1. Introduction
Convex optimization [
1,
2,
3,
4] has become an efficient and important method to solve multi-dimensional problems in many fields, such as energy management [
5,
6,
7], transportation management [
8], trajectory optimization [
9,
10,
11,
12,
13], image restoration [
14], text summarization [
15], cryptography [
16], robotics [
17], machine learning [
18], and many others.
Methods for solving optimization problems using the dual approach are being intensively developed [
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31] as they can greatly simplify the solution of certain types of nonlinear programming problems. The dual approach is efficient at low computational costs for obtaining the characteristics of the dual function, which is typical, for example, for minimizing separable functions with linear constraints. When the number of constraints is significantly less than the number of variables, the transition from the original problem to the dual one enables us to obtain a problem of much smaller dimensionality.
In the article, we consider methods for solving a convex programming problem with a strongly convex objective function based on the dual approach. The complexity of optimizing the dual function in the problem of convex programming, in contrast to the dual functions considered in [
19], lies in the presence of constraints on the positivity of the variables. It seems reasonable to develop and investigate ways to reduce such a problem to an unconstrained optimization problem, where modern efficient numerical methods for optimizing smooth and non-smooth functions are applicable.
The standard way to reduce such a problem to an unconstrained optimization problem is to replace the components of the dual variables by their moduli [
32] (modulus method). Given a strongly convex objective function in a convex programming problem, the dual function is differentiable with a Lipschitz gradient in the range of positivity of the variables [
33,
34,
35,
36,
37]. Replacing the components of the dual function variables by their moduli [
32], we obtain a multi-extremal function that is differentiable with a Lipschitz gradient in the range of the sign constancy of the components of the generated variables (SCV) and having a local extremum determining the extremal dual variables. The ambiguity of the gradient arises in the regions of the sign change of the components of the transformed dual variables corresponding to inactive constraints. The components of the gradients corresponding to such variables at the boundary of adjacent SCV regions are equal in magnitude and have opposite signs.
We show that the cone of possible directions (CPD) for improving the dual function performance index, determined by a set of gradients in the neighborhood of a point from the boundary region for adjacent SCV regions, narrows as it approaches the extremum. RSM methods are suitable for such a situation [
38,
39,
40,
41,
42,
43]. The organization of RSM methods is to find the descent direction that enables us to go beyond a particular neighborhood of the current extremum [
40,
41,
42,
43], i.e., they find a descent direction that is gradient-consistent with all gradients in the neighborhood of the current extremum approximation. The narrower the CPD, the lower the convergence rate and the higher the computational cost of finding the RSM optimum [
40,
41,
42,
43]. Thus, with the modulus method of transforming dual variables, the dual function is non-smooth, and its degree of degeneracy increases as it approaches the extremum. This negatively affects the convergence rate of the minimization method and leads to a decrease in the accuracy of the resulting solution. In this case, it becomes necessary to involve complex subgradient methods of accelerated convergence for solving the problem.
Considering the noted shortcomings of the modulus transformation, it is important to search for a transformation of dual variables without gradient discontinuities. Our contribution is as follows. We propose a quadratic transformation of dual variables for the optimization problems with the number of constraints much less than the number of variables. The quadratic transformation method has proved successful in the problem of imposing constraints on the pollutant emissions of enterprises [
33], which aroused interest in studying the properties of the function transformed in this way. In this work, we prove that in the case of a quadratic transformation, the gradient of the newly formed function is Lipschitz. In addition to subgradient methods, the noted property enables us to exploit methods of unconstrained minimization of smooth functions in solving the problem. As a result of a quadratic method compared to a modulus one, this is an increase in the convergence speed of the minimization method and the accuracy of the resulting solution when using well-studied and proven fast-converging methods for minimizing smooth functions.
We conducted a computer experiment for practical analysis of the methods for transforming dual variables. Models of convex programming problems similar in properties to those used in the software package for environmental monitoring of atmospheric air (ERA-AIR) [
33] were taken as tests. Based on the extremum conditions, convex programming problems with two-sided constraints were generated with a number of variables up to 10,000 and a number of linear constraints up to 1000. The number of active two-sided and linear constraints varied.
To solve test problems, we used the multi-step subgradient method [
43], subgradient methods with a change in the space metric [
40,
41,
42], the BFGS (Broyden–Fletcher–Goldfarb-Shanno) quasi-Newtonian method [
44,
45,
46,
47], and the conjugate gradient method [
34]. In the case of a quadratic transformation, the number of iterations required to solve the problem was reduced and the accuracy of its solution was increased. Problems with a quadratic transformation of the dual function variables were also successfully solved by rapidly converging methods for minimizing smooth functions: the conjugate gradient method [
34] and the quasi-Newtonian BFGS method [
44,
45,
46,
47].
The noted transformations of dual variables were used in the program module for calculating the MPE, which is the part of the software package for environmental monitoring of atmospheric air, ERA-AIR. In related literature, the authors present different types of models for this applied problem: regression models [
48,
49], the particle swarm optimization model [
50], the fuzzy c-means model [
50], and a nonlinear programming model [
51,
52,
53].
The rest of the paper is organized as follows. In
Section 2, we formulate the dual problem for a convex programming problem with a strongly convex objective function and a summary of the results of the duality theory necessary for further research. In
Section 3, we study the previously known modulus method for reducing the dual problem to an unconstrained optimization, and we propose the quadratic transformation of dual variables in
Section 4. In
Section 5, we provide a description of test problems, and we present the results of their solution in
Section 6. In
Section 7, we present the results of solving the applied problem of calculating the MPE of enterprises using the software package for environmental monitoring of atmospheric air. In
Section 8, we summarize the work.
2. The Problem Formulation
Consider the convex programming problem:
In contrast to [
15], where linear equality constraints are used, constraints (2) have the form of inequalities, which imposes restrictions on the positivity of dual variables.
Assumption 1. In problem (1)–(2), assume that f is a strongly convex function, gi are convex functions, set Q ⊂ Rn is a convex closed bounded set, and the Slater condition is satisfied, i.e., there is an interior point x0 of the set Q, such that the following conditions are satisfied: We form the Lagrangian function
where
yT = (
y1,
y2,…,
ym) are the Lagrange multipliers and
gT(
x) = (
g1(
x),
g2(
x),…,
gm(
x)). Here and in the following, we denote by 〈
y,
g〉 the scalar product of vectors
y,
g.
According to [
34], we introduce the dual function
and formulate the dual problem
Let us introduce the function
ϕ(
y) = −
ψ(
y),
y ≥ 0. Instead of (6), we get the problem of minimizing a convex function
If Assumption 1 holds, then the function
ψ(
y) is differentiable [
34]. The gradients of the functions
ψ(
y) and
ϕ(
y) are [
19]:
where
. The gradient
in the area
y ≥ 0 satisfies the Lipschitz condition [
34,
54]
Here and below, is the norm of the vector a.
For m << n and given a simple method for finding the minimum point of the Lagrangian with respect to x, the transition to the dual problem may simplify the solution. The complexity of solving the problem (7) lies in the presence of the constraint y ≥ 0, which prevents the use of efficient numerical methods of unconstrained optimization. In this paper, we consider two ways to reduce the constrained optimization problem (7) to the unconstrained minimization problem and study their properties theoretically and experimentally.
3. Qualitative Analysis of the Modulus Transformation of Dual Variables
Assume that Assumption 1 holds for the primal convex programming problem (1), (2). To reduce problem (7) to an unconstrained optimization problem, we use the following transformation of variables [
32]:
The transformation method (10) was previously called the modulus method. Let us denote
θ(
u) =
ϕ(
y(
u)). The minimization problem (7) under such a variables substitution takes the form
The problem (11) is multi-extremal, but in each of the quadrants determined by the sign constancy of the components of the variable
u, the function is convex, and the components of its gradient are given by the expression
In each of the quadrants, the gradient satisfies the Lipschitz condition. Note that, because of the convexity of the function, the gradients in the corresponding quadrants are also subgradients. At points on the boundaries of adjacent quadrants, we have gradients of adjacent areas. For this reason, to solve the problem of minimizing the function (11), we can use relaxation subgradient methods, in which the descent direction is chosen so that leaving the neighborhood of the current minimum is possible by one-dimensional minimization along this direction.
Using a two-dimensional problem as an example, let us consider the problem of increasing the degree of conditionality of the problem at the extremum area. Let us assume that the number of constraints in the problem (1), (2) is
m = 2, and the minimum in the corresponding problem (11) is at the point
Here, we assume that only the first condition is active. The gradients (12) at the point (13) at
u2 = 0, depending on whether they belong to the area
u2 ≥ 0 or
u2 ≤ 0, respectively, have the form
Since constraint g2(x) is inactive, .
For a small
, let us consider the gradients of problem (11) on the boundary of the domains at
u2 = 0 in the point
determined by belonging to half-planes
u2 ≥ 0 and
u2 ≤ 0, respectively:
Since the gradients in the half-planes u2 ≥ 0 and u2 ≤ 0 satisfy the Lipschitz condition and , the value δ1 determines the smallness of the values ε1 and ε2. Here ε1 < 0, since the gradients (16) are subgradients of the function θ(u) that is convex in the corresponding half-planes. Therefore, each subgradient represents a normal on the tangential hyperplane to the level surface, and the reverse direction of the subgradients shows the half-plane of the minimum point for this hyperplane.
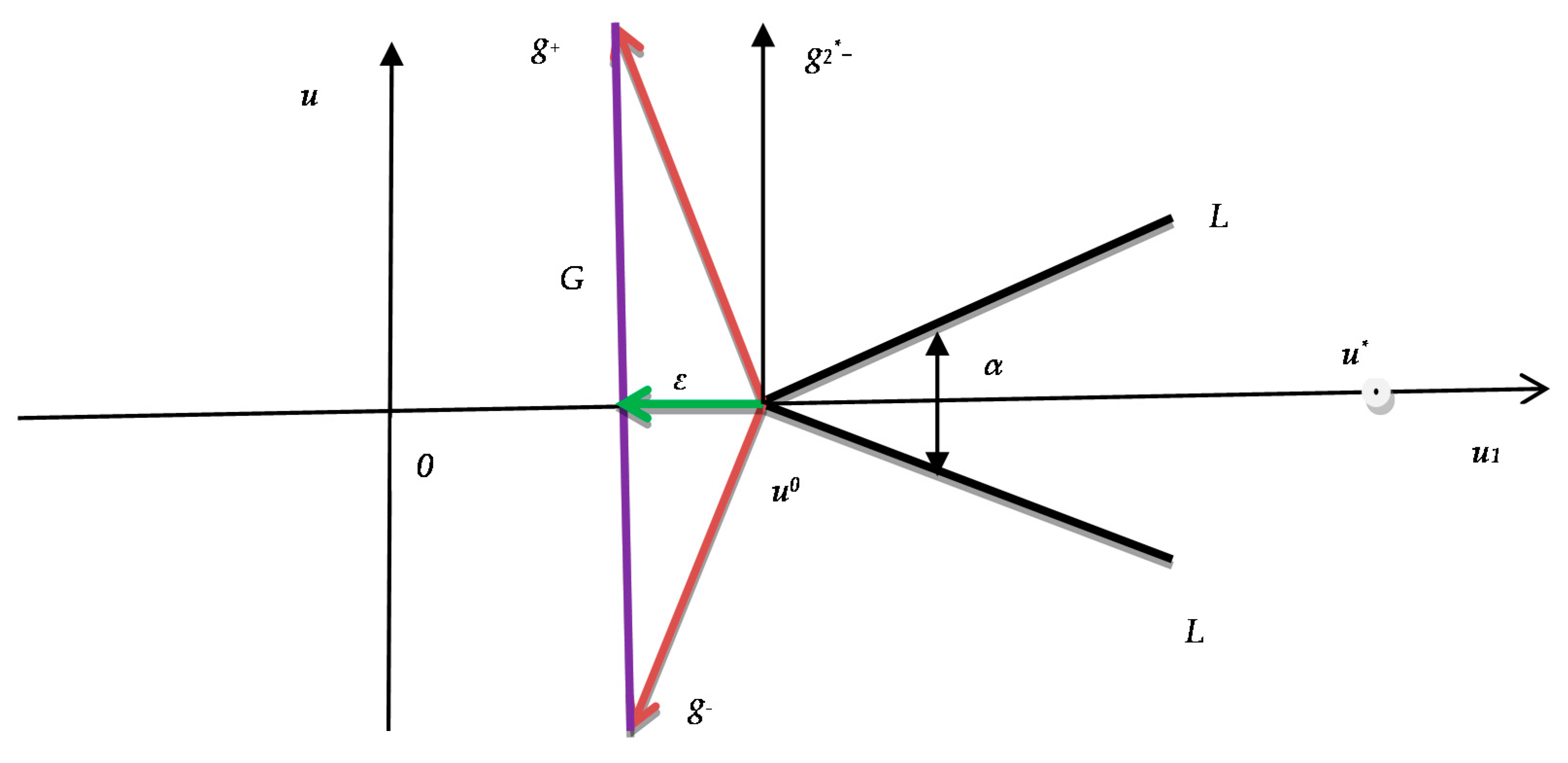
In plane
u1,
u2,
Figure 1 shows points
,
u0, gradients
,
and the line segments
L+,
L−, whose normals are the corresponding gradients
,
. The set
G is the convex hull of the gradients
,
. To reduce the function from the point
u0, we need to find the direction falling into the interior of the cone with the opening angle
α, bounded by the lines
L+,
L−. The value of the angle
α is proportional to the component
ε1. Since the gradients of each of the half-planes satisfy the Lipschitz condition, the values of
ε1 and
ε2 decrease as the minimum is approached, i.e., as the value
δ1 in (15) decreases. Thus, the cone of possible directions for decreasing the function narrows as it approaches the minimum.
Let us consider the effect of the above feature on the convergence rate of relaxation subgradient methods. According to research [
40,
41,
42,
43], an RSM contains a built-in algorithm for finding the descent direction that forms an acute angle with all subgradients in the neighborhood of the current minimum. Minimizing the function along the opposite direction (with a minus sign) allows us to go beyond the neighborhood of the current minimum. RSMs are formed as follows. Let us consider the problem of minimizing a function
f(
x) in
Rn solved.
In the RSM, successive approximations are built according to the equations [
40,
41,
42,
43]:
where the descent direction
sk is chosen as a solution to the system of inequalities [
40,
41,
42,
43]:
Here,
G is the subgradient set in the neighborhood of the current minimum point xi. The system of inequalities (18) in the RSM is solved by iterative methods, using subgradients calculated on the descent trajectory of the minimization algorithm. As experience shows, RSMs are suitable for solving smooth and non-smooth non-convex minimization problems. Theoretical studies show that the speed of finding the descent direction is determined by the ratio of the lengths of the minimum to the length of the maximum vectors of the convex hull of subgradients in the current minimum domain. It decreases as the value of this ratio decreases. In the example, this ratio for set
G at the point
u0 is equal to
This means that the cost of finding the direction of descent in the RSM method is increased at δ1 → 0.
Since the components of the gradients along u2 near the extremum are practically fixed and non-zero in gradient-type methods, the region near u2 = 0 is the area of attraction for the sequence of points searched for a minimum when approaching the extreme value by subgradient methods. Therefore, it is appropriate to use the described problem of narrowing the cone of permissible directions to decrease the objective function as one approaches the extremum.
The narrowing of the cone of admissible directions leads to an increase in the computational cost of subgradient methods, which is confirmed by a computational experiment. To improve the accuracy in solving the problem, it is necessary to apply more complex subgradient methods with a change in the space metric [
40,
41,
42] and use parameter settings that significantly increase the computational cost.
4. Qualitative Analysis of the Quadratic Transformation of Dual Variables
Let assumption 1 be satisfied with respect to the primal problem of convex programming (1), (2). To reduce the problem (7) to an unconstrained optimization problem, we use the transformation of variables in the following form:
The transformation method (20) was previously called the quadratic method. Let us denote Φ(
u) =
ϕ(
y(
u)). The minimization problem (7) under such a change of variables becomes
Problem (21) is multiextremal, with each minimum
u* giving the optimal value of the dual variables
y(
u*). Given the expressions (8) for the function
ϕ(
y), the gradient components of the function are given by
We want to show that the gradient of the function Φ(u) satisfies the Lipschitz condition.
Theorem 1. Let Assumption 1 hold for the primal convex programming problem (1), (2) and, then, in the bounded domainthe gradient of the function satisfies the Lipschitz condition. Proof of Theorem 1. Denote
,
,
,
,
and write the components of the gradient difference
Form vectors
with components
,
. Taking into account the notation and properties of the norm, we obtain from (24)
Let us estimate
taking into account (9):
Here, the last inequality is derived on the basis of the estimate
Get an estimate of
:
Finally, taking into account (23), we obtain the proof
where
. □
Gradient minimization methods are suitable for solving minimization problems with a Lipschitz gradient [
34].
5. Test Problems
We formed the following problems for testing:
Here, the parameters
c,
A,
b,
d are defined when tests are created. The constraints (27) together with (28) can be represented as follows
Denote
,
. Constraints (29) can be rewritten as
For problem (26) and (30), we write the Lagrange function
where
is the vector of Lagrange multipliers of the combined group of linear constraints (30)
The optimality conditions for the problem (26), (30) includes the stationarity conditions
and conditions of complementary slackness
In a linear programming problem, conditions (32)–(34) are sufficient for a feasible point x to be a minimum point [
30]. In a non-linear programming problem, conditions (32)–(34) and
are sufficient for a feasible point
x to be a local minimum [
19]. Based on the conditions (32)–(34), we will generate our test problems.
Algorithm for generating the test problem is as follows.
- (1)
Determine the number m of constraints, dimension n of the problem, the number mb of active constraints in (27), the number md of active constraints from the set of constraints , the number ma of active constraints from the set of constraints . We assume that the active constraints in each group are the first constraints.
- (2)
Define the elements of the matrix A according to the equation Aij = r(p,q), where r(p,q) is a uniformly distributed random number on the interval [p,q], 0 < p < q.
for i: =1 to m do
for j: =1 to n do
A[i,j]: =r(5,10).
- (3)
Set the boundaries 0 ≤ a ≤ d of the set Q, the optimal point x and the Lagrange multipliers yd,ya:yd = 0, ya = 0. Set the optimal point x by a generator of uniformly distributed numbers a < x < d. Set the boundaries of set Q
for i: =1 to n do
begin
a[i]: =5;
ya[i]: =0;
d[i]: =15;
yd[i]: =0;
end;
- (4)
To determine the first mb active constraints from the set of constraints Ax − b ≤ 0, we set the mb components of the vectors yb and b (yb,i > 0, bi = (Ax)i). The remaining components of the vector b are set according to the rule bi = (Ax)i(1 + 1/i + 0.1), and the Lagrange multipliers for them are assumed to be zero: yb,i = 0. Calculate b = Ax.
for i: =1 to n do
b[i]: =0;
for i: =1 to m do
for j: =1 to n do
b[i]: =b[i] + A[i,j] × x[j];
Set Lagrange multipliers for the active constraints
for i: =1 to m do
yb[i]: =0;
for i: =1 to mb do
yb[i]: =1;
Define the right side b for inactive constraints
for i: =mb + 1 to m do
b[i]: =b[i] × (1 + 1/I + 0.1);
- (5)
Find the parameters c in the representation of the function f(x,c) from (26), solving the system of Equation (32) with respect to c.
Since the elements of the matrix A are positive, the problem generated by the presented algorithm can be interpreted as a cost minimization problem under resource constraints. The resulting test problems are of the form (26)–(28) with the parameters c, A, b, d determined by given: the number m of constraints, the dimension n, the number mb of active constraints (27), the number of variables md lying on the upper boundary of the set Q, and the number ma of variables lying on the lower boundary of the set Q.
Table 1 shows the form of the test functions
f(
x) and the corresponding names of the dual functions.
A linear programming problem for the function
f1 was generated. Since some of the constraints (27) may not be satisfied for known dual variables, a regularized function [
34]
was used to solve the generated problem, with α = 0.01. The function
f2 has the parameter ε = 0.01.
Our functions are separable. Therefore, the solution of the problem necessary to obtain the dual function decomposes into a series of one-dimensional minimization problems.
Consider the solution of the problem (21) with the function
f(
x,
c) =
f2. Variables
u and
y are related according to (20), which means
Under the condition that there are no constraints on the variable
x, having solved the system
we obtain
Given the constraints
a ≤
x ≤
d, the solution
x(
y(
u)) has the form
The parameters u, x, y resulting from the solution of the minimization problem are denoted by , and the optimal parameters are . Having solved the unconstrained minimization problem (21), we find the parameters and Lagrange multipliers . The solution of the primal problem follows from the Equations (35) and (36).
For the dual function (5), the following relations
are fulfilled for any admissible
x and
y. Therefore, to assess the quality of the obtained solution, we will use the indicator
The second indicator will be obtained based on the assessment of the quality of the point
. The obtained solution of the primal problem may not satisfy the constraints (27). Therefore, the value of the objective function
may turn out to be less than
not suitable. In order to evaluate the quality of the approximation of the minimum value, we need to obtain a solution in the admissible area. Taking into account the specifics of the test problems, we will make its rough correction by moving to the admissible region along the ray
, where the vector
a is the lower bound of the set
Q. Let us denote
. We set
, where
is the maximum value
at which the point satisfies the constraints (27). Taking into account that the inequality
is fulfilled, the quality of the approximation of the objective function is estimated using the indicator
6. Solving Test Problems
Table 2,
Table 3,
Table 4 and
Table 5 show the results for dimensions
n = 1000,
m = 100. Each table contains the results of calculations for three functions with two ways of dual variable transformation. The number
mb of active constraints is varied.
The tables use labels
n for the number of variables of the primal problem (1),
m for the number of constraints in (2),
mb for the number of active constraints in (2),
md for the number of active constraints from the set of constraints
for
Q, and
ma for the number of active constraints from the set of constraints
for
Q. Each of the problems is specified by the name of the function from
Table 1 and the parameters (
N_
F,
nx,
ny,
mb,
ma,
md).
To solve problems (11), (31), we used the subgradient methods: sub [
43], Shor [
32], Orty [
42], and yv [
41] implemented with the one-dimensional search from [
41,
42,
43]. To solve problem (31), we used additional methods for minimizing smooth functions: the Polak–Ribière–Polyak conjugate gradient method (Msgr_PPR) [
34] and the quasi-Newtonian method BFGS [
44,
45,
46,
47].
The following conclusions have been made:
When varying the number mb of active constraints, no important differences in accuracy and number of function and gradient evaluations were found.
In the case of a modulus transformation of dual variables, due to manifestations of the degeneracy of the function, the calculation accuracy by the multi-step method sub is significantly inferior compared to the method yv with a change in the space metric of the RSM.
Due to the low dimensionality of the dual problem, the quality of the solution is somewhat lower for a modulus transformation of the dual variables than for the quadratic transformation for RSM with a change in the space metric.
The cost of solving the problem with a modulus transformation of dual variables increases significantly compared to a quadratic transformation.
The methods used for minimizing smooth functions (the conjugate gradient method and the quasi-Newtonian method) have excellent results both in terms of accuracy and number of function and gradient evaluations.
Table 6,
Table 7 and
Table 8 show the results for large-scale problems. The number
mb of active constraints is varied.
The performed computer experiment confirms the efficiency of the quadratic transformation.
7. Solving Applied Problem
For calculating MPE in the software package ERA-AIR [
55], two optimization models of the form (26)–(28) with objective functions
and
are implemented. For
f1 components
ci = −1, and for
f3 components
ci =
di,
i = 1,2,…,
n, where
di are vector
d components from (28). The variables
xi of the problem are the volumes of atmospheric pollution from pollution sources, the number of which can reach about 10,000. Constraints of the problem (27) are:
where the left part in (41) is the total concentration for all sources of atmospheric pollution,
bj is permissible concentration at the
j-th point, and
Aji is concentration per volume of emission from source
i in quota location
j. It is assumed that the vector
x components satisfy two-sided constraints (28). In (28), vector
d is the current state of MPE limitations for sources, and
a is the technical capability to reduce emissions.
As an example, we present the data collected as a consolidated volume of MPE for Kemerovo city in 2003 [
56] and give a solution to the problem of emission quotas for 1085 sources. Sources emit nitrogen dioxide into the atmosphere (MPC = 0.2 mg/m
3). For air pollution and emission quotas calculations (vector
x), we used the ERA-AIR software complex [
55]. The calculations were carried out on a regular grid of 22 km by 24 km with a step of 250 m.
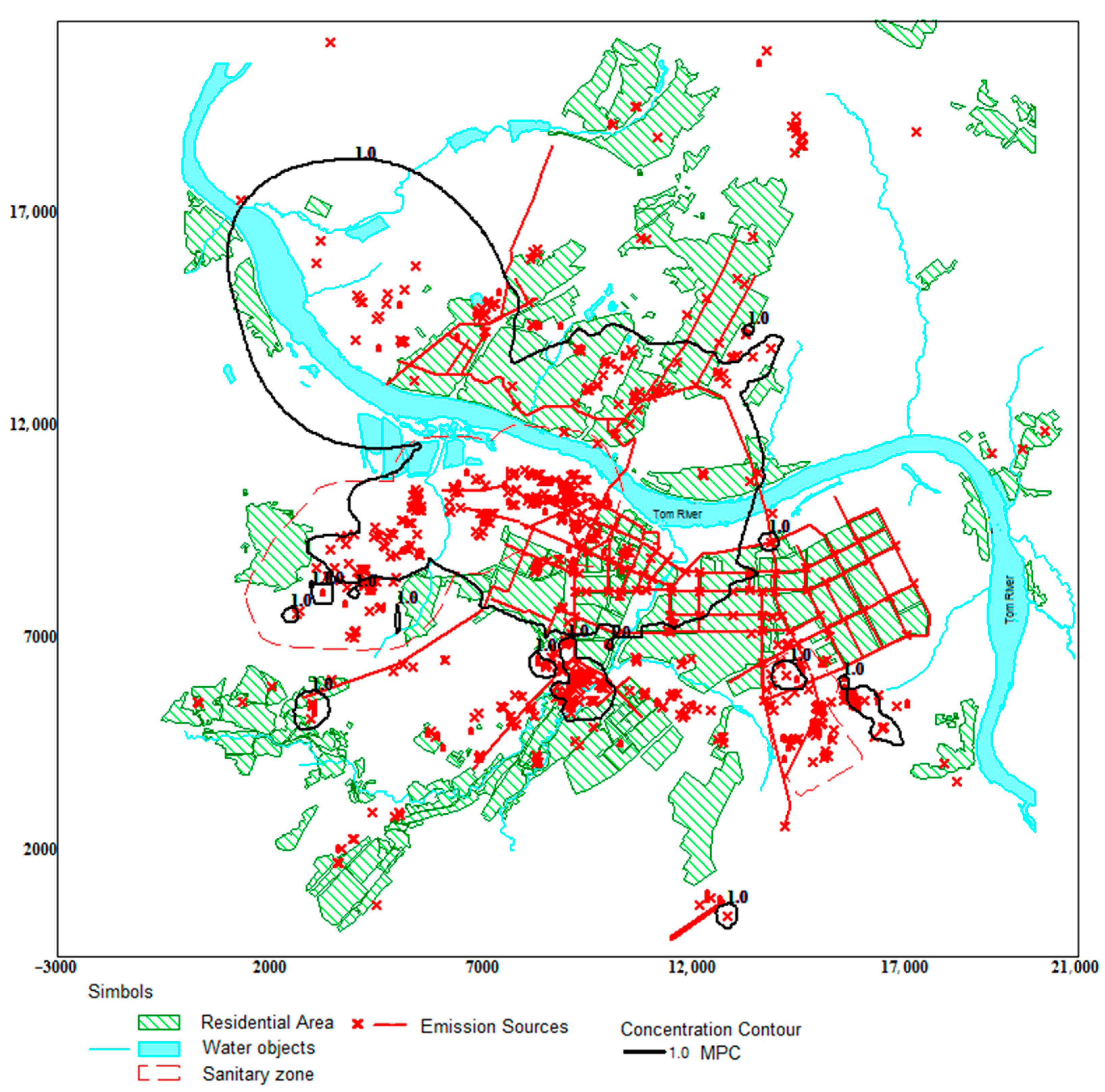
Figure 2 shows the area exceeding the maximum one-time surface concentrations, obtained by calculating, according to the Russian regulatory methodology in search mode, the maximum in terms of the wind speed and direction. It can be seen that the pollution zone with an excess of the MPC (inside the black line) covers the living sector closest to the industrial site, where compliance with MPC is required. To select points for the constraints (27) on the concentration, an additional calculation was performed to cover the living sector with 300 calculated points, which will be the set of quota points.
To solve the problem in the selected quota points, the influence coefficients
Aji are calculated, which form the matrix
A. All elements of the
bj vector in this example are equal to MPC, but their individual values can be set. The vectors
a and
d of constraints (28) on the solution search area
x are given as follows: the vector
d is a set of emissions from all 1085 sources for which the initial calculation was carried out, and the vector
a = 0.1
d. Thus, the MPE for each source cannot exceed its existing emission, and the allowable emission reduction at the source cannot be more than 90%. The problem was solved by various methods. The coefficients of socio-economic significance [
57] were chosen to be the same and were given above, and, in this example, these are the components of the vector
C.
The ERA-AIR software package includes modules for calculating source emission reductions (necessary to achieve MPC) using methods [
58,
59]. The first of them [
58] enables one to find a unique solution to the system of inequalities (41), but it is not an optimization one. The second [
59] makes it possible to achieve MPC with a minimum reduction in emissions, with a total for the entire set of emission sources in the city. Recently, a method for solving problem (3–5) [
57] considered in [
33] has been added to them.
In this work, we used the modulus and quadratic methods of transforming the variables of the dual function. We used the linear programming model with regularization
[
59] and the non-linear emission quota model
[
57]. Due to property (37) for the function
f3, we can use a criterion for evaluating the quality of the solution, similar to (38)
where
fd is calculated by the previously described method (39), (40), and the point
ŷ is the solution found for the dual problem.
Using the quadratic method, we obtained solutions for the model f3 with an accuracy by each of the above methods. For the modulus method , at the same time, the cost of the function and the gradient calculations is approximately two times higher than with the quadratic method.
Table 9 shows the results of changes in total emissions when MPC is reached in a living sector.
The solution of the optimization problem with the function f1 makes enables us to provide limits on pollution while leaving a noticeably larger total value of emissions compared to the other two methods. The main purpose of the numerical experiment is to demonstrate the efficiency of the proposed methods in solving the problems of calculating quotas for a fairly large industrial city. The necessary preliminary testing of the methods was carried out in order to ensure the trouble-free operation of the minimization methods built into the system when calculating numerous variants of the problem that arise due to the dependence of the coefficients of the matrix A on air temperature, wind strength, and direction.
8. Conclusions
In the problem of convex programming with a strongly convex objective function, we studied the possibility of reducing the dual problem to an unconstrained minimization problem under the constraint of positivity of the variables. Two methods of transforming the components of the dual variables were studied. In the case of a modulus transformation of dual variables, it is shown that the dual function is non-smooth, and its degree of degeneracy increases as it approaches the extremum. This fact negatively affects the convergence rate of the minimization method and leads to a decrease in the accuracy of the resulting solution. This leads to the necessity of involving complex subgradient methods of accelerated convergence with a change in the space metric for solving the problem.
The proposed quadratic method for transforming dual variables has been investigated theoretically. We have proved that in the case of a quadratic transformation of dual variables, the dual function has a Lipschitz gradient. This property of the gradient makes it possible to apply efficient methods of unconstrained minimization of smooth functions. In this case, in comparison with the modulus method, the convergence rate of the minimization method and the accuracy of solving the problem increase. Our computer experiment confirms the efficiency of the quadratic transformation.
Based on the research conducted, the following general conclusions can be drawn.
Firstly, in the case of modulus transformation of dual variables at high dimensions, due to the high degree of the function degeneracy, in order to obtain sufficient computational accuracy, it is necessary to use subgradient minimization methods with a change in the space metric, which is confirmed by comparing the results of the multi-step sub method and the yv method.
Secondly, the quality of the solution of the dual minimization problem with the modulus method is significantly reduced in comparison with the quadratic transformation.
Thirdly, the cost of solving the dual minimization problem with the modulus method increases significantly compared to the quadratic transformation.
Fourthly, the methods used for minimizing smooth functions (the conjugate gradient method and the quasi-Newtonian method) have results both in accuracy and in the cost of the function and gradient calculations commensurate with the best results for RSMs.
The results of solving an applied problem are commensurate in accuracy and quality with the results for similar test problems.
Author Contributions
Conceptualization, V.K. and E.T.; methodology, V.K., E.T., A.B., E.C. and P.S.; software, V.K. and A.B.; validation, L.K., E.T. and P.S.; formal analysis, E.T., P.S. and A.B.; investigation, V.K., E.T. and E.C.; resources, L.K.; data curation, P.S. and A.B.; writing—original draft preparation, V.K. and E.T.; writing—review and editing, E.T., P.S. and L.K.; visualization, V.K. and E.T.; supervision, V.K. and P.S.; project administration, P.S.; funding acquisition, P.S. and L.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Ministry of Science and Higher Education of the Russian Federation (Grant No. 075-15-2022-1121).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Zhao, T.H.; Shi, L.; Chu, Y.M. Convexity and concavity of the modified Bessel functions of the first kind with respect to Hölder means. Rev. De La Real Acad. De Cienc. Exactas Físicas Y Naturales. Ser. A. Matemáticas 2020, 114, 96. [Google Scholar] [CrossRef]
- Zhao, T.H.; Wang, M.K.; Chu, Y.M. Monotonicity and convexity involving generalized elliptic integral of the first kind. Rev. De La Real Acad. De Cienc. Exactas Físicas Y Naturales. Ser. A. Matemáticas 2021, 115, 46. [Google Scholar] [CrossRef]
- Khan, M.A.; Adnan; Saeed, T.; Nwaeze, E.R. A New Advanced Class of Convex Functions with Related Results. Axioms 2023, 12, 195. [Google Scholar] [CrossRef]
- Khan, M.A.; Ullah, H.; Saeed, T. Some estimations of the Jensen difference and applications. Math. Methods Appl. Sci. 2022, 1–30. [Google Scholar] [CrossRef]
- Li, Y.; Tang, X.; Lin, X.; Grzesiak, L.; Hu, X. The role and application of convex modeling and optimization in electrified vehicles. Renew. Sustain. Energy Rev. 2022, 153, 111796. [Google Scholar] [CrossRef]
- Gbadega, P.A.; Sun, Y. Primal–dual interior-point algorithm for electricity cost minimization in a prosumer-based smart grid environment: A convex optimization approach. Energy Rep. 2022, 8, 681–695. [Google Scholar] [CrossRef]
- Liu, B.; Sun, C.; Wang, B.; Liang, W.; Ren, Q.; Li, J.; Sun, F. Bi-level convex optimization of eco-driving for connected Fuel Cell Hybrid Electric Vehicles through signalized intersections. Energy 2022, 252, 123956. [Google Scholar] [CrossRef]
- Huotari, J.; Manderbacka, T.; Ritari, A.; Tammi, K. Convex optimisation model for ship speed profile: Optimisation under fixed schedule. J. Mar. Sci. Eng. 2021, 9, 730. [Google Scholar] [CrossRef]
- Dong, C.; Yang, H.; Li, S.; Li, B. Convex optimization of asteroid landing trajectories driven by solar radiation pressure. Chin. J. Aeronaut. 2022, 35, 200–211. [Google Scholar] [CrossRef]
- Li, Y.; Wei, C.; He, Y.; Hu, R. A convex approach to trajectory optimization for boost back of vertical take-off/vertical landing reusable launch vehicles. J. Frankl. Inst. 2021, 358, 3403–3423. [Google Scholar] [CrossRef]
- Sagliano, M.; Mooij, E. Optimal drag-energy entry guidance via pseudospectral convex optimization. Aerosp. Sci. Technol. 2021, 117, 106946. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhao, D.; Li, X.; Kong, C.; Su, M. Convex Optimization for Rendezvous and Proximity Operation via Birkhoff Pseudospectral Method. Aerospace 2022, 9, 505. [Google Scholar] [CrossRef]
- Li, W.; Li, W.; Cheng, L.; Gong, S. Trajectory Optimization with Complex Obstacle Avoidance Constraints via Homotopy Network Sequential Convex Programming. Aerospace 2022, 9, 720. [Google Scholar] [CrossRef]
- Shen, Z.; Chen, Q.; Yang, F. A convex relaxation framework consisting of a primal–dual alternative algorithm for solving ℓ0 sparsity-induced optimization problems with application to signal recovery based image restoration. J. Comput. Appl. Math. 2023, 421, 114878. [Google Scholar] [CrossRef]
- Popescu, C.; Grama, L.; Rusu, C. A Highly scalable method for extractive text summarization using convex optimization. Symmetry 2021, 13, 1824. [Google Scholar] [CrossRef]
- Yu, W. Convex optimization of random dynamic voltage and frequency scaling against power attacks. Integration 2022, 82, 7–13. [Google Scholar] [CrossRef]
- Bolívar-Nieto, E.A.; Summers, T.; Gregg, R.D.; Rezazadeh, S. A convex optimization framework for robust-feasible series elastic actuators. Mechatronics 2021, 79, 102635. [Google Scholar] [CrossRef]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization methods for large-scale machine learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Anikin, A.S.; Gasnikov, A.V.; Dvurechensky, P.E.; Tyurin, A.I.; Chernov, A.V. Dual approaches to the minimization of strongly convex functionals with a simple structure under affine constraints. Comput. Math. Math. Phys. 2017, 57, 1262–1276. [Google Scholar] [CrossRef]
- Nesterov, Y. Primal-dual subgradient methods for convex problems. Math. Program. Ser. B 2009, 120, 261–283. [Google Scholar] [CrossRef]
- Nemirovski, A.; Onn, S.; Rothblum, U.G. Accuracy certificates for computational problems with convex structure. Math. Oper. Res. 2010, 35, 52–78. [Google Scholar] [CrossRef]
- Devolder, O. Exactness, Inexactness and Stochasticity in First-Order Methods for Large-Scale Convex Optimization. Ph.D. Thesis, CORE UCLouvain, Louvain-la-Neuve, Belgium, 2013. [Google Scholar]
- Nesterov, Y. New primal-dual subgradient methods for convex optimization problems with functional constraints. In Proceedings of the International Workshop “Optimization and Statistical Learning”, Les Houches, France, 11–16 January 2015. [Google Scholar]
- Nesterov, Y. Complexity Bounds for Primal-Dual Methods Minimizing the Model of Objective Function. CORE Discussion Papers. 2015. Available online: https://uclouvain.be/en/research-institutes/lidam/core/core-discussion-papers.html (accessed on 27 January 2023).
- Gasnikov, A.V.; Gasnikova, E.V.; Dvurechensky, P.E.; Ershov, E.I.; Lagunovskaya, A.A. Search for the stochastic equilibria in the transport models of equilibrium flow distribution. Proc. MIPT 2015, 7, 114–128. [Google Scholar]
- Komodakis, N.; Pesquet, J.-C. Playing with Duality: An overview of recent primal-dual approaches for solving large-scale optimization problems. IEEE Signal Process. Mag. 2015, 32, 31–54. [Google Scholar] [CrossRef]
- Dvurechensky, P.; Shtern, S.; Staudigl, M. First-order methods for convex optimization. EURO J. Comput. Optim. 2021, 9, 100015. [Google Scholar] [CrossRef]
- Cohen, M.B.; Sidford, A.; Tian, K. Relative lipschitzness in extragradient methods and a direct recipe for acceleration. In Proceedings of the Innovations in Theoretical Computer Science Conference (ITCS 2021), Cambridge, MA, USA, 6–8 January 2021; pp. 62:1–62:18. [Google Scholar] [CrossRef]
- Dvurechensky, P.E.; Gasnikov, A.V.; Nurminski, E.A.; Stonyakin, F.S. Advances in Low-Memory Subgradient Optimization. In Numerical Nonsmooth Optimization; Bagirov, A., Gaudioso, M., Karmitsa, N., Mäkelä, M., Taheri, S., Eds.; Springer: Cham, Switzerland, 2020; pp. 19–59. [Google Scholar]
- Ghadimi, S.; Lan, G.; Zhang, H. Generalized uniformly optimal methods for non-linear programming. J. Sci. Comput. 2019, 79, 1854–1881. [Google Scholar] [CrossRef]
- Tang, Y.; Qu, G.; Li, N. Semi-global exponential stability of augmented primal–dual gradient dynamics for constrained convex optimization. Syst. Control Lett. 2020, 144, 104754. [Google Scholar] [CrossRef]
- Shor, N. Minimization Methods for Nondifferentiable Functions; Springer: Berlin/Heidelberg, Germany, 1985. [Google Scholar]
- Krutikov, V.; Bykov, A.; Tovbis, E.; Kazakovtsev, L. Method for calculating the air pollution emission quotas. In Mathematical Optimization Theory and Operations Research. MOTOR 2021; Communications in Computer and Information Science; Strekalovsky, A., Kochetov, Y., Gruzdeva, T., Orlov, A., Eds.; Springer: Cham, Switzerland, 2021; Volume 1476, pp. 342–357. [Google Scholar] [CrossRef]
- Polyak, B.T. Introduction to Optimization; Optimization Software: New York, NY, USA, 1987. [Google Scholar]
- Dvurechensky, P.; Gasnikov, A.; Ostroukhov, P.; Uribe, C.; Ivanova, A. Near-Optimal Tensor Methods for Minimizing the Gradient Norm of Convex Function. 2019. Available online: https://arxiv.org/abs/1912.03381v3 (accessed on 27 January 2023).
- Nesterov, Y. Inexact accelerated high-order proximal-point methods. Math. Program. 2023, 197, 1–26. [Google Scholar] [CrossRef]
- Nesterov, Y. Inexact high-order proximal-point methods with auxiliary search procedure. SIAM J. Comput. 2021, 31, 2807–2828. [Google Scholar] [CrossRef]
- Wolfe, P. Note on a method of conjugate subgradients for minimizing nondifferentiable functions. Math. Program. 1974, 7, 380–383. [Google Scholar] [CrossRef]
- Lemarechal, C. An extension of Davidon methods to non-differentiable problems. Math. Program. Study 1975, 3, 95–109. [Google Scholar]
- Krutikov, V.; Meshechkin, V.; Kagan, E.; Kazakovtsev, L. Machine Learning Algorithms of Relaxation Subgradient Method with Space Extension. In Mathematical Optimization Theory and Operations Research. MOTOR 2021; Lecture Notes in Computer Science; Pardalos, P., Khachay, M., Kazakov, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12755, pp. 477–492. [Google Scholar]
- Krutikov, V.N.; Stanimirovic, P.S.; Indenko, O.N.; Tovbis, E.M.; Kazakovtsev, L.A. Optimization of Subgradient Method Parameters Based on Rank-Two Correction of Metric Matrices. J. Appl. Ind. Math. 2022, 16, 427–439. [Google Scholar] [CrossRef]
- Krutikov, V.; Gutova, S.; Tovbis, E.; Kazakovtsev, L.; Semenkin, E. Relaxation subgradient algorithms with machine learning procedures. Mathematics 2022, 10, 3959. [Google Scholar] [CrossRef]
- Krutikov, V.N.; Vershinin, Y.N. The subgradient multistep minimization method for nonsmooth high-dimensional problems. Vestn. Tomsk. Gos. Univ. Mat. I Mekhanika 2014, 3, 5–19. (In Russian) [Google Scholar]
- Broyden, C.G. The convergence of a class of double-rank minimization algorithms. J. Inst. Math. Appl. 1970, 6, 76–90. [Google Scholar] [CrossRef]
- Fletcher, R. A new approach to variable metric algorithms. Comp. J. 1970, 13, 317–322. [Google Scholar] [CrossRef]
- Goldfarb, D.F. A family of variable-metric methods derived by variational means. Math. Comp. 1970, 24, 23–26. [Google Scholar] [CrossRef]
- Shanno, D. Conditioning of quasi-Newton methods for function minimization. Math. Comp. 1970, 24, 647–656. [Google Scholar] [CrossRef]
- Yu, B.; Lee, W.S.; Rafiq, S. Air Pollution Quotas and the Dynamics of Internal Skilled Migration in Chinese Cities. IZA Discussion Paper Series. Available online: https://www.iza.org/publications/dp/13479/air-pollution-quotas-and-the-dynamics-of-internal-skilled-migration-in-chinese-cities (accessed on 2 February 2023).
- Zhao, C.; Kahn, M.E.; Liu, Y.; Wang, Z. The consequences of spatially differentiated water pollution regulation in China. J. Environ. Econ. Manag. 2018, 88, 468–485. [Google Scholar] [CrossRef]
- Yu, S.; Wei, Y.M.; Wang, K. Provincial allocation of carbon emission reduction targets in China: An approach based on improved fuzzy cluster and Shapley value decomposition. Energy Policy 2014, 66, 630–644. [Google Scholar] [CrossRef]
- Pozo, C.; Galan-Martin, A.; Cortes-Borda, D.; Sales-Pardo, M.; Azapagic, A.; Guimera, R.; Guillen-Gosalbez, G. Reducing global environmental inequality: Determining regional quotas for environmental burdens through systems optimization. J. Clean. Prod. 2020, 270, 121828. [Google Scholar] [CrossRef]
- Liu, H.; Lin, B. Cost-based modeling of optimal emission quota allocation. J. Clean. Prod. 2017, 149, 472e484. [Google Scholar] [CrossRef]
- Wang, X.; Cai, Y.; Xu, Y.; Zhao, H.; Chen, J. Optimal strategies for carbon reduction at dual levels in China based on a hybrid nonlinear grey-prediction and quota-allocation model. J. Clean. Prod. 2014, 83, 185–193. [Google Scholar] [CrossRef]
- Nugroho, S.A.; Taha, A.F.; Hoang, V. Nonlinear Dynamic Systems Parameterization Using Interval-Based Global Optimization: Computing Lipschitz Constants and Beyond. IEEE Trans. Automat. Contr. 2022, 67, 3836–3850. [Google Scholar] [CrossRef]
- The ERA-AIR Software Complex. Available online: https://lpp.ru/ (accessed on 18 February 2023).
- Azhiganich, T.E.; Alekseichenko, T.G.; Bykov, A.A. Conducting summary calculations of atmospheric pollution in Kemerovo for emission regulation and diagnostic assessments. In Proceedings of the V City Scientific and Practical Conference, Kemerovo, Russia, 17–18 November 2003; pp. 41–45. [Google Scholar]
- Ministry of Natural Resources of the Russian Federation. The Order of the Ministry of Natural Resources of the Russian Federation Dated 29.11.2019 N 814 “On Approval of the Rules for Emissions Quotas of Pollutants (except Radioactive Substances) into the atmosphere” (Registered with the Ministry of Justice of the Russian Federation on 24.12.2019 n 56956); Ministry of Natural Resources of the Russian Federation: Moscow, Russia, 2019.
- Russian State Ecological Committee. The Order 16.02.1999 N 66. Regulations on Using the Sistem of Aggregate Calculations of Atmospheric Pollution for Finding Admissible Quotas of Industrial and Motor Transport Emissions; Russian State Ecological Committee: Moscow, Russia, 1999. [Google Scholar]
- Meshechkin, V.V.; Bykov, A.A.; Krutikov, V.N.; Kagan, E.S. Distributive Model of Maximum Permissible Emissions of Enterprises into the Atmosphere and Its Application. IOP Conf. Ser. Earth Environ. Sci. 2019, 224, 012019. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 



{kind=link}
{kind=link}