
From Data to Human-Readable Requirements: Advancing Requirements Elicitation through Language-Transformer-Enhanced Opportunity Mining

 , , and
, , and 
Abstract
:1. Introduction
2. Background and Related Work
2.1. Requirements Elicitation
2.2. Artificial-Intelligence-Supported Requirements Elicitation
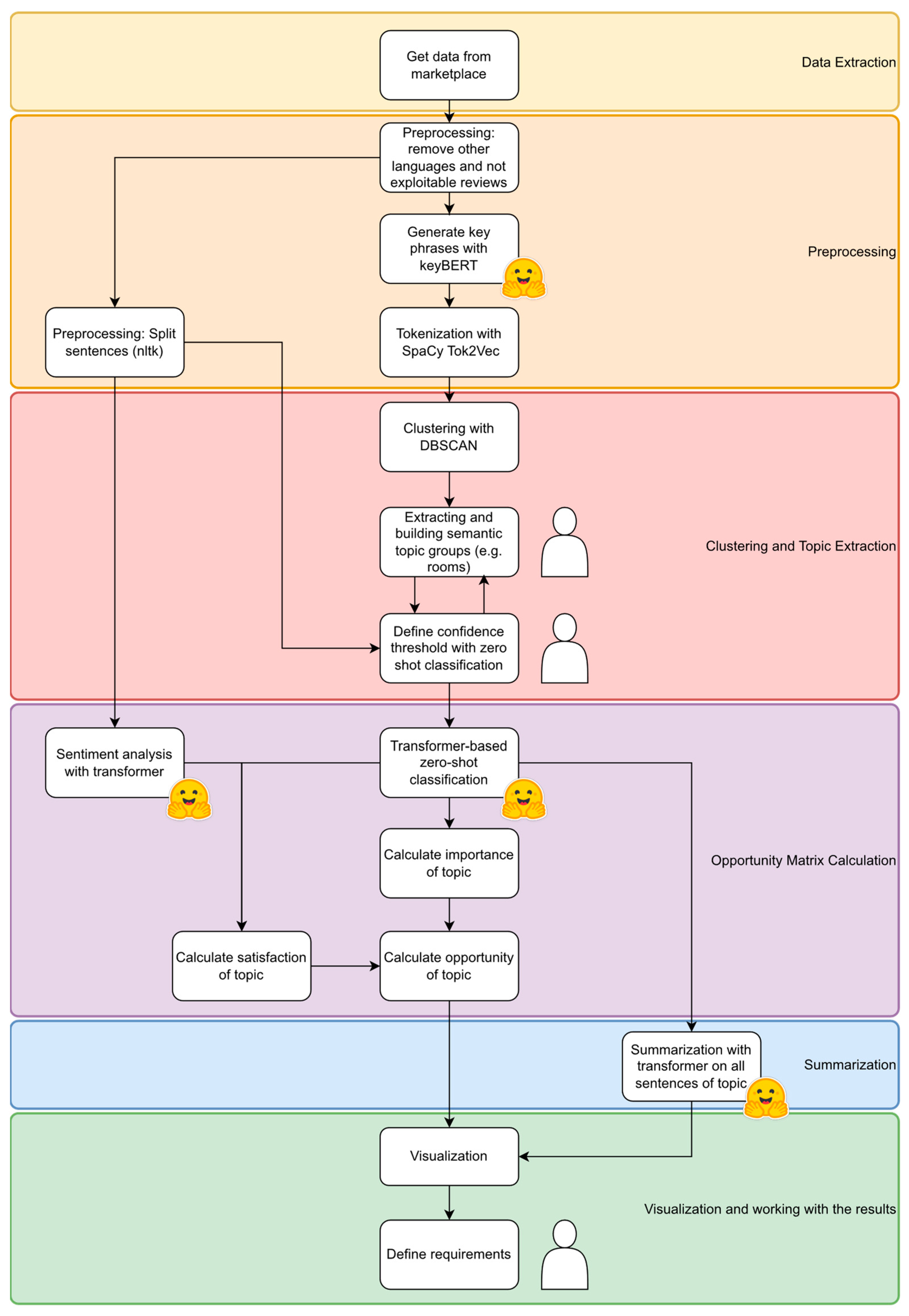
3. Proposed Methodology
3.1. Data Retrieval: Extraction of Online Reviews
3.2. Data Preprocessing and Transformer-Based Key-Phrase Generation
| Algorithm 1: Preprocessing and removal of not exploitable reviews | |
| Input: | df_review_texts = DataFrame with all crawled raw reviews |
| Output: | Cleaned DataFrame ready for keyword generation and sentence split |
| 1 | for comment in df.review_texts: |
| 2 | trim comment |
| 3 | if comment contains three complete words: |
| 4 | regex.remove(emojy_pattern, comment) |
| 5 | if spacy.language_detect of comment is ‘en’: |
| 6 | keep comment |
| 7 | goto next comment |
| 8 | delete comment |
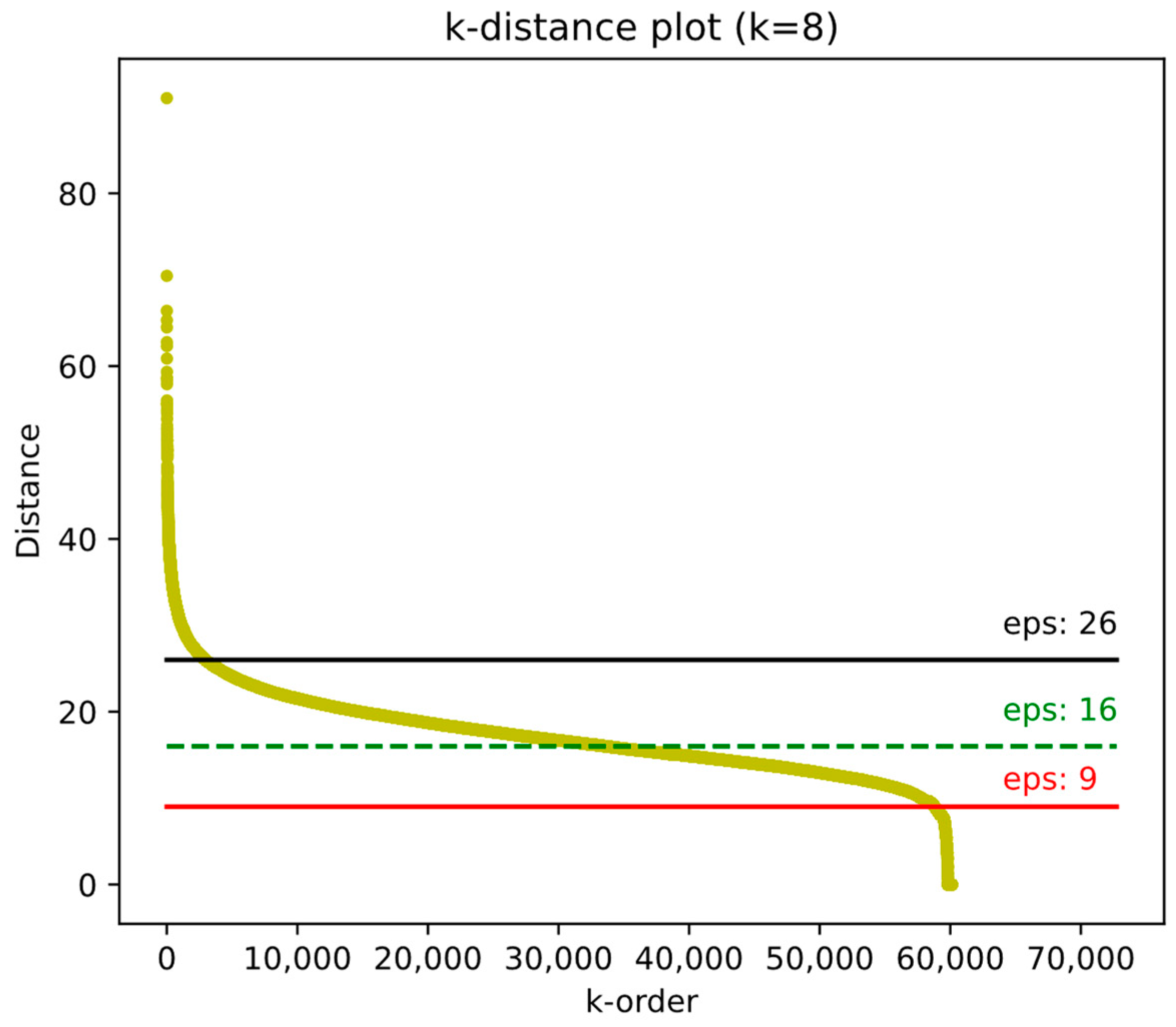
3.3. New Approach to Topic Modeling
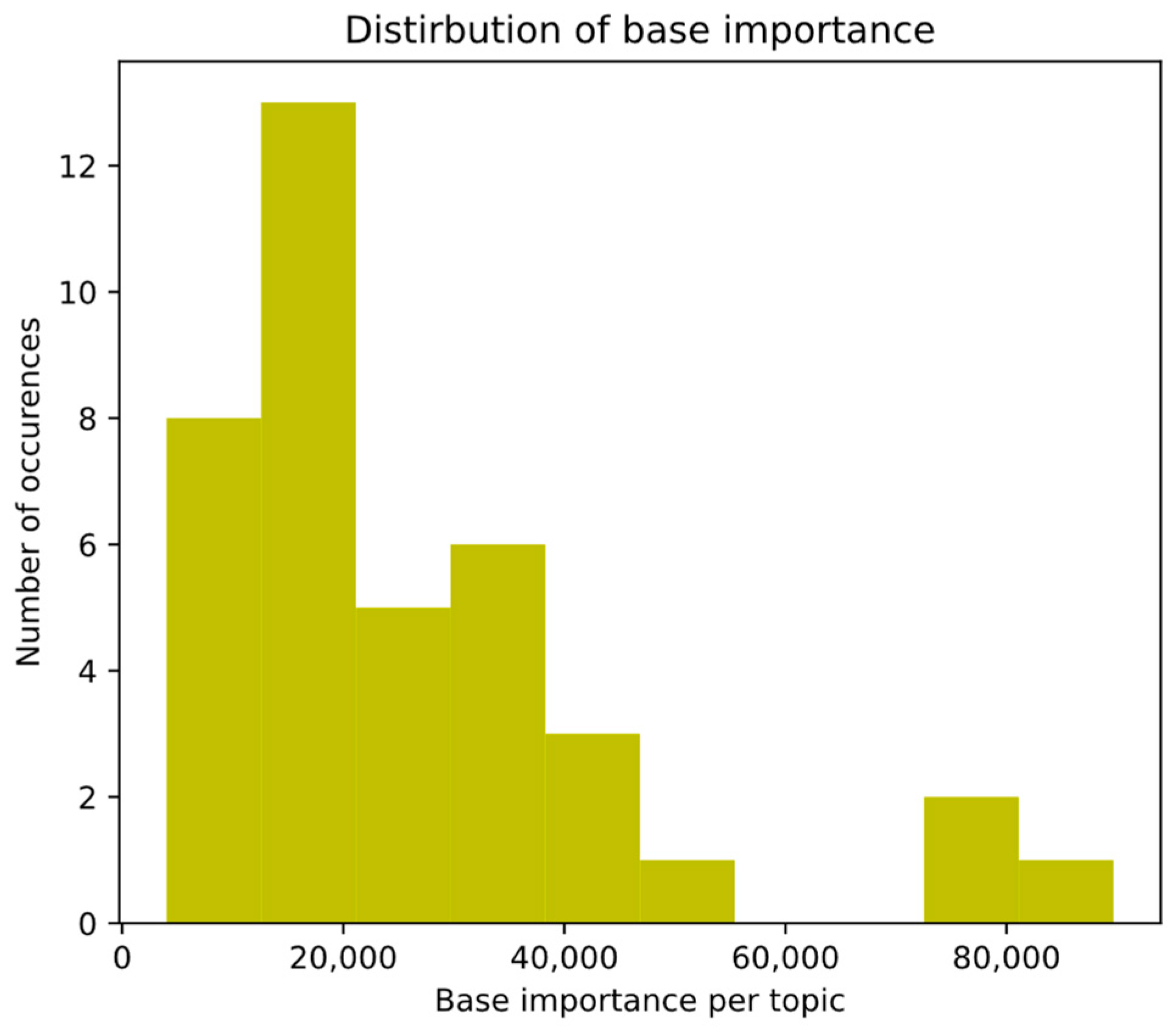
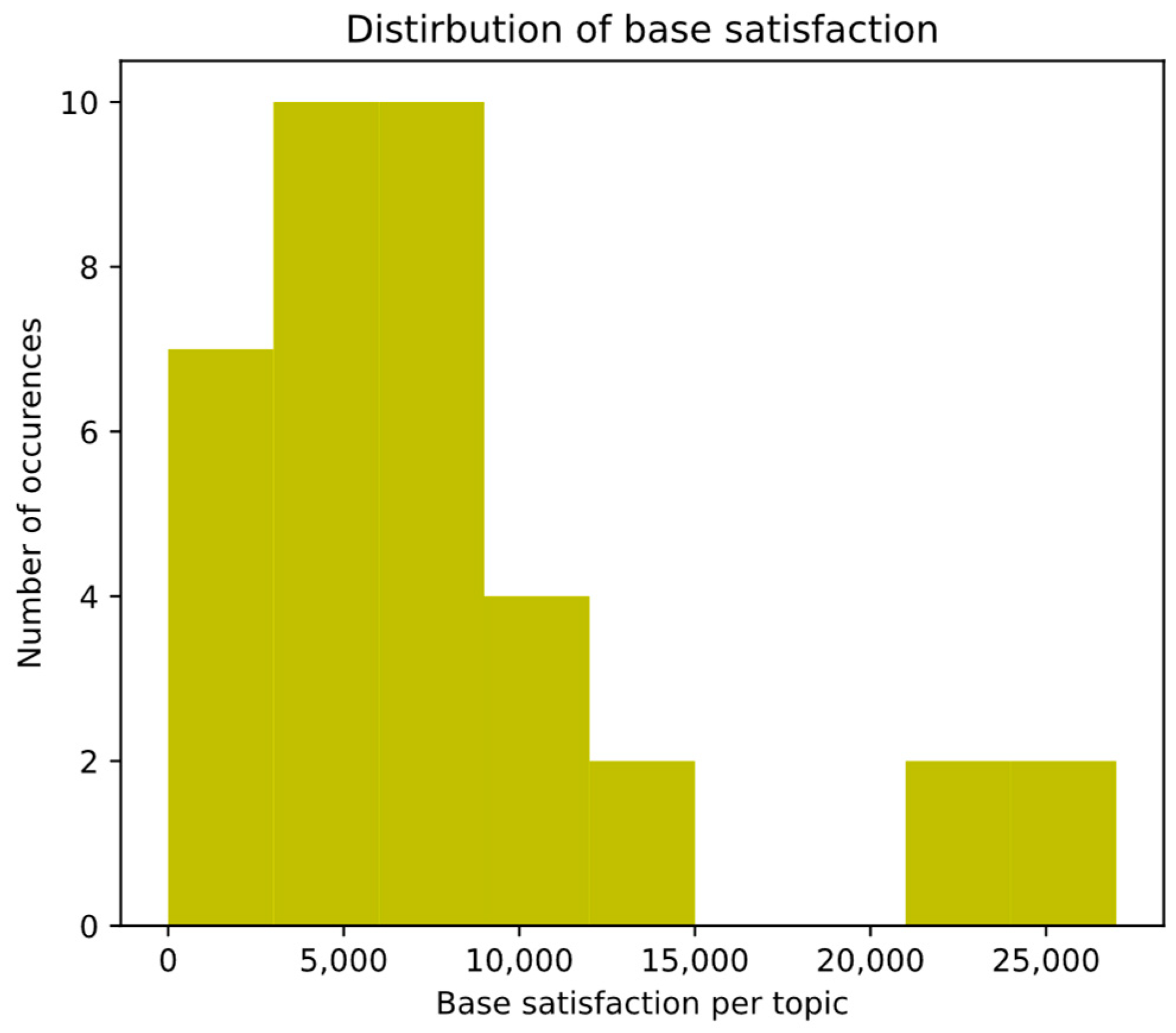
3.4. Opportunity-Matrix Calculation Utilizing Zero-Shot Transformers and Transformer-Based Sentiment Analysis
| Algorithm 2: Calculation of importance, satisfaction and opportunity | |
| Input | df_sentence = Dataframe with contribution scores of every topic and sentiment score per sentence topic_list = List of topics that should be considered when calculating importance, satisfaction and opportunity base_importance = Empty/None base_satisfaction = Empty/None |
| Output | df_opportunity = Dataframe with importance, satisfaction and opportunity score of every considered topic |
| 1 | if base_importance is None and base_satisfaction is None: |
| 2 | importance = empty dictionary |
| 3 | satisfaction = empty dictionary |
| 4 | for topic in df_sentence: |
| 5 | topic_importance = 0 |
| 6 | topic_satisfaction = 0 |
| 7 | for sentence in df_sentence[topic, sentiment]: |
| 8 | topic_importance += contribution_of_sentence |
| 9 | topic_satisfaction += contribution_of_sentence * sentiment_of_sentence |
| 10 | importance[topic] = topic_importance |
| 11 | satisfaction[topic] = topic_satisfaction |
| 12 | base_importance = copy of importance |
| 13 | base_satisfaction = copy of satisfaction |
| 14 | importance = copy of all topics in base_importance which are mentioned in topic_list |
| 15 | satisfaction = copy of all topics in base_satisfaction which are mentioned in topic_list |
| 16 | get maximimum and minimum value of importance and satisfaction of topics |
| 17 | for each topic in topic_list: |
| 18 | importance[topic] = 10 * ((importance_of_topic − minimum_importance)/(maximimum_importance − minimum_importance)) |
| 19 | satisfaction[topic] = 10 * ((satisfaction_of_topic − minimum_satisfaction)/(maximimum_ satisfaction − minimum_satisfaction)) |
| 20 | opportunity = empty dictionary |
| 21 | for each topic in topic_list: |
| 22 | opportunity[topic] = importance_of_topic + max(importance_of_topic − satisfaction_of_topic OR 0) |
| 23 | create dataframe with importance, satisfaction, and opportunity of each topic |
3.5. Summarization with Transformer
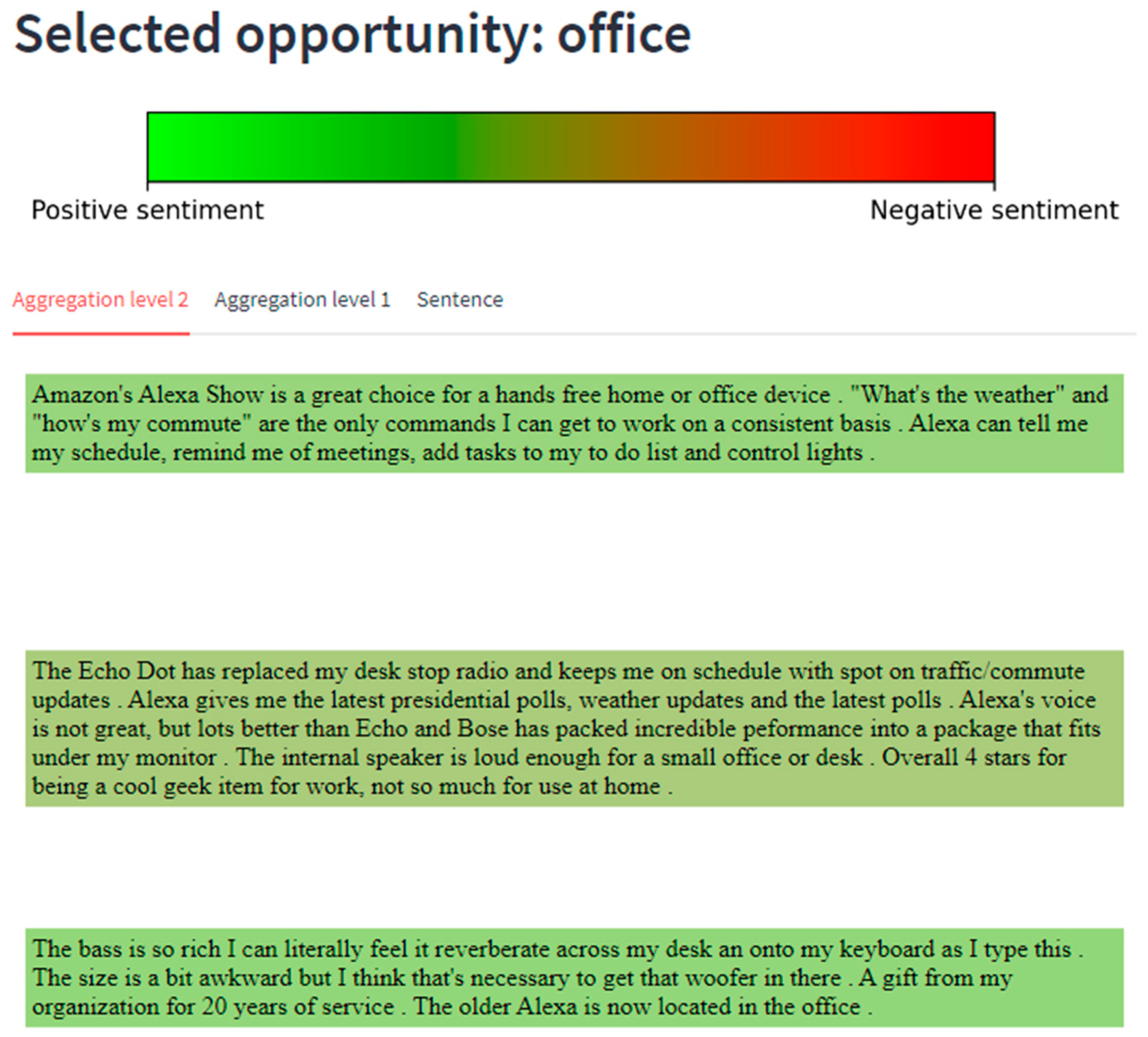
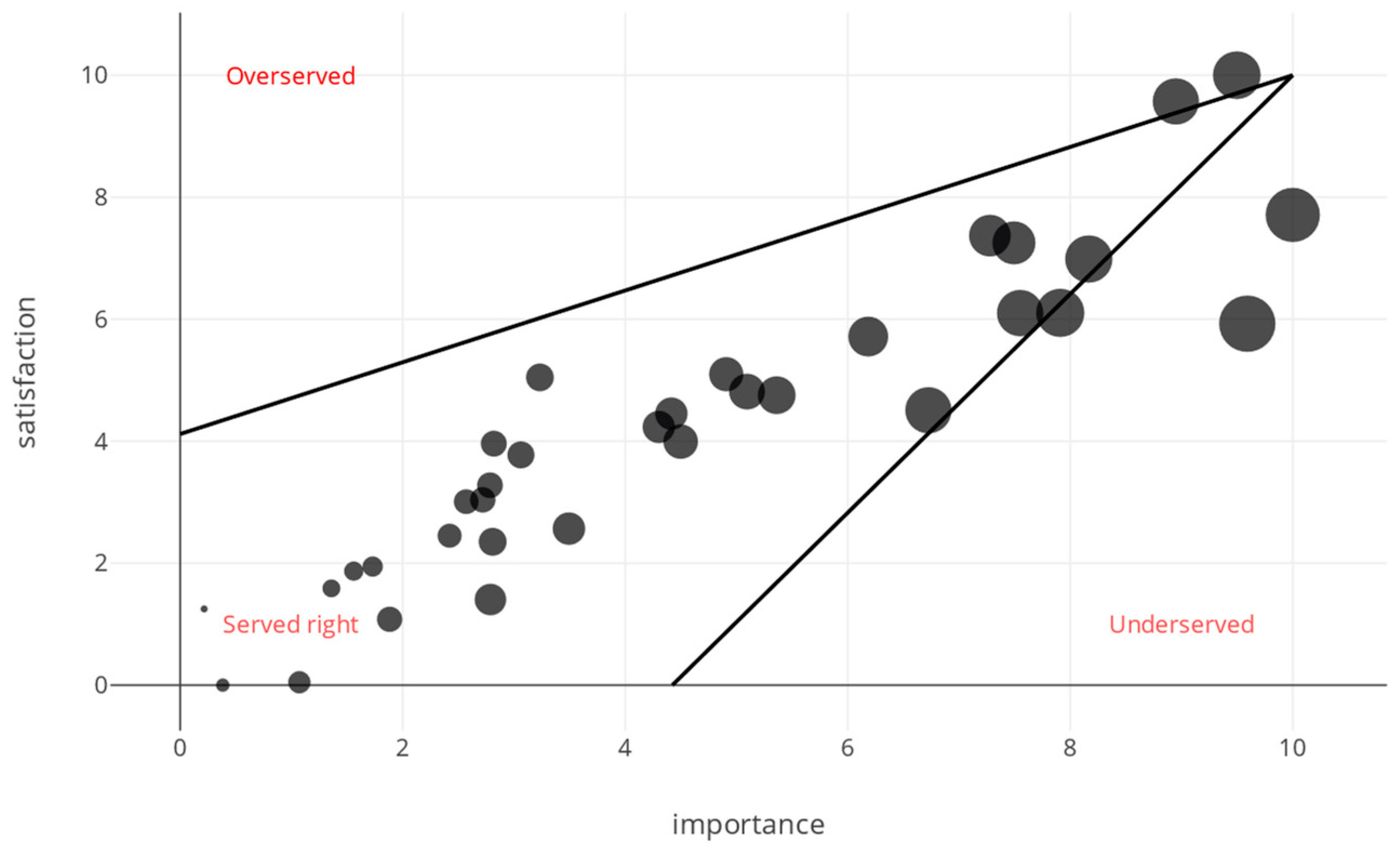
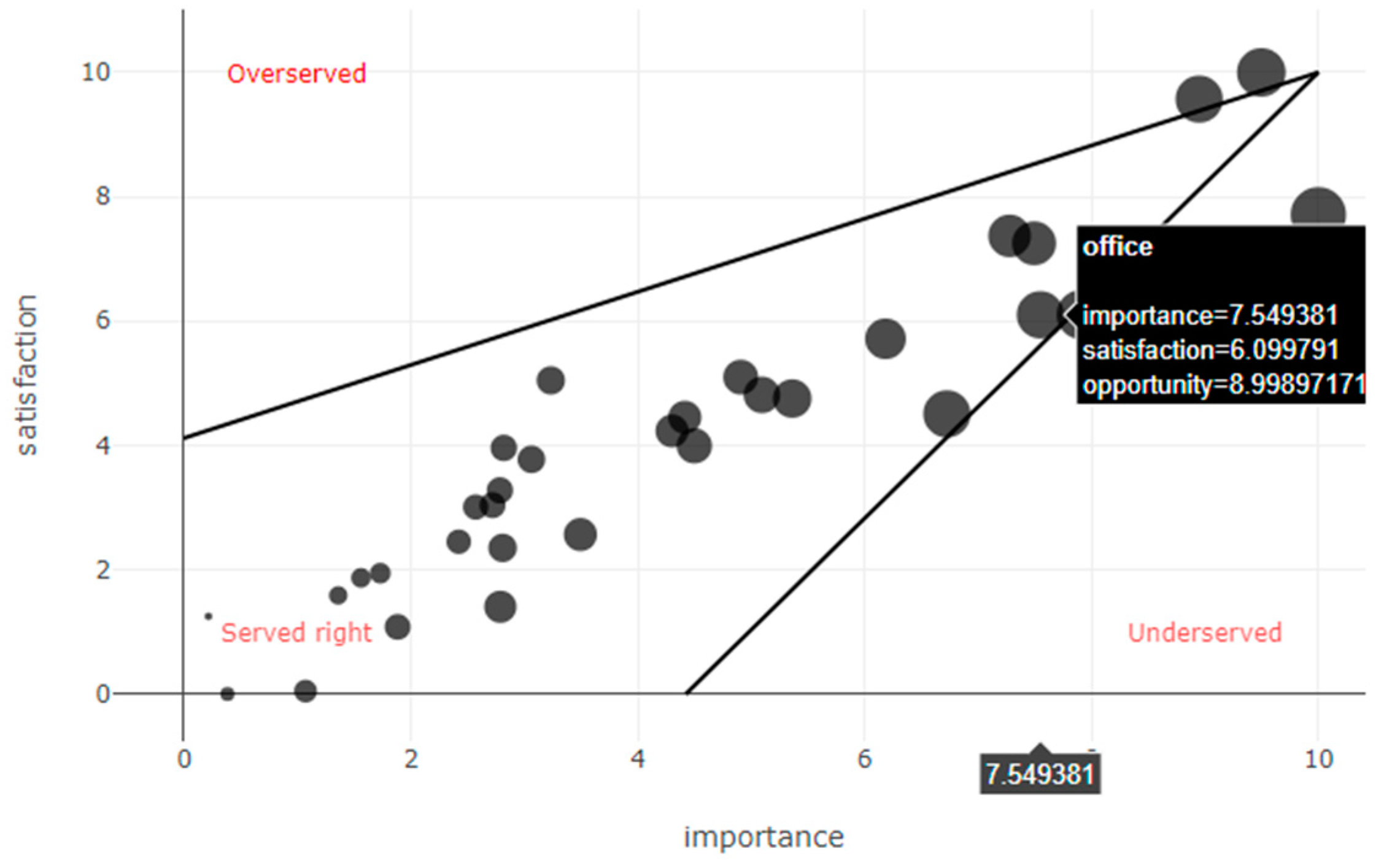
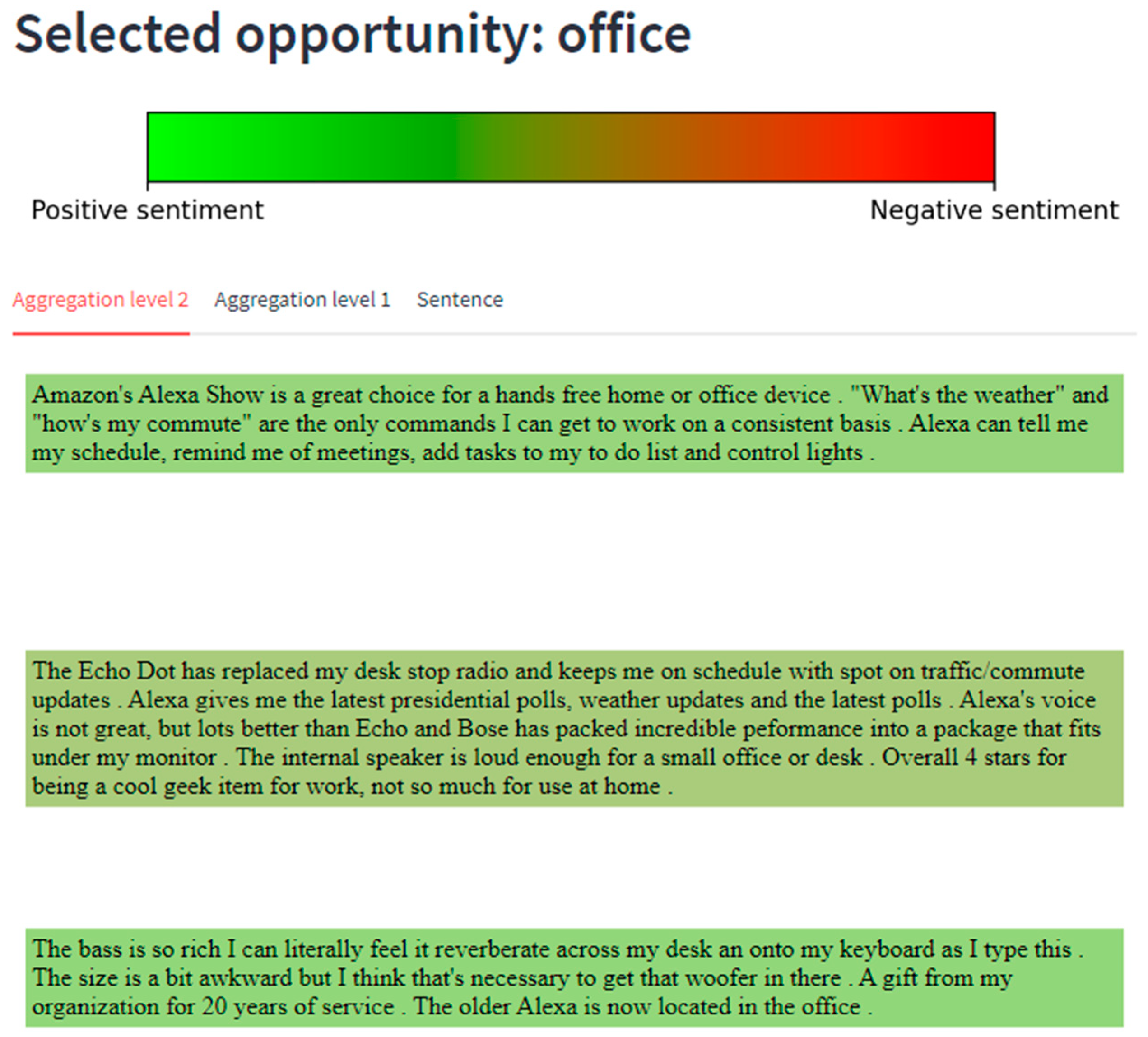
3.6. Visualization and Working with the Results
4. Case Study: Amazon Echo Dot
5. Results and Discussion
5.1. Results for Alexa Echo Dot
5.1.1. Technical Requirements
5.1.2. Design Requirements
5.1.3. Functional Requirements
5.2. Discussion
5.2.1. Comparison with Previous Studies
5.2.2. Key Improvements to Requirements Elicitation
5.2.3. Limitations of the Proposed Method
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alrumaih, H.; Mirza, A.; Alsalamah, H. Domain Ontology for Requirements Classification in Requirements Engineering Context. IEEE Access 2020, 8, 89899–89908. [Google Scholar] [CrossRef]
- Goldberg, D.M.; Abrahams, A.S. Sourcing Product Innovation Intelligence from Online Reviews. Decis. Support Syst. 2022, 157, 113751. [Google Scholar] [CrossRef]
- Lim, S.; Henriksson, A.; Zdravkovic, J. Data-Driven Requirements Elicitation: A Systematic Literature Review; Springer: Singapore, 2021; Volume 2, ISBN 0123456789. [Google Scholar]
- Horn, N.; Buchkremer, R. The Application of Artificial Intelligence to Elaborate Requirements Elicitation. In Proceedings of the 17th International Technology, Education and Development Conference, Valencia, Spain, 6–8 March 2023; pp. 2102–2109. [Google Scholar]
- Pohl, K. Requirements Engineering: Fundamentals, Principles, and Techniques; Springer Publishing Company, Incorporated: Cham, Switzerland, 2010. [Google Scholar]
- Zowghi, D.; Coulin, C. Requirements Elicitation: A Survey of Techniques, Approaches, and Tools. In Engineering and Managing Software Requirements; Springer: Berlin/Heidelberg, Germany, 2005; pp. 19–46. [Google Scholar] [CrossRef]
- Henriksson, A.; Zdravkovic, J. Holistic Data-Driven Requirements Elicitation in the Big Data Era. Softw. Syst. Model. 2022, 21, 1389–1410. [Google Scholar] [CrossRef]
- Surana, C.S.R.K.; Shriya; Gupta, D.B.; Shankar, S.P. Intelligent Chatbot for Requirements Elicitation and Classification. In Proceedings of the 2019 4th International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Bangalore, India, 17–18 May 2019; pp. 866–870. [Google Scholar]
- Khan, J.A.; Xie, Y.; Liu, L.; Wen, L. Analysis of Requirements-Related Arguments in User Forums. In Proceedings of the 2019 IEEE 27th International Requirements Engineering Conference (RE), Jeju Island, Republic of Korea, 23–27 September 2019; pp. 63–74. [Google Scholar]
- Zhou, F.; Ayoub, J.; Xu, Q.; Yang, X.J. A Machine Learning Approach to Customer Needs Analysis for Product Ecosystems. J. Mech. Des. 2020, 142, 011101. [Google Scholar] [CrossRef]
- Gülle, K.J.; Ford, N.; Ebel, P.; Brokhausen, F.; Vogelsang, A. Topic Modeling on User Stories Using Word Mover’s Distance. In Proceedings of the 2020 IEEE Seventh International Workshop on Artificial Intelligence for Requirements Engineering (AIRE), Zurich, Switzerland, 1 September 2020; pp. 52–60. [Google Scholar]
- Jiang, W.; Ruan, H.; Zhang, L.; Lew, P.; Jiang, J. For User-Driven Software Evolution: Requirements Elicitation Derived from Mining Online Reviews. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Tainan, Taiwan, 13–16 May 2014; pp. 584–595. [Google Scholar]
- Mekala, R.R.; Irfan, A.; Groen, E.C.; Porter, A.; Lindvall, M. Classifying User Requirements from Online Feedback in Small Dataset Environments Using Deep Learning. In Proceedings of the 2021 IEEE 29th International Requirements Engineering Conference (RE), Notre Dame, IN, USA, 20–24 September 2021; pp. 139–149. [Google Scholar]
- Joung, J.; Kim, H.M. Automated Keyword Filtering in Latent Dirichlet Allocation for Identifying Product Attributes from Online Reviews. J. Mech. Des. 2021, 143, 084501. [Google Scholar] [CrossRef]
- Zhang, D.; Shen, Z.; Li, Y. Requirement Analysis and Service Optimization of Multiple Category Fresh Products in Online Retailing Using Importance-Kano Analysis. J. Retail. Consum. Serv. 2023, 72, 103253. [Google Scholar] [CrossRef]
- Lee, T.Y.; Bradlow, E.T. Automated Marketing Research Using Online Customer Reviews. J. Mark. Res. 2011, 48, 881–894. [Google Scholar] [CrossRef]
- Dafaalla, H.; Abaker, M.; Abdelmaboud, A.; Alghobiri, M.; Abdelmotlab, A.; Ahmad, N.; Eldaw, H.; Hasabelrsoul, A. Deep Learning Model for Selecting Suitable Requirements Elicitation Techniques. Appl. Sci. 2022, 12, 9060. [Google Scholar] [CrossRef]
- Sainani, A.; Anish, P.R.; Joshi, V.; Ghaisas, S. Extracting and Classifying Requirements from Software Engineering Contracts. In Proceedings of the 2020 IEEE 28th International Requirements Engineering Conference (RE), Zurich, Switzerland, 31 August–4 September 2020; pp. 147–157. [Google Scholar]
- Alturaief, N.; Aljamaan, H.; Baslyman, M. AWARE: Aspect-Based Sentiment Analysis Dataset of Apps Reviews for Requirements Elicitation. In Proceedings of the 2021 36th IEEE/ACM International Conference on Automated Software Engineering Workshops (ASEW), Melbourne, VIC, Australia, 15–19 November 2021; pp. 211–218. [Google Scholar]
- Franch, X.; Henriksson, A.; Ralyté, J.; Zdravkovic, J. Data-Driven Agile Requirements Elicitation through the Lenses of Situational Method Engineering. In Proceedings of the 2021 IEEE 29th International Requirements Engineering Conference (RE), Notre Dame, IN, USA, 20–24 September 2021; pp. 402–407. [Google Scholar]
- Chen, R.; Wang, Q.; Xu, W. Mining User Requirements to Facilitate Mobile App Quality Upgrades with Big Data. Electron. Commer. Res. Appl. 2019, 38, 100889. [Google Scholar] [CrossRef]
- HaCohen-Kerner, Y.; Dilmon, R.; Hone, M.; Ben-Basan, M.A. Automatic Classification of Complaint Letters According to Service Provider Categories. Inf. Process. Manag. 2019, 56, 102102. [Google Scholar] [CrossRef]
- Kühl, N.; Mühlthaler, M.; Goutier, M. Supporting Customer-Oriented Marketing with Artificial Intelligence: Automatically Quantifying Customer Needs from Social Media. Electron. Mark. 2020, 30, 351–367. [Google Scholar] [CrossRef]
- Bhowmik, T.; Niu, N.; Savolainen, J.; Mahmoud, A. Leveraging Topic Modeling and Part-of-Speech Tagging to Support Combinational Creativity in Requirements Engineering. Requir. Eng. 2015, 20, 253–280. [Google Scholar] [CrossRef]
- Jeong, B.; Yoon, J.; Lee, J.-M. Social Media Mining for Product Planning: A Product Opportunity Mining Approach Based on Topic Modeling and Sentiment Analysis. Int. J. Inf. Manag. 2019, 48, 280–290. [Google Scholar] [CrossRef]
- Qiu, G.; Liu, B.; Bu, J.; Chen, C. Opinion Word Expansion and Target Extraction through Double Propagation. Comput. Linguist. 2011, 37, 9–27. [Google Scholar] [CrossRef]
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Horn, N.; Gampfer, F.; Buchkremer, R. Latent Dirichlet Allocation and T-Distributed Stochastic Neighbor Embedding Enhance Scientific Reading Comprehension of Articles Related to Enterprise Architecture. AI 2021, 2, 179–194. [Google Scholar] [CrossRef]
- Kano, N. Attractive Quality and Must-Be Quality. J. Jpn. Soc. Qual. Control 1984, 31, 147–156. [Google Scholar]
- Horn, N.; Erhardt, M.S.; Di Stefano, M.; Bosten, F.; Buchkremer, R. Vergleichende Analyse Der Word-Embedding-Verfahren Word2Vec und GloVe Am Beispiel von Kundenbewertungen Eines Online-Versandhändlers. In Künstliche Intelligenz in Wirtschaft & Gesellschaft; Springer Fachmedien Wiesbaden: Wiesbaden, Gemrny, 2020; pp. 559–581. ISBN 9783658295509. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Kusner, M.J.; Sun, Y.; Kolkin, N.I.; Weinberger, K.Q. From Word Embeddings to Document Distances. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Van Vliet, M.; Groen, E.C.; Dalpiaz, F.; Brinkkemper, S. Identifying and Classifying User Requirements in Online Feedback via Crowdsourcing. In Proceedings of the Requirements Engineering: Foundation for Software Quality: 26th International Working Conference, REFSQ 2020, Pisa, Italy, 24–27 March 2020; Proceedings 26. pp. 143–159. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhao, Z.; Zhang, L.; Lian, X.; Gao, X.; Lv, H.; Shi, L. ReqGen: Keywords-Driven Software Requirements Generation. Mathematics 2023, 11, 332. [Google Scholar] [CrossRef]
- Dalpiaz, F.; Dell’Anna, D.; Aydemir, F.B.; Çevikol, S. Requirements Classification with Interpretable Machine Learning and Dependency Parsing. In Proceedings of the 2019 IEEE 27th International Requirements Engineering Conference (RE), Jeju Island, South Korea, 23–27 September 2019; pp. 142–152. [Google Scholar]
- Panichella, S.; Ruiz, M. Requirements-Collector: Automating Requirements Specification from Elicitation Sessions and User Feedback. In Proceedings of the 2020 IEEE 28th International Requirements Engineering Conference (RE), Zurich, Switzerland, 31 August–4 September 2020; pp. 404–407. [Google Scholar]
- Abadeer, M.; Sabetzadeh, M. Machine Learning-Based Estimation of Story Points in Agile Development: Industrial Experience and Lessons Learned. In Proceedings of the 2021 IEEE 29th International Requirements Engineering Conference Workshops (REW), Notre Dame, IN, USA, 20–24 September 2021; pp. 106–115. [Google Scholar]
- Rankovic, N.; Rankovic, D.; Ivanovic, M.; Lazic, L. A New Approach to Software Effort Estimation Using Different Artificial Neural Network Architectures and Taguchi Orthogonal Arrays. IEEE Access 2021, 9, 26926–26936. [Google Scholar] [CrossRef]
- Al Qaisi, H.; Quba, G.Y.; Althunibat, A.; Abdallah, A.; Alzu’bi, S. An Intelligent Prototype for Requirements Validation Process Using Machine Learning Algorithms. In Proceedings of the 2021 International Conference on Information Technology (ICIT), Amman, Jordan, 14–15 July 2021; pp. 870–875. [Google Scholar]
- Osman, M.H.; Zaharin, M.F. Ambiguous Software Requirement Specification Detection: An Automated Approach. In Proceedings of the 5th International Workshop on Requirements Engineering and Testing, Gothenburg, Germany, 2 June 2018; pp. 33–40. [Google Scholar]
- Gardner, H.; Blackwell, A.F.; Church, L. The Patterns of User Experience for Sticky-Note Diagrams in Software Requirements Workshops. J. Comput. Lang. 2020, 61, 100997. [Google Scholar] [CrossRef]
- Akbar, M.A.; Sang, J.; Nasrullah; Khan, A.A.; Mahmood, S.; Qadri, S.F.; Hu, H.; Xiang, H. Success Factors Influencing Requirements Change Management Process in Global Software Development. J. Comput. Lang. 2019, 51, 112–130. [Google Scholar] [CrossRef]
- Naumchev, A.; Meyer, B.; Mazzara, M.; Galinier, F.; Bruel, J.-M.; Ebersold, S. AutoReq: Expressing and Verifying Requirements for Control Systems. J. Comput. Lang. 2019, 51, 131–142. [Google Scholar] [CrossRef]
- Myers, D.; McGuffee, J.W. Choosing Scrapy. J. Comput. Sci. Coll. 2015, 31, 83–89. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 7 November 2019. [Google Scholar]
- Goyal, N.; Du, J.; Ott, M.; Anantharaman, G.; Conneau, A. Larger-Scale Transformers for Multilingual Masked Language Modeling. In Proceedings of the RepL4NLP 2021—6th Workshop on Representation Learning for NLP, Online, 6 August 2021. [Google Scholar]
- Sharma, P.; Li, Y. Self-Supervised Contextual Keyword and Keyphrase Retrieval with Self-Labelling. Preprints 2019. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the ICLR Workshop, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–11. [Google Scholar]
- Ye, Z.; Geng, Y.; Chen, J.; Chen, J.; Xu, X.; Zheng, S.; Wang, F.; Zhang, J.; Chen, H. Zero-Shot Text Classification via Reinforced Self-Training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3014–3024. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN Revisited, Revisited: Why and How You Should (Still) Use DBSCAN. ACM Trans. Database Syst. 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Pelicon, A.; Pranjić, M.; Miljković, D.; Škrlj, B.; Pollak, S. Zero-Shot Learning for Cross-Lingual News Sentiment Classification. Appl. Sci. 2020, 10, 5993. [Google Scholar] [CrossRef]
- Mansar, Y.; Gatti, L.; Ferradans, S.; Guerini, M.; Staiano, J. Fortia-FBK at SemEval-2017 Task 5: Bullish or Bearish? Inferring Sentiment towards Brands from Financial News Headlines. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 817–822. [Google Scholar] [CrossRef]
- Xiong, G.; Yan, K. Multi-Task Sentiment Classification Model Based on DistilBert and Multi-Scale CNN. In Proceedings of the 2021 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 25–28 October 2021; pp. 700–707. [Google Scholar] [CrossRef]
- Kicken, K.; De Maesschalck, T.; Vanrumste, B.; De Keyser, T.; Shim, H.R. Intelligent Analyses on Storytelling for Impact Measurement. In Proceedings of the Sixth Workshop on Noisy User-generated Text (W-NUT 2020), Online, 19 November 2020. [Google Scholar]
- Hoffmann, O.; Cropley, D.; Cropley, A.; Nguyen, L.; Swatman, P. Creativity, Requirements and Perspectives. Australas. J. Inf. Syst. 2005, 13, 69. [Google Scholar] [CrossRef]
- Suwa, M.; Gero, J.; Purcell, T. Unexpected Discoveries and S-Invention of Design Requirements: A Key to Creative Designs. Des. Stud. 2006, 21, 297–320. [Google Scholar]
- Reimers, N. Pretrained Models Pretrained Models. Available online: https://www.sbert.net/docs/pretrained_models.html (accessed on 8 August 2023).
- Yin, W.; Hay, J.; Roth, D. Benchmarking Zero-Shot Text Classification: Datasets, Evaluation and Entailment Approach. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 7 November 2019. [Google Scholar]
- Tesfagergish, S.G.; Kapočiūtė-Dzikienė, J.; Damaševičius, R. Zero-Shot Emotion Detection for Semi-Supervised Sentiment Analysis Using Sentence Transformers and Ensemble Learning. Appl. Sci. 2022, 12, 8662. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 7871–7880. [Google Scholar]
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Manuel Bronstein Bringing You the Next-Generation Google Assistant. Available online: https://blog.google/products/assistant/next-generation-google-assistant-io/ (accessed on 8 August 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
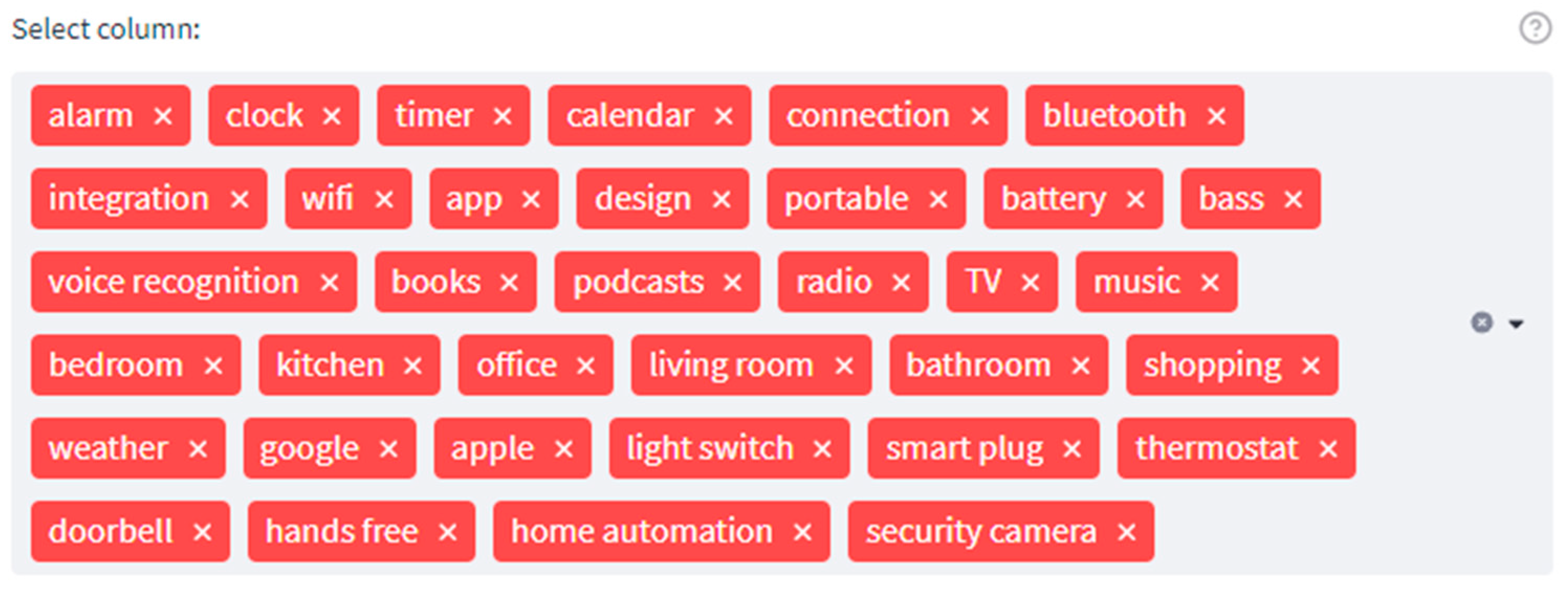
| Topic Group | Topics |
|---|---|
| Clock | Alarm, clock, reminder, timer, calendar |
| Media | Books, podcasts, radio, TV, music |
| Room | Bedroom, kitchen, office, living room, bathroom |
| Connection | Connection, Bluetooth, integration, Wi-Fi, set up, app |
| Design_mobile_sound_voice | Design, portable, battery, bass, sound, voice recognition |
| Skills_competitors | Shopping, news, weather, google, apple |
| Smart home | Light switch, smart plug, thermostat, doorbell, hands-free, home automation, security camera |
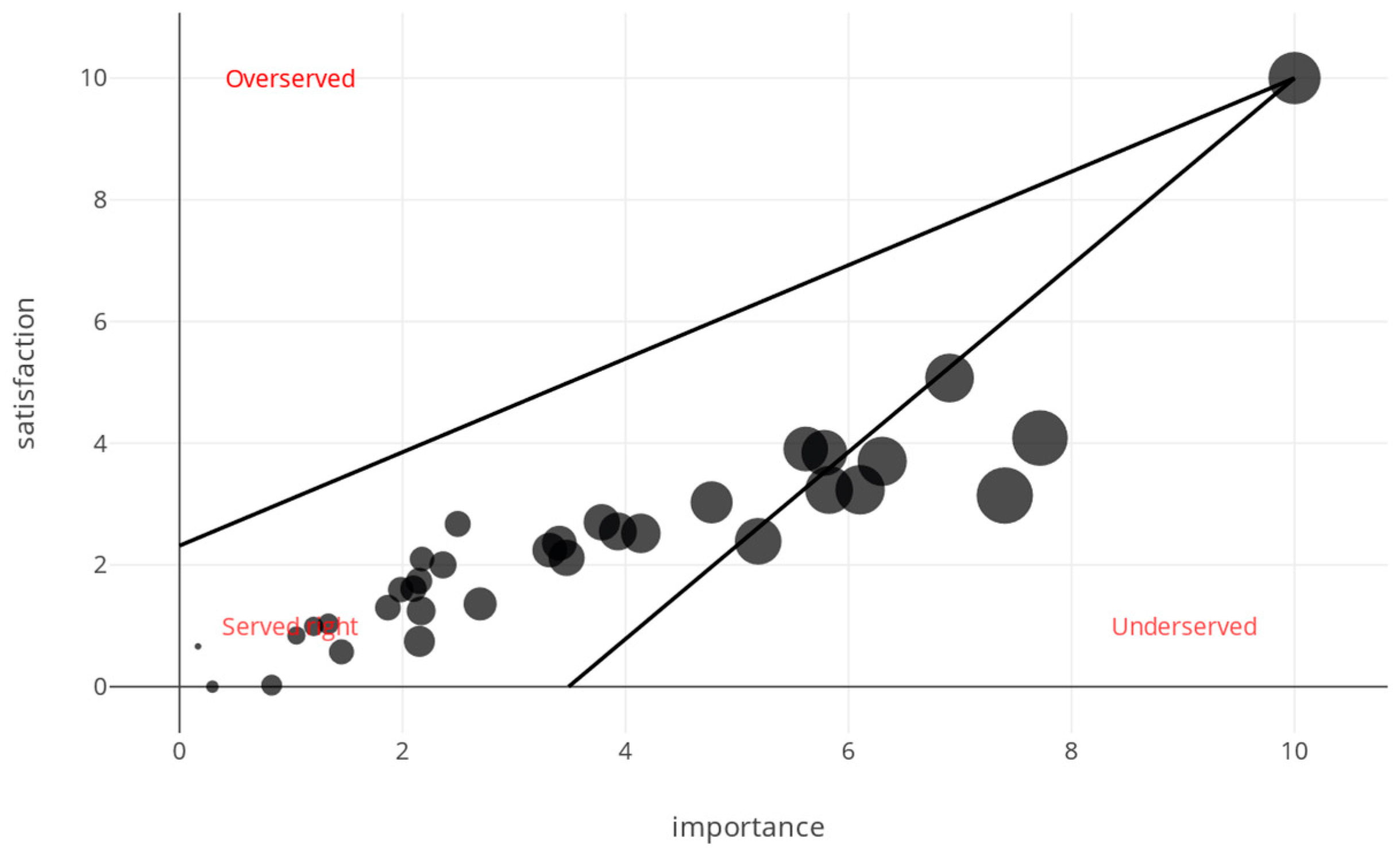
| Topic | Importance | Satisfaction | Opportunity | Served |
|---|---|---|---|---|
| Alarm | 2.15 | 0.74 | 3.56 | Served right |
| Clock | 2.36 | 2.00 | 2.75 | Served right |
| Timer | 3.79 | 2.70 | 4.87 | Served right |
| Calendar | 2.18 | 2.10 | 2.25 | Served right |
| Connection | 3.47 | 2.12 | 4.83 | Served right |
| Bluetooth | 0.17 | 0.66 | 0.17 | Served right |
| Integration | 2.49 | 2.67 | 2.49 | Served right |
| Wi-Fi | 0 | 0.46 | 0 | Served right |
| App | 1.20 | 0.99 | 1.42 | Served right |
| Design | 1.33 | 1.03 | 1.64 | Served right |
| Portable | 7.40 | 3.14 | 11.66 | Served right |
| Battery | 0.30 | 0 | 0.59 | Served right |
| Bass | 0.83 | 0.03 | 1.63 | Served right |
| Sound | 10 | 10 | 10 | Served right |
| Voice recognition | 5.19 | 2.39 | 7.99 | Underserved |
| Books | 1.87 | 1.30 | 2.44 | Served right |
| Podcasts | 3.41 | 2.36 | 4.45 | Served right |
| Radio | 7.72 | 4.09 | 11.34 | Underserved |
| TV | 6.10 | 3.23 | 8.97 | Underserved |
| Music | 6.91 | 5.07 | 8.74 | Underserved |
| Bedroom | 6.30 | 3.70 | 8.90 | Underserved |
| Kitchen | 4.77 | 3.03 | 6.52 | Served right |
| Office | 5.83 | 3.23 | 8.42 | Underserved |
| Living room | 5.78 | 3.84 | 7.72 | Served right |
| Bathroom | 3.32 | 2.24 | 4.40 | Served right |
| Shopping | 2.15 | 1.74 | 2.56 | Served right |
| Weather | 2.10 | 1.61 | 2.59 | Served right |
| 3.93 | 2.55 | 5.31 | Served right | |
| Apple | 1.98 | 1.59 | 2.37 | Served right |
| Light switch | 2.70 | 1.36 | 4.03 | Served right |
| Thermostat | 2.17 | 1.25 | 3.09 | Served right |
| Doorbell | 1.33 | 1.03 | 1.64 | Served right |
| Hands-free | 4.13 | 2.52 | 5.76 | Served right |
| Home automation | 5.61 | 3.91 | 7.33 | Served right |
| Security camera | 1.05 | 0.84 | 1.26 | Served right |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harth, P.; Jähde, O.; Schneider, S.; Horn, N.; Buchkremer, R. From Data to Human-Readable Requirements: Advancing Requirements Elicitation through Language-Transformer-Enhanced Opportunity Mining. Algorithms 2023, 16, 403. https://doi.org/10.3390/a16090403
Harth P, Jähde O, Schneider S, Horn N, Buchkremer R. From Data to Human-Readable Requirements: Advancing Requirements Elicitation through Language-Transformer-Enhanced Opportunity Mining. Algorithms. 2023; 16(9):403. https://doi.org/10.3390/a16090403
Chicago/Turabian StyleHarth, Pascal, Orlando Jähde, Sophia Schneider, Nils Horn, and Rüdiger Buchkremer. 2023. "From Data to Human-Readable Requirements: Advancing Requirements Elicitation through Language-Transformer-Enhanced Opportunity Mining" Algorithms 16, no. 9: 403. https://doi.org/10.3390/a16090403
APA StyleHarth, P., Jähde, O., Schneider, S., Horn, N., & Buchkremer, R. (2023). From Data to Human-Readable Requirements: Advancing Requirements Elicitation through Language-Transformer-Enhanced Opportunity Mining. Algorithms, 16(9), 403. https://doi.org/10.3390/a16090403