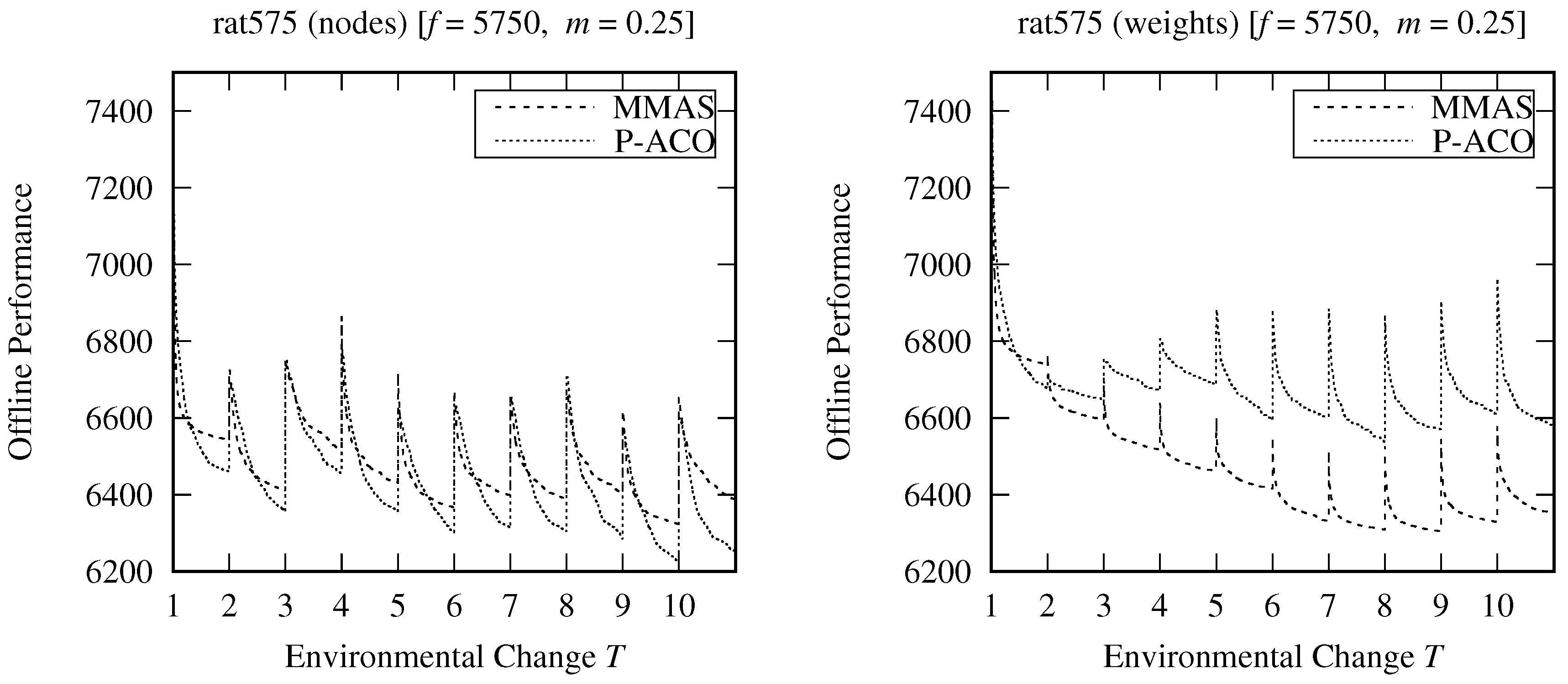
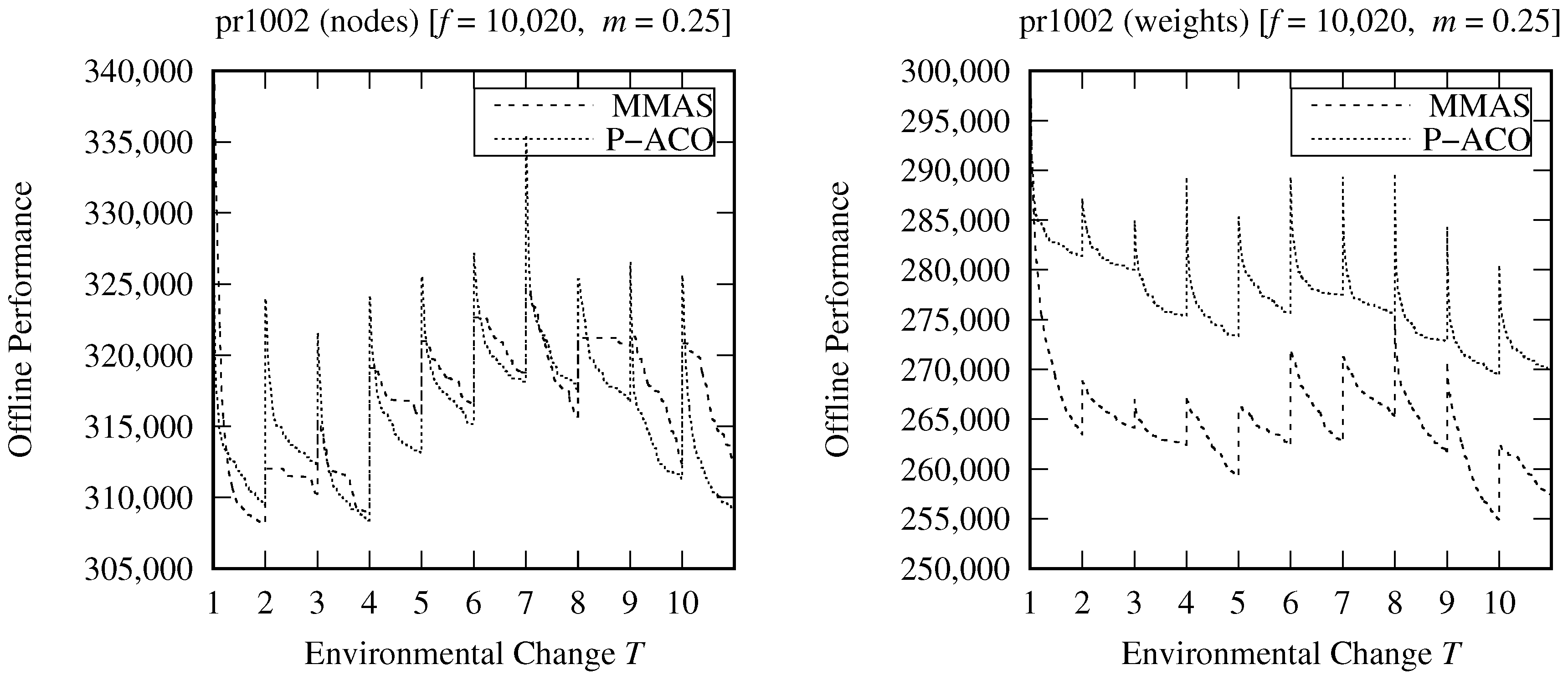
A more advanced way is to use the pheromone update policy of the population-based ACO (P-ACO) that has been specifically designed to address optimization problems with dynamic environments [
13]. The overall P-ACO pheromone procedure is presented in Algorithm 2, lines 21–33. In particular, an archive, i.e.,
, of iteration-best ants is maintained. For every iteration
t, the iteration-best ant enters
, and a positive constant pheromone update is added to the trails associated with the arcs that belong to its solution as follows:
where
is the constant pheromone value added,
is the solution of the iteration-best ant,
K is the size of
, and
and
are the maximum and initial pheromone trail values, respectively.
Whenever a dynamic change occurs, the solutions represented by the current ants in the population list may become invalid (e.g., when existing nodes are removed and replaced with new nodes). Therefore, these solutions are repaired heuristically using the
KeepElite principle [
33]. Specifically, the affected nodes are removed from the solution, reconnecting the successor and predecessor nodes. The new nodes are inserted in the best possible position of the solution, causing, in this way, the least increase in the solution quality. At the same time, the corresponding pheromone trails associated with the arcs of the affected nodes are updated.
When
is full, the current iteration-best ant needs to replace an existing ant, say
r, in
, following a negative constant update to its corresponding pheromone trails, which is defined as follows:
where
is the constant deducted pheromone value (the same with the added value) and
is the solution of the ant to be replaced, typically the oldest entry of the population list
. Note that pheromone evaporation is not used in the P-ACO algorithm. However, it is able to adapt to the changes because outdated pheromone trails are removed directly from the population list.
The overall application of
AS and P-ACO algorithms for the DTSP is described in Algorithm 3. It is worth mentioning that in both
AS and P-ACO, the solution of the best-so-far ant is repaired using
KeepElite, and the heuristic information is updated, reflecting the newly generated distances as in Equation (
2), whenever a dynamic change occurs (see Algorithm 3, lines 16–33).
| Algorithm 3 ACO for DTSP |
- 1:
- 2:
- 3:
for do - 4:
- 5:
- 6:
end for - 7:
while termination condition not met do - 8:
Construct Solutions(t) % Algorithm 1 - 9:
find best ant at iteration t - 10:
if is better than then - 11:
- 12:
- 13:
end if - 14:
Pheromone Update() % Algorithm 2 - 15:
if dynamic change occurs then - 16:
if AS || P-ACO then - 17:
Repair - 18:
for do - 19:
- 20:
end for - 21:
if P-ACO then - 22:
for do - 23:
- 24:
end for - 25:
for each ant do - 26:
Repair - 27:
for each arc do - 28:
- 29:
end for - 30:
end for - 31:
end if - 32:
end if - 33:
end if - 34:
- 35:
end while
|













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}