
On the Estimation of Logistic Models with Banking Data Using Particle Swarm Optimization



Abstract
1. Introduction
2. Logistic Models Review
2.1. Verhulst Model
2.2. Pearl and Reed Generalization Model
2.3. Von Bertalanffy Model
2.4. Richards Model
2.5. Gompertz Model
2.6. Hyper-Gompertz Model
2.7. Blumberg Model
2.8. Turner et al. Model
2.9. Tsoularis Model
3. Particle Swarm Optimization
| Algorithm 1 PSO Algorithm |
|
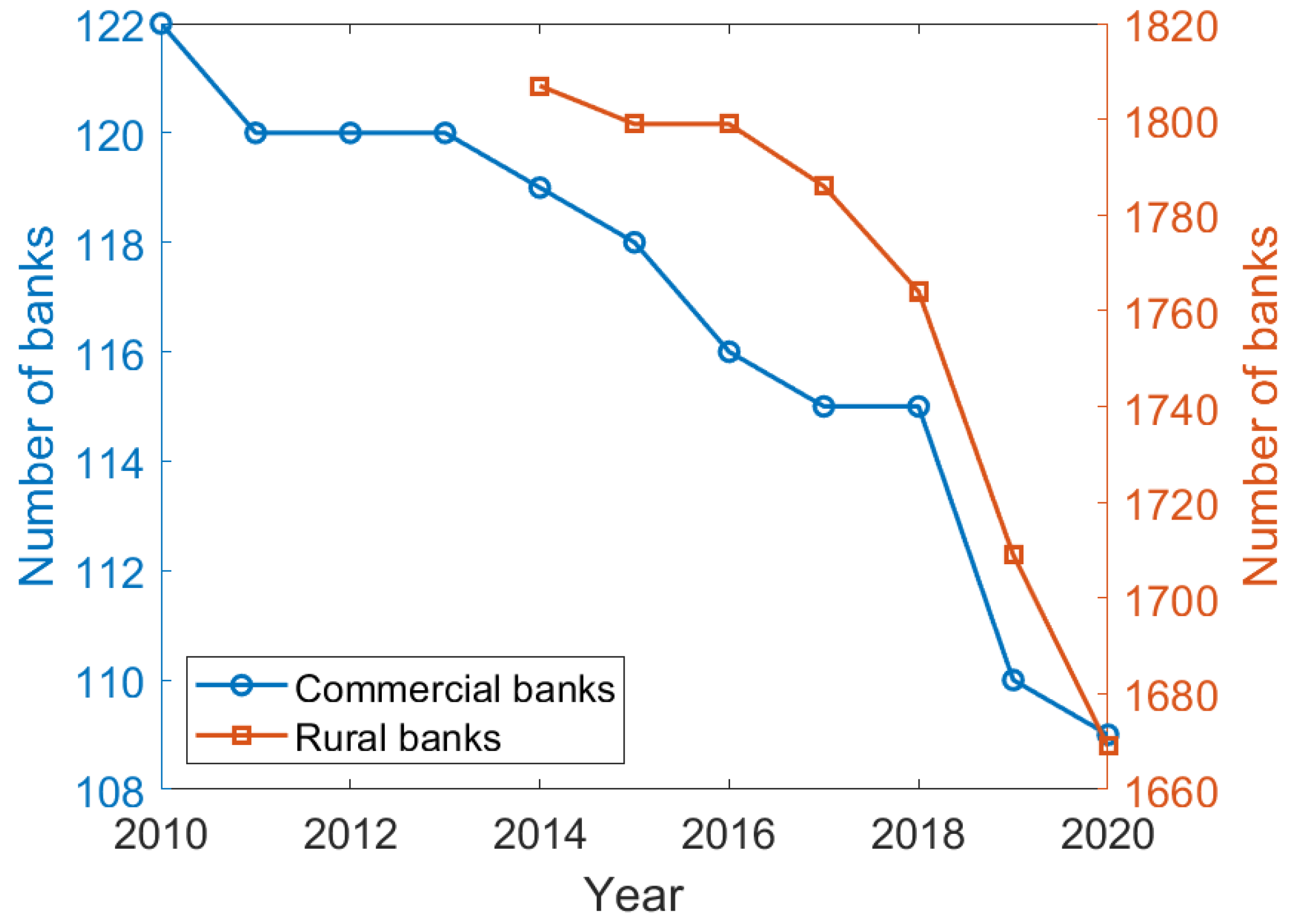
4. Implementation
5. Numerical Results
6. Benchmarking with Spiral Optimization Algorithm
7. Tuning PSO Parameters
8. New Logistic Model
9. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| PSO | Particle Swarm Optimization |
| MAPE | Mean Absolute Percentage Error |
| RMSE | Root Mean Square Error |
References
- Pearl, R.; Reed, L.J. On the rate of growth of the population of the United States since 1790 and its mathematical representation. Proc. Nat. Acad. Sci. USA 1920, 6, 275–288. [Google Scholar] [CrossRef] [PubMed]
- Pearl, R.; Reed, L.J. A further note on the mathematical theory of population growth. Proc. Nat. Acad. Sci. USA 1922, 8, 365–368. [Google Scholar] [CrossRef]
- Fekedulegn, D.; Siurtain, M.P.M.; Colbert, J.J. Parameter Estimation of Nonlinear Growth Models in Forestry. Silva Fenn. 1999, 33, 327–336. [Google Scholar] [CrossRef]
- McKendrick, A.G.; Pai, M.K. The Rate of Multiplication of Micro-organisms: A Mathematical study. Proc. R. Soc. Edinb. 1911, 31, 649–655. [Google Scholar] [CrossRef]
- Sanders, M.J. A Simple Method for Estimating the von Bertalanffy Growth Constants for Determining Length from Age and Age from Length. In Length-Based Methods in Fisheries Research; Pauly, D., Morgan, G.R., Eds.; International Center for Living Aquatic Resources Management Kuwait Institut for Scientific Research: Manila, Philippines, 1987. [Google Scholar]
- Windarto, W.; Eridani, E.; Purwati, U.D. A new modified logistic growth model for empirical use. Commun. Biomath. Sci. 2018, 1, 122–131. [Google Scholar] [CrossRef]
- Nuraini, N.; Khairudin, K.; Apri, M. Modeling Simulation of COVID-19 in Indonesia Based on Early Endemic Data. Commun. Biomath. Sci. 2020, 3, 1–8. [Google Scholar] [CrossRef]
- Rozema, E. Epidemic models for SARS and measles. Coll. Math. J. 2007, 38, 246–259. [Google Scholar] [CrossRef]
- Sumarti, N.; Fadhlurrahman, A.; Widyani, H.R.; Gunadi, I. The Dynamical System of the Deposit and Loan Volumes of a Commercial Bank Containing Interbank Lending and Saving Factors. Southeast Asian Bull. Math. 2018, 42, 757–772. [Google Scholar]
- Ansori, M.F.; Sidarto, K.A.; Sumarti, N. Model of deposit and loan of a bank using spiral optimization algorithm. J. Indones. Math. Soc. 2019, 25, 292–301. [Google Scholar] [CrossRef]
- Ansori, M.F.; Sidarto, K.A.; Sumarti, N. Logistic models of deposit and loan between two banks with saving and debt transfer factors. In Proceedings of the 8th SEAMS-UGM International Conference on Mathematics and Its Applications 2019, Yogyakarta, Indonesia, 29 July–1 August 2019; Utami, H., Kusumo, F.A., Susyanto, N., Susanti, Y., Eds.; AIP Publishing: Melville, NY, USA, 2019; Volume 2192, p. 060002. [Google Scholar] [CrossRef]
- Ansori, M.F.; Sidarto, K.A.; Sumarti, N.; Gunadi, I. Dynamics of Bank’s Balance Sheet: A System of Deterministic and Stochastic Differential Equations Approach. Int. J. Math. Comput. Sci. 2021, 16, 871–884. [Google Scholar]
- Pastijn, H. Chaotic Growth with the Logistic Model of P.-F. Verhulst. In The Logistic Map and the Route to Chaos: From The Beginnings to Modern Applications; Ausloos, M., Dirickx, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 3–11. [Google Scholar] [CrossRef]
- von Bertalanffy, L. A quantitative theory of organic growth (Inquiries on growth laws. II). Hum. Biol. 1938, 10, 181–213. [Google Scholar]
- von Bertalanffy, L. Quantitative Laws in Metabolism and Growth. Q. Rev. Biol. 1957, 32, 217–231. [Google Scholar] [CrossRef] [PubMed]
- Richards, F.J. A Flexible Growth Function for Empirical Use. J. Exp. Bot. 1959, 10, 290–301. [Google Scholar] [CrossRef]
- Blumberg, A.A. Logistic growth rate functions. J. Theor. Biol. 1968, 21, 42–44. [Google Scholar] [CrossRef]
- Turner, M.E.; Bradley, E.L.; Kirk, K.A.; Pruitt, K.M. A theory of growth. Math. Biosci. 1976, 29, 367–373. [Google Scholar] [CrossRef]
- Tsoularis, A.; Wallace, J. Analysis of Logistic Growth Models. Math. Biosci. 2002, 2, 21–55. [Google Scholar] [CrossRef]
- Gompertz, B. On the Nature of the Function Expressive of the Law of Human Mortality, and on a New Mode of Determining the Value of Life Contingencies. Philos. Trans. R. Soc. Lond. 1825, 2, 513–583. [Google Scholar] [CrossRef]
- Ma, Y.; Paligorova, T.; Peydro, J.L. Expectations and Bank Lending; Unpublished Working Paper; University of Chicago: Chicago, IL, USA, 2021. [Google Scholar]
- Heckmann-Draisbach, L.; Memmel, C. How good are banks’ forecasts? Int. Rev. Financ. Anal. 2024, 95, 103475. [Google Scholar] [CrossRef]
- Falato, A.; Xiao, J. Expectations and credit slumps. SSRN 2024, 4650869. [Google Scholar] [CrossRef]
- Tamura, K.; Yasuda, K. Primary Study of Spiral Dynamics Inspired Optimization. IEEJ Trans. Electr. Electron. Eng. 2011, 6, 98–100. [Google Scholar] [CrossRef]
- Tamura, K.; Yasuda, K. Spiral Dynamics Inspired Optimization. J. Adv. Comput. Intell. Intell. Inform. 2011, 15, 1116–1122. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y.; Ding, S.; Liang, D.; He, H. A novel particle swarm optimization algorithm with Lévy flight and orthogonal learning. Swarm Evol. Comput. 2022, 75, 101207. [Google Scholar] [CrossRef]
- Meng, X.; Li, H. An adaptive co-evolutionary competitive particle swarm optimizer for constrained multi-objective optimization problems. Swarm Evol. Comput. 2024, 91, 101746. [Google Scholar] [CrossRef]
- Meng, X.; Li, H. Heterogeneous pbest-guided comprehensive learning particle swarm optimization. Appl. Soft Comput. 2024, 162, 111874. [Google Scholar] [CrossRef]
- Hao, H.; Zhu, H. A self-learning particle swarm optimization for bi-level assembly scheduling of material-sensitive orders. Comput. Ind. Eng. 2024, 195, 110427. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence (Cat. No.98TH8360), Anchorage, AK, USA, 4–9 May 1998; pp. 69–73. [Google Scholar] [CrossRef]
- Byrne, D.M. The Taguchi approach to parameter design. ASQ’s Annu. Qual. Congr. Proc. 1986, 40, 168. [Google Scholar]
- Freddi, A.; Salmon, M.; Freddi, A.; Salmon, M. Introduction to the Taguchi method. In Design Principles and Methodologies: From Conceptualization to first Prototyping with Examples and Case Studies; Springer: New York, NY, USA, 2019; pp. 159–180. [Google Scholar]
- Yukalov, V.I.; Yukalova, E.P.; Sornette, D. Punctuated evolution due to delayed carrying capacity. Phys. D Nonlinear Phenom. 2009, 238, 1752–1767. [Google Scholar] [CrossRef]
- Turner, M.E.; Blumenstein, B.A.; Sebaugh, J.L. A Generalization of the Logistic Law of Growth. Biometrics 1969, 25, 577–580. [Google Scholar] [CrossRef]
- Nelder, J.A. The Fitting of a Generalization of the Logistic Curve. Biometrics 1961, 17, 89–110. [Google Scholar] [CrossRef]
- Brownlee, J. Clever Algorithms: Nature-Inspired Programming Recipes, 1st ed.; Lulu.com: Morrisville, NC, USA, 2011. [Google Scholar]
- Bhandari, V.S.; Kulkarni, S.H. Optimization of heat sink for thyristor using particle swarm optimization. Results Eng. 2019, 4, 100034. [Google Scholar] [CrossRef]
- Cai, X.; Gao, L.; Li, F. Sequential approximation optimization assisted particle swarm optimization for expensive problems. Appl. Soft Comput. 2019, 83, 105659. [Google Scholar] [CrossRef]
- Josaphat, B.P.; Ansori, M.F.; Syuhada, K. On Optimization of Copula-Based Extended Tail Value-at-Risk and Its Application in Energy Risk. IEEE Access 2021, 9, 122474–122485. [Google Scholar] [CrossRef]
- Aroniadi, C.; Beligiannis, G.N. Applying Particle Swarm Optimization Variations to Solve the Transportation Problem Effectively. Algorithms 2023, 16, 372. [Google Scholar] [CrossRef]
- Shafeek, Y.A.; Ali, H.I. Application of Particle Swarm Optimization to a Hybrid H∞/Sliding Mode Controller Design for the Triple Inverted Pendulum System. Algorithms 2024, 17, 427. [Google Scholar] [CrossRef]
- Azami, P.; Passi, K. Detecting Fake Accounts on Instagram Using Machine Learning and Hybrid Optimization Algorithms. Algorithms 2024, 17, 425. [Google Scholar] [CrossRef]
- Panagiotakis, C. Particle Swarm Optimization-Based Unconstrained Polygonal Fitting of 2D Shapes. Algorithms 2024, 17, 25. [Google Scholar] [CrossRef]
- Kannan, S.K.; Diwekar, U. An Enhanced Particle Swarm Optimization (PSO) Algorithm Employing Quasi-Random Numbers. Algorithms 2024, 17, 195. [Google Scholar] [CrossRef]
- Capel, M.I.; Salguero-Hidalgo, A.; Holgado-Terriza, J.A. Parallel PSO for Efficient Neural Network Training Using GPGPU and Apache Spark in Edge Computing Sets. Algorithms 2024, 17, 378. [Google Scholar] [CrossRef]
- Sulaiman, A.T.; Bello-Salau, H.; Onumanyi, A.J.; Mu’azu, M.B.; Adedokun, E.A.; Salawudeen, A.T.; Adekale, A.D. A Particle Swarm and Smell Agent-Based Hybrid Algorithm for Enhanced Optimization. Algorithms 2024, 17, 53. [Google Scholar] [CrossRef]
- Bartle, R.G.; Sherbert, D.R. Introduction to Real Analysis, 3rd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2000. [Google Scholar]
- Wang, W.; Chen, Y.; Yang, C.; Li, Y.; Xu, B.; Xiang, C. An enhanced hypotrochoid spiral optimization algorithm based intertwined optimal sizing and control strategy of a hybrid electric air-ground vehicle. Energy 2022, 257, 124749. [Google Scholar] [CrossRef]
- Sumarti, N.; Sidarto, K.A.; Kania, A.; Edriani, T.S.; Aditya, Y. A method for finding numerical solutions to Diophantine equations using Spiral Optimization Algorithm with Clustering (SOAC). Appl. Soft Comput. 2023, 145, 110569. [Google Scholar] [CrossRef]
- Fauzi, I.S. Developing Insurance Mathematical Model to Assess Economic Burden of Dengue Outbreaks. J. Nonlinear Model. Anal. 2024, 6, 693. [Google Scholar] [CrossRef]
- Fauzi, I.S.; Nuraini, N.; Sari, A.M.; Wardani, I.B.; Taurustiati, D.; Simanullang, P.M.; Lestari, B.W. Assessing the impact of booster vaccination on diphtheria transmission: Mathematical modeling and risk zone mapping. Infect. Dis. Model. 2024, 9, 245–262. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.R.; Ali, S.M.; Fathollahi-Fard, A.M.; Kabir, G. A novel particle swarm optimization-based grey model for the prediction of warehouse performance. J. Comput. Des. Eng. 2021, 8, 705–727. [Google Scholar] [CrossRef]
- Wang, H.; Geng, Q.; Qiao, Z. Parameter tuning of particle swarm optimization by using Taguchi method and its application to motor design. In Proceedings of the 2014 4th IEEE International Conference on Information Science and Technology, Shenzhen, China, 26–28 April 2014; pp. 722–726. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rough K for Com. Bank | Rough K for Rural Bank | |||
|---|---|---|---|---|
| 0 | 71/12 | 142/12 | 12,431,437 | 206,126 |
| 2/12 | 71/12 | 140/12 | 12,022,655 | 199,172 |
| 4/12 | 71/12 | 138/12 | 11,342,372 | 200,580 |
| 1/12 | 72/12 | 143/12 | 14,254,951 | 215,716 |
| 3/12 | 72/12 | 141/12 | 13,313,955 | 204,998 |
| 5/12 | 72/12 | 139/12 | 12,619,803 | 204,283 |
| Parameter | The Search Space |
|---|---|
| for Pearl–Reed generalization model | |
| r for Verhulst, Richards, Gompertz, hyper-Gompertz, Blumberg, Turner et al., and Tsoularis models | |
| r for von Bertalanffy model | |
| for Richards, Turner et al., and Tsoularis models | |
| for Blumberg and Tsoularis models | |
| for hyper-Gompertz model | |
| for Blumberg, Turner et al., and Tsoularis models |
| K | Stop | MAPE t. | MAPE v. | RMSE t. | RMSE v. | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P-R | 0.1375 | 0.0156 | 4.28 × | 8,228,341 | 62 | 7.33 | 5,114,283 | 1.68% | 5.78% | 101,902 | 489,191 | |
| r | ||||||||||||
| V | 0.1844 | 15,071,474 | 25 | 11.22 | 7,535,737 | 3.06% | 2.29% | 139,536 | 203,508 | |||
| vB | 29.3160 | 142,549,510 | 25 | 44.89 | 42,236,895 | 4.21% | 1.93% | 174,153 | 181,636 | |||
| R | 0.6557 | 4.2911 | 8,255,810 | 42 | 8.16 | 5,599,424 | 2.45% | 4.82% | 113,273 | 412,614 | ||
| G | 0.0431 | 86,377,000 | 27 | 31.76 | 31,776,323 | 3.50% | 5.77% | 163,688 | 491,075 | |||
| hG | 0.0432 | 1 | 85,794,137 | 115 | 31.70 | 31,561,899 | 3.11% | 4.67% | 160,263 | 402,819 | ||
| B | 0.0718 | 1.0683 | 4.7342 | 48,868,588 | 66 | 13.17 | 8,997,285 | 3.07% | 3.33% | 142,053 | 287,811 | |
| Tu | 0.2014 | 2.6711 | 1.0062 | 946,0970 | 150 | 8.54 | 5,778,078 | 2.62% | 2.07% | 118,677 | 182,535 | |
| Ts | 0.5401 | 2.9998 | 0.9158 | 3.0812 | 13,585,176 | 150 | 14.08 | 6,091,104 | 2.77% | 0.52% | 122,988 | 55,416 |
| K | Stop | MAPE t. | MAPE v. | RMSE t. | RMSE v. | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P-R | 0.1838 | 0.0080 | 4.00 | 162,036 | 57 | 8.42 | 94,498 | 1.34% | 2.57% | 961 | 4655 | |
| r | ||||||||||||
| V | 0.2052 | 259,816 | 24 | 11.28 | 129,908 | 2.16% | 2.82% | 1587 | 4180 | |||
| vB | 8.3632 | 2,157,160 | 26 | 38.58 | 612,388 | 4.16% | 0.72% | 2597 | 1274 | |||
| R | 0.5296 | 3.0127 | 153,790 | 74 | 8.63 | 96,968 | 1.57% | 2.97% | 1086 | 5291 | ||
| G | 0.0443 | 1,919,658 | 24 | 33.49 | 706,203 | 2.73% | 7.20% | 2339 | 10,268 | |||
| hG | 0.0447 | 1 | 1,872,938 | 146 | 33.09 | 689,016 | 2.38% | 6.51% | 2131 | 9299 | ||
| B | 0.0878 | 1.0875 | 4.2360 | 712,615 | 64 | 12.33 | 145,580 | 2.12% | 3.69% | 1656 | 5337 | |
| Tu | 0.2165 | 2.4256 | 1.0072 | 166,654 | 150 | 8.86 | 99,583 | 1.66% | 1.74% | 1111 | 3475 | |
| Ts | 0.2477 | 4.3027 | 0.9657 | 4.6135 | 195,562 | 150 | 13.75 | 95,839 | 1.58% | 2.92% | 1117 | 5159 |
| Algorithm | Tsoularis Model for Commercial Banks Data | Verhulst Model for Rural Banks Data | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MAPE t. | MAPE v. | MAPE t. | MAPE v. | ||||||||
| SpO | 0.8027 | 2.1869 | 0.8894 | 3.4229 | 20,757,461 | 3.04% | 2.98% | 0.2043 | 264,499 | 2.17% | 3.24% |
| PSO | 0.5401 | 2.9998 | 0.9158 | 3.0812 | 13,585,176 | 2.77% | 0.52% | 0.2052 | 259,816 | 2.16% | 2.82% |
| PSO’s Parameter | Level 1 | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|---|
| Number of particles (m) | 10 | 50 | 100 | 200 | 300 |
| Weighted coefficient () | 0.5 | 1 | 1.5 | 2 | 2.5 |
| Weighted coefficient () | 0.5 | 1 | 1.5 | 2 | 2.5 |
| Inertia weight (w) | 1 | 2 | 3 | 4 | 5 |
| Maximum iteration () | 25 | 50 | 75 | 100 | 150 |
| Case Data | New Model | Tsoularis Model | Verhulst Model |
|---|---|---|---|
| Commercial banks | MAPE t. MAPE v. | MAPE t. MAPE v. | None |
| Rural banks | MAPE t. MAPE v. | None | MAPE t. MAPE v. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ansori, M.F.; Sidarto, K.A.; Sumarti, N.; Gunadi, I. On the Estimation of Logistic Models with Banking Data Using Particle Swarm Optimization. Algorithms 2024, 17, 507. https://doi.org/10.3390/a17110507
Ansori MF, Sidarto KA, Sumarti N, Gunadi I. On the Estimation of Logistic Models with Banking Data Using Particle Swarm Optimization. Algorithms. 2024; 17(11):507. https://doi.org/10.3390/a17110507
Chicago/Turabian StyleAnsori, Moch. Fandi, Kuntjoro Adji Sidarto, Novriana Sumarti, and Iman Gunadi. 2024. "On the Estimation of Logistic Models with Banking Data Using Particle Swarm Optimization" Algorithms 17, no. 11: 507. https://doi.org/10.3390/a17110507
APA StyleAnsori, M. F., Sidarto, K. A., Sumarti, N., & Gunadi, I. (2024). On the Estimation of Logistic Models with Banking Data Using Particle Swarm Optimization. Algorithms, 17(11), 507. https://doi.org/10.3390/a17110507