


Transfer Reinforcement Learning for Combinatorial Optimization Problems

 ,
,  , , , and
, , , and 
Abstract
:1. Introduction
- A transfer reinforcement learning approach between two classical combinatorial optimization problems. The asymmetric traveling salesman problem is the source domain, and the sequential ordering problem is the objective domain.
- Apply transfer learning to these problems and statistically analyze the results obtained with the transfer.
- Develop a new AutoRL algorithm, apply it to the problems studied and analyze its results.
2. Background
2.1. Reinforcement Learning
- (i)
- Perceive the current state (s);
- (ii)
- Perform an action (a);
- (iii)
- Receive a reward ().
| Algorithm 1: SARSA algorithm | |
| 1 | Set the parameters: |
| 2 | In each s,a do Q(s,a) = 0 |
| 3 | Observe the state s |
| 4 | Select action a using policy -greedy |
| 5 | do |
| 6 | Run the action a |
| 7 | Receive the immediate reward r(s,a) |
| 8 | Observe the new state s′ |
| 9 | Select action a′ using policy -greedy |
| 10 | |
| 11 | s = s′ |
| 12 | a = a′ |
| 13 | while the stop criterion is satisfied; |
2.2. Combinatorial Optimization
- Decision variables are the criteria that will be manipulated in the search for the optimal solution.
- The objective function is the function that contains the decision variables that will be altered during the search for the best solution to the problem. It should be noted that every combinatorial optimization issue has at least one objective function.
- Restrictions are conditions imposed on the problem to ensure that the solution found is feasible. It is important to note that it is not mandatory for a problem to have constraints, in which case all solutions are considered feasible.
- The traveling salesman problem;
- The knapsack problem;
- The sequential ordering problem;
- The quadratic assignment problem.
2.3. Traveling Salesman Problem
- Task sequencing;
- Drilling printed circuit boards;
- Analysis of crystal structures;
- Handling of stock items;
- Optimizing the movement of cutting tools;
- Postal delivery routing.
Formulation
2.4. Sequential Ordering Problem
2.5. Automated Machine Learning
2.6. Transfer Learning
3. Methodology
- Problems with the same objective function: The objective function is a main characteristic of the mathematical modeling of a combinatorial optimization problem. This was a relevant criterion in deciding the two problems evaluated in this paper (the ATSP and SOP), considering that both aim to minimize the distance of a route.
- Similar datasets: The similarity between datasets can be assessed through the analysis of metafeatures, such as by performing descriptive statistics [12]. In this paper, the simulated domains have instances in the TSPLIB library. Furthermore, the instances selected for the target problem (SOP) originate from the source domain (ATSP), adding some variations such as precedence restrictions. These characteristics reinforce the similarities across the evaluated datasets.
- Transfer from the simpler domain to the more complex domain: This point reflects the relevance of decreasing the computational cost in the objective problem while promoting accelerated learning and advancing performance in the best solution. In this paper, the ATSP is the source domain (simplest), and the SOP is the objective domain (more complex), as the second problem adds precedence restrictions.
3.1. Dataset
- The symmetric traveling salesman problem: the cost of traveling between two nodes is the same, regardless of the direction of travel;
- The asymmetric traveling salesman problem: the cost of traveling between two nodes depends on the direction of travel;
- The sequential ordering problem: this problem has precedence restrictions and also considers that the cost of traveling between two nodes depends on the direction adopted for travel.
- Problem: instance name;
- Nodes: number of nodes in the problem;
- Best known solution: the best known value presented by TSPLIB.
3.2. Reinforcement Learning Model
- States are the locations that must be visited to form the route. Thus, the number of states varies according to the number of nodes (N) in the instance.
- Actions represent the possible movements between locations (states). The initial number of actions is equivalent to the number of states in the model. However, the actions available for execution vary according to the cities already visited when developing the route.
- Reinforcements are the cost of travel () between the departure city (i) and the destination city (j), given as a function of the cost of travel (). The greater the distance between the nodes, the more negative the reinforcement will be, according to Equation (9):
| Algorithm 2: Algorithm for analyzing precedence restrictions in the selection of actions from RL to SOP (RLSOP) [37] | |
| 1 | a_t = e-greedy(); |
| 2 | cont = 0; |
| 3 | while cont == 0 do |
| 4 | if there are precedence restrictions for the selected action then |
| 5 | if at least one action corresponding to the precedence constraints of a_t has not yet been selected then |
| 6 | cont = 0; |
| 7 | else |
| 8 | cont = 1; |
| 9 | end |
| 10 | end |
| 11 | if cont == 0 then |
| 12 | remove the action a_t from the list of available actions at time t; |
| 13 | a_t = e-greedy(); |
| 14 | end |
| 15 | end |
| 16 | Return to_t; |
3.3. Transfer Learning Approach
- Generation of the knowledge base;
- Experiments for transfer learning;
- Elaboration of the methodology for analysis.
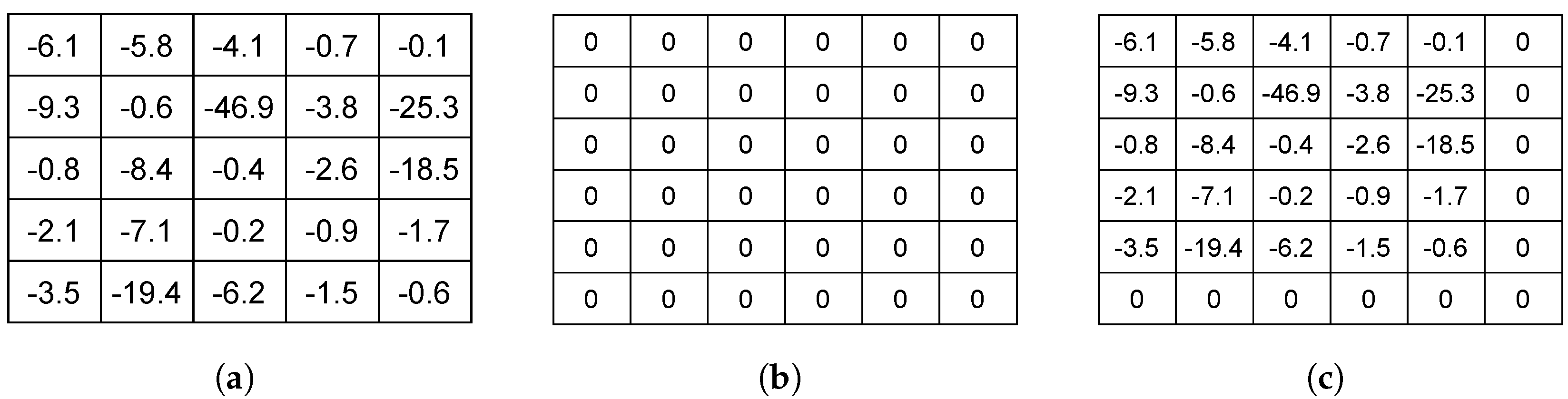
3.3.1. Generation of the Knowledge Base
3.3.2. Experiments for Transfer Learning
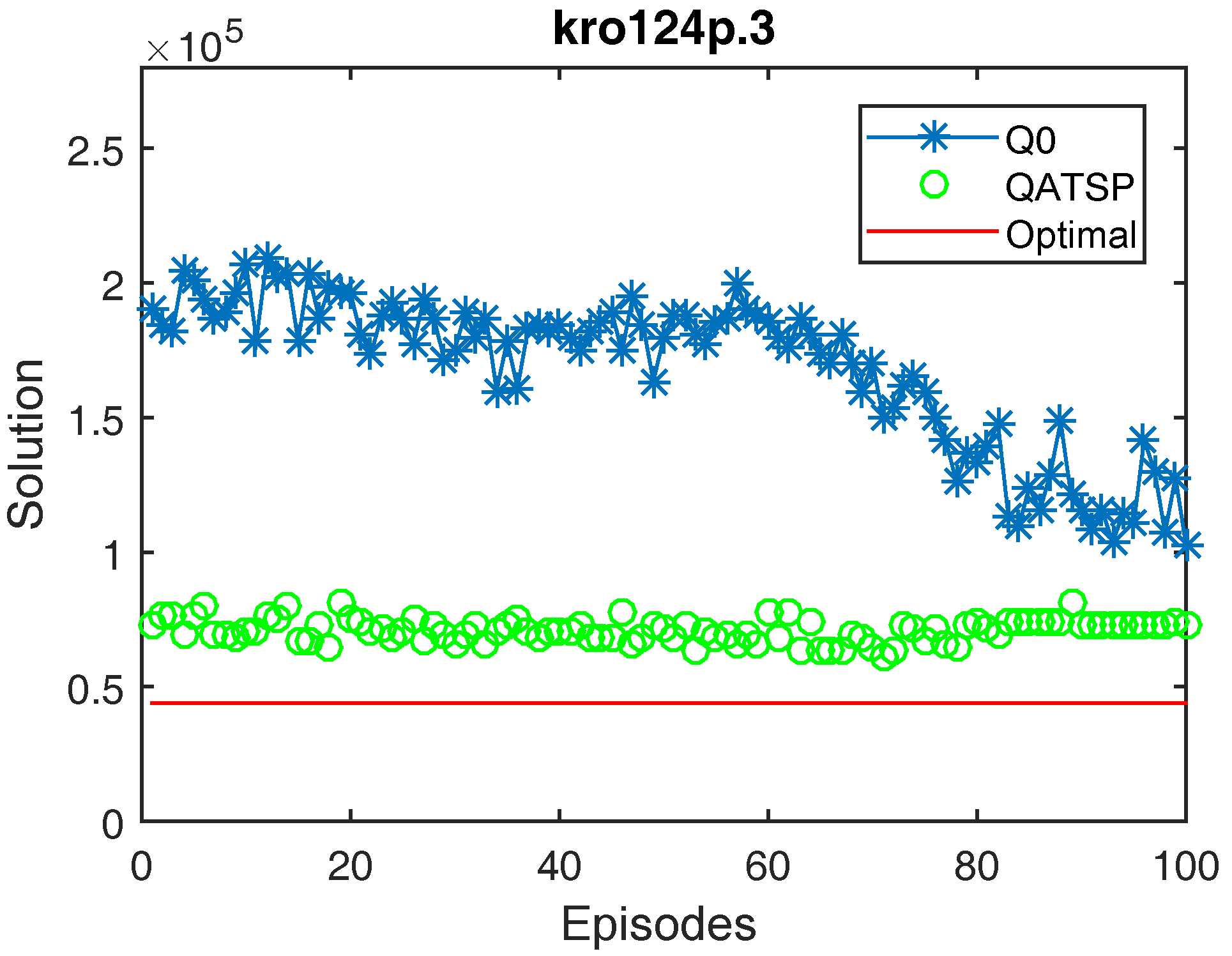
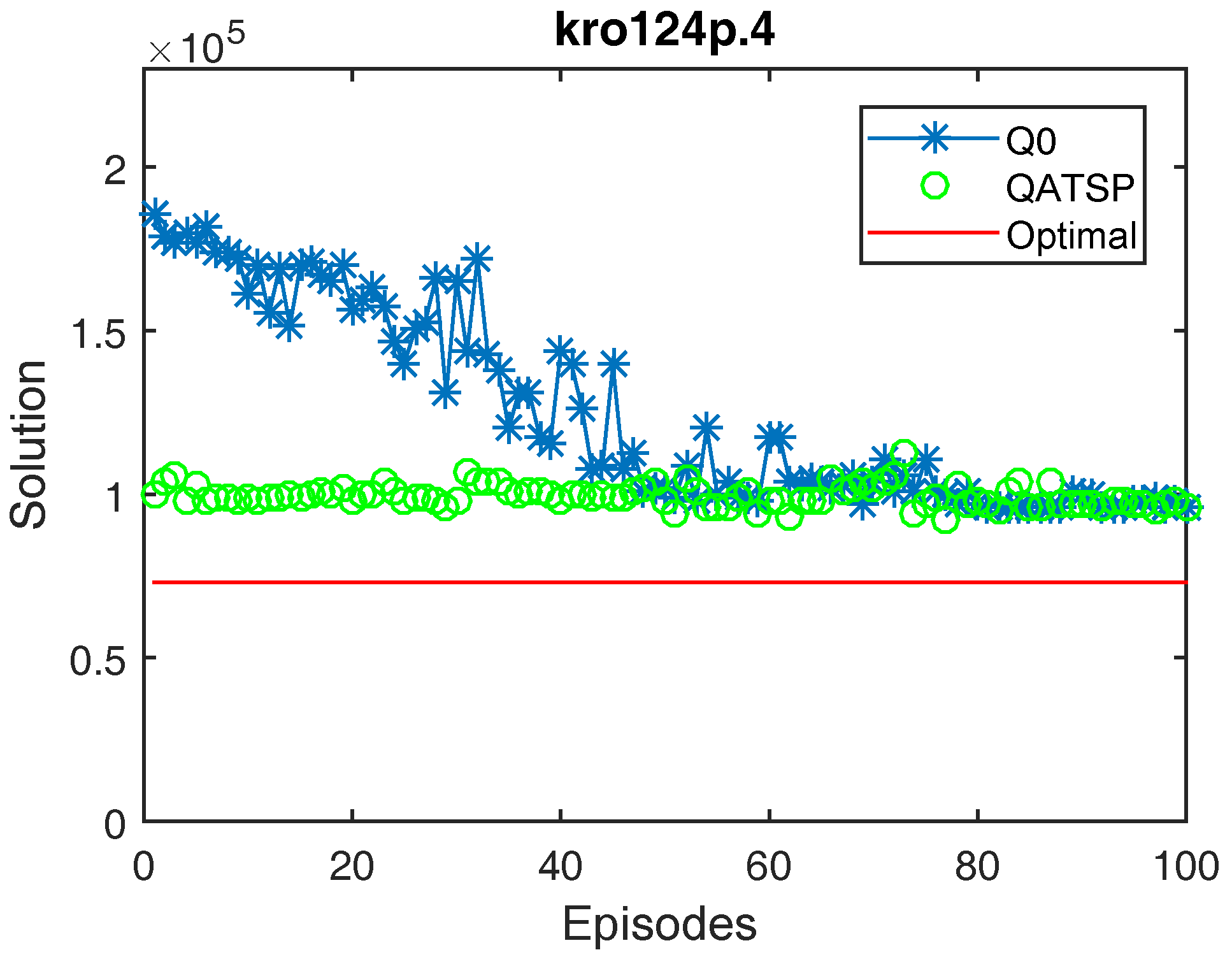
- Q0, meaning without transfer learning. The learning matrix was initialized with all null values.
- The QATSP, adopting the knowledge base generated from the experiments with the source domain (ATSP).
3.3.3. Analysis Methodology
- (i)
- Preliminary analysis;
- (ii)
- Computational time analysis;
- (iii)
- Results visualization and interpretation.
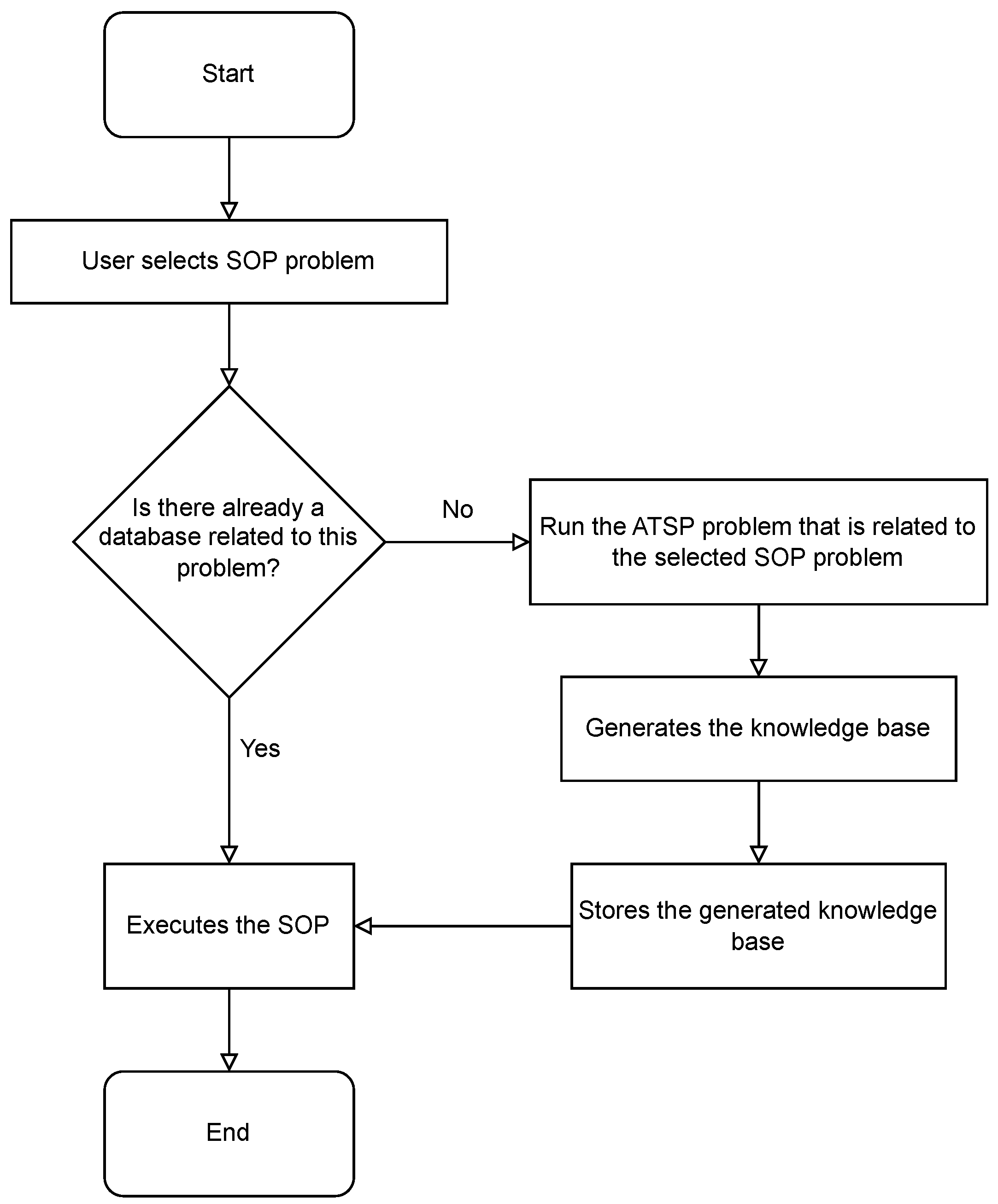
3.4. Automated Transfer Reinforcement Learning Method
- A new automated transfer reinforcement learning algorithm (Auto_TL_RL).
- Automated transfer reinforcement learning experiments.
3.4.1. Automated Transfer Reinforcement Learning Algorithm (Auto_TL_RL)
| Algorithm 3: Auto_TL_RL Algorithm | |
| 1 | Specify the SOP instance to be executed |
| 2 | Extract the size of the SOP instance |
| 3 | Set the parameter: |
| 4 | Set the number of episodes: 1000 |
| Stage 1 | |
| 5 | Checking the existence of the knowledge base |
| Stage 2 | |
| 6 | Specify the ATSP instance that will be executed |
| 7 | Extract the size of the ATSP instance |
| 8 | Set the parameters: and |
| 9 | Set the number of epochs: 5 |
| 10 | foreach ∈ do |
| 11 | foreach ∈ do |
| 12 | for epoch to numberEpochs do |
| 13 | SARSA(, , sizeOfInstance) |
| 14 | end |
| 15 | end |
| 16 | end |
| 17 | Stores the database generated |
| Stage 3 | |
| 18 | Set the parameters: and |
| 19 | Set the number of epochs: 10 |
| 20 | for epoch to numberEpochs do |
| 21 | SARSA(, , sizeOfInstance) |
| 22 | end |
3.4.2. Automated Transfer Reinforcement Learning Experiments
4. Results
4.1. Results of Preliminary Analysis
4.1.1. Preliminary Analysis
4.1.2. Computational Time Analysis
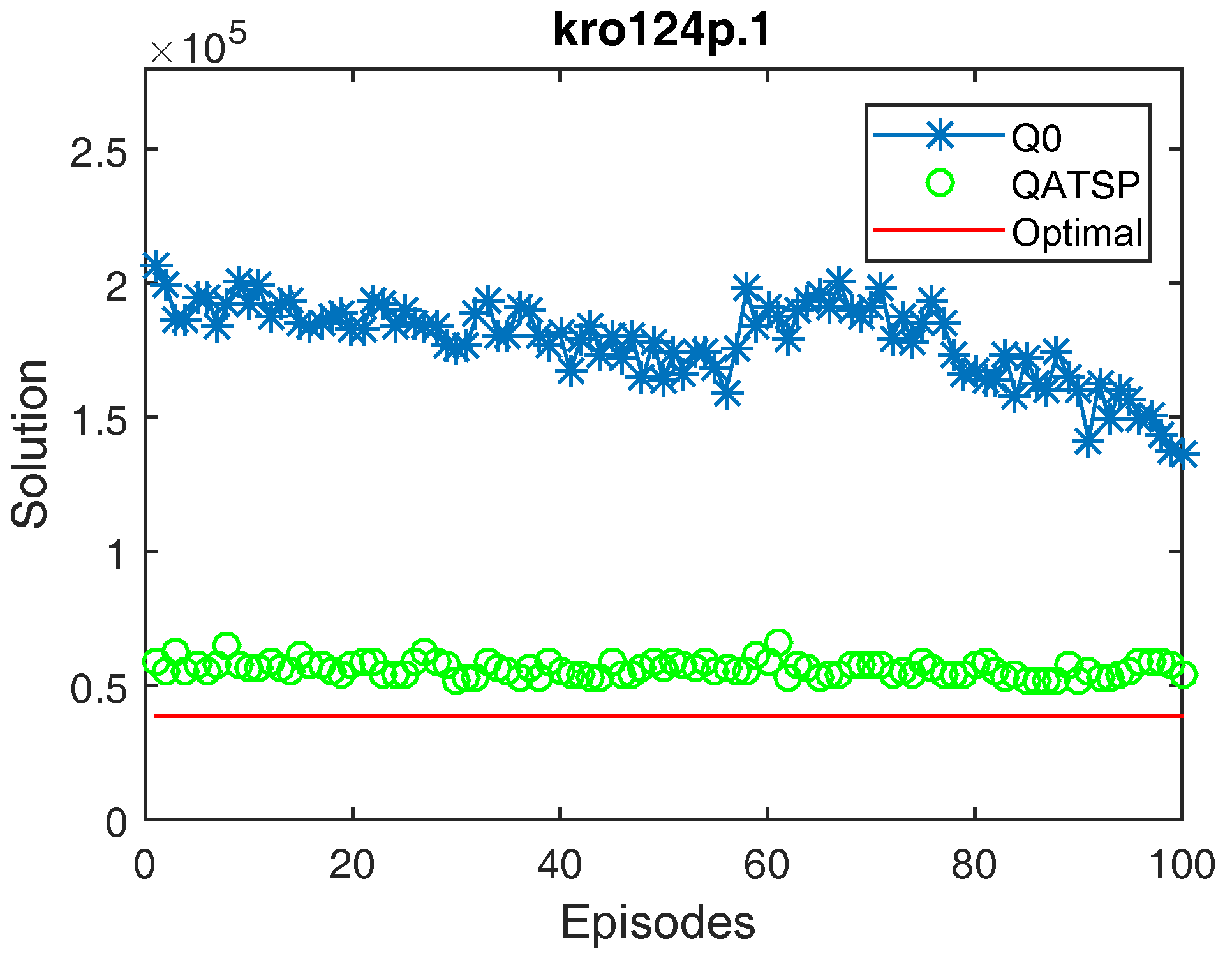
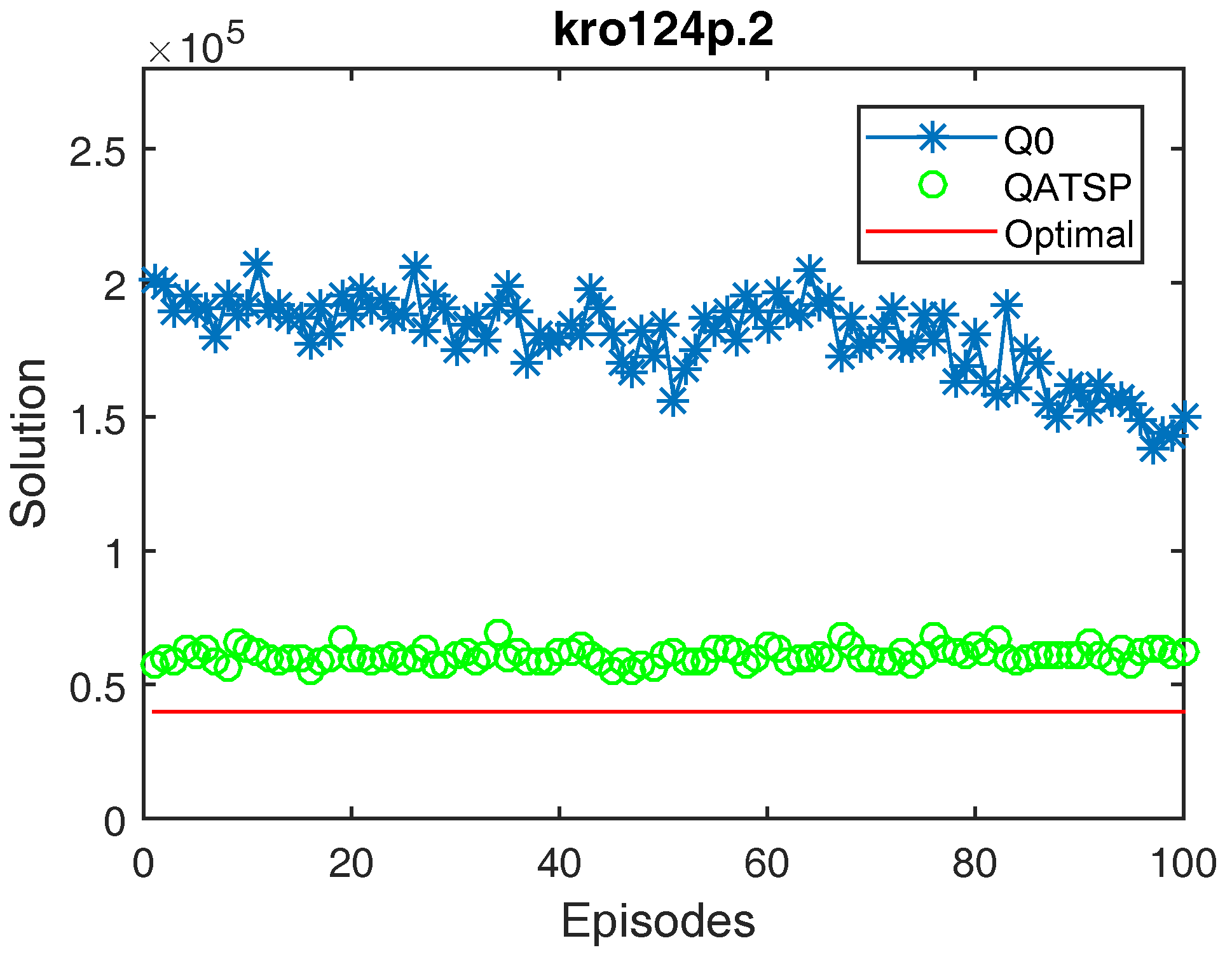
4.1.3. Results Visualization and Interpretation
4.2. Results of Automated Transfer Learning
5. Comparison with Other Studies
6. Conclusions
- Results visualization and interpretation of the impact on the final route distance results obtained with the transfer of learning between classical combinatorial optimization problems;
- Statistical analysis of the impact on the computational time and route distance results obtained by applying learning transfer between combinatorial optimization problems;
- Development of a methodology for learning transfer from the source domain (ATSP) to the target domain (SOP);
- Proposal of a methodology to perform learning transfer in an automated way;
- Proposal of an AutoML algorithm for transfer learning applied to combinatorial optimization problems with reinforcement learning.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Reinforcement learning | |
| Machine learning | |
| Automated machine learning | |
| Automated reinforcement learning | |
| Transfer learning | |
| Traveling salesman problem | |
| Asymmetric traveling salesman problem | |
| Sequential ordering problem | |
| Traveling Salesman Problem Library | |
| automated transfer reinforcement learning algorithm | |
| Markov decision processes | |
| S | State |
| s | Current state |
| New state | |
| A | Action |
| a | Current action |
| New action | |
| R | Reinforcements |
| T | State transition model |
| t | Statistical test |
| Q | Learning matrix |
| Learning matrix at the current time | |
| Learning matrix at a future time | |
| Distance calculated in the initial episode | |
| Distance in the final episode | |
| Smallest solution found | |
| Matrix started with null values | |
| Matrix from ATSP instance | |
| Cost between cities i and j | |
| State–action–reward–state–action | |
| N | Number of nodes |
| Kolmogorov–Smirnov |
References
- Ghanem, M.C.; Chen, T.M.; Nepomuceno, E.G. Hierarchical reinforcement learning for efficient and effective automated penetration testing of large networks. J. Intell. Inf. Syst. 2023, 60, 281–303. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Technical note Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Russell, S.J.; Norving, P. Artificial Intelligence, 3rd ed.; Pearson: Upper Saddle River, NJ, USA, 2013. [Google Scholar]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Vazquez-Canteli, J.R.; Nagy, Z. Reinforcement learning for demand response: A review of algorithms and modeling techniques. Appl. Energy 2019, 235, 1072–1089. [Google Scholar] [CrossRef]
- Mazyavkina, N.; Sviridov, S.; Ivanov, S.; Burnaev, E. Reinforcement learning for combinatorial optimization: A survey. Comput. Oper. Res. 2021, 134, 105400. [Google Scholar] [CrossRef]
- Ruiz-Serra, J.; Harré, M.S. Inverse Reinforcement Learning as the Algorithmic Basis for Theory of Mind: Current Methods and Open Problems. Algorithms 2023, 16, 68. [Google Scholar] [CrossRef]
- Deák, S.; Levine, P.; Pearlman, J.; Yang, B. Reinforcement Learning in a New Keynesian Model. Algorithms 2023, 16, 280. [Google Scholar] [CrossRef]
- Engelhardt, R.C.; Oedingen, M.; Lange, M.; Wiskott, L.; Konen, W. Iterative Oblique Decision Trees Deliver Explainable RL Models. Algorithms 2023, 16, 282. [Google Scholar] [CrossRef]
- Parker-Holder, J.; Rajan, R.; Song, X.; Biedenkapp, A.; Miao, Y.; Eimer, T.; Zhang, B.; Nguyen, V.; Calandra, R.; Faust, A.; et al. Automated Reinforcement Learning (AutoRL): A Survey and Open Problems. J. Artif. Intell. Res. 2022, 74, 517–568. [Google Scholar] [CrossRef]
- Afshar, R.R.; Zhang, Y.; Vanschoren, J.; Kaymak, U. Automated Reinforcement Learning: An Overview. arXiv 2022, arXiv:2201.05000. [Google Scholar]
- Brazdil, P.; van Rijn, J.N.; Soares, C.; Vanschoren, J. Metalearning: Applications to Automated Machine Learning and Data Mining; Springer Nature: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28, pp. 2962–2970. [Google Scholar]
- Tuggener, L.; Amirian, M.; Rombach, K.; Lorwald, S.; Varlet, A.; Westermann, C.; Stadelmann, T. Automated Machine Learning in Practice: State of the Art and Recent Results. In Proceedings of the 2019 6th Swiss Conference on Data Science (SDS), Bern, Switzerland, 14 June 2019; pp. 31–36. [Google Scholar] [CrossRef]
- Chen, L.; Hu, B.; Guan, Z.H.; Zhao, L.; Shen, X. Multiagent Meta-Reinforcement Learning for Adaptive Multipath Routing Optimization. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 5374–5386. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.; Chen, P.; Yang, H. Metalearning-Based Fault-Tolerant Control for Skid Steering Vehicles under Actuator Fault Conditions. Sensors 2022, 22, 845. [Google Scholar] [CrossRef]
- Taylor, M.E.; Stone, P. Transfer Learning for Reinforcement Learning Domains: A Survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- Carroll, J.L.; Peterson, T. Fixed vs. Dynamic Sub-Transfer in Reinforcement Learning. In Proceedings of the International Conference on Machine Learning and Applications, Las Vegas, NV, USA, 24–27 June 2002; pp. 3–8. [Google Scholar]
- Cao, Z.; Kwon, M.; Sadigh, D. Transfer Reinforcement Learning Across Homotopy Classes. IEEE Robot. Autom. Lett. 2021, 6, 2706–2713. [Google Scholar] [CrossRef]
- Peterson, T.S.; Owens, N.E.; Carroll, J.L. Towards automatic shaping in robot navigation. In Proceedings of the 2001 ICRA. IEEE International Conference on Robotics and Automation (Cat. No.01CH37164), Seoul, Republic of Korea, 21–26 May 2001; Volume 1, pp. 517–522. [Google Scholar]
- Wang, H.; Fan, S.; Song, J.; Gao, Y.; Chen, X. Reinforcement learning transfer based on subgoal discovery and subtask similarity. IEEE/CAA J. Autom. Sin. 2014, 1, 257–266. [Google Scholar]
- Tommasino, P.; Caligiore, D.; Mirolli, M.; Baldassarre, G. A Reinforcement Learning Architecture That Transfers Knowledge Between Skills When Solving Multiple Tasks. IEEE Trans. Cogn. Dev. Syst. 2019, 11, 292–317. [Google Scholar]
- Arnekvist, I.; Kragic, D.; Stork, J.A. VPE: Variational Policy Embedding for Transfer Reinforcement Learning. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 36–42. [Google Scholar]
- Gao, D.; Wang, S.; Yang, Y.; Zhang, H.; Chen, H.; Mei, X.; Chen, S.; Qiu, J. An Intelligent Control Method for Servo Motor Based on Reinforcement Learning. Algorithms 2024, 17, 14. [Google Scholar] [CrossRef]
- Hou, Y.; Ong, Y.S.; Feng, L.; Zurada, J.M. An Evolutionary Transfer Reinforcement Learning Framework for Multiagent Systems. IEEE Trans. Evol. Comput. 2017, 21, 601–615. [Google Scholar] [CrossRef]
- Da Silva, F.; Reali Costa, A. A survey on transfer learning for multiagent reinforcement learning systems. J. Artif. Intell. Res. 2019, 64, 645–703. [Google Scholar] [CrossRef]
- Cai, L.; Sun, Q.; Xu, T.; Ma, Y.; Chen, Z. Multi-AUV Collaborative Target Recognition Based on Transfer-Reinforcement Learning. IEEE Access 2020, 8, 39273–39284. [Google Scholar] [CrossRef]
- Ottoni, A.L.; Nepomuceno, E.G.; Oliveira, M.S.d.; Oliveira, D.C.d. Reinforcement learning for the traveling salesman problem with refueling. Complex Intell. Syst. 2022, 8, 2001–2015. [Google Scholar] [CrossRef]
- Gambardella, L.M.; Dorigo, M. Ant-Q: A reinforcement learning approach to the traveling salesman problem. In Proceedings of the 12th International Conference on Machine Learning, Tahoe, CA, USA, 9–12 July 1995; pp. 252–260. [Google Scholar]
- Bianchi, R.A.C.; Ribeiro, C.H.C.; Costa, A.H.R. On the relation between Ant Colony Optimization and Heuristically Accelerated Reinforcement Learning. In Proceedings of the 1st International Workshop on Hybrid Control of Autonomous System, Pasadena, CA, USA, 13 July 2009; pp. 49–55. [Google Scholar]
- Júnior, F.C.D.L.; Neto, A.D.D.; De Melo, J.D. Hybrid metaheuristics using reinforcement learning applied to salesman traveling problem. In Traveling Salesman Problem, Theory and Applications; IntechOpen: London, UK, 2010. [Google Scholar]
- Costa, M.L.; Padilha, C.A.A.; Melo, J.D.; Neto, A.D.D. Hierarchical Reinforcement Learning and Parallel Computing Applied to the k-server Problem. IEEE Lat. Am. Trans. 2016, 14, 4351–4357. [Google Scholar] [CrossRef]
- Alipour, M.M.; Razavi, S.N.; Feizi Derakhshi, M.R.; Balafar, M.A. A Hybrid Algorithm Using a Genetic Algorithm and Multiagent Reinforcement Learning Heuristic to Solve the Traveling Salesman Problem. Neural Comput. Appl. 2018, 30, 2935–2951. [Google Scholar] [CrossRef]
- Lins, R.A.S.; Dória, A.D.N.; de Melo, J.D. Deep reinforcement learning applied to the k-server problem. Expert Syst. Appl. 2019, 135, 212–218. [Google Scholar] [CrossRef]
- Carvalho Ottoni, A.L.; Geraldo Nepomuceno, E.; Santos de Oliveira, M. Development of a Pedagogical Graphical Interface for the Reinforcement Learning. IEEE Lat. Am. Trans. 2020, 18, 92–101. [Google Scholar] [CrossRef]
- Silva, M.A.L.; de Souza, S.R.; Souza, M.J.F.; Bazzan, A.L.C. A reinforcement learning-based multi-agent framework applied for solving routing and scheduling problems. Expert Syst. Appl. 2019, 131, 148–171. [Google Scholar] [CrossRef]
- Ottoni, A.L.C.; Nepomuceno, E.G.; de Oliveira, M.S.; de Oliveira, D.C.R. Tuning of Reinforcement Learning Parameters Applied to SOP Using the Scott–Knott Method. Soft Comput. 2020, 24, 4441–4453. [Google Scholar] [CrossRef]
- Escudero, L. An inexact algorithm for the sequential ordering problem. Eur. J. Oper. Res. 1988, 37, 236–249. [Google Scholar] [CrossRef]
- Gambardella, L.M.; Dorigo, M. An Ant Colony System Hybridized with a New Local Search for the Sequential Ordering Problem. Informs J. Comput. 2000, 12, 237–255. [Google Scholar] [CrossRef]
- Letchford, A.N.; Salazar-González, J.J. Stronger multi-commodity flow formulations of the (capacitated) sequential ordering problem. Eur. J. Oper. Res. 2016, 251, 74–84. [Google Scholar] [CrossRef]
- Skinderowicz, R. An improved Ant Colony System for the Sequential Ordering Problem. Comput. Oper. Res. 2017, 86, 1–17. [Google Scholar] [CrossRef]
- Hopfield, J.; Tank, D. “Neural” computation of decisions in optimization problems. Biol. Cybern. 1985, 52, 141–152. [Google Scholar] [CrossRef]
- Jäger, G.; Molitor, P. Algorithms and experimental study for the traveling salesman problem of second order. In Proceedings of the Second International Conference, COCOA 2008, St. John’s, NL, Canada, 21–24 August 2008; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); 5165 LNCS. pp. 211–224. [Google Scholar] [CrossRef]
- Takashima, Y.; Nakamura, Y. Theoretical and Experimental Analysis of Traveling Salesman Walk Problem. In Proceedings of the 2021 IEEE Asia Pacific Conference on Circuit and Systems (APCCAS), Penang, Malaysia, 22–26 November 2021; pp. 241–244. [Google Scholar]
- Alhenawi, E.; Khurma, R.A.; Damaševičius, R.; Hussien, A.G. Solving Traveling Salesman Problem Using Parallel River Formation Dynamics Optimization Algorithm on Multi-core Architecture Using Apache Spark. Int. J. Comput. Intell. Syst. 2024, 17, 4. [Google Scholar] [CrossRef]
- Shobaki, G.; Jamal, J. An exact algorithm for the sequential ordering problem and its application to switching energy minimization in compilers. Comput. Optim. Appl. 2015, 61, 343–372. [Google Scholar] [CrossRef]
- Libralesso, L.; Bouhassoun, A.; Cambazard, H.; Jost, V. Tree search algorithms for the Sequential Ordering Problem. arXiv 2019, arXiv:abs/1911.12427. [Google Scholar]
- Tavares Neto, R.F.; Godinho Filho, M.; Da Silva, F.M. An ant colony optimization approach for the parallel machine scheduling problem with outsourcing allowed. J. Intell. Manuf. 2015, 26, 527–538. [Google Scholar] [CrossRef]
- Reinelt, G. TSPLIB—A Traveling Salesman Problem Library. ORSA J. Comput. 1991, 3, 376–384. [Google Scholar] [CrossRef]
- Reinelt, G. Tsplib95; University Heidelberg: Heidelberg, Germany, 1995. [Google Scholar]
- Liu, Y.; Cao, B.; Li, H. Improving ant colony optimization algorithm with epsilon greedy and Levy flight. Complex Intell. Syst. 2021, 7, 1711–1722. [Google Scholar] [CrossRef]
- Goldbarg, M.C.; Luna, H. Combinatorial Optimization and Linear Programming: Models and Algorithms; Elsevier Publishing House: Rio de Janeiro, Brazil, 2015. [Google Scholar]
- Queiroz dos Santos, J.P.; de Melo, J.D.; Duarte Neto, A.D.; Aloise, D. Reactive Search strategies using Reinforcement Learning, local search algorithms and Variable Neighborhood Search. Expert Syst. Appl. 2014, 41, 4939–4949. [Google Scholar] [CrossRef]
- Almeida, C.P.d.; Gonçalves, R.A.; Goldbarg, E.F.; Goldbarg, M.C.; Delgado, M.R. Transgenetic Algorithms for the Multi-objective Quadratic Assignment Problem. In Proceedings of the 2014 Brazilian Conference on Intelligent Systems, Sao Paulo, Brazil, 18–22 October 2014; pp. 312–317. [Google Scholar] [CrossRef]
- Bengio, Y.; Lodi, A.; Prouvost, A. Machine Learning for Combinatorial Optimization: A Methodological Tour d’Horizon. arXiv 2018, arXiv:1811.06128. [Google Scholar] [CrossRef]
- Bianchi, R.A.; Celiberto, L.A., Jr.; Santos, P.E.; Matsuura, J.P.; De Mantaras, R.L. Transferring knowledge as heuristics in reinforcement learning: A case-based approach. Artif. Intell. 2015, 226, 102–121. [Google Scholar] [CrossRef]
- Pedro, O.; Saldanha, R.; Camargo, R. A tabu search approach for the prize collecting traveling salesman problem. Electron. Notes Discret. Math. 2013, 41, 261–268. [Google Scholar] [CrossRef]
- Montemanni, R.; Dell’Amico, M. Solving the Parallel Drone Scheduling Traveling Salesman Problem via Constraint Programming. Algorithms 2023, 16, 40. [Google Scholar] [CrossRef]
- Bodin, L.; Golden, B.; Assad, A.; Ball, M. Routing and Scheduling of Vehicles and Crews—The State of the Art. Comput. Oper. Res. 1983, 10, 63–211. [Google Scholar]
- Majidi, F.; Openja, M.; Khomh, F.; Li, H. An Empirical Study on the Usage of Automated Machine Learning Tools. In Proceedings of the 2022 IEEE International Conference on Software Maintenance and Evolution (ICSME), Limassol, Cyprus, 2–7 October 2022; pp. 59–70. [Google Scholar]
- Ottoni, A.L.C.; Souza, A.M.; Novo, M.S. Automated hyperparameter tuning for crack image classification with deep learning. Soft Comput. 2023, 27, 18383–18402. [Google Scholar] [CrossRef]
- Barreto, C.A.d.S.; Canuto, A.M.d.P.; Xavier-Júnior, J.C.; Feitosa-Neto, A.; Lima, D.F.A.; Costa, R.R.F.d. PBIL AutoEns: An Automated Machine Learning Tool integrated to the Weka ML Platform. Braz. J. Dev. 2019, 5, 29226–29242. [Google Scholar] [CrossRef]
- Chauhan, K.; Jani, S.; Thakkar, D.; Dave, R.; Bhatia, J.; Tanwar, S.; Obaidat, M.S. Automated Machine Learning: The New Wave of Machine Learning. In Proceedings of the 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 5–7 March 2020; pp. 205–212. [Google Scholar] [CrossRef]
- Olson, R.S.; Moore, J.H. TPOT: A tree-based pipeline optimization tool for automating machine learning. In Proceedings of the Workshop on Automatic Machine Learning, New York, NY, USA, 24 June 2016; pp. 66–74. [Google Scholar]
- Li, Y.; Wu, J.; Deng, T. Meta-GNAS: Meta-reinforcement learning for graph neural architecture search. Eng. Appl. Artif. Intell. 2023, 123, 106300. [Google Scholar] [CrossRef]
- Ottoni, L.T.C.; Ottoni, A.L.C.; Cerqueira, J.d.J.F. A Deep Learning Approach for Speech Emotion Recognition Optimization Using Meta-Learning. Electronics 2023, 12, 4859. [Google Scholar] [CrossRef]
- Mantovani, R.G.; Rossi, A.L.D.; Alcobaça, E.; Vanschoren, J.; de Carvalho, A.C.P.L.F. A meta-learning recommender system for hyperparameter tuning: Predicting when tuning improves SVM classifiers. Inf. Sci. 2019, 501, 193–221. [Google Scholar] [CrossRef]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. (Eds.) Automated Machine Learning: Methods, Systems, Challenges; Springer: Berlin/Heidelberg, Germany, 2019; in press; Available online: http://automl.org/book (accessed on 1 December 2023).
- Fernández, F.; Veloso, M. Probabilistic policy reuse in a reinforcement learning agent. In Proceedings of the Fifth International Joint Conference on Autonomous Agents and Multiagent Systems, Hakodate, Japan, 8–12 May 2006; pp. 720–727. [Google Scholar]
- Feng, Y.; Wang, G.; Liu, Z.; Feng, R.; Chen, X.; Tai, N. An Unknown Radar Emitter Identification Method Based on Semi-Supervised and Transfer Learning. Algorithms 2019, 12, 271. [Google Scholar] [CrossRef]
- Pavlyuk, D. Transfer Learning: Video Prediction and Spatiotemporal Urban Traffic Forecasting. Algorithms 2020, 13, 39. [Google Scholar] [CrossRef]
- Islam, M.M.; Hossain, M.B.; Akhtar, M.N.; Moni, M.A.; Hasan, K.F. CNN Based on Transfer Learning Models Using Data Augmentation and Transformation for Detection of Concrete Crack. Algorithms 2022, 15, 287. [Google Scholar] [CrossRef]
- Surendran, R.; Chihi, I.; Anitha, J.; Hemanth, D.J. Indoor Scene Recognition: An Attention-Based Approach Using Feature Selection-Based Transfer Learning and Deep Liquid State Machine. Algorithms 2023, 16, 430. [Google Scholar] [CrossRef]
- Pavliuk, O.; Mishchuk, M.; Strauss, C. Transfer Learning Approach for Human Activity Recognition Based on Continuous Wavelet Transform. Algorithms 2023, 16, 77. [Google Scholar] [CrossRef]
- Durgut, R.; Aydin, M.E.; Rakib, A. Transfer Learning for Operator Selection: A Reinforcement Learning Approach. Algorithms 2022, 15, 24. [Google Scholar] [CrossRef]
- Ottoni, A.L.C.; Nepomuceno, E.G.; de Oliveira, M.S. A Response Surface Model Approach to Parameter Estimation of Reinforcement Learning for the Travelling Salesman Problem. J. Control. Autom. Electr. Syst. 2018, 29, 350–359. [Google Scholar] [CrossRef]
- Montgomery, D.C. Design and Analysis of Experiments, 9th ed.; John Wiley & Sons.: New York, NY, USA, 2017. [Google Scholar]
- Lopes, R.H. Kolmogorov-Smirnov Test. Int. Encycl. Stat. Sci. 2011, 1, 718–720. [Google Scholar]
- Souza, G.K.B.; Ottoni, A.L.C. AutoRL-TSP-RSM: Automated reinforcement learning system with response surface methodology for the traveling salesman problem. Braz. J. Appl. Comput. 2021, 13, 86–100. [Google Scholar] [CrossRef]
- Anghinolfi, D.; Montemanni, R.; Paolucci, M.; Gambardella, L.M. A hybrid particle swarm optimization approach for the sequential ordering problem. Comput. Oper. Res. 2011, 38, 1076–1085. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem | Nodes | Best Known Solution |
|---|---|---|
| br17 | 17 | 39 |
| p43 | 43 | 5620 |
| ry48p | 48 | 14,422 |
| ft53 | 53 | 6905 |
| ft70 | 70 | 38,673 |
| kro124p | 100 | 36,230 |
| Problem | Nodes | Best Known Solution |
|---|---|---|
| br17.10 | 18 | 55 |
| br17.12 | 18 | 55 |
| p43.1 | 44 | 28,140 |
| p43.2 | 44 | 28,480 |
| p43.3 | 44 | 28,835 |
| p43.4 | 44 | 83,005 |
| ry48p.1 | 49 | 14,422 |
| ry48p.2 | 49 | 16,074 |
| ry48p.3 | 49 | 19,490 |
| ry48p.4 | 49 | 31,446 |
| ft53.1 | 54 | 7531 |
| ft53.2 | 54 | 8026 |
| ft53.3 | 54 | 10,262 |
| ft53.4 | 54 | 14,425 |
| ft70.1 | 71 | 39,313 |
| ft70.2 | 71 | 40,101 |
| ft70.3 | 71 | 42,535 |
| ft70.4 | 71 | 53,530 |
| kro124p.1 | 101 | 38,762 |
| kro124p.2 | 101 | 39,841 |
| kro124p.3 | 101 | 43,904 |
| kro124p.4 | 101 | 73,021 |
| 9999 | 3 | 5 | 48 | 48 | 8 | 8 | 5 | 5 | 3 | 3 | 0 | 3 | 5 | 8 | 8 | 5 |
| 3 | 9999 | 3 | 48 | 48 | 8 | 8 | 5 | 5 | 0 | 0 | 3 | 0 | 3 | 8 | 8 | 5 |
| 5 | 3 | 9999 | 72 | 72 | 48 | 48 | 24 | 24 | 3 | 3 | 5 | 3 | 0 | 48 | 48 | 24 |
| 48 | 48 | 74 | 9999 | 0 | 6 | 6 | 12 | 12 | 48 | 48 | 48 | 48 | 74 | 6 | 6 | 12 |
| 48 | 48 | 74 | 0 | 9999 | 6 | 6 | 12 | 12 | 48 | 48 | 48 | 48 | 74 | 6 | 6 | 12 |
| 8 | 8 | 50 | 6 | 6 | 9999 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 50 | 0 | 0 | 8 |
| 8 | 8 | 50 | 6 | 6 | 0 | 9999 | 8 | 8 | 8 | 8 | 8 | 8 | 50 | 0 | 0 | 8 |
| 5 | 5 | 26 | 12 | 12 | 8 | 8 | 9999 | 0 | 5 | 5 | 5 | 5 | 26 | 8 | 8 | 0 |
| 5 | 5 | 26 | 12 | 12 | 8 | 8 | 0 | 9999 | 5 | 5 | 5 | 5 | 26 | 8 | 8 | 0 |
| 3 | 0 | 3 | 48 | 48 | 8 | 8 | 5 | 5 | 9999 | 0 | 3 | 0 | 3 | 8 | 8 | 5 |
| 3 | 0 | 3 | 48 | 48 | 8 | 8 | 5 | 5 | 0 | 9999 | 3 | 0 | 3 | 8 | 8 | 5 |
| 0 | 3 | 5 | 48 | 48 | 8 | 8 | 5 | 5 | 3 | 3 | 9999 | 3 | 5 | 8 | 8 | 5 |
| 3 | 0 | 3 | 48 | 48 | 8 | 8 | 5 | 5 | 0 | 0 | 3 | 9999 | 3 | 8 | 8 | 5 |
| 5 | 3 | 0 | 72 | 72 | 48 | 48 | 24 | 24 | 3 | 3 | 5 | 3 | 9999 | 48 | 48 | 24 |
| 8 | 8 | 50 | 6 | 6 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 50 | 9999 | 0 | 8 |
| 8 | 8 | 50 | 6 | 6 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 50 | 0 | 9999 | 8 |
| 5 | 5 | 26 | 12 | 12 | 8 | 8 | 0 | 0 | 5 | 5 | 5 | 5 | 26 | 8 | 8 | 9999 |
| 0 | 3 | 5 | 48 | 48 | 8 | 8 | 5 | 5 | 3 | 3 | 0 | 3 | 5 | 8 | 8 | 5 | 1,000,000 |
| 0 | 3 | 48 | 8 | 5 | 0 | 0 | 3 | 0 | 3 | 8 | 5 | 3 | |||||
| 3 | 0 | 72 | 48 | 48 | 24 | 3 | 5 | 3 | 0 | 48 | 24 | 5 | |||||
| 48 | 74 | 0 | 0 | 6 | 6 | 12 | 48 | 48 | 48 | 48 | 74 | 6 | 6 | 12 | 48 | ||
| 48 | 74 | 0 | 0 | 6 | 6 | 12 | 48 | 48 | 48 | 48 | 74 | 6 | 6 | 12 | 48 | ||
| 8 | 50 | 6 | 6 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 50 | 0 | 0 | 8 | 8 | |
| 8 | 50 | 6 | 6 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 50 | 0 | 0 | 8 | 8 | |
| 5 | 26 | 12 | 12 | 8 | 0 | 0 | 5 | 5 | 5 | 26 | 8 | 8 | 0 | 5 | |||
| 5 | 26 | 12 | 12 | 8 | 8 | 0 | 0 | 5 | 5 | 5 | 5 | 26 | 8 | 8 | 0 | 5 | |
| 0 | 3 | 48 | 8 | 8 | 5 | 0 | 0 | 3 | 0 | 3 | 8 | 8 | 5 | 3 | |||
| -1 | 0 | 3 | 48 | 48 | 8 | 8 | 5 | 5 | 0 | 0 | 3 | 0 | 3 | 8 | 8 | 5 | 3 |
| 3 | 5 | 48 | 48 | 8 | 8 | 5 | 5 | 3 | 3 | 0 | 3 | 5 | 8 | 8 | 5 | 0 | |
| 0 | 3 | 48 | 48 | 8 | 5 | 5 | 0 | 0 | 3 | 0 | 3 | 8 | 8 | 5 | 3 | ||
| 3 | 0 | 72 | 48 | 48 | 24 | 3 | 3 | 5 | 3 | 0 | 48 | 48 | 24 | 5 | |||
| 8 | 50 | 6 | 6 | 0 | 8 | 8 | 8 | 8 | 50 | 0 | 0 | 8 | 8 | ||||
| 8 | 50 | 6 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 50 | 0 | 0 | 8 | 8 | |||
| 5 | 26 | 12 | 12 | 8 | 8 | 0 | 0 | 5 | 5 | 5 | 5 | 26 | 8 | 8 | 0 | 5 | |
| 0 |
| Problem | Nodes | Restrictions | Best Known Solution |
|---|---|---|---|
| br17.10 | 18 | 48 | 55 |
| br17.12 | 18 | 55 | 55 |
| ft53.1 | 54 | 117 | 7536 |
| ft53.2 | 54 | 135 | 8026 |
| ft53.3 | 54 | 322 | 10,262 |
| ft53.4 | 54 | 865 | 14,425 |
| kro124p.1 | 101 | 232 | 38,762 |
| kro124p.2 | 101 | 267 | 39,841 |
| kro124p.3 | 101 | 465 | 43,904 |
| kro124p.4 | 101 | 2504 | 73,021 |
| p43.1 | 44 | 96 | 28,140 |
| p43.2 | 44 | 119 | 28,480 |
| p43.3 | 44 | 181 | 28,835 |
| p43.4 | 44 | 581 | 83,005 |
| Parameters | Quantity | Values |
|---|---|---|
| 8 | 0.01; 0.15; 0.30; 0.45; 0.60; 0.75; 0.90; 0.99 | |
| 8 | 0.01; 0.15; 0.30; 0.45; 0.60; 0.75; 0.90; 0.99 | |
| 1 | 0.01 | |
| Combinations | - | |
| Epochs per Combination | 5 | - |
| Episodes per Epoch | 1000 | - |
| Episodes per Combination | - | |
| Total Epochs | - | |
| Total Episodes | = 320,000 | - |
| Parameters | Quantity | Values |
|---|---|---|
| 1 | 0.75 | |
| 1 | 0.15 | |
| 1 | 0.01 | |
| Combinations | - | |
| Epochs per Combination | 10 | - |
| Episodes per Epoch | 1000 | - |
| Episodes per Combination | = 10,000 | - |
| Total Epochs | 10 | - |
| Total Episodes | = 10,000 | - |
| Problem | Q0 | QATSP | D(%) | t | p |
|---|---|---|---|---|---|
| br17.10 | 99.6 | 117.2 | 17.67 | −3.20 | 0.01 |
| br17.12 | 92.7 | 100.8 | 8.74 | −2.14 | 0.06 |
| ft53.1 | 19,054.3 | 10,003.9 | −47.50 | 126.10 | 0.00 |
| ft53.2 | 19,735.9 | 12,057.4 | −38.91 | 138.95 | 0.00 |
| ft53.3 | 19,583.6 | 16,173.2 | 7.41 | 25.40 | 0.00 |
| ft53.4 | 19,360.0 | 18,245.4 | −5.76 | 26.56 | 0.00 |
| kro124p.1 | 179,266.4 | 56,146.9 | −68.68 | 789.13 | 0.00 |
| kro124p.2 | 179,859.2 | 59,280.3 | −67.04 | 432.24 | 0.00 |
| kro124p.3 | 168,223.3 | 71,605.7 | −57.43 | 221.92 | 0.00 |
| kro124p.4 | 124,900.0 | 99,131.0 | −20.63 | 67.09 | 0.00 |
| p43.1 | 72,411.4 | 30,453.1 | −57.94 | 117.94 | 0.00 |
| p43.2 | 71,953.6 | 32,726.0 | −54.52 | 101.90 | 0.00 |
| p43.3 | 67,146.8 | 33,151.5 | −50.63 | 84.45 | 0.00 |
| p43.4 | 93,488.1 | 86,304.4 | −7.68 | 25.96 | 0.00 |
| Problem | Q0 | QATSP | D(%) | t | p |
|---|---|---|---|---|---|
| br17.10 | 0.33 | 0.22 | −33.33 | 3.24 | 0.01 |
| br17.12 | 0.30 | 0.22 | −26.67 | 9.62 | 0.00 |
| ft53.1 | 0.65 | 0.59 | −9.23 | 2.87 | 0.01 |
| ft53.2 | 0.84 | 0.66 | −21.43 | 9.95 | 0.00 |
| ft53.3 | 1.79 | 0.89 | −50.28 | 60.65 | 0.00 |
| ft53.4 | 2.62 | 1.27 | −51.53 | 73.37 | 0.00 |
| kro124p.1 | 1.63 | 1.15 | −29.45 | 10.42 | 0.00 |
| kro124p.2 | 2.12 | 1.12 | −47.17 | 73.63 | 0.00 |
| kro124p.3 | 3.36 | 1.57 | −53.27 | 57.10 | 0.00 |
| kro124p.4 | 7.61 | 2.88 | −62.16 | 158.77 | 0.00 |
| p43.1 | 0.55 | 0.59 | 7.27 | .49 | 0.15 |
| p43.2 | 0.79 | 0.72 | −8.86 | 4.53 | 0.00 |
| p43.3 | 1.13 | 1.08 | −4.42 | 2.73 | 0.01 |
| p43.4 | 1.84 | 1.51 | 7.93 | 27.04 | 0.00 |
| ATSP | SOP | Best Known Solution | Without Auto_TL_RL | With Auto_TL_RL |
|---|---|---|---|---|
| br17 | br17.10 | 55 | 57 | 55 |
| br17.12 | 55 | 57 | 57 | |
| p43 | p43.1 | 28,140 | 28,765 | 28,715 |
| p43.2 | 28,480 | 29,265 | 29,170 | |
| p43.3 | 28,835 | 29,545 | 29,535 | |
| p43.4 | 83,005 | 84,110 | 83,985 | |
| ry48p | ry48p.1 | 14422 | 18,154 | 17,922 |
| ry48p.2 | 16,074 | 18,549 | 18,459 | |
| ry48p.3 | 19,490 | 22,789 | 22,853 | |
| ry48p.4 | 31,446 | 38,235 | 37,679 | |
| ft53 | ft53.1 | 7531 | 8852 | 9056 |
| ft53.2 | 8026 | 9839 | 9588 | |
| ft53.3 | 10,262 | 12,598 | 12,594 | |
| ft53.4 | 14,425 | 17,650 | 16,935 | |
| ft70 | ft70.1 | 39,313 | 43,460 | 42,707 |
| ft70.2 | 40,101 | 44,841 | 44,499 | |
| ft70.3 | 42,535 | 48,015 | 48,311 | |
| ft70.4 | 53,530 | 60,049 | 59,275 |
| Proposed | [37] | [39] | [80] | ||
|---|---|---|---|---|---|
| Dataset | TSPLIB | 🗸 | 🗸 | 🗸 | 🗸 |
| SOPLIB | – | – | – | 🗸 | |
| Algorithm | Ant Colony System | – | – | 🗸 | – |
| Particle Swarm Optimization | – | – | 🗸 | ||
| Reinforcement Learning | 🗸 | 🗸 | – | – | |
| Meta-learning | Hyperparameter Tuning | – | 🗸 | – | 🗸 |
| Transfer Learning | 🗸 | – | – | – | |
| AutoML | 🗸 | – | – | – |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Souza, G.K.B.; Santos, S.O.S.; Ottoni, A.L.C.; Oliveira, M.S.; Oliveira, D.C.R.; Nepomuceno, E.G. Transfer Reinforcement Learning for Combinatorial Optimization Problems. Algorithms 2024, 17, 87. https://doi.org/10.3390/a17020087
Souza GKB, Santos SOS, Ottoni ALC, Oliveira MS, Oliveira DCR, Nepomuceno EG. Transfer Reinforcement Learning for Combinatorial Optimization Problems. Algorithms. 2024; 17(2):87. https://doi.org/10.3390/a17020087
Chicago/Turabian StyleSouza, Gleice Kelly Barbosa, Samara Oliveira Silva Santos, André Luiz Carvalho Ottoni, Marcos Santos Oliveira, Daniela Carine Ramires Oliveira, and Erivelton Geraldo Nepomuceno. 2024. "Transfer Reinforcement Learning for Combinatorial Optimization Problems" Algorithms 17, no. 2: 87. https://doi.org/10.3390/a17020087
APA StyleSouza, G. K. B., Santos, S. O. S., Ottoni, A. L. C., Oliveira, M. S., Oliveira, D. C. R., & Nepomuceno, E. G. (2024). Transfer Reinforcement Learning for Combinatorial Optimization Problems. Algorithms, 17(2), 87. https://doi.org/10.3390/a17020087