1. Introduction
The forest ecosystem plays a critical role in the global terrestrial carbon cycle, and it is the research topic of major scientific projects, such as the International Geosphere-Biosphere Program, the World Climate Research Programme, and an International Programme of Biodiversity Science [
1,
2]. Forest biomass can directly reflect the status and changes of forest ecosystem, and it is the basis for the rational utilization of forest resources and for improving the ecological environment [
3,
4]. Accurate and rapid estimation of forest biomass is particularly important for improving the efficiency of time, capital, and labor of forest resource investigation and studying the carbon cycle of the terrestrial ecosystem in large areas [
5,
6].
The traditional field measurement for forest aboveground biomass (AGB), which is more accurate for a small forest stand, cannot be used at the regional scale because it is too costly, labor intensive, and time consuming [
7,
8]. Remote sensing data, which have fast, real-time, dynamic, and regional-scale characteristics, are a frequently used data source for monitoring the dynamics of forests with the development of remote sensing technology [
9,
10]. Previous studies have shown that remote sensing data had a high correlation with AGB and can effectively predict and monitor forest biomass at the regional scale; thus, various types of remote sensing systems have been used for AGB estimation [
11,
12].
Among all available satellites, Landsat is currently the only satellite program to provide consistent, cross-calibrated data spanning more than 40 years for global surface observation [
13,
14]. The advantages of the global coverage reflective with increasing spectral and spatial fidelity, the unique record of the land surface and its change over time, the 40+ year coherent and temporally overlapping observatories and cross-sensor calibration, and free and open data access policy greatly stimulate new science and applications of Landsat [
15,
16]. Many countries have used the Landsat archive to carry out institutional systematic mapping and monitoring of forests in large areas, e.g., Canada used Landsat TM and ETM+ data in 2002 to produce the Earth Observation for Sustainable Development map of forests [
17]; Australia used Landsat 5 and 7 data for national-scale carbon inventories [
18]; and Brazil’s National Institute for Space Research used Landsat data to monitor the annual deforestation rates of the Amazon since 1988 [
19]. Landsat 8 was successfully launched on 11 February 2013, to ensure the continuity of the Landsat record. In addition to being consistent with the Landsat legacy, the significantly improved signal-to-noise ratio of Landsat 8 promises to enable better sensitivity of vegetation targets [
16]. Therefore, Landsat 8 was used frequently to monitor the status, disturbance, and recovery of forests [
20,
21].
For remote sensing-based biomass estimation, multiple types of variables such as spectral bands, vegetation indices, and texture measures can be used as predictor variables for modeling [
22,
23]. The previous studies have testified the importance of selecting appropriate variables in improving AGB modeling [
24,
25]. Variable selection (also known as feature selection) can select a most effective variable subset from the full variable set to reduce variable space dimension, and improve the generalization and intelligibility of the model [
26]. Variable selection is one of the most important steps in AGB modeling. Stepwise regression, which is the most commonly used method of variable selection of linear regression model, is simple and easy to perform [
27]. Many variable selection algorithms (such as the random forest algorithm) include variable ranking based on some evaluation strategies as a principal or auxiliary selection mechanism because of their simplicity, scalability, and good empirical success [
28,
29].
In addition to variable selection, it is crucial to select a suitable algorithm to establish AGB estimation models. The traditional statistical regression algorithm, which can build a linear relationship between forest AGB and remote sensing data, is simple and easy to calculate. One of the traditional regression algorithms, the linear regression (LR) method was the most widely used method for AGB estimation in the previous studies [
9,
30]. However, the traditional statistical regression method cannot effectively express the complex relationship between forest AGB and remote sensing data under an indeterminate distribution of data. Therefore, the machine learning algorithms, such as K-nearest neighbor (KNN), support vector machine, artificial neural network, and decision tree, are applied to the remote sensing-based AGB estimation for improving the nonlinear estimation ability of the biomass model [
31,
32,
33,
34]. Previous studies have indicated that algorithms based on the decision tree, such as random forest (RF) and gradient boosting (GB), have an excellent performance in biomass estimation [
35,
36]. The RF is not only a variable selection algorithm but is also used as a nonlinear regression algorithm for AGB estimation because of its advantages of fewer adjustable parameters, high speed and efficiency, and the ability of variable importance calculation and permutation [
37,
38]. The extreme gradient boosting (XGBoost), as an advanced GB system, is widely used by data scientists and has provided state-of-the-art results for many fields, especially the financial field, such as credit risk assessment [
39], but its potential has not been fully utilized in forestry.
The importance of field investigation for remote sensing-based AGB modeling is self-evident. Since 1973, China has conducted a continuous forest inventory, and in this process has established a comprehensive database covering many aspects of forest resources, involving forest health, timber production, and forest ecosystem services. The National Forest Continuous Inventory (NFCI), which is the first level of the forest inventory system of China, was designed to provide reliable data of the current status of and changes in the forests in the form of an integrated spatial database [
40]. The NFCI survey is carried out every five years at the provincial scale. The sample plots have been systematically located at the graticule intersection of the national topographic map (scale of 1:100,000 or 1:50,000) [
41]. Each tree with a diameter at breast height greater than or equal to 5 cm in the sample plot was tagged and permanently numbered for remeasurement in subsequent inventory periods. The NFCI is important for the formulation and refinement of state forest planning, management, and policy [
42]. Therefore, the NFCI was widely used in many studies, including assessment and monitoring of forest status, conditions and changes, carbon sink and source identification, biomass estimation, and biodiversity [
30,
43].
In this paper, we used the NFCI data and Landsat 8 Operational Land Imager (OLI) data in combination with the LR and two machine learning algorithms, e.g., RF and XGBoost, to establish models for AGB estimation under the condition of known forest types and then created the AGB map for the study area using the optimal models. The specific objectives of this study were as follows: (1) to explore the influence of variable selection for the LR, RF, and XGBoost; (2) to validate the ability of the RF and XGBoost for estimating AGB; (3) to compare the accuracy of the LR, RF, and XGBoost models of different forest types; and (4) to draw the AGB map for the study area.
6. Discussion
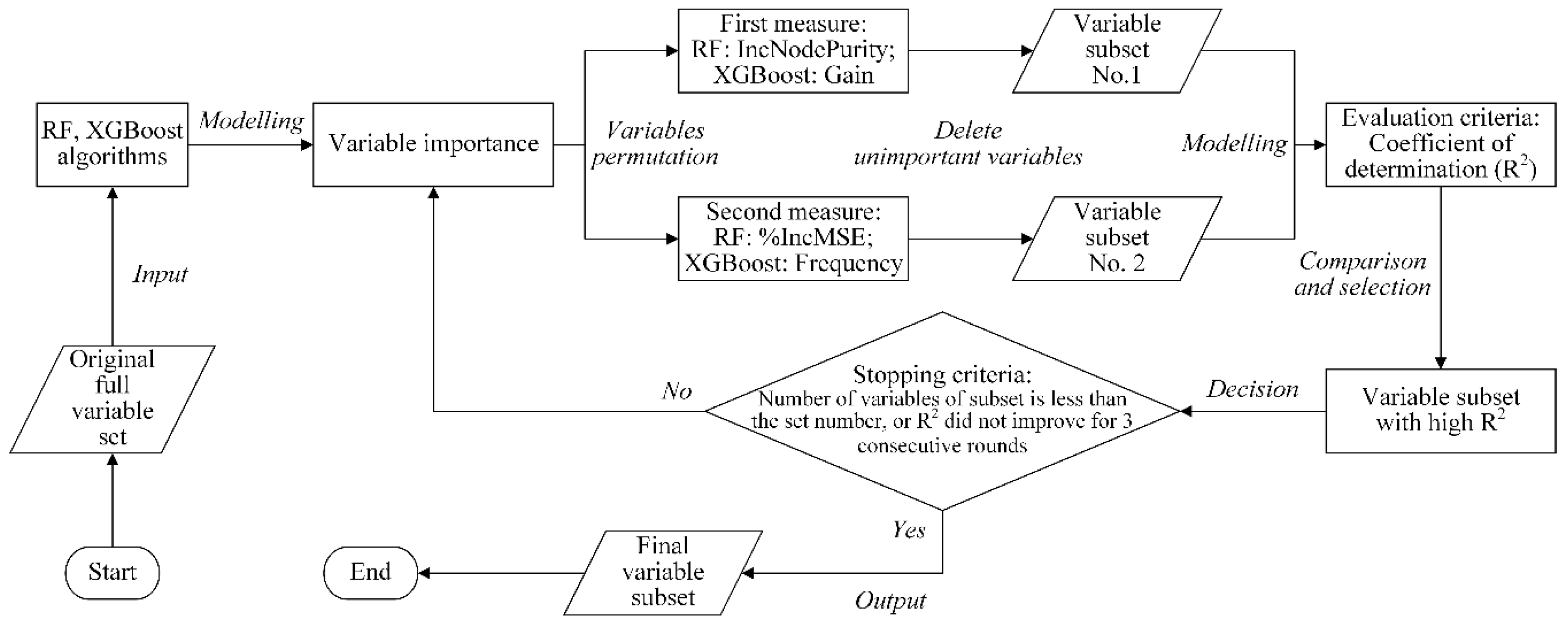
Through this experiment, we increased our understanding of the importance of variable selection, which can influence the performance of machine learning algorithms. Variable selection is one of the most important processes in modeling, which can reduce data dimension and the storage space of data, speed the estimation process, and improve the interpretability and performance of models [
29].
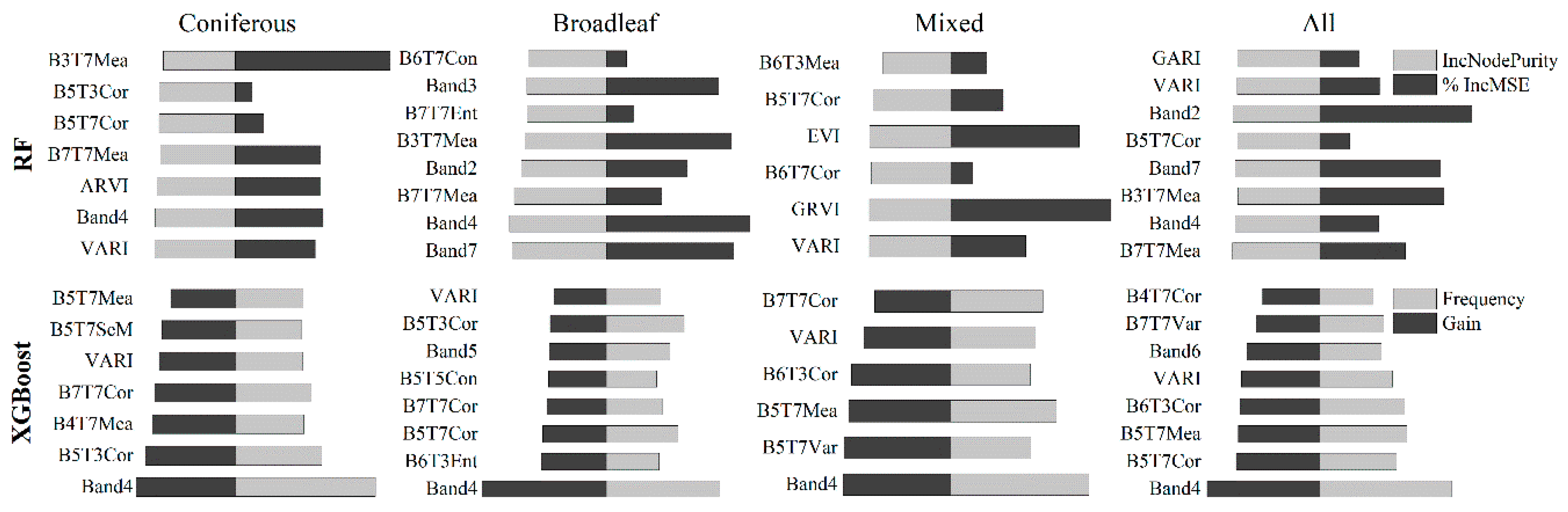
Multiple predictor variables, such as spectral bands, vegetation indices, and textures, were extracted from remote sensing images and were used for modeling AGB in this paper. However, these predictors cannot all be used for modeling due to their high correlations and high numbers. The performance of models was significantly impacted by the number of selected predictor variables (
Figure 6,
Table 5). Through the variable selection, the number of predictor variables was reduced from hundreds to several, which makes it easier to interpret the model. In this study, the Red (
Band4), NIR (
Band5), SWIR (
Band7) bands, and the derived variables played a more important role than other bands. In models of AGB estimation, the SWIR band is more sensitive to the shadow of vegetation and humidity of soil and is less influenced by the atmospheric conditions [
16,
22,
68]; the NIR band of Landsat 8, of which the wavelength range was adjusted to 0.845–0.885 µm to exclude the effect of water-vapor absorption at 0.825 µm, is more sensitive to vegetation of different types [
13,
69]; and the red band is usually used to distinguish the vegetation type [
21,
64,
70]. We cannot ignore the fact that the vegetation index variables were also selected frequently, especially
VARI, which exists in all XGBoost models. Compared with other vegetation indices,
VARI is minimally sensitive to the atmospheric effect, and the estimation error of vegetation affected by the atmosphere is less than 10% in a large area [
71,
72].
In addition, the textures, which are dominant in all models, were also critical for AGB estimation, although the importance of the texture predictor variables was different from that in previous studies [
24,
30,
66]. However, for the different forest types, texture variables and spectral variables played different roles in AGB models (
Figure 4). For example, the spectral variables were more important than texture variables in the RF model of the broadleaf forest, while the texture variables were more important in the RF model of the coniferous forest. This illustrated that the role of texture variables and spectral variables was dependent on forest structure: in the broadleaf and mixed forest with multiple species and complex structure, the models tended to select the spectral variables, while in the coniferous forest with relatively fewer species and simple structure, the models tended to choose texture variables [
63,
64,
73].
Due to the different characters between spectral variables and texture variables, their combination is beneficial to improve the performance of AGB models, and this improvement was evident in all models. Moreover, the influence of variable selection was different for RF and XGBoost. We found that the accuracy of the XGBoost algorithm varied greatly with the number of selected variables compared with RF (
Figure 6). The RF algorithm can be regarded as a parallel ensemble algorithm because the decision tree of RF is independent; thus, RF is not sensitive to inclusion of the noisy predictor variables [
74,
75], whereas the decision tree of XGBoost is generated based on the previous tree; thus, the noisy predictor variables will influence the accuracy of the subsequent new tree [
76,
77].
The LR algorithm, which assumes a linear relationship between predictor and predicted variables, was used frequently in most early biomass estimation studies due to the interpretability of LR [
30,
78]. However, the relationship between remote sensing data and AGB is complex; thus, the traditional statistical regression algorithm cannot efficiently describe the relationship between them. Therefore, machine learning algorithms such as random forest and gradient boosting, which can establish a complex non-linear relationship between vegetation information and remote sensing images with an indeterminate distribution of data, were introduced to improve the accuracy of AGB estimation [
79].
In our study, we extracted 170 predictor variables from Landsat 8 images; then, a few variables were selected from these through the variable selection process to build RF and XGBoost models (
Figure 4). We found that the machine learning algorithms prevented overfitting and significantly improved the estimation accuracy compared with the LR models, and the result also indicated that the XGBoost model worked better than the RF model (
Figure 7). The XGBoost algorithm, which is a highly flexible algorithm with the ability to correct the residual error to generate a new tree based on the previous tree, provided an improvement in processing a regularized learning objective to avoid overfitting [
54].
Before this study, few studies had used the XGBoost algorithm to estimate AGB. Li et al. [
30] used a linear mixed-effects model and linear dummy variable model to estimate AGB in the western Hunan Province of China; the R
2 values of total vegetation were 0.41; Zhu et al. [
6] used multiple algorithms (LR, KNN, logistic regression) to estimate AGB for the Xiangjiang River, and the results indicated the machine learning algorithm had a good performance for AGB estimation. In contrast, the results obtained by machine learning methods in this study were better, and the XGBoost algorithm had a good performance in AGB estimation and could reduce underestimation and overestimation to some extent.
In this paper, we established the models based on forest type to improve the accuracy of AGB estimation, and the results indicated this method was valuable. We found that the models based on forest type had a better performance at the lower and higher values compared to the models of all plots with non-classification of forest types, especially XGBoost (
Figure 7 and
Figure 9). In addition, the problem of overestimation and underestimation, which are the main factors influencing AGB modeling performance, was not completely solved, although the performance of models had a significant improvement compared with the previous studies. As to this problem, it is decided by the algorithm itself on one hand. The decision trees, which are the key components of the RF and XGBoost methods, cannot extrapolate outside the training set. On the other hand, it is related to the remote sensing data. For plots with low AGB values, the shrubs, grass, and bare soil will influence the reflectance of bands; the pixel of Landsat 8 with relatively low spatial resolution (30 × 30 m) is a mixed pixel, which cannot accurately express the spectral information of land cover. For plots with high AGB values, the saturation in multispectral sensors such as Landsat 8 OLI is the main reason for underestimation of AGB [
80,
81]. Therefore, remote sensing data with higher spatial and radiometric resolution such as LIDAR data and hyperspectral data, or the approach of mixed pixel decomposition, may be solutions for AGB estimation. Meanwhile, a modeling approach based on the AGB range may be a useful method for improving the prediction of AGB, but it needs more sample plots.
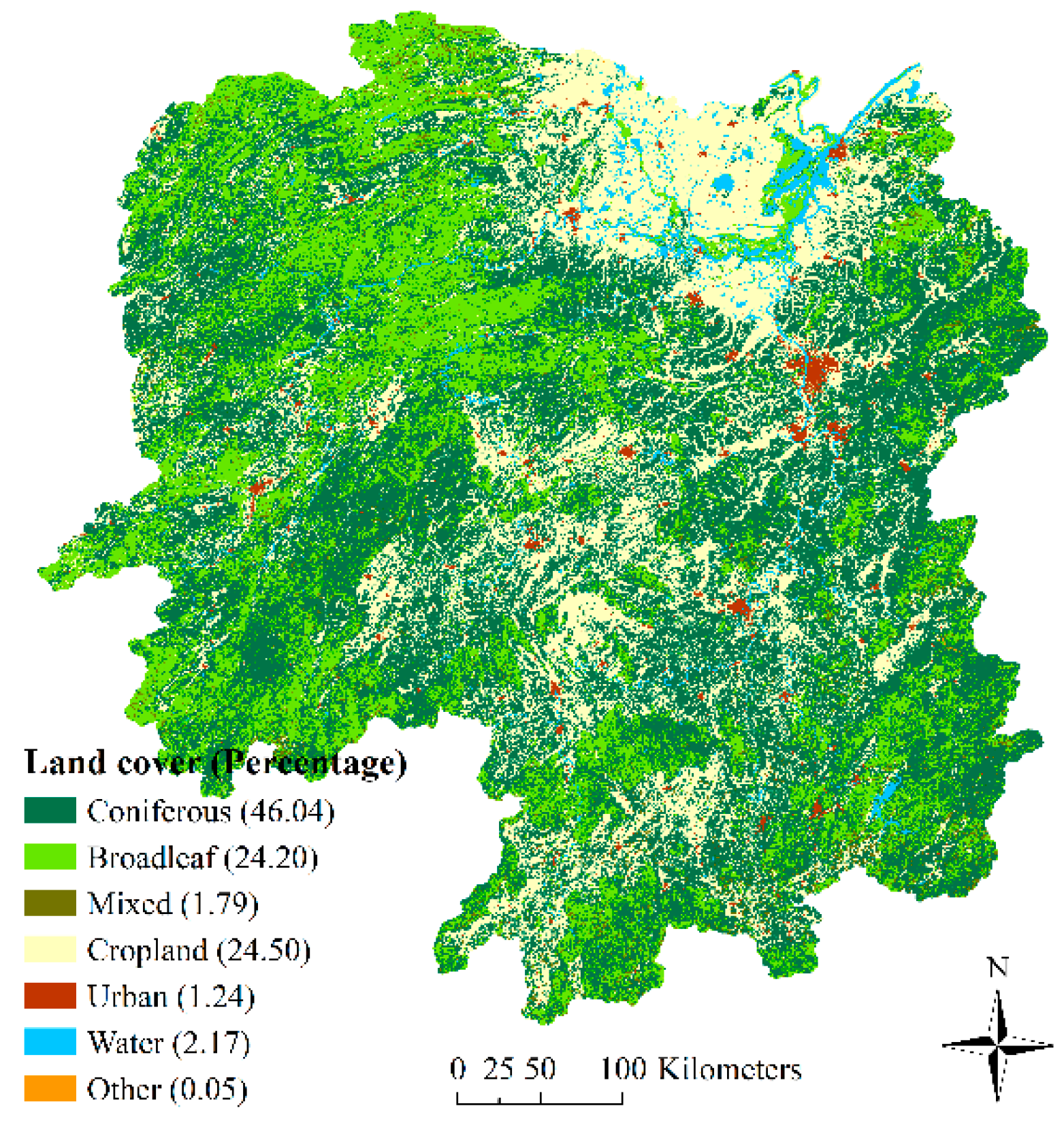
The subtropical forests of China are distributed in 13 provinces, including Zhejiang, Jiangsu, Anhui, Fujian, Jiangxi, Hubei, Hunan, Guangdong, Guangxi, Hainan, Guizhou, Sichuan, and Yunnan. They are one of the dominant distribution areas of forest resources in China. It is necessary to monitor the subtropical forest change because the forests have been influenced by the improved silviculture, woody encroachment, climate change, and human activities. The forest biomass estimation based on traditional field measurements is a relatively accurate method, but it is impossible to implement for such large areas of subtropical forests. Therefore, remote sensing-based estimation of forest biomass change is a very important method. The NFCI data, which has been checked and revised many times by the state and provincial forest departments before it is released, is the only available data with highest quality in the provincial scale at present. However, the residual atmospheric effects and calibration errors in satellite data cannot be completely eliminated. Therefore, until the more effective satellite data are available, we can only hope to improve the accuracy of forest biomass estimation by using new modeling methods. Despite certain inaccuracies, the performance of the biomass estimation method used in this study exceeds our expectations, and the selected modeling method of XGBoost seems to be more effective. The results show that the NFCI data in combination with Landsat 8 can be successfully applied to biomass estimation. Although the XGBoost models had the relatively high RMSE and RMSE% values, the total accuracies of models were significantly increased with the variable selection, and it is still manifested that the methods in this paper were very important and useful for the provincial-scale accurate estimation of forest biomass, and these methods can also be used to other similar areas. In addition, we must admit that there are still many sections that could be improved in our research, such as methods of variable selection, variable data cleaning, and parameter optimization for machine learning. We will do further research in these aspects in the future.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









