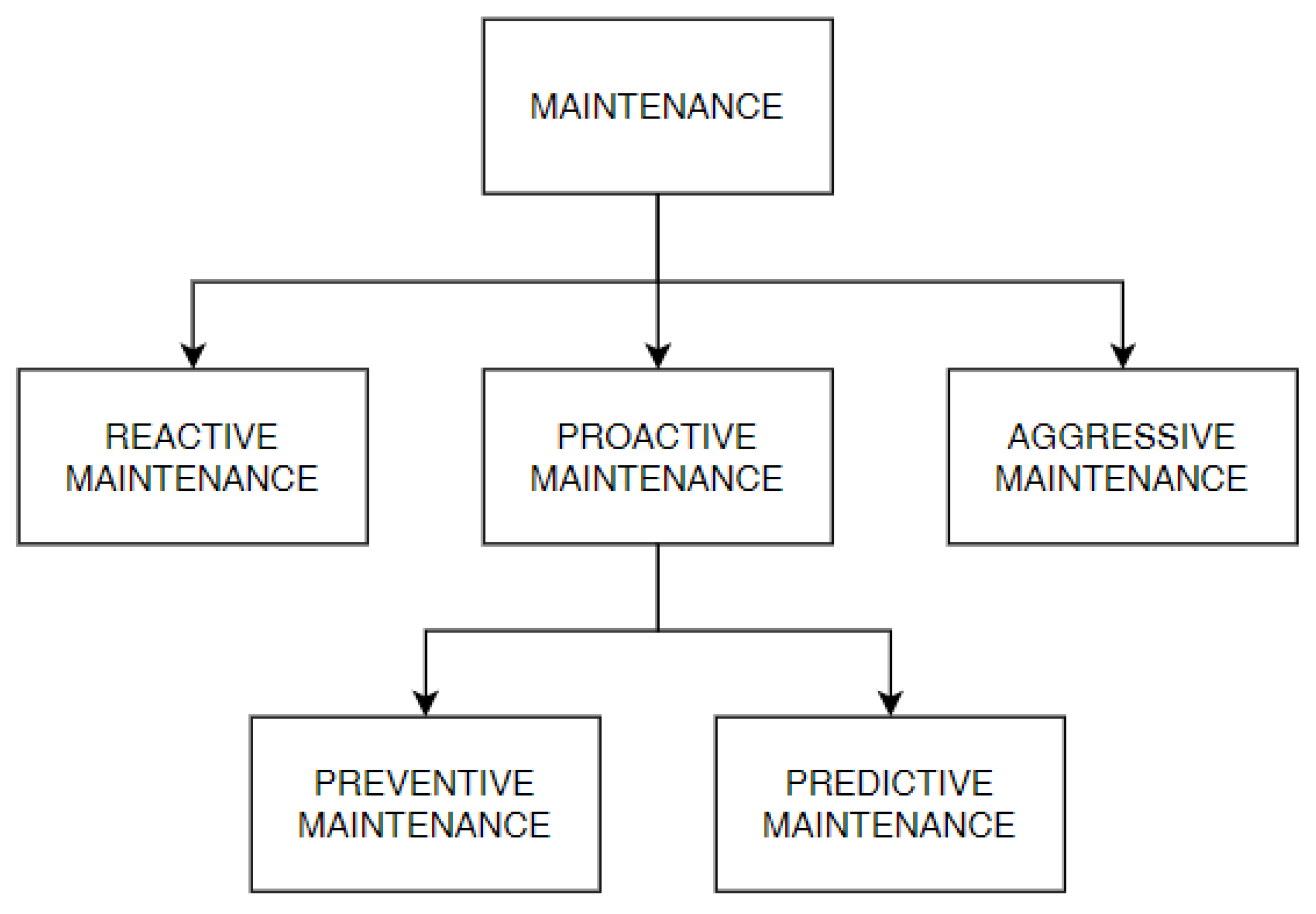
3.3. AI Unit
The AI Unit is shown in
Figure 3, the framework’s “brain”. As a standard ML approach, the parts that compose the process flow are represented in
Figure 4:
As mentioned before, the idea of this paper is to give a different use of ML compared to a normal flow. A common approach follows the standard way that a dataset is divided into Training Set, Testing Set, and Validation Set; in this case, the framework continuously works in testing mode to compute the prediction error for every dataset that arrives in the database. Monitoring this error makes it possible to understand if a deviation occurs in the collected dataset. Every time that data collected are similar to the ones used for Training, the error obtained is low. In contrast, if an issue happens in the machine, the error tends to increase due to different behavior in the data pattern collected. This type of detection does not predict only problems; it can also understand when a novelty related to a change appears in the dataset (typical in a real situation, an example can be environmental changes).
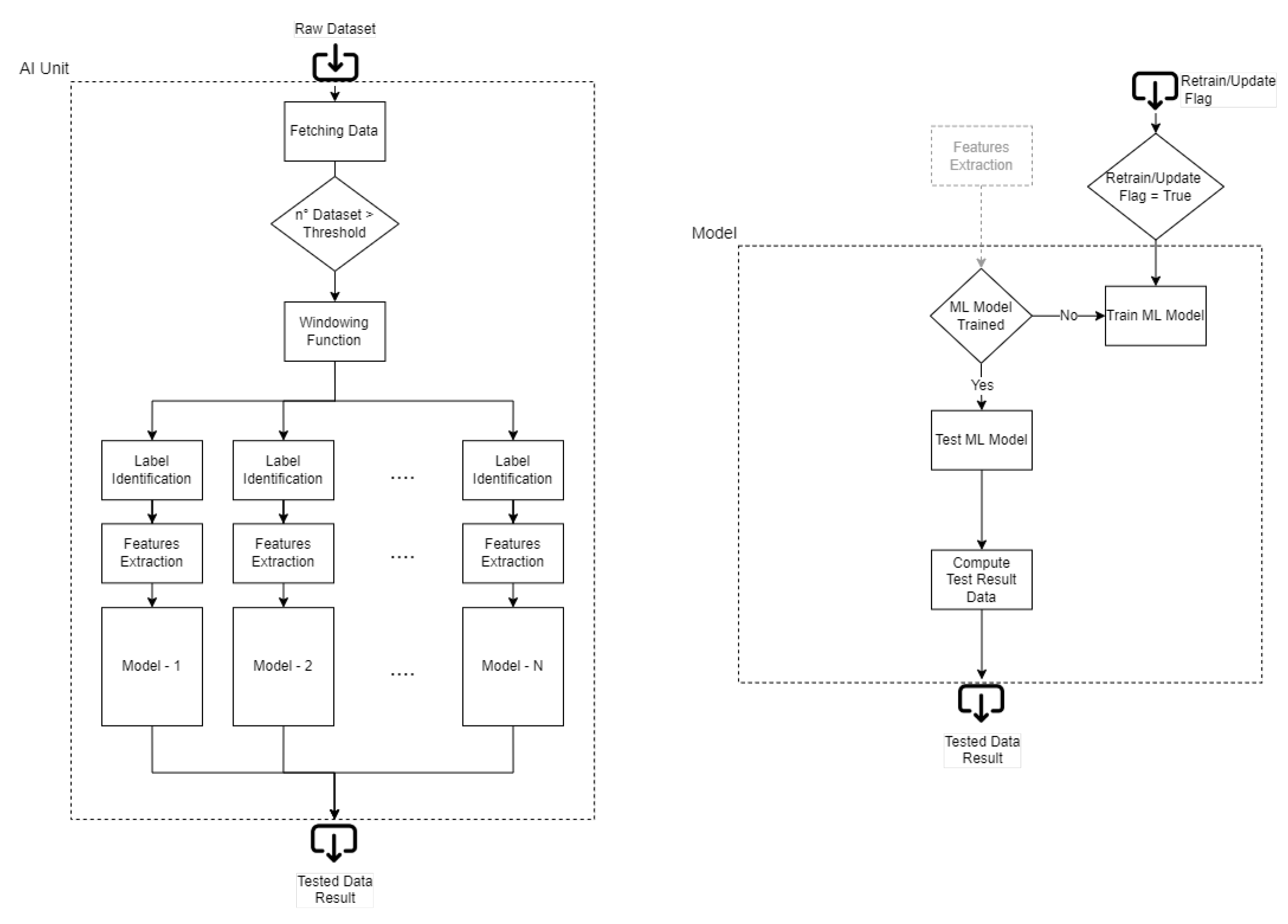
For this reason, the trained dataset must represent the whole machine’s behavior. The number of datasets chosen for the training depends on the framework’s application: by increasing the number of training datasets, the prediction’s accuracy increases too (the risk of a false positive due to a change is low); however, training the framework with a small number of datasets allows using it earlier, but the maintainer may work more during the first days by updating it (the risk of detecting a change is higher). A trade-off concerning the duration of the training process has to be defined. Generally, companies that design machines/components always have a period in which the machine/component is calibrated and tested; this period can last from a few days to an entire month, and it could be useful for the training process. An entire environmental changes cycle (such as the morning, the afternoon, and the night) can be useful for gathering all the possible components’ changes. Sometimes the data collected can change over the day: during the morning, when the temperature is low, the machine has a certain accuracy that changes during the afternoon due to the higher temperature reached. There is no general rule explaining how many datasets are gathered; a possible hint is to collect one week’s worth of data to record a consistent dataset. The best situation in which this framework can be trained is at the beginning of the machine’s life (e.g., after the assembly process). Nevertheless, the framework can also be trained after years of machine work; in this case, the framework performs the training at that moment and cannot recognize preexisting faults due to the absence of healthy datasets. However, the nature of failures leads to a machine’s worsening over time, detecting them also if training is performed with a partially faulty system; hence, thanks to the system’s adaptability, the absence of a healthy dataset is not a problem, but it may afflict the framework’s accuracy. The first stage of the ML process flow is preprocessing, which consists in taking every single dataset from the database and recognizing which kind of features are stored (such as Acceleration, Sound, or Temperature). Then the AI manager applies a windowing function for each type of feature recognized: the windowing approach divides the large dataset’s features into a parametrized small number of windows (for example, acceleration is divided into
windows, sound into
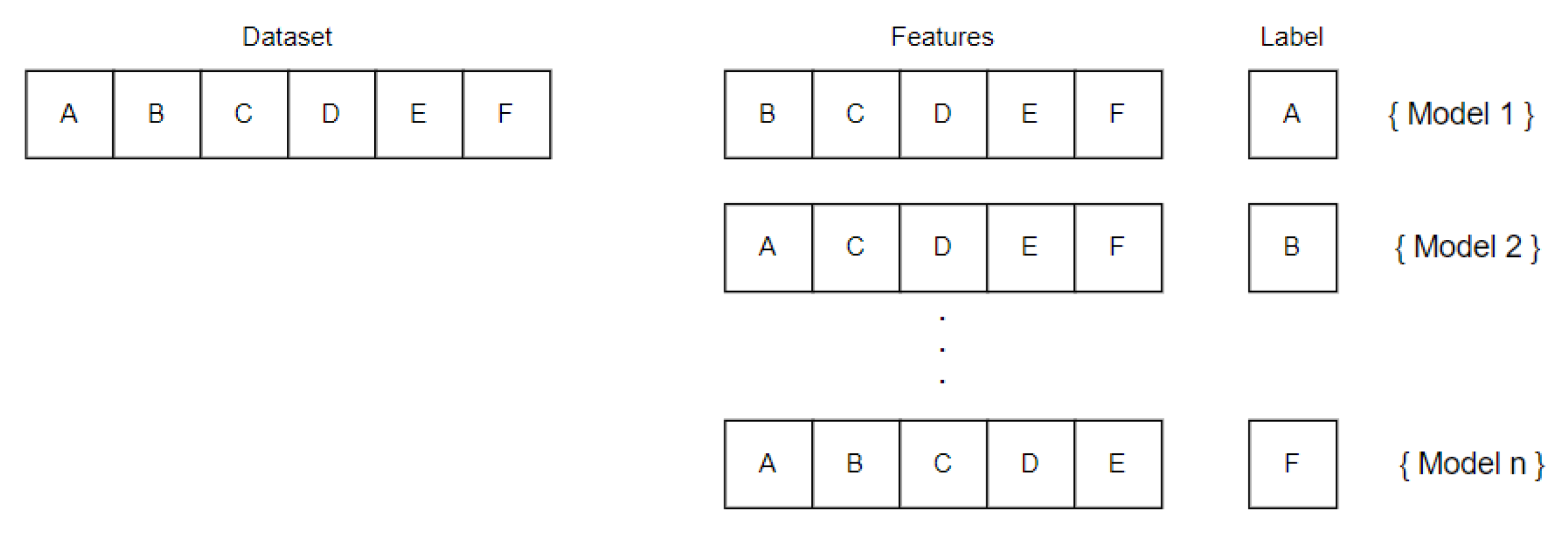
windows) depending on the resolution wanted in the framework recognition: a higher number of windows corresponds to a higher prediction’s resolution; on the other hand, the system works more complexly due to the higher number of windows to predict. Each window is associated with a predictor (AIUP), which uses
window as a label and the others as features (
Figure 5). Thanks to the windowing approach, each window is used to perform computation by condensing the initial amount of data (a cumulative sum is used for each window in this paper). The mathematical representation of the windowing function and cumulative absolute sum for each window is reported below:
While the cumulative absolute sum function used is the following:
The feature extraction and labeling phase follow the preprocessing stage. This block is responsible for preparing data for the following ML model training. With a multi-threading approach, a feature is extracted from the dataset by converting it to a label; this procedure is done for each window/feature, creating a number of labels equal to the number of windows and predictors. This rule is schematized in the following figure:
At the end of the preprocessing stage, a number of trainsets equal to the number of windows are created; each trainset is used for the related ML model training. Then, the testing phase follows the training one. The same preprocessing approach is applied to each new dataset; in the end, the label related to model is predicted and compared with the real one, computing the error used for novelty detection. Hence, the AI Unit can be divided into two different macro-stages:
The first part is related to the training process in which the system waits for a predefined number of data to train the models;
The second part is the testing process in which incoming data are continuously tested to compute the predictions’ error results.
For the Training phase, three regressors are tested to visualize the potential differences in the prediction behavior. The models used during the evaluation are:
Linear Regressor;
Decision Tree Regressor;
Random Forest Regressor.
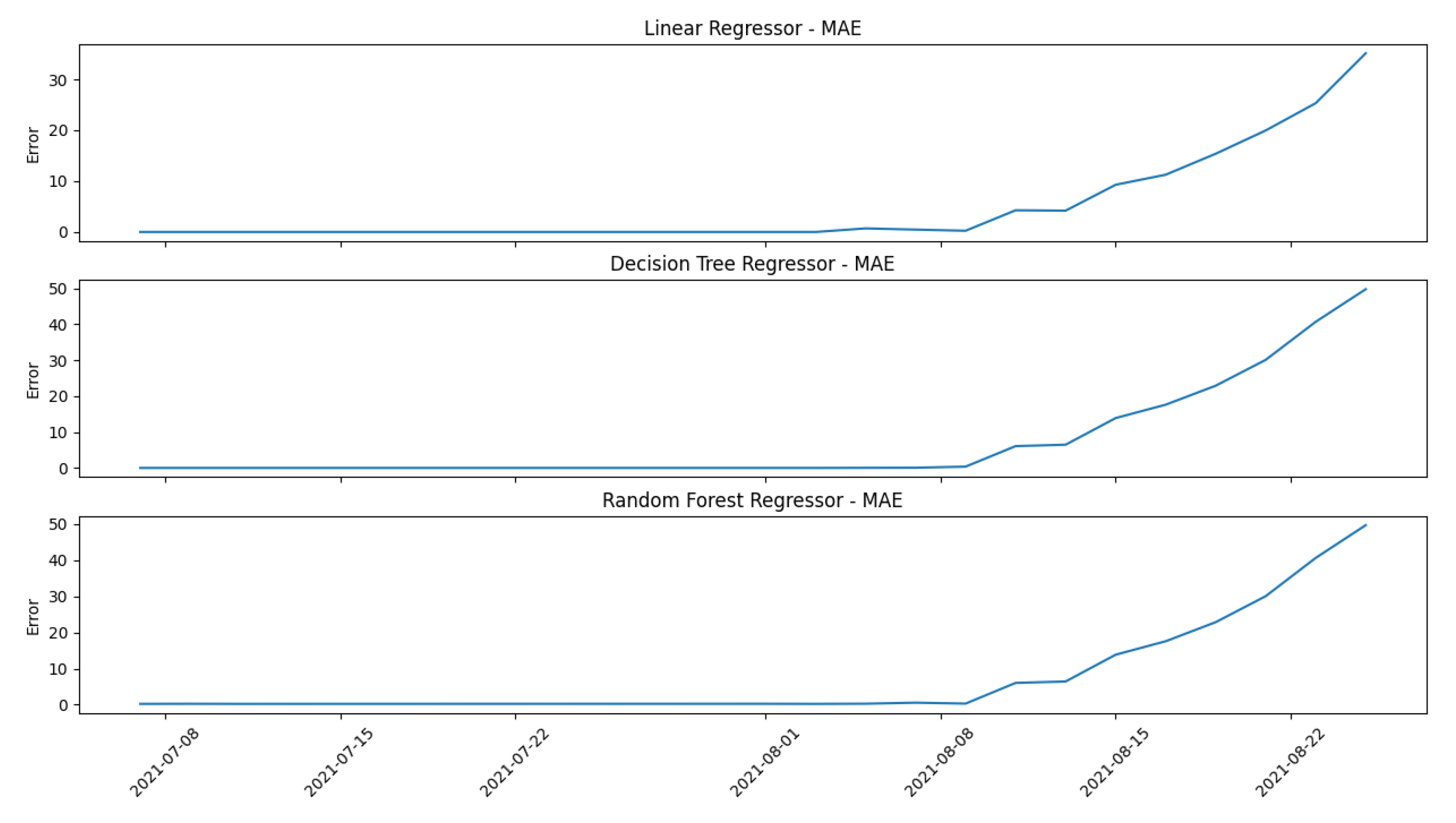
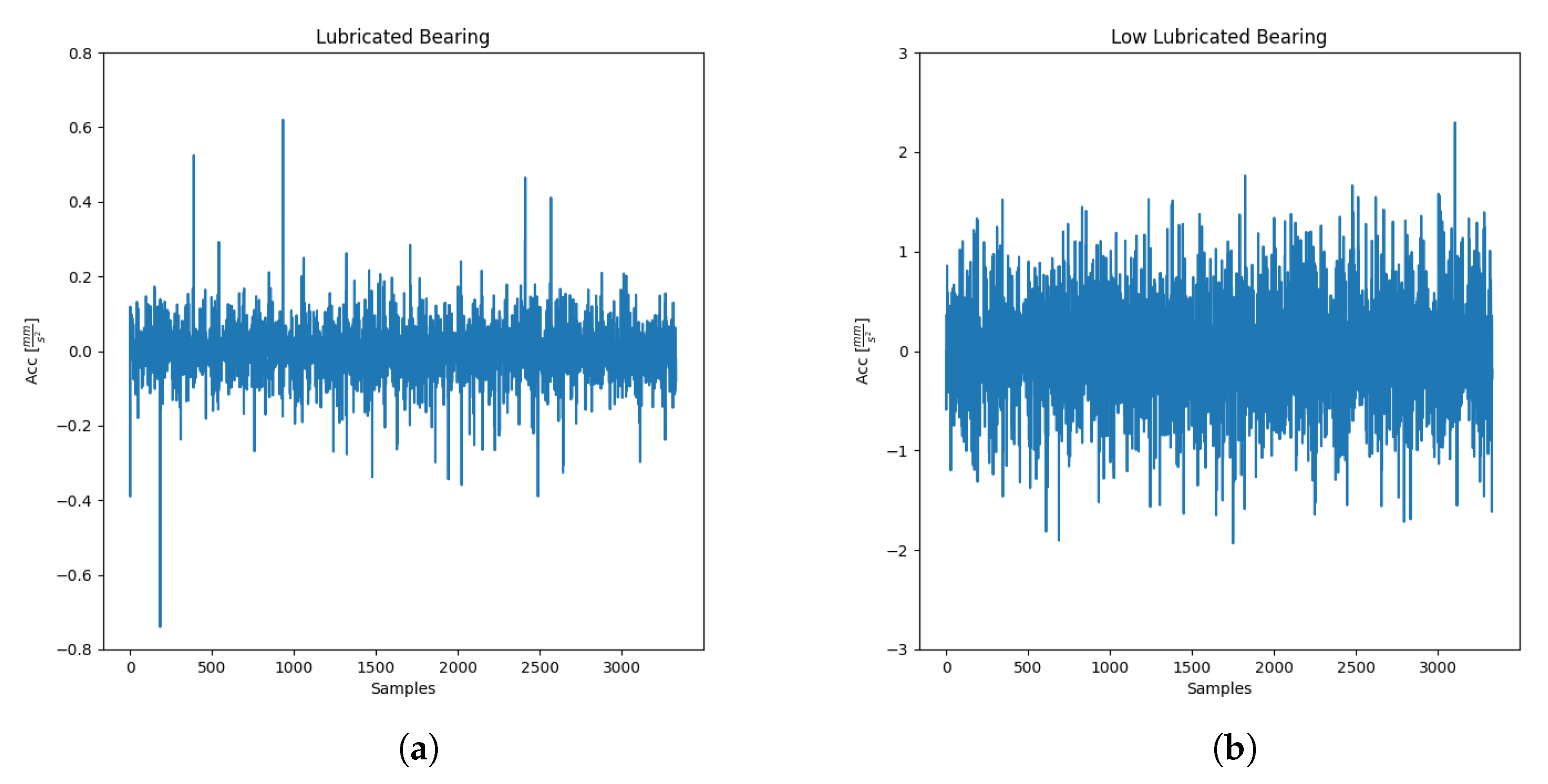
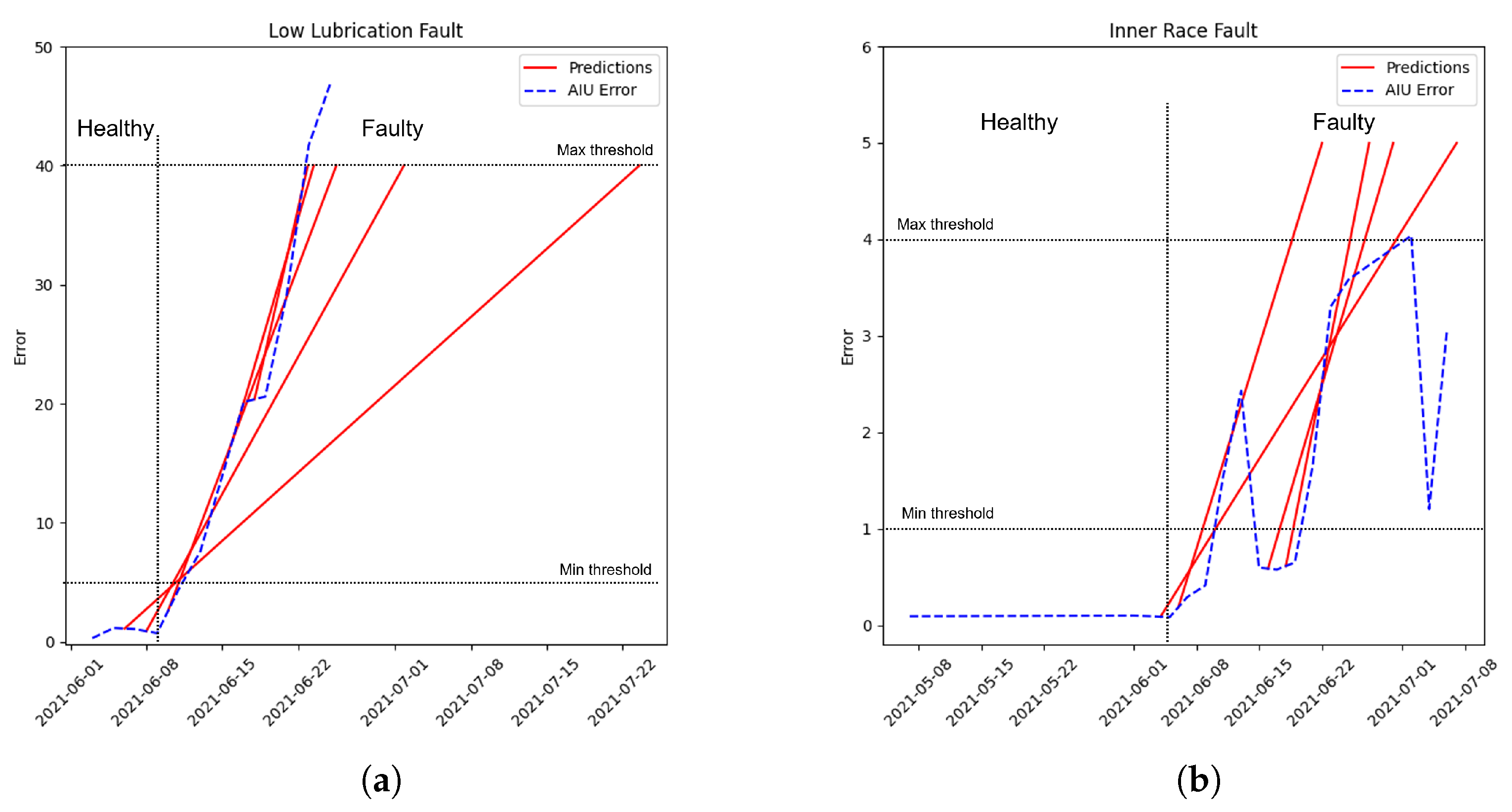
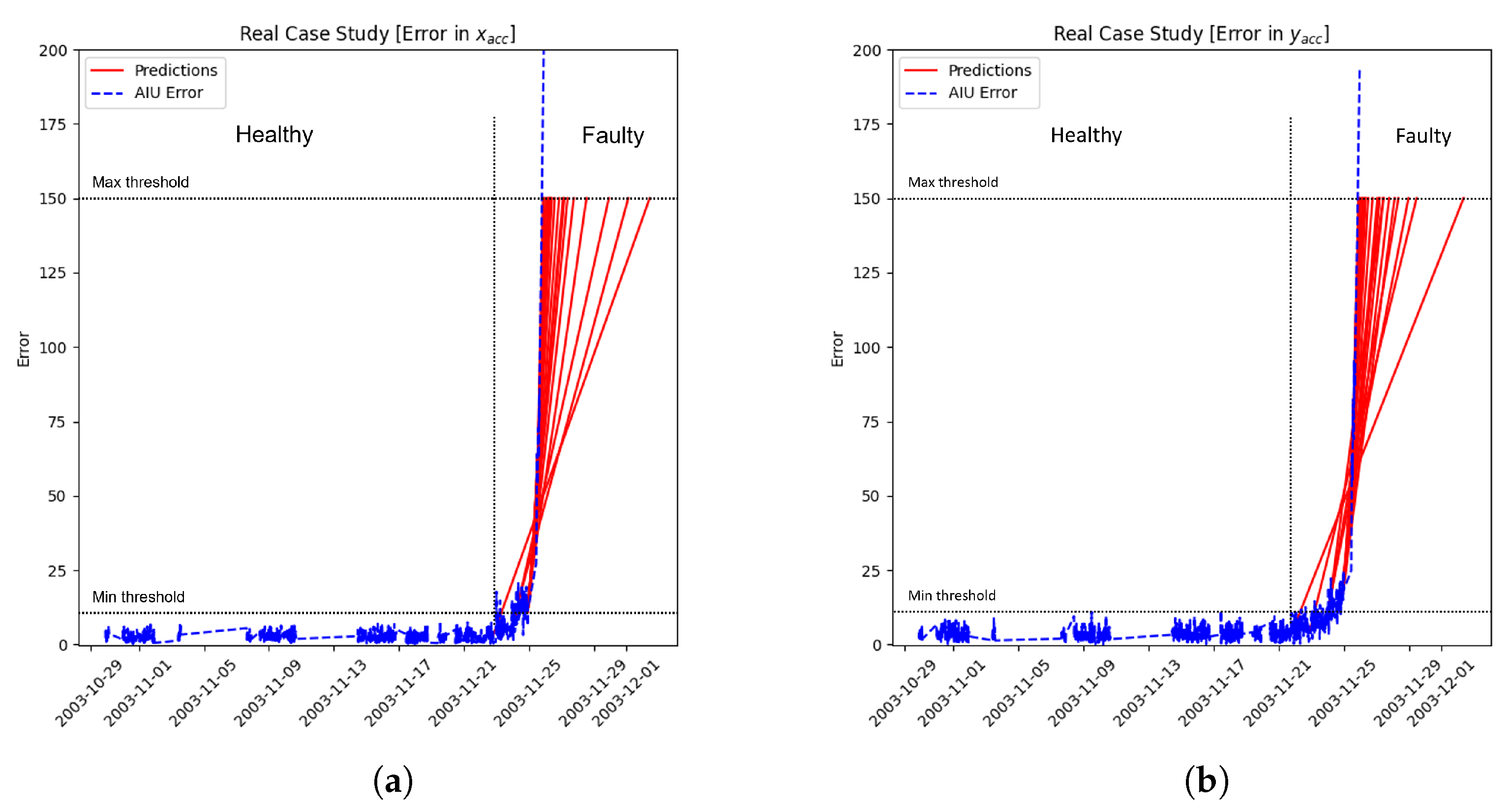
The “Low Lubrication Case” of the “Digital Model” (better explained in the following paragraph) is used as a representative example to see how the mentioned models work in order to compare them. Generally, a system works always in the same way: at the beginning of life, when it is healthy, the error computed by the model’s prediction is low; when the failure appears, the error’s prediction starts to increase. A further confirmation that a general system works in this manner is shown in
Section 5 in which the real cases behave exactly like the digital model used for the proof-of-concept, starting with a low error that increases at the end of the life when the failure appears. This general behavior is shown in
Figure 6 and
Figure 7: the former concerns the models’ selection, while the latter represents the errors’ selection.
The results obtained by comparing the three models are almost identical. In the Linear Regressor model, the y-scale has a lower variance in terms of the range in which the error can span, while in the other two models, the y-scale range is almost the same. The user can choose one of the three models with no particular weakness; generally, the tree models have better accuracy than the easier Linear Regressor, but this one has the advantage of being faster when the training process is performed. Decision Tree Regressor and Random Forest Regressor work similarly from a general point of view: the former works only with decisions while the latter works with decision trees. The main difference between them concerns the accuracy obtained and the computation’s complexity: a Decision Tree Regressor has lower computational complexity and accuracy than a Random Forest Regressor. The operator can choose one of the three models depending on the application in which the framework operates: for example, if there are no “computational effort thresholds”, such as a workstation or a computer, a Random Forest Regressor can be used to obtain an accurate prediction, while if the aim is to deploy the framework in a stand-alone embedded device, a Linear Regressor or a Decision Tree Regressor can be used in order to reduce the overall computational effort. The paper’s framework is uploaded in a workstation to compute the predictions and results; hence, a Random Forest Regressor is chosen as the reference model.
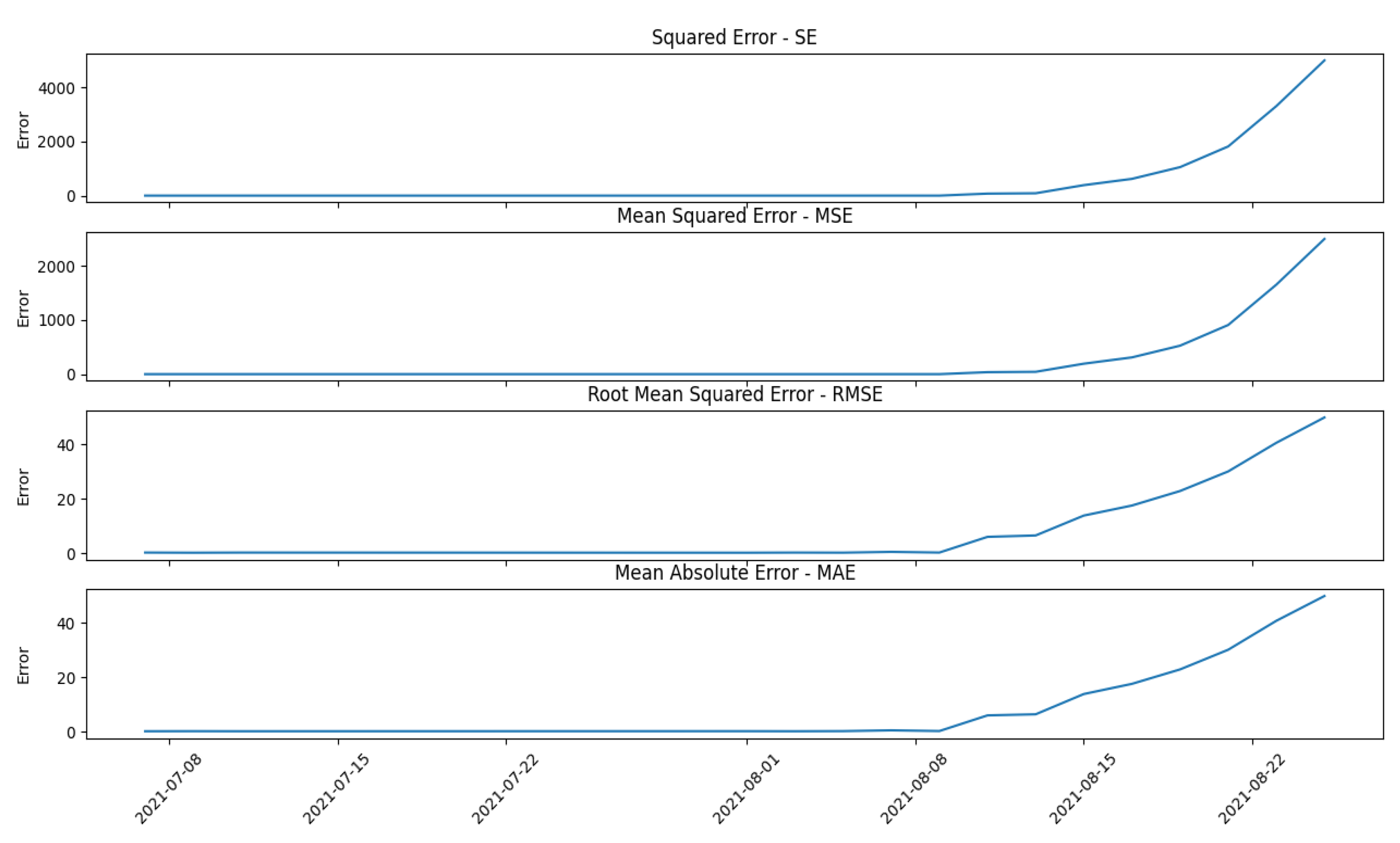
Furthermore, different errors were also evaluated during the study: Squared Error (SE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE), with the shape reported below:
where
is the real value while
is the predicted one.
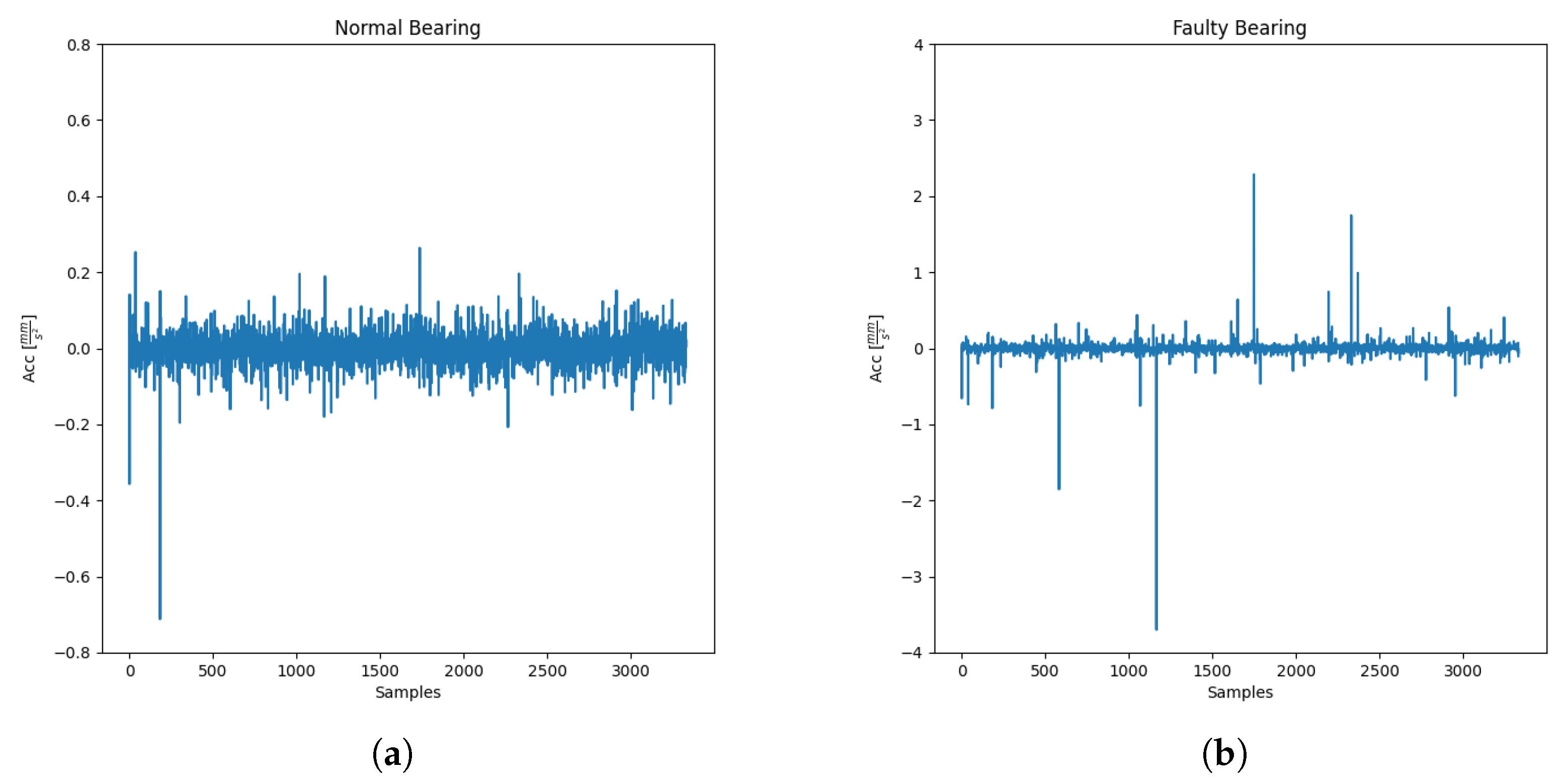
Figure 7 shows different error pictures computed on the same predictor using a Random Forest Regressor (RFR).
As shown in
Figure 7 there is a substantial difference between the obtained results; the last two graphs are more disrupted than the first two because they follow the prediction’s behavior faster. As in the AI model selection case, there is no particular rule for the error model selection. A possible solution could be to configure all four error models to monitor the deviation by creating dedicated predictor agents to perform the computation, but this creates waste from a computational energy point of view. The latter two error models show very similar behavior because of the huge likeness in the formula behind them; with the same number of samples, the MAE has
while RMSE has
, multiply the square root member. The similarity in the graphs above is due to the number of data used for the computation: when the number is low, the
and
are very comparable, also bringing a similarity in the results obtained. In this case, the operator can again choose which error model or which error models the framework has to use to monitor the behavior of the machine. In this paper and the following case studies, the error chosen for the evaluation is the MAE.
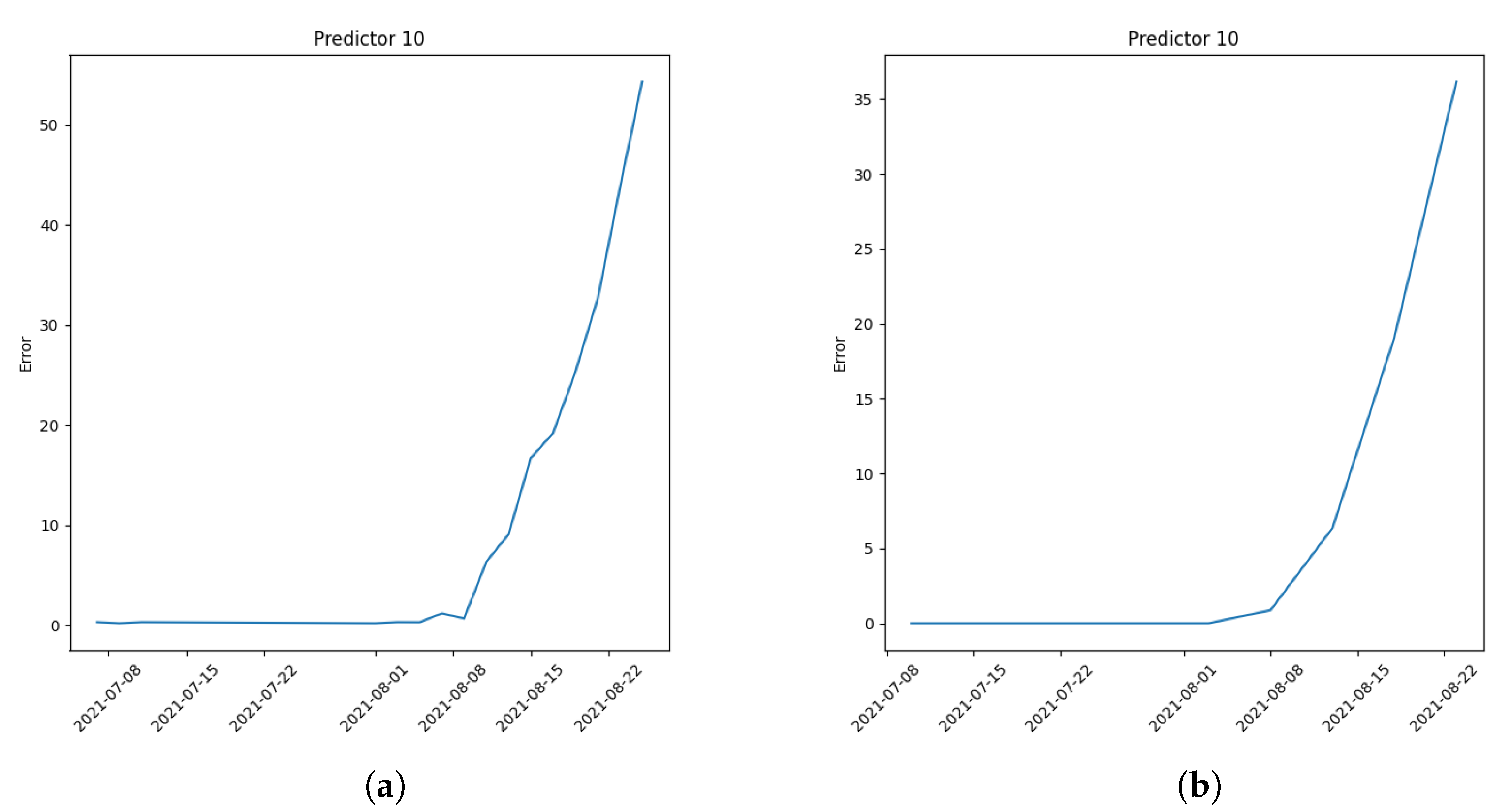
Figure 8a,b show two examples in which the error is computed with two sample ranges
n;
Figure 8a shows the last two records while
Figure 8b shows the last five records:
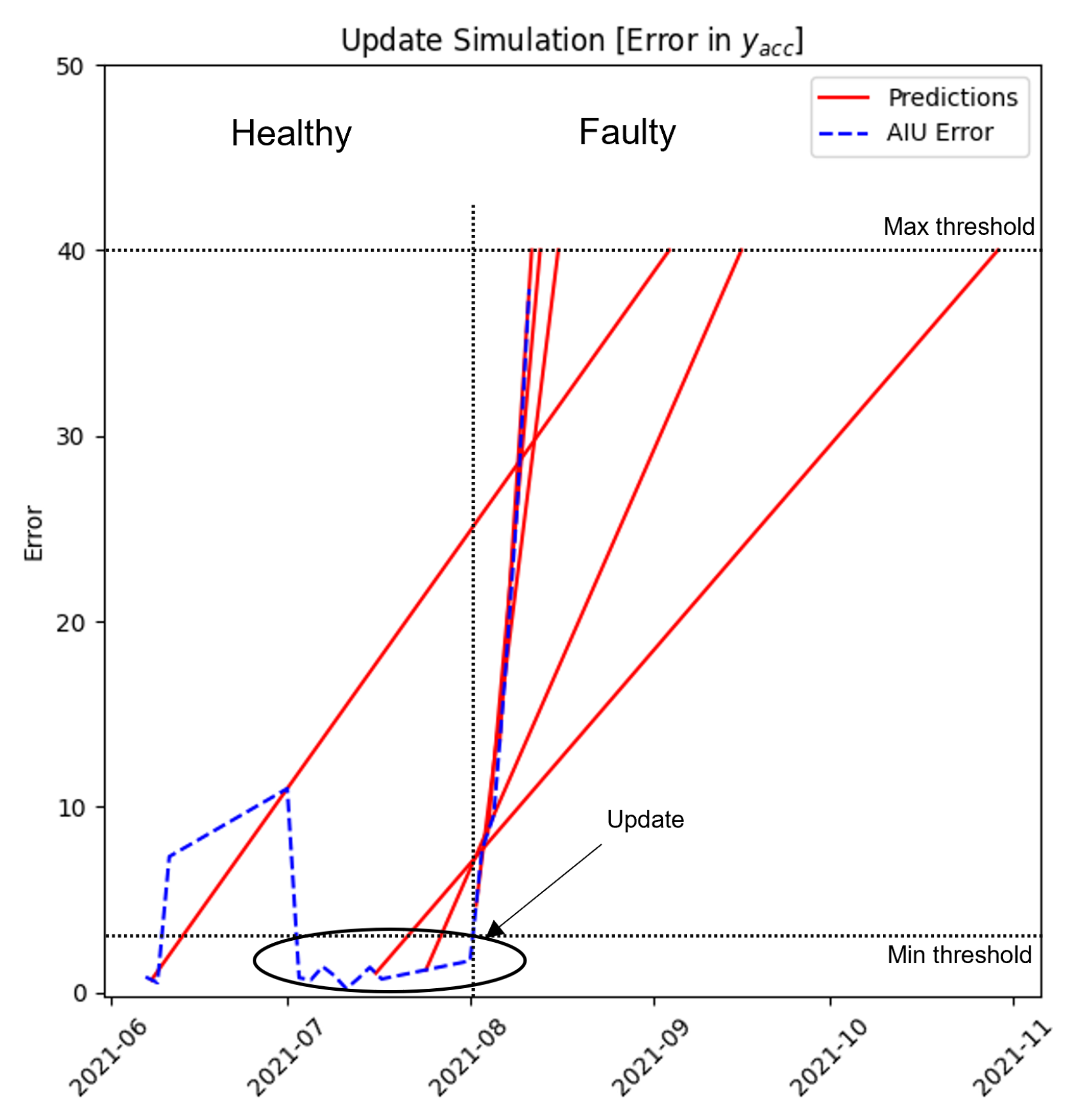
A two-sample error is chosen for the following experimental executions because of its ability to predict quickly. Another ability of the main framework concerns the possibility of updating or retraining the already trained models: as explained above, Novelty Detection can understand when something new happens in the system; this change can be related to an issue or a change does not create any problem. For this reason, when a novelty appears, the maintainer has to examine if the problem truly exists in order to choose one of the following procedures:
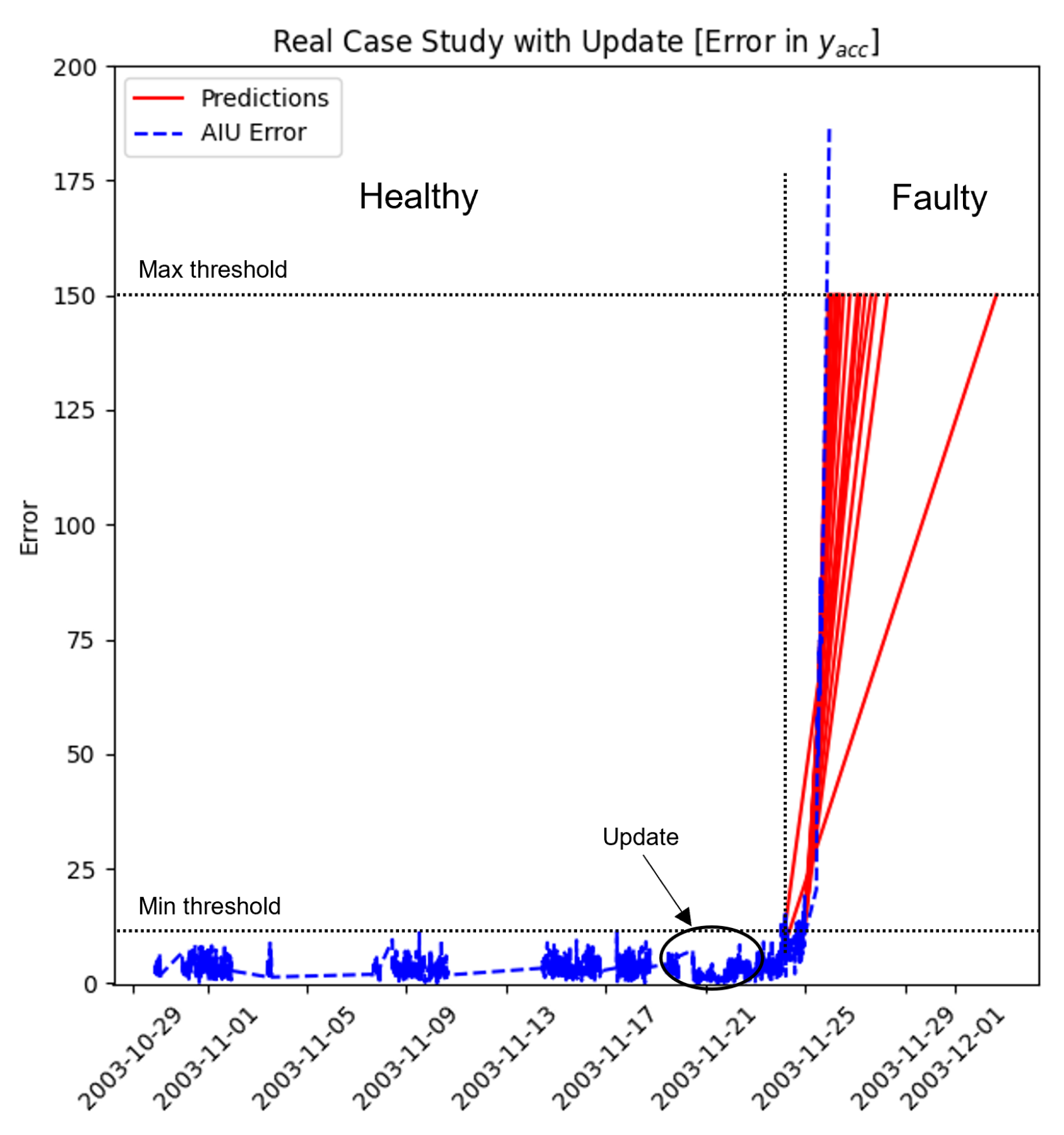
Models Update: in the case in which the data collected are different from the trained ones, but this change is not related to an issue in the machine, the maintainer can update the framework with the last parametrized n data, considering the incoming data as good ones. Thanks to the models’ update, a substantial reduction of the error value is performed;
Models Retrain: when a problem or a component substitution is performed in the machine, the retraining process is necessary due to the inevitable data change in the prediction (a common change could be a shift error in the data collected). The maintainer can decide to retrain the models by neglecting all previous ones and returning to the beginning phase.
An example of the update/retrain function is shown in the following “Digital Model” paragraph. The model update function also collects consistent datasets of the component under study to help the beginning data collection, which is useful to create the machine’s behavior history for future PdM implementation.
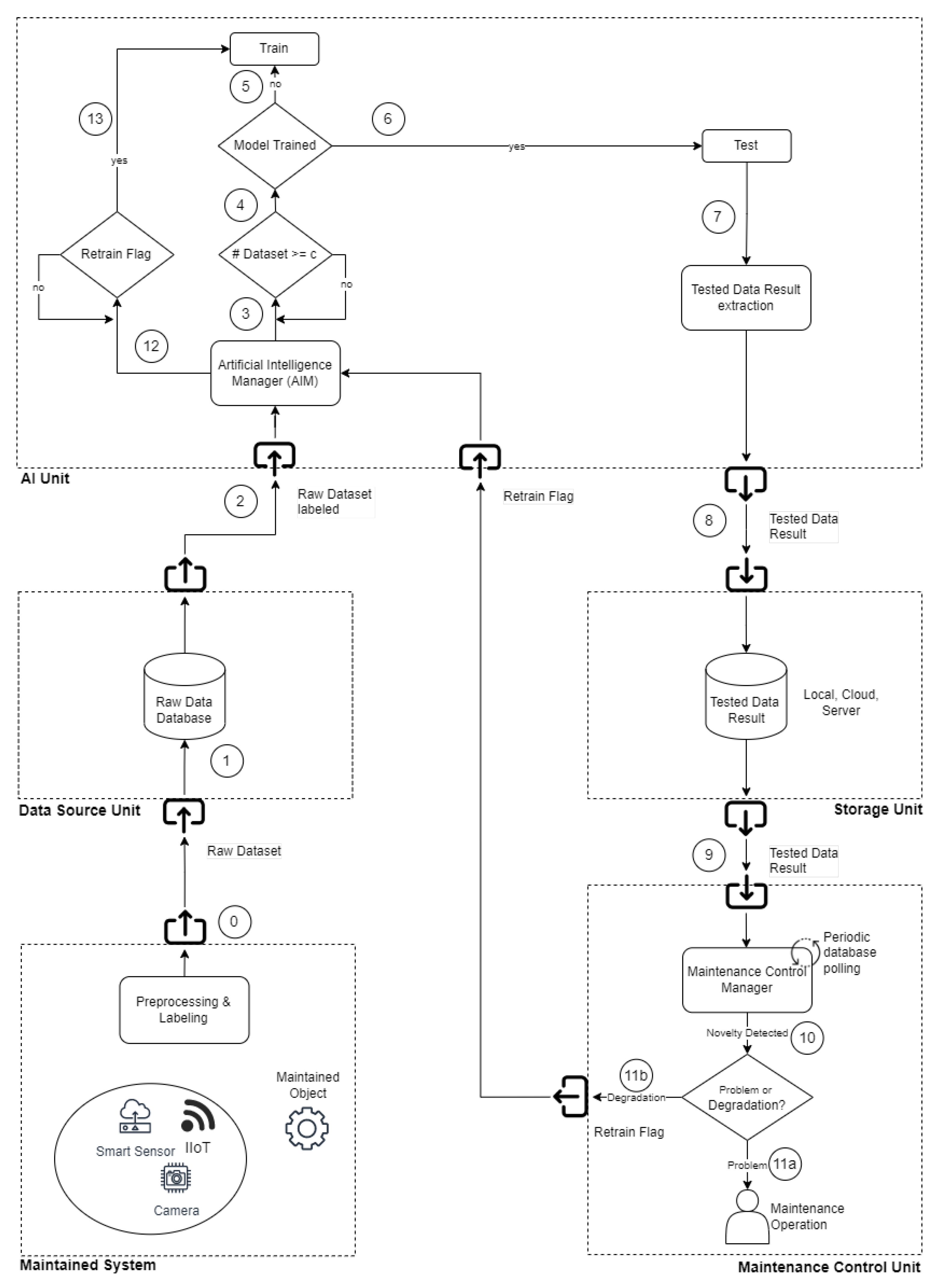
Recapping the AI Unit’s phases (
Figure 3):
Data Fetching Phase: in a continuous loop, the Unit waits for new data uploaded in the local/remote database to take them for the following Training or Testing phase;
Training Phase: when a predefined number of datasets are uploaded to the database (depending on how long the train dataset collection lasts), the framework understands that the training process can start. After the Training process, several models are created as a function of the features extracted (hence depending on the number of windows of the windowing function);
Testing Phase: after the training phase, every dataset uploaded is processed by the framework with a number of predictors equal to the number of models previously created. Then, every predictor estimates its label with an error; the upcoming failures conduct the dataset to change its shape, increasing the error in the prediction. The number of predictors equal to the number of features can help in error recognition by covering all the data distribution.
Retraining/Updating Phase: in some cases, the model error deviates without a real problem on the machine; in this case, the maintainer can update the models trained, considering incoming new data as “normal”, resetting the error value. The retraining process is necessary when a maintenance operation is performed; then, past data are neglected, and only new data are used for future predictions.
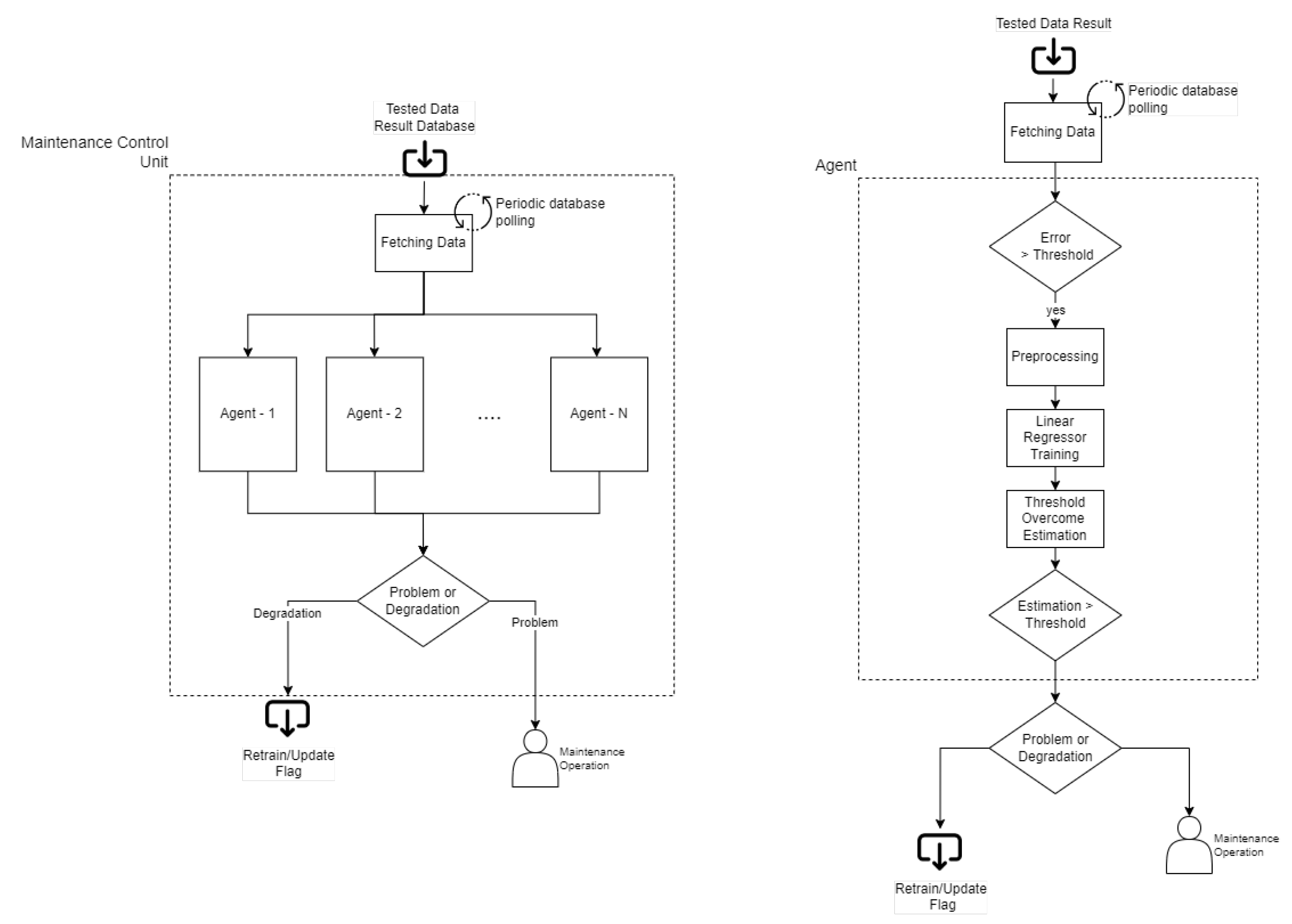
3.5. Maintenance Control Unit
The Maintenance Control Unit (MCU) is developed as a software Multi-Agent System (MAS), composed of a system and an application level. This section analyzes the MCU system and application levels from an architectural, functional, and procedural point of view by entering into its implementation details.
As presented, NDF measures the evolution over time of a system using a set of metrics and predicts the time in which these measures become relevant to detect system model changes. As explained above, two main modules can be identified in the NDF environment: AIU and MCU. AIU computes raw data and provides information about model accuracy over time using prediction error. MCU monitors this model’s accuracy degradation over time to detect relevant changes in system behavior compared to the trained ones. Hence, MCU performs:
Sensing error over time, produced by AIUPs;
Evaluating current AIUPs’ errors by applying a set of condition-action rules;
Performing time predictions of AIUPs’ errors degradation through their most recent data result;
Producing maintenance events to notify AIUPs’ models changes.
AIU consumes raw data from a system and provides different error data types. MCU processes these results to detect changes, making the Remaining Time to Retrain (RTR) predictions. RTR is similar to RUL in a PdM environment; however, it is related to a different type of prediction: in RUL, the prediction concerns the computation of the remaining time before the occurrence of a failure; on the other end, RTR concerns the computation of the remaining time before exceeding a threshold defined as a warning value.
MCU performs its task by separately analyzing all errors collected by AIU. Since the results collected are related to different AIUPs, MCU can be divided into smaller independent units (agents), and each of them computes a result for a fixed model (AIUP) (
Figure 9). For this reason, MCU is developed as a software MAS.
Two main “actors” can be identified in the architecture’s MAS:
Agent Manager (AM) detains control flow of the system process and manages the life cycle of single agents. It is responsible for maintaining, scheduling, and executing each agent over time;
Agents interfaced with the Agent Manager: they solve their designed job by executing their Agent Program (AP) into the system process. Each agent holds its intelligence internally in terms of capabilities and features.
Generally, AM acts as a dummy entity, and the whole complexity of the system is moved onto the agents. Furthermore, a secondary actor appears in the MCU, the Agent System (AS). AS controls AM and is responsible for initializing and configuring agents, launching AM execution, and waiting into sleep mode until AM execution ends or an AM exception occurs.
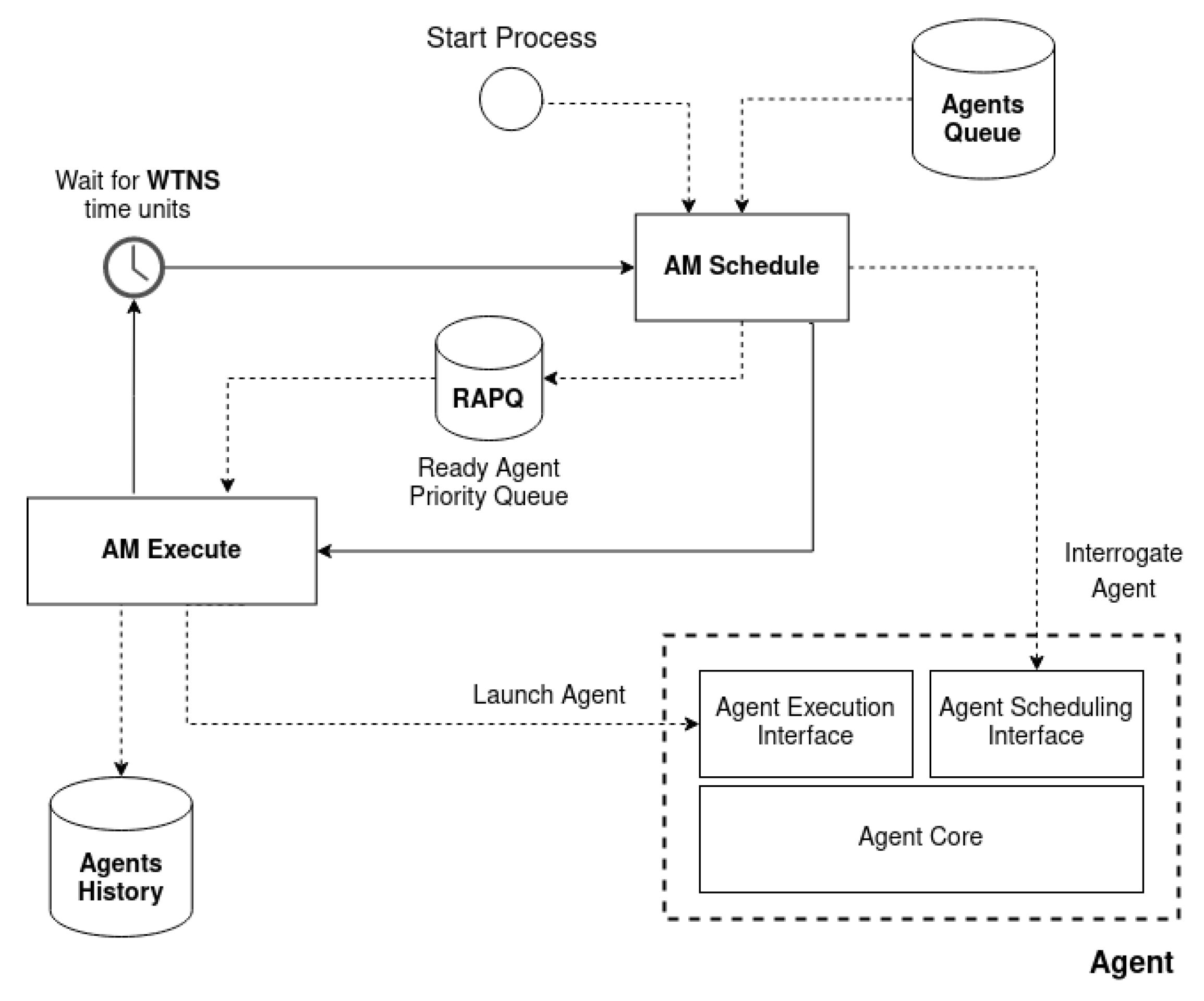
AM is implemented in the MCU system control layer and is not involved in the MCU application process. During AS initialization, the AM and all agents are loaded. Until AS launches AM, the AM main process will start, and AS will go idle. As shown in
Figure 10 the AM main process comprises a stoppable loop of three sequential phases identified as agents scheduling, executing, and waiting for the next scheduling. During agents scheduling, AM collects ready agents and computes the Wait Time for the Next Scheduling (WTNS). During agents execution, AM executes the collected ready agents. To increase MCU’s reliability, the AM will wait for a Maximum Wait Time for Execution (MWTE). Finally, AM will sleep for WTNS time units before the next scheduling.
Model Change Detector Agent (MCDA) architecture is developed as an agent that perceives the environment and its state, applies some condition-action rules, and executes a given action. Each agent executes its program by performing the following operations:
Sense environment and obtains k errors back in time, related to a given AIUPs’.
Applies a condition-action-based rule to evaluate the last error value and detect model changes. The agent works in a specific operative range composed of low and high thresholds (lowest and highest bounds). The lowest bound represents when the agent starts its prediction, while the highest bound represents the maximum error allowed. This last value is used for the RTR prediction;
Performs an “Average” computation of the parametrized k errors selected back in time; when the lowest bound is overcome, the system triggers the related software agent that takes the last k errors back in time, dividing this errors-set into two different parts, an “oldest” and a “newest” part; at the end, an error and time average are computed for both the first and the second part selected, obtaining two points useful for the following trend identification phase;
Performs the trend degradation analysis by training a Linear Regressor (LR) on the two points computed in the phase before and making a prediction on the time of reaching a certain error value;
Apply a condition-action-based rule on the predicted time to degradation value to decide whether the model changes. The notification is performed if the predicted time is closer to a parametrized notification prevention tolerance time. Otherwise, the agent program ends. This approach avoids notifying model changes, which error threshold value will most likely be reached in a long time;
Notify model change for a given predictor and error type. The notification is performed thanks to the interface actuation function that permits emitting a notification with a related message. The notification message contains the detected predictor that changes with the time prediction of reaching the error threshold value.
The MCU application architecture is composed of different MCDAs that operate independently over time. Each MCDA executes its AP periodically.
To summarize, MCU is implemented as a leader-follow, time-triggered agent system. Both system and application architecture are entirely developed using multi-threading and Object Oriented Programming approaches. Additionally, inheritance and polymorphism are used to develop the hereditary hierarchy of agents. Thanks to its code reusability optimization and extendability, this MAS allows the development of new applications easily through new agents.


 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}