
Transfer Learning and Analogical Inference: A Critical Comparison of Algorithms, Methods, and Applications

Abstract
:1. An Introduction to Human and Artificial Intelligence Learning
- Identify critical differences and similarities between transfer learning and analogical inference;
- Review relevant evidence from the fields of computer vision and natural language processing;
- Make recommendations for future research integrating transfer learning and analogical inference.
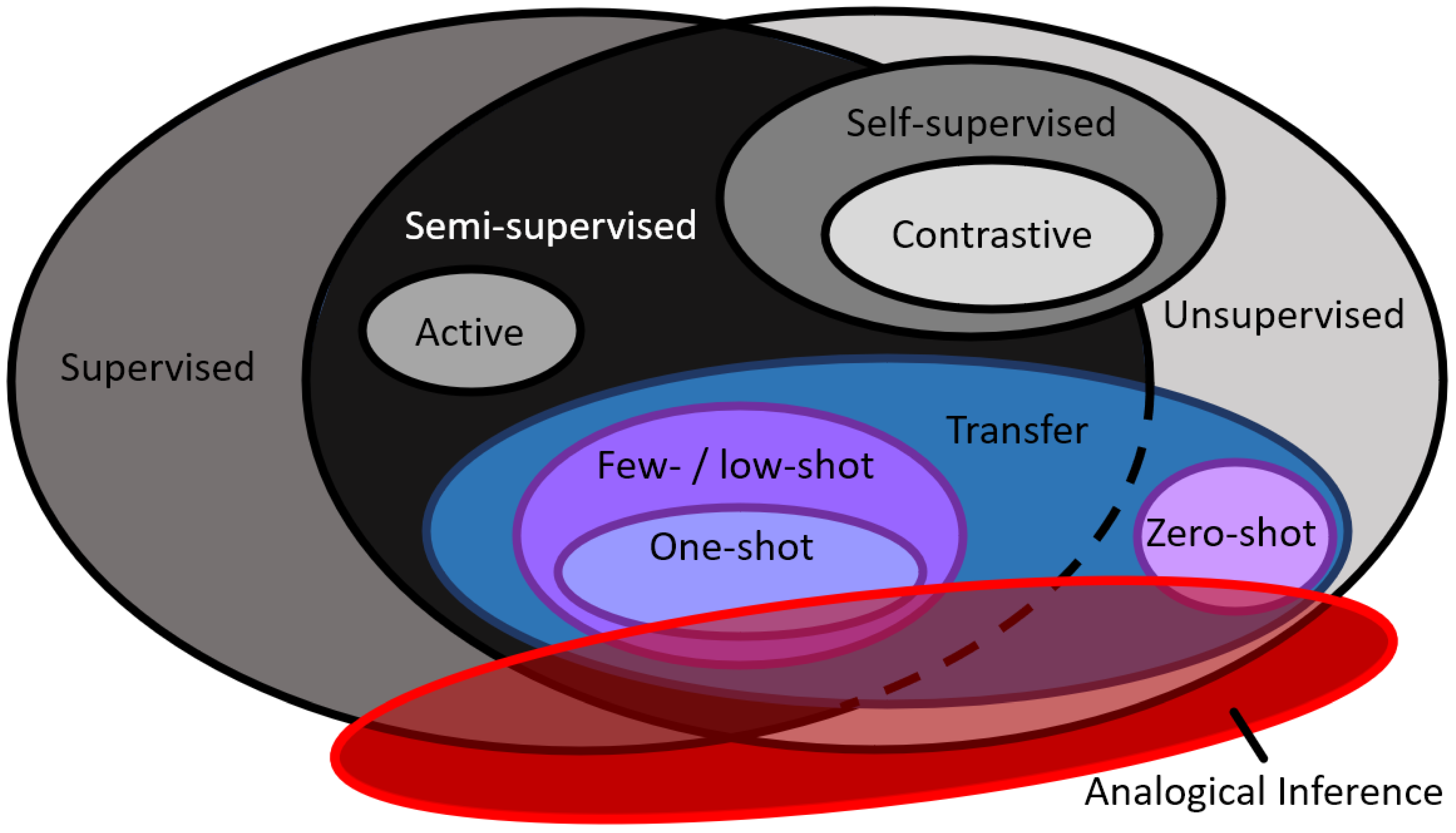
2. Brief Overview of Machine Learning
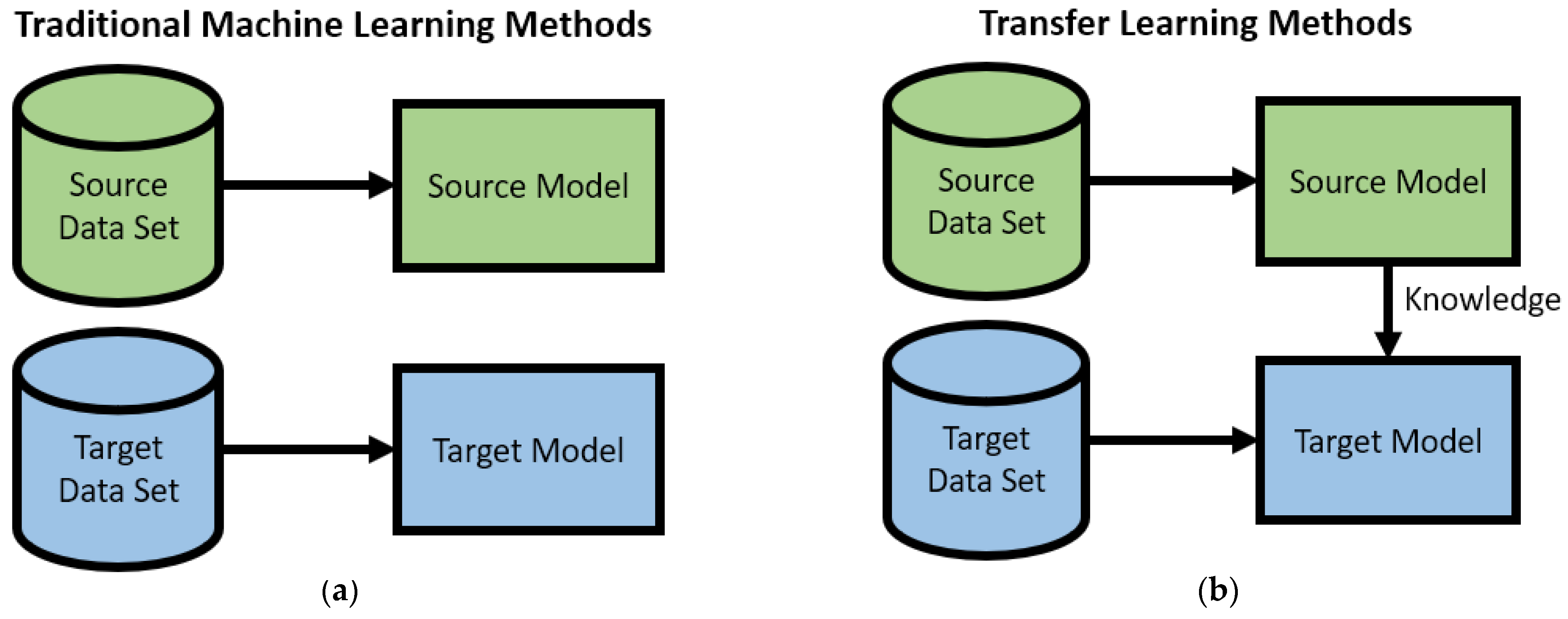
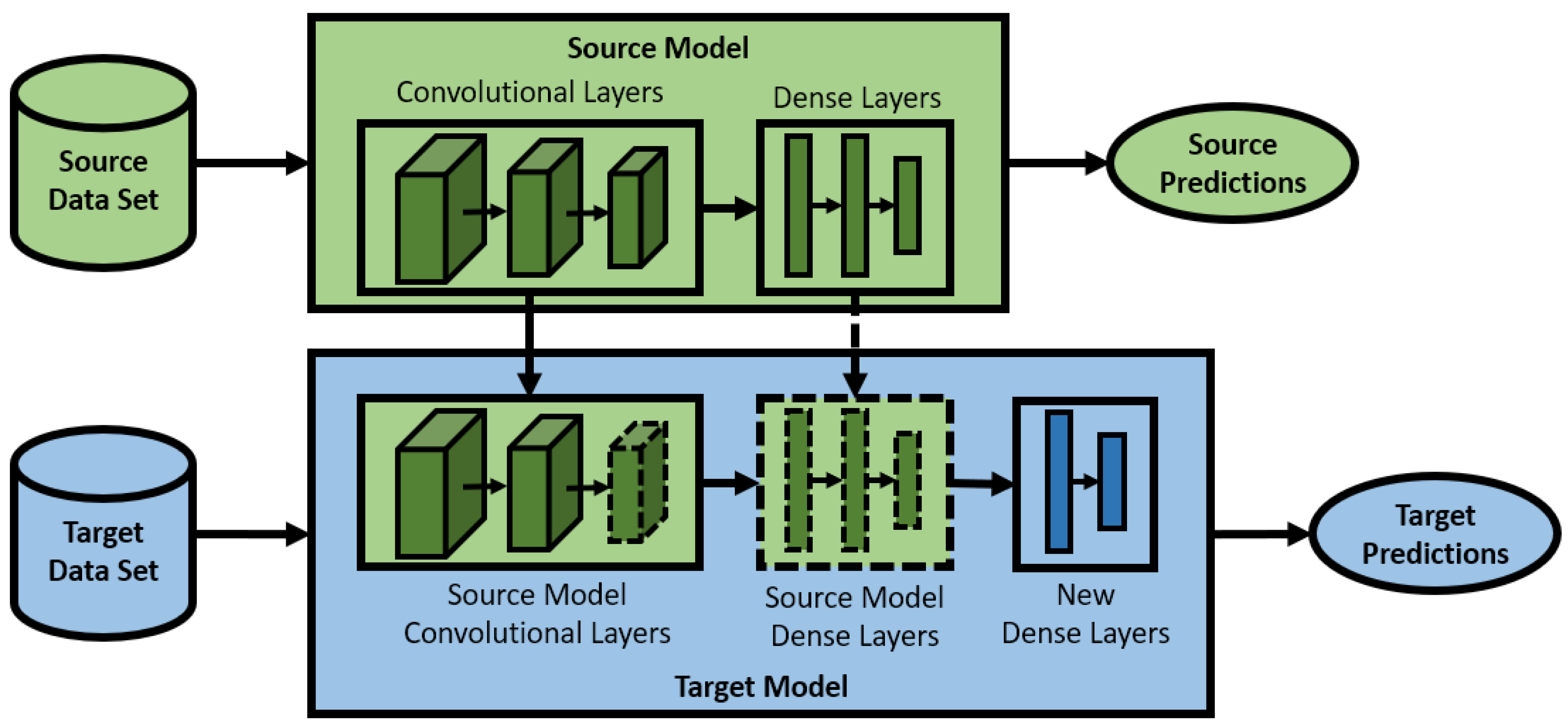
3. What Is Transfer Learning?
4. What Is Analogical Inference?
- Retrieval—accessing a similar scenario from long-term memory;
- Mapping—the aligning of elements, structures, and concepts between the source and target;
- Evaluation—judgment of the quality of specific aspects, such as the inferences made, mapping created, and/or the analogy in general.

5. Comparisons of Transfer Learning and Analogical Inference in Two Application Domains
5.1. Computer Vision
5.2. Natural Language Processing

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Cognitive-Science-Inspired Architectures | Vector Space Models (VSMs) | Transformer Language Models |
|---|---|---|---|
| Primary task(s) | Map elements between a base domain to a target domain and/or infer new elements within the target domain | Derive quantitative relationships (typically similarity via the cosine distance) between two bodies of text via static word embeddings | Derive contextual meaning for completing general verbal tasks such as text generation, translation, etc. |
| Solvable Types of Analogy | |||
| Word-based | Yes | Yes | Yes |
| Sentence-based | Yes * | No | Maybe |
| Story-based | Yes * | No | Maybe |
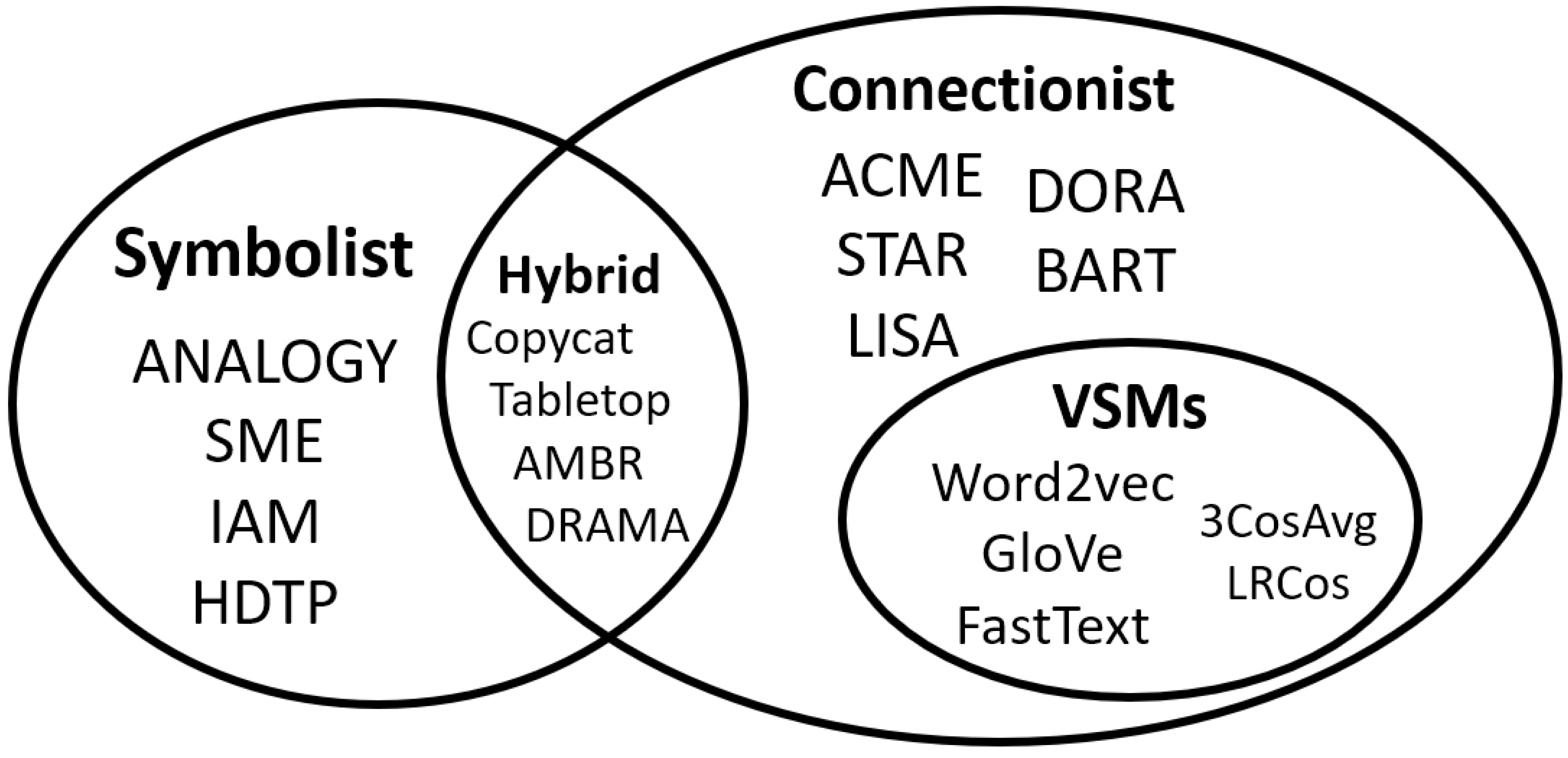
| Example algorithms/ models |
| ||
5.3. Summary
6. Future Directions
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kemp, C.; Goodman, N.D.; Tenenbaum, J.B. Learning to learn causal models. Cog. Sci. 2010, 34, 1185–1243. [Google Scholar] [CrossRef] [PubMed]
- Illeris, K. A Comprehensive Understanding of Human Learning. In Contemporary Theories of Learning, 2nd ed.; Illeris, K., Ed.; Routledge: New York, NY, USA, 2018; pp. 1–14. [Google Scholar]
- Meltzoff, A.N.; Kuhl, P.K.; Movellan, J.; Sejnowski, T.J. Foundations for a new science of learning. Science 2009, 325, 284–288. [Google Scholar] [CrossRef] [PubMed]
- Lansdell, B.J.; Kording, K.P. Towards learning-to-learn. Curr. Opin. Behav. Sci. 2019, 29, 45–50. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Tenenbaum, J.B. Theory-based causal induction. Psy. Rev. 2009, 116, 661–716. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mitchell, M. Abstraction and analogy-making in artificial intelligence. Ann. N. Y. Acad. Sci. 2021, 1505, 79–101. [Google Scholar] [CrossRef] [PubMed]
- Gobet, F.; Lane, P.C.R.; Croker, S.; Cheng, P.C.H.; Jones, G.; Oliver, I.; Pine, J.M. Chunking mechanisms in human learning. Trends Cogn. Sci. 2001, 5, 236–243. [Google Scholar] [CrossRef]
- Barnett, S.M.; Ceci, S.J. When and where do we apply what we learn?: A taxonomy for far transfer. Psychol. Bull. 2002, 128, 612–637. [Google Scholar] [CrossRef]
- Billard, A.G.; Calinon, S.; Dillmann, R. Learning from humans. In Springer Handbook of Robotics; Siciliano, B., Khatib, O., Eds.; Springer: Secaucus, NJ, USA, 2016; pp. 1995–2014. [Google Scholar] [CrossRef]
- Lake, B.M.; Ullman, T.D.; Tenenbaum, J.B.; Gershman, S.J. Building machines that learn and think like people. Behav. Brain Sci. 2017, 40, e253. [Google Scholar] [CrossRef] [Green Version]
- Domingos, P. The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World; Basic Books: New York, NY, USA, 2015. [Google Scholar]
- Reed, S. Building bridges between AI and cognitive psychology. AI Mag. 2019, 40, 17–28. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comp. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. An overview of multi-task learning. Natl. Sci. Rev. 2018, 5, 30–43. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, F.; Qi, Z.; Duan, K.; Dongbo, X.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Ouali, Y.; Hudelot, C.; Tami, M. An overview of deep semi-supervised learning. arXiv 2020, arXiv:2006.05278. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedone, F. A survey on contrastive self-supervised learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]
- Le-Khac, P.H.; Healy, G.; Smeaton, A.F. Contrastive representation learning: A framework and review. IEEE Access 2020, 8, 193907–193934. [Google Scholar] [CrossRef]
- Alqahtani, H.; Kavakli-Thorne, M.; Kumar, G. Applications of generative adversarial networks (GANs): An updated review. Arch. Computat. Methods Eng. 2021, 28, 525–552. [Google Scholar] [CrossRef]
- Zhu, Z.; Lin, K.; Jain, A.K.; Zhou, J. Transfer learning in deep reinforcement learning: A survey. arXiv 2020, arXiv:2009.07888. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Song, Y.; Wang, T.; Mondal, S.K.; Sahoo, J.P. A comprehensive survey of few-shot learning: Evolution, applications, challenges, and opportunities. arXiv 2022, arXiv:2205.06743. [Google Scholar] [CrossRef]
- Pourpanah, F.; Zbdar, M.; Luo, Y.; Zhou, X.; Wang, R.; Lim, C.P.; Wang, X.-Z.; Wu, Q.M.J. A review of genearlized zero-shot learning methods. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 2022; pp. 1–20. [Google Scholar] [CrossRef]
- Yang, G.; Ye, Z.; Zhang, R.; Huang, K. A comprehensive survey of zero-shot image classification: Methods, implementation, and fair evaluation. AIMS ACI 2022, 2, 1–31. [Google Scholar] [CrossRef]
- Gentner, D.; Smith, L.A. Analogical Learning and Reasoning. In The Oxford Handbook of Cognitive Psychology; Reisberg, D., Ed.; Oxford University Press: Oxford, UK, 2013; pp. 668–681. [Google Scholar] [CrossRef]
- Gentner, D.; Maravilla, F. Analogical Reasoning. In International Handbook of Thinking & Reasoning, 1st ed.; Ball, L.J., Thopson, V.A., Eds.; Routledge: London, UK, 2017; pp. 186–203. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. Eng. App. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Bozinovski, S. Reminder of the first paper on transfer learning in neural networks, 1976. Informatica 2020, 44, 1–12. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In Artificial Neural Networks and Machine Learning, Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 5–7 October 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 270–279. [Google Scholar] [CrossRef] [Green Version]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Know. and Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Perkins, D.N.; Salomon, G. Transfer of learning. In International Encyclopedia of Education, 2nd ed.; Husén, T., Postlethwaite, T.N., Eds.; Pergamon Press: Oxford, UK, 1992; pp. 425–441. [Google Scholar]
- Ichien, N.; Lu, H.; Holyoak, K.J. Verbal analogy problem sets: An inventory of testing materials. Behav. Res. Methods. 2020, 52, 1803–1816. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I.; Elisseeff, A. An Introduction to Feature Extraction. In Feature Extraction: Studies in Fuzziness and Soft Computing; Guyon, I., Nikaravesh, M., Gunn, S., Zadeh, L.A., Eds.; Springer: Berlin, Germany, 2006; pp. 1–24. [Google Scholar] [CrossRef] [Green Version]
- Guyson, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Chellappa, R.; Turaga, P. Feature Selection. In Computer Vision: A Reference Guide; Ikeuchi, K., Ed.; Springer: Cham, Switzerland, 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Li, Z.; Hoeim, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, Z.; Wen, Z.; Wang, Y.; Wu, Q.; Tan, M. Towards effective deep transfer via attentive feature alignment. Neural Netw. 2021, 128, 98–109. [Google Scholar] [CrossRef]
- Jia, W.; Sun, M.; Lian, J.; Hou, S. Feature dimensionality reduction. Complex Intell. Syst. 2022, 8, 2663–2693. [Google Scholar] [CrossRef]
- Van Der Maaten, L.; Postma, E.O.; Van den Herik, H.J. Dimensionality reduction: A comparative review. J. Mach. Learn. Res. 2009, 10, 13. [Google Scholar]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Yoo, C.; Zing, G.; Oh, H.; El Fakhri, G.; Kang, J.-W.; Woo, J. Deep unsupervised domain adaptation: A review of recent advances and perspectives. APSIPA Trans. Signal Inf. Process. 2022, 11, 1–50. [Google Scholar] [CrossRef]
- Farahani, A.; Pourshojae, B.; Rasheed, K.; Arabnia, H. A concise review of transfer learning. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence, Las Vegas, NV, USA, 16–18 December 2020; pp. 344–351. [Google Scholar] [CrossRef]
- Ribani, R.; Marengoni, M. A survey of transfer learning for convolutional neural networks. In Proceedings of the 2019 32nd SIBGRAPI Conference on Graphics, Patterns and Images Tutorials, Rio de Janeiro, Brazil, 28–31 October 2019; pp. 46–57. [Google Scholar] [CrossRef]
- Ranaweera, M.; Mahmoud, Q.H. Virtual to real-world transfer learning: A systematic review. Electronics 2021, 10, 1491. [Google Scholar] [CrossRef]
- Holyoak, K.J. The pragmatics of analogical transfer. In The Psychology of Learning and Motivation; Bower, G.H., Ed.; Elsevier Science: Stanford, CA, USA, 1986; Volume 19, pp. 59–87. [Google Scholar]
- Raven, J.C.; Court, J.H. Raven's Progressive Matrices; Western Psychological Services: Los Angeles, CA, USA, 1938. [Google Scholar]
- Santoro, A.; Raposo, D.; Barrett, D.G.T.; Malinowski, M.; Rascanu, R.; Battaglia, P.; Lillicrap, T. A simple neural network module for relational reasoning. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, C.; Gao, F.; Baoxiong, J.; Zhu, Y.; Song-Chun, Z. RAVEN: A dataset for relational and analogical visual reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, United States, 16–20 June 2019; pp. 5317–5327. [Google Scholar]
- Hill, F.; Santoro, A.; Barrett, D.G.T.; Morcos, A.; Lillicrap, T. Learning to make analogies by contrasting abstract relational structure. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar] [CrossRef]
- Christie, S.; Gao, Y.; Ma, Q. Development of analogical reasoning: A novel perspective from cross-cultural studies. Child Dev. Perspect. 2020, 14, 164–170. [Google Scholar] [CrossRef]
- Morsanyi, K.; Stamenkovic, D.; Holyoak, K.J. Analogical reasoning in autism: A systematic review and meta-analysis. In Thinking, Reasoning, and Decision Making in Autism, 1st ed.; Morsanyi, K., Byrne, R.M.J., Eds.; Routledge: London, UK, 2020; pp. 59–87. [Google Scholar] [CrossRef]
- Goswami, U. Analogical reasoning: What develops? A review of research and theory. Child Dev. 1991, 62, 1–22. [Google Scholar] [CrossRef]
- Vendetti, M.S.; Matlen, B.J.; Richland, L.E.; Bunge, S.A. Analogical reasoning in the classroom: Insights from cognitive science. Mind Brain Educ. 2015, 9, 100–106. [Google Scholar] [CrossRef] [Green Version]
- Guerin, J.M.; Wade, S.L.; Mano, Q.R. Does reasoning training improve fluid reasoning and academic achievement for children and adolescents? A systematic review. Trends Neurosci. Educ. 2021, 23, 100153. [Google Scholar] [CrossRef]
- Evans, T.G. A heuristic program to solve geometric-analogy problems. In Proceedings of the April 21–23, 1964, Spring Joint Computer Conference, Washington, DC, USA, 21–23 April 1964; pp. 327–338. [Google Scholar] [CrossRef]
- Gentner, D.; Forbus, K.D. Computational models of analogy. Wiley Interdiscip. Rev. Cogn. Sci. 2011, 2, 266–276. [Google Scholar] [CrossRef]
- French, R.M. The computational modeling of analogy-making. Trends Cogn. Sci. 2002, 6, 200–205. [Google Scholar] [CrossRef]
- Combs, K.; Bihl, T.J.; Ganapathy, S.; Staples, D. Analogical reasoning: An algorithm comparison for natural language processing. In Proceedings of the 55th Hawaii International Conference on System Sciences, Maui, HI, USA, 3–7 January 2022; pp. 1310–1319. [Google Scholar] [CrossRef]
- Schoonen, T. Possibility, relevant similarity, and structural knowledge. Synthese 2022, 200, 39. [Google Scholar] [CrossRef]
- Hajian, S. Transfer of learning and teaching: A review of transfer theories and effective instructional practices. IAFOR J. Educ. 2019, 7, 93–111. [Google Scholar] [CrossRef]
- Bar, M. The proactive brain: Using analogies and associations to generate prediction. Trends Cogn. Sci. 2007, 11, 280–289. [Google Scholar] [CrossRef] [PubMed]
- Levy, O.; Goldberg, Y. Linguistic regularities in sparse and explicit word representations. In Proceedings of the Eighteenth Conference on Computational Natural Language Learning, Baltimore, MD, USA, 26–27 June 2014; pp. 171–180. [Google Scholar] [CrossRef]
- Eliasmith, C.; Thagard, P. Integrating structure and meaning: A distributed model of analogical mapping. Cog. Sci. 2001, 25, 245–286. [Google Scholar] [CrossRef]
- Duncker, K.; Lees, L.S. On problem-solving. Psychol. Monogr. 1945, 58, i–113. [Google Scholar] [CrossRef]
- Tammina, S. Transfer learning using VGG-16 with deep convolutional neural network for classifying images. Int. J. of Sci. Res. Publ. 2019, 9, 143–150. [Google Scholar] [CrossRef]
- Rajagopal, A.K.; Subramanian, R.; Ricci, E.; Vieriu, R.; Lanz, O.; Kalpathi, R.R.; Sebe, N. Exploring transfer learning approaches for head pose classification from multi-view surveillance images. Int. J. Comput. Vis. 2014, 109, 146–167. [Google Scholar] [CrossRef] [Green Version]
- Kan, M.; Wu, J.; Shan, S.; Chen, X. Domain adaptation for face recognition: Targetize source domain bridged by common subspace. Int. J. Comput. Vis. 2014, 109, 94–109. [Google Scholar] [CrossRef]
- Romera-Paredes, B.; Aung, M.S.H.; Pontil, M.; Bianchi-Berthouze, N.; Williams, A.C.D.C.; Watson, P. Transfer learning to account for idiosyncrasy in face and body expressions. In Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April 2013. [Google Scholar] [CrossRef]
- LeCun, Y.; Huang, F.J.; Bottou, L. Learning methods for generic object recognition with invariance to pose and lighting. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–4 July 2004; pp. ii–104. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Li, D.; Mohapatra, D.; Elhoseny, M. Automatic removal of complex shadows from indoor videos using transfer learning and dynamic thresholding. Comput. Electr. Eng. 2018, 70, 813–825. [Google Scholar] [CrossRef]
- Gong, R.; Dai, D.; Chen, Y.; Li, W.; Paudel, D.P.; Gool, L.V. Analogical image translation for fog generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar] [CrossRef]
- Li, Q.; Tang, S.; Peng, X.; Ma, Q. A method of visibility detection based on the transfer learning. J. Atmos. Ocean. Technol. 2019, 36, 1945–1956. [Google Scholar] [CrossRef]
- Saenko, K.; Kulis, B.; Fritze, M.; Darrell, T. Adapting visual category models to new domains. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 213–226. [Google Scholar] [CrossRef]
- Gopalan, R.; Li, R.; Chellappa, R. Domain adaptation for object recognition: An unsupervised approach. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 999–1006. [Google Scholar] [CrossRef]
- Soh, J.W.; Cho, S.; Cho, N.I. Meta-transfer learning for zero-shot super-resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3516–3525. [Google Scholar] [CrossRef]
- Fleuret, F.; Li, T.; Dubout, C.; Wampler, E.K.; Yantis, S.; Geman, D. Comparing machines and humans on a visual categorization test. Proc. Natl. Acad. Sci. USA 2011, 108, 17621–17625. [Google Scholar] [CrossRef] [Green Version]
- Kimg, J.; Ricci, M.; Serre, T. Not-So-CLEVR: Learning same–different relations strains feedforward neural networks. Interface Focus. 2018, 8, 20180011. [Google Scholar] [CrossRef]
- Barrett, D.G.T.; Hill, F.; Santoro, A.; Morcos, A.S.; Lillicrap, T. Measuring abstract reasoning in neural networks. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 511–520. [Google Scholar] [CrossRef]
- Hu, S.; Ma, Y.; Liu, X.; Wei, Y.; Bai, S. Stratified rule-aware network for abstract visual reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar] [CrossRef]
- Bongard, M.M. Pattern Recognition; Nauka Press: Moscow, Russia, 1967. [Google Scholar]
- Yun, X.; Bohn, T.; Ling, C. A deeper look at Bongard problems. In Advances in Artificial Intelligence, Proceedings of the Canadian Conference on Artificial Intelligence, Virtual, 13–15 May 2020, pp.; pp. 528–539. [CrossRef]
- Kunda, M. Visual mental imagery: A view from artificial intelligence. Cortex 2018, 105, 155–172. [Google Scholar] [CrossRef] [PubMed]
- Małkiński, M.; Mańdziuk, J. A review of emerging research directions in abstract visual reasoning. arXiv 2022, arXiv:2202.10284. [Google Scholar] [CrossRef]
- Lovett, A.; Forbus, K. Modeling visual problem solving as analogical reasoning. Psychol. Rev. 2017, 124, 60–90. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.; Liu, Q.; Ichien, N.; Yuille, A.L.; Holyoak, K.J. Seeing the meaning: Vision meets semantics in solving pictorial analogy problems. In Proceedings of the Annual Conference of the Cognitive Science Society, Austin, TX, USA, 24–27 July 2019; pp. 2201–2207. [Google Scholar]
- Kunda, M.; Soulières, I.; Rozga, A.; Goel, A. Methods for classifying errors on the Raven’s standard progressive matrices test. In Proceedings of the Annual Meeting of the Cognitive Science Society, Berlin, Germany, 31 July–3 August 2013; pp. 2796–2801. [Google Scholar]
- Yang, Y.; McGreggor, K.; Kunda, M. Visual-imagery-based analogical construction in geometric matrix reasoning task. arXiv 2022, arXiv:2208.13841. [Google Scholar] [CrossRef]
- Youngsung, K.; Shin, J.; Yang, E.; Hwang, S.J. Few-shot visual reasoning with meta-analogical contrastive learning. Advances in Neural Information Processing Systems. In Proceedings of the 34th Conference on Neural Information Processing Systems, Virtual, 6–12 December 2020. [Google Scholar] [CrossRef]
- Spratley, S.; Ehinger, K.; Miller, T. A closer look at generalisation in RAVEN. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; pp. 601–616. [Google Scholar] [CrossRef]
- Webb, T.; Fu, S.; Bihl, T.; Holyoak, K.J.; Lu, H. Zero-shot visual reasoning through probabilistic analogical mapping. arXiv 2022, arXiv:2209.15087. [Google Scholar] [CrossRef]
- Falkenhainer, B.; Forbus, K.D.; Gentner, D. The structure mapping engine: Algorithm and examples. Artif. Intell. 1989, 41, 1–63. [Google Scholar]
- Halford, G.S.; Wilson, W.H.; Philips, S. Processing capacity defined by relational complexity: Implications for comparative, developmental, and cognitive psychology. Behav. Brain Sci. 1998, 21, 803–831. [Google Scholar] [CrossRef] [Green Version]
- Hummel, J.E.; Holyoak, K.J. Distributed representations of structure: A theory of analogical access and mapping. Psychol. Rev. 1997, 104, 427–466. [Google Scholar] [CrossRef]
- Hummel, J.E.; Holyoak, K.J. A symbolic-connectionist theory of relational inference and generalization. Psychol. Rev. 2003, 110, 220–264. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems, Proceedings of the 26th Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119.
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Rogers, A.; Drozd, A.; Li, B. The (too many) problems of analogical reasoning with word vectors. In Proceedings of the 6th Joint Conference on Lexical and Computational Semantics, Vancouver, BC, Canada, 3–4 August 2017; pp. 135–148. [Google Scholar] [CrossRef]
- Günther, F.; Rinaldi, L.M.M. Vector-space models of semantic representation from a cognitive perspective: A discussion of common misconceptions. Perspect. Psychol. Sci. 2019, 14, 1006–1033. [Google Scholar] [CrossRef] [Green Version]
- Peterson, J.C.; Chen, D.; Griffiths, T.L. Parallelograms revisited: Exploring the limitations of vector space models for simple analogies. Cognition 2020, 205, 104440. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Settlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. In Proceedings of the Eighth International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 2 March 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Advances in Proceedings of the Neural Information Processing Systems, 34th Conference on Neural Information Processing Systems, Virtual, 6–12 December 2020. [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized autoregressive pretraining for language understanding. In Proceedings of the Advances in Neural Information Processing Systems, 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5753–5763. [Google Scholar]
- Reis, E.S.D.; Costa, C.A.D.; Silveira, D.E.D.; Bavaresco, R.S.; Barbosa, J.L.V.; Antunes, R.S.; Gomes, M.M.; Federizzi, G. Transformers aftermath: Current research and rising trends. Commun. ACM 2021, 64, 154–163. [Google Scholar] [CrossRef]
- Schomacker, T.; Tropmann-Frick, M. Language representation models: An overview. Entropy 2021, 23, 1422. [Google Scholar] [CrossRef]
- Naseem, U.; Razzak, I.; Khan, S.K.; Prasad, M. A comprehensive survey on word representation models: From classical to state-of-the-art word representation language models. ACM T. Asian Low-Reso. 2021, 20, 1–35. [Google Scholar] [CrossRef]
- Wang, H.; Yang, Q. Transfer learning by structural analogy. In Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; pp. 513–518. [Google Scholar]
- Honda, H.; Hagiwara, M. Analogical reasoning with deep learning-based symbolic processing. IEEE Access 2021, 9, 121859–121870. [Google Scholar] [CrossRef]
- Marquer, E.; Alsaidi, S.; Decker, A.; Murena, P.-A.; Couceiro, M. A deep learning approach to solving morphological analogies. In Proceedings of the 30th Interrnational Confernce on Case-based Reasoning, Nancy, France, 12–15 September 2022; pp. 159–174. [Google Scholar] [CrossRef]
- Durrani, N.; Sajjad, H.; Dalvi, F. How transfer learning impacts linguistic knowledge in deep NLP models? In Proceedings of the Findings of the Association for Computational Linguistics 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; pp. 4947–4957. [Google Scholar] [CrossRef]
- Lu, H.; Chen, D.; Holyoak, K.J. Bayesian analogy with relational transformations. Psychol. Rev. 2012, 119, 617–648. [Google Scholar] [CrossRef] [Green Version]
- Lu, H.; Wu, Y.N.; Holyoak, K.J. Emergence of analogy from relation learning. Proc. Natl. Acad. Sci. USA 2019, 116, 4176–4181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, H.; Ichien, N.; Holyoak, K.J. Probabilistic analogical mapping with semantic relation networks. Psychol. Rev. 2022, 129, 1078–1103. [Google Scholar] [CrossRef] [PubMed]
- Holyoak, K.J.; Thagard, P. Analogical mapping by constraint satisfaction. Cogn. Sci. 1989, 13, 295–355. [Google Scholar] [CrossRef]
- Kokiov, B. A hybrid model of reasoning by analogy. In Advances in Connectionist and Neural Computation Theory Vol. 2: Analogical Connections; Holyoak, K., Barnden, J., Eds.; Ablex Publishing Corporation: New York, NY, USA, 1994; pp. 247–318. [Google Scholar]
- Doumas, L.A.A.; Hummel, J.E.; Sandhofer, C.M. A theory of the discovery and predication of relational concepts. Psychol. Rev. 2008, 115, 1–43. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Berstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
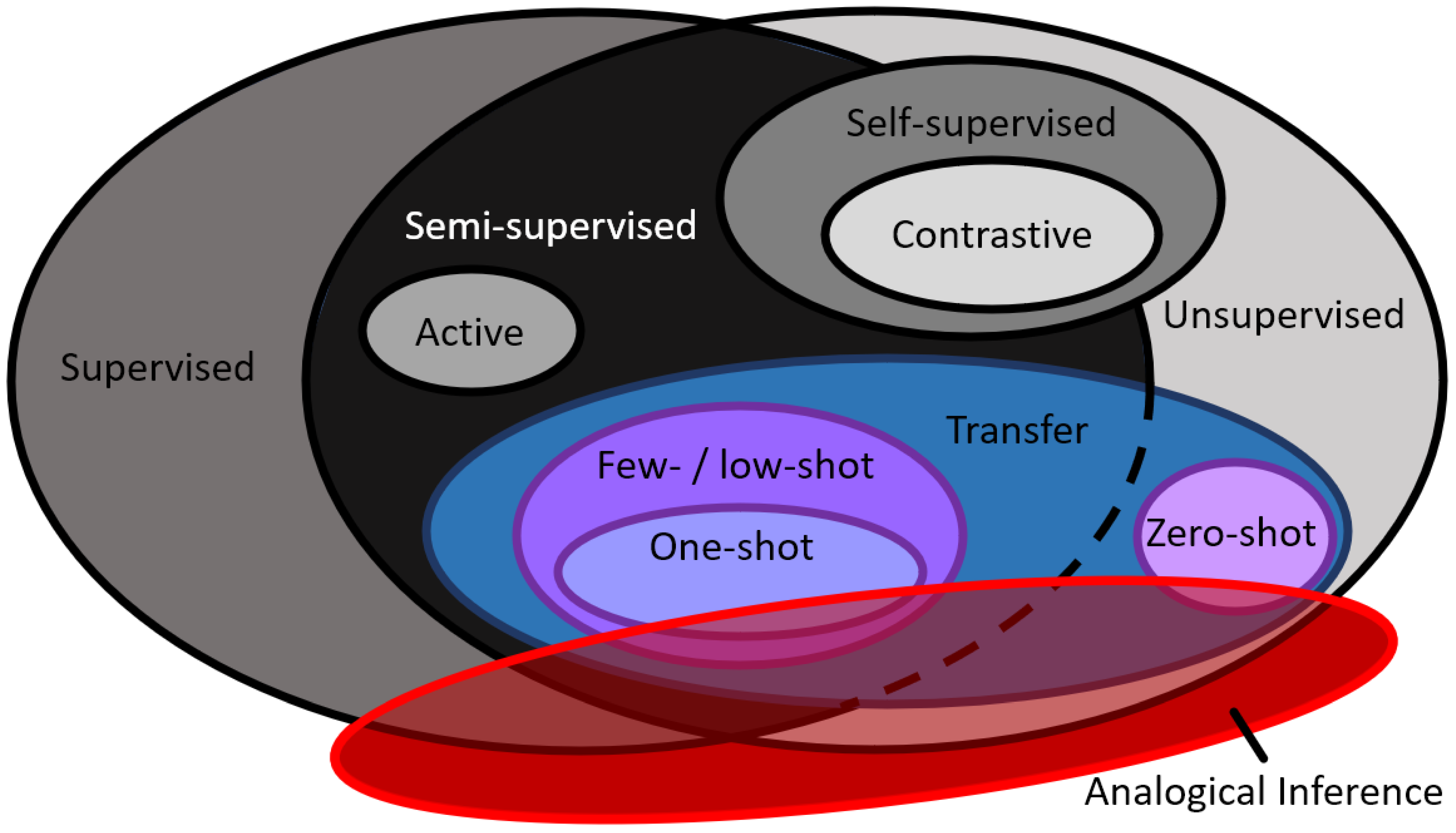







| Family of Learning | Description |
|---|---|
| Symbolist (AKA inductive) | An inductive-reasoning-based method which is based on representing concepts through “symbols” which can be mathematically manipulated |
| Connectionism | A bottom-up approach inspired by the brain’s ability to function based on firing neurons (“activation”) |
| Bayesian | A technique based using on estimated event probability to predict outcomes, popular in causal situations |
| Evolutionary | A biological-inspired approach based on the ability to evolve and mutate in hopes of achieving better performance |
| Analogizers | A method based on identifying patterns and similarities between two domains and learning through various types of reasoning |
| Type of Learning | Description |
|---|---|
| Deep | A subset of ML that utilizes artificial neural networks (ANNs) with three or more layers, sometimes called “deep neural networks (DNNs)” |
| Supervised | Prediction of a classification or value (in the case of regression) where the data (used for training and testing) are all labeled and known |
| Unsupervised | Utilizes only unlabeled data typically for clustering or association problems |
| Semi-supervised | A hybrid approach between supervised and unsupervised involving labeled and unlabeled data |
| Self-supervised | A type of unsupervised and/or semi-supervised methods where arbitrary labels are created for each data instance allowing it to act as a supervised learning problem |
| Contrastive | Type of self-supervised methods where data instances are compared to one another to determine their clustering into classes |
| Reinforcement | Approach utilizing a reward/penalty system upon evaluation of the environment and its goal(s) |
| Multi-view | An instance where a specific problem can be accurately viewed in two different manners |
| Multi-task | Technique focused on solving multiple related problems/tasks simultaneously |
| Ensemble | A method that combines individual models into a larger model to improve performance |
| Active | A specific type of semi-supervised learning where an “oracle,” commonly a human, is used to derive information about or assess the algorithm and/or its performance |
| Online | A method that is best applied when the data to train the algorithm is introduced sequentially as the algorithm’s parameters are fine-tuned |
| Zero-shot | Type of learning where an algorithm has “unseen” data outside of its initial training dataset with the ability to accurately identify and classify said unseen data |
| Few-shot/low-shot/one-shot/multi-shot | A semi-supervised approach that uses a very small dataset of labeled instances (or only one instance in the case of one-shot) |
| Transfer | A technique where some portion of knowledge from one domain is transferred and applied to a different but related domain |
| Analogical inference | Method where an analogy is formed between two different but related domains to draw inferences between each other as well as specifically the target domain |
| Transfer Learning | Analogical Inference | |
|---|---|---|
| Transferred Knowledge Representation | Feature spaces | Relational structures |
| Primary Tasks | Classification Generation | Classification Generation Mapping Retrieval |
| Amount of Required Training Data | Large amounts | Small amounts |
| Scope of Transfer | Near | Near and Far |
| Task Number | Task | Computer Vision | Natural Language Processing |
|---|---|---|---|
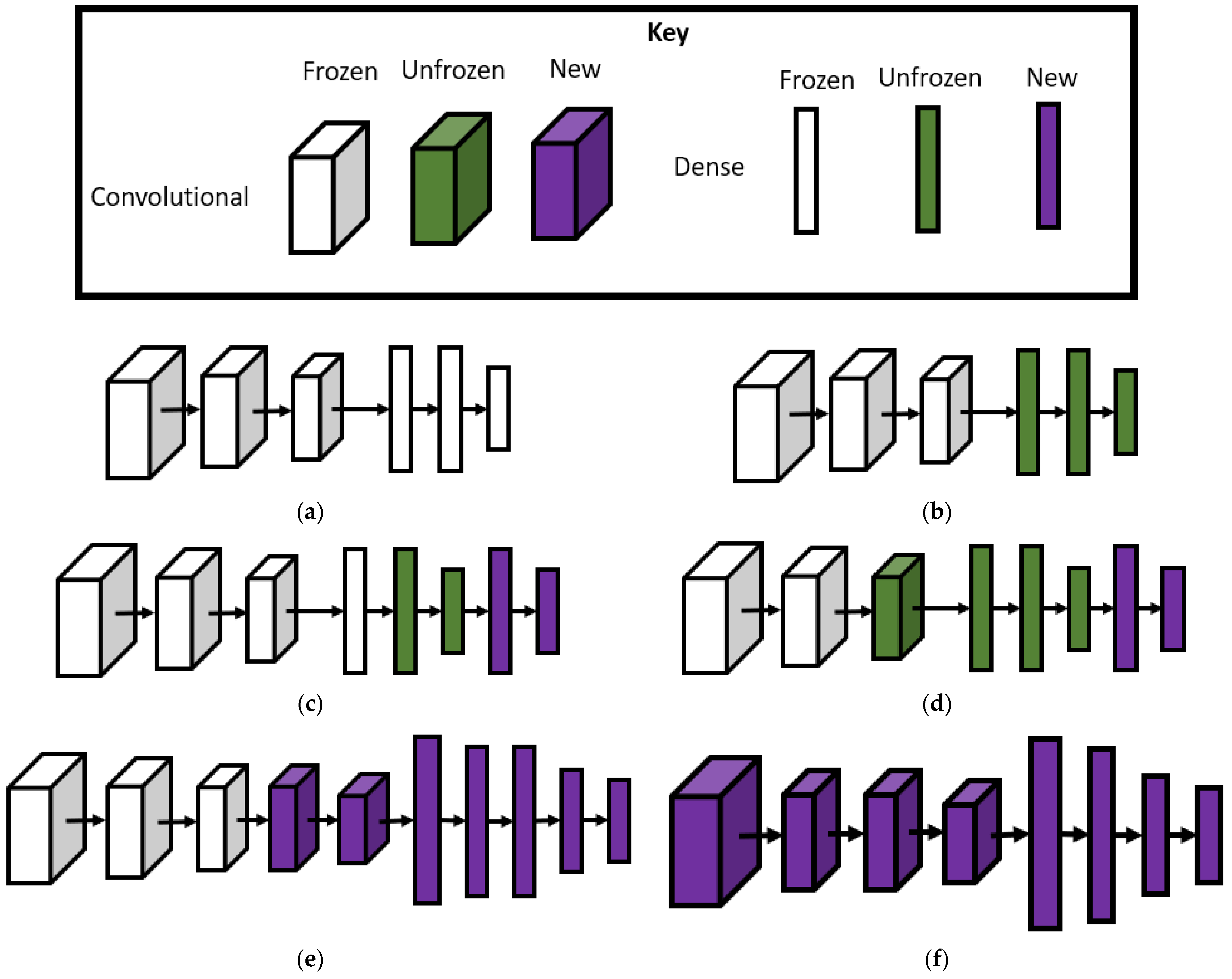
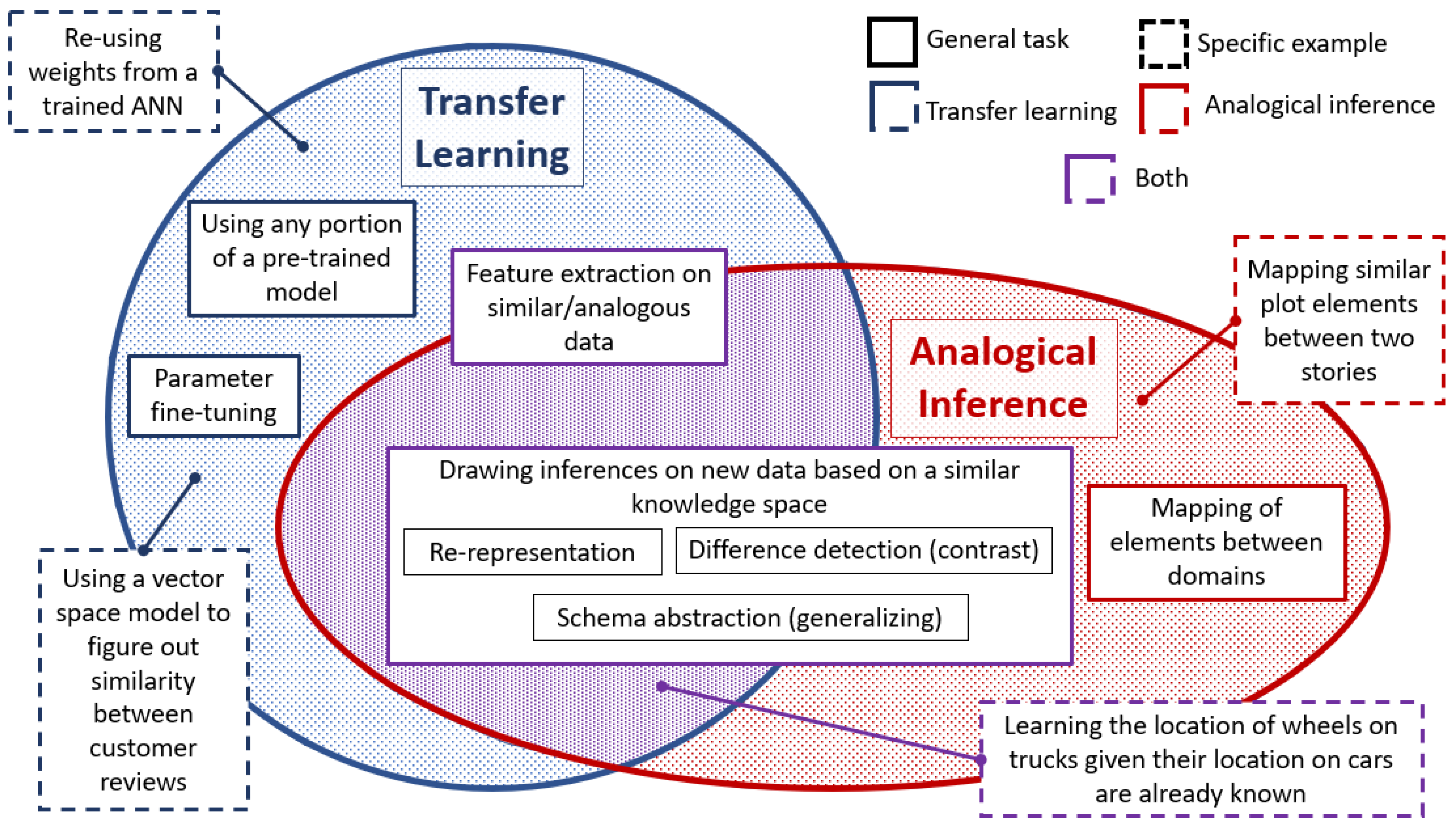
| 1 | Using any portion of a pre-trained model | Utilizing a pre-trained ANN architecture with frozen layers to predict a subset of the classes it was originally trained on | Utilizing a pre-trained vector space model to determine the similarity between two documents |
| 2 | Parameter fine-tuning | Utilizing a pre-trained ANN architecture with unfrozen layers to predict image classes in the target dataset A more specific case of Task 1 | Adjusting the parameter values on a support vector machine to classify good and negative customer reviews |
| 3 | Feature extraction on similar/ analogous data | Transfer learning: Identifying important features on a target dataset given the features of a source dataset | Transfer learning: Identifying the most relevant words within a text document |
| Analogical inference: Given the important visual elements of the source portion of an analogy, identifying the important elements of its target counterpart | Analogical inference: Given the important textual elements of the source portion of an analogy, identifying the important elements of its target counterpart | ||
| 4 | Drawing inference on new data based on a similar knowledge space | Transfer learning: Identifying the location of four wheels on a truck given their locations on a car | Identifying the best D-word to complete the given incomplete textual analogy, A:B::C:? |
| Analogical inference: Inferring that since trucks have four wheels and cars are like trucks, cars must also have four wheels | |||
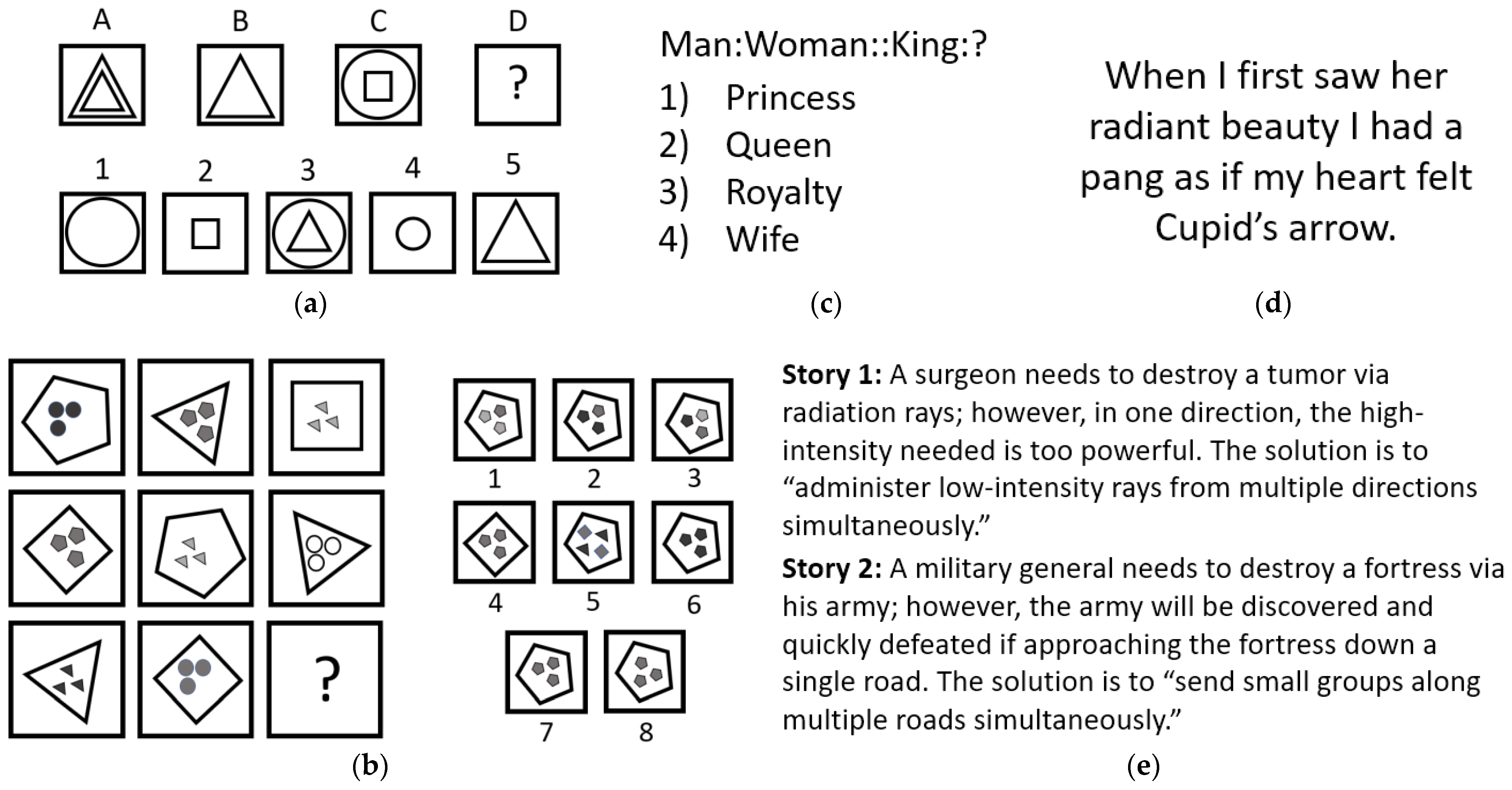
| 5 | Mapping elements between two domains | Deciding which geometric elements of a source image corresponds best to the geometric elements of a target image (for example, utilizing A and C of Figure 6a, the large triangle of A can map to either the large or small square of C) | Given two analogous stories, identify which elements (characters, plot, setting, etc.) in the source story maps to the target story (for example, Figure 6e, determining whether to map the military general to the surgeon or the patient) |
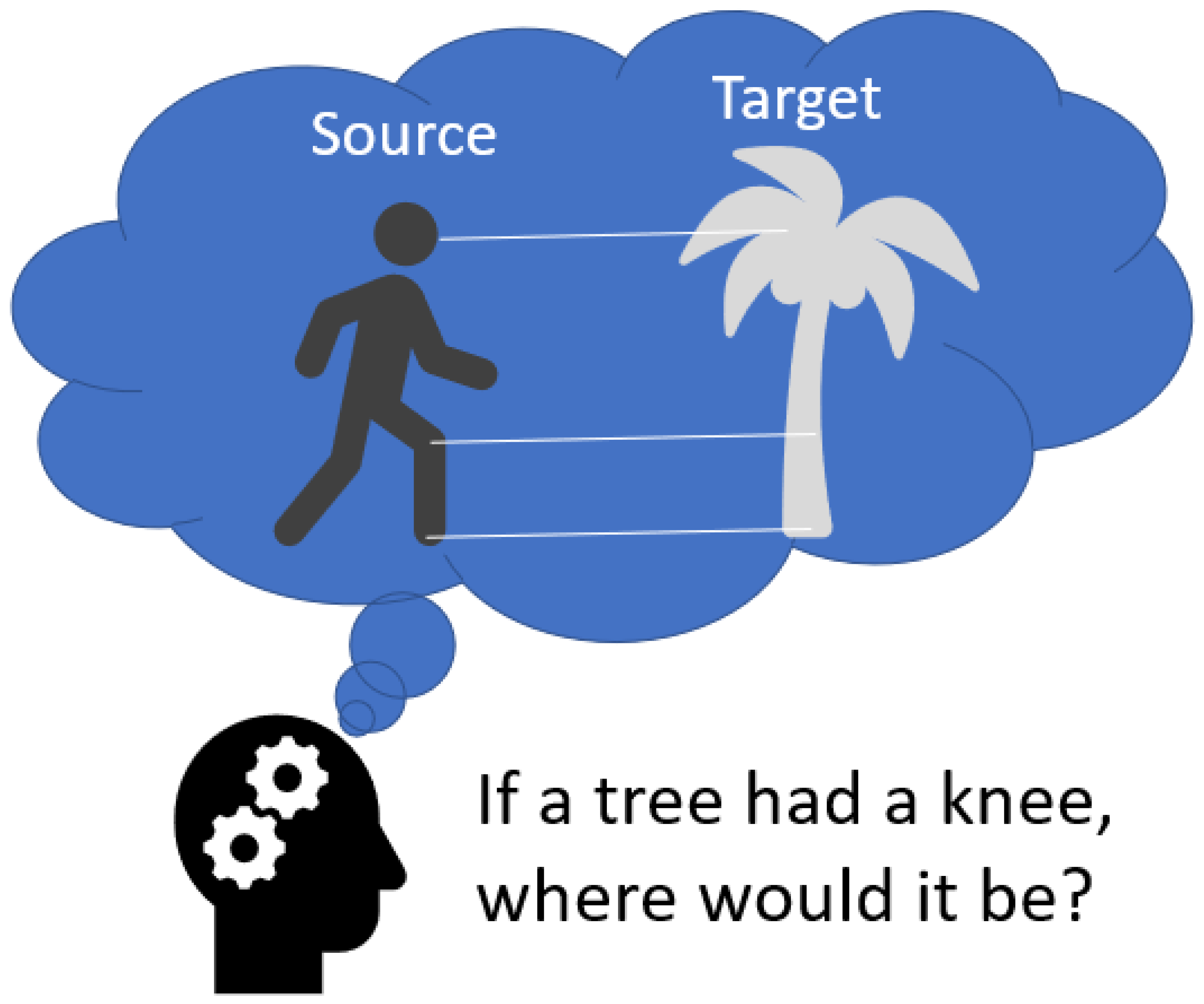
| 6 | Re-representation | Identifying where a knee would be on a tree given its location on a human | Identifying the underlying common relationship between two different words that are usually not synonymous (for example, the relationship between the two sentences, “The runner trained for the marathon” and “The student studied for the test,” could be re-representations of the word “preparing”) |
| 8 | Schema abstraction (generalization) | Creation of a general representational structure (or schema) that derives from the identified relationships within the source and target data | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Combs, K.; Lu, H.; Bihl, T.J. Transfer Learning and Analogical Inference: A Critical Comparison of Algorithms, Methods, and Applications. Algorithms 2023, 16, 146. https://doi.org/10.3390/a16030146
Combs K, Lu H, Bihl TJ. Transfer Learning and Analogical Inference: A Critical Comparison of Algorithms, Methods, and Applications. Algorithms. 2023; 16(3):146. https://doi.org/10.3390/a16030146
Chicago/Turabian StyleCombs, Kara, Hongjing Lu, and Trevor J. Bihl. 2023. "Transfer Learning and Analogical Inference: A Critical Comparison of Algorithms, Methods, and Applications" Algorithms 16, no. 3: 146. https://doi.org/10.3390/a16030146
APA StyleCombs, K., Lu, H., & Bihl, T. J. (2023). Transfer Learning and Analogical Inference: A Critical Comparison of Algorithms, Methods, and Applications. Algorithms, 16(3), 146. https://doi.org/10.3390/a16030146