Abstract
This study addresses the challenge of detecting crimes against individuals in public security applications, particularly where the availability of quality data is limited, and existing models exhibit a lack of generalization to real-world scenarios. To mitigate the challenges associated with collecting extensive and labeled datasets, this study proposes the development of a novel dataset focused specifically on crimes against individuals, including incidents such as robberies, assaults, and physical altercations. The dataset is constructed using data from publicly available sources and undergoes a rigorous labeling process to ensure both quality and representativeness of criminal activities. Furthermore, a 3D convolutional neural network (Conv 3D) is implemented for real-time video analysis to detect these crimes effectively. The proposed approach includes a comprehensive validation of both the dataset and the model through performance comparisons with existing datasets, utilizing key evaluation metrics such as the Area Under the Curve of the Receiver Operating Characteristic (AUC-ROC). Experimental results demonstrate that the proposed dataset and model achieve an accuracy rate between 94% and 95%, highlighting their effectiveness in accurately identifying criminal activities. This study contributes to the advancement of crime detection technologies, offering a practical solution for implementation in surveillance and public safety systems in urban environments.
1. Introduction
In recent decades, the rapid advancement of technology has driven accelerated urbanization globally. This phenomenon has led to a significant increase in population density in urban areas, necessitating the development of essential infrastructure and services—such as electrical grids, water supply, transportation systems, and public safety mechanisms—to improve the quality of life in these regions [1,2]. In this context, the concept of smart cities has emerged as a technological response designed to optimize urban resource management through the integration of interconnected and advanced systems [3,4]. With the evolution of technologies such as Big Data and the Internet of Things (IoT), these systems can interact and operate autonomously, optimizing processes in areas including security, disaster management, and resource efficiency [5].
One of the critical factors in improving citizens’ quality of life is crime prevention. Urban regions with high population density are often associated with elevated crime rates, making it increasingly challenging to ensure public safety. According to the Organization for Economic Cooperation and Development (OECD), public safety is a fundamental element of citizens’ well-being, making it a priority for public administrations across the globe [6]. Furthermore, crime statistics reported by SIEDCO (Sistema de Información Estadístico, Delincuencial Contravencional y Operativo de la Policía Nacional—National Police Statistical, Criminal, Contravening, and Operational System) [7] indicate that the most common crimes in Colombia include the following:
- Robbery;
- Domestic violence;
- Vehicle theft;
- Sexual crimes;
- Homicide;
- Extortion.
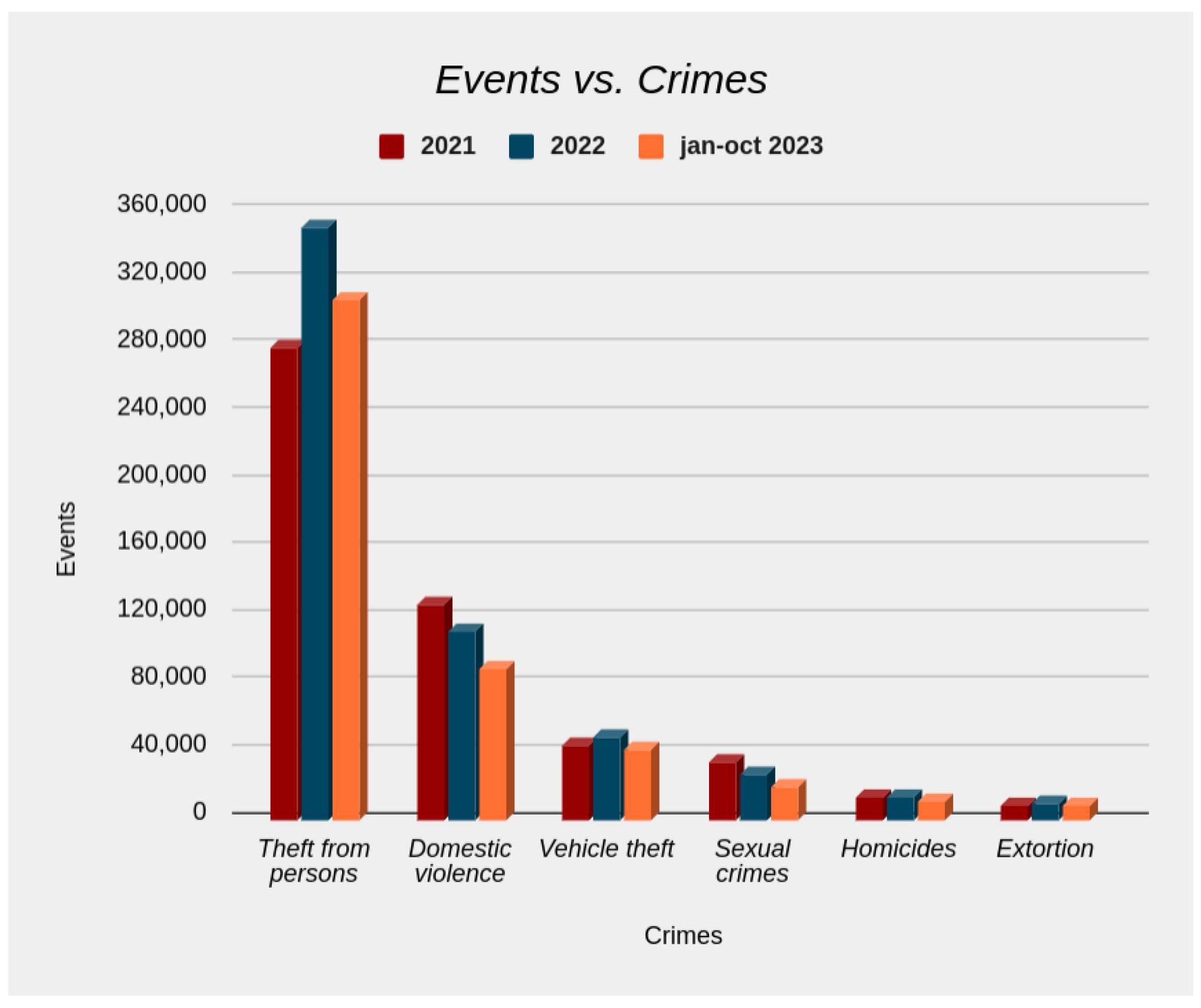
Figure 1 presents crime statistics reported over the last three years in Colombia, emphasizing the prevalence of robbery, which averages approximately 310,000 incidents annually. Improving the deployment of police resources in each region is crucial to prevent such crimes.
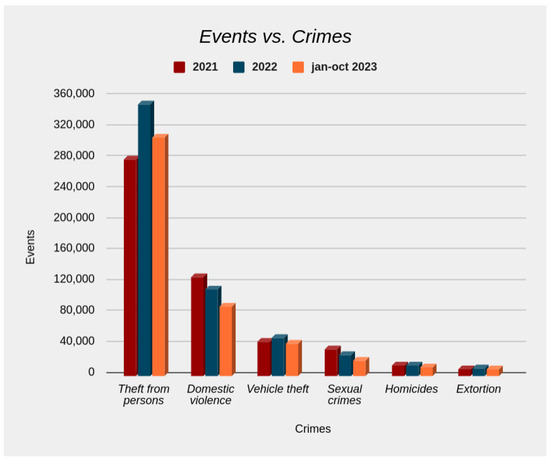
Figure 1.
Crime statistics in Colombia; source: [7].
According to the above, public safety remains a top priority in the context of smart cities. The interconnection of various urban elements provides opportunities for optimizing resource management, preventing crimes, and ultimately improving citizens’ quality of life. Given the prevalence of robbery as a major challenge for public safety in Medellín (Colombia), targeted efforts to prevent crime are essential. This study is part of the project titled “Administración inteligente de problemas de seguridad ciudadana a través de modelos y herramientas generados a partir de plataformas para territorios inteligentes apoyadas por estrategias de participación ciudadana en la ciudad de Medellín” (Intelligent Administration of Citizen Security Problems through Platform-Generated Models and Tools for Smart Cities Supported by Citizen Participation Strategies in the City of Medellín). The project is implemented through a collaboration between the Mayor’s Office of Medellín, the Universidad de Antioquia, and the Universidad Nacional de Colombia. Its main objective is to develop technological strategies aiming to address public security issues in the metropolitan area.
In this context, several efforts have been made to improve crime prevention, including the use of person re-identification systems that employ facial recognition databases and convolutional neural networks, achieving performance rates of up to 98% [8]. Additionally, deep learning models have been employed to strengthen facial recognition processes in urban surveillance systems, demonstrating the feasibility of achieving real-time results with response times on the order of 20 ms [9]. These technologies provide critical support to security agencies and contribute to public safety. However, these approaches are often constrained by the quality and diversity of the training datasets, as well as their dependence on ideal environmental conditions, such as appropriate lighting and unobstructed views. Moreover, scaling these models to diverse urban environments with varying levels of complexity and infrastructure remains challenging. This study addresses some of these limitations by developing a novel crime detection dataset that encompasses a broader range of real-world scenarios, focusing specifically on crimes against individuals under different conditions, and by implementing an evaluation framework to validate model performance across varying environmental contexts.
Researchers have proposed various architectures to process the vast amounts of information collected from cities [10]. These proposals benefit not only individual citizens but also the overall functioning and well-being of urban areas. Privacy remains a critical issue when handling citizens’ personal data, and many urban surveillance systems are underutilized due to the overwhelming volume of information that cannot be effectively processed by human operators. There is substantial interest in leveraging this information to develop datasets, such as the Large-scale Anomaly Detection (LAD) dataset [11], to train machine learning models that assist in crime prevention. Video anomaly detection (VAD) aims to identify unusual patterns of behavior or appearance. This is an ongoing research area that contributes to public safety by exploiting the data collected by surveillance systems [12].
Anomalous events in videos are generally infrequent, which makes anomaly detection challenging due to the limited availability of labeled data. One approach to addressing this is Multiple-Instance Learning (MIL), which focuses on identifying events or labels for segments of a video treated as a set of instances or fragments. Deep learning models, particularly those involving 3D convolutional neural networks (CNNs), have been combined with MIL techniques, resulting in an 8% improvement compared to conventional models [13]. In this context, 3D CNNs extend the capabilities of traditional 2D CNNs—widely used in image processing—by operating on image sequences (videos) or volumetric data, incorporating both spatial and temporal dimensions. In the context of crime detection in videos, these networks facilitate the analysis of motion patterns, changes, and evolution over time, allowing for a more comprehensive understanding of dynamic scenes.
This literature review has shown that current methods for crime detection, which often rely on machine learning and deep learning techniques, face significant challenges when applied in real-world environments. A major limitation is the quality of the datasets used for training these models. Existing datasets are frequently limited in both size and diversity, meaning that they do not adequately capture the wide range of scenarios and conditions encountered in real-world settings. For instance, variations in lighting, camera angles, occlusions, and diverse environmental contexts are often underrepresented, resulting in a lack of robustness in model performance. Furthermore, many datasets are curated under controlled conditions that do not reflect the complexities of urban environments, where crimes can occur under unpredictable circumstances. Consequently, these models struggle to generalize effectively, leading to decreased accuracy when applied beyond their training context. Addressing this gap requires the development of datasets that are more representative of real-world diversity, incorporating a broader range of crime-related scenarios to enhance model reliability and generalizability.
To contribute to addressing the challenges of citizen security, this paper presents the development of a novel dataset specifically designed for detecting crimes against individuals in video footage. Unlike other, more general datasets, this dataset focuses exclusively on incidents such as robberies, assaults, and physical altercations. The primary objective of this study is to evaluate the effectiveness of the newly developed dataset through the application of existing deep learning models. To achieve this, we employ 3D convolutional neural network (3D CNN) techniques, which can capture both the spatial and temporal dimensions of criminal incidents. Based on the above, the main contributions of this work can be summarized as follows:
- Development of a novel crime detection dataset specifically focused on crimes against individuals.
- Implementation of a Conv 3D model for real-time video analysis.
- Comparative evaluation of the proposed dataset against existing datasets to assess its effectiveness.
- Presentation of key metrics to validate the model’s performance.
The remainder of this paper is organized as follows: Section 2 discusses the background and theoretical foundations necessary to understand the employed techniques. Section 3 details the development of the new dataset. Section 4 presents the evaluation of the implemented models and the corresponding results. Finally, Section 5 concludes the paper and suggests potential directions for future work.
2. Related Work
In the context of smart cities, public safety represents a critical area of focus, prompting the academic community to develop various applications to address this challenge. One such initiative is Safest PATH [14], which aims to enhance pedestrian safety through the utilization of underutilized urban resources, including surveillance cameras and computer-equipped vehicles. Additional studies have concentrated on developing spatio-temporal prediction models based on time series analysis to identify high-risk areas and predict crime trends. These models, which have been evaluated using real data from cities such as New York and Chicago [15], have demonstrated performance improvements of up to 5% compared to similar approaches. For example, in [16], the Holt exponential smoothing method with monthly seasonality was employed and tested in Pittsburgh, Pennsylvania, showing that these models provide a more consistent level of accuracy compared to traditional policing practices. Another related solution is CriClust [17], a platform designed to identify patterns in crime series using a hybrid clustering model that incorporates geometric projection and a dual mural scheme. The results indicated that the model reliably identified inherent crime patterns within the dataset and scaled effectively with varying data volumes.
There is a strong emphasis on developing solutions using deep learning techniques that incorporate both spatial and temporal dimensions. A notable example is the development of a weakly supervised learning model based on Multiple-Instance Learning (MIL), as proposed by [18]. In this approach, videos are labeled at the video level rather than on a segment-by-segment basis. Using a dataset comprising 1900 surveillance videos, this method demonstrated significant improvements in anomaly detection, achieving an Area Under the Curve (AUC) of 75.41%, outperforming conventional methods. These findings are of particular significance to the academic community, as they establish a solid foundation for addressing public safety concerns through the automated detection of anomalous events in real-world scenarios. Further research has investigated novel perspectives on the MIL approach utilizing graph convolutional neural networks (GCNs) [19], with some models demonstrating accuracies exceeding 80%. It has been suggested, however, that further optimization of classification methods could yield even better results. Additionally, a new model was developed to address the limitations associated with geometric transformations in CNNs by incorporating a deformable convolution module [20].
The Multiple-Instance Learning (MIL) approach has been extensively studied in recent years, with the RTFM (Robust Temporal Feature Magnitude Learning) method demonstrating considerable efficacy in addressing its inherent limitations. RTFM enhances traditional MIL methods by employing a temporal feature magnitude learning function, which improves the discrimination between normal and anomalous segments in weakly supervised video datasets. This method has been evaluated on benchmark datasets such as UCF-Crime, achieving an anomaly detection accuracy of up to 98.6%. Furthermore, RTFM’s efficiency in processing training samples renders it suitable for real-time surveillance applications, providing significant performance improvements over conventional MIL approaches.
Deep Autoencoders (AEs) are also widely utilized in anomaly detection, particularly due to their capacity to learn latent representations of normal data and identify deviations from expected behavior. Advanced approaches, including Dynamic Prototype Units (DPU) and meta-learning techniques [21], have substantially enhanced this process by enabling rapid adaptation to novel environments while avoiding overgeneralization. These methods have demonstrated effective performance, achieving accuracies exceeding 85% in anomaly detection, and have also exhibited rapid inference times, making them particularly suitable for real-time video surveillance systems.
Anomaly detection using weak labels has been extensively studied in the context of crime. This technique can also be applied to other domains, such as detecting traffic-related issues, accidents, and other factors affecting public safety. A notable implementation is presented in [22], which proposes the Weakly Supervised Anomaly Localization (WSAL) model for detecting anomalies in videos using video-level labels. This approach focuses on the temporal localization of anomalous segments within video sequences, utilizing a Hierarchical Context Encoder (HCE) model that evaluates both dynamic variations and immediate segment semantics. The results obtained on the UCF-Crime dataset, as well as the novel Traffic Anomaly Detection (TAD) dataset, demonstrate substantial improvements over existing methods, achieving an AUC of 85.38% on UCF-Crime and 89.64% on TAD, thereby surpassing the state of the art in both cases.
Similarly, [23] presents a multimodal approach to violence detection in videos, integrating both visual and auditory signals. This study introduces the “XD-Violence” dataset, which comprises 4754 untrimmed videos with weak labels alongside a neural network that fuses visual and auditory features. The results show an improvement in average precision (AP) of up to 3.5% compared to unimodal approaches. Additionally, the proposed architecture supports online detection with a minor reduction in performance, highlighting its potential applicability in real-time scenarios.
Despite advancements in deep learning models, online crime detection continues to present significant challenges. One primary issue is the rarity and unpredictability of criminal incidents and anomalies, resulting in a scarcity of labeled data. This limitation constrains the models’ ability to generalize effectively to real-world scenarios. Furthermore, online detection necessitates rapid processing times to ensure timely analysis and decision-making capabilities. The variability in crime scenes and environmental conditions, including factors such as lighting and camera angles, further complicates the development of robust solutions. Moreover, these systems must achieve high accuracy while minimizing false positives—an objective that becomes particularly challenging in situations involving unreliable or insufficiently labeled data.
In [24], a comprehensive review of violence detection techniques is presented, aiming to elucidate their significance for public safety and crime prevention. The study provides an extensive overview of the most advanced methods for detecting violence in video content, categorizing them into three primary groups: traditional machine learning techniques, support vector machines (SVM), and deep learning. Furthermore, the review examines feature extraction techniques and object detection methods associated with each category, as well as the datasets and video attributes that play a critical role in the violence recognition process. Key challenges in automatic violence detection include the substantial variability in violent behaviors and contexts, which complicates the task of identifying consistent patterns, along with the need for improvements in accuracy, speed, and reliability to support real-time video surveillance systems.
In [25], a detailed compilation of datasets, metrics, and techniques for action detection in unedited videos is presented, which is highly applicable to crime detection tasks. Action detection in these videos poses considerable challenges due to the rapid occurrence of events and the difficulty in acquiring sufficient training examples. Several datasets have been developed to facilitate the training and testing of action detection algorithms. Additionally, this work analyzes different methodologies from various perspectives, organizing them into distinct categories to enhance their comprehension and applicability in this domain. The study also emphasizes recent advancements in spatio-temporal detection, which involves localizing actions across both temporal and spatial dimensions, making it particularly relevant for video analysis applications, such as surveillance and security monitoring. Within this context, learning methods are categorized based on the type of supervision employed.
Methods According to the Type of Learning
- Fully Supervised Methods: These methods require precise labels for each action within the training data. While they achieve high accuracy, they often face limitations due to the scarcity of accurately labeled large datasets. Many of these techniques focus on spatio-temporal approaches to action detection [26,27,28,29].
- Weakly Supervised Methods: These methods operate with labels that may be imprecise or exist only at the video level. This approach allows for training on larger datasets due to the increased availability of data [30,31,32,33].
- Unsupervised Methods: These models learn patterns without explicit labels, making them valuable when precise labels are unavailable or when the objective is to explore unexpected patterns in the data [34,35].
- Semi-Supervised Methods: These methods leverage both labeled and unlabeled data to enhance performance. They are particularly effective in situations where only a limited amount of labeled data is available [36,37,38].
- Self-supervised methods: The model is trained to learn from its own predictions, which can be beneficial when precise labels are scarce [39,40,41].
Several studies have aimed to provide researchers with tools for addressing anomaly detection. One notable example is the LAD dataset, developed as a benchmark for anomaly detection in video sequences. It comprises 2000 video sequences featuring 14 categories of anomalies, such as crashes, fires, violence, and robberies. The creation of this dataset was motivated by the need for larger databases with more detailed labels (at both the video and frame levels) to facilitate the accurate detection of anomalous events. Public sources, including YouTube and YouKu, were utilized to collect these videos. Testing a model based on a 3D deep neural network on this dataset yielded satisfactory results, achieving an accuracy exceeding 86%, which underscores the utility of the dataset for anomaly detection research and its potential application in public security.
Another noteworthy example is the work by [42], which proposes a new benchmark for video anomaly detection by framing the task as a supervised classification problem in an “open-set” context. This approach involves incorporating both normal and abnormal events during the training phase, while the anomalies detected during inference belong to distinct, previously unseen categories. The UBnormal dataset includes 29 virtual scenes with a total of 236,880 frames, with anomalies annotated at the pixel level to facilitate fully supervised methods. Experimental results demonstrated that UBnormal can enhance the performance of existing anomaly detection models, even when applied to real-world datasets. Performance improvements of up to 1.3% in Area Under the Curve (AUC) were observed, highlighting the relevance of UBnormal in advancing research on video anomaly detection.
The quality and relevance of datasets are fundamental to the success of any machine learning model. Intelligent systems depend on robust and diverse datasets to perform complex tasks, such as facial recognition, product recommendations, and disease prediction. These datasets enable models to learn underlying patterns and generalize their performance to previously unseen scenarios. However, one of the primary challenges in this domain is the scarcity of accurate and comprehensively labeled data. Labeled datasets are particularly crucial for training and validating deep learning models, especially in critical applications such as crime detection in video footage.
The UCFCrime dataset [18], developed by the University of Central Florida, is widely used for anomaly detection in surveillance videos. It consists of 1900 untrimmed videos with a total duration of 128 h, capturing real-world incidents involving 13 types of anomalies, such as abuse, arrests, accidents, vandalism, robberies, and explosions. This dataset is particularly valuable due to its variety and the realism of the anomalies captured, making it an essential resource for researching crime and anomaly detection in videos. Numerous studies have employed UCFCrime to develop anomaly detection techniques, and additional subsets like UCF-Crime2Local [43] and HR-Crime [44] have been established. These subsets focus on human-related anomalies, excluding videos with technical issues (e.g., focus problems) or those concentrating on specific anomalies.
XD-Violence [23] is an extensive dataset that integrates both visual and audio information for detecting violence in untrimmed videos. It comprises 217 h of footage across 4754 untrimmed videos, covering six categories of violence: abuse, car accidents, explosions, fights, riots, and shootings. The dataset was compiled from films and online videos sourced from YouTube. While the videos are labeled at the video level, frame-level annotations are available in the test set, enabling more precise temporal event detection. XD-Violence is regarded as a benchmark for violence detection, alongside other datasets such as LAD [11], RWF-2000 (Real-World Fighting) [45], and Real-Life Violence Situations (RLVS) [46]. LAD was designed with frame-level labels to facilitate the development of supervised learning methods.
Additional datasets, such as Ubi Fights [47] and CCTV-Fights [48], focus on the detection of violence and abnormal events like fights and robberies. These datasets are essential for developing video surveillance technologies that can enhance public safety and assist with crime prevention. More comprehensive information on these datasets is provided in Table 1.

Table 1.
Datasets focused on crime.
The datasets discussed above encompass crimes against individuals, which represent a significant public safety concern in Colombia. These datasets cover a range of categories, including fights, vandalism, and robberies, as seen in UCFCrime, XD-Violence, LAD, and others, providing crucial labels necessary for the training process. The data contained in these datasets are instrumental for machine learning models to learn relevant patterns and make accurate predictions in real-time applications. However, many publicly available datasets lack representativeness with respect to the most prevalent types of crimes in Colombia, such as robberies, which remain one of the country’s primary security issues. Additionally, some datasets suffer from class imbalance and lack diversity in the scenarios and contexts represented, complicating the ability of models to generalize effectively to real-world urban environments. Furthermore, certain datasets lack detailed and consistent temporal labeling, which is crucial for training models that aim to detect crimes accurately in video sequences. This paper introduces CrimeDetection, a novel dataset specifically designed to address crimes against individuals. Compiled from multiple sources and meticulously labeled, this dataset provides a foundational resource for training and evaluating machine learning models aimed at detecting criminal activities in public safety contexts. Furthermore, this study presents the implementation of a deep learning model to evaluate the efficacy of the newly developed dataset for crime detection purposes.
3. Crime Detection Dataset
In the development of machine learning applications, access to high-quality data is essential. Large volumes of data are required to effectively learn to distinguish between the desired classes or categories for analysis. Evaluating a dataset involves analyzing various aspects to determine its quality, utility, and applicability in specific contexts. For instance, in [49,50], the authors propose methods for evaluating datasets—one based on category overlap and another assessing the impact of dataset size on model performance. The conclusions from these studies indicate that dataset quality significantly influences the classification process, thereby underscoring the importance of thoroughly evaluating dataset quality.
Based on the aforementioned considerations, specific criteria (Table 2) are suggested to determine which datasets should be employed for training and developing the model.
Table 2.
Evaluation criteria for a dataset.
The evaluation of datasets for crime detection must adhere to criteria that ensure the quality, applicability, and effectiveness of the dataset for training and validating the machine learning model. The process for assessing representativeness involves determining whether the dataset includes sufficient samples of crimes against individuals in various environments (e.g., urban, residential, and commercial). Ensuring diversity requires evaluating the types of events represented in the dataset, verifying whether it includes varied incidents such as fights, robberies, and assaults in both real and simulated environments, thereby covering different scenarios of interest. The size of the dataset is assessed by calculating the total number of samples available for each type of crime. A suitable dataset should have a substantial number of examples to facilitate model training without overfitting or facing issues related to data scarcity.
The balance between criminal and non-criminal incidents is also a critical factor. An imbalanced dataset can bias the model, making it essential to examine whether the different incident classes are represented equitably. The quality of labeling is evaluated by determining whether incidents are accurately labeled at the fragment level, ensuring temporal consistency. This involves reviewing video sequences to verify that the labels effectively capture the onset, progression, and conclusion of the incident. Lastly, the accessibility of the dataset is assessed by determining whether it is publicly available and how easily researchers and developers can access it. The objective is to ensure that the dataset is available on open platforms or academic repositories, promoting its use within the research community.
The selection of datasets was driven by the need to address crimes against individuals, which represent a significant public safety concern in various regions, particularly in Colombia. To identify the most suitable datasets, a comprehensive investigation was conducted to pinpoint commonly used datasets for anomaly and violence detection in videos, with a specific focus on those involving physical violence, robbery, and other crimes against individuals. Each identified dataset was evaluated according to the criteria of representativeness, diversity, size, class balance, labeling quality, temporal consistency, and accessibility. This evaluation facilitated the identification of datasets that provide relevant and sufficient information for analysis, ensuring that the selected datasets are appropriate for training models capable of detecting and predicting criminal activities in real-world scenarios.
Several datasets were reviewed during the selection process, and while they are relevant to the field of violence and anomaly detection in videos, they presented certain limitations based on the defined evaluation criteria. These datasets include the following:
- UBnormal: A dataset with pixel-level annotations. Although the labeling is highly detailed, it primarily focuses on general anomalies and does not adequately cover crimes against individuals, which is the central focus of this study.
- XD-Violence: While this dataset offers a valuable multimodal approach for anomaly detection, its frame-level labeling is limited, and most incidents do not involve real-life scenarios.
To address the limitations found in the available datasets, a new dataset was developed to classify incidents into two primary categories:
- Criminal Incidents: This category includes situations involving physical violence, robbery, assault, and other crimes related to aggression against individuals. Multiple examples of these incidents were included across various contexts and environments to ensure representativeness and diversity.
- Non-Criminal Incidents: To prevent bias and ensure proper balance, this category includes everyday events that do not involve any criminal behavior. This provides the necessary negative examples to train deep learning models, enhancing their ability to distinguish between criminal and non-criminal incidents.
This approach ensures that the proposed dataset addresses the limitations identified in other datasets, allowing for a more comprehensive analysis that is tailored to the needs of public safety applications.
Based on the criteria described above, the following datasets were selected for analysis:
- RWF2000 (Real-world Fighting situations)
- LAD2000 (Large-scale Anomaly Detection)
- Real-Life Violence Situations
- Ubi-Fights (Urban Fights)
- UCF-Crime (Crime Activities)
Dataset Development
We propose the creation of a novel dataset that integrates sections from various existing data sources. This process is critical, as precisely labeled data are essential for both training and validating the deep learning model implemented in this study. The development of this dataset will provide researchers with the necessary tools to evaluate their models and analyze the visual characteristics associated with criminal situations. Crime detection is inherently challenging due to the diversity of crime types and their distinct visual features. Therefore, the primary objective of this new dataset is to improve crime detection systems by enhancing their ability to identify criminal incidents across a range of contexts and situations.
The development process involves a rigorous and meticulous selection and processing of video data. Videos sourced from pre-existing datasets were manually reviewed to ensure that each video either clearly represented crimes against individuals or non-criminal incidents that could serve as control samples. This manual review was a crucial component of the development process, as the quality and accuracy of the labels depended significantly on whether the videos effectively captured the entirety of the criminal or non-criminal situation.
Each video was segmented into non-overlapping 5-s fragments, with a frames-per-second (FPS) rate ranging between 25 and 30 FPS, resulting in samples of approximately 125 frames per fragment, as illustrated in Figure 2. Ensuring temporal consistency in each video clip was a key aspect of this process. Only the samples that consistently depicted the labeled incident throughout the entire 5-s duration were selected. This procedure was conducted with precision to ensure that each sample consistently and accurately represented the labeled incident.

Figure 2.
Samples of the dataset.
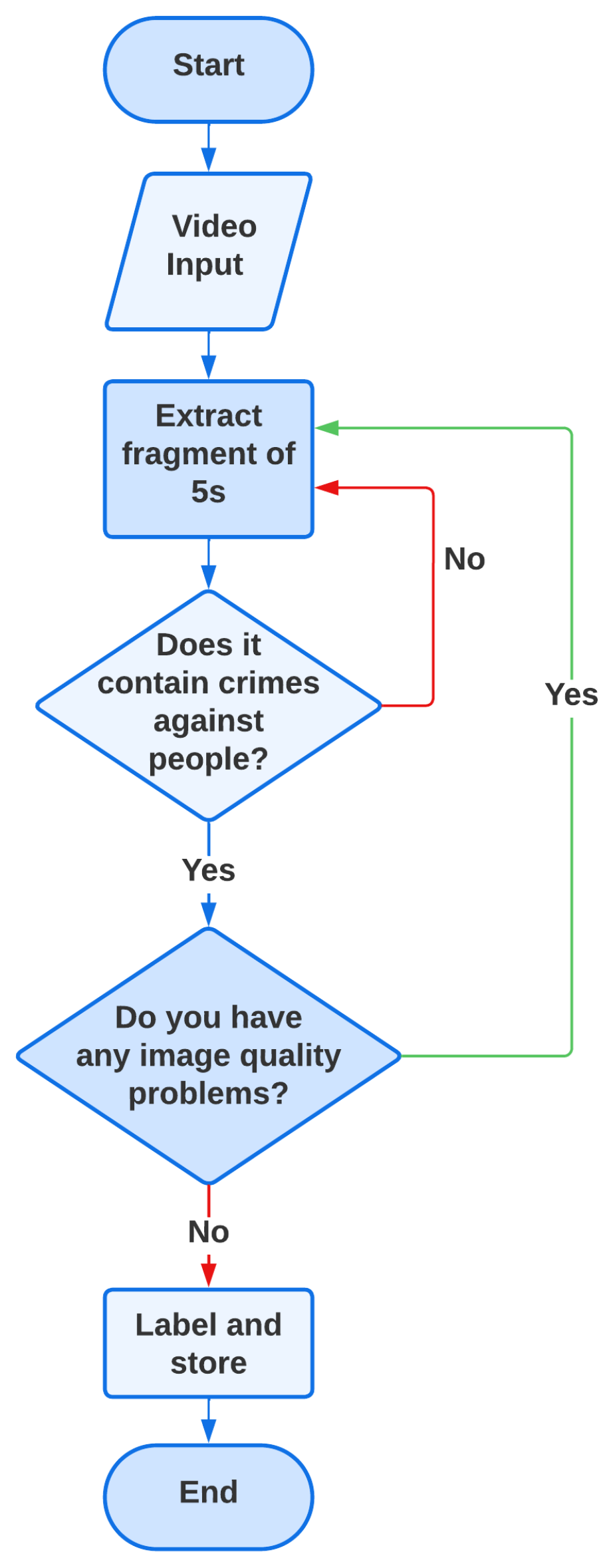
The proposed dataset is specifically focused on incidents involving crimes against individuals, such as robberies, assaults, fights, and abuse, as illustrated in Figure 3. Videos depicting property damage or those with low quality or focus issues were excluded. Each sample is meticulously labeled to contribute effectively to the supervised training of models, ensuring that the input data are consistent and accurately represent the incidents of interest. Figure 4 presents a flowchart illustrating the methodology applied.

Figure 3.
Frame sequence of a criminal event.
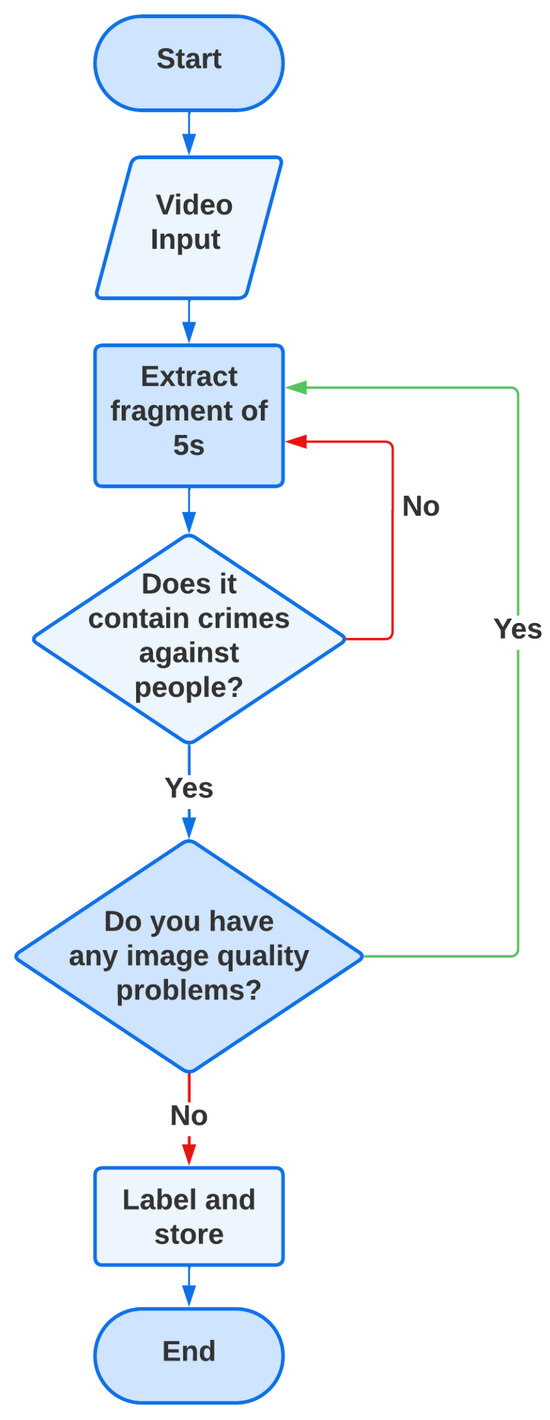
Figure 4.
Pipeline of data collection.
Table 3 provides a description of the developed dataset, while Table 4 offers a detailed analysis of the criteria established for evaluating a high-quality dataset.
Table 3.
CrimeDetection dataset.
Table 4.
Dataset criteria.
4. Machine Learning Model
As highlighted in numerous recent studies, the academic community primarily focuses on the use of 3D convolutional neural networks (3D CNNs) and Long Short-Term Memory (LSTM) networks for anomaly detection in video sequences. Three-dimensional CNNs are particularly effective for analyzing video data, as they capture spatial and temporal information across three dimensions, enabling a comprehensive understanding of motion and changes within video frames. LSTM models, conversely, excel in modeling long-term temporal relationships, which is essential for detecting gradual changes or anomalies over time. In [24], the authors emphasize that these two approaches have become the predominant methods for video anomaly detection due to their demonstrated effectiveness in capturing the inherent spatial and temporal complexities of video data. Many of the existing proposals employing these models have demonstrated strong performance, with Area Under the Curve (AUC) values ranging from 80% to 95%, indicating substantial discriminatory capabilities. However, it is important to note that many of these studies have been conducted using datasets with insufficient samples, which limits the ability of these models to generalize effectively in real-world applications.
The objective is to implement a model capable of effectively detecting crimes by incorporating 3D convolutional layers. This approach is expected to yield good performance in crime detection. The architectural elements, listed in the next section and described in terms of their primary functions, have been carefully selected to support the proposed architecture.
Architecture Description
The proposed model comprises multiple 3D convolutional layers, pooling layers, and fully connected layers with regularization mechanisms. A detailed description of each component is provided below:
- Batch Normalization:
- −
- Applied to the input layer to stabilize and accelerate the training process, thereby reducing the risk of overfitting and facilitating faster convergence.
- 3D Convolutions and MaxPooling3D:
- −
- The model employs eight 3D convolutional layers, each with varying numbers of filters and kernel sizes, to capture both spatial and temporal features in the video data. The convolutional kernels vary between dimensions (1, 3, 3) and (3, 1, 1), enabling the model to capture diverse spatial and temporal characteristics. After each set of convolutional layers, a 3D max-pooling layer is applied with varying pool sizes (e.g., (1, 2, 2), (2, 2, 2), (8, 1, 1)). This pooling operation reduces the spatial dimensionality, allowing for compact feature extraction while lowering computational costs.
- Dropout:
- −
- A dropout layer with a rate of 20% is introduced to mitigate the risk of overfitting by randomly deactivating neurons during training, thereby encouraging the model to learn more robust features.
- Convolutional Filters:
- −
- The model begins with 16 filters, progressively increasing to 128 filters in the final convolutional layers. This progression allows the model to learn low-level features (such as edges and textures) in the initial layers and high-level features (such as objects and patterns) in the deeper layers.
- Dense Layer and Sigmoid Activation:
- −
- A dense layer with 128 neurons is included after the flattening layer, using Rectified Linear Unit (ReLU) activation to maintain non-linearity. Finally, a single output neuron with sigmoid activation is used to provide the binary classification (crime/no crime).
This architecture leverages 3D convolutions to effectively capture spatio-temporal features in video data, making it well suited for detecting criminal activities that involve both spatial patterns and temporal dynamics.
5. Experimental Results
The training process of the proposed model begins with a predefined architecture that integrates multiple 3D convolutional layers specifically designed to capture both spatial and temporal features from input video sequences. To validate the robustness and efficiency of this architecture, a series of experimental configurations were applied to two publicly available datasets commonly used in the literature: RWF2000 and RLVS.
The initial purpose of these experiments was to evaluate the model’s performance on these public datasets, establishing a comparative benchmark prior to applying the model to the newly developed dataset introduced in this study. The model’s performance was subsequently contrasted with the results obtained when utilizing the proposed dataset, which was specifically designed to address limitations found in existing datasets, such as representativeness, class balance, and precise labeling. This experimental approach not only allows for the evaluation of the model’s effectiveness but also serves to validate the relevance and quality of the proposed dataset.
The experimental configurations included variations in video sequence length, frame sampling rate, and video resolution. These parameters were carefully adjusted to analyze their impact on the model’s overall performance. Particular attention was paid to metrics such as accuracy, the AUC-ROC, and processing time, with the objective of identifying improvements in the model’s ability to discriminate between criminal and non-criminal incidents.
The experiments were designed using a data partitioning strategy consisting of three sets: training, validation, and evaluation. To ensure robust training and mitigate the risk of model overfitting, 80% of the data were allocated to the training set, which the model used to adjust its weight and learn the inherent features of the data. Ten percent (10%) of the data were reserved for the validation set, which was employed during training to continuously assess model performance and adjust hyperparameters as necessary without directly influencing the learning process. Finally, the remaining 10% were assigned to the evaluation set, providing an objective measurement of the model’s final performance and ensuring a fair and unbiased assessment.
A total of 30 epochs were conducted, during which the model was trained from scratch. In each epoch, the model adjusted to the training data, and its performance was evaluated on the validation set. This methodology ensured a comprehensive evaluation of the model’s ability to generalize to unseen data.
5.1. Experiments with RWF2000 and Real-Life Violence Situations (RLVS) Datasets
In this initial phase, the objective was to evaluate how sample length influences the model’s performance. Multiple shorter samples were generated from the original videos, each of which had an approximate length of 125 frames. In the first experiment, 64-frame samples were extracted with a sampling frequency of every two frames, maintaining a balance between the volume of data and the information contained in each sample. Subsequently, additional experiments were conducted by dividing the samples into 20-frame and 10-frame segments. While this strategy increased the number of available instances for training, it also resulted in a reduction in the amount of information contained in each sample. The experiments are organized according to these configurations and are presented in Table 5.
Table 5.
RWF2000 and RLVS experiments at 256-pixel resolution.
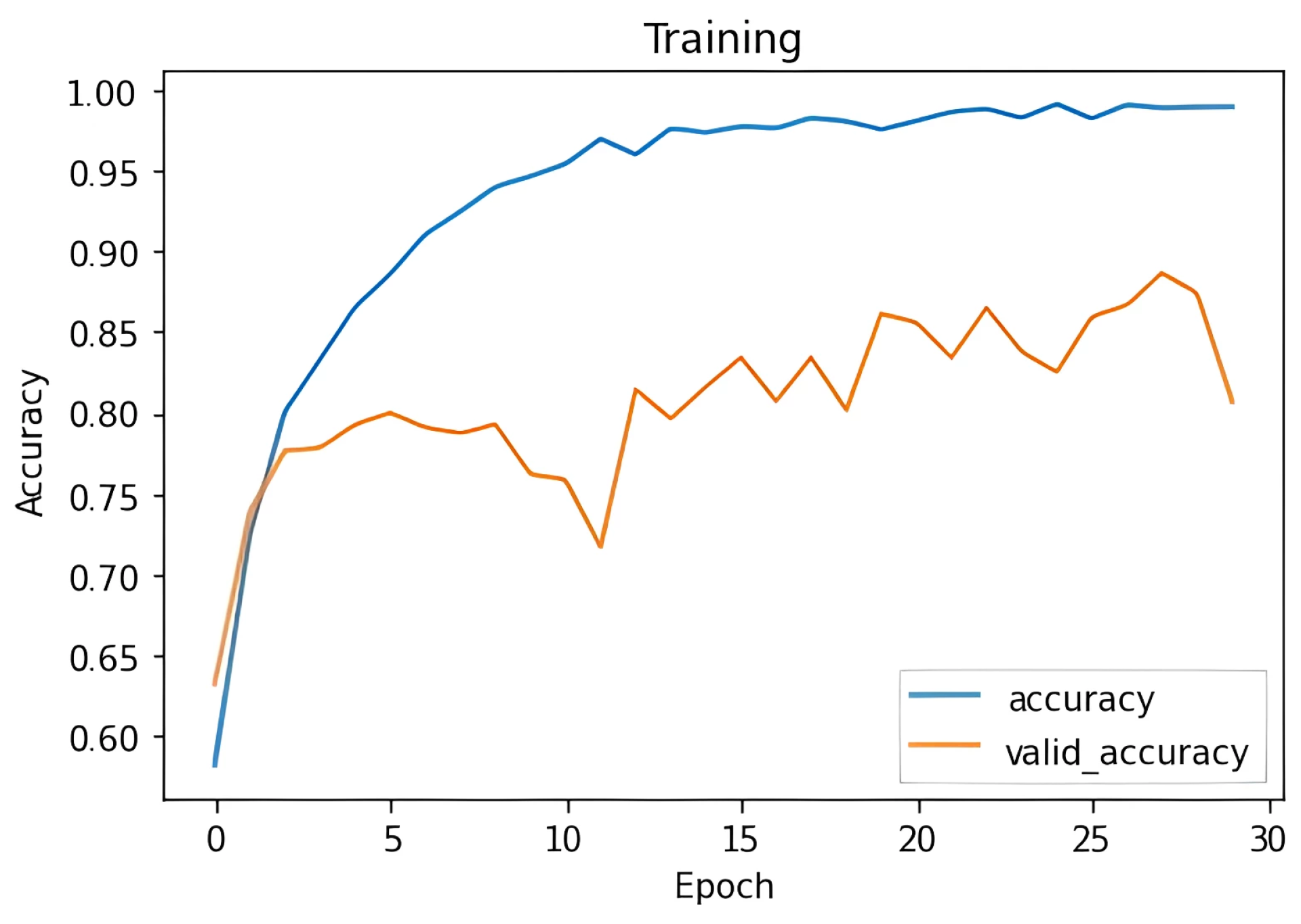
In general, all experiments conducted during this stage exhibited a similar training pattern, as illustrated in Figure 5, corresponding to Experiment 5. The figure shows how the model’s accuracy steadily increased during the initial epochs of training, reaching values close to 98%. However, validation accuracy exhibited some fluctuations before eventually stabilizing at a value lower than that observed in the training set. This behavior is typical in deep neural networks when facing overfitting issues, where the model performs well on training data but struggles to generalize effectively on unseen validation data.
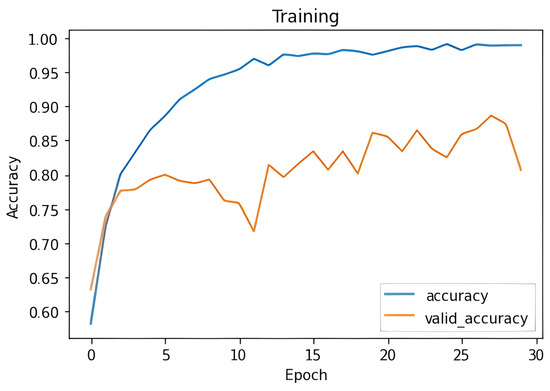
Figure 5.
Experiment datasets RWF2000 and RLVS with varying sample length.
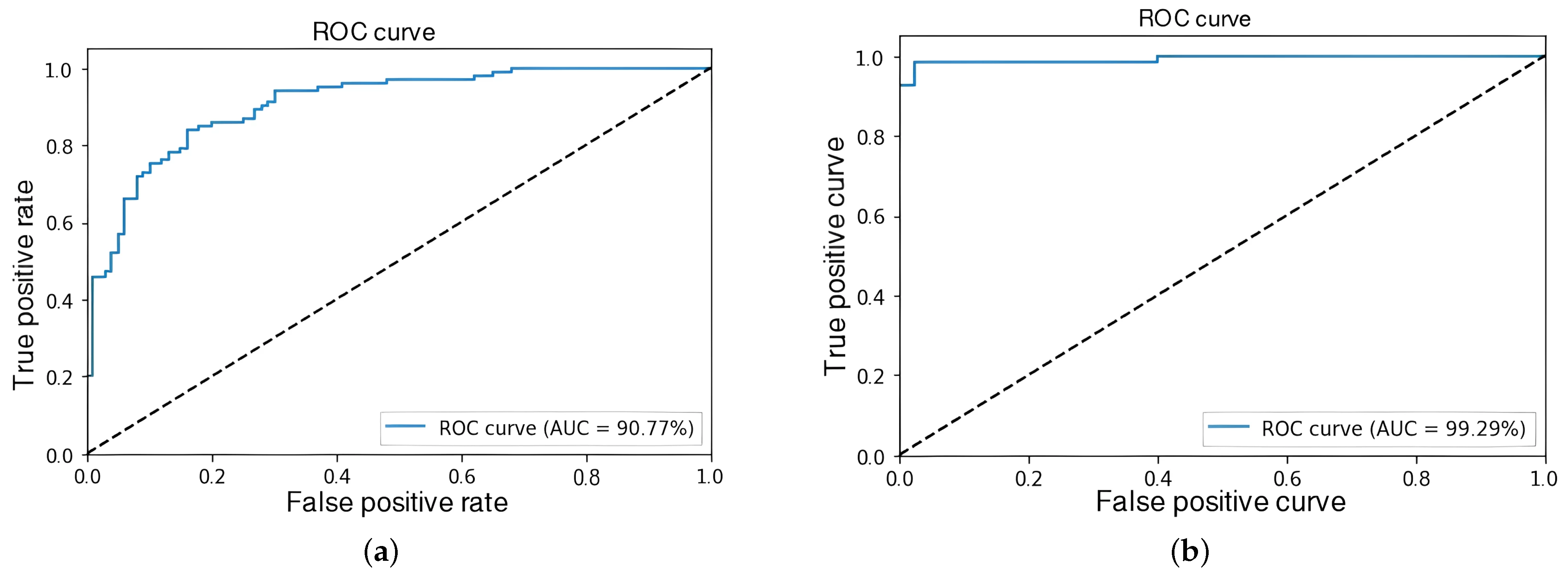
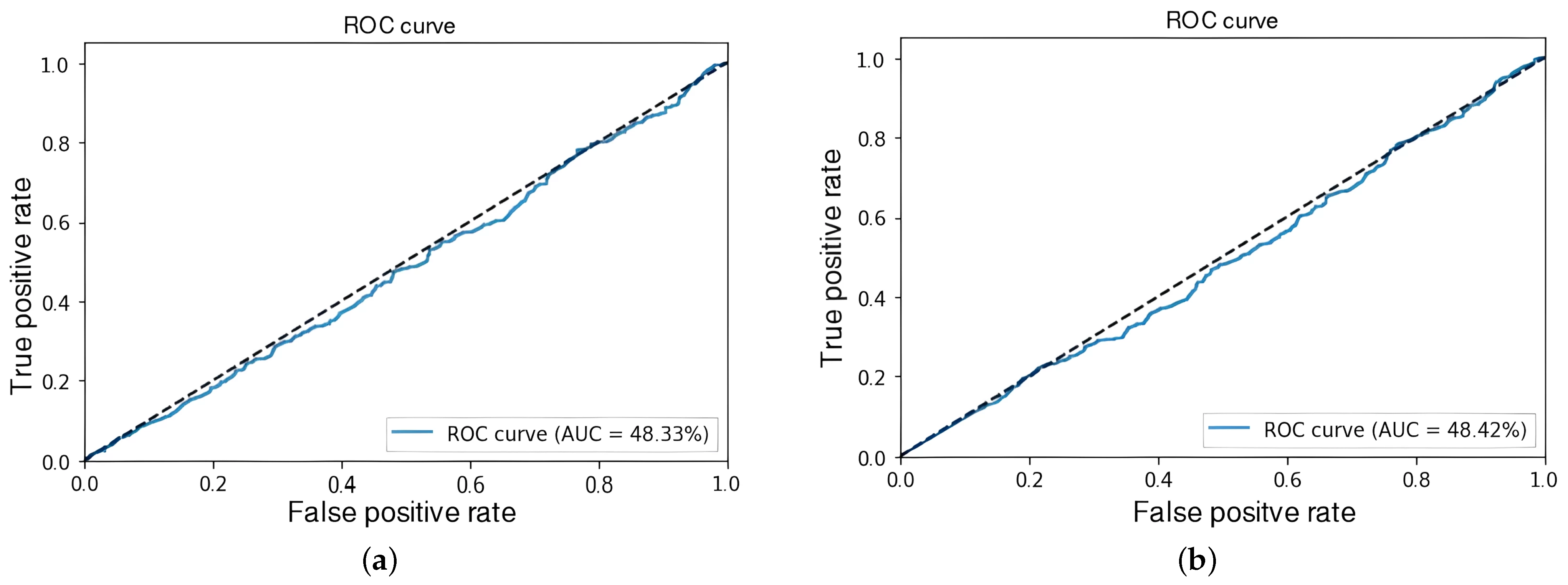
The objective at this stage was to evaluate the influence of sample length on event detection to identify an efficient configuration that enables reduced reaction times—an essential factor for potential implementation in real-time detection applications. The results indicated that as sample length decreased, the model’s ability to accurately discriminate events gradually diminished, as depicted in Figure 6 and Figure 7. Consequently, a sample length of 64 frames was established for subsequent experiments to strike a balance between model accuracy and feasibility in real-time scenarios.
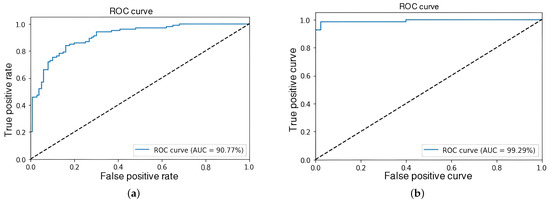
Figure 6.
ROC-AUC curves at 64 frames. (a) Experiment 1. (b) Experiment 4.
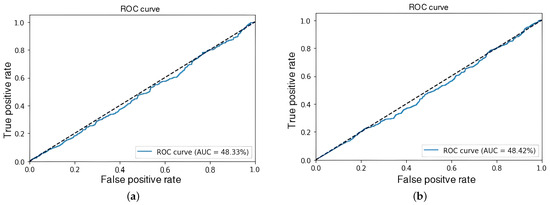
Figure 7.
ROC-AUC curve at 10 frames. (a) Experiment 3. (b) Experiment 6.
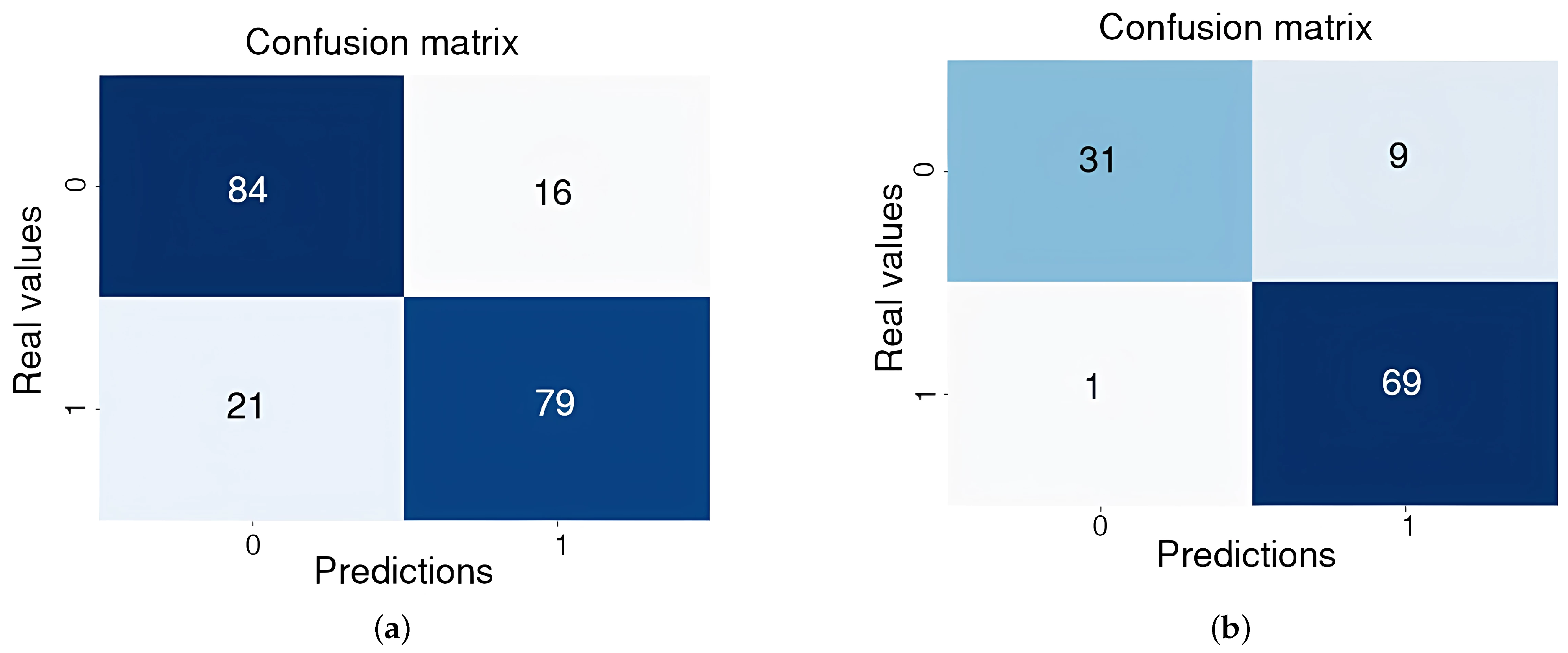
To gain a more in-depth understanding of the results obtained with 64-frame samples in Experiments 1 and 4—yielding AUC values of 90.77% and 99.29%, respectively—the corresponding confusion matrices are presented in Figure 8. These figures demonstrate that the model achieved a certain level of precision in distinguishing between criminal and normal events.
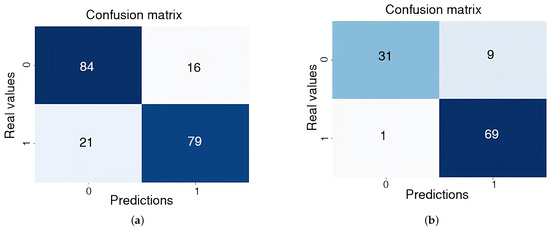
Figure 8.
Confusion matrix training at 64 frames. (a) Experiment 1. (b) Experiment 4.
In the confusion matrix for Experiment 1, the model demonstrated a balanced performance, correctly classifying 79 positive events and 84 negative events. However, 16 false positives and 21 false negatives were also observed.
In the confusion matrix for Experiment 4, the model correctly identified 69 positive (criminal) events and 31 negative (normal) events. Despite this, nine false positives and one false negative occurred, indicating that while the model exhibited good accuracy, classification errors persisted, suggesting that the model faced challenges in efficiently discriminating between both classes.
Although the results are promising, the number of false positives and false negatives observed in both experiments underscores the need for further experimentation with larger and more diverse datasets to enhance the model’s generalizability across various real-world situations.
5.2. Experiments with CrimeDetection Dataset
This section evaluates the performance of the proposed model using the CrimeDetection dataset, with a specific focus on analyzing how different video resolutions affect its crime detection capabilities. Various resolution configurations were employed, as detailed in Table 6, beginning with a resolution of 256 × 256 pixels and progressively reducing it to 64 × 64 pixels.
Table 6.
Experiments on CrimeDetection dataset.
The primary objective of this analysis is to determine whether reducing video resolution significantly impacts the model’s accuracy and its ability to distinguish between criminal and non-criminal incidents. Lower resolutions are advantageous for achieving faster processing and reducing computational resource demands. However, a lower resolution may lead to a loss of critical visual information essential for accurate crime detection. To address this, the resolution configurations were carefully selected to achieve a balance between efficiency and accuracy, with the aim of maximizing model performance even under scenarios with limited processing resources.
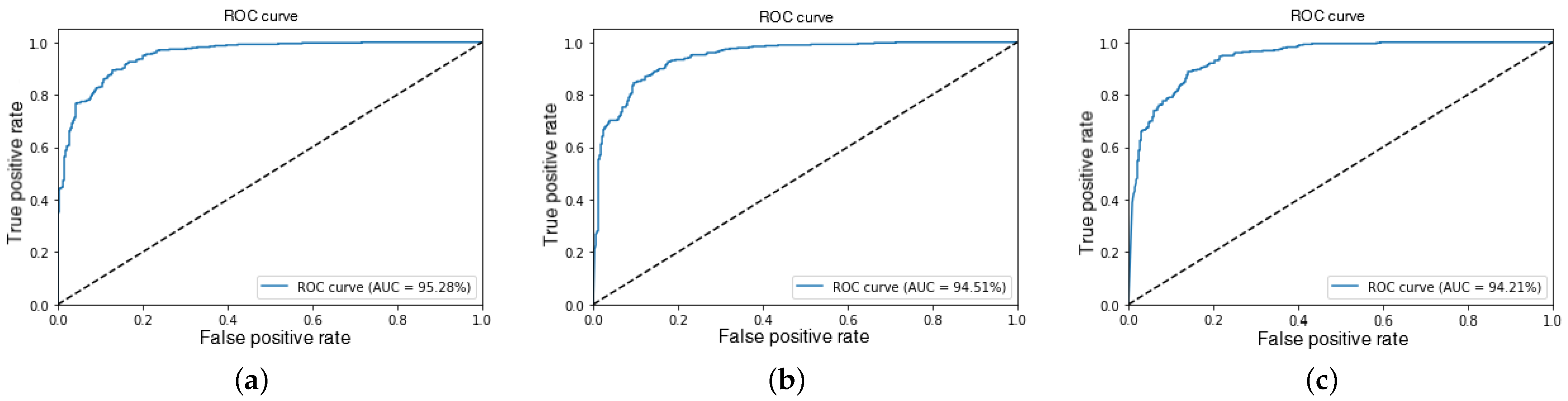
Based on the results from Experiments 7, 8, and 9, represented in Figure 9, it was observed that the model’s ability to discriminate between positive and negative events remained stable despite the progressive reduction in input video resolution. Notably, even with lower-resolution video inputs, the model’s performance in terms of AUC and accuracy did not exhibit significant degradation.

Figure 9.
ROC-AUC curves for CrimeDetection in Experiments 7 (a), 8 (b), and 9 (c).
One of the primary benefits of reducing video resolution is the substantial improvement in training times. Specifically, training times decreased from 8.13 h in Experiment 7 to 2.20 h and 1.87 h in Experiments 8 and 9, respectively. Although training time is not a critical metric for inference performance, it becomes relevant during the initial model setup and future experimental testing phases, as well as when considering system scalability. In this context, the reduction in training time without compromising model accuracy or predictive capability represents a crucial factor for the implementation of the model in a real-time crime detection environment.
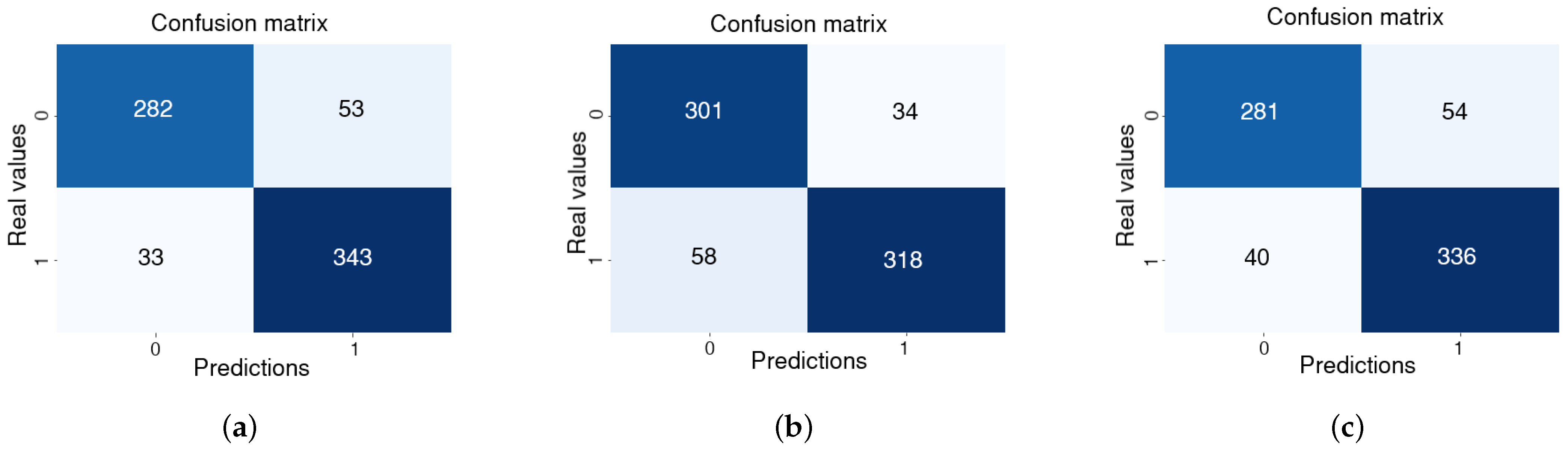
The outcomes of these experiments, presented in Figure 10, indicate satisfactory model performance in the classification task. The model’s predictions closely align with the true classes, demonstrating its ability to effectively differentiate between criminal incidents and non-criminal situations. The confusion matrices for Experiments 7, 8, and 9 (Figure 10) reveal consistent results, with strong model performance reflected in a high degree of alignment between predicted and actual class labels. The confusion matrices indicate a high level of precision in detecting criminal events, with relatively few false positives and false negatives.
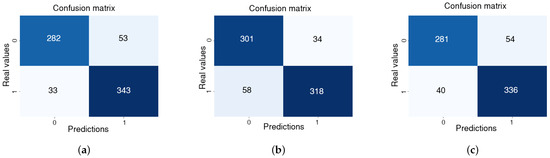
Figure 10.
Confusion matrices for Experiments 7 (a), 8 (b), and 9 (c) using CrimeDetection.
Furthermore, the AUC-ROC values obtained in these experiments range from 94.21% to 95.28%, further reinforcing the model’s ability to accurately distinguish between criminal and non-criminal incidents. This AUC-ROC range, approaching the ideal 100%, suggests an excellent capacity for class discrimination. This level of performance is particularly important to ensure the model’s reliability for use in security applications. The results consistently demonstrate improvements in model precision and accuracy.
The overall performance of the model, as measured by AUC-ROC metrics and the low incidence of classification errors, suggests that the model is sufficiently robust for deployment in real-world applications. This makes it a promising tool for security and surveillance environments, where the ability to respond promptly to critical situations and accurately detect criminal activity in real time is fundamental for operational success.
5.3. Discussion
To properly interpret the results, it is crucial to understand the implications of false positives and false negatives within the context of crime detection. A false positive occurs when the model incorrectly predicts the presence of a criminal incident in the video when, in fact, no crime is occurring. This type of error results in false alarms, which can lead to the unnecessary mobilization of resources and distract authorities, thereby negatively affecting operational efficiency. Conversely, a false negative occurs when the model fails to detect a crime that is taking place. This type of error is particularly critical as it represents a failure to identify real crimes, thereby jeopardizing public safety. The inability to detect a crime in a timely manner may prevent authorities from intervening promptly, potentially leading to serious consequences, including harm to individuals. Therefore, minimizing false negatives is essential for ensuring the overall effectiveness of a surveillance system.
Table 7 demonstrates that the CrimeDetection dataset yields the most favorable results in terms of both false positive and false negative rates, making it the most efficient and promising dataset for effective crime detection in this context. In comparison, the RWF2000 dataset exhibits a higher false negative rate (21.0%), indicating that the model is more likely to miss actual criminal incidents. Similarly, the RLVS dataset shows a higher false positive rate (22.5%), resulting in an increased occurrence of false alarms compared to the CrimeDetection dataset.
Table 7.
Resulting false positive rates and false negative rates.
5.4. Implementation
The selection and configuration of appropriate hardware is essential for the effective execution of video analysis models. To accommodate the processing demands of analyzing large volumes of video data, a system with robust technical specifications was selected. The incorporation of a Graphics Processing Unit (GPU) was necessary to accelerate parallel processing and improve inference times for the models. The technical specifications of the equipment used for conducting the experiments are detailed in Table 8.
Table 8.
Hardware technical specifications.
The models demonstrated an average prediction time of approximately 90 ms, indicating their suitability for real-world applications. This result is particularly significant for public safety and video surveillance applications, where rapid detection and response to anomalous events are crucial. This performance metric confirms that the proposed models can be effectively deployed in real-world environments, thereby enhancing public safety and contributing to the overall well-being of the community.
6. Conclusions
Contribution to the Development of Crime-Specific Datasets: This study contributes by creating a dataset focused on crimes against individuals, including robberies, assaults, and fights, which improves upon existing general-purpose datasets. The inclusion of temporal labeling and a range of scenarios provides a resource for training deep learning models aimed at real-time public safety applications.
Innovation in the Use of 3D Neural Networks for Crime Video Analysis: The implemented model, based on 3D convolutional neural networks (3D CNNs), demonstrates accuracy in detecting criminal events (ranging from 94% to 95%) and shows the capability of this approach to capture the temporal and spatial dynamics of video sequences. This technique advances the use of deep learning models for surveillance and highlights its potential to enhance public security systems.
Optimization of Processing and Scalability in Surveillance Systems: The experiments demonstrate that reducing video resolution and sample length does not significantly affect model accuracy, allowing for improved computational performance without compromising crime detection. This optimization supports the system’s implementation in real-time surveillance environments and highlights its scalability for urban applications.
Contribution to Public Safety through Real-Time Detection: The developed model, with a response time of 90 ms, proves suitable for the real-time detection of criminal activities, making it a viable tool for smart city implementation. This detection capability, combined with reduced false positives and negatives, offers a solution for crime prevention and resource optimization in public safety systems.
Future Work
One of the main areas of future work is the implementation of real-world tests to validate the effectiveness of the model under dynamic and complex conditions. While the results obtained in controlled laboratory environments are promising, it is necessary to evaluate the system’s performance in urban surveillance scenarios, where conditions vary drastically in terms of lighting, movement of people and vehicles, and camera placement.
It is recommended to carry out pilot deployments in collaboration with local authorities in urban areas with high crime incidence. These trials will allow for the analysis of the model’s behavior with real-time data and in unforeseen situations, such as sudden changes in weather conditions or equipment failures. Through these tests, the system can be fine-tuned to minimize false positives and false negatives in real-world situations, optimizing its ability to detect crimes accurately and efficiently.
Another important aspect is the integration of the system with existing surveillance infrastructure, such as public and private security cameras. It is essential to evaluate the model’s interoperability with various platforms and devices to ensure its applicability and scalability in smart cities. These tests will also help define the technical requirements for large-scale implementation and will allow for performance adjustments based on available resources, such as cloud processing capacity or local servers.
Finally, it is essential to conduct longitudinal studies to measure the system’s impact on crime prevention and reduction in test areas. Analyzing metrics such as law enforcement response rates, the number of crimes detected, and the efficiency of police resource use will be crucial. These studies are key to determining the added value of the system in terms of public safety and justifying its large-scale adoption.
Author Contributions
Conceptualization, J.C.L.L., F.B.M. and L.A.F.B.; methodology, J.C.L.L.; software, J.C.L.L.; validation, J.C.L.L., F.B.M. and L.A.F.B.; formal analysis, J.C.L.L.; investigation, J.C.L.L.; resources, F.B.M. and L.A.F.B.; data curation, J.C.L.L.; writing—original draft preparation, F.B.M. and L.A.F.B.; writing—review and editing, F.B.M. and L.A.F.B.; visualization, J.C.L.L.; supervision, F.B.M. and L.A.F.B.; project administration, F.B.M. and L.A.F.B.. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Science, Technology, and Innovation Fund (FCTeI) of the General Royalties System (SGR) under the project identified by code BPIN 2020000100044, Universidad de Antioquia, and Universidad Nacional de Colombia.
Data Availability Statement
The data supporting the reported results are available upon reasonable request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Anthopoulos, L.G. Understanding the Smart City Domain: A Literature Review. In Transforming City Governments for Successful Smart Cities; Rodríguez-Bolívar, M.P., Ed.; Springer International Publishing: Cham, Switzerland, 2015; pp. 9–21. [Google Scholar] [CrossRef]
- UN-Habitat. World Cities Report 2020: The Value of Sustainable Urbanization; United Nations Human Settlements Programme: Nairobi, Kenya, 2020. [Google Scholar]
- Rathore, M.; Ahmad, A.; Paul, A.; Rho, S. Urban planning and building smart cities based on the Internet of Things using Big Data analytics. Comput. Netw. 2016, 101, 63–80. [Google Scholar] [CrossRef]
- Simić, M.; Perić, M.; Popadić, I.; Perić, D.; Pavlović, M.; Vučetić, M.; Stanković, M. Big Data and Development of Smart City: System Architecture and Practical Public Safety Example. Serbian J. Electr. Eng. 2020, 17, 337–355. [Google Scholar] [CrossRef]
- Al Nuaimi, E.; Al Neyadi, H.; Mohamed, N.; Al-Jaroodi, J. Applications of Big Data to Smart Cities. J. Internet Serv. Appl. 2015, 6, 25. [Google Scholar] [CrossRef]
- OECD Better Life Index. Available online: https://www.oecdbetterlifeindex.org/ (accessed on 22 March 2023).
- Policía Nacional de Colombia. Estadística Delictiva. Available online: https://www.policia.gov.co/estadistica-delictiva (accessed on 22 March 2023).
- Medapati, P.K.; Murthy, P.H.S.T.; Sridhar, K.P. LAMSTAR: For IoT-based face recognition system to manage the safety factor in smart cities. Trans. Emerg. Telecommun. Technol. 2019, 31, e3843. [Google Scholar] [CrossRef]
- Zhu, C.; Yang, Y. Face Detection and Recognition Based on Deep Learning in the Monitoring Environment. Commun. Comput. Inf. Sci. 2018, 901, 698–705. [Google Scholar] [CrossRef]
- Rathore, M.; Paul, A.; Ahmad, A.; Chilamkurti, N.; Hong, W.H.; Seo, H. Real-time secure communication for Smart City in high-speed Big Data environment. Future Gener. Comput. Syst. 2018, 83, 638–652. [Google Scholar] [CrossRef]
- Wan, B.; Jiang, W.; Fang, Y.; Luo, Z.; Ding, G. Anomaly Detection in Video Sequences: A Benchmark and Computational Model. IET Image Process. 2021, 15, 3454–3465. [Google Scholar] [CrossRef]
- Ullah, W.; Ullah, A.; Hussain, T.; Khan, A.; Baik, S.W. An Efficient Anomaly Recognition Framework Using an Attention Residual LSTM in Surveillance Videos. Sensors 2021, 21, 2811. [Google Scholar] [CrossRef] [PubMed]
- Ullah, W.; Ullah, A.; Haq, I.U.; Muhammad, K.; Sajjad, M.; Baik, S.W. CNN features with bi-directional LSTM for real-time anomaly detection in surveillance networks. Multimed. Tools Appl. 2021, 80, 16979–16995. [Google Scholar] [CrossRef]
- Pang, Y.; Zhang, L.; Ding, H.; Fang, Y.; Chen, S. SPATH: Finding the Safest Walking Path in Smart Cities. IEEE Trans. Veh. Technol. 2019, 68, 7071–7079. [Google Scholar] [CrossRef]
- Catlett, C.; Cesario, E.; Talia, D.; Vinci, A. Spatio-temporal crime predictions in smart cities: A data-driven approach and experiments. Pervasive Mob. Comput. 2019, 53, 62–74. [Google Scholar] [CrossRef]
- Gorr, W.; Olligschlaeger, A.; Thompson, Y. Short-term forecasting of crime. Int. J. Forecast. 2003, 19, 579–594. [Google Scholar] [CrossRef]
- Isafiade, O.E.; Bagula, A.B. Series mining for public safety advancement in emerging smart cities. Future Gener. Comput. Syst. 2020, 108, 777–802. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world Anomaly Detection in Surveillance Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. [Google Scholar] [CrossRef]
- Zhong, J.X.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph Convolutional Label Noise Cleaner: Train a Plug-And-Play Action Classifier for Anomaly Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1237–1246. [Google Scholar] [CrossRef]
- Zhang, S.; Yu, H. Person Re-Identification by Multi-Camera Networks for Internet of Things in Smart Cities. IEEE Access 2018, 6, 76111–76117. [Google Scholar] [CrossRef]
- Lv, H.; Chen, C.; Cui, Z.; Xu, C.; Li, Y.; Yang, J. Learning Normal Dynamics in Videos with Meta Prototype Network. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Lv, H.; Zhou, C.; Cui, Z.; Xu, C.; Li, Y.; Yang, J. Localizing Anomalies from Weakly-Labeled Videos. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021 2021. [Google Scholar]
- Wu, P.; Liu, J.; Shi, Y.; Sun, Y.; Shao, F.; Wu, Z.; Yang, Z. Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision. In Proceedings of the Computer Vision and Pattern Recognition, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Ramzan, M.; Abid, A.; Khan, H.U.; Awan, S.M.; Ismail, A.; Ahmed, M.; Ilyas, M.; Mahmood, A. A Review on State-of-the-Art Violence Detection Techniques. IEEE Access 2019, 7, 107560–107575. [Google Scholar] [CrossRef]
- Vahdani, E.; Tian, Y. Deep Learning-Based Action Detection in Untrimmed Videos: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4302–4320. [Google Scholar] [CrossRef] [PubMed]
- Oneata, D.; Revaud, J.; Verbeek, J.; Schmid, C. Spatio-temporal Object Detection Proposals. In Proceedings of the Computer Vision–ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 737–752. [Google Scholar]
- Hou, R.; Chen, C.; Shah, M. Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos. arXiv 2017, arXiv:1703.10664. [Google Scholar]
- Cuzzolin, F.; Singh, G.; Saha, S.; Sapienza, M.; Torr, P. Online Real time Multiple Spatiotemporal Action Localisation and Prediction on a Single Platform. arXiv 2017, arXiv:1611.08563. [Google Scholar]
- Weinzaepfel, P.; Harchaoui, Z.; Schmid, C. Learning to track for spatio-temporal action localization. arXiv 2015, arXiv:1506.01929. [Google Scholar]
- Bojanowski, P.; Lajugie, R.; Bach, F.R.; Laptev, I.; Ponce, J.; Schmid, C.; Sivic, J. Weakly Supervised Action Labeling in Videos Under Ordering Constraints. arXiv 2014, arXiv:1407.1208. [Google Scholar]
- Huang, D.; Fei-Fei, L.; Niebles, J.C. Connectionist Temporal Modeling for Weakly Supervised Action Labeling. arXiv 2016, arXiv:1607.08584. [Google Scholar]
- Islam, A.; Radke, R.J. Weakly Supervised Temporal Action Localization Using Deep Metric Learning. arXiv 2020, arXiv:2001.07793. [Google Scholar]
- Gao, M.; Zhou, Y.; Xu, R.; Socher, R.; Xiong, C. WOAD: Weakly Supervised Online Action Detection in Untrimmed Videos. arXiv 2020, arXiv:2006.03732. [Google Scholar]
- Sener, F.; Yao, A. Unsupervised Learning and Segmentation of Complex Activities from Video. arXiv 2018, arXiv:1803.09490. [Google Scholar]
- Kukleva, A.; Kuehne, H.; Sener, F.; Gall, J. Unsupervised learning of action classes with continuous temporal embedding. arXiv 2019, arXiv:1904.04189. [Google Scholar]
- Ji, J.; Cao, K.; Niebles, J.C. Learning Temporal Action Proposals With Fewer Labels. arXiv 2019, arXiv:1910.01286. [Google Scholar]
- Tarvainen, A.; Valpola, H. Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Lin, X.; Shou, Z.; Chang, S. LPAT: Learning to Predict Adaptive Threshold for Weakly-supervised Temporal Action Localization. arXiv 2019, arXiv:1910.11285. [Google Scholar]
- Jain, M.; Ghodrati, A.; Snoek, C.G.M. ActionBytes: Learning From Trimmed Videos to Localize Actions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1168–1177. [Google Scholar] [CrossRef]
- Chen, M.; Li, B.; Bao, Y.; AlRegib, G.; Kira, Z. Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation. arXiv 2020, arXiv:2003.02824. [Google Scholar]
- Gong, G.; Zheng, L.; Jiang, W.; Mu, Y. Self-Supervised Video Action Localization with Adversarial Temporal Transforms. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Virtual, 19–26 August 2021; Zhou, Z.H., Ed.; 2021; pp. 693–699. [Google Scholar] [CrossRef]
- Acsintoae, A.; Florescu, A.; Georgescu, M.I.; Mare, T.; Sumedrea, P.; Ionescu, R.T.; Khan, F.S.; Shah, M. UBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection. In Proceedings of the Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Landi, F.; Snoek, C.G.M.; Cucchiara, R. Anomaly Locality in Video Surveillance. arXiv 2019, arXiv:1901.10364. [Google Scholar]
- Boekhoudt, K.; Matei, A.; Aghaei, M.; Talavera, E. HR-Crime: Human-Related Anomaly Detection in Surveillance Videos. arXiv 2021, arXiv:2108.00246. [Google Scholar]
- Cheng, M.; Cai, K.; Li, M. RWF-2000: An Open Large Scale Video Database for Violence Detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4183–4190. [Google Scholar] [CrossRef]
- Soliman, M.M.; Kamal, M.H.; El-Massih Nashed, M.A.; Mostafa, Y.M.; Chawky, B.S.; Khattab, D. Violence Recognition from Videos using Deep Learning Techniques. In Proceedings of the 2019 Ninth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 8–9 December 2019; pp. 80–85. [Google Scholar] [CrossRef]
- Degardin, B.; Proença, H. Iterative weak/self-supervised classification framework for abnormal events detection. Pattern Recognit. Lett. 2021, 145, 50–57. [Google Scholar] [CrossRef]
- Perez, M.; Kot, A.C.; Rocha, A. Detection of Real-world Fights in Surveillance Videos. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2662–2666. [Google Scholar] [CrossRef]
- Oh, S. A new dataset evaluation method based on category overlap. Comput. Biol. Med. 2011, 41, 115–122. [Google Scholar] [CrossRef] [PubMed]
- Althnian, A.; AlSaeed, D.; Al-Baity, H.; Samha, A.; Dris, A.B.; Alzakari, N.; Abou Elwafa, A.; Kurdi, H. Impact of Dataset Size on Classification Performance: An Empirical Evaluation in the Medical Domain. Appl. Sci. 2021, 11, 796. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).