3.1. Model Development
Let there be firms and technological topics (henceforth called topics). At each given point in time t, we map firm i’s location in the topic space. The resulting map forms an n-dimensional hypercube image of the topics, with each axis of the hypercube representing each jth topic. Comparing the firm’s location across time (e.g., t to t + 1) allows us to represent its migration within the topic space.
In this version of the model, we bounded each axis as continuous variable between 0 and 1 (other lengths could be chosen without loss of generality). Therefore, the firm’s location on that axis can be thought of as the propensity for the firms’ innovations at time
t to relate to topic
j. If a firm has more than one innovation at time
t, where the firm lies in [0,1] on axis
j will depend on the average across the innovations. For instance, if five innovations focus on topic
j (=1) and five do not (=0), then the value for
j = 0.5. We discuss how we handle real world patent data in
Section 3.2.
We defined firm i’s position at time t using the vector of topics, where is the jth element. For the sake of completeness, we defined as the set of firms whose positions at time we defined by the matrix .
We defined the velocity of a firm as follows:
where the weights (
) sum to 1.
A,
C, and
S stand for alignment, cohesion, and separation, respectively, which we derived from Reynolds’ (1987) swarm program.
L and
P stand for leader following and performance feedback, which we describe below. We defined these three velocity vectors as follows:
Alignment determines the firm’s propensity to move (or in our case, search) in the direction of a competitive reference group. When the weight on alignment is high, firms will shift the direction of their search as the firms within the reference group change their search direction. A set of firms with high alignment will appear to ‘flock’ together, or in our applied case, searching the same technologies. When the weight is low, shifts in the reference group’s behavior have little influence on the focal firm.
Cohesion determines the firm’s propensity to move towards the average position or center of mass of its competitors. When modeling animal behavior, such as a flock of birds, cohesion controls how tightly they stay together. In firm search, when a firm has high cohesion, it searches closer to the search positions of its reference group.
For both alignment and cohesion, the reference groups (
F) can be defined flexibly so as to encompass the competing firms that most likely influence the focal firm’s search. Therefore, Equations (
2) and (
3) can be used to model a wide range of competitive imitation strategies.
Separation determines whether firms can take the same position as other firms within the hypercube. The ε parameter in (
4) can be thought of as the minimum separation threshold between firms on the search space. Setting ε = 0 allows for collocation, while setting ε to a very small number insures some minimal “separation”.
In addition to the three classic parameters—alignment, cohesion, and separation—we added two additional ones that capture theoretically interesting firm search behavior. Evolutionary economic models suggest that firms will be influenced by their past performance and may exhibit path-dependent behavior. To incorporate this element into our model, we defined the following equation:
where, for the
th firm,
is a uniform random number in [0,1],
is the historical personal best (measured by the fitness function), and
is a weight allowing the firm to choose between full exploration
(which is a totally random move) and full exploitation
(only follow its own personal best).
Organizational theory suggests that a firm may follow specific competitors, such as the leader in the market [
64]. We modeled this possibility as follows:
where
is the leader’s position which is chosen from all the personal bests and
is a scaler to gauge how a firm decides to follow the industry leader, e.g., a negative
indicates that the firm chooses to move away from the leader. In our demonstration, we defined the leader based on who has the highest performance at time
t − 1. The ability to define
in a variety of ways allows for a simple yet flexible way of modeling a variety of variations of imitative behavior.
To update a firm’s position, we used the following formula:
In
Section 4, we describe how to fit this model to data and provide some example results on a test sample of patent data.
In a simulation of firms’ behaviors, one starts with a randomly chosen landscape (
-dimensional
) with a set of chosen parameter values
, and
. These allow one to first calculate Equation (
2) through (
6) and then Equation (
1). Once the velocity (Equation (
1)) is calculated, the next landscape
can be calculated by Equation (7). The process repeats as many times as one desires. In a long simulation, the parameters that describe the initial landscape are ultimately irrelevant. For example, if
,
,
and
are high, then the swarm will converge to a single point ultimately. Or alternatively, if
and
are high, then firms move in a group (much like a school of fish).
Note that while the parameter values could change over time, they are not made to do so. This is because we want to observe the search behavior over time (e.g., so that we can examine if firms converge or diverge from each other). Most likely, in real situations such as ours they will be time-varying. However, an empirical concern is whether there is enough data to solve for time-varying parameters. This issue is discussed in the next section.
In our empirical work here, we used data to solve for the parameter values in order to examine and explain how firms interact with one another. Using data, we first obtained all the positions of all the firms, i.e.,
for all
. This allowed us to calculate all the (empirical) velocities by taking the difference of two consecutive landscapes using Equation (7). In the broadest sense, all the parameters can be solved at once. However, this might result in a situation in which parameters become uninterpretable. We hence chose to study the two most relevant velocities (behaviors) in our data—leader following (Equation (
6)) and firm exploration (Equation (
5)). Then we combined these partial results into a grand optimization. Details are explained in the next section.
In solving the parameters, we discovered that in some cases, closed form solutions (of the parameters) can be derived. This can be easily done via taking derivatives of the fitness function with respect to the parameters. Details are given in the next section.
A pseudo code is provided for a more clear description of the algorithm in the
Appendix A,
swarm(w_a, w_c, w_l, w_p, ntim). In a simulation, the values of these swarm parameters are pre-determined. The swarm algorithm computes the fitness value, personal best, and the global best in each iteration. Then the entire history of movements of the particles (firms) are recorded and studied. In this paper, fitness value, personal best, and global best (along with firm positions in topic space) are input from data. We then set
ntim=1 and solve for the four parameters in each iteration.
3.2. Data
To examine a firm’s innovative search direction, we need information on its R&D projects. While this information is not typically publicly available, we can assess the outcomes of their successful searches by using patent data. Patent data has been a key source of information on innovation in the strategy and economics literature [
65].
Data on U.S. patents and patent citations come from the U.S. Patent and Trademark Office (USPTO) and the Patent Network Dataverse [
66], for which firm-level identifiers have been mapped in prior research [
67,
68]. For each patent, we used the abstract, assigned technology class, patent assignee, and the patent’s application date. To tie a patent to a year (our unit of time in our study), we used application dates rather than grant dates because the application date better approximates the time in which the firm searched the topic.
In our demonstration, we used patent data on the 11 3-digit USPTO patent classes most closely associated with communications technologies (see
Table 1) during the period 1985–2007. The sample timeframe and patent classes have been used extensively in the prior technology strategy and innovation economics literature, e.g., [
69,
70]. We selected communication technologies for several other reasons. First, firms in this industry tend to patent most innovations. Therefore, patent data likely reflect the search behavior of these firms. Second, the time between the initial outlays for R&D and patenting is short compared to other areas like drug discovery, thus using the firm’s patent application dates is a good proxy for its current search focus. Third, prior work on this industry suggests that firms might exhibit a variety of search behaviors.
Much of the prior innovation literature in strategy and economics uses the 3-digit technology class or the lower level, subclass, to categorize patents [
71]. However, using such levels of classification schemes, while useful in many research settings, may not be sufficiently nuanced for our purposes. For instance, firms searching for innovations within multiplex communications (technology class 370) may focus on a variety of topics (space division multiplexing, code division multiplexing, time division multiplexing, etc.). To best perform the analysis, a more nuanced measure of “topics” is needed.
We used latent Dirichlet allocation (LDA) to create topics from patent abstracts. LDA is a commonly used, unsupervised machine learning technique to create topics from text [
72]. Most work on LDA uses the researchers’ own inputs to define the number of topics, however, that can be problematic in this setting for two reasons. One, researchers may not have the expertise to suggest the appropriate number of topics within a technology class. Two, creating an algorithm to select topic size may allow for more consistency across researchers and remove the potential of user-induced measurement bias. Therefore, we chose the number of topics by maximizing the coherence score, a commonly used construct in LDA that measures how similar the words on a topic are to each other. In this sample, we used the CV coherence score [
73] to choose topics. Several other commonly used alternatives—UMass coherence Score, UCI coherence Score, and Word2vec coherence score—produce similar results.
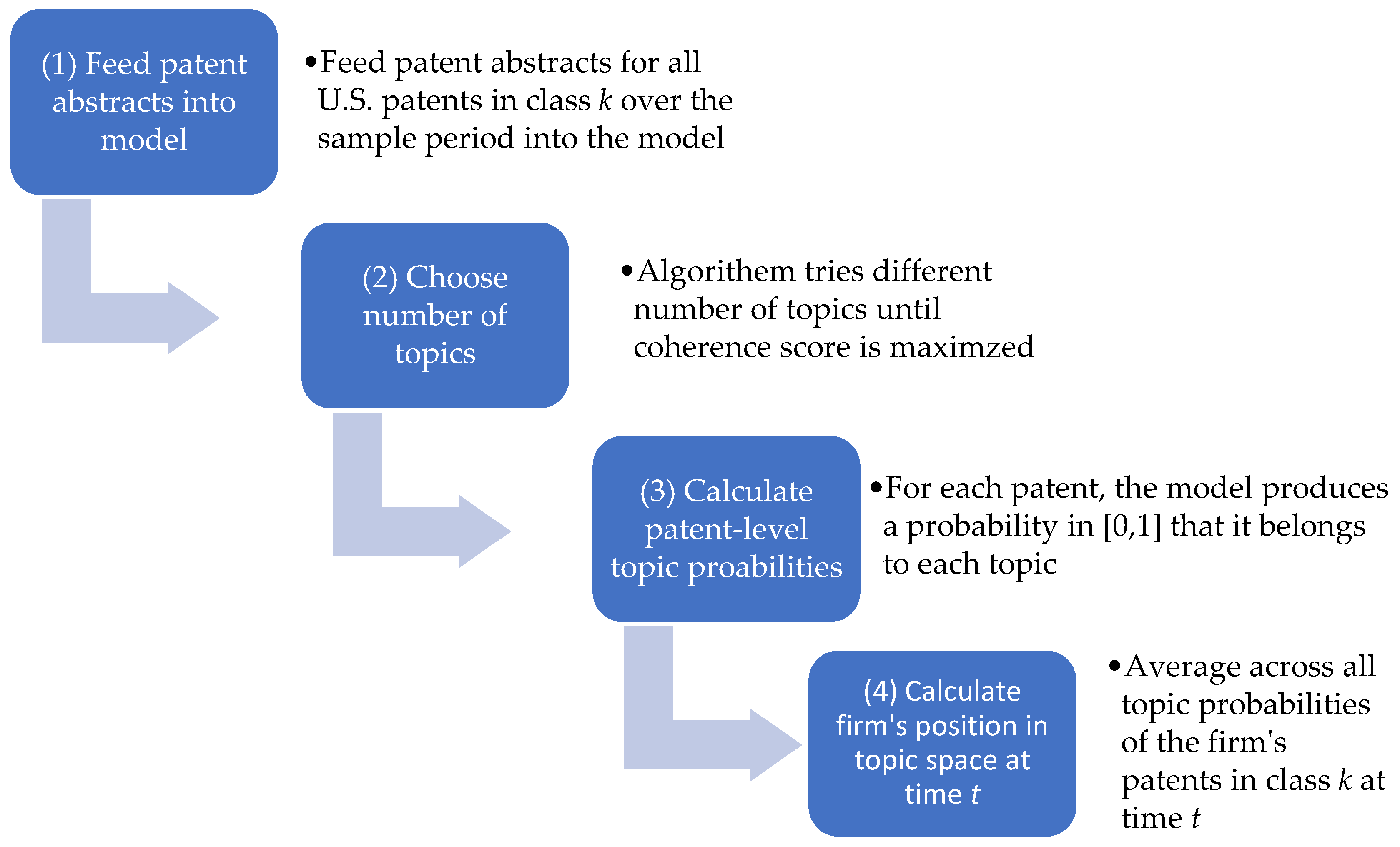
To create the topic space, for each patent class, we fed all patent abstracts for the entire sample period in to the LDA model using the LDA program from the Natural Language Toolkit in Python. Note that all U.S. patents during the entire sample period were used, not just patents from the firms that we studied. The number of topics that maximizes the coherence score was chosen, which determines the
n-dimensional hypercube. LDA provides a probability that each patent is associated with a particular topic. For each firm in each year
t, the coordinate in the cube (e.g., position on each axis
j) is calculated by averaging the probabilities across all the firm’s patents. We summarize the process for obtaining a firm’s position in topic space from patent data in
Figure 1.
To create a tractable sample of firms for demonstration purposes, we included only public firms that were in the top 20 in terms of patenting in each of the 11 technology classes. This yielded a total of 32 large firms that are extremely active in the communication technologies space. Note that such a sample should bias our model findings away from follow-the-leader and imitative strategies, as these firms are the leaders who will most likely follow their own feedback.
The resulting sample has 11 separate topic landscapes (one for each technology class). The number of topics varies from 10 to 47 depending on the technology class. The time dimension (t) was set to a year, and we calibrated the parameters using the 1991–2007 period. Note that we started our analysis in 1991 when communication technology patenting had more density.








{kind=link}
{kind=link}
{kind=link}