
On Finding Optimal (Dynamic) Arborescences

 ,
,
Abstract
:1. Introduction
2. Optimal Arborescences
2.1. Edmonds’ Algorithm
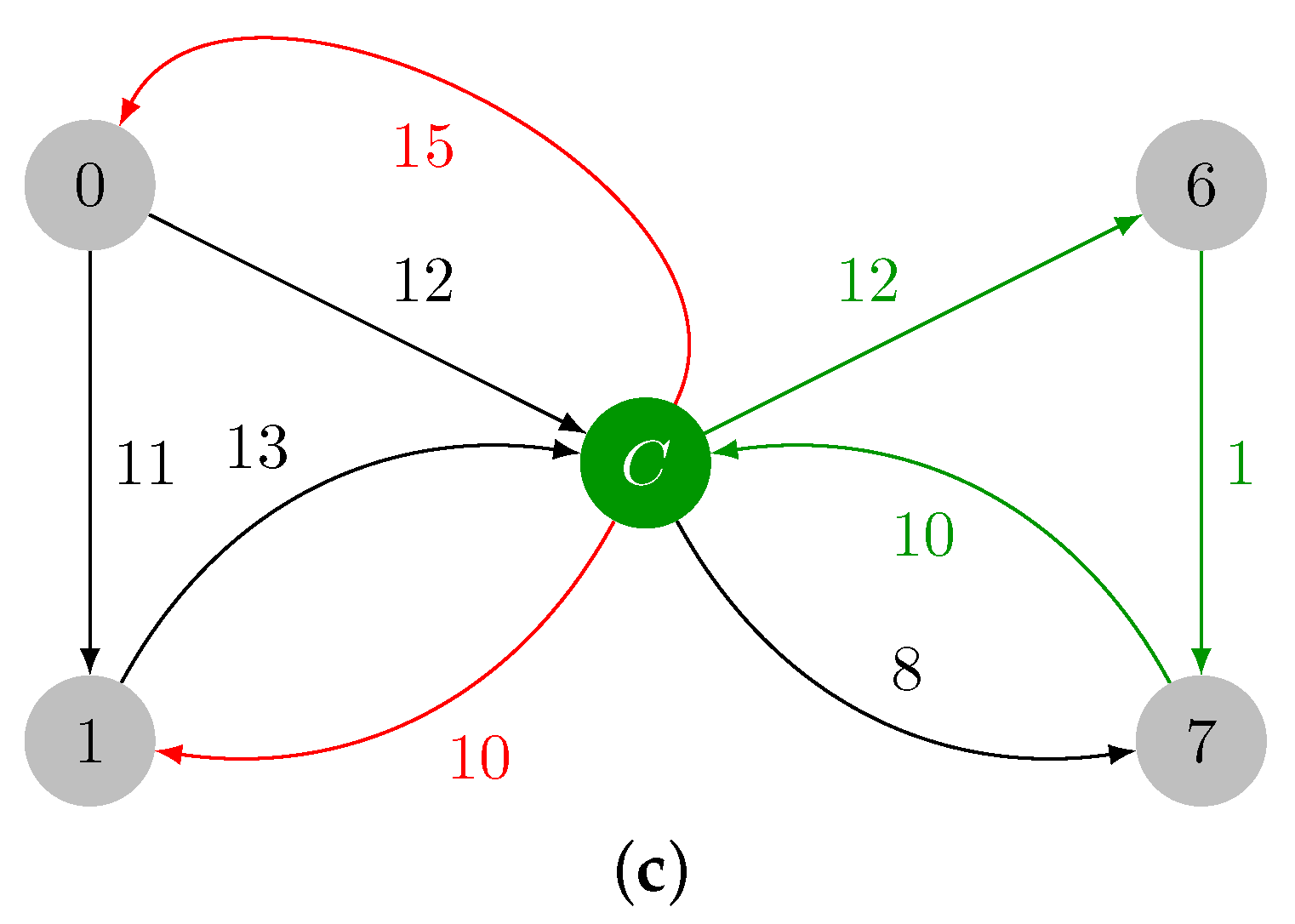
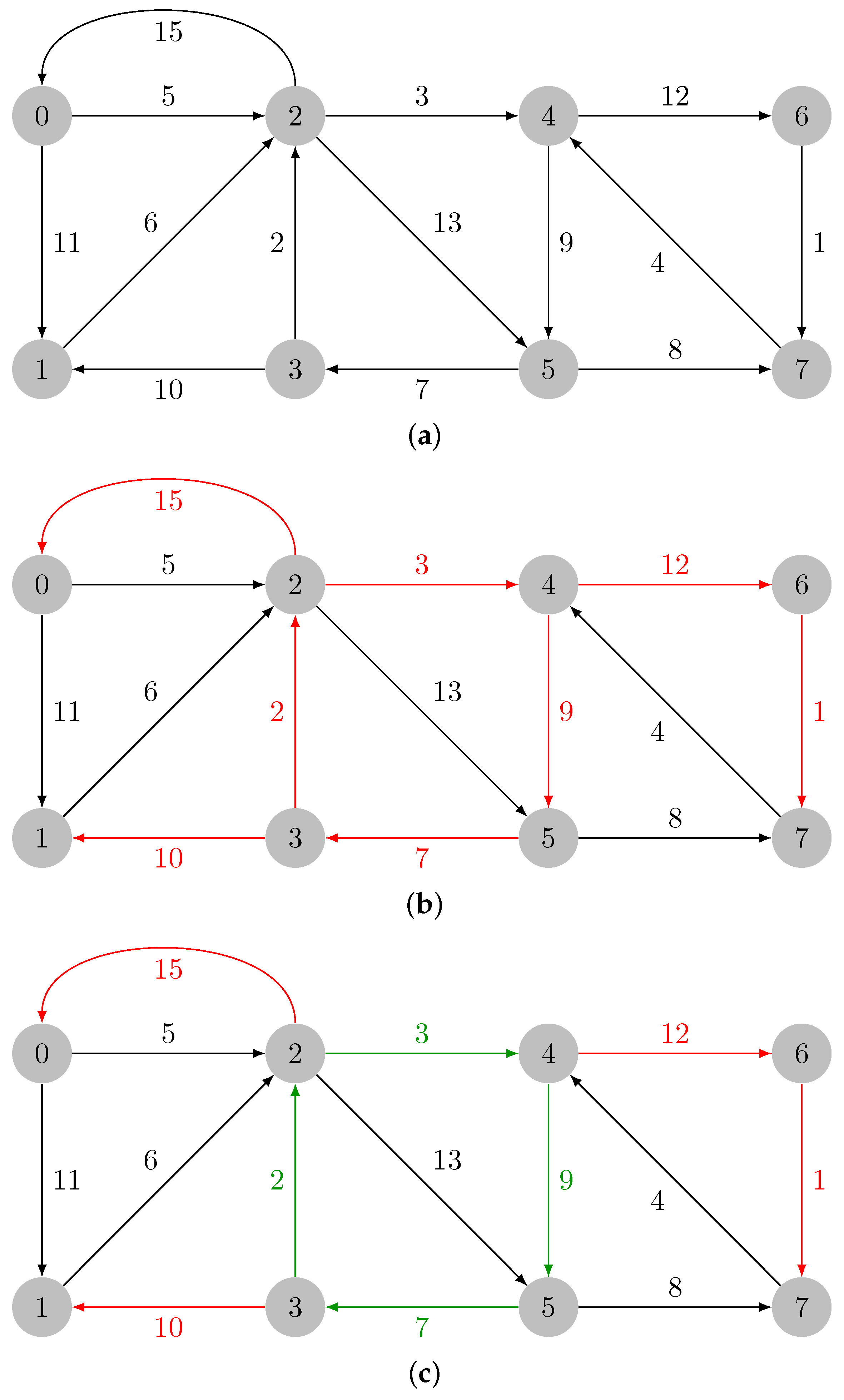
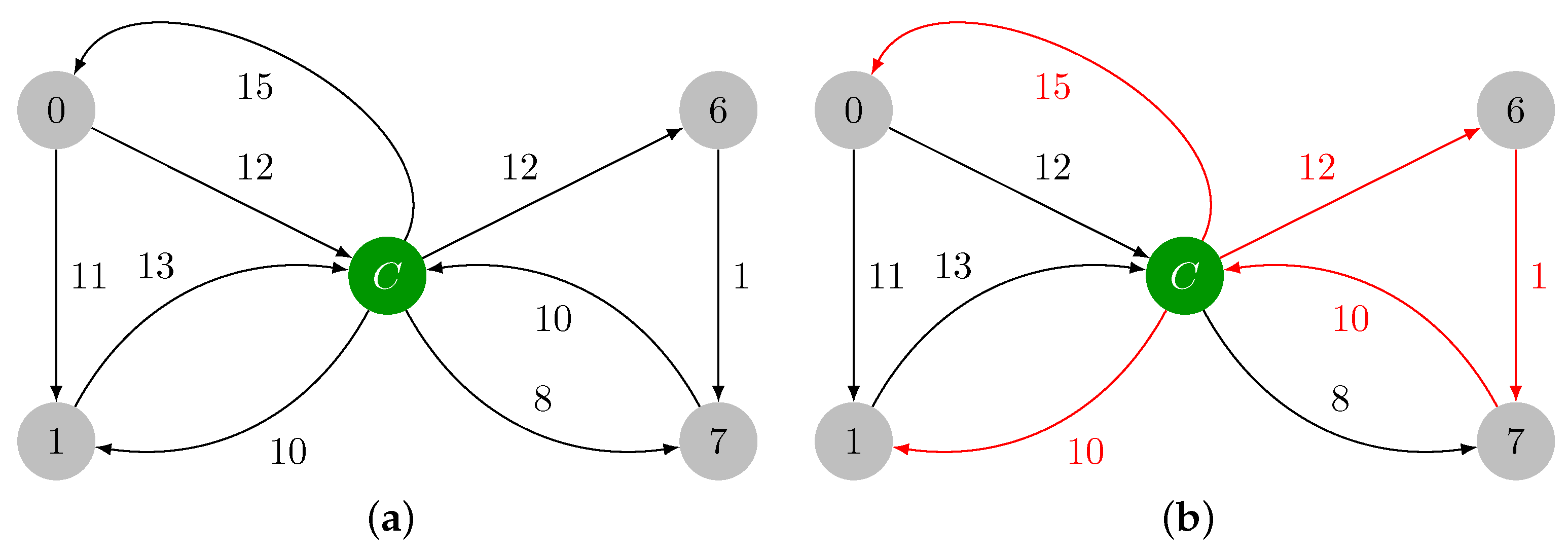
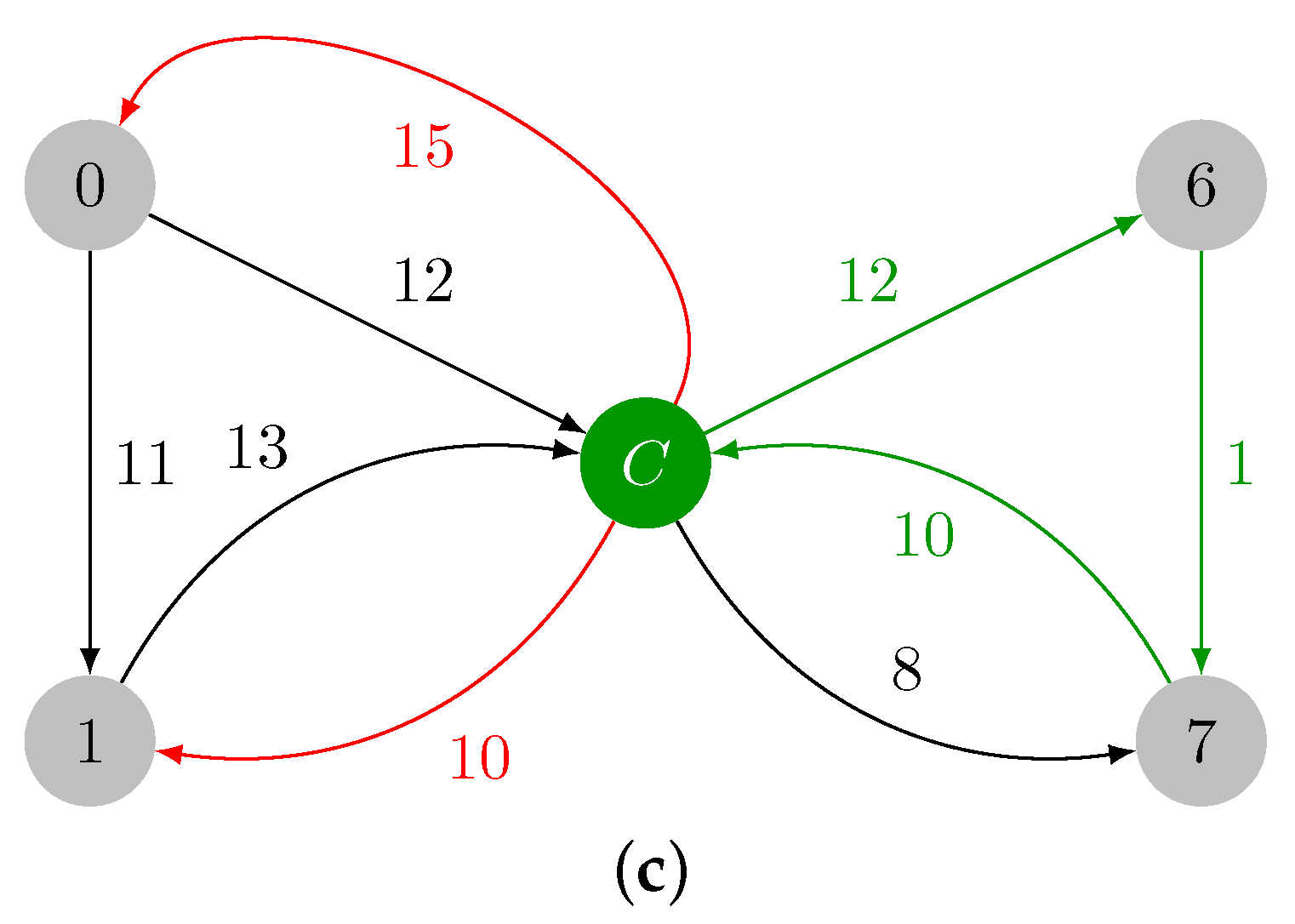
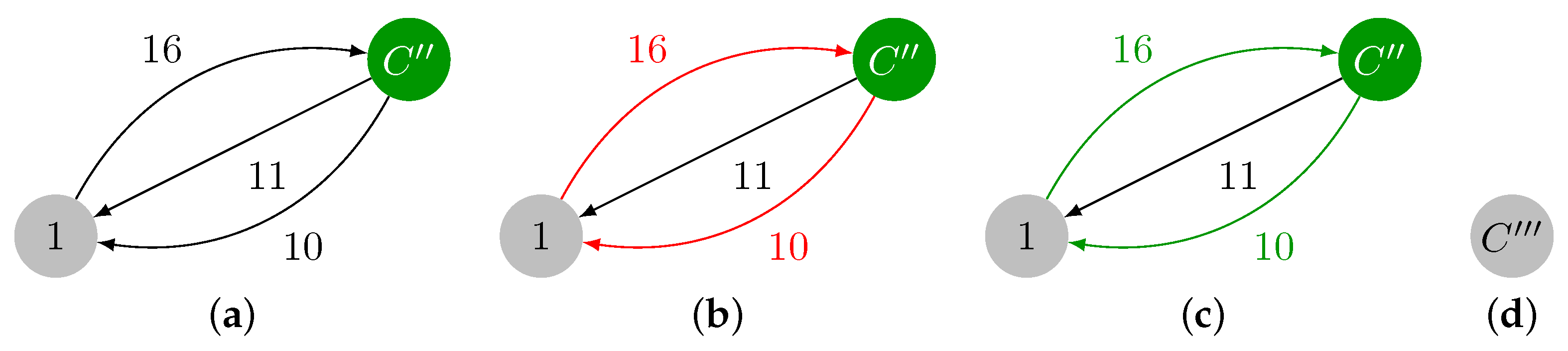
2.1.1. Contraction Phase
- Loop edge removal: If , then .
- Unmodified edge preservation: If , then .
- Edges originating from the new vertex: If , then .
- Edges incident to the new vertex: If , then , and .
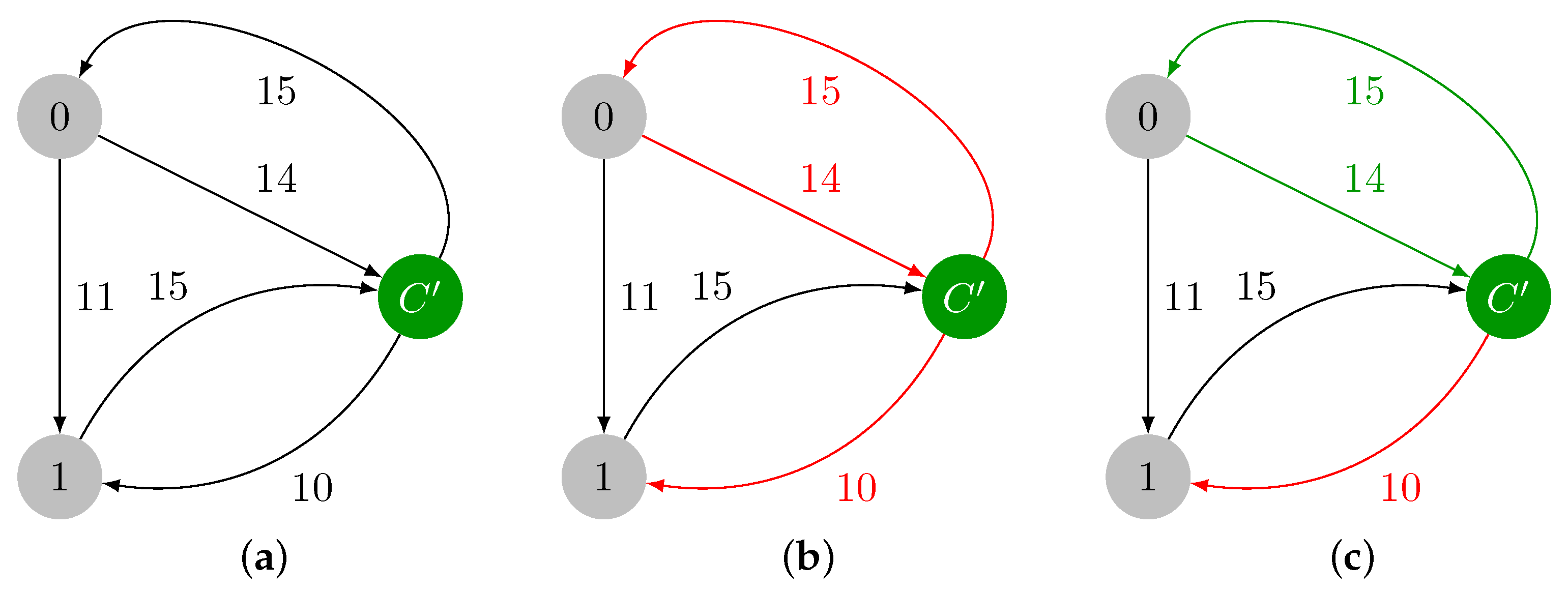
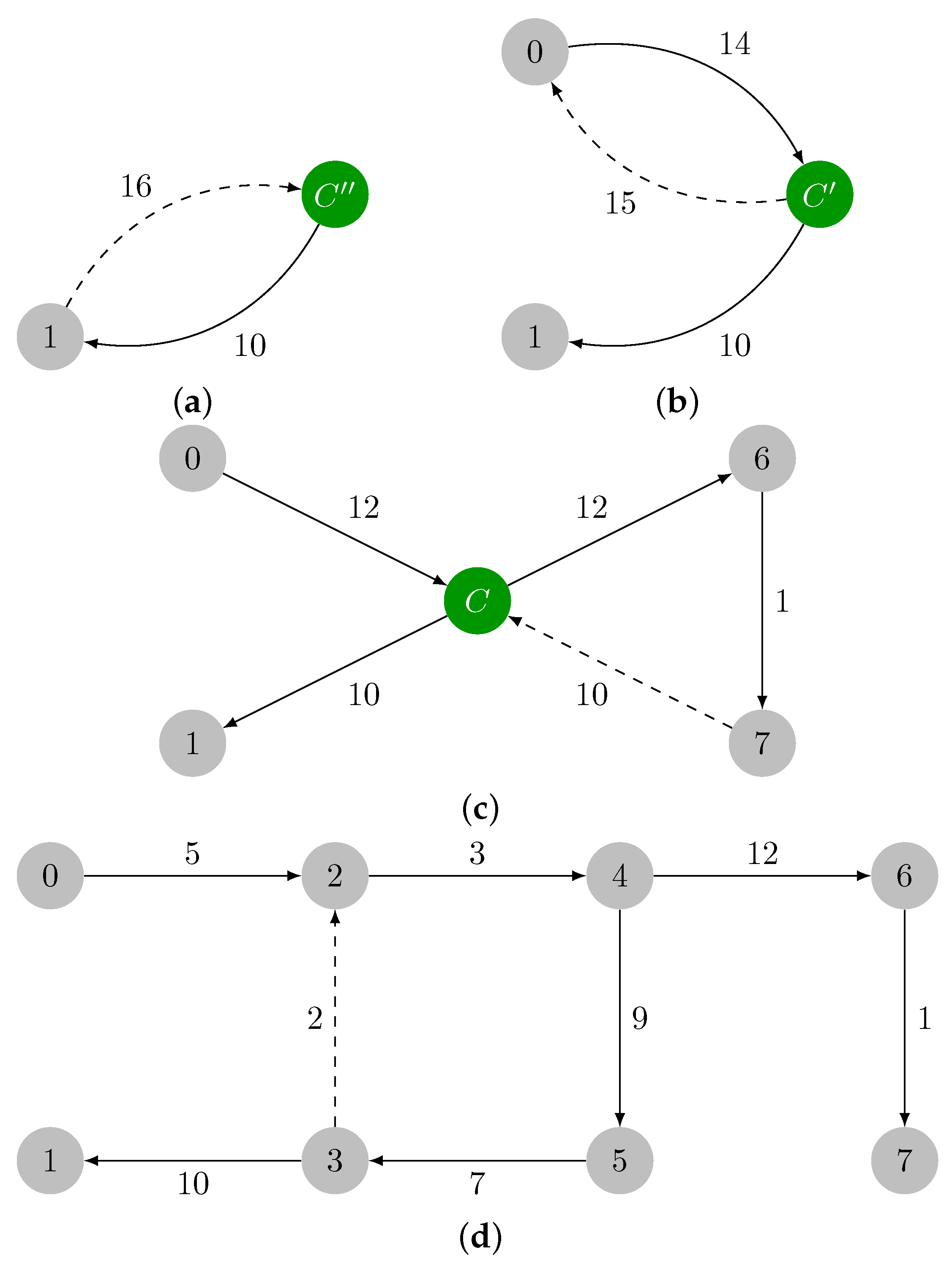
2.1.2. Expansion Phase
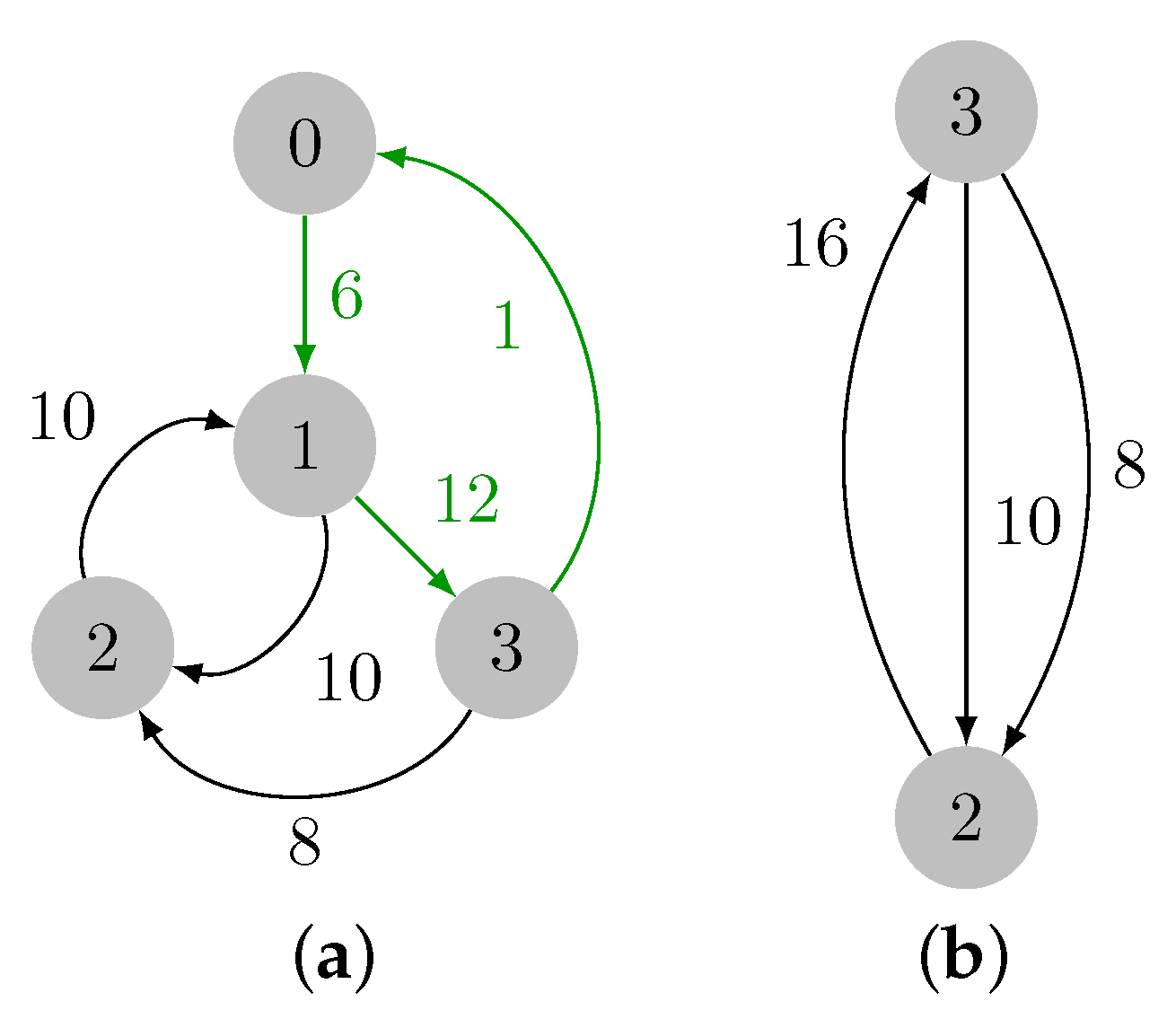
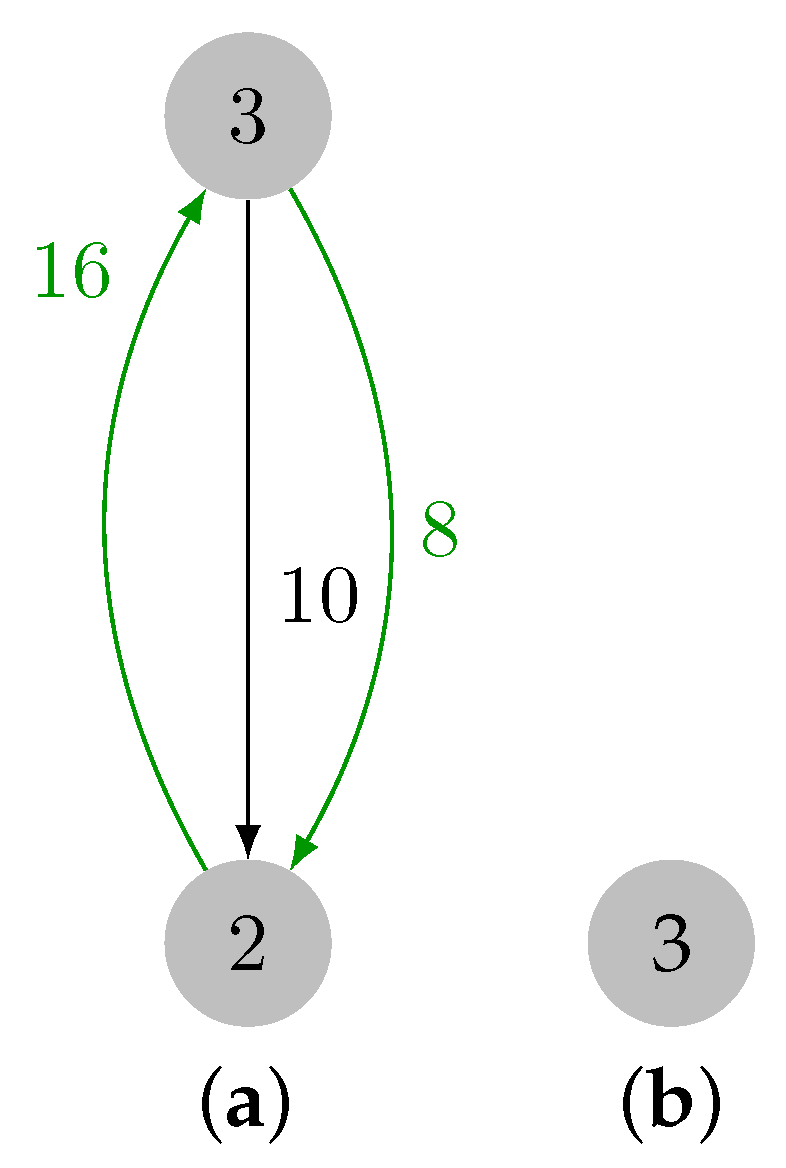
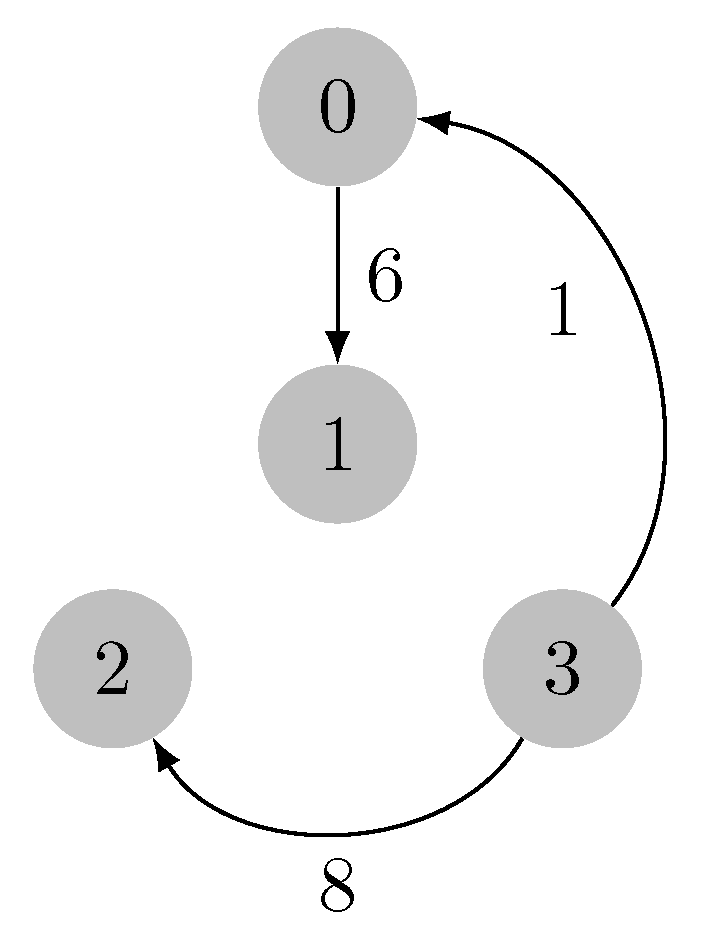
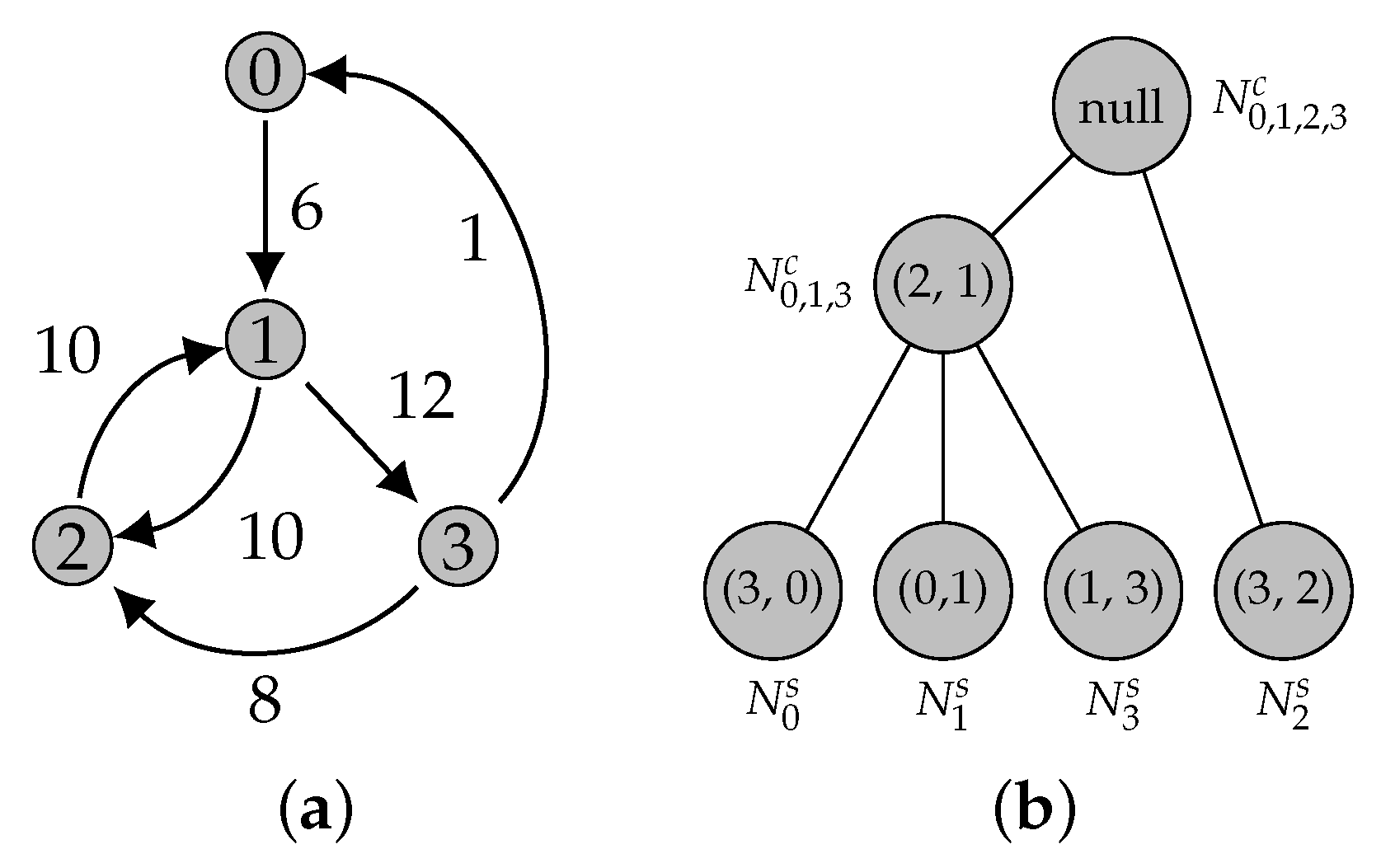
2.1.3. Illustrative Example
2.2. Tarjan Algorithm
2.2.1. Initialization
| Algorithm 1 Initialization of Tarjan algorithm. |
|
2.2.2. Contraction Phase
| Algorithm 2 Main loop body of the contraction phase. |
|
| Algorithm 3 Continuation of the main loop body of the contraction phase. |
|
| Algorithm 4 Continuation of the main loop body of the contraction phase. |
|
2.2.3. Expansion Phase
| Algorithm 5 Expansion phase. |
|
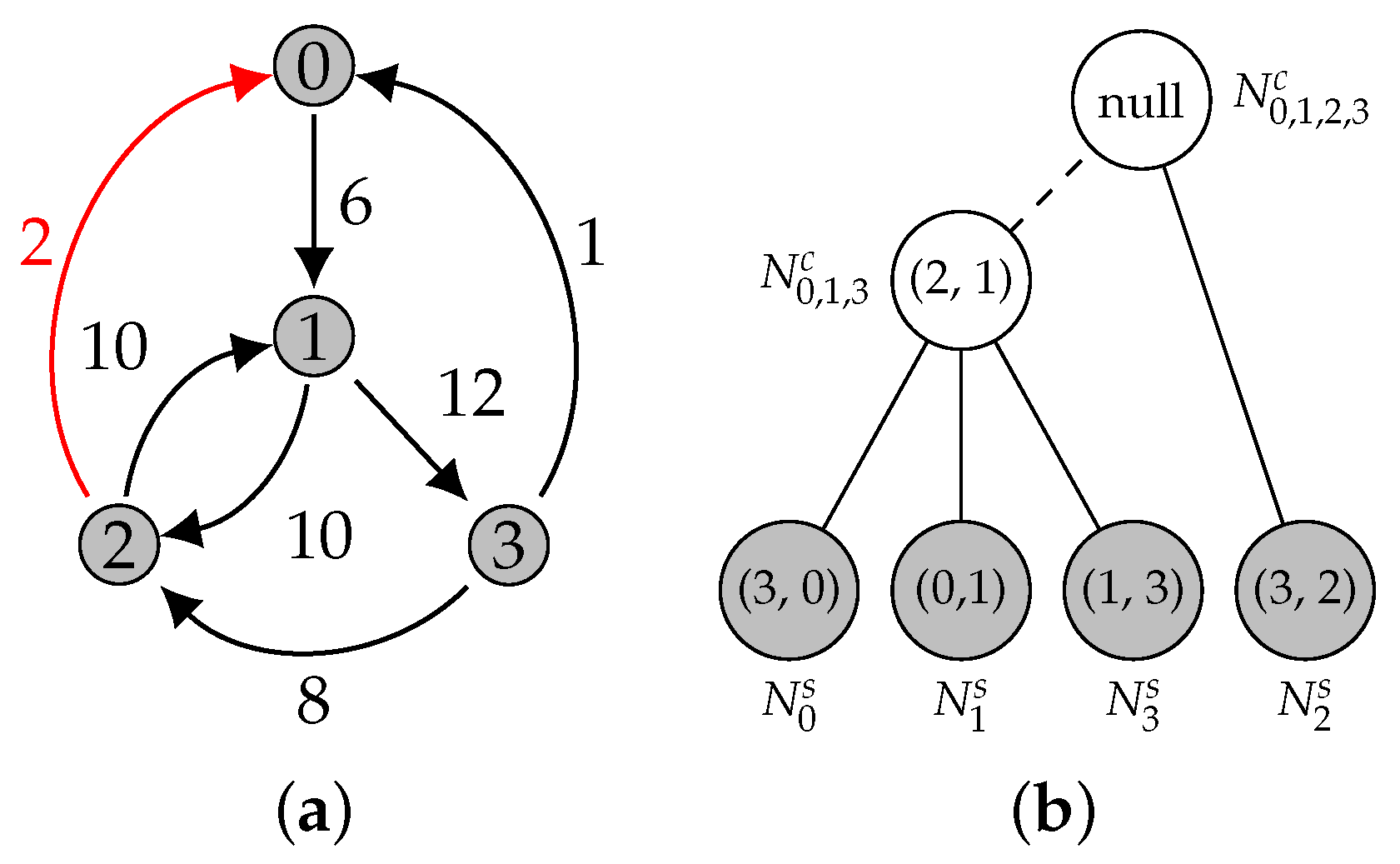
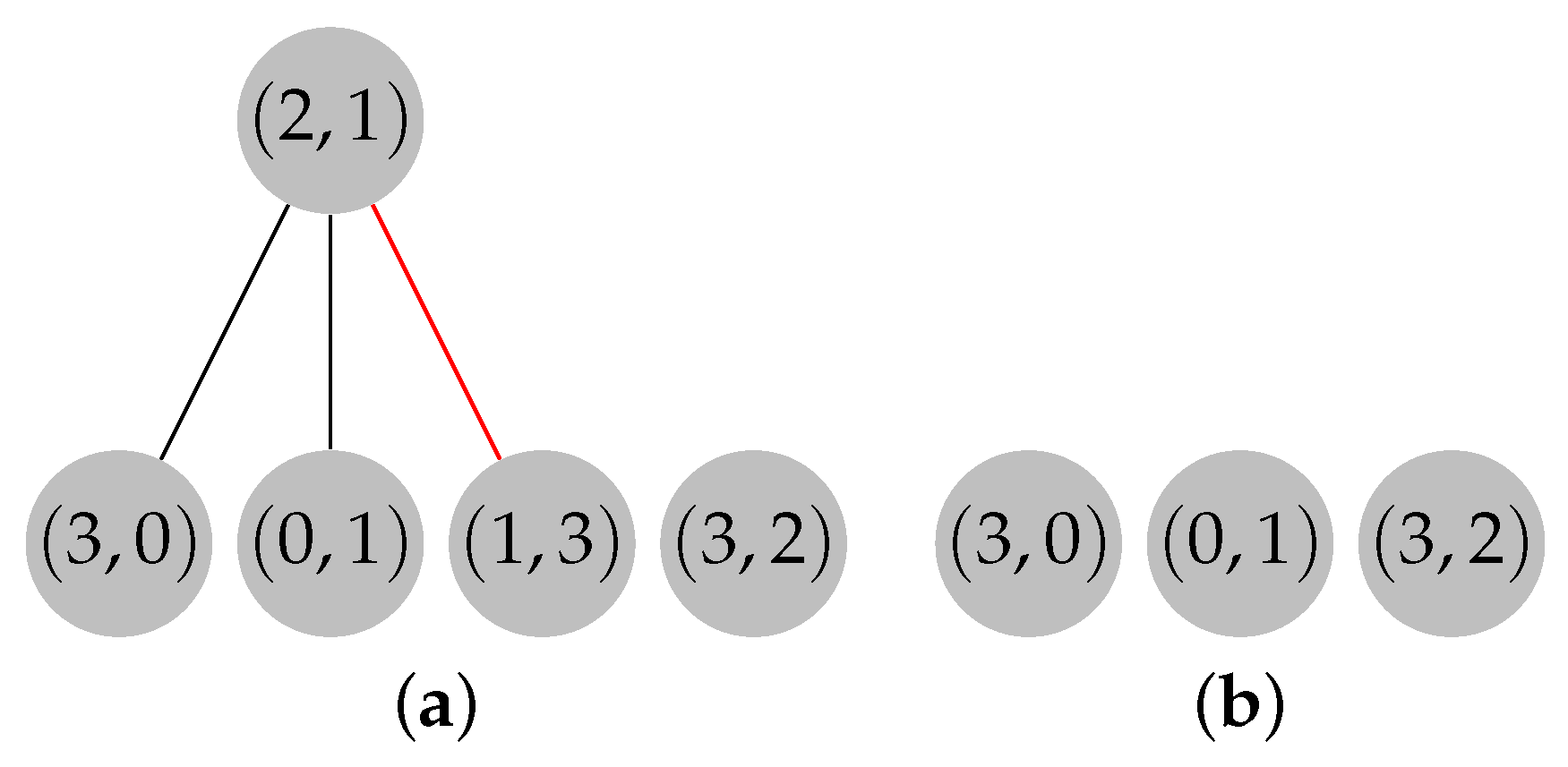
2.2.4. Illustrative Example
3. Optimal Dynamic Arborescences
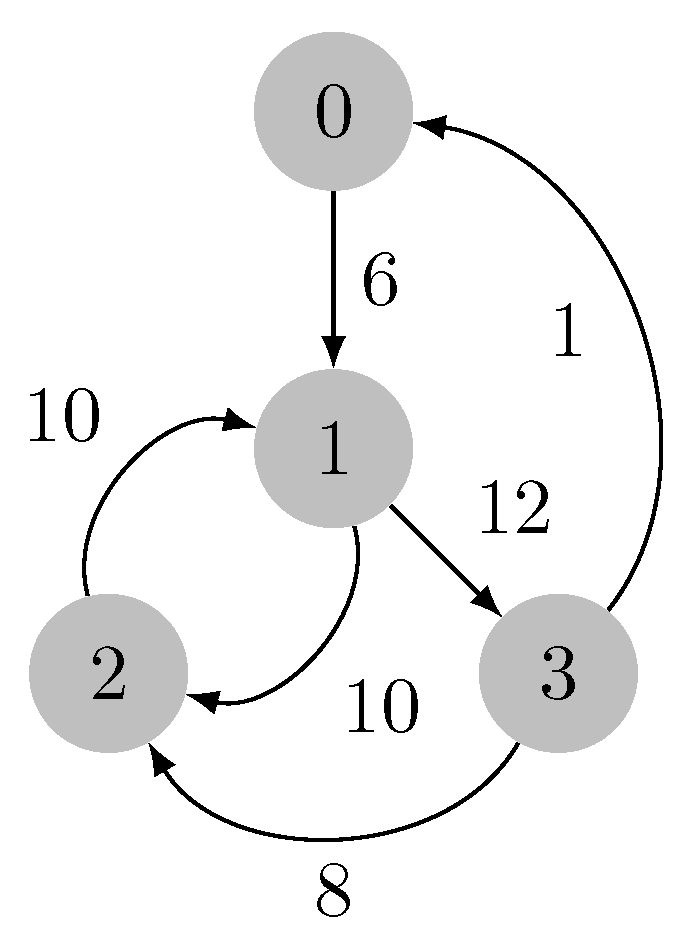
3.1. ATree
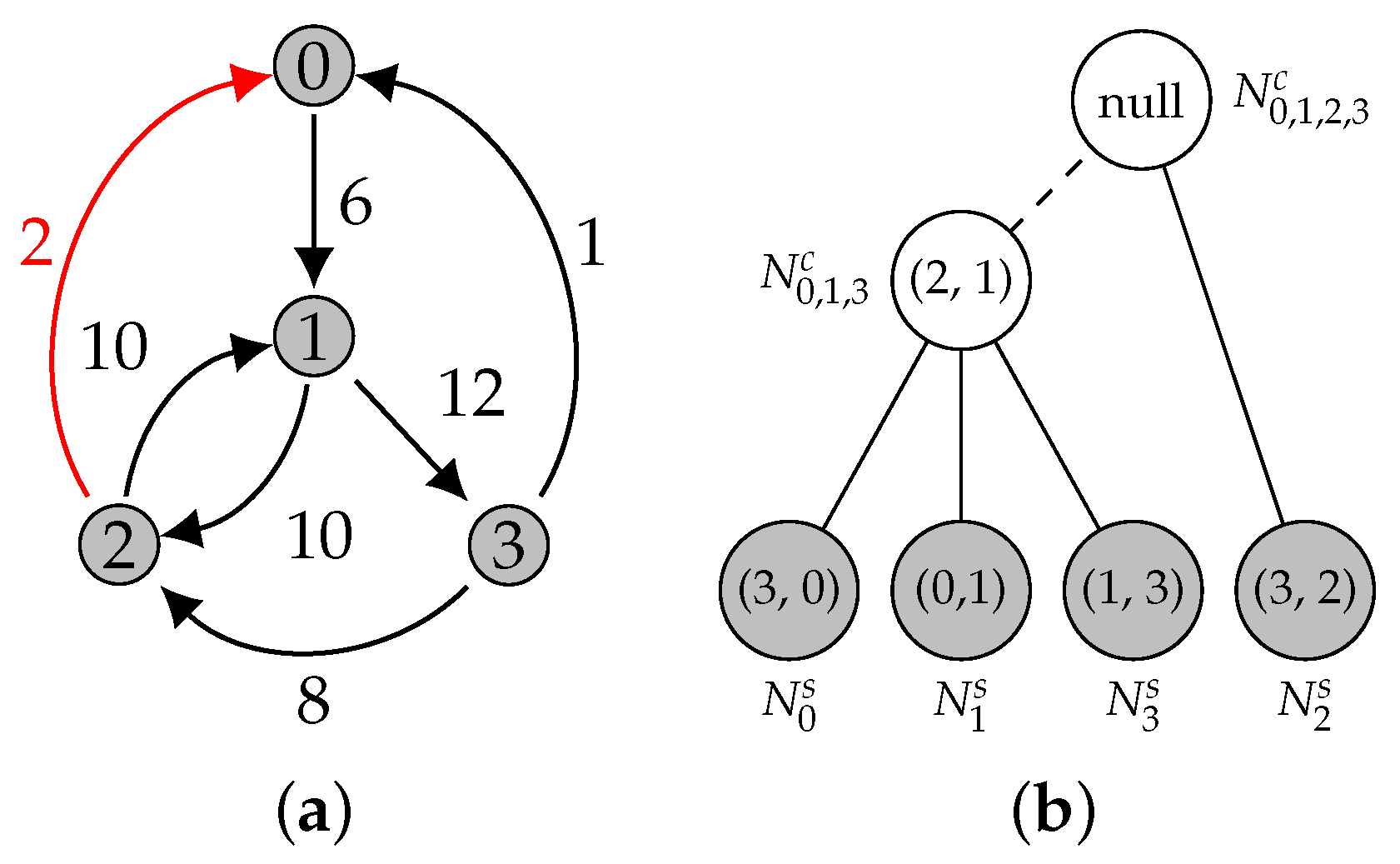
3.2. Edge Deletion
3.3. Edge Insertion
3.4. ATree Data Structure
| Algorithm 6 Finding a candidate node in the ATree; is the edge to be inserted. |
|
4. Implementation Details and Analysis
4.1. Incidence Lists
4.2. Disjoint Sets
4.3. Queues
4.4. Forest
4.5. Complexity
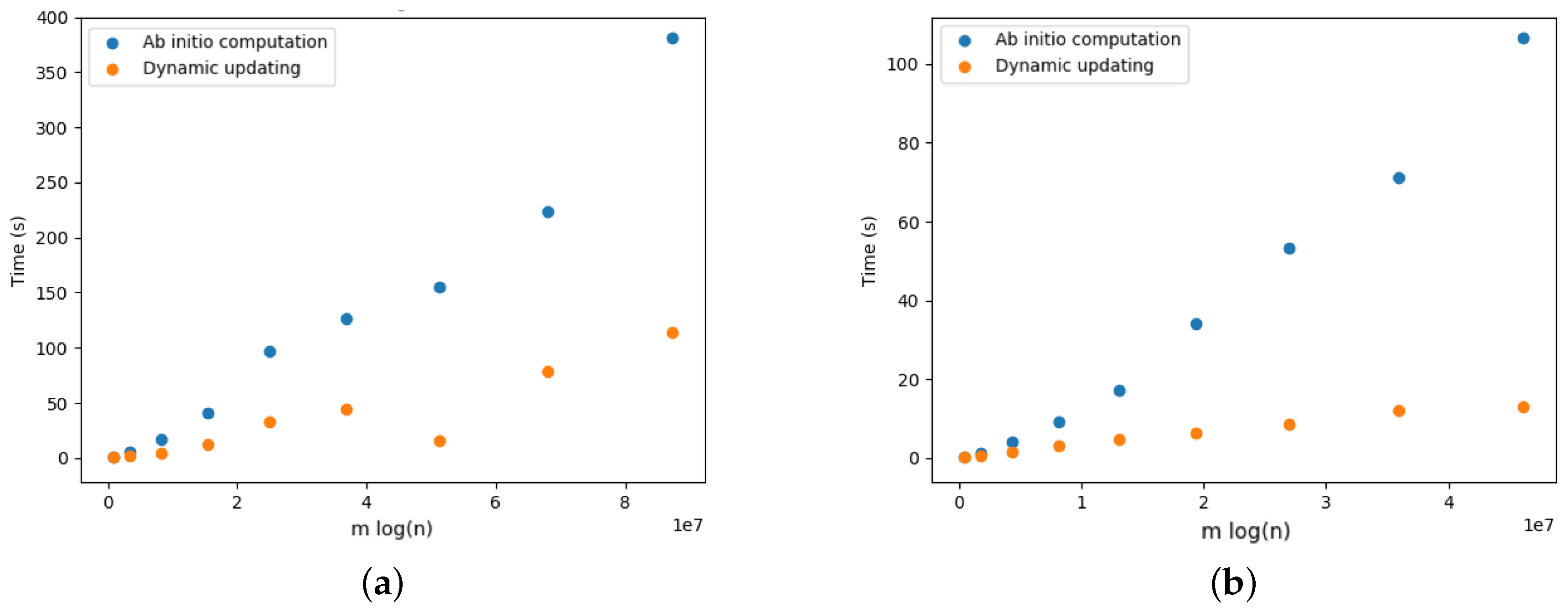
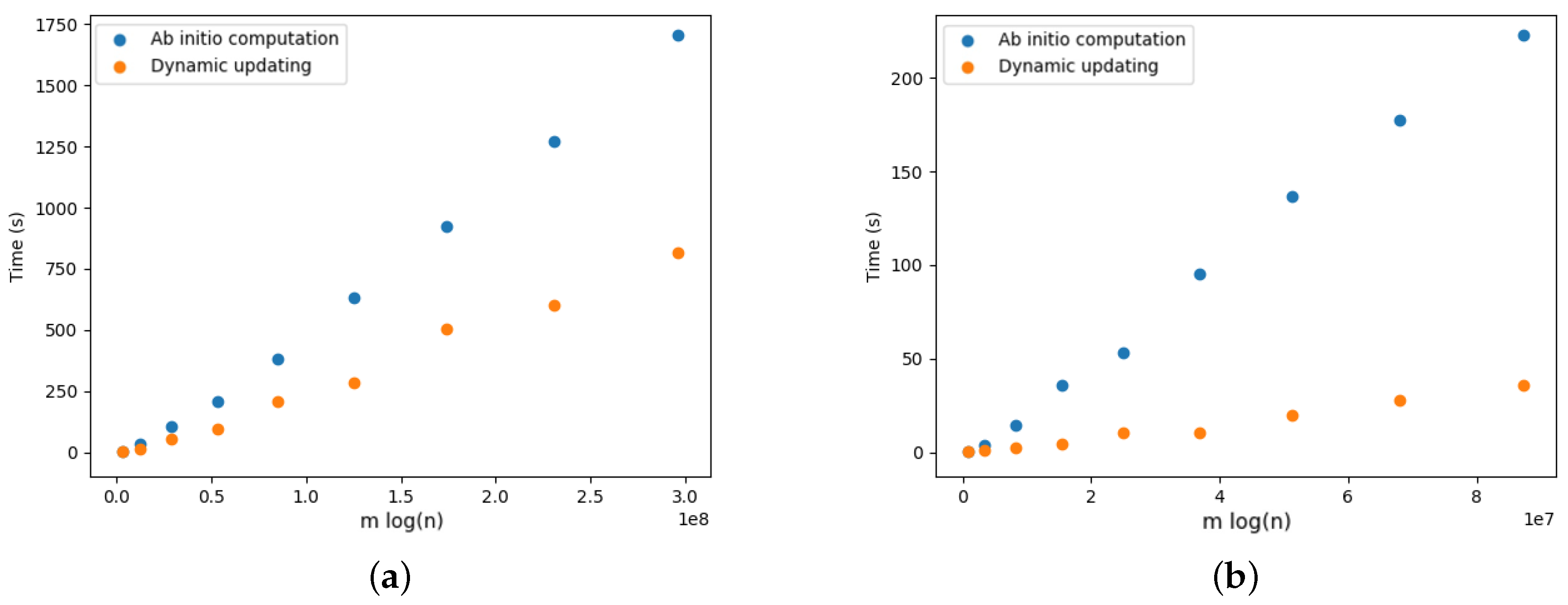
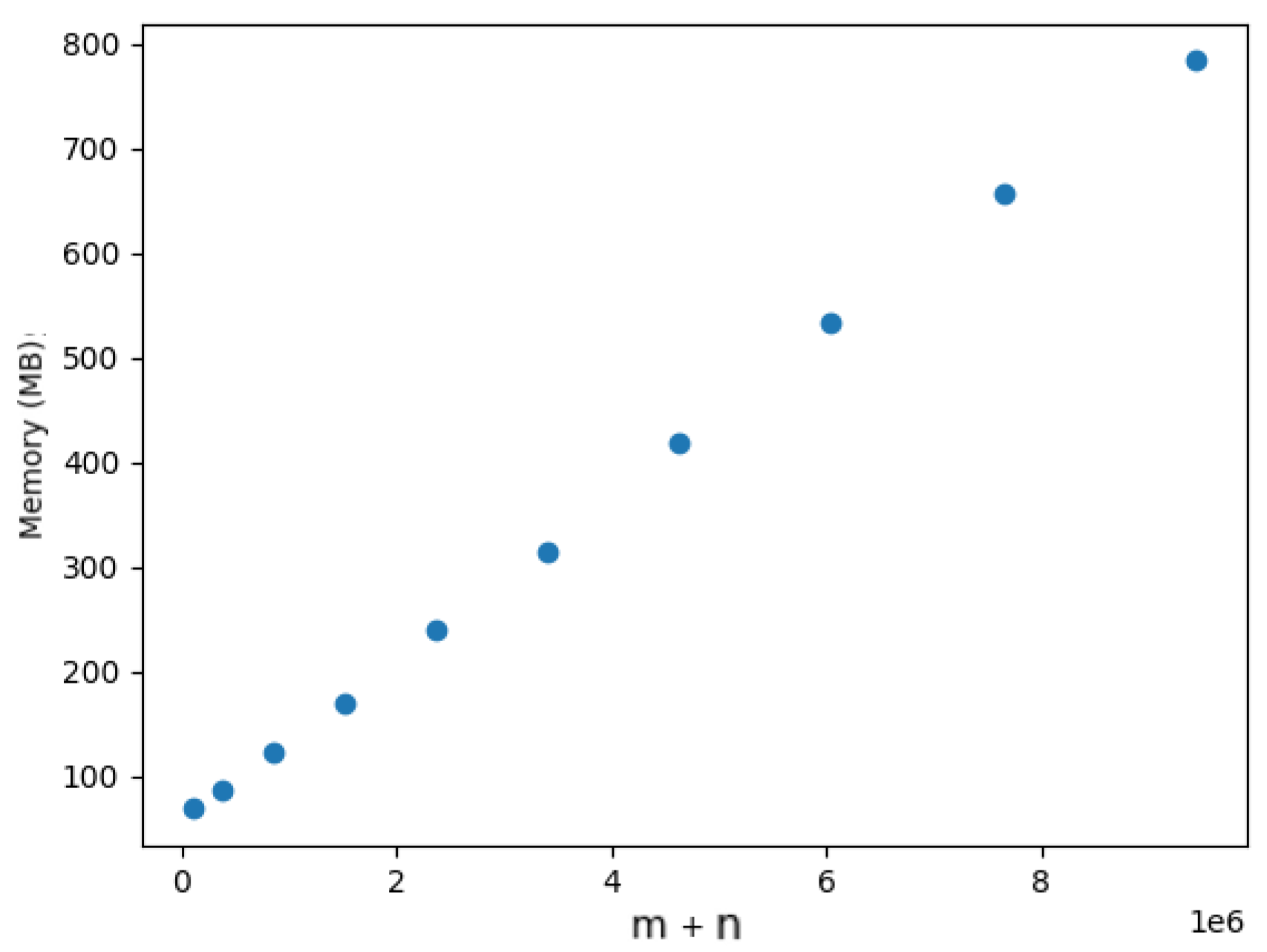
5. Experimental Evaluation
5.1. Datasets
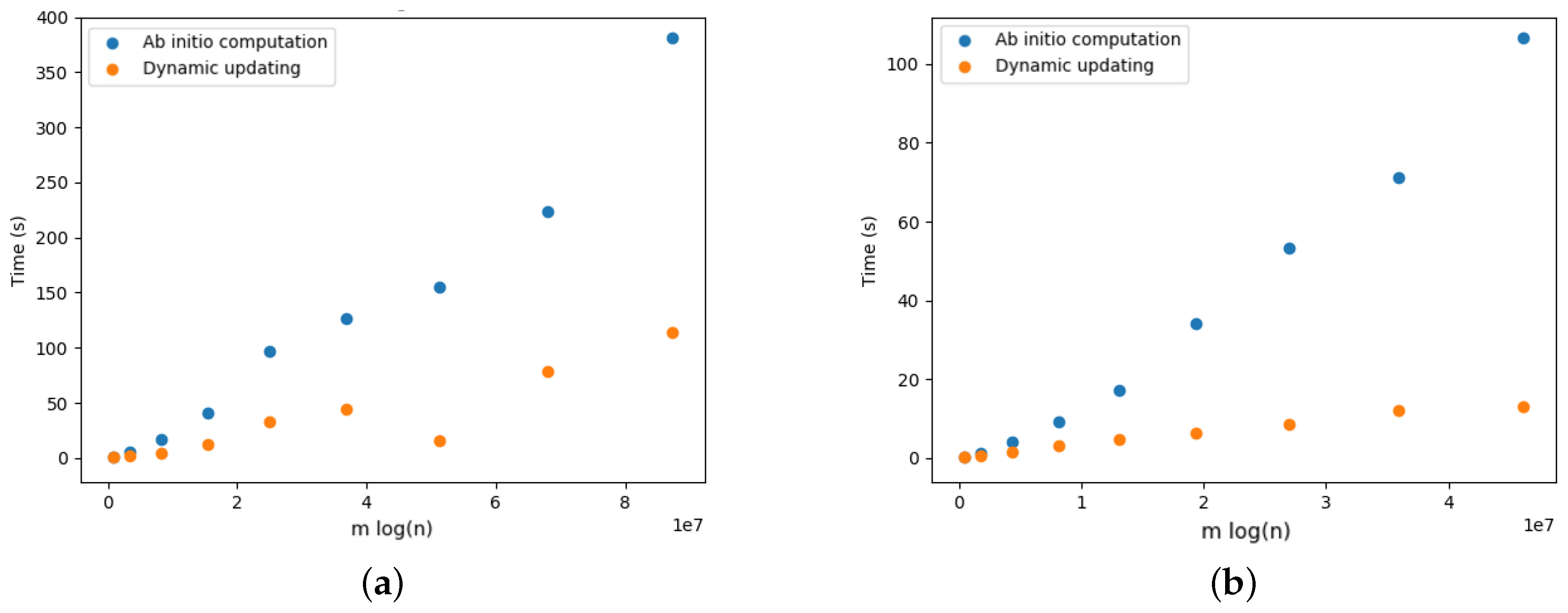
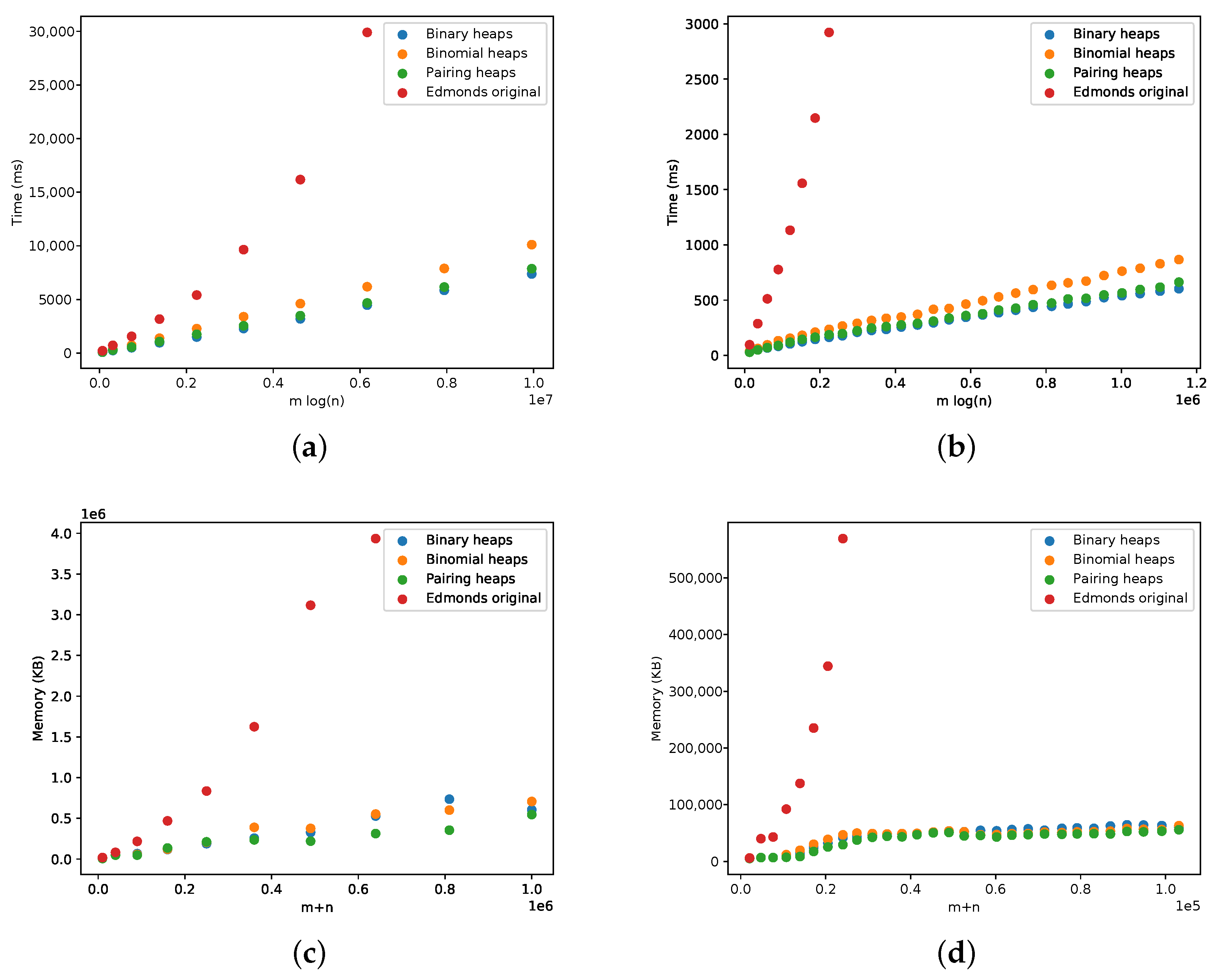
5.2. Edmonds’ versus Tarjan
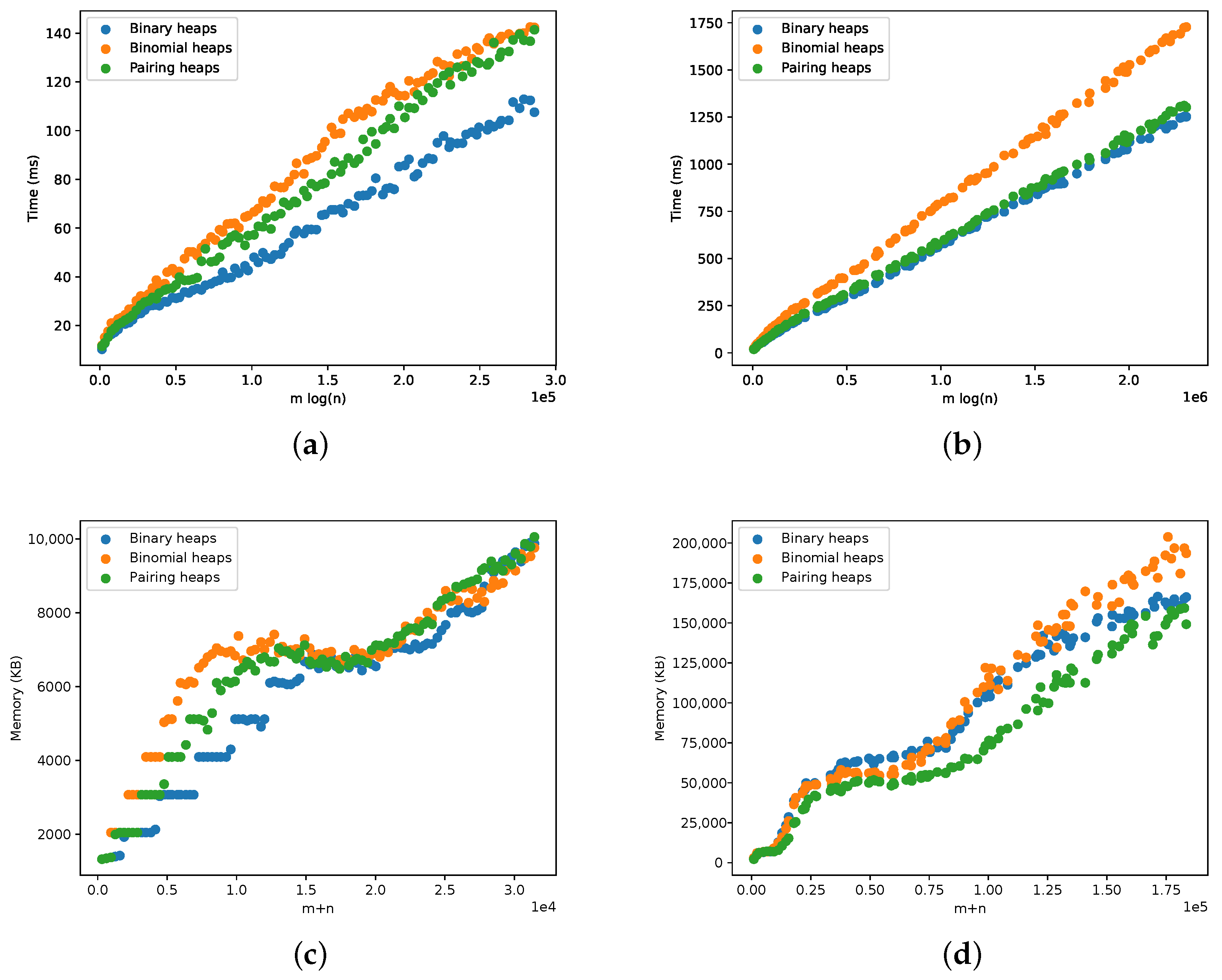
5.3. Different Heap Implementations
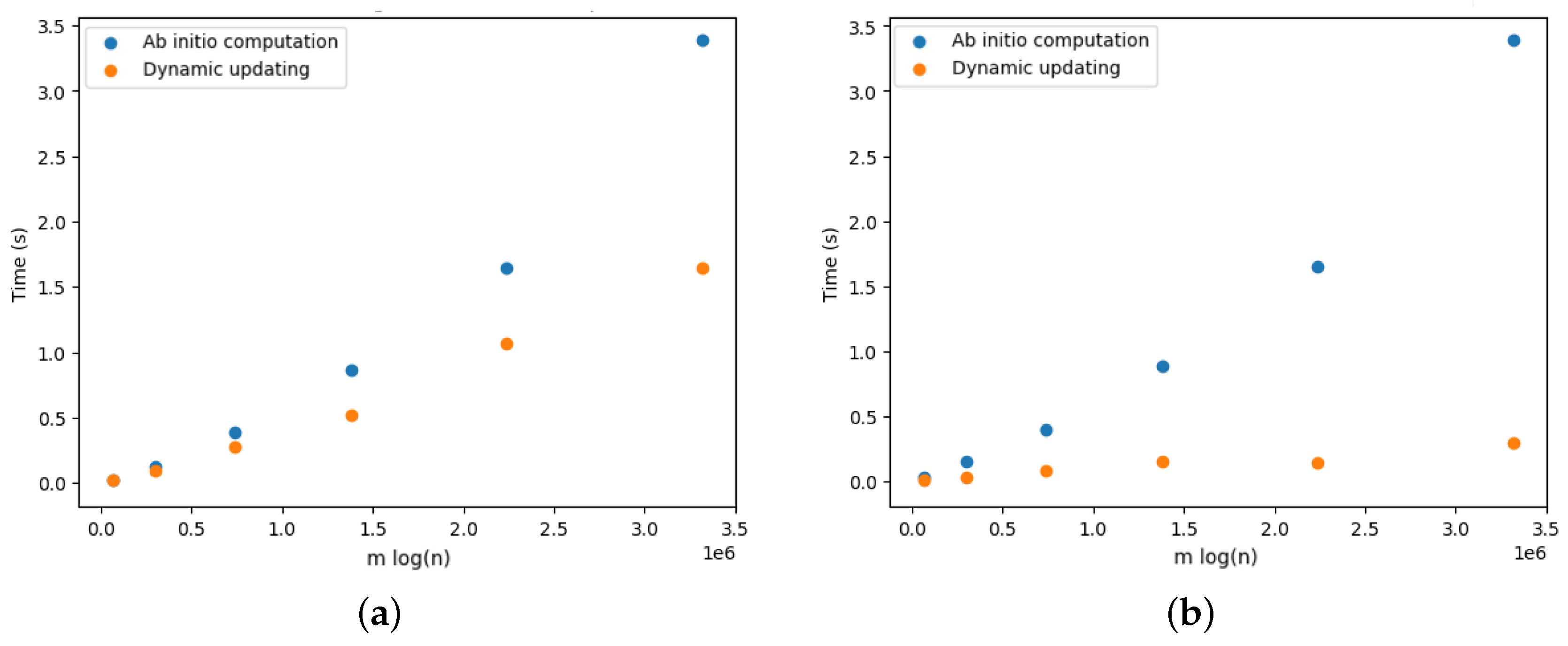
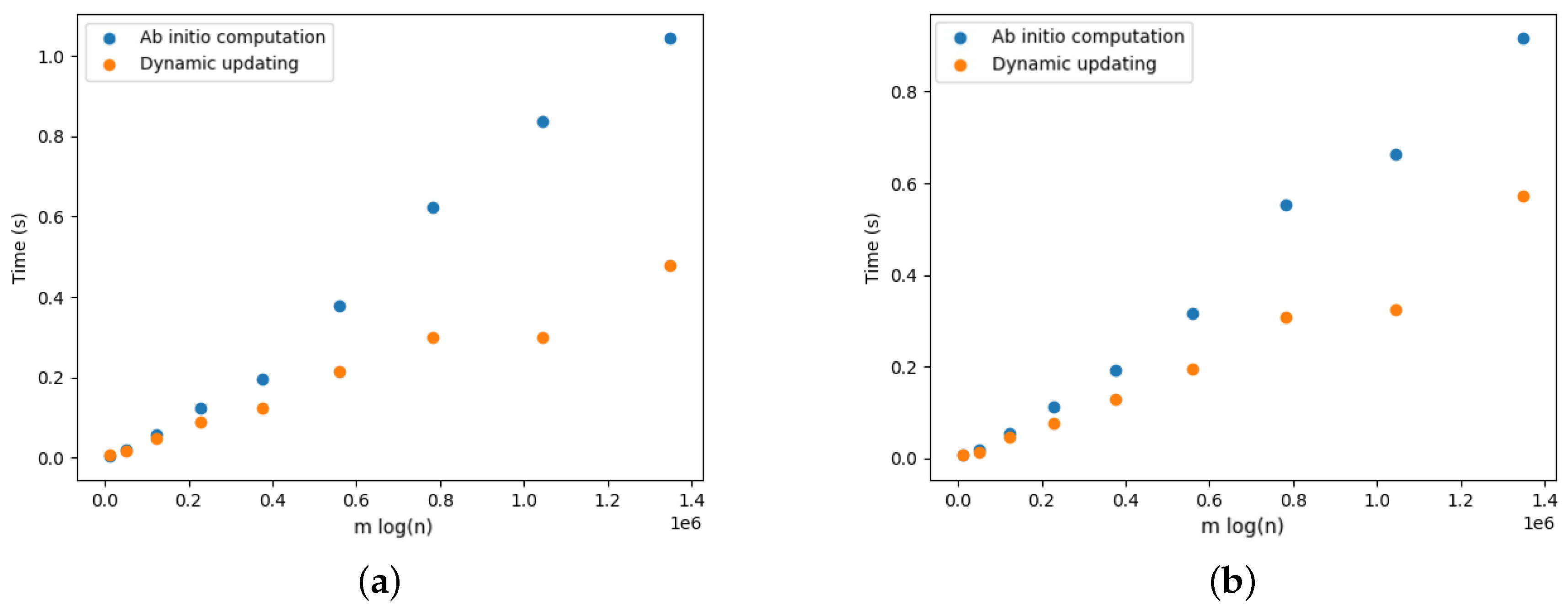
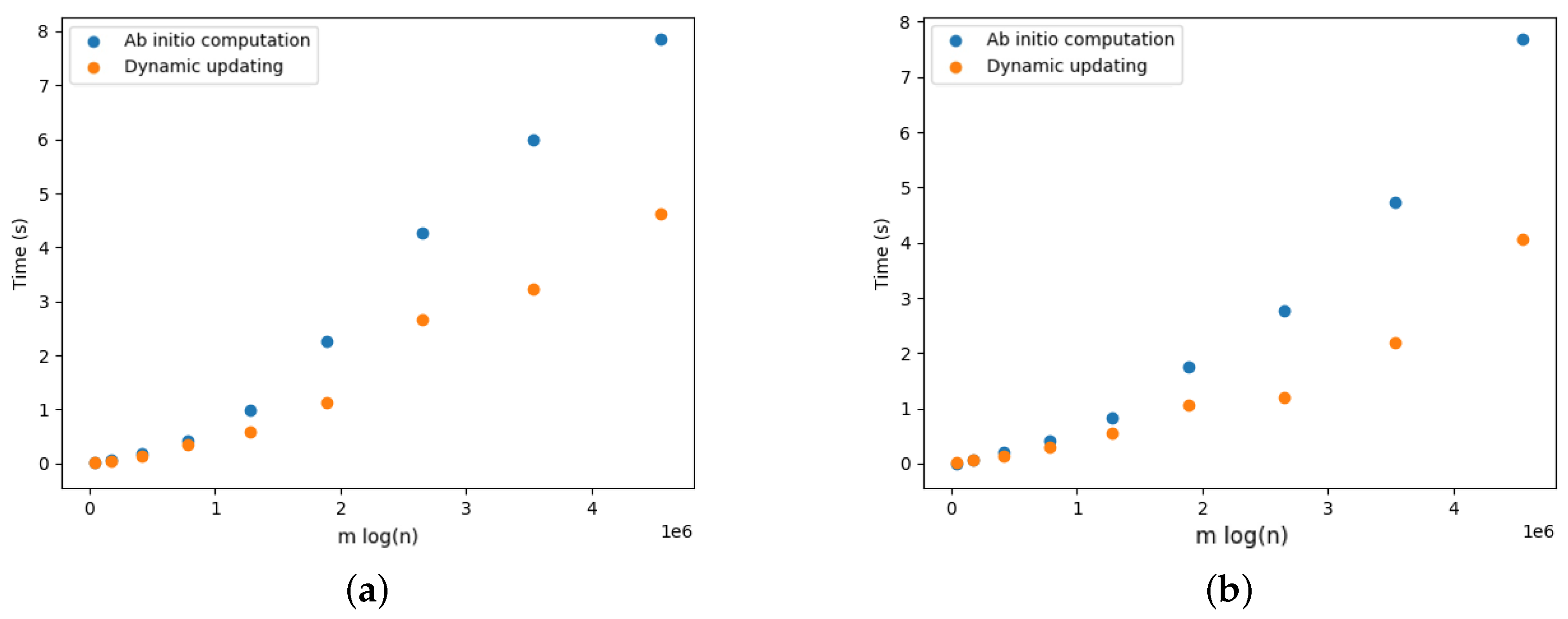
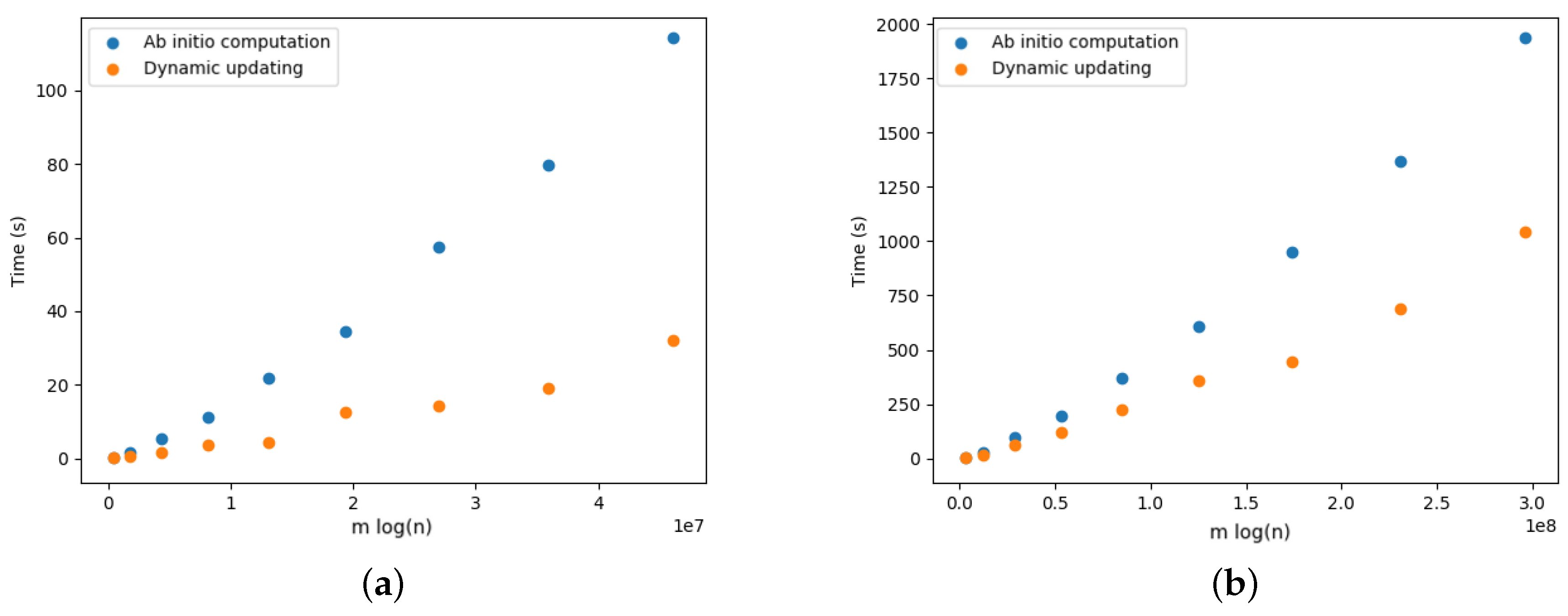
5.4. Dynamic Optimal Arborescences
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Thai, M.T.; Wang, F.; Du, D.Z. On the construction of a strongly connected broadcast arborescence with bounded transmission delay. IEEE Trans. Mob. Comput. 2006, 5, 1460–1470. [Google Scholar]
- Fortz, B.; Gouveia, L.; Joyce-Moniz, M. Optimal design of switched Ethernet networks implementing the Multiple Spanning Tree Protocol. Discrete Appl. Math. 2018, 234, 114–130. [Google Scholar] [CrossRef]
- Gerhard, R. The Traveling Salesman: Computational Solutions for TSP Applications; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1994; Volume 840. [Google Scholar]
- Cong, J.; Kahng, A.B.; Leung, K.S. Efficient algorithms for the minimum shortest path Steiner arborescence problem with applications to VLSI physical design. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 1998, 17, 24–39. [Google Scholar] [CrossRef]
- Coscia, M. Using arborescences to estimate hierarchicalness in directed complex networks. PLoS ONE 2018, 13, e0190825. [Google Scholar] [CrossRef]
- Zhou, Z.; Alikhan, N.F.; Sergeant, M.J.; Luhmann, N.; Vaz, C.; Francisco, A.P.; Carriço, J.A.; Achtman, M. GrapeTree: Visualization of core genomic relationships among 100,000 bacterial pathogens. Genome Res. 2018, 28, 1395–1404. [Google Scholar] [CrossRef]
- Vaz, C.; Nascimento, M.; Carriço, J.A.; Rocher, T.; Francisco, A.P. Distance-based phylogenetic inference from typing data: A unifying view. Brief. Bioinform. 2021, 22, bbaa147. [Google Scholar] [CrossRef] [PubMed]
- Chu, Y.J.; Liu, T. On the shortest arborescence of a directed graph. Sci. Sin. 1965, 14, 1396–1400. [Google Scholar]
- Edmonds, J. Optimum branchings. J. Res. Natl. Bur. Stand. B 1967, 71, 233–240. [Google Scholar] [CrossRef]
- Bock, F. An algorithm to construct a minimum directed spanning tree in a directed network. Dev. Oper. Res. 1971, 29, 29–44. [Google Scholar]
- Tarjan, R.E. Finding optimum branchings. Networks 1977, 7, 25–35. [Google Scholar] [CrossRef]
- Camerini, P.M.; Fratta, L.; Maffioli, F. A note on finding optimum branchings. Networks 1979, 9, 309–312. [Google Scholar] [CrossRef]
- Gabow, H.N.; Galil, Z.; Spencer, T.; Tarjan, R.E. Efficient algorithms for finding minimum spanning trees in undirected and directed graphs. Combinatorica 1986, 6, 109–122. [Google Scholar] [CrossRef]
- Fischetti, M.; Toth, P. An efficient algorithm for the min-sum arborescence problem on complete digraphs. ORSA J. Comput. 1993, 5, 426–434. [Google Scholar] [CrossRef]
- Aho, A.V.; Johnson, D.S.; Karp, R.M.; Kosaraju, S.R.; McGeoch, C.C.; Papadimitriou, C.H.; Pevzner, P. Emerging opportunities for theoretical computer science. ACM SIGACT News 1997, 28, 65–74. [Google Scholar] [CrossRef]
- Sanders, P. Algorithm engineering—An attempt at a definition. In Efficient Algorithms; Springer: Berlin, Germany, 2009; pp. 321–340. [Google Scholar]
- Tofigh, A.; Sjölund, E. Implementation of Edmonds’s Optimum Branching Algorithm. Available online: https://github.com/atofigh/edmonds-alg/ (accessed on 4 November 2023).
- Hagberg, A.; Schult, D.; Swart, P. NetworkX. Available online: https://networkx.org/documentation/stable/reference/algorithms/ (accessed on 4 November 2023).
- Espada, J. Large Scale Phylogenetic Inference from Noisy Data Based on Minimum Weight Spanning Arborescences. Master’s Thesis, IST, Universidade de Lisboa, Lisbon, Portugal, 2019. [Google Scholar]
- Böther, M.; Kißig, O.; Weyand, C. Efficiently computing directed minimum spanning trees. In Proceedings of the 2023 Symposium on Algorithm Engineering and Experiments (ALENEX), Florence, Italy, 22–23 January 2023; pp. 86–95. [Google Scholar]
- Pollatos, G.G.; Telelis, O.A.; Zissimopoulos, V. Updating directed minimum cost spanning trees. In Proceedings of the International Workshop on Experimental and Efficient Algorithms, Menorca, Spain, 24–27 May 2006; pp. 291–302. [Google Scholar]
- Barabási, A.L. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Galler, B.A.; Fisher, M.J. An improved equivalence algorithm. Commun. ACM 1964, 7, 301–303. [Google Scholar] [CrossRef]
- Tarjan, R.E.; Van Leeuwen, J. Worst-case analysis of set union algorithms. J. ACM (JACM) 1984, 31, 245–281. [Google Scholar] [CrossRef]
- Williams, J. Algorithm 232: Heapsort. Commun. ACM 1964, 7, 347–348. [Google Scholar]
- Vuillemin, J. A data structure for manipulating priority queues. Commun. ACM 1978, 21, 309–315. [Google Scholar] [CrossRef]
- Fredman, M.L.; Sedgewick, R.; Sleator, D.D.; Tarjan, R.E. The pairing heap: A new form of self-adjusting heap. Algorithmica 1986, 1, 111–129. [Google Scholar] [CrossRef]
- Pettie, S. Towards a final analysis of pairing heaps. In Proceedings of the 46th Annual IEEE Symposium on Foundations of Computer Science (FOCS’05), Pittsburgh, PA, USA, 23–25 October 2005; pp. 174–183. [Google Scholar]
- Larkin, D.H.; Sen, S.; Tarjan, R.E. A back-to-basics empirical study of priority queues. In Proceedings of the 2014 Sixteenth Workshop on Algorithm Engineering and Experiments (ALENEX), Portland, OR, USA, 5 January 2014; pp. 61–72. [Google Scholar]
- Gilbert, E.N. Random graphs. Ann. Math. Stat. 1959, 30, 1141–1144. [Google Scholar] [CrossRef]
- Hagberg, A.A.; Schult, D.A.; Swart, P.J. Exploring Network Structure, Dynamics, and Function using NetworkX. In Proceedings of the 7th Python in Science Conference, Pasadena, CA, USA, 19–24 August 2008; Varoquaux, G., Vaught, T., Millman, J., Eds.; pp. 11–15. [Google Scholar]
- Bollobás, B.; Borgs, C.; Chayes, J.T.; Riordan, O. Directed scale-free graphs. In Proceedings of the SODA, Baltimore, MD, USA, 12–14 January 2003; Volume 3, pp. 132–139. [Google Scholar]
- Chung, F.R.K.; Lu, L.; Dewey, T.G.; Galas, D.J. Duplication Models for Biological Networks. J. Comput. Biol. 2003, 10, 677–687. [Google Scholar] [CrossRef]
- Zhou, Z.; Alikhan, N.F.; Mohamed, K.; Fan, Y.; Achtman, M.; Brown, D.; Chattaway, M.; Dallman, T.; Delahay, R.; Kornschober, C.; et al. The EnteroBase user’s guide, with case studies on Salmonella transmissions, Yersinia pestis phylogeny, and Escherichia core genomic diversity. Genome Res. 2020, 30, 138–152. [Google Scholar] [CrossRef] [PubMed]
- Sleator, D.D.; Tarjan, R.E. A Data Structure for Dynamic Trees. J. Comput. Syst. Sci. 1983, 26, 362–391. [Google Scholar] [CrossRef]
- Russo, L.M. A study on splay trees. Theor. Comput. Sci. 2019, 776, 1–18. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
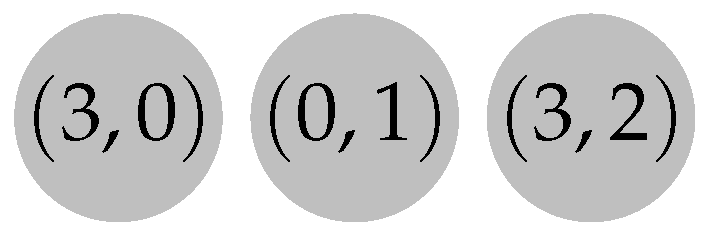{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | ||
|---|---|---|
| clostridium.Griffiths | 440 | |
| Moraxella.Achtman7GeneMLST | 773 | |
| Salmonella.Achtman7GeneMLST | 5464 | |
| Yersinia.McNally | 369 |
| Dataset % | Ab Initio (MB) | Dynamic Updating (MB) | Memory Ratio |
|---|---|---|---|
| 10 | 6.94 | 21.05 | 3.03 |
| 20 | 7.87 | 24.14 | 3.07 |
| 30 | 8.90 | 27.73 | 3.12 |
| 40 | 10.54 | 32.52 | 3.09 |
| 50 | 12.54 | 39.12 | 3.12 |
| 60 | 14.93 | 46.76 | 3.11 |
| 70 | 17.98 | 55.34 | 3.08 |
| 80 | 21.42 | 65.21 | 3.05 |
| 90 | 26.29 | 77.17 | 2.94 |
| 100 | 31.18 | 89.37 | 2.87 |
| Dataset % | Ab Initio (MB) | Dynamic Updating (MB) | Memory Ratio |
|---|---|---|---|
| 10 | 7.93 | 23.97 | 3.02 |
| 20 | 9.71 | 30.16 | 3.11 |
| 30 | 13.17 | 40.63 | 3.09 |
| 40 | 17.10 | 54.86 | 3.21 |
| 50 | 23.80 | 74.08 | 3.21 |
| 60 | 30.80 | 106.20 | 3.45 |
| 70 | 43.92 | 133.99 | 3.05 |
| 80 | 49.65 | 163.36 | 3.29 |
| 90 | 63.66 | 219.69 | 3.45 |
| 100 | 79.70 | 263.23 | 3.30 |
| Dataset % | Ab Initio (MB) | Dynamic Updating (MB) | Memory Ratio |
|---|---|---|---|
| 10 | 20.96 | 85.10 | 4.06 |
| 20 | 38.98 | 142.42 | 3.65 |
| 30 | 78.79 | 240.36 | 3.05 |
| 40 | 131.39 | 415.18 | 3.16 |
| 50 | 195.35 | 565.25 | 2.89 |
| 60 | 261.86 | 841.66 | 3.21 |
| 70 | 376.26 | 1100.50 | 2.92 |
| 80 | 465.27 | 1374.02 | 2.95 |
| 90 | 612.67 | 1684.40 | 2.75 |
| 100 | 724.01 | 1997.67 | 2.76 |
| Dataset % | Ab Initio (MB) | Dynamic Updating (MB) | Memory Ratio |
|---|---|---|---|
| 10 | 125.32 | 415.93 | 3.32 |
| 20 | 156.31 | 513.5 | 3.29 |
| 30 | 214.65 | 680.62 | 3.17 |
| 40 | 295.80 | 908.01 | 3.07 |
| 50 | 411.26 | 1201.33 | 2.92 |
| 60 | 534.45 | 1585.99 | 2.97 |
| 70 | 714.39 | 2056.44 | 2.88 |
| 80 | 898.64 | 2479.41 | 2.76 |
| 90 | 1098.49 | 3026.20 | 2.75 |
| 100 | 1306.95 | 3640.20 | 2.79 |
| Dataset % | Ab Initio (MB) | Dynamic Updating (MB) | Memory Ratio |
|---|---|---|---|
| 10 | 62.60 | 210.45 | 3.36 |
| 20 | 154.52 | 520.83 | 3.37 |
| 30 | 319.87 | 1041.22 | 3.26 |
| 40 | 575.05 | 1772.00 | 5.54 |
| 50 | 886.04 | 2667.96 | 3.01 |
| 60 | 1274.59 | 3883.46 | 3.04 |
| 70 | 1754.89 | 5242.21 | 2.99 |
| 80 | 2285.91 | 6841.03 | 2.99 |
| 90 | 2872.80 | 8574.12 | 2.99 |
| 100 | 3435.51 | 10,482.84 | 3.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Espada, J.; Francisco, A.P.; Rocher, T.; Russo, L.M.S.; Vaz, C. On Finding Optimal (Dynamic) Arborescences. Algorithms 2023, 16, 559. https://doi.org/10.3390/a16120559
Espada J, Francisco AP, Rocher T, Russo LMS, Vaz C. On Finding Optimal (Dynamic) Arborescences. Algorithms. 2023; 16(12):559. https://doi.org/10.3390/a16120559
Chicago/Turabian StyleEspada, Joaquim, Alexandre P. Francisco, Tatiana Rocher, Luís M. S. Russo, and Cátia Vaz. 2023. "On Finding Optimal (Dynamic) Arborescences" Algorithms 16, no. 12: 559. https://doi.org/10.3390/a16120559
APA StyleEspada, J., Francisco, A. P., Rocher, T., Russo, L. M. S., & Vaz, C. (2023). On Finding Optimal (Dynamic) Arborescences. Algorithms, 16(12), 559. https://doi.org/10.3390/a16120559