1. Introduction
Over the past years, different solutions have been proposed to reduce instructors’ workload and facilitate the interaction between teachers and students [
1]. An early example of such a technique is one-to-one interaction models, which are well suited for courses with a small number of students. However, assessment clustering becomes challenging when large classes with hundreds of students, or massive online open online courses, are involved. Accordingly, reducing instructors’ workloads in the above situations becomes important in educational systems. To address this challenge, Artificial Intelligence (AI) has been used in intelligent tutoring systems to cluster similar texts. Examples of such systems can be seen in computer science courses, programming courses, or detecting plagiarism [
2,
3].
Unsupervised clustering is an important research topic in data science, machine learning and artificial intelligence. It has been used in a wide range of applications, ranging from document analysis [
4] to image retrieval [
5], for various systems. During the past few decades, a lot of clustering algorithms have been proposed, such as Kmeans [
6], Gaussian mixture model [
5], and Self Organising Map (SOM) [
7]. Although unsupervised clustering algorithms have been studied widely, the performance of these traditional clustering methods generally deteriorate when the data dimensionality is high, due to unreliable similarity metrics. The assumptions underlying the dimensionality reduction techniques are generally independent of the assumptions of the clustering techniques, which is known as the curse of dimensionality. To solve this problem, a common way is to transform data from high dimensionality to lower dimensionality by applying dimension reduction techniques, like principle component analysis (PCA) [
8] or feature selection methods [
9]. Then, clustering is performed in the lower dimensional feature space. However, this scheme ignores the interconnection between feature learning and clustering. To address this issue, with the development of deep learning, such feature transformation can be achieved by using Deep Neural Networks (DNNs), referred to as deep clustering. There are two different stages for deep clustering, representation and clustering, which can be combined by two strategies. On the one hand, the clustering stage can be adopted after the representation stage [
10]. On the other hand, the representation and clustering stages can be jointly combined [
11].
Deep Embedded Clustering (DEC) [
12] has been proposed to improve the deep feature representation results by simultaneously learning feature representations and cluster assignments. However, DEC does not make use of prior knowledge to guide the learning process. Semi-supervised Deep Embedded Clustering (SDEC) is proposed to overcome this limitation [
13,
14]. Some pioneering work proposes to simultaneously learn embedded features and perform clustering by explicitly defining a clustering-oriented loss. Though promising performance has been demonstrated in various applications, a vital ingredient has been overlooked, which is that the defined clustering loss may corrupt feature space. This, then, leads to non-representative meaningless features, and this, in turn, hurts clustering performance. To address this issue, an Improved Deep Embedded Clustering (IDEC) algorithm is proposed to take care of data structure preservation [
15].
To cluster similar features, the Kmeans clustering algorithm was used in [
12,
13,
15]. Although Kmeans is a simple and effective clustering algorithm, it is especially sensitive to the choice of K and the initial starting conditions [
16]. With its natural property of the neural network, SOM can solve these problems. When combining the Kmeans algorithm with representation, the centres are determined which cannot adjust when training [
12,
13,
15]. This kind of alternation learning method would suffer from the error accumulated during the alternation between the stages of representation learning and clustering, which results in sub-optimal clustering performance. Moreover, the aforementioned methods can only deal with offline tasks, i.e., the clustering is based on the whole dataset, which limits their application on large-scale online learning scenarios [
17]. To conquer the aforementioned offline limitation, a one-stage online deep clustering method called Contrastive Clustering is proposed [
17,
18].
In this paper, we present a novel model by considering the contrastive learning loss and clustering loss to enable learning distributed representations of assessments with deeply embedded clustering to cluster similar assessments. Compared to [
19,
20], we propose using Pre-trained language models (PLMs) to represent assessment content as vectors because PLMs have been shown to be effective in improving natural language processing (NLP) tasks [
21,
22]. Specifically, we use BERT (Bidirectional Encoder Representation from Transformers) [
23] for this purpose. In this context, Instance-wise Contrastive Learning (Instance-CL) has recently achieved remarkable success in self-supervised learning. Supervised Contrastive Learning (SCL) [
24] term fine-tuned to the objective can significantly improve the performance on natural language understanding tasks from the GLUE benchmark [
25]. Compared to [
12,
13,
15], the effectiveness of SCL is studied in this paper. How to use SCL, however, can be challenging to cluster assessments. To address these challenges, we propose a general clustering framework that transforms assessments into vectors in terms of SCL loss and clustering assessments. The major contributions of the paper are summarized as follows:
A deep embedding strategy is used jointly to cluster similar texts, which can improve the representation of texts.
A loss, based on supervised contrastive learning and Kullback Leibler (KL) divergence [
15], is used on clustering texts, which can not only cluster similar texts, but also distinguish the difference in a cluster.
A general framework for clustering is proposed, which compares different clustering algorithms. SOM is first combined with deep representation. The results show the effectiveness of our proposed models in clustering texts which can significantly reduce instructor workload in marking assessments.
The rest of the paper is organized as follows. In
Section 2, we discuss the related work, and in
Section 3 we detail the problem descriptions and proposed models. The general framework is proposed in
Section 4. Finally, the experimental results are reported in
Section 5, followed by conclusions and future research directions in
Section 6.
2. Related Work
To reduce instructors’ workload, a series of text techniques such as text mining [
26,
27,
28,
29], text clustering [
12,
13,
15], and text representation [
23,
30] were studied. Natural language processing (NLP) has been used widely in different applications. Neural models have become a dominant approach in NLP. For encoding texts, bi-directional LSTMs (BiLSTMs) [
30] have been a dominant method among various neural networks, in terms of state-of-the-art studies in language modeling [
31], machine translation [
32], syntactic parsing [
33] and question answering [
34]. Sequential information flow for LSTM leads to relatively weaker power in capturing long-range dependencies, which results in lower performance during encoding longer sentences. To solve the problem, the sentence similar function was studied, based on word2vector similar elements [
35], while word2vector only represented static word information. Sentence2vector considers information in a sentence while it ignores the information in assessments. Pre-trained BERT is easily fine-tuned with an additional output layer to create a state-of-the-art model for a wide range of tasks which suggests that BERT representations are potential universal text embedding. BERT [
23] was applied to short answer grading. A python-based RESTful service, that utilizes the BERT model for text embedding, and Kmeans clustering, to identify sentences closest to the centroid for summary selection [
36,
37,
38], provides students with a utility that could summarize lecture content, based on the desired number of sentences. A Sentence-BERT (SBERT), a modification of the pre-trained BERT network, that uses siamese and triplet network structures, was proposed to derive semantically meaningful sentence embedding that can be compared using cosine-similarity [
39].
Deep Embedded Clustering. To improve the representation performance for clustering, there are two categories of deep clustering algorithms in existing studies: (i) clustering applied after having learned a representation, and (ii) approaches jointly optimized by feature learning and clustering. The first category of algorithms takes advantage of existing unsupervised deep learning frameworks and techniques. For example, autoencoder is used to learn low dimensional features of an original graph [
40], and then runs the Kmeans algorithm to get clustering results [
41]. A clustering loss is defined in the second category of algorithms, which simulates classification error in supervised deep learning. DEC [
12] learns a mapping from the observed space to a low-dimensional latent space with deep neural networks, which can obtain feature representations and cluster assignments simultaneously and starts with pre-training an autoencoder and then removing the decoder. Existing deep embedded clustering algorithms only consider Kmeans algorithms and only work for offline tasks [
17]. To solve this problem, the SOM algorithm was used in this paper, which has never before been considered for text representation in existing studies.
SOM Algorithms. SOM has the special property of effectively creating spatially organized internal representations of various features of input signals and their abstractions [
42]. SOM is an automatic data analysis method that is widely applied to clustering problems and data exploration in industry, finance, natural sciences, and linguistics [
43,
44]. A SOM-similar network is designed to simultaneously implement encoding and clustering purposes on data samples, which are jointly trained with a Generative Adversarial Network (GAN) to optimize a newly defined clustering loss [
45]. Principal Component Analysis (PCA) was combined with a SOM to determine the pull-off adhesion between concrete layers [
46]. SOM algorithms have been used widely to cluster similar tasks [
19,
20,
47]. However, there are no existing studies that combine SOM with BERT in text representation and clustering.
Contrastive Learning. Contrastive learning has recently become a dominant component in self-supervised learning for natural language processing. It aims to embed augmented versions of the same sample close to each other, while trying to distinguish embedding from different samples [
48,
49]. Therefore, different instances are isolated in the learned embedding space with local invariance, which is preserved for each instance. Contrastive learning at a particular instance, considers the level [
48,
49] while performing, whereas the method simultaneously conducts contrastive learning at both the instance- and cluster-level following the observation of label as representation [
17]. Existing works aimed to learn a general representation, which is off-the-shelf for the downstream tasks. On the contrary, the method is specifically designed for clustering, which could be the first successful attempt at task-specified contrastive learning. In this paper, contrastive learning loss was first used on clustering texts with SOM, which has never before been considered in existing studies [
23,
50,
51,
52,
53,
54].
In this paper, we first combine text representation and contrastive learning with SOM algorithms in deep-embedded clustering, which has never been considered in the existing studies.
4. Algorithms
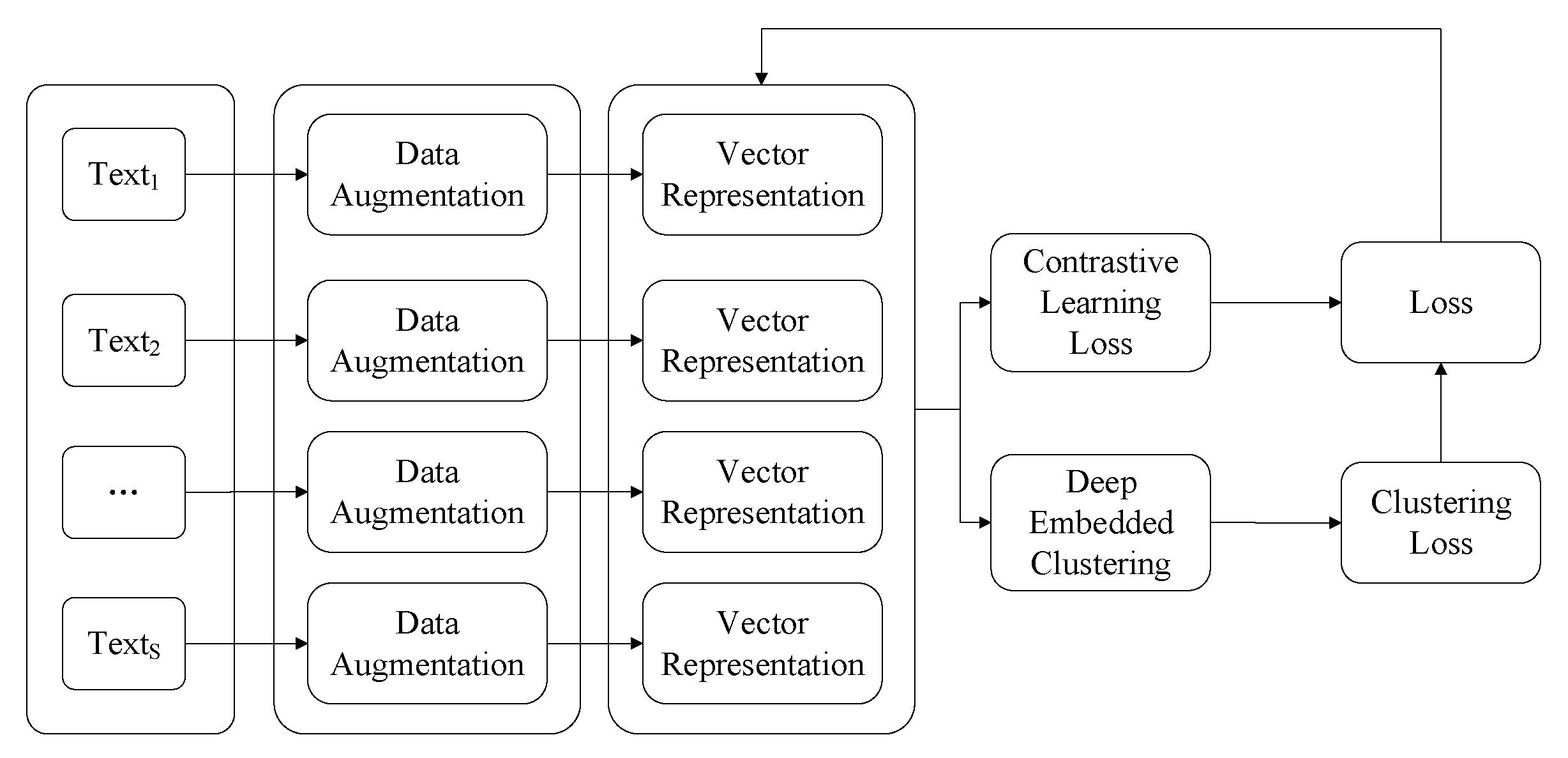
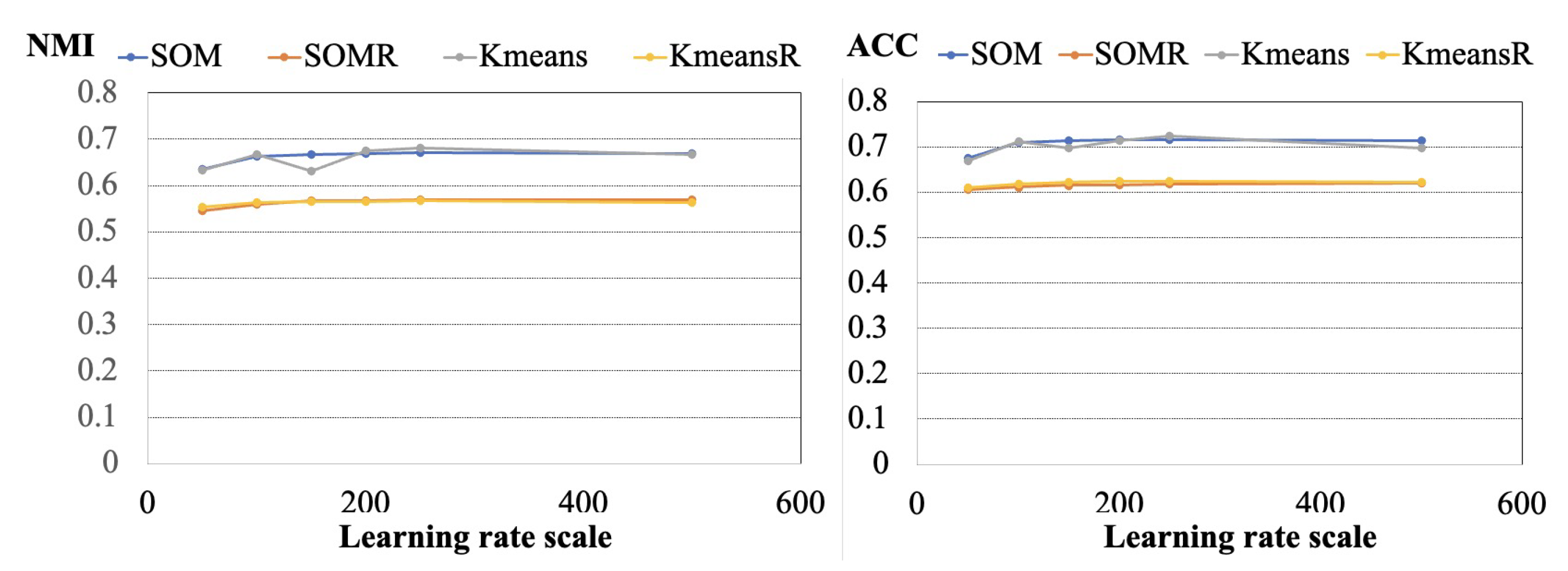
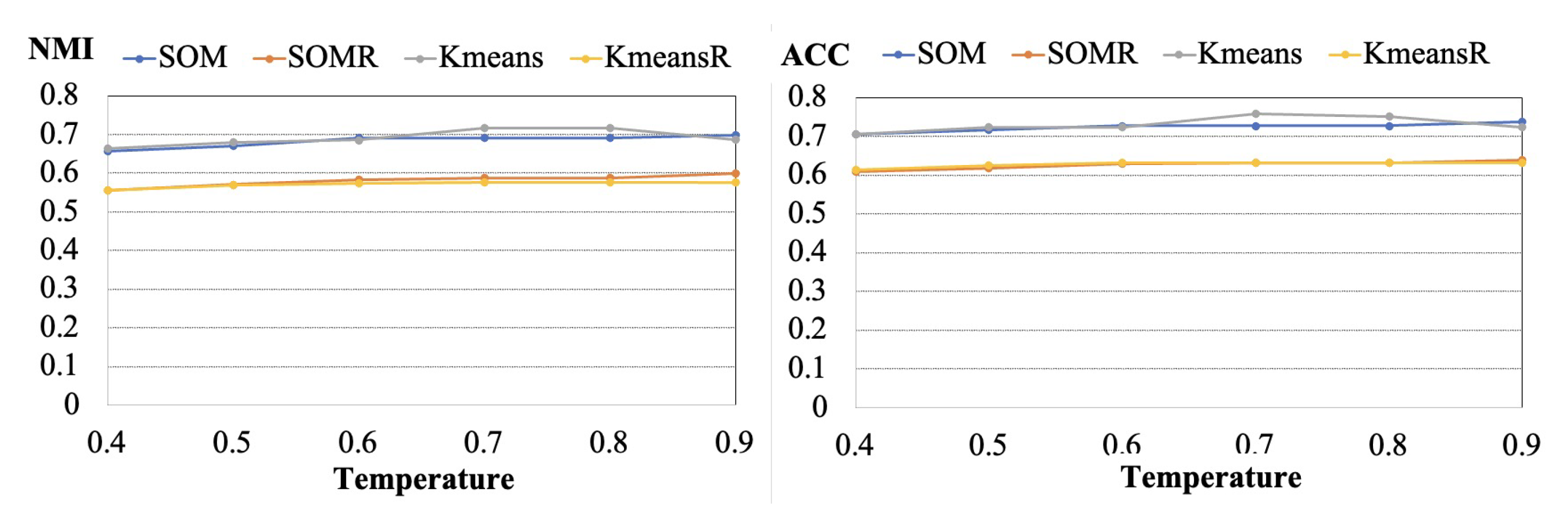
To cluster similar assessments, Distill BERT was first used to transform texts into vectors with a text augmentation technique. After augmentation, contrastive learning and clustering techniques were adopted to cluster similar texts. Since for different clustering algorithms the efficiency is different. We propose three different clustering algorithms with the proposed model. The proposed algorithm framework is described in Algorithm 1. To calculate the efficiency of Algorithm 1, the adopt Accuracy (ACC) and Normalized Mutual Information (NMI) are measured. NMI is calculated by NMI where Y is the real label, C is the clustering label, H(.) is the cross entropy, and I(.;.) is the mutual information.
To describe the algorithm framework clearly in Algorithm 1, the input data contains dataset S, training epochs E, temperature in contrastive learning and the structure of augmentation, while the output results are ACC and NMI. A mini-batch of texts is selected from dataset S. For each input sample , two random augmentations are generated where , which represents a different view of the text and contains some subset of the information in the original sample. () are denoted as the augmented text of an assessment . After text augmentation, the contrastive loss is calculated according to the temperature . Texts are transformed into vectors by DistilBERT. The predicted labels are obtained after the clustering algorithms. By comparing predicted labels to ground truth labels, the clustering loss is calculated. According to the instance loss and clustering loss, the overall loss is obtained. The ACC and NMI metrics are calculated.
The deeply embedded clustering framework is described in Algorithm 1. For vector clustering techniques, there are three different strategies: label as representation, Kmeans algorithm, and SOM algorithm. For label as representation, the dimension of vectors is projected to the number of clusters by multiple neuron networks. The index of the maximum values of the vector is represented as the label of clusters. After all of the vectors are projected to the fixed dimensions, Kmeans and SOM algorithms are used to cluster similar vectors together, respectively. To calculate the clustering centers for the label as representation algorithms, Kmeans and SOM algorithms are adopted, respectively.
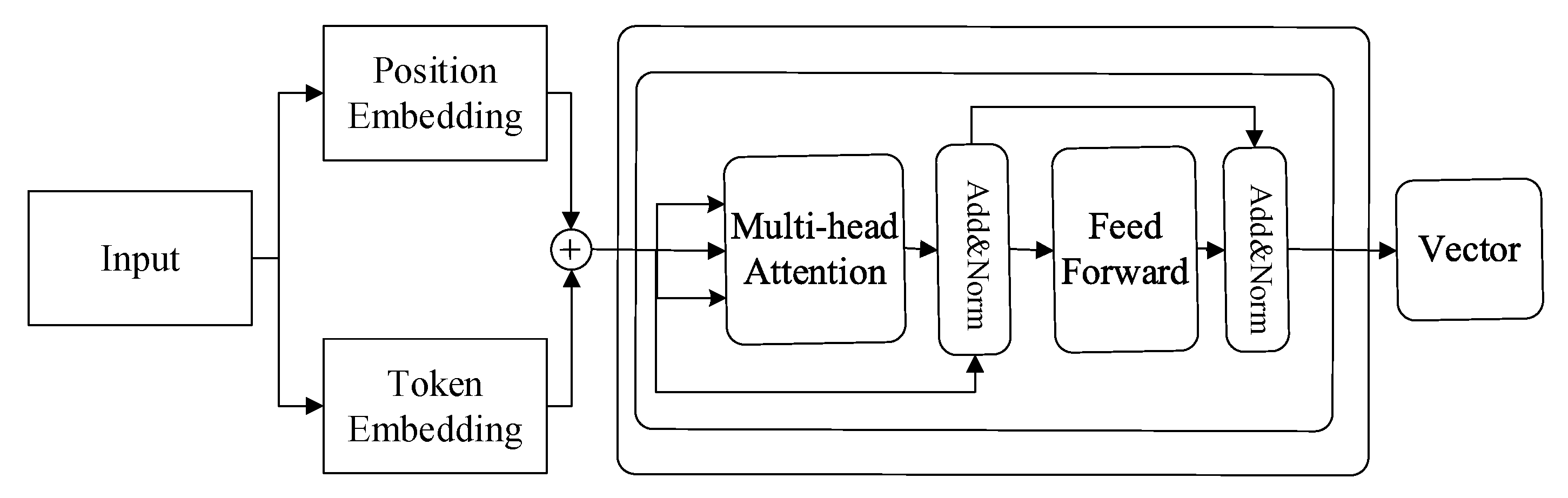
The label as a representation algorithm is shown in Algorithm 2. The input of the algorithm is the matrices , and which are made up of where are represented by DistilBERT. The labels are initialized first. According to the idea of the label as representation, all the represented vectors are projected to K dimensions. The index of the maximum value selects the label for the projected vectors. The time complexity of the Algorithm 2 is .
The Kmeans clustering algorithm is described in Algorithm 3. To describe Algorithm 3 clearly,
are denoted as the initial centroids. All the vectors in
Z are compared with
K centroids. The vector with the minimum distance to the centroid
is assigned to
. After all the vectors are assigned, new centroids are calculated in terms of new
(
). The procedure is repeated until the conditions are not satisfied. The label
L for
Z is obtained with the final centroids. The labels
for
and
are obtained, similarly. The time complexity for Algorithm 3 is
.
| Algorithm 1: Deep Embedded Clustering Framework |
![Algorithms 16 00158 i001]() |
| Algorithm 2: Label as Representation Algorithm |
![Algorithms 16 00158 i002]() |
The SOM clustering algorithm is described in Algorithm 4. The input data includes parameters
for the map, the input matrix
Z, the iteration times
T, and the parameter
. The weight matrix
W is initialized where each raw is a unit vector. To compare the input matrix
W to
Z, each raw of
Z is normalized to a unit vector. By comparing
Z to
W, the distance from
to all the neurons is calculated. The neuron with the minimum distance is selected as the winner. The label of
is determined. The learning rate is updated. After that,
is calculated by Equation (
9) with new
. The weights are updated by the new
. The procedure is repeated until
. The time complexity of Algorithm 4 is
.
| Algorithm 3: Kmeans Clustering Algorithm |
![Algorithms 16 00158 i003]() |
| Algorithm 4: SOM Clustering Algorithm |
![Algorithms 16 00158 i004]() |



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}