1. Introduction
Since the burst of the United States housing bubble in 2008, a large amount of recent behavioural macroeconomics literature has emerged in response to what many regard as the extreme modelling assumption of rational (model-consistent) expectations—henceforth RE. Its defining characteristic is to limit the cognitive skills of at least a group of agents in the model. One strand of this literature achieves this by introducing simple ‘heuristic’ learning rules which can be thought of as parsimonious forms of forecasting rules (as in References [
1,
2,
3,
4]). This, we argue, fits well the behavioural approach of assuming agents in the model with limited cognitive skills who behave according to bounded rationality—henceforth BR.
However, this raises the opposite concern regarding the bounds on BR: with heuristic rule-of-thumb behaviour, agents may fall considerably short of building RE, and such models are particularly vulnerable to the Lucas critique when policy scenarios are studied. The problem is that agents can depart from rationality in an infinite number of ways, leading into the “the wilderness of bounded rationality problem” of Reference [
5]. The challenge posed by the wilderness is clearly demonstrated by the sheer size of literature on behavioural macroeconomics and the huge number of equilibria proposed. Surveys include References [
6,
7,
8,
9].
The concern of behavioural models regarding RE are shared by the recent Agent-Based(AB) alternatives. This approach represents economic agents as well as various social and environmental phenomena as autonomous virtual entities that interact during simulation experiments following pre-defined rules. In standard macroeconomic models, agents’ decisions consist of behavioural equations or, in the case of dynamic stochastic general equilibrium (DSGE) models, micro-founded first-order conditions satisfying a dynamic optimisation problem, that are continuous functions of the current and past state of the economy. The AB approach provides a potentially more flexible way of modelling the cognitive capabilities of decision makers and their responses to both the macro- and individual micro-environment (for example, the authors of Reference [
10] studied the inter-linkages between the real and financial sides of the economy using an AB framework in which different types of agents interact on different markets following simple heuristic rules).
When emotional states, cognitive limitations and past information play a key role in economic behaviour, the AB decision process serves as a promising approach for accounting for the behaviour of heterogeneous rule-possessing agents. In AB models, economies can represent out-of-equilibrium behaviour and non-market clearing and can be regarded as “evolving systems of autonomous interacting agents” Reference [
11]. Hence, while DSGE assumes that agents have very sophisticated computational capabilities and live in very simple environments, AB models assume that people use simple behavioural rules to cope with complex and dynamic environments. Many of the features of AB models in addition to non-RE, such as heterogeneous agents and unemployment, are now being incorporated into DSGE models. The bounded-rational behavioural models with learning can be then seen as a genre with both classical DSGE and AB modelling features (see Reference [
12] for further discussions).
In response to the wilderness concern, the literature on BR models adopts a basic general heterogeneous expectations framework pioneered by Reference [
13]. To limit the departure from rationality, the approach of
reinforcement learning proposes that, although adaptation can be slow and there can be a random component of choice, the higher the “payoff” (defined appropriately) from taking an action in the past, the more likely it will be taken in the future. We adopt a heterogeneous RE-BR model of this type. The idea behind this correction mechanism in which agents evaluate the payoff function is rooted in discrete choice theory, which is extensively studied in the fields of experimental economics and cognitive psychology. Recent studies have shown that, when managing their incentive structures, agents with market-consistent information may not follow rational choice theory and do not always correct irrational behaviour even if they have sufficient knowledge available to correct it Reference [
14]. Instead, a recent study by Reference [
15] conducted several experiments to analyse how agents decide between different alternatives. The results showed that people tend to evaluate their perceived efficacy to correct the error by following rational principles based on cognitively assessing the costs and benefits (payoff) associated with the correction.
In addition to the selection mechanism, for given proportions of RE and BR agents, there then exists a choice of learning model:
Euler versus the
anticipated utility approach (following Reference [
16])—henceforth EL and AU. In both approaches, agents cannot form model-consistent expectations. Under EL, agents forecast their own one-period-ahead decisions, whereas under AU, agents form beliefs over the future infinite time horizon of aggregate states and prices which are exogenous to their decisions (AU, also known the “infinite time-horizon” framework, is closely related to the “internal rationality” (IR) approach of Reference [
17]). Under both IR and AU, agents maximise utility, given their constraints and a consistent set of probability beliefs about payoff-relevant variables that are external. Then with IR, beliefs take the form of a well-defined probability measure over a stochastic process (the “fully Bayesian” plan). The authors of Reference [
18] compared the IR vs. AU and found that AU can closely approximate the fully Bayesian optimisation. The two approaches then differ with respect to what agents learn about—their own future one-period ahead decision for EL and variables exogenous to the agents for AU.
In this paper, we introduce heterogeneity in a full Brock–Hommes new Keynesian (NK) model with a composite specification of BR and RE agents allowing for a wealth distribution between the two groups. A third-order perturbation solution leads to a demonstration of the effects of reinforcement learning in our NK boundedly rational model environment. The primary interest of this paper is to study the effect of learning on the business cycle and its implications for the design of optimal policy strategies within the BR environment. To this end, the discussions are organised around a number of issues that we aim to address. Can our model with an endogenous selection mechanism generate endogenous persistence and non-normality in the frequency distribution of macroeconomic aggregates? Does the composition of the types of agents change with reinforcement learning and the nature of the shocks hitting the economy? What are the welfare implications based on a behavioural macroeconomic model of this type?
In particular, the main contributions of this paper are as follows: (1) we develop a micro-founded framework that models the endogenous composition of RE and non-RE agents with reinforcement learning along the lines of Reference [
19]; (2) we carry out our simulations based on different parameterisations of the model and focus on an assessment of the model-implied moments, including the simulated impulse response functions. Furthermore, in
Appendix A,
Appendix B,
Appendix C,
Appendix D,
Appendix E,
Appendix F and
Appendix G we discuss the sources of instability and indeterminacy in our setup featuring the BR agents who solve their decision problems using the EL and AU expectation formation schemes. The highly non-linear structure of the BR specification in which agents endogenously select the heuristic rules is crucial for conducting optimal policy in macroeconomic models.
Our paper aims to contribute to both the learning and macroeconomic literature. The investigation on the role of BR behaviour in understanding the dynamics in economic activity observed empirically and guiding policy choices is not a trivial one. Various attempts modify the baseline NK model to account for hybrid heterogeneous expectations and BR. An approach that is closely related to ours in this regard is from the earlier contributions of References [
3,
19,
20], in which they studied calibrated composite heterogeneous expectations models of RE and BR agents and discuss implications for the business cycle and designing stabilisation policies. In our setting, we focus on the major BR approaches with reinforcement learning—a highly non-linear structure within BR which is methodologically relevant for capturing movements that are non-normally distributed in empirical data. We also investigate the effect on rationality when we subject our model to the occurrence of more volatile exogenous shocks.
The rest of the paper is structured as follows.
Section 2 sets out the standard linear RE NK model used in the literature and then proceeds to the Brock–Hommes composite model of rational and boundedly rational agents.
Section 3 goes back to the non-linear foundations of the model.
Section 4 describes the specific market-consistent environment in which households and firms form their expectations. Then,
Section 5 presents our main results.
Section 5.3 discusses how we choose the set of parameter values that avoids chaotic dynamics. Finally,
Section 6 concludes the paper.
Appendix A,
Appendix B,
Appendix C,
Appendix D,
Appendix E,
Appendix F and
Appendix G contain further details and results on the model’s stability and the construction of the model.
4. AU Learning and Market-Consistent Information
With anticipated utility (AU) learning, our learning model is one where agents make fully optimal decisions, given their individual specification of beliefs, but have no macroeconomic model to form expectations of aggregate variables. We draw a clear distinction between aggregate and internal quantities so that identical agents in our model are not aware of this equilibrium property (nor any others).
To close the model, we need to specify the manner in which households and firms form their expectations. To do so, we assume that variables which are local to the agents, in a geographical sense, are observable within the period, whereas variables that are strictly macroeconomic are only observable with a lag. This categorisation regarding information about the current state of the economy follows Reference [
29], which distinguishes between the local information that agents acquire directly through their interactions in markets and statistics that are collected and summarised, usually by governments, and are made available to the wider public. (This paper actually focuses on a third category, information provided by the news media, and allows for imperfect information in the form of noisy signals, issues which go beyond the scope of our paper.) The policy rate is announced by the central bank; thus, it is observed without a lag, and it is common knowledge. Given this, we assume an adaptive expectations forecasting rule given below by (
38) and (
39) about variables external to agents’ decisions. Let
, then household expectations are given by
Expressing
and
in (
29) as forward-looking summations and using (
37), we arrive at the individual learning consumption equation
which is now expressed in terms of one-step ahead forecasts by
Households make inter-temporal decisions for their consumption and hours supplied given adaptive expectations of the wage rate, the nominal interest rate, inflation and profits. These macro-variables may in principle be observed with or without a one-period lag (), but as stated earlier, we assume for market-specific variables , and for aggregate inflation . However, we assume that the current nominal interest rate, , is announced and therefore is observed without a lag.
We distinguish household and firm expectations
,
. Then, for retail firm
m
where one-step ahead forecasts are given by the adaptive expectations rule
Retail firms make inter-temporal decisions for their price and output given adaptive expectations of the aggregate inflation rate and their post-shock real marginal shock wage rate. As before, these variables may be observed with or without a one-period lag (), but for aggregate inflation, we assume as for households, but for the market-specific variable . Note that we can in principle distinguish between households’ and firms’ expectations of inflation.
5. Heterogeneous Expectations across Agents
Now we come to the full Brock–Hommes NK model but with BR-AU rather than EL boundedly rational agents. We argue that our benchmark models, namely, an agent-level learning behavioural NK model with infinite horizon learners (AU) who use the standard Brock–Hommes forecast heuristics to form expectations, and a composite version with fixed proportions of agents forming both RE and AU in a NK setting, are selected because we want to compare the equilibrium features and empirical performance of these assumptions in an informational, consistent environment. We assume that all RE agents know the composite model, and moreover, we impose informational inconsistency by assuming that they have the same imperfect information set as the BR-AU agents. The latter do not know the model, but they make individually optimal decisions given individual observations of the states and belief formations. The composite RE-BR model then has an equilibrium (in non-linear form)
Zero net wealth in aggregateimplies that .
We first consider the properties of the model with fixed exogenous proportions of RE and BR agents. Then, in
Section 5.2, we allow these proportions to be determined endogenously.
5.1. Exogenous Proportions of RE and BR Agents
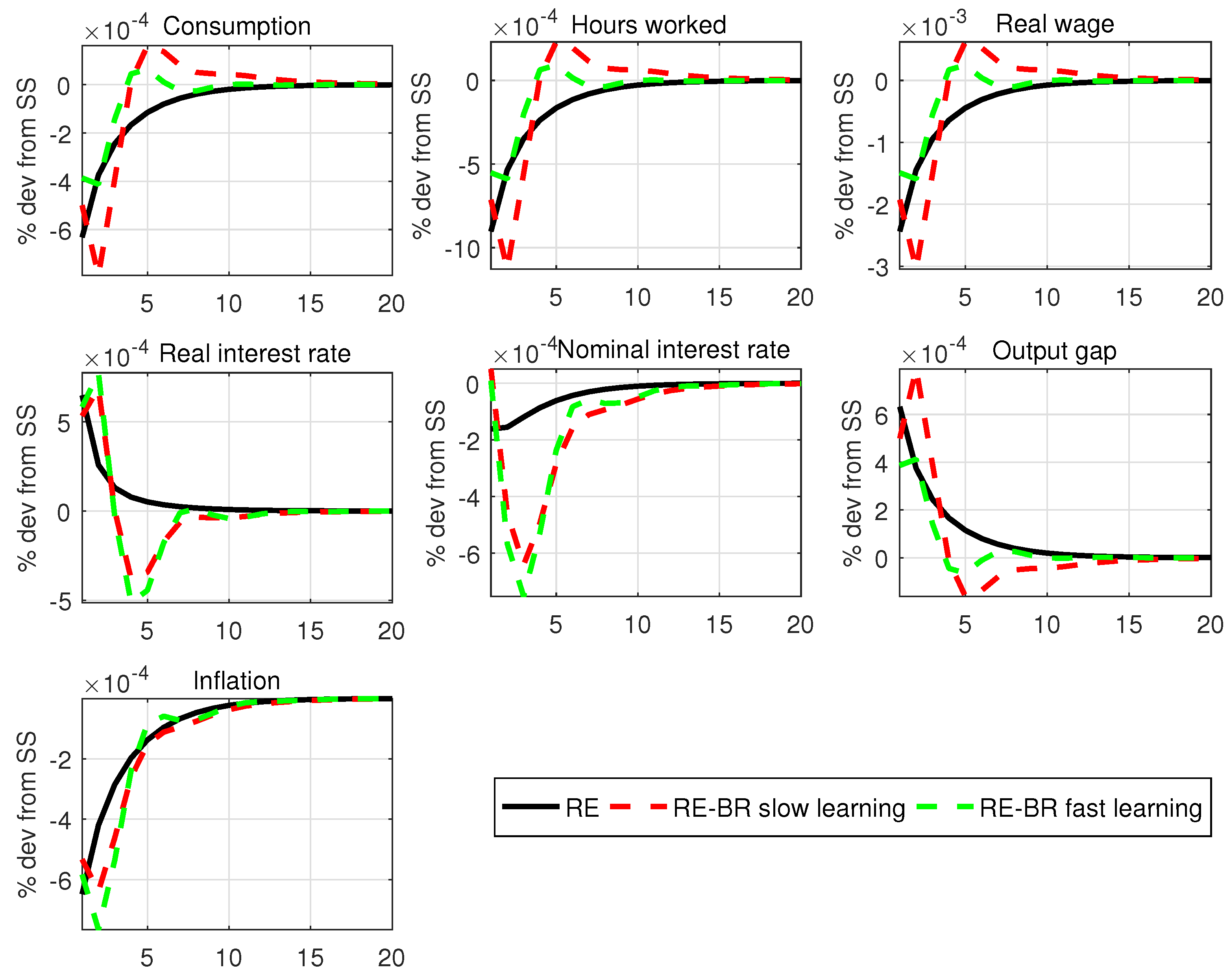
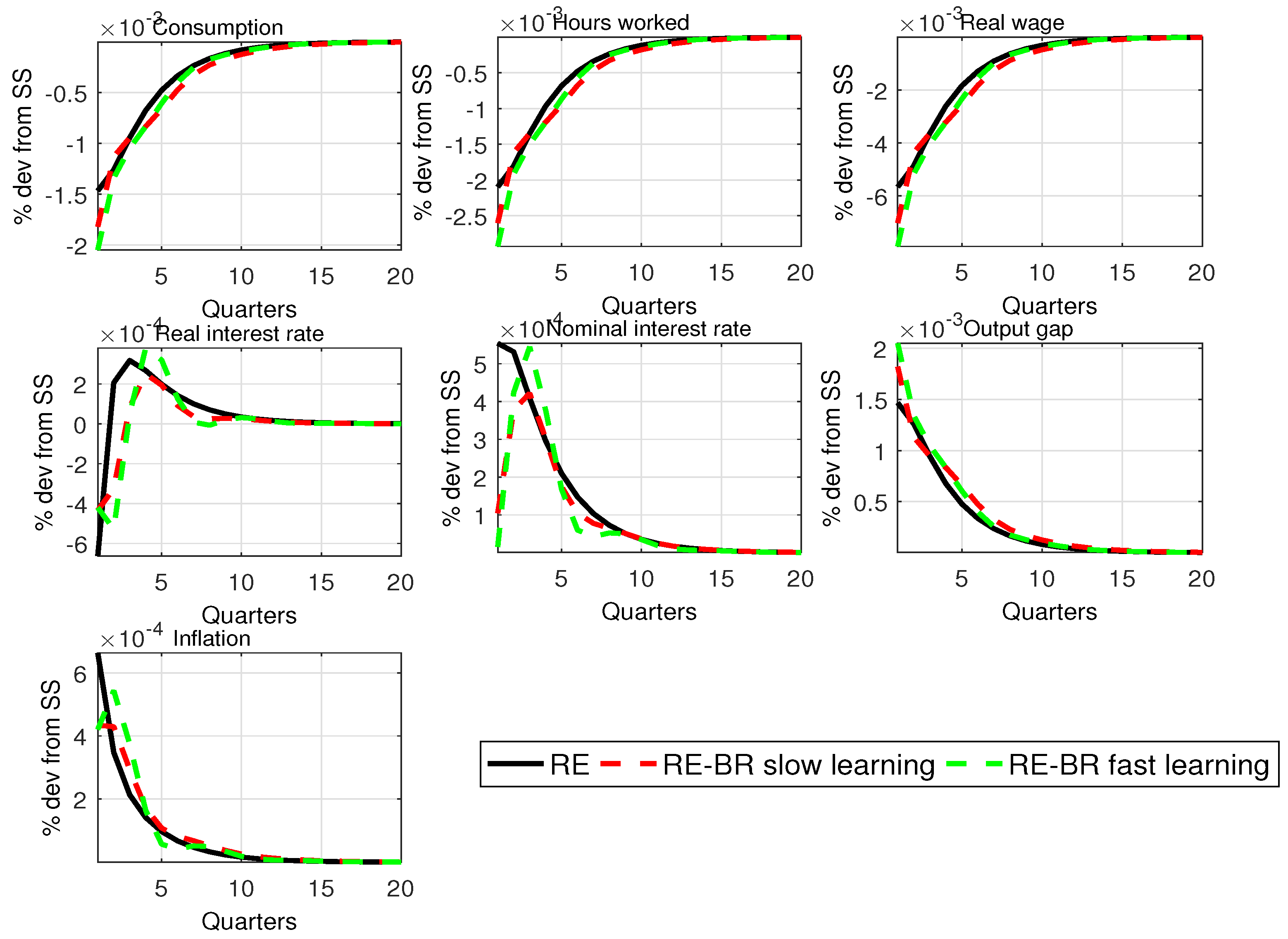
For our model of BR with AU,
Figure 1 plots the impulse response functions (IRFs) with standard parameters for the rule for a shock to monetary policy under fast and slow learning.
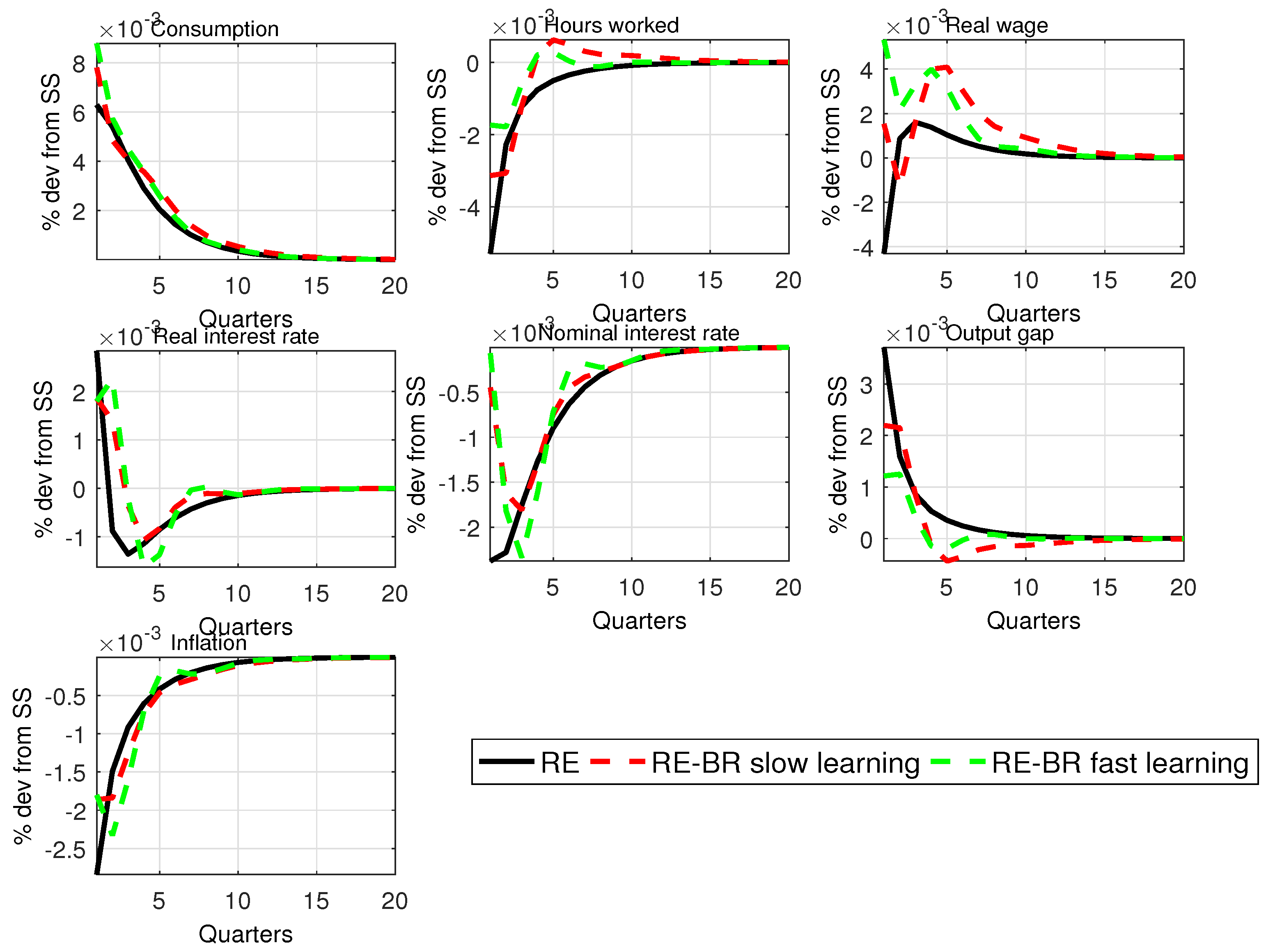
Figure A3 and
Figure A4 in
Appendix F show IRFs for the technology and mark-up shocks. Not surprisingly, fast learning sees an IRF converge faster to the RE case, but in either case, BR introduces
more persistence compared with RE. This suggests that this feature should lead to a better fit of the data without relying on other persistence mechanisms (shocks, habit or price indexing). The stability properties of the model are examined in the WP version of the paper and
Appendix A.
5.2. Endogenous Proportions of RE and BR Agents with Reinforcement Learning
Proportions of rational households (
) and firms (
) are given by (
8)
where fitness for households and firms
is given by
Table 1 provides a third-order perturbation solution of the non-linear NK RE-BR model. We use the Bayesian estimation of the model in Reference [
30] where the model is linearised and the proportions
and
are fixed. Non-linear estimation would be required to pin down the parameters
,
in the steady state in the BR scenarios and
,
and
in the reinforcement learning process, which goes beyond the scope of this paper. Thus, here we impose them as reported in the table (
). We also scale the estimated standard deviations of the shocks using a parameter
. For the robustness of our results, we perform additional simulations, for different choice of the memory parameters, and present the results with
and
in
Appendix G. The robustness exercise assumes instead that agents have some memory of past observations.
The main results from these simulations are as follows. First, reinforcement learning introduces
high kurtosis and skewness in macroeconomic variables, the absence of kurtosis in the standard NK model, often highlighted in the literature (see, for example, Reference [
3]), is in part simply the consequence of linearisation, and non-normality is a feature of higher order approximations. Second, reinforcement learning with stronger switching processes (i.e.,
) coupled with higher volatility of exogenous shocks results in the numbers of rational agents increasing from the estimated deterministic steady state value of
to
and
for households and firms, respectively, in the stochastic steady state. Third, given that BR is a welfare-reducing friction in these models, it follows that volatility can actually be welfare-increasing in our heterogeneous expectations setting. Furthermore, when we assume that agents have some memory of past observations when revising their expectations given their forecast performances, the simulated skewness and kurtosis are lower compared to the case when no memory is assumed in the learning process.
Our main results clearly suggest that, when the switching process between groups of heterogeneous agents becomes more deterministic depending on agents’ willingness to learn from the past performance when predicting future outcomes, this leads to an increase in the level of rationality in the BR macroeconomy. This result is in line with the finding in Reference [
3]. The cognitive effect of this selection mechanism is much stronger with the occurrence of large exogenous shocks. This group behaviour not only plays a key role in explaining the dynamic properties of the data, revaluating the importance of expectations in driving economic fluctuations in the spirit of Keynes’ concept of animal spirits, but has important implications for the optimal control of policy in the spirit of the Lucas critique. Depending on intentions on the part of policymakers, the model suggests that different versions of policy can be designed and devised in a game between policymakers and the economy, with uncertainty as to which expectation formation is selected.
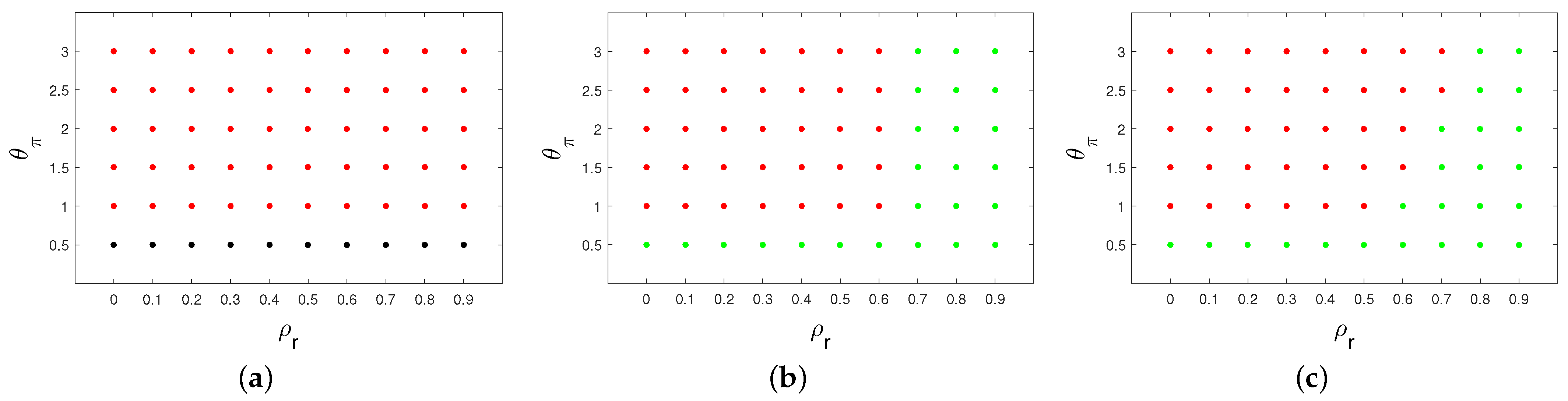
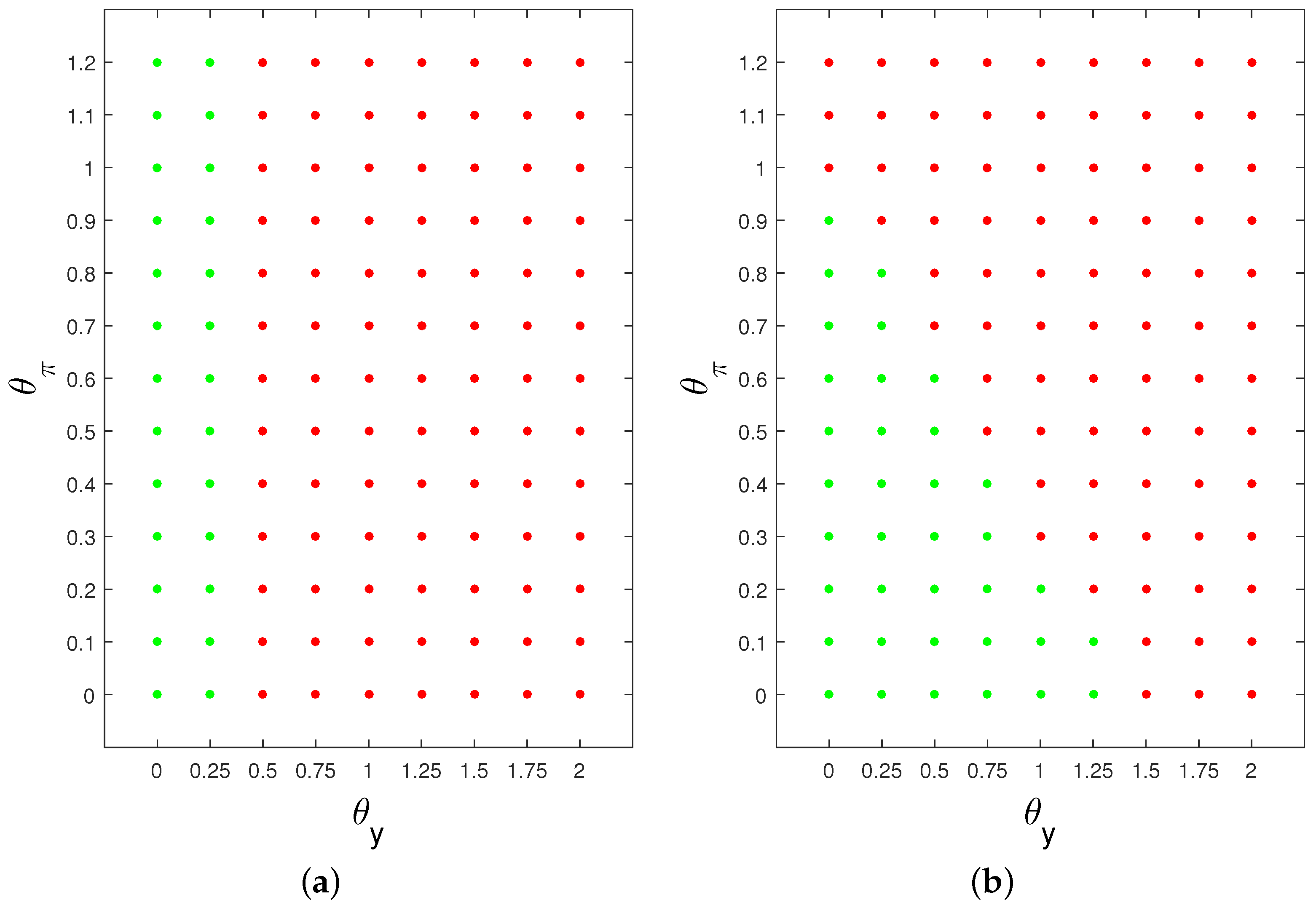
5.3. The Possibility of Bifurcation and Chaotic Dynamics
Non-linear models in general open up the possibility that, for certain parameter values or initial conditions, they may exhibit chaotic dynamics. How are the obtained results related to such dynamics? This possibility is examined using the model of this paper in Reference [
22].
The conclusions are: first, the RE determinancy condition for the linearised model in the vicinity of the deterministic steady state ensures local determinancy and stability in the model with a fixed proportion n of fully rational agents. Second, if the linear form of the model starts from a position of indeterminacy, an increase in the fixed cost of being fully rational can lead to the loss of local stability via a Hopf bifurcation. This Hopf bifurcation appears to be super-critical, giving rise to stable limit cycles. As the speed at which agents learn increases, a rational route to randomness appears to follow, which we explore with numerical methods. From a policy point of view, the main conclusion is that local indeterminacy about the steady state can be avoided by a careful choice of interest-rate rule that obeys a “Taylor condition” modified to allow for persistence. This is the case for our simulations which avoid chaotic dynamics.
6. Conclusions
This paper studies an NK behavioural model for which boundedly rational beliefs of economic agents are about payoff-relevant macroeconomic variables that are exogenous to their decision rules. Reinforcement learning is at the core of the heterogeneous expectations model and leads to the striking result that a high volatility of exogenous shocks, by assisting the learning process, can be welfare-increasing.
The results from our simulations have a range of practical and theoretical implications. From a practical point of view, our model provides a behavioural explanation for the important properties of the business cycle dynamics and (ir)rationality under market economy. Our findings shed more light on the underlying mechanism that guides policy choices in a society comprising policymakers and agents who form heterogeneous expectations. Regarding the theoretical implications, our results for a simple NK model suggest a new agenda for constructing empirical medium-sized NK models for agents’ behaviours under imperfect information. Future work will embed the RE-BR composite model into a richer NK macroeconomic model along the lines of Reference [
31], use non-linear estimation methods to identify a number of parameters involving reinforcement learning that are not identified using linear Bayesian estimation, and examine optimal monetary policy.
Another potential direction for future research is to investigate how reinforcement learning affects the possible chaotic dynamics of the model. We know that an increase in the fixed cost of being fully rational can lead to the loss of local stability. If we enter a region of local instability, but global boundedness, we see chaotic dynamics as highlighted generally in Reference [
25]. In addition, from Reference [
22], who plotted the simulated trajectories for various parameter values with an almost purely stochastic switching process (
), it is evident that, when the level of rationality varies according to reinforcement learning, it is likely that we see very different stability/determinancy properties of the model, which imply that uncertainty as to how expectations and learning are processed can lead to a policy rule that is unstable or has infinite multiple equilibria (i.e., is indeterminate).
As with any research, there are limitations in our study that should be addressed in future work. We have alluded to the wilderness of non-rational expectations posed by the sheer size of the literature on behavioural macroeconomics and the huge number of equilibria proposed. Any analysis based on only one choice of model clearly has limitations when turning to policy implications. A policy that works well for one particular choice may perform badly using a different model. One solution to this problem proposed by References [
32,
33] is to choose a policy to maximise weighted average inter-temporal welfare across a set of competing models and to weigh models based on relative forecasting performance. In other studies, the proportions of rational and non-rational agents are fixed; a possible avenue for future research would be to extend the analysis to time-varying endogenous proportions as in this paper.
Finally, there remains a wide range of views over the asymmetric macroeconomic effects of economic shocks (e.g., news, energy and monetary policy) as well as over the variations in these effects with respect to economic conditions and states. Different strands of literature offer different explanations on the existence of non-linearities, focusing on the sources of the shocks, econometric specifications and time-variation in impact and policy responses (see Reference [
34] for a recent study that addresses the latter two aspects). We argue that the modelling approach and non-linear techniques used in our paper add an important dimension to this strand of literature by providing a variety of starting points for future work that investigates the non-linear effects of shocks that may originate from the time-varying nature of expectation formations and complex adaptive systems.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
