1. Introduction
In recent years, text-to-speech (TTS) systems have undergone significant advancements, which were largely driven by the adoption of deep learning (DL) techniques. These systems transform written text into natural-sounding speech through a multi-stage process. However, traditional approaches often necessitate trade-offs between the quality of the synthesized speech, the speed of generation, and the complexity of the training process.
One prevalent approach leverages a two-stage architecture [
1,
2]. In the initial stage, the system generates intermediate representations, such as linguistic features [
2] or mel-spectrograms—a representation capturing the frequency content of an audio signal over time [
1] from the preprocessed text. To generate mel-spectrograms from the preprocessed text, the system typically utilizes techniques like text-to-speech (TTS) models that convert the text into spectrogram images. These spectrograms represent how the frequency content of the audio signal varies over time, providing a structured format for subsequent stages of audio synthesis. The second stage then translates these representations into raw audio waveforms [
2,
3]. While this method has yielded realistic speech, it suffers from limitations. Training these models often requires sequential training or fine-tuning, hindering efficiency. Additionally, their reliance on predefined intermediate features restricts the utilization of potentially beneficial learned representations, limiting the system’s ability to further improve performance.
To address these shortcomings, alternative approaches have been explored, such as non-autoregressive methods [
4,
5] and generative adversarial networks (GANs) [
6]. Non-autoregressive models aim to overcome the slow generation speed inherent to autoregressive systems such as Tacotron 2 [
1] and Transformer TTS [
7] by eliminating the sequential nature of the process. These models can synthesize speech significantly faster, making them more suitable for real-time applications. On the other hand, GAN-based methods have shown promise in generating high-quality waveforms, potentially surpassing the quality achieved by two-stage approaches [
8,
9]. Recent efforts have focused on developing efficient end-to-end training methods for TTS models [
10,
11]. These methods aim to bypass the two-stage pipeline entirely and directly convert text into speech. While these approaches offer potential performance improvements by leveraging learned representations throughout the entire process, they often fall short of the quality achieved by two-stage systems, highlighting the ongoing challenge of balancing efficiency and quality in TTS.
The Sorani Kurdish dialect is predominantly spoken by Kurdish communities in Iraq and Iran, representing a significant linguistic and cultural identity within these regions. Despite its importance, Sorani Kurdish has faced challenges in modern technological advancements, particularly in the realm of TTS conversion. TTS technology plays a crucial role in enhancing accessibility and inclusivity for languages and dialects worldwide. However, the development of TTS systems for Sorani Kurdish has been relatively limited compared to more widely spoken languages. This discrepancy poses a barrier to the full participation of Sorani Kurdish speakers in digital communication, education, and accessibility tools that rely on TTS technology.
This study presents a parallel end-to-end TTS method to address the limitations of both traditional two-stage architectures and recent end-to-end methods. The proposed model is named Kurdish TTS (KTTS), as it will be developed to generate more natural-sounding Central Kurdish audio than that generated by current two-stage models. The goal of this study is to achieve high-quality speech synthesis while maintaining efficiency and simplified training protocols. Our approach utilizes a variational autoencoder (VAE) that is pre-trained for audio waveform reconstruction. This involves aligning the prior distribution established by the pre-trained encoder with the posterior distribution of the text encoder within latent variables. To augment the expressive capabilities of our method and enable the synthesis of high-fidelity speech waveforms, we employ adversarial training [
6] in the waveform reconstruction. By aligning latent distributions and integrating the stochastic duration predictor, our method facilitates the real-time generation of natural Kurdish audio speech. The proposed model is trained directly to maximize the log-likelihood of speech, and this is coupled with the alignment process.
One of the crucial steps in developing a TTS system is the creation of a high-quality speech corpus. Developing models that capture the prosodic patterns of Kurdish is essential for creating natural-sounding synthesized speech. Other contributions of this research work can be summarized as follows:
A novel end-to-end method for Kurdish text-to-speech conversion based on a VAE framework is introduced. The proposed VAE effectively maps input waveforms to a latent space representation and reconstructs them.
A robust training procedure is developed to align the latent variables of the text encoder with those of the pre-trained waveform encoder of the VAE. This involves ensuring that the prior distribution established by the pre-trained encoder matches with the posterior distribution of the text encoder within latent variables.
The proposed KTTS directly regenerates waveforms from input text by bypassing the intermediate stages required to create mel-spectrograms or linguistic features.
A new dataset comprising aligned pairs of Central Kurdish text sequences and corresponding audio recordings is curated. This dataset serves as a valuable resource for advancing research in Kurdish text-to-speech synthesis.
The rest of this article is organized as follows:
Section 2 offers a review of the TTS literature,
Section 3 explains the methodology for KTTS, and
Section 4 details the experimental setup, including the dataset and training parameters. In
Section 5, we present the results and a discussion, and finally,
Section 6 provides conclusions based on our findings.
2. TTS Literature Review
This section provides an overview of existing TTS systems, categorizing them into one-stage and two-stage approaches. It also briefly discusses the existing literature on Kurdish TTS systems. Transformers, initially introduced by Vaswani et al. in 2017 [
12], have revolutionized natural language processing by capturing long-range dependencies among input tokens, which is particularly beneficial for tasks like text-to-speech (TTS) synthesis. In recent years, their application to TTS development has yielded significant improvements in the naturalness and intelligibility of synthesized speech. This advance underscores the versatility and power of transformers in handling complex sequential data, highlighting their potential in other domains as well. In the following two subsections, we summarize state-of-the-art TTS systems, which are mostly based on transformer architectures.
2.1. One-Stage Systems
One-stage text-to-speech (TTS) systems streamline the process of converting text into synthetic speech by employing a direct transformation model. These systems leverage end-to-end neural network architectures, such as sequence-to-sequence models with attention mechanisms, to map raw text directly to acoustic waveforms. In variational inference with adversarial learning for end-to-end text-to-speech (VITS) [
13], a duration predictor is introduced to improve the rhythm of the generated utterances. VITS was extended to allow the generation of diverse utterances for multi-language speakers using your-TTS. Although these models allow sampling from the input tokens, the quality of these generated utterances is still inferior to that obtained with single-speaker systems [
14].
In ref. [
4], the authors introduced FastSpeech, a non-autoregressive version of transformer TTS [
7]. They used the original model as a teacher and extracted the character durations from it. To generate all output frames, they trained a student model using a convolutional duration prediction.
In 2021, Ren et al. introduced Fast Speech 2 [
10], a non-autoregressive version of transformer TTS. The researchers used external durations to improve the training process and reduce the development costs. This approach assumes that the alignment model used for the language is of high quality.
Recent advancements include models like VITS 2 [
15], which combines variational inference with normalizing flows and adversarial learning to directly generate high-fidelity speech waveforms from text. In ref. [
16], the authors proposed a framework for building controllable TTS systems that can generate speech with specific attributes. It combines a sequence-to-sequence TTS model with a conditional variational autoencoder (CVAE) to learn disentangled representations of speech attributes. The system enables flexible and controllable speech synthesis. The integration of large language models, such as LLaMA, into TTS systems, has been shown to enhance semantic understanding and generate more expressive speech [
17], highlighting the potential for semantic-aware TTS systems to further improve synthesis quality.
Our proposed model lies in the category of one-stage systems, where no intermediate stages are needed to create mel-spectrograms and then to convert mel-spectrograms into waveforms, as our system regenerates waveforms directly from input text.
2.2. Two-Stage Systems
Two-stage TTS systems introduce an intermediate step between text processing and waveform generation, typically predicting a mel-spectrogram before synthesizing the final speech output. This approach separates the linguistic and acoustic modeling stages, allowing for more fine-grained control and potentially higher-quality synthetic speech.
The SC-GlowTTS system [
18] is a flow-based multi-speaker text recognition system that takes the predicted parameters of an external speaker embedding into account. SNAC [
19], on the other hand, utilizes a coupling layer to explicitly normalize the input.
The basic Glow-TTS [
20] architecture consists of a flow-based determinate duration predictor, a transformer-equipped encoder, and a flow-dependent decoder. The transformer-based encoder produces a linear approximation of the prior distribution mean by translating the input tokens’ phonetic embedding into a representation with an 80-dimensional structure. The z-sampling method can also be utilized to express the distribution’s z-sampled value:
In training, the duration predictor only predicts the mean µ and the temperature T, while at inference time, it chooses a value of T that is usually smaller than 1. A latent representation of the distribution is then sampled from the prior data to generate a mel-spectrogram.
In 2017, Vaswani et al. introduced the concept of transformer TTS [
12]. In 2019, Li et al. [
7] tested the effectiveness of this technology by developing an algorithm that can predict the mel-spectrogram for English phonemes. The evaluation of the transformer TTS system showed that it was very promising, but it was not feasible to use it in a production setting because the auto-regressive approach was time-consuming. The evaluation of the mean opinion score (MOS) of a phonemicized dataset using a non-autoregressive model was not significantly different from the results when using the transformer TTS system. The authors also used a pitch prediction module with FastPitch [
21] to complement the duration predictor in their work from the Tactron2 model that they introduced [
1]. The authors claimed that the quality of their results was similar when using durations and phonemes from a Montreal forced alignment (MFA) model [
22].
Diff-TTS [
23] uses a diffusion probabilistic model to first generate mel-spectrograms, which are then converted to speech using advanced vocoder models like HiFi-GAN [
9]. More recently, models such as WaveGrad 2 [
24] and EfficientTTS 2 [
25] focus on optimizing the two-stage process for faster and more efficient synthesis without compromising on quality. In 2023, the MelStyleTTS [
26] proposed a style transfer technique for mel-spectrograms, allowing for greater expressiveness in synthetic speech. Two-stage systems have been shown to produce more natural and expressive speech compared to their one-stage counterparts, although they may introduce additional latency and complexity in the synthesis pipeline.
4. Methodology
This section explains the proposed method and its architecture. As illustrated in
Figure 1, our approach for Kurdish text-to-speech conversion comprises three key procedures: VAE for waveform reconstruction (
Figure 1A), training (
Figure 1B), and inference (
Figure 1A). Detailed descriptions of the components and blocks employed within our framework will be explained in this section.
4.1. Variational Autoencoder
To effectively pre-train a VAE for waveform reconstruction, several key components and formulas are essential. The VAE framework aims to learn a probabilistic mapping from an input waveform x to a latent space representation z and subsequently reconstructs the input as . This process involves two primary objectives: maximizing the likelihood of generating the input data given the latent variables and enforcing the learned latent space to follow a prior distribution.
The wave encoder , an approximate posterior distribution that is parameterized by , maps the input waveform x to a latent space representation z, where , with and representing the mean and variance of the latent space distribution, respectively. Subsequently, the wave decoder parameterized by generates the reconstructed output conditioned on the sampled latent variable z.
For training our VAE, the total loss
is the sum of two terms: the reconstruction loss
and Kullback–Leibler
divergence.
is expressed by the negative log-likelihood
capturing the probabilistic aspect of reconstruction, ensuring that the generated output closely resembles the input data distribution. For
, we simply use the mean square error (MSE) between the input
x and the reconstructed output
. Second, the
divergence term enforces a regularization constraint, guiding the latent space towards a predefined prior distribution
, which is a Gaussian distribution of
. Now, the target is to find the optimal
and
such that
4.2. Training Procedure
During the training, we take the pre-trained wave encoder from the previous step with its parameters frozen to generate the latent representation z of the target waveform x.
Our ultimate goal is to model the conditional distribution of the waveform data
by transforming a conditional prior distribution
through the pre-trained wave decoder
, where
c represents the input text sequence (see
Figure 1C). We parameterize the prior distribution with the parameters
of the text encoder and an alignment function
A, which is discussed in
Section 4.3.
To achieve this, we need to minimize the distance between the posterior distribution of the pre-trained wave encoder
and the prior distribution
. Once again, we employ KL divergence to force the latent space
z to conform to
. The KL divergence is, then,
where
The prior distribution’s statistics, denoted as and , are computed using the text encoder, which can transform the text condition into the corresponding statistics, and , with representing the length of the input text.
4.3. Alignment Prediction
The alignment function
A denotes the mapping from the index of the latent representation of waveform
z to the corresponding index of statistics from the text encoder,
, whenever
follows a normal distribution
. We presume that
A maintains both monotonicity and subjectivity to prevent skipping or repeating the input text. Subsequently, the prior distribution can be articulated as follows:
where
is the length of the input waveform.
Similar to [
20], we employ a monotonic alignment search to find the parameters
and the alignment
A that maximize the log-likelihood of waveform data, as shown in Equation (
7).
Throughout the training process, we keep the parameters of the pre-trained VAE
and
frozen. Consequently, our objective is to find the optimal alignment function
, after which we update
using gradient descent:
4.4. Duration Prediction
Given the absence of ground-truth labels for the alignment, it becomes necessary to estimate the alignment at every training iteration. The duration of each input token
can be computed by summing the columns within each row of the estimated alignment, as shown in Equation (
9). This duration calculation serves as our ground truth for training a deterministic duration predictor,
.
During the training procedure, we train
to re-predict the duration computed in Equation (
9) from the optimal alignment
. This duration prediction also helps predict
during the inference process. We train
with the MSE loss, as outlined in Equation (
10), by integrating it on top of the text encoder (see
Figure 1). In order to prevent interference with the maximum likelihood objective, we employ the stop gradient technique on the input of the duration predictor during the backward pass [
33].
where
where
denotes the stop gradient operator, and
is the hidden representation of the text encoder.
4.5. Inference Procedure
Throughout the inference process, which is illustrated in
Figure 1C, the statistical parameters
and
of the prior distribution, along with
, are obtained by the text encoder and duration predictor. Then, a latent variable is sampled from the prior distribution
, and concurrently, a waveform
is synthesized by transforming the sampled
z using the pre-trained wave decoder. Instead of feeding the entire latent representation
z, we segment
z into slices with a size of 32, each corresponding to a brief audio clip. The pre-trained wave decoder sequentially receives the slices and up-samples (transforms) them to the corresponding audio clips.
4.6. Model Architecture
4.6.1. Text Encoder
To handle Central Kurdish text, our initial step involves converting text sequences into International Phonetic Alphabet (IPA) sequences through the utilization of open-source software [
34]. Additionally, we incorporate several custom-defined phonemes to accommodate the distinct characters present in Central Kurdish, as outlined in
Appendix A.2. Then, the text encoder converts the phoneme embedding sequence into the hidden phoneme representation
. We follow the encoder structure of the transformer [
12], as shown in
Figure 2, with some slight modifications. We remove the positional encoding and add learnable positional encoding. We build the text encoder with eight blocks of transformer encoders, each with eight multi-head self-attention modules. The dimension of phoneme embeddings and the hidden size of the self-attention (hidden representations) are set to 256 following the recommendation by FASTSPEECH [
10].
The positional encoder depicted in
Figure 3 employs a grouped 1D convolution comprising 64 filters with a kernel size of 3 to generate a relative positional vector from the latent features. This vector is subsequently combined with the embedding of phonemes (tokens) to encode their positions relative to each other. We append a linear projection layer on top of the transformer encoder to predict the statistics of the prior distribution,
and
, from the hidden representation
.
4.6.2. Wave Encoder
To build our wave encoder, we utilize a transformer encoder structure identical to that employed in the text encoder, as depicted in
Figure 4. This choice aids the text encoder network in converging more swiftly when the KL divergence is applied for the difference between the two distributions.
In designing the feature encoding block, we adopt a similar structure to that outlined in ref. [
35] with slight changes, as depicted in
Figure 5. To enhance the processing efficiency, we opted for a configuration of five 1D convolutional blocks instead of the original seven, achieving comparable results according to empirical validation. Additionally, we substitute the GEUL activation layers with PRELU. The receptive field of the feature encoder spans a total context of 2200 samples, corresponding to 100 ms at the 22 kHz input sample rate. Consequently, this feature encoder extracts features from the raw waveform and tokenizes it, with each token representing a 100 ms segment. These tokens are subsequently processed by the transformer encoder.
4.6.3. Wave Decoder
Our wave decoder architecture is modeled after WaveNet [
2], as illustrated in
Figure 6. It comprises a transposed 1D convolution with a filter size of 64, along with 30 dilated residual convolution blocks. The skip channel size and kernel size of the 1D convolution are configured to 64 and 3, respectively. The wave decoder receives a sliced hidden representation
z with a channel size of 256 generated by the wave or text encoder, corresponding to a brief audio clip, as its input. It then utilizes transposed 1D convolution to upsample the slice, aligning it with the length of the corresponding audio clip.
Similar to prior works [
2,
13,
36], we incorporate adversarial training into the wave decoder. The discriminator
D in the adversarial training adopts the same structure and configurations as those of Parallel WaveGAN [
36].
D distinguishes between the waveform
generated by the wave decoder and the ground-truth waveform
x. We optimize the wave decoder by incorporating the multi-resolution short-time Fourier transform (STFT) loss in conjunction with the discriminator loss from the least squares generative adversarial network (LSGAN), aligning with the methodology of Parallel WaveGAN [
36].
4.6.4. Duration Predictor
predicts the distribution of phoneme durations from the hidden representation
. To build its architecture, we stack two residual blocks, as shown in
Figure 7. Each of these blocks consists of a convolutional layer containing 256 filters, each with a kernel size of 3, alongside a PRELU activation function and layer normalization followed by an FC. PRELU is chosen for its ability to learn negative slope values, mitigating the issue of dead neurons associated with RELU. Additionally, the inclusion of residual connections serves to mitigate vanishing gradients, thereby enhancing performance and reducing overfitting by encouraging feature reuse.
5. Experiments
This section details the dataset creation, categorization, and recording process, followed by an overview of the corpus statistics and technical specifications. The training approach, including the dataset partitioning and pre-training of the VAE, is outlined, along with the GPU usage and optimization techniques, providing a concise overview of our experimental setup.
5.1. Dataset
Text-to-speech systems depend on the availability of a corpus containing pairs of speech and corresponding text. This study explores voice data of the Central Kurdish dialect for TTS systems. We started by creating an audio- and text-pairing dataset featuring a male individual who spoke in Central Kurdish. The recording process was carried out by a male dubber in a recording studio. The 6078 sentences that we collected from the text corpus were categorized into 12 categories, including sports, science, literature, health, and everything else. Training sentences were then created using the collected information, resulting in 4255 (70%) sentences. The validation set contained 608 (10%) random sentences. The testing set contained 1215 (20%) sentences that were randomly selected from the overall dataset. The sentences were then improved through various web sources.
Table 2 illustrates the subjects and the number of sentences. The process of recording speech files ended after 30 days. The dataset can be accessed through the following link [
37].
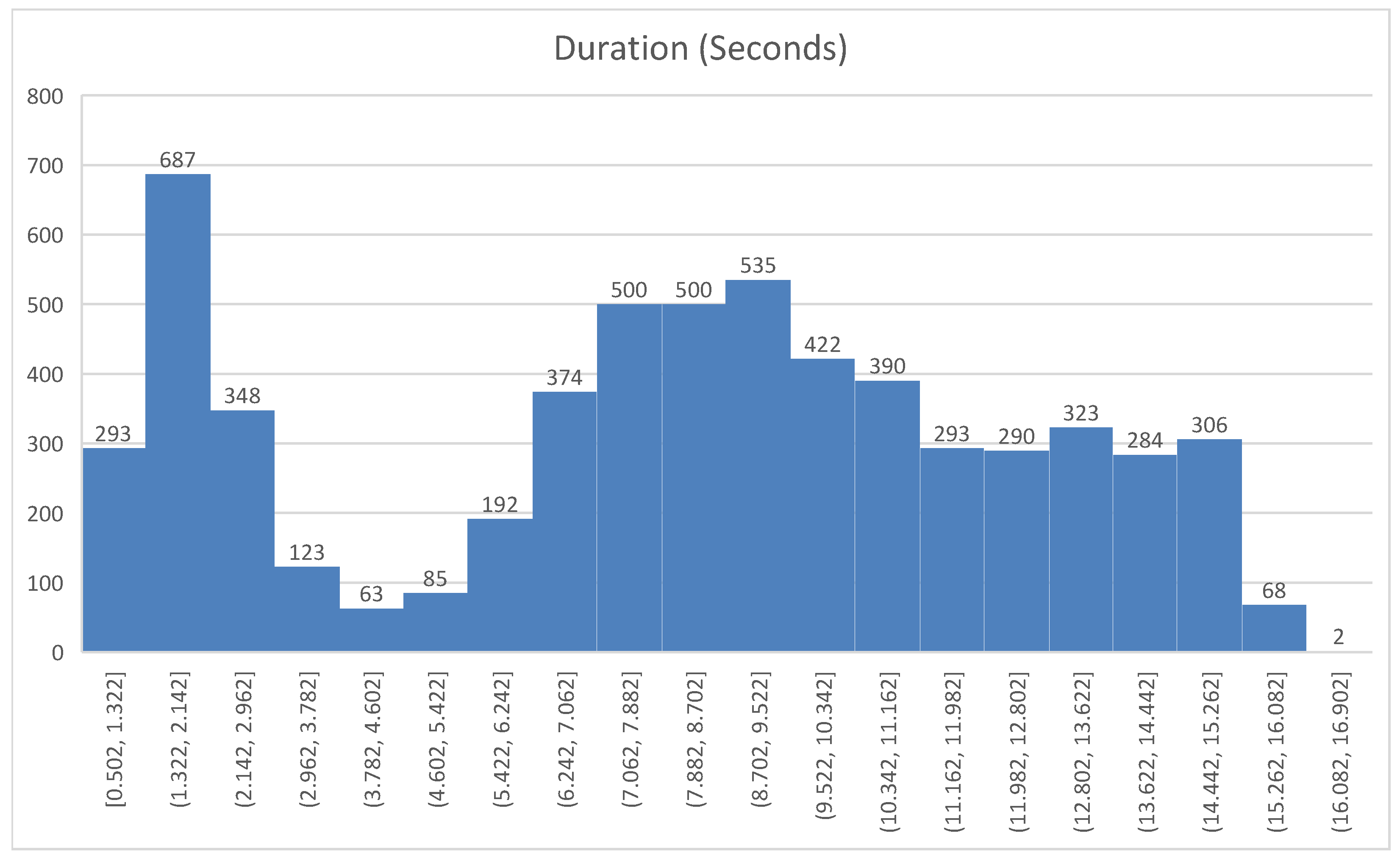
Some features of the recorded files can be summarized as follows: (a) 6078 WAV files and over 13.63 h of recorded speech were captured; (b) the output of the files was recorded at a rate of 22,050 kHz; (c) the quantization process was carried out using 16 bits of signed data; (d) the stored speech audio files were in the format known as PCM, and a mono channel was utilized to record the audio streams; (e) the shortest audio file length was 0.502 s; (f) the longest audio file length was 16.781 s; (g) the mean audio file length was 8.076 s.
The audio files are stored in wave format, while the text sentences are saved in an Excel file. The audio files are organized in a single folder. The audio file’s name includes the extension names, while the transcript is the text of the speech referenced to the audio file with an ID which is the name of the audio file. The dataset was prepared to comply with the Gaussian distribution to be more effective in training models avoiding bias in record length. A statistical figure of the dataset has been created to show more clarity on the number of audio records of similar length recordings as depicted in
Figure 8.
5.2. Training
We first split the dataset into the following three subsets: 70% for training, 10% for validation, and 20% for testing. Before starting the training procedure to align the wave and text encoders, we pre-trained the VAE using only the audio waveforms. The VAE takes an input audio
x and attempts to reconstruct
after compressing
x into
z. To reduce the training time, memory usage, and complexity, we fed a randomly selected sliced hidden representation
z with a window size of 32 to the wave decoder. To compute the STFT and LSGAN losses, we extracted the corresponding audio segments from the ground-truth raw waveforms as training targets. We followed the Parallel WaveGAN [
36] for the details of the adversarial training.
After the VAE had converged, we utilized the pre-trained wave encoder to initiate the training procedure. The aim was to align the latent distribution of the text encoder with that of the pre-trained wave encoder so that it could later be recognized by the pre-trained wave decoder.
The training of both the VAE and the alignment of the wave and text encoders was conducted on two RTX A5000 GPUs manufactured by NVIDIA sourced from Denver, Colorado in United States of America. The VAE was trained using a batch size of 18 waveforms per GPU. The optimization was performed by utilizing the Adam optimizer [
38] with the parameters set to
,
, and
. The learning rate decay was scheduled by a factor of
per epoch, starting from an initial value of
. It took 430 K steps for training until convergence.
The training for the alignment of the wave and text encoders was executed with a batch size of 12 sentences per GPU by utilizing the AdamW optimizer [
39] with the parameters
,
, and a weight decay of
. The learning rate decay followed a schedule of
factors per epoch, starting from an initial learning rate of
. The training process reached convergence after 820 K steps.
6. Results and Discussion
In this section, we evaluate the performance of KTTS in terms of audio quality and inference speed.
6.1. Audio Quality
We evaluated the generated synthetic audio files in the test set to obtain the MOS to measure the audio quality. We kept the sentence content consistent among the different models so as to exclude other interference factors and avoid biases by only examining the audio quality. Each audio was listened to by at least 54 evaluators who were all native speakers of Central Kurdish. We compared the MOSs of the audio samples generated by our KTTS model with those of other well-known TTS models, which included (a) the GT (the ground-truth audio), (b) Tacotron 2 [
1] (Mel + multi-band MelGAN [
40]), (c) VITS [
13], a conditional variational autoencoder with adversarial learning for end-to-end text-to-speech conversion, and (d) Glow TTS [
20], a generative flow for text-to-speech conversion via monotonic alignment search (Mel + multi-band MelGAN). For each model, only ratings greater than one were considered, while those equal to or below this threshold were excluded from the analysis. The results are shown in
Table 3. It can be seen that our KTTS outperformed the mentioned one-stage TTS system, and it reached the quality of the two-stage TTS systems.
6.2. Inference Speed
This section compares the inference speed of KTTS with that of both two-stage and one-stage systems. The comparison was conducted on a server with an “AMD Ryzen threadripper pro 3955wx” CPU with 16 cores, 256 GB of memory, and one NVIDIA RTX A5000 GPU with 24 GB of memory.
Table 4 shows that the proposed model sped up the inference process by 8.32x compared with that of the one-stage VITS system [
13]. Regarding the two-stage systems, the proposed model sped up the inference process by 47.49x with respect to Glow TTS [
20] and by 53.73x with respect to Tacotron 2 [
1], as the two-stage systems needed more processing time because two parallel models were included in their inference processes.
A real-time factor (RTF) comparison was conducted in order to evaluate the model’s efficiency in synthesizing speech.
Table 5 shows that the proposed model outperformed the other one-stage and two-stage models in real time.
Since our approach relies on VAEs, it is important to acknowledge some inherent limitations of this method. VAEs, though promising in various applications, including TTS, face certain challenges. Being an unsupervised learning system, VAEs lack precise control over the speech features they generate. A key drawback of VAEs is the need to balance regularization and reconstruction accuracy, which can sometimes lead to distorted speech outputs. Additionally, the alignment between synthesized speech and input text is not explicitly defined in VAEs. Moreover, VAEs require meticulous tuning of several hyperparameters, such as the dimensionality of the latent space, the choice of a prior distribution, and the weighting of loss and reconstruction terms. These factors necessitate careful consideration to optimize performance and mitigate potential issues.
The proposed approach may yield suboptimal results under certain conditions, such as a lack of sufficient training data, complex phonetic variability, and real-time constraints. These conditions can involve complex computations and latent space sampling during inference, which may be computationally expensive.




 ” is pronounced as palatal approximants “/j/”, and the “/i/” as it is referred to as a “vowel”. The letter “
” is pronounced as palatal approximants “/j/”, and the “/i/” as it is referred to as a “vowel”. The letter “ ” is also called a bilabial approximant, and it is pronounced as a a vowel: “/u/” or “/ʊ/”. The letter “
” is also called a bilabial approximant, and it is pronounced as a a vowel: “/u/” or “/ʊ/”. The letter “ ”, which is pronounced as “/u/”, a long vowel. Although it is one phoneme, it is not considered as a separate character in the keyboard layout released by the Department of Information Technology of the Regional Government of Kurdistan in 2014.
”, which is pronounced as “/u/”, a long vowel. Although it is one phoneme, it is not considered as a separate character in the keyboard layout released by the Department of Information Technology of the Regional Government of Kurdistan in 2014.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}