3.1. General information
All calculations were performed on an AMD Athlon XP 3000+ personal computer running Microsoft Windows XP SP3 operating system. The programs were in-house scripts written in MATLAB version 7.5, except for the analysis of variance (ANOVA), SVM, and RF. ANOVA was performed in Microsoft Excel version 12.0. The SVM calculations were performed by the LIBSVM software version 2.89 with MATLAB interface [
18]. The RF program was obtained from reference [
19]. The training of RBFCCN was implemented through fminbnd and fminunc functions by their default parameters from the optimization toolbox version 3.1.2 of MATLAB. The fminunc function uses the Broyden-Fletcher-Goldfarb-Shanno (BFGS) quasi-Newton method with a cubic line search procedure. The fminbnd function is based on golden section search and parabolic interpolation algorithm. In the RBFCCN, RBFN, and SCRBFN, the weights of the output neurons were updated by the SVD algorithm. The SVD algorithm was implemented by the MATLAB function pinv. All ANNs and PLS-DA applied binary coding for determine the classes from the outputs.
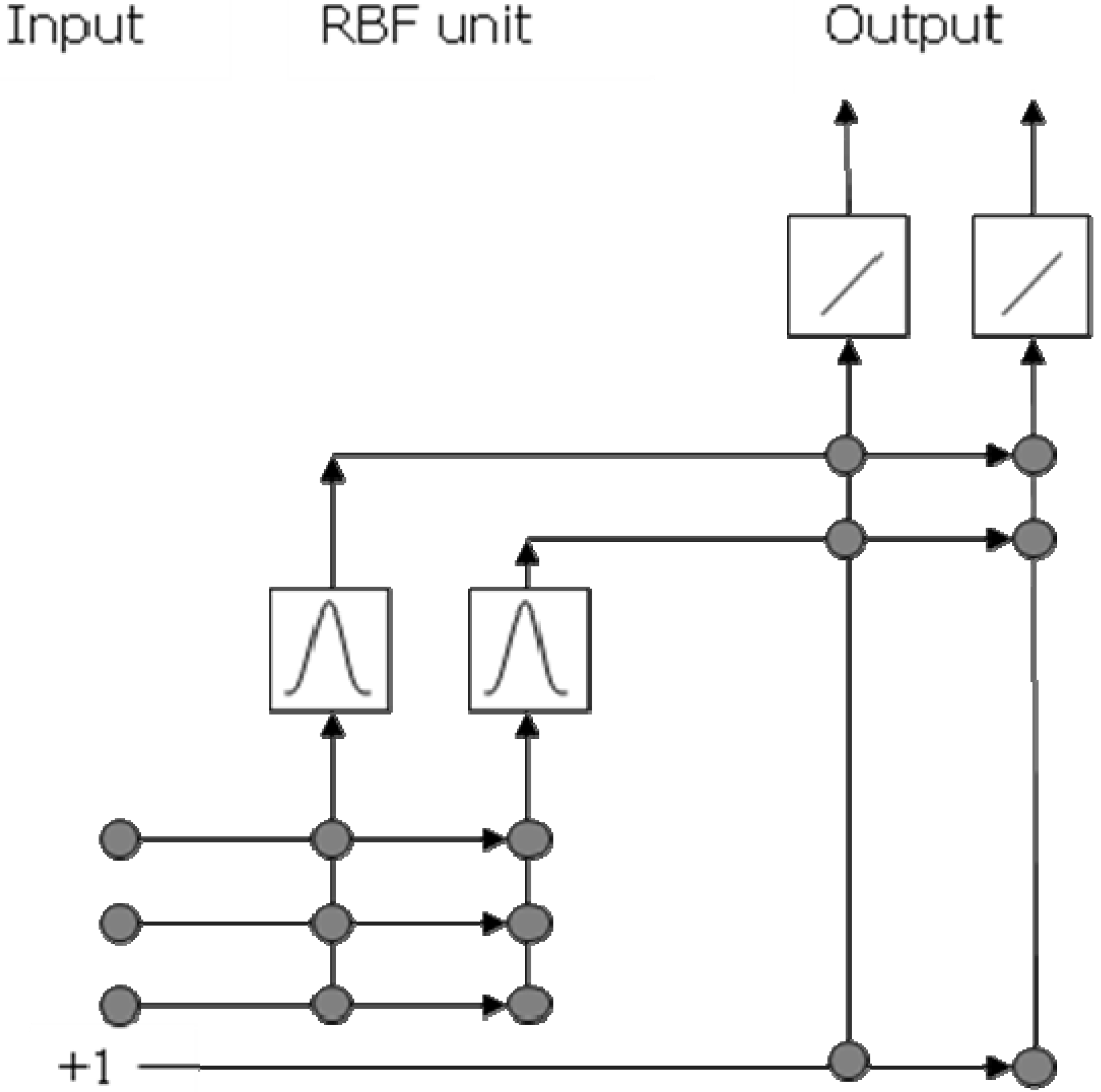
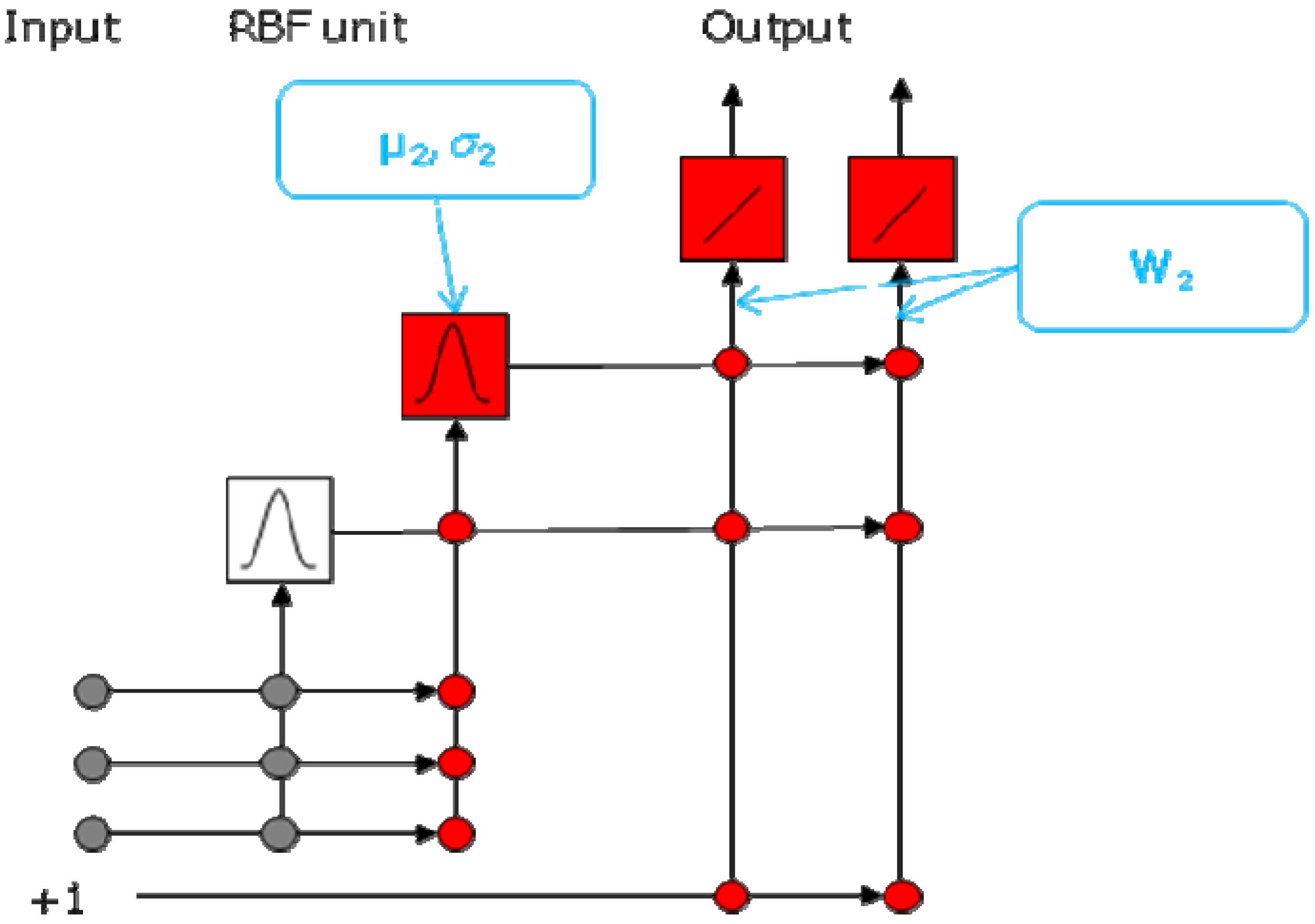
Instead of training neural networks to achieve the minimum error of an external validation set, all the neural networks (the BNNs, SCRBFNs, RBFNs, and RBFCCNs) compared in this work were trained to a given RRMSEC in each data set. All the neural networks and PLS-DA applied the binary coding method to set the training target value, and the method to identify the class membership stated above. The BNNs used in this work consists of three layers: one input layer, one hidden layer and one output layer. The sigmoid neuron was used in the hidden layer, and the output layer was linear. The two-stage training method of RBFN was applied. The centroids and radii of RBFN were initialized by the K-means clustering, and optimized by back-propagation. The centroid of the
kth hidden neuron
µk was initialized by the mean of the objects in the
kth cluster, and the radius of the
kth hidden neuron
σk was initialized by:
for which
µq is the three nearest neighbors of
µk. The details of this method are described in reference [
20]. In the SCRBFNs, the parameter
λ in the linear averaging clustering algorithm was adjusted gradually to achieve the RRMSEC.
For the RBFN model, the number of hidden neurons
h equals to the number of training classes. For the BNN model,
h is empirically proposed by:
for which
l denotes the number of variables of the data set,
n denotes the number of classes of the training object, and round denotes round to the closest integer. Because two synthetic data sets were relatively simple in data size that have less variables and classes,
h was fixed without further evaluations. To demonstrate the numbers of hidden neurons was appropriate, independent tests were performed by evaluating BNNs on two chemical data sets with 0.5
h and 2
h hidden neurons so that the network performances can be observed by significantly decreasing or increasing the hidden layer size.
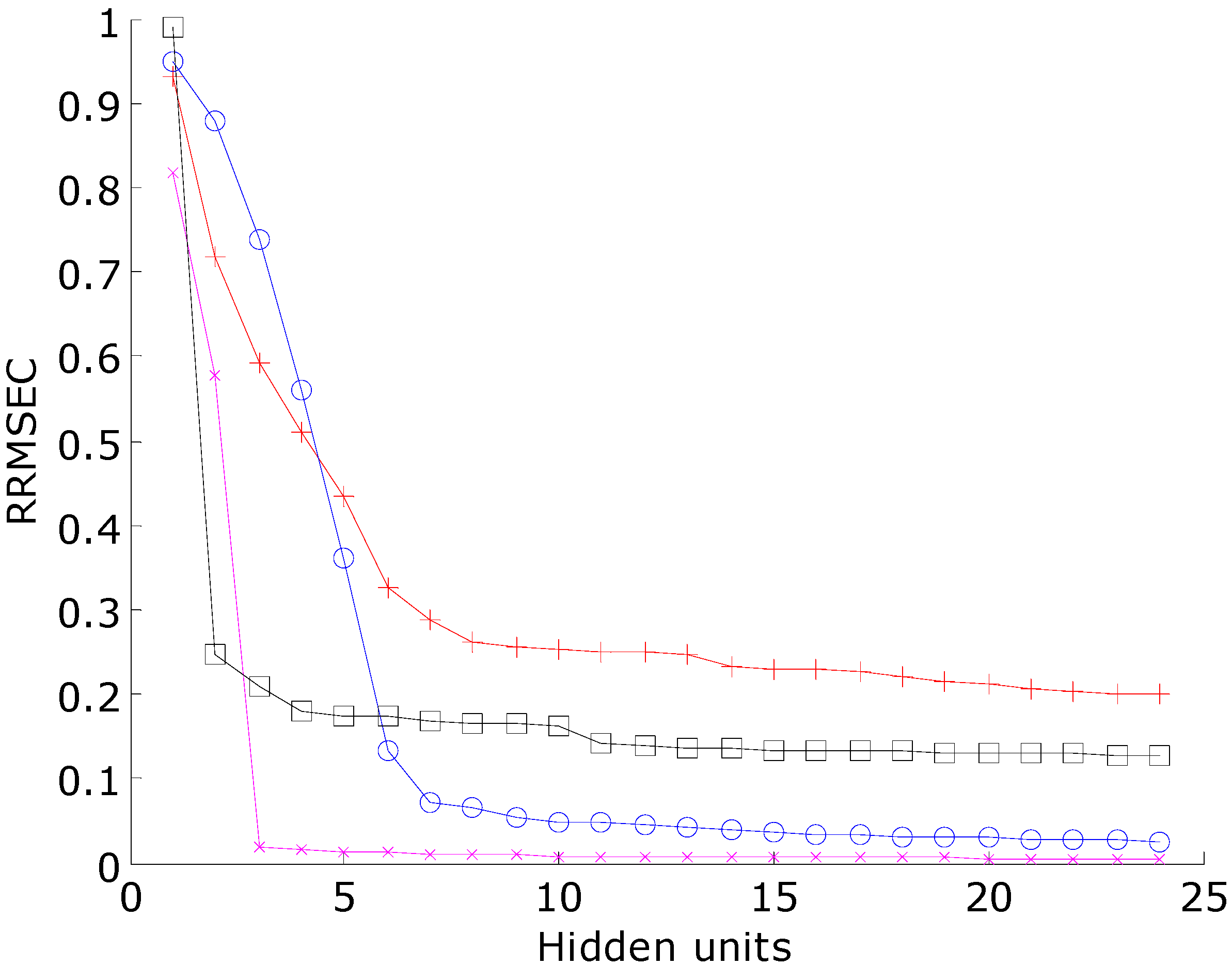
Table 1 gives the average prediction accuracies of the BNN models of Italian olive oil and the training set of the PCB data set. For the Italian olive oil data set, the BNN models with 7 and 14 hidden neurons did not significantly differ with respect to prediction accuracy. The BNN models with four hidden neurons had too few hidden units to model the data sufficiently. For the PCB dataset, the effect of the three different numbers of hidden neurons on the prediction results was not significant. The BNNs with extra hidden neurons will not overfit the data if trained to the same RRMSEC. As a result, the heuristic equation of
h was appropriate.
Table 1.
Average prediction accuracies of the BNN models with 95% confidence intervals of Italian olive oil and the training set of the PCB data set. The BNN was trained by different number of hidden neurons with 30 BLPs.
Table 1.
Average prediction accuracies of the BNN models with 95% confidence intervals of Italian olive oil and the training set of the PCB data set. The BNN was trained by different number of hidden neurons with 30 BLPs.
| Data set | Number of hidden neurons | Prediction accuracy |
|---|
| Olive oil | 7 | 95.5 ± 0.3 |
| | 14 | 95.9 ± 0.4 |
| | 4 | 87.7 ± 0.2 |
| PCB | 13 | 99.9 ± 0.1 |
| | 26 | 99.9 ± 0.1 |
| | 7 | 99.9 ± 0.1 |
To determine the learning rates and momenta of the BNNs and RBFNs, these networks were trained by three different sets of learning rates and momenta with BLPs. The number of bootstraps was 30 and the number of partitions was two.
Table 2 gives the prediction results by the Italian olive oil data set and the training set of the PCB data set. The training parameters of the back-propagation networks did not significantly affect the comparison of the modeling methods. These sets of learning parameters were also trained by the two synthetic data sets and same results were obtained. For each data set, there was no statistical difference of the BNN and RBFN prediction results at a 95% confidence interval by two-way ANOVA with interaction. Therefore, the learning rates and momenta were fixed respectively at 0.001 and 0.5 for all further evaluations.
Table 2.
Average prediction accuracies of the BNN and RBFN models with 95% confidence intervals of Italian olive oil and the PCB data sets. The BNN and RBFN were trained by three different sets of learning rates and momenta with 30 BLPs.
Table 2.
Average prediction accuracies of the BNN and RBFN models with 95% confidence intervals of Italian olive oil and the PCB data sets. The BNN and RBFN were trained by three different sets of learning rates and momenta with 30 BLPs.
| Data set | Learning rate | Momentum | BNN | RBFN |
|---|
| Olive oil | 0.001 | 0.5 | 95.5 ± 0.3 | 92.0 ± 0.7 |
| | 1 × 10-4 | 0.5 | 95.4 ± 0.3 | 91.9 ± 0.7 |
| | 0.001 | 0 | 95.6 ± 0.3 | 91.5 ± 0.6 |
| PCB | 0.001 | 0.5 | 99.9 ± 0.1 | 92.4 ± 5.5 |
| | 1 × 10-4 | 0.5 | 99.5 ± 0.2 | 90.8 ± 6.3 |
| | 0.001 | 0 | 99.9 ± 0.1 | 94.1 ± 4.8 |
The PLS-DA was implemented by the non-linear iterative partial least squares (NIPALS) algorithm. The number of latent variables was determined by minimizing the root mean squared prediction error in each test. As a result, the PLS-DA was a biased reference method. The numbers of latent variables in the PLS-DA models may vary between runs.
All the SVMs used the Gaussian RBF as their kernel functions. Two SVM parameters: the cost c and the RBF kernel parameter γ must be adjusted before each prediction. The grid search of parameter pairs (c, γ), in which c = 2i, i = -2, -1, 0, …, 20; γ = 2j, j = -10, -9, -8, …, 10, was performed to determine their value by achieving the best training accuracies. The defaults of the remaining parameters were used. Because the result of the RF algorithm is not sensitive to the parameter selected, 1,000 trees with the default setting of the number of variables to split on at each node is used in all evaluations.
The BLPs generates precision measures of the classification. Bootstrapping is a method that re-samples the data. Latin partition is a modified cross-validation method, in which the class distributions are maintained at constant proportions among the entire data set and the randomized splits into training and prediction sets. After the data set was partitioned during each bootstrap, it was evaluated by all the modeling methods in the study. Because bootstrapping runs the evaluation repeatedly, the confidence interval of the prediction errors can also be obtained. The number of bootstraps was 30 and the number of partitions was two for evaluating all the data sets in this study. The results are reported as prediction accuracy, which is the percentage of correctly predicted objects. To determine the classification ability of RBFCCN, four data sets were tested, including the novel class data set, imbalanced data set, Italian olive oil data set, and the PCB data set. The numbers of variables, objects, and classes of data sets are given in
Table 3. The modeling parameters of the ANNs, PLS-DA, SVM, and RF method are given in
Table 4. Similar to the latent variables used in the PLS-DA models, the numbers of hidden neurons used to train SCRBFN and RBFCCN models may vary between different runs. Therefore, only typical latent variables and numbers of hidden neurons are reported.
Table 3.
The numbers of variables, objects, and classes of the data sets evaluated.
Table 3.
The numbers of variables, objects, and classes of the data sets evaluated.
| | Novel class | Imbalanced | Olive oil | PCB |
|---|
| | Training | Test | Training | Test | BLP validation | BLP validation | External validation |
|---|
| Variables | 2 | 2 | 2 | 2 | 8 | 18a | 18a |
| Objects | 400 | 100 | 610 | 10 | 478 | 131 | 154 |
| Classes | 4 | 1 | 3 | 1 | 6 | 7 | 8b |
Table 4.
The modeling parameters of the ANNs, PLS-DA, SVM, and RF method. Hidden units are the number of hidden units in the trained network model. Latent variables are the number of latent variables used in the PLS-DA models. The RBF kernel parameter is denoted by γ in the SVM method. Mtry is the number of variables to split on at each node in the RF method.
Table 4.
The modeling parameters of the ANNs, PLS-DA, SVM, and RF method. Hidden units are the number of hidden units in the trained network model. Latent variables are the number of latent variables used in the PLS-DA models. The RBF kernel parameter is denoted by γ in the SVM method. Mtry is the number of variables to split on at each node in the RF method.
| | Modeling parameters | Novel class | Imbalanced | Olive oil | PCB |
|---|
| | RRMSEC threshold | 0.02 | 0.2 | 0.4 | 0.1 |
| BNN | Learning rate | 0.001 | 0.001 | 0.001 | 0.001 |
| | Momentum | 0.5 | 0.5 | 0.5 | 0.5 |
| | Hidden units | 4 | 3 | 7 | 13 |
| RBFN | Learning rate | 0.001 | 0.001 | 0.001 | 0.001 |
| | Momentum | 0.5 | 0.5 | 0.5 | 0.5 |
| | Hidden units | 4 | 3 | 6 | 7 |
| SCRBFN | Hidden units | - | 17 | ~6 | ~20-30 |
| RBFCCN | Hidden units | 4 | 3 | ~6 | ~8 |
| PLS-DA | Latent variables | - | 2 | ~8 | ~16-18 |
| SVM | Cost | - | 210 | 210 | 213 |
| | γ | - | 2-1 | 1 | 2-5 |
| RF | Number of trees | - | 1000 | 1000 | 1000 |
| | Mtry | - | 1 | 2 | 4 |
3.2. Detection of a novel class using a synthetic data set
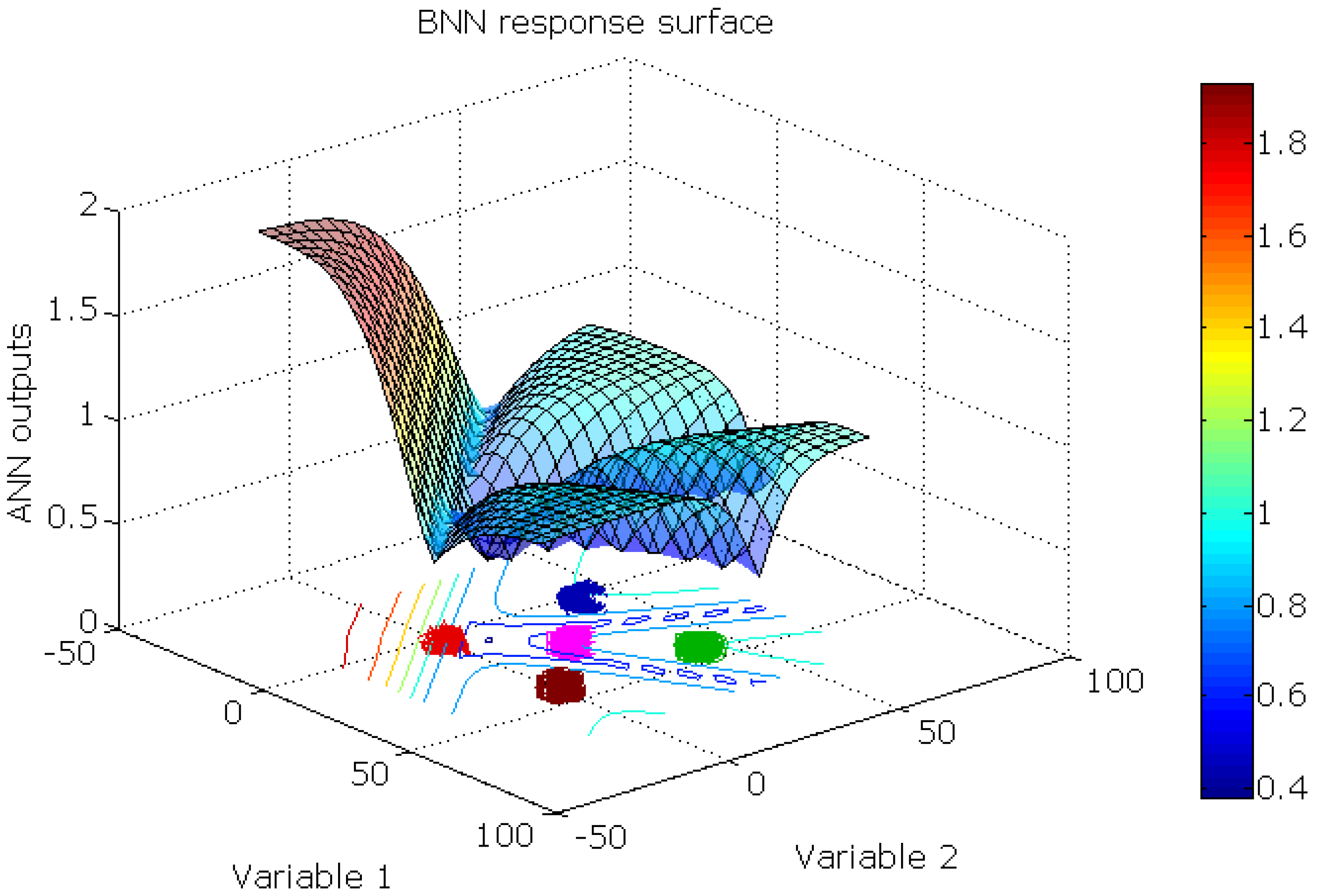
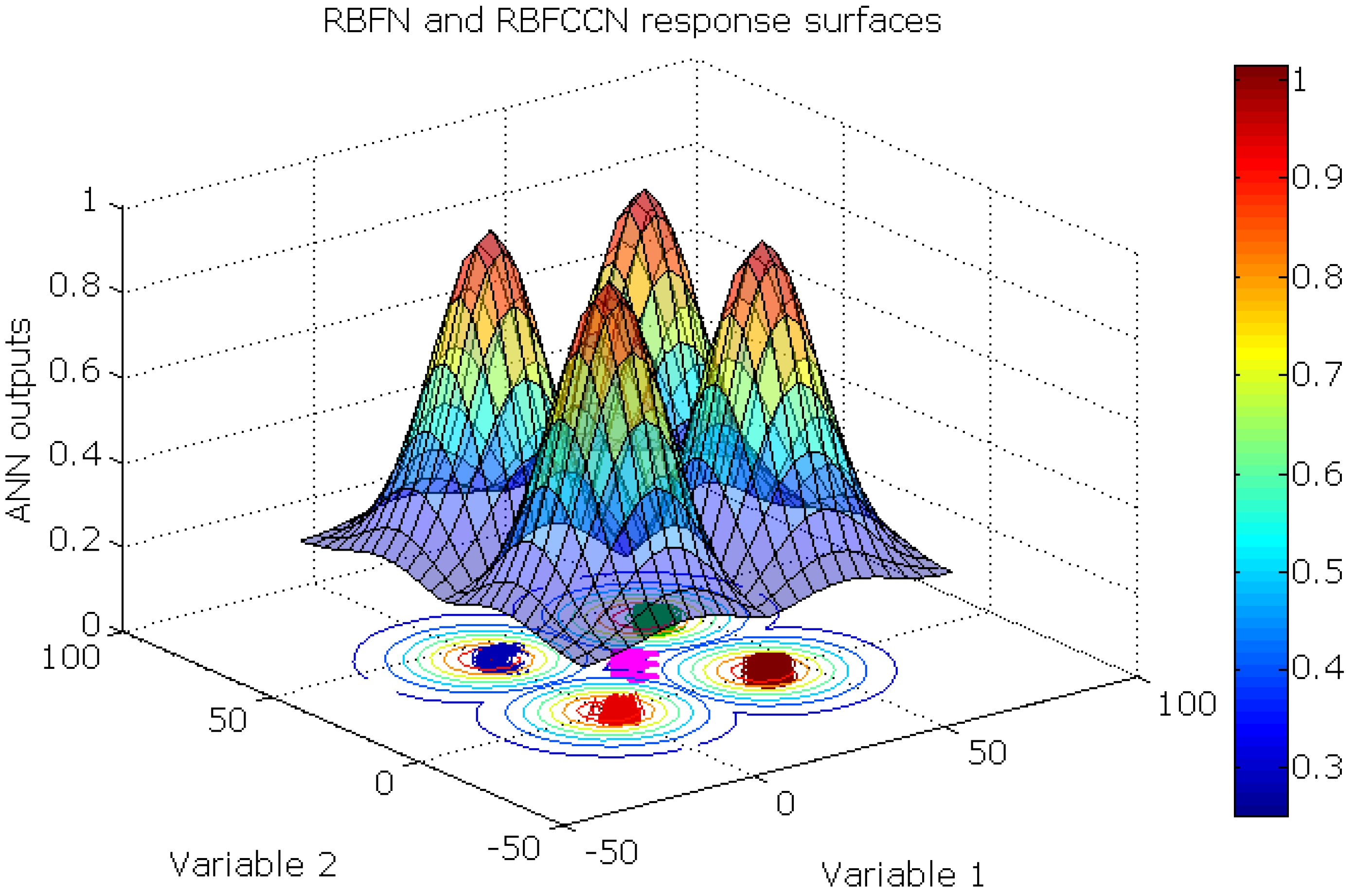
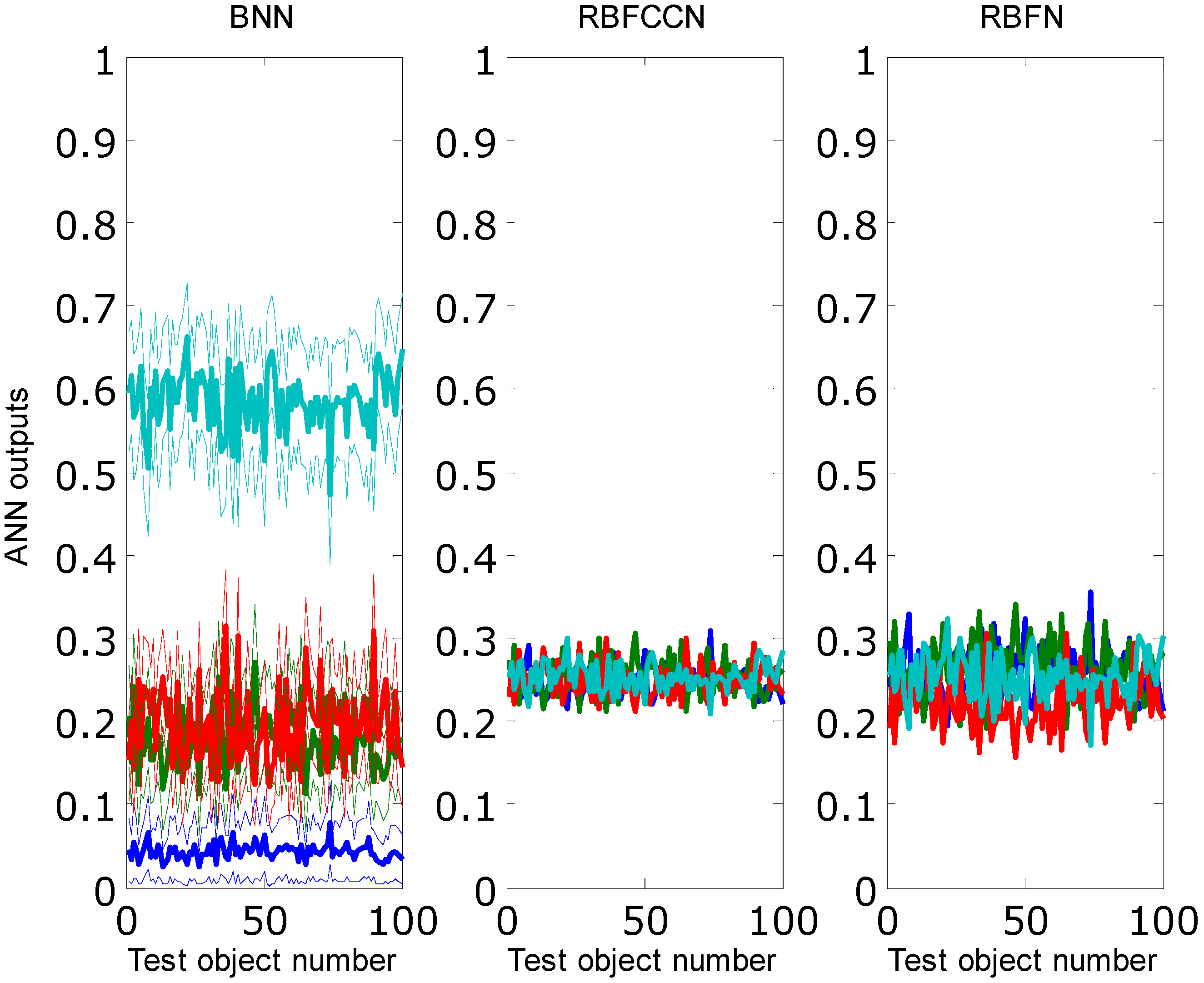
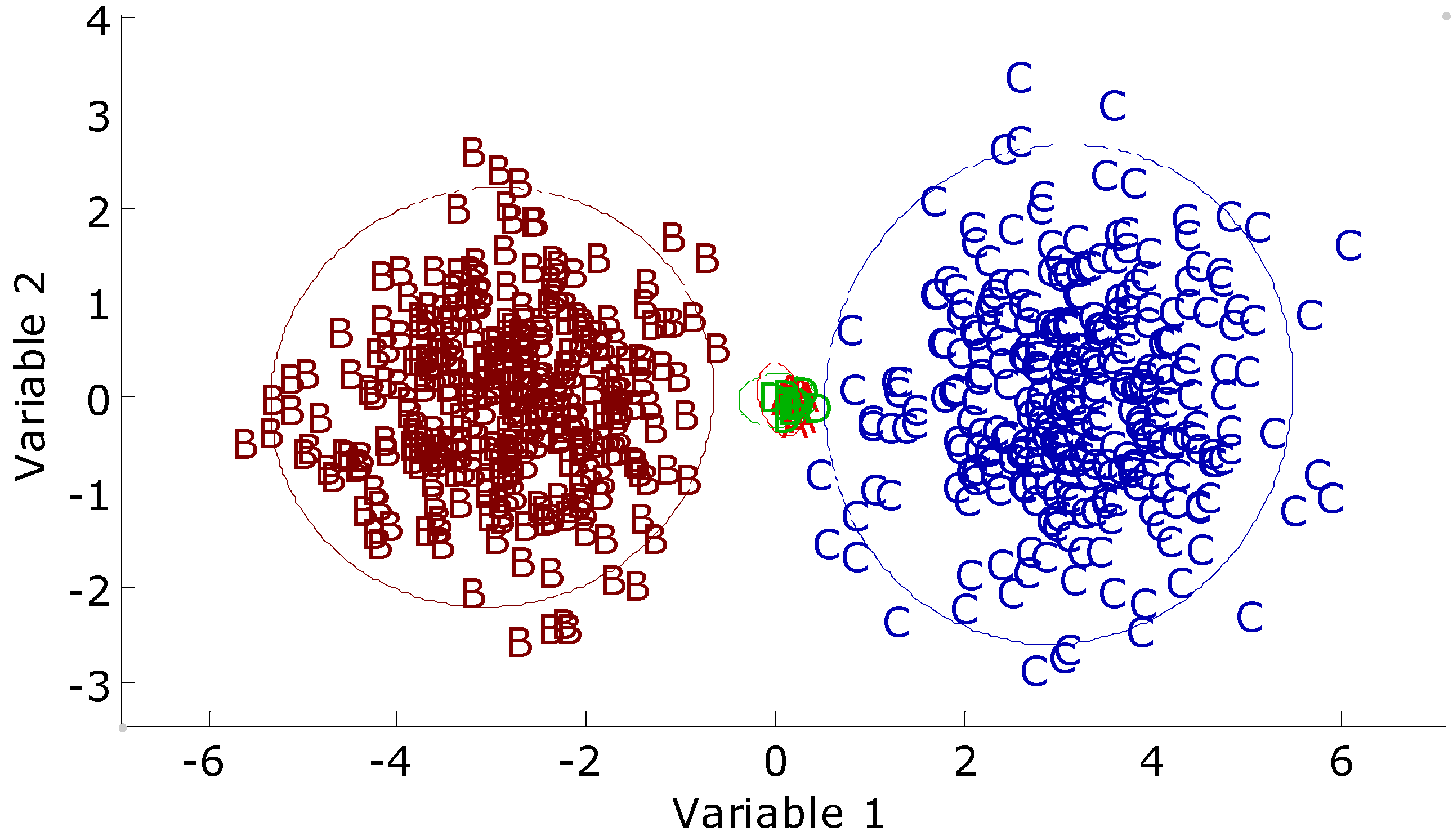
This synthetic data set was designed to test the BNN, RBFN, and RBFCCN abilities to respond to a novel class during prediction. The training set comprised two variables and four classes. Each training class and the test objects had 100 objects. Each class was normally distributed with means of (0.0, 0.0), (40.0, 0.0), (0.0, 40.0), and (40.0, 40.0), respectively, with a standard deviation of 1.5. The test objects were distributed about a mean of (20.0, 20.0) with a standard deviation of 1.5. Both networks were trained repeatedly 30 times on this data set to obtain statistically reliable results.
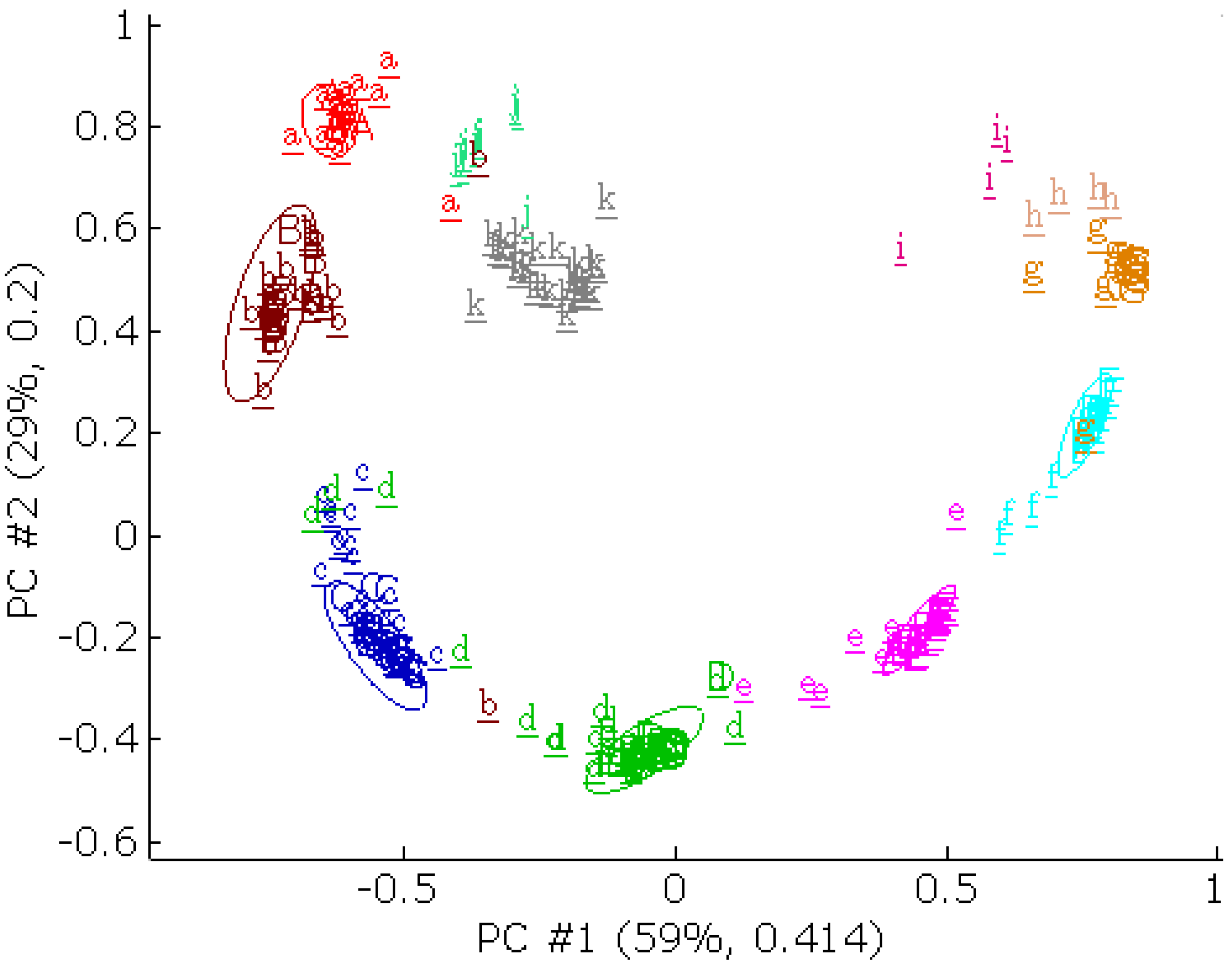
3.5. PCB data set
In the PCB data set, PCB congeners with different numbers of chlorine atoms were classified by their electron ionization mass spectra. The data set was used previously [
8,
12]. The mass spectra were obtained from reference [
23]. These spectra were split into the training set and the external validation set. The PCB congeners in the training set contained 2 to 8 chlorine atoms. Most of the PCB congeners have duplicate spectra with variable quality. Among these duplicate spectra, the one with the lowest record number was selected as training spectra, because it was the spectrum of highest quality. The PCB congeners in the external validation set contained 0 to 10 chlorine atoms. The external validation set was built from the remaining duplicate spectra, PCB congeners that have less than 10 objects, and 27 non-PCB compounds. The congeners that contain 0, 1, 9 and 10 chlorine atoms were uniquely different from any of the training classes. The external validation set contained 45 unique spectra.
Each spectrum was centered by its mean and normalized to unit vector length. The spectra were transformed to a unit mass-to-charge ratio scale that ranged from 50 to 550 Th and any peaks outside this range were excluded. Because the raw data were underdetermined, i.e., there were more variables than objects, the dimensions of PCB data set were further reduced by using the modulo method of preprocessing [
24,
25]. This compression method is especially effective for mass spectral data. Based on the previous study [
8] by the principal component analysis (PCA), the divisor value of 18 was chosen. The compressed spectra were centered about their mean and normalized to unit vector length. The training RRMSEC thresholds were 0.1.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






