

Deep Learning-Based Boolean, Time Series, Error Detection, and Predictive Analysis in Container Crane Operations


Abstract
1. Introduction
1.1. Background
- Optimisation of Productivity and Efficiency: Timely error detection and prevention optimise crane performance and operational efficiency. By identifying and addressing errors promptly, operators can minimise the impact on productivity and throughput, ensuring that cranes operate at maximum capacity and efficiency [6]. This can be achieved by predicting errors early so that they do not turn into faults and result in failures. This performance optimisation contributes to container terminal operations’ overall productivity and profitability.
- Prevention of Operational Disruptions: Timely error detection allows for the early identification of potential issues or malfunctions in crane operations [7]. By promptly identifying errors, operators can take corrective actions to prevent operational disruptions, such as crane breakdowns or delays in cargo handling. This proactive approach helps to maintain the smooth flow of operations within container terminals, minimising downtime and ensuring the efficient utilisation of resources [8].
- Enhancement of Safety Protocols: Early detection of errors enables operators to implement safety protocols and procedures to mitigate risks and hazards associated with crane operations. By promptly addressing errors, operators can prevent accidents, injuries, and damage to cargo or infrastructure, safeguarding personnel’s well-being and preserving the integrity of terminal facilities [9].
- Reduction of Maintenance Costs: Detecting, diagnosing, and predicting errors early can help reduce maintenance costs associated with crane operations. By identifying potential errors before the said errors escalate into significant failures, operators can implement preventive and prescriptive maintenance measures to address underlying issues and prolong the lifespan of equipment [10]. This proactive maintenance approach helps to minimise downtime, repair costs, and operational disruptions, ultimately leading to cost savings for terminal operators [11].
- Compliance with Regulatory Standards: Timely error detection ensures compliance with regulatory standards and industry regulations governing crane operations. By promptly identifying and addressing errors, operators can maintain adherence to safety guidelines and operational protocols mandated by regulatory authorities. This compliance not only ensures the safety of personnel and assets but also helps to avoid potential fines and legal liabilities associated with non-compliance [12,13].
1.2. Research Objectives, Motivation, and Contributions
1.3. Deep Learning Overview
- Deep learning algorithms, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), have demonstrated exceptional capability in handling complex and high-dimensional data [18]. In container crane operations, where data streams from various sensors, control systems, and operational logs are abundant and diverse, deep learning models can effectively process these data to identify subtle patterns and anomalies indicative of errors.
- Deep learning models excel in capturing temporal dependencies and dynamic relationships within sequential data [19]. In container crane operations, where crane movements, cargo handling processes, and environmental conditions evolve, deep learning algorithms can analyse historical data to predict future states, enabling proactive error detection and prevention [20].
- The scalability and adaptability of deep learning models make them well-suited for real-time and offline monitoring and decision-making in dynamic operational environments. By continuously learning from new data and adapting to changing conditions, deep learning-based error detection systems can enhance operational safety, optimise resource utilisation, and mitigate potential risks in container crane operations [21,22].
1.4. Workflow
2. State-of-the-Art Review
- Complexity of Operational Data: Container crane operations generate vast amounts of data, including sensor readings, crane movements, cargo handling, and environmental conditions. Deep learning algorithms, such as RNNs and CNNs, excel at processing high-dimensional and sequential data [18], making them well-suited to analysing the intricate dynamics of crane operations.
- Temporal Dependencies: Crane operations exhibit temporal dependencies, where actions and events at one time step influence subsequent states and outcomes. RNNs, particularly LSTM networks, are designed to capture and learn from temporal dependencies in sequential data, enabling accurate modelling of the temporal evolution of crane operations and the detection of abnormal patterns or deviations [26,27].
- Feature Learning: Deep learning models can automatically learn relevant features from raw data, eliminating the need for manual feature engineering. In the context of error detection in container crane operations, deep learning algorithms can extract informative features from sensor data, crane trajectories, and operational logs, enabling more effective detection of anomalies and deviations indicative of errors.
- Adaptability to Complex Environments: container crane operations are subject to various environmental factors, such as wind, weather conditions, and sea states, which can influence crane performance and introduce uncertainties [28,29]. Deep learning models, with their capacity to learn from diverse and noisy data sources, exhibit robustness and adaptability to complex operating environments, enhancing the reliability and accuracy of error detection systems [22].
- Scalability and Generalisation: Deep learning algorithms are inherently scalable and can handle large volumes of data, making them suitable for analysing the extensive datasets generated by container terminal operations. Moreover, deep learning models can generalise unseen data well, enabling effective error detection across different terminal configurations, crane types, and operating conditions [30].
- Continuous Learning and Improvement: Deep learning models support continuous learning and improvement through iterative training on new data. As additional operational data become available, deep learning-based error detection systems can be updated and refined to adapt to evolving operational conditions, improving their effectiveness over time [16,31].
- Recurrent Neural Networks (RNNs): RNNs are adept at handling sequential data, rendering them suitable for time-series analysis. RNNs can effectively capture temporal dependencies in crane operation data [51].
- Long Short-Term Memory (LSTM): LSTM networks, a variant of RNNs, are designed to address the vanishing gradient problem. LSTMs are particularly adept at modelling long-term dependencies and have been successfully utilised to predict crane behaviour.
- Gated Recurrent Unit (GRU): GRUs are another RNN variant that maintains memory while being computationally efficient. GRUs have shown promise in predicting input force values for crane control.
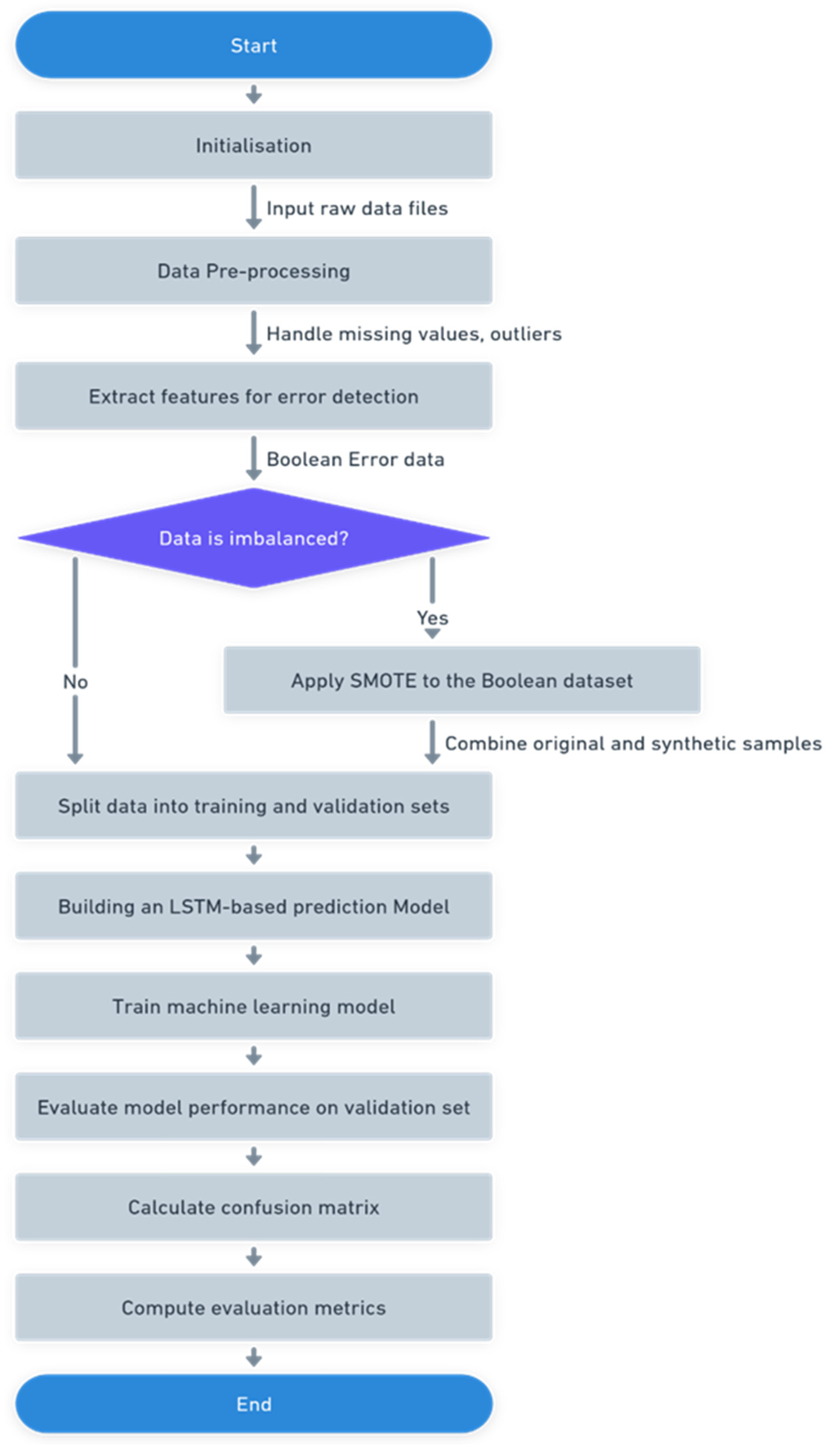
3. Methodology
4. Results
4.1. Evaluation Metrics
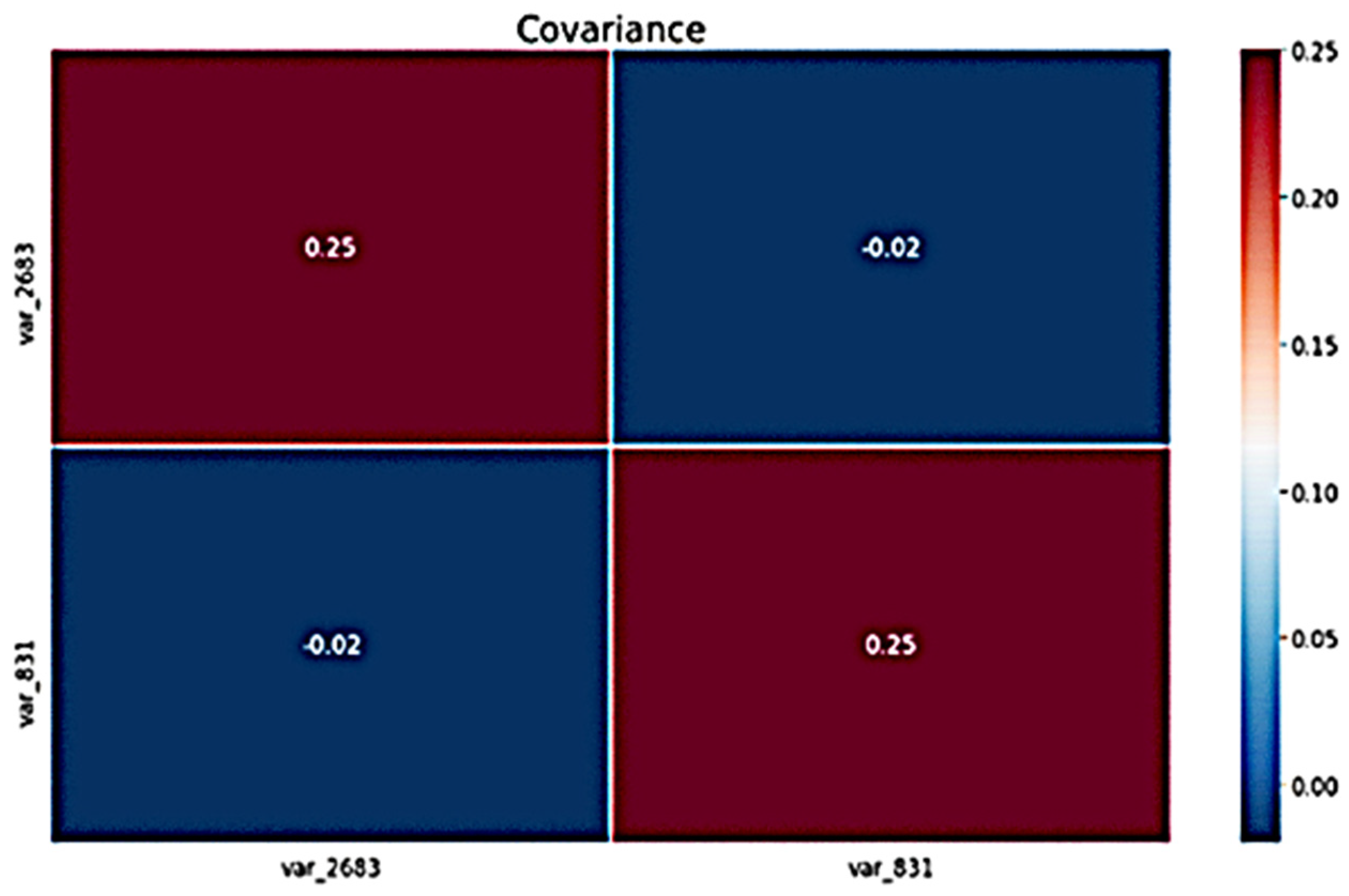
4.1.1. Covariance
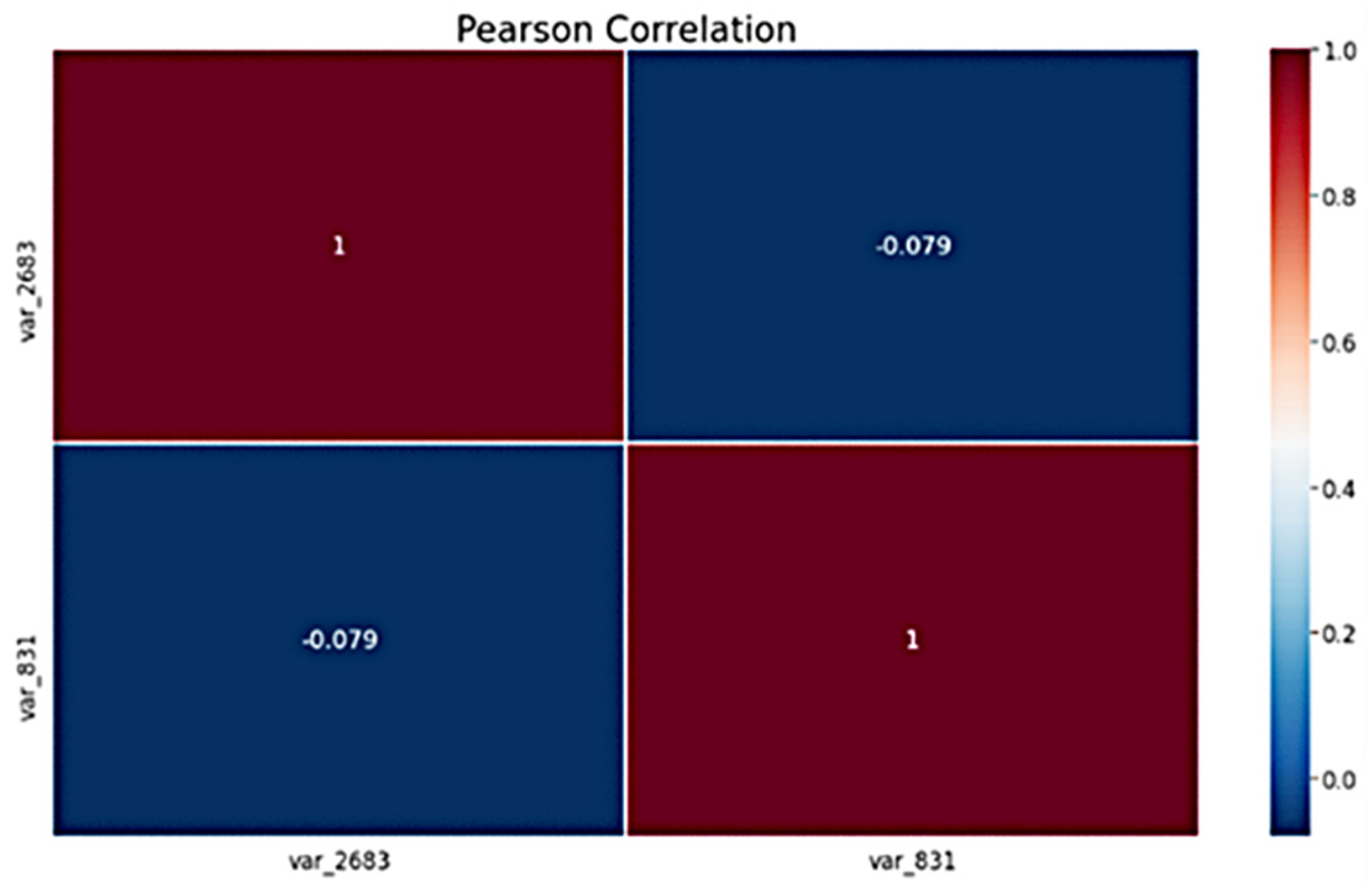
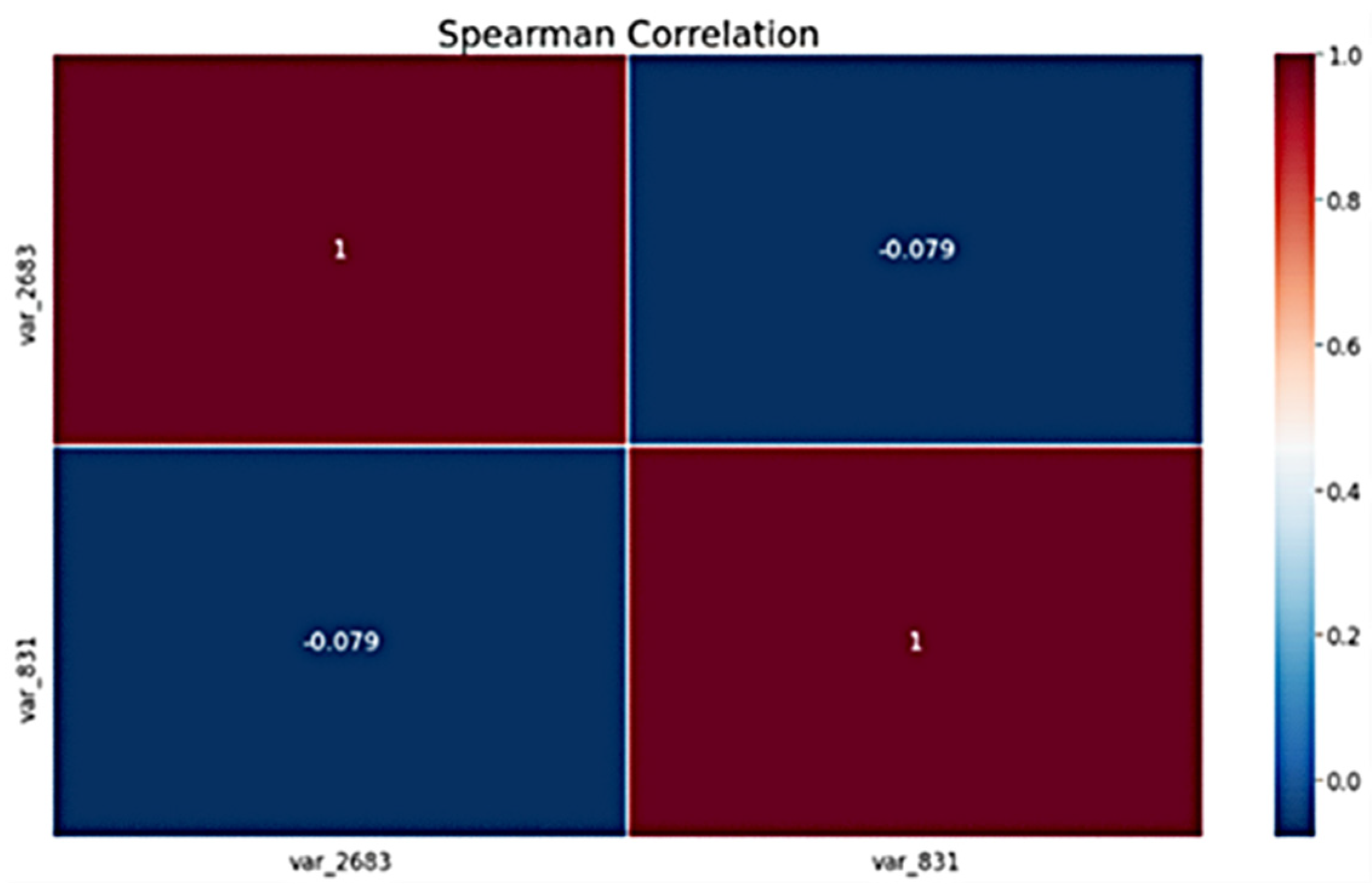
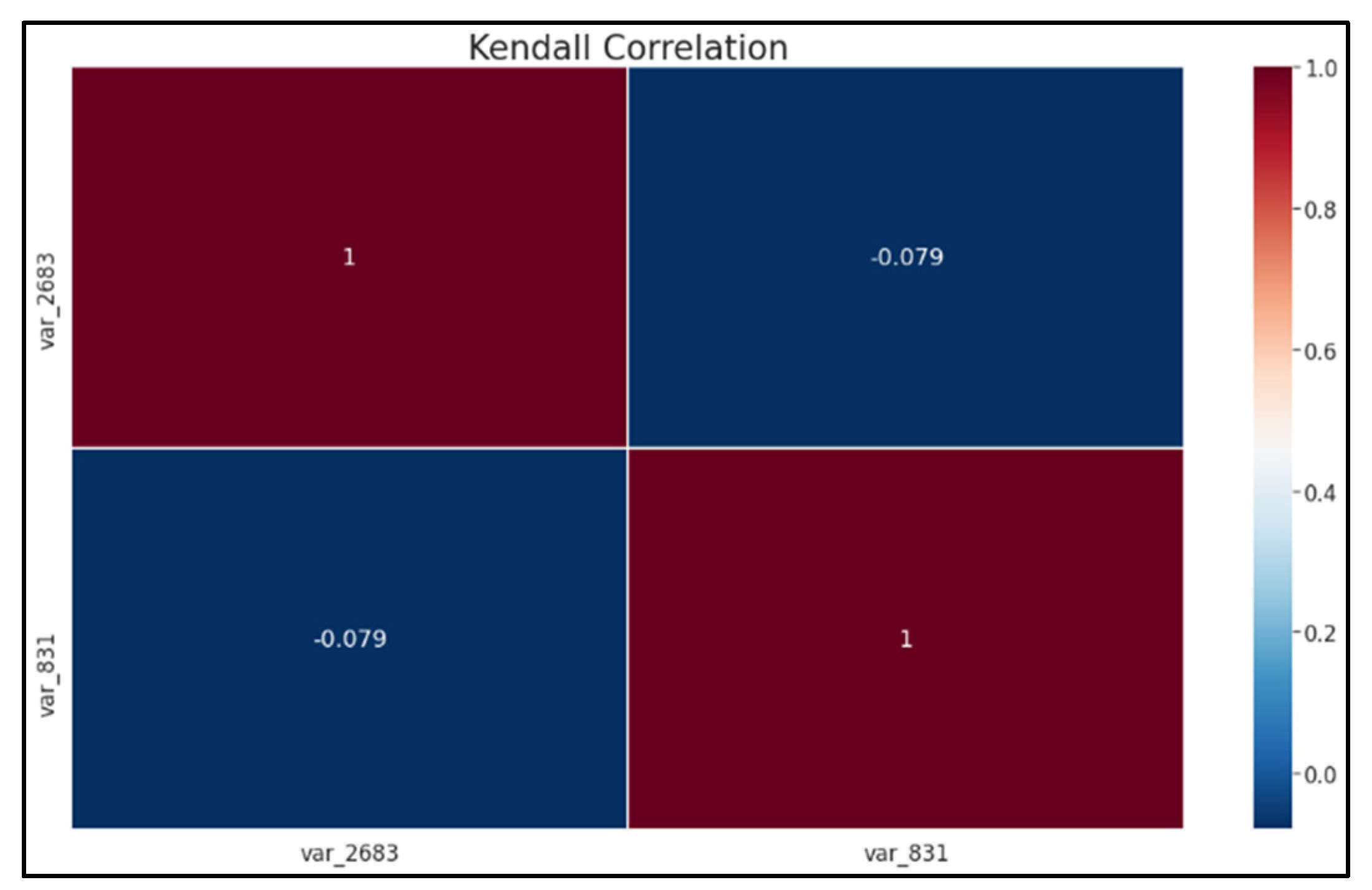
4.1.2. Correlation Matrix
Pearson Correlation
Spearman Correlation
Kendall Correlation
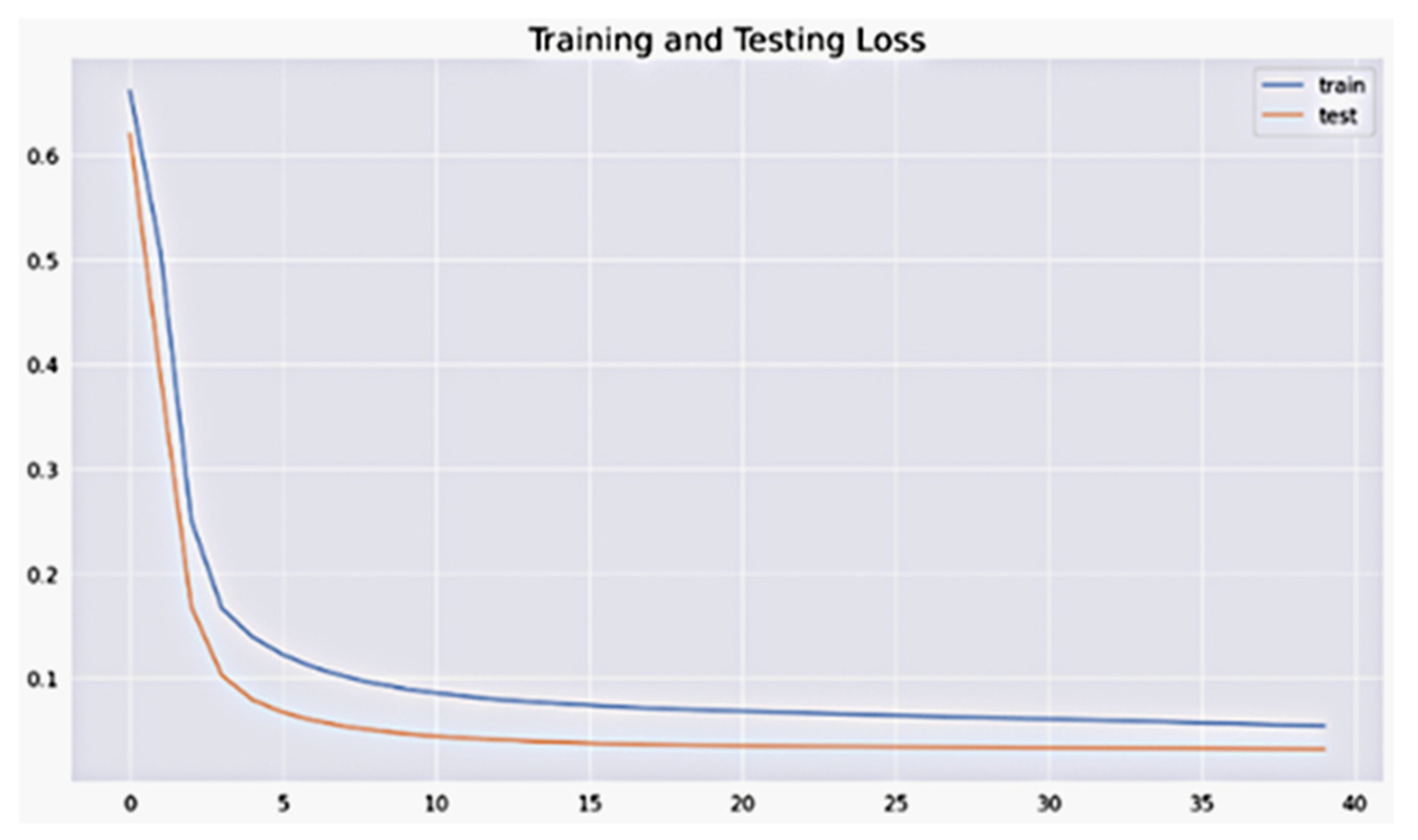
4.1.3. Training and Test Loss Function
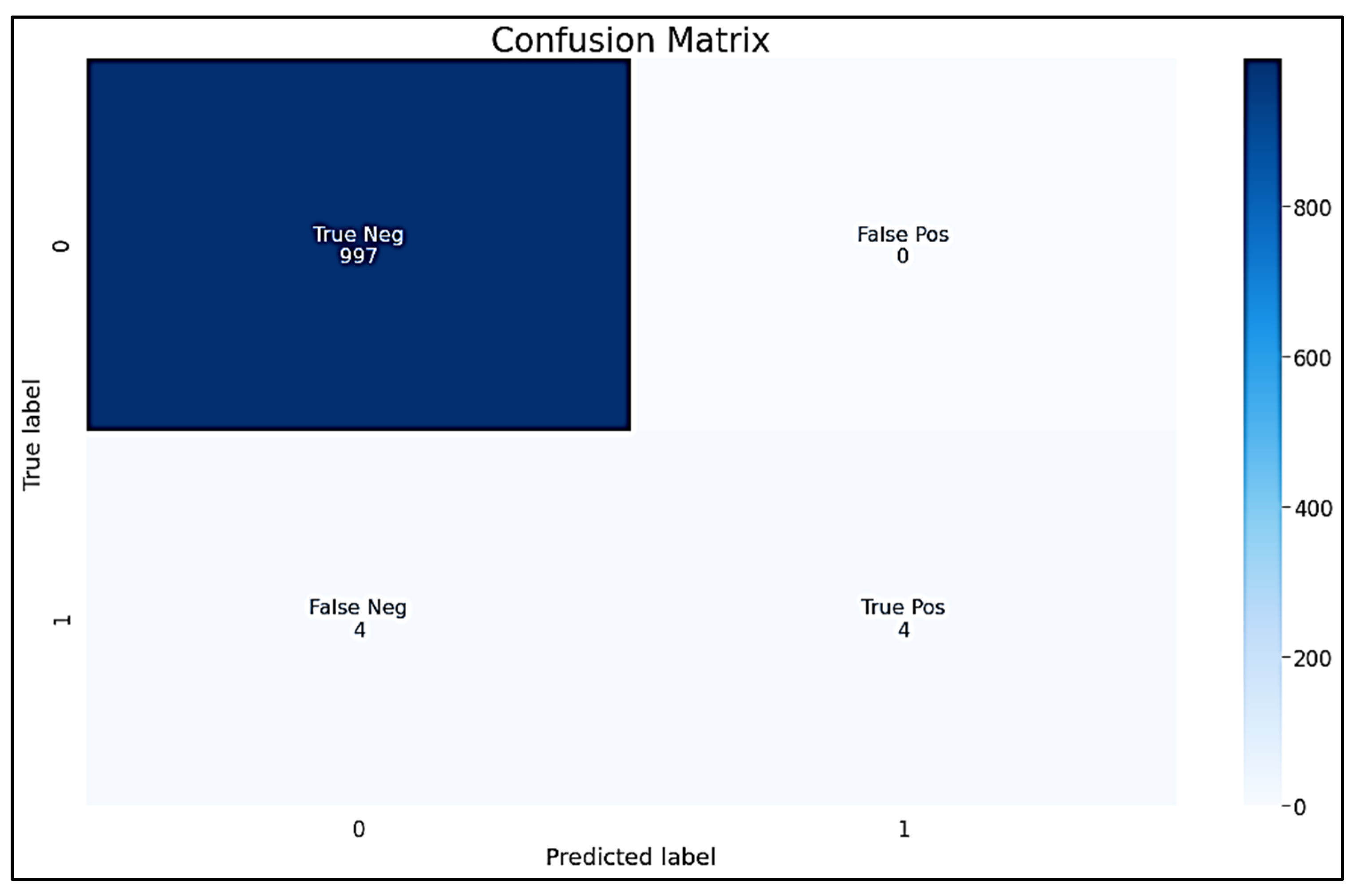
4.1.4. Confusion Matrix
- True Negatives (TN): Instances correctly predicted as class 0. These are desirable predictions—correctly identifying instances as negative (class 0);
- False Positives (FP): Instances incorrectly predicted as class 1 when they are actually class 0. These are errors—instances wrongly classified as positive (class 1) when they are not;
- False Negatives (FN): Instances incorrectly predicted as class 0 when they are actually class 1. These are also errors—instances wrongly classified as negative when they are positive;
- True Positives (TP): Instances correctly predicted as class 1. These are desirable predictions—correctly identifying instances as positive.
- True Negative (TN): The model correctly predicted negative instances (the actual outcome was negative). There are 997 true negatives;
- False Positive (FP): The model incorrectly predicted positive instances (the actual negative outcome). Here, there are nine false positives;
- False Negative (FN): The model incorrectly predicted negative instances (the actual positive outcome). The matrix shows four false negatives;
- True Positive (TP): The model correctly predicted positive instances (the actual outcome was positive). In this matrix, there are four true positives.
4.1.5. Accuracy, Precision, Recall, F1 Score
4.2. Error Data Time Series Prediction
5. Discussion
- Human-Induced Errors: Human operators still play a significant role in quay crane operations despite automation advancements. Their decisions and actions can lead to errors, affecting productivity and safety [64].
- Imbalanced data: A dataset is called imbalanced when there are substantial disparities in the number of examples of each class, resulting in one or more classes being underrepresented in the dataset [70]. This phenomenon has been established in several real-world datasets gathered in industrial settings.
- Because there was a significant time difference between the data array files, the data array files could not be merged for analysis; instead, analysis was performed on each data array file separately.
- For time series forecasting, the data were scaled down from milliseconds to seconds, because the data in milliseconds were not continuous, i.e., (1, 2, 3, …, 999).
- There may be a good chance of error as the dataset size was small, so the LSTM model could not properly and correctly predict new data. By adding more data, this issue can be resolved.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mordor Intelligence. Container Shipping Market—Size, Share & Growth Analysis. Mordor Intelligence Industry Reports. [Online]. Available online: https://www.mordorintelligence.com/industry-reports/global-container-shipping-market (accessed on 17 July 2024).
- Lindeberg, E.; Improving the Operational Performance of STS Cranes. Västerås, Sweden, February 2011. Available online: www.porttechnology.org (accessed on 18 June 2021).
- Ship-to-Shore (STS) Container CranesMarket Size, Share, Industry Forecast 2028. Available online: https://www.fortunebusinessinsights.com/ship-to-shore-sts-container-cranes-market-102880 (accessed on 15 June 2021).
- Zrniü, N.; Hoffmann, K. Development of Design of Ship-To-Shore Container Cranes: 1959–2004. In International Symposium on History of Machines and Mechanisms; Springer: Dordrecht, The Netherlands, 2007. [Google Scholar] [CrossRef]
- Khoukhi, A.; Khalid, M.H. Hybrid computing techniques for fault detection and isolation, a review. Comput. Electr. Eng. 2015, 43, 17–32. [Google Scholar] [CrossRef]
- Saltzer, J.H.; Frans Kaashoek, M. 2.2: Faults, Failures, and Fault-Tolerant Design 2.2.1: Faults, Failures, and Modules. In Principles of Computer System Design; Massachusetts Institute of Technology LibreTexts: Davis, CA, USA, 2024; Chapter 2.2; pp. 1–461. Available online: https://eng.libretexts.org/@go/page/58498 (accessed on 19 July 2024).
- Safaei, M.M.; Hejazian, S.; Pedrammehr, S.; Pakzad, M.; Ettefagh, M.; Fotouhi, M. Damage Detection of Gantry Crane with a Moving Mass Using Artificial Neural Network. Buildings 2024, 14, 458. [Google Scholar] [CrossRef]
- Wang, Z.; Cheng, J.; Hu, H. A Proactive-Reactive-Based Approach for Continuous Berth Allocation and Quay Crane Assignment Problems with Hybrid Uncertainty. J. Mar. Sci. Eng. 2024, 12, 182. [Google Scholar] [CrossRef]
- Gattuso, D.; Pratico, F.G.; Longo, R.; Cassone, G.; Vigna, M.; Sceni, R. Rail operations in freight terminals: Safety issues and proposed methodology. In 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems, MT-ITS 2017—Proceedings, Naples, Italy, 26–28 June 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 164–169. [Google Scholar] [CrossRef]
- Huang, M.; Liu, Z.; Tao, Y. Mechanical fault diagnosis and prediction in IoT based on multi-source sensing data fusion. Simul. Model. Pract. Theory 2020, 102, 101981. [Google Scholar] [CrossRef]
- Meddaoui, A.; Hain, M.; Hachmoud, A. The benefits of predictive maintenance in manufacturing excellence: A case study to establish reliable methods for predicting failures. Int. J. Adv. Manuf. Technol. 2023, 128, 3685–3690. [Google Scholar] [CrossRef]
- Fernandes, M.; Canito, A.; Bolón-Canedo, V.; Conceição, L.; Praça, I.; Marreiros, G. Data analysis and feature selection for predictive maintenance: A case-study in the metallurgic industry. Int. J. Inf. Manag. 2019, 46, 252–262. [Google Scholar] [CrossRef]
- Yeoh, J.K.W.; Wong, J.H.; Peng, L. Integrating Crane Information Models in BIM for Checking the Compliance of Lifting Plan Requirements. In Proceedings of the 33rd International Symposium on Automation and Robotics in Construction (ISARC 2016), Auburn, AL, USA, 18–21 July 2016; Available online: https://www.iaarc.org/publications/fulltext/ISARC2016-Paper192.pdf (accessed on 20 July 2024).
- Chu, F.; Gailus, S.; Liu, L.; Ni, L. The Future of Port Automation|McKinsey. 2018. Available online: https://www.mckinsey.com/industries/travel-logistics-and-infrastructure/our-insights/the-future-of-automated-ports (accessed on 18 May 2024).
- Lepenioti, K.; Pertselakis, M.; Bousdekis, A.; Louca, A.; Lampathaki, F.; Apostolou, D.; Mentzas, G.; Anastasiou, S. Machine Learning for Predictive and Prescriptive Analytics of Operational Data in Smart Manufacturing. In Advanced Information Systems Engineering Workshops; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- What Is Deep Learning?|A Beginner’s Guide. Available online: https://www.scribbr.com/ai-tools/deep-learning/ (accessed on 19 May 2024).
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Kumar, A.; Gaur, N.; Chakravarty, S.; Alsharif, M.H.; Uthansakul, P.; Uthansakul, M. Analysis of spectrum sensing using deep learning algorithms: CNNs and RNNs. Ain Shams Eng. J. 2024, 15, 102505. [Google Scholar] [CrossRef]
- Ubal, C.; Di-Giorgi, G.; Contreras-Reyes, J.E.; Salas, R. Predicting the Long-Term Dependencies in Time Series Using Recurrent Artificial Neural Networks. Mach. Learn. Knowl. Extr. 2023, 5, 1340–1358. [Google Scholar] [CrossRef]
- Heilig, L.; Stahlbock, R.; Voß, S. From Digitalization to Data-Driven Decision Making in Container Terminals. arXiv 2019, arXiv:1904.13251. [Google Scholar]
- Shin, H.-S.; Lee, S.-P.; Ha, Y.-S.; Kim, H.-S. Designing container crane control learning model using deep learning. J. Adv. Mar. Eng. Technol. 2023, 47, 2023–2234. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep Learning for Anomaly Detection: A Survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Shagluf, A.; Longstaff, A.P.; Fletcher, S. (PDF) Maintenance Strategies to Reduce Downtime Due to Machine Positional Errors, Maintenance Performance Measurement and Management (MPMM). Available online: https://www.researchgate.net/publication/267864966_Maintenance_Strategies_to_Reduce_Downtime_Due_to_Machine_Positional_Errors (accessed on 18 July 2024).
- Fernandes, M.; Corchado, J.M.; Marreiros, G. Machine learning techniques applied to mechanical fault diagnosis and fault prognosis in the context of real industrial manufacturing use-cases: A systematic literature review. Appl. Intell. 2022, 52, 14246–14280. [Google Scholar] [CrossRef] [PubMed]
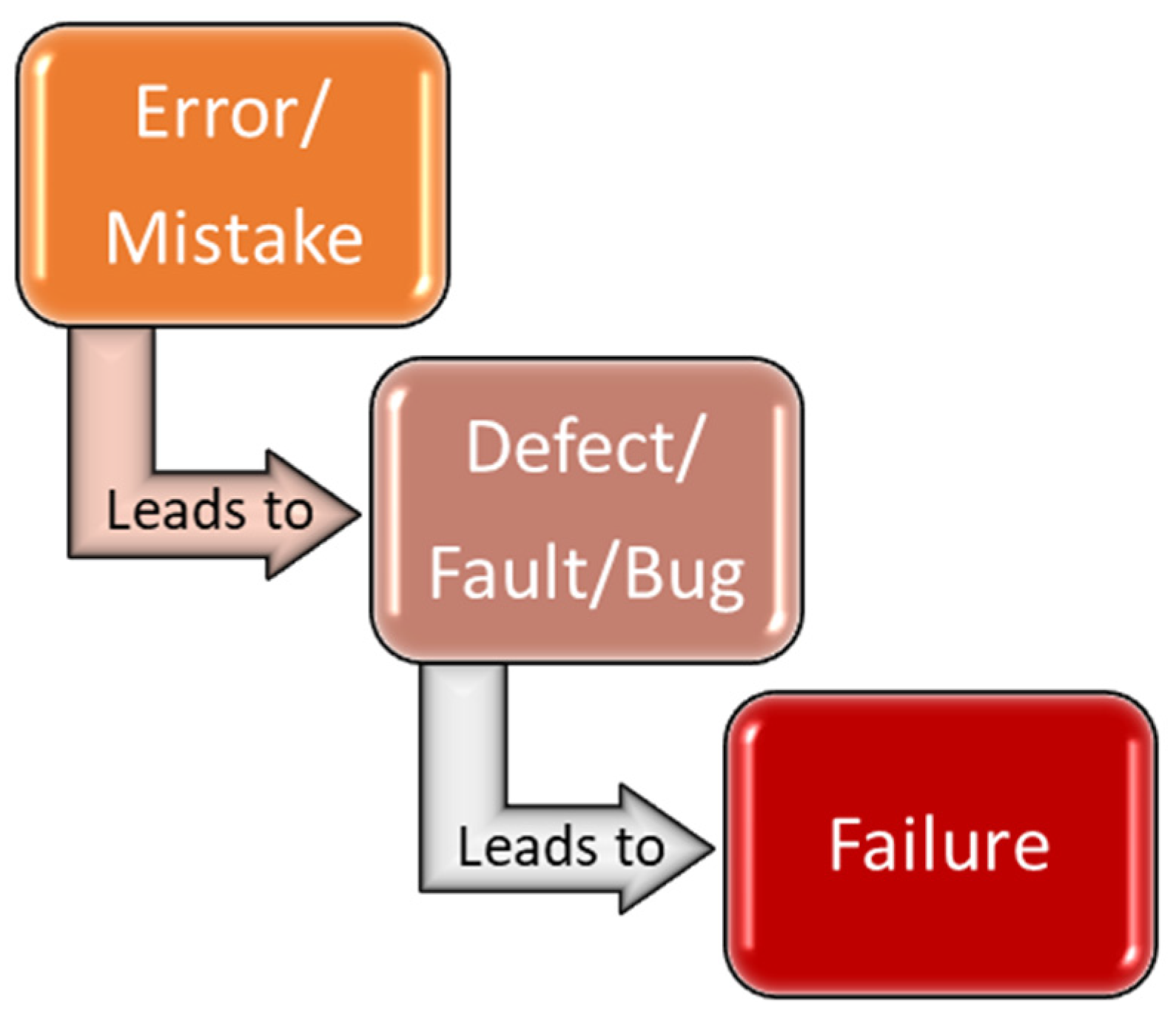
- Software Testing—Bug vs Defect vs Error vs Fault vs Failure—GeeksforGeeks. Available online: https://www.geeksforgeeks.org/software-testing-bug-vs-defect-vs-error-vs-fault-vs-failure/ (accessed on 22 April 2024).
- Jalayer, M.; Orsenigo, C.; Vercellis, C. Fault detection and diagnosis for rotating machinery: A model based on convolutional LSTM, Fast Fourier and continuous wavelet transforms. Comput. Ind. 2021, 125, 103378. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Wang, J.; Mao, K. Learning to monitor machine health with convolutional Bi-directional LSTM networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef] [PubMed]
- Zrnic, N.; Petković, Z.; Bošnjak, S.M. Automation of ship-to-shore container cranes: A review of state-of-the-art. FME Transactions 2005, 33, 111–121. Available online: https://www.researchgate.net/publication/228936324_Automation_of_ship-to-shore_container_cranes_A_review_of_state-of-the-art (accessed on 24 March 2024).
- Tran, Q.H.; Huh, J.; Nguyen, V.B.; Kang, C.; Ahn, J.H.; Park, I.J. Sensitivity analysis for ship-to-shore container crane design. Appl. Sci. 2018, 8, 1667. [Google Scholar] [CrossRef]
- Li, Z. Deep Learning Driven Approaches for Predictive Maintenance A Framework of Intelligent Fault Diagnosis and Prognosis in the Industry 4.0 Era. Ph.D. Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2018. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. 2015. Available online: http://www.deeplearningbook.org/ (accessed on 15 June 2024).
- Liu, W.; Xiao, J. A new method of detection the wear of crane rails and its error analysis. J. Mech. Strength 2014, 36, 878–883. Available online: https://www.researchgate.net/publication/293095272_A_new_method_of_detection_the_wear_of_crane_rails_and_its_error_analysis (accessed on 19 March 2024).
- Mohammadfam, I.; Borgheipour, H.; Tehrani, G.; Madadi, S. Identification and assessment of human errors among tower crane operators using SHERPA and CREAM techniques. J. Health Saf. Work. 2020, 10, 5–8. [Google Scholar]
- Jakovlev, S.; Eglynas, T.; Jusis, M.; Voznak, M.; Partila, P.; Tovarek, J. Detecting Physical Impacts to the Corners of Shipping Containers during Handling Operations Performed by Quay Cranes. J. Mar. Sci. Eng. 2023, 11, 794. [Google Scholar] [CrossRef]
- Gao, X.; Yeh, H.G.; Marayong, P. A high-speed color-based object detection algorithm for quayside crane operator assistance system. In Proceedings of the 11th Annual IEEE International Systems Conference, SysCon 2017—Proceedings, Montreal, QC, Canada, 24–27 April 2017. [Google Scholar] [CrossRef]
- Westerberg, S.; Shiriaev, A. Virtual Environment-Based Teleoperation of Forestry Machines: Designing Future Interaction Methods. J. Hum.-Robot. Interact. 2013, 2, 84–110. [Google Scholar] [CrossRef]
- Ren, W.; Wu, Z.; Zhang, L. Real-time planning of a lifting scheme in mobile crane mounted controllers. Can. J. Civ. Eng. 2016, 43, 542–552. [Google Scholar] [CrossRef]
- Watanabe, M.; Momoi, Y.; Odai, M.; Ieshige, K. Simultaneous estimation for rope tension and load of cranes using motor driving signals. Trans. JSME 2023, 89. [Google Scholar] [CrossRef]
- Lei, Z.; Behzadipour, S.; Al-Hussein, M.; Hermann, U. Application of robotic obstacle avoidance in crane lift path planning. In Proceedings of the 28th ISARC, Seoul, Republic of Korea, 29 June–2 July 2011. [Google Scholar]
- Lehner, P.; Křivý, V.; Krejsa, M.; Pařenica, P.; Kozák, J. Stochastic Service Life Prediction of Existing Steel Structure Loaded by Overhead Cranes. Procedia Struct. Integr. 2018, 13, 1539–1544. [Google Scholar] [CrossRef]
- Shang, K.C.; Tseng, W.J. A risk analysis of stevedoring operations in seaport container terminals. J. Mar. Sci. Technol. 2010, 18, 201–210. [Google Scholar] [CrossRef]
- Ismail, R.M.T.R.; That, N.D.; Ha, Q.P. Modelling and robust trajectory following for offshore container crane systems. Autom. Constr. 2015, 59, 179–187. [Google Scholar] [CrossRef]
- Liu, J.; Qin, X.; Sun, Y.; Zhang, Q. Response Prediction Model for Structures of Quayside Container Crane Based on Monitoring Data. J. Perform. Constr. Facil. 2021, 35. [Google Scholar] [CrossRef]
- Jo, J.H.; Kim, S. Key Performance Indicator Development for Ship-to-Shore Crane Performance Assessment in Container Terminal Operations. J. Mar. Sci. Eng. 2020, 8, 6. [Google Scholar] [CrossRef]
- Cheng, C.; Liu, X.; Zhou, B.; Yuan, Y. Intelligent Fault Diagnosis With Noisy Labels via Semisupervised Learning on Industrial Time Series. IEEE Trans. Ind. Inform. 2023, 19, 7724–7732. [Google Scholar] [CrossRef]
- Lee, X.Y.; Kumar, A.; Vidyaratne, L.; Rao, A.R.; Farahat, A.; Gupta, C. An ensemble of convolution-based methods for fault detection using vibration signals. In Proceedings of the 2023 IEEE International Conference on Prognostics and Health Management (ICPHM 2023), Montreal, QC, Canada, 5–7 June 2023; pp. 172–179. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, M.; Feng, Z.; Ruifang, L.V.; Lu, C.; Dai, Y.; Dong, L. Gated recurrent unit-enhanced deep convolutional neural network for real-time industrial process fault diagnosis. Process Saf. Environ. Prot. 2023, 175, 129–149. [Google Scholar] [CrossRef]
- How To Code RNN and LSTM Neural Networks in Python. Available online: https://www.nbshare.io/notebook/249468051/How-To-Code-RNN-and-LSTM-Neural-Networks-in-Python/ (accessed on 28 April 2022).
- Quiñones-Grueiro, M.; Llanes-Santiago, O.; Silva Neto, A.J. Fault Diagnosis in Industrial Systems. Stud. Syst. Decis. Control 2021, 309, 1–14. [Google Scholar] [CrossRef]
- Illustrated Guide to LSTM’s and GRU’s: A Step by Step Explanation|by Michael Phi|towards Data Science. Available online: https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21 (accessed on 13 April 2021).
- Maheswaranathan, N.; Williams, A.H.; Golub, M.D.; Ganguli, S.; Sussillo, D. Reverse engineering recurrent networks for sentiment classification reveals line attractor dynamics. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 15696–15705. [Google Scholar]
- Alizadeh, Z.; Yazdi, J.; Kim, J.H.; Al-Shamiri, A.K. Assessment of Machine Learning Techniques for Monthly Flow Prediction. Water 2018, 10, 1676. [Google Scholar] [CrossRef]
- Ahmad, J.; Tahir, A.; Larijani, H.; Ahmed, F.; Aziz Shah, S.; Hall, A.J.; Buchanan, W.J. Energy demand forecasting of buildings using random neural networks. J. Intell. Fuzzy Syst. 2020, 38, 4753–4765. [Google Scholar] [CrossRef]
- Li, S.; Li, W.; Member, S.; Cook, C.; Gao, Y. Deep Independently Recurrent Neural Network (IndRNN). arXiv 2019, arXiv:1910.06251v3. [Google Scholar]
- Abid, A.; Khan, M.T.; Iqbal, J. A review on fault detection and diagnosis techniques: Basics and beyond. Artif. Intell. Rev. 2021, 54, 3639–3664. [Google Scholar] [CrossRef]
- Shahin, M.; Chen, F.F.; Hosseinzadeh, A.; Zand, N. Using machine learning and deep learning algorithms for downtime minimization in manufacturing systems: An early failure detection diagnostic service. Int. J. Adv. Manuf. Technol. 2023, 128, 3857–3883. [Google Scholar] [CrossRef]
- Leite, D.; Martins, A.; Rativa, D.; De Oliveira, J.F.L.; Maciel, A.M.A. An Automated Machine Learning Approach for Real-Time Fault Detection and Diagnosis. Sensors 2022, 22, 6138. [Google Scholar] [CrossRef]
- Darban, Z.Z.; Webb, G.I.; Pan, S.; Aggarwal, C.C.; Salehi, M. Deep Learning for Time Series Anomaly Detection: A Survey. arXiv 2022, arXiv:2211.05244v2. [Google Scholar]
- Song, J.; Lee, Y.C.; Lee, J. Deep generative model with time series-image encoding for manufacturing fault detection in die casting process. J. Intell. Manuf. 2023, 34, 3001–3014. [Google Scholar] [CrossRef]
- Gui, X.; Zhang, J. Deep Metric Learning Model for Imbalanced Fault Diagnosis. arXiv 2021, arXiv:2107.03786. [Google Scholar]
- Liu, H.; Ma, R.; Li, D.; Yan, L.; Ma, Z. Machinery Fault Diagnosis Based on Deep Learning for Time Series Analysis and Knowledge Graphs. J. Signal Process. Syst. 2021, 93, 1433–1455. [Google Scholar] [CrossRef]
- Pang, J.L. Adaptive fault prediction and maintenance in production lines using deep learning. Int. J. Simul. Model. 2023, 22, 734–745. [Google Scholar] [CrossRef]
- Brownlee, J.; How to Calculate Correlation Between Variables in Python. Machine Learning Mastery. Available online: https://machinelearningmastery.com/how-to-use-correlation-to-understand-the-relationship-between-variables/ (accessed on 14 April 2022).
- Li, A. Human error risk prioritization in crane operations based on CPT and ICWGT. PLoS ONE 2024, 19, e0297120. [Google Scholar] [CrossRef] [PubMed]
- Eglynas, T.; Jusis, M.; Jakovlev, S.; Senulis, A.; Andziulis, A.; Gudas, S. Analysis of the efficiency of shipping containers handling/loading control methods and procedures. Adv. Mech. Eng. 2019, 11. [Google Scholar] [CrossRef]
- Maboudi, M.; Alamouri, A.; De Arriba López, V.; Bajauri, M.S.; Berger, C.; Gerke, M. Drone-Based Container Crane Inspection: Concept, Challenges And Preliminary Results. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2021, V-1-2021, 121–128. [Google Scholar] [CrossRef]
- Shan, J.; Zhang, M.; Zhang, D.; Zhou, X.; Li, H.; Wang, B. Container Cranes. In Handbook of Port Machinery; Springer: Singapore, 2024; pp. 451–678. [Google Scholar] [CrossRef]
- Viellechner, A.; Spinler, S. Novel Data Analytics Meets Conventional Container Shipping: Predicting Delays by Comparing Various Machine Learning Algorithms. Available online: https://hdl.handle.net/10125/63897 (accessed on 12 June 2024).
- Tian, X.; Yan, R.; Liu, Y.; Wang, S. A smart predict-then-optimize method for targeted and cost-effective maritime transportation. Transp. Res. Part B Methodol. 2023, 172, 32–52. [Google Scholar] [CrossRef]
- Handling Imbalanced Data for Classification—GeeksforGeeks. Available online: https://www.geeksforgeeks.org/handling-imbalanced-data-for-classification/ (accessed on 12 June 2024).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methodology | Description | Reference |
|---|---|---|
| Fault Detection and Diagnosis (FDD) | These methodologies detect emerging irregularities and predict their consequences for the system’s behaviour. | [55] |
| Data-Driven Fault Diagnosis | This approach uses machine learning algorithms for mechanical fault detection or fault prognosis in manufacturing equipment. | [24] |
| An array of ML, DL, and DHL Algorithms | These algorithms can potentially perform early fault detection that would lead to future machine failure. | [56] |
| Automated Machine Learning Approach | This approach is used for real-time fault detection and diagnosis in discrete manufacturing machines. | [57] |
| Methodology | Description | Reference |
|---|---|---|
| Deep Learning for Time Series Anomaly Detection | This approach uses specialised deep learning models for detecting anomalous patterns in time series data. | [58] |
| Deep Generative Models | Variational autoencoder reconstruction along the projection pathway (VAE-RaPP) and a fence generative adversarial network (Fence GAN) are used to deal with imbalanced time series data obtained from manufacturing applications. | [59] |
| Deep Metric Learning Model | This model considers imbalanced fault data and a quadruplet data pair design manner. | [60] |
| ATT-1D CNN-GRU Model | This model combines a one-dimensional CNN, GRU, attention mechanism, and KG (knowledge graph) for fault diagnosis. | [61] |
| Deep-Learning-Based Adaptive Fault Prediction | This approach integrates a comprehensive convolutional feature extraction module, a customised gating module, and a multi-layered progressive extraction module. | [62] |
| Timestamp | var_831 |
|---|---|
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 1 |
| 12/11/2020 20:35 | 1 |
| 12/11/2020 20:35 | 1 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 0 |
| 12/11/2020 20:35 | 1 |
| 12/11/2020 20:35 | 1 |
| 12/11/2020 20:35 | 1 |
| 12/11/2020 20:36 | 1 |
| 12/11/2020 20:36 | 1 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 1 |
| 12/11/2020 20:36 | 1 |
| 12/11/2020 20:36 | 1 |
| 12/11/2020 20:36 | 1 |
| 12/11/2020 20:36 | 1 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
| 12/11/2020 20:36 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awasthi, A.; Krpalkova, L.; Walsh, J. Deep Learning-Based Boolean, Time Series, Error Detection, and Predictive Analysis in Container Crane Operations. Algorithms 2024, 17, 333. https://doi.org/10.3390/a17080333
Awasthi A, Krpalkova L, Walsh J. Deep Learning-Based Boolean, Time Series, Error Detection, and Predictive Analysis in Container Crane Operations. Algorithms. 2024; 17(8):333. https://doi.org/10.3390/a17080333
Chicago/Turabian StyleAwasthi, Amruta, Lenka Krpalkova, and Joseph Walsh. 2024. "Deep Learning-Based Boolean, Time Series, Error Detection, and Predictive Analysis in Container Crane Operations" Algorithms 17, no. 8: 333. https://doi.org/10.3390/a17080333
APA StyleAwasthi, A., Krpalkova, L., & Walsh, J. (2024). Deep Learning-Based Boolean, Time Series, Error Detection, and Predictive Analysis in Container Crane Operations. Algorithms, 17(8), 333. https://doi.org/10.3390/a17080333