1. Introduction
The earliest known mature writing system in China is represented by oracle bone inscriptions [
1,
2]. Chinese character development and construction were significantly influenced by the characters of OBIs, and as a longstanding literary form, OBIs contain a wealth of information that holds significant value for our understanding of global history, character evaluation, and many other aspects [
3]. In-depth research on these objects enables us to continuously explore the treasures of ancient civilization and thus contribute to the history and promotion of Chinese traditional culture. In 2017, OBIs were successfully entered into the Memory of the World Register, demonstrating that the cultural value and historical significance of OBIs are recognized worldwide. With the comprehensive improvement of public cultural understanding in society, it is increasingly important to improve and enhance the dissemination and utilization of OBIs, allowing them to move out of the realm of study and into the public domain. This will revitalize their legacy in the current era and gradually draw attention in the academic community for new research directions. One of the fundamental research tasks regarding OBIs is detection. Rapidly detecting OBIs using information technology significantly contributes to the acceleration of research and development in OBI studies. Many OBIs remained entombed within ruins until they were unearthed in 1899 [
4]. Given the frequent incompleteness and low clarity of oracle bones that have endured years of burial underground, the precise detection and identification of OBIs has consistently posed a challenging task.
OBI detection falls under the umbrella of object detection, which constitutes an important research area in computer vision. The primary objective of this domain is to autonomously pinpoint the location of target objects and classify them in videos or images. Currently, OBI detection technology may be broadly classified into two groups: deep learning-based OBI detection and classical methods-based OBI detection. In terms of traditional methods, Xiaosong Shi [
5] used a method based on connected components for oracle bone script detection, but this method is not very effective regarding complex backgrounds or noisy oracle bone rubbing images.
As computer technology continues to evolve, object detection algorithms rooted in deep learning have emerged as the prevailing trend. In recent years, many experts and scholars, both domestically and internationally, have dedicated significant effort toward researching OBI detection by using deep learning techniques. OBI detection algorithms rooted in deep learning can be primarily categorized into two types: two-stage and one-stage detection algorithms. Of these, YOLO [
6] and SSD [
7] fall under the umbrella of one-stage detection algorithms, and Faster R-CNN [
8], RFBNet [
9], etc., are two-stage detection algorithms. RefineDet [
10] is an improvement based on the SSD algorithm and effectively blends the strengths of both types. Although two-stage detection algorithms have higher accuracy, their implementation is complex and computationally intensive, the inference speed is slow, and they perform poorly when detecting small and dense objects. Conversely, one-stage detection algorithms are fast, accurate, and widely applicable. In research on one-stage detection algorithms, the YOLO series is used extensively across a range of diverse scenarios because of its excellent performance; these algorithms are lightweight, have a low background false-alarm rate, show good performance in detecting small objects, have strong model generalization abilities, and have a fast detection speed. For instance, YOLO can be used to detect objects in pictures taken by unmanned aerial vehicles [
11], for traffic sign recognition [
12], for steel surface defect detection [
13], etc. Lin Meng [
14] at Ritsumeikan University in Japan enhanced the SSD algorithm to improve the detection accuracy of small-font oracle bone characters. Jici Xing [
15] constructed an OBI detection dataset and analyzed the detection performance of representative general detection frameworks (comprising Faster R-CNN, SSD, RefineDet, RFBnet, and YOLOv3 [
16]) applied to this dataset, thus improving the best-performing YOLOv3, achieving an F-measure of 80.1%. Guoying Liu [
17] proposed a multi-scale Gaussian kernel-based oracle bone detector. Xinren Fu [
18] proposed a pseudo-label-based oracle bone script detection architecture. While the algorithm demonstrated promising performance on the training set, its detection accuracy was suboptimal on the validation and test sets. While these algorithms have enhanced the performance of object detection to a certain degree, there is still room for further refinement in terms of detection accuracy. According to research results in the literature [
15], YOLOv3 performs well among mainstream deep learning models.
YOLOv8 is the latest version (as of 1 January 2024) of the YOLO series, released by Ultralytics in 2023. YOLOv8 adopts a more efficient network structure and more advanced algorithm technology, enhancing the precision and rapidity of object detection even further. YOLOv8 includes multiple models at different scales, and YOLOv8_n stands out as the most compact and efficient model within this series, offering the quickest performance among its counterparts.
In conclusion, to further improve the precision of detection, the present study focused on the uneven target size and significant noise of OBI rubbing images as well as real-time detection. Using the YOLOv8_n model as a baseline, our primary advancements were as follows:
Given the concentration of oracle bone script detection data, some oracle bone characters in certain images are small. To enhance detection performance for small objects, a detection head with a scale of 160 × 160 was added;
Some of the images in the OBI detection dataset are of poor quality, and the WIoU (Wise-IoU) [
19] loss function prioritizes ordinary-quality anchor boxes; therefore, the loss function was modified to WIoU;
The noise in the OBI rubbing images is quite severe. To focus the model on recognizing key points—the oracle bone characters—and to reduce focus on other information, the CBAM (convolutional block attention module) [
20] was embedded in the network architecture.
Given what is currently known in the field of deep learning, no target detection algorithm combines a small object detection head, WIoU, and a CBAM with YOLOv8, as proposed in this paper, and neither is there such a technology for OBI detection.
2. Materials and Methods
2.1. Experiment Dataset
2.1.1. Dataset Introduction
This experiment’s OBI detection dataset comes from the Oracle Bone Inscription Information Processing Laboratory of Anyang Normal University. The OBI detection dataset is a set of annotated data used to train and evaluate OBI detection algorithms. The dataset contains OBI rubbing images and related annotation information. The image set contains all the image data. There are 8895 training annotations and 411 verification annotations, all saved in JSON files.
The oracle bone inscriptions have become blurry after being buried underground for a long time, causing varying degrees of corrosion in the bones. The dataset was obtained by scanning the rubbing images, and some images in the dataset contain a large quantity of noise and cracks, as shown in
Figure 1. During the training process, these low-quality images can interfere with the model’s ability to learn about image features.
The proportion of oracle bone annotation box sizes in the OBI detection dataset is shown in
Figure 2. The sizes of the oracle bone characters vary, but they tend to be on the smaller side.
2.1.2. Processing Label Information
In the OBI detection dataset, the annotation file records the name of the image (img_name) and the specific position information of each OBI character. The annotation of the OBI character is implemented through a rectangular box, and the JSON file contains the coordinates for the upper left and lower right corners of every bounding box, denoted as and , respectively. The bounding box in YOLOv8 saves the coordinates of the bounding box’s center point, width, and height, denoted as center_x, center_y, width, and height, respectively. It is important to emphasize that the bounding box coordinate values have undergone normalization, resulting in a range between 0 and 1. At the same time, in the annotation set, the “height value” denotes the proportion of the annotation box’s actual height in relation to the overall image height, whereas the “width value” signifies the ratio of the annotation box’s actual width to the width of the image.
To ensure that YOLOv8 can accurately locate each oracle bone inscription, it is necessary to obtain the width and height parameters of the target image being processed, denoted as
img_width and
img_height, respectively. Then, the annotation information needs to be transformed according to Formulas (1)–(4).
Owing to the absence of categorical data pertaining to the characters within the dataset, this experiment treats all oracle bone characters as a single target and assigns them the same class label.
2.2. Input Data Assumptions
This study uses an improved YOLOv8 model to detect oracle bone inscriptions in the OBI detection dataset. To ensure effective training and accurate evaluation, the assumptions for the input data are as follows:
All input images are in standard JPEG image format;
The color space of the input images is RGB, and each image has three color channels;
In the data preprocessing stage, all bounding box labels in the original JSON file are converted using Formulas (1)–(4);
The class label is represented by an integer, starting with 0. Since all oracle bone inscriptions in the dataset are treated as a single category in this study, it is assumed that 0 represents this unique class label;
The label file is converted into a txt file in the preprocessing stage; irrelevant label information from the original JSON file in the oracle bone inscription detection dataset is removed during data preprocessing, specifically parity bits; each oracle bone inscription’s label information is on a separate line in the label file, consisting of the class label and the bounding box information; the data are separated by spaces;
None of the input images have undergone any form of data preprocessing and are maintained in their unaltered state. The dataset has been cleansed to ensure a one-to-one correspondence between images and label files. The label information has been preprocessed to meet the model’s requirements;
Considering the characteristics of the OBI detection dataset, it is assumed that the oracle bone characters in the dataset have diverse forms and varied sizes and a random distribution of noise and cracks in the images.
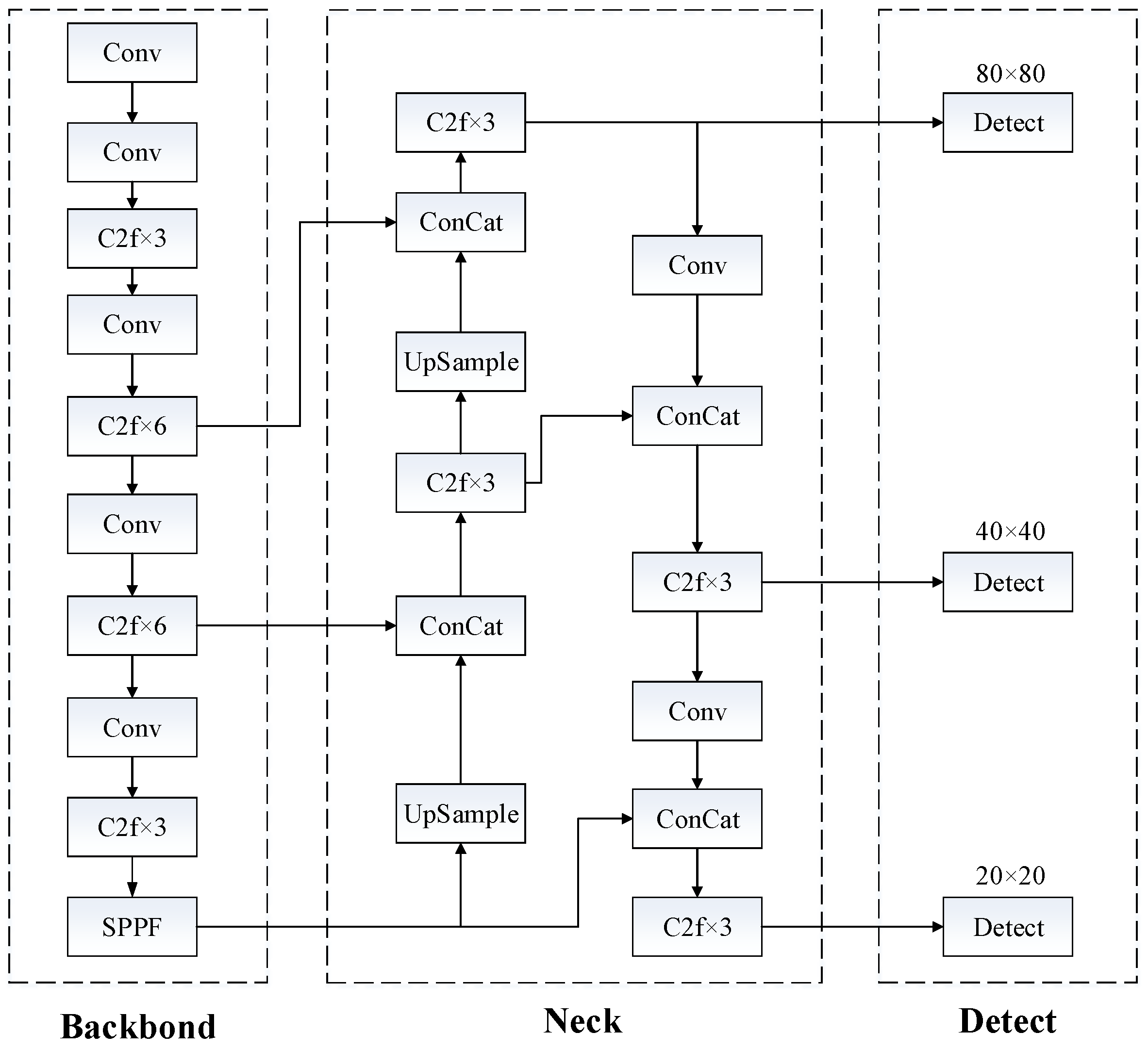
2.3. YOLOv8_n Network Model
Figure 3 shows that the YOLOv8_n model comprises three fundamental components: the backbone, the neck, and the detection module. The detection layer outputs three differently sized feature maps, specifically 20 × 20, 40 × 40, and 80 × 80.
Compared with previous versions, YOLOv8_n has an optimized and improved network structure, adopting a more efficient feature extraction network and a lighter model structure. Firstly, the previous version’s C3 structure was substituted with a C2f structure that exhibits a more abundant gradient flow. This change allows the model to better handle gradient flow, thereby improving its performance. Secondly, YOLOv8_n adjusts the channel numbers of models at different scales, enabling the model to more precisely manage objectives of varying sizes and further improve its accuracy. Additionally, YOLOv8_n introduces new data augmentation techniques and regularization methods to enhance both the generalization capacity and robustness of the model. Through these techniques, YOLOv8_n can more effectively accommodate various scenarios and environments, therefore improving its performance in practical applications.
2.4. The Proposed Method
2.4.1. Adding Small Target Detection Head
By analyzing the proportion of oracle bone annotation box sizes in the OBI detection dataset, it can be seen that it comprises OBI characters of varying sizes. Owing to the large downsampling factor of YOLOv8_n, obtaining feature information on small targets poses a challenge for deeper feature maps during the learning process. Therefore, small targets are prone to problems due to their size, including undetection or poor detection performance. T.L. introduced a small object detection head into a traffic sign recognition algorithm based on YOLOv5 [
12]. Taking inspiration from this, to enhance the sensitivity of small OBI characters, this study incorporates an additional layer specifically designed to detect small targets, integrating shallower and deeper feature maps to comprehensively capture and use global contextual information. In addition, a dedicated 160 × 160 scale detection head solely devoted to this task is also incorporated, which uses shallower, higher-resolution feature maps as inputs to achieve greater precision in detection. Furthermore, adding the new detection head supplements the existing three, resulting in a structure with four detection heads, significantly enhancing the overall target detection performance. The detection head is intricately designed. It extracts features from the second layer of the backbone network and then integrates the features extracted from the neck network through the concatenation operation. Finally, by using the output of the 19th layer as a crucial part of small target detection, it precisely detects small targets. The network structure is illustrated in
Figure 4, with its modifications highlighted in blue.
2.4.2. Improving the Loss Function
The loss function for bbox (bounding box) regression is pivotal in achieving accurate object detection. By learning to predict the location of bboxes, the model can closely approximate true bounding boxes, providing precise localization and crucial information about key areas for detecting objects. YOLOv8_n uses CIoU (Complete IoU) [
21,
22] as its loss function for bbox regression, as shown in Formulas (5)–(8).
where IoU [
23] denotes the intersection over the union between the predicted and ground-truth box.
where
and
denote the central points of the prediction box and the ground-truth box,
are the width and height of the smallest enclosing box covering the two boxes,
is a positive trade-off parameter, and
measures the consistency of the aspect ratio.
The width and height of the ground-truth box are indicated by
and
, where
and
stand for the width and height of the prediction box, respectively.
As a result of the unavoidable presence of substandard instances within the training data, the penalty for low-quality examples can be augmented by considering factors, ultimately leading to a decline in the model’s generalization capabilities. In addition, when the overlap between the predicted box and the ground-truth box is very small or non-existent, CIoU may not provide effective gradient information. To tackle these challenges, this study uses the WIoU loss function. WIoU is a type of boundary loss based on the non-monotonic dynamic focusing method that evaluates the anchor boxes’ quality through outlier evaluation and offers a prudent strategy for allocating gradient gains. The proposed strategy effectively diminishes the competitiveness of superior-quality anchor boxes and simultaneously mitigates adverse gradients emanating from inferior examples. As a result, WIoU concentrates on moderate-quality anchor boxes, leading to an improvement in the detector’s overall performance. The distance attention is shown in Formulas (9) and (10).
To avoid generalizing the gradients with WIoU, which could potentially hinder convergence, the computational graph does not include or (denoted by the superscript ∗). This effectively removes the convergence-hindering factor. Therefore, there is no need to introduce new metrics. When the anchor boxes align well with the target box, WIoU diminishes the penalty imposed by the geometric factors, thereby allowing for minimal intervention during training and enhancing the model’s generalization capability.
The primary step in implementing WIoU is computing the basic IoU value. Building on this, the final loss value is further refined by introducing distance attention mechanisms and dynamic adjustment factors. Subsequently, the obtained WIoU values are integrated into the loss function to replace the original CIoU loss component. During the model training phase, optimization adjustments are made based on the values of WIoU to more precisely calibrate the predicted bounding box positions and shapes.
2.4.3. Adding CBAM Attention Module
The complex background of OBI rubbing images and the small image area occupied by some of the detection targets lead to the presence of a significant proportion of extraneous features in the image iteration. To selectively enhance the feature channels that contain the most target information while also minimizing the disruption caused by invalid targets, enhancing the detection effect of the targets of interest, and thus enhancing the model’s overall detection precision, this study embeds CBAM into the OBI detection algorithm. In recent years, attention modules have emerged rapidly, and common attention mechanisms include SE [
24], GAM [
25], EMA [
26], and CBAM.
CBAM innovatively incorporates a spatial attention mechanism based on retaining the original channel attention mechanism, thereby comprehensively optimizing the network in terms of both channel and spatial dimensions. This measure enables an optimized network to more accurately capture key features encompassing both channel-wise and spatial aspects, significantly improving the model’s efficiency in extracting features from both the channel and spatial dimensions.
Figure 5 illustrates the structure of the CBAM.
The CBAM processes the input feature map,
, by first obtaining its channel attention feature,
. Multiplying the features element-wise with
F yields the channel-refined feature
. It then computes the spatial attention feature
of
, multiplies it with
element-wise, and obtains the final refined feature. This enhanced refined feature is used as the input for subsequent network layers, effectively preserving key information while suppressing noise and irrelevant information. Formulas (11) and (12) outline the entire attention procedure.
The input feature map undergoes max-pooling and average-pooling operations and feeds the resulting feature map into a shared multi-layer perceptron. Then, the feature maps generated by the shared MLP are combined, and the outcome is scaled by using the sigmoid function to derive the channel attention,
. Multiplying
with the feature map element-wise yields the channel-refined feature. The channel attention module’s architecture is schematically represented in
Figure 6.
The channel attention module successively applies max-pooling and average-pooling to the refined channel features, stacks the results along the same dimension, adjusts the channel numbers using a convolutional layer, and utilizes the sigmoid function to derive spatial attention,
. Eventually, the channel-refined feature is element-wise multiplied with
to obtain the final refined feature.
Figure 7 illustrates the spatial attention module’s structure.
CBAMs can be easily integrated into most mainstream networks, thus effectively improving the ability of network models to extract features without significantly increasing the computational complexity and number of parameters. Therefore, in this paper, the CBAM is embedded before the SPPF in the YOLOv8_n model.
2.5. Experimental Setup
2.5.1. Evaluation Metrics
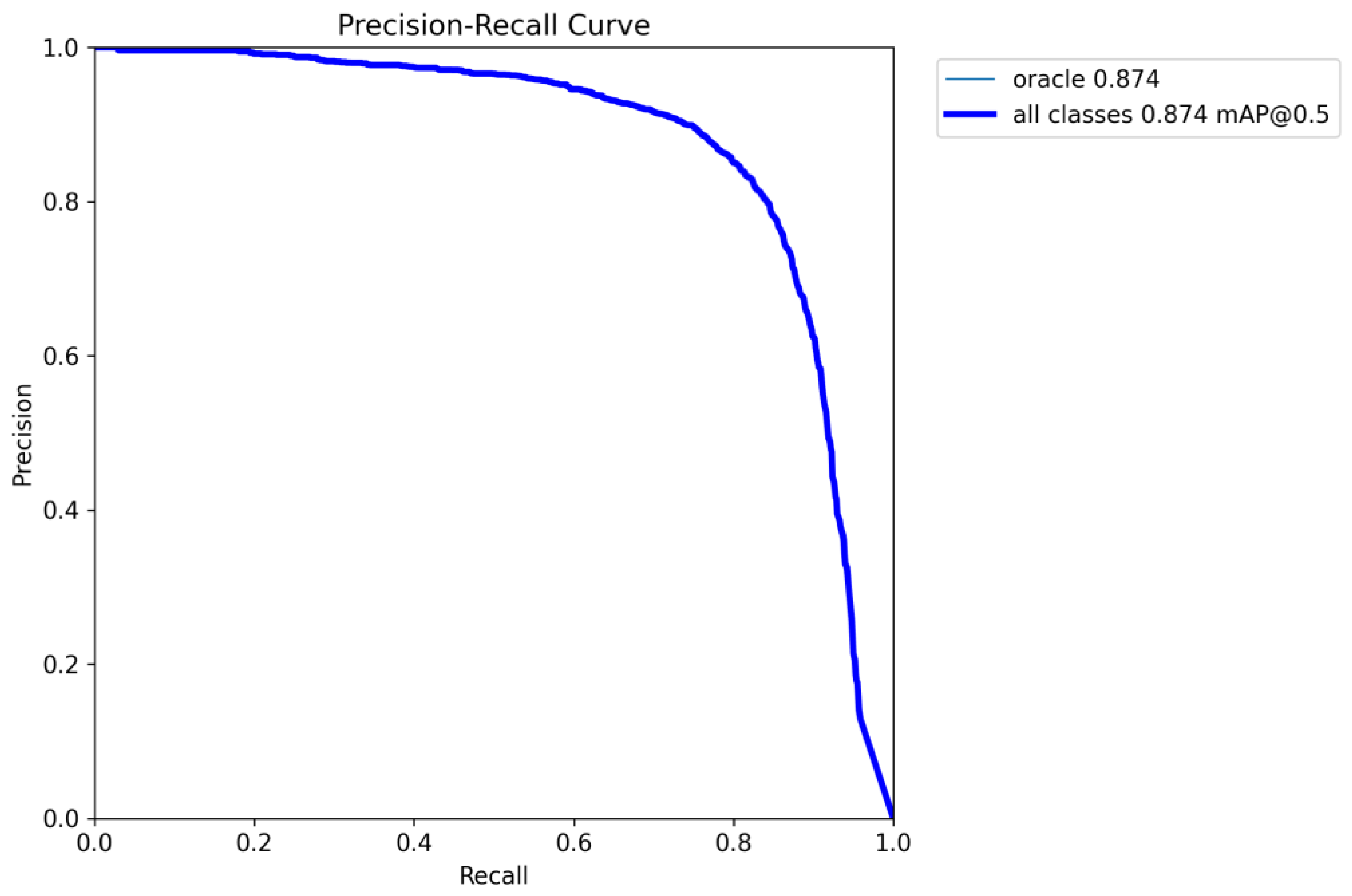
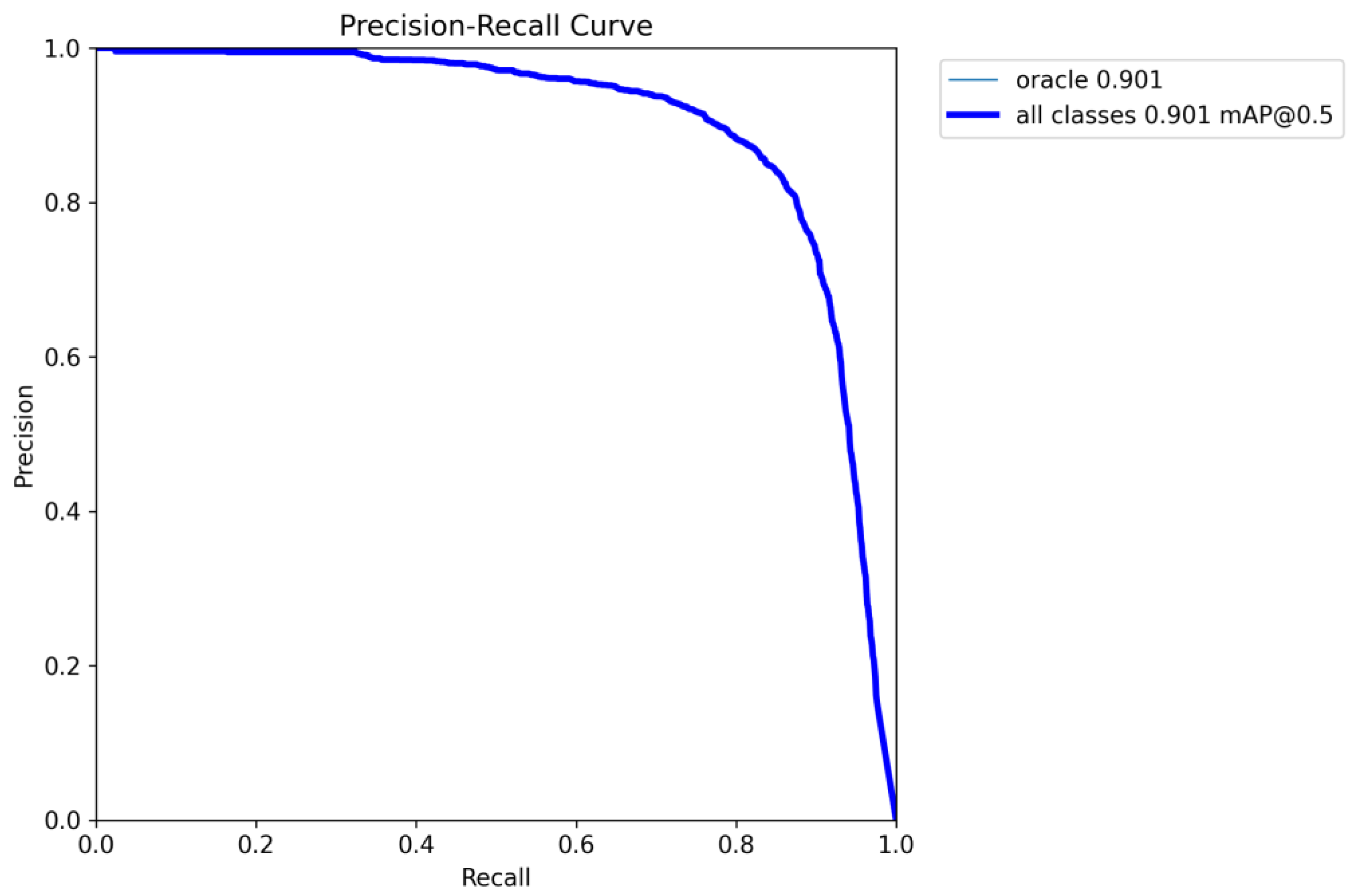
Given that the dataset download page on the Yin Qi Wen Yuan website explicitly requires the use of F-measure as the metric for evaluating model detection performance, this study complies with this requirement. The experiment uses the balanced F-measure of precision and recall metric as the evaluation metric. Formulas (13)–(15) are calculated for precision, recall, and F-measure.
where TP denotes the count of accurately identified positive samples, FP represents the count of negative samples mistakenly labeled as positive, and FN signifies the count of positive samples incorrectly identified as negative.
2.5.2. Experimental Environment
The experimental environment utilized in this study is presented in
Table 1.
2.5.3. Experimental Design
To thoroughly investigate the contribution of the model’s improvements to its overall achievement, thus laying the foundation for future optimization work on the model, we designed an ablation experiment. In this experiment, a step-by-step introduction strategy was adopted to sequentially integrate the small target detection head, adjusted loss function, and an attention mechanism into the baseline model. Furthermore, to specifically study the effects of different attention mechanisms, GAM, SE, EMA, and CBAM were, respectively, embedded in the network’s 9th layer on the basis of adding a small target detection head and adjusting the loss function.
Throughout the training phase, the OBI images in their original forms underwent scaling to achieve a resolution of 640 × 640 pixels. The learning rate commenced at 0.01 and remained unchanged, terminating at the same value. Every experimental iteration comprised 100 epochs, and the batch size for image processing was consistently maintained at 32. During training, all other parameters were set to the default values of the YOLOv8 model.
4. Discussion
Due to the large quantity of noise and cracks in the dataset, the improved algorithm’s loss function was changed from IoU to WIoU and incorporated CBAM embedded into the backbone network. Compared with the traditional IoU loss function, WIoU provides a more accurate target detection assessment by more comprehensively considering the relationship between the target region and its surroundings. Its advantage is more pronounced when dealing with low-quality examples, as it effectively avoids overfitting the model to these examples, thereby enhancing the overall model performance. The CBAM consists of two key attention mechanisms—channel and spatial attention—allowing the network to dynamically adjust the feature extraction based on the characteristics of the current task and input image. Therefore, the proposed improved algorithm shows significantly better detection results for images with noise compared with the baseline model, leading to an overall improvement in detection performance.
The improved algorithm can meet the requirements of real-time detection in practical applications, but it also has certain limitations. Adding additional downsampling, C2f, and convolution operations to the model increases FLOPs decreases computational efficiency and prolongs model training time. The next research direction is finding ways to enhance detection performance for OBIs while ensuring computational efficiency.
To study the expandability of the proposed algorithm, an experiment was conducted on the NEU-DET open dataset. Given the lack of convergence after 100 epochs, the training rounds were increased to 200, keeping all other settings consistent with the OBI experiment. The experimental results are shown in
Table 6. On the NEU-DET dataset, the detection performance of the improved algorithm increased by 3.13% compared with the baseline model. Therefore, the improved algorithm can be extended to detecting complex, small target background images in areas such as industrial defect detection and UAV aerial image analysis.
During the model training process, some technical challenges gradually emerged. The primary issue lies in the lack of strict one-to-one correspondence between the images and labels in the dataset, necessitating a comprehensive data-cleaning process to ensure a strict correspondence between images and labels. Additionally, the label format of the original dataset did not align with the requirements of the YOLOv8 algorithm. To address this challenge, it is necessary to accurately retrieve the actual dimensions of each image based on the label information of the dataset and recalculate the label data accordingly, thereby ensuring the effectiveness and accuracy of model training.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}