
Rotating Machinery Fault Detection Using Support Vector Machine via Feature Ranking

Abstract
:1. Introduction
2. Basic Rotation Machinery Faults
2.1. Misalignment and Imbalance Fault
2.2. Basic of Bearing and Its Typical Fault
3. Data Collection and Processing
3.1. Original Data
3.2. A Subset of Data for This Study
3.3. Response Labelling
3.4. Data Observation
3.4.1. Time Domain Data
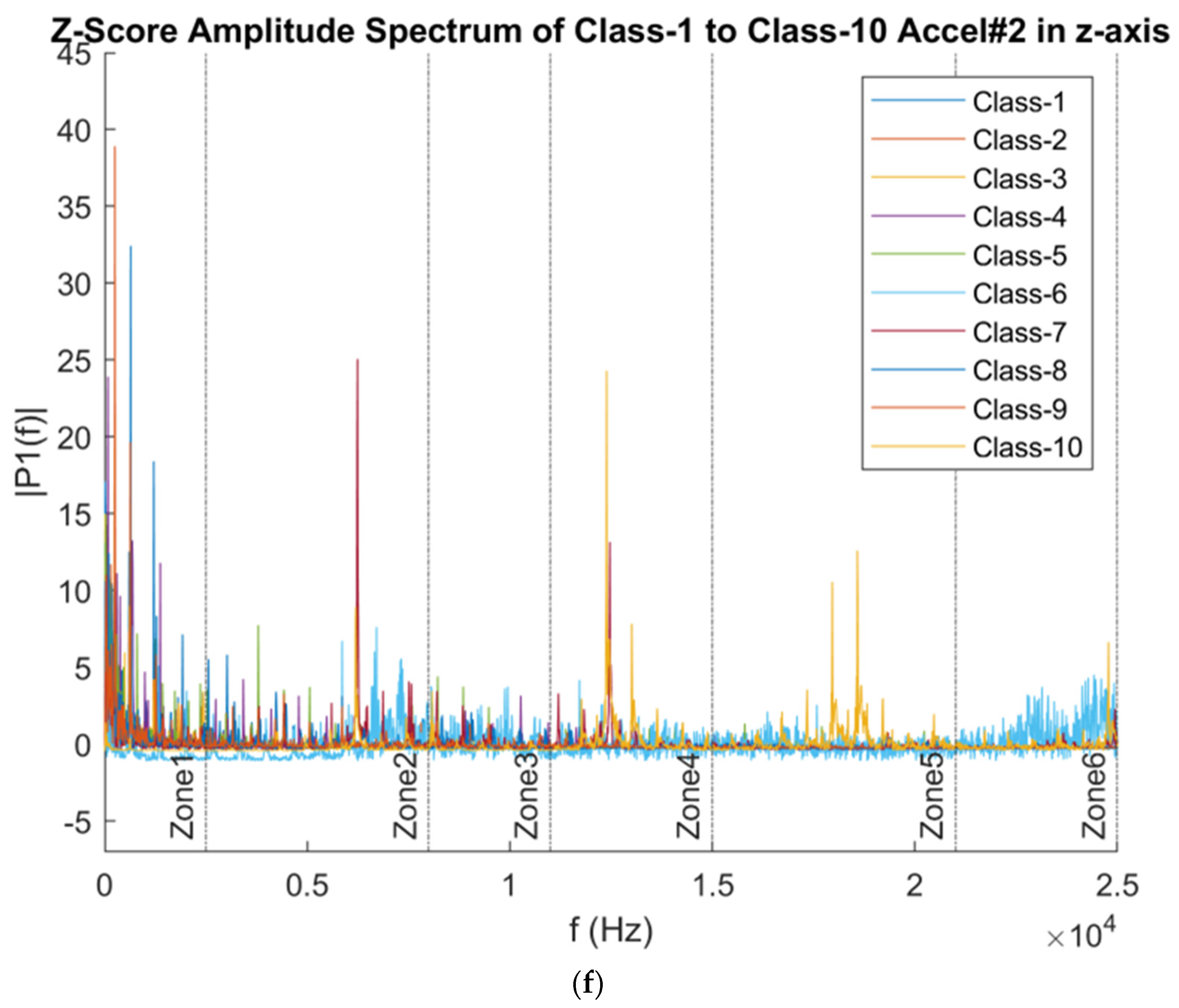
3.4.2. Frequency Domain Data
3.4.3. Sample Window
3.4.4. Power Band
3.4.5. 58 Predictors
4. Decision Tree and Important Predictors
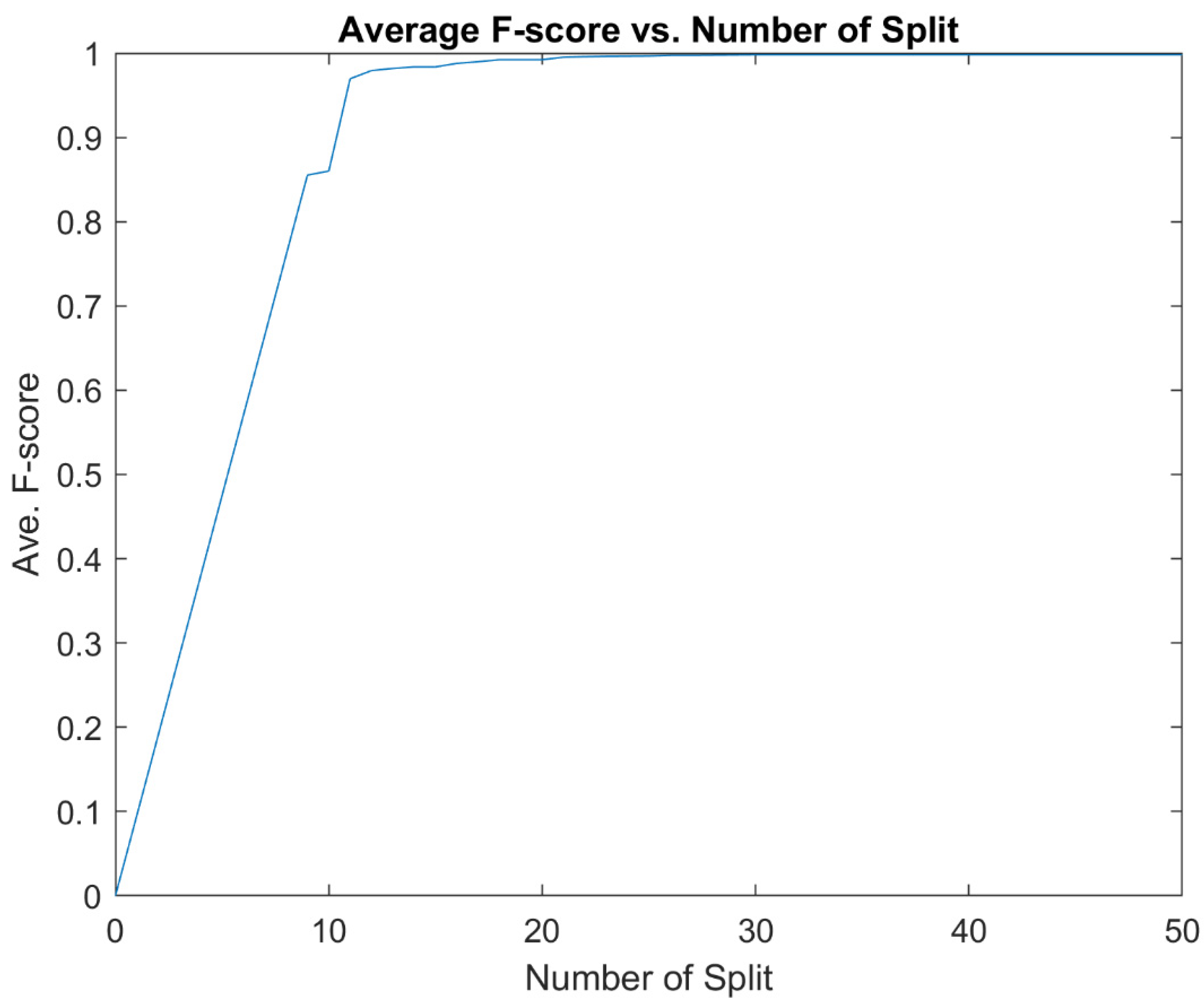
4.1. Initial Decision Tree and 11 Important Predictors
4.2. Improved Decision Tree Model with 11 Predictors
5. Explore Different Machine Learning Models with ClassificationLearner
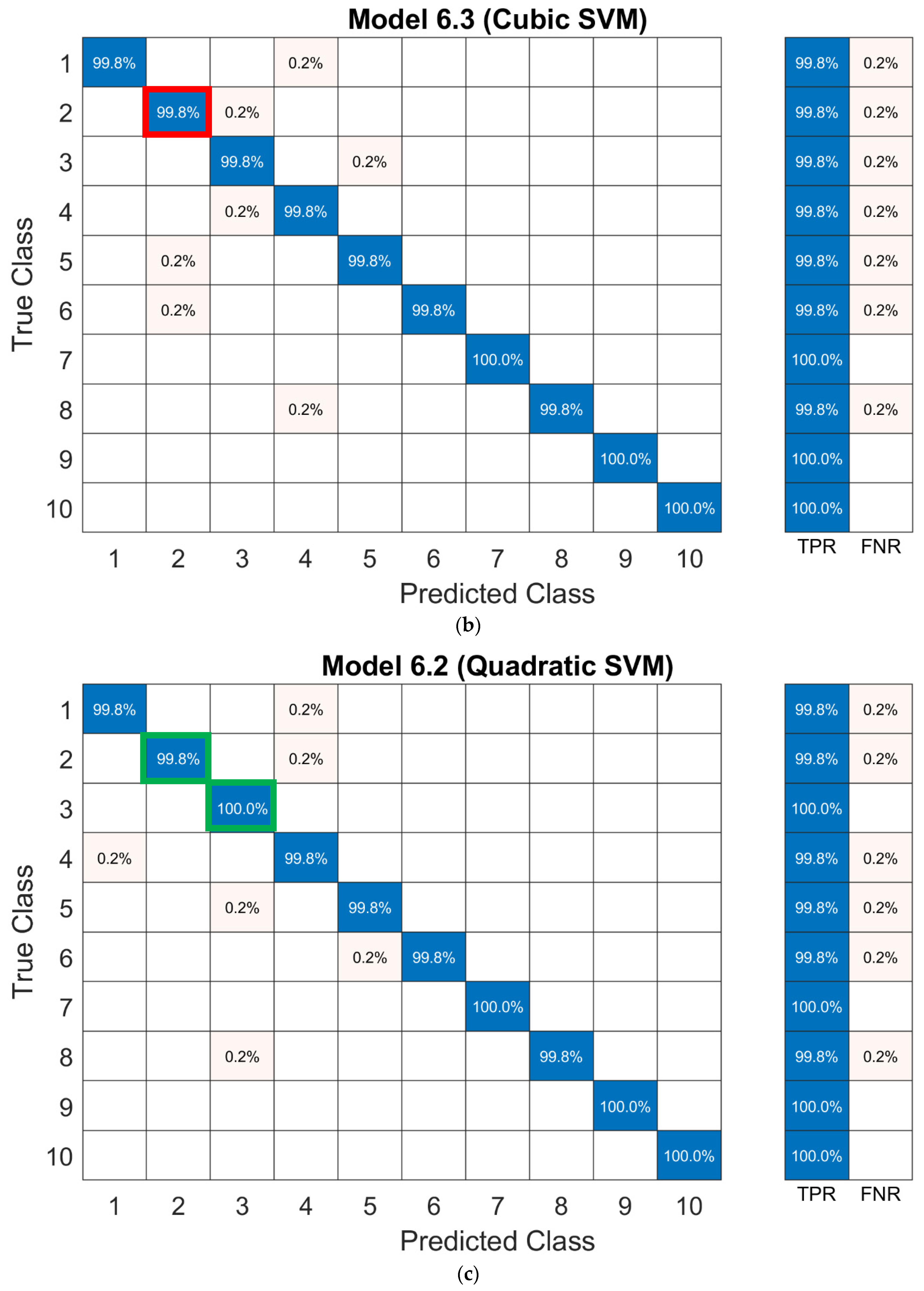
5.1. Classification Learner with All 58 Predictors
5.2. Improved Quadratic SVM Model with 58 Predictors
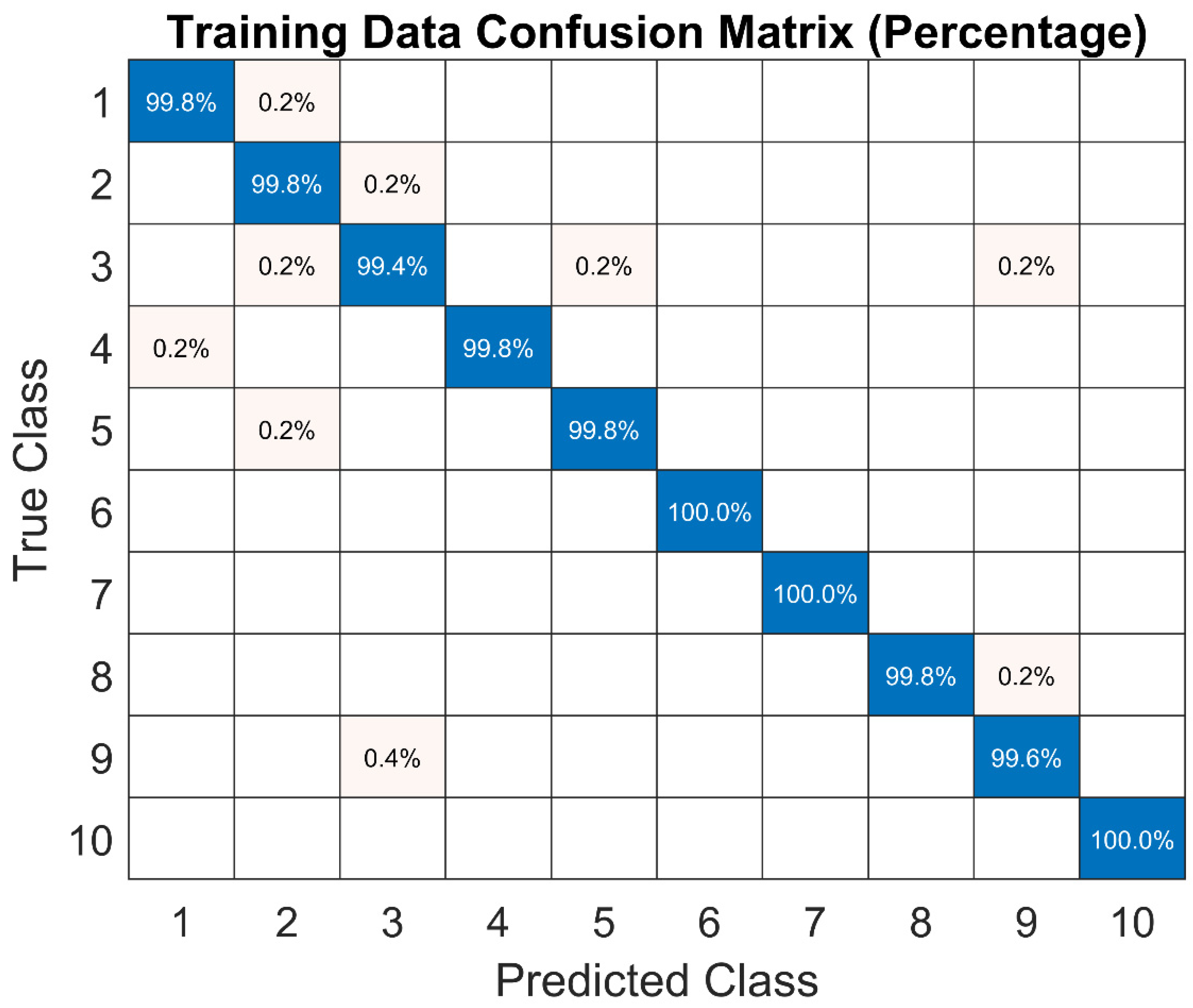
6. Model Evaluation
- (1)
- Data Set#1: first 2,500,000 records
- (2)
- Data Set#2: random 2,500,000 records with random record indexes: 40, 45, 7, 45, 31, 5, 14, 27, 47, 42
- (3)
- Data Set#3: random 2,500,000 records with random record indexes: 33, 2, 44, 46, 33, 38, 37, 20, 33, 8
- (4)
- Predictor Set#1:#22. numZeroCross_2z, #31. BandPower2_1z, #12. Var_1y, #15. Ver_2y, #38. BandPower3_3x, #57. BandPower6_2y, #11. Var_1x, #25. BandPower1_1z, #16. Var_2z, #37. BandPower3_1z, #13. Var_1z
- (5)
- Predictor Set#2:#53. BandPower6_1x, #11. Var_1x, #15. Var_2y, #56. BandPower6_2x, #32. BandPower2_2x, #12. Var_1y, #13. Var_1z, #54. BandPower6_1y, #6. Avg_1y, #1. Avg_tach, #2. Avg_mic
- (6)
- Predictor Set#3:#53. BandPower6_1x, #16. Var_2z, #15. Var_2y, #54. BandPower6_1y, #14. Var_2x, #12. Var_1y, #13. Var_1z, #11. Var_1x, #9. Avg_2y, #1. Avg_tach, #2. Avg_mic
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Riberiro, F.; Marins, M.; Sergio, N.; Eduardo, S. Rotating Machinery Fault Diagnosis using Similarity-based Model. Simp. Bras. Telecomunicac Oese Process. Sinais 2017, 35, 277–281. [Google Scholar] [CrossRef]
- Liu, J.; Wang, W.; Golnaraghi, F. An Enhanced Diagnostic Scheme for Bearing Condition Monitoring. IEEE Trans. Instrum. Meas. 2010, 59, 309–321. [Google Scholar] [CrossRef]
- Li, P.; Kong, F.; He, Q.; Liu, Y. Multiscale Slope Feature Extraction for Rotating Machinery Fault Diagnosis using Wavelet Analysis. Measurement 2013, 46, 497–505. [Google Scholar] [CrossRef]
- Li, B.; Zhang, P.; Liu, D.; Mi, S.; Ren, G.; Tian, H. Feature Extraction for Rolling Element Bearing Fault Diagnosis Utilizing Generalized S Transform and Two-Dimensional Non-Negative Matrix Factorization. J. Sound Vib. 2010, 330, 2388–2399. [Google Scholar] [CrossRef]
- Rauber, T.W.; de Assis Boldt, F.; Varejao, F.M. Heterogeneous Feature Models and Feature Selection Applied to Bearing Fault Diagnosis. IEEE Trans. Ind. Electron. 2015, 62, 637–646. [Google Scholar] [CrossRef]
- Wu, S.-D.; Wu, P.-H.; Wu, C.-W.; Ding, J.-J.; Wang, C.-C. Bearing Fault Diagnosis Based on Multiscale Permutation Entropy and Support Vector Machine. Entropy 2012, 14, 1343–1356. [Google Scholar] [CrossRef]
- Tong, Z.; Wei, L.; Zhang, B.; Gao, H.; Zhu, X.; Zio, E. Bearing Fault Diagnosis Based on Discriminant Analysis Using Multi-View Learning. Mathematics 2022, 10, 3889. [Google Scholar] [CrossRef]
- Alexakos CKarnavas, Y.; Drakaki, M.; Tziafettas, I. A Combined Short Time Fourier Transform and Image Classification Transformer Model for Rolling Element Bearings Fault Diagnosis in Electric Motors. Mach. Learn. Knowl. Extr. 2021, 3, 228–242. [Google Scholar] [CrossRef]
- Tran, T.; Lundgren, J. Drill Fault Diagnosis Based on The Scalogram and MEL Spectrogram of Sound Signals using Artificial Intelligence. IEEE Access 2020, 8, 203655–203666. [Google Scholar] [CrossRef]
- Li, C.; Sánchez, R.-V.; Zurita, G.; Cerrada, M.; Cabrera, D. Fault Diagnosis for Rotating Machinery Using Vibration Measurement Deep Statistical Feature Learning. Sensors 2016, 16, 895. [Google Scholar] [CrossRef] [PubMed]
- Zhen, J. Rotating Machinery Fault Diagnosis Based on Adaptive Vibration Signal Processing under Safety Environment Conditions. Math. Probl. Eng. 2022, 2022, 1543625. [Google Scholar] [CrossRef]
- Rajabi, S.; Azari, M.S.; Santini, S.; Flammini, F. Fault Diagnosis in Industrial Rotating Equipment Based on Permutation Entropy, Signal Processing and Multi-Output Neuro-Fuzzy Classifier. Expert Syst. Appl. 2022, 206, 117754. [Google Scholar] [CrossRef]
- Mba, D.; Cooke, A.; Roby, D.; Hewitt, G. Opportunities Offered by Acoustic Emission for Shaft-Steal Rubbing in Power Generation Turbines: A Case Study. In Proceedings of the International Conference on Condition Monitoring, Oxford, UK, 2–4 July 2003; pp. 2–4. [Google Scholar]
- Kim, Y.; Tan, A.; Mathew, J.; Yang, B. Experimental Study on Incipient Fault Detection of Low-Speed Rolling Element Bearings: Time Domain Statistical Parameters. In Proceedings of the 12th Asia-Pacific Vibration Conference, Sapporo, Japan, 6–9 August 2007; pp. 6–9. [Google Scholar]
- Kim, E.; Tan, C.A.; Mathew, J.; Kosse, V.; Yang, B.-S. A Comparative Study on The Application of Acoustic Emission Technique and Acceleration Measurements for Low-Speed Condition Monitoring. In Proceedings of the 12th Asia-Pacific Vibration Conference, Sapporo, Japan, 6–9 August 2007; pp. 1–11. [Google Scholar]
- Mba, D. The Detection of Shaft-Seal Rubbing in Large-Scale Turbines using Acoustic Emission. In Proceedings of the 14th International Congress on Condition Monitoring and Diagnostic Engineering Management (COMADEM’2001), Manchester, UK, 4–6 September 2001; pp. 21–28. [Google Scholar]
- Tan, C.K.; Mba, D. Limitation of Acoustic Emission for Identifying Seeded Defects in Gearboxes. J. Nondestruct. Eval. 2005, 24, 11–28. [Google Scholar] [CrossRef]
- Altaf, M.; Uzair, M.; Naeem, M.; Ahmad, A.; Badshah, S.; Shah, J.A.; Anjum, A. Automatic and Efficient Fault Detection in Rotating Machinery using Sound Signals. Acoust. Aust. 2019, 47, 125–139. [Google Scholar] [CrossRef]
- Hong, G.; Suh, D. Mel Spectrogram-Based Advanced Deep Temporal Clustering Model with Unsupervised Data for Fault Diagnosis. Expert Syst. Appl. 2023, 217, 119551. [Google Scholar] [CrossRef]
- Gundewar, S.K.; Kane, P.V. Rolling Element Bearing Fault Diagnosis using Supervised Learning Methods—Artificial Neural Network and Discriminant Classifier. Int. J. Syst. Assur. Eng. Manag. 2022, 13, 2876–2894. [Google Scholar] [CrossRef]
- Shubita, R.R.; Alsadeh, A.S.; Khater, I.M. Fault Detection in Rotating Machinery Based on Sound Signal Using Edge Machine Learning. IEEE Access 2023, 11, 6665–6672. [Google Scholar] [CrossRef]
- Jalayer, M.; Orsenigo, C.; Vercellis, C. Fault Detection and Diagnosis for Rotating Machinery: A Model Based on Convolutional LSTM, Fast Fourier and Continuous Wavelet Transforms. Comput. Ind. 2021, 125, 103378. [Google Scholar] [CrossRef]
- Inyang, U.I.; Petrunin, I.; Jennions, I. Diagnosis of Multiple Faults in Rotating Machinery Using Ensemble Learning. Sensors 2023, 23, 1005. [Google Scholar] [CrossRef] [PubMed]
- Das, O.; Bagci Das, D.; Birant, D. Machine Learning for Fault Analysis in Rotating Machinery: A Comprehensive Review. Heliyon 2023, 9, 6. [Google Scholar] [CrossRef] [PubMed]
- NMB Technologies. What is a Ball Bearing? Available online: https://nmbtc.com/white-papers/what-is-a-ball-bearing/ (accessed on 1 November 2022).
- Machinery Fault Dataset. Kaggle. Available online: https://www.kaggle.com/datasets/uysalserkan/fault-induction-motor-dataset/discussion/361583 (accessed on 1 November 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specification | Value | Unit |
|---|---|---|
| Motor | 1/4 | CV DC |
| Frequency range | 700–3600 | rpm |
| System weight | 22 | kg |
| Axis diameter | 16 | mm |
| Axis length | 520 | mm |
| Rotor | 15.24 | cm |
| Bearings distance | 390 | mm |
| Specification | Value | Unit |
| Number of balls | 8 | |
| Balls diameter | 0.7145 | cm |
| Inner diameter | 2.8519 | cm |
| FTF | 0.375 | CPM/rpm |
| BPFO | 2.998 | CPM/rpm |
| BPFI | 5.002 | CPM/rpm |
| BSF | 1.871 | CPM/rpm |
| Mode | No. of Sequence | Description |
|---|---|---|
| Normal | 49 | 49 sequences with a fixed rotation speed within the range from 737 rpm to 3686 rpm with steps of approximately 60 rpm |
| Horizontal Misalignment | 197 | Same 49 sequences from 0.5 mm to 2 mm |
| Vertical Misalignment | 301 | Same 49 sequences from 0.51 mm to 1.9 mm |
| Imbalance | 333 | Same 49 sequences from 6 g to 35 g |
| Underhang bearing—Inner fault | 188 | 42~49 sequence from 0 to 35 |
| Underhang bearing—Outer race | 184 | 37~49 sequence from 0 to 35 |
| Underhang bearing—Ball Fault | 186 | 38~49 sequence from 0 to 35 |
| Overhang bearing—Inner fault | 188 | 41~49 sequence from 0 to 35 |
| Overhang bearing—Outer race | 188 | 41~49 sequence from 0 to 35 |
| Overhang bearing—Ball Fault | 137 | 20~49 sequence from 0 to 35 |
| Mode | No. of Sequence | Total Record |
|---|---|---|
| Normal | 1 | 250,000 |
| Horizontal Misalignment—1 m | 1 | 250,000 |
| Vertical Misalignment—0.51 mm | 1 | 250,000 |
| Imbalance—6 g | 1 | 250,000 |
| Underhang bearing—Inner fault-6 g | 1 | 250,000 |
| Underhang bearing—Outer race-6 g | 1 | 250,000 |
| Underhang bearing—Ball Fault-6 g | 1 | 250,000 |
| Overhang bearing—Inner fault-6 g | 1 | 250,000 |
| Overhang bearing—Outer race-6 g | 1 | 250,000 |
| Overhang bearing—Ball Fault-6 g | 1 | 250,000 |
| Class | Accuracy | Precision | Recall | F-Score |
| 1 | 99.96% | 99.8% | 99.8% | 99.8% |
| 2 | 99.92% | 99.402% | 99.8% | 99.601% |
| 3 | 99.88% | 99.4% | 99.4% | 99.4% |
| 4 | 99.98% | 100% | 99.8% | 99.9% |
| 5 | 99.96% | 99.8% | 99.8% | 99.8% |
| 6 | 100% | 100% | 100% | 100% |
| 7 | 100% | 100% | 100% | 100% |
| 8 | 99.98% | 100% | 99.8% | 99.9% |
| 9 | 99.92% | 99.6% | 99.6% | 99.6% |
| 10 | 100% | 100% | 100% | 100% |
| Class | Accuracy | Precision | Recall | F-score |
|---|---|---|---|---|
| 1 | 99.96% | 100% | 99.8%% | 99.6% |
| 2 | 99.92% | 99.206% | 99.602% | 100% |
| 3 | 99.82% | 98.614% | 99.104% | 99.6% |
| 4 | 99.96% | 99.8% | 99.8% | 99.8% |
| 5 | 99.92% | 100% | 99.598% | 99.2% |
| 6 | 100% | 100% | 100% | 100% |
| 7 | 99.99% | 99.599% | 99.499% | 99.4% |
| 8 | 99.94% | 99.8% | 99.7% | 99.6% |
| 9 | 99.98% | 100% | 99.9% | 99.8% |
| 10 | 100% | 100% | 100% | 100% |
| Model Number | Model Type | Neural Network | Predictors | Accuracy (Validation) |
|---|---|---|---|---|
| 3.1 | Decision Tree | Fine Tree | All | 99.1% |
| 3.2 | Decision Tree | Medium | All | 98.9% |
| 3.3 | Decision Tree | Coarse Tree | All | 50.0% |
| 4.1 | Linear Discriminant | Linear Discriminant | All | 99.1% |
| 5.2 | Naïve Bayes | Kernel Naïve Bayes | All | 87.7% |
| 6.1 | SVM | Linear SVM | All | 99.8% |
| 6.2 | SVM | Quadratic SVM | All | 99.8% |
| 6.3 | SVM | Cubic SVM | All | 99.8% |
| 6.4 | SVM | Fine Gaussian SVM | All | 41.0% |
| 6.5 | SVM | Medium Gaussian SVM | All | 99.3% |
| 6.6 | SVM | Coarse Gaussian SVM | All | 99.6% |
| 7.1 | KNN | Fine KNN | All | 99.0% |
| 7.2 | KNN | Medium KNN | All | 97.9% |
| 7.3 | KNN | Coarse KNN | All | 91.0% |
| 7.4 | KNN | Cosine KNN | All | 98.6% |
| 7.5 | KNN | Cubic KNN | All | 97.4% |
| 7.6 | KNN | Weighted KNN | All | 98.4% |
| 8.1 | Kernel | SVM Kernel | All | 92.4% |
| 8.2 | Kernel | Logistic Regression Kernel | All | 91.5% |
| 9.1 | Ensemble | Boosted Trees | All | 99.4% |
| 9.2 | Ensemble | Bagged Trees | All | 99.4% |
| 9.3 | Ensemble | Subspace Discriminant | All | 98.1% |
| 9.4 | Ensemble | Subspace KNN | All | 91.4% |
| 9.5 | Ensemble | RUS Boosted Trees | All | 98.9% |
| 10.1 | Neural Network | Narrow Neural Network | All | 99.3% |
| 10.2 | Neural Network | Medium Neural Network | All | 99.4% |
| 10.3 | Neural Network | Wide Neural Network | All | 99.5% |
| 10.4 | Neural Network | Bilayer Neural Network | All | 99.3% |
| 10.5 | Neural Network | Trilayered Neural Network | All | 99.4% |
| Model Number | Model Type | Neural Network | Predictors | Accuracy (Validation) | Training Time |
|---|---|---|---|---|---|
| 6.2 | SVM | Quadratic SVM | All | 99.8% | 16.3 s |
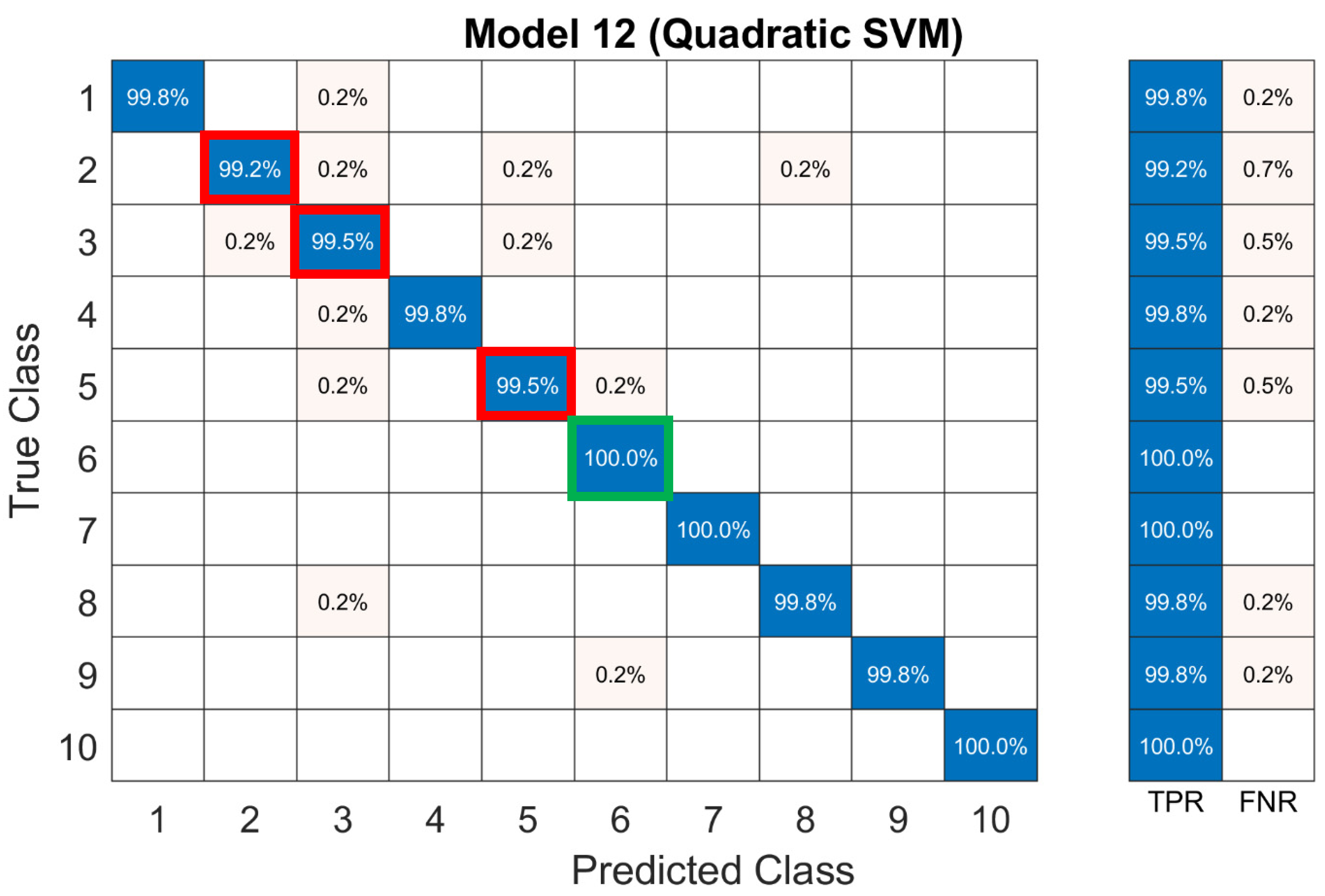
| 12 | SVM | Quadratic SVM | Only 11 Predictors | 99.7% | 6.9 s |
| Model# | Trained Data Set | Classifier | Classifier Type | Predictors | Training Accuracy (Validation) | Test with Data Set#1 | Test with Data Set#2 | Test with Data Set#3 |
|---|---|---|---|---|---|---|---|---|
| Version#1-6.2 | Data Set#1(1) | SVM | Quadratic SVM | All | 99.80% | 100.00% | 15.10% | 19.50% |
| Version#1-12 | Data Set#1 | SVM | Quadratic SVM | Predictor set#1(4) | 99.70% | 99.90% | 18.50% | 21.40% |
| Version#2-#1 | Data Set #2 (2) | SVM | Quadratic SVM | All | 99.80% | 25.90% | 99.80% | 44.60% |
| Version#2-#3 | Data Set #2 | SVM | Quadratic SVM | Predictor set#2(5) | 99.80% | 20.00% | 100.00% | 47.60% |
| Version#3-#3 | Data Set #3(3) | SVM | Quadratic SVM | All | 99.80% | 23.50% | 46.70% | 99.90% |
| Version#3-#4 | Data Set #3 | SVM | Quadratic SVM | Predictor set#3(6) | 99.80% | 30.30% | 56% | 99.90% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huynh, H.H.; Min, C.-H. Rotating Machinery Fault Detection Using Support Vector Machine via Feature Ranking. Algorithms 2024, 17, 441. https://doi.org/10.3390/a17100441
Huynh HH, Min C-H. Rotating Machinery Fault Detection Using Support Vector Machine via Feature Ranking. Algorithms. 2024; 17(10):441. https://doi.org/10.3390/a17100441
Chicago/Turabian StyleHuynh, Harry Hoa, and Cheol-Hong Min. 2024. "Rotating Machinery Fault Detection Using Support Vector Machine via Feature Ranking" Algorithms 17, no. 10: 441. https://doi.org/10.3390/a17100441