
Audiovisual Biometric Network with Deep Feature Fusion for Identification and Text Prompted Verification


Abstract
:1. Introduction
2. Literature Overview
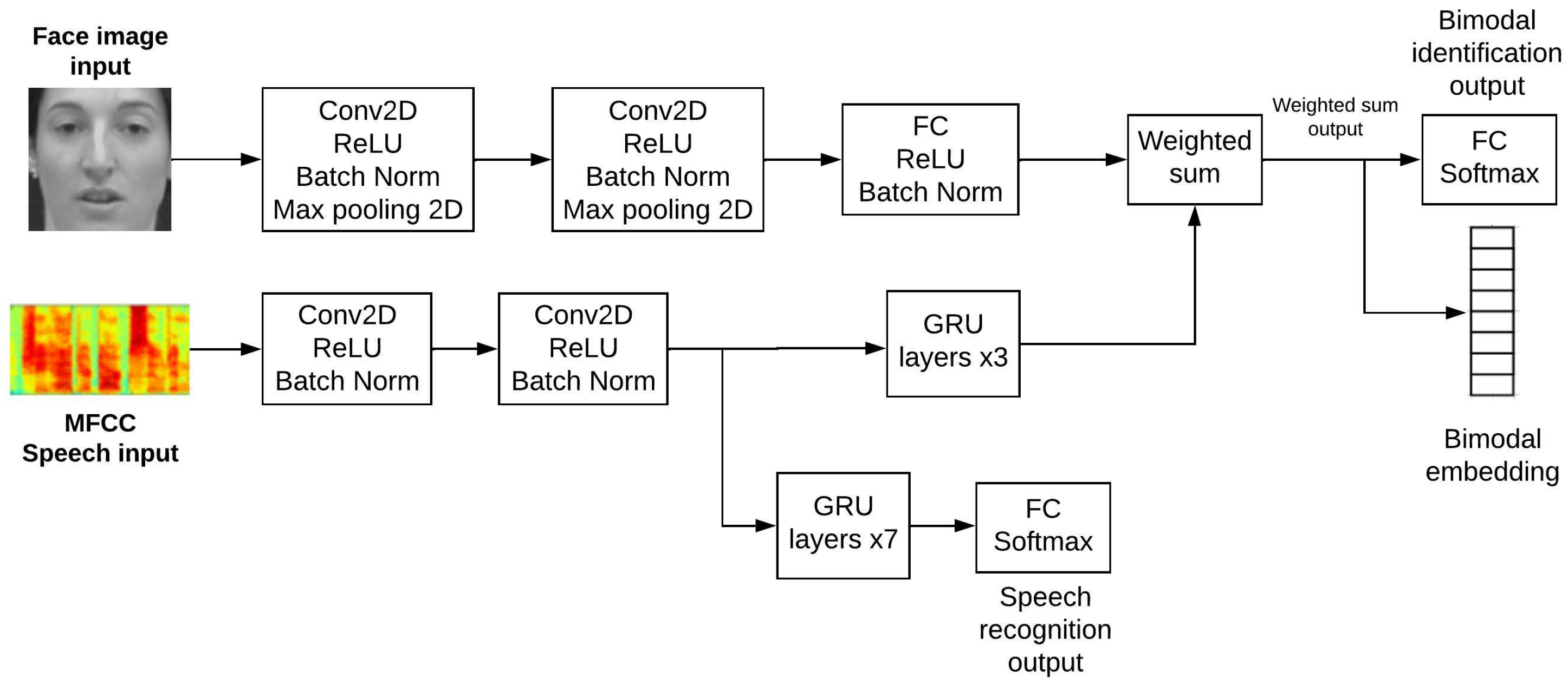
3. Structure of the Proposed Biomodal Multitask Network
3.1. Feature Extraction
3.2. Bimodal Data Fusion
3.3. Outputs
3.4. Training and Testing Data
3.4.1. Speech Data Preprocessing
3.4.2. Face Data Preprocessing
3.5. Network Training
Joint Loss Function
4. Experimental Evaluation
4.1. Identification Evaluation
4.2. Speech Recognition Evaluation
4.3. Text Prompted Verification
4.3.1. Bimodal Embeddings Matching
4.3.2. Binary Classifier
4.3.3. Verification Evaluation
5. Results and Discussion
5.1. Identification Results
5.2. Speech Recognition Results
5.3. Text Prompted Verification Results
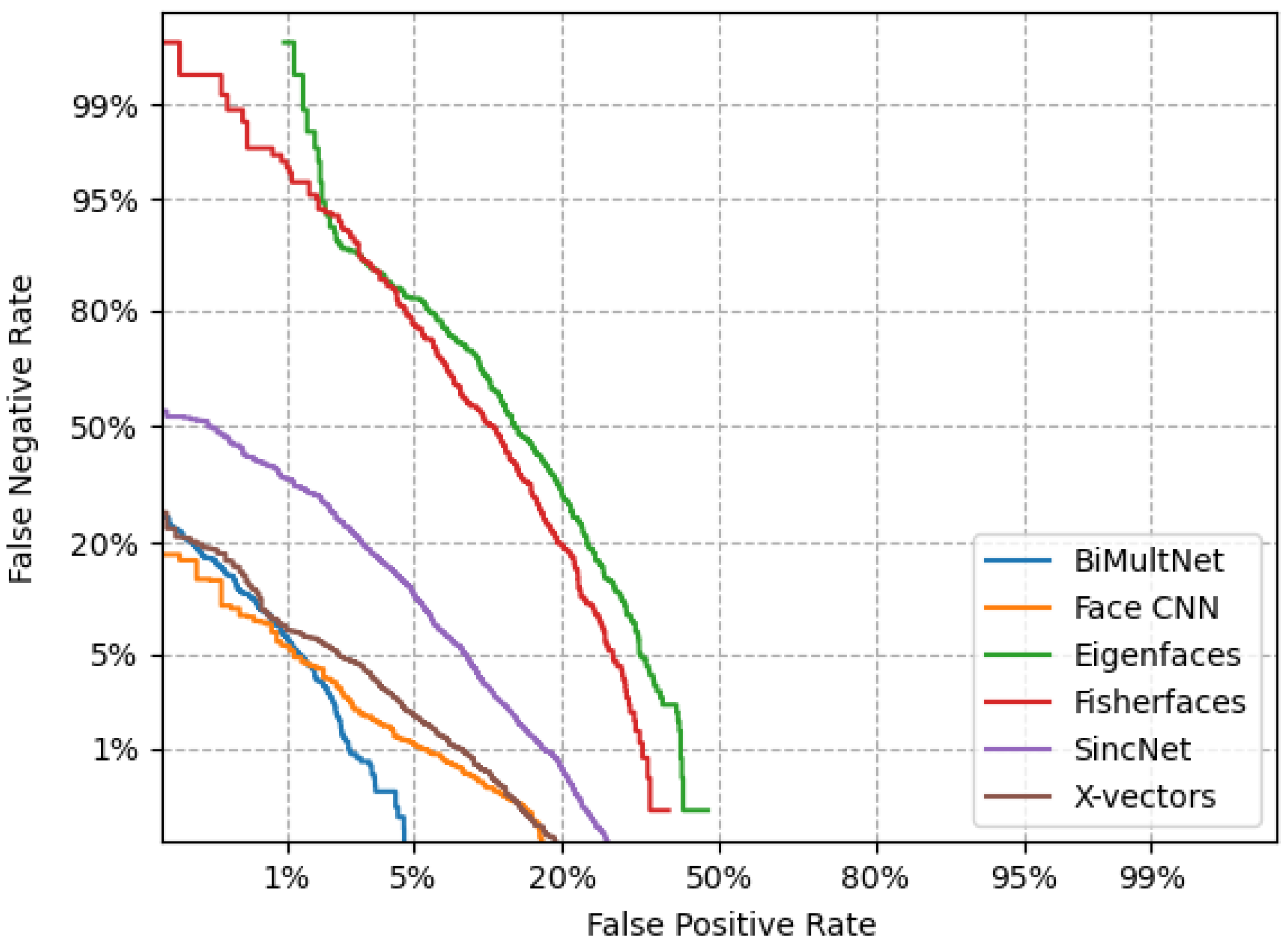
5.4. Comparison of Results with Other Approaches
5.4.1. Identification
5.4.2. Verification
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Minaee, S.; Abdolrashidi, A.; Su, H.; Bennamoun, M.; Zhang, D. Biometrics recognition using deep learning: A survey. arXiv 2019, arXiv:1912.00271. [Google Scholar] [CrossRef]
- Modak, S.K.S.; Jha, V.K. Multibiometric fusion strategy and its applications: A review. Inf. Fusion 2019, 49, 174–204. [Google Scholar] [CrossRef]
- Sabhanayagam, T.; Venkatesan, V.P.; Senthamaraikannan, K. A comprehensive survey on various biometric systems. Int. J. Appl. Eng. Res. 2018, 13, 2276–2297. [Google Scholar]
- Dahea, W.; Fadewar, H. Multimodal biometric system: A review. Int. J. Res. Adv. Eng. Technol. 2018, 4, 25–31. [Google Scholar]
- Dinca, L.M.; Hancke, G.P. The fall of one, the rise of many: A survey on multi-biometric fusion methods. IEEE Access 2017, 5, 6247–6289. [Google Scholar] [CrossRef]
- Fierrez, J.; Morales, A.; Vera-Rodriguez, R.; Camacho, D. Multiple classifiers in biometrics. part 1: Fundamentals and review. Inf. Fusion 2018, 44, 57–64. [Google Scholar] [CrossRef]
- Singh, M.; Singh, R.; Ross, A. A comprehensive overview of biometric fusion. Inf. Fusion 2019, 52, 187–205. [Google Scholar] [CrossRef]
- Marín-Jiménez, M.J.; Castro, F.M.; Guil, N.; De la Torre, F.; Medina-Carnicer, R. Deep multi-task learning for gait-based biometrics. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 106–110. [Google Scholar]
- Li, J.; Sun, M.; Zhang, X.; Wang, Y. Joint decision of anti-spoofing and automatic speaker verification by multi-task learning with contrastive loss. IEEE Access 2020, 8, 7907–7915. [Google Scholar] [CrossRef]
- Al Alkeem, E.; Yeun, C.Y.; Yun, J.; Yoo, P.D.; Chae, M.; Rahman, A.; Asyhari, A.T. Robust deep identification using ECG and multimodal biometrics for industrial internet of things. Ad. Hoc. Netw. 2021, 121, 102581. [Google Scholar] [CrossRef]
- Tao, F.; Busso, C. End-to-end audiovisual speech recognition system with multitask learning. IEEE Trans. Multimed. 2020, 23, 1–11. [Google Scholar] [CrossRef]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face recognition systems: A survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fuad, M.T.H.; Fime, A.A.; Sikder, D.; Iftee, M.A.R.; Rabbi, J.; Al-Rakhami, M.S.; Gumaei, A.; Sen, O.; Fuad, M.; Islam, M.N. Recent advances in deep learning techniques for face recognition. IEEE Access 2021, 9, 99112–99142. [Google Scholar] [CrossRef]
- Kalaiarasi, P.; Esther Rani, P. A Comparative Analysis of AlexNet and GoogLeNet with a Simple DCNN for Face Recognition. In Advances in Smart System Technologies; Springer: Singapore, 2021; pp. 655–668. [Google Scholar]
- Pratama, Y.; Ginting, L.M.; Nainggolan, E.H.L.; Rismanda, A.E. Face recognition for presence system by using residual networks-50 architecture. Int. J. Electr. Comput. Eng. 2021, 11, 5488. [Google Scholar] [CrossRef]
- William, I.; Rachmawanto, E.H.; Santoso, H.A.; Sari, C.A. Face recognition using facenet (survey, performance test, and comparison). In Proceedings of the 2019 fourth international conference on informatics and computing (ICIC), Semarang, Indonesia, 16–17 October 2019; pp. 1–6. [Google Scholar]
- Nandy, A. A densenet based robust face detection framework. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Gwyn, T.; Roy, K.; Atay, M. Face recognition using popular deep net architectures: A brief comparative study. Future Internet 2021, 13, 164. [Google Scholar] [CrossRef]
- Li, X.; Niu, H. Feature extraction based on deep-convolutional neural network for face recognition. Concurr. Comput. Pract. Exp. 2020, 32, 1-1. [Google Scholar] [CrossRef]
- Pei, Z.; Xu, H.; Zhang, Y.; Guo, M.; Yang, Y.H. Face recognition via deep learning using data augmentation based on orthogonal experiments. Electronics 2019, 8, 1088. [Google Scholar] [CrossRef] [Green Version]
- Sarkar, A.K.; Tan, Z.H. Incorporating pass-phrase dependent background models for text-dependent speaker verification. Comput. Speech Lang. 2018, 47, 259–271. [Google Scholar] [CrossRef] [Green Version]
- Dehak, N.; Kenny, P.J.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-end factor analysis for speaker verification. IEEE Trans. Audio, Speech, Lang. Process. 2010, 19, 788–798. [Google Scholar] [CrossRef]
- Liu, Y.; He, L.; Tian, Y.; Chen, Z.; Liu, J.; Johnson, M.T. Comparison of multiple features and modeling methods for text-dependent speaker verification. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 629–636. [Google Scholar]
- Novoselov, S.; Kudashev, O.; Shchemelinin, V.; Kremnev, I.; Lavrentyeva, G. Deep cnn based feature extractor for text-prompted speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5334–5338. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Jung, J.; Heo, H.; Yang, I.; Yoon, S.; Shim, H.; Yu, H. D-vector based speaker verification system using Raw Waveform CNN. In Proceedings of the 2017 International Seminar on Artificial Intelligence, Networking and Information Technology (Anit 2017), Bangkok, Thailand, 2–3 December 2017; Volume 150, pp. 126–131. [Google Scholar]
- Muckenhirn, H.; Doss, M.M.; Marcell, S. Towards directly modeling raw speech signal for speaker verification using CNNs. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4884–4888. [Google Scholar]
- Ravanelli, M.; Bengio, Y. Speaker recognition from raw waveform with sincnet. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 1021–1028. [Google Scholar]
- Tripathi, M.; Singh, D.; Susan, S. Speaker recognition using SincNet and X-vector fusion. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 12–14 October 2020; Springer: Cham, Switzerland, 2020; pp. 252–260. [Google Scholar]
- Chowdhury, L.; Zunair, H.; Mohammed, N. Robust deep speaker recognition: Learning latent representation with joint angular margin loss. Appl. Sci. 2020, 10, 7522. [Google Scholar] [CrossRef]
- Bai, Z.; Zhang, X.L. Speaker recognition based on deep learning: An overview. Neural Netw. 2021, 140, 65–99. [Google Scholar] [CrossRef]
- Mandalapu, H.; PN, A.R.; Ramachandra, R.; Rao, K.S.; Mitra, P.; Prasanna, S.M.; Busch, C. Audio-visual biometric recognition and presentation attack detection: A comprehensive survey. IEEE Access 2021, 9, 37431–37455. [Google Scholar] [CrossRef]
- Ryu, R.; Yeom, S.; Kim, S.H.; Herbert, D. Continuous multimodal biometric authentication schemes: A systematic review. IEEE Access 2021, 9, 34541–34557. [Google Scholar] [CrossRef]
- Talreja, V.; Valenti, M.C.; Nasrabadi, N.M. Multibiometric secure system based on deep learning. In Proceedings of the 2017 IEEE Global conference on Signal and Information Processing (globalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 298–302. [Google Scholar]
- Xin, Y.; Kong, L.; Liu, Z.; Wang, C.; Zhu, H.; Gao, M.; Zhao, C.; Xu, X. Multimodal feature-level fusion for biometrics identification system on IoMT platform. IEEE Access 2018, 6, 21418–21426. [Google Scholar] [CrossRef]
- Olazabal, O.; Gofman, M.; Bai, Y.; Choi, Y.; Sandico, N.; Mitra, S.; Pham, K. Multimodal biometrics for enhanced iot security. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NA, USA, 7–9 January 2019; pp. 886–893. [Google Scholar]
- Wu, L.; Yang, J.; Zhou, M.; Chen, Y.; Wang, Q. LVID: A multimodal biometrics authentication system on smartphones. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1572–1585. [Google Scholar] [CrossRef]
- Alay, N.; Al-Baity, H.H. Deep learning approach for multimodal biometric recognition system based on fusion of iris, face, and finger vein traits. Sensors 2020, 20, 5523. [Google Scholar] [CrossRef]
- Maity, S.; Abdel-Mottaleb, M.; Asfour, S.S. Multimodal biometrics recognition from facial video with missing modalities using deep learning. J. Inf. Process. Syst. 2020, 16, 6–29. [Google Scholar]
- mehdi Cherrat, E.; Alaoui, R.; Bouzahir, H. Convolutional neural networks approach for multimodal biometric identification system using the fusion of fingerprint, finger-vein and face images. PeerJ Comput. Sci. 2020, 6, e248. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Cheng, D.; Jia, P.; Dai, Y.; Xu, X. An efficient android-based multimodal biometric authentication system with face and voice. IEEE Access 2020, 8, 102757–102772. [Google Scholar] [CrossRef]
- Leghari, M.; Memon, S.; Dhomeja, L.D.; Jalbani, A.H.; Chandio, A.A. Deep feature fusion of fingerprint and online signature for multimodal biometrics. Computers 2021, 10, 21. [Google Scholar] [CrossRef]
- Liu, M.; Wang, L.; Lee, K.A.; Zhang, H.; Zeng, C.; Dang, J. Exploring Deep Learning for Joint Audio-Visual Lip Biometrics. arXiv 2021, arXiv:2104.08510. [Google Scholar]
- Luo, Z.; Li, J.; Zhu, Y. A deep feature fusion network based on multiple attention mechanisms for joint iris-periocular biometric recognition. IEEE Signal Process. Lett. 2021, 28, 1060–1064. [Google Scholar] [CrossRef]
- Iula, A.; Micucci, M. Multimodal Biometric Recognition Based on 3D Ultrasound Palmprint-Hand Geometry Fusion. IEEE Access 2022, 10, 7914–7925. [Google Scholar] [CrossRef]
- Rajasekar, V.; Predić, B.; Saracevic, M.; Elhoseny, M.; Karabasevic, D.; Stanujkic, D.; Jayapaul, P. Enhanced multimodal biometric recognition approach for smart cities based on an optimized fuzzy genetic algorithm. Sci. Rep. 2022, 12, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Vijay, M.; Indumathi, G. Deep belief network-based hybrid model for multimodal biometric system for futuristic security applications. J. Inf. Secur. Appl. 2021, 58, 102707. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H.; Sun, Z.; Tan, T. Deep feature fusion for iris and periocular biometrics on mobile devices. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2897–2912. [Google Scholar] [CrossRef]
- Moreno-Rodriguez, J.C.; Atenco-Vazquez, J.C.; Ramirez-Cortes, J.M.; Arechiga-Martinez, R.; Gomez-Gil, P.; Fonseca-Delgado, R. BIOMEX-DB: A Cognitive Audiovisual Dataset for Unimodal and Multimodal Biometric Systems. IEEE Access 2021, 9, 111267–111276. [Google Scholar] [CrossRef]
- Sanderson, C.; Lovell, B.C. Multi-region probabilistic histograms for robust and scalable identity inference. In Proceedings of the International Conference on Biometrics, Alghero, Italy, 2–5 June 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 199–208. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Seltzer, M.L.; Khudanpur, S. A study on data augmentation of reverberant speech for robust speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5220–5224. [Google Scholar]
- Snyder, D.; Chen, G.; Povey, D. Musan: A music, speech, and noise corpus. arXiv 2015, arXiv:1510.08484. [Google Scholar]
- Mahmood, A.; Utku, K. Speech recognition based on convolutional neural networks and MFCC algorithm. Adv. Artif. Intell. Res. 2021, 1, 6–12. [Google Scholar]
- van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T.; the Scikit-Image Contributors. scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef]
- Wang, X.; Wang, K.; Lian, S. A survey on face data augmentation for the training of deep neural networks. Neural Comput. Appl. 2020, 32, 15503–15531. [Google Scholar] [CrossRef] [Green Version]
- Jung, A.B.; Wada, K.; Crall, J.; Tanaka, S.; Graving, J.; Reinders, C.; Yadav, S.; Banerjee, J.; Vecsei, G.; Kraft, A.; et al. Imgaug. Available online: https://github.com/aleju/imgaug (accessed on 1 February 2020).
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 173–182. [Google Scholar]
- Zenkel, T.; Sanabria, R.; Metze, F.; Niehues, J.; Sperber, M.; Stüker, S.; Waibel, A. Comparison of decoding strategies for ctc acoustic models. arXiv 2017, arXiv:1708.04469. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Cheng, J.M.; Wang, H.C. A method of estimating the equal error rate for automatic speaker verification. In Proceedings of the 2004 International Symposium on Chinese Spoken Language Processing, Singapore, 13–16 December 2006; pp. 285–288. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Aliyu, I.; Bomoi, M.A.; Maishanu, M. A Comparative Study of Eigenface and Fisherface Algorithms Based on OpenCV and Sci-kit Libraries Implementations. Int. J. Inf. Eng. Electron. Bus. 2022, 14, 30–40. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Author | Modalities | Features | Classifier | Fusion method | Database and no. of Subjects | Performance |
|---|---|---|---|---|---|---|
| Talreja et al., 2017 [34] | Iris and face. | Pretrained VGG-19 extracted features. | Fully connected layer architecture (FCA). Bilinear architecture (BLA). | Two-stream CNN with FCA or BLA. | CASIA-Webface: 10,575. ND-Iris-0405: 1355. WVU-Multimodal: 2263. | Verification: Genuine Acceptance Rate (GAR) Best FCA 99.65%. Best BLA 99.99%. |
| Xin et al., 2018 [35] | Face, fingerprint and finger vein. | Principal Component Analysis (PCA), Endpoint and Crosspoint features, Fine point features. Fisher vectors. | KNN, Support Vector Machine (SVM) and Bayes Classifiers. | Concatenation of fisher vectors with GMM. | Self acquired: 50. | Identification: Accuracy 50 subjects 88%. 20 subjects 90%. 15 subjects 93.3%. |
| Olazabal et al., 2019 [36] | Face and voice. | Histogram of oriented gradients (HOG), LBP and MFCC. | K-nearest neighbors (KNN) algorithm. | Discriminant correlation analysis (DCA). | CSUF-SG5: 27. | Verification: EER 8.04%. |
| Wu et al., 2019 [37] | Voice and lip movement. | MFCC and spectral analysis. | Gaussian Mixture Models (GMM). | Frequency domain convolution. | Self acquired: 104. | Verification: Area under the curve (AUC) 0.95. |
| Alay et al., 2020 [38] | Iris, face, and finger vein. | CNN extracted features. | 3 VGG-16 networks. | Features concatenation. Mean rule. Product rule. | SDUMLA-HMT: 106. | Identification: Accuracy Feature fusion 99.39%. Mean rule 100%. Product rule 100%. |
| Maity et al., 2020 [39] | Frontal face, profile face, and ears. | Two-dimensional Gabor filters. | Auto-encoders with Deep Belief Networks (DBN). | Weighted sum. | WVU: 402. HONDA/UCSD: 35. | Identification: Accuracy WVU database 99.17%. HONDA/UCSD 97.14%. |
| Mehdi et al., 2020 [40] | Fingerprint, finger vein, and face. | CNN extracted features. | Three-stream CNN. | Weighted sum and weighted product. | SDUMLA-HMT: 106. | Identification: Accuracy Weighted sum 99.73%. Weighted product 99.70%. |
| Zhang et al., 2020 [41] | Face and voice. | Local Binary Pattern (LBP) and MFCC. | LBP matching. GMM. | Weighted sum. | XJTU: 102. | Verification: True Acceptance Rate (TAR) 100%. False Rejection Rate (FRR) 0%. False Acceptance Rate (FRR) 0%. |
| Alkeem et al., 2021 [10] | Electrocardiogram (ECG), face, and fingerprint. Gender identification. | ResNet50 and CNN extracted features. | Multitask network with 2 Resnet50 streams and 1 CNN stream. | Features concatenation. Sum, max and product rules. | Virtual dataset: 58. Extracted from ECG-ID, PTB ECG, Faces95 and FVC2006 databases. | Identification: Accuracy Feature fusion 98.97%. Sum rule 98.95%. Product rule 96.55%. Max rule 89.66%. |
| Leghari et al., 2021 [42] | Fingerprint and online signature. | CNN extracted features. | Two stream CNN. | Features concatenation. | Self acquired: 280. | Identification: Accuracy Early fusion 99.1%. Late fusion 98.35%. |
| Liu et al., 2021 [43] | Face and voice. | CNN extracted features, MFCC. | Two-stream CNN. | Feature concatenation. | Deep Lip (virtual database): 150. Extracted from: GRID, LOMBARDIGRID and TCD-TIMIT databases. | Verification: EER First test 0.84%. Second test 1.11%. |
| Luo et al., 2021 [44] | Iris and periocular area. | CNN extracted features. | Two-stream CNN with residual blocks. | Features fusion with co-attention mechanism. | CASIA- Iris-Thousand: 690. ND-IRIS- 0405: 267. | Verification: EER CASIA 0.13%. ND-IRIS 0.37%. |
| Iula et al., 2022 [45] | Hand geometry and palmprint. | 2D and 3D templates. | Templates matching. | Weighted sum. | Self acquired: 40. | Verification: EER 0.08%. Identification: Accuracy 100%. |
| Rajasekar et al., 2022 [46] | Iris and fingerprint. | Log-Gabor filters. | Fuzzy Genetic algorithm. | Optimized weighted sum. | CASIA iris V3 and FVC2006. | Identification: Accuracy 99.98%. Verification: EER 0.18%. |
| Vijay et al., 2021 [47] | Ear, iris, and finger veins. | Random transform, Daugman’s rubber sheet model and Adaptive threshold. | Multi Support Vector Neural Network (Multi-SVNN) | Deep Belief Network (DBN). | SDUMLA- HMT: 106. AMI ear database: 100. | Verification: Accuracy 95.36%. Sensitivity 95.86%. Specificity 98.79% |
| Layers | Filters/Neurons/Units | Size | Stride | Activation Function |
|---|---|---|---|---|
| Speech processing layers | ||||
| Convolution 2D | 32 | 7 × 5 | 2 × 2 | ReLU |
| Batch Normalization | - | - | - | - |
| Convolution 2D | 64 | 7 × 3 | 2 × 1 | ReLU |
| Batch Normalization | - | - | - | - |
| GRU (×3) | 512 (×3) | - | - | Tanh/Sigmoid (×3) |
| GRU (×7) | 512 (×7) | - | - | Tanh/Sigmoid (×7) |
| Face processing layers | ||||
| Convolution 2D | 32 | 3 × 3 | 1 × 1 | ReLU |
| Max Pooling 2D | - | 2 × 2 | 1 × 1 | - |
| Batch Normalization | - | - | - | - |
| Convolution 2D | 64 | 5 × 5 | 1 × 1 | ReLU |
| Max Pooling 2D | - | 2 × 2 | 1 × 1 | - |
| Batch Normalization | - | - | - | - |
| Fully connected | 512 | - | - | ReLU |
| Fusion and output layers | ||||
| Weighted Sum | - | - | - | - |
| Fully connected | 45 | - | - | Softmax |
| Fully connected | 27 | - | - | Softmax |
| Image Transformations | No Transformation | Brightness | Horizontal Flip | Rotation | Combination of Transformations |
|---|---|---|---|---|---|
| Signal to Noise Ratio (dB) | |||||
| Noiseless | 99.93 ± 0.13 | 100 | 99.66 ± 0.26 | 92.66 ± 1.98 | 88.79 ± 2.02 |
| 0 | 100 | 99.73 ± 0.32 | 99.79 ± 0.16 | 94.66 ± 1.67 | 88.59 ± 1.79 |
| 5 | 100 | 99.79 ± 0.26 | 99.86 ± 0.16 | 94.46 ± 1.96 | 87.86 ± 2.39 |
| 10 | 99.93 ± 0.13 | 100 | 99.73 ± 0.25 | 95.06 ± 0.97 | 87.53 ± 1.4 |
| 15 | 99.93 ± 0.13 | 99.86 ± 0.26 | 99.93 ± 0.13 | 93.46 ± 0.85 | 89.53 ± 1.93 |
| SNR (dB) | WER (%) |
|---|---|
| Noiseless | 0.9 ± 0.55 |
| 0 | 4.9 ± 0.63 |
| 5 | 2.75 ± 0.62 |
| 10 | 1.79 ± 0.55 |
| 15 | 1.45 ± 0.56 |
| Image Transformations | No Transformation | Brightness | Horizontal Flip | Rotation | Combination of Transformations |
|---|---|---|---|---|---|
| Signal to Noise Ratio (dB) | |||||
| Noiseless | 0.74 ± 0.65 | 0.97 ± 0.95 | 1.34 ± 1.09 | 3.44 ± 0.71 | 3.27 ± 1.46 |
| 0 | 0.93 ± 0.98 | 0.97 ± 0.57 | 1.82 ± 2.02 | 3.31 ± 0.97 | 3.06 ± 0.96 |
| 5 | 0.83 ± 0.98 | 0.97 ± 0.7 | 1.74 ± 1.43 | 2.53 ± 0.66 | 3.32 ± 1.66 |
| 10 | 1.01 ± 0.68 | 1.18 ± 0.47 | 2.06 ± 2.11 | 2.67 ± 0.44 | 3.57 ± 1.35 |
| 15 | 0.44 ± 0.55 | 0.97 ± 0.58 | 1.55 ± 1.54 | 2.87 ± 0.84 | 3.82 ± 1.44 |
| Recognition Model | Image Transformations | ||||
|---|---|---|---|---|---|
| No Transformation | Brightness | Horizontal Flip | Rotation | Combined Transformations | |
| BiMultNet (Face modality) | 100 | 100 | 99.33 ± 0.13 | 95.06 ± 0.97 | 89.53 ± 1.93 |
| Face ResNet | 98.22 ± 1.21 | 84.79 ± 2.5 | 96.06 ± 0.99 | 98.39 ± 1.25 | 98.19 ± 1.04 |
| Eigenfaces | 99.93 ± 0.13 | 96.53 ± 1.81 | 99.33 ± 0.13 | 79.53 ± 4.87 | 43.06 ± 3.86 |
| Fisherfaces | 97.12 ± 4.26 | 94.93 ± 8.96 | 94.59 ± 7.15 | 50.26 ± 20.03 | 44.79 ± 18.9 |
| Signal to noise ratio (dB) | |||||
| Noiseless | 0 | 5 | 10 | 15 | |
| BiMultNet (Speech modality) | 100 | 100 | 100 | 100 | 99.93 ± 0.13 |
| SincNet | 98.22 ± 1.21 | 84.79 ± 2.5 | 96.06 ± 0.99 | 98.39 ± 1.25 | 98.19 ± 1.04 |
| X-vectors | 94.04 ± 1 | 82.24 ± 0.64 | 91.15 ± 1.06 | 92.95 ± 0.71 | 93.68 ± 0.89 |
| Recognition Model | Image Transformations | ||||
|---|---|---|---|---|---|
| No Transformation | Brightness | Horizontal Flip | Rotation | Combined Transformations | |
| BiMultNet (Face modality) | 0.44 ± 0.55 | 0.97 ± 0.57 | 1.34 ± 1.09 | 2.53 ± 0.66 | 3.06 ± 0.96 |
| Face ResNet | 1.02 ± 0.27 | 2.19 ± 0.89 | 1.4 ± 0.32 | 4.46 ± 0.66 | 6.08 ± 1.38 |
| Eigenfaces | 4.44 ± 0.96 | 18.61 ± 4.45 | 4.82 ± 2.07 | 32.41 ± 2.88 | 46.56 ± 1.84 |
| Fisherfaces | 8.67 ± 6.1 | 11.05 ± 11.21 | 13.06 ± 7.84 | 36.54 ± 5.41 | 39.58 ± 7.25 |
| Signal to noise ratio (dB) | |||||
| Noiseless | 0 | 5 | 10 | 15 | |
| BiMultNet (Speech modality) | 0.74 ± 0.65 | 0.93 ± 0.98 | 0.83 ± 0.98 | 1.01 ± 0.68 | 0.44 ± 0.55 |
| SincNet | 3 ± 0.62 | 14.97 ± 1.18 | 7.15 ± 1.36 | 4.27 ± 0.88 | 3.28 ± 0.7 |
| X-vectors | 2.22 ± 0.39 | 5.8 ± 0.75 | 3.16 ± 0.55 | 2.5 ± 0.37 | 2.27 ± 0.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atenco, J.C.; Moreno, J.C.; Ramirez, J.M. Audiovisual Biometric Network with Deep Feature Fusion for Identification and Text Prompted Verification. Algorithms 2023, 16, 66. https://doi.org/10.3390/a16020066
Atenco JC, Moreno JC, Ramirez JM. Audiovisual Biometric Network with Deep Feature Fusion for Identification and Text Prompted Verification. Algorithms. 2023; 16(2):66. https://doi.org/10.3390/a16020066
Chicago/Turabian StyleAtenco, Juan Carlos, Juan Carlos Moreno, and Juan Manuel Ramirez. 2023. "Audiovisual Biometric Network with Deep Feature Fusion for Identification and Text Prompted Verification" Algorithms 16, no. 2: 66. https://doi.org/10.3390/a16020066
APA StyleAtenco, J. C., Moreno, J. C., & Ramirez, J. M. (2023). Audiovisual Biometric Network with Deep Feature Fusion for Identification and Text Prompted Verification. Algorithms, 16(2), 66. https://doi.org/10.3390/a16020066