1. Introduction
Tourism is a widespread activity and a huge industry in our time and era. According to the United Nations’ World Tourism Organization, more than 900 million tourists travelled internationally in 2022 alone. In general, tourism can have a great impact on various aspects of social and economic life—including local infrastructure, transportation, land use, housing prices and even local lifestyle and associated entrepreneurship activities [
1,
2,
3]. In their travels, tourists have to select among numerous alternatives of landmarks, places and in general
points of interest (POIs) they can visit. This can be challenging for travellers that have no prior experience of or “inside knowledge” regarding their destination, and even more so for short-term visits. The exhaustive examination of all the possibilities is clearly impossible, thus an information system that can assist them in narrowing their options down to a more tight set would be of much use to tourists. As a result, a booming industry of travel-related
recommender systems (RSs) [
4] has been developed, in order to provide users with recommendations most relevant to their interests. Such systems are embedded in almost every modern mobile tour guide and similar applications.
Recommender systems are divided into three main categories with respect to the methods they adopt, namely the
content-based (CB),
collaborative filtering (CF) and
hybrid RSs [
4,
5,
6]. Nevertheless, they can further be grouped into additional categories, such as
Bayesian recommenders, which employ Bayesian updating of user models for efficient personalized recommendations [
7,
8,
9]. A recent research work on
travel recommenders [
10] has classified these into three major categories: hotel, restaurant and tourism recommenders. The latter can be related to tour planning, group recommendations, touristic attractions-related packages or travel packages. Recently, Bayesian recommender algorithms have been combined with social choice-theoretic methods to enable personalized and fair recommendations of touristic POIs, both in single-user and group recommendation environments [
11,
12].
Now, although
semantic similarity measures have been mainly exploited in the domains of text analysis [
13] and natural language processing [
14], they have also been employed to correlate the preferences of tourists with touristic attractions. All semantic similarity measures describe the relations between different ontologies, and are classified into two categories [
15]. The first corresponds to those that generate a hierarchical structure in order to measure similarity and are termed
hierarchy similarity measures, while the second correlates ontologies without constructing a hierarchy tree and are termed
non-hierarchy similarity measures.
Against this background, in this paper we put forward a novel recommender algorithm that is a hybrid of two approaches: a novel content-based (CB) recommender utilizing semantic similarity measures, and a Bayesian one. In fact, our CB recommender algorithm is itself, in some sense, a “hybrid” of two (CB) approaches that employ two types of semantic similarity measures—a hierarchy and a non-hierarchy one.
The hierarchy similarity measure of choice is the
Extended Wu–Palmer (XWP) similarity, a variation of the metric proposed in [
16], in which POIs lie on the nodes of a hierarchy tree, whereas the other metric is a novel non-hierarchy similarity measure called
Weighted Extended Jaccard Similarity (WEJS) measure.
WEJS calculates the correlation between different POIs by taking into account both the user’s preferences and the POIs’ features values. Thus it produces personalized recommendations. Subsequently, our CB algorithm combines these two measures into a
hybrid (the term hybrid here denotes a combination of two similarity measures and it should not be confused with the hybrid recommender algorithm that is the final outcome of our work) similarity measures-based method. Finally, this CB algorithm is combined with a Bayesian Inference component that is responsible for building a user model via a lightweight Bayesian elicitation process that asks the user to rate
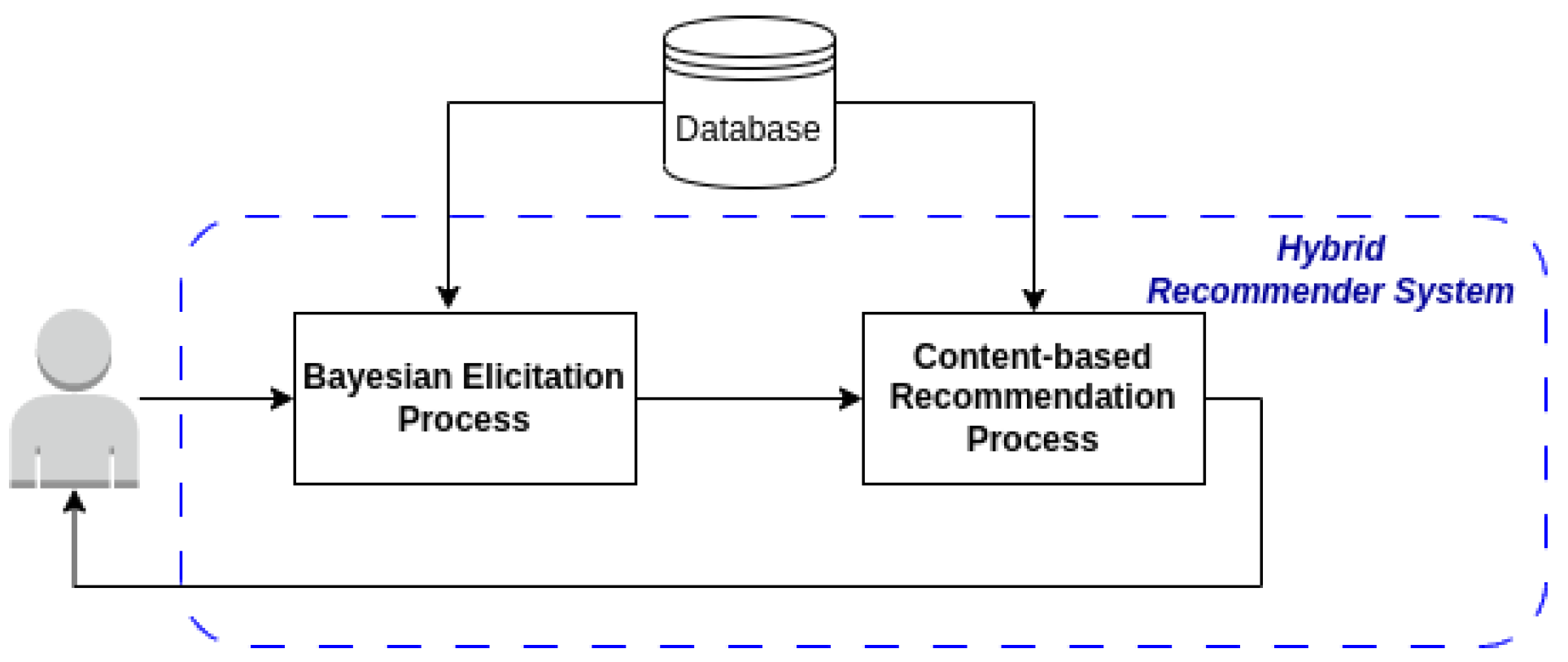
generic images (corresponding to generic types of POIs). Then, a set of generic POI items corresponding to the user preferences captured by the Bayesian component are fed into the CB algorithm that eventually recommends the actual POIs that are most similar to the constructed user model. The high-level structure of our novel
Hybrid RS is presented in
Figure 1.
As such, the eventual
Hybrid RS we propose has two desired properties that a simple Bayesian or a simple CB RS could not exploit. Specifically, the usage of a probability-density-based (usually a multi-dimensional Gaussian distribution) representation [
17] along with
Bayesian Inference provides us with a formal way to model the high uncertainty that exists in such settings [
18], while the CB technique enables our system to utilize data regarding (i) hierarchical structures that contain the available POIs; (ii) the “distance” between POIs’ characteristics and users’ personal interests, via exploiting information contained in user-specific weights assigned to different features.
Now, a common issue arising in recommender systems and especially in Collaborative Filtering techniques is the well-known
cold-start problem. This refers to the inability of algorithms to provide meaningful recommendations due to the lack of ratings when a new user or item to recommend enters the system [
19,
20]. This can have a great impact on users’ experience when using travel planning applications related especially to short-term travels, since almost all users are new and presumably interact with the application only a handful of times. Therefore, the (short-term) efficiency of recommender algorithms incorporated in such applications is of utmost importance. In our case, we effectively circumvent and tone down the impact of the cold-start problem, by not employing a CF approach (i.e., by not relying on and comparing with others’ ratings) for producing personalized recommendations—but by using a Bayesian updating approach to elicit and maintain user profiles. Specifically, in our work we directly elicit new users’ preferences by presenting generic images to them, maintain their profiles as explained in the paper, and make recommendations based on their elicited interests. Avoiding the cold-start problem can be viewed as an advantage of our recommendation approach especially in the context of short-term tourist visits. Of course, quickly arriving at accurate user profiles is a challenge, which can be dealt with effectively via the use of appropriate easy-to-maintain priors [
8,
9,
11,
12].
We evaluate our
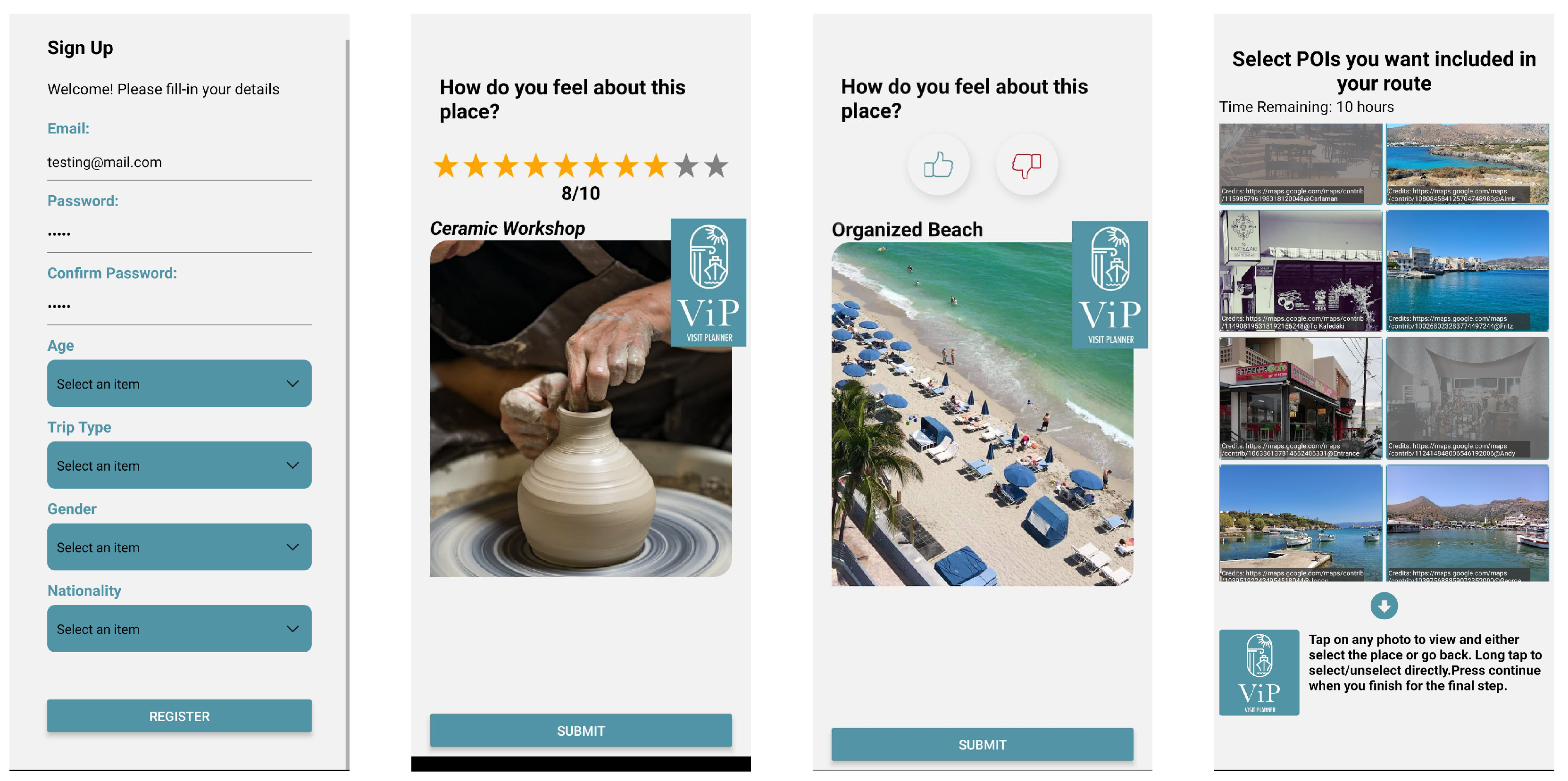
Hybrid RS and its components using a real-world dataset from a popular tourist destination, the city of Agios Nikolaos in Crete, Greece. The data related to user preferences were collected by means of a survey answered by actual tourists, while data on POIs were collected via close collaboration with the local municipality, other sources of local knowledge and web sources. Our datasets and algorithms were constructed to be utilized within a real-world mobile app that offers personalized recommendations and tour scheduling services to short-term visitors of Agios Nikolaos and its vicinity. The app (see
Figure 2), developed in close partnership with the city’s municipal authority, incorporates several recommender algorithms and a deterministic method for the recommendation of personalized itineraries [
21], and is currently available at Google Play Store (
https://play.google.com/store/apps/details?id=com.netmechanics.vip&pli=1, accessed on 17 February 2023).
The experiments we conducted verify the excellent performance of our RS algorithms, which regularly exhibit a precision of over 83%. In some detail, while our CB recommender components are shown to be quite effective in producing accurate personalized recommendations, our final Hybrid RS demonstrates a superior ability to extract the users’ profiles and utilize them in its operation. In particular, its use is shown to result in even more precise personalized recommendations than those generated by the CB recommenders, and it does so exploiting a lightweight Bayesian elicitation process that requires only a low number of interactions with a user in order to “learn” her profile.
In a nutshell, our work in this paper results in several contributions:
- 1.
We employ for the first time within a recommender algorithm a novel non-hierarchy similarity measure, the
Weighted Extended Jaccard Similarity (WEJS) (originally introduced in [
22]).
- 2.
We combine it with a hierarchy-based similarity measure to give rise to a novel hybrid CB recommendations algorithm.
- 3.
We combine that CB algorithm with a Bayesian component to put forward a novel Hybrid Recommender System.
- 4.
We evaluate our recommender algorithms via extensive simulations conducted on a real-world dataset, with results testifying to their effectiveness in producing accurate personalized recommendations.
- 5.
Last but not least, our algorithm is already incorporated in a real-world tour planning mobile app for short-term visitors of a popular touristic destination.
The rest of this paper is structured as follows. In
Section 2 we present background and briefly review related work.
Section 3 is devoted to a detailed description of our CB recommender system component which combines two different similarity measures for personalized recommendations, while in
Section 4 we illustrate the
Hybrid Recommender System which utilizes a Bayesian inference algorithm so as to extract a user’s preferences before the recommendation process as can be seen in
Figure 1. Finally, in
Section 5 we illustrate the results of the experiments conducted in real-world data, and in
Section 6 we provide a conclusion and future research directions.
2. Background and Related Work
Recommender systems are considered to be personalized and non-personalized [
4,
23]. Personalized recommender systems extrapolate user’s preferences to create efficient recommendations based on the users’ past interaction with the system [
8]. On the contrary, non-personalized recommenders suggest items that are most relevant and popular among all users. For instance the Netflix [
24] movie platform recommends the top N items to every user as a list.
Recommender systems may also be classified into several other types: for example, content-based (CB), collaborative filtering (CF), context-aware, Bayesian—while the term “Hybrid” characterizes a recommender that produces recommendations via combining algorithms that belong in several categories. Usually CB and CF are seen as constituting the two main (non-hybrid) approaches [
4,
5].
In a nutshell, CB RSs exploit information from previous user–system interactions to provide effective recommendations. Particularly, these systems suggest items that are very similar to items the user has liked in previous interactions. CF algorithms, by contrast, analyze user’s ratings to calculate the similarity between them. CF recommenders intuitively work under the assumption that, when items are rated by two users in a similar way, they probably share same interests and will provide similar ratings to other items. As mentioned in the introduction, the
cold-start problem refers to the inability of such algorithms to make recommendations which are personalized and relevant to users’ preferences, due to the lack of ratings when dealing with new users or items-to-recommend [
19]; this problem is of vital importance in applications related to the tourism domain [
20], and thus several ways to tackle cold-start in this domain are proposed in the literature. For instance, Feng et al. [
19] propose a ranking model which is a hybrid between a CF ratings-oriented and a Bayesian personalized pairwise ranking-oriented one, while Zheng et al. [
20] employ a hybrid CF-based method that refines item opinion reputation and user preferences, by utilizing opinion-mining technology to mine text reviews and subsequently assess the destinations’ preference ranking when matched against preferred features chosen by users via means of an artificial interaction module.
Now, there are numerous travel- or tourism-related RSs, which may be classified into several categories [
10]. The majority of these systems suggest POIs that relate to tourist attractions (e.g., monuments, museums or hotels), ideally those that are closely related to the preferences of each visitor while, naturally, in terms of underlying recommendation technology used, a tourism RS may belong to any one of the aforementioned RS classes. We now proceed to briefly review several such systems and algorithms, along with certain recommender approaches that may lie outside the tourism domain but are of interest to our work in this paper.
To begin with, a recommender algorithm, along with a social interactions mechanism, is equipped in a tourist guide application, presented by [
25], with the goal of locating undiscovered touristic POIs. An integrated CF system is employed to suggest touristic locations that have been already rated by the users. Lim et al. [
26] tackle a tour itinerary planning problem modelled in the context of the well-known orienteering problem, and propose several recommendation algorithm variants that take into account POI popularity to a lesser or greater extent, while assuming user preferences relate to the user’s visit durations at POIs of particular categories. The authors of [
27] proposed a picture-based recommender technique for proposing tourism sites to a specific individual. Particularly, any set of images is picked by the user and then is imported into computer vision models that generate a profile with respect to the tourist’s interests. Sarkar et al. [
28] introduced a Crow Search Optimization-based Hybrid Recommendation model capable of generating precise recommendations to travelers though the combination of CB and CF techniques. In their algorithm, undiscovered items are presented to a user based on similar item selection from past interactions. Thus, the similarity between the items is calculated via a combined employment of Jaccard Similarity and Simple Matching Coefficient (SMC) as similarity metrics. In addition, their method is improved as Collaborative Filtering for Java (CF4J) and is enhanced with the Jaccard Similarity metric. They assess experimentally their approach through data provided by the well-known travel-related platform TripAdvisor. Riyani et al. [
29] introduced a hybrid RS that works under implicit ratings and semantic similarity in order to provide effective recommendations in a different domain. In greater detail, their suggested method is divided into three filtering components: content-based, collaborative and hybrid, and it makes use of tagging attributes to provide more relevant suggestions on discussion groups. The WordNet lexical database [
30] is used to extract the semantic importance of the tags, which are then grouped in a hierarchical framework depending on their semantic relevance.
Now, Bayesian recommenders explicitly model their underlying uncertainty regarding user preferences by efficiently maintaining and exploiting prior distributions over their user models, with the purpose of progressively improving the accuracy of their recommendations. Specifically, Bayesian methods have been proved quite significant in tackling uncertainty in applications with implicit feedback. In [
31] researchers derived a generic optimization criterion using a Bayesian analysis of the problem and presented a learning algorithm which is able to provide solutions which satisfy the aforementioned criterion. Sun et al. [
32] demonstrated a method using Bayesian Graph Convolutional Neural Networks for modeling the interaction of users with items in implicit recommendations setting. Nevertheless, Bayesian approaches are of course able to deal with and improve recommendations where users share explicit feedback to the system.
For instance, concerning the domain of our interest, the authors of [
18] focus on travel personalized recommendations and demonstrate interesting applications by utilizing freely available community-contributed photos. In more detail, they introduce a probabilistic Bayesian framework for mobile recommendations and test it on over ten million images gathered from 19 large cities. Furthermore, Babas et al. [
8] propose a Bayesian approach that models
both the items under recommendation and the user preferences by the same underlying distribution. (In their case, this distribution was the multivariate Gaussian distribution.) This is what they term as the “
You Are What You Consume” concept. Their recommendation movie technique exhibits performance results that are comparable to the (at the time) state of the art of a popular CF method for movie recommendations, as shown via an experimental evaluation on data from the MovieLens dataset. It is interesting that this is achieved without the approach having to consult previously obtained or processed data about the user. We adopt certain aspects of their approach during the preference elicitation process of our
Hybrid RS.
Finally, although providing solutions to a different application domain, a work that bears certain similarities with our, because of the fact that it utilizes semantic similarity measures and hierarchies of items-to-recommend, is that of [
33]. The authors, in particular, provide a museum RS for cellphones that merges a CB approach with semantic similarity measures and a semantically enriched CF method to propose relevant museum exhibits to the visitors. Contextual post filtering is implemented to create a personalized tour of the museum depending on the physical environment and location of the visitor. In opposition to our approach, the authors only employ
Wu–Palmer and
Jaccard similarity metrics; they do not utilize Bayesian inference. They limit themselves to museum collections since their method is strongly dependent on the usage of specialized ontologies for artworks and cultural heritage, while that paper comes without any kind of evaluation for the approach it proposes.
3. Content-Based Recommender Component
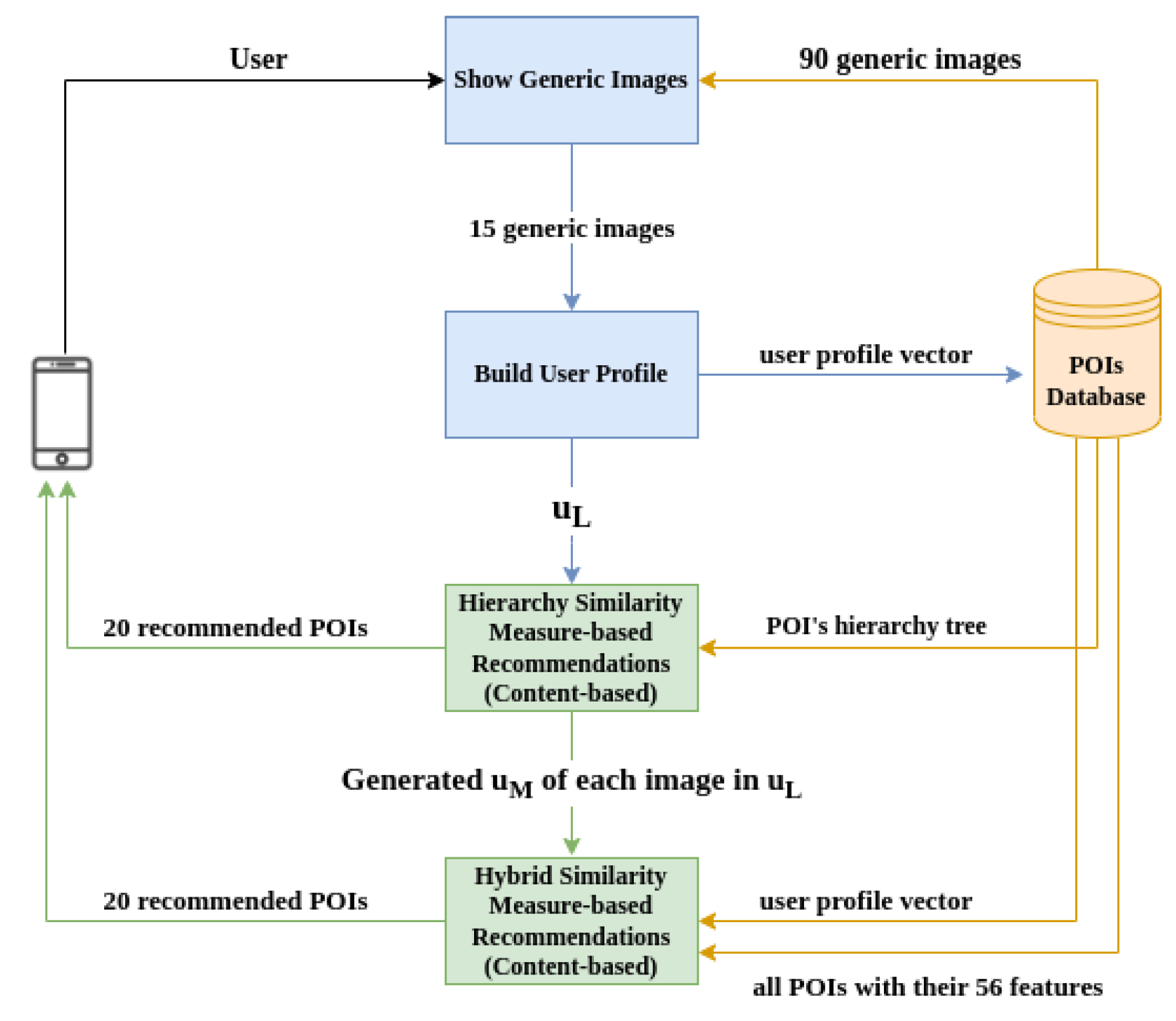
In this section we describe the content-based (CB) component of our Hybrid RS. As mentioned in the introduction, this component makes use of two main sub-components: (i) a hierarchy similarity measure-based sub-component and (ii) a hybrid similarity measure-based component which takes as input the output of the aforementioned sub-component and employs a novel non-hierarchy similarity measure (specifically, WEJS, the Weighted Extended Jaccard Similarity). We hereby refer to the former sub-component as the Hierarchy Similarity Measure-based Recommendations (Hierarchy SMbR) algorithm, and to the latter as the Hybrid Similarity Measure-based Recommendations (Hybrid SMbR) algorithm.
The
Hierarchy SMbR calculates the most similar POIs with respect to the user preferences via a well-established hierarchy tree structure. The
Hybrid SMbR makes use of the aforementioned hierarchy similarity measure and the
WEJS—which takes into account both the POIs’ features (i.e.,
content of POIs) and the user preferences, as we explain in detail later in this section. Our
CB Recommender constitutes an algorithmic engine combining the
Hierarchy and
Hybrid SMbRs along with two preference elicitation-related parts: (i) the
Show Generic Images; (ii) the
Build User Profile, as illustrated in
Figure 3. The
POIs Database stores and also provides all the essential information for the proper operation of our proposed algorithmic engine. The connection of the three components of our implementation with the database is depicted with orange arrows in
Figure 3, each of which inserts different input data to the sub-components, as required for their operation.
Now, the construction of the
user profile is implemented by the combination of the
Show Generic Images part of the engine that takes as input 90
generic images retrieved from the database, and the
Build User Profile part. In order for the
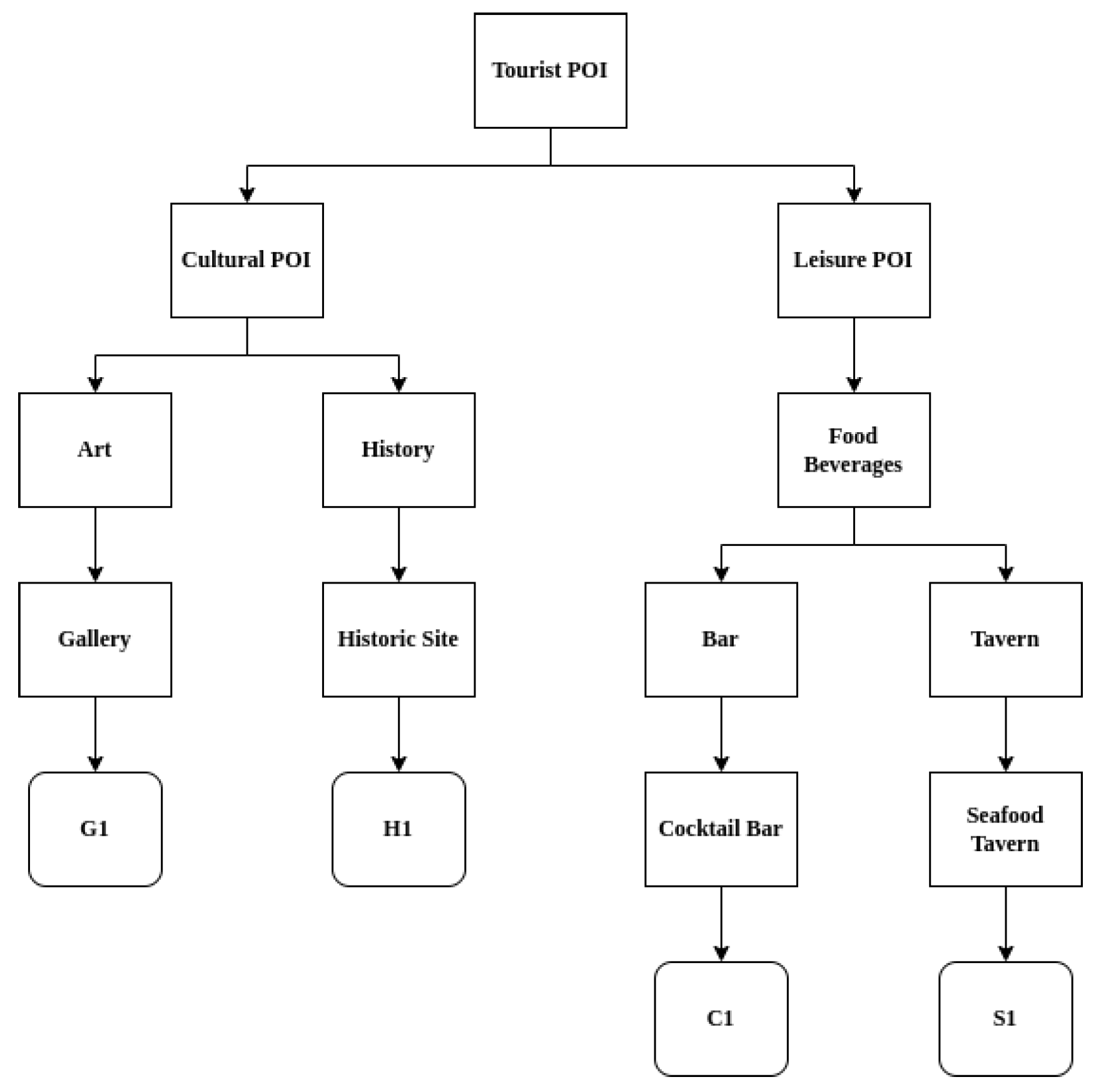
Hierarchy SMbR algorithm to work properly, it is important to have an appropriate hierarchy of POIs. To this end, we have constructed a hierarchy of POIs for our application domain, the resort town of Agios Nikolaos, in close collaboration with local stakeholders (e.g., the municipality authorities). A snapshot of the constructed tree hierarchy, containing some of the POIs’ categories we identified, is shown in
Figure 4. Our complete hierarchy tree can be found in
Appendix A. In our hierarchy, the POIs are inserted in the last layer of the tree structure as leaves, under a layer containing the ninety (90) different POI categories included in the hierarchy. We included 430 POIs in our hierarchy, located in Agios Nikolaos and its vicinity.
The POIs’ database stores our hierarchy and, of course, POIs, and specifies 56 features (each one with a distinct value) for all 430 POIs. The POI’s
character is represented by the first 12 features, with values ranging from 1 to 10, reflecting the extent to which each feature characterizes the POI in question. These 12 “POI character” features were identified as such given the findings of a survey we conducted among real tourists visiting Agios Nikolaos in order to collect data on the preferences of tourists visiting the city. In
Appendix B we include the questionnaire we compiled and used in the aforementioned survey. For instance, the POI’s
character could be a combination of cultural and leisure features, e.g., a monastery that offers wine to its visitors. The other 44 features represent the
characteristics of a POI (e.g., the amenities a POI may offer). In contrast to the
Hierarchy SMbR which only requires the POIs hierarchy in order to function, the
Hybrid SMbR exploits all such features of all POIs stored in our database, along with the
user profile vector. We now proceed to describe all the main parts of the
CB Recommender algorithmic engine in detail.
3.1. Constructing a User Profile for Content-Based Recommendations
The first process executed by our algorithm is the construction of the user profile. For this purpose, we use two different components, namely the Show Generic Images and Build User Profile components. Ninety (90) generic images (or, generic POIs) are also stored in our database, and are each related to a specific category of POIs. In other words, these generic POIs are pictures that illustrate POIs which are not contained to the database, and, importantly, are represented only by the first 12 features which demonstrate the character of the generic POI depicted in them.
The hierarchy tree we utilize in our algorithm is asymmetrical, i.e., it can have an arbitrary number of children per node, and all branches may have different length. Generic POIs and actual POIs are inserted as leaves in the tree structure, lying under its layer that contains 90 nodes corresponding to the 90 different POI categories. Although every generic image, corresponding as it does to a specific category of POIs, lies on a specific leaf of the hierarchy tree, actual POIs may lie on more than one leaf. As mentioned earlier, in
Figure 4 we visualize a snapshot of the POIs’ hierarchy structure, generated by real-world data containing specific examples of POIs and categories. Namely, G1 is a gallery and C1 is a cocktail bar, connected to the categories “Gallery” and “Cocktail Bar” respectively. We should highlight that the percentage of POIs and generic images related to “Leisure” is
, while those related to “Culture” belong to the other
. Those proportions are derived from the responses of actual tourists that participated in the aforementioned survey.
The
Show Generic Images part of our algorithmic engine depicted in
Figure 3 is responsible for selecting randomly and presenting to the user only 15 (The choice of presenting to the user “15” generic images was made since, as [
34] indicates, completing a survey with 15 questions requires five to seven minutes only, while pressing a “like” or “dislike” indicator on an image is arguably much faster than responding to a question. In practice, experimentation with our real-world app shows that a real user “likes” or “dislikes” the 15 images presented to her within 45 s) out of 90
generic images preserving the proportion of leisure and cultural generic POIs. Subsequently, these 15
generic images are imported to the
Build User Profile. Based on [
27], we adopt an elicitation process in which the user either “likes” or “dislikes” each of the aforementioned 15
generic images that are presented to her in sequence, resulting in the generation of the
user profile vector. Notably, the user is allowed to terminate this process at any time (i.e., she does not have to interact with all 15 images).
To build the
user profile, we act as follows. In accordance with the work of ref. [
8], we represent the
user profile as a
vector containing the first 12 features of the POIs in our dataset—that is, the features which demonstrate the
character of a POI. We then populate this vector with values as follows: We first construct the set of all generic images that the user has “liked”—let this set be denoted as
. Then, for each one of the 12 “character features”, we calculate the average of its values in the
set of “liked” generic images and insert this average as the value of the corresponding element in the
user profile vector.
3.2. Hierarchy Similarity Measure-Based Recommendations
The
Hierarchy SMbR is a sub-component of the CB recommender algorithm which is capable of providing recommendations via a hierarchy similarity measure called
XWP. This metric is based on a similarity measure introduced in [
16], which is an extended version of
Wu–Palmer (WP) [
35]. More specifically, the semantic similarity between two concepts
, by employing
, is described as:
where
,
represent the number of edges between the
root node and the ontologies
respectively, while
N is the number of edges between the
root node and the
Least Common Ancestor (LCA) of
X and
Y. When the
WP similarity score is close to 0, ontologies
are very distant, while when it approaches 1,
X and
Y are quite similar.
The extended version of
WP, or
as we denote it, computes the semantic relation between the ontologies
and is defined as:
where
H is the height of the hierarchy structure and
L represents the minimum distance between ontologies
X and
Y. Furthermore, the
factor is zero when the compared ontologies’ LCA is in their neighborhood, otherwise it equals one. In our instantiation of the
XWP measure, we define the neighborhood of a particular node to be the set of all other nodes which have a distance less than or equal to 2 from it.
The left part of
Figure 5 depicts an overview of the
Hierarchy SMbR-based recommendation process.
Specifically, the
vector of “liked” images is given as an input to the
Hierarchy SMbR sub-component and for every “liked” generic image contained in this set we compute the
similarity distance between it and each POI in our database. Now, the
M most relevant POIs to each generic image
i according to
XWP are stored in a set, denoted as
, alongside their similarity scores. For instance, as
Figure 5 illustrates, if the user has “liked”
N generic images during the elicitation process, our system will create one set for every “liked” image, i.e.,
. The POIs included in all
sets are grouped together, and their corresponding
XWP similarity scores are transformed into a probability distribution by a normalization process—i.e., the
Normalization Process part of the
Hierarchy SMbR component (illustrated in blue) in
Figure 5. Finally, if the standalone operation of this sub-module is desired, we sample out 20 POIs in order to be presented to the user.
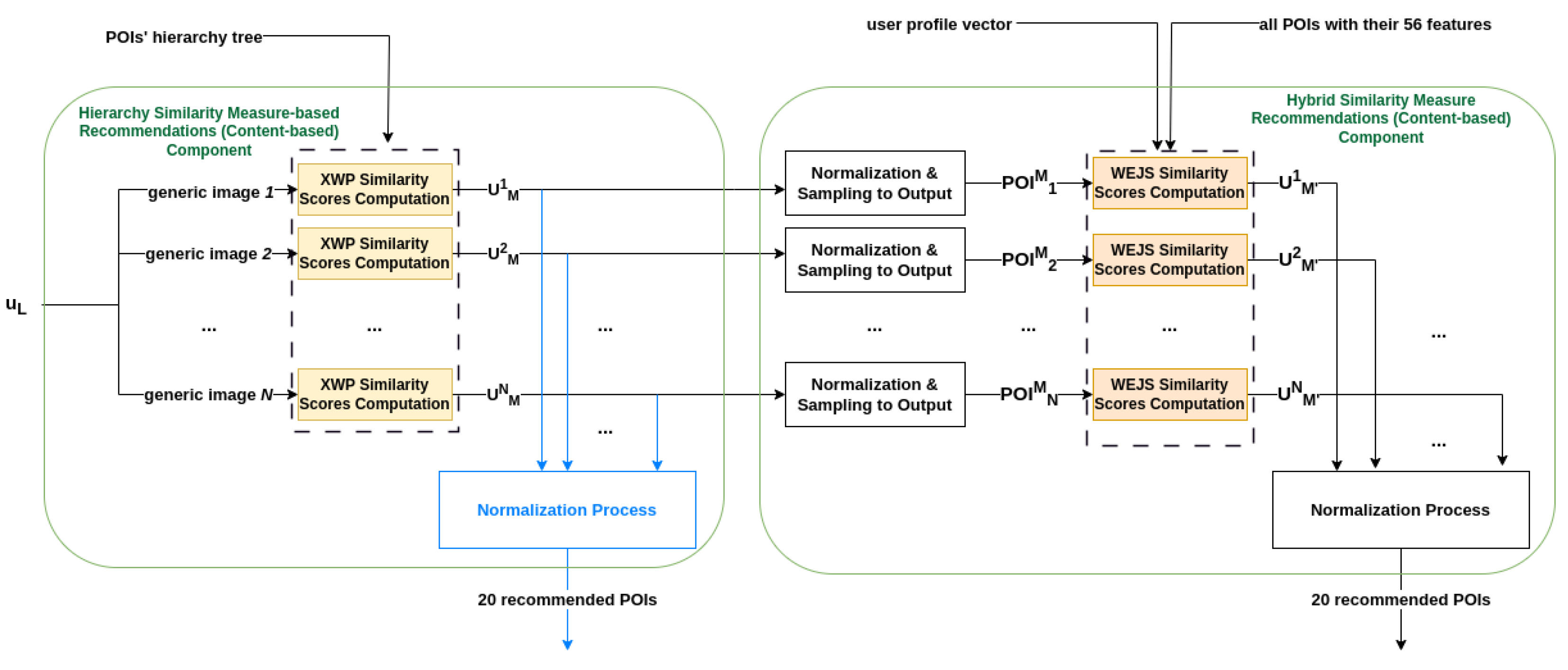
3.3. Hybrid Similarity Measure-Based Recommendations
However, the Hierarchy SMbR sub-component need not operate alone, but can be extended to our (“hybrid”) CB recommender as follows.
We now add a sub-component that performs
Hybrid similarity measure-based recommendations (right part of
Figure 5), and which incorporates a non-hierarchy similarity measure, the Weighted Extended Jaccard Similarity (
WEJS) [
22], combining it with the (hierarchy-based)
XWP. In detail, as illustrated in
Figure 5, the
Hybrid SMbR sub-component takes three different inputs: (i) the
sets produced by
Hierarchy SMbR (we remind the reader that each such set corresponds to a generic image in
); (ii) the
user profile vector (i.e., the 12 feature-based vector generated by the
Build User Profile component); and (iii) the POIs included in the database alongside their features. Our system transforms the
XWP similarity outcomes into probability distributions for each
produced by the hierarchy similarity measure via the
Normalization & Sampling to Output component. Specifically, after this transformation, each
similarity score of a POI in a specific
set is mapped to a value in the range of [0,1], while the summation of all such values for POIs in the
in question equals 1. Given these probabilities, we sample out of each
(corresponding to an image in
), one POI for computing its
WEJS similarity score (via the Equation (
4) formula explained below in detail). As
Figure 5 indicates, we denote the drawn POI of
set as
, where
. After the employment of
WEJS similarity score, for each
, a new set, denoted as
, is generated, and it contains at most
similar POIs along with their corresponding
similarity scores. Following this, all generated sets
,
, are concatenated, and their
similarity scores are converted into probabilities. Finally the system samples out 20 POIs, and recommends them to the user.
Now,
WEJS is a novel metric computing the relevance of sets of ontologies inspired by the well-known
Jaccard Similarity (JS) one, which is calculated by this formula:
where
represents the cardinality of the intersection of sets
X and
Y, while
constitutes the size of the union of the aforementioned sets.
JS is zero when the compared sets are disjoint, while it is equal to one when the sets are identical.
On the other hand,
WEJS is computed by the following expression:
where
X and
Y in our application domain correspond to two distinct POIs—i.e., to the sets of these POIs’ feature values. Moreover,
and
represent the value of the
feature of
X’s and
Y’s intersection; thus,
is 1 if they are identical, otherwise it is 0.
(respectively
) is given by the output of Algorithm 1, and corresponds to the weight of the
(
) feature of the intersection (union) of POIs
X,
Y. As such,
WEJS measure exploits the generated weights of all POI’s last 44 features (i.e.,
characteristics) with the purpose of comparing the intersection members (i.e., features) of two POIs, and it utilizes only those with equal values. Intuitively, two items would be considered by
WEJS highly similar, and also of high recommendation value to a user, if they share the exact same characteristics (i.e., share features with the exact same values), and these characteristics are deemed important (i.e., they are highly “weighted” by the user) [
22].
As mentioned, Algorithm 1 presents the method of generating the weights vector with respect to the user preferences for the POI’s
characteristics, or, as we term it, the
weights user profile vector. As seen in Algorithm 1, the cosine similarity distance metric [
36] is employed between the twelve features of the
user profile vector and each actual POI’s twelve
character features. The most similar POIs are selected according to a
cosine threshold. This threshold was empirically set to
during in our experiments. Then, the total appearances of their last 44 features with non-empty values are counted.Finally, these features’ counters are normalized into weights comprising the generated
of the user, to be used in the
WEJS calculation.
| Algorithm 1 Weights generation of the user profile |
- 1:
← user profile vector - 2:
← all POIs with their 56 features - 3:
← count vector of length 44 initialized to zero - 4:
for each in do - 5:
← first 12 features of - 6:
← last 44 features of - 7:
if (, ) then - 8:
for each f in do - 9:
if then - 10:
- 11:
←
|
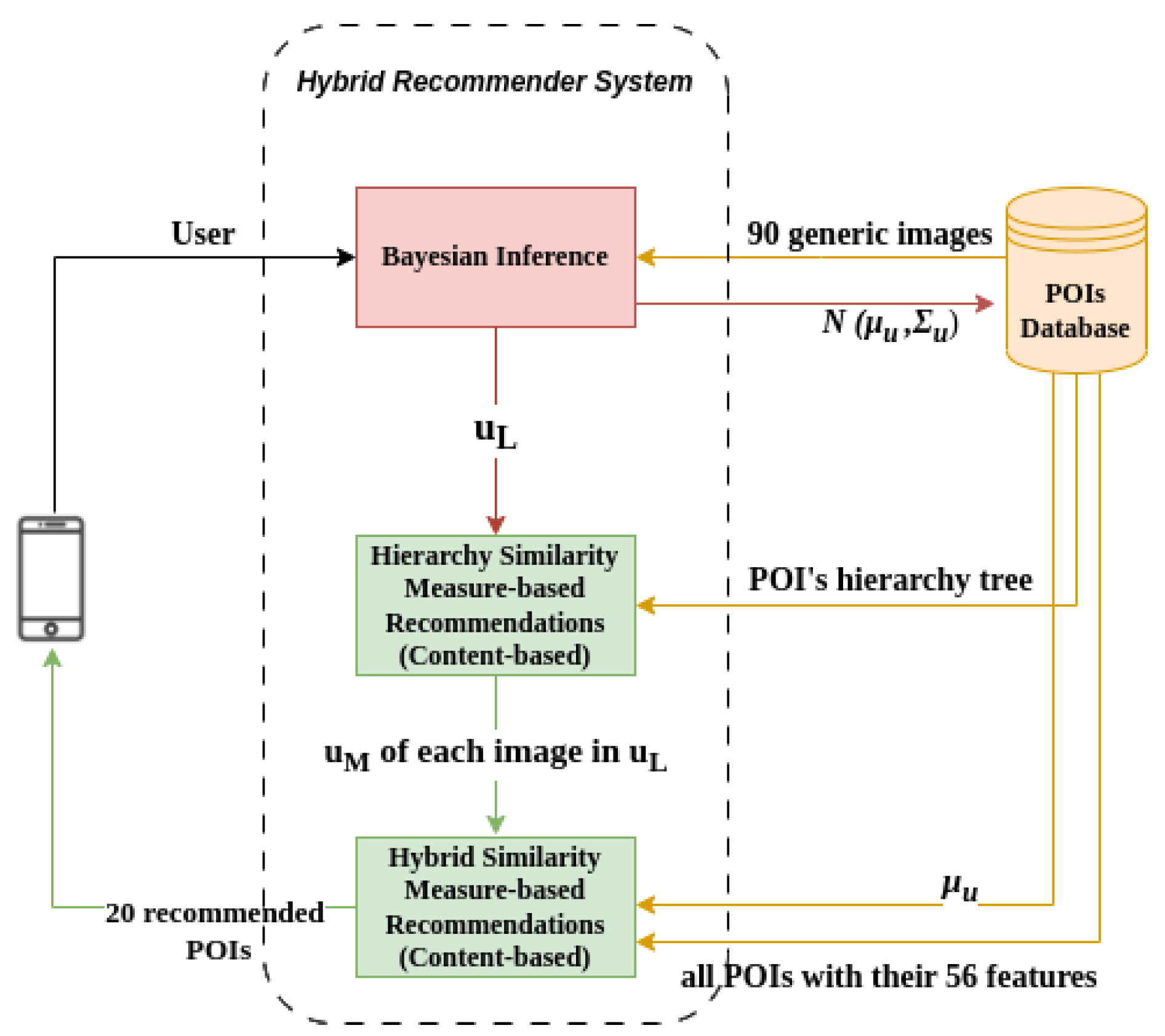
4. A Hybrid Recommender System
Here, we describe our
Hybrid RS which combines the aforementioned
CB Recommender with a
Bayesian Inference component used for user profile elicitation. During that process, we adopt the
You Are What You Consume approach of [
8]: that is, we model the the POIs of the travel destination (i.e., items) and the users, using multivariate normal distributions over ranges of values as a common representation, describing the degree that each feature describes a specific user or item.
Figure 6 depicts the overall architecture of the proposed system. Notice how the elicitation process of
Section 3.1 (or, the blue boxes in
Figure 3) is now replaced with a process of
Bayesian Inference, the functionality of which we explicate immediately below.
4.1. Bayesian Inference of the User Profile
Initially, when a user enters our
Hybrid RS for the first time, the preference elicitation process—i.e., the
Bayesian Inference component in
Figure 6)—initiates. We chose to adopt an iterative picture-based elicitation process that presents to the user a set of
n generic images, each of which illustrates a specific type of POI, in order to derive information regarding her interests. Subsequently, the user selects the image which is most relevant to her interests and provides a rating for each image on a 10-level Likert scale, where 10 represents the situation where the image matches perfectly with her preferences. Note that a detailed description of this process can be found in [
11]. After each iteration, our system exploits the provided rating of the selected generic image and draws a specific number of samples from its distribution. The number of samples ranges form 40 to 500 depending on the user’s rating. Intuitively, the user’s rating and the logistic function [
37] are utilized with the aim of computing the precise number of samples
In more detail, a high rating provided by the user for a generic image represents high similarity between the distributions of the image and the user, while a small rating means that this image does not match completely with her preferences. As such, more samples should be drawn in the case of the high rating resulting to the construction of a better model based on the user’s interests. Subsequently, once our algorithm has computed the exact number of samples that should be drawn, it performs a Bayesian Inference procedure [
8,
11] in order to update its belief regarding the interests of the user. In particular, we chose to employ the Normal-Inverse Wishart (NIW) distribution which is a multivariate four-parameter family of continuous probability distributions, while it retains the property of
conjugacy of a multivariate Gaussian distribution where the mean and covariance matrix are unknown. Generally, a closed form for the computation of the posterior distribution is provided by the usage of conjugate priors, resulting in a computationally efficient Bayesian updating procedure. Formally, the update procedure of the prior hyperparameters—
,
(the mean vector),
(degrees of freedom) and
(the precision matrix)— is performed by drawing samples directly from the observed data to obtain the posterior ones, as follows:
where
n is the number of samples,
are the drawn samples provided by the data,
represents the sample mean and
S is the scatter matrix.
Thus, our algorithm can generate a normal distribution representing the user preferences at any given time: after m iterations our system has constructed a multivariate normal distribution that represents the preferences of user u, denoted as , where and are the mean vector and the covariance matrix of the generated distribution, respectively.
Additionally, our system stores the selected image from each iteration in order to exploit such information in the CB recommendations stage of the hybrid approach. As such, during the elicitation process, we create a set, denoted as , which contains the images that the user selected in each iteration.
Thus, the output of our Bayesian elicitation process is: (i) a multivariate Gaussian distribution, , that describes the preferences of user u, where is employed so as to compute the weights in WEJS (i.e., replaces the user profile vector in Algorithm 1); and (ii) the set that contains the generic images that u has selected as most preferred during the elicitation process.
4.2. Content-Based Recommendations
Subsequently, our proposed system proceeds with our
content-based (CB) recommendation technique. In particular, our system employs the
hybrid similarity measure (
Hybrid SMbR) discussed earlier, in order to produce the final set of personalized recommendations. We remind the reader that, via this hybrid measure, our algorithmic engine combines
XWP similarity, (i.e., the hierarchy similarity measure employed in the
Hierarchy SMbR sub-component in
Figure 6—see
Section 3.2), and our
Weighted Extended Jaccard Similarity (WEJS) index (i.e., a non-hierarchy similarity measure employed in the
Hybrid SMbR component in
Figure 6—see
Section 3.3), to generate recommendations that best match the user preferences.
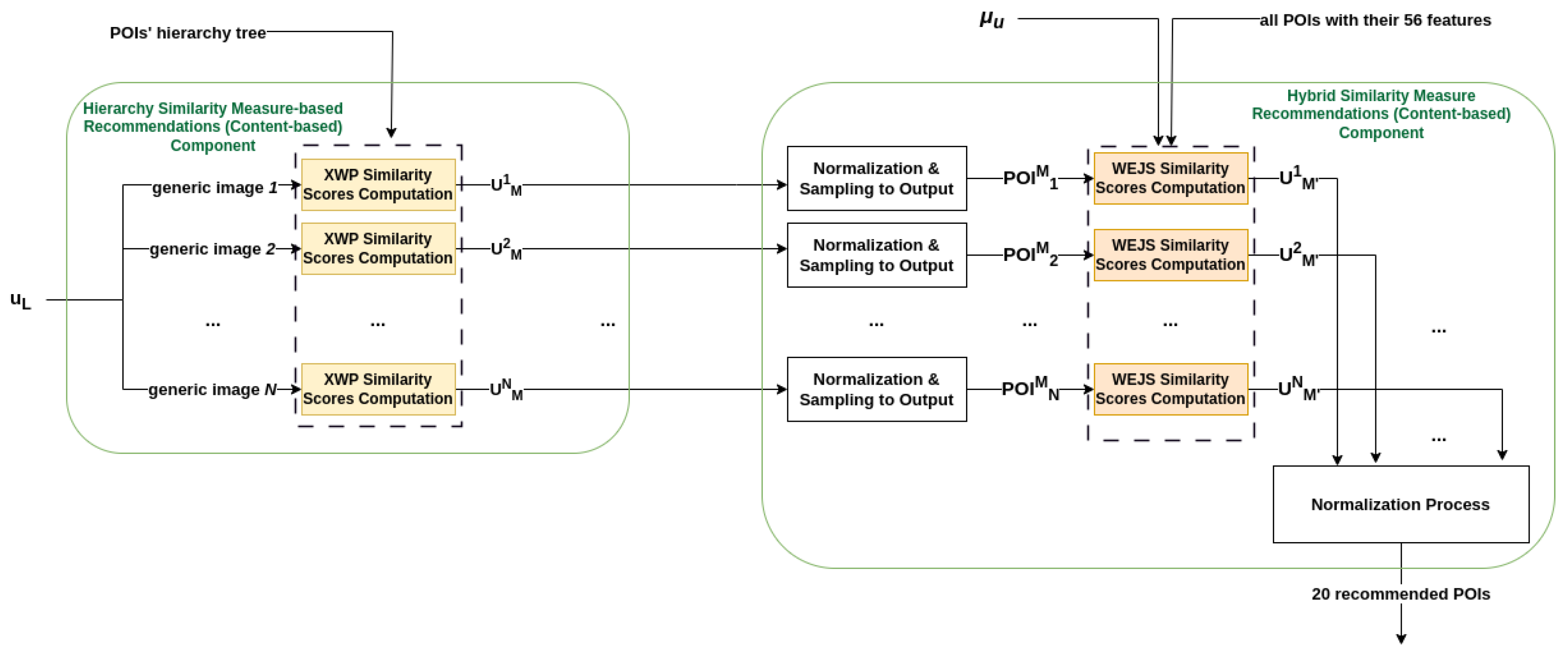
Figure 7 depicts the
CB recommender component of the
Hybrid RS. Notice that this figure is almost identical to
Figure 5, with two changes: First, the
Hierarchy SMbR sub-component is now not allowed to produce final recommendations (the blue
Normalization Process and its output are now removed), but only provides input to the
Hybrid SMbR sub-component. This is since our experiments in
Section 5 point to the
Hybrid SMbR being a better choice (than solely
Hierarchy SMbR) for a
CB recommender component of our final
Hybrid RS. The second change is that
replaces the
user profile vector as input in the
WEJS metric, since our (hybrid)
CB recommender is now combined with the Bayesian elicitation module that produces a user profile in the form of a
multivariate Gaussian distribution.
The implementation of the overall
Hybrid recommendations process is summarized in Algorithm 2 below. The algorithm begins with the
Bayesian Inference process, which produces the set
and the distribution
describing the derived user profile. It proceeds with the generation of
sets by employing
XWP similarity between the
set and the POIs in our dataset (see line 7 in Algorithm 2). Subsequently, one POI is sampled out from each
set via the
Normalization & Sampling to Output component, and is provided as input to the
WEJS measure along with the
(see line 12 in Algorithm 2). Finally, for each selected POI a (new)
set is created, and all such sets are concatenated (see line 13 in Algorithm 2) in order to derive the final recommendations.
| Algorithm 2 Hybrid Recommender Algorithm |
- 1:
← Bayesian Inference - 2:
← all POIs with their 56 features - 3:
for each generic image in do - 4:
X← generic image - 5:
for each POI in POIs do - 6:
Y← POI - 7:
← POIs’ Hierarchy) - 8:
Single POI ← Normalization_and_Sampling_to_Output () - 9:
S← Single POI - 10:
for each POI in POIs do - 11:
Y← POI - 12:
← - 13:
Recommendations ← Recommendations - 14:
20 Recommended POIs ← Normalization (Recommendations)
|
5. Experimental Evaluation and Results
In this section we assess the performance of our algorithms on real-world data comprising 430 points of interest from the city of Agios Nikolaos by using a lab computer with AMD Ryzen 7 3700x 8-core processor x 16 CPU with a GeForce RTX 3080 GPU. We collected information related to users’ preferences from questionnaires filled out by 150 actual short-term visitors and used these data to generate a set of 600 synthetic users. We categorized the synthetic users to six different age classes (100 tourists per class), namely 17–25, 26–35, 36–45, 46–55, 56–67 and 67+.
In order to generate the synthetic users’ profiles, we proceeded as follows. We first computed an average profile for each age class, containing the average values of the 12 features representing user preferences, as listed in the filled-in questionnaires of the real tourists belonging to that particular class. Specifically, these 12 features were used: Family friendly facilities and activities, Luxury Accommodation, Affordable Prices, Culture, Shopping Local Products, Sun and Sea, Rural Tourism, Sports and Adventure, General Shopping, Nightlife, Cuisine and Gastronomy, Archaeology or History. (We remind the reader that these 12 features correspond to the 12 “POI character” features, in accordance to the “You Are What You Consume” approach.) Subsequently, for each class, we sampled 100 random user profiles from a multivariate normal distribution, generated using the mean vector from the average “real tourist” profile mentioned above; its covariance matrix is diagonal with all its eigenvalues equal to 2.
We assess the
content-based and
Hybrid recommender (described in
Section 3 and
Section 4) separately in the following subsections, and we compare their results. In our experimental setting each (synthetic) user interacts with the recommenders 30 times (each time without storing any information about the model for the next run of the system). Thus the set of generic images provided to her is not necessarily always the same. As explained in the previous sections, the elicitation process differs between the two CB (see
Section 3.1) and Hybrid (see
Section 4.1) recommenders, both in the number of generic images presented to the user and their functionality.
For each user, we utilize
k-means clustering [
38] to classify all POIs to two distinct categories, specifically, those that are close to her profile, termed the
relevant POIs, while the complementary set is that of
irrelevant POIs. Since we are interested primarily in the intersection of POIs which are relevant to those recommended by each of our algorithms, we denote as
the average cardinality of this set of POIs over all 100 users per age group, and over 30 runs per user.
We evaluate the performance of our algorithms by employing the well-known
precision and
recall measures of recommendations’ quality [
39]. Notably, precision is the quotient of the number of recommended relevant POIs over the number of all (relevant and irrelevant) recommended POIs; the latter, in our case, is always 20. Recall is the quotient of the number of recommended relevant POIs over the number of all (recommended and non-recommended) relevant POIs.
Now, let us provide an intuitive interpretation of precision and recall. Recall decreases when the non-recommended relevant POIs increase, while the precision is greater when the algorithm recommends fewer irrelevant POIs. Therefore, we can utilize recall in order to provide an assessment tool for users who evaluate the performance of our application based on whether they did not visit a relevant POI. On the other hand, we employ precision to model the evaluation of our algorithms from users who are interested in not visiting any irrelevant POI. Furthermore, we highlight that the number of recommended relevant POIs cannot exceed 20, however the relevant POIs are far more than this number; thus, the value of recall will always be much lower than 1. For instance, if the number of relevant POIs is 272, recall cannot exceed . Hence, recall in our results should always be assessed based on its corresponding maximum value, denoted below as Recall Upper Bound (or Recall UB for short). We focus mainly on the value of precision for reasons of clarity, and because we (reasonably) assume that the users’ “assessment-profile” is closer to that of precision rather than recall, intuitively, short-term visitors cannot possibly explore every relevant POI with respect to their interests, but they tend to be frustrated when they spend time on irrelevant POIs.
5.1. Evaluation of Our Content-Based Recommendation Algorithms
We first conduct a series of experiments in order to evaluate the performance of the semantic similarity-based algorithms that are contained in the CB component of our system—i.e., the methods introduced in
Section 3.2 and
Section 3.3) of this paper. Since our experiments involve synthetic users, our CB recommendation process requires the identification of images a synthetic user “likes”. This is carried out by comparing the
cosine similarity among the values of the (twelve) features of the “
actual” (synthetic) user profile and the values of the corresponding features representing the (fifteen) “generic” images displayed to the user by the elicitation component (termed “Show Generic Images” in
Figure 3) of the CB recommendation process. In case the cosine similarity between an image and the profile exceeds a threshold, set to
, the image is considered to be “selected” (or “liked”) by the user; otherwise it is not. The “liked” images make up the
set of images fed into the
Hierarchy SMbR, while the
Build User Profile sub-component (cf.
Figure 3) also constructs a
user profile that the (hybrid) CB recommender can use for its recommendations. We now proceed with the comparison between the performance of the
hierarchy SMbR algorithm (i.e., the output of the
Normalization Process in blue color in
Figure 5) and the
hybrid SMbR (i.e., the output of the
Normalization Process in black color in
Figure 5).
In
Table 1 and
Table 2 we illustrate the aforementioned measures of quality (i.e., precision and recall) of our application, together with the number of relevant POIs,
and
Recall UB for each age group. (We remind the reader that Recall UB (i.e., Recall Upper Bound) stands for the maximum possible value of Recall that could be attained by an algorithm capable of “optimally” eliciting and exploiting users’ preferences in this setting, i.e., no algorithm could have performed better than this value.) The results of
Table 1 concern the
Hierarchy SMbR, while those of
Table 2 correspond to the
Hybrid SMbR of the CB recommender. We observe that the results (i.e., the values of
Precision, and the respective values of
Recall compared to
Recall UB) between the two recommendation processes are quite satisfactory, as
Precision is regularly higher than or close to 80%, while
Recall reaches values close to or higher than 80% of the respective
Recall UB ones. In general, the two
CB methods appear to be comparable to each other:
Hierarchy SMbR achieves a better performance for younger users, while Hybrid SMbR attains greater values of precision and recall for the age groups 56–67 and 67+.
In addition,
Table 3 illustrates the average precision of the algorithms across all age groups. We can observe that the
Hybrid SMbR has an average precision value that is slightly greater than the one of the
Hierarchy SMbR. Of course, this small difference in precision alone would not be enough in order to pick the
Hybrid SMbR as the preferable CB recommender system between the two. However, another drawback of the
Hierarchy SMbR is that the
set is always the same for all users who “liked” a particular generic image, as such the generated recommendations would be quite similar for these users. Moreover, the method does not take into account a user profile. These characteristics clearly do not contribute to diverse or personalized recommendations.
On the other hand, the
WEJS measure used by the
Hybrid SMbR module combines information about the user’s preferences and the content of the POIs, by taking into account the
user profile vector and all 56 features of the POIS. As such, we expect
Hybrid SMbR to result in recommendations that are both more personalized and more diverse. We explicate the latter point and the meaning of the term “diversity”, by providing an example: when the system recommends a monastery which produces its own wine, it is probable to also recommend a liqueur store that sells the monastery’s wine, even though liqueur stores are not in the vicinity of monasteries in the hierarchy tree, thus
Hierarchy SMbR could not have possibly captured this connection. (This point is also supported by the experiments in [
22] evaluating the
WEJS measure.) Moreover, the
Hybrid SMbR is also able to exploit information about the user profile captured via the elicitation process. For those reasons, we pick the
Hybrid SMbR to be the
CB recommender method of choice for our overall
Hybrid RS, which we now proceed to evaluate.
5.2. Evaluation of the Complete Hybrid Recommender System
In this section we evaluate the complete
Hybrid recommender algorithm. As explained earlier, we now adopt the iterative elicitation process introduced in
Section 4.1, which results in a multivariate Gaussian distribution,
, that describes the preferences of user
u. In detail, we run a series of user–system interactions with varying “slates”. A slate in our case corresponds to an implicit “query” presented to the user, comprising of a number
n of images for the user to select a preferred one from. We experiment with varying numbers of slates
posed to the user, and with varying numbers
of generic images presented to the user in a slate (“query”). The testing of various such
combinations of
elicitation slates, images shown per slate pairs, aims to assess the trade-off between the information offered to the algorithms (expected, naturally, to improve their performance), and the frustration caused to users when the time required from them to spend “marking” (generic) images for elicitation purposes increases [
40]. Thus, as also explained in
Section 4.1, during each
elicitation instance, the user selects the generic images that are more appealing to her, given her interests. The “selected” images are stored in the
set, and used alongside
to recommend POIs to the user (as explained in
Figure 7 and Algorithm 2).
In
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12 we present the average values of precision and recall, alongside with the (average) number of relevant POIs,
(the average number of relevant POIs among the 20 recommended) and
Recall UB for all age groups, each of which comprises 100 users who enter the system 30 times. Furthermore, we illustrate the average precision values for every
combination in
Table 13.
As seen in
Table 13, our
Hybrid RS outperforms the aforementioned
Cb algorithms regarding the average values of
Precision for all pairs of
, and also almost always outperforms them in terms of
Recall (the latter’s values are regularly about 85% of those of
Recall UB, i.e., our method regularly returns about 17 recommendations that are relevant to the user profile, out of the 20 relevant recommendations that it could have possibly returned). However, slightly higher precision outcomes are observed for some age groups (namely 56–67,
) for the
Hybrid SMbR CB recommender (see
Table 2). Overall, it is clear that the
Hybrid RS has a much more stable performance than the CB recommenders, achieving outcomes that are consistently higher than
for all pairs (apart from the
age group), and consistently including about 17 POIs that are relevant to the user interests, in its 20 returned recommendations.
According to
Table 13 our
Hybrid recommender achieves the best results for its variant using values of
during elicitation—i.e., when the user is presented four times with six images each time. Now, for larger values of combinations
, the cardinality of the set
is larger (
). This creates the possibility for more irrelevant POIs being contained in the sets
and
, and as a result they may be presented in the final recommendations to the user— naturally, when the proportion of the irrelevant POIs is high, the precision results decrease. We can see a possible manifestation of this behaviour in the precision outcome of the
pair, which is lower than the respective
, even though more information is potentially elicited from the user in the
case. That information probably results to a “blurring” of the user model.
Hence, since it is better than all other combinations for average precision, as listed in
Table 13, combined with the fact that being presented with fewer slates (
instead of 5 or 6) results in a “lighter”, less tiresome elicitation process for the user, we consider the variant of our
Hybrid RS that uses the
elicitation slates,
images shown per slate〉 pair as the one to incorporate into our final system.
We remind the reader that we primarily focus on precision values, since it can measure the frustration of users spending time on irrelevant POIs (as discussed in the beginning of
Section 5). Interestingly, we note that the performance of our methods in terms of precision is quite satisfactory (as precision almost always exceeds
), also when contrasted with the performance of other recommendation algorithms used in the tourism domain: for instance, the approaches of [
20,
26] report precision values under
. In addition, our algorithms effectively circumvent the cold-start problem, which is key for the quality of the recommendations, especially in the setting of our mobile application (i.e., short-term tourist visits).
6. Conclusions and Future Work
In this work a novel Hybrid Recommender System is introduced for the tourist domain, combining a Bayesian preference elicitation technique and a content-based recommendation process. The experimental assessment of the proposed Hybrid Recommender System, as well as the content-based recommendation techniques is performed on a real-world dataset, constructed during the development of a real-world travel planning mobile application, and incorporated knowledge derived from a survey involving actual tourists. The content-based recommender component of our system combines a hierarchy similarity measure with a novel non-hierarchical one. Our experimental results verify the effective performance of several variants of our proposed Hybrid RS, indicating that—compared to the exclusively content-based techniques—they return many more POIs relevant to the inferred user profile. In addition, when comparing the performance of the various Hybrid RS variants against each other, we are able to come up with a “winner”: the most preferable Hybrid RS variant is the one using an elicitation slates, shown images per slate〉 pair as input to its Bayesian Inference component.
Now, despite the fact that our experimental findings are encouraging, they were performed with only synthetic users and, while we concentrated on a specific real-world dataset linked to our recommendation algorithm for the location of interest, it would be beneficial to evaluate our algorithms with various other datasets. In ongoing and future work, we aim to conduct a large-scale evaluation of our system via utilizing feedback provided by real users of our (already available online) mobile application, following all required policies and provisions for protecting users’ privacy. Since different versions of our real-world application incorporate several recommender algorithms (additional to those presented in this paper), such experiments will also provide us with the opportunity to compare these methods against each other, and to come up with modifications, algorithmic improvements, and even novel hybrid solutions.



 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}