
Efficient and Robust Arabic Automotive Speech Command Recognition System


Abstract
:1. Introduction
- We constructed the first automotive speech recognition system in the Arabic language in the Arab world.
- We built the first Moroccan Arabic dataset in the automotive speech recognition field that is representative and simulates real-time conditions.
- We developed a hybrid deep-learning model that combines Bidirectional Long Short-Term Memory architecture and a Convolutional Neural Network into one unified architecture Bi-LSTM-CNN for driver command reorganization in the Arabic language.
- We developed a model that outperformed the proposed method in the state-of-the-art literature.
2. Literature Review
3. Methodology
3.1. Dataset Building
3.1.1. Command Choice
- Q1: Do you think a voice-controlled option will improve the driving experience?
- Q2: If you would use voice control in your car, what commands feel safe to use?
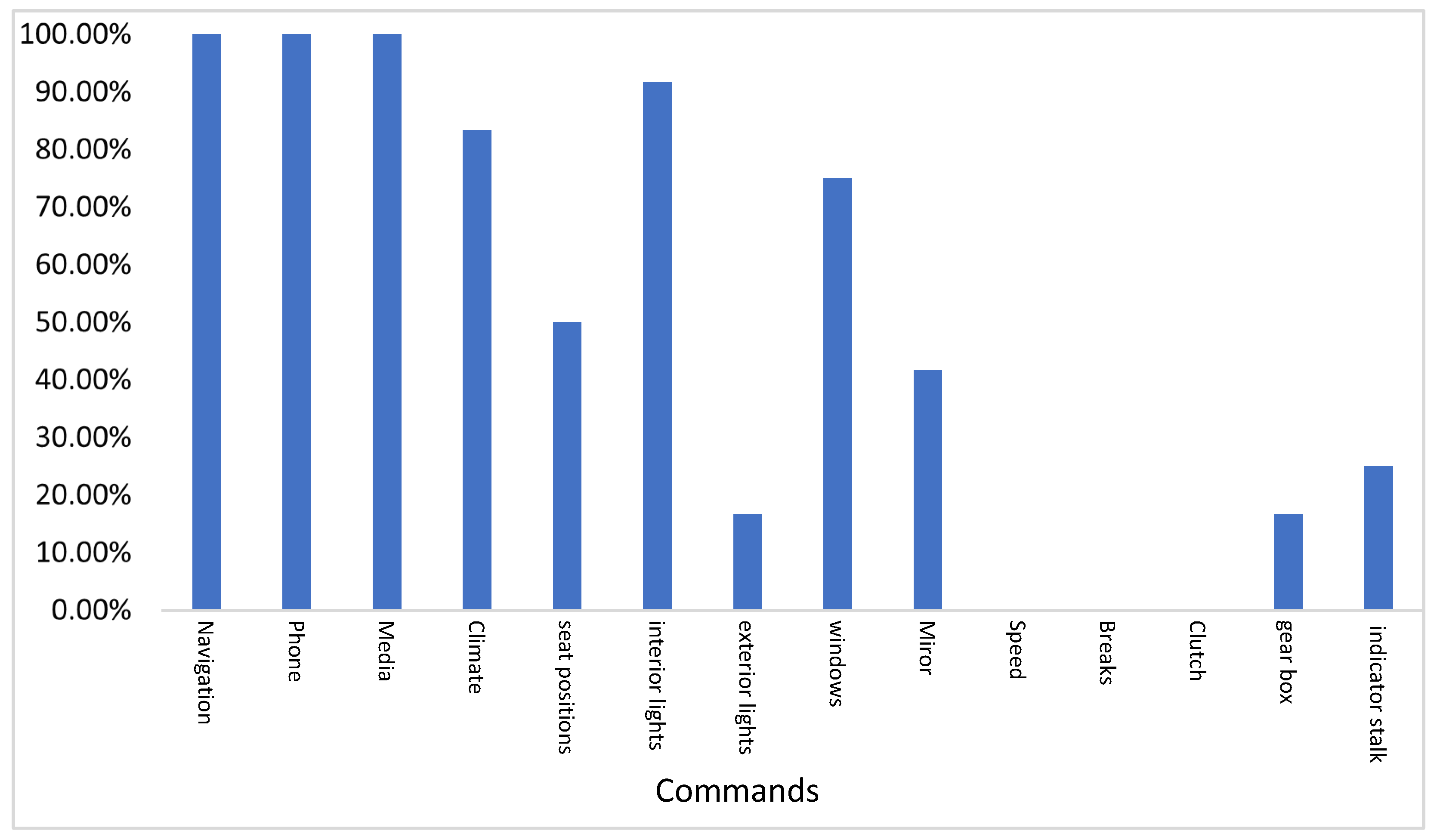
- High Acceptance Rate: Navigation, Phone, and Media commands were highly accepted, receiving 100% acceptance rates, while climate control commands had an 83.33% acceptance rate and interior lights received a slightly higher rate of 91.67%. Additionally, the acceptance rate for window commands was 75%.
- Low Acceptance Rate: Commands concerning seat positions, exterior lights, mirror adjustments, and gear shifting received low acceptance rates.
- Zero Acceptance Rate: Speed, Brakes, and Clutch controlling commands received 0% acceptance rates.
3.1.2. Final Dataset Description
3.2. Speech Feature Extraction
3.2.1. Mel-Frequency Cepstral Coefficient (MFCC)
3.2.2. Weighted Mel-Frequency Cepstral Coefficient (WMFCC)
3.2.3. Spectral Subband Centroids (SSCs)
3.3. Classifier Selection
3.3.1. Machine-Learning Models
3.3.2. Deep-Learning Models
Convolutional Neural Networks (CNN)
Long Short-Term Memory Networks (LSTM)
Bidirectional Long Short-Term Memory Networks (Bi-LSTM)
BiLSTM-CNN Architecture
3.3.3. Transformers
Fine-Tuning the Wav2vec2 Model
3.4. Out-of-Corpus Command Handling
4. Experiment Results and Discussion
4.1. Dataset Collection Procedure
- Northern dialect/Jebli.
- Northeastern dialect/Rif Amazigh language/Tarifite.
- Eastern Moroccan dialect/Oriental Moroccan Arabic/Bedwi.
- Nord-Ouest dialect/Standard Moroccan Arabic dialect/Rubi.
- languages of the Middle Atlas/Tamazight.
- languages of the Souss/Tachelhite.
- Sahara Arabic dialects/Hassani Arabic/Ribi.
4.2. Data Split
4.3. Performance Measures
4.4. Preliminary Results
4.5. Data Augmentations
5. Conclusions and Feature Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Keyword | Translation | Pronunciation |
|---|---|---|---|
| Com-1 | حل البيبان | Unlock doors | Ħall alabibaːn |
| Com-2 | سد البيبان | Lock doors | Sadd alabibaːn |
| Com-3 | حل الكوفر | Open the backdoor | Ħall alakawfar |
| Com-4 | سد الكوفر | Close the backdoor | Sadd alakawfar |
| Com-5 | شعل الراديو | Turn radio on | ʃaʕal alaɾaːdijuː |
| Com-6 | طفي الراديو | Turn radio off | tˤɑfiː alaɾaːdijuː |
| Com-7 | بدل الإذاعة | Change the radio station | Badal ala ʔiðaːʕa |
| Com-8 | نقص الصوت | Decrease volume | naqɑsˤɑ al sˤɑwwat |
| Com-9 | زيد الصوت | Increase volume | zaid ala sˤɑwwat |
| Com-10 | جاوب ابيل | Answer the call | ǯaːwab ʔabi:l |
| Com-11 | قطع ابيل | Decline the call | qɑtˤɑʕ ʔabi:l |
| Com-12 | شعل الضو | Turn light on | ʃaʕal dˤɑwʔ |
| Com-13 | طفي الضو | Turn light of | tˤɑfiː dˤɑwʔ |
| Com-14 | هبط السرجم | lower the side window | Habit saɾaǯam |
| Com-15 | طلع السرجم | Raise the side window | tˤɑlaʕ saɾaǯam |
| Com-16 | كاين الحرارة | It’s hot/release cold air | kaːin ala ħaɾaːɾa |
| Com-17 | كاين البرد | It’s cold/release hot air | kaːin ala bard |
| Com-18 | خدم السويكالاص | Activate windshield wiper | Xadam s-suː ka-las |
| Com-19 | وقف السويكالاص | Deactivate windshield wiper | waqɑf s-suː ka-las |
| Com-20 | حل كابو | Open the bonnet door | Ħall ka:po |
References
- Dukic, T.; Hanson, L.; Holmqvist, K. Wartenberg Effect of button location on driver’s visual behaviour and safety perception. Ergonomics 2005, 48, 399–410. [Google Scholar] [CrossRef] [PubMed]
- Simons-Morton, B.G.; Guo, F.; Klauer, S.G.; Ehsani, J.P.; Pradhan, A.K. Keep Your Eyes on the Road: Young Driver Crash Risk Increases According to Duration of Distraction. J. Adolesc. Health 2014, 54, S61–S67. [Google Scholar] [CrossRef] [PubMed]
- Cades, D.; Arndt, S.; Kwasniak, A.M. Driver distraction is more than just taking eyes off the road. ITE J.-Inst. Transp. Eng. 2011, 81, 26–28. [Google Scholar]
- Vikström, F.D. Physical Buttons Outperform Touchscreens in New Cars, Test Finds. Available online: https://www.vibilagare.se/english/physical-buttons-outperform-touchscreens-new-cars-test-finds (accessed on 3 January 2024).
- Dhouib, A.; Othman, A.; El Ghoul, O.; Khribi, M.K.; Al Sinani, A. Arabic Automatic Speech Recognition: A Systematic Literature Review. Appl. Sci. 2022, 12, 8898. [Google Scholar] [CrossRef]
- Arab Countries/Arab League Countries 2024. Available online: https://worldpopulationreview.com/country-rankings/arab-countries (accessed on 21 February 2024).
- Huang, X.; Baker, J.; Reddy, R. A historical perspective of speech recognition. Commun. ACM 2014, 57, 94–103. [Google Scholar] [CrossRef]
- Ghandoura, A.; Hjabo, F.; Al Dakkak, O. Building and benchmarking an Arabic Speech Commands dataset for small-footprint keyword spotting. Eng. Appl. Artif. Intell. 2021, 102, 104267. [Google Scholar] [CrossRef]
- Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Ibrahim, A.E.B.; Saad, R.S.M. Intelligent Categorization of Arabic Commands Utilizing Machine Learning Techniques with Short Effective Features Vector. Int. J. Comput. Appl. 2022, 184, 25–32. [Google Scholar] [CrossRef]
- Hamza, A.; Fezari, M.; Bedda, M. Wireless voice command system based on kalman filter and HMM models to control manipulator arm. In Proceedings of the 2009 4th International Design and Test Workshop, IDT 2009, Riyadh, Saudi Arabia, 15–17 November 2009. [Google Scholar] [CrossRef]
- Paliwal, K.; Basu, A. A speech enhancement method based on Kalman filtering. In Proceedings of the ICASSP ‘87, IEEE International Conference on Acoustics, Speech, and Signal Processing, Dallas, TX, USA, 6–9 April 1987; Volume 12, pp. 177–180. [Google Scholar] [CrossRef]
- El-emary, I.M.M.; Fezari, M.; Attoui, H. Hidden Markov model/Gaussian mixture models (HMM/GMM) based voice command system: A way to improve the control of remotely operated robot arm TR45. Sci. Res. Essays 2011, 6, 341–350. [Google Scholar]
- Abed, A.A.; Jasim, A.A. Design and implementation of wireless voice controlled mobile robot. Al-Qadisiyah J. Eng. Sci. 2016, 9, 135–147. [Google Scholar]
- Hyundai. Available online: http://webmanual.hyundai.com/STD_GEN5_WIDE/AVNT/EU/English/voicerecognitionsystem.html (accessed on 27 October 2023).
- Toyota. Available online: https://toyota-en-us.visteoninfotainment.com/how-to-voice-recognition (accessed on 26 October 2023).
- Acura. Available online: https://www.acurainfocenter.com/the-latest/rdx-voice-commands-made-easy (accessed on 28 October 2023).
- Soufiyan Ouali, Said El Gerouani, Automative Morrocan Arabic Speech Dataset. Available online: https://github.com/SoufiyaneOuali/Automative-Morrocan-Arabic-Speech-Command-Datset (accessed on 23 February 2024).
- Hibare, R.; Vibhute, A. Feature Extraction Techniques in Speech Processing: A Survey. Int. J. Comput. Appl. 2014, 107, 975–8887. [Google Scholar] [CrossRef]
- Mohanty, A.; Cherukuri, R.C. A Revisit to Speech Processing and Analysis. Int. J. Comput. Appl. 2020, 175, 1–6. [Google Scholar] [CrossRef]
- Bhandari, A.Z.; Melinamath, C. A Survey on Automatic Recognition of Speech via Voice Commands. Int. J. New Innov. Eng. Technol. 2017, 6, 1–4. [Google Scholar]
- Kurzekar, P.K.; Deshmukh, R.R.; Waghmare, V.B.; Shrishrimal, P.P. A Comparative Study of Feature Extraction Techniques for Speech Recognition System. Int. J. Innov. Res. Sci. Eng. Technol. 2007, 3297, 2319–8753. [Google Scholar] [CrossRef]
- Këpuska, V.Z.; Elharati, H.A.; Këpuska, V.Z.; Elharati, H.A. Robust Speech Recognition System Using Conventional and Hybrid Features of MFCC, LPCC, PLP, RASTA-PLP and Hidden Markov Model Classifier in Noisy Conditions. J. Comput. Commun. 2015, 3, 1–9. [Google Scholar] [CrossRef]
- Chapaneri, S.V. Spoken Digits Recognition using Weighted MFCC and Improved Features for Dynamic Time Warping. Int. J. Comput. Appl. 2012, 40, 6–12. [Google Scholar] [CrossRef]
- Mukhedkar, A.S.; Alex, J.S.R. Robust feature extraction methods for speech recognition in noisy environments. In Proceedings of the 1st International Conference on Networks and Soft Computing, ICNSC 2014—Proceedings, Guntur, India, 19–20 August 2014; pp. 295–299. [Google Scholar] [CrossRef]
- Gupta, S.; Shukla, R.S.; Shukla, R.K. Weighted Mel frequency cepstral coefficient based feature extraction for automatic assessment of stuttered speech using Bi-directional LSTM. Indian J. Sci. Technol. 2021, 14, 457–472. [Google Scholar] [CrossRef]
- Kinnunen, T.; Zhang, B.; Zhu, J.; Wang, Y. Speaker verification with adaptive spectral subband centroids. In Advances in Biometrics; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2007; Volume 4642, pp. 58–66. [Google Scholar] [CrossRef]
- Přibil, J.; Přibilová, A.; Matoušek, J. GMM-based speaker age and gender classification in Czech and Slovak. J. Electr. Eng. 2017, 68, 3–12. [Google Scholar] [CrossRef]
- Majeed, S.A.; Husain, H.; Samad, S.A.; Idbeaa, T.F. Mel frequency cepstral coefficients (mfcc) feature extraction enhancement in the application of speech recognition: A comparison study. J. Theor. Appl. Inf. Technol. 2015, 79, 38–56. Available online: www.jatit.org (accessed on 22 February 2024).
- Tyagi, V.; McCowan, I.; Misra, H.; Bourlard, H. Mel-Cepstrum Modulation Spectrum (MCMS) features for robust ASR. In Proceedings of the 2003 IEEE Workshop on Automatic Speech Recognition and Understanding, ASRU 2003, St. Thomas, VI, USA, 30 November–4 December 2003; pp. 399–404. [Google Scholar] [CrossRef]
- Dev, A.; Bansal, P. Robust Features for Noisy Speech Recognition using MFCC Computation from Magnitude Spectrum of Higher Order Autocorrelation Coefficients. Int. J. Comput. Appl. 2010, 10, 975–8887. [Google Scholar] [CrossRef]
- Paliwal, K.K. Spectral subband centroids as features for speech recognition. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings, Santa Barbara, CA, USA, 17 December 1997; pp. 124–131. [Google Scholar] [CrossRef]
- Thian, N.P.H.; Sanderson, C.; Bengio, S. Spectral subband centroids as complementary features for speaker authentication. In Biometric Authentication; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2004; Volume 3072, pp. 631–639. [Google Scholar] [CrossRef]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Alsobhani, A.; Alabboodi, H.M.A.; Mahdi, H. Speech Recognition using Convolution Deep Neural Networks. J. Phys. Conf. Ser. 2021, 1973, 012166. [Google Scholar] [CrossRef]
- Noh, S.H. Analysis of Gradient Vanishing of RNNs and Performance Comparison. Information 2021, 12, 442. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zaman, K.; Sah, M.; Direkoglu, C.; Unoki, M. A Survey of Audio Classification Using Deep Learning. IEEE Access 2023, 11, 106620–106649. [Google Scholar] [CrossRef]
- Turner, R.E. An Introduction to Transformers. arXiv 2024, arXiv:2304.10557v5. [Google Scholar]
- Zhang, Y.; Li, B.; Fang, H.; Meng, Q. Spectrogram transformers for audio classification. In Proceedings of the 2022 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 21–23 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Wyatt, S.; Elliott, D.; Aravamudan, A.; Otero, C.E.; Otero, L.D.; Anagnostopoulos, G.C.; Smith, A.O.; Peter, A.M.; Jones, W.; Leung, S.; et al. Environmental sound classification with tiny transformers in noisy edge environments. In Proceedings of the 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14 June–31 July 2021; pp. 309–314. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv 2020, arXiv:2006.11477. [Google Scholar]
- Hsu, W.-N.; Bolte, B.; Tsai, Y.-H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. arXiv 2021, arXiv:2106.07447. [Google Scholar] [CrossRef]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep Speech: Scaling up end to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Pennell, C.R. Morocco: From Empire to Independence; Oneworld Publications: London, UK, 2009. [Google Scholar]
- Hachimi, A. Dialect Leveling, Maintenance and Urban Identitiy in Morocco Fessi Immigrants in Casablanca; University of Hawai’i at Manoa: Honolulu, HI, USA, 2005. [Google Scholar]
- Horisons de France. Maroc, Atlas Historique, Géographique, Economique. 1935. Available online: https://www.cemaroc.com/t147-maroc-atlas-historique-geographique-economique-1935 (accessed on 9 May 2024).
- Boukous, A. Revitalisation de l’amazighe Enjeux et stratégies. Lang. Soc. 2013, 143, 9–26. [Google Scholar] [CrossRef]









| Model | Train Acc% | Val Acc% | Train Loss | Val Loss | Params |
|---|---|---|---|---|---|
| KNN | 79.99 | 51.96 | - | - | - |
| RF | 98 | 58.912 | - | - | - |
| SVM | 40.29 | 36.72 | - | - | - |
| LR | 37.57 | 36.54 | - | - | - |
| CNN | 98.62 | 71.44 | 0.0450 | 1.0101 | 765,844 |
| LSTM | 97.30 | 56.86 | 0.1648 | 1.7204 | 512,020 |
| Bi-LSTM | 95.98 | 66.31 | 0.0274 | 1.3029 | 1,386,004 |
| BiLSTM-CNN | 99.26 | 73.55 | 0.0112 | 1.0070 | 813,588 |
| Features/Model | KNN% | RF% | SVM% | LR% | CNN% | LSTM% | BiLSTM% | BiLSTM-CNN% |
|---|---|---|---|---|---|---|---|---|
| MFCC | 57.48 | 70.85 | 52.05 | 45.27 | 83.33 | 55.97 | 79.95 | 81.37 |
| SCC | 42.07 | 55.53 | 26.56 | 24.24 | 58.56 | 41.44 | 58.73 | 62.30 |
| WMFCC | 65.86 | 85.83 | 57.75 | 46.35 | 92.06 | 75.85 | 90.96 | 91.62 |
| MFCC + SCC | 57.66 | 71.66 | 55.08 | 49.73 | 81.46 | 54.19 | 77.90 | 78.07 |
| WMFCC + SCC | 65.33 | 87.79 | 70.94 | 59.36 | 92.16 | 78.52 | 91.05 | 93.67 |
| MFCC + WMFCC | 64.94 | 84.48 | 81.18 | 73.51 | 91.44 | 69.85 | 87.24 | 89.65 |
| MFCC + WMFCC + SCC | 63.99 | 84.76 | 83.96 | 73.53 | 89.75 | 67.02 | 90.46 | 90.55 |
| Features/Model | KNN% | RF% | SVM% | LR% | CNN% | LSTM% | BiLSTM% | BiLSTM-CNN% |
|---|---|---|---|---|---|---|---|---|
| MFCC | 74 | 85 | 50 | 42 | 88.99 | 77.58 | 91.49 | 92.08 |
| SCC | 65 | 69 | 23 | 22 | 67.29 | 64.30 | 73.93 | 76.06 |
| WMFCC | 79 | 88 | 53 | 43 | 93.27 | 83.96 | 93.72 | 97.17 |
| MFCC + SCC | 75 | 87 | 54 | 47 | 89.30 | 70.72 | 90.42 | 93.82 |
| WMFCC + SCC | 77 | 89 | 65 | 53 | 94.13 | 84.00 | 94.63 | 98.48 |
| MFCC + WMFCC | 78 | 88 | 78 | 67 | 93.05 | 80.26 | 94.30 | 96.66 |
| MFCC + WMFCC + SCC | 78 | 89 | 80 | 69 | 93.00 | 79.41 | 94.16 | 95.75 |
| Features/ Article Ref | Hamza et al. (2009) [11] | Hamza et al. (2009) [11] | Ibrahim and Saad (2022) [10] | Ghandoura et al. (2021) [8] | Our Model |
|---|---|---|---|---|---|
| Dataset Size | 4800 | 4800 | 720 | 12,000 | 5600 |
| Number of Commands | 12 | 12 | 5 | 40 | 20 |
| Model used | HMM | HMM &GMM | SVM | CNN | BiLSTM—CNN |
| Performance (Accuracy) | 76% | 82% | 95.48% | 97.97% | 98.48% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouali, S.; El Garouani, S. Efficient and Robust Arabic Automotive Speech Command Recognition System. Algorithms 2024, 17, 385. https://doi.org/10.3390/a17090385
Ouali S, El Garouani S. Efficient and Robust Arabic Automotive Speech Command Recognition System. Algorithms. 2024; 17(9):385. https://doi.org/10.3390/a17090385
Chicago/Turabian StyleOuali, Soufiyan, and Said El Garouani. 2024. "Efficient and Robust Arabic Automotive Speech Command Recognition System" Algorithms 17, no. 9: 385. https://doi.org/10.3390/a17090385