Modeling Height–Diameter Relationship for Poplar Plantations Using Combined-Optimization Multiple Hidden Layer Back Propagation Neural Network


 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Materials
2.2. Modelling Approach
2.2.1. Traditional Approach
2.2.2. Mixed-Effects Modeling Approach
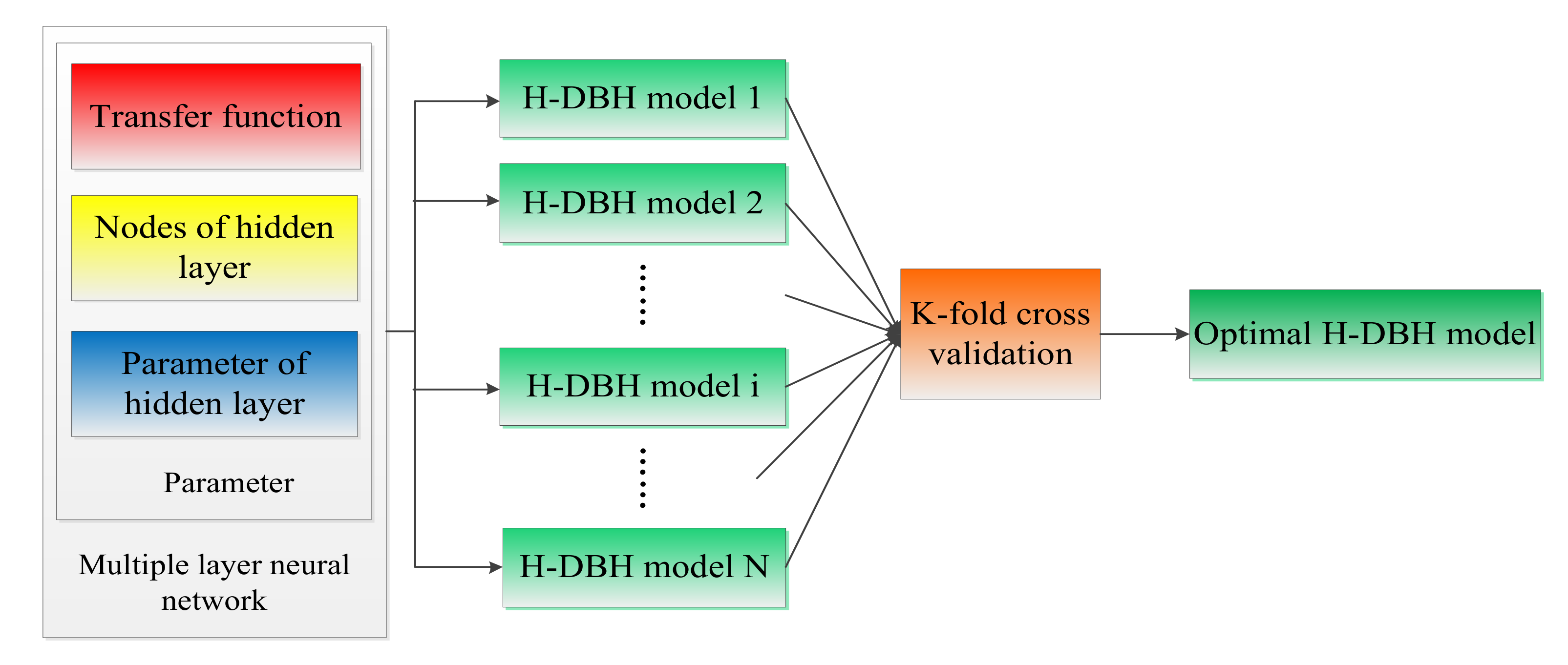
2.2.3. BP Neural Network
- Setting up of the BP Neural Network Structure
- Normalizing Input and Output Factors
- Training the Model
- Model Evaluation
- Model Selection
- Step 1.
- A sample set S is randomly divided into k disjoint subsets, the number of samples in each subset is m/k, and these subsets are denoted by S1, S2, ……, Sk.
- Step 2.
- For each model , following is done:For n = 1 to k{Take as a training set;Train the model , and get the corresponding hypothetical function ;Take as a verification set, and calculate the model generalization error .}Calculate the average of ,, and get the average generalization error of model .
- Step 3.
- Calculate the average generalization error of all the models, and select the model with the smallest average generalization error, which is the best model.
3. Results
3.1. Model Generation and Performance
3.2. Transfer Function
3.3. Comparison with Traditional Model Accuracy
3.4. Comparison with Mixed-Effects Model Accuracy
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Data Accessibility
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neurons of Each Layer | MSE | Iterations | MSE | Iterations | MSE | Iterations | MSE | Iterations |
|---|---|---|---|---|---|---|---|---|
| tan:tan:tan | tan:tan:log | tan:log:tan | tan:log:log | |||||
| 1:2:2:2:1 | 0.0884 | 26.2 | 0.0556 | 31.0 | 0.0940 | 33.6 | 0.1014 | 23.2 |
| 1:2:2:5:1 | 0.1020 | 18.2 | 0.0772 | 26.8 | 0.0505 | 19.4 | 0.0572 | 21.0 |
| 1:2:2:8:1 | 0.0461 | 24.0 | 0.0795 | 14.6 | 0.0878 | 17.8 | 0.0710 | 15.8 |
| 1:2:2:11:1 | 0.3880 | 23.8 | 0.0563 | 17.8 | 0.0945 | 21.6 | 0.0708 | 18.8 |
| 1:2:5:2:1 | 0.0674 | 45.0 | 0.0863 | 22.2 | 0.0800 | 17.2 | 0.1039 | 16.6 |
| 1:2:5:5:1 | 0.1028 | 14.6 | 0.1228 | 13.6 | 0.1759 | 25.4 | 0.0801 | 16.2 |
| 1:2:5:8:1 | 0.1194 | 24.2 | 0.0803 | 18.6 | 0.0518 | 15.4 | 0.1179 | 17.6 |
| 1:2:5:11:1 | 0.0761 | 18.4 | 0.0918 | 37.4 | 0.1213 | 20.4 | 0.0785 | 13.4 |
| 1:2:8:2:1 | 0.0776 | 24.8 | 0.1195 | 18.6 | 0.0511 | 21.8 | 0.0585 | 31.6 |
| 1:2:8:5:1 | 0.1066 | 16.4 | 0.0936 | 16.8 | 0.1049 | 17.2 | 0.1071 | 21.8 |
| 1:2:8:8:1 | 0.0560 | 19.2 | 0.0986 | 13.6 | 0.0545 | 15.8 | 0.0548 | 14.8 |
| 1:2:8:11:1 | 0.0788 | 43.2 | 0.0673 | 19.0 | 0.0899 | 15.8 | 0.0965 | 16.4 |
| 1:2:11:2:1 | 0.1351 | 19.4 | 0.1037 | 15.2 | 0.0803 | 25.6 | 0.0843 | 19.2 |
| 1:2:11:5:1 | 0.0772 | 15.0 | 0.0578 | 16.2 | 0.0621 | 19.0 | 0.0711 | 20.4 |
| 1:2:11:8:1 | 0.1403 | 40.2 | 0.1037 | 14.8 | 0.1418 | 16.0 | 0.1167 | 22.4 |
| 1:2:11:11:1 | 0.1180 | 25.4 | 0.0833 | 22.2 | 0.1200 | 25.4 | 0.1007 | 15.4 |
| 1:5:2:2:1 | 0.0660 | 18.4 | 0.1323 | 20.0 | 0.0446 | 23.2 | 0.0711 | 15.0 |
| 1:5:2:5:1 | 0.0624 | 16.4 | 0.0763 | 26.8 | 0.1192 | 25.0 | 0.0679 | 18.2 |
| 1:5:2:8:1 | 0.1065 | 27.8 | 0.1056 | 21.2 | 0.3581 | 17.8 | 0.0730 | 13.6 |
| 1:5:2:11:1 | 0.0892 | 19.2 | 0.0813 | 19.6 | 0.0796 | 22.0 | 0.1183 | 15.2 |
| 1:5:5:2:1 | 0.0630 | 20.2 | 0.0989 | 22.4 | 0.0733 | 16.4 | 0.1106 | 18.6 |
| 1:5:5:5:1 | 0.0625 | 14.6 | 0.0864 | 22.0 | 0.0981 | 17.0 | 0.0678 | 14.0 |
| 1:5:5:8:1 | 0.1087 | 19.4 | 0.1020 | 13.6 | 0.0501 | 13.8 | 0.0528 | 14.6 |
| 1:5:5:11:1 | 0.0537 | 20.2 | 0.0595 | 15.2 | 0.0634 | 14.2 | 0.1059 | 19.0 |
| 1:5:8:2:1 | 0.0716 | 13.6 | 0.0802 | 18.2 | 0.0752 | 20.6 | 0.0762 | 16.6 |
| 1:5:8:5:1 | 0.1409 | 13.4 | 0.1006 | 16.8 | 0.0676 | 18.2 | 0.0626 | 13.4 |
| 1:5:8:8:1 | 0.1101 | 18.8 | 0.1258 | 13.2 | 0.0652 | 15.6 | 0.0980 | 14.4 |
| 1:5:8:11:1 | 0.0590 | 16.8 | 0.1035 | 13.0 | 0.1775 | 16.6 | 0.1028 | 14.4 |
| 1:5:11:2:1 | 0.0665 | 17.0 | 0.0815 | 17.8 | 0.0509 | 16.0 | 0.0975 | 22.4 |
| 1:5:11:5:1 | 0.1387 | 14.2 | 0.0685 | 20.4 | 0.0796 | 14.4 | 0.1302 | 15.4 |
| 1:5:11:8:1 | 0.1145 | 12.8 | 0.0873 | 15.6 | 0.0919 | 17.8 | 0.0965 | 12.4 |
| 1:5:11:11:1 | 0.1451 | 15.2 | 0.0756 | 22.8 | 0.0856 | 12.8 | 0.0726 | 20.0 |
| 1:8:2:2:1 | 0.0709 | 15.8 | 0.0780 | 16.4 | 0.0689 | 15.0 | 0.0668 | 28.2 |
| 1:8:2:5:1 | 0.0814 | 34.8 | 0.0831 | 19.6 | 0.0698 | 16.4 | 0.0687 | 15.0 |
| 1:8:2:8:1 | 0.1178 | 19.8 | 0.0752 | 20.6 | 0.0593 | 16.8 | 0.0603 | 26.0 |
| 1:8:2:11:1 | 0.0814 | 17.6 | 0.0837 | 16.8 | 0.0580 | 19.4 | 0.0798 | 16.0 |
| 1:8:5:2:1 | 0.0811 | 15.6 | 0.1080 | 34.0 | 0.1530 | 18.4 | 0.0958 | 17.8 |
| 1:8:5:5:1 | 0.0916 | 15.4 | 0.0892 | 18.0 | 0.0653 | 13.6 | 0.1192 | 13.8 |
| 1:8:5:8:1 | 0.1110 | 13.8 | 0.0951 | 14.8 | 0.0814 | 13.6 | 0.1123 | 13.0 |
| 1:8:5:11:1 | 0.0899 | 15.8 | 0.0793 | 14.0 | 0.1076 | 12.6 | 0.0679 | 15.0 |
| 1:8:8:2:1 | 0.0939 | 15.6 | 0.1011 | 18.4 | 0.0859 | 14.8 | 0.1391 | 22.8 |
| 1:8:8:5:1 | 0.0772 | 18.0 | 0.1049 | 16.4 | 0.1353 | 14.6 | 0.1907 | 15.8 |
| 1:8:8:8:1 | 0.1859 | 14.0 | 0.0428 | 16.6 | 0.0793 | 13.2 | 0.1157 | 21.0 |
| 1:8:8:11:1 | 0.0812 | 16.2 | 0.1838 | 19.2 | 0.1607 | 14.2 | 0.0922 | 19.0 |
| 1:8:11:2:1 | 0.0957 | 22.8 | 0.0654 | 13.0 | 0.0578 | 21.6 | 0.1096 | 16.4 |
| 1:8:11:5:1 | 0.0544 | 13.0 | 0.0711 | 18.2 | 0.0579 | 16.2 | 0.0672 | 13.8 |
| 1:8:11:8:1 | 0.0937 | 12.4 | 0.1274 | 20.2 | 0.1468 | 17.0 | 0.0652 | 13.6 |
| 1:8:11:11:1 | 0.1193 | 23.2 | 0.1547 | 16.2 | 0.0652 | 15.4 | 0.0747 | 12.6 |
| 1:11:2:2:1 | 0.0767 | 16.6 | 0.0734 | 20.4 | 0.0953 | 17.2 | 0.0704 | 17.2 |
| 1:11:2:5:1 | 0.1564 | 13.8 | 0.0763 | 16.4 | 1.6445 | 21.2 | 0.0640 | 18.2 |
| 1:11:2:8:1 | 0.1009 | 17.4 | 0.0469 | 15.2 | 0.1369 | 12.4 | 0.1474 | 22.0 |
| 1:11:2:11:1 | 0.2392 | 42.4 | 0.1206 | 18.8 | 0.0919 | 18.6 | 0.0650 | 24.2 |
| 1:11:5:2:1 | 0.0780 | 26.4 | 0.0896 | 16.6 | 0.0711 | 16.6 | 0.1083 | 14.2 |
| 1:11:5:5:1 | 0.1551 | 13.8 | 0.1454 | 14.8 | 0.0846 | 13.8 | 0.0958 | 17.6 |
| 1:11:5:8:1 | 0.0814 | 15.6 | 0.0607 | 18.0 | 0.1620 | 15.8 | 0.0813 | 16.6 |
| 1:11:5:11:1 | 0.0987 | 15.0 | 0.0752 | 18.2 | 0.1069 | 13.4 | 0.1012 | 12.6 |
| 1:11:8:2:1 | 0.0901 | 16.0 | 0.0598 | 15.6 | 0.1069 | 14.6 | 0.0917 | 23.4 |
| 1:11:8:5:1 | 0.0838 | 17.0 | 0.1097 | 12.4 | 0.0570 | 15.8 | 0.0956 | 15.2 |
| 1:11:8:8:1 | 0.1041 | 14.4 | 0.1094 | 15.4 | 0.1474 | 15.2 | 0.1147 | 16.2 |
| 1:11:8:11:1 | 0.1105 | 21.8 | 0.1220 | 18.6 | 0.1508 | 15.0 | 0.0504 | 14.2 |
| 1:11:11:2:1 | 0.0755 | 18.4 | 0.0560 | 24.2 | 0.1350 | 12.0 | 0.0854 | 15.0 |
| 1:11:11:5:1 | 0.0785 | 18.6 | 0.0872 | 15.6 | 0.0854 | 11.8 | 0.1641 | 18.8 |
| 1:11:11:8:1 | 0.1129 | 16.0 | 0.0883 | 22.0 | 0.0946 | 13.2 | 0.1444 | 12.4 |
| 1:11:11:11:1 | 0.1004 | 14.6 | 0.1252 | 13.6 | 0.1538 | 13.2 | 0.0893 | 21.0 |
| 1:2:2:2:1 | 0.0985 | 20.6 | 0.0852 | 23.4 | 0.0840 | 42.4 | 0.1218 | 17.6 |
| 1:2:2:5:1 | 0.0861 | 66.2 | 0.1063 | 22.2 | 0.1230 | 18.4 | 0.0853 | 18.0 |
| 1:2:2:8:1 | 0.1157 | 19.2 | 0.0684 | 20.0 | 0.0812 | 40.2 | 0.1089 | 15.0 |
| 1:2:2:11:1 | 0.3540 | 26.6 | 0.0730 | 27.4 | 0.0613 | 22.0 | 0.0941 | 15.4 |
| 1:2:5:2:1 | 0.1066 | 29.6 | 0.0931 | 17.8 | 0.1062 | 17.4 | 0.3278 | 27.6 |
| 1:2:5:5:1 | 0.1151 | 17.2 | 0.0905 | 17.4 | 0.2043 | 16.8 | 0.0690 | 14.4 |
| 1:2:5:8:1 | 0.0749 | 18.2 | 0.0859 | 23.8 | 0.0686 | 17.0 | 0.0782 | 14.4 |
| 1:2:5:11:1 | 0.0578 | 15.0 | 0.0469 | 17.4 | 0.1966 | 18.0 | 0.1248 | 21.0 |
| 1:2:8:2:1 | 0.1176 | 21.6 | 0.0458 | 19.2 | 0.0827 | 19.2 | 0.0691 | 21.0 |
| 1:2:8:5:1 | 0.0885 | 17.6 | 0.0719 | 17.2 | 0.1539 | 16.8 | 0.0821 | 20.6 |
| 1:2:8:8:1 | 0.0824 | 25.0 | 0.1182 | 14.6 | 0.0804 | 21.4 | 0.0681 | 18.0 |
| 1:2:8:11:1 | 0.0797 | 19.6 | 0.0807 | 17.0 | 0.0580 | 13.2 | 0.0983 | 17.2 |
| 1:2:11:2:1 | 0.1024 | 15.6 | 0.1074 | 18.2 | 0.0727 | 32.4 | 0.0829 | 17.2 |
| 1:2:11:5:1 | 0.0961 | 15.4 | 0.0696 | 16.6 | 0.0785 | 15.0 | 0.0819 | 23.0 |
| 1:2:11:8:1 | 0.0922 | 19.6 | 0.0723 | 19.0 | 0.0921 | 15.6 | 0.0797 | 30.0 |
| 1:2:11:11:1 | 0.0733 | 19.8 | 0.0872 | 13.8 | 0.0734 | 15.2 | 0.1016 | 14.4 |
| 1:5:2:2:1 | 0.0874 | 13.4 | 0.0864 | 23.8 | 0.0673 | 24.0 | 0.0782 | 16.6 |
| 1:5:2:5:1 | 0.0769 | 17.8 | 0.0715 | 19.2 | 0.0668 | 15.6 | 0.1170 | 15.8 |
| 1:5:2:8:1 | 0.0651 | 14.0 | 0.0718 | 20.8 | 0.0729 | 19.8 | 0.1238 | 18.8 |
| 1:5:2:11:1 | 0.0661 | 19.0 | 0.0894 | 14.6 | 0.0793 | 14.4 | 0.1327 | 15.0 |
| 1:5:5:2:1 | 0.1260 | 15.4 | 0.1682 | 15.6 | 0.0627 | 17.8 | 0.1830 | 14.8 |
| 1:5:5:5:1 | 0.1038 | 13.4 | 0.0750 | 15.8 | 0.0748 | 18.8 | 0.0991 | 16.8 |
| 1:5:5:8:1 | 0.0684 | 13.0 | 0.0522 | 33.8 | 0.0786 | 17.6 | 0.0999 | 15.2 |
| 1:5:5:11:1 | 0.1568 | 17.4 | 0.0920 | 18.0 | 0.0900 | 18.8 | 0.1166 | 19.2 |
| 1:5:8:2:1 | 0.0793 | 23.4 | 0.0947 | 17.4 | 0.0521 | 14.0 | 0.1257 | 19.4 |
| 1:5:8:5:1 | 0.1234 | 21.6 | 0.1050 | 19.0 | 0.0716 | 19.2 | 0.1332 | 21.6 |
| 1:5:8:8:1 | 0.0903 | 14.0 | 0.0794 | 11.6 | 0.1379 | 19.0 | 0.0695 | 17.4 |
| 1:5:8:11:1 | 0.1751 | 17.4 | 0.1073 | 18.2 | 0.1630 | 21.2 | 0.0895 | 13.2 |
| 1:5:11:2:1 | 0.0927 | 18.2 | 0.1065 | 15.4 | 0.0739 | 32.4 | 0.1177 | 24.8 |
| 1:5:11:5:1 | 0.0941 | 13.2 | 0.0847 | 16.2 | 0.0821 | 21.2 | 0.0702 | 13.8 |
| 1:5:11:8:1 | 0.2084 | 20.6 | 0.0703 | 13.6 | 0.0994 | 14.0 | 0.1120 | 22.0 |
| 1:5:11:11:1 | 0.0896 | 22.0 | 0.0832 | 21.2 | 0.0895 | 14.2 | 0.0853 | 13.2 |
| 1:8:2:2:1 | 0.1322 | 14.8 | 0.1244 | 16.0 | 0.0948 | 16.0 | 0.0940 | 17.6 |
| 1:8:2:5:1 | 0.0963 | 13.0 | 0.0981 | 16.0 | 0.1278 | 21.8 | 0.0717 | 16.8 |
| 1:8:2:8:1 | 0.1204 | 15.0 | 0.0961 | 15.8 | 0.0900 | 29.2 | 0.0823 | 19.8 |
| 1:8:2:11:1 | 0.0550 | 22.4 | 0.1335 | 12.8 | 0.1197 | 13.2 | 0.0694 | 14.2 |
| 1:8:5:2:1 | 0.0824 | 17.2 | 0.0804 | 23.6 | 0.1899 | 22.6 | 0.0671 | 18.4 |
| 1:8:5:5:1 | 0.0693 | 17.6 | 0.1303 | 20.4 | 0.0820 | 15.6 | 0.0867 | 15.4 |
| 1:8:5:8:1 | 0.0930 | 14.8 | 0.1011 | 13.2 | 0.1109 | 12.6 | 0.1415 | 15.0 |
| 1:8:5:11:1 | 0.2495 | 17.4 | 0.0850 | 13.2 | 0.0676 | 15.2 | 0.1607 | 13.0 |
| 1:8:8:2:1 | 0.0538 | 15.2 | 0.0825 | 21.6 | 0.1115 | 18.0 | 0.1038 | 25.6 |
| 1:8:8:5:1 | 0.0827 | 12.4 | 0.0513 | 15.4 | 0.0678 | 14.2 | 0.1517 | 16.4 |
| 1:8:8:8:1 | 0.1120 | 17.0 | 0.0994 | 15.6 | 0.1560 | 15.0 | 0.0733 | 12.2 |
| 1:8:8:11:1 | 0.1027 | 17.4 | 0.1331 | 13.4 | 0.1040 | 14.6 | 0.0763 | 21.0 |
| 1:8:11:2:1 | 0.0499 | 15.0 | 0.0648 | 18.6 | 0.0955 | 20.0 | 0.0762 | 29.6 |
| 1:8:11:5:1 | 0.1685 | 16.4 | 0.1082 | 13.0 | 0.0982 | 15.6 | 0.0786 | 12.4 |
| 1:8:11:8:1 | 0.0700 | 13.2 | 0.1409 | 12.4 | 0.1046 | 19.0 | 0.1053 | 22.6 |
| 1:8:11:11:1 | 0.1234 | 18.2 | 0.0767 | 18.2 | 0.0686 | 16.6 | 0.0789 | 19.2 |
| 1:11:2:2:1 | 0.0864 | 19.2 | 0.0585 | 20.2 | 0.0655 | 20.4 | 0.0920 | 15.0 |
| 1:11:2:5:1 | 0.2456 | 17.2 | 0.1119 | 16.4 | 0.0881 | 23.6 | 0.1038 | 14.8 |
| 1:11:2:8:1 | 0.0570 | 19.2 | 0.0852 | 21.8 | 0.0724 | 17.8 | 0.1493 | 26.4 |
| 1:11:2:11:1 | 0.1345 | 18.2 | 0.1407 | 19.2 | 0.1392 | 14.4 | 0.0836 | 16.2 |
| 1:11:5:2:1 | 0.1205 | 18.6 | 0.0658 | 20.6 | 0.0561 | 16.8 | 0.1163 | 16.8 |
| 1:11:5:5:1 | 0.0736 | 17.2 | 0.0896 | 17.2 | 0.0867 | 17.0 | 0.1203 | 23.6 |
| 1:11:5:8:1 | 0.0746 | 15.6 | 0.1327 | 16.4 | 0.0625 | 20.0 | 0.1371 | 17.2 |
| 1:11:5:11:1 | 0.0634 | 14.6 | 0.0999 | 18.4 | 0.0862 | 15.6 | 0.1830 | 19.8 |
| 1:11:8:2:1 | 0.0918 | 19.4 | 0.1124 | 25.2 | 0.1609 | 13.8 | 0.0704 | 16.4 |
| 1:11:8:5:1 | 0.2184 | 19.4 | 0.0709 | 14.0 | 0.1025 | 14.6 | 0.1356 | 15.6 |
| 1:11:8:8:1 | 0.1078 | 17.8 | 0.0873 | 14.4 | 0.0806 | 15.4 | 0.1091 | 13.0 |
| 1:11:8:11:1 | 0.0693 | 15.4 | 0.1357 | 16.6 | 0.0812 | 14.2 | 0.1164 | 16.0 |
| 1:11:11:2:1 | 0.0992 | 15.2 | 0.0919 | 14.8 | 0.1202 | 16.4 | 0.0973 | 14.0 |
| 1:11:11:5:1 | 0.0992 | 16.8 | 0.1095 | 13.6 | 0.0990 | 17.2 | 0.0652 | 13.6 |
| 1:11:11:8:1 | 0.1335 | 19.4 | 0.0798 | 17.2 | 0.0928 | 15.8 | 0.0991 | 17.0 |
| 1:11:11:11:1 | 0.1030 | 13.8 | 0.1092 | 22.0 | 0.1025 | 14.8 | 0.1140 | 12.6 |
| Equations | Parameter Estimates | ||
|---|---|---|---|
| a | b | c | |
| Richards | 13.2393 | 0.1119 | 1.9216 |
| Logistic | 12.3167 | 7.0594 | 0.1959 |
| Gompertz | 12.6456 | 3.0414 | 0.1447 |
| Korf | 16.9864 | 11.9539 | 1.0749 |
| Mitscherlich | 22.2102 | 0.0331 | |
| Schumacher | 18.0091 | 10.6440 | |

References
- Burkhart, H.E.; Tomé, M. Modeling Forest Trees and Stands; Springer: Noordwijkerhout, The Netherlands, 2016. [Google Scholar]
- Watt, M.S.; Dash, J.P.; Bhandari, S.; Watt, P. Comparing parametric and non-parametric methods of predicting Site Index for radiata pine using combinations of data derived from environmental surfaces, satellite imagery and airborne laser scanning. For. Ecol. Manag. 2015, 357, 1–9. [Google Scholar] [CrossRef]
- Sharma, M. Comparing Height-diameter Relationships of Boreal Tree Species Grown in Plantations and Natural Stands. For. Sci. 2016, 62, 70–77. [Google Scholar] [CrossRef]
- Sharma, R.P.; Breidenbach, J. Modeling height-diameter relationships for Norway spruce, Scots pine, and downy birch using Norwegian national forest inventory data. For. Sci. Technol. 2015, 11, 44–53. [Google Scholar] [CrossRef]
- Sánchez, C.A.L.; Varela, J.G.; Dorado, F.C.; Alboreca, A.R.; Soalleiro, R.R.; González, J.G.Á.; Rodríguez, F.S. A height-diameter model for Pinus radiata D. Don in Galicia (Northwest Spain). Ann. For. Sci. 2003, 60, 237–245. [Google Scholar]
- Castedo, D.F.; Diéguez-Aranda, U.; Barrio, A.M.; Rodríguez, M.S.; Von Gadow, K. A generalized height-diameter model including random components for radiata pine plantations in northwestern Spain. For. Ecol. Manag. 2006, 229, 202–213. [Google Scholar] [CrossRef]
- Schmidt, M.; Kiviste, A.; Gadow, K.V. A spatially explicit height-diameter model for Scots pine in Estonia. Eur. J. For. Res. 2011, 130, 303–315. [Google Scholar] [CrossRef] [Green Version]
- Kearsley, E.; Moonen, P.C.; Hufkens, K.; Doetterl, S.; Lisingo, J.; Bosela, F.B.; Boeckx, P.; Beeckman, H.; Verbeeck, H. Model performance of tree height-diameter relationships in the central Congo Basin. Ann. For. Sci. 2017, 74, 7. [Google Scholar] [CrossRef] [Green Version]
- Richards, F.J. A Flexible Growth Function for Empirical Use. J. Exp. Bot. 1959, 10, 290–301. [Google Scholar] [CrossRef]
- Temesgen, H.; Hann, D.W.; Monleon, V.J. Regional Height-diameter Equations for Major Tree Species of Southwest Oregon. West. J. Appl. For. 2007, 22, 213–219. [Google Scholar] [CrossRef] [Green Version]
- Zang, H.; Lei, X.; Zeng, W. Height-diameter equations for larch plantations in northern and northeastern China: A comparison of the mixed-effects, quantile regression and generalized additive models. Forestry 2016, 89, 434–445. [Google Scholar] [CrossRef]
- Koirala, A.; Kizha, A.R.; Baral, S. Modeling Height-diameter Relationship and Volume of Teak (Tectona grandis L. F.) in Central Lowlands of Nepal. J. Trop. For. Environ. 2017, 7, 28–42. [Google Scholar] [CrossRef]
- Castaño-Santamaría, J.; Crecente Campo, F.; Fernández-Martínez, J.L.; Barrio-Anta, M.; Obeso, J.R. Tree height prediction approaches for uneven-aged beech forests in northwestern Spain. For. Ecol. Manag. 2013, 307, 63–73. [Google Scholar] [CrossRef]
- Scrinzi, G.; Marzullo, L.; Galvagni, D. Development of a neural network model to update forest distribution data for managed alpine stands. Ecol. Model. 2007, 206, 331–346. [Google Scholar] [CrossRef]
- Leduc, D.J.; Matney, T.G.; Belli, K.L.; Baldwin, V.C. Predicting Diameter Distributions of Longleaf Pine Plantations: A Comparison between Artifical Neural Networks and Other Accepted Methodologies; USDA Forest Service, Southern Research Station: Asheville, NC, USA, 2001. [Google Scholar]
- Diamantopoulou, M.J.; Milios, E. Modelling total volume of dominant pine trees in reforestations via multivariate analysis and artificial neural network models. Biosyst. Eng. 2010, 105, 306–315. [Google Scholar] [CrossRef]
- Özçelik, R.; Diamantopoulou, M.J.; Crecente-Campo, F.; Eler, U. Estimating Crimean juniper tree height using nonlinear regression and artificial neural network models. For. Ecol. Manag. 2013, 306, 52–60. [Google Scholar] [CrossRef]
- Castro, R.V.O.; Soares, C.P.B.; Leite, H.G.; Lopes de Souza, A.; Saraiva Nogueira, G.; Bolzan Martins, F. Individual growth model for Eucalyptus stands in Brazil using artificial neural network. Forestry 2013, 1–12. [Google Scholar]
- Leite, H.G.; Silva, M.L.M.D.; Binoti, D.H.B.; Fardin, L.; Takizawa, F.H. Estimation of inside-bark diameter and heartwood diameter for Tectona grandis, Linn. trees using artificial neural networks. Eur. J. For. Res. 2011, 130, 263–269. [Google Scholar] [CrossRef]
- Nandy., S.; Singh, R.; Ghosh, S.; Watham, T.; Kushwaha, S.P.S.; Kumar, A.S.; Dadhwal, V.K. Neural network-based modelling for forest biomass assessment. Carbon Manag. 2017, 8, 305–317. [Google Scholar] [CrossRef]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S-PLUS, 3rd ed.; Springer: New York, NY, USA, 1999. [Google Scholar]
- Pearl, R.; Reed, L.J. On the rate of growth of the population of the United States since 1790 and its mathematical representation. Proc. Natl. Acad. Sci. USA 1920, 6, 275–288. [Google Scholar] [CrossRef] [Green Version]
- Winsor, C.P. The Gompertz Curve as a Growth Curve. Proc. Natl. Acad. Sci. USA 1932, 18, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Lundqvist, B. On the height growth in cultivated stands of pine and spruce in Northern Sweden. Medd. Fran Statens Skogforsk. Band 1957, 47, 1–64. [Google Scholar]
- Levin, I.; Nitsan, J. Use of the Mitscherlich equation in designing factorial fertilizer field experiments to reduce the number of treatments. Plant Soil 1964, 21, 249–252. [Google Scholar] [CrossRef]
- Alder, D.; Montenegro, F. A yield model for Cordia alliodora plantations in Ecuador. Int. For. Rev. 1999, 1, 242–250. [Google Scholar]
- Pinheiro, J.C.; Bates, D.M. Mixed-Effects Models in S and S-PLUS; Springer: New York, NY, USA, 2000. [Google Scholar]
- Fu., L.; Sun, H.; Sharma, R.P.; Lei, Y.; Zhang, H.; Tang, S. Nonlinear mixed-effects crown width models for individual trees of Chinese fir (Cunninghamia lanceolata) in South-Central China. For. Ecol. Manag. 2013, 302, 210–220. [Google Scholar] [CrossRef]
- Fu, L.; Zhang, H.; Sharma, R.P.; Pang, L.; Wang, G. A generalized nonlinear mixed-effects height to crown base model for Mongolianoak in northeast China. For. Ecol. Manag. 2017, 384, 34–43. [Google Scholar] [CrossRef]
- Fu, L.; Wang, M.; Wang, Z.; Song, X.; Tang, S. Maximum likelihood estimation of nonlinear mixed-effects models with crossed random effects by combining first order conditional linearization and sequential quadratic programming. Int. J. Biomath. 2019. [Google Scholar] [CrossRef]
- Fu, L.; Duan, G.; Ye, Q.; Meng, X.; Luo, P.; Sharma, R.P.; Sun, H.; Wang, G.; Liu, Q. Prediction of Individual Tree Diameter Using a Nonlinear Mixed-Effects Modeling Approach and Airborne LiDAR Data. Remote Sens. 2020, 12, 1066. [Google Scholar] [CrossRef] [Green Version]
- Hecht-Nielsen, R. Komogorovs Mapping Neural Network Existence Theorem. In Proceedings of the International Conference on Neural Networks; MIT Press: Cambridge, MA, USA, 1987; pp. 11–13. [Google Scholar]
- Ding, S.; Su, C.; Yu, J. An optimizing BP neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Neog, D.K. Microstrip Antenna and Artificial Neural Network; LAP LAMBERT Academic Publishing: Saarbrücken, Germany, 2010. [Google Scholar]
- Han, W.; Nan, L.; Su, M.; Chen, Y.; Li, R.; Zhang, X. Research on the Prediction Method of Centrifugal Pump Performance Based on a Double Hidden Layer BP Neural Network. Energies 2019, 12, 2709. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Ling, J.; Kou, L. Performance Comparison between GA-BP Neural Network and BP Neural Network. Chin. J. Health Stat. 2013, 30, 173–494. [Google Scholar]
- Zhang, Y.; Yang, Y. Cross-validation for selecting a model selection procedure. J. Econom. 2015, 187, 95–112. [Google Scholar] [CrossRef]
- Moré, J.J. The levenberg-marquardt algorithm, implementation and theory. In Numerical Analysis; Lecture Notes in Mathematics, 630; Watson, G.A., Ed.; Springer: Berlin, Germany, 1977. [Google Scholar]
- Ding, S.; Chang, X.H. Application of Improved BP Neural Networks Based on LM Algorithm in Characteristic Curve Fitting of Fiber-Optic Micro-Bend Sensor. Adv. Mater. Res. 2014, 889, 825–828. [Google Scholar]
- Arlot, S.; Lerasle, M. Why V=5 Is Enough in V-Fold Cross-Validation. 2014. Available online: https://hal.archives-ouvertes.fr/hal-00743931v2 (accessed on 14 April 2020).



| Data | Variable | Min | Max | Mean | Std |
|---|---|---|---|---|---|
| Fitting data set | DBH (cm) | 5.9 | 25.7 | 11.5 | 3.0 |
| Height (m) | 2.5 | 13.0 | 8.3 | 1.9 | |
| Validation data set | DBH (cm) | 7.0 | 22.0 | 10.4 | 3.4 |
| Height (m) | 3.7 | 14.1 | 7.5 | 2.2 |
| Name of Equation | Form of Equation | Source |
|---|---|---|
| Richards | H = 1.3 + a(1 − exp(−bDBH))c | [9] |
| Logistic | H= 1.3 + a/(1 + bexp(−cDBH)) | [22] |
| Gompertz | H = 1.3 + aexp(−bexp(−cDBH)) | [23] |
| Korf | H = 1.3 + aexp(−bDBH(−c)) | [24] |
| Mitscherlich | H = 1.3 + a(1−exp(−bDBH)) | [25] |
| Schumacher | H = 1.3 + aexp(−b/DBH) | [26] |
| Neurons in Each Layer | MSE | Iterations | MSE | Iterations |
|---|---|---|---|---|
| logsig | tansig | |||
| 1: 2: 1 | 0.1107 | 24.0 | 0.3057 | 16.0 |
| 1: 5: 1 | 0.0827 | 14.3 | 0.0669 | 15.0 |
| 1: 8: 1 | 0.0568 | 13.1 | 0.1143 | 17.0 |
| 1:11: 1 | 0.0556 | 11.0 | 0.0437 | 13.1 |
| Neurons of Each Layer | MSE | Iterations | MSE | Iterations | MSE | Iterations | MSE | Iterations |
|---|---|---|---|---|---|---|---|---|
| log:log | tan:tan | tan:log | log:tan | |||||
| 1:2:2:1 | 0.1237 | 15.2 | 0.0881 | 39.6 | 0.0790 | 22.6 | 0.1071 | 16.6 |
| 1:2:5:1 | 0.0764 | 15.2 | 0.1751 | 19.4 | 0.0446 | 21.4 | 0.1087 | 23.0 |
| 1:2:8:1 | 0.0743 | 17.6 | 0.0813 | 16.6 | 0.0884 | 23.4 | 0.1467 | 18.6 |
| 1:2:11:1 | 0.0839 | 19.8 | 0.0935 | 21.6 | 0.0801 | 15.8 | 0.0948 | 20.6 |
| 1:5:2:1 | 0.0626 | 17.0 | 0.0936 | 13.0 | 0.0558 | 14.2 | 0.0757 | 15.0 |
| 1:5:5:1 | 0.0416 | 16.2 | 0.0854 | 19.4 | 0.1017 | 15.0 | 0.0832 | 22.4 |
| 1:5:8:1 | 0.0897 | 14.2 | 0.0584 | 17.2 | 0.1091 | 16.2 | 0.0971 | 12.8 |
| 1:5:11:1 | 0.0764 | 17.6 | 0.1323 | 20.6 | 0.0950 | 14.4 | 0.1214 | 12.0 |
| 1:8:2:1 | 0.0610 | 14.6 | 0.0986 | 17.0 | 0.0644 | 13.8 | 0.1582 | 14.4 |
| 1:8:5:1 | 0.0971 | 13.6 | 0.0948 | 13.4 | 0.0869 | 14.0 | 0.1304 | 18.8 |
| 1:8:8:1 | 0.0599 | 21.0 | 0.0841 | 12.2 | 0.0978 | 13.4 | 0.0586 | 13.2 |
| 1:8:11:1 | 0.1060 | 13.6 | 0.1441 | 17.4 | 0.1004 | 13.0 | 0.0983 | 13.4 |
| 1:11:2:1 | 0.0750 | 22.4 | 0.0852 | 17.8 | 0.0530 | 15.0 | 0.1272 | 16.4 |
| 1:11:5:1 | 0.1573 | 12.8 | 0.2539 | 17.6 | 0.1400 | 12.2 | 0.0887 | 18.8 |
| 1:11:8:1 | 0.1058 | 23.4 | 0.1720 | 17.0 | 0.1020 | 15.8 | 0.0917 | 12.2 |
| 1:11:11:1 | 0.1402 | 12.8 | 0.2726 | 23.4 | 0.0766 | 14.4 | 0.1651 | 13.0 |
| Category | Number of Neural Network | Best Neural Network Structure | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Average MSE | MSE (min) | Ratio of MSE < 0.1 | Average Iterations | Iterations (min) | Neurons of Each Layer | Transfer Function | Iterations | ||
| Single hidden layer | 8 | 0.1045 | 0.0437 | 62.50% | 15 | 11.0 | 1:11:1 | tansig | 13.0 |
| Double hidden layer | 64 | 0.1027 | 0.0416 | 62.50% | 16 | 12.0 | 1:5:5:1 | logsig:logsig | 16.2 |
| Triple hidden layer | 512 | 0.1010 | 0.0428 | 62.89% | 21 | 11.6 | 1:8:8:8:1 | tansig:tansig:logsig | 16.6 |
| Evaluation Index | Richards | Logistic | Gompertz | Korf | Mitscherlich | Schumacher | Neural Network |
|---|---|---|---|---|---|---|---|
| R2 | 0.6794 | 0.6774 | 0.6771 | 0.6757 | 0.6837 | 0.6788 | 0.7541 |
| RMSE | 1.2713 | 1.2752 | 1.2758 | 1.2786 | 1.2628 | 1.2724 | 1.1133 |
| MAE | 1.0887 | 1.1041 | 1.0972 | 1.0858 | 1.0963 | 1.0809 | 0.9482 |
| Variance Function | Formula | AIC | BIC | loglik |
|---|---|---|---|---|
| Exponential function | 283.8982 | 295.8084 | −136.9491 | |
| Power function | 283.9949 | 295.9051 | −136.9975 | |
| Power function with constant | 285.9949 | 300.2871 | −136.9975 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, J.; Hu, Z.; Sharma, R.P.; Wang, G.; Meng, X.; Wang, M.; Wang, Q.; Fu, L. Modeling Height–Diameter Relationship for Poplar Plantations Using Combined-Optimization Multiple Hidden Layer Back Propagation Neural Network. Forests 2020, 11, 442. https://doi.org/10.3390/f11040442
Shen J, Hu Z, Sharma RP, Wang G, Meng X, Wang M, Wang Q, Fu L. Modeling Height–Diameter Relationship for Poplar Plantations Using Combined-Optimization Multiple Hidden Layer Back Propagation Neural Network. Forests. 2020; 11(4):442. https://doi.org/10.3390/f11040442
Chicago/Turabian StyleShen, Jianbo, Zongda Hu, Ram P. Sharma, Gongming Wang, Xiang Meng, Mengxi Wang, Qiulai Wang, and Liyong Fu. 2020. "Modeling Height–Diameter Relationship for Poplar Plantations Using Combined-Optimization Multiple Hidden Layer Back Propagation Neural Network" Forests 11, no. 4: 442. https://doi.org/10.3390/f11040442