
Framework for Evaluating Potential Causes of Health Risk Factors Using Average Treatment Effect and Uplift Modelling

Abstract
:1. Introduction
1.1. Traditional Approaches to Establishing the Relationship between Benzene Exposure and AML
1.2. Current Trends in Estimating Causation for Health Outcomes Using Machine Learning Methods
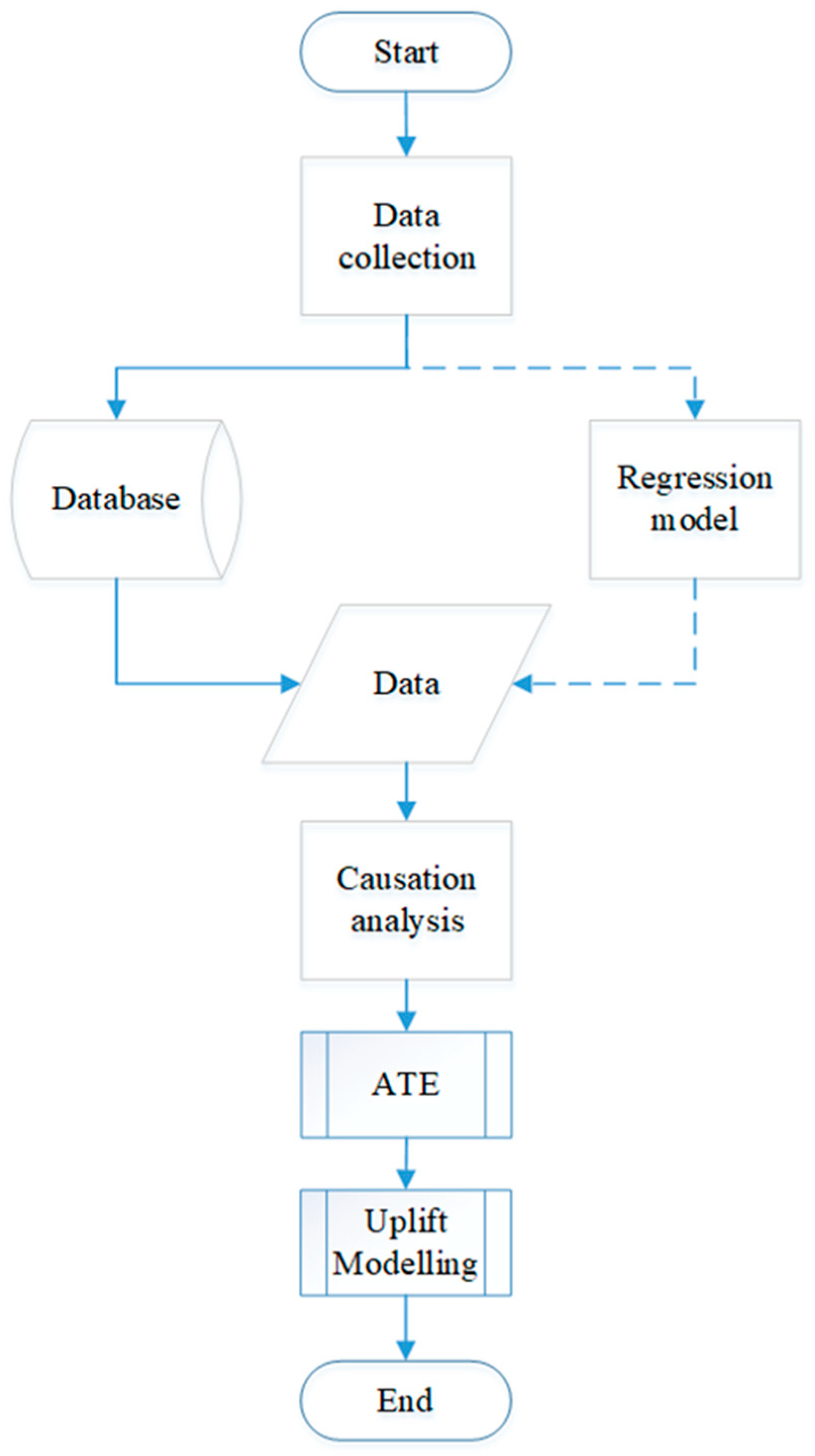
2. Methods
2.1. Case Study
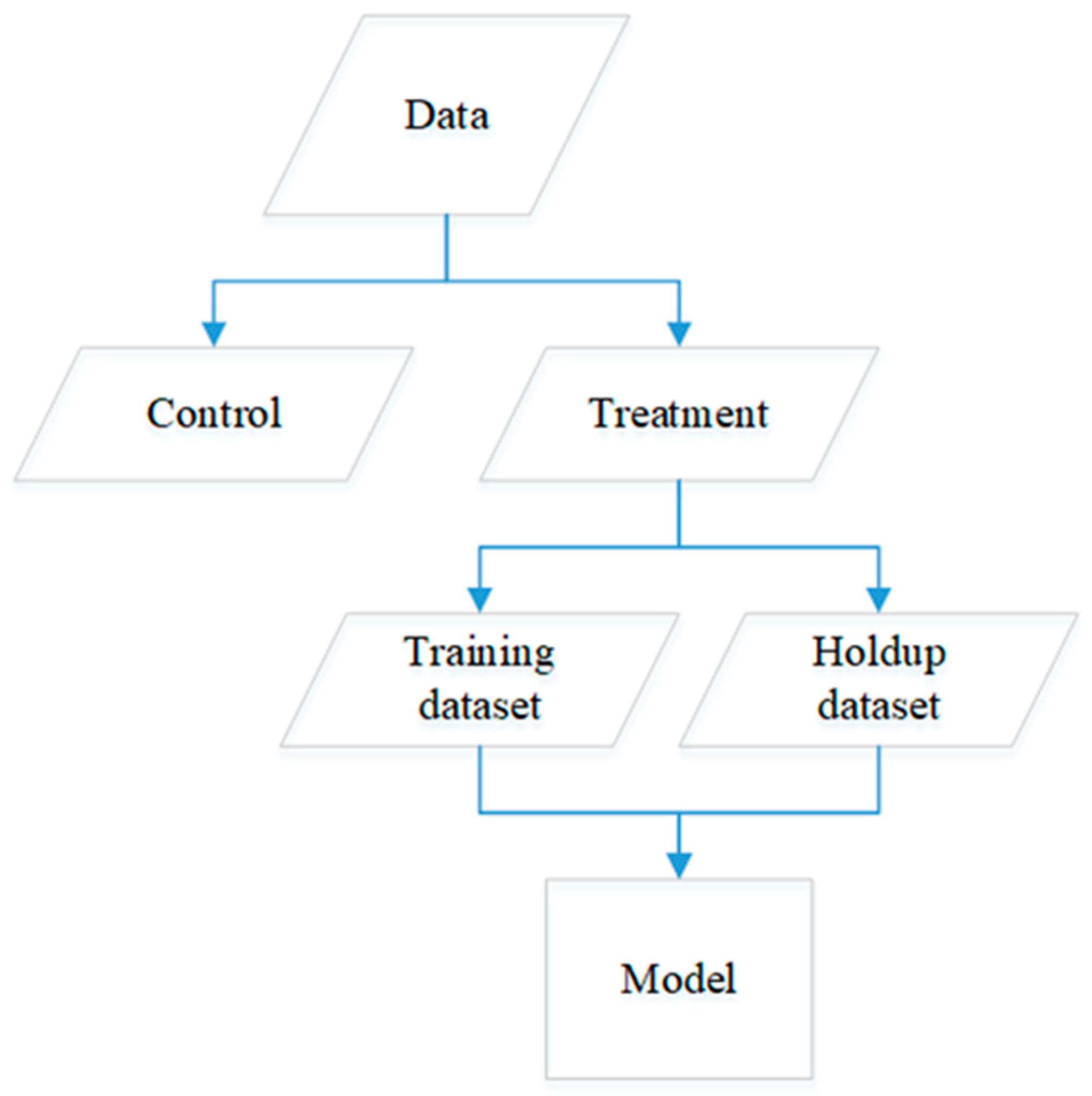
2.2. Data Generation and Preparation for Uplift
2.3. Distribution of Benzene Exposure
2.4. Causation between Exposure to Benzene and Risk of Developing AML
2.5. Causation Codes
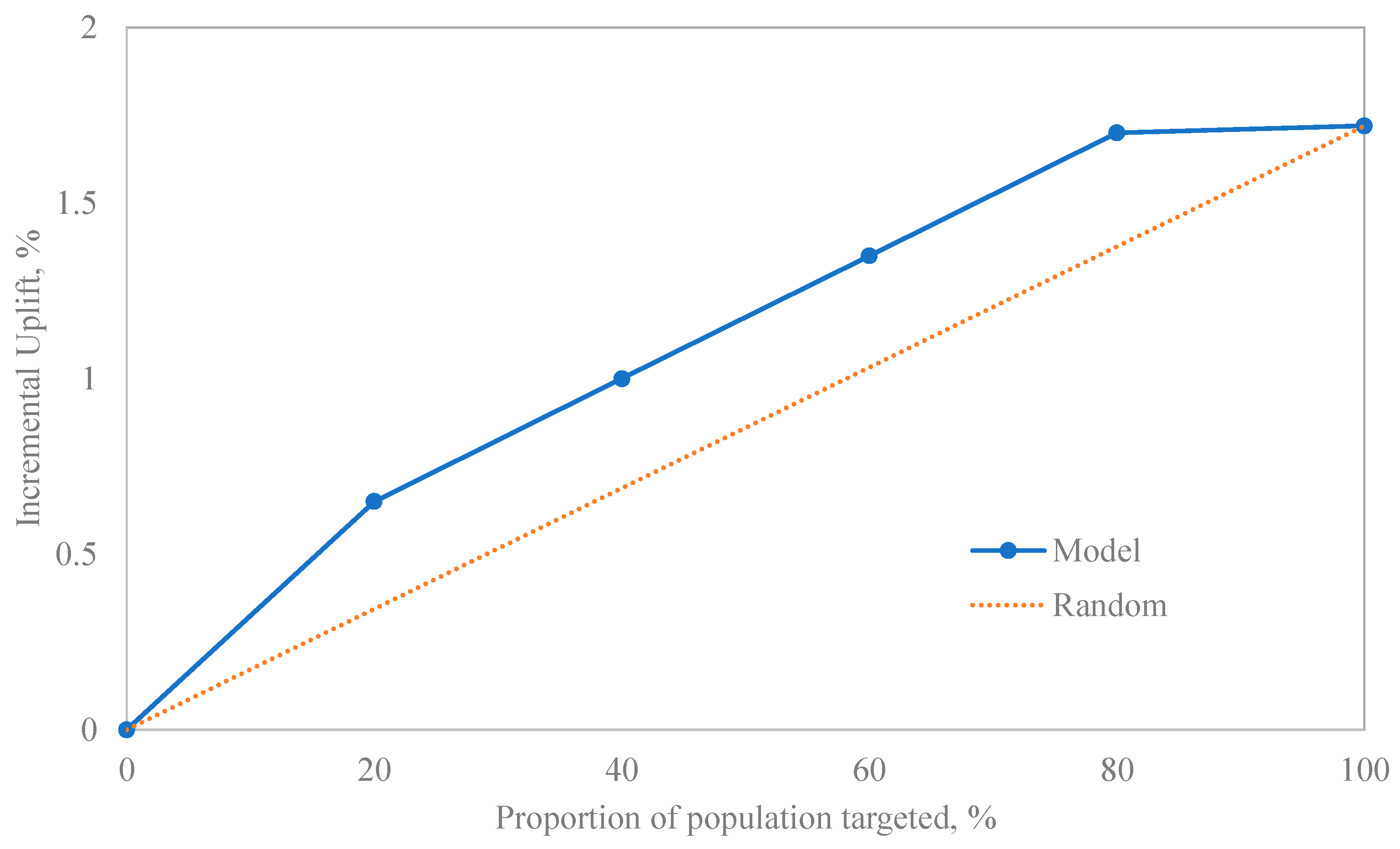
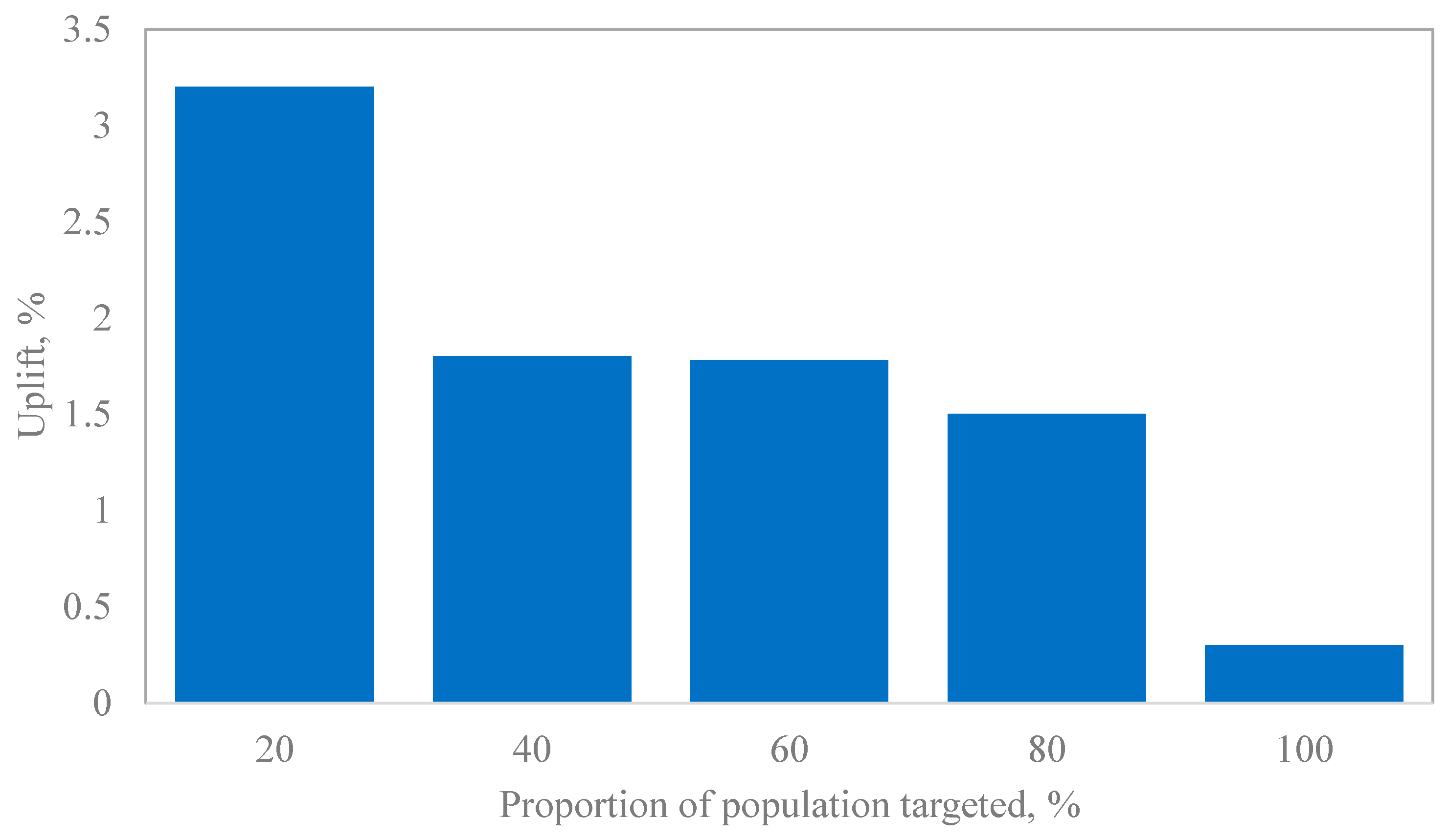
2.6. Results Interpretation
3. Results
3.1. Indoor Benzene Distribution
3.2. Outdoor Benzene Distribution
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- What Is Acute Myeloid Leukemia (AML)? What Is AML? Available online: https://www.cancer.org/cancer/acute-myeloid-leukemia/about/what-is-aml.html (accessed on 8 February 2023).
- Administrator Just Diagnosed, Just Diagnosed with Acute Myeloid Leukemia (AML). Available online: https://childrensoncologygroup.org/just-diagnosed-with-acute-myeloid-leukemia-aml- (accessed on 8 February 2023).
- Ross, J.A.; Potter, J.D.; Robison, L.L. Infant leukemia, topoisomerase II inhibitors, and the MLL gene. JNCI J. Natl. Cancer Inst. 1994, 86, 1678–1680. [Google Scholar] [CrossRef]
- Ross, J.A.; Davies, S.M.; Potter, J.D.; Robison, L.L. Epidemiology of childhood leukemia, with a focus on infants. Epidemiol. Rev. 1994, 16, 243–272. [Google Scholar] [CrossRef] [PubMed]
- Pyatt, D.; Hays, S. A review of the potential association between childhood leukemia and benzene. Chem.-Biol. Interact. 2010, 184, 151–164. [Google Scholar] [CrossRef]
- Belson, M.; Kingsley, B.; Holmes, A. Risk factors for acute leukemia in children: A review. Environ. Health Perspect. 2007, 115, 138–145. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rinsky, R.A. Benzene and leukemia: An epidemiologic risk assessment. Environ. Health Perspect. 1989, 82, 189–191. [Google Scholar] [CrossRef]
- Costantini, A.S.; Dsc, A.B.; Vineis, P.; Kriebel, D.; Tumino, R.; Ramazzotti, V.; Rodella, S.; Stagnaro, E.; Crosignani, P.; Amadori, D.; et al. Risk of leukemia and multiple myeloma associated with exposure to benzene and other organic solvents: Evidence from the Italian Multicenter Case-control study. Am. J. Ind. Med. 2008, 51, 803–811. [Google Scholar] [CrossRef] [PubMed]
- Hill, S.A.B. The environment and disease: Association or causation? J. R. Soc. Med. 2015, 108, 32–37. [Google Scholar] [CrossRef]
- Cox, L.A. Modernizing the Bradford Hill criteria for assessing causal relationships in observational data. Crit. Rev. Toxicol. 2018, 48, 682–712. [Google Scholar] [CrossRef]
- Kaatsch, P.; Kaletsch, U.; Meinert, R.; Miesner, A.; Hoisl, M.; Schüz, J.; Michaelis, J. Erman case control study on childhood leukaemia—Basic considerations, methodology and summary of the results. Klin. Pädiatrie 1998, 210, 185–191. [Google Scholar] [CrossRef]
- Shu, X.O.; Gao, Y.T.; Tu, J.T.; Zheng, W.; Brinton, L.A.; Linet, M.S.; Fraumeni, J.F. A population-based case-control study of childhood leukemia in Shanghai. Cancer 1988, 62, 635–644. [Google Scholar] [CrossRef]
- Buckley, J.D.; Chard, R.L.; Baehner, R.L.; Nesbit, M.E.; Lampkin, B.C.; Woods, W.G.; Denman Hammond, G. Improvement in outcome for children with acute nonlymphocytic leukemia. A report from the Childrens Cancer Study Group. Cancer 1989, 63, 1457–1465. [Google Scholar] [CrossRef]
- Magnani, C.; Pastore, G.; Luzzatto, L.; Terracini, B. Parental occupation and other environmental factors in the etiology of leukemias and Non-Hodgkin’S lymphomas in childhood: A case-control study. Tumori J. 1990, 76, 413–419. [Google Scholar] [CrossRef] [PubMed]
- Freedman, D.M.; Stewart, P.; Kleinerman, R.A.; Wacholder, S.; Hatch, E.E.; Tarone, R.E.; Robison, L.L.; Linet, M.S. Household solvent exposures and childhood acute lymphoblastic leukemia. Am. J. Public Health 2001, 91, 564–567. [Google Scholar] [CrossRef] [Green Version]
- Alderton, L.E.; Spector, L.G.; Blair, C.K.; Roesler, M.; Olshan, A.F.; Robison, L.L.; Ross, J.A. Child and maternal household chemical exposure and the risk of acute leukemia in children with Down’s syndrome: A Report from the Children’s Oncology Group. Am. J. Epidemiol. 2006, 164, 212–221. [Google Scholar] [CrossRef] [Green Version]
- Chang, J.S. Parental smoking and childhood leukemia. Methods Mol. Biol. 2009, 472, 103–137. [Google Scholar] [CrossRef] [PubMed]
- Lichtman, M.A. Cigarette smoking, cytogenetic abnormalities, and acute myelogenous leukemia. Leukemia 2007, 21, 1137–1140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nordlinder, R.; Jarvholm, B. Environmental exposure to gasoline and leukemia in children and young adults-an ecology study. Int. Arch. Occup. Environ. Health 1997, 70, 57–60. [Google Scholar] [CrossRef] [PubMed]
- Reynolds, P.; Von Behren, J.; Gunier, R.B.; Goldberg, D.E.; Hertz, A. Residential exposure to traffic in California and childhood cancer. Epidemiology 2004, 15, 6–12. [Google Scholar] [CrossRef]
- Crosignani, P.; Tittarelli, A.; Borgini, A.; Codazzi, T.; Rovelli, A.; Porro, E.; Contiero, P.; Bianchi, N.; Tagliabue, G.; Fissi, R.; et al. Childhood leukemia and road traffic: A population-based case-control study. Int. J. Cancer 2003, 108, 596–599. [Google Scholar] [CrossRef]
- Steffen, C.; Auclerc, M.F.; Auvrignon, A.; Baruchel, A.; Kebaili, K.; Lambilliotte, A.; Leverger, G.; Sommelet, D.; Vilmer, E.; Hémon, D.; et al. Acute childhood leukaemia and environmental exposure to potential sources of benzene and other hydrocarbons; a case-control study. Occup. Environ. Med. 2004, 61, 773–778. [Google Scholar] [CrossRef] [Green Version]
- Harrison, R.M.; Leung, P.L.; Somervaille, L.; Smith, R.; Gilman, E. Analysis of incidence of childhood cancer in the West Midlands of the United Kingdom in relation to proximity to main roads and petrol stations. Occup. Environ. Med. 1999, 56, 774–780. [Google Scholar] [CrossRef] [Green Version]
- Raaschou-Nielsen, O.; Hvidtfeldt, U.A.; Roswall, N.; Hertel, O.; Poulsen, A.H.; Sørensen, M. Ambient benzene at the residence and risk for subtypes of childhood leukemia, lymphoma and CNS tumor. Int. J. Cancer 2018, 143, 1367–1373. [Google Scholar] [CrossRef] [Green Version]
- Heck, J.E.; Park, A.S.; Qiu, J.; Cockburn, M.; Ritz, B. Risk of leukemia in relation to exposure to Ambient Air Toxics in pregnancy and early childhood. Int. J. Hyg. Environ. Health 2013, 217, 662–668. [Google Scholar] [CrossRef] [Green Version]
- Wan, F. Conditional or unconditional logistic regression for frequency matched case-control design? Stat. Med. 2022, 41, 1023–1041. [Google Scholar] [CrossRef]
- Kuo, C.-L.; Duan, Y.; Grady, J. Unconditional or conditional logistic regression model for age-matched case–control data? Front. Public Health 2018, 6, 57. [Google Scholar] [CrossRef] [Green Version]
- De Graaf, M.A.; Jager, K.J.; Zoccali, C.; Dekker, F.W. Matching, an appealing method to avoid confounding? Nephron Clin. Pract. 2011, 118, c315–c318. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pearce, N. Analysis of matched case-control studies. BMJ 2016, 352, i969. [Google Scholar] [CrossRef] [Green Version]
- Stoltzfus, J.C. Logistic Regression: A brief primer. Acad. Emerg. Med. 2011, 18, 1099–1104. [Google Scholar] [CrossRef]
- Gonfalonieri, A. Introduction to Causality in Machine Learning. Medium. 9 July 2020. Available online: https://towardsdatascience.com/introduction-to-causality-in-machine-learning-4cee9467f06f (accessed on 8 February 2023).
- Sanchez, P.; Voisey, J.P.; Xia, T.; Watson, H.I.; O’Neil, A.Q.; Tsaftaris, S.A. Causal machine learning for healthcare and Precision Medicine. R. Soc. Open Sci. 2022, 9, 220638. [Google Scholar] [CrossRef] [PubMed]
- Venkatasubramaniam, A.; Mateen, B.A.; Shields, B.M.; Hattersley, A.T.; Jones, A.G.; Vollmer, S.J.; Dennis, J.M. Comparison of causal forest and regression-based approaches to evaluate treatment effect heterogeneity: An application for type 2 diabetes precision medicine. medRxiv 2022. [Google Scholar] [CrossRef]
- Chipman, H.A.; George, E.I.; McCulloch, R.E. Bart: Bayesian additive regression trees. Ann. Appl. Stat. 2010, 4, 266–298. [Google Scholar] [CrossRef]
- Côté, M.; Lamarche, B. Artificial intelligence in nutrition research: Perspectives on current and future applications. Appl. Physiol. Nutr. Metab. 2022, 47, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Fedak, K.M.; Bernal, A.; Capshaw, Z.A.; Gross, S. Applying the Bradford Hill criteria in the 21st Century: How data integration has changed causal inference in molecular epidemiology. Emerg. Themes Epidemiol. 2015, 12, 14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gailmard, S. Causal Inference: Inferring causation from Correlation. In Statistical Modeling and Inference for Social Science; Cambridge University Press: Cambridge, UK, 2018; pp. 335–357. [Google Scholar] [CrossRef]
- Haneuse, S.; Saegusa, T.; Lumley, T. osDesign: An r package for the analysis, evaluation, and design of two-phase and case-control studies. J. Stat. Softw. 2011, 43, 1–29. [Google Scholar] [CrossRef] [PubMed]
- Lebel, E.D.; Michanowicz, D.R.; Bilsback, K.R.; Hill, L.A.L.; Goldman, J.S.W.; Domen, J.K.; Jaeger, J.M.; Ruiz, A.; Shonkoff, S.B.C. Composition, emissions, and air quality impacts of hazardous air pollutants in unburned natural gas from residential stoves in California. Environ. Sci. Technol. 2022, 56, 15828–15838. [Google Scholar] [CrossRef] [PubMed]
- Centers for Disease Control and Prevention. United States and Puerto Rico Cancer Statistics, 1999–2019 Incidence Request. Available online: https://wonder.cdc.gov/cancer-v2019.HTML (accessed on 8 February 2023).
- Mann, H.S.; Crump, D.; Brown, V. Personal exposure to benzene and the influence of attached and integral garages. J. R. Soc. Promot. Health 2001, 121, 38–46. [Google Scholar] [CrossRef] [PubMed]
- Uplift Modelling—Github Pages. Available online: https://humboldt-wi.github.io/blog/research/theses/uplift_modeling_blogpost/ (accessed on 9 February 2023).
- Quality Measures for Uplift Models—Stochastic Solutions. Available online: https://www.stochasticsolutions.com/pdf/kdd2011late.pdf (accessed on 9 February 2023).
- CHE408UofT—Overview. Available online: https://github.com/CHE408UofT (accessed on 14 March 2023).






{kind=link}
{kind=link}
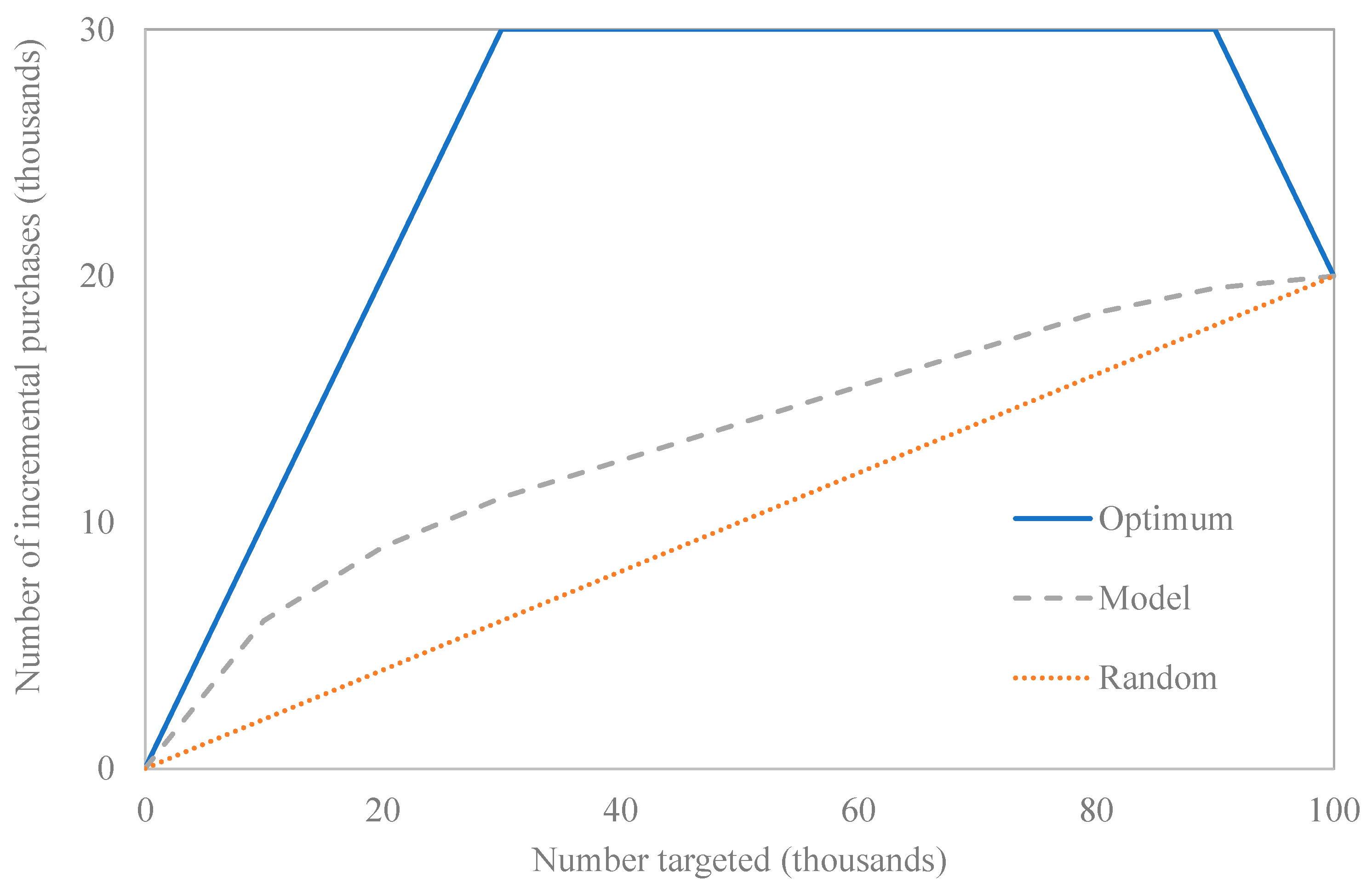{kind=link}
{kind=link}
{kind=link}
| Person | Socioeconomic Status | Race | Birthplace | Parity | Benzene | BINaml | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| … | … | … | … | … | … | … | … | … | … | … |
| 61 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 62 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 63 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| Agent | Mean/Standard Deviation | Inter-Quartile Range (IQR) | Minimum | Percentile | Maximum | |||
|---|---|---|---|---|---|---|---|---|
| 10th | 25th | 75th | 90th | |||||
| Benzene, ppbv * | 1.268/0.830 | 1.197 | 0.151 | 0.410 | 0.591 | 1.788 | 2.574 | 4.600 |
| Agent | Mean/Standard Deviation | Inter-Quartile Range (IQR) * | Minimum | Percentile | Maximum | |||
|---|---|---|---|---|---|---|---|---|
| 10th | 25th | 75th | 90th | |||||
| Benzene, ppbv | 5.650/2.825 | 1.197 | 0.700 | - | - | - | - | 12.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galatro, D.; Trigo-Ferre, R.; Nakashook-Zettler, A.; Costanzo-Alvarez, V.; Jeffrey, M.; Jacome, M.; Bazylak, J.; Amon, C.H. Framework for Evaluating Potential Causes of Health Risk Factors Using Average Treatment Effect and Uplift Modelling. Algorithms 2023, 16, 166. https://doi.org/10.3390/a16030166
Galatro D, Trigo-Ferre R, Nakashook-Zettler A, Costanzo-Alvarez V, Jeffrey M, Jacome M, Bazylak J, Amon CH. Framework for Evaluating Potential Causes of Health Risk Factors Using Average Treatment Effect and Uplift Modelling. Algorithms. 2023; 16(3):166. https://doi.org/10.3390/a16030166
Chicago/Turabian StyleGalatro, Daniela, Rosario Trigo-Ferre, Allana Nakashook-Zettler, Vincenzo Costanzo-Alvarez, Melanie Jeffrey, Maria Jacome, Jason Bazylak, and Cristina H. Amon. 2023. "Framework for Evaluating Potential Causes of Health Risk Factors Using Average Treatment Effect and Uplift Modelling" Algorithms 16, no. 3: 166. https://doi.org/10.3390/a16030166
APA StyleGalatro, D., Trigo-Ferre, R., Nakashook-Zettler, A., Costanzo-Alvarez, V., Jeffrey, M., Jacome, M., Bazylak, J., & Amon, C. H. (2023). Framework for Evaluating Potential Causes of Health Risk Factors Using Average Treatment Effect and Uplift Modelling. Algorithms, 16(3), 166. https://doi.org/10.3390/a16030166