
A Machine Learning Approach to Identifying Risk Factors for Long COVID-19


Abstract
1. Introduction
- (i)
- Past COVID-19 infection: history of probable or confirmed COVID-19 infection;
- (ii)
- Onset of symptoms: usually three months from onset of COVID-19 symptoms;
- (iii)
- Duration of symptoms: symptoms lasting for at least two months;
- (iv)
2. Methods
2.1. Sample and Inclusion Criteria
2.2. Features (Variables)
2.3. Data Analysis
2.4. Sensitivity Analysis
3. Results
3.1. Descriptive Statistics
3.2. Model Results
3.3. Sensitivity Analysis Results
4. Discussion
4.1. Model Performance
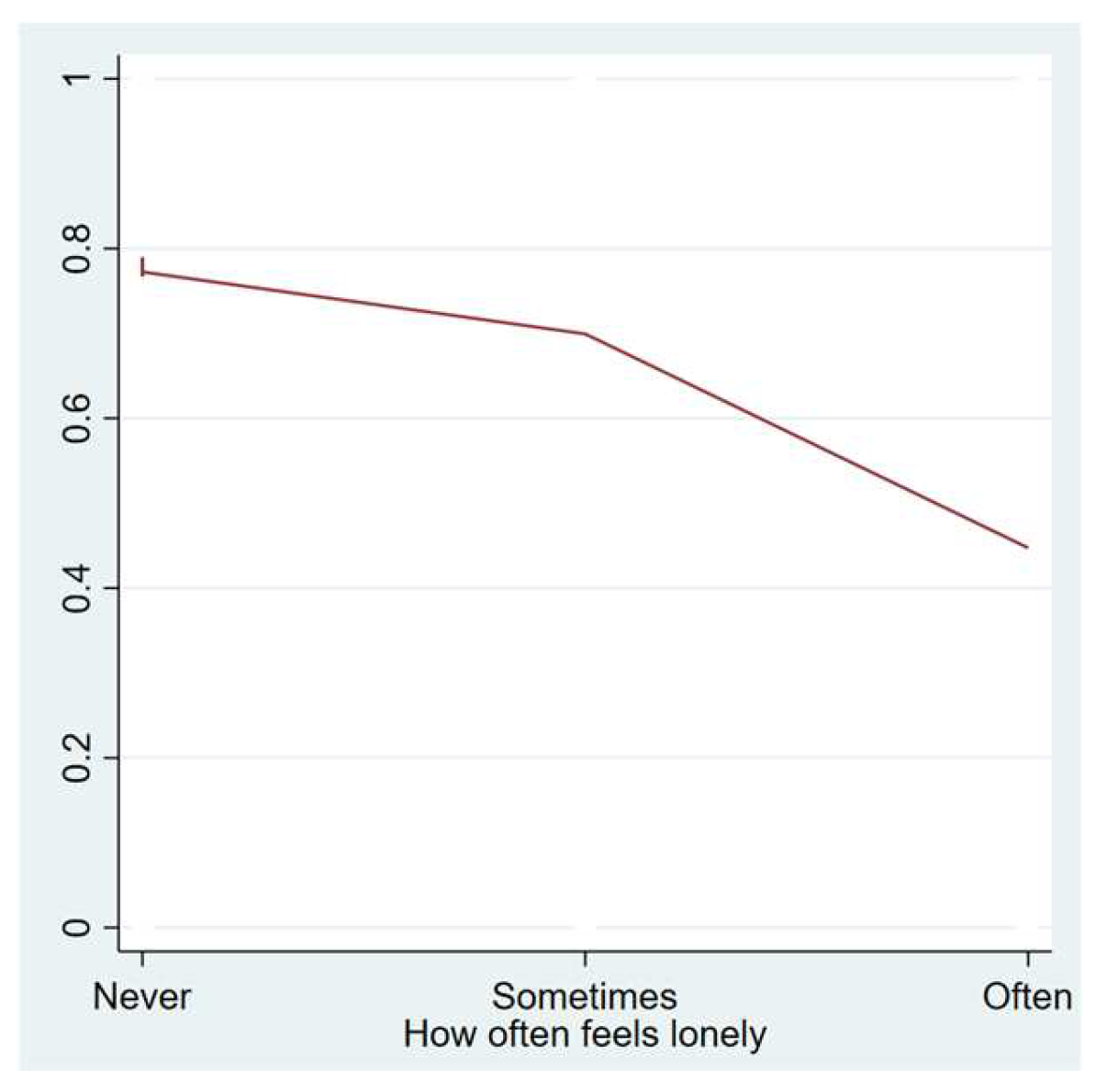
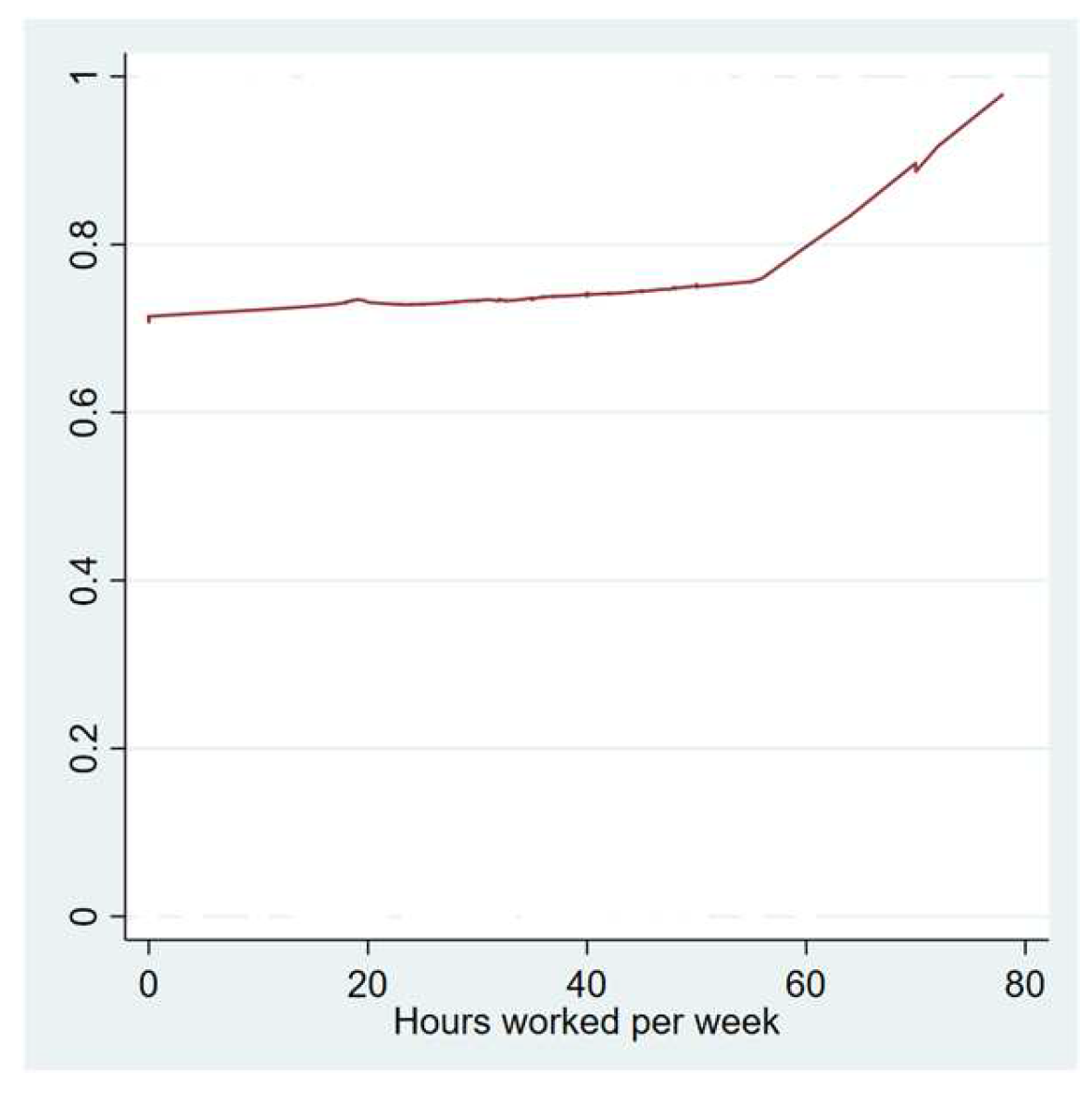
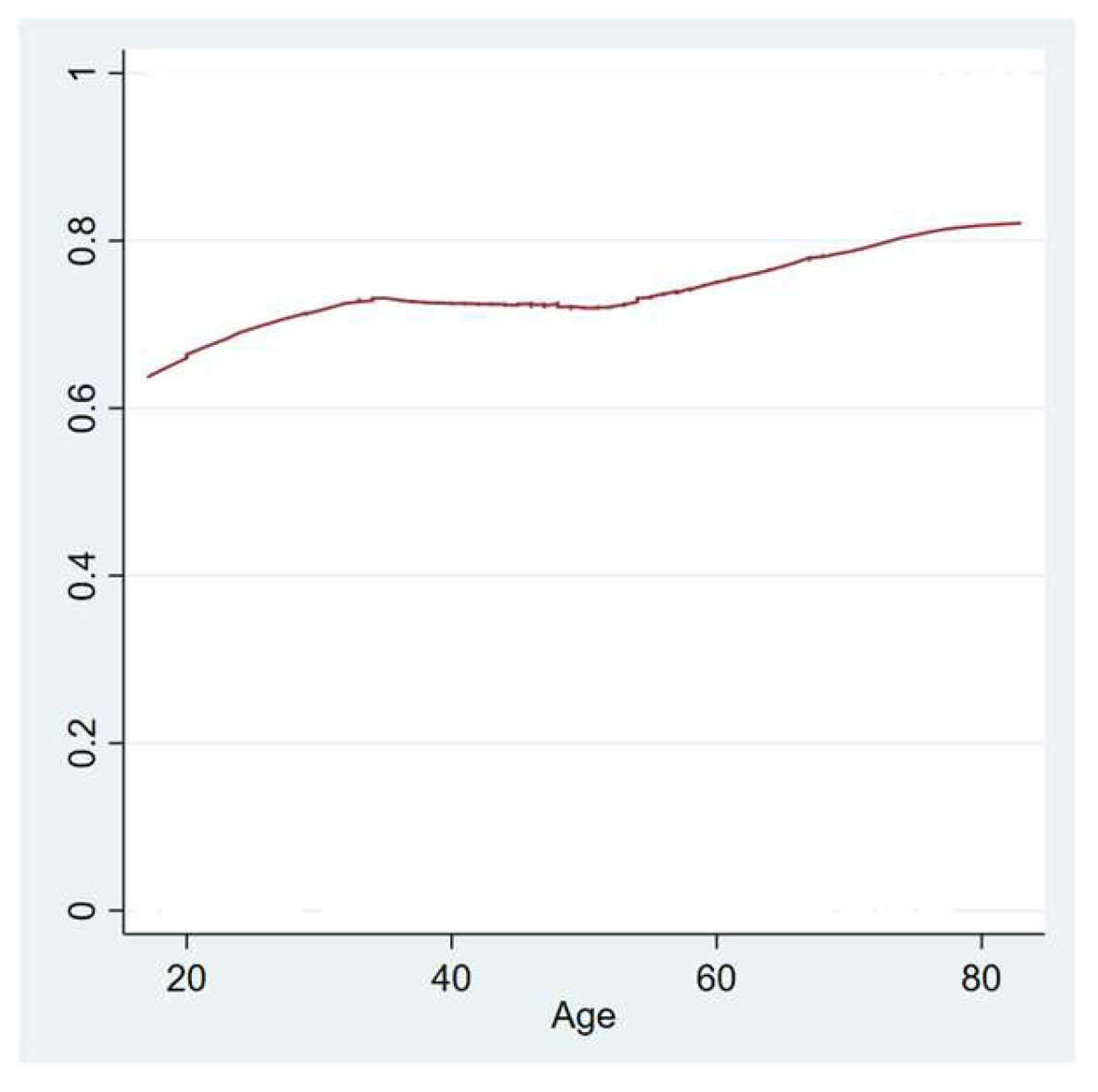
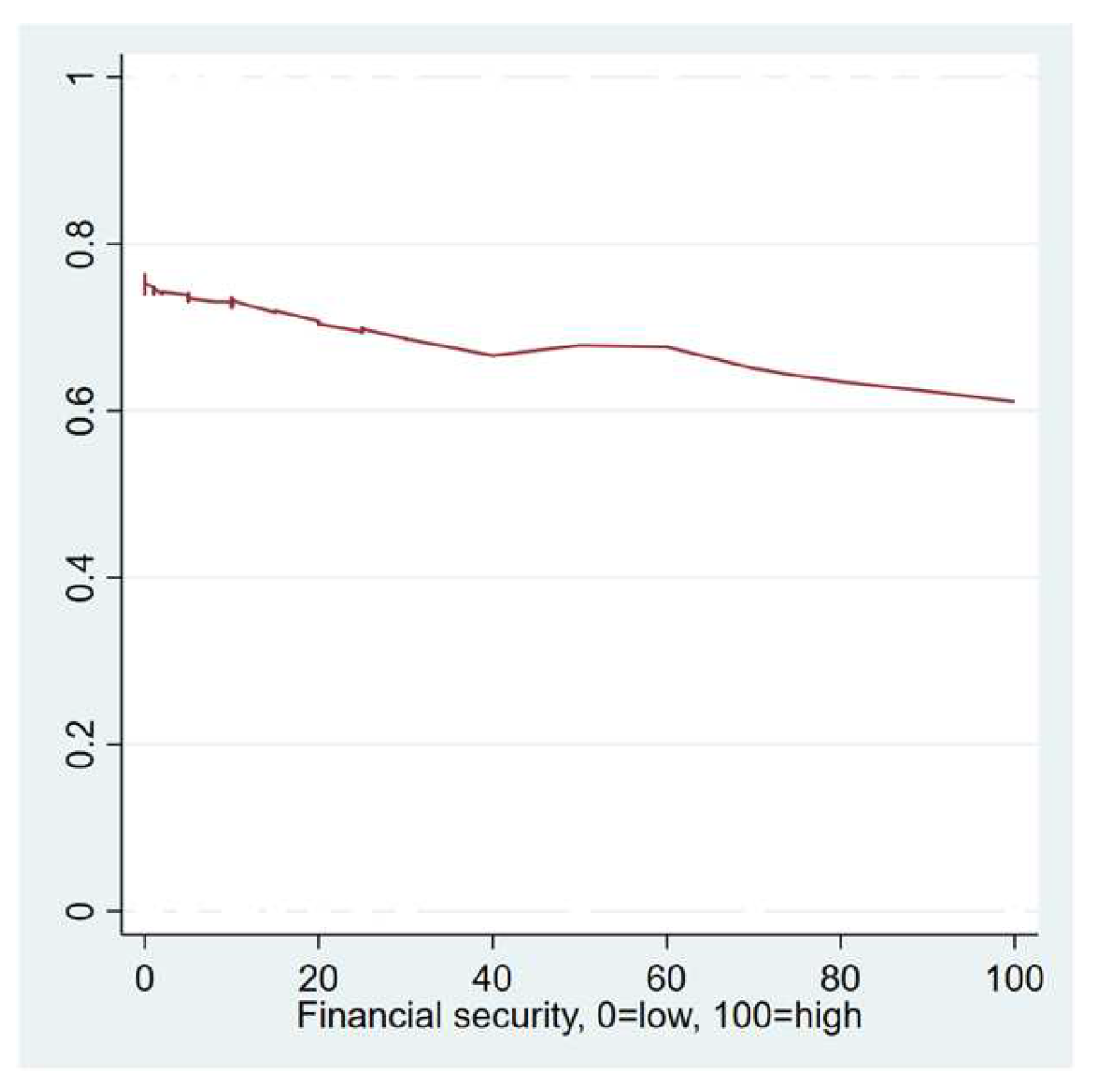
4.2. Identified Risk Factors for Long COVID-19
4.3. Sensitivity Analysis Discussion
4.4. Strengths and Limitations
4.5. Future Implications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Michelen, M.; Manoharan, L.; Elkheir, N.; Cheng, V.; Dagens, A.; Hastie, C.; O’Hara, M.; Suett, J.; Dahmash, D.; Bugaeva, P.; et al. Characterising long COVID: A living systematic review. BMJ Glob. Health 2021, 6, e005427. [Google Scholar] [CrossRef] [PubMed]
- Soriano, J.B.; Murthy, S.; Marshall, J.C.; Relan, P.; Diaz, J.V. A clinical case definition of post-COVID-19 condition by a Delphi consensus. Lancet Infect. Dis. 2022, 22, e102–e107. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Haupert, S.R.; Zimmermann, L.; Shi, X.; Fritsche, L.G.; Mukherjee, B. Global Prevalence of Post-Coronavirus Disease 2019 (COVID-19) Condition or Long COVID: A Meta-Analysis and Systematic Review. J. Infect. Dis. 2022, 226, 1593–1607. [Google Scholar] [CrossRef] [PubMed]
- National Institute for Health and Care Excellence: Clinical Guidelines. In COVID-19 Rapid Guideline: Managing the Long-Term Effects of COVID-19; National Institute for Health and Care Excellence (NICE): London, UK, 2020.
- Davis, H.E.; McCorkell, L.; Vogel, J.M.; Topol, E.J. Long COVID: Major findings, mechanisms and recommendations. Nat. Rev. Microbiol. 2023, 21, 133–146. [Google Scholar] [CrossRef] [PubMed]
- Long COVID. Long COVID. Centers for Disease Control and Prevention. Updated 14 March 2024. Available online: https://www.cdc.gov/coronavirus/2019-ncov/long-term-effects/index.html (accessed on 30 September 2024).
- Australian Institute of Health and Welfare. Long COVID in Australia—A Review of the Literature. 2022. Available online: https://www.aihw.gov.au/reports/covid-19/long-covid-in-australia-a-review-of-the-literature (accessed on 15 June 2024).
- Luo, D.; Mei, B.; Wang, P.; Li, X.; Chen, X.; Wei, G.; Kuang, F.; Li, B.; Su, S. Prevalence and risk factors for persistent symptoms after COVID-19: A systematic review and meta-analysis. Clin. Microbiol. Infect. 2024, 30, 328–335. [Google Scholar] [CrossRef] [PubMed]
- Malik, P.; Patel, K.; Pinto, C.; Jaiswal, R.; Tirupathi, R.; Pillai, S.; Patel, U. Post-acute COVID-19 syndrome (PCS) and health-related quality of life (HRQoL)-A systematic review and meta-analysis. J. Med. Virol. 2022, 94, 253–262. [Google Scholar] [CrossRef] [PubMed]
- Tsampasian, V.; Elghazaly, H.; Chattopadhyay, R.; Debski, M.; Naing, T.K.P.; Garg, P.; Clark, A.; Ntatsaki, E.; Vassiliou, V.S. Risk Factors Associated with Post-COVID-19 Condition: A Systematic Review and Meta-analysis. JAMA Intern. Med. 2023, 183, 566–580. [Google Scholar] [CrossRef] [PubMed]
- Durstenfeld, M.S.; Peluso, M.J.; Peyser, N.D.; Lin, F.; Knight, S.J.; Djibo, A.; Khatib, R.; Kitzman, H.; O’brien, E.; Williams, N.; et al. Factors Associated with Long COVID Symptoms in an Online Cohort Study. Open Forum Infect. Dis. 2023, 10, ofad047. [Google Scholar] [CrossRef] [PubMed]
- Lundberg-Morris, L.; Leach, S.; Xu, Y.; Martikainen, J.; Santosa, A.; Gisslén, M.; Li, H.; Nyberg, F.; Bygdell, M. COVID-19 vaccine effectiveness against post-COVID-19 condition among 589 722 individuals in Sweden: Population based cohort study. BMJ 2023, 383, e076990. [Google Scholar] [CrossRef] [PubMed]
- Padilla, S.; Ledesma, C.; García-Abellán, J.; García, J.A.; Fernández-González, M.; de la Rica, A.; Galiana, A.; Gutiérrez, F.; Masiá, M. Long COVID across SARS-CoV-2 variants, lineages, and sublineages. iScience 2024, 27, 109536. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, A.; Nirantharakumar, K.; Hughes, S.; Myles, P.; Williams, T.; Gokhale, K.M.; Taverner, T.; Chandan, J.S.; Brown, K.; Simms-Williams, N.; et al. Symptoms and risk factors for long COVID in non-hospitalized adults. Nat. Med. 2022, 28, 1706–1714. [Google Scholar] [CrossRef] [PubMed]
- Thompson, E.J.; Williams, D.M.; Walker, A.J.; Mitchell, R.E.; Niedzwiedz, C.L.; Yang, T.C.; Huggins, C.F.; Kwong, A.S.F.; Silverwood, R.J.; Di Gessa, G.; et al. Long COVID burden and risk factors in 10 UK longitudinal studies and electronic health records. Nat. Commun. 2022, 13, 3528. [Google Scholar] [CrossRef] [PubMed]
- Pfaff, E.R.; Girvin, A.T.; Bennett, T.D.; Bhatia, A.; Brooks, I.M.; Deer, R.R.; Dekermanjian, J.P.; Jolley, S.E.; Kahn, M.G.; Kostka, K.; et al. Identifying who has long COVID in the USA: A machine learning approach using N3C data. Lancet Digit. Health 2022, 4, e532–e541. [Google Scholar] [CrossRef] [PubMed]
- Antony, B.; Blau, H.; Casiraghi, E.; Loomba, J.J.; Callahan, T.J.; Laraway, B.J.; Wilkins, K.J.; Antonescu, C.C.; Valentini, G.; Williams, A.E.; et al. Predictive models of long COVID. eBioMedicine 2023, 96, 104777. [Google Scholar] [CrossRef] [PubMed]
- Kessler, R.; Philipp, J.; Wilfer, J.; Kostev, K. Predictive Attributes for Developing Long COVID-A Study Using Machine Learning and Real-World Data from Primary Care Physicians in Germany. J. Clin. Med. 2023, 12, 3511. [Google Scholar] [CrossRef] [PubMed]
- University of Essex; Institute for Social and Economic Research. Understanding Society: COVID-19 Study, 2020–2021, 10th ed.; UK Data Service: Essex, UK, 2021. [Google Scholar] [CrossRef]
- COVID-19. University of Essex, Institute for Social and Economic Research. Available online: https://www.understandingsociety.ac.uk/documentation/covid-19/ (accessed on 23 November 2023).
- JASP; Version 0.17.2; JASP Team: Amsterdam, The Netherlands, 2023.
- Harding, J.L.; Oviedo, S.A.; Ali, M.K.; Ofotokun, I.; Gander, J.C.; Patel, S.A.; Magliano, D.J.; Patzer, R.E. The bidirectional association between diabetes and long-COVID-19—A systematic review. Diabetes Res. Clin. Pract. 2023, 195, 110202. [Google Scholar] [CrossRef] [PubMed]
- Renaud-Charest, O.; Lui, L.M.; Eskander, S.; Ceban, F.; Ho, R.; Di Vincenzo, J.D.; Rosenblat, J.D.; Lee, Y.; Subramaniapillai, M.; McIntyre, R.S. Onset and frequency of depression in post-COVID-19 syndrome: A systematic review. J. Psychiatr. Res. 2021, 144, 129–137. [Google Scholar] [CrossRef] [PubMed]
- Zakia, H.; Pradana, K.; Iskandar, S. Risk factors for psychiatric symptoms in patients with long COVID: A systematic review. PLoS ONE 2023, 18, e0284075. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Quan, L.; Chavarro, J.E.; Slopen, N.; Kubzansky, L.D.; Koenen, K.C.; Kang, J.H.; Weisskopf, M.G.; Branch-Elliman, W.; Roberts, A.L. Associations of Depression, Anxiety, Worry, Perceived Stress, and Loneliness Prior to Infection with Risk of Post-COVID-19 Conditions. JAMA Psychiatry 2022, 79, 1081–1091. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predictor Variable | Long COVID-19 | Valid (N) | Missing | Mean | Standard Deviation | Relative Frequency (%) or Minimum, Maximum |
|---|---|---|---|---|---|---|
| Age | No | 161 | 0 | 48.199 | 14.011 | 17.000, 77.000 |
| Yes | 440 | 0 | 49.927 | 14.094 | 18.000, 83.000 | |
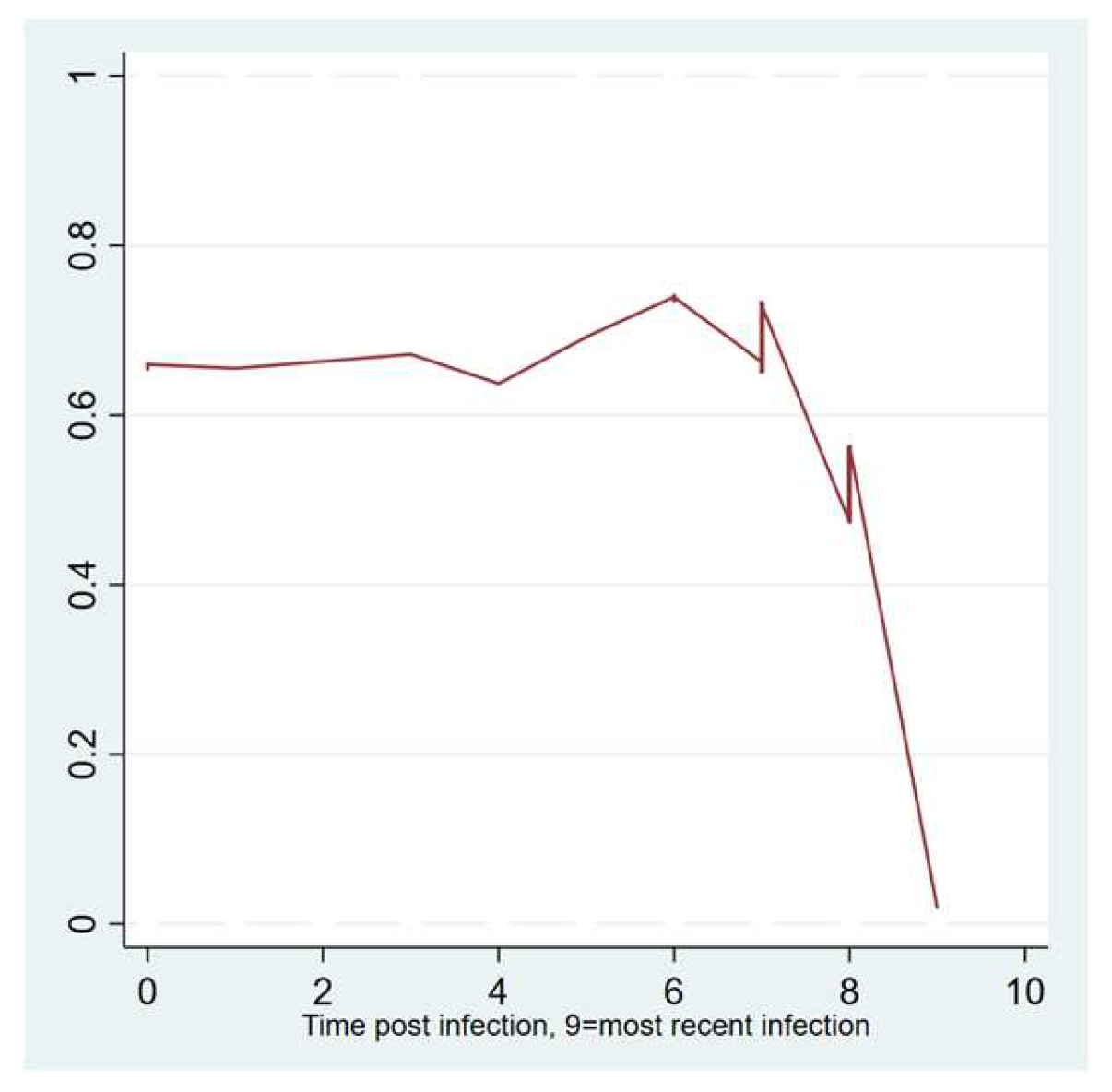
| Timing of acute COVID-19 infection | No | 161 | 0 | 6.534 | 2.973 | 0.000, 9.000 |
| Yes | 440 | 0 | 4.707 | 3.217 | 0.000, 9.000 | |
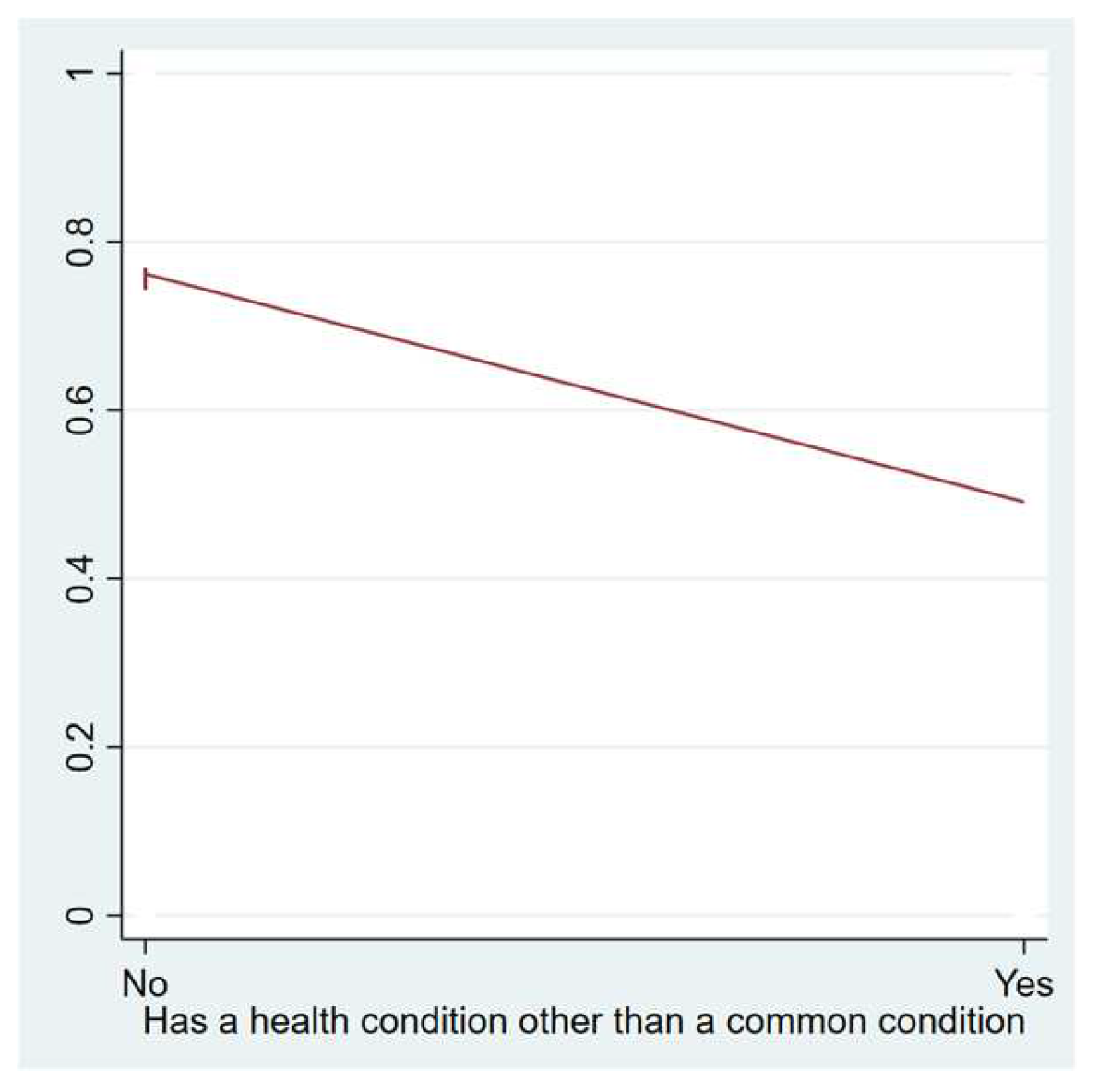
| Other/uncommon chronic condition 0.000 = No 1.000 = Yes | No | 161 | 0 | - | - | No = 81.988 Yes = 18.012 |
| Yes | 440 | 0 | - | - | No = 93.636 Yes = 6.364 | |
| Feels lonely often 1.000 = Never 2.000 = Sometimes 3.000 = Often | No | 161 | 0 | - | - | Never = 54.658 Sometimes = 32.298 Often = 13.043 |
| Yes | 437 | 3 | - | - | Never = 68.421 Sometimes = 27.689 Often = 3.890 | |
| Number of hours worked per week | No | 161 | 0 | 21.938 | 19.009 | 0.000, 60.000 |
| Yes | 438 | 2 | 23.566 | 19.408 | 0.000, 78.000 | |
| Financial security in next 3 months | No | 155 | 6 | 11.258 | 23.452 | 0.000, 100.000 |
| Yes | 420 | 20 | 7.481 | 18.860 | 0.000, 100.000 |
| Trees | 94 |
| Features per split | 5 |
| n (train) | 327 |
| n (validation) | 82 |
| n (test) | 102 |
| Validation accuracy | 0.780 |
| Test accuracy | 0.892 |
| OOB accuracy | 0.962 |
| Observed | |||
| Long COVID-19 | No Long COVID-19 | ||
| Predicted | Long COVID-19 | 74 | 9 |
| No Long COVID-19 | 2 | 17 | |
| Sensitivity (recall, true positive rate) | 0.974 |
| Specificity (true negative rate) | 0.654 |
| False positive rate | 0.346 |
| False negative rate | 0.026 |
| Precision (positive predictive value) | 0.892 |
| Negative predictive value | 0.895 |
| Accuracy | 0.892 |
| F1 score | 0.931 |
| Matthews correlation coefficient | 0.702 |
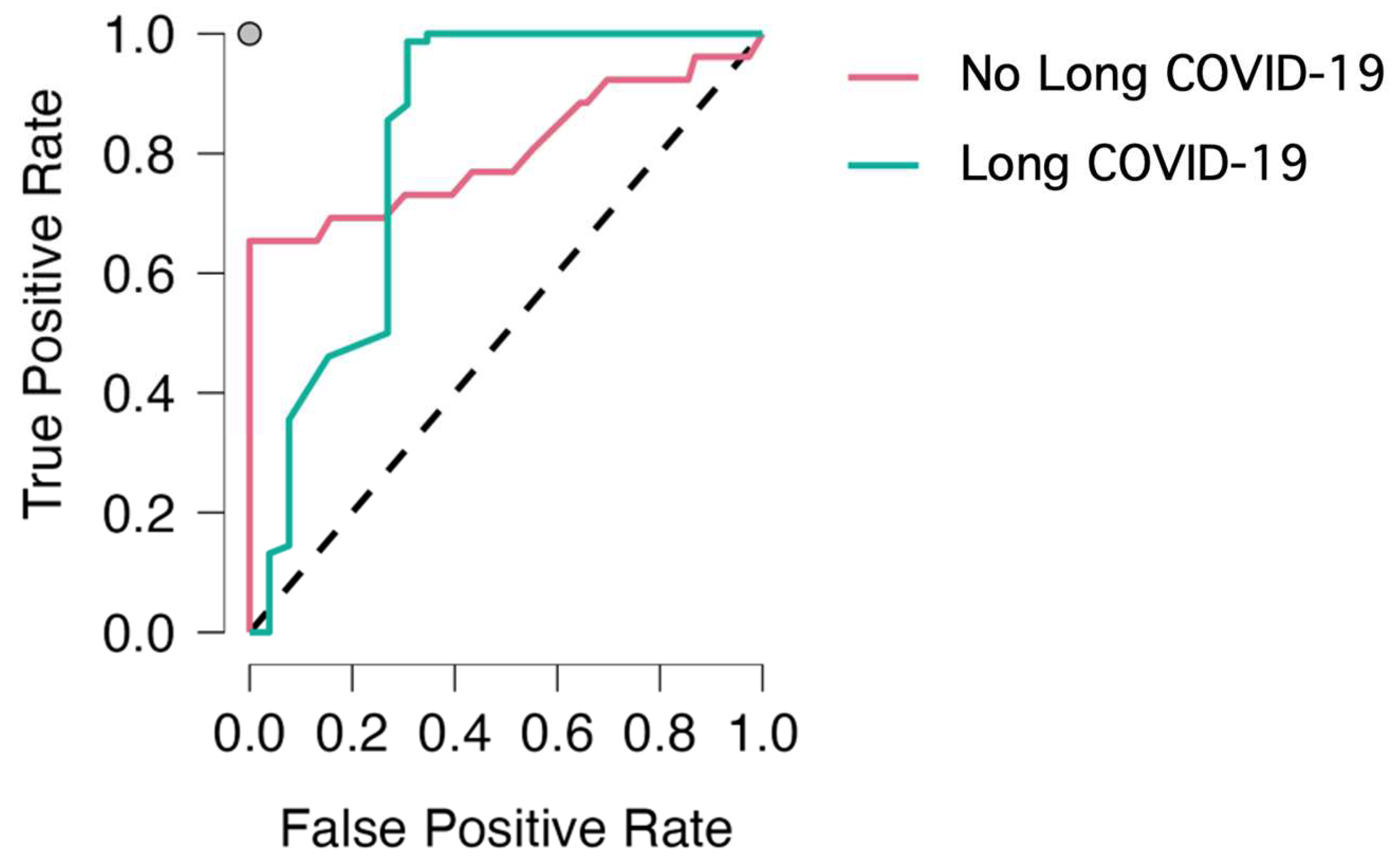
| Area under the receiver operating characteristic curve (AUROC) | 0.791 |
| False discovery rate | 0.108 |
| False omission rate | 0.105 |
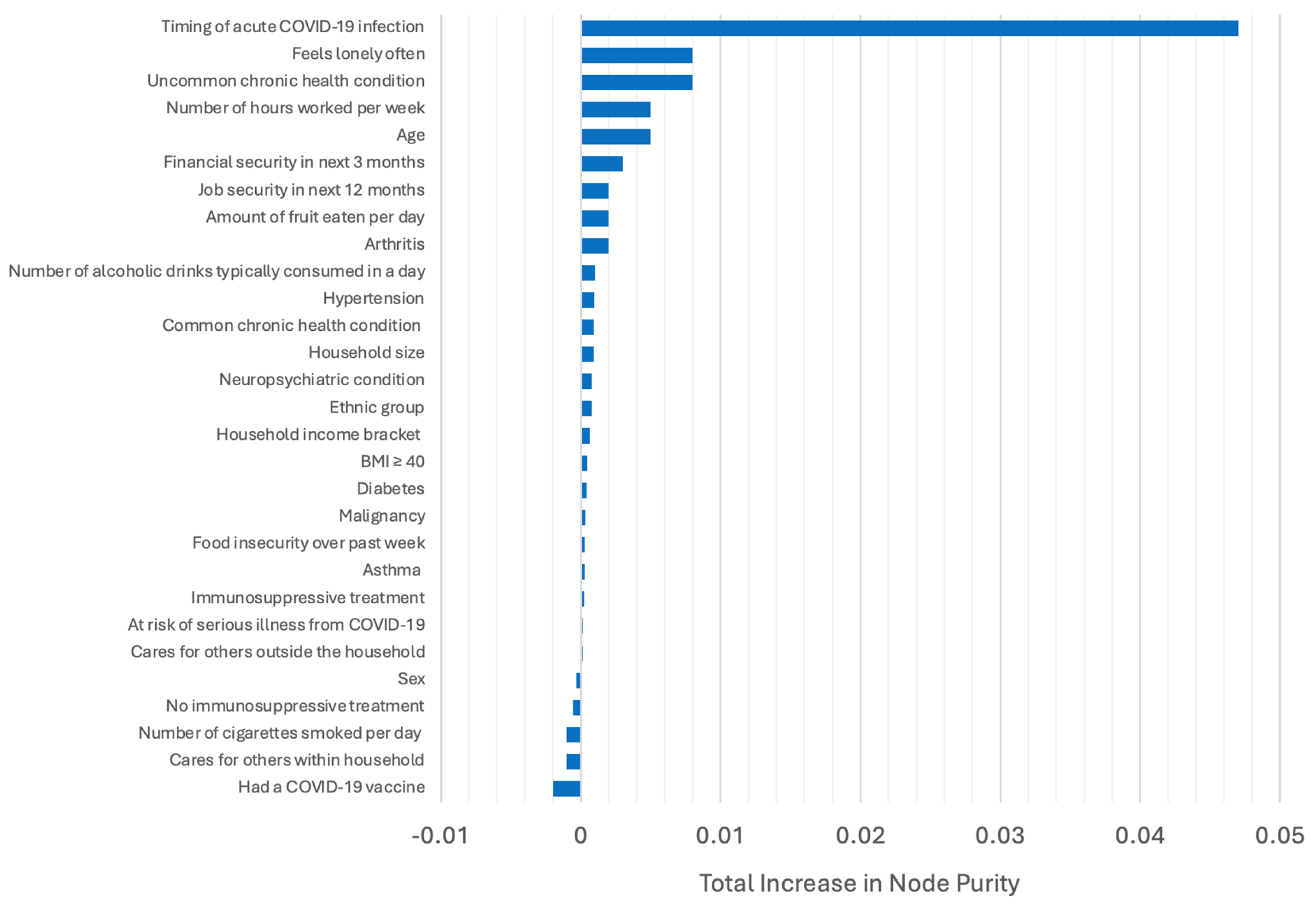
| Predictor Variable | Total Increase in Node Purity | Mean Decrease in Accuracy |
|---|---|---|
| Timing of acute COVID-19 infection | 0.047 | 0.120 |
| Feels lonely often | 0.008 | 0.011 |
| Uncommon chronic health condition | 0.008 | 0.010 |
| Number of hours worked per week | 0.005 | −0.008 |
| Age | 0.005 | −0.006 |
| Financial security in next 3 months | 0.003 | −0.001 |
| Job security in next 12 months | 0.002 | 4.939 × 10−4 |
| Amount of fruit eaten per day | 0.002 | −0.004 |
| Arthritis | 0.002 | −0.002 |
| Number of alcoholic drinks typically consumed in a day | 0.001 | 0.005 |
| Hypertension | 9.650 × 10−4 | −1.318 × 10−5 |
| Common chronic health condition | 9.372 × 10−4 | 0.004 |
| Household size | 9.360 × 10−4 | 0.003 |
| Neuropsychiatric condition | 7.889 × 10−4 | −0.001 |
| Ethnic group | 7.773 × 10−4 | −0.003 |
| Household income bracket | 6.385 × 10−4 | 0.001 |
| BMI ≥ 40 | 4.676 × 10−4 | −0.001 |
| Diabetes | 4.320 × 10−4 | 2.604 × 10−4 |
| Malignancy | 3.094 × 10−4 | 4.576 × 10−4 |
| Food insecurity over past week | 2.961 × 10−4 | −2.935 × 10−5 |
| Asthma | 2.667 × 10−4 | −8.832 × 10−4 |
| Immunosuppressive medication | 2.164 × 10−4 | 1.407 × 10−4 |
| At risk of serious illness from COVID-19 | 1.472 × 10−4 | 1.447 × 10−4 |
| Cares for others outside the household | 6.645 × 10−5 | −0.005 |
| Sex | −3.437 × 10−4 | −0.002 |
| No immunosuppressive treatment | −5.427 × 10−4 | 6.861 × 10−4 |
| Number of cigarettes smoked per day | −0.001 | −8.703 × 10−4 |
| Cares for others within household | −0.001 | −7.602 × 10−4 |
| Had a COVID-19 vaccine | −0.002 | 0.001 |
| Total Increase in Node Purity | Node Purity Rank in Main Analysis | |
|---|---|---|
| Timing of acute COVID-19 infection | 0.016 | 1 |
| Age | 0.009 | 5 |
| Number of hours worked per week | 0.005 | 4 |
| Financial security in next 3 months | 0.005 | 6 |
| Feels lonely often | 0.004 | 2 |
| Had a COVID-19 vaccine | 0.004 | 28 |
| Hypertension | 0.004 | 11 |
| Common chronic health condition | 0.003 | 12 |
| Job security in next 12 months | 0.001 | 7 |
| Asthma | 0.001 | 21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Machado, R.; Soorinarain Dodhy, R.; Sehgal, A.; Rattigan, K.; Lalwani, A.; Waynforth, D. A Machine Learning Approach to Identifying Risk Factors for Long COVID-19. Algorithms 2024, 17, 485. https://doi.org/10.3390/a17110485
Machado R, Soorinarain Dodhy R, Sehgal A, Rattigan K, Lalwani A, Waynforth D. A Machine Learning Approach to Identifying Risk Factors for Long COVID-19. Algorithms. 2024; 17(11):485. https://doi.org/10.3390/a17110485
Chicago/Turabian StyleMachado, Rhea, Reshen Soorinarain Dodhy, Atharve Sehgal, Kate Rattigan, Aparna Lalwani, and David Waynforth. 2024. "A Machine Learning Approach to Identifying Risk Factors for Long COVID-19" Algorithms 17, no. 11: 485. https://doi.org/10.3390/a17110485
APA StyleMachado, R., Soorinarain Dodhy, R., Sehgal, A., Rattigan, K., Lalwani, A., & Waynforth, D. (2024). A Machine Learning Approach to Identifying Risk Factors for Long COVID-19. Algorithms, 17(11), 485. https://doi.org/10.3390/a17110485