
Cross-Project Defect Prediction Based on Domain Adaptation and LSTM Optimization



Abstract
:1. Introduction
- Better feature representation: Minimizing noise and balancing the dataset to maintain the significant characteristics of the original data and reduce data distribution differences can help to find and choose the most relevant features. This can help the model learn more accurate feature representations and enhance model performance.
- Reduce overfitting: Imbalanced datasets and different data distribution can lead to overfitting of the model. When data are imbalanced, the model prioritizes the majority class and overlooks the minority class and, when data are distributed differently, the prediction of target data becomes ineffective. Balancing data and reducing noise from the dataset can help overcome the overfitting problem, simplifying the model ij order to learn from the minority class, and feature selection can help in minimizing data distribution differences to prevent model overfitting.
- In this research, we propose a novel CPDP model, SCAG-LSTM, that integrates SMOTE-ENN, CFS-BFS and Bi-LSTM with Bi-GRU and Attention Mechanism to construct a cross project defect prediction model that enhances software defect prediction performance.
- We demonstrate that the proposed novel domain adaptive framework reduces the effect of data distribution and class imbalance problems.
- We optimize the LSTM model with Bi-GRU and Attention Mechanism to efficiently capture semantic and contextual information and dependencies.
- To verify the efficiency of the proposed approach, we conducted experiments on PROMISE and AEEEM datasets to compare the proposed approach with the existing CPDP methodologies.
2. Related Work
2.1. Cross-Project Defect Prediction
2.2. Domain Adaptation
3. Methodology
3.1. Proposed Approach Framework
3.2. Proposed Features Selection Approach
| Algorithm 1. Pseudocode of CFS |
Input:
|
3.3. Proposed Imbalanced Learning Approach
| Algorithm 2. Pseudocode of SMOTE Edited Nearest Neighbor (SMOTE-ENN) |
Input:
|
3.4. Model Building
- (1)
- Calculates the merit of each feature and selects the top features based on the highest merit.
- (2)
- Selects the top k features based on the highest merit and creates the dataset.
- (1)
- Generating synthetic samples of the minority class using the k-nearest neighbors’ algorithm.
- (2)
- Removing any noisy or redundant samples from the resampled dataset using the Edited Nearest Neighbors (ENN) algorithm.
- (1)
- Bi-LSTM (Bidirectional Long Short-Term Memory) with 220 nodes
- (2)
- Bi-GRU (Bidirectional Gated Recurrent Unit) with 220 nodes
- (3)
- LSTM with 220 nodes
- (4)
- Attention Layer
| Algorithm 3. Proposed Approach. |
| Input: - Source Datasets: {, , …, } -Target Dataset: T Output: - Predicted Defects for T 1: Feature Selection for each source dataset (n): Calculate the merit (S_selected) for each feature in S(n) Select the top features based on highest merit and create S_selected end for 2: Select Features for Target Dataset T_selected = Features selected from T using the features selected in step 1 3: Handle Class Imbalance (SMOTE-ENN) S_resampled = Apply SMOTE-ENN to S_selected to handle class imbalance T_resampled = Apply SMOTE-ENN to T_selected to handle class imbalance 4: Split the Target Dataset S_x, S_y = Split (S_resampled, Size = 0.2) T_x, T_y = Split (T_resampled, Size = 0.2) 5: Build a Classifier Model = Sequential Neural Network - Layer 1: Bi-LSTM with 220 nodes - Layer 2: Bi-GRU with 220 nodes - Layer 3: LSTM with 220 nodes - Layer 4: Attention Layer 6: Train the Classifier Model.fit (T_resampled) 7: Predict Defects for T_y Result = Model.predict (T_y) 8: Output Return Result as Predicted Defects for T_y End |
4. Experimental Setups
4.1. Benchmark Datasets
4.2. Evaluation Metrics
4.3. Baseline Models
4.4. Research Questions
5. Experimental Results
5.1. Research Question—RQ1
5.2. Research Question—RQ2
5.3. Research Question—RQ3
6. Threats to Validity
6.1. Internal Validity
6.2. External Validity
6.3. Construct Validity
6.4. Conclusion Validity
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khan, M.A.; Elmitwally, N.S.; Abbas, S.; Aftab, S.; Ahmad, M.; Fayaz, M.; Khan, F. Software defect prediction using artificial neural networks: A systematic literature review. Sci. Program. 2022, 2022, 2117339. [Google Scholar] [CrossRef]
- Alenezi, M. Internal quality evolution of open-source software systems. Appl. Sci. 2021, 11, 5690. [Google Scholar] [CrossRef]
- Aljumah, S.; Berriche, L. Bi-LSTM-based neural source code summarization. Appl. Sci. 2022, 12, 12587. [Google Scholar] [CrossRef]
- Alqmase, M.; Alshayeb, M.; Ghouti, L. Quality assessment framework to rank software projects. Autom. Softw. Eng. 2022, 29, 41. [Google Scholar] [CrossRef]
- Akimova, E.N.; Bersenev, A.Y.; Deikov, A.A.; Kobylkin, K.S.; Konygin, A.V.; Mezentsev, I.P.; Misilov, V.E. A survey on software defect prediction using deep learning. Mathematics 2021, 9, 1180. [Google Scholar] [CrossRef]
- Thota, M.K.; Shajin, F.H.; Rajesh, P. Survey on software defect prediction techniques. Int. J. Appl. Sci. Eng. 2020, 17, 331–344. [Google Scholar]
- Matloob, F.; Ghazal, T.M.; Taleb, N.; Aftab, S.; Ahmad, M.; Khan, M.A.; Abbas, S.; Soomro, T.R. Software defect prediction using ensemble learning: A systematic literature review. IEEE Access 2021, 9, 98754–98771. [Google Scholar] [CrossRef]
- Gong, L.N.; Jiang, S.J.; Jiang, L. Research progress of software defect prediction. J. Softw. 2019, 30, 3090–3114. [Google Scholar]
- Pal, S.; Sillitti, A. A classification of software defect prediction models. In Proceedings of the 2021 International Conference Nonlinearity, Information and Robotics (NIR), Innopolis, Russia, 26–29 August 2021; pp. 1–6. [Google Scholar]
- Pan, C.; Lu, M.; Xu, B.; Gao, H. An improved CNN model for within-project software defect prediction. Appl. Sci. 2019, 9, 2138. [Google Scholar] [CrossRef]
- Bhat, N.A.; Farooq, S.U. An empirical evaluation of defect prediction approaches in within-project and cross-project context. Softw. Qual. J. 2023, 31, 917–946. [Google Scholar] [CrossRef]
- Malhotra, R.; Khan, A.A.; Khera, A. Simplify Your Neural Networks: An Empirical Study on Cross-Project Defect Prediction. In Proceedings of the Computer Networks and Inventive Communication Technologies: Fourth ICCNCT 2021, Coimbatore, India, 1–2 April 2022; pp. 85–98. [Google Scholar]
- Vescan, A.; Găceanu, R. Cross-Project Defect Prediction using Supervised and Unsupervised Learning: A Replication Study. In Proceedings of the 2023 27th International Conference on System Theory, Control and Computing (ICSTCC), Timisoara, Romania, 11–13 October 2023; pp. 440–447. [Google Scholar]
- Sasankar, P.; Sakarkar, G. Cross-Project Defect Prediction: Leveraging Knowledge Transfer for Improved Software Quality Assurance. In Proceedings of the International Conference on Electrical and Electronics Engineering, Barcelona, Spain, 19–21 August 2023; pp. 291–303. [Google Scholar]
- Jing, X.-Y.; Chen, H.; Xu, B. Cross-Project Defect Prediction. In Intelligent Software Defect Prediction; Springer: Berlin/Heidelberg, Germany, 2024; pp. 35–63. [Google Scholar]
- Bala, Y.Z.; Samat, P.A.; Sharif, K.Y.; Manshor, N. Cross-project software defect prediction through multiple learning. Bull. Electr. Eng. Inform. 2024, 13, 2027–2035. [Google Scholar] [CrossRef]
- Tao, H.; Fu, L.; Cao, Q.; Niu, X.; Chen, H.; Shang, S.; Xian, Y. Cross-Project Defect Prediction Using Transfer Learning with Long Short-Term Memory Networks. IET Softw. 2024, 2024, 5550801. [Google Scholar] [CrossRef]
- Fan, X.; Zhang, S.; Wu, K.; Zheng, W.; Ge, Y. Cross-Project Software Defect Prediction Based on SMOTE and Deep Canonical Correlation Analysis. Comput. Mater. Contin. 2024, 78, 1687–1711. [Google Scholar] [CrossRef]
- Saeed, M.S.; Saleem, M. Cross Project Software Defect Prediction Using Machine Learning: A Review. Int. J. Comput. Innov. Sci. 2023, 2, 35–52. [Google Scholar]
- Malhotra, R.; Meena, S. Empirical validation of feature selection techniques for cross-project defect prediction. Int. J. Syst. Assur. Eng. Manag. 2023, 1–13. [Google Scholar] [CrossRef]
- Xing, Y.; Qian, X.; Guan, Y.; Yang, B.; Zhang, Y. Cross-project defect prediction based on G-LSTM model. Pattern Recognit. Lett. 2022, 160, 50–57. [Google Scholar] [CrossRef]
- Pandey, S.K.; Tripathi, A.K. Class imbalance issue in software defect prediction models by various machine learning techniques: An empirical study. In Proceedings of the 2021 8th International Conference on Smart Computing and Communications (ICSCC), Kochi, India, 1–3 July 2021. [Google Scholar]
- Goel, L.; Sharma, M.; Khatri, S.K.; Damodaran, D. Cross-project defect prediction using data sampling for class imbalance learning: An empirical study. Int. J. Parallel Emergent Distrib. Syst. 2021, 36, 130–143. [Google Scholar] [CrossRef]
- Xing, Y.; Lin, W.; Lin, X.; Yang, B.; Tan, Z. Cross-project defect prediction based on two-phase feature importance amplification. Comput. Intell. Neurosci. 2022, 2022, 2320447. [Google Scholar] [CrossRef] [PubMed]
- Goel, L.; Nandal, N.; Gupta, S. An optimized approach for class imbalance problem in heterogeneous cross project defect prediction. F1000Research 2022, 11, 1060. [Google Scholar] [CrossRef]
- Nevendra, M.; Singh, P. Cross-Project Defect Prediction with Metrics Selection and Balancing Approach. Appl. Comput. Syst. 2022, 27, 137–148. [Google Scholar] [CrossRef]
- Jin, C. Cross-project software defect prediction based on domain adaptation learning and optimization. Expert Syst. Appl. 2021, 171, 114637. [Google Scholar] [CrossRef]
- Sun, Z.; Li, J.; Sun, H.; He, L. CFPS: Collaborative filtering based source projects selection for cross-project defect prediction. Appl. Soft Comput. 2021, 99, 106940. [Google Scholar] [CrossRef]
- Saeed, M.S. Role of Feature Selection in Cross Project Software Defect Prediction—A Review. Int. J. Comput. Inf. Manuf. (IJCIM) 2023, 3, 37–56. [Google Scholar]
- Khatri, Y.; Singh, S.K. An effective feature selection based cross-project defect prediction model for software quality improvement. Int. J. Syst. Assur. Eng. Manag. 2023, 14 (Suppl. S1), 154–172. [Google Scholar] [CrossRef]
- Liu, C.; Yang, D.; Xia, X.; Yan, M.; Zhang, X. A two-phase transfer learning model for cross-project defect prediction. Inf. Softw. Technol. 2019, 107, 125–136. [Google Scholar] [CrossRef]
- Xu, Z.; Li, L.; Yan, M.; Liu, J.; Luo, X.; Grundy, J.; Zhang, Y.; Zhang, X. A comprehensive comparative study of clustering-based unsupervised defect prediction models. J. Syst. Softw. 2021, 172, 110862. [Google Scholar] [CrossRef]
- Ni, C.; Liu, W.-S.; Chen, X.; Gu, Q.; Chen, D.-X.; Huang, Q.-G. A cluster based feature selection method for cross-project software defect prediction. J. Comput. Sci. Technol. 2017, 32, 1090–1107. [Google Scholar] [CrossRef]
- Abdu, A.; Zhai, Z.; Abdo, H.A.; Algabri, R.; Lee, S. Graph-Based Feature Learning for Cross-Project Software Defect Prediction. Comput. Mater. Contin. 2023, 77, 161–180. [Google Scholar] [CrossRef]
- Goyal, S. Handling class-imbalance with KNN (neighbourhood) under-sampling for software defect prediction. Artif. Intell. Rev. 2022, 55, 2023–2064. [Google Scholar] [CrossRef]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A systematic review on imbalanced data challenges in machine learning: Applications and solutions. ACM Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Bennin, K.E.; Keung, J.; Phannachitta, P.; Monden, A.; Mensah, S. Mahakil: Diversity based oversampling approach to alleviate the class imbalance issue in software defect prediction. IEEE Trans. Softw. Eng. 2017, 44, 534–550. [Google Scholar] [CrossRef]
- Vuttipittayamongkol, P.; Elyan, E. Neighbourhood-based undersampling approach for handling imbalanced and overlapped data. Inf. Sci. 2020, 509, 47–70. [Google Scholar] [CrossRef]
- Gong, L.; Jiang, S.; Jiang, L. An improved transfer adaptive boosting approach for mixed-project defect prediction. J. Softw. Evol. Process 2019, 31, e2172. [Google Scholar] [CrossRef]
- Kumar, A.; Kaur, A.; Singh, P.; Driss, M.; Boulila, W. Efficient Multiclass Classification Using Feature Selection in High-Dimensional Datasets. Electronics 2023, 12, 2290. [Google Scholar] [CrossRef]
- Yuan, Z.; Chen, X.; Cui, Z.; Mu, Y. ALTRA: Cross-project software defect prediction via active learning and tradaboost. IEEE Access 2020, 8, 30037–30049. [Google Scholar] [CrossRef]
- Rao, K.N.; Reddy, C.S. A novel under sampling strategy for efficient software defect analysis of skewed distributed data. Evol. Syst. 2020, 11, 119–131. [Google Scholar] [CrossRef]
- Fan, G.; Diao, X.; Yu, H.; Yang, K.; Chen, L. Software defect prediction via attention-based recurrent neural network. Sci. Program. 2019, 2019, 6230953. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Tomek, I. An Experiment with the Edited Nearest-Nieghbor Rule. IEEE Trans. Syst. Man Cybern 1976, 6, 448–452. [Google Scholar]
- Farid, A.B.; Fathy, E.M.; Eldin, A.S.; Abd-Elmegid, L.A. Software defect prediction using hybrid model (CBIL) of convolutional neural network (CNN) and bidirectional long short-term memory (Bi-LSTM). PeerJ Comput. Sci. 2021, 7, e739. [Google Scholar] [CrossRef]
- Uddin, M.N.; Li, B.; Ali, Z.; Kefalas, P.; Khan, I.; Zada, I. Software defect prediction employing BiLSTM and BERT-based semantic feature. Soft Comput. 2022, 26, 7877–7891. [Google Scholar] [CrossRef]
- D’Ambros, M.; Lanza, M.; Robbes, R. An extensive comparison of bug prediction approaches. In Proceedings of the 2010 7th IEEE Working Conference on Mining Software Repositories (MSR 2010), Cape Town, South Africa, 2–3 May 2010; pp. 31–41. [Google Scholar]
- Jureczko, M.; Madeyski, L. Towards identifying software project clusters with regard to defect prediction. In Proceedings of the 6th International Conference on Predictive Models in Software Engineering, Timișoara, Romania, 12–13 September 2010; pp. 1–10. [Google Scholar]
- Zhao, Y.; Zhu, Y.; Yu, Q.; Chen, X. Cross-project defect prediction considering multiple data distribution simultaneously. Symmetry 2022, 14, 401. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, J.; Sun, H.; Zhu, X. Collaborative filtering based recommendation of sampling methods for software defect prediction. Appl. Soft Comput. 2020, 90, 106163. [Google Scholar] [CrossRef]
- Palatse, V.G. Exploring principal component analysis in defect prediction: A survey. Perspect. Commun. Embed.-Syst. Signal-Process.-PiCES 2020, 4, 56–63. [Google Scholar]
- Lei, T.; Xue, J.; Wang, Y.; Niu, Z.; Shi, Z.; Zhang, Y. WCM-WTrA: A Cross-Project Defect Prediction Method Based on Feature Selection and Distance-Weight Transfer Learning. Chin. J. Electron. 2022, 31, 354–366. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Proposed Techniques | Datasets | Advantages | Limitation |
|---|---|---|---|---|
| Abdu et al., (2023) [34] | Learns representations of program items and extracts features from control flow graphs (CFGs) and data dependency graphs (DDGs) using NetworkX. | PROMISE datasets | Provides a methodical approach by utilizing graph elements from CFG and DDG to create a predictive model using LSTM. | Strictly depending on CFG and DDG as graph characteristics would not be able to collect all the context-relevant information required for defect prediction. |
| Liu et al., (2019) [31] | Built and assessed a two-phase CPDP transfer learning model (TPTL). | PROMISE datasets | Discovered that the model effectively lessened the TCA+ instability issue. | The study was an attempt to provide a process for choosing quality source projects. There are no suggestions for feature engineering, preprocessing techniques, or random datasets lacking comparable metrics. |
| Zhou Xu et al., (2021) [32] | Extensive empirical analysis on forty unsupervised models. | Open-source dataset with 27 project versions | The performance of the various clustering-based models varied significantly, and the clustering-based unsupervised systems did not always perform better on defect data when the three types of features were combined. | The feature engineering improvements and time/cost improvements required for the chosen DP unsupervised models were not included in the study. |
| Ni et al., (2020) [33] | Training data selection for CPDP | Relink and AEEEM | Better outcomes compared to WPDP, conventional CPDP, and TCA+ in terms of AUC and F-measure. | Limited emphasis was placed on feature selection in favor of instance selection in order to minimize the distribution divergence between the target and reference data. |
| Elyan et al., (2019) [37] | Undersampling to eliminate any overlapped data points in order to address class imbalance in binary datasets. | Simulated and real-world datasets | We offer four approaches based on neighborhood searching with various criteria to find and remove instances of the majority class. | Processing times are lengthened when the application is limited to one minority class at a time. |
| Jin et al., (2021) [27] | Domain adaptation (DA)was implemented with kernel twin support vector machines (KTSVMs). KTSVMs with DA functions, or DA-KTSVM, were also employed as the CPDP model in this study. | Open-source datasets | According to their research, DA-KTSVMO was able to outperform WPDP models in terms of prediction accuracy as well as outperform other CPDP models. | The study recommended that the best use of the sufficient data already in existence be made, with consideration given to the reuse of data that are deficient. |
| Gong et al., (2019) [38] | ITrAda-Boost, or transfer adaptive boosting, is a technique for handling small amounts of labeled data. | open source four datasets | Set to work the idea of stratification integrated in closest neighbor (STr-NN). To reduce the data distribution difference between the source and target datasets, first utilize the TCA technique and then the STr-NN technique. | Needs to be examined in light of its viability in comparison to other relevant models. |
| Kumar et al., (2023) [40] | K-Nearest Neighbor with 10-fold cross-validation for Sequential Forward Selection. | UCI repository | Combined filter and wrapper methods with Mutual Information, the Sequential Forward Method, and 10-fold cross-validation were used to choose the best features. | To validate the system, the model’s performance feasibility should be assessed. |
| Dataset | Project | Number of Instances | Defective Instances % |
|---|---|---|---|
| AEEEM | EQ | 325 | 39.692 |
| JDT | 997 | 20.662 | |
| LC | 399 | 16.040 | |
| ML | 1862 | 13.158 | |
| PDE | 1492 | 14.008 | |
| PROMISE | Ivy2.0 | 352 | 11.36 |
| Poi3.0 | 442 | 64.09 | |
| Xerces1.4 | 508 | 76.81 | |
| Synapse1.2 | 256 | 33.63 | |
| Xalan2.6 | 875 | 53.13 |
| Baseline Models | Reference No. | Advantages | Disadvantages |
|---|---|---|---|
| TPTL [31] | Liu et al., 2019 | The two-phase transfer learning model improves prediction accuracy and efficiency by utilizing transfer learning. | Generalizability is limited because of the concentration on a particular collection of defect datasets. |
| ALTRA [41] | Yuan et al., 2020 | ALTRA employs utilization of active learning to overcome the data distribution differences across source and target projects. | Limits the validation on different datasets by just conducting empirical research on the PROMISE dataset. |
| DAKTSVMO [27] | Jin et al., 2021 | Its ability to align the data distribution across different software projects allows for domain adaptation in CPDP. | Lack of comparison with different domain adaption approaches. |
| MSCPDP [50] | Zhao et al., 2022 | Ability to leverage information from multiple sources projects for enhanced prediction accuracy. | Did not entirely outperform more advanced single-source single-target approaches. |
| TFIA [24] | Xing et al., 2022 | Feature-level filtering strategy to improve data distribution differences between projects. | Doesn’t investigate how changing certain parameters affects the performance of the model |
| GBCPDP [34] | Abdu et al., 2023 | Uses graph features taken from CFG and DDG to build a predictive model using LSTM, offering a systematic framework. | Relying exclusively on CFG and DDG as graph features could fail to capture all necessary context-relevant data for defect prediction. |
| Source | Target | F1-Measure | AUC | ||
|---|---|---|---|---|---|
| Without SMOTE-ENN | With SMOTE-ENN | Without SMOTE-ENN | With SMOTE-ENN | ||
| EQ | JDT | 0.580 | 0.900 | 0.447 | 0.875 |
| EQ | LC | 0.588 | 0.917 | 0.416 | 0.750 |
| EQ | ML | 0.563 | 0.895 | 0.413 | 0.731 |
| EQ | PDE | 0.457 | 0.879 | 0.412 | 0.771 |
| JDT | EQ | 0.578 | 0.892 | 0.602 | 0.900 |
| JDT | LC | 0.494 | 0.879 | 0.510 | 0.810 |
| JDT | ML | 0.489 | 0.887 | 0.427 | 0.762 |
| JDT | PDE | 0.483 | 0.875 | 0.420 | 0.761 |
| LC | EQ | 0.488 | 0.878 | 0.510 | 0.846 |
| LC | JDT | 0.491 | 0.923 | 0.515 | 0.848 |
| LC | ML | 0.481 | 0.869 | 0.422 | 0.738 |
| LC | PDE | 0.478 | 0.871 | 0.429 | 0.760 |
| ML | EQ | 0.480 | 0.893 | 0.513 | 0.848 |
| ML | JDT | 0.466 | 0.899 | 0.509 | 0.823 |
| ML | LC | 0.499 | 0.938 | 0.507 | 0.835 |
| ML | PDE | 0.487 | 0.873 | 0.418 | 0.750 |
| PDE | EQ | 0.489 | 0.908 | 0.514 | 0.883 |
| PDE | JDT | 0.497 | 0.891 | 0.412 | 0.791 |
| PDE | LC | 0.480 | 0.884 | 0.519 | 0.820 |
| PDE | ML | 0.495 | 0.877 | 0.415 | 0.725 |
| Average | 0.503 | 0.891 | 0.466 | 0.801 | |
| Source | Target | F1-Measure | AUC | ||
|---|---|---|---|---|---|
| Without SMOTE-ENN | With SMOTE-ENN | Without SMOTE-ENN | With SMOTE-ENN | ||
| synapse_1.2 | poi-2.5 | 0.390 | 0.651 | 0.502 | 0.674 |
| synapse_1.2 | xerces-1.2 | 0.378 | 0.602 | 0.519 | 0.712 |
| camel-1.4 | ant-1.6 | 0.381 | 0.656 | 0.514 | 0.669 |
| camel-1.4 | jedit_4.1 | 0.378 | 0.636 | 0.480 | 0.612 |
| xerces-1.3 | poi-2.5 | 0.332 | 0.595 | 0.499 | 0.633 |
| xerces-1.3 | synapse_1.1 | 0.328 | 0.588 | 0.501 | 0.602 |
| xerces-1.2 | xalan-2.5 | 0.330 | 0.571 | 0.513 | 0.722 |
| lucene_2.2 | xalan-2.5 | 0.393 | 0.612 | 0.520 | 0.733 |
| synapse_1.1 | poi-3.0 | 0.387 | 0.602 | 0.497 | 0.630 |
| ant-1.6 | poi-3.0 | 0.319 | 0.520 | 0.460 | 0.619 |
| camel-1.4 | ant-1.6 | 0.430 | 0.782 | 0.537 | 0.713 |
| lucene_2.2 | ant-1.6 | 0.417 | 0.772 | 0.522 | 0.729 |
| log4j-1.1 | ant-1.6 | 0.415 | 0.745 | 0.528 | 0.733 |
| log4j-1.1 | lucene_2.0 | 0.402 | 0.733 | 0.527 | 0.757 |
| lucene_2.0 | log4j-1.1 | 0.449 | 0.742 | 0.560 | 0.719 |
| lucene_2.0 | xalan-2.5 | 0.342 | 0.546 | 0.501 | 0.669 |
| jedit_4.1 | camel-1.4 | 0.401 | 0.678 | 0.498 | 0.644 |
| jedit_4.1 | xalan-2.4 | 0.376 | 0.552 | 0.517 | 0.680 |
| Average | 0.380 | 0.643 | 0.510 | 0.680 | |
| Source | Target | F1-Measure | AUC | ||
|---|---|---|---|---|---|
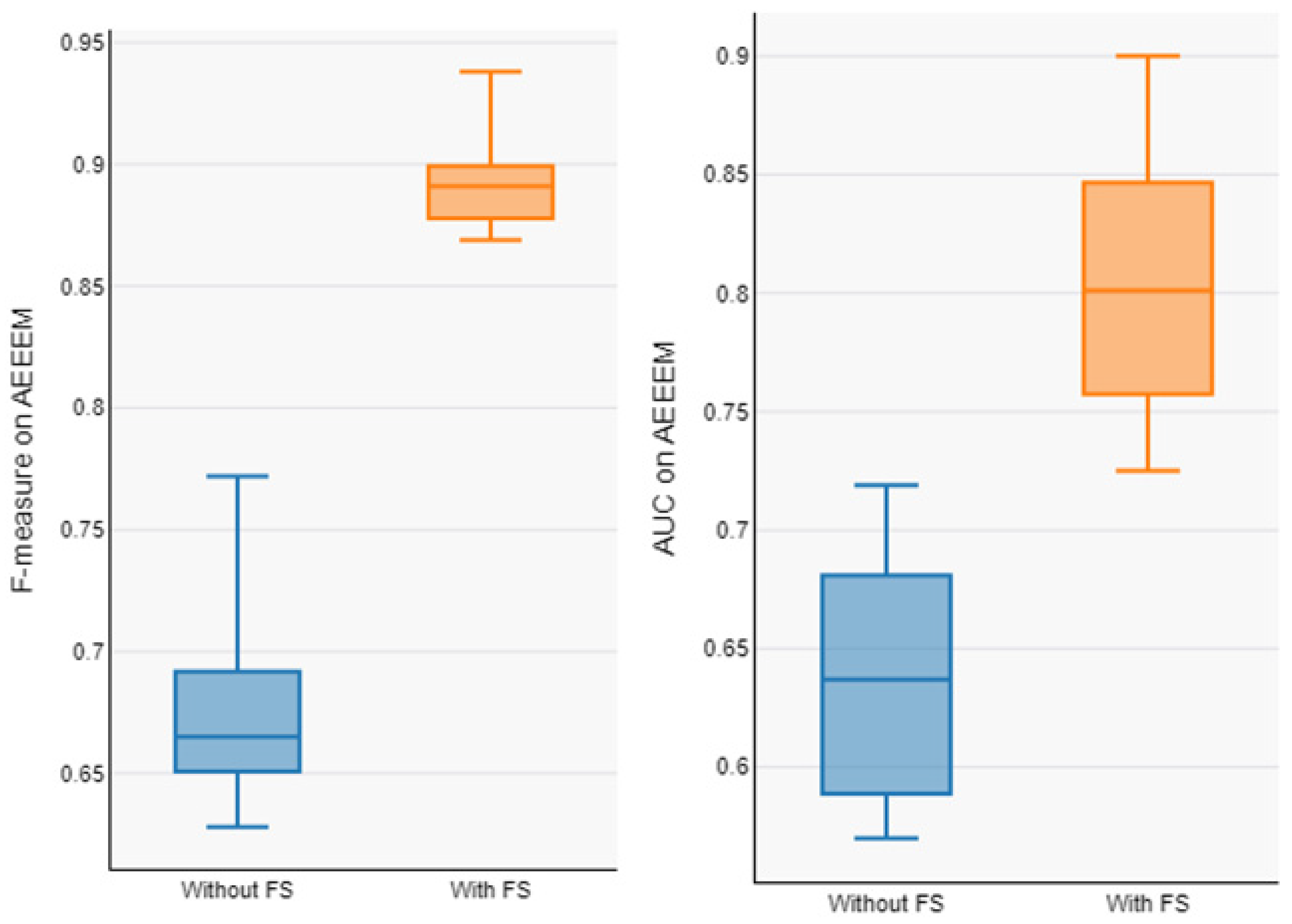
| Without FS | With FS | Without FS | With FS | ||
| EQ | JDT | 0.737 | 0.900 | 0.681 | 0.875 |
| EQ | LC | 0.742 | 0.917 | 0.590 | 0.750 |
| EQ | ML | 0.677 | 0.895 | 0.589 | 0.731 |
| EQ | PDE | 0.659 | 0.879 | 0.610 | 0.771 |
| JDT | EQ | 0.668 | 0.892 | 0.719 | 0.900 |
| JDT | LC | 0.652 | 0.879 | 0.670 | 0.810 |
| JDT | ML | 0.661 | 0.887 | 0.680 | 0.762 |
| JDT | PDE | 0.649 | 0.875 | 0.586 | 0.761 |
| LC | EQ | 0.650 | 0.878 | 0.570 | 0.846 |
| LC | JDT | 0.760 | 0.923 | 0.674 | 0.848 |
| LC | ML | 0.643 | 0.869 | 0.571 | 0.738 |
| LC | PDE | 0.651 | 0.871 | 0.592 | 0.760 |
| ML | EQ | 0.665 | 0.893 | 0.688 | 0.848 |
| ML | JDT | 0.669 | 0.899 | 0.660 | 0.823 |
| ML | LC | 0.772 | 0.938 | 0.688 | 0.835 |
| ML | PDE | 0.644 | 0.873 | 0.580 | 0.750 |
| PDE | EQ | 0.733 | 0.908 | 0.699 | 0.883 |
| PDE | JDT | 0.665 | 0.891 | 0.629 | 0.791 |
| PDE | LC | 0.654 | 0.884 | 0.681 | 0.820 |
| PDE | ML | 0.628 | 0.877 | 0.588 | 0.725 |
| Average | 0.678 | 0.891 | 0.637 | 0.801 | |
| Source | Target | F1-Measure | AUC | ||
|---|---|---|---|---|---|
| Without FS | With FS | Without FS | With FS | ||
| synapse_1.2 | poi-2.5 | 0.422 | 0.651 | 0.450 | 0.674 |
| synapse_1.2 | xerces-1.2 | 0.409 | 0.602 | 0.508 | 0.712 |
| camel-1.4 | ant-1.6 | 0.419 | 0.656 | 0.498 | 0.669 |
| camel-1.4 | jedit_4.1 | 0.410 | 0.636 | 0.512 | 0.612 |
| xerces-1.3 | poi-2.5 | 0.390 | 0.595 | 0.445 | 0.633 |
| xerces-1.3 | synapse_1.1 | 0.357 | 0.588 | 0.409 | 0.602 |
| xerces-1.2 | xalan-2.5 | 0.348 | 0.571 | 0.521 | 0.722 |
| lucene_2.2 | xalan-2.5 | 0.452 | 0.612 | 0.578 | 0.733 |
| synapse_1.1 | poi-3.0 | 0.502 | 0.602 | 0.436 | 0.630 |
| ant-1.6 | poi-3.0 | 0.480 | 0.520 | 0.456 | 0.619 |
| camel-1.4 | ant-1.6 | 0.520 | 0.782 | 0.533 | 0.713 |
| lucene_2.2 | ant-1.6 | 0.518 | 0.772 | 0.513 | 0.729 |
| log4j-1.1 | ant-1.6 | 0.526 | 0.745 | 0.520 | 0.733 |
| log4j-1.1 | lucene_2.0 | 0.503 | 0.733 | 0.547 | 0.757 |
| lucene_2.0 | log4j-1.1 | 0.519 | 0.742 | 0.578 | 0.719 |
| lucene_2.0 | xalan-2.5 | 0.398 | 0.546 | 0.490 | 0.669 |
| jedit_4.1 | camel-1.4 | 0.457 | 0.678 | 0.453 | 0.644 |
| jedit_4.1 | xalan-2.4 | 0.350 | 0.552 | 0.495 | 0.680 |
| Average | 0.443 | 0.643 | 0.496 | 0.680 | |
| Source | Target | ALTRA | MSCPDP | TFIA | Ours |
|---|---|---|---|---|---|
| EQ | JDT | 0.448 | 0.411 | 0.873 | 0.900 |
| EQ | LC | 0.449 | 0.260 | 0.903 | 0.917 |
| EQ | ML | 0.304 | 0.244 | 0.875 | 0.895 |
| EQ | PDE | 0.415 | 0.260 | 0.864 | 0.879 |
| JDT | EQ | 0.526 | 0.266 | 0.862 | 0.892 |
| JDT | LC | 0.704 | 0.256 | 0.875 | 0.879 |
| JDT | ML | 0.725 | 0.259 | 0.883 | 0.887 |
| JDT | PDE | 0.713 | 0.283 | 0.866 | 0.875 |
| LC | EQ | 0.465 | 0.307 | 0.862 | 0.878 |
| LC | JDT | 0.868 | 0.486 | 0.911 | 0.923 |
| LC | ML | 0.862 | 0.298 | 0.855 | 0.869 |
| LC | PDE | 0.792 | 0.269 | 0.866 | 0.871 |
| ML | EQ | 0.710 | 0.162 | 0.886 | 0.893 |
| ML | JDT | 0.751 | 0.312 | 0.883 | 0.899 |
| ML | LC | 0.808 | 0.123 | 0.925 | 0.938 |
| ML | PDE | 0.806 | 0.227 | 0.865 | 0.873 |
| PDE | EQ | 0.644 | 0.233 | 0.897 | 0.908 |
| PDE | JDT | 0.800 | 0.391 | 0.881 | 0.891 |
| PDE | LC | 0.800 | 0.16 | 0.873 | 0.884 |
| PDE | ML | 0.800 | 0.219 | 0.853 | 0.877 |
| Average | 0.670 | 0.271 | 0.878 | 0.891 |
| Source | Target | ALTRA | MSCPDP | TFIA | Ours |
|---|---|---|---|---|---|
| EQ | JDT | 0.266 | 0.628 | 0.735 | 0.875 |
| EQ | LC | 0.286 | 0.640 | 0.738 | 0.750 |
| EQ | ML | 0.253 | 0.557 | 0.702 | 0.731 |
| EQ | PDE | 0.203 | 0.557 | 0.740 | 0.771 |
| JDT | EQ | 0.388 | 0.575 | 0.719 | 0.900 |
| JDT | LC | 0.271 | 0.574 | 0.726 | 0.810 |
| JDT | ML | 0.605 | 0.574 | 0.707 | 0.762 |
| JDT | PDE | 0.668 | 0.583 | 0.721 | 0.761 |
| LC | EQ | 0.297 | 0.585 | 0.710 | 0.846 |
| LC | JDT | 0.441 | 0.667 | 0.768 | 0.848 |
| LC | ML | 0.341 | 0.590 | 0.732 | 0.738 |
| LC | PDE | 0.605 | 0.576 | 0.755 | 0.760 |
| ML | EQ | 0.579 | 0.528 | 0.755 | 0.848 |
| ML | JDT | 0.309 | 0.585 | 0.730 | 0.823 |
| ML | LC | 0.540 | 0.529 | 0.806 | 0.835 |
| ML | PDE | 0.287 | 0.558 | 0.724 | 0.750 |
| PDE | EQ | 0.373 | 0.551 | 0.785 | 0.883 |
| PDE | JDT | 0.388 | 0.620 | 0.754 | 0.791 |
| PDE | LC | 0.375 | 0.542 | 0.763 | 0.820 |
| PDE | ML | 0.491 | 0.558 | 0.718 | 0.725 |
| Average | 0.398 | 0.578 | 0.739 | 0.801 |
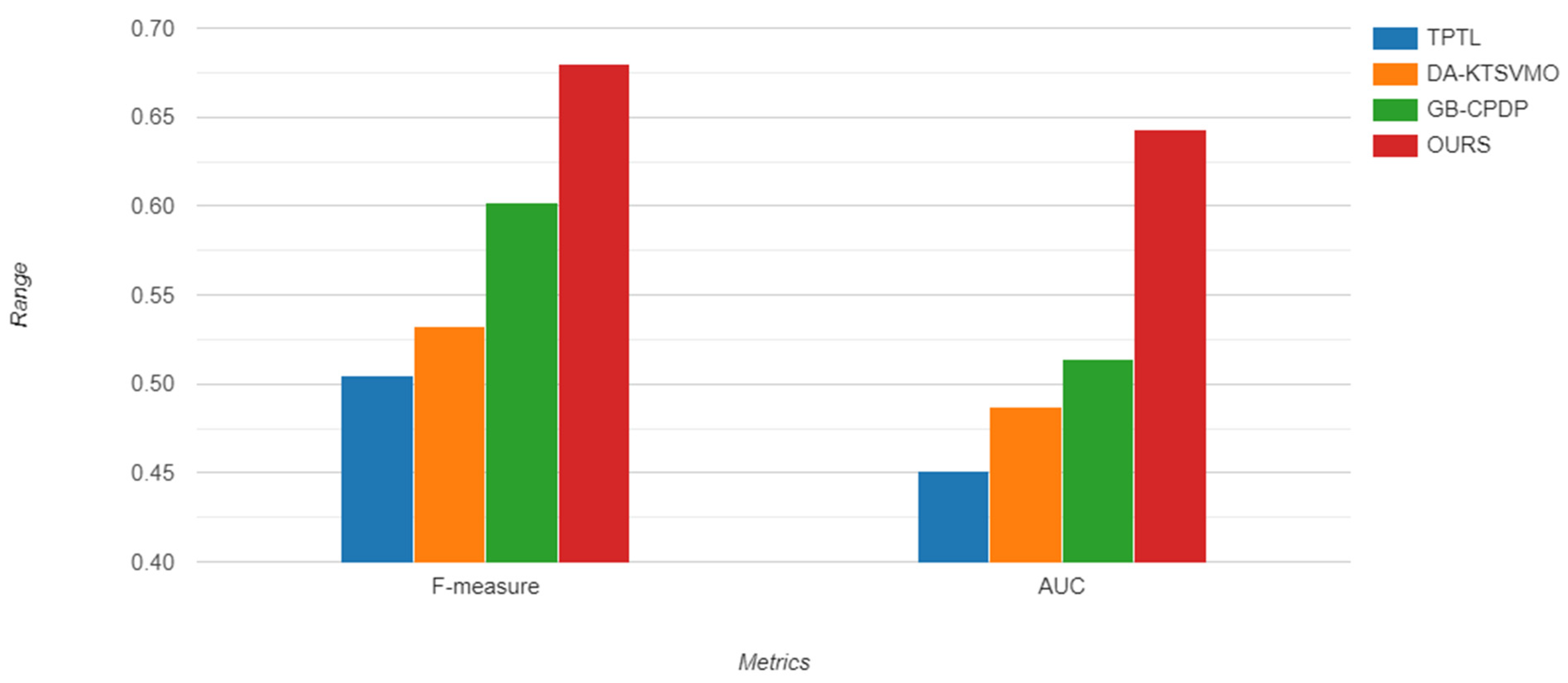
| Source | Target | TPTL | DA-KTSVMO | GB-CPDP | Ours |
|---|---|---|---|---|---|
| synapse_1.2 | poi-2.5 | 0.462 | 0.533 | 0.631 | 0.651 |
| synapse_1.2 | xerces-1.2 | 0.433 | 0.542 | 0.466 | 0.602 |
| camel-1.4 | ant-1.6 | 0.575 | 0.463 | 0.416 | 0.656 |
| camel-1.4 | jedit_4.1 | 0.396 | 0.402 | 0.356 | 0.636 |
| xerces-1.3 | poi-2.5 | 0.349 | 0.537 | 0.544 | 0.595 |
| xerces-1.3 | synapse_1.1 | 0.536 | 0.329 | 0.469 | 0.588 |
| xerces-1.2 | xalan-2.5 | 0.447 | 0.462 | 0.383 | 0.571 |
| lucene_2.2 | xalan-2.5 | 0.506 | 0.438 | 0.502 | 0.612 |
| synapse_1.1 | poi-3.0 | 0.342 | 0.566 | 0.537 | 0.602 |
| ant-1.6 | poi-3.0 | 0.353 | 0.315 | 0.384 | 0.520 |
| camel-1.4 | ant-1.6 | 0.556 | 0.511 | 0.652 | 0.782 |
| lucene_2.2 | ant-1.6 | 0.377 | 0.539 | 0.669 | 0.772 |
| log4j-1.1 | ant-1.6 | 0.595 | 0.585 | 0.676 | 0.745 |
| log4j-1.1 | lucene_2.0 | 0.478 | 0.576 | 0.622 | 0.733 |
| lucene_2.0 | log4j-1.1 | 0.419 | 0.561 | 0.489 | 0.742 |
| lucene_2.0 | xalan-2.5 | 0.510 | 0.510 | 0.514 | 0.546 |
| jedit_4.1 | camel-1.4 | 0.447 | 0.502 | 0.501 | 0.678 |
| jedit_4.1 | xalan-2.4 | 0.332 | 0.386 | 0.443 | 0.552 |
| Average | 0.451 | 0.487 | 0.514 | 0.643 |
| Source | Target | TPTL | DA-KTSVMO | GB-CPDP | Ours |
|---|---|---|---|---|---|
| synapse_1.2 | poi-2.5 | 0.485 | 0.498 | 0.593 | 0.674 |
| synapse_1.2 | xerces-1.2 | 0.485 | 0.563 | 0.681 | 0.712 |
| camel-1.4 | ant-1.6 | 0.541 | 0.655 | 0.532 | 0.669 |
| camel-1.4 | jedit_4.1 | 0.329 | 0.441 | 0.466 | 0.612 |
| xerces-1.3 | poi-2.5 | 0.588 | 0.477 | 0.568 | 0.633 |
| xerces-1.3 | synapse_1.1 | 0.488 | 0.468 | 0.502 | 0.602 |
| xerces-1.2 | xalan-2.5 | 0.471 | 0.437 | 0.696 | 0.722 |
| lucene_2.2 | xalan-2.5 | 0.621 | 0.702 | 0.568 | 0.733 |
| synapse_1.1 | poi-3.0 | 0.493 | 0.510 | 0.571 | 0.630 |
| ant-1.6 | poi-3.0 | 0.518 | 0.383 | 0.572 | 0.619 |
| camel-1.4 | ant-1.6 | 0.603 | 0.642 | 0.661 | 0.713 |
| lucene_2.2 | ant-1.6 | 0.411 | 0.570 | 0.658 | 0.729 |
| log4j-1.1 | ant-1.6 | 0.631 | 0.509 | 0.682 | 0.733 |
| log4j-1.1 | lucene_2.0 | 0.529 | 0.621 | 0.613 | 0.757 |
| lucene_2.0 | log4j-1.1 | 0.546 | 0.571 | 0.647 | 0.719 |
| lucene_2.0 | xalan-2.5 | 0.632 | 0.604 | 0.594 | 0.669 |
| jedit_4.1 | camel-1.4 | 0.267 | 0.355 | 0.556 | 0.644 |
| jedit_4.1 | xalan-2.4 | 0.425 | 0.563 | 0.669 | 0.680 |
| Average | 0.504 | 0.532 | 0.602 | 0.680 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Javed, K.; Shengbing, R.; Asim, M.; Wani, M.A. Cross-Project Defect Prediction Based on Domain Adaptation and LSTM Optimization. Algorithms 2024, 17, 175. https://doi.org/10.3390/a17050175
Javed K, Shengbing R, Asim M, Wani MA. Cross-Project Defect Prediction Based on Domain Adaptation and LSTM Optimization. Algorithms. 2024; 17(5):175. https://doi.org/10.3390/a17050175
Chicago/Turabian StyleJaved, Khadija, Ren Shengbing, Muhammad Asim, and Mudasir Ahmad Wani. 2024. "Cross-Project Defect Prediction Based on Domain Adaptation and LSTM Optimization" Algorithms 17, no. 5: 175. https://doi.org/10.3390/a17050175
APA StyleJaved, K., Shengbing, R., Asim, M., & Wani, M. A. (2024). Cross-Project Defect Prediction Based on Domain Adaptation and LSTM Optimization. Algorithms, 17(5), 175. https://doi.org/10.3390/a17050175