1. Introduction
Clustering is a key technique in unsupervised learning and is employed across various domains such as computer vision, natural language processing, and bioinformatics. Its primary objective is to assemble related items and disclose hidden patterns within data. Confronting complex datasets, however, can prove challenging, as conventional clustering approaches may not be effective. In response to this issue, Bayesian nonparametric methods have gained popularity in recent years as a potent means of organising large datasets. These approaches offer a versatile and potent solution for managing the data’s unpredictability and complexity, making them a crucial tool in the field of clustering. Clustering is crucial in the fields of information science and big-data management for organizing and handling huge volumes of data. In recent years, exponential data proliferation has increased the demand for efficient and effective solutions to handle, manage, and analyse enormous data volumes. Clustering can accomplish this by grouping comparable data points together, hence lowering the dataset’s size and making it simpler to examine. Apart from traditional techniques, there are much more promising ones. The product partition model (PPM) is one of the most widely used Bayesian nonparametric clustering algorithms. PPMs are a class of models that classify data into clusters and assign a set of parameters to each cluster. They use a prior over the parameters to draw conclusions about the clusters. Despite the efficacy of PPMs, a single clustering solution may not be enough for complicated datasets, resulting in the development of consensus clustering. Consensus clustering is a kind of ensemble clustering that produces a final grouping by combining the results of numerous clustering methods [
1,
2].
The motivation behind this work lies in addressing the challenges associated with clustering complex datasets, which is crucial for efficient big-data management and analysis. The determination of the number of clusters and handling of high-dimensional data are significant challenges that arise while dealing with these complex datasets. To tackle these challenges, we propose an innovative method that combines Bayesian mixture models with consensus clustering.
Our method is designed to address the challenges of clustering extensive datasets and identifying the ideal number of clusters. By merging the strengths of PPMs, Markov chain Monte Carlo (MCMC), and consensus clustering, we aim to produce reliable and precise clustering outcomes. MCMC methods enable the estimation of PPM parameters, making them a powerful tool for sampling from intricate distributions. Moreover, split-and-merge techniques allow the MCMC algorithm to navigate the parameter space and generate samples from the posterior distribution of the parameters [
3,
4,
5].
The incorporation of consensus clustering with Bayesian mixture models facilitates the examination of complex and high-dimensional datasets, thereby improving the effectiveness and efficiency of big-data management. Our suggested approach also holds the potential to uncover hidden data patterns, which can lead to improved decision-making processes and offer a competitive edge across various industries.
The proposed utilization of Bayesian nonparametric ensemble methods for clustering intricate datasets demonstrates considerable promise in the realms of information science and big-data management. Combining PPMs, MCMC, and consensus clustering results in a robust and accurate clustering solution. Further research could refine this method and explore its application in real-world situations.
The remainder of this article is structured as follows:
Section 2 presents a concise overview of Bayesian nonparametric methods, particularly PPMs, and their applicability in clustering.
Section 3 describes consensus clustering and its application to ensemble methods. In
Section 3.3, we present our proposed method, which incorporates PPMs and consensus clustering.
Section 4 conducts experiments to illustrate the efficacy of the proposed method for clustering complex datasets. Finally,
Section 6 concludes the paper, discussing potential future research and the significance of our proposed method in the field of big-data analysis and management.
2. Related Work
Cluster analysis has been utilised extensively in numerous disciplines to identify patterns and structures within data. Caruso et al. [
6] applied cluster analysis to an actual mixed-type dataset and reported their findings. Meanwhile, Absalom et al. [
7] provided a comprehensive survey of clustering algorithms, discussing the state-of-the-art machine learning applications, taxonomy, challenges, and future research prospects. Jiang et al. [
8] conducted a survey of cluster analysis for gene expression data. Furthermore, Huang et al. [
9] proposed a locally weighted ensemble clustering method that assigns weights to individual partitions based on local information. These studies demonstrate the diversity of clustering methods and their applications, emphasizing the importance of choosing the appropriate method for specific datasets.
Consensus clustering utilises
W runs of a base model or learner (such as
K-means clustering) and combines the
W suggested partitions into a consensus matrix, where the
-th entries reflect the percentage of model runs in which the
ith and
jth individuals co-cluster. This ratio indicates the degree of confidence in the co-clustering of any two elements. Moreover, ensembles may reduce computational execution time. This occurs because individual learners may be weaker (and hence consume less of the available data or stop before complete convergence), and the learners in the vast majority of ensemble techniques are independent of one another, enabling the use of a parallel environment for each of the faster model runs [
10].
Bayesian clustering is a popular machine-learning technique for grouping data points into clusters based on their probability distributions. Hidden Markov models (HMM) [
11] have been used to model the underlying probabilistic structure of data in Bayesian clustering. Accelerating hyperparameters via Bayesian optimizations can also help in building automated machine learning (AutoML) schemes [
12], while such optimizations can also be applied in Tiny Machine Learning (TinyML) environments wherein devices can be trained to fulfil ML tasks [
13]. Ensemble Bayesian Clustering [
14] is a variation of Bayesian clustering that combines multiple models to produce more robust results, while cluster analysis [
15] extends traditional clustering methods by considering the uncertainty in the data, which leads to more accurate results.
Traditional clustering algorithms require a preset selection of the number of clusters
K, which can be challenging as it plagues many investigations, with researchers often depending on certain rules to choose a final model. Various selections of
K are compared, for instance, using an evaluation metric for
K. Techniques for selecting
K using the consensus matrix are offered in [
16]; however, this implies that any uncertainty over
K is not reflected in the final clustering, and each model run utilises the same, fixed number of clusters. An alternative clustering technique incorporates cluster analysis within a statistical framework [
17], which implies that models may be formally compared and issues such as choosing
K can be represented as a model-selection problem using relevant tools.
In recent years, various clustering techniques have been developed to address the challenges associated with traditional clustering methods. Locally weighted ensemble clustering [
9] leverages the advantages of ensemble clustering while accounting for the local structure of the data, leading to more accurate and robust results. Consensus clustering, a type of ensemble clustering, combines multiple runs of a base model into a consensus matrix to increase confidence in co-clustering [
16]. Enhanced ensemble clustering via fast propagation of cluster-wise similarities [
18,
19] improves the efficiency and effectiveness of clustering by propagating cluster-wise similarities more rapidly. Real-world applications of these clustering techniques can be found in various domains, such as gene expression analysis, cell classification in flow cytometry experiments, and protein localization estimation [
20,
21,
22].
Recent advancements in ensemble clustering have addressed various challenges posed by high-dimensional data and complex structures. Yan and Liu [
23] proposed a consensus clustering approach specifically designed for high-dimensional data, while Niu et al. [
24] developed a multi-view ensemble clustering approach using a joint affinity matrix to improve the quality of clustering. Huang et al. [
25] introduced an ensemble hierarchical clustering algorithm that considers merits at both cluster and partition levels. In addition, Zhou et al. [
26] presented a clustering ensemble method based on structured hypergraph learning, and Zamora and Sublime [
27] proposed an ensemble and multi-view clustering method based on Kolmogorov complexity. Huang et al. [
28] tackled the challenge of high-dimensional data by developing a multidiversified ensemble clustering approach, focusing on various aspects such as subspaces, metrics, and more. Huang et al. [
29] also proposed an ultra-scalable spectral clustering and ensemble clustering technique. Wang et al. [
30] developed a Markov clustering ensemble method, and Huang et al. [
31] presented a fast multi-view clustering approach via ensembles for scalability, superiority, and simplicity. These studies showcase the diverse range of ensemble clustering techniques developed to address complex data challenges and improve the performance of clustering algorithms.
Clustering ensemble techniques have been developed and applied across various domains, addressing the challenges and limitations of traditional clustering methods. Nie et al. [
32] concentrated on the analysis of scRNA-seq data, discussing the methods, applications, and difficulties associated with ensemble clustering in this field. Boongoen and Iam-On [
33] presented an exhaustive review of cluster ensembles, highlighting recent extensions and applications. Troyanovsky [
34] examined the ensemble of specialised cadherin clusters in adherens junctions, demonstrating the versatility of ensemble clustering methods. Zhang and Zhu [
35] introduced Ensemble Clustering based on Bayesian Network (ECBN) inference for single-cell RNA-seq data analysis, offering a novel method for addressing the difficulties inherent to this data format. Hu et al. [
36] proposed an ultra-scalable ensemble clustering method for cell-type recognition using scRNA-seq data of Alzheimer’s disease. Bian et al. [
37] developed an ensemble consensus clustering method, scEFSC, for accurate single-cell RNA-seq data analysis based on multiple feature selections. Wang and Pan [
38] introduced a semi-supervised consensus clustering method for gene expression data analysis, while Yu et al. [
39] explored knowledge-based cluster ensemble approaches for cancer discovery from biomolecular data. Finally, Yang et al. [
40] proposed a consensus clustering approach using a constrained self-organizing map and an improved Cop-Kmeans ensemble for intelligent decision support systems, showcasing the broad applicability of ensemble clustering techniques in various fields.
Bayesian mixture models, with their adaptable densities, are highly attractive for data analysis across various types. The number of clusters
K can be inferred directly from the data as a random variable, resulting in joint modelling of
K and the clustering process [
41,
42,
43,
44,
45,
46]. Inference of the number of clusters can be achieved through methods such as the Dirichlet process [
41], finite mixture models [
42,
43], or over-fitting mixture models [
44]. These models have found success in a wide range of biological applications, including gene expression profiles [
20], cell classification in flow cytometry experiments [
21,
47] and scRNAseq experiments [
48], as well as protein localization estimation [
22]. Bayesian mixture models can also be extended to jointly cluster multiple datasets [
49,
50].
MCMC techniques are the most-used method for executing Bayesian inference, and they are used to build a chain of clusterings. The convergence of the chain is evaluated to see if its behaviour conforms to the asymptotic theory predicted. However, despite the ergodicity of MCMC approaches, individual chains often fail to investigate the complete support of the posterior distribution and have lengthy runtimes. Some MCMC algorithms attempt to overcome these issues, often at the expense of higher computing cost every iteration (see [
51,
52]).
Preliminaries
Dirichlet processes (DPs) are a family of stochastic processes. A Dirichlet process defines a distribution over probability measures
, where for any finite partition of
, say
, the random vector
is jointly generalized under a Dirichlet Distribution (
is a random variable since
G itself is a random measure and is sampled from the Dirichlet process), written as
where
is called the concentration parameter and
is the base distribution;
collectively is called the base measure.
Dirichlet processes are really useful in the task of nonparametric clustering via using a mixture of Dirichlet processes (commonly DP mixture models or Infinite mixture models). In fact, a DP mixture model can be seen as an extension of Gaussian mixture models over a nonparametric setting. The basic DP mixture model follows the following generative story:
where
DP denotes sampling from a Dirichlet process given a base measure.
When we are dealing with DP mixture models for clustering, it helps to integrate out
G with respect to the prior on
G [
53]. Therefore, we can write the clustering problem in an alternate representation, although the underlying model remains the same.
where
is the cluster assignment for the
point and
are the likelihood parameters for each cluster.
K denotes the number of clusters, and being a nonparametric model, we assume
.
If the likelihood and the base distribution are conjugate, we can easily derive a posterior representation for the cluster assignments or the latent classes and use inference techniques such as mean-field VB and Markov chain Monte Carlo. The work [
53] also describes various inference methods in the case of a non-conjugate base distribution.
Dirichlet processes are extremely useful for clustering purposes as they do not assume an inherent base distribution, and therefore it is possible to apply Dirichlet process priors over complex models.
4. Experimental Results
In this section, we present the experimental results based on the methods from the preceding sections.
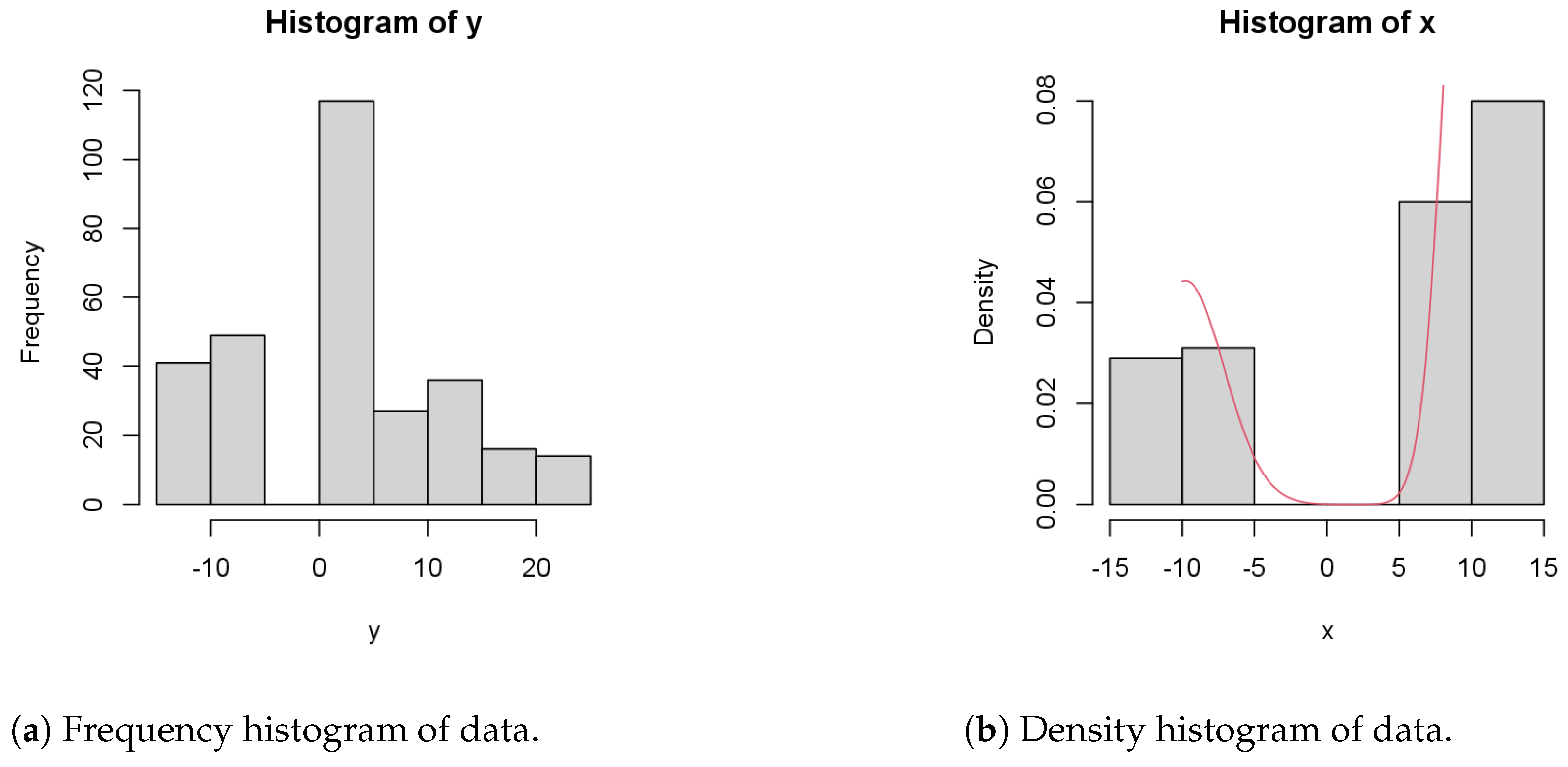
Figure 2a shows the frequency histogram of
y observations of the data, while
Figure 2b shows the histogram of
x and the density of the data.
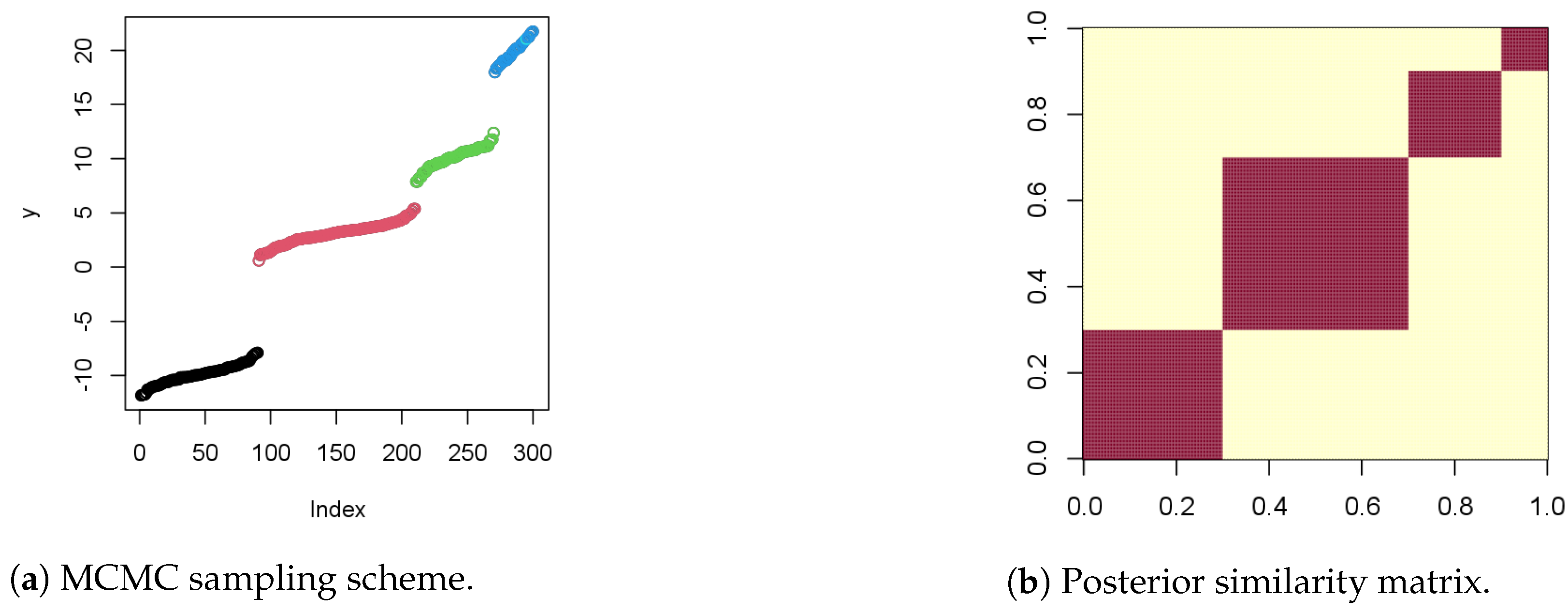
Figure 3a shows the MCMC sampling structure and the repetitive areas on
y points over 300 iterations, while
Figure 3b shows the posterior similarity matrix.
For the experimental results, the following posterior parameters were utilized
, which represent the means of the posterior distributions for each of the four clusters;
represent the variances of the posterior distributions for each of the four clusters;
represent the proportions (or mixing weights) of the posterior distributions for each of the four clusters. The simulation parameters are the means
and variances
of the clusters, as well as the mixing proportions
of the Poisson process mixture. The values represent the estimated proportion of each of the four clusters in the PPM. The standard deviations give the uncertainty around these estimated proportions, with the lower and upper bounds indicating the credible interval. It is worth noting that the results presented in the table are just one possible output of the simulation study, and other simulations with different parameter settings may produce different results.
Table 1 shows the results of a simulation study of PPM and consensus clustering.
The clustering results of the proposed method in the MCMC framework are shown in
Table 2. We conduct tests by adjusting the hyperparameters for different scenarios for which various numbers of clusters are produced, and their means and variances are calculated.
5. Further Extensions for Big Data Systems
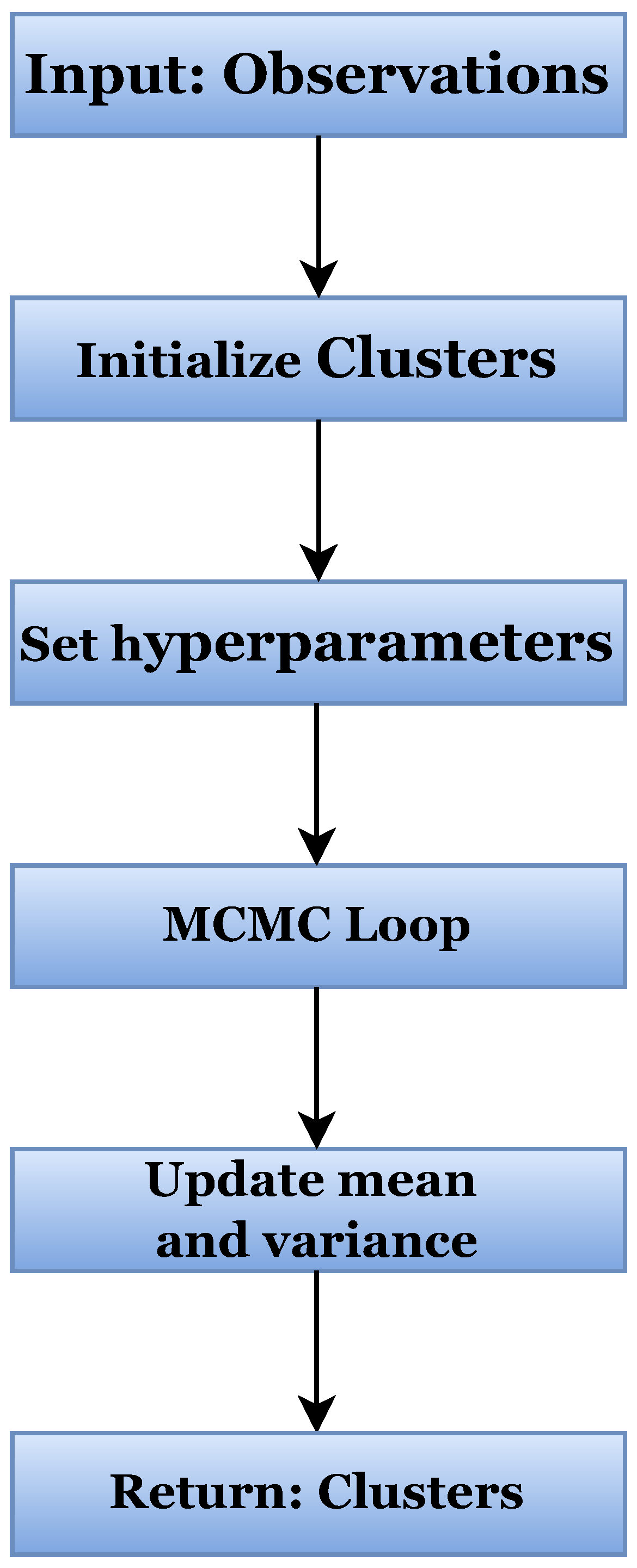
In this section, we propose further extensions for big-data systems and how these methods can be applied to the information science sector. Algorithm 2 is a method for clustering big datasets into groups based on the similarities between observations, with a variety of applications in fields such as information science, big-data systems, and businesses. The algorithm uses Hamiltonian Monte Carlo (HMC) sampling to estimate the posterior distribution of the clusters and their means and variances. One of the main challenges in dealing with big data is the processing time required to analyse and cluster large datasets. By partitioning the MCMC iterations into equal portions and allocating each part to a worker, parallelization of the algorithm helps to surmount this difficulty. This parallelizes the clustering procedure, thereby substantially reducing the processing time.
| Algorithm 2 Parallel Bayesian nonparametric clustering using HMC |
- 1:
Input: Observations , Hyperparameters , m, MCMC iterations , Number of parallel workers - 2:
Output: Clusters and their means and variances - 3:
Initialize clusters and assign observations: - 4:
Set up - 5:
Assign all observations into a cluster - 6:
Set hyperparameters: - 7:
Set values for and m - 8:
Partition MCMC iterations: - 9:
Partition the MCMC iterations into equal parts - 10:
MCMC Loop: - 11:
for in 1 to do - 12:
Use HMC to sample the posterior distribution of K, , and - 13:
Loop over the assigned MCMC iterations - 14:
Update K, , and based on the samples - 15:
end for - 16:
Combine results: - 17:
Combine the results from to obtain the final K, , and - 18:
Return: Clusters j and their and
|
Algorithm 2 boasts a wide range of applications spanning numerous fields such as computer science, big-data systems, and business. In the realm of information science, this algorithm can be employed to consolidate extensive datasets based on similarities, thereby uncovering the data’s underlying structure. In the context of business, the algorithm can be applied to cluster customers according to their purchasing behaviours and preferences, yielding valuable insights that enable targeted marketing and sales strategies.
In the domain of big-data systems, the algorithm is capable of clustering massive datasets into groups sharing similar traits, which reduces data storage and processing demands. Moreover, clustering analogous data facilitates parallel processing, consequently boosting efficiency and accelerating processing times. Beyond business and information science, the algorithm can also be utilized in human resource management, where it can group employees based on their skill sets and experiences. This clustering empowers organizations to streamline talent acquisition, leading to increased productivity and employee satisfaction.
Ultimately, the algorithm serves as a potent instrument for analysing vast datasets, generating insightful information, and improving decision-making processes across various sectors. Future research could explore the algorithm’s additional applications and assess its performance in diverse contexts.
Algorithm 1 can be adapted in Apache Spark by dividing the data into smaller chunks and distributing them among different nodes in a cluster. The algorithm can be executed in parallel on each node and the results can be combined to get the final clustering results. Each iteration of the MCMC loop can be implemented as a map-reduce operation, wherein the map operation performs the MCMC updates on a portion of the data and the reduce operation aggregates the results from all the map operations to get the updated clustering results. The map operation includes the operations mentioned in the initial algorithm: updating the and and adjusting the cluster labels if needed. The reduce operation combines the results from all the map operations and produces the updated clustering results, allowing for efficient parallel processing of large datasets and meeting big-data processing requirements in a scalable manner using Apache Spark.
The results of Algorithm 2 are shown in
Table 3. This method is similar to Algorithm 1; however, here we utilize Hamiltonian Monte Carlo instead of MCMC.
Integrating Algorithm 2 with Apache Spark, as demonstrated in Algorithm 3, allows for efficient and scalable processing of massive datasets in a distributed computing environment. Leveraging Spark’s capabilities, the algorithm can handle the increasing demands of big-data systems by dividing the data into
P partitions and executing parallel MCMC iterations across multiple nodes within a cluster. This approach enables faster processing times and accommodates growing data sizes while maintaining the accuracy and effectiveness of the clustering method. Additionally, the implementation in Spark paves the way for further development and optimization of Bayesian nonparametric clustering techniques in distributed computing environments, enabling better insights and more effective decision-making processes in various application domains. Finally, the results of Algorithm 3 are shown in
Table 4.
Ultimately, we present the performance of all of the proposed algorithms in
Table 5. We utilize famous real-world datasets such as CIFAR-10, MNIST, and Iris. The hyperparameters for each experiment are
and
m, and we evaluate the clustering accuracy and the time required for the method to complete. The time column is measured in seconds. As we can observe from the table, the fastest clustering was on the Iris dataset, but note that this dataset is smaller in terms of size compared with the other two. As for the method with the highest accuracy, it appears that BNP-MCMC (Algorithm 1) has the highest accuracy on the Iris dataset while having satisfactory accuracy on the other methods. Moreover, the parallel method appears to further improve the accuracy by some decimal points. Lastly, the Spark version of the proposed method produces similar results but outperforms the other methods with regards to time.
| Algorithm 3 Bayesian nonparametric clustering in MCMC on Apache Spark |
- 1:
Input: Observations , Hyperparameters , m, MCMC iterations - 2:
Output: Clusters j and their and - 3:
Divide the observations into P partitions - 4:
Initialize clusters and assign observations: - 5:
Assign all observations in each partition into a cluster - 6:
Set hyperparameter values for and m - 7:
for in 1 to do - 8:
Parallel Processing: - 9:
for p in 1 to P do - 10:
for i in 1 to n in partition p do - 11:
if is NOT a singleton then - 12:
Draw a new value from from Equation ( 27) - 13:
else - 14:
Draw a new value from from Equation ( 27) - 15:
end if - 16:
if any cluster is removed then - 17:
Adjust the labels to maintain a sequence from 1 to k - 18:
end if - 19:
end for - 20:
Update mean and variance for each cluster j in partition p - 21:
end for - 22:
Merge the updated and from partitions to obtain the global values - 23:
Update mean and variance for base distribution and - 24:
end for - 25:
Return: Clusters j and their and
|
6. Conclusions and Future Work
In the context of this work, we have proposed a novel approach for clustering complex datasets using Bayesian nonparametric ensemble methods that have the potential to revolutionize the field of information science and big-data management. Our approach generates a robust and accurate final clustering solution, addressing the challenges related to determining the number of clusters and managing high-dimensional datasets. By combining the strengths of PPMs, MCMC, and consensus clustering, our proposed method provides a more comprehensive and informative clustering solution, enabling efficient and effective management of massive datasets.
Further study could concentrate on improving the proposed method in a variety of ways. One area of research could be the creation of more efficient algorithms for computing the consensus matrix, thereby reducing the execution time of the approach. In addition, the incorporation of additional data sources into the model could result in more exhaustive clustering solutions. In addition, the use of more adaptive methods for determining optimal hyperparameters and the development of sophisticated techniques for dealing with data noise and outliers could improve the efficacy of the approach. Improving the comprehensibility and clarity of the proposed method for non-expert users could foster its widespread adoption across a more extensive array of applications and industries.
Exploration of the proposed implementation in various real-world contexts presents a promising avenue for future research. For example, the technique could be deployed to discern and classify diverse tumour types by examining their presentation in medical imaging data. Within the realm of natural language processing, the method could be harnessed to categorize text into specific topics. Additionally, in the financial industry, the suggested approach could be employed to cluster financial data, facilitating the recognition of patterns for stock price forecasting and fraud detection.
In summary, the proposed strategy of employing Bayesian nonparametric ensemble methods for clustering intricate datasets holds substantial promise for the proficient and effective handling of enormous datasets and has the potential to transform the landscape of information science and big-data management. Future research in this area could lead to significant advancements in the field, enabling the solution of increasingly complex problems in various disciplines.


 ,
, 







{kind=link}
{kind=link}
{kind=link}