
A Neural-Network-Based Competition between Short-Lived Particle Candidates in the CBM Experiment at FAIR



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
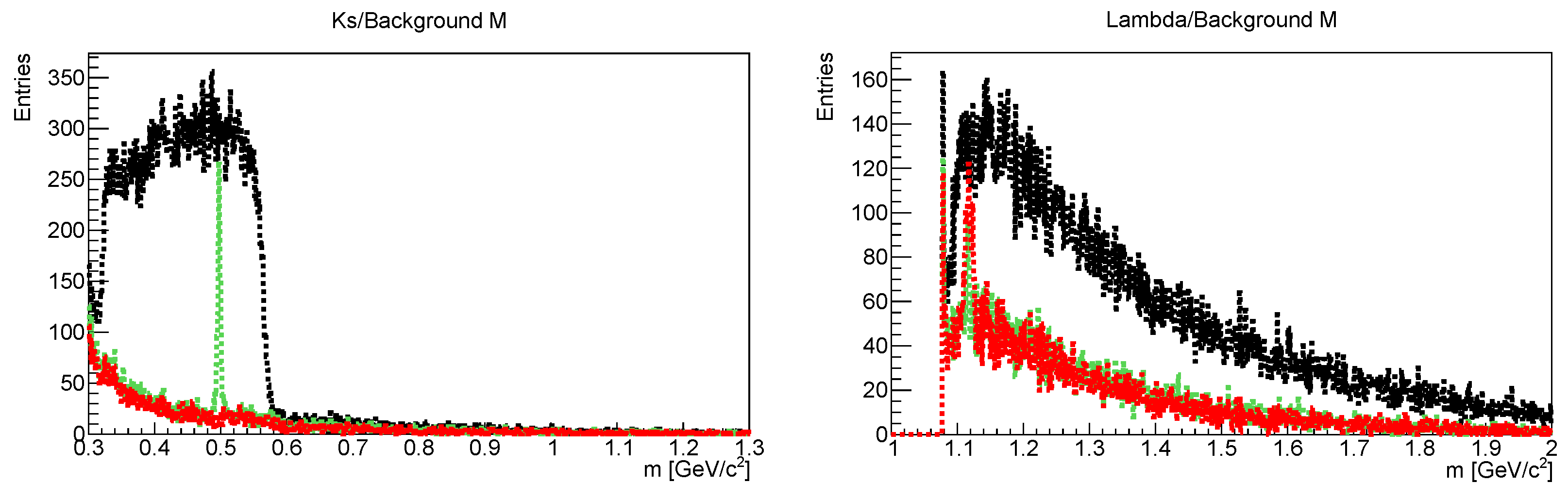
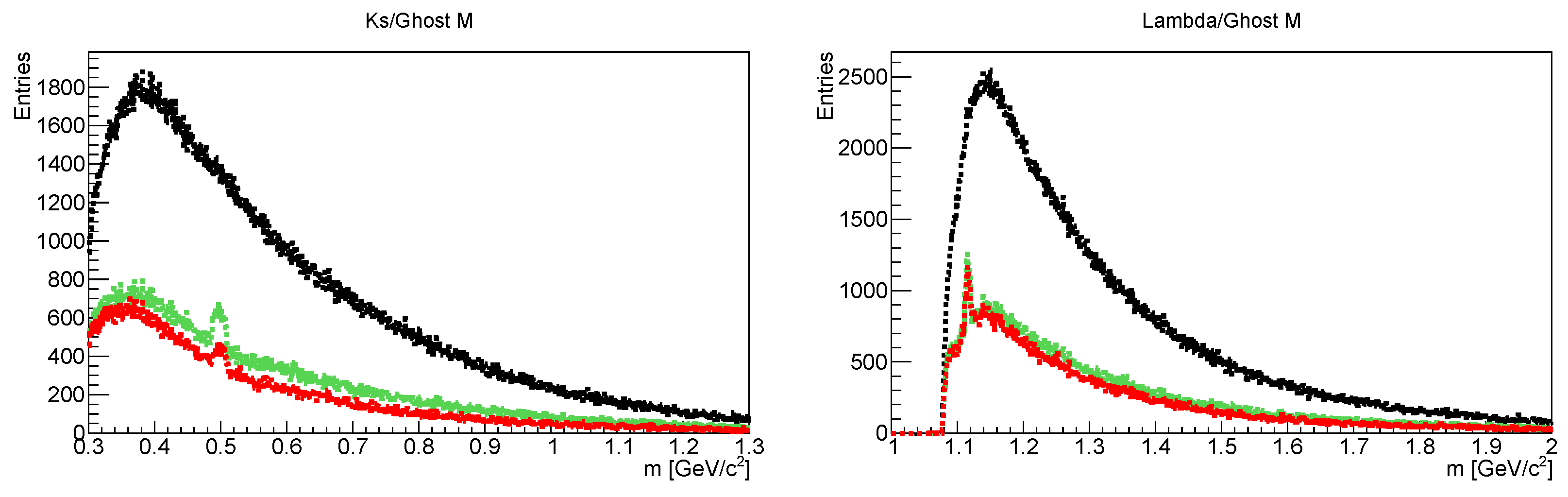
2.1. Particle Competition of and
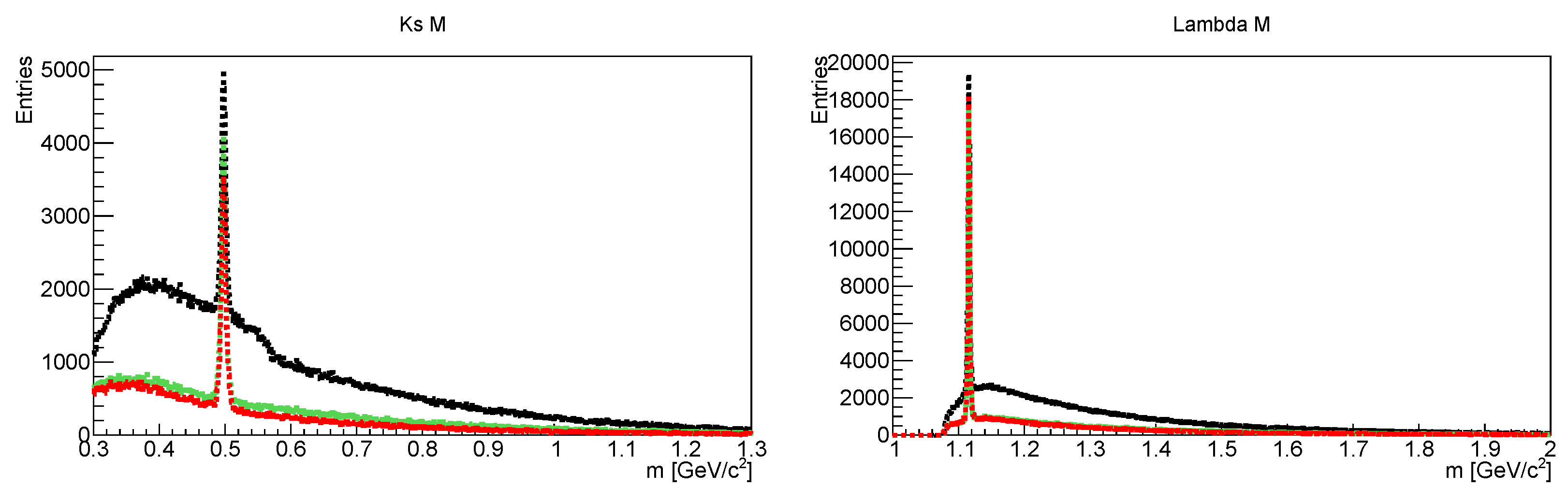
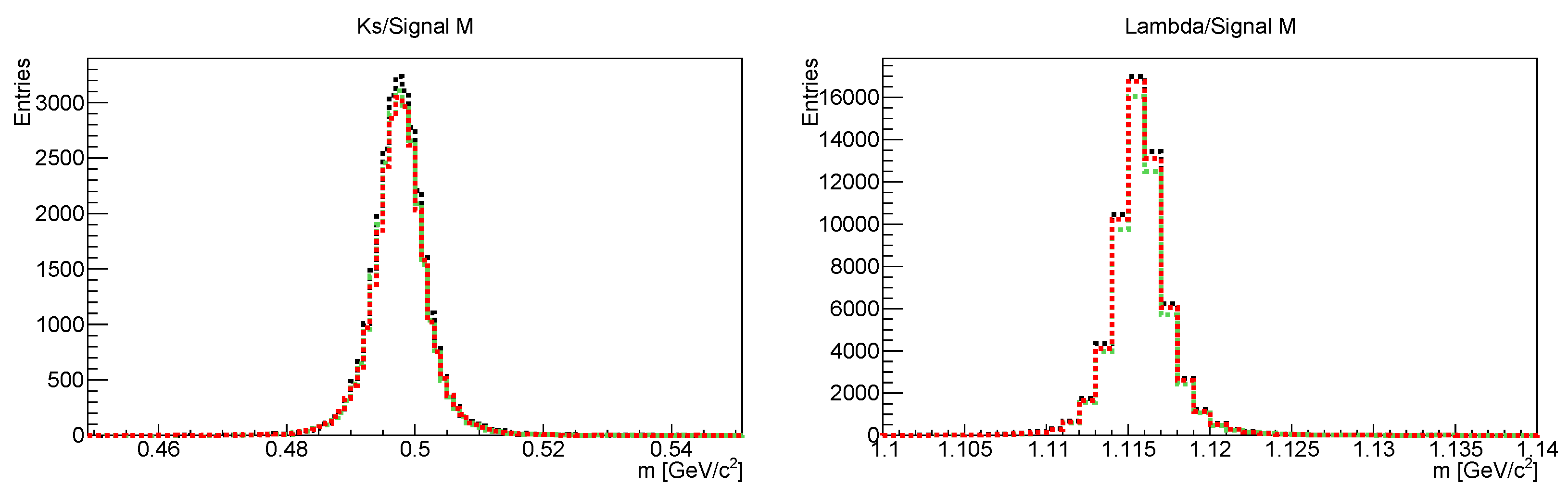
2.2. Data Extraction Using the KF Particle Finder Package
2.3. Performance Measurements in the KF Particle Finder Package
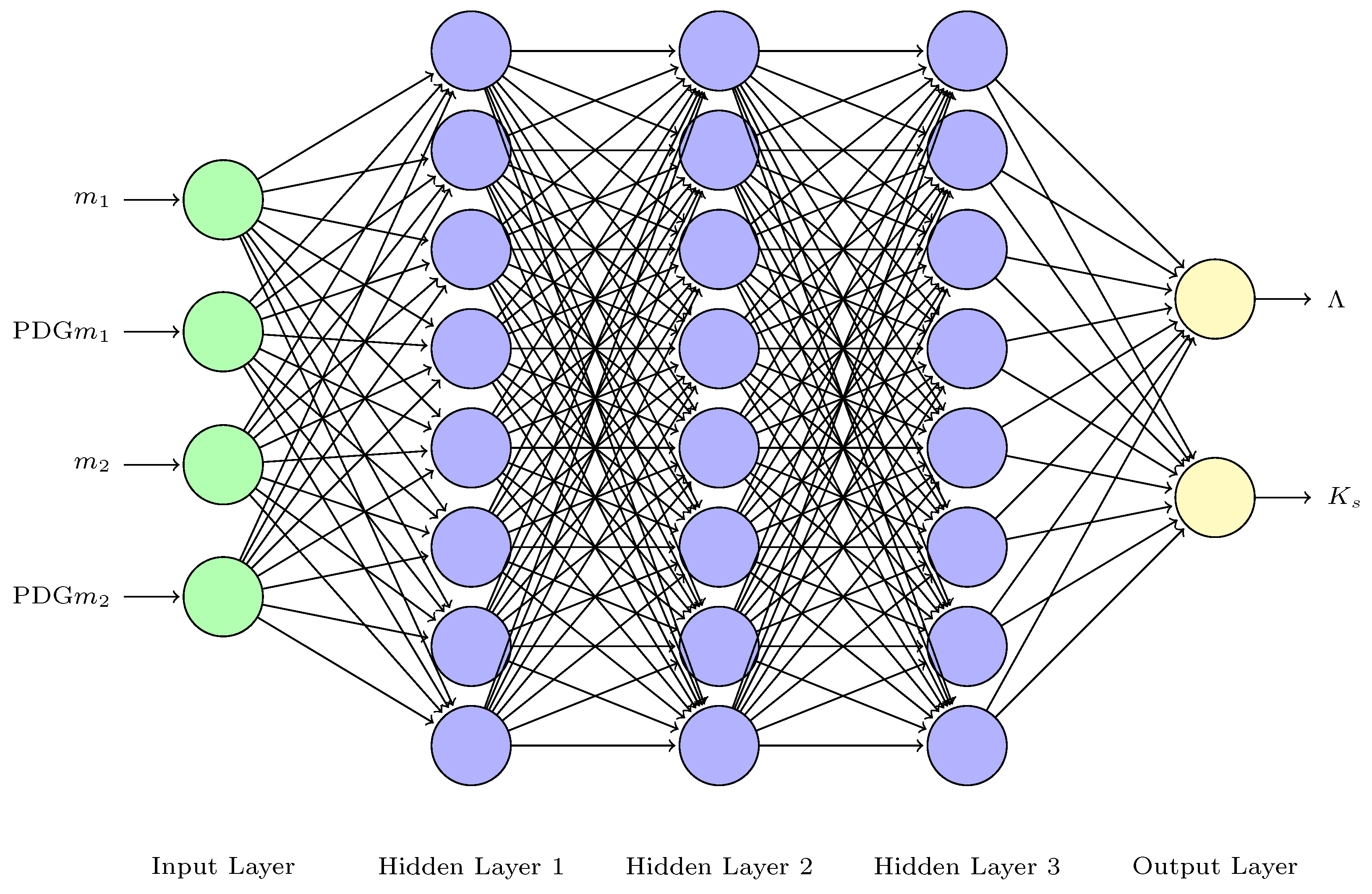
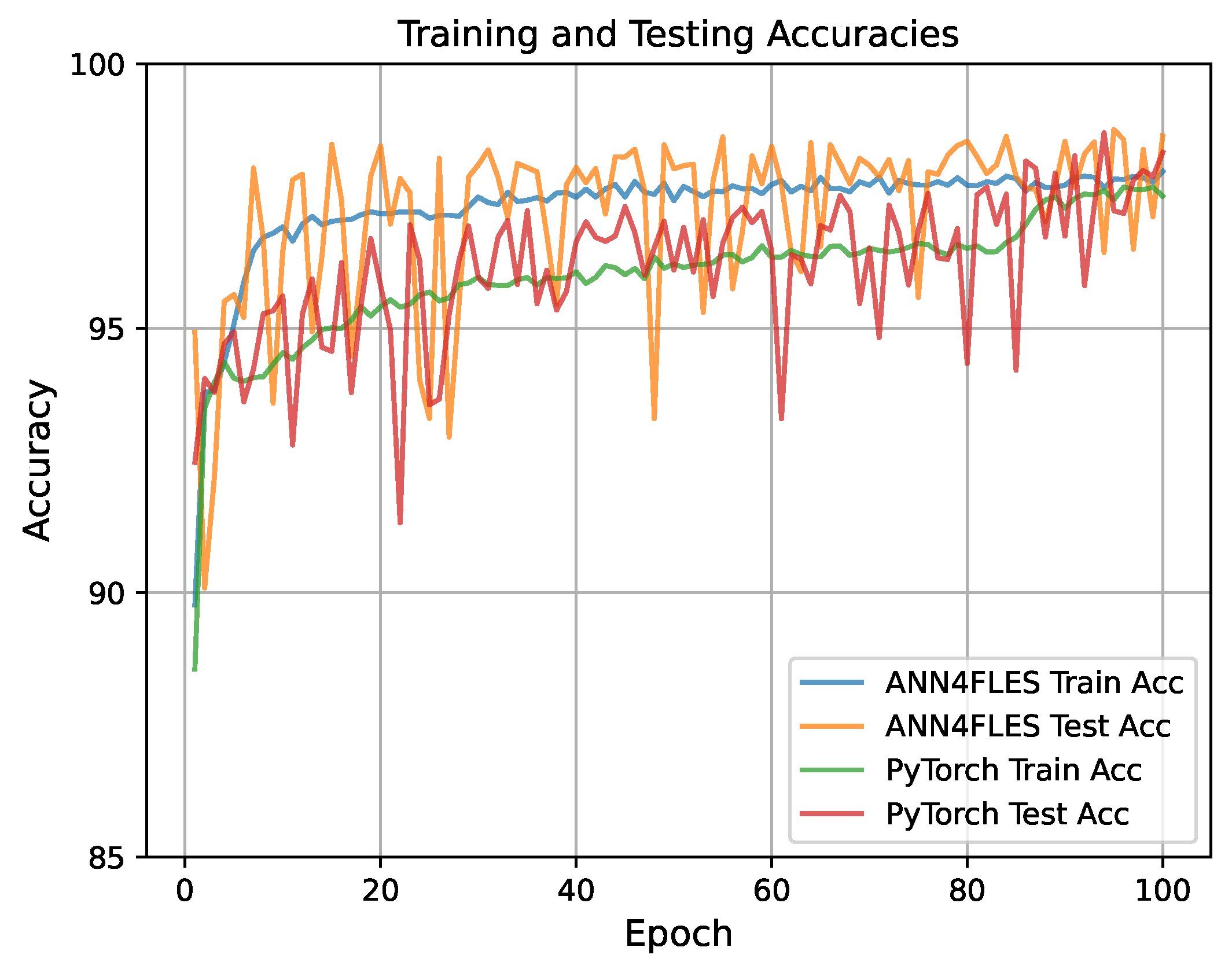
2.4. Training and Testing Using ANN4FLES and PyTorch
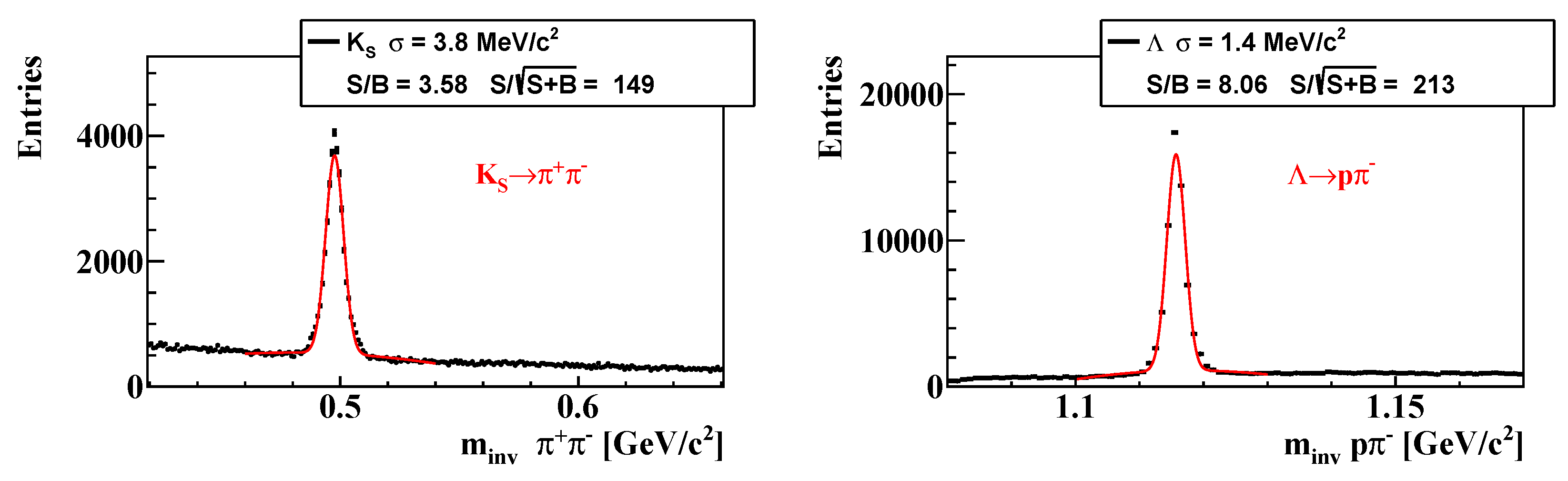
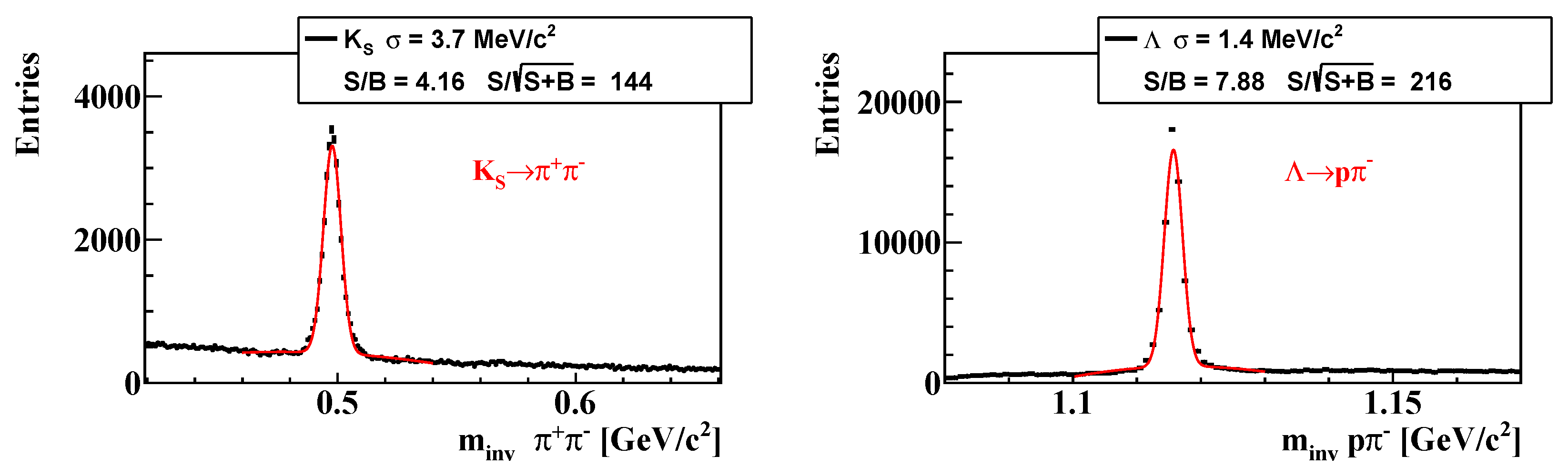
3. Results
Particle Competition Based on Mass and PDG Mass
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Tsoulos, I.G.; Gavrilis, D.; Glavas, E. Solving differential equations with constructed neural networks. Neurocomputing 2009, 72, 2385–2391. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Bourilkov, D. Machine and deep learning applications in particle physics. Int. J. Mod. Phys. 2019, 34, 1930019. [Google Scholar] [CrossRef] [Green Version]
- Shlomi, J.; Battaglia, P.; Vlimant, J.R. Graph neural networks in particle physics. Mach. Learn. Sci. Technol. 2020, 2, 021001. [Google Scholar] [CrossRef]
- Sturm, C.; Stöcker, H. The Facility for Antiproton and Ion Research FAIR. Phys. Part. Nucl. Lett. 2011, 8, 865–868. [Google Scholar] [CrossRef]
- Friman, B.; Höhne, C.; Knoll, J.; Leupold, S.; Randrup, J.; Rapp, R.; Senger, P. (Eds.) The CBM Physics Book, 1st ed.; Lecture Notes in Physics; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Ablyazimov, T.; Abuhoza, A.; Adak, R.; Adamczyk, M.; Agarwal, K.; Aggarwal, M.M.; Ahammed, Z.; Ahmad, F.; Ahmad, N.; Ahmad, S.; et al. Challenges in QCD matter physics –The scientific programme of the Compressed Baryonic Matter experiment at FAIR. Eur. Phys. J. A 2017, 53, 60. [Google Scholar] [CrossRef] [Green Version]
- Friese, V. The CBM experiment at GSI/FAIR. Nuclear Phys. A 2006, 774, 377–386. [Google Scholar] [CrossRef]
- Friese, V. Simulation and reconstruction of free-streaming data in CBM. J. Phys. Conf. Ser. 2011, 331, 032008. [Google Scholar] [CrossRef]
- Agarwal, K. The Compressed Baryonic Matter (CBM) Experiment at FAIR–Physics, Status and Prospects. Phys. Scr. 2023, 98, 3. [Google Scholar] [CrossRef]
- Akishina, V. Four-Dimensional Event Reconstruction in the CBM Experiment. Ph.D. Thesis, J. W. Goethe University, Frankfurt, Germany, 2016. [Google Scholar]
- Kisel, I.; Kulakov, I.; Zyzak, M. Standalone First Level Event Selection Package for the CBM Experiment. IEEE Trans. Nucl. Sci. 2013, 60, 3703–3708. [Google Scholar] [CrossRef]
- Banerjee, A.; Kisel, I.; Zyzak, M. Artificial neural network for identification of short-lived particles in the CBM experiment. Int. J. Mod. Phys. A 2020, 35, 2043003. [Google Scholar] [CrossRef]
- Rafelski, J.; Müller, B. Strangeness Production in the Quark-Gluon Plasma. Phys. Rev. Lett. 1982, 48, 1066–1069. [Google Scholar] [CrossRef]
- Zyla, P.A.; Barnett, R.M.; Beringer, J.; Dahl, O.; Dwyer, D.A.; Groom, D.E.; Lin, C.J.; Lugovsky, K.S.; Pianori, E.; Robinson, D.J.; et al. Particle Data Group. Prog. Theor. Exp. Phys. 2020, 2020, 083C01. [Google Scholar]
- Amsler, C.; Doser, M.; Antonelli, M.; Asner, D.; Babu, K.S.; Baer, H.; Band, H.R.; Barnett, R.M.; Beringer, J.; Bergren, E.; et al. Particle Data Group. Phys. Lett. B 2008, 667, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Zyzak, M. Online Selection of Short-Lived Particles on Many-Core Computer Architectures in the CBM Experiment at FAIR. Ph.D. Thesis, J. W. Goethe University, Frankfurt, Germany, 2016. [Google Scholar]
- Kisel, P. KF Particle Finder Package: Missing Mass Method for Reconstruction of Strange Particles in CBM (FAIR) and STAR (BNL) Experiments. Ph.D. Thesis, Goethe University, Frankfurt, Germany, 2023. [Google Scholar]
- Bleicher, M.; Zabrodin, E.; Spieles, C.; Bass, S.A.; Ernst, C.; Soff, S.; Bravina, L.; Belkacem, M.; Weber, H.; Stöcker, H. Relativistic hadron-hadron collisions in the ultra-relativistic quantum molecular dynamics model. J. Phys. Nucl. Part. Phys. 1999, 25, 1859. [Google Scholar] [CrossRef] [Green Version]
- Agostinelli, S.; Allison, J.; Amako, K.A.; Apostolakis, J.; Araujo, H.; Arce, P.; Asai, M.; Axen, D.; Banerjee, S.; Barrand, G.; et al. Geant4—A simulation toolkit. Nucl. Instrum. Methods Phys. Res. Sect. Accel. Spectrometers Detect. Assoc. Equip. 2003, 506, 250–303. [Google Scholar] [CrossRef] [Green Version]
- Friese, V.; for the CBM Collaboration. The high-rate data challenge: Computing for the CBM experiment. J. Phys. Conf. Ser. 2017, 898, 112003. [Google Scholar] [CrossRef] [Green Version]
- Senger, P.; Friese, V. CBM Progress Report 2022; Number CBM PR 2022; GSI: Darmstadt, Germany, 2022; p. 161. [Google Scholar]
- Höhne, C.; Rami, F.; Staszel, P. The Compressed Baryonic Matter Experiment at FAIR. Nucl. Phys. News 2006, 16, 19–23. [Google Scholar] [CrossRef] [Green Version]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation. Parallel Distrib. Process. 1986, 1, 318–363. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- torch.nn.Linear—PyTorch 1.9.0 Documentation. 2023. Available online: https://pytorch.org/docs/stable/generated/torch.nn.Linear.html (accessed on 30 March 2023).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Broyden, C. A new double-rank minimisation algorithm. Preliminary report. Am. Math. Soc. Not. 1969, 16, 670. [Google Scholar]
- Fletcher, R. A new approach to variable metric algorithms. Comput. J. 1970, 13, 317–322. [Google Scholar] [CrossRef] [Green Version]
- Cassing, W.; Bratkovskaya, E.L. Parton transport and hadronization from the dynamical quasiparticle point of view. Phys. Rev. C 2008, 78, 034919. [Google Scholar] [CrossRef] [Green Version]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belousov, A.; Kisel, I.; Lakos, R. A Neural-Network-Based Competition between Short-Lived Particle Candidates in the CBM Experiment at FAIR. Algorithms 2023, 16, 383. https://doi.org/10.3390/a16080383
Belousov A, Kisel I, Lakos R. A Neural-Network-Based Competition between Short-Lived Particle Candidates in the CBM Experiment at FAIR. Algorithms. 2023; 16(8):383. https://doi.org/10.3390/a16080383
Chicago/Turabian StyleBelousov, Artemiy, Ivan Kisel, and Robin Lakos. 2023. "A Neural-Network-Based Competition between Short-Lived Particle Candidates in the CBM Experiment at FAIR" Algorithms 16, no. 8: 383. https://doi.org/10.3390/a16080383
APA StyleBelousov, A., Kisel, I., & Lakos, R. (2023). A Neural-Network-Based Competition between Short-Lived Particle Candidates in the CBM Experiment at FAIR. Algorithms, 16(8), 383. https://doi.org/10.3390/a16080383