1. Introduction
Over the past decade, many researchers have shown significant research interest in the classification and management of chronic diseases. As a chronic disease, gout can cause severe pain and has been linked to several health conditions, including heart disease, kidney damage, and diabetes [
1,
2]. It is important to diagnose gout in patients, as this can lead to more effective treatment strategies and reduce the likelihood of disease progression while alleviating patient suffering. The traditional method for diagnosing gout relies on the patient’s biochemical indicators and medical images. This approach can be expensive and financially burdensome for the patient. Fortunately, the use of machine learning saves a great deal of time and enhances the effectiveness of the diagnosis; it depends on the availability of clinical data and patient medical records [
3]. Computer-assisted diagnosis has the potential to reduce the dependence on expensive imaging and testing procedures, resulting in more cost-effective and accessible diagnostic solutions for patients. Previous work has diagnosed medical conditions by collecting information from electronic medical records and creating machine learning models.
Based on the clinical record, gout can be classified into four distinct periods: asymptomatic hyperuricemia, acute gouty attack, intercritical period, and chronic tophaceous gout [
4]. However, studies of gout patients have not focused on the four distinct periods of the disease; instead, they typical categorize patients as having either gout or asymptomatic hyperuricemia [
5]. Additionally, medical diagnoses often involve imbalanced datasets, which can lead to biased predictions towards the majority class [
6]. The class imbalance problem (CLP) is the non-uniform distribution of classes in a dataset. The term ‘majority class’ refers to the class with the highest number of instances, while the term ‘minority class’ refers to the class with the lowest number of instances [
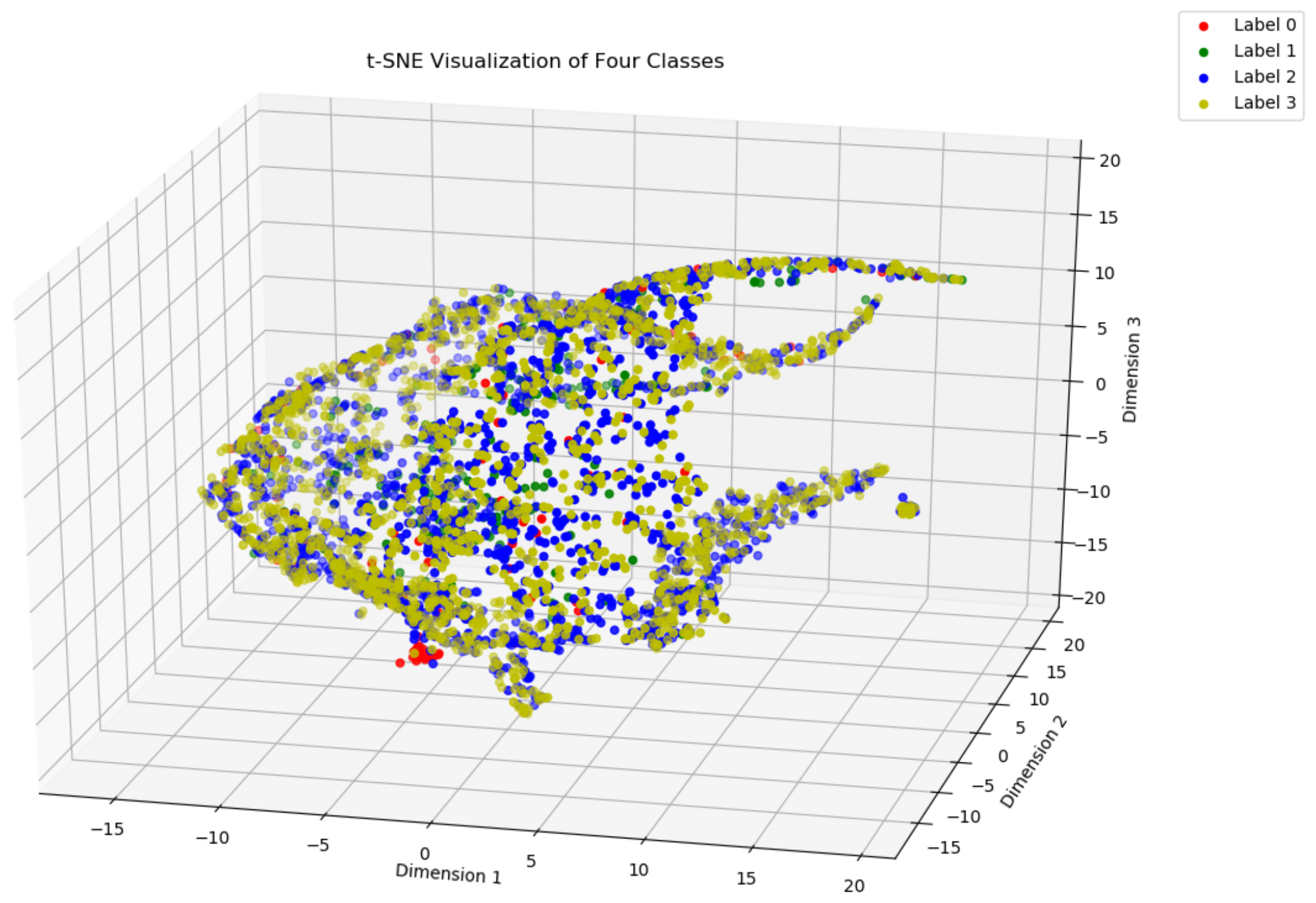
7]. A classifier trained with imbalanced data tends to be biased towards the majority class and may overlook the more important minority class. Models often exclude the minority class in order to achieve higher accuracy, which can lead to biased results. Addressing data imbalance in gout can improve the model’s ability to learn the features from the minority classes, reducing the risk of misdiagnosis during gout diagnosis. In medical diagnostics, the SMOTE algorithm, which creates synthetic examples by interpolating between minority class instances and their k-nearest neighbors, is the primary method for addressing class imbalance [
8]. Nevertheless, SMOTE has some weaknesses. It depends on the parameter k and the quality of the generated samples; it also has an over-density of synthetic samples. On the other hand, medical diagnostics often employ separate classifiers that fail to fully extract the dataset’s features, which reduces the classification’s effectiveness [
9].
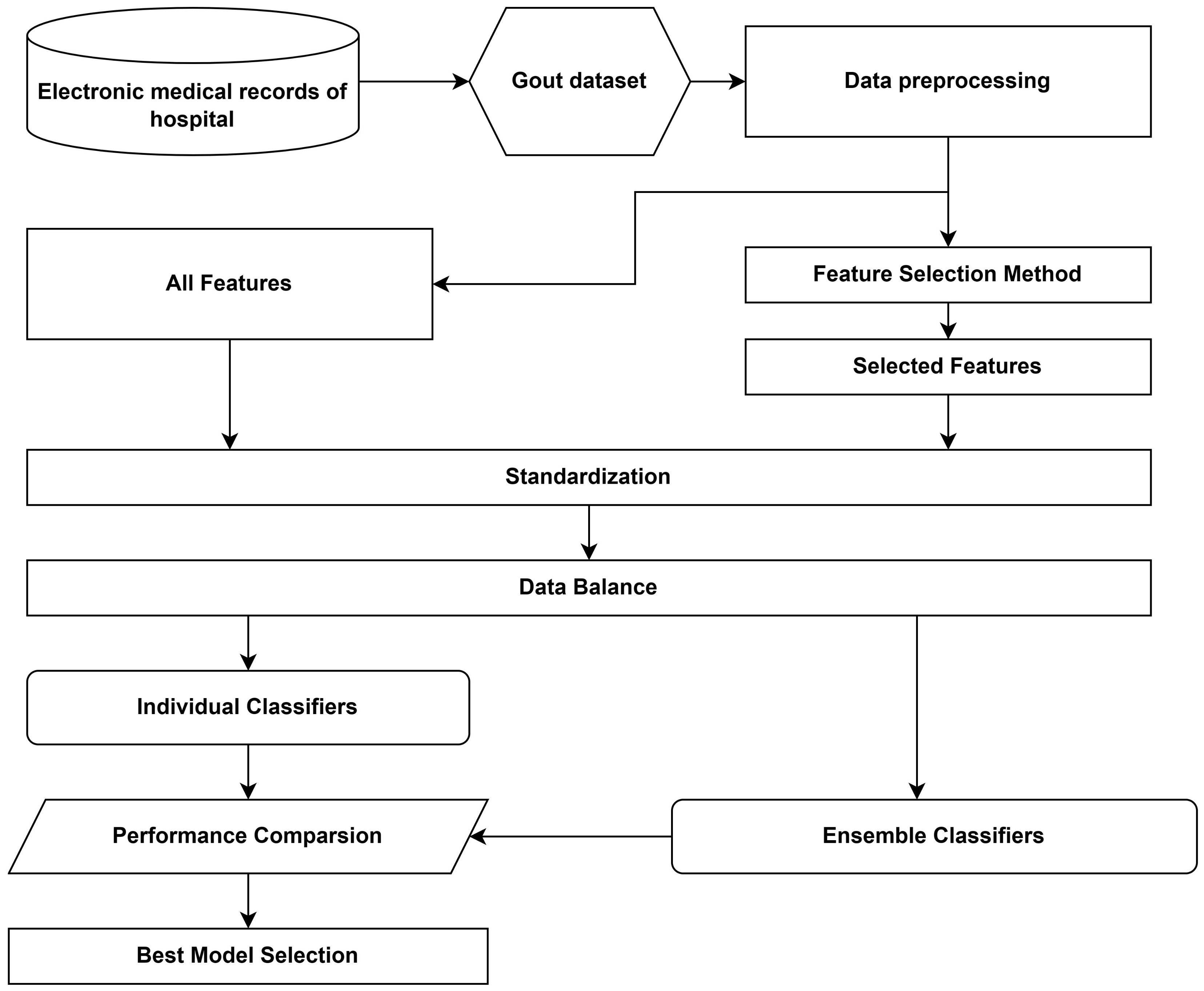
This study addresses the lack of research for accurately staging gout beyond a simple diagnosis and aims to address the imbalance in gout data. To address the imbalanced data problem, this study proposes a new hybrid sampling strategy based on an extended natural neighbor. And, ensemble learning is then combined to alleviate the problem of data imbalance. After acquiring and preprocessing data from hospital medical records, ENaNSMOTE-Tomek link is proposed as a solution to the imbalanced data problem caused by the gout dataset. ENaNSMOTE-Tomek link uses extended natural neighbors with SMOTE to generate new samples for the minority class and removes noise with Tomek link, achieving data balance. The bagging ensemble strategy is used to improve the recognition accuracy of both the majority and minority classes by addressing the uneven distribution of the data. Because the study utilized a dataset with an imbalanced distribution of classes and a relatively high number of features, correlation analysis and random forest are used to select features that improve the accuracy of the proposed models. Feature selection aims to identify the features that significantly impact the final prediction results, and random forest can calculate feature importance and reduce model calculation costs. Also, this study uses six classifiers—support vector machines (SVMs), decision trees (DTs), k-nearest neighbors (KNN), gradient boosting (GB), multilayer perceptron (MLP), and extreme gradient boosting (XGB)—and selects the optimal classifier through a proposed resampling method and ensemble learning for the diagnosis of gout. This study employs commonly used classification performance metrics, including accuracy, precision, recall, and F1 score. Additionally, AUC, a performance metric that captures imbalanced classification, is also utilized. All experimental results are based on physical examination and clinical laboratory indicators of real gout patients.
Figure 1 illustrates the method and process of this algorithm. The key contributions of this study are as follows:
(1) A predictive model is proposed for accurately classifying different periods of gout. Experimental results demonstrate that it outperforms the same type of disease diagnosis approach for diseases such as heart disease and diabetes.
(2) The ENaNSMOTE-Tomek link algorithm is proposed to address the issue of imbalanced data. The algorithm uses the extended natural neighbors to generate reliable samples for the minority class and employs data cleaning techniques by using Tomek links.
(3) An ensemble model that combines a bagging technique and a hybrid resampling technique is proposed to handle the CIP in the classification of gout.
(4) This study utilizes correlation analysis and random forests to reduce the number of attributes and to enhance the performance of classifiers.
The paper is structured as follows:
Section 2 presents the literature review.
Section 3 provide a comprehensive explanation of the methods used in this study.
Section 4 provides a comprehensive review of the experiment.
Section 5 provides an overview of the results.
Section 6 concludes the entire work.
2. Literature Review
The diagnosis of gout patients is primarily based on pathology and pharmacology. For instance, Xue et al. classified patients with gout and clinical hyperuricemia based on target serum urate levels [
10]. Wang et al. utilized oxylipin biomarkers to differentiate between gout and hyperuricemia [
11]. Shen et al. used potential biomarkers of metabolites to distinguish between gout and hyperuricemia [
12]. Also, some progress has been made in predicting gout using traditional machine learning. Cheng et al. employed machine learning and natural language processing techniques to automatically detect gout attacks from electronic clinical records [
13]. Bai et al. introduced neighborhood rough sets into multivariate variational mode decomposition and used them to construct a method for classifying potential gout patients [
14]. Ma et al. applied deep reinforcement learning to solve the gout staging task [
15].
Research has been conducted in the literature to develop disease diagnostics based on machine learning models in order to create more accurate prediction models. Rois et al. used a random forest algorithm, while Bisht et al. employed the k-nearest neighbors method to predict the factors that contribute to perceived stress [
16,
17]. Jaques et al. utilized support vector machines to predict students’ happiness [
18]. Chou et al. and Laila et al. both used machine learning algorithms to predict the onset and early-stage risk of diabetes, respectively. Chou et al. employed a decision tree, while Laila et al. used a random forest [
19,
20]. Nilashi et al. proposed a KNN + SOM + PCA + Fuzzy support vector machine (SVM) model for diagnosing heart disease [
21]. Almazroi et al. used decision trees to predict heart disease by utilizing clinical records [
22]. Ahmad et al. utilized a gradient boosting classifier to diagnose human heart disease [
23].
Resolving imbalanced data can improve predictions and reduce errors in medical diagnosis. For data balancing in cardiovascular disease, RandomOverSampler has been used [
24]. In order to improve the survival rate of heart failure patients, the extra tree classifier (ETC) was proposed; it uses SMOTE to balance the data [
25]. Also, the authors used SMOTE to classify diabetes and reliable stress levels [
26,
27]. Fitriyani et al. proposed using extreme gradient boosting with SMOTE-ENN to solve the cardiovascular prediction problem [
28]. The use of ensemble methods for classification has gained momentum in recent years. Ensemble techniques combine the predictions of multiple base classifiers to produce a final result, resulting in improved accuracy. They are objective and avoid subjective evaluations, as demonstrated from the following articles. For example, Baker employed different machine learning methods with majority votes to predict credit card fraud transactions [
29]. In the field of disease diagnosis, Liu utilized DNN, IF, and LR with ensemble learning to evaluate stroke records [
30]. Meanwhile, Mehr employed random forest, extra tree (ET), AdaBoost, and MLP (multilayer perceptron) with ensemble learning, along with various feature selection methods, to classify polycystic ovary syndrome [
31]. Similarly, Emine used AdaBoost ensemble learning to classify neuromuscular disorders, while Schreiber developed machine learning models using ensemble methods to identify patients with VIPN-free survival [
32,
33]. Asif employed an ensemble voting method to combine random forest, extreme gradient boosting, and gradient boosting to enhance the prediction of heart disease [
9].
Previous studies have shown that disease diagnosis models perform well. However, there are still several shortcomings. Classification on imbalanced datasets can result in biased outcomes, as most standard classification algorithms favor the majority class, leading to poor prediction accuracy for the minority class. To balance the data distribution, most prior studies employed the SMOTE method [
24,
25,
26,
27,
28], which has some disadvantages. The quality of the samples generated by SMOTE depends on the parameter k, which is difficult to determine due to the variety of datasets. It is important to consider these limitations when using SMOTE for data augmentation. Additionally, the new samples generated by SMOTE use the same number of nearest neighbors without considering the sample distribution, which may result in noisy examples. Furthermore, SMOTE only generates synthetic samples along the line segment between two minority samples, which may cause an over-density of synthetic samples. Currently, models are trained using simple machine learning algorithms such as DT [
16], SVM [
15], XGB [
28], or KNN [
10]. Recent developments in machine learning methodologies have enabled the successful use of ensemble learning frameworks and deep learning in computational biology and healthcare. These advancements have led to the development of more reliable and stable models, enhancing the performance for the diagnosis of gout.
6. Conclusions
This paper presents a study on the classification of periods of gout that can aid medical professionals with diagnosing the disease quickly and accurately. The proposed method can assist doctors with diagnosing gout. By referring to diagnostic results and exercising professional judgment, the accuracy of diagnoses can be improved, reducing the economic burden to patients. Solving the data imbalance problem in medical diagnosis is necessary to improve the accuracy of the model, and this paper proposes a new method that can solve the medical data imbalance problem. To address data imbalance in medical datasets, a resampling method ENaNSMOTE-Tomek link was proposed. The proposed method generates high-quality resampled data using the extended natural neighbor algorithm and filters out synthetic data by assessing pairs of samples that exhibit a Tomek link. The proposed approach enhances the performance of machine learning models in dealing with severely imbalanced data by improving the quality of resampled data. Additionally, a bagging algorithm was utilized for data balancing, which overcomes the limitations of individual classifiers and provides more accurate classification of gout staging in noisy and highly imbalanced environments. Six classifiers—SVM, DT, KNN, GB, MLP, and XGB—were implemented and compared using metrics. The results demonstrate that the proposed ensemble model, bagging-XGB, with the proposed resampling method outperforms all other models with an accuracy of 80.87% and an AUC of 87.10%. Although the proposed method performs well in gout, it is important to note that the study is limited by the relatively small size of the training dataset in terms of the number of patients. For future work, the effective use of a small amount of labeled data and a large amount of unlabeled data for semi-supervised learning or self-supervised learning using unlabeled data only are important directions for our work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}