
Acoustic Echo Cancellation with the Normalized Sign-Error Least Mean Squares Algorithm and Deep Residual Echo Suppression


Abstract
:1. Introduction
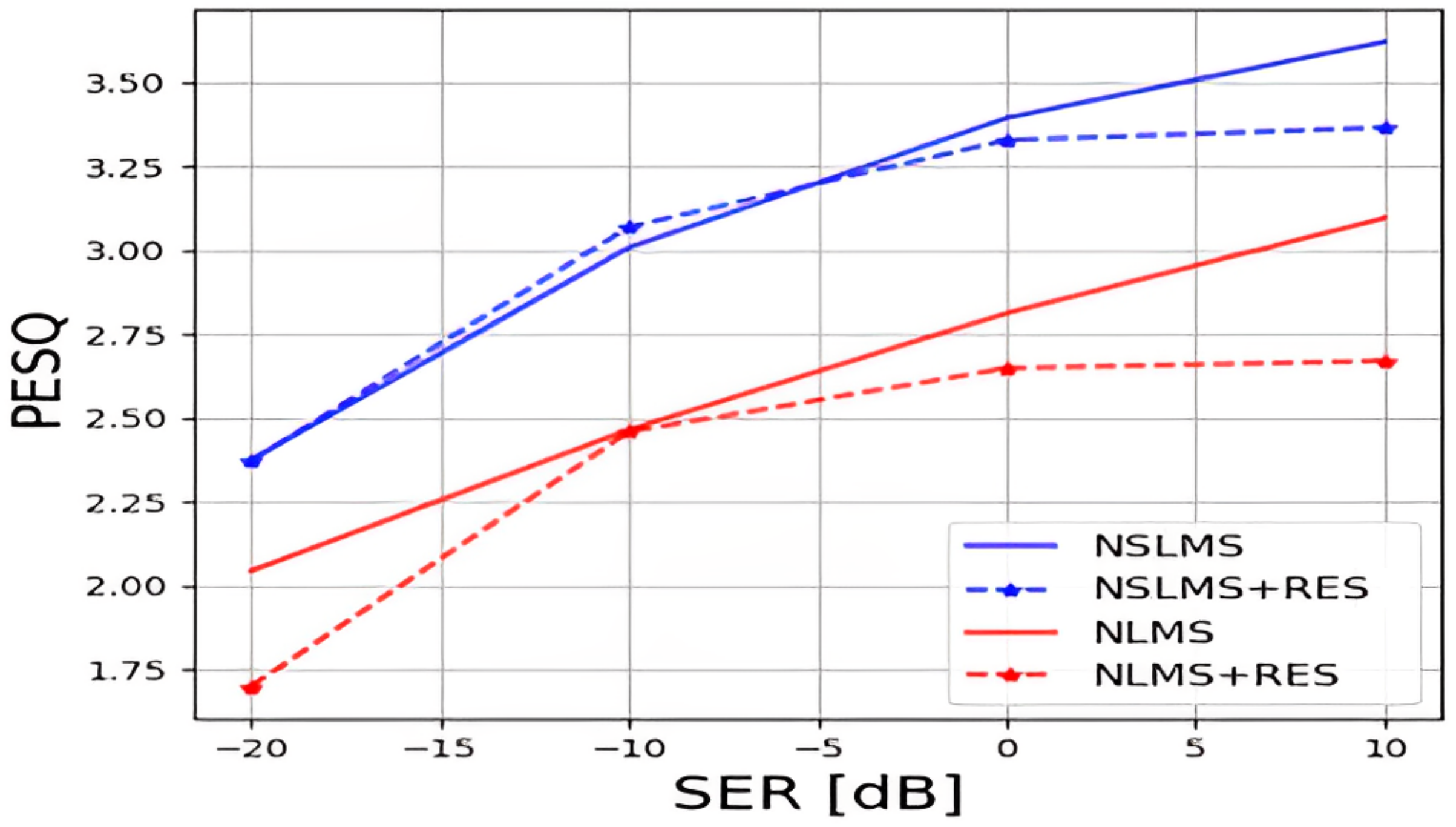
- The performance of the NSLMS is superior to that of the common NLMS, both as a standalone linear AEC and combined with a deep-learning residual echo suppressor. More generally, the reported findings indicated that the linear AEC significantly impacted the performance of the following residual echo suppressor and should be carefully chosen.
- When combined with a pre-trained speech denoiser, the NSLMS brings a more significant performance improvement than when combined with a residual echo suppressor. This indicated that the outputs of the NSLMS were less structured and more akin to noise than the NLMS outputs. Therefore, with the NSLMS, employing a pre-trained speech denoiser might be a viable alternative to training a residual echo suppressor.
- The DCCRN architecture, initially proposed for speech enhancement, is offered to perform residual echo suppression. While requiring only a minor modification to adapt to the residual echo suppression task, the proposed residual echo suppressor outperformed the larger, pre-trained speech denoiser.
2. Materials and Methods
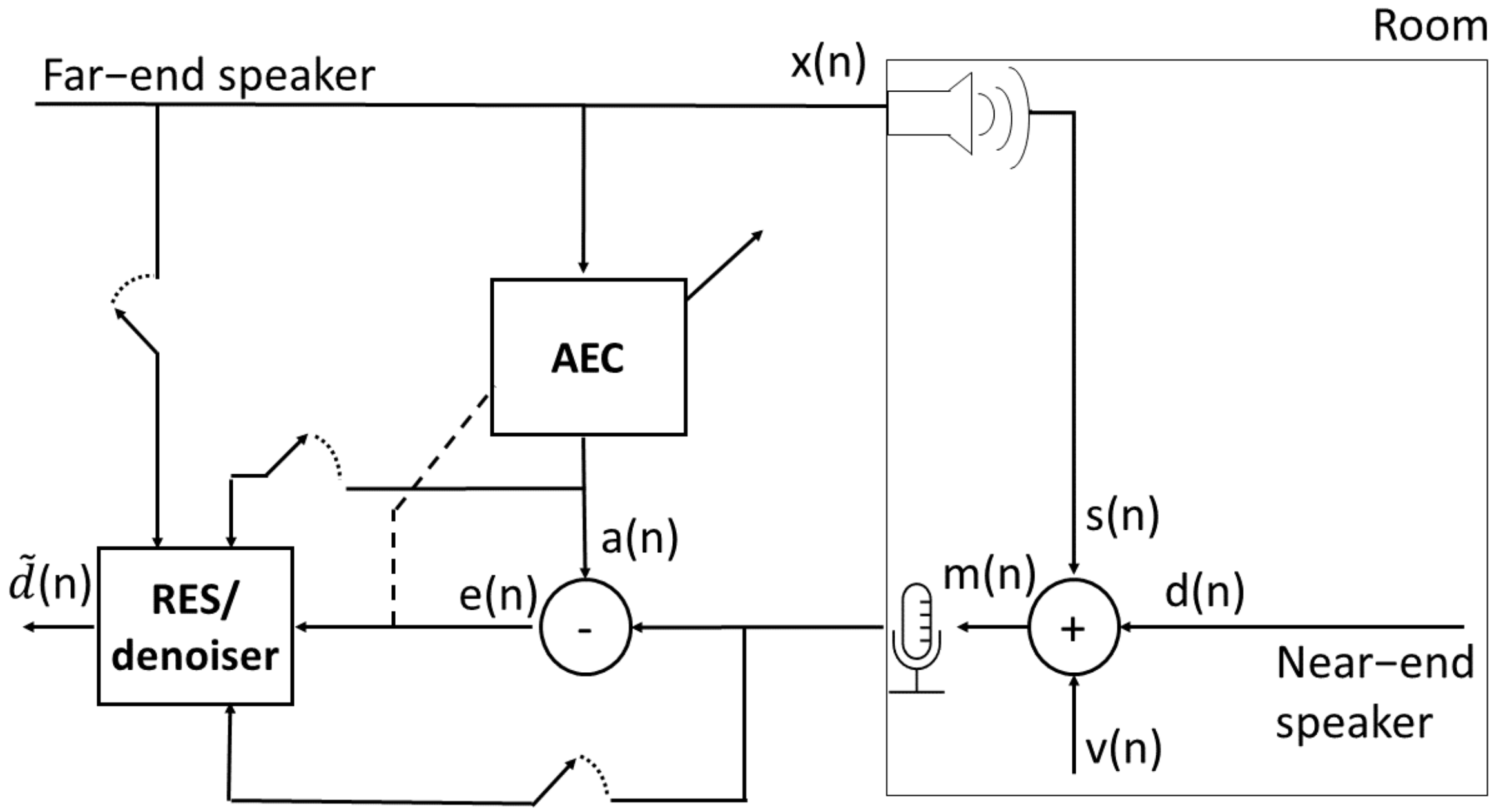
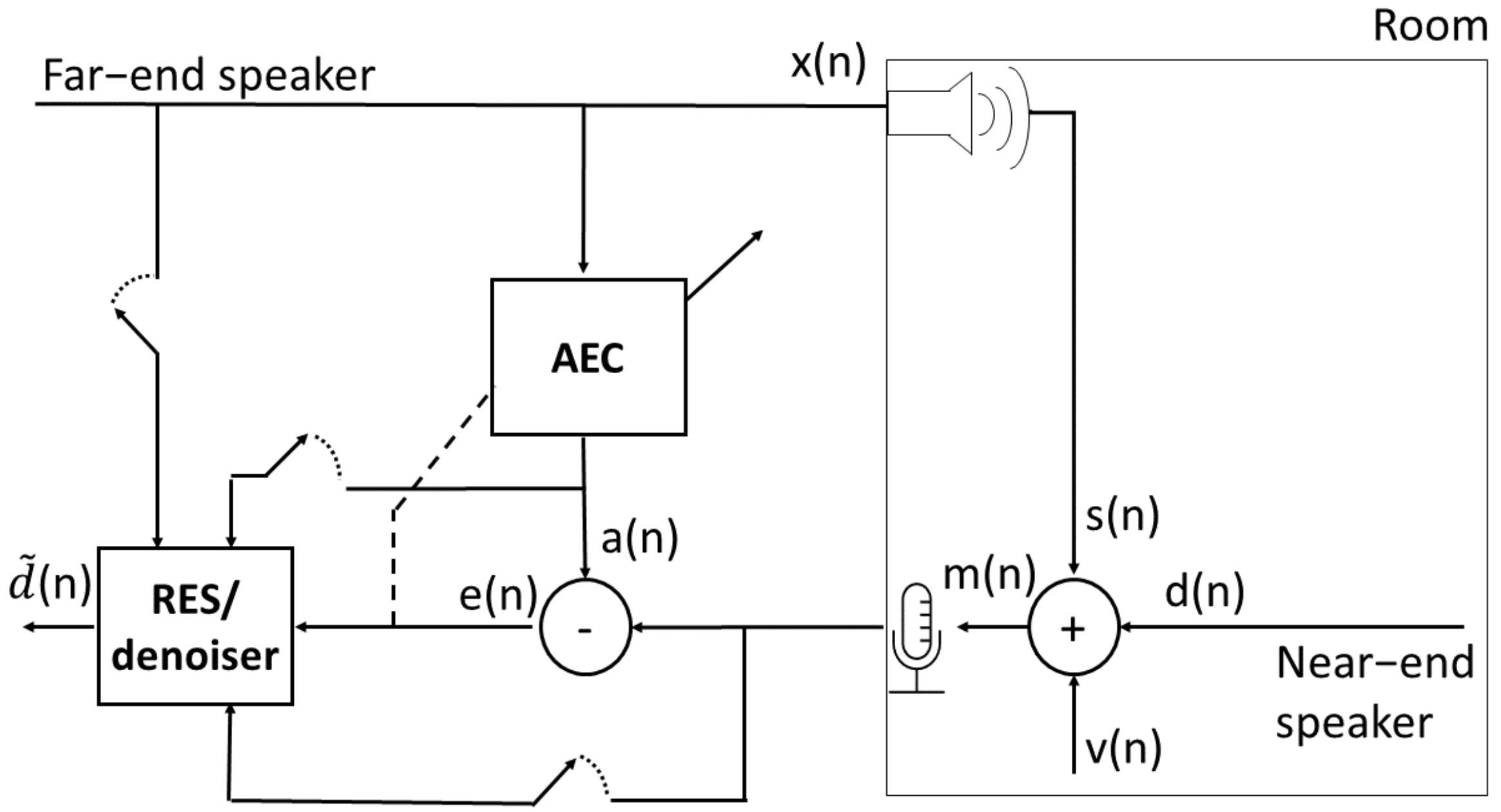
2.1. Problem Formulation
2.2. System Components
2.2.1. Linear Acoustic Echo Cancellers
2.2.2. Residual Echo Suppression Model
2.2.3. Speech Denoising Model
2.3. Datasets
2.4. Implementation Details
3. Results
3.1. Performance Measures
3.2. Experimental Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AEC | Acoustic echo canceller |
| CRM | Complex ratio mask |
| DCCRN | Deep complex convolution network |
| DNS | Deep noise suppression |
| DNSMOS | Deep noise suppression mean opinion score |
| ENR | Echo-to-noise ratio |
| GLU | Gated linear unit |
| LSTM | Long short-term memory |
| MRI | Magnetic resonance imaging |
| NLMS | Normalized least mean squares |
| NSLMS | Normalized sign-error least mean squares |
| PESQ | Perceptual evaluation of speech quality |
| PReLU | Parametric rectified linear unit |
| ReLU | Rectified linear unit |
| RES | Residual echo suppressor |
| SER | Signal-to-echo ratio |
| SLMS | Sign-error least mean squares |
| STFT | Short-time Fourier transform |
| T-F | Time-frequency |
References
- Sondhi, M.; Morgan, D.; Hall, J. Stereophonic Acoustic Echo Cancellation-an Overview of the Fundamental Problem. IEEE Signal Process. Lett. 1995, 2, 148–151. [Google Scholar] [CrossRef] [PubMed]
- Benesty, J.; Gänsler, T.; Morgan, D.R.; Sondhi, M.M.; Gay, S.L. Advances in Network and Acoustic Echo Cancellation; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Macchi, O. Adaptive Processing: The Least Mean Squares Approach; John Wiley and Sons Inc.: Hoboken, NJ, USA, 1995. [Google Scholar]
- Rusu, A.G.; Ciochină, S.; Paleologu, C.; Benesty, J. An Optimized Differential Step-Size LMS Algorithm. Algorithms 2019, 12, 147. [Google Scholar] [CrossRef] [Green Version]
- Bershad, N. Analysis of the Normalized LMS Algorithm with Gaussian Inputs. IEEE Trans. Acoust. Speech Signal Process. 1986, 34, 793–806. [Google Scholar] [CrossRef]
- Rusu, A.G.; Paleologu, C.; Benesty, J.; Ciochină, S. A Variable Step Size Normalized Least-Mean-Square Algorithm Based on Data Reuse. Algorithms 2022, 15, 111. [Google Scholar] [CrossRef]
- Koike, S. Analysis of Adaptive Filters Using Normalized Signed Regressor LMS Algorithm. IEEE Trans. Signal Process. 1999, 47, 2710–2723. [Google Scholar] [CrossRef]
- Farhang-Boroujeny, B. Adaptive Filters: Theory and Applications; John Wiley and Sons Inc.: Hoboken, NJ, USA, 1998. [Google Scholar]
- Freire, N.; Douglas, S. Adaptive Cancellation of Geomagnetic Background Noise Using a Sign-Error Normalized LMS algorithm. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Minneapolis, MN, USA, 27–30 April 1993; Volume 3, pp. 523–526. [Google Scholar]
- Pathak, N.; Panahi, I.; Devineni, P.; Briggs, R. Real Time Speech Enhancement for the Noisy MRI Environment. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; pp. 6950–6953. [Google Scholar]
- Guerin, A.; Faucon, G.; Le Bouquin-Jeannes, R. Nonlinear Acoustic Echo Cancellation Based on Volterra Filters. IEEE Trans. Speech Audio Process. 2003, 11, 672–683. [Google Scholar] [CrossRef]
- Malik, S.; Enzner, G. State-Space Frequency-Domain Adaptive Filtering for Nonlinear Acoustic Echo Cancellation. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 2065–2079. [Google Scholar] [CrossRef]
- Wang, Z.; Na, Y.; Liu, Z.; Tian, B.; Fu, Q. Weighted Recursive Least Square Filter and Neural Network Based Residual Echo Suppression for the AEC-Challenge. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Virtual, 6–11 June 2021; pp. 141–145. [Google Scholar]
- Ivry, A.; Cohen, I.; Berdugo, B. Deep Residual Echo Suppression with A Tunable Tradeoff Between Signal Distortion and Echo Suppression. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Virtual, 6–11 June 2021; pp. 126–130. [Google Scholar]
- Franzen, J.; Fingscheidt, T. Deep Residual Echo Suppression and Noise Reduction: A Multi-Input FCRN Approach in a Hybrid Speech Enhancement System. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 666–670. [Google Scholar]
- Ma, L.; Huang, H.; Zhao, P.; Su, T. Acoustic Echo Cancellation by Combining Adaptive Digital Filter and Recurrent Neural Network. arXiv 2020, arXiv:2005.09237. [Google Scholar]
- Defossez, A.; Synnaeve, G.; Adi, Y. Real Time Speech Enhancement in the Waveform Domain. arXiv 2020, arXiv:2006.12847. [Google Scholar]
- Hu, Y.; Liu, Y.; Lv, S.; Xing, M.; Zhang, S.; Fu, Y.; Wu, J.; Zhang, B.; Xie, L. DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement. arXiv 2020, arXiv:2008.00264. [Google Scholar]
- Koizumi, Y.; Yatabe, K.; Delcroix, M.; Masuyama, Y.; Takeuchi, D. Speech Enhancement Using Self-Adaptation and Multi-Head Self-Attention. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 181–185. [Google Scholar]
- Ortiz-Echeverri, C.J.; Rodríguez-Reséndiz, J.; Garduño-Aparicio, M. An approach to STFT and CWT learning through music hands-on labs. Comput. Appl. Eng. Educ. 2018, 26, 2026–2035. [Google Scholar] [CrossRef]
- Crochiere, R.E.; Rabiner, L.R. Section 7.6. In Multirate Digital Signal Processing; Prentice Hall PTR: Hoboken, NJ, USA, 1983. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar]
- Défossez, A.; Usunier, N.; Bottou, L.; Bach, F. Music Source Separation in the Waveform Domain. arXiv 2019, arXiv:1911.13254. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. arXiv 2016, arXiv:1612.08083. [Google Scholar]
- Valentini-Botinhao, C. Noisy Speech Database for Training Speech Enhancement Algorithms and TTS Models; Centre for Speech Technology Research (CSTR), School of Informatics, University of Edinburgh: Edinburgh, UK, 2017. [Google Scholar]
- Reddy, C.K.A.; Beyrami, E.; Dube, H.; Gopal, V.; Cheng, R.; Cutler, R.; Matusevych, S.; Aichner, R.; Aazami, A.; Braun, S.; et al. The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Speech Quality and Testing Framework. arXiv 2020, arXiv:2001.08662. [Google Scholar]
- Sridhar, K.; Cutler, R.; Saabas, A.; Parnamaa, T.; Loide, M.; Gamper, H.; Braun, S.; Aichner, R.; Srinivasan, S. ICASSP 2021 Acoustic Echo Cancellation Challenge: Datasets, Testing Framework, and Results. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Virtual, 6–11 June 2021; pp. 151–155. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR Corpus Based on Public Domain Audio Books. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2015; pp. 5206–5210. [Google Scholar]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S.; Dahlgren, N.L. DARPA TIMIT Acoustic Phonetic Continuous Speech Corpus CDROM. NIST Speech Disc 1-1.1.; Technical Report LDC93S1; National Institute of Standards Technolology: Gaithersburg, MD, USA, 1993. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Rix, A.; Beerends, J.; Hollier, M.; Hekstra, A. Perceptual Evaluation of Speech Quality (PESQ)-A New Method for Speech Quality Assessment of Telephone Networks and Codecs. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar]
- Reddy, C.K.A.; Gopal, V.; Cutler, R. DNSMOS: A Non-Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Virtual, 6–11 June 2021; pp. 6493–6497. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FE | DT | DT + NE | |||
|---|---|---|---|---|---|
| ERLE | DNSMOS | PESQ | DNSMOS | PESQ | |
| NLMS | |||||
| NSLMS | |||||
| NLMS + Denoiser | |||||
| NSLMS + Denoiser | |||||
| NLMS + RES | |||||
| NSLMS + RES | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shachar, E.; Cohen, I.; Berdugo, B. Acoustic Echo Cancellation with the Normalized Sign-Error Least Mean Squares Algorithm and Deep Residual Echo Suppression. Algorithms 2023, 16, 137. https://doi.org/10.3390/a16030137
Shachar E, Cohen I, Berdugo B. Acoustic Echo Cancellation with the Normalized Sign-Error Least Mean Squares Algorithm and Deep Residual Echo Suppression. Algorithms. 2023; 16(3):137. https://doi.org/10.3390/a16030137
Chicago/Turabian StyleShachar, Eran, Israel Cohen, and Baruch Berdugo. 2023. "Acoustic Echo Cancellation with the Normalized Sign-Error Least Mean Squares Algorithm and Deep Residual Echo Suppression" Algorithms 16, no. 3: 137. https://doi.org/10.3390/a16030137
APA StyleShachar, E., Cohen, I., & Berdugo, B. (2023). Acoustic Echo Cancellation with the Normalized Sign-Error Least Mean Squares Algorithm and Deep Residual Echo Suppression. Algorithms, 16(3), 137. https://doi.org/10.3390/a16030137