1. Introduction
With the rapid development of information technologies and widespread usage of smart phones, digital imaging has become a more and more important medium to acquire information and communicate with other people. These digital images generally suffer impairments during the process of acquisition, compression, transmission, processing and storage. In addition, these phenomena have brought us great difficulties in studying images and understanding the objective world. Because of this, the image quality assessment (IQA) metrics have become a fundamentally important and challenging work. Effective IQA metrics could play important roles in applications such as dynamic monitoring and adjustment of image quality, optimizing the parameter settings of image processing systems, and searching high quality images of medical imaging and so on [
1]. For one thing, high quality images can help doctors to judge the severity of the disease in medical fields. For another, such as high-definition televisions, personal digital assistants, internet video streaming, and video on demand, necessitate the means to evaluate the images quality of this information. Therefore, in order to obtain high quality and high fidelity images, the study of image quality evaluation has important practical significance [
2,
3].
Because human beings represent terminals for the majority of processed digital images, subjective assessment is the ultimate criterion and reliable image quality assessment method. However, the subjective assessment methods hinder its application in practice because of its disadvantages, such as time-consuming, expensive, complex and laborious. Thus, the goal of objective IQA is to automatically evaluate the quality of images as near to human perception as possible [
2].
Based on the availability of a reference image, objective IQA metrics can be classified into full reference (FR), reduced reference (RR), and no reference (NR) approaches [
4]. Only recently did FR-IQA methods reach a satisfactory level of performance, as demonstrated by high correlations with human subjective judgments of visual perception. SSIM [
5], MS-SSIM [
6] and VSNR [
7] are examples of successful FR-IQA algorithms. These metrics are based on measuring the similarity between the distorted image and its corresponding original image. However, in real-world applications, where the original is not available, FR metrics are not used. This strictly limits the application domain of FR-IQA algorithms. In addition, the NR-IQA is the only possible algorithm that can be used in the practical application. However, a number of NR-IQA metrics have been testified that they do not always correlate with the perceived image quality [
8,
9].
Presently, NR-IQA algorithms generally follow one of two trends: The distortion-specific and general-purpose methods. The former evaluate the distorted image of a specific type while the latter directly measure the image quality evaluation without knowing the type of image distortion. Since the result of evaluation ultimately depends on the feeling of the observers, image evaluation with more perfect and more suitable for the actual quality must be based on human visual, psychological characteristics and organic combine the subjective and objective evaluation methods. A large number of studies have shown that: considering the human visual system (HVS) evaluation methods are better than that without considering the characteristics of HVS evaluation methods [
10,
11,
12,
13]. However, existing no-reference image quality assessment algorithms are failed to give full consideration to the human visual features [
10].
At present, there are some problems in the field of image quality assessment:
Unable to obtain the original image.
Difficult to determine whether the type of distortion of the distorted image exists.
Existing methods lack of considering human visual characteristics.
How to ensure the characteristics to be not significantly difference caused by the distortion images with same degree yet different types.
In this paper, based on the existing image quality evaluation methods, we draw the human visual attention region mechanism and the HVS characteristics into the no reference image quality assessment method. Then, we propose a universal no-reference image quality assessment method based on visual perception.
The rest of this paper is organized as follows. In
Section 2, we describe the current research about no reference image quality assessment methods and visual saliency. In
Section 3, we introduce the extraction model of visual region of interest. In
Section 4, we provide an overview of the method. In
Section 5, we describe blind/reference image spatial quality evaluator (BRISQUE) algorithm and the prediction model is provided in
Section 6. We present the results in
Section 7, and we conclude in
Section 8.
2. Previous Work
Before proceeding, we state some salient aspects of NR-IQA methods. Present day depending on whether we know the type of distortion image or not, NR-IQA methods can be divided into two categories: distortion-specific approaches and general-purpose approaches [
14].
Distortion-specific algorithm is capable of assessing the quality of images distorted by a particular distortion type, such as blockiness, ringing, blur after compress, and noise generated during image transmission. In literatures [
15,
16,
17,
18], the authors proposed some approaches for JPEG compression images. In [
17], Zhou et al. aimed to develop NR-IQA algorithms for JPEG images. At first, they not only established a JPEG image database, but also subjective experiments were conducted on the database. Furthermore, they proposed a computational and memory efficient NR IQA model for JPEG images, and estimated the blockiness by the average differences across block boundaries. They used the average absolute difference between in-block image samples and the zero-crossing rate to estimate the activity of the image signal. At last, subjective experiment results were used to train the model, which achieved good quality prediction performance. For JPEG2000 compression, distortion in an image is generally modeled by measuring edge-spread using an edge-detection based approach and this edge spread is related to quality [
5,
19,
20,
21,
22]. The literatures [
23,
24,
25] are evaluation algorithms for blur. QingBin Sang et al. calculated image structural similarity by constructing fuzzy counterpart [
20]. Firstly, they used a low pass filter to blur the original blurred image and produce re-blurred image. Then they divided the edge dilation image into 8 × 8 blocks. In addition, the sub-blocks were classified into edge dilation block and smooth block. In addition, the gradient structural similarity index was defined by different weighs according to the different types of blocks. Finally, the blur average value of the whole image was produced. The experimental results were shown that the method was more reasonable and stable than others. However, these distortion-specific methods are obviously limited by the fact that it is necessary to know the distortion types in advance, which makes their application field limited [
3].
Universal methods are applicable to all distortion types and can be used in any occasion. In recent years, researchers proposed many universal no reference image quality assessment methods. However, most of these methods relied on the prior knowledge of subjective value and distortion types, and used machine learning methods to get the image quality evaluation score. Some meaningful universal methods are reported in the literature [
8,
26,
27,
28,
29,
30,
31]. In [
26], the author proposed a new two-step framework for no-reference image quality assessment based on natural scene statistics (NSS), namely Blind Image Quality Indices, (BIQI). Firstly, the algorithm estimated the presence of a set of distortions in the image. Secondly, they evaluated the quality of the image according to those distortions. In literature [
27], Moorthy et al. proposed a blind IQA method based on the hypothesis that natural scenes have some certain statistical properties. In addition, those properties can make the quality of image degeneration. This algorithm was called Distortion Identification- based Image Verity and Integrity Evaluation (DIIVINE) and also was a two-step framework. The DIIVINE mainly consists of three steps. Firstly, the wavelet coefficients were normalized. Then, they calculated the statistical characteristics of the wavelet coefficients, such as scale and orientation selective statistics, orientation selective statistics, correlations across scales and spatial correlation. Finally, the quality of the image was calculated using those statistical features. The method has achieved a good performance on evaluation. In literature [
8], the authors supposed in Discrete Cosine Transform (DCT) domain the change of image statistical characteristics can predict image quality, and proposed Blind Image Integrity Notator using DCT Statistics algorithm (BLIINDS). Subsequently, Saad et al. extended the BLIINDS algorithm, and proposed an alternate approach that relies on a statistical model of local DCT coefficients which they dubbed blind image integrity notator using DCT statistic (BLIINDS-II) [
28]. To begin with, they partitioned the image into n × n blocks and computed the local DCT coefficient. Then, they applied a generalized Gaussian density model to each block of DCT coefficients. Furthermore, they computed functions of the derived model parameters. Finally, they used a simple Bayesian model to predict the quality score of the image. In literature [
29], Mittal et al. proposed a natural scene statistic-based NR IQA model that operated in the spatial domain, namely blind/reference image spatial quality evaluator (BRISQUE). This method did not compute distortion-specific features, but used scene statistics of locally normalized luminance coefficients to evaluate the quality of the image instead. Since Ruderman found that these normalized luminance values strongly tend towards a unit normal Gaussian characteristic [
30] for natural images, this method used this theory to preprocess the image. Then, they extracted features in spatial domain. Those features mainly contain generalized Gauss distribution characteristics and correlation of adjacent coefficients. Finally, those features were used to map the quality to human rating via SVR model. Over the course of last few years, a number of researchers have devoted time to improving the assessment accuracy of NR IQA methods by taking advantage of known natural scene statistics characteristics. These methods are failed to give full consideration to the human visual characteristics [
2]. There is also a deviation between the predicted qualities and the real qualities, since the human visual system is the ultimate assessor of image quality. In addition, almost all of the no reference image quality assessment methods are based on gray scale images, and they do not make full use of the color characteristics of the image.
Through above analysis of NR IQA methods, at present, both in distortion-specific and general-purpose methods, almost all of the methods use statistical characteristics of natural images to establish quality evaluation model, and have achieved better effect of evaluation. However, considering the statistical characteristics of natural images can hardly reflect the whole regularities of image quality. There is still a certain gap with the subjective consistency of human vision.
Since the HVS is the ultimate assessor of image quality, a number of image quality assessment methods based on an important feature of the HVS, namely, visual perception, are emerging in the present day [
10]. Among them, the research of region of interest (or visual saliency) is a major branch of the HVS. In the field of image processing, ROI of an image are the areas that differ significantly from their adjacent regions. They can immediately attract our eyes and capture our attention. Therefore, the ROI is a very important region in the image quality assessment. On the other hand, how to build a computational visual saliency model has been attracting tremendous attention in recent years [
32].
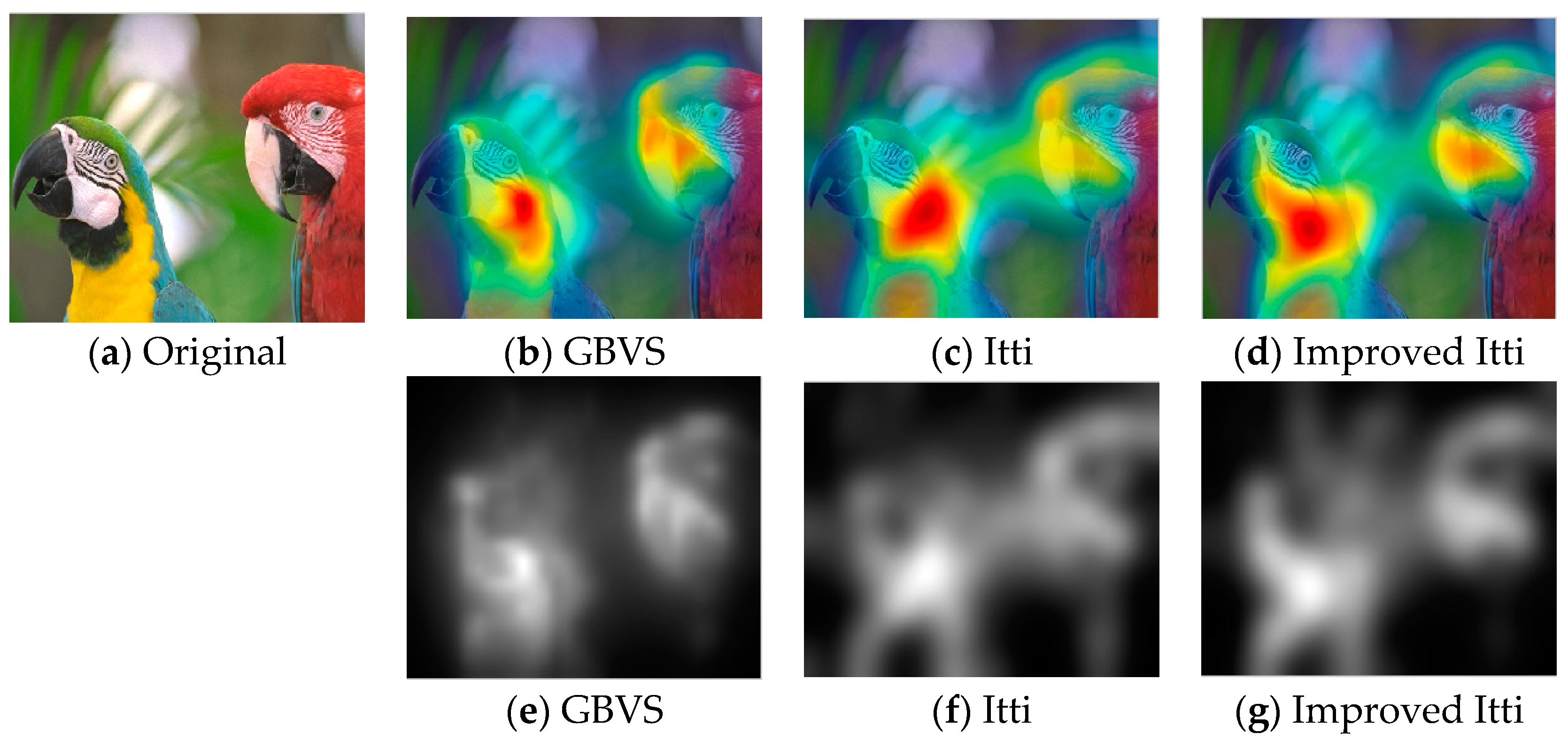
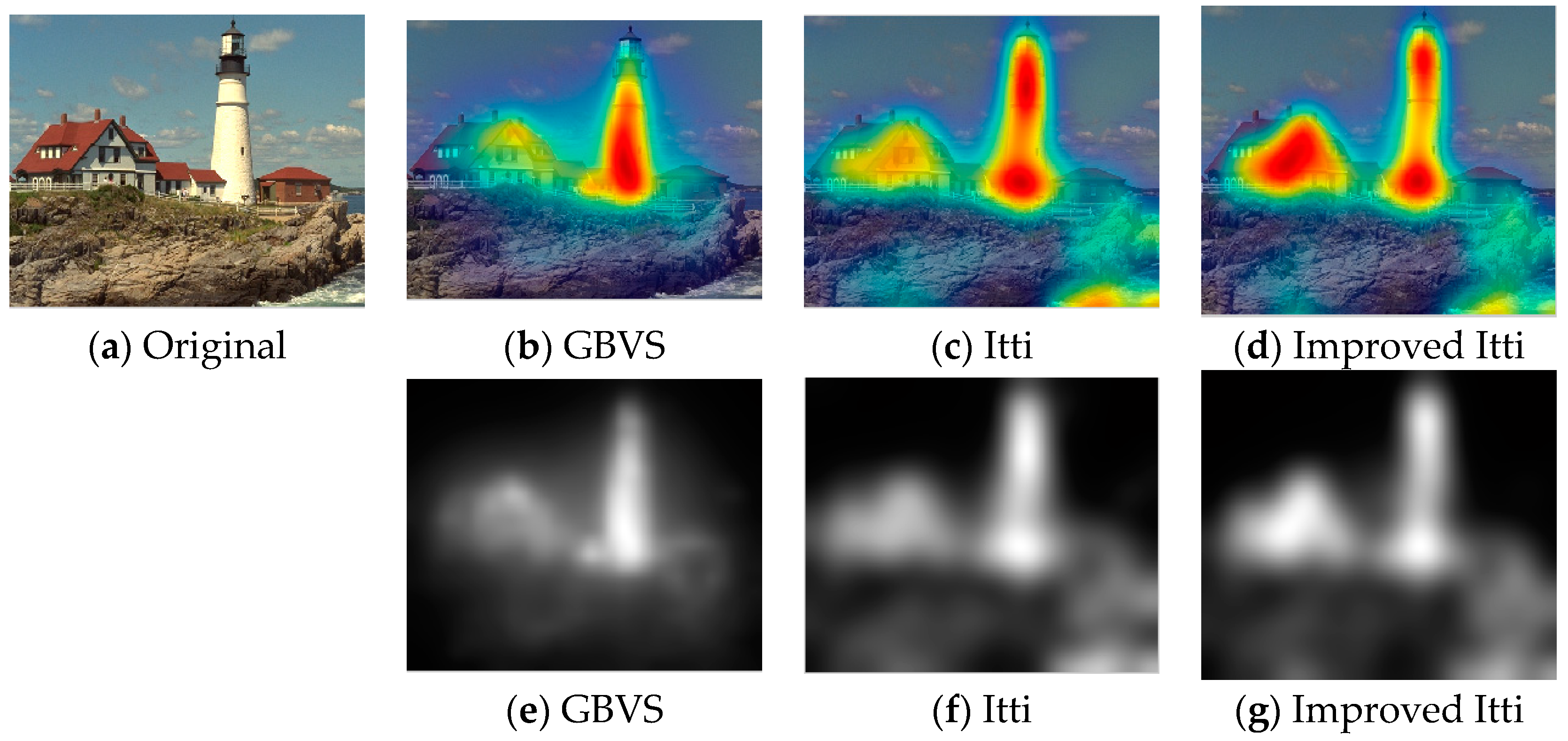
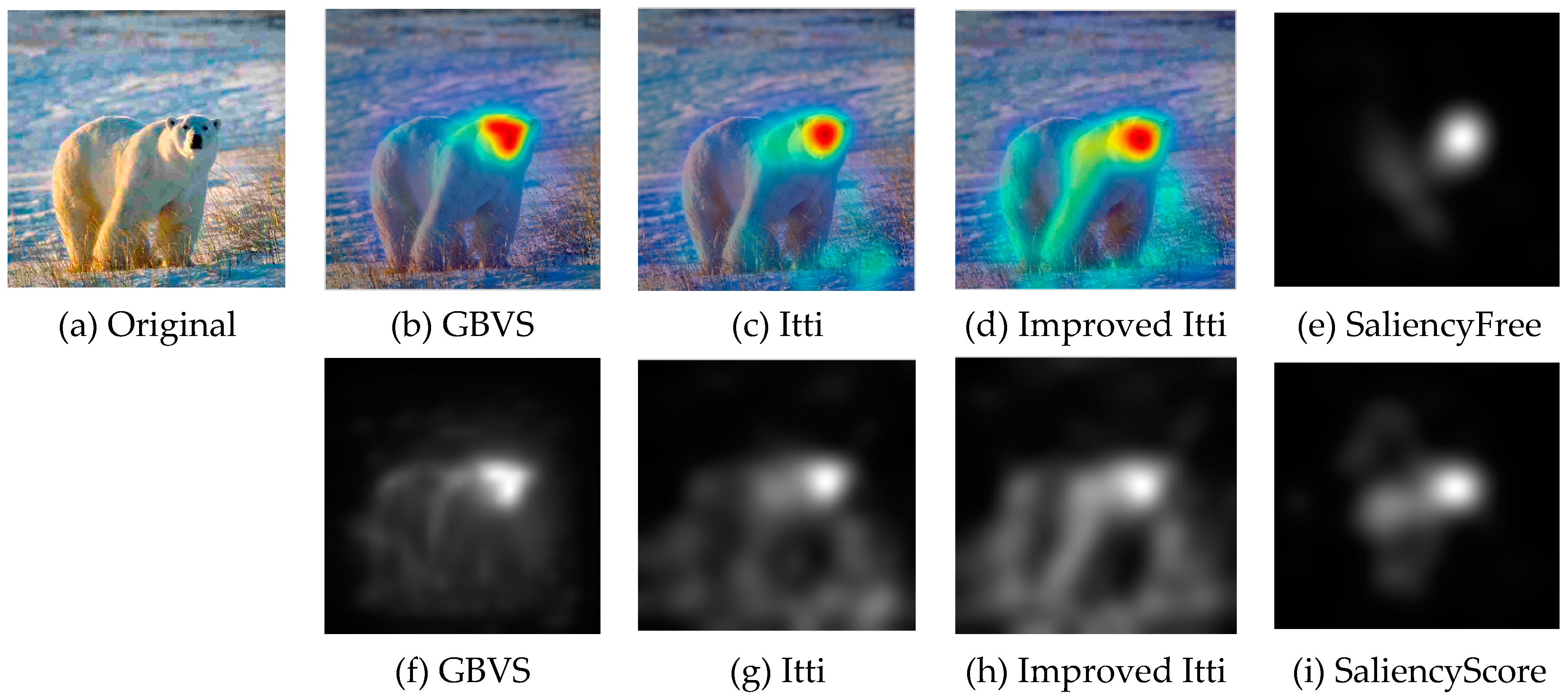
Nowadays, a number of computational models to simulate human visual attention have been studied by scholars and some powerful models have been proposed. For further details of ROI refer to [
9,
10,
11,
12,
32,
33,
34,
35,
36]. In [
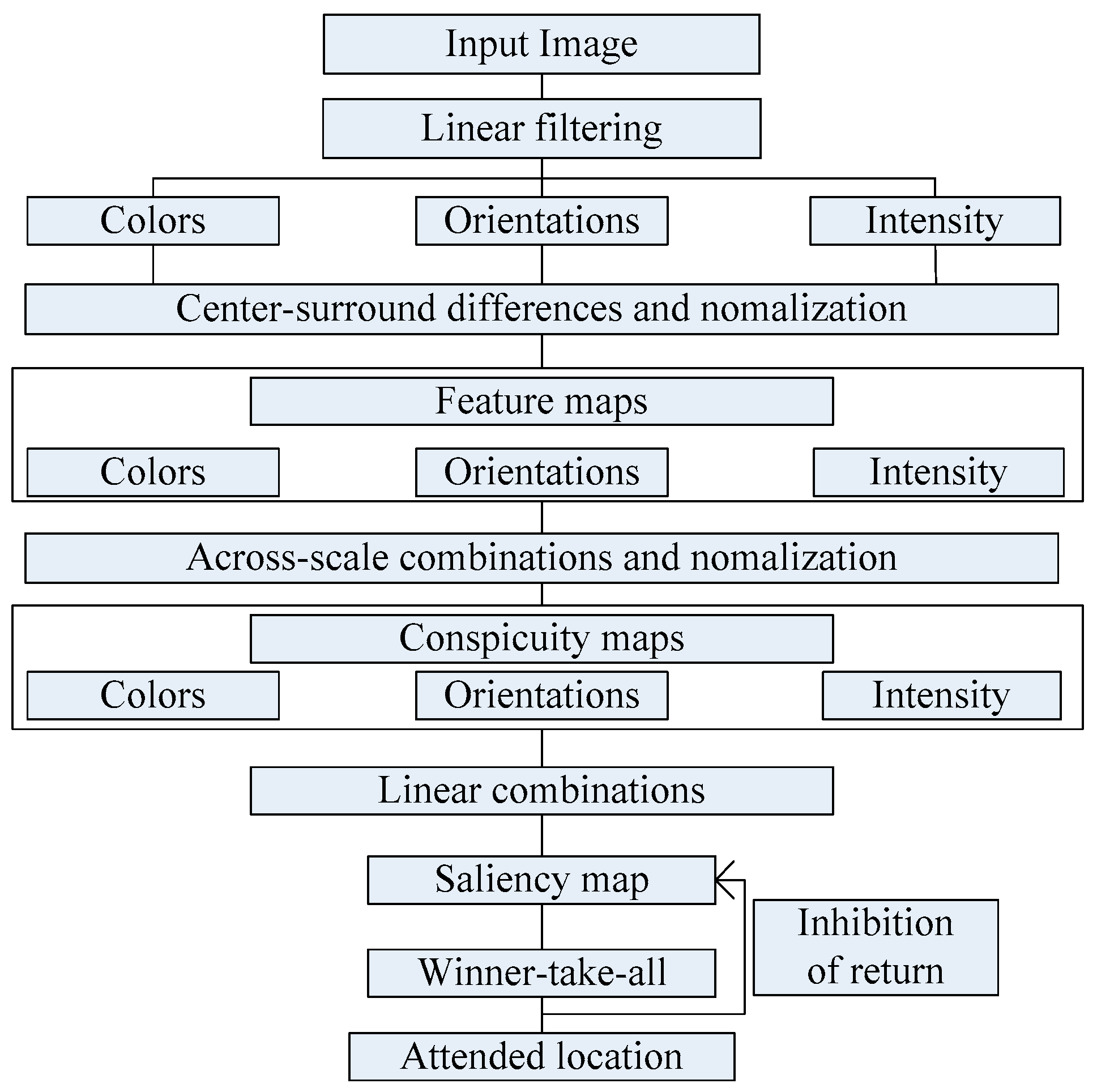
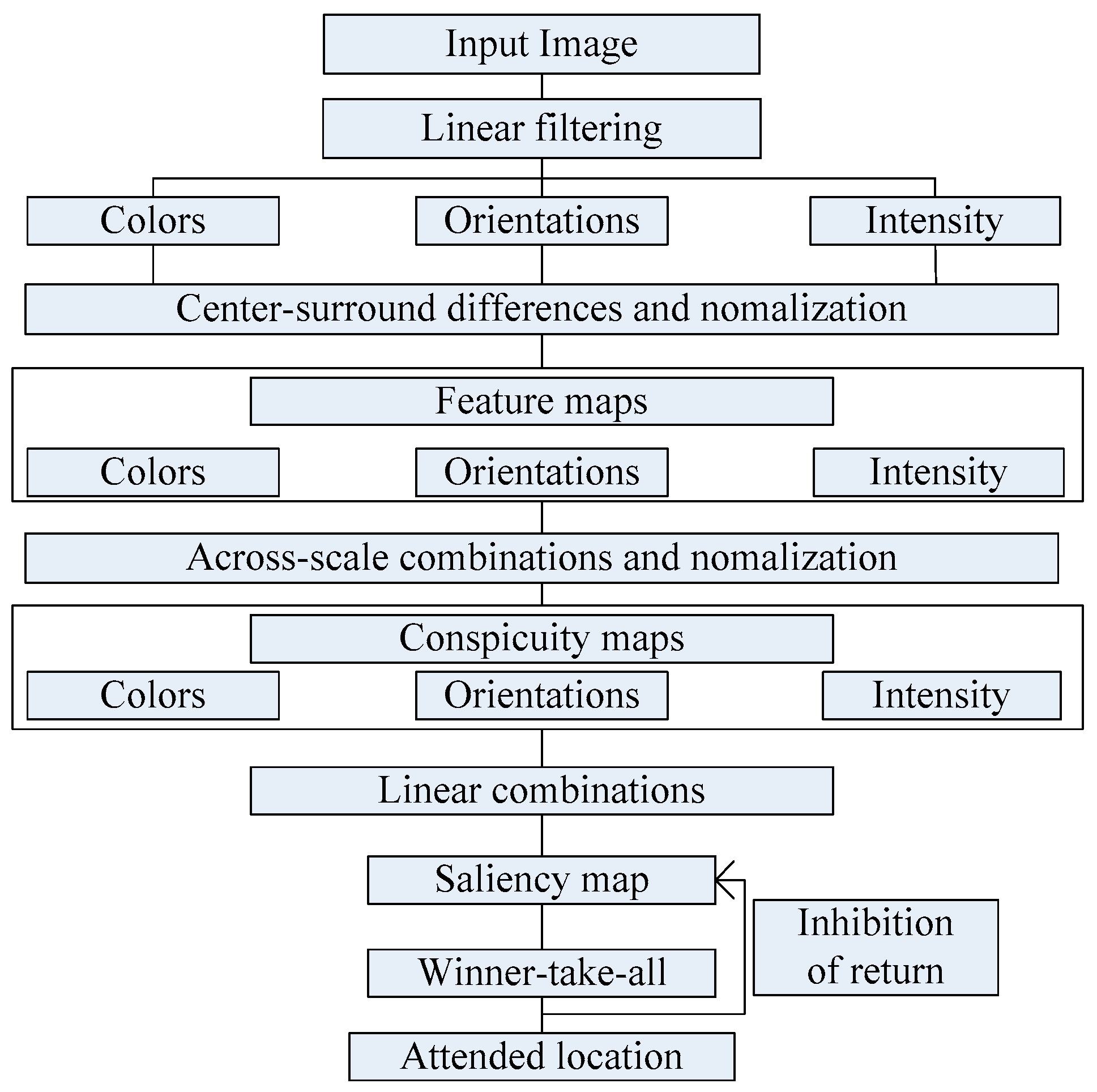
33], Itti et al. proposed a visual saliency model which was the first influential and best known visual saliency model. In this paper, we call it Itti model. Itti model mainly contains two aspects. Firstly, they introduced image pyramids for feature extraction, which makes the visual saliency computation efficient. Secondly, Itti et al. proposed the biologically inspired “center-surround difference” operation to compute feature dependent saliency maps across scales [
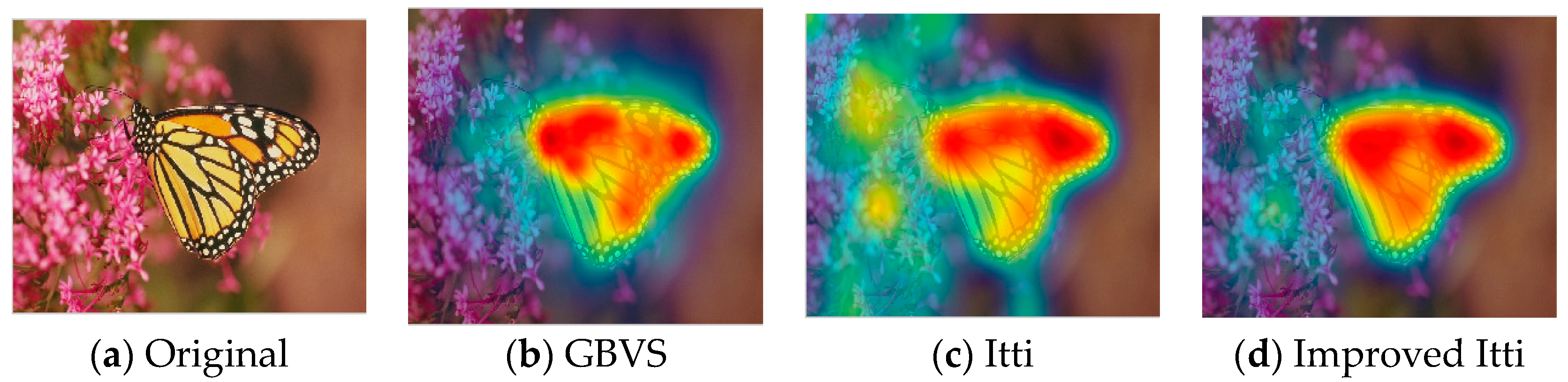
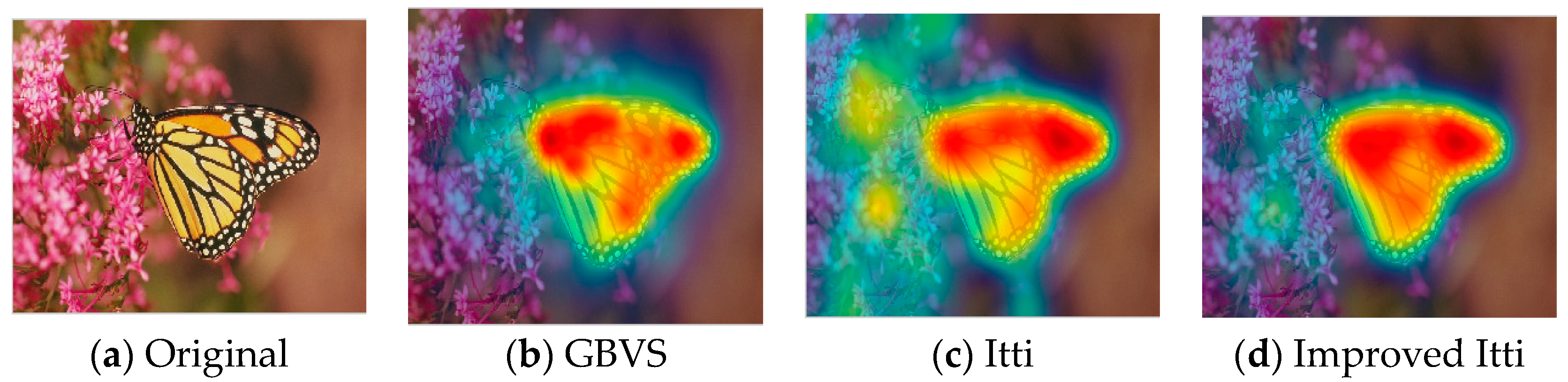
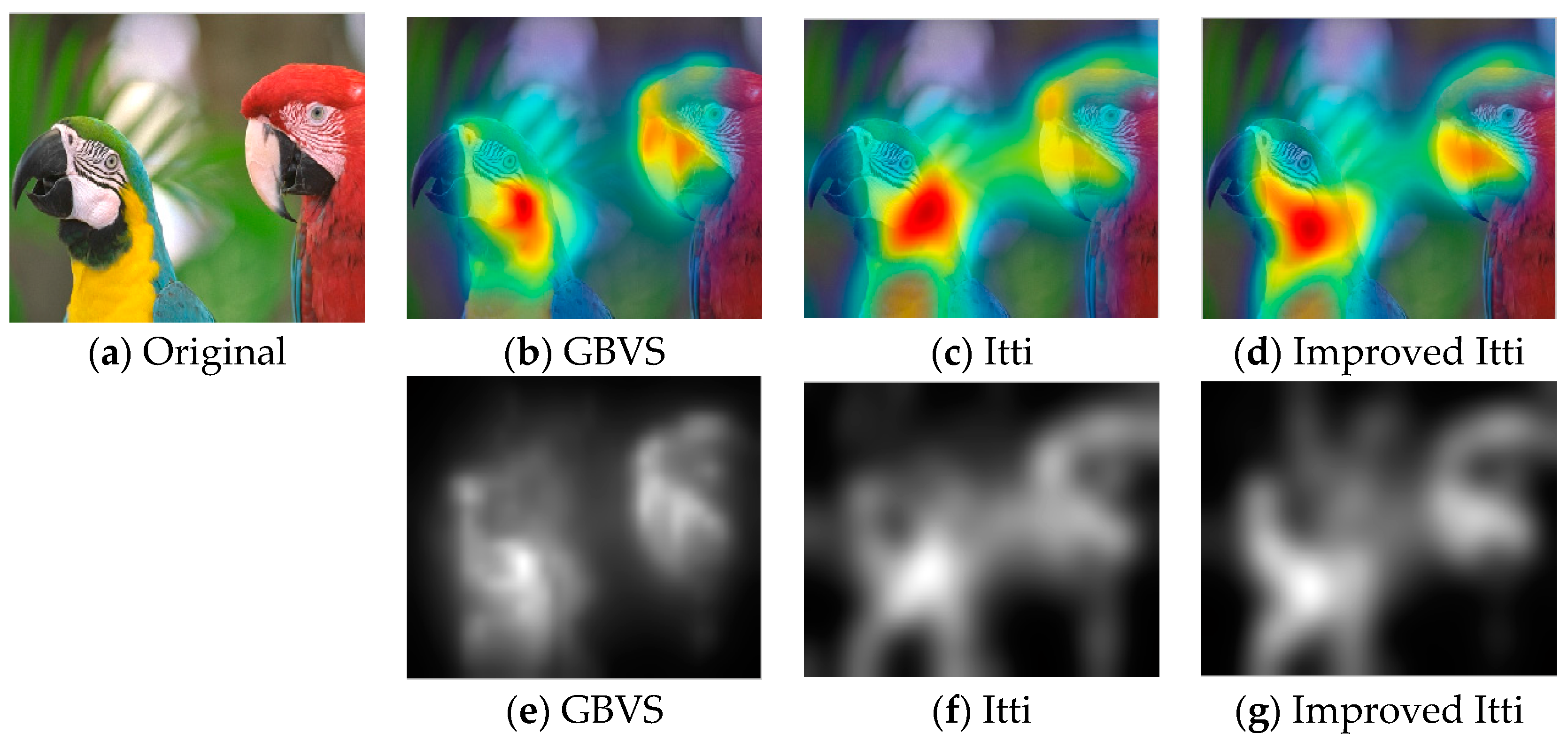
32]. This model effectively breaks down the complex problem of scene understanding by rapidly selecting. Following the Itti model, Harel et al. proposed the graph-based visual saliency (GBVS) model [
37]. The GBVS was introduced a novel graph-based normalization and combination strategy, and was a new bottom-up visual saliency model. It mainly consists of two steps. The first step is forming activation maps on certain feature channels. In addition, the second step is normalizing them in a way which highlights salient and admits combination with other maps. Experimental results show that the GBVS predicts ROI more reliably than other algorithms.
In this paper, we mainly study the human visual characteristics, extract the region of interest, and combine the statistical characteristics of the natural image as the measurement index of the distortion image. Finally, do experiments on the database LIVE [
38], the experimental results show that the features extraction and the learning method are reasonable, and correlate quite well with human perception.
4. Overview of the Method
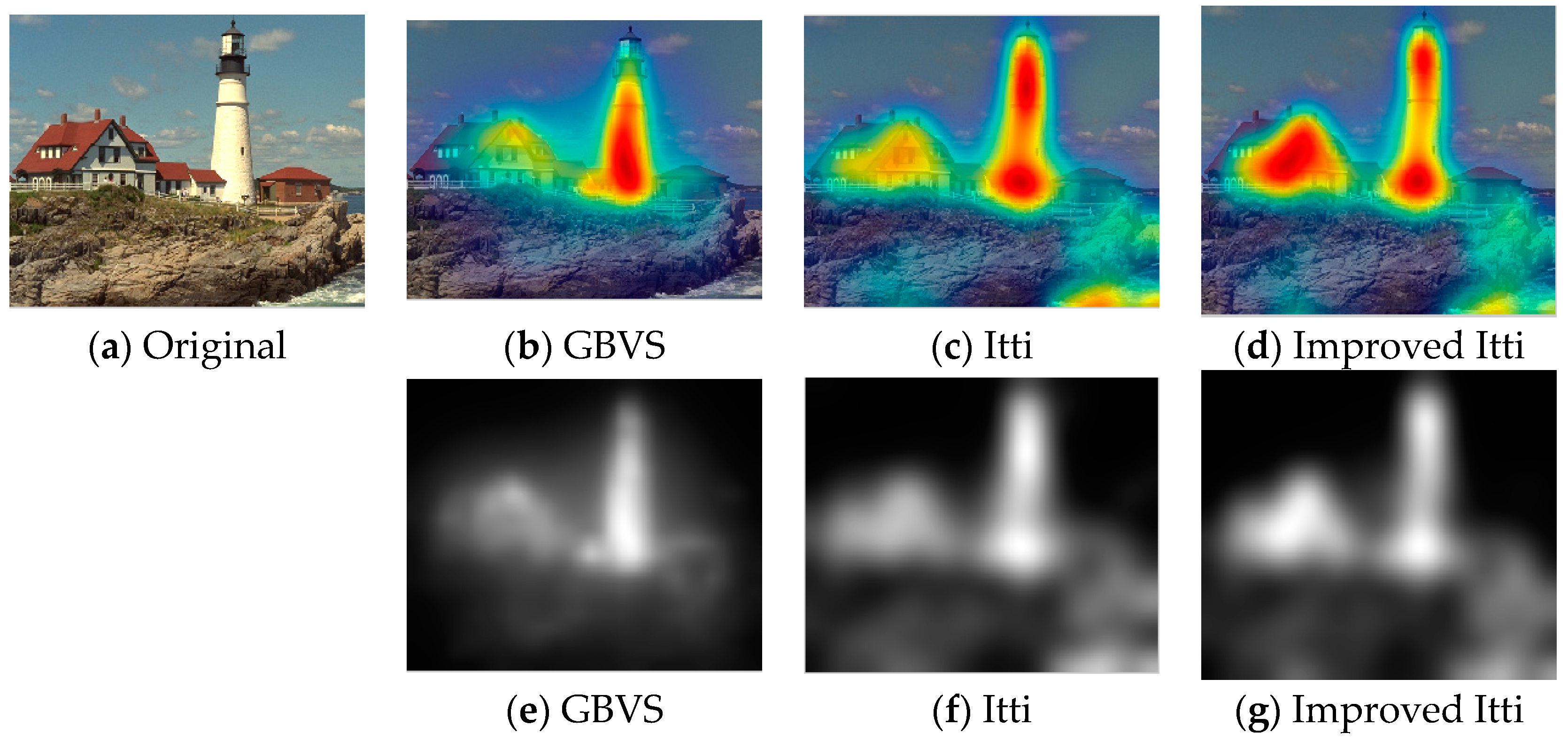
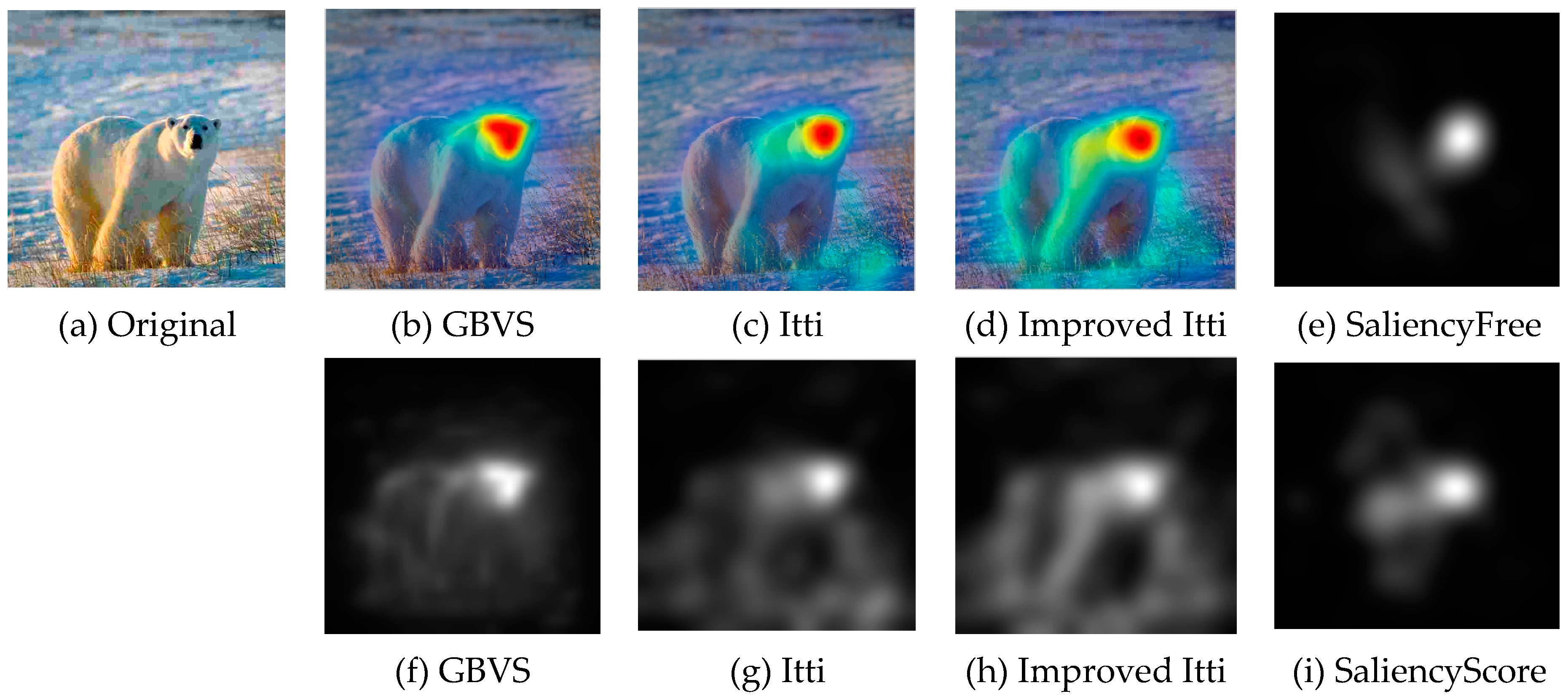
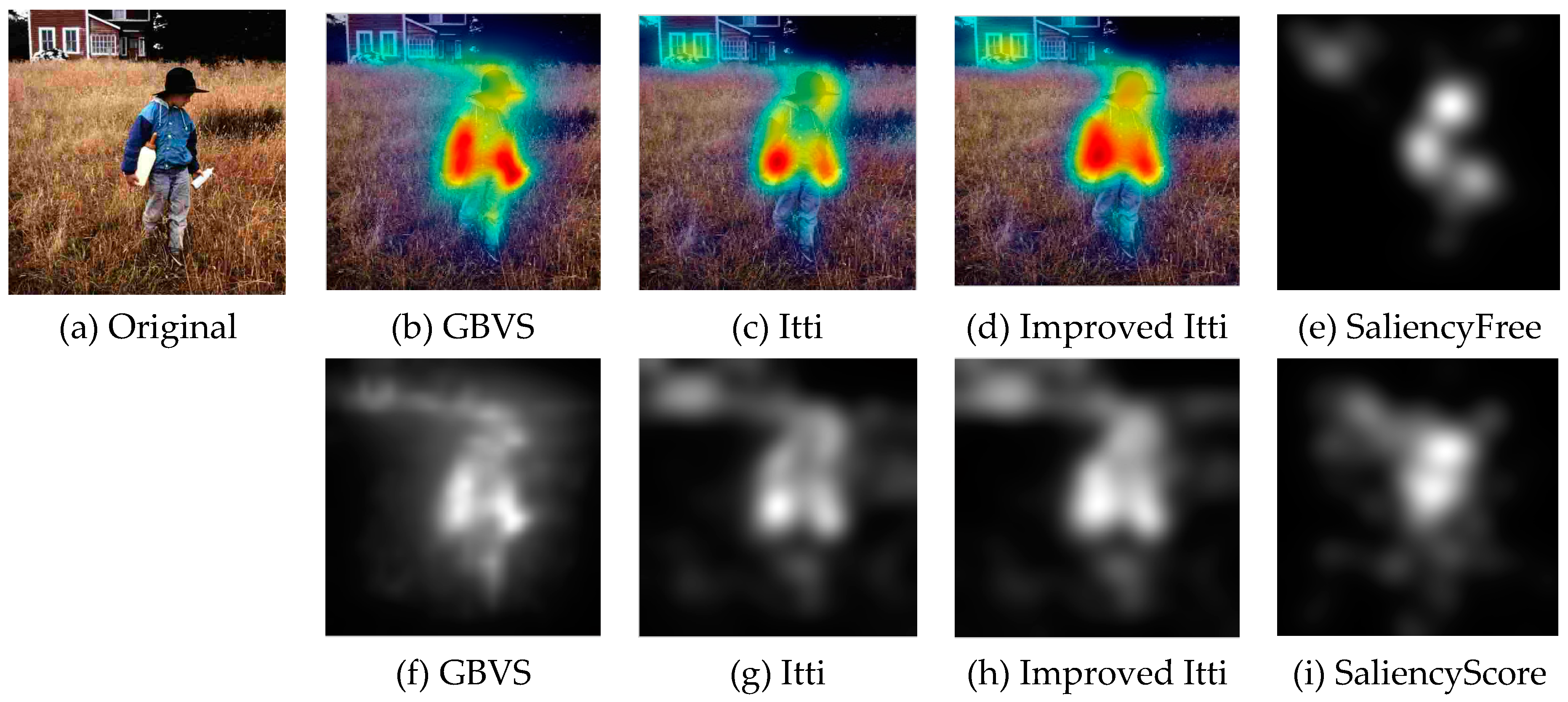
Currently no reference image quality evaluation algorithm can be divided into two categories: distortion-specific methods and universal methods. However, the distortion-specific methods are limited in the practical application because the prior need to determine the type of the distorted images. The general-purpose methods do not depend on the type of distorted images, and have prospect of practical application. However, the existing algorithms are almost to extract natural statistical characteristics of image, and rarely take into account the visual characteristics of the human eye. Thus, in practical application, there is a deviation between the evaluation result and the result of the human eye perception. As shown in
Figure 5 and
Figure 6, due to the visual characteristics of the human eye, in the same picture, different regions (such as interest and non interest areas) in the same image quality damage degree will make the human eye produce different visual experience. Under the same Gauss fuzzy, the visual observation effect of
Figure 5 is better than
Figure 6.
In the observation of the image, human eye will be the first to pay attention to the visual characteristics of the more prominent areas. Although the image suffered the same damage, because of the different regions, the human eye subjective feelings are different. Based on the background, this paper proposes a method of image quality evaluation based on visual perception. Firstly, we extract the region of interest. Secondly, extract the features from the regions of interest and regions of non-interest. Finally, the extracted features are fused effectively, and the image quality evaluation model is established. The proposed approach we called region of interest blind/reference image spatial quality evaluator (ROI-BRISQUE).
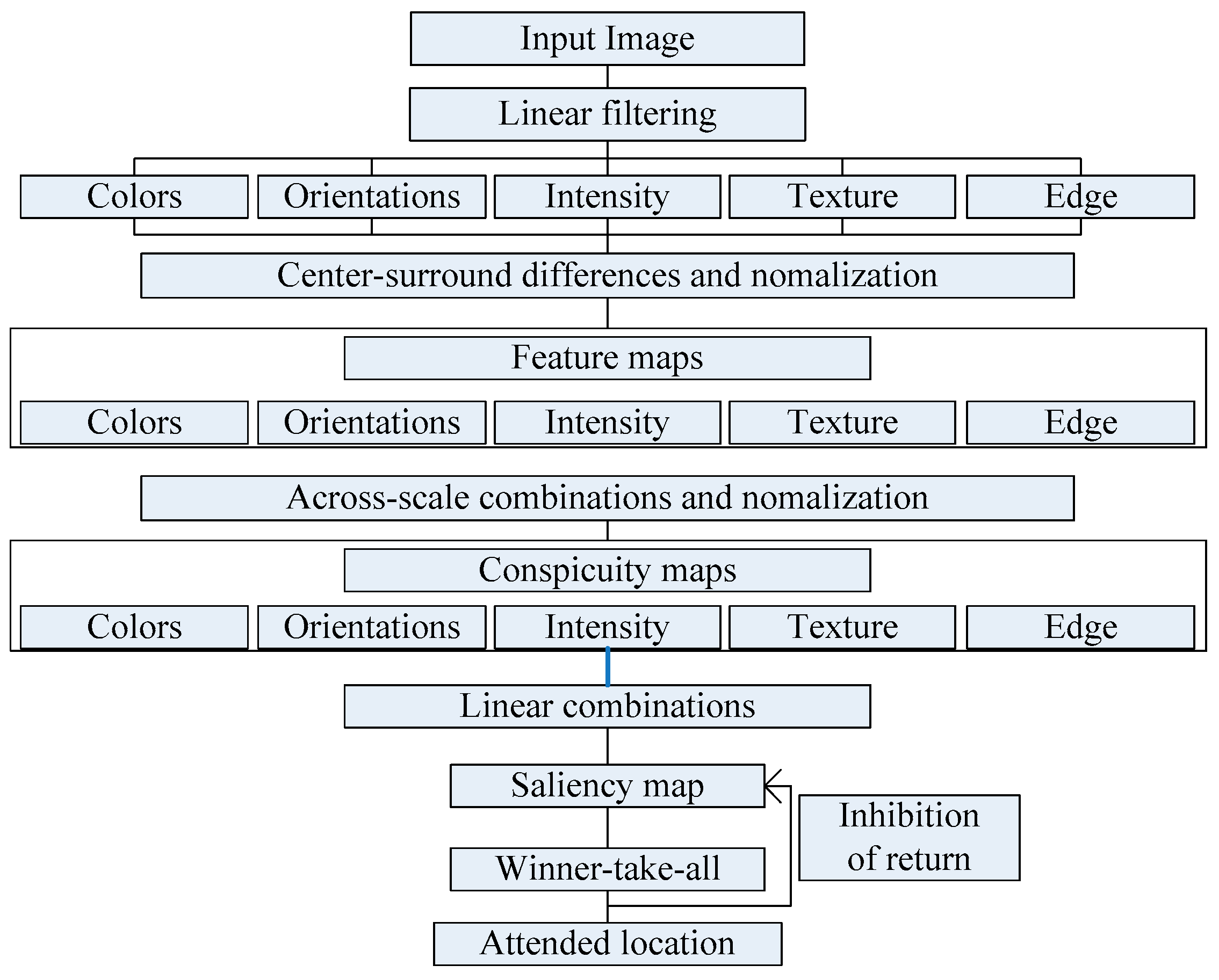
Figure 7 is the framework of the proposed method in this paper.
The method of this paper is described as follows:
Firstly, the LIVE image database is divided into two categories: training images and testing images. In addition, we extract the region of interest and features on the training images. Then, we use the feature vectors as the input of the ε-SVR, the DMOS of the corresponding image as the output target to train the image quality evaluation model. Finally, the image quality prediction model is used to predict the quality of the distorted image.
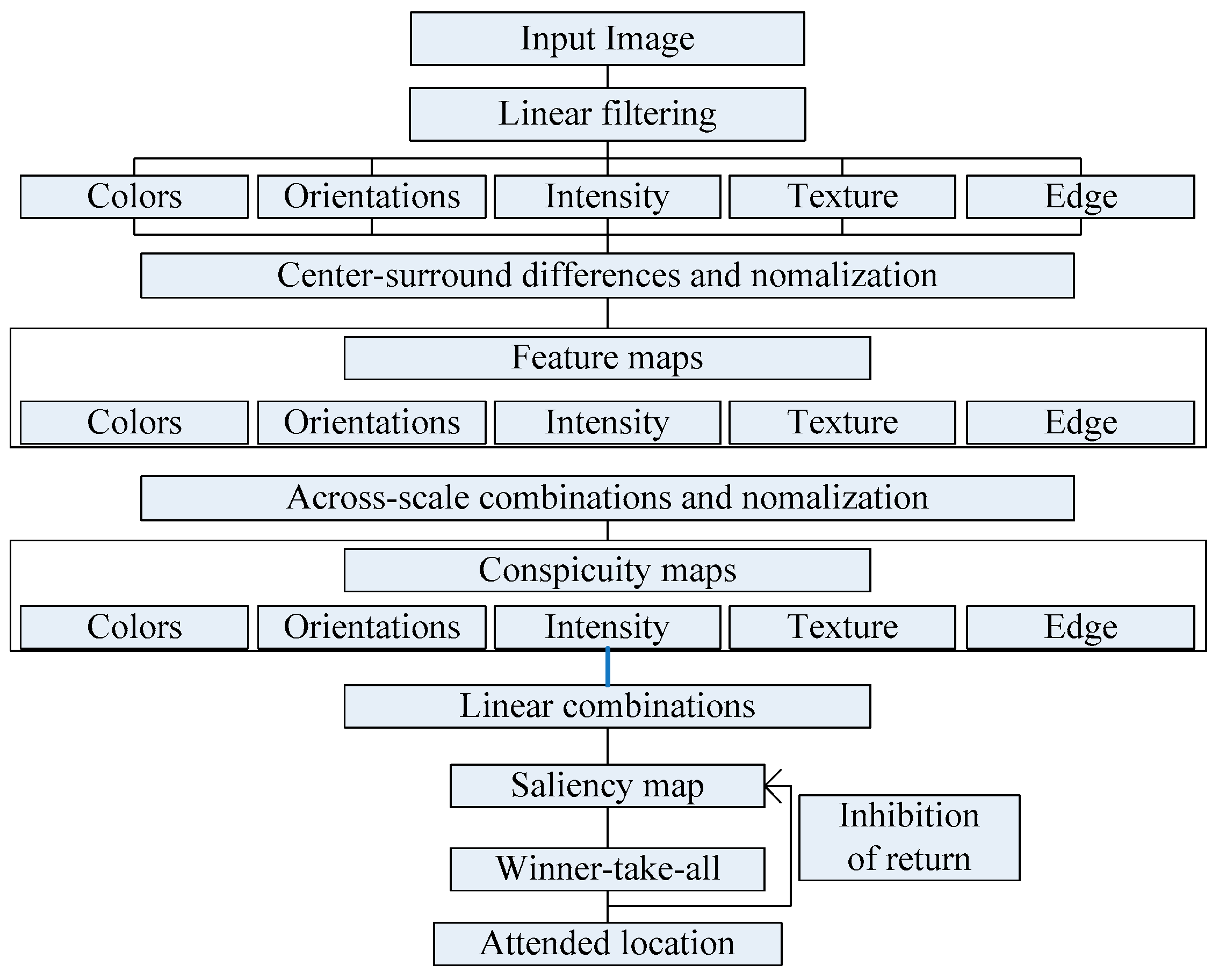
This paper focuses on the image region of interest extraction. The traditional Itti model calculates the salient region of the image by extracting the underlying features of the image color, brightness and direction. It can search out the attention region. However, there are still some shortcomings, for instance, the contour of the salient region is not clear. In order to extract the region of interest more accurately, we add texture and edge structure features to the Itti model. Then, we use the improved model to extract the region of interest and region of non-interest, and use BRISQUE algorithm to extract the natural statistical features of the image respectively. Moreover, the characteristics of the region of interest and region of non interest are fused to get the measure factor of the image. We train the image quality evaluation model, which the measure factor as the input and the DMOS value of corresponding image as the output target of SVR. Finally, the quality of the distorted image is predicted by the trained evaluation model.
8. Conclusions
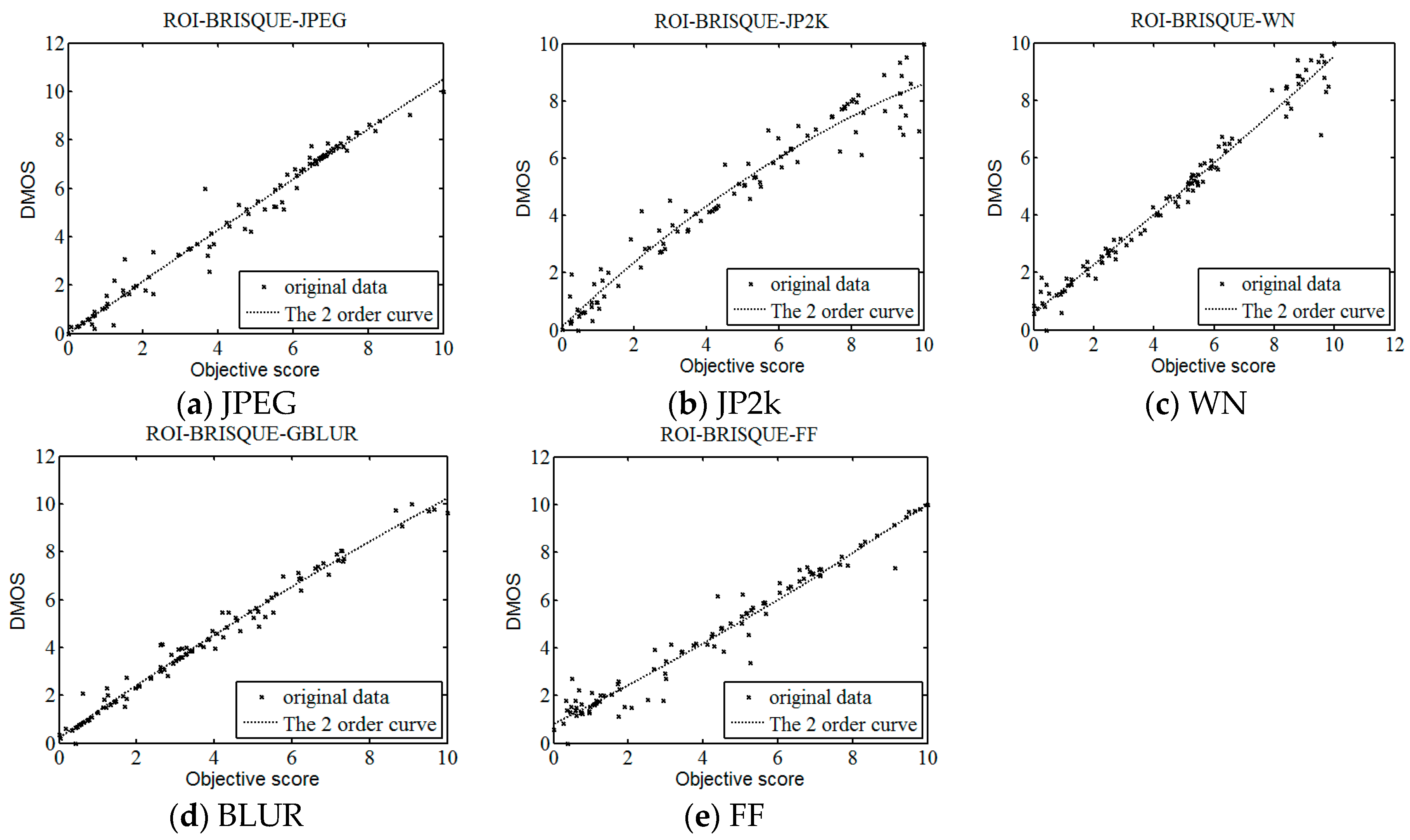
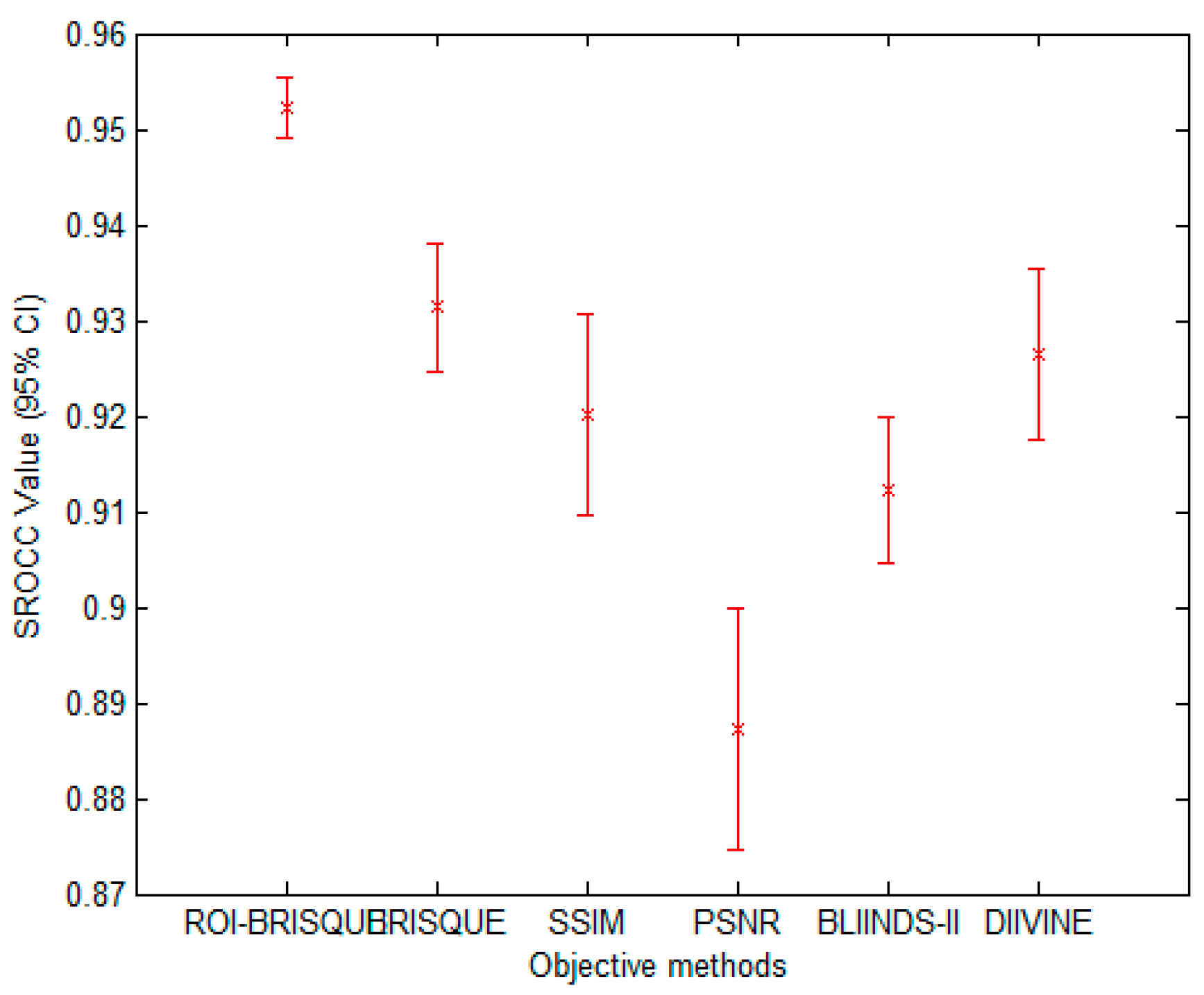
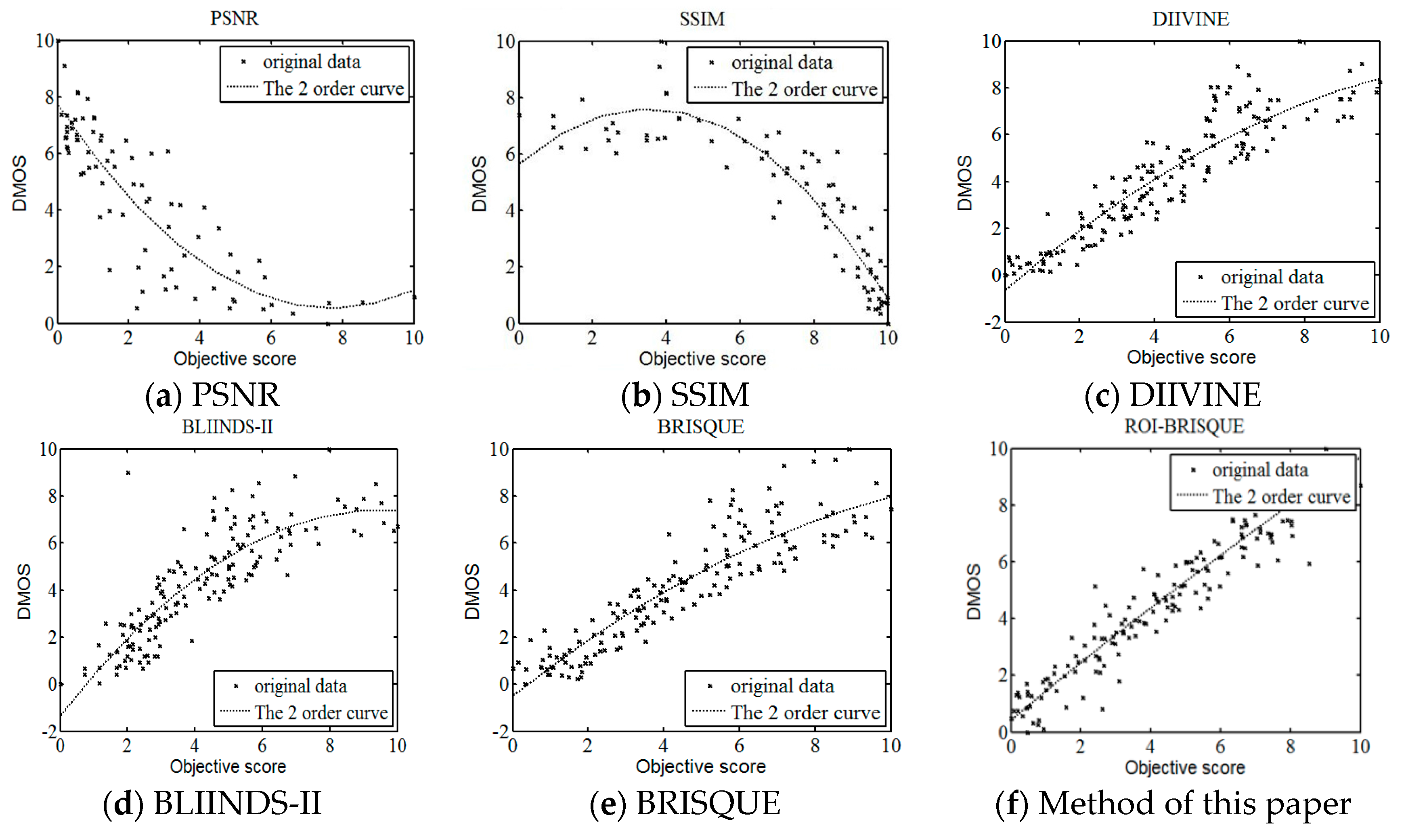
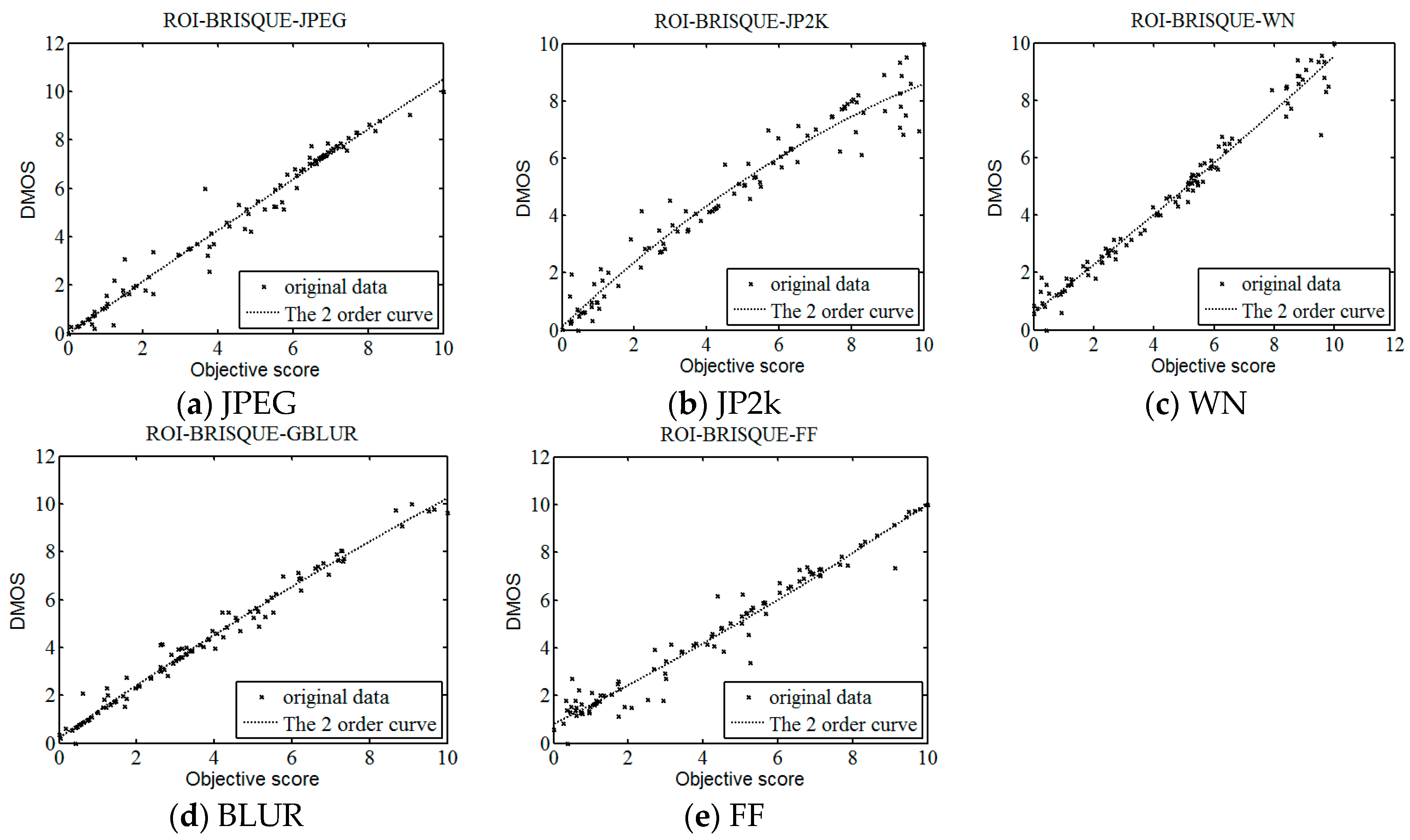
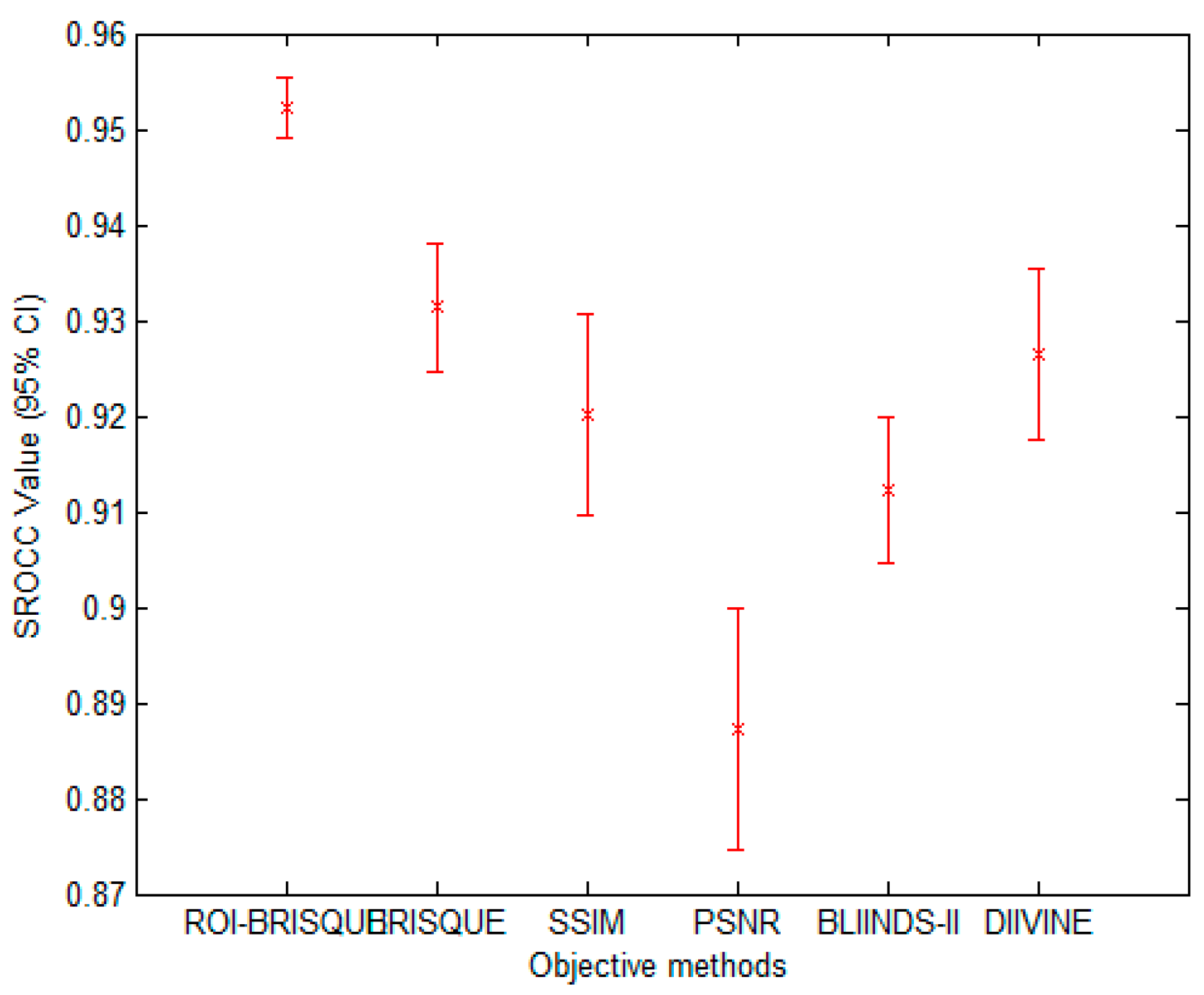
With the development of information technology, digital images have been widely used in every corner of our life and work, the research of image quality assessment algorithm also has very important practical significance. In this letter, we describe a framework for constructing an objective no-reference image quality assessment measure. The framework is unique, since it absorbs the features of human visual system. On the basis of human visual attention mechanism and BRISQUE method, this paper proposes a new NR IQA method based on visual perception, which we named as ROI-BRISQUE. First, we detailed the algorithm and the extraction model of ROI, and demonstrated the ROI consistent quite well with human perception. Then, we used BRISQUE method to extract image features and evaluated the ROI-BRISQUE index in terms of correlation with subjective quality score, and demonstrated that algorithm is statistically better than some state of the art IQA indices. At last, we demonstrated that ROI-BRISQUE performs consistently across different databases with similar distortions.
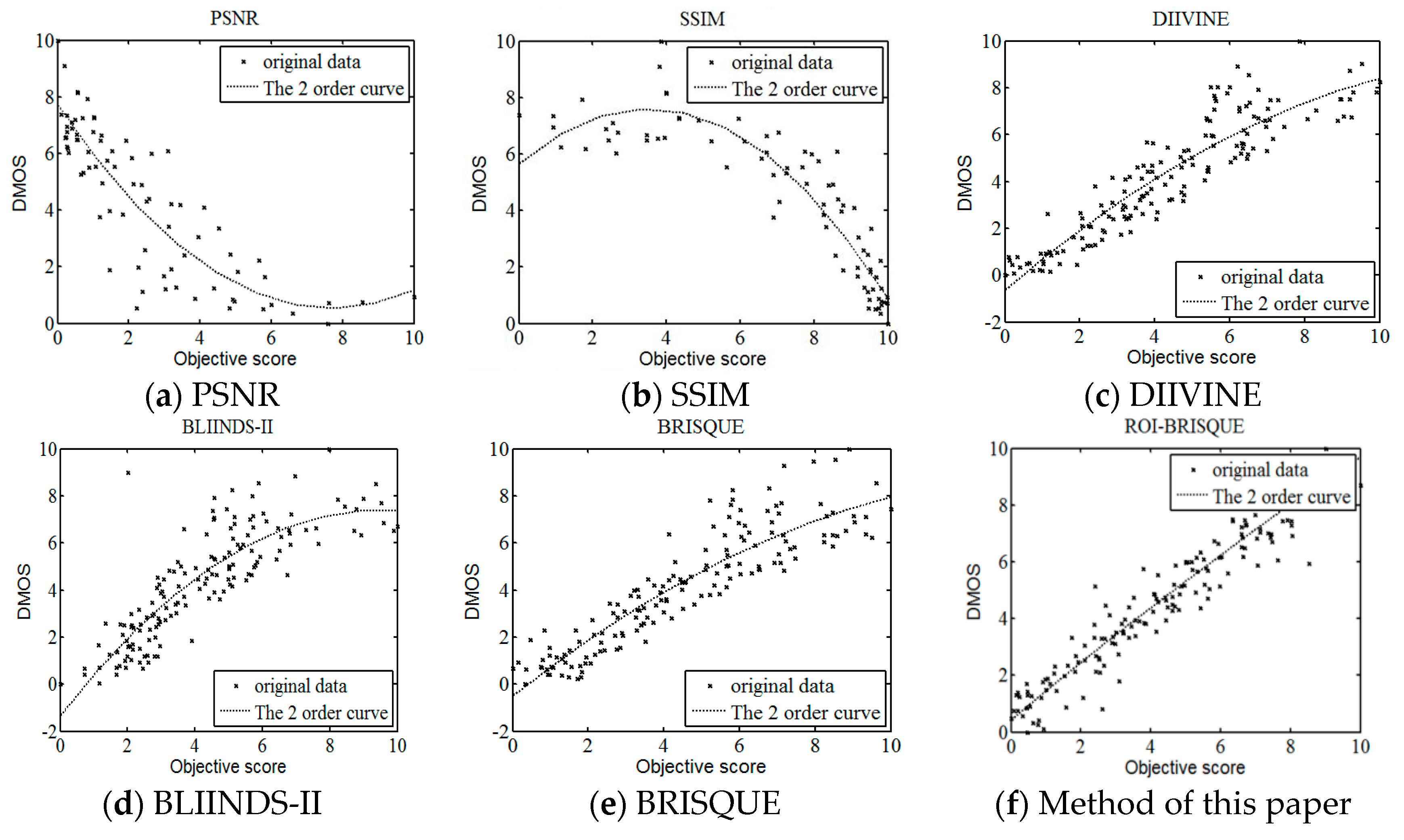
Further, the experimental results show that the new ROI-BRISQUE algorithm can be easily trained for a LIVE IQA database. In addition, it may be easily extended beyond the distortions considered here making it suitable for general-purpose blind IQA problems. The method correlates highly with visual perception of quality, and outperforms the full-reference PSNR and SSIM measure and the recent no-reference BLIINDS-II, DIIVINE indexes, and excels the performance of the no-reference BRISQUE index.
In the future, we will make further efforts to improve ROI-BRISQUE, such as further exploring human visual system and extracting the region of interest accurately.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}