
A Case-Study Comparison of Machine Learning Approaches for Predicting Student’s Dropout from Multiple Online Educational Entities



Abstract
:
1. Introduction
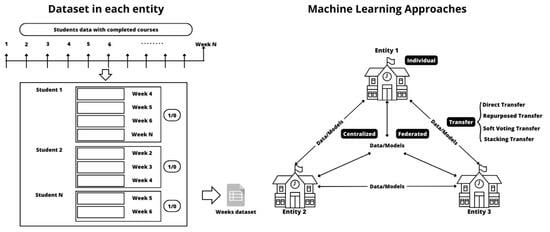
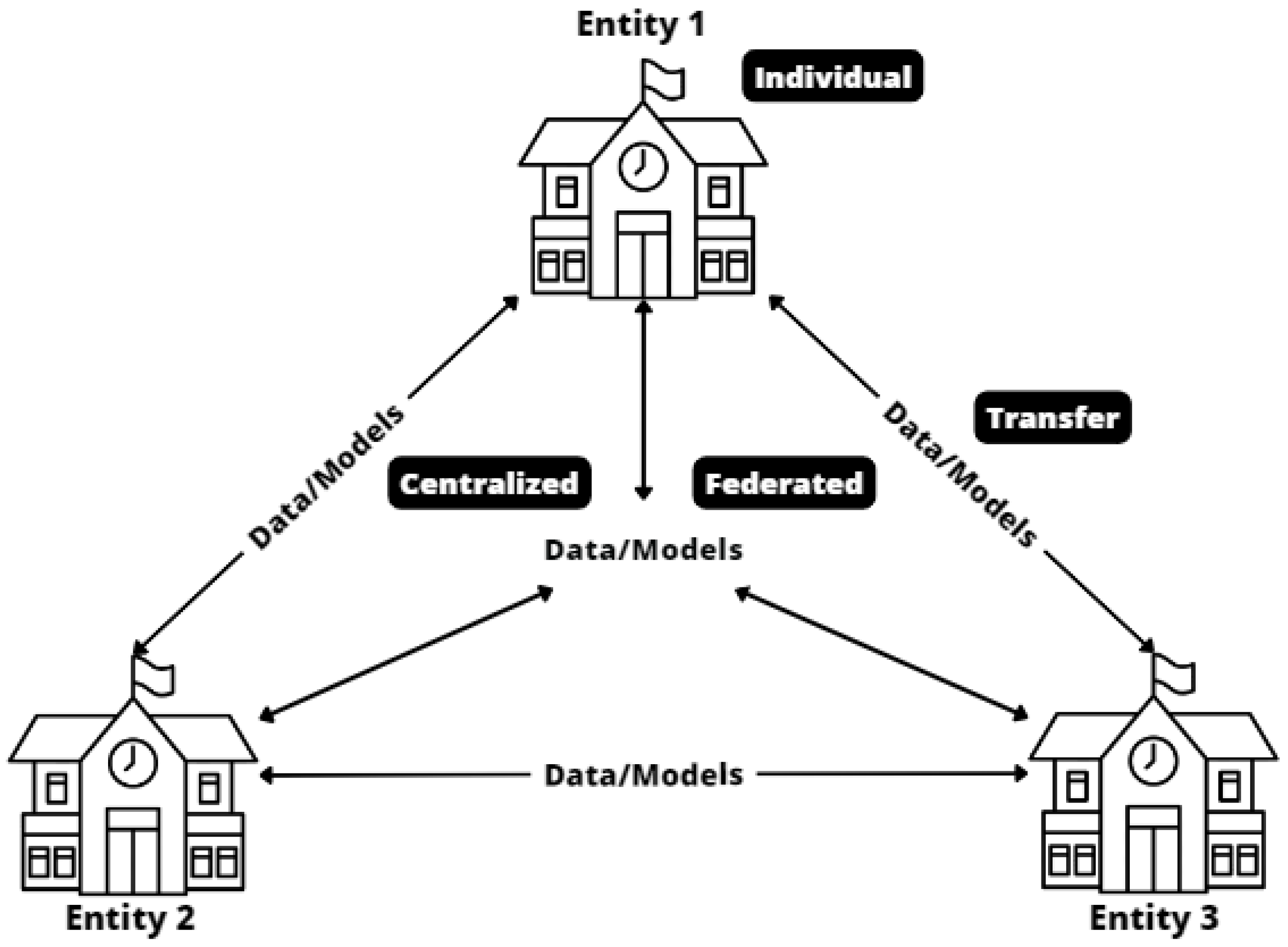
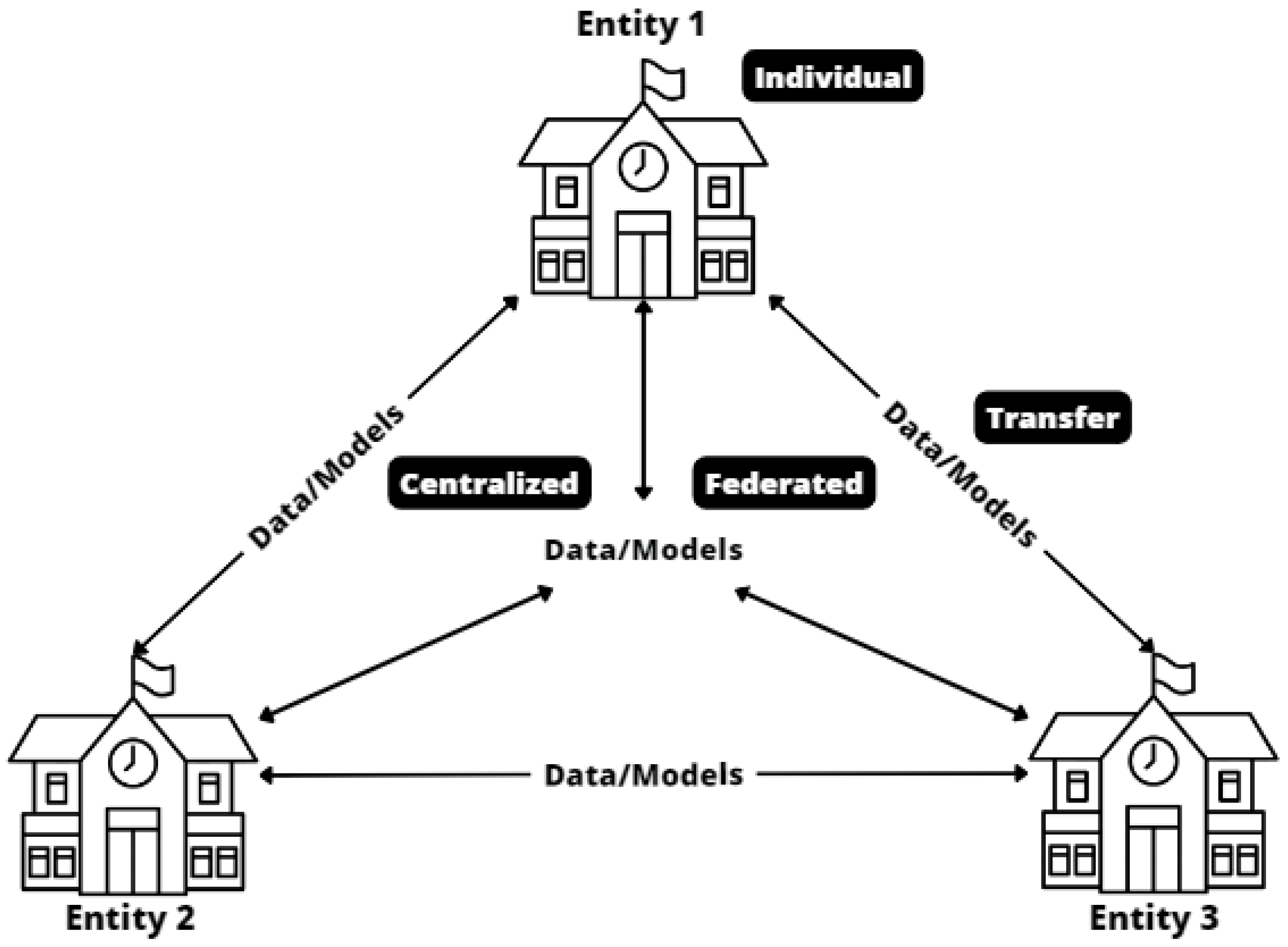
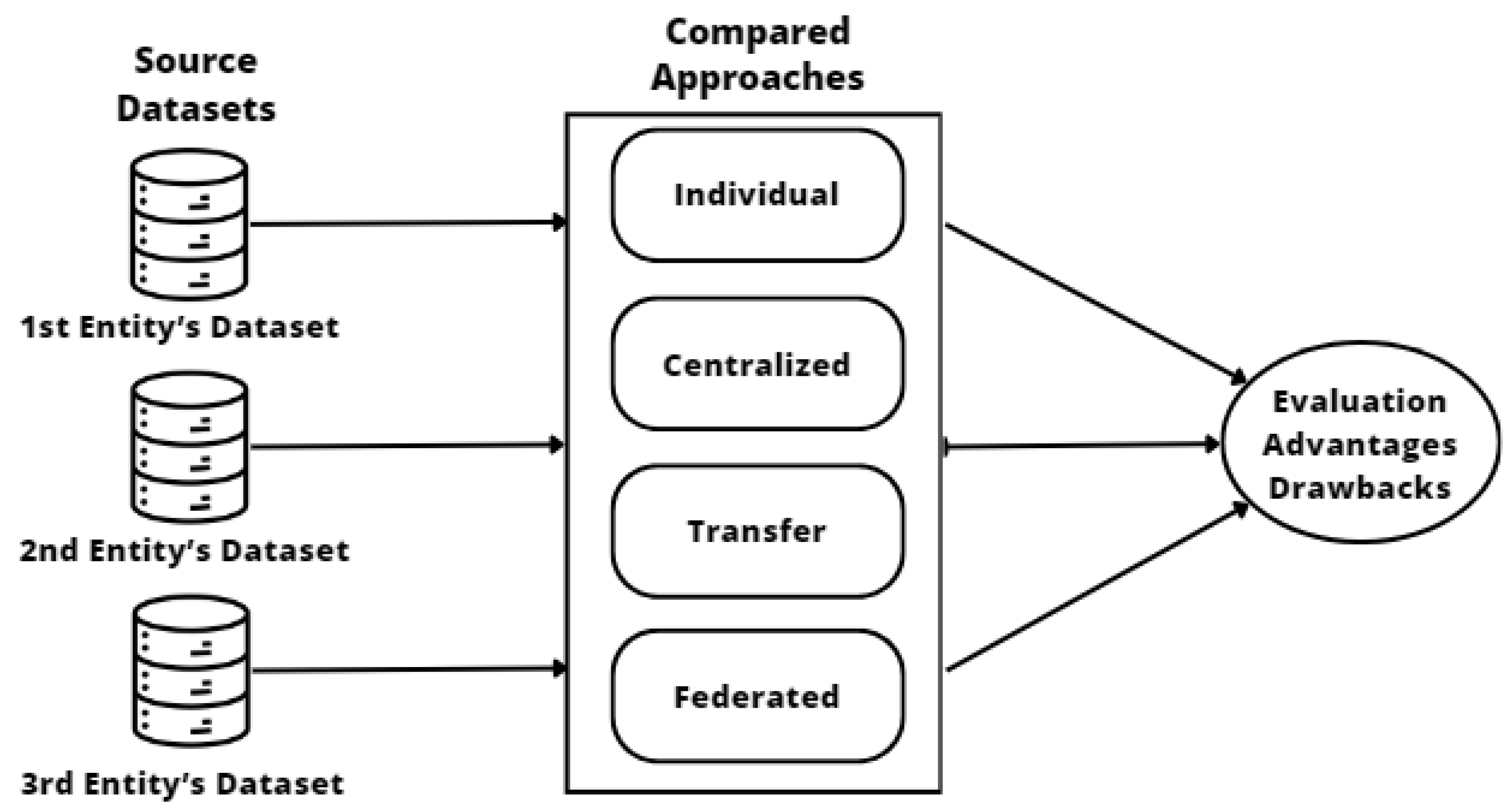
2. Machine Learning Approaches
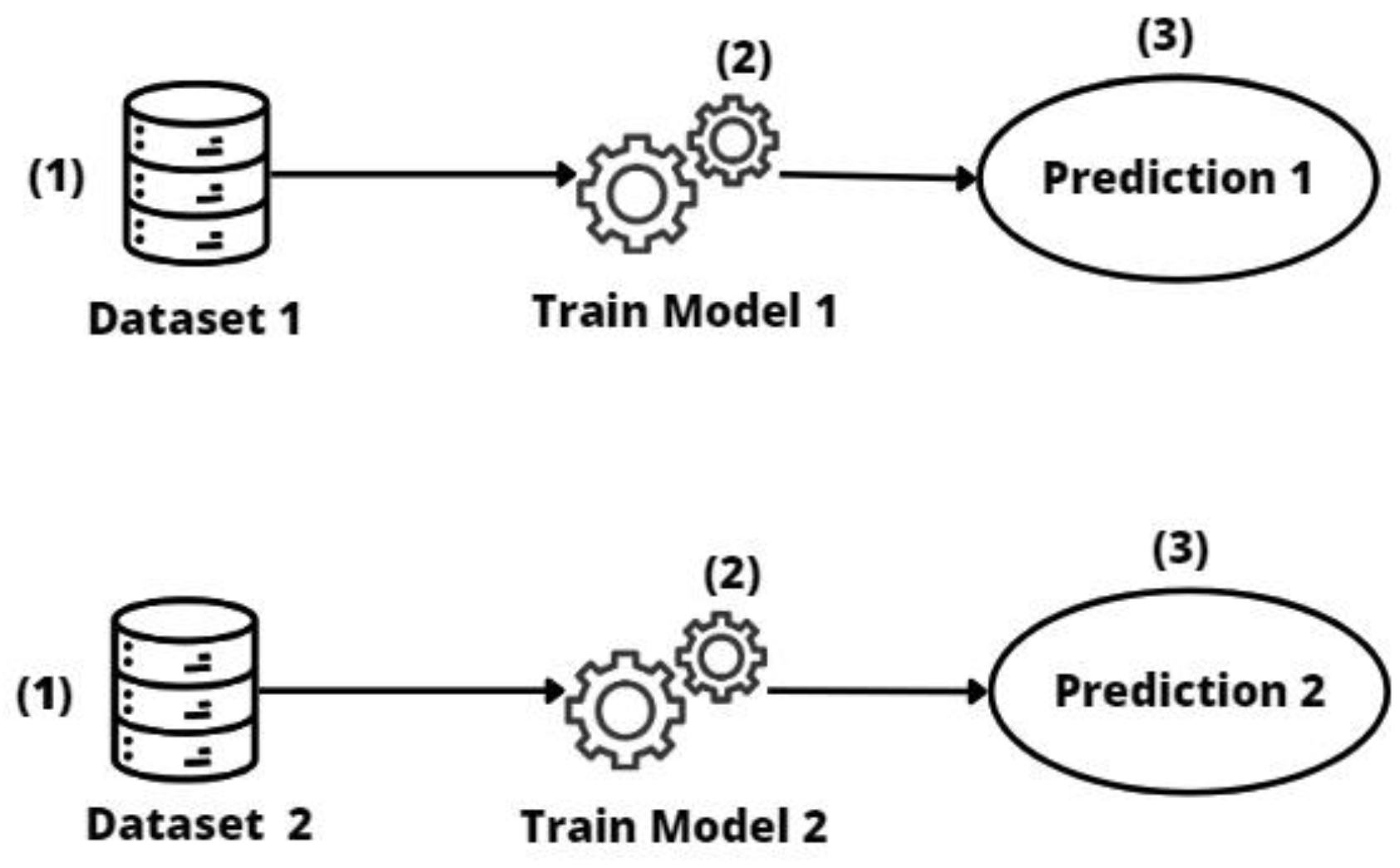
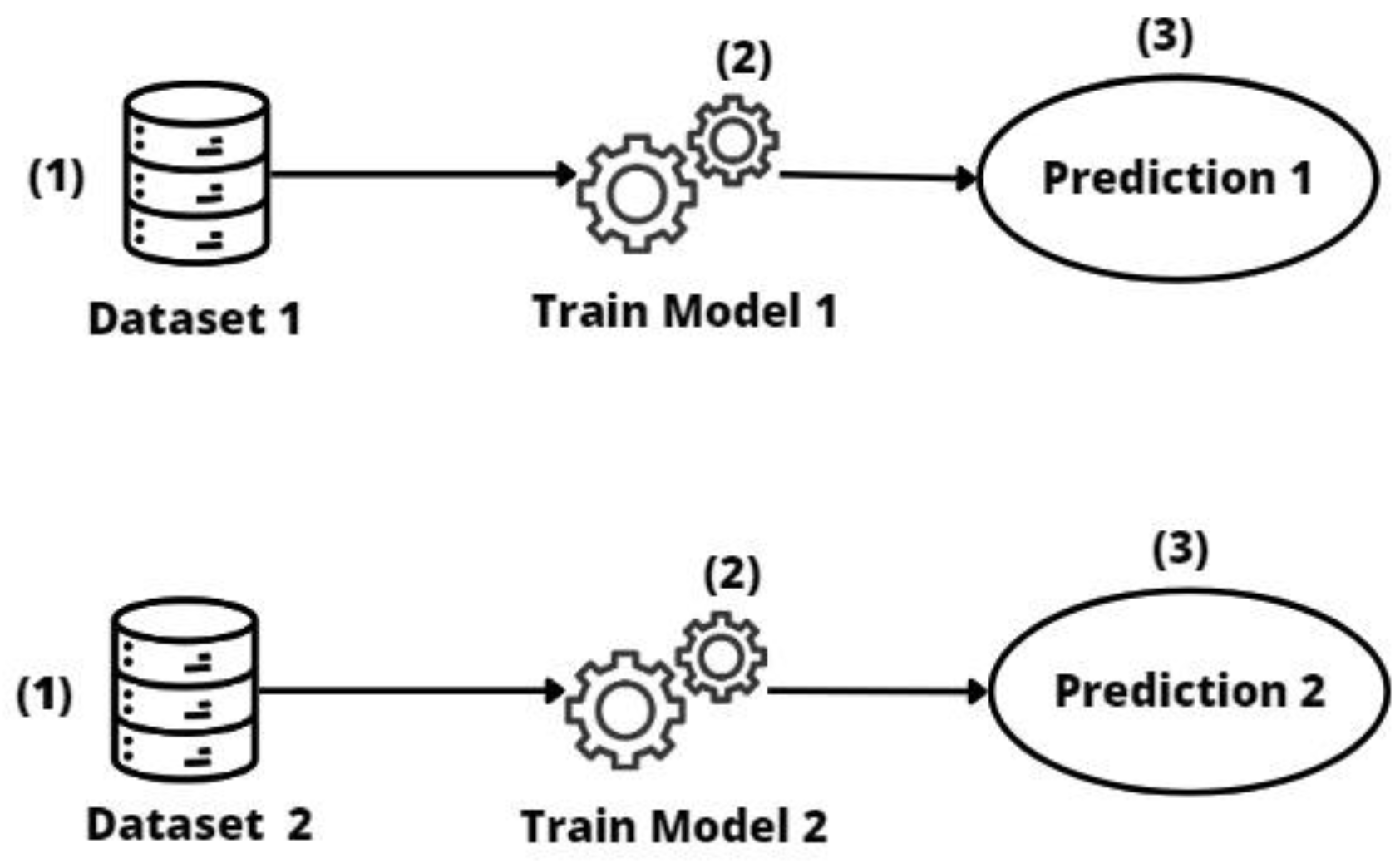
2.1. Individual Models
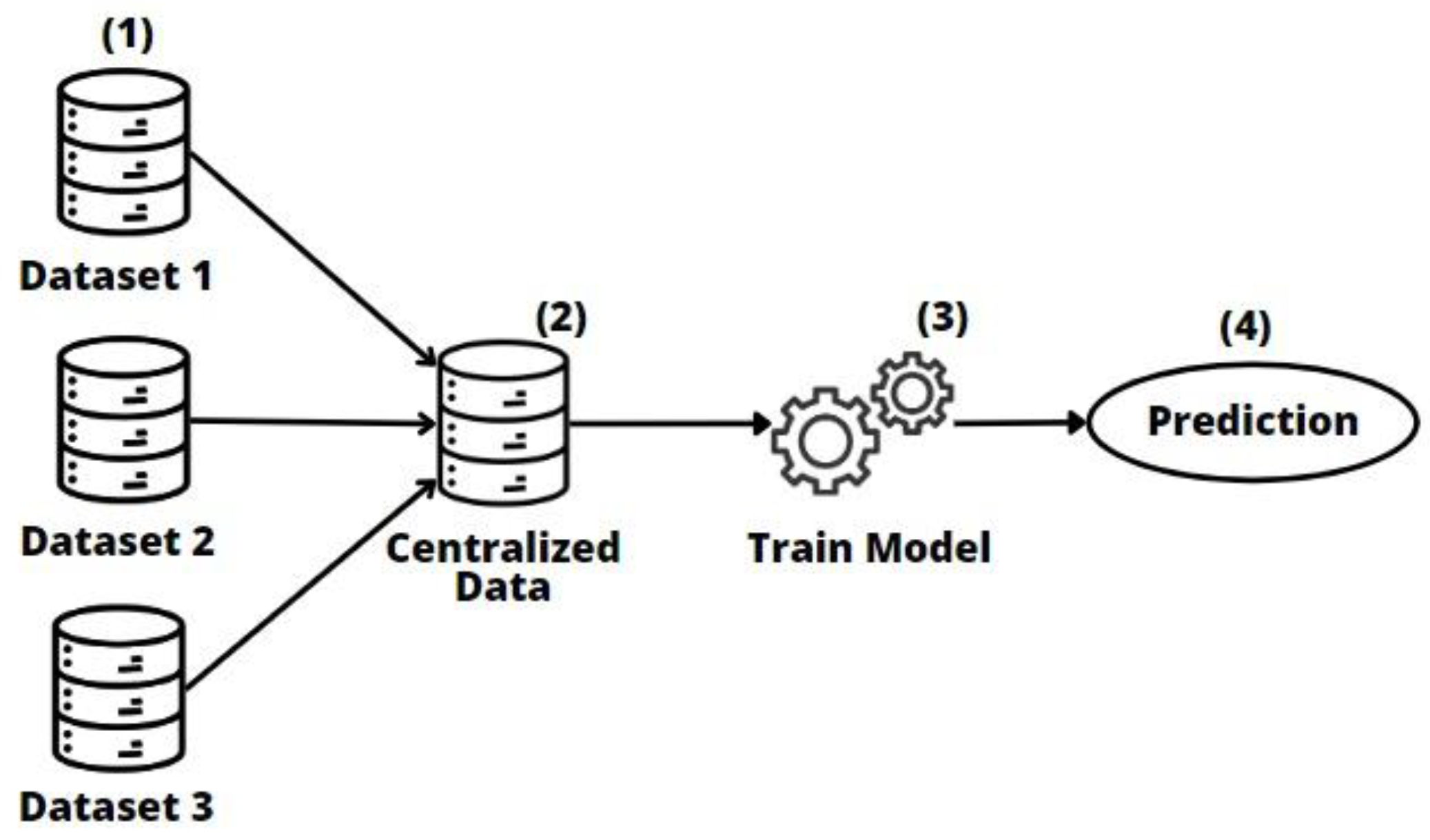
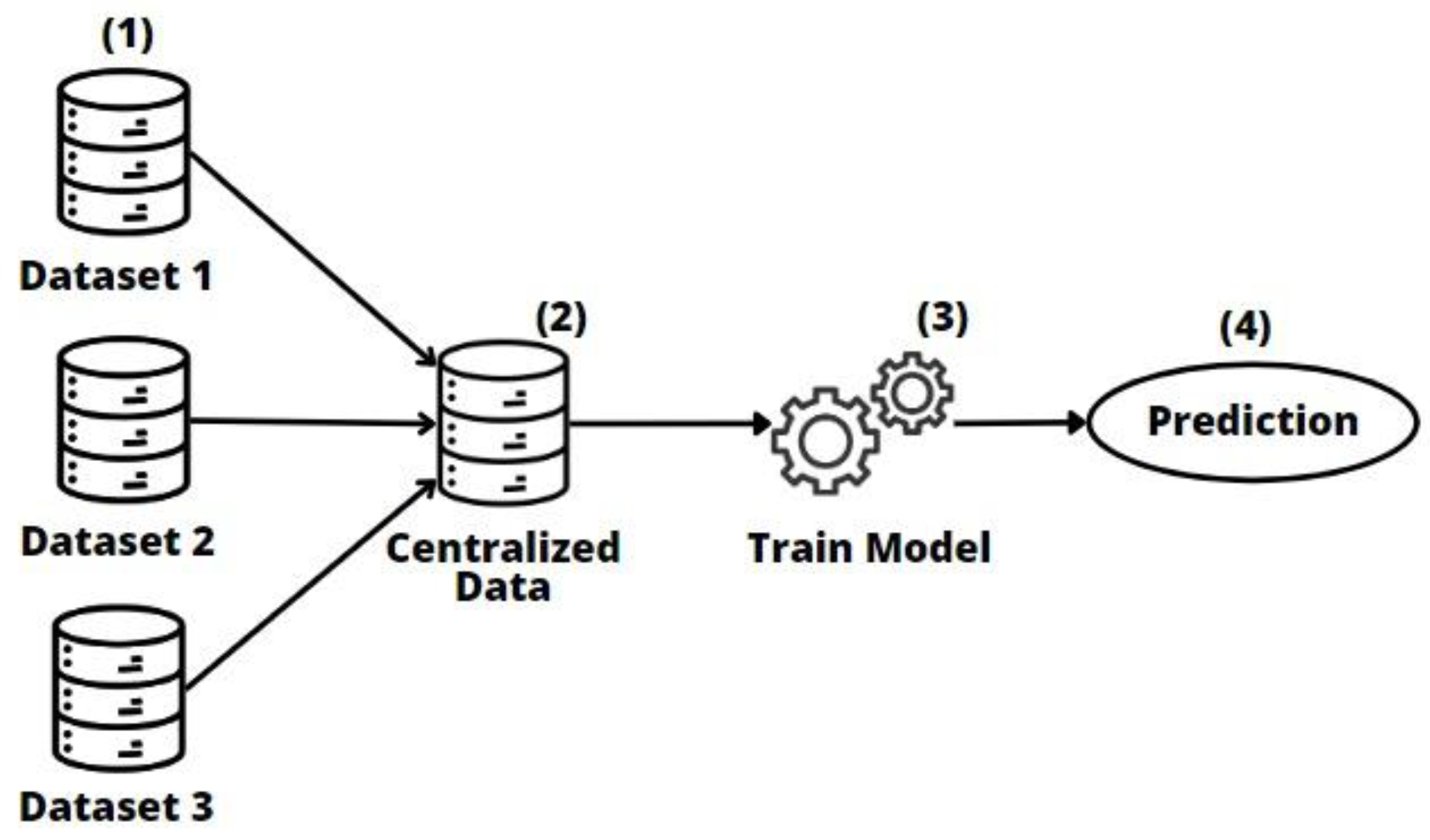
2.2. Centralized Model
2.3. Transfer Learning
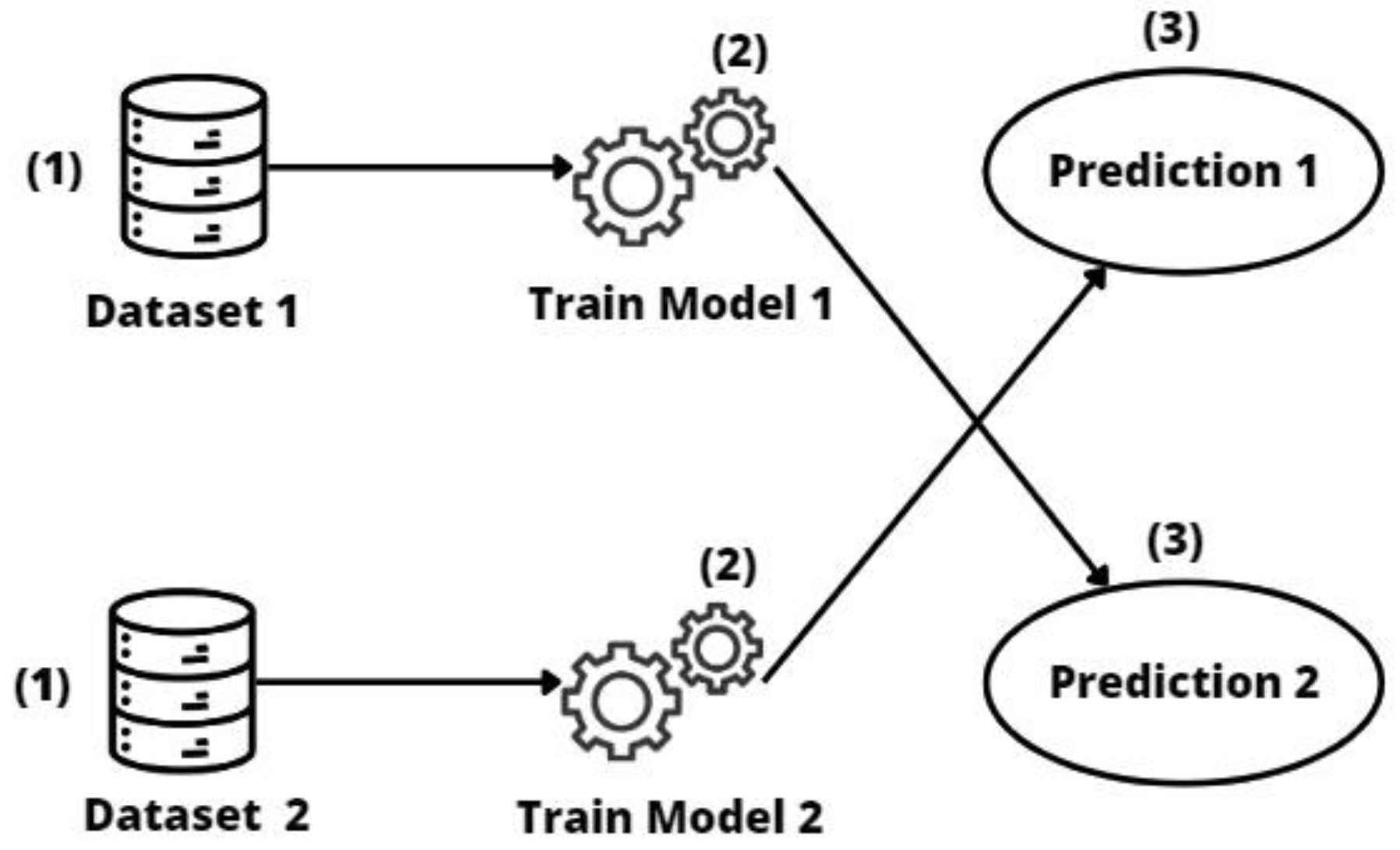
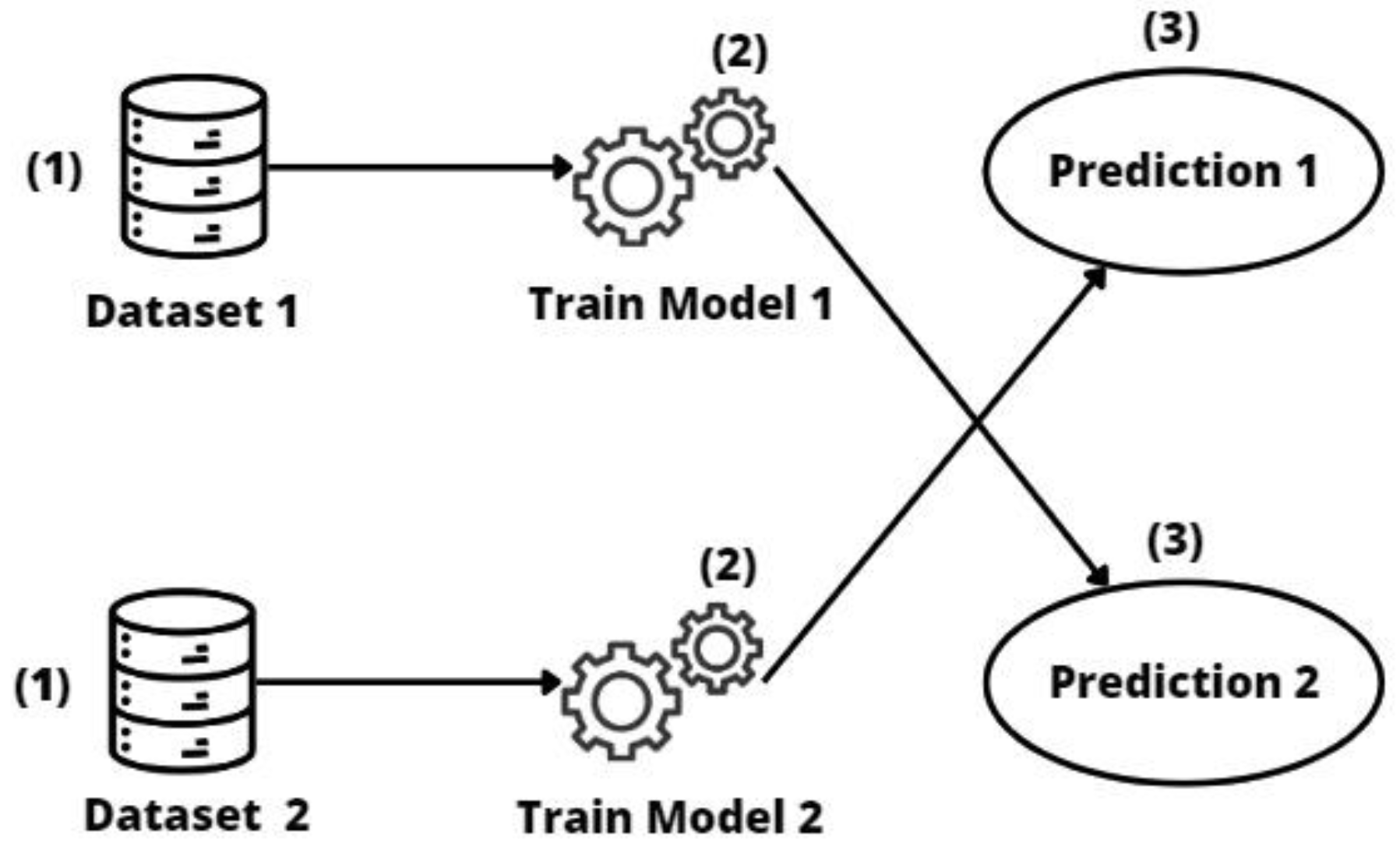
2.3.1. Direct Transfer
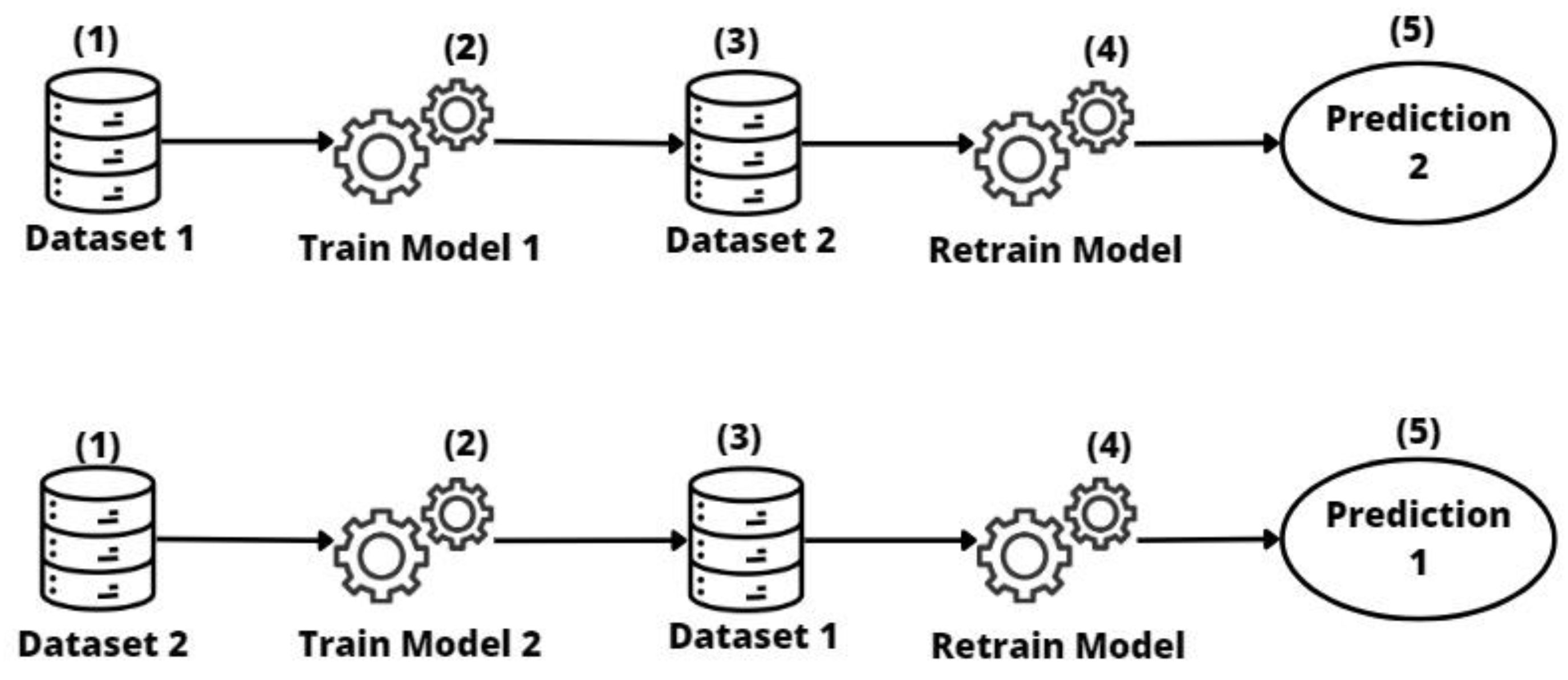
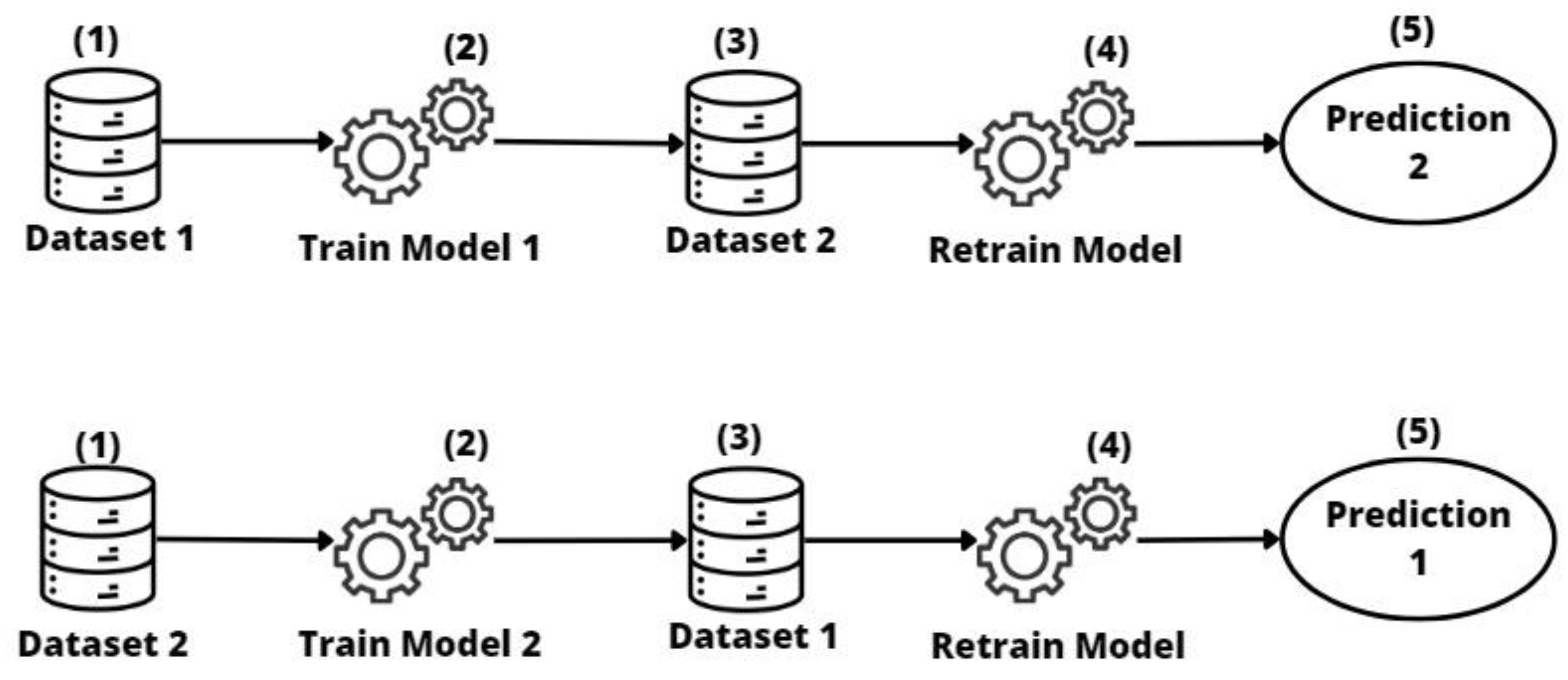
2.3.2. Repurposed Transfer
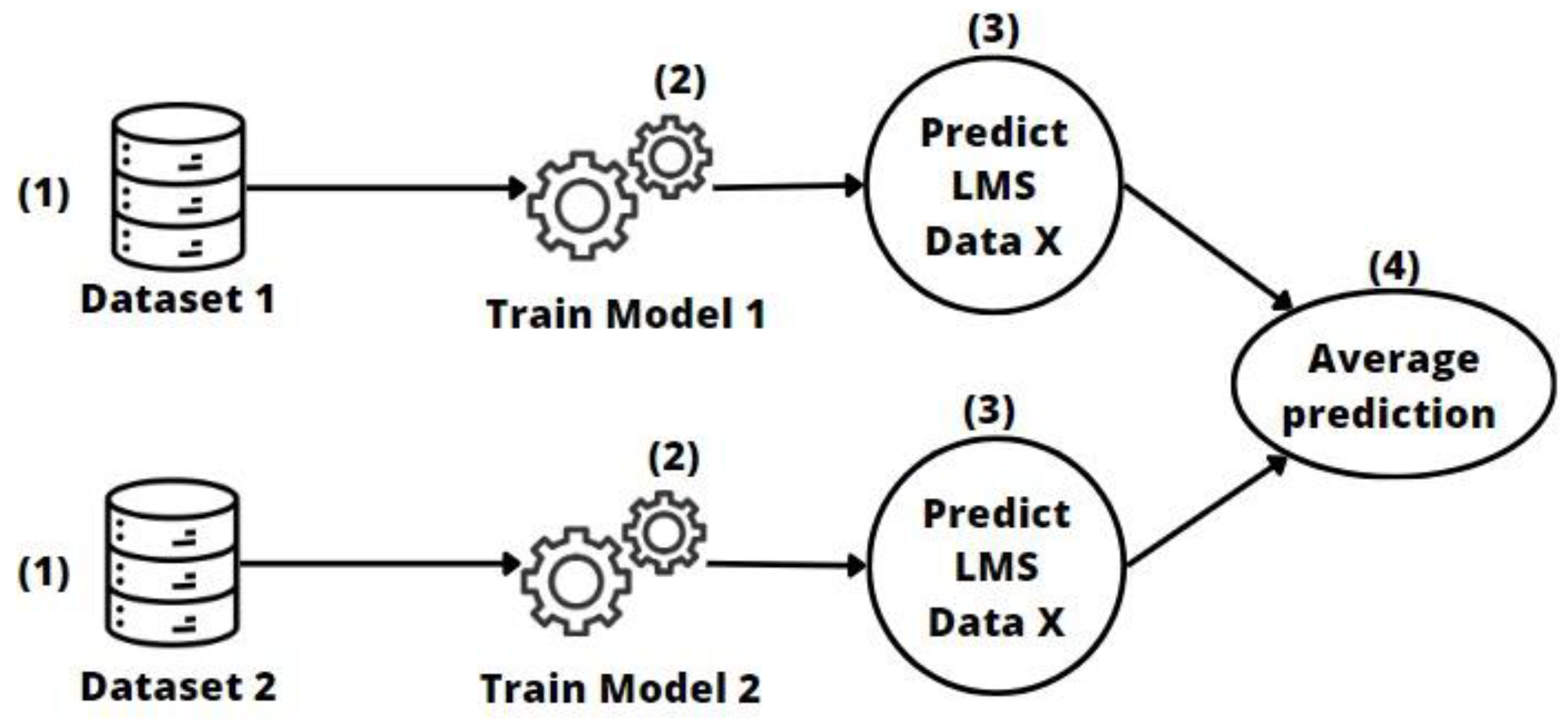
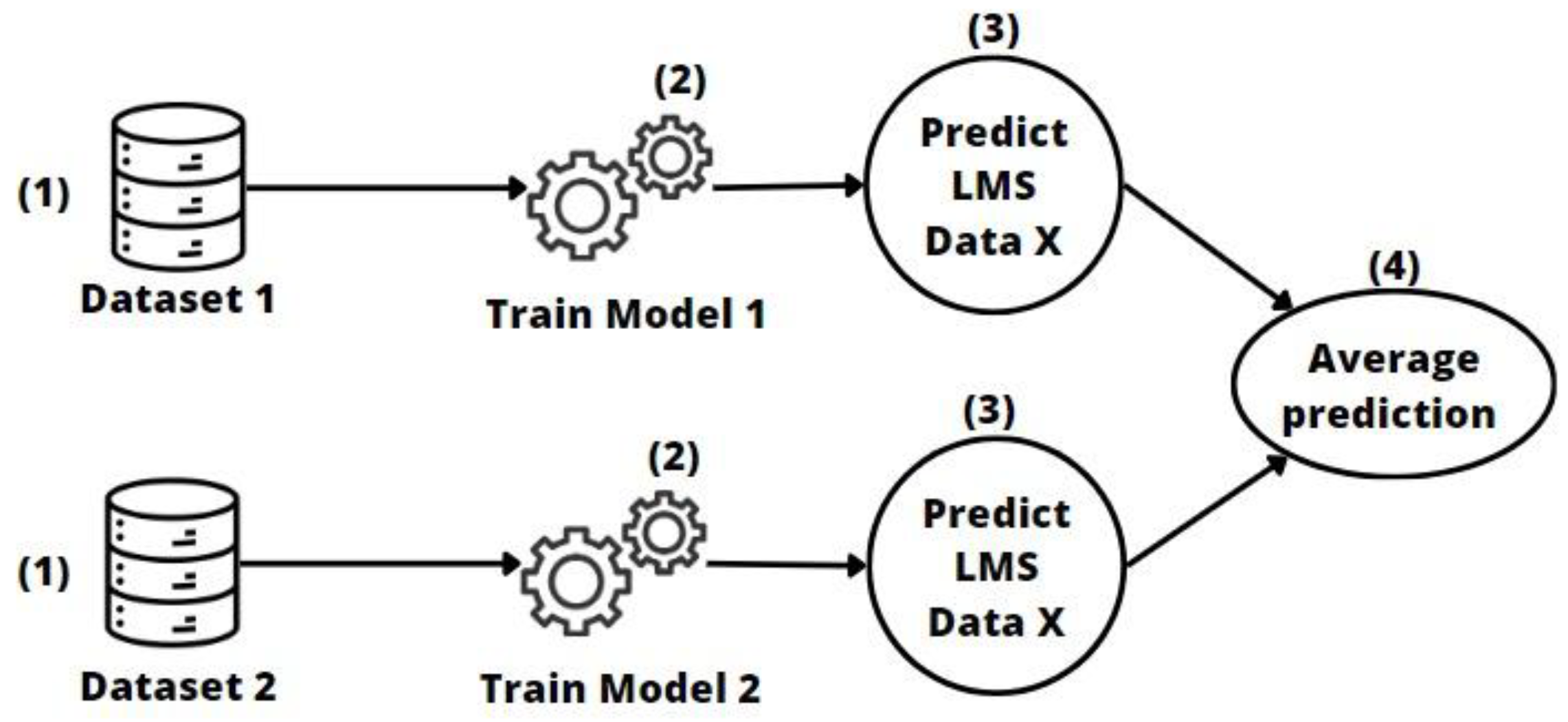
2.3.3. Soft-Voting Transfer
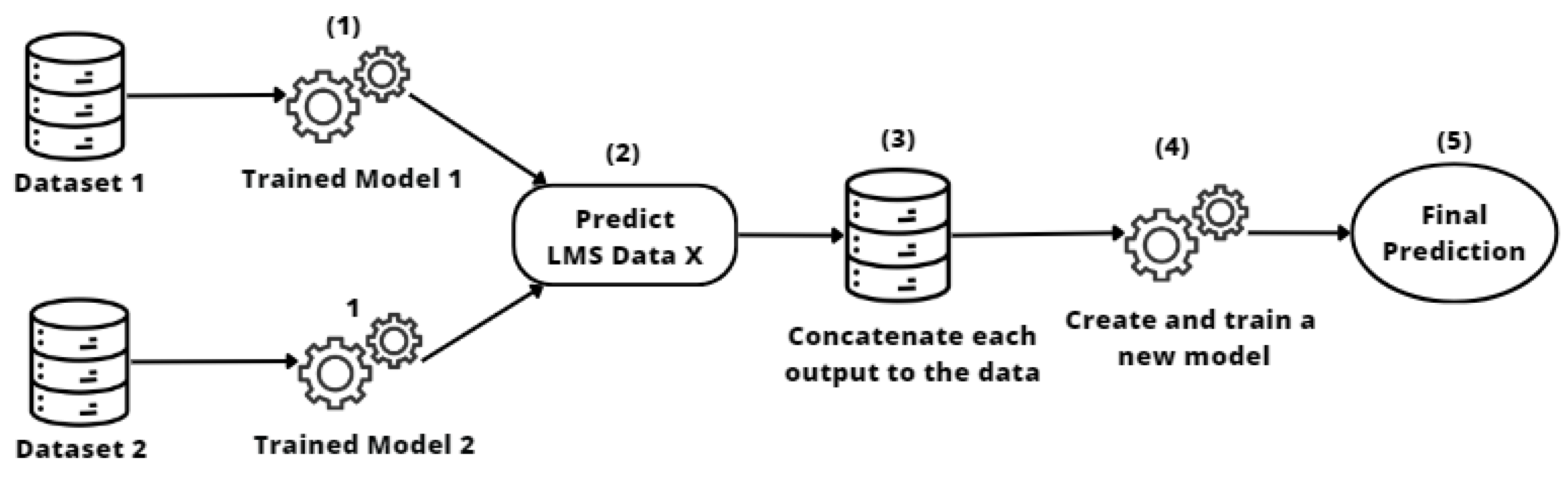
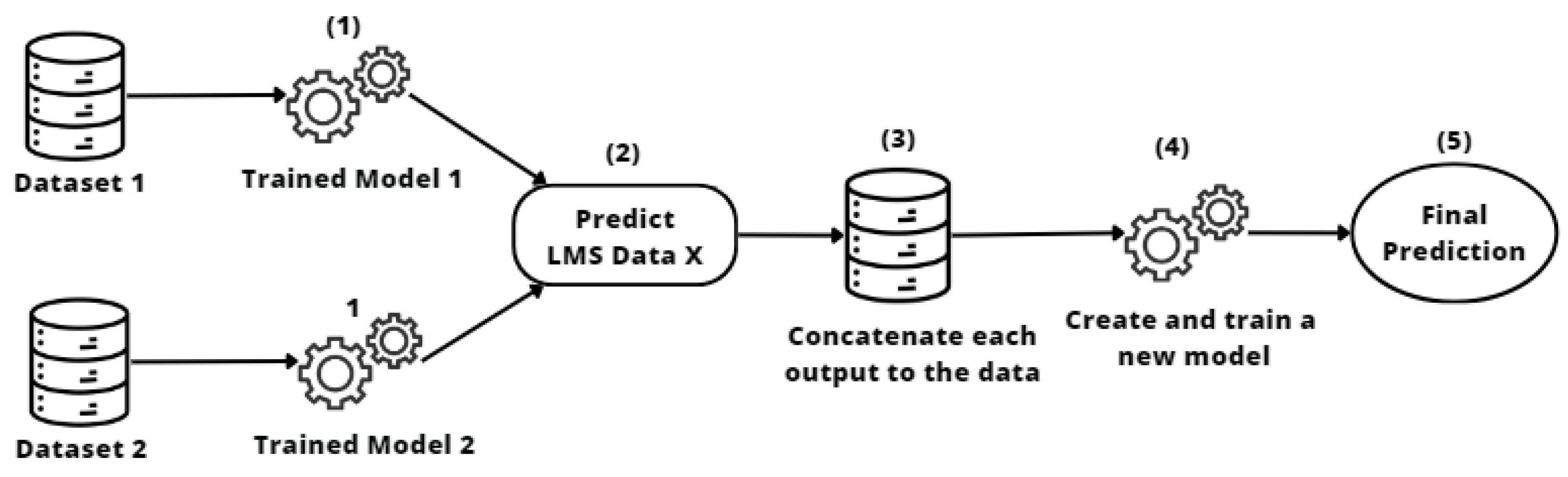
2.3.4. Stacking Transfer
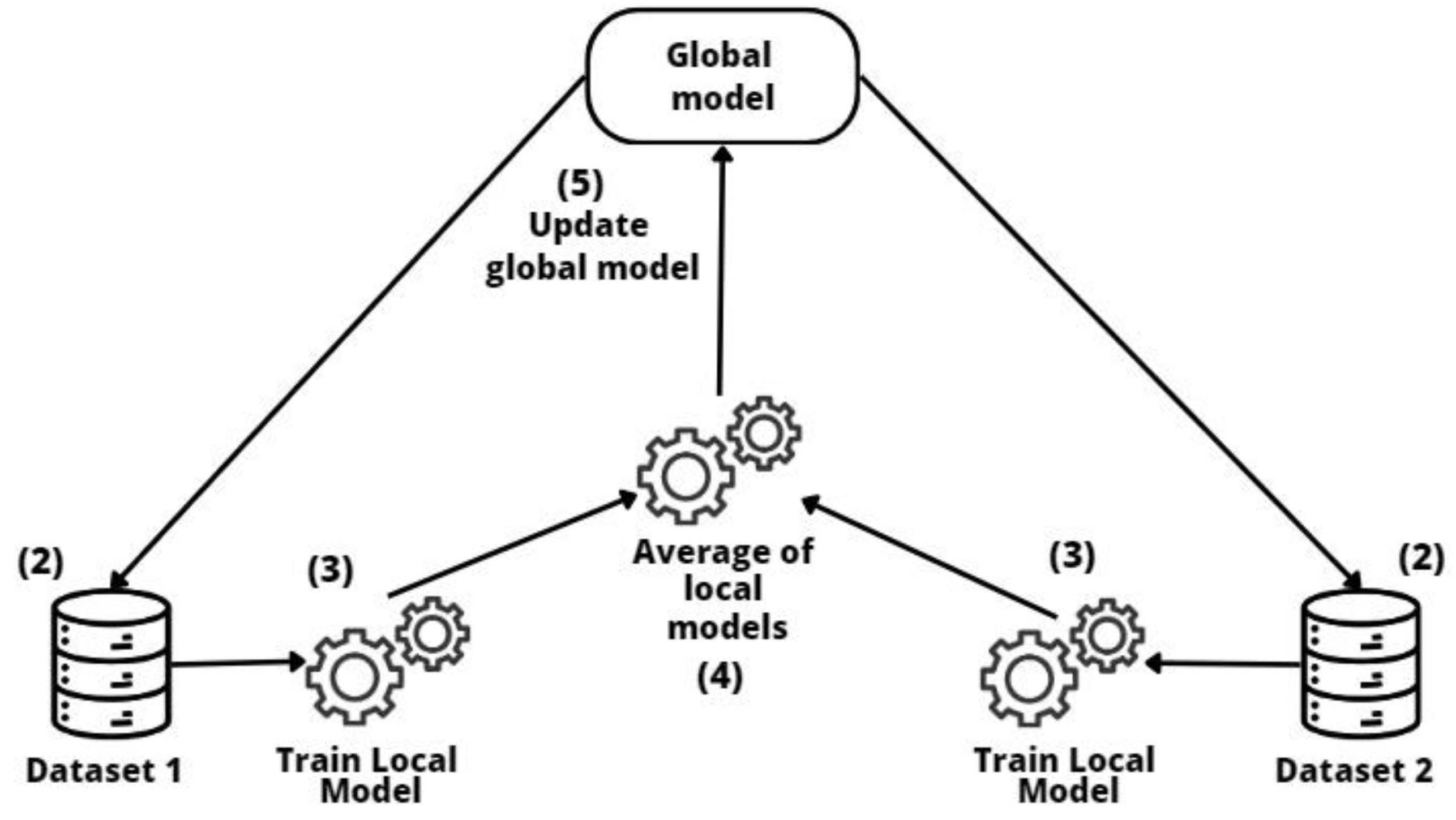
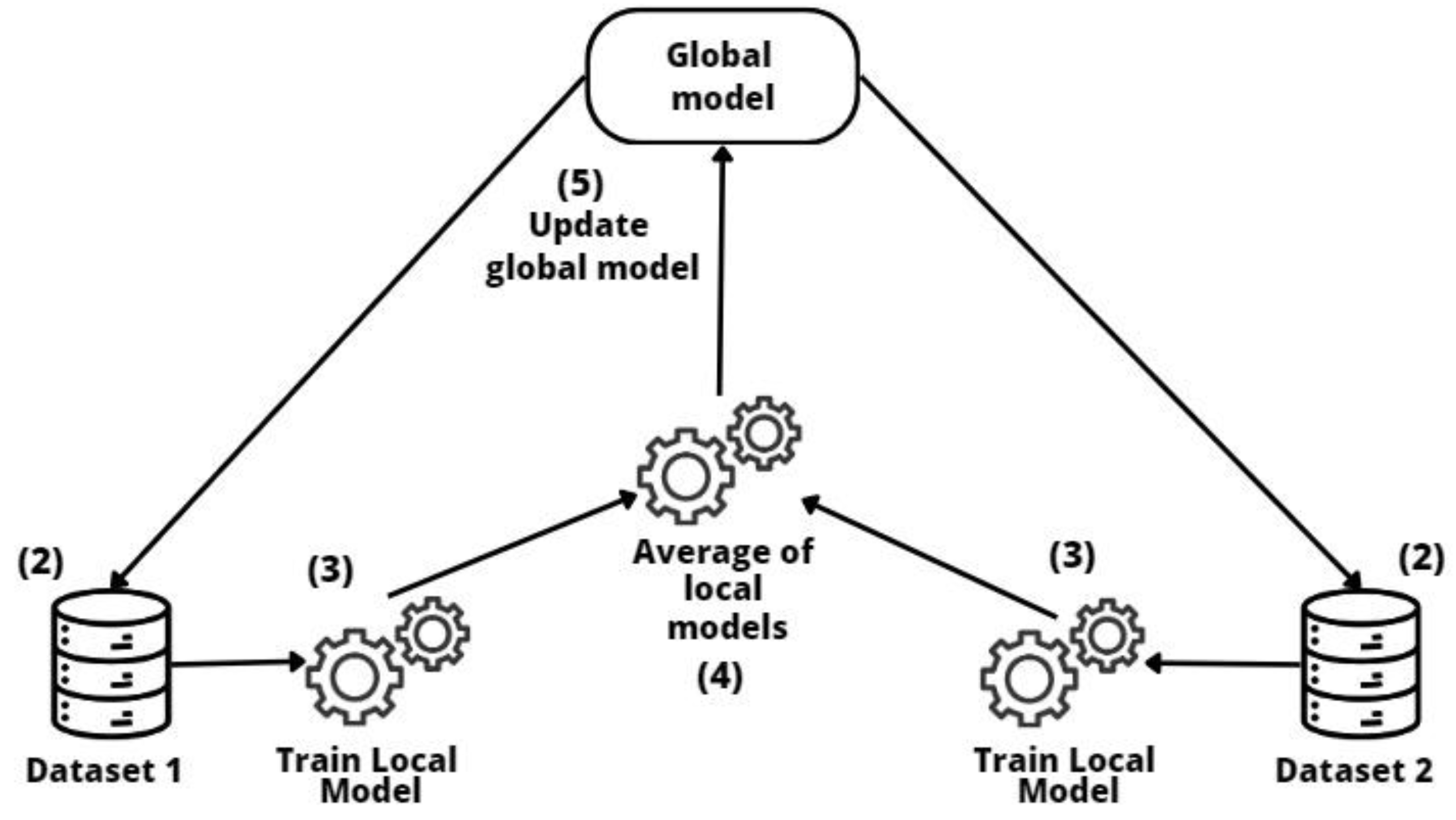
2.4. Federated Learning
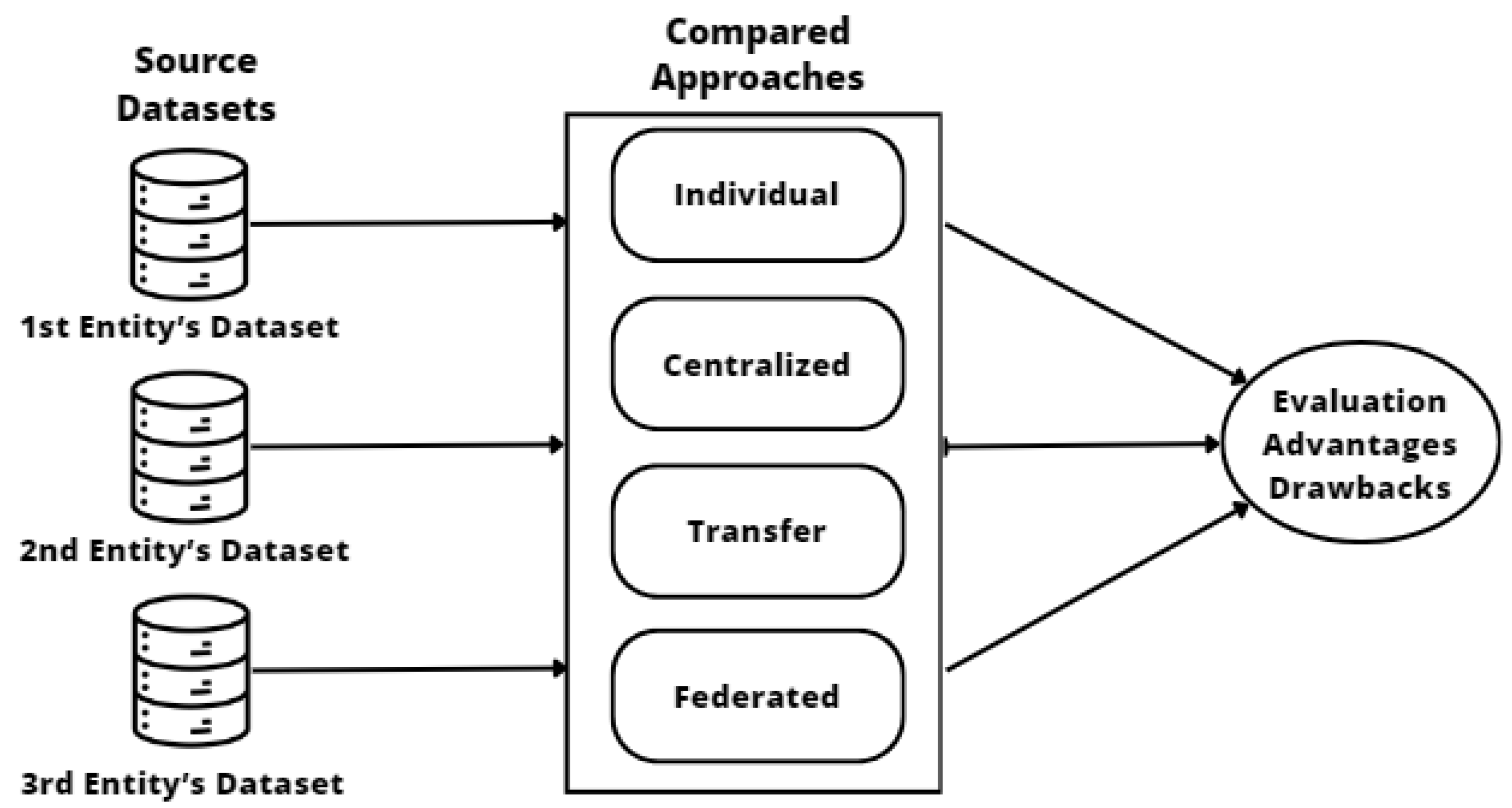
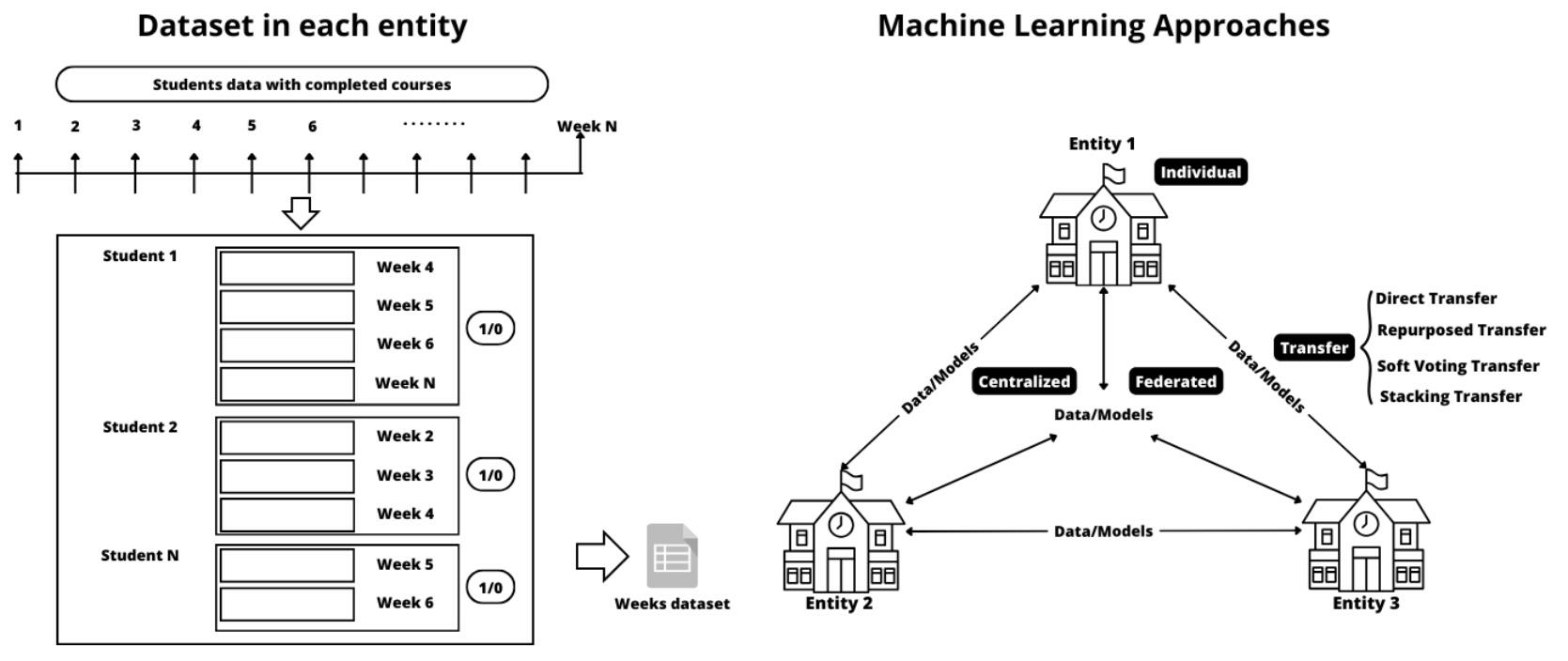
3. Materials and Methods
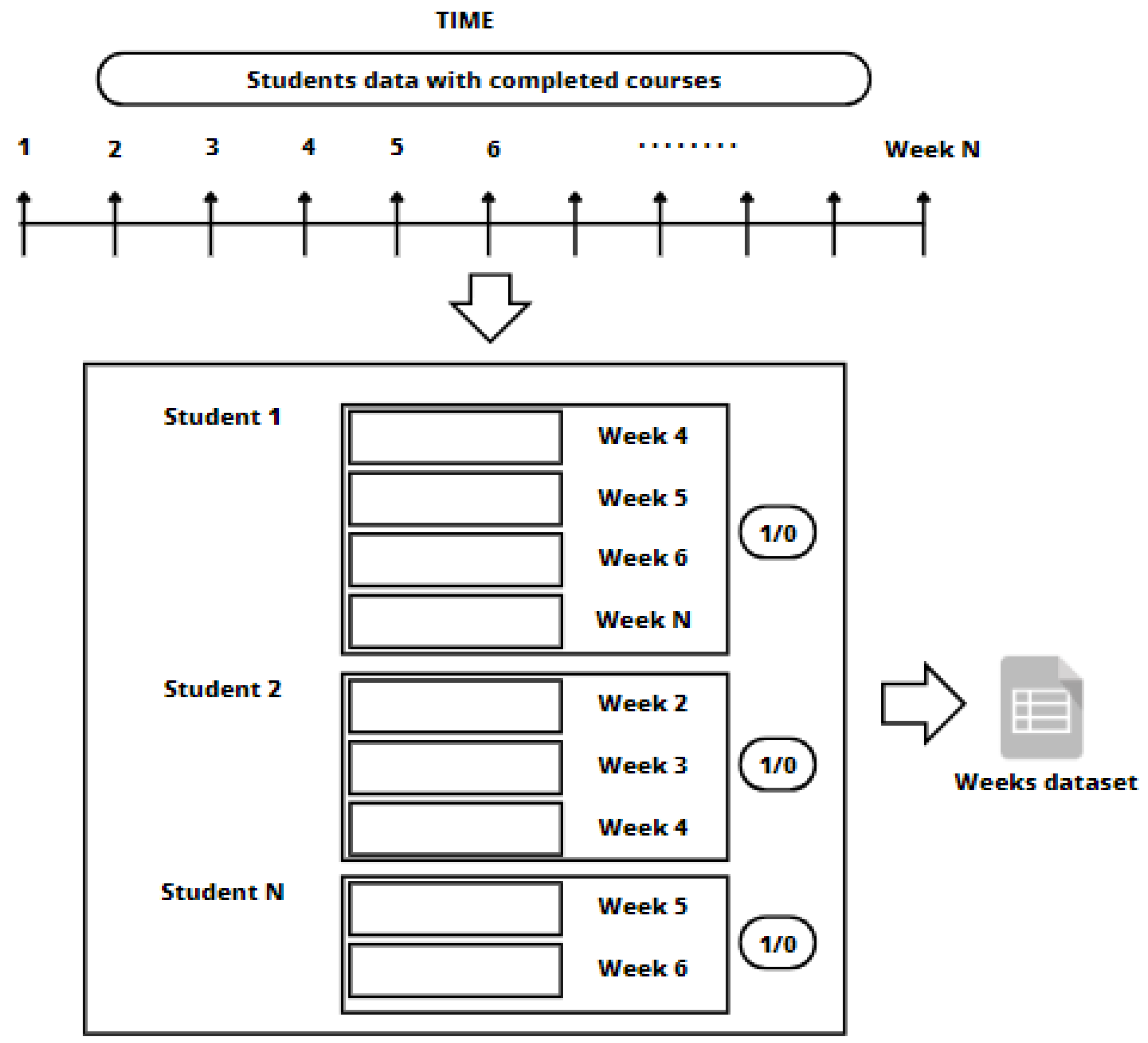
3.1. Data
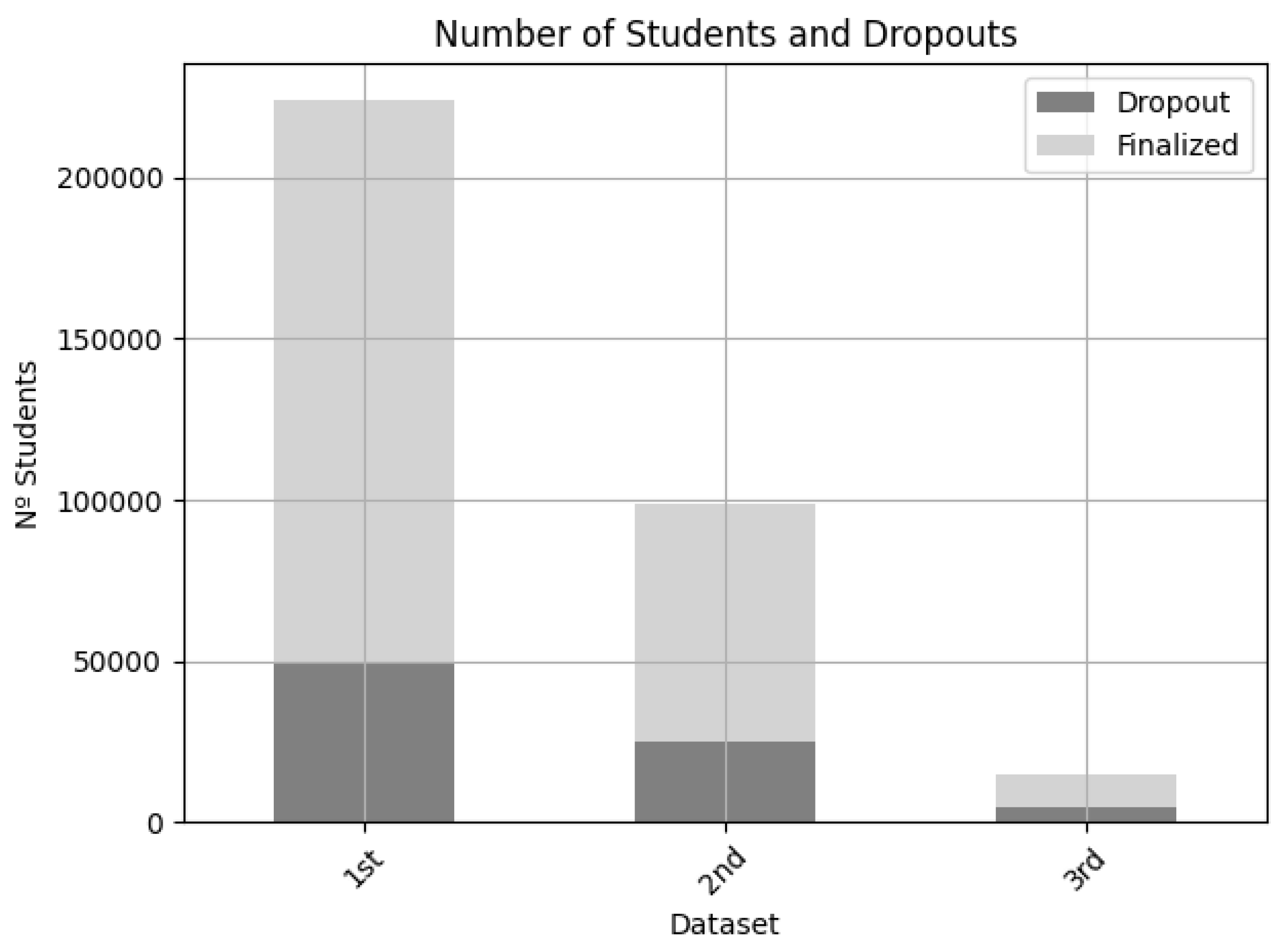
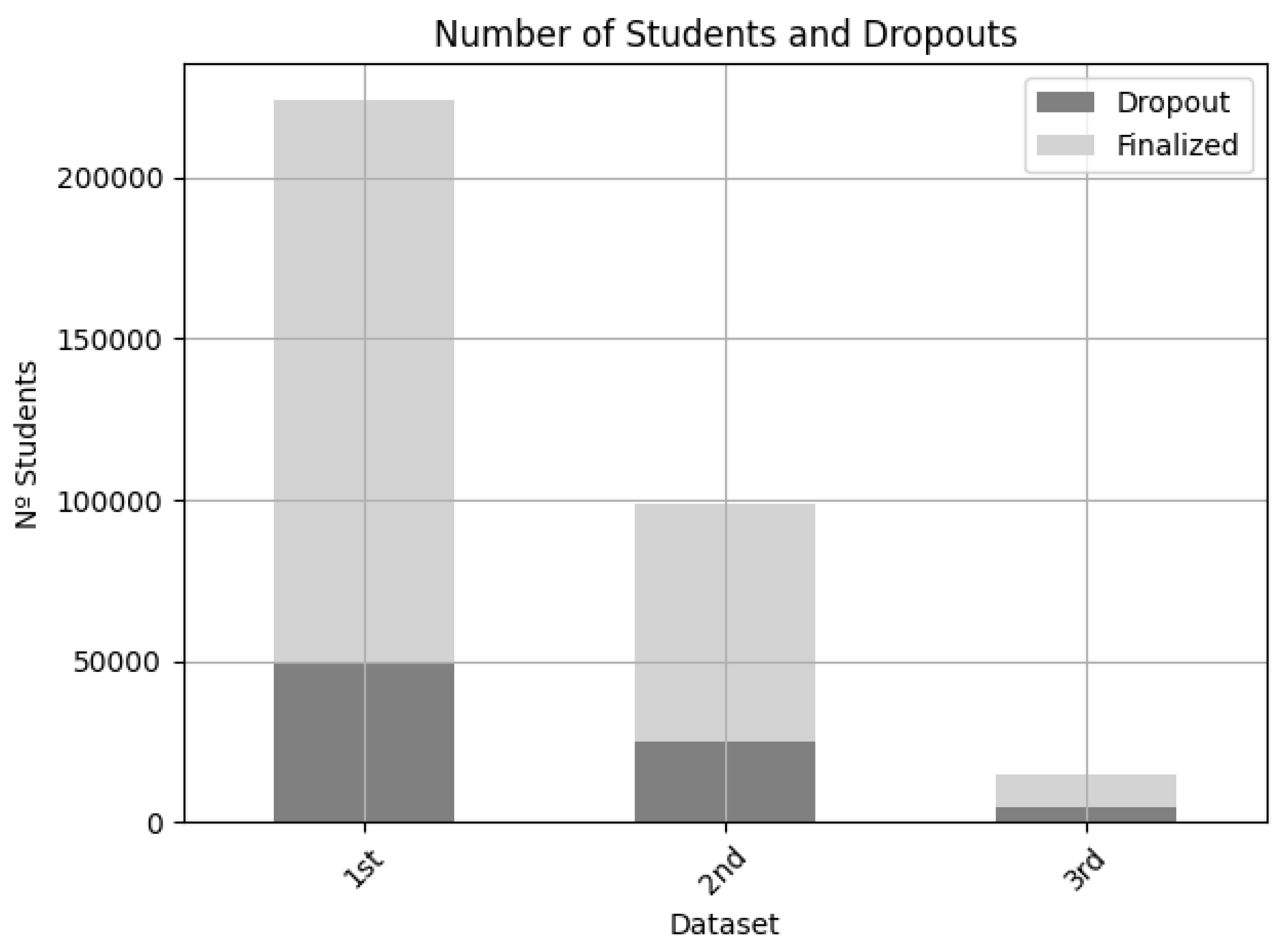
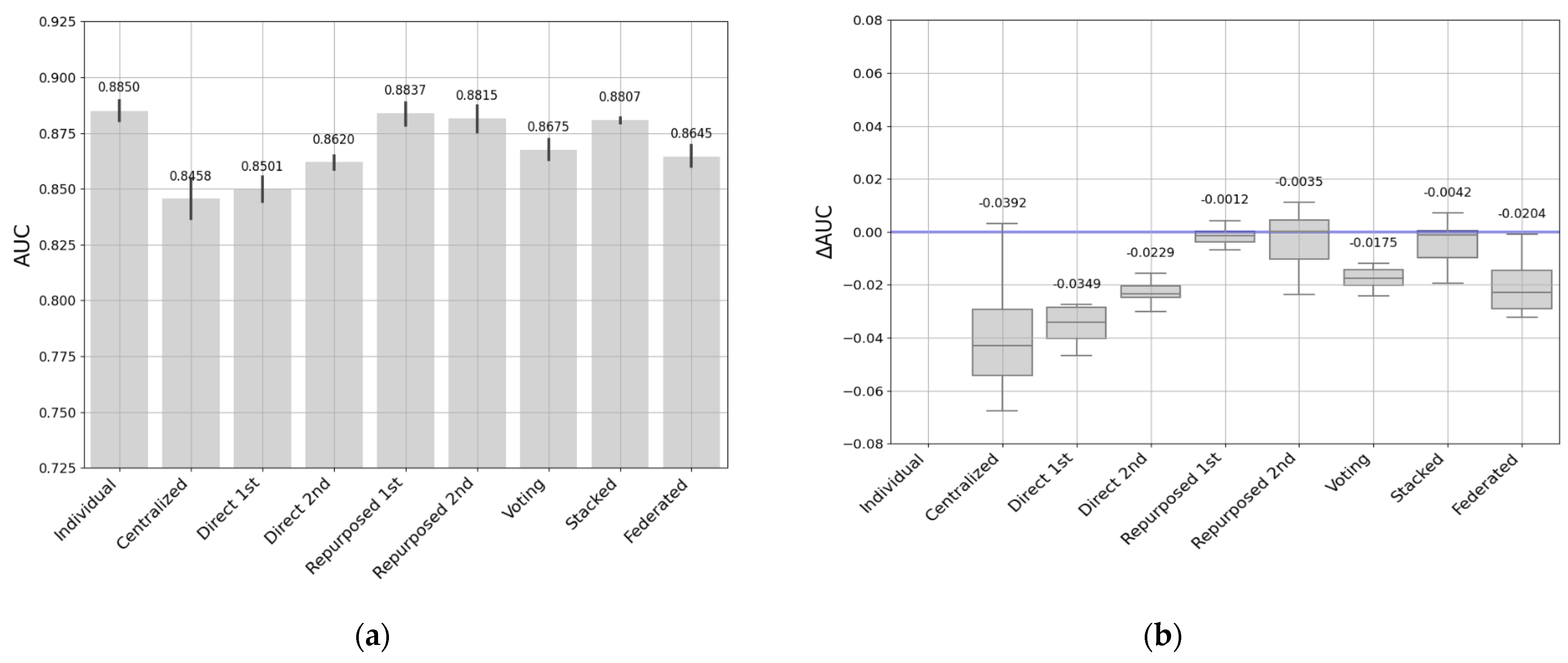
- The first entity’s dataset comprised 224,136 students and 7706 courses of which 174,556 students completed their courses (78%), and 49,580 dropped out before finishing the course (22%). This was a large dataset.
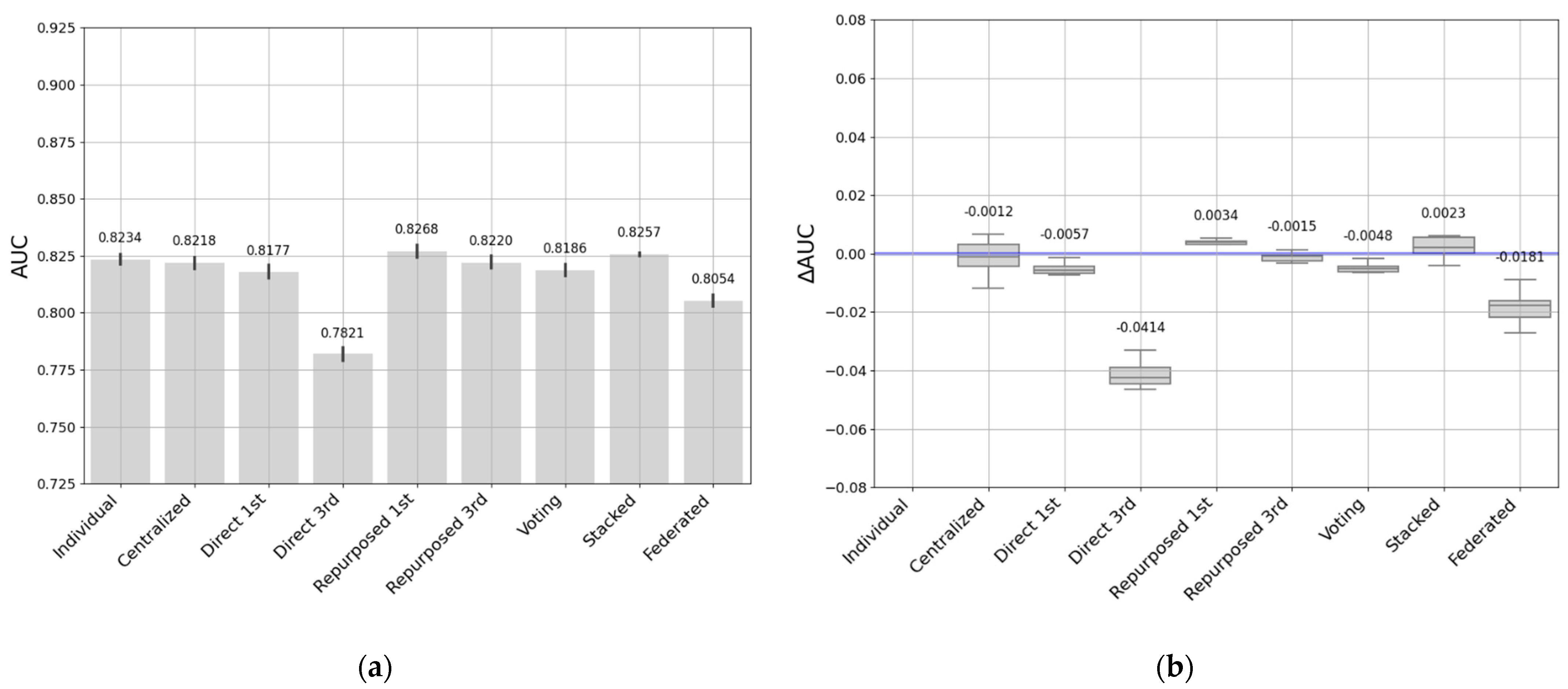
- The second entity’s dataset comprised 98,829 students and 5871 courses of which 74,048 students completed their courses (75%), and 24,781 dropped out before finishing the course (25%). This was a medium dataset.
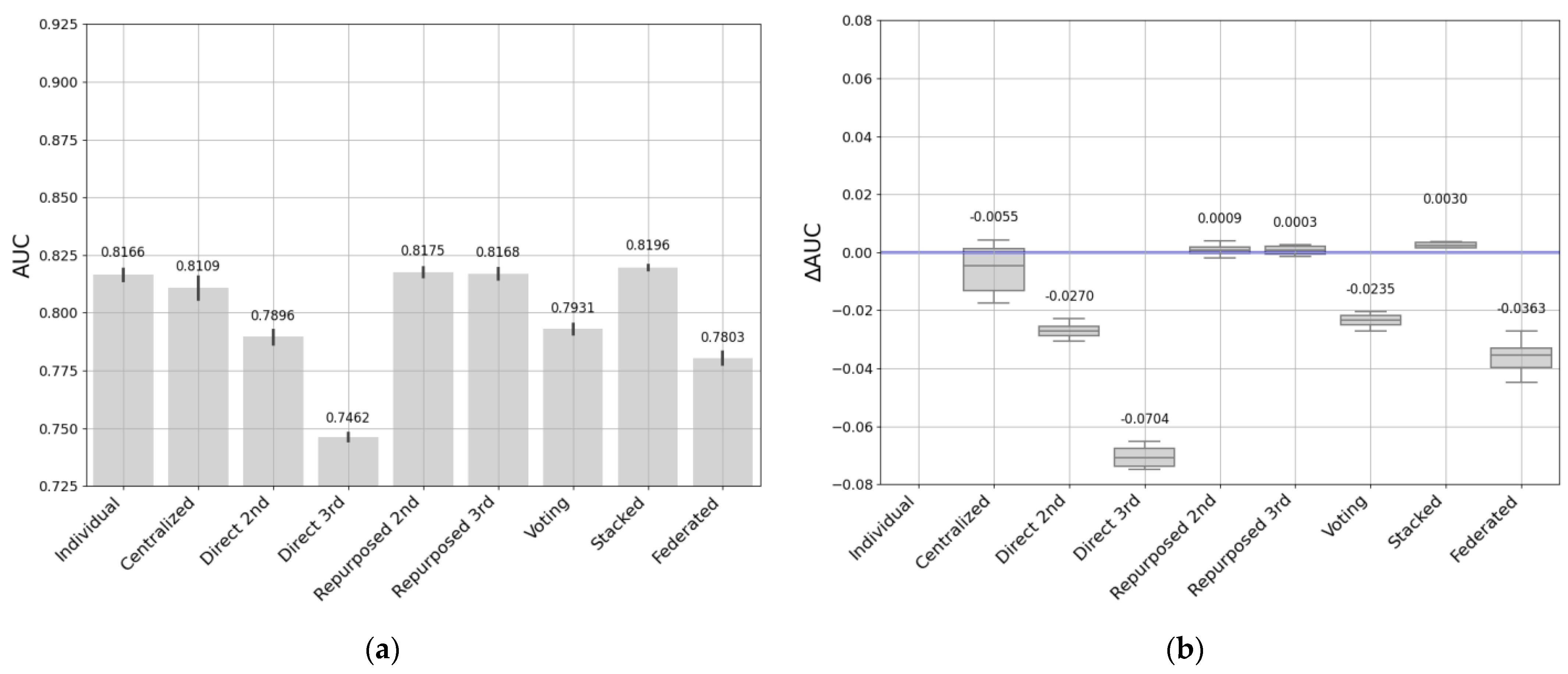
- The third entity’s dataset comprised 15,023 students and 517 courses of which 10,552 students completed their courses (77%), and 4382 dropped out before finishing the course (23%). This was a small dataset.
- Data cleaning: if a null or unknown value was found in any attribute, it was replaced with a value of 0.
- Data normalization/scaling: to bring all numerical values into the same range, they were rescaled to the range [0–1] using the standard min–max scaler normalization, as shown in Equation (1):
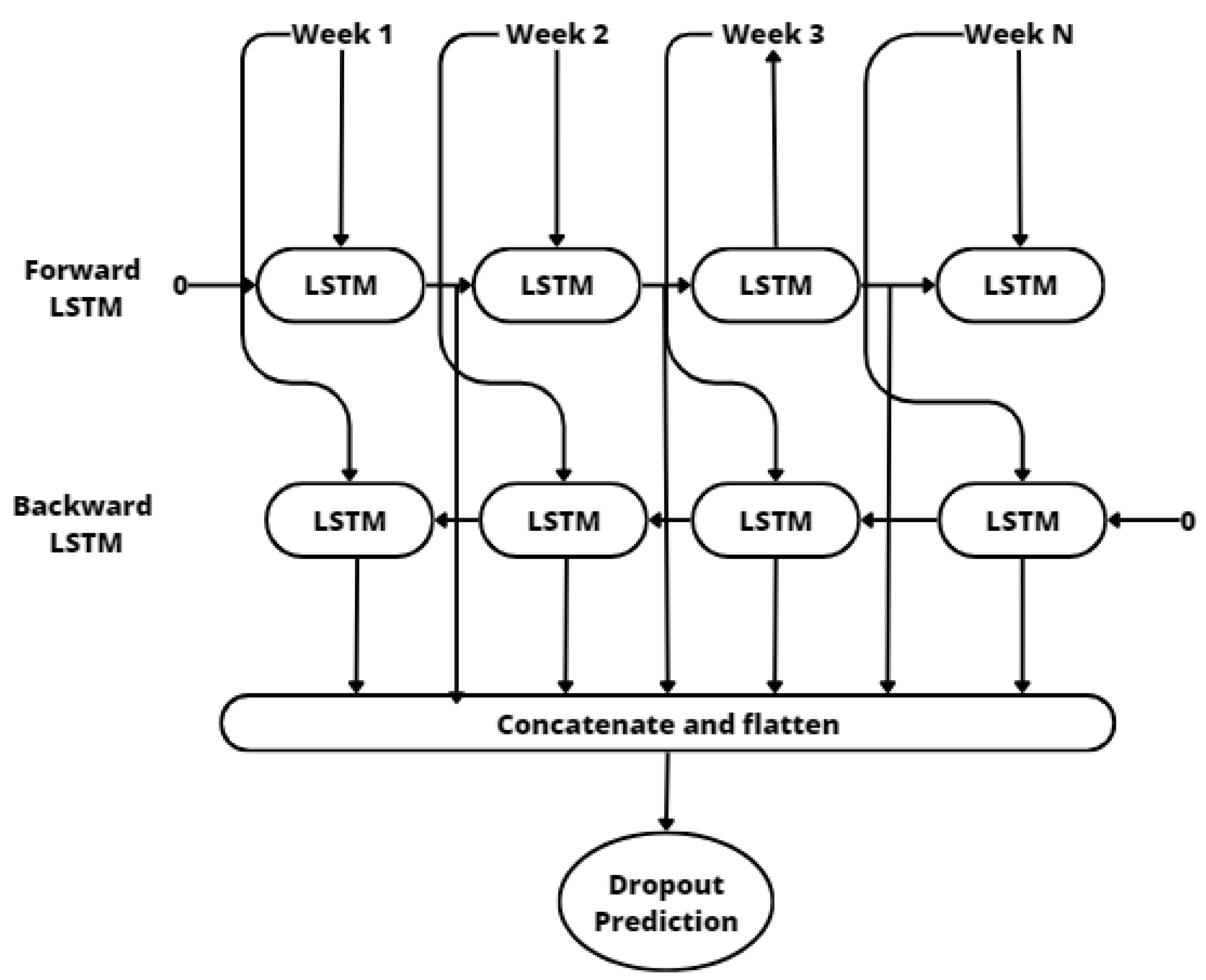
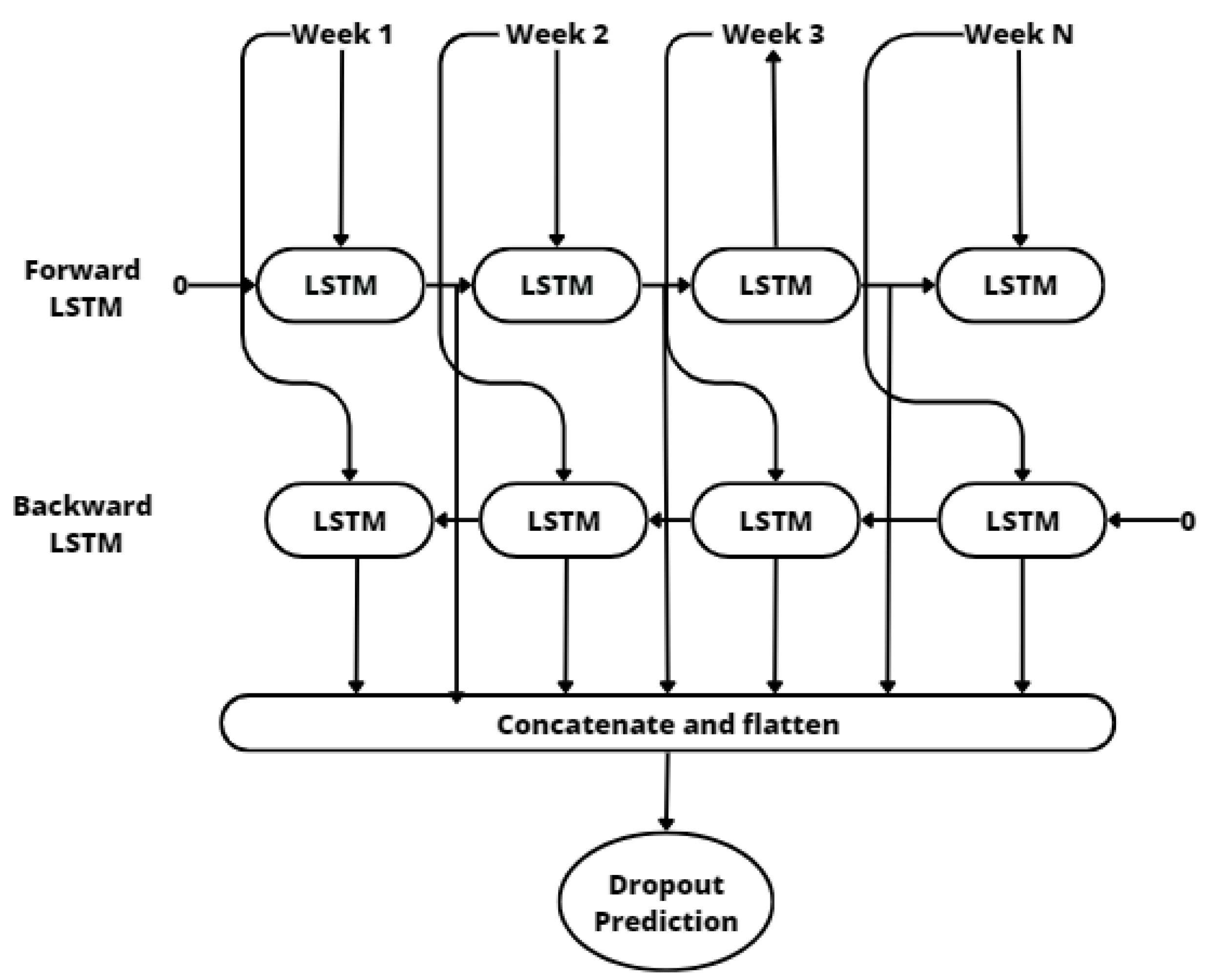
3.2. Prediction Model
4. Results
- AUC-ROC: The area under the ROC curve is one of the most important metrics used to represent the expected performance of a classifier based on the area under the receiver operating characteristic curve (AUC). The AUC is formally defined as the result of applying a prediction threshold, denoted as in Equation (2),where represents the prediction threshold applied to model predictions, and TPR and FPR represent the true positive rate and false positive rates, respectively. AUC scores are limited to a range of zero to one, with a random predictor achieving an AUC of 0.5. Given the unbalanced distribution of the data, we used the AUC-ROC to assess the overall predictive accuracy of our models in accurately capturing dropout patterns.
- ΔAUC: The increment in AUC-ROC is defined to measure changes in predictive performance as shown in Equation (3):where AUC(T’) refers to the AUC of an individual model, and AUC(T) refers to a model trained with another approach. This allowed us to compare, for example, how AUC values were affected by different approaches. If ΔAUC was close to zero, we could conclude that the model performs approximately the same as individual models, but if it was positive or negative, the model performed better or worse, respectively, in context T relative to T’.
5. Discussion
- When there are privacy concerns, the most immediately appealing alternative to individual models seems to be federated learning. However, this approach never improves on the baseline. There are some transfer approaches (such as stacking or repurposed transfer learning) that can be used in those cases since they improve on the baseline and do not have to share data.
- In terms of performance, it seems better to train models on the source context and continue with the training process on the target (repurposed) than to merge all data together in a centralized approach.
- When the resources needed for each approach are important, one positive aspect of centralized and federated learning is that only one model is trained and maintained. However, other approaches—not based on external centralized servers, such as stacking or repurposed transfer learning—need to deal with a large number of models, since the source models need to be created and more importantly, infrastructure and resources are needed for training and managing the models in the target contexts, which may lead to high resource consumption there.
6. Conclusions and Future Work
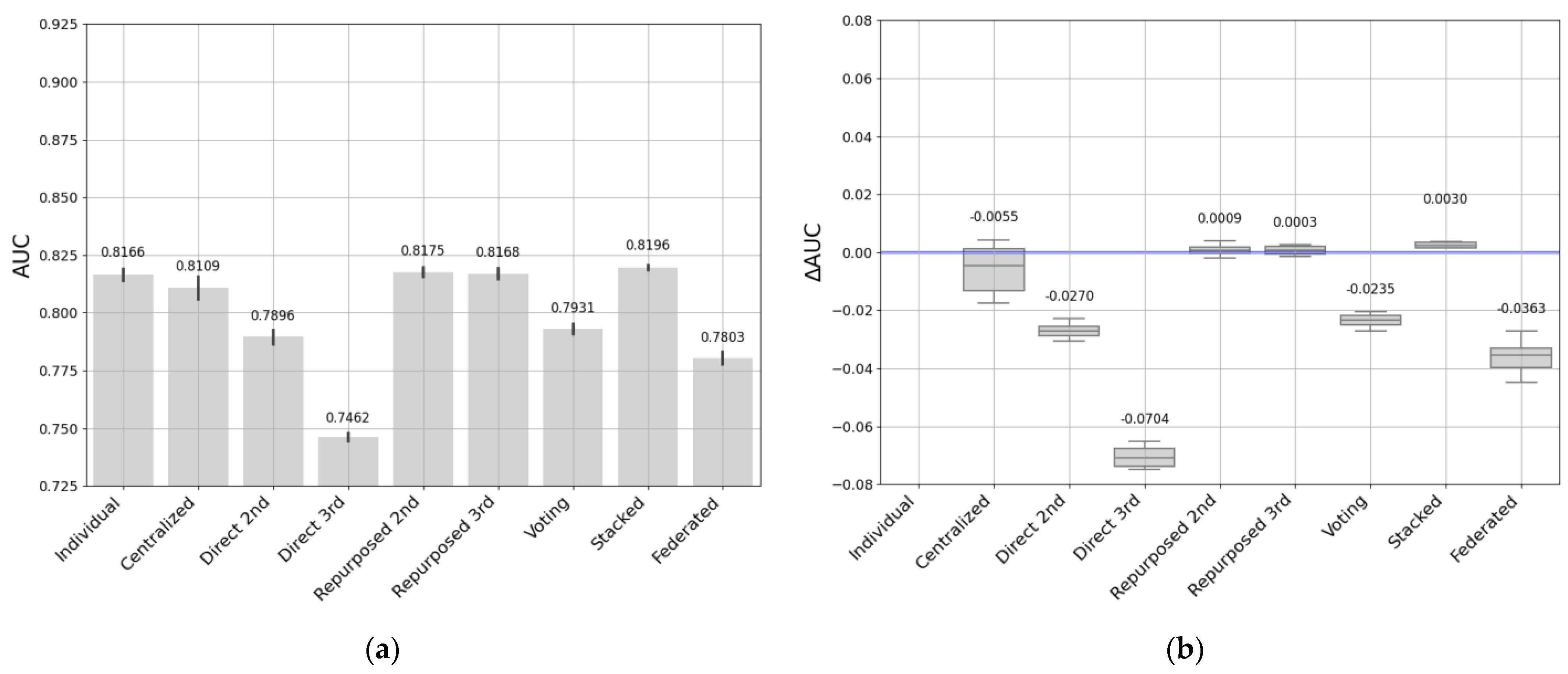
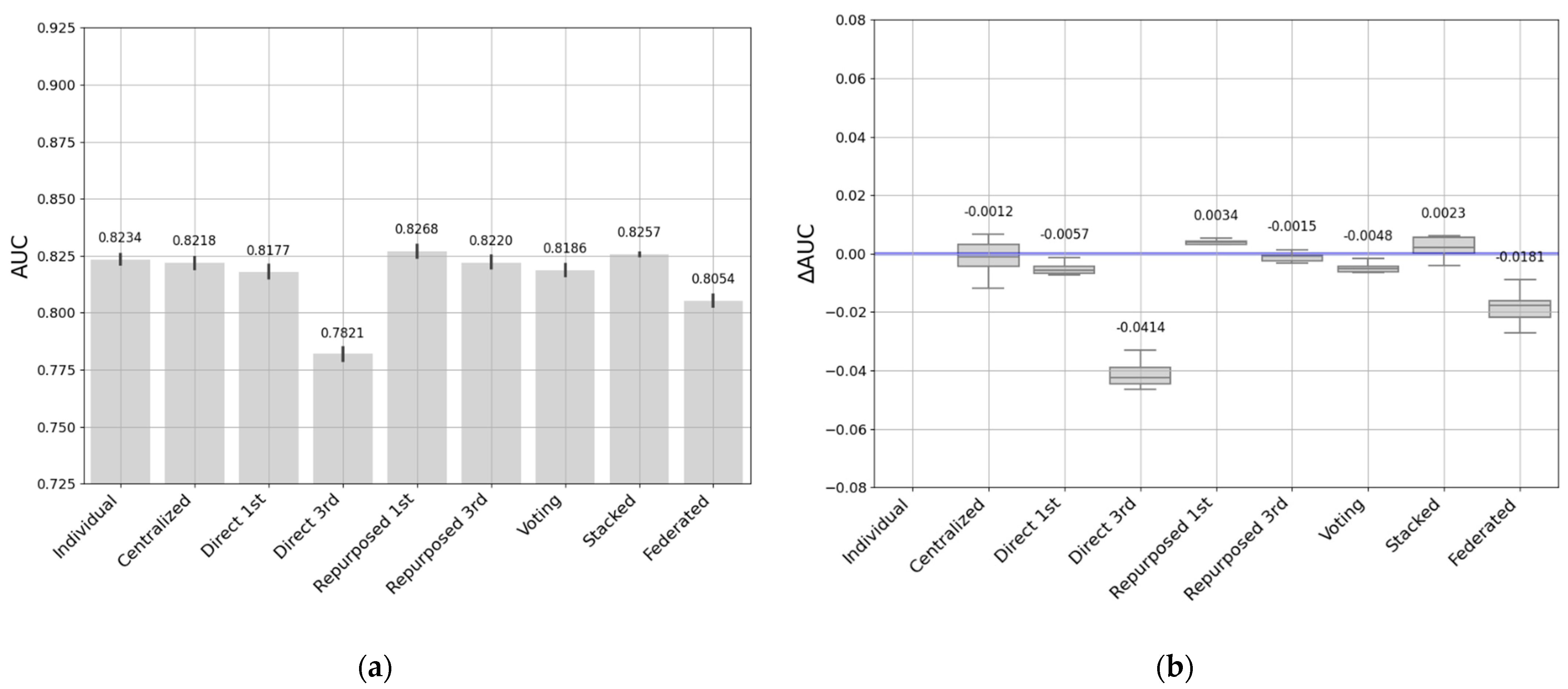
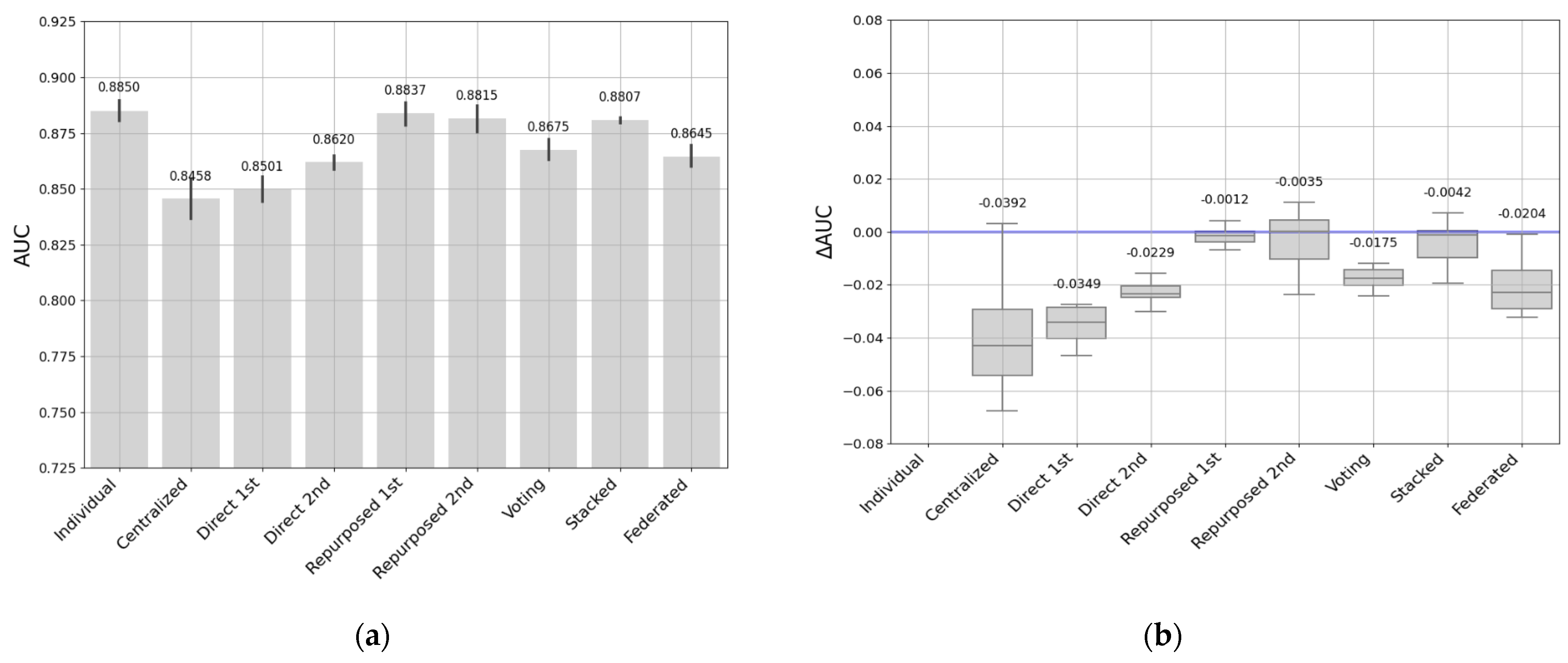
- The individual models fit the data well at each entity. However, this requires training as many individual models as there are entities. Collecting data takes time and resources to maintain so many models. We found that these models tended to have better performance on smaller datasets, and performance may drop when entities have larger datasets.
- Centralized models can build robust, generalizable models by combining data from multiple educational entities. However, in the process of data aggregation, it is critical to address privacy concerns and biases. In addition, the size of the data can influence the effectiveness of this approach: when applied to a larger dataset as a target, it often yields better results, while when applied to smaller or more specific datasets it can lead to decreased performance. It is a good option when data from different entities can be combined, so that these entities do not have to work to create and maintain predictive models.
- Direct transfer has been shown to be feasible and useful in situations where the previously trained model is accurate and adequately matches the particularities of the target data. Direct transfer approaches may be influenced by the sizes of the source and target datasets, and in cases where the datasets are more similar, it seems to produce good results and minimize the duplication of effort between entities.
- Repurposed transfer learning produced the best results for different sizes of entity datasets. This approach improves performance by being specialized on the target dataset without the need to have a large quantity of data. Nevertheless, the entity must have the resources to maintain this model.
- Soft-voting models achieved good performance on medium- and small-sized entities, while there were greater performance differences with the largest dataset. It would be a good option when there are similarities in data sizes and context, and when entities are looking to improve performance by sharing models rather than sharing all their data.
- The stacked transfer technique produced robust, consistent results in all our experiments. It outperformed the individual models, demonstrating its effectiveness in improving model generalizability and adaptability, allowing us to learn and benefit from the strengths of each individual model. This approach improves performance when entities can collaborate effectively by combining predictions from their individual models.
- Federated learning addresses privacy and security issues without sharing critical data. Although there may be a slight decrease in performance, this approach stands out for its resilience and potential in environments where privacy is a priority. Similar to other approaches, the performance of federated learning can also be influenced by data size. It typically performs well with small- to medium-sized datasets while maintaining data privacy but may face challenges with large datasets due to communication and resource constraints.
- If the institution does not have their own data (labeled) to train and maintain a model, in this case, they should use zero-shot techniques such as direct transfer or voting, although both obtain worse prediction results than an individual model. In the case where a partner institution has a similar context, we would choose direct transfer or combine the capabilities of different models using the soft-voting approach.
- If the institution has collected a few data (small-size dataset), individual models would not be the best option because they may not optimally converge. The best option is to use pretrained models from other institutions as a starting point and adapt them to the institution’s local data. Among the most promising options are repurposed transfer and stacking transfer. We also mention the federated learning approaches which, although they obtained worse results, show a promising result to be studied in the future. We also note that the use of a centralized model can generate a greater dispersion and be biased by data from larger institutions.
- If the institution has a great quantity of data (medium- and large-size dataset), the main recommendation is to maintain and train an individual model, since approaches such as centralized and repurposed approaches do not offer significant advantages in terms of performance. However, as a strategic alternative, a stacked ensemble is highlighted as demonstrating superior performance and can be considered especially useful when institutions look for collaborations with others, even when the individual model is already efficient.
- Dropout timestamp: In our research, we did not consider the specific timestamp at which the dropout occurred. In particular, in our datasets, the students could start and finish courses at any time, so it was hard to identify the exact dropout time, as it was not a feature provided to us. In fact, the online course provider manually labeled dropouts after dropout, once the student was contacted to confirm dropping out. As a future line of research, it would be interesting to identify that moment (preferably by the use of any automatic method), as long as the dataset can provide it. The use of that new indicator could be of great power to analyze aspects such as the connection of dropouts with the difficulty weight of the modules in the courses, to identify dropouts as early as possible, to identify the topics inside a course that have more influence on dropouts, or to detect similar dropout behaviors among students. All of them would represent pieces of knowledge of great value that could be used to design interventions to effectively prevent dropout.
- Model scalability and efficiency: As data volumes continue to rise, model scalability and efficiency become increasingly important. Future research efforts could involve extensive experiments with more entities of different sizes and domains, for example, different education levels, not only higher education. This may help produce deeper insights into how dataset size and the specific domain impact the performance of predicting student dropout models. In our research, we employed data based on the activity levels of the student in the LMS Moodle system. As a future line of research, it would be interesting to study the performance of our approaches in other LMS systems, since some studies have shown that student dropout and performance may also depend on the LMS system used [30], and it could be a new variable to increase the knowledge of our models
- Exploration of heterogeneous and multimodal data: Although this study focused on homogeneous data, future research could consider including heterogeneous data, where entities or datasets have different rather than identical attributes. An exploration of heterogeneous data could provide a broader, more accurate view of student behavior and characteristics. In this study, we used only attributes related to students’ activities. The inclusion of multimodal attributes, encompassing text, video, and audio, obtained from sources such as forum postings and recordings, has the potential to enrich the predictive modeling process by capturing a broader range of student interactions and experiences.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Keshavamurthy, U.; Guruprasad, H.S. Learning analytics: A survey. Int. J. Comput. Trends Technol. 2015, 18, 6. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining and learning analytics: An updated survey. WIREs Data Min. Knowl. Discov. 2020, 10, e1355. [Google Scholar] [CrossRef]
- Smith, B.G. E-learning Technologies: A Comparative Study of Adult Learners Enrolled on Blended and Online Campuses Engaging in a Virtual Classroom. Ph.D. Thesis, Capella University, Minneapolis, MN, USA, 2010. [Google Scholar]
- Dalipi, F.; Imran, A.S.; Kastrati, Z. MOOC dropout prediction using machine learning techniques: Review and research challenges. In Proceedings of the IEEE Global Engineering Education Conference (EDUCON’18), Santa Cruz de Tenerife, Spain, 17–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1007–1014. [Google Scholar] [CrossRef]
- Prenkaj, B.; Velardi, P.; Stilo, G.; Distante, D.; Faralli, S. A survey of machine learning approaches for student dropout prediction in online courses. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Solomon, D. Predicting performance and potential difficulties of university students using classification: Survey paper. Int. J. Pure Appl. Math. 2018, 118, 2703–2707. [Google Scholar]
- Márquez-Vera, C.; Cano, A.; Romero, C.; Noaman, A.Y.M.; Fardoun, H.M.; Ventura, S. Early dropout prediction using data mining: A case study with high school students. Expert Syst. 2016, 33, 107–124. [Google Scholar] [CrossRef]
- Donoso-Díaz, S.; Iturrieta, T.N.; Traverso, G.D. Sistemas de Alerta Temprana para estudiantes en riesgo de abandono de la Educación Superior. Ens. Avaliação Políticas Públicas Em Educ. 2018, 26, 944–967. [Google Scholar] [CrossRef]
- Shafiq, D.A.; Marjani, M.; Habeeb, R.A.A.; Asirvatham, D. Student Retention Using Educational Data Mining and Predictive Analytics: A Systematic Literature Review. IEEE Access 2022, 10, 72480–72503. [Google Scholar] [CrossRef]
- Xing, W.; Du, D. Dropout prediction in MOOCs: Using deep learning for personalized intervention. J. Educ. Comput. Res. 2019, 57, 547–570. [Google Scholar] [CrossRef]
- Miao, Q.; Lin, H.; Hu, J.; Wang, X. An intelligent and privacy-enhanced data sharing strategy for blockchain-empowered Internet of Things. Digit. Commun. Netw. 2022, 8, 636–643. [Google Scholar] [CrossRef]
- Gardner, J.; Yang, Y.; Baker, R.S.; Brooks, C. Modeling and Experimental Design for MOOC Dropout Prediction: A Replication Perspective. In Proceedings of the 12th International Conference on Educational Data Mining (EDM 2019), Montréal, QC, Canada, 2–5 July 2019. [Google Scholar]
- Fauzi, M.A.; Yang, B.; Blobel, B. Comparative Analysis between Individual, Centralized, and Federated Learning for Smartwatch Based Stress Detection. J. Pers. Med. 2022, 12, 1584. [Google Scholar] [CrossRef]
- Fachola, C.; Tornaría, A.; Bermolen, P.; Capdehourat, G.; Etcheverry, L.; Fariello, M.I. Federated Learning for Data Analytics in Education. Data 2023, 8, 43. [Google Scholar] [CrossRef]
- Tsiakmaki, M.; Kostopoulos, G.; Kotsiantis, S.; Ragos, O. Transfer Learning from Deep Neural Networks for Predicting Student Performance. Appl. Sci. 2020, 10, 2145. [Google Scholar] [CrossRef]
- Gardner, J.; Yu, R.; Nguyen, Q.; Brooks, C.; Kizilcec, R. Cross-Institutional Transfer Learning for Educational Models: Implications for Model Performance, Fairness, and Equity. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, Chicago, IL, USA, 12–15 June 2023. [Google Scholar] [CrossRef]
- Vitiello, M.; Walk, S.; Chang, V.; Hernandez, R.; Helic, D.; Guetl, C. Mooc Dropouts: A Multi-System Classifier; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 300–314. [Google Scholar] [CrossRef]
- Jayaprakash, S.M.; Moody, E.W.; Lauría, E.J.M.; Regan, J.R.; Baron, J.D. Early alert of academically at-risk students: An open source analytics initiative. J. Learn. Anal. 2014, 1, 6–47. [Google Scholar] [CrossRef]
- Li, X.; Song, D.; Han, M.; Zhang, Y.; Kizilcec, R.F. On the limits of algorithmic prediction across the globe. arXiv 2021, arXiv:2103.15212. [Google Scholar]
- Ocumpaugh, J.; Baker, R.; Gowda, S.; Heffernan, N.; Heffernan, C. Population validity for educational data mining models: A case study in affect detection. Br. J. Educ. Technol. 2014, 45, 487–501. [Google Scholar] [CrossRef]
- López-Zambrano, J.; Lara, J.A.; Romero, C. Towards portability of models for predicting students’ final performance in university courses starting from moodle Logs. Appl. Sci. 2020, 10, 354. [Google Scholar] [CrossRef]
- Smietanka, M.; Pithadia, H.; Treleaven, P. Federated learning for privacy-preserving data access. Int. J. Data Sci. Big Data Anal. 2021, 1, 1. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Agüera y Arcas, B. Federated Learning of Deep Networks Using Model Averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Peng, S.; Yang, Y.; Mao, M.; Park, D. Centralized Machine Learning Versus Federated Averaging: A Comparison using the MNIST Dataset. KSII Trans. Internet Inf. Syst. 2022, 16, 742–756. [Google Scholar] [CrossRef]
- Guo, S.; Zeng, D.; Dong, S. Pedagogical Data Analysis via Federated Learning toward Education 4.0. Am. J. Educ. Inf. Technol. 2020, 4, 56–65. [Google Scholar]
- He, J.; Bailey, J.; Rubinstein, B.; Zhang, R. Identifying at-risk students in massive open online courses. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar] [CrossRef]
- Whitehill, J.; Mohan, K.; Seaton, D.; Rosen, Y.; Tingley, D. Delving deeper into MOOC student dropout prediction. arXiv 2017, arXiv:1702.06404. [Google Scholar]
- Porras, J.M.; Porras, A.; Fernández, J.; Romero, C.; Ventura, S. Selecting the Best Approach for Predicting Student Dropout in Full Online Private Higher Education; LASI: Singapore, 2023. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Kanetaki, Z.; Stergiou, C.; Bekas, G.; Troussas, C.; Sgouropoulou, C. The impact of different learning approaches based on MS Teams and Moodle on students’ performance in an on-line mechanical CAD module. Glob. J. Eng. Educ. 2021, 23, 185–190. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Description |
|---|---|
| discussions_viewed | Number of discussions the student has seen |
| htm_completed | Number of HTML pages completed |
| vid_completed | Number of completed video views |
| exa_completed | Number of examinations completed |
| autoeva_completed | Number of self-assessments completed |
| n_posts | Number of posts or messages viewed |
| n_discussions | Number of discussions held in the period |
| assignment_submited | Number of tasks performed |
| com_tutor | Number of times connected to the tutor |
| Hours in course | Number of hours spent |
| Course visits | Number of visits to the course |
| Target | Source | Approach | Z-Test (p-Value) | T-Test (p-Value) |
|---|---|---|---|---|
| 1st | 1st + 2nd + 3rd | Centralized | 0.073 | 0.090 |
| 2nd | Direct transfer | <0.001 * | 0.015 * | |
| 3rd | Direct transfer | <0.001 * | <0.001 * | |
| 2nd | Repurposed transfer | 0.109 | 0.164 | |
| 3rd | Repurposed transfer | 0.710 | 0.732 | |
| 2nd + 3rd | Voting | <0.001 * | <0.001 * | |
| 1st + 2nd + 3rd | Stacking | 0.021 * | 0.046 * | |
| 1st + 2nd + 3rd | Federated | <0.001 * | <0.001 * | |
| 2nd | 1st + 2nd + 3rd | Centralized | 0.623 | 0.569 |
| 1st | Direct transfer | <0.001 * | <0.001 * | |
| 3rd | Direct transfer | <0.001 * | <0.001 * | |
| 1st | Repurposed transfer | 0.106 | 0.120 | |
| 3rd | Repurposed transfer | 0.623 | 0.087 | |
| 1st + 3rd | Voting | <0.001 * | <0.001 * | |
| 1st + 2nd + 3rd | Stacking | 0.035 * | 0065 * | |
| 1st + 2nd + 3rd | Federated | <0.001 * | <0.001 * | |
| 3rd | 1st + 2nd + 3rd | Centralized | <0.001 * | <0.001 * |
| 1st | Direct transfer | <0.001 * | <0.001 * | |
| 2nd | Direct transfer | <0.001 * | <0.001 * | |
| 1st | Repurposed transfer | 0.253 | 0.307 | |
| 2nd | Repurposed transfer | 0.317 | 0.368 | |
| 1st + 2nd | Voting | <0.001 * | <0.001 * | |
| 1st + 2nd + 3rd | Stacking | 0.101 | 0.136 | |
| 1st + 2nd + 3rd | Federated | <0.001 * | <0.001 * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Porras, J.M.; Lara, J.A.; Romero, C.; Ventura, S. A Case-Study Comparison of Machine Learning Approaches for Predicting Student’s Dropout from Multiple Online Educational Entities. Algorithms 2023, 16, 554. https://doi.org/10.3390/a16120554
Porras JM, Lara JA, Romero C, Ventura S. A Case-Study Comparison of Machine Learning Approaches for Predicting Student’s Dropout from Multiple Online Educational Entities. Algorithms. 2023; 16(12):554. https://doi.org/10.3390/a16120554
Chicago/Turabian StylePorras, José Manuel, Juan Alfonso Lara, Cristóbal Romero, and Sebastián Ventura. 2023. "A Case-Study Comparison of Machine Learning Approaches for Predicting Student’s Dropout from Multiple Online Educational Entities" Algorithms 16, no. 12: 554. https://doi.org/10.3390/a16120554
APA StylePorras, J. M., Lara, J. A., Romero, C., & Ventura, S. (2023). A Case-Study Comparison of Machine Learning Approaches for Predicting Student’s Dropout from Multiple Online Educational Entities. Algorithms, 16(12), 554. https://doi.org/10.3390/a16120554